SPSS操作与数值变量统计描述
SPSS Modeler数据挖掘操作之数值型变量的基本分析

3
描述集中趋势的统计量一般有均值、中位数等 描述离散程度的统计量一般有方差、标准差和极差等 为分析数值型变量之间相关程度,还应该计算简单相关系数或者绘制散点图
等。
计算基本描述统计量
4
这里,对电信客户数据的分析目标是:计算基本服务累计开通月数、上月基 本费用的基本描述统计量,并分析上述变量与年龄、家庭月收入、家庭人口 之间,以及基本服务累计开通月数与基本费用之间输出内容
本例的计算结果
8
以开通月数为例,平均开通月数 为34.1,但由于数据的极差-71, 和数据的标准差-21.36都比较大, 说明开通月数的取值差异较大。
另外开通月数与年龄和收入都有 一定的正相关性,而与家庭人数 的相关性为极弱的负相关性
SPSS Modeler数据挖掘操作之
数值型变量的基本分析
版权说明
1
本文档操作案例选编自中国人民大学出版社《基于SPSS Modeler的数据挖掘》薛 薇编著,若作者对本资料持有异议,请及时与本网站联系,我们将第一时间妥善 处理。
数据的基本分析
2
数据的基本分析一般从简单变量的分析入手,到多变量的相关性研究。通常, 可通过描述性分析,计算关于数据分布特征的描述统计量,确切掌握数据的 分布特点。
选择【输出】选项卡中的【统计量】节点,连接到数据流的适当位置
5
在【编辑】选项进行节点的参数设置,如图所示
参数设置方法
6
检查:选择需要计算描述统计量的变量。 统计量:选择需要计算哪些描述统计量,可以包括图中所示的计数、均值、
总和、最小值、最大值等 相关:指定【检查】框中的变量与哪些变量进行相关性分析
常用统计学方法--SPSS操作步骤

4.1 一般资料对比
4.1 一般资料对比
4.1 一般资料对比
4.1 一般资料对比
4.1 一般资料对比
4.1 一般资料对比
两组患者一般情况见表1,表中数据组间差异均无显著性意义(P> 0.05),具有可比性。
4.2 终点指标对比
4.2 终点指标对比
4.2 终点指标对比
4.2 终点指标对比-组内比较
2.2 计数与等级资料的描述
2.3 统计描述:spss
定量资料的正态性检验:小样本选S-W,本例中,P大于0.05,数据符合正态分布
2.3 统计描述:spss
均值、标准差
2.3 统计描述:spss
中位数、四分位数
03 统 计 学 推 断
3.1 统计学方法选择思路
研究目的
资料类型
计量资料
等级资料
计数资料
统计描述 离集统 散中计 程趋图 度势表
统计推断 统计推断
no 条件
t方
检差
验
分 析
秩 和 检 验
统计描述 相构率 对成 比比
统计推断
2
检 验
3.2 t检验
单样本t检验:已知样本均数与 已知总体均数的比较。
满足以下条件 1. 计量资料 2. 单因素 3. 样本均数和总体均数的比较 4. 服从正态分布
3.5 计数资料:X2检验
行X列表资料的X2检验
3.5 计数资料:X2检验
1、所有理论频数≥5,看Pearson ChiSquare的结果; 2、超过20%的理论频数<5或至少1个理论频 数<1,看Fisher’s Exact Test结果
04 简 单 案 例
4.1 一般资料对比
1、建立三线表; 2、注意不同的统计量值; 3、注明数据的单位
【003期】统计指南SPSS

