第12章 索引与散列
查找排序
解:① 先设定3个辅助标志: low,high,mid, 显然有:mid= (low+high)/2 ② 运算步骤:
(1) low =1,high =11 ,故mid =6 ,待查范围是 [1,11]; (2) 若 S[mid] < key,说明 key[ mid+1,high] , 则令:low =mid+1;重算 mid= (low+high)/2;. (3) 若 S[mid] > key,说明key[low ,mid-1], 则令:high =mid–1;重算 mid ; (4)若 S[ mid ] = key,说明查找成功,元素序号=mid; 结束条件: (1)查找成功 : S[mid] = key (2)查找不成功 : high<low (意即区间长度小于0)
while(low<=high)
{ mid=(low+high)/2; if(ST[mid].key= = key) return (mid); /*查找成功*/
else if( key< ST[mid].key) high=mid-1; /*在前半区间继续查找*/ else } return (0); /*查找不成功*/
4 5 6 7
0
1
2
90
10
(c)
20
40
K=90
80
30
60
Hale Waihona Puke 25(return i=0 )
6
讨论:怎样衡量查找效率?
——用平均查找长度(ASL)衡量。
如何计算ASL?
数据结构基础知识整理

数据结构基础知识整理*名词解释1、数据:是信息的载体,能够被计算机识别、存储和加工处理。
*2、数据元素:是数据的基本单位,也称为元素、结点、顶点、记录。
一个数据元素可以由若干个数据项组成,数据项是具有独立含义的最小标识单位。
*3、数据结构:指的是数据及数据之间的相互关系,即数据的组织形式,它包括数据的逻辑结构、数据的存储结构和数据的运算三个方面的内容。
*4、数据的逻辑结构:指数据元素之间的逻辑关系,即从逻辑关系上描述数据,它与数据的存储无关,是独立于计算机的。
*5、数据的存储结构:指数据元素及其关系在计算机存储器内的表示。
是数据的逻辑结构用计算机语言的实现,是依赖于计算机语言的。
*6、线性结构:其逻辑特征为,若结构是非空集,则有且仅有一个开始结点和一个终端结点,并且其余每个结点只有一个直接前趋和一个直接后继。
*7、非线性结构:其逻辑特征为一个结点可能有多个直接前趋和直接后继。
*8、算法:是任意一个良定义的计算过程,它以一个或多个值作为输入,并产生一个或多个值作为输出;即一个算法是一系列将输入转换为输出的计算步骤。
*9、算法的时间复杂度T(n):是该算法的时间耗费,它是该算法所求解问题规模n趋向无穷大时,我们把时间复杂度T(n)的数量级(阶)称为算法的渐近时间复杂度。
*10、最坏和平均时间复杂度:由于算法中语句的频度不仅与问题规模n有关,还与输入实例等因素有关;这时可用最坏情况下时间复杂度作为算法的时间复杂度。
而平均时间复杂度是指所有的输入实例均以等概率出现的情况下,算法的期望运行时间。
*11、数据的运算:指对数据施加的操作。
数据的运算是定义在数据的逻辑结构上的,而实现是要在存储结构上进行。
*12、线性表:由n(n≥0)个结点组成的有限序列。
其逻辑特征反映了结点间一对一的关系(一个结点对应一个直接后继,除终端结点外;或一个结点对应一个直接前趋,除开始结点外),这是一种线性结构。
*13、顺序表:顺序存储的线性表,它是一种随机存取结构。
动态哈希

散列前缀
i
共 2i 个 桶 地 址 数 据
i1
桶1
可扩充散列数据结构
01.. 10.. 11..
i位二进制数 • • • 桶2
00..
i2
i3
桶3
可扩充散列一般结构
2、动态散列实现
可扩充散列实现过程
dept_name
Comp.Sci. Finance History Music Physics
h(dept_name) 1100 0110 0100 0110 0100 0110 0100 0110 1000 0100 1100 0100 1100 0100 1100 0100 0110 0110 0010 0110 0010 0110 0010 0110 0111 0101 0111 0101 0111 0101 0111 0101 0001 0101 1000 0101 1000 0101 1000 0101
2
00004 Li Finance
dept_name Comp.Sci. Finance History
h(dept_name) 1100 0110 0100 0110 0100 0110 0100 0110 1000 0100 1100 0100 1100 0100 1100 0100 0110 0110 0010 0110 0010 0110 0010 0110
2
00005 Sun 00002 Zhou History Music
1 2
00001 Zhao 00004 Li Comp.Sci. Finance
dept_name Comp.Sci. Finance History
h(dept_name) 1100 0110 0100 0110 0100 0110 0100 0110 1000 0100 1100 0100 1100 0100 1100 0100 0110 0110 0010 0110 0010 0110 0010 0110
计算机导论课后习题答案(00002)