3⃞统计目标:实用为主⃞心法口诀:变量选方法、设计看类型、目的定乾坤3.1变量就是观察单位的某项特征,简单点就是我们研究的指标。
变量可分为:数值变量、名义变量和等级变量,每种变量的属性和特征都是不同的,所采用的统计分析方法也不同。
(1)数值变量(连续变量、计量变量)测大小。
采用定量的方法测得其数值的大小。
如,身高、体重。
(2)等级变量(顺序变量)比高低。
从变量取值可见,可以比较出程度的关系。
如,年级、职称。
(3)名义变量(反映不同的属性和类别,无高低大小之分)数数目。
受试对象按照属性分类后,对不同组进行数一数计数就可以了。
如,性别、生源地。
注:一般来说,心理测量时在顺序量表上进行的,因为对于人的智力、性格、兴趣、态度等来说,绝对零点是难以确定的,而且,在心理测量中,相等单位也是很难获得的。
不过,利用某种统计方法,可以把顺序量表得到的数据换算为等距数据来进行统计。
变量类型是每类分析方法的基石,区分好变量类型,便可找到合适的分析方法。
了解基本统计名词概念,可有助于理解分析结果指标意义。
例如,后面我们要提到的差异检验,主要包括T 检验、单因素方差分析和卡方检验。
三种检验对变量类型的要求是不一样的,T 检验和单因素方差分析适用于检验分类数据和连续数据之间的差异(T 检验要求分类数据仅有两个水平,单因素方差分析要求有三个或三个以上水平),而卡方检验适用于分类数据与分类数据之间的差异。
图3- 1注:这里的分类变量特指名义变量(计数变量)。
根据数据所反映的测量水平,可以将数据分为称名数据、顺序数据、等距数据和等比数据。
四种数据的特点如下:(一)称名数据(名义变量)又称名义数据,按事物的某种属性对其进行平行的分类或分组。
(只能测度事物之间的类别差,其他差别无法得知)例如,按照性别将人口分为男、女两类,按肤色分为白种人、黄种人、棕种人、黑种人四类,按洲别分为亚洲人、欧洲人、美洲人、非洲人、澳洲人五类。
(二)顺序数据(顺序变量、等级变量)又称等级数据,是对事物之间等级差别和顺序差别的一种测度。
数据统计分析SPSS教程完整版

市场研究
市场细分
利用SPSS对市场数据进行统计分析,识别 不同消费群体的特征和需求,为市场细分提 供依据。
营销策略制定
通过SPSS分析市场趋势和消费者行为,为 企业制定有针对性的营销策略提供数据支持。
社会调查与分析
要点一
社会问题研究
利用SPSS对社会问题进行定量分析,探究问题背后的原因 和影响因素。
线性回归分析
线性回归分析概述
01
线性回归分析是预测一个因变量与一个或多个自变量之间线性
关系的方法。
最小二乘法
02
最小二乘法是一种常用的回归分析方法,通过最小化预测值与
实际值之间的平方差来估计回归系数。
多元线性回归
03
当一个因变量受到多个自变量的影响时,可以使用多元线性回
归来预测其值。
非线性回归分析
非线性回归分析概述
非线性回归分析是预测因变量与自变量之间非线性关系的方法。
多项式回归
多项式回归是一种常见的非线性回归形式,通过将自变量多次方来 拟合非线性关系。
逻辑回归
逻辑回归是一种用于二元分类问题的回归分析方法,通过将因变量 转换为概率值来进行预测。
06
聚类分析与判别分析
K-均值聚类分析
总结词
独立样本T检验
总结词
用于比较两个独立样本的均值是否存在显著差异。
详细描述
独立样本T检验用于比较两个独立样本的均值。在独立样本T检验中,我们假设两个样本分别来自不同的总体,并 检验这两个总体的均值是否存在显著差异。通过计算T统计量,我们可以判断两个样本的均值是否存在显著差异。
配对样本T检验
总结词
用于比较两个相关样本的均值是否存在显著差异。
spss基本操作

观测量排序
Step01:打开观测量排序对话框
打开SPSS软件,选择菜单栏中的【File(文件)】→ 【Data(数据)】→【Sort Cases(排序个案)】命令,弹出 【Sort Cases(排序个案)】对话框。
27
Step02:选择排序变量
在左侧的候选变量列表框中选择主排序变量,单 击右向箭头按钮,将其移动至 【Sort by(排序依 据)】列表框中。
启动SPSS后看到的第一个窗口便是数据编辑窗口,如图所示。在数据编辑 窗口中可以进行数据的录入、编辑以及变量属性的定义和编辑,是SPSS的 基本界面。主要由以下几部分构成:标题栏、菜单栏、工具栏、编辑栏、 变量名栏、观测序号、窗口切换标签、状态栏。
5
标题栏:显示数据编辑的数据文件名。 菜单栏:通过对这些菜单的选择,用户可以进行几乎所有的SPSS
Step04:单击【OK】按钮,操作结束。
注意:数据文件转置后,数据属性的定义都会丢失,因 此用户要慎重选择本功能。
29
实例内容:国家财政分项目收入数据
Step1:选定对话框 Step2: 选择转置变量 Step3: 新变量命名
Step4: 完成操作
国家财政分项目收入数据.sav
30
文件合并
• 【data(数据)】→【Merge Files(合并文件)】菜单中 有两个命令选项:【Add Cases(添加个案)】和【Ad d Variables(添加变量)】。
21
最后,单击【OK(确定)】按钮,数 据即可导入 成功。此时,SPSS的 数据浏览窗口中会出现相关的 数据
内容。 弹出的对话框中的【Read variable names from the first row of date
spss语法总结归纳

spss语法总结归纳SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,被广泛应用于社会科学领域的数据处理和分析中。
SPSS语法是一种命令式的语言,通过编写语法脚本来完成各种数据处理和统计分析任务。
本文将对SPSS语法进行总结归纳,帮助读者更好地掌握SPSS语法的基本使用方法。
一、数据导入与整理在开始进行数据处理和分析前,需要将原始数据导入SPSS软件,并进行必要的整理和清洗。
1. 数据导入使用"GET DATA"命令可以导入各种数据格式的文件,如Excel、CSV等。
可以指定文件路径和名称,也可以通过对话框选择文件。
导入后的数据将被自动命名为默认的数据集名称。
2. 变量定义在导入数据后,需要对变量进行定义和设置。
使用"VARIABLES"命令可以完成变量定义。
可以指定变量名称、变量类型(如数值型、字符型等)、缺失值定义等信息。
3. 数据整理对于数据集中的无效数据或缺失值,可以使用SPSS语法进行处理。
例如,可以使用"SELECT IF"命令根据某个变量的条件进行数据筛选;使用"RECODE"命令对变量进行重编码;使用"COMPUTE"命令计算新的变量等。
二、数据分析与统计SPSS语法有丰富的统计分析功能,下面将介绍常用的一些统计分析命令。
1. 描述统计描述统计是对数据进行概括和总结的方法。
使用"DESCRIPTIVES"命令可以计算变量的均值、标准差、最小值、最大值等统计量;使用"FREQUENCIES"命令可以计算变量的频数和频率分布。
2. 参数检验参数检验是对样本数据与总体进行比较的方法,主要用于推断性统计分析。
使用"T-TEST"命令可以进行两组样本均值的差异检验;使用"ONEWAY"命令可以进行多组样本均值的差异检验。
SPSS的变量设置和基本操作
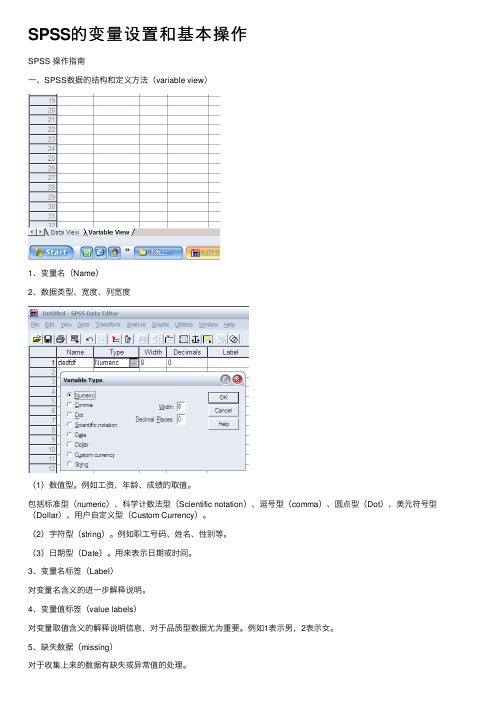
SPSS的变量设置和基本操作SPSS 操作指南⼀、SPSS数据的结构和定义⽅法(variable view)1、变量名(Name)2、数据类型、宽度、列宽度(1)数值型。
例如⼯资、年龄、成绩的取值。
包括标准型(numeric)、科学计数法型(Scientific notation)、逗号型(comma)、圆点型(Dot)、美元符号型(Dollar)、⽤户⾃定义型(Custom Currency)。
(2)字符型(string)。
例如职⼯号码、姓名、性别等。
(3)⽇期型(Date)。
⽤来表⽰⽇期或时间。
3、变量名标签(Label)对变量名含义的进⼀步解释说明。
4、变量值标签(value labels)对变量取值含义的解释说明信息,对于品质型数据尤为重要。
例如1表⽰男,2表⽰⼥。
5、缺失数据(missing)对于收集上来的数据有缺失或异常值的处理。
字符型变量或数值型变量,可以是1⾄3个特定的离散值(discrete missingvalues)数值型变量,哟过户缺失值可以在⼀个连续的闭区间内并同时再附加⼀个区间以外的离散值(Range plus one optional discrete)6、度量尺度(measure)定距型数据(Scale),通常是指诸如⾝⾼、体重、收⼊等的连续型数据。
也包括诸如⼈数、商品件数等离散型数据。
包括了等距量表和等⽐量表。
定序型数据(ordinal)具有内在的固有⼤⼩或⾼低顺序,不同于定距型数据,⼀般可以⽤数值或字符表⽰。
如职称变量可以有低级、中级、⾼级三个取值,可以分别为1、2和3表⽰。
定类型数据(norminal)没有内在固有⼤⼩或⾼低顺序,⼀般以数值或字符表⽰的分类数据。
如性别、民族等。
操作:仔细看看居民储蓄的数据,理解数据结构的含义。
⼆、分类汇总的操作界⾯调整⾄左下⾓的data view。
1、分类汇总按照某分类进⾏分类汇总计算。
例如想知道不同户⼝的居民取款⾦额是否较⼤差距。
SPSS统计分析—描述性统计分析