计算机导论课后习题答案计算机科学导论第七章1应用程序和操作系统的不同点是什么?操作系统是一个程序,有利于应用程序的执行。
2操作系统的组成是什么?内存管理器,进程管理器,设备管理器,文件管理器。
3单道程序和多道程序之间有何区别?单道程序,只有一个程序在内存中。
多道程序,多个程序同时在内存中,但是计算机的资源只分配给正在运行的程序。
4分页调度和分区调度有什么区别?分区调度把内存分为若干个区,把程序整个的放入区中。
分页调度提高了分区调度的效率,在分页调度下,内存被分为大小相等的若干部分,程序也被分为大小相等的部分。
分区调度需要把程序装载到连续的内存上。
分页调度可以吧把程序装载到不连续的内存当中。
5为什么请求分页调度比常规页面调度具有更高的效率?在常规的分页调度中,整个程序必须同时在内存中,以便为程序执行。
但是在请求分页调度中,有部分页面的程序可以在内存中。
这意味着,在请求分页调度中,在给定的时间中,更多的程序可以使用计算机的资源。
6程序和作业之间有何联系?作业和进程之间有何联系?程序和进程之间有何联系?从一个程序被选中执行,到其运行结束并再次成为一个程序的这段过程中,该程序称为作业。
7程序驻留在哪里?作业驻留在哪里?进程驻留在哪里?程序和作业驻留在磁盘上,进程驻留在内存中。
8作业调度器和进程调度器有什么区别?作业调度器负责从作业中创建一个进程和终止一个进程。
进程调度器将一个进程从一个状态转入另一个状态。
9为什么操作系统需要队列?一个操作系统需要使用队列,因为在同一时间可以有许多作业和进程同时活跃。
为了共享所有的资源,队列是必要的,以确保作业和进程都得到他们需要的资源。
31一个计算机装有一个单道程序的操作系统。
如果内存容量为64MB,操作系统需要4MB的内存,那么该计算机执行一个程序可用的最大内存为多少?64-4=60MB33 70/(70+10)=87.5%34一个多道程序的操作系统用一个适当的分配计划把60MB内存分为10MB,12MB,18MB,20MB。
数据结构_(严蔚敏C语言版)_学习、复习提纲.
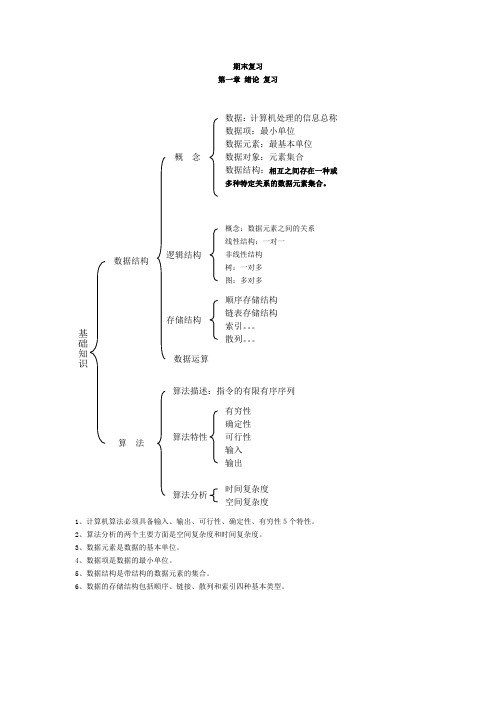
期末复习 第一章 绪论 复习1、计算机算法必须具备输入、输出、可行性、确定性、有穷性5个特性。
2、算法分析的两个主要方面是空间复杂度和时间复杂度。
3、数据元素是数据的基本单位。
4、数据项是数据的最小单位。
5、数据结构是带结构的数据元素的集合。
6、数据的存储结构包括顺序、链接、散列和索引四种基本类型。
基础知识数据结构算 法概 念逻辑结构 存储结构数据运算数据:计算机处理的信息总称 数据项:最小单位 数据元素:最基本单位数据对象:元素集合数据结构:相互之间存在一种或多种特定关系的数据元素集合。
概念:数据元素之间的关系 线性结构:一对一非线性结构 树:一对多 图:多对多顺序存储结构 链表存储结构 索引。
散列。
算法描述:指令的有限有序序列算法特性 有穷性 确定性 可行性 输入 输出 算法分析时间复杂度 空间复杂度第二章 线性表 复习1、在双链表中,每个结点有两个指针域,包括一个指向前驱结点的指针 、一个指向后继结点的指针2、线性表采用顺序存储,必须占用一片连续的存储单元3、线性表采用链式存储,便于进行插入和删除操作4、线性表采用顺序存储和链式存储优缺点比较。
5、简单算法第三章 栈和队列 复习线性表顺序存储结构链表存储结构概 念基本特点基本运算定义逻辑关系:前趋 后继节省空间 随机存取 插、删效率低 插入 删除单链表双向 链表 特点一个指针域+一个数据域 多占空间 查找费时 插、删效率高 无法查找前趋结点运算特点:单链表+前趋指针域运算插入删除循环 链表特点:单链表的尾结点指针指向附加头结点。
运算:联接1、 栈和队列的异同点。
2、 栈和队列的基本运算3、 出栈和出队4、 基本运算第四章 串 复习栈存储结构栈的概念:在一端操作的线性表 运算算法栈的特点:先进后出 LIFO初始化 进栈push 出栈pop队列顺序队列 循环队列队列概念:在两端操作的线性表 假溢出链队列队列特点:先进先出 FIFO基本运算顺序:链队:队空:front=rear队满:front=(rear+1)%MAXSIZE队空:frontrear ∧初始化 判空 进队 出队取队首元素第五章 数组和广义表 复习串存储结构运 算概 念顺序串链表串定义:由n(≥1)个字符组成的有限序列 S=”c 1c 2c 3 ……cn ”串长度、空白串、空串。
数据库对象课件

联接视图 2-1
Stud_details
Sub_details
Studn Studnam Submrk Subn
o
e
s
o
1
Rob
45
2
2
James 33
4
3
Jesica 40
4
Subn o 联接视图2
4
5
Subnam e English Maths Science
CREATE VIEW Stud_sub_view AS
Subn o
Subnam e
1 Rob
45
2
English
2
James
33 Stu因d_为deSta4tiulsdn中o旳既主是M键at,hs
也是联接成果中旳主键
3 Jesica 40
4
Maths
19
视图中旳函数
• 视图中能够使用单行函数、分组函数和体 现式 CREATE VIEW item_view AS
14
创建视图 3
使用 WITH CHECK OPTION 选项创 C建R视EA图TE OR REPLACE VIEW pause_view AS
SELECT * FROM order_master WHERE ostatus = 'p' WITH CHECK OPTION CONSTRAINT chk_pv;
SQL> INSERT INTO toys (toyid, toyname, toyprice) VALUES ( toys_seq.NEXTVAL, ’MAGIC PENCIL’, 75);
指定序列旳下一种值
SQL> SELECT toys_seq.CURRVAL FROM dual;
数据库技术与应用第二版答案