Skewness
中位数 Median
方差
Variance
峰度
Kurtosis
众数
Mode
极小值
Minimum
和
Sum
极大值
Maximum
全距
Range
均值的标准 误差
S.E.mean
• 【Descriptive Statistics】子菜单
• ① Frequencies:产生变量值的频数分布表,并可计算常见 描述性统计量和绘制相对应的统计图。
• 执行【Analyze】/【Descriptive Statistics】/ 【Crosstabs】命令,弹出如图所示对话框
• 结果解读
1、列联表 2、卡方检验结果
3、条图
相对比描述——Ratio
• 在实际问题中,研究者有时除了希望了解变量自身的统计特 征,还希望得到两个变量相对比之间的统计描述。
适用范围:更适用于对分类变量以及不服从正态分布的连 续性变量进行描述。
• 学生身高频数表:已知有某地120名12岁男童身高数据,编 制其传统的简易频数表。
执行【Analyze】/【Descriptive Statistics】/ 【Frequencies】命令,弹出如下所示对话框
• 结果解读 1、频数表
每个格子中的理论频数T是在假定两组的发癌率相等(均等于两组 合计的发癌率)的情况下计算出来的,如第一行第一列的理论频数 为71*91/113=57.18,故卡方值越大,说明实际频数与理论频数的 差别越明显,两组发癌率不同的可能性越大。
2、卡方检验方法的适用条件
• 吸烟习惯与患病率的关系
调查339名50岁以上吸烟习惯与患慢性气管炎病的关系,如 上表所示。试问吸烟者与不吸烟者慢性气管炎患病率是否有 所不同。 ◆ 数据的预处理:WEIGHT CASE
SPSS教程2:利用SPSS进行统计描述

在教育技术研究过程中收集到大量的资料数据,但从这些杂乱无章的资料中,很难对其总体水平与分布状况做出评价判断。
因此,必须采用一些适当的方法对这些资料进行处理,使之简约化、分类化、系统化,从中发现它们的分布规律,掌握总体的特征,以便对其水平做出客观的评价。
统计描述方法,是研究简缩数据并描述这些数据的统计方法。
将搜集来的大量数据资料,加以整理、归纳和分组,简缩成易于处理和便于理解的形式,并计算所得数据的各种统计量,如平均数、标准差、以及描述有关事物或现象的分布情况、波动范围和相关程度等,以揭示其特点和规律。
(一)数据资料的整理和表示在教育技术研究中,我们用各种方法搜集来的资料,一般是零散的,它只反映个别现象的个别特征,必须经过整理加工,使之系统化,才能计算统计指标,进行统计分析,为进一步研究提供有用的信息,首先要进行的是统计整理,它包含以下几部分内容:1.数据检查主要检查数据的完整性与正确性。
统计资料完整性的检查,就是要根据调查项目检查是否填写齐全,避免遗漏,删去重复。
正确性检查,就是检查搜集的资料是否真实可靠。
特别是统计数字的真实性是统计工作的生命,统计资料的检查整理必须抓紧这一环。
数据检查可分为逻辑检查和计算检查两种方法。
逻辑检查,是从理论和一般常识上来检查资料内容是否合理,指标之间是否矛盾。
计算检查是检查统计数字在计算方法和计算结果上有否错误。
2.数据分类数据分类就是把搜集来的数据进行分组归类。
数据分类要做到既不重复、不遗漏,又不混淆,一般又可分为品质分类和数量分类。
品质分类:是按事物性质划分为不同的组别、种类。
如以性别为标志可分为男与女;按“理解能力”、“学习态度”等为标志,又可分为好、较好、一般、差等几种水平,每种水平可看成类,每一类可给以相当的数量。
可以通过各类所包含的数据再进行数量化的比较和分析。
数量分类:是按数量的属性分类。
有顺序排列法、等级排列法和次数分布法等。
⒊数据的排序数据排序:将各数据从大到小或从小到大进行排列。
spss实验一基本统计方法