第5章习题解答1.选择题(1)为数据表创建索引的目的是_______。
A.提高查询的检索性能B.节省存储空间C.便于管理D.归类(2)索引是对数据库表中_______字段的值进行排序。
A.一个B.多个C.一个或多个D.零个(3)下列_______类数据不适合创建索引。
A.经常被查询搜索的列B.主键的列C.包含太多NULL值的列D.表很大(4)有表student(学号, 姓名, 性别, 身份证号, 出生日期, 所在系号),在此表上使用_______语句能创建建视图vst。
A.CREA TE VIEW vst AS SELECT * FROM studentB.CREA TE VIEW vst ON SELECT * FROM studentC.CREA TE VIEW AS SELECT * FROM studentD.CREA TE TABLE vst AS SELECT * FROM student(5)下列_______属性不适合建立索引。
A.经常出现在GROUP BY字句中的属性B.经常参与连接操作的属性C.经常出现在WHERE字句中的属性D.经常需要进行更新操作的属性(6)下面关于索引的描述不正确的是_______。
A.索引是一个指向表中数据的指针B.索引是在元组上建立的一种数据库对象C.索引的建立和删除对表中的数据毫无影响D.表被删除时将同时删除在其上建立的索引(7)SQL的视图是_______中导出的。
A.基本表B.视图C.基本表或视图D.数据库(8)在视图上不能完成的操作是_______。
A.更新视图数据B.查询C.在视图上定义新的基本表D.在视图上定义新视图(9)关于数据库视图,下列说法正确的是_______。
A.视图可以提高数据的操作性能B.定义视图的语句可以是任何数据操作语句C.视图可以提供一定程度的数据独立性D.视图的数据一般是物理存储的(10)在下列关于视图的叙述中,正确的是_______。
数据结构复习题090612

《数据结构与算法》复习题一、选择题。
1.在数据结构中,从逻辑上可以把数据结构分为:线性结构和非线性结构。
2.数据结构在计算机内存中的表示是指:数据的存储结构。
3.在数据结构中,与所使用的计算机无关的是数据的:逻辑结构。
4.在存储数据时,通常不仅要存储各数据元素的值,而且还要存储:数据元素之间的关系。
5.在决定选取何种存储结构时,普通不考虑:各结点的值如何。
6.以下说法正确的选项是:一些外表上很不相同的数据可以有相同的逻辑结构。
7.算法分析的目的是:分析算法的效率以求改良,算法分析的两个主要方面是空间复杂度和时间复杂度。
11.在以下的表达中,正确的选项是二维数组是其:数据元素为线性表的线性表。
12.通常要求同一逻辑结构中的所有数据元素具有相同的特性,这意味着:不仅数据元素所包含的数据项的个数要相同,而且对应的数据项的类型要一致。
13.链表不具备的特点是:可随机访问任一结点。
14.不带头结点的单链表 head 为空的判定条件是: head == NULL。
15.带头结点的单链表 head 为空的判定条件是: head->next ==NULL。
16.假设某表最常用的操作是在最后一个结点之后插入一个结点或者删除最后一个结点,那末采用:带头结点的双循环链表存储方式最节省运算时间。
17.需要分配较大空间,插入和删除不需要挪移元素的线性表,其存储结构是:静态链表。
18.非空的循环单链表 head 的尾结点〔由 p 所指向〕满足: p->next ==head。
20.如果最常用的操作是取第 i 个结点及其前驱,那末采用:顺序表存储方式最节省时间。
21.在一个具有 n 个结点的有序单链表中插入一个新结点并仍然保持有序的时间复杂度是 O〔n〕。
22.在一个长度为 n〔n>1〕的单链表上,设有头和尾两个指针,执行:删除单链表中的最后一个元素操作与链表的长度有关。
23.与单链表相比,双链表的优点之一是:顺序访问相邻结点更灵便。
引言及C++语言回顾

8/7/2013
30
传值参数(Value Parameters)
程序1-1 计算一个整数表达式 int Abc(int a, int b, int c) { return a+b+b*c+4; } X=10; Y=20; z=Abc(2,x,y)
顺序存储;火车车厢重排;字典;线性表描 第六章 队列 述;跳表描述:类skipnode,类skiplist 第七章 跳表和散列
8/7/2013
4
教学日历
周次 时数 教学方式 内 容 课程章节 9 4 讲课 顺序存储;火车车厢重排;字典;线性表描 第六章 队列 述;跳表描述:类skipnode,类skiplist 第七章 跳表和散列 10 4 讲课 散列表描述;应用:文本压缩的原理,LZW 第七章 跳表和散列 规则;树定义 ADT,二叉树 ADT 第八章 二叉树 11 4 讲课 结点类,二叉树类,各种方法及其实现;各 第八章 二叉树 种遍历方法。应用:设置信号放大器,在线 等价类
8/7/2013
3
教学日历
周次 时数 教学方式 内 容 课程章节 4 4 讲课 间接寻址;模拟指针;描述方法的比较;应 第三章 数据描述 用:箱子排序,基数排序,等价类,凸包 6 4 讲课 ADT ; C++ 数 组 ; Java 数 组 , 行 优 先 ; 第四章 数组和矩阵 ARRAY1D,ARRAY2D;矩阵:Matrix类 特殊矩阵:各种顺序存储下的特殊矩阵 7 4 讲课 稀疏矩阵;矩阵运算。堆栈, 应用:括号匹配,汗诺塔,火车车厢重排 8 4 讲课 第四章 数组和矩阵 第五章 堆栈
数据结构的散列与索引技术

数据结构的散列与索引技术散列与索引技术是数据结构中常用的两种方法,用于优化数据的存储和查找过程。
散列技术是通过哈希函数将数据映射到一个固定长度的数组中,而索引技术是通过建立索引表来加速数据检索。
本文将详细介绍散列与索引技术的原理、应用场景以及其在实际开发中的使用方法。
1. 散列技术散列技术是一种将数据映射到哈希表的方法,通过哈希函数将关键字转化为一个数组中的地址,从而实现对数据的快速访问。
散列技术的核心是哈希函数的设计,一个好的哈希函数能够使数据均匀地散列到哈希表中,尽量避免碰撞(即不同的关键字映射到了同一个地址)的发生。
1.1 哈希函数的设计原则一个好的哈希函数应该满足以下几个原则:1.1.1 均匀性原则:哈希函数应能够将数据均匀地散列到哈希表中,避免碰撞的发生。
1.1.2 简单性原则:哈希函数的计算应简单快速,以提高散列效率。
1.1.3 一致性原则:对于相同的关键字,哈希函数应始终返回相同的散列地址。
1.1.4 随机性原则:哈希函数的输出应具有随机性,避免出现特定模式的散列结果。
1.2 常见的散列方法常见的散列方法包括直接定址法、除留余数法、平方取中法等。
除留余数法是最常用的散列方法之一,其思想是通过对关键字取余数来获取散列地址。
例如,对于一个哈希表的大小为n的散列表,哈希函数可以定义为:h(key) = key % n。
2. 索引技术索引技术是建立索引表来加速数据的检索过程。
索引表通常由键值和指向数据的指针组成,可以根据键值快速地查找到对应的数据记录。
索引技术的核心是索引表的设计,索引表的结构应具有高效的查找和更新操作。
2.1 主索引与辅助索引主索引是基于主关键字建立的索引表,通过主索引可以直接找到对应的数据记录。
辅助索引是基于其他非主关键字建立的索引表,通过辅助索引可以加速对数据的查询和过滤操作。
主索引和辅助索引的组合可以构建复杂的索引结构,以满足不同的查找需求。
2.2 B树索引B树是一种常用的平衡多路查找树,广泛应用于数据库系统中的索引结构。
空间数据库实习总结

202年空间数据库实习总结202*年空间数据库实习总结空间数据库实习总结经过对空间数据库的课堂教学的学习,我们对空间数据库的建立有了理论上的基础,于十八周进行了空间数据库的课程设计实习。
此次实习主要在计算机上实现,在ArcCatalog和ArcGIS软件平台上进行。
旨在让学生在已基本掌握各种空间数据库的存贮和管理技术的基础上,进行空间数据维护和管理的训练,在GIS原理、空间数据库理论、常用软件功能和相关专业知识之间建立起联系,培养学生具有编写实习报告的能力。
本实习可加深学生对各种空间数据库的原理和方法的理解,为后续的GIS软件设计课程及GIS科学研究打下良好的基础。
在独立完成《地理信息系统实习教程》第八篇“空间数据维护与管理”的所有练习后,我们基本上对拓扑规则有一定了解,对建立拓扑关系和应用拓扑关系对数据质量的检验的操作方法也有一定了解;对建立Geodatabase 数据库,将CAD的DWG文件转换成可以被ArcGIS接受的线要素等,进而转换成多边形,再生成网格;具体操作了投影变换、坐标变换的练习,进行了坐标转换、左边拉伸、接边、影像配准等等操作;还进行了对数据源和元数据的学习在此基础上我们可以建立基本的数据库Geodatabase。
最后,进行了“重庆交通大学空间数据库”设计,由于缺乏基本数据,所以此次“重庆交通大学空间数据库”的设计只有基本的思路设计,即需求分析,概念设计(概念模型的建立,即“实体关系”模型即E-R模型的建立),逻辑设计(逻辑数据模型即关系模型的建立),物理设计(物理数据模型的建立)。
在此次实习过程中,扩展阅读:空间数据库考试复习总结1、什么叫空间数据库?数据库的发展历程。
答:空间数据库是存在于电脑信息介质(如硬盘、光盘)上,而且数据按一定的格式存放,可长期存储、有组织的、可共享的数据集合。
数据库发展经历了三个阶段:(1)人工管理阶段(五十年代中期以前)(2)文件系统阶段(五十年代后期至六十年代后期)(3)数据库系统阶段(七十年代初至现在)发展历程:1、全文件方式2、文件+关系数据库(RDBS)空间数据管理由文件==〉文件集合==〉专用型空间数据库如:早期的Arc/Info,MapInfo系统3、全关系型数据库方式OracleSpatial4、面向对象关系型数据库方式(ArcGIS方式)5、面向对象(OO)的空间数据库方式。
实用综合教程第三版1课后答案听力

实用综合教程第三版1课后答案听力数据库原理与应用教程第三版课后答案第 1 章数据库概述 2.与文件管理相比,数据库管理有哪些优点?答:将相互关联的数据集成在一起,具有较少的数据冗余,程序与数据相互独立,保证数据的安全可靠,最大限度地保证数据的正确性,数据可以共享并能保证数据的一致性。
3.比较文件管理和数据库管理数据的主要区别。
请问:数据库系统与文件系统较之实际上就是在应用程序和存储数据的数据库之间减少了一个系则复软件,即为数据库管理系统,使以前在应用程序中由开发人员同时实现的很多繁杂的操作方式和功能,都可以由这个系统软件顺利完成,这样应用程序不再须要关心数据的存储方式,而且数据的存储方式的变化也不再影响应用程序。
而在文件系统中,应用程序和数据的存有储是密切有关的,数据的存储方式的任何变化都会影响至应用程序,因此有利于应用领域程序的保护。
4.数据库管理方式中,应用程序是否需要关心数据的存储位置和结构?为什么?答:不需要。
因为在数据库系统中,数据的存储位置以及存储结构保存在数据库管理系统中,从数据到物理存储位置的转换是由数据库管理系统自动完成的。
6.在数据库系统中,应用程序可以不通过数据库管理系统而轻易出访数据库文件吗?请问:无法。
7.数据独立性指的是什么?它能带来哪些好处?答:数据独立性指的是数据的逻辑独立性和物理独立性。
逻辑独立性带来的好处是当表达现实世界信息的逻辑结构发生变化时,可以不影响应用程序;物理独立性增添的好处就是当数据的存储结构发生变化时,可以不影响数据的逻辑非政府结构,从而也不影响应用程序。
8.数据库系统由哪几部分组成,每一部分在数据库系统中的作用大致是什么?答:数据库系统由三个主要部分组成,即数据库、数据库管理系统和应用程序。
数据库是数据的汇集,它以一定的组织形式存于存储介质上;数据库管理系统就是管理数据库的系统软件,它可以同时实现数据库系统的各种功能;应用程序指以数据库数据为核心的应用程序。
sql server 2008 数据库应用与开发教程 课后习题参考答案

SQL Server 2008数据库应用与开发教程(第二版)第一章习题参考答案1.简述SQL Server 2008系统中主要数据库对象的特点。
答:主要的数据库对象包括数据库关系图、表、视图、同义词、存储过程、函数、触发器、程序集、类型、规则和默认值等。
“表”节点中包含了数据库最基本、最重要的对象——表。
表实际用来存储系统数据和用户数据,是最核心的数据库对象。
“视图”节点包含了数据库中的视图对象。
视图是一种虚拟表,用来查看数据库中的一个或多个表,视图是建立在表基础之上的数据库对象,它主要以SELECT语句形式存在。
在“同义词”节点中包含了数据库中的同义词对象。
这是Microsoft SQL Server 2008系统新增的一种对象。
“可编程性”对象是一个逻辑组合,它包括存储过程、函数、触发器、程序集、类型、规则和默认值等对象。
数据库中的函数对象包含在“函数”节点中。
函数是接受参数、执行复杂操作并将结果以值的形式返回的例程。
2.SQL Server 2008数据库管理系统产品分为哪几个版本,各有什么特点?答:SQL Server 2008数据库管理系统产品的服务器版本包括了企业版和标准版,专业版本主要包括以下版本:工作组版(Workgroup)、开发人员版(Developer)、免费精简版(Express)、Web版,以及免费的集成数据库SQL Server Compact 3.5。
3.SQL Server 2008包含哪些组件,其功能各是什么?答:SQL Server 2008的体系结构是对SQL Server的组成部分和这些组成部分之间的描述。
Microsoft SQL Server 2008系统由4个组件组成,这4个组件被称为4个服务,分别是数据库引擎、Analysis Services、Reporting Services和Integration Services。
数据库引擎是Microsoft SQL Server 2008系统的核心服务,负责完成数据的存储、处理、查询和安全管理等操作。
散列函数的应用及其安全性

散列函数的应⽤及其安全性⽬录:⼀,给出散列函数的具体应⽤。
⼆,结合⽣⽇攻击、以及2004、2005年王晓云教授有关MD5安全性和2017年google公司SHA-1的安全性,说明散列函数的安全性以及⽬前安全散列函数的发展。
问题2的回答可以结合下⾯给出的第⼀个链接。
三,结合md5算法中的选择前缀碰撞以及第⼆个链接中的helloworld.exe和goodbyworld.exe两个可执⾏⽂件的md5消息摘要值和两个⽂件的执⾏结果说明md5算法来验证软件完整性时可能出现的问题。
⼀,给出散列函数的具体应⽤。
哈希函数(英语:Hash Function)是⼀种从任何⼀种数据中创建⼩的数字“指纹”的⽅法。
散列函数把消息或数据压缩成摘要,使得数据量变⼩,将数据的格式固定下来。
该函数将数据打乱混合,重新创建⼀个叫做散列值的指纹。
散列值通常⽤来代表⼀个短的随机字母和数字组成的字符串。
好的散列函数在输⼊域中很少出现散列冲突。
在散列表和数据处理中,不抑制冲突来区别数据,会使得数据库记录更难找到。
由于散列函数的应⽤的多样性,它们经常是专为某⼀应⽤⽽设计的。
例如,加密散列函数假设存在⼀个要找到具有相同散列值的原始输⼊的敌⼈。
⼀个设计优秀的加密散列函数是⼀个“单向”操作:对于给定的散列值,没有实⽤的⽅法可以计算出⼀个原始输⼊,也就是说很难伪造。
为加密散列为⽬的设计的函数,如MD5,被⼴泛的⽤作检验散列函数。
这样软件下载的时候,就会对照验证代码之后才下载正确的⽂件部分。
此代码有可能因为环境因素的变化,如机器配置或者IP地址的改变⽽有变动。
以保证源⽂件的安全性。
总体来说,散列函数的具体应⽤主要有以下⽅⾯:1.错误校正使⽤⼀个散列函数可以很直观的检测出数据在传输时发⽣的错误。
在数据的发送⽅,对将要发送的数据应⽤散列函数,并将计算的结果同原始数据⼀同发送。
在数据的接收⽅,同样的散列函数被再⼀次应⽤到接收到的数据上,如果两次散列函数计算出来的结果不⼀致,那么就说明数据在传输的过程中某些地⽅有错误了。
索引与散列

简单删除
删除55
被删关键码所在叶结点不是根结点且删除前该结 点中关键码个数 n m/2,则直接删去该关键码并 将修改后的结点写回磁盘,删除结束。 被删关键码所在叶结点删除前关键码个数 n = m/2 -1,若这时与该结点相邻的右兄弟 (或左兄弟) 结点的关键码个数 n m/2,则可按以下步骤调整 该结点、右兄弟 (或左兄弟) 结点以及其双亲结点, 以达到新的平衡。 将双亲结点中刚刚大于 (或小于) 该被删关键码 的关键码 Ki (1 i n) 下移; 将右兄弟 (或左兄弟) 结点中的最小 (或最大)关 键码上移到双亲结点的 Ki 位臵;
次索引结构 在次索引中,列出该属性的所有取值,并对每一个取值建立有序链表, 把所有具有相同属性值的对象按存放地址递增的顺序或按主关键码递 增的顺序链接在一起。 次索引的索引项由次关键码、链表长度和链表本身等三部分组成。通 过对“性别”和“婚否”次索引中的“女性”链和“已婚”链进行求 “交”运算,就能够找到所有既是女性又已婚的职工对象
B树的插入
B树是从空树起,逐个插入关键码而生成的。在B树,每个 非失败结点的关键码个数都在 [ m/2 -1, m-1] 之间。 插入在某个叶结点开始。如果在关键码插入后结点中的关 键码个数超出了上界 m-1,则结点需要“分裂”,否则可 以直接插入。
实现结点“分裂”的原则是: 设结点 p 中已经有 m-1 个关键码,当再插入一个关键码后结点 中的状态为 ( m, P0, K1, P1, K2, P2, ……, Km, Pm) 其中 Ki < Ki+1, 1 i < m 这时必须把结点 p 分裂成两个结点 p 和 q,它们包含的信息分 别为: 结点 p: ( m/2 -1, P0, K1, P1, ……, Km/2 -1, Pm/2 -1) 结点 q: (m - m/2, Pm/2, Km/2+1, Pm/2+1, ……, Km, Pm) 位于中间的关键码 Km/2 与指向新结点 q 的指针形成一个二元组 ( Km/2, q ),插入到这两个结点的双亲结点中去。
C#本质论(中文版-第12章)

300 第 12 章 集 合
Predicate<T>类型的一个参数,它是对称为委托的一个方法的引用。代码清单12-3演示了如何使 用FindAll()方法。
代码清单12-3 演示FindAll()及其Predicate委托参数
using System; using System.Collections.Generic;
与此相反,检查一个特定的值是否在字典集合中是相当花费时间的一个操作,它具有线性性能特 征。为此,你使用的是ContainsValue()方法,它顺序搜索集合中的每一个元素。
为了移除一个字典元素,要使用Remove()方法,向它传递键,而不是元素的值。 字典类没有特定的顺序。元素使用散列码存储到一个散列表类型的数据结构中,这样可以实现快 速检索(调用GetHashCode(),并向它传递键,即可获取散列码)。所以,使用foreach循环来遍历 一个字典类,可以不按特定的顺序来访问值。由于同时需要键和值才能将一个元素添加到字典中,所 以从foreach循环返回的数据类型对于Dictionary<TKey, TValue>来说是KeyValuePair<TKey, TValue>,对于Hashtable来说是DictionaryEntry。代码清单12-6演示了如何使用foreach来遍 历Dictionary<TKey, TValue>集合,输出12-3展示了结果。
在代码清单12-5中,需要注意的第一件事情是索引运算符不需要一个整数。相反,索引数据类型 是由声明Dictionary<TKey, TValue>变量时的第一个类型参数TKey指定的(对于Hashtable,数 据类型是object)。在本例中,键的数据类型是Guid,值的数据类型则是string。
重复数据删除的三种算法

厂商采纳的执行重复数据删除的基本方法有三种与及各种的优缺点。
第一种是基于散列(hash)的方法,Data Domain、飞康、昆腾的DXi 系列设备都是采用SHA-1, MD-5 等类似的算法将这些进行备份的数据流断成块并且为每个数据块生成一个散列(hash)。
如果新数据块的散列(hash)与备份设备上散列索引中的一个散列匹配,表明该数据已经被备份,设备只更新它的表,以说明在这个新位置上也存在该数据。
基于散列(hash)的方法存在内置的可扩展性问题。
为了快速识别一个数据块是否已经被备份,这种基于散列(hash)的方法会在内存中拥有散列(hash)索引。
当被备份的数据块数量增加时,该索引也随之增长。
一旦索引增长超过了设备在内存中保存它所支持的容量,性能会急速下降,同时磁盘搜索会比内存搜索更慢。
因此,目前大部分基于散列(hash)的系统都是独立的,可以保持存储数据所需的内存量与磁盘空间量的平衡,这样,散列(hash)表就永远不会变得太大。
第二种方法是基于内容识别的重复删除,这种方法主要是识别记录的数据格式。
它采用内嵌在备份数据中的文件系统的元数据识别文件;然后与其数据存储库中的其它版本进行逐字节地比较,找到该版本与第一个已存储的版本的不同之处并为这些不同的数据创建一个增量文件。
这种方法可以避免散列(hash)冲突(请参阅下面的“不要惧怕冲突”),但是需要使用支持的备份应用设备以便设备可以提取元数据。
ExaGrid Systems的InfiniteFiler就是一个基于内容识别的重复删除设备,当备份数据时,它采用CommVault Galaxy 和Symantec Backup Exec 等通用的备份应用技术从源系统中识别文件。
完成备份后,它找出已经被多次备份的文件,生成增量文件(deltas)。
多个 InfiniteFilers合成一个网格,支持高达30 TB的备份数据。
采用重复删除方法的ExaGrid在存储一个1GB的 .PST文件类的新信息时表现优异,但它不能为多个不同的文件消除重复的数据,例如在四个.PST文件具有相同的附件的情况下。
哈希索引散列索引

哈希索引散列索引介绍哈希索引(Hash Index)和散列索引(Hashing Index)是数据库中常用的索引技术,用于提高数据的检索效率。
本文将深入探讨哈希索引和散列索引的原理、优缺点以及应用场景。
哈希索引哈希索引是一种基于哈希表的索引结构,通过将索引列的值通过哈希函数映射到一个固定长度的哈希码,然后将哈希码作为索引的关键字进行存储和检索。
哈希函数哈希函数是哈希索引的核心,它将任意长度的输入转换为固定长度的输出。
好的哈希函数应该具备以下特点: - 快速计算:哈希函数的计算速度应该很快,以保证索引的高效性。
- 均匀分布:哈希函数应该能够将输入的不同值映射到不同的哈希码上,以减少哈希冲突的概率。
- 低冲突率:哈希函数应该尽量避免冲突,即不同的输入值映射到相同的哈希码上。
哈希索引的构建过程1.创建哈希表:哈希索引首先需要创建一个哈希表,用于存储索引的关键字和对应的数据地址。
2.哈希函数映射:对于每个索引列的值,通过哈希函数将其映射到一个哈希码上。
3.存储索引:将哈希码作为关键字,将数据地址存储到哈希表中。
4.检索数据:对于查询操作,通过哈希函数将查询条件的值映射到哈希码,然后在哈希表中查找对应的数据地址。
哈希索引的优点•快速检索:由于哈希索引通过哈希函数映射到固定长度的哈希码,因此可以通过哈希码直接访问到对应的数据地址,大大提高了检索效率。
结构,占用的空间更小。
哈希索引的缺点•哈希冲突:由于哈希函数的映射是有限的,不同的输入值可能映射到相同的哈希码上,导致哈希冲突。
哈希冲突会增加数据的检索时间,并且需要解决冲突的方法,如链地址法、开放地址法等。
•不支持范围查询:哈希索引只能进行等值查询,不支持范围查询。
因为哈希函数将不同的值映射到不同的哈希码上,无法按照值的大小进行排序。
散列索引散列索引是一种基于散列函数的索引结构,它将索引列的值通过散列函数计算得到一个散列码,然后将散列码作为索引的关键字进行存储和检索。
李春葆《数据结构教程》(第4版)章节题库-文件(圣才出品)

第12章文件一、选择题1.哈希文件使用哈希函数将记录的关键字值计算转化为记录的存放地址,因为哈希函数是一对一的关系,则选择好的()方法是哈希文件的关键。
A.哈希函数B.除余法中的质数C.冲突处理D.哈希函数和冲突处理【答案】D【解析】哈希表是根据文件中关键字的特点设计一种哈希函数和处理冲突的方法将记录散列到存储设备上。
2.下述文件中适合于磁带存储的是()。
A.顺序文件B.索引文件C.哈希文件D.多关键字文件【答案】A【解析】磁带存储是一种顺序存储,顺序文件(sequential file)是记录按其在文件中的逻辑顺序依次进入存储介质而建立的,即顺序文件中物理记录的顺序和逻辑记录的顺序是一致的。
因此顺序文件适合磁带存储。
二、判断题1.倒排文件是对次关键字建立索引。
()【答案】√【解析】倒排文件是对每一个次关键字项建立次关键字索引(称为倒排表),将所有具有相同次关键字的记录的物理记录号都填入倒排表为此次关键字的表中。
2.倒排序文件的优点是维护简单。
()【答案】×【解析】倒排文件的优点是检索记录较快。
特别是对某些询问,不用读取记录,就可得到解答。
3.哈希表与哈希文件的唯一区别是哈希文件引入了“桶”的概念。
()【答案】×【解析】哈希文件是使用一个函数(算法)来完成一种将关键字映射到存储器地址的映射,根据用户给出的关键字,经函数计算得到目标地址,再进行目标的检索。
哈希表是根据关键码值而直接进行访问的数据结构。
4.文件系统采用索引结构是为了节省存储空间。
()【答案】×【解析】是为了缩短查找的时间,牺牲了一部分存储空间。
5.对处理大量数据的外存介质而言,索引顺序存取方法是一种方便的文件组织方法。
()【答案】×【解析】索引顺序存取方法插入操作比较麻烦,对于处理大量数据,会有大量的记录进入溢出区,而基本区中又浪费很多空间。
6.对磁带机而言,ISAM是一种方便的文件组织方法。
最新数据结构习题19325教学内容

一.算法的基本概念【例1】算法是指()。
(A)计算机程序(B)计算机的计算方法(C)计算机的存取方式(D)解决问题的有限运算序列【答案】D【例2】算法的基本特性不包括()。
(A)输入性(B)确定性(C)高效性(D)可执行性【答案】C【例3】算法的工作量大小和实现算法所需的存储单元多少分别称为算法的()和()。
(1)(A)可执行性(B)时间复杂度(C)空间复杂度(D)计算机的效率(2)(A)确定性(B)时间复杂度(C)空间复杂度(D)存储的合理性【答案】(1)B (2)C【例4】时间复杂性最好,执行时间最短的是()。
(A)O(log2n) (B)O(nlog2n)(C)O(n) (D)O(n³)【答案】A【例5】下面程序段的时间复杂度是()。
For(int a=0;a<n;a++)For(int b=1;b<m;b++)A[a][b]=1;(A)O(n) (B)O(n×m)(C)O(n+m) (D)O(n+m-1)【答案】B【例6】下列程序段的时间复杂度为()。
For(i=1;i<n;i++){y=y+1; ①for(j=0;j<=(2*n);j++)x++; ②}(A)O(n-1) (B) O(n)(C)O(n2) (D) O(2n+1)【答案】C【例7】下列程序段的时间复杂度为()。
i=1;while(i<=n)i=i*2;(A)O(1) (B) O(n)(C)O(log2n) (D) O(2n)【答案】C【例8】算法的执行遵循“输入―计算―________”的模式,算法的________体现算法的功能。
【答案】输出输出【例9】式子a*(3a2+6a-3)的时间复杂度是________。
【答案】O(a3)【例10】当有非法数据输入时,算法能做出适当的处理,体现了算法的________。
【答案】健壮性【考点解析】一个算法必须能够处理非法数据的输入,且不能产生不可预测的结果,这是算法的健壮性所必须的,处理非法数据的能力体现了算法的健壮性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
如果外层索引也无法完全放在主存中,那么可以 新创建另一层索引 在插入和删除时,各层索引都必须进行更新
S.J.T.U.
多级索引(续…)
S.J.T.U.
索引更新:删除
单层索引删除
稠密索引: • 如果删除的记录是唯一具有这个特定搜索码值的记 录,那么就从索引中删除此索引记录 • 否则:
另一种方案称为开散列(不使用溢出桶),不适合数据库
S.J.T.U.
散列索引
散列索引将搜索码及其相应的指针组织成散列文 件结构 严格来说,散列索引总是辅助索引
如果文件本身是散列组织的,就不需要另外建立一个 独立的主索引 我们使用散列索引表示辅助散列索引和散列组织文件
S.J.T.U.
散列索引的例子
S.J.T.U.
SQL中的索引定义
创建一个索引
create index <index-name> on <relation-name> (<attribute-list>) 范例:create index b-index on branch(branch_name)
使用create unique index声明指定的搜索码 是候选码 删除一个索引
– 将新块中出现的第一个搜索码值插入到索引中 – 如果新记录含有块中的最小搜索码值,则更新执行该块的 索引项
• 否则,索引不做任何改动
S.J.T.U.
辅助索引
索引记录指向保存所有记录指针的“桶” 辅助索引必须是稠密的
S.J.T.U.
B+树索引文件
B+树索引是顺序索引文件的一种替代方案 顺序索引文件的缺陷
• 如果该搜索码值不在索引中,则在索引中合适的位置插 入该搜索码值的索引记录 • 否则
– 如果索引记录存储所有记录的指针,则在索引记录中增加 一个指向新记录的指针 – 否则,将待插入的记录放到具有相同搜索码值的其他记录 之后
S.J.T.U.
索引更新:插入(续…)
单层索引插入
稀疏索引
• 假设索引为每个块保存一个索引项 • 如果系统产生一个新块
顺序索引和散列的比较
周期性重组的代价 插入和删除的相对频率如何 是否愿意在增加最坏情况下的访问时间为代价优 化平均访问时间 查询的类型有哪些
获取特定搜索码值对应的记录时,散列效率更高 对于范围查询而言,顺序索引效率更高
实际商业数据库的情况
PostgreSQL支持散列索引,但不鼓励使用 支持静态索引结构,但不支持散列索引 SQLServer只支持B+树
也成为非聚集索引(non-clustering index)
索引顺序文件:搜索码上具有聚集索引
S.J.T.U.
S.J.T.U.
稠密索引文件
稠密索引(Dense Index):文件中的每个搜索 码值都有一个索引记录
S.J.T.U.
稀疏索引文件
稀疏索引(Sparse Index):只为搜索码的某些 值建立索引记录
S.J.T.U.
动态散列
有利于数据库大小动态改变的情况 允许散列函数动态改变 可扩充散列(extendable hashing)
散列函数产生的值范围相对较大,如32位二进制数 在记录插入时按需创建桶 使用i位作为附加的桶地址表的入口偏移量
S.J.T.U.
可扩充散列的一般结构
S.J.T.U.
– 如果索引记录存储所有记录的指针,则从索引记录中删除 指向被删除记录的指针 – 否则,如果删除的记录是具有该搜索码的第一条记录,那 么更新索引记录,使其指向下一条记录
S.J.T.U.
索引更新:删除(续…)
单层索引删除
稀疏索引: • 如果索引中不包含被删除记录搜索码值的索引记录, 索引不做任何修改 • 否则
S.J.密索引相比
更少的存储空间,插入和删除时更少的维护开销 定位记录时通常比稠密索引更慢
权衡(Tradeoff):为每个块建立一个索引项的 稀疏索引也许是个较好的折中
S.J.T.U.
多级索引
如果主索引无法完全放在主存中,访问开销变得 很大 解决方法:将主索引像顺序文件一样放在磁盘上, 然后在其上建立稀疏索引
search-key pointer
索引文件通常比原文件小很多 两种基本的索引类型
顺序索引:搜索码按某种排序方式存放 散列索引:搜索码分布在散列“桶”中
S.J.T.U.
索引评价因素
访问类型:能有效支持的访问类型
找到具有特定属性值的记录 找到具有特点属性值范围的记录
访问时间 插入时间 删除时间 空间开销
S.J.T.U.
B+树节点结构
典型节点
Ki:搜索码值 Pi:
• 对于非叶节点:指向子节点的指针 • 对于叶节点:指向记录的指针
在节点中的搜索码值满足
K1 < K2 < K3 < . . . < Kn–1
S.J.T.U.
B+树的范例
S.J.T.U.
静态散列
术语桶(bucket)表示能存储一条或多条记录的 一个存储单元 在散列文件组织中,通过对搜索码值的散列函数 (hash function)计算,直接得到包含目标记 录的桶 散列函数h是一个从K到B的函数
S.J.T.U.
处理桶溢出
桶会发生溢出,原因是
桶数量不足 记录分布的偏斜(skew)
• 不同的记录具有相同的搜索码 • 所选择的散列函数造成了不均匀分布
尽管桶溢出可以在一定程度上消减,但不可能完 全消除,需要进行桶溢出处理。
S.J.T.U.
处理桶溢出 (续…)
溢出链:桶的所有溢出桶使用一个链表连接起来 上述散列结构称为闭散列(closed hashing)
随着文件的增大,性能下降 需要定期的文件重新组织
B+树索引文件的优势
在插入和删除的情况下,自行进行重组 无需对整个文件进行重组
B+树的缺点
额外的插入和删除开销,空间开销
优势大于缺点,被广泛使用
S.J.T.U.
B+树索引文件 (续…)
B+树是具有以下特性的根树
树根到树叶的每条路径长度相同 每个非根非叶节点具有n/2到n个子节点 每个叶节点具有(n–1)/2到n–1个值
– 如果被删除的记录是具有该搜索码值的唯一记录,那么用 下一个搜索码值的索引记录替换相应的索引记录。如果下 一个搜索码值已存在索引项,则删除而不是替换该索引项 – 否则,如果删除的记录是具有该搜索码的第一条记录,那 么更新索引记录,使其指向下一条记录
S.J.T.U.
索引更新:插入
单层索引插入
稠密索引
drop index <index-name>
大部分数据库系统支持指定索引的类型
S.J.T.U.
S.J.T.U.
K:所有搜索码值的集合 B:所有桶地址的集合
不同的搜索码所对应的记录可能映射到同一个桶, 因此必须对整个桶进行顺序检索以确定记录
S.J.T.U.
散列文件组织的范例
account文件的散列结构,以branch_name 作为搜索码
10个桶 散列函数h返回字母的二进制表示之和对10取模的结果
• 如: h(Perryridge) = 5 =3 h(Round Hill) = 3 h(Brighton)
S.J.T.U.
散列文件组织的范例
S.J.T.U.
散列函数
最坏的散列函数将所有的搜索码值映射到同一个 桶中 理想的散列函数分布是均匀的:从所有可能的搜 索值集合中为每个桶分配同样数量的搜索码值 理想的散列函数分布是随机的:不管搜索码值实 际怎样分布,每个桶应分配到的搜索码值数目几 乎相同 通常散列函数在搜索码字符二进制表示上执行计 算
S.J.T.U.
顺序索引
在顺序索引中,索引条目按搜索码的某种顺序存 放 主索引(Primary Index):包含记录的文件按 搜索码指定的顺序排序
也称为聚集索引(clustering index) 主索引的搜索码多数是主码,但不是必须的
辅助索引(Secondary Index):搜索码指定的 顺序和文件中记录的物理顺序不一致
索引与散列
S.J.T.U.
陆海宁
索引和散列
基本概念 顺序索引 B+树索引文件 B-树索引文件 静态散列 动态散列 顺序索引和散列的比较 SQL中的索引定义 多码访问
S.J.T.U.
基本概念
索引机制用于加速数据访问
类似于:图书馆里的目录卡
搜索码:在文件中查找记录的属性或属性集 索引文件包含以下形式的记录(称为索引条目)