在SPSS 中进行实验一的基本统计方法包括描述统计和推论统计两个方面。
描述统计用于对实验数据的整体特征进行描述,而推论统计则用于对样本数据进行推断,从而得出总体的结论。
以下是在SPSS 中进行实验一时常用的基本统计方法:描述统计:1. 均值(Mean):计算数据的平均值,反映数据的集中趋势。
2. 标准差(Standard Deviation):衡量数据的离散程度。
3. 频数统计(Frequencies):统计分类变量的频数分布。
4. 中位数(Median):数据的中间值,不受极端值影响。
5. 最大最小值(Minimum, Maximum):显示数据的最大值和最小值。
6. 百分位数(Percentiles):显示数据的分位数,如四分位数等。
推论统计:1. 相关分析(Correlation):分析两个连续变量之间的关系。
2. t检验(Independent Samples T-Test, Paired Samples T-Test):比较两组样本均值是否存在显著差异。
3. 方差分析(ANOVA):比较两个或多个组之间均值是否存在显著差异。
4. 卡方检验(Chi-Square Test):用于比较分类变量之间的关联性。
5. 线性回归(Linear Regression):分析自变量和因变量之间的线性关系。
6. 非参数检验(Mann-Whitney U Test, Kruskal-Wallis Test):适用于非正态分布数据或秩次数据的假设检验。
以上是在SPSS 中常用的实验一基本统计方法,通过这些方法可以对实验数据进行全面的描述和分析,从而得出科学、客观的结论。
在使用这些方法时,需要根据实际情况选择合适的统计方法,并正确解读结果。
spss 相关统计学概念与描述性统计分析

某市1982年110名7岁男童的身高资料:
序号 数据cm
统计…
正态曲线
条形图 饼图 直方图 图表…
身高的各项统计学指标
统计 表 身 高(cm) N 110 0 Mean 119.725 Std. Error of Mean .452 Median 119.900 Mode 120.0 集中趋势指标 Std. Deviation 4.741 Variance 22.479 Skewness .156 偏度系数 离散趋势指标 Std. Error of Skewness .230 分布参数估计值 Kurtosis -.025 峰度系数 Std. Error of K urtosis .457 Range 24.3 Minimum 108.2 Maximum 132.5 Sum 13169.8 Percentiles 2.5 110.688 25 116.375 50 四分位数 119.900 75 122.800 97.5 130.568 Valid Missing
频数表分析( Frequencies过程 )
Frequencies分析过程可产生频数分布图、条形图、饼图、 直方图、计算任意百分位数、分布参数估计值、集中趋势与 离散趋势等各项统计学指标。 Analyze / Descriptive Statistics / Frequencies…
统计…
图表… 显 示 频 数 表
方差齐性检验及分布-水平散点图
数据转换方式
描述性统计指标
Descriptives 空 腹血 清 胰 岛 素 样生 长 因 子-1 性别 女 Mean 95% Confidence Interval for Mean 5% Trimmed Mean Median Variance Std. Deviation Minimum Maximum Range Interquartile Range Skewness Kurtosis Mean 95% Confidence Interval for Mean 5% Trimmed Mean Median Variance Std. Deviation Minimum Maximum Range Interquartile Range Skewness Kurtosis 统计 283.6224 237.8991 329.3458 265.6581 229.2000 34594.21 185.9952 53.71 984.8 931.1 224.7725 1.548 2.942 233.5008 202.7589 264.2428 217.8517 189.9600 19821.26 140.7880 80.73 822.9 742.1 152.5800 1.832 4.241 标 准误 22.8944
SPSS描述性统计分析

SPSS描述性统计分析SPSS是一种常用的统计分析软件,可以进行各种描述性统计分析。
描述性统计分析是对数据进行整体性的描述和总结,从中提取出关键的统计指标,包括数据的中心趋势、离散程度、分布形态和相关性等。
首先,数据的中心趋势是统计数据中心部分分布位置的指标。
常见的中心趋势统计指标有均值、中位数和众数等。
均值是将所有数据相加后除以总数,可以反映数据的平均水平;中位数是将数据按大小排列后处于中间位置的数,可以反映数据的中间位置;众数是数据中出现最频繁的数值,可以反映数据的集中趋势。
其次,数据的离散程度是统计数据分布的分散程度的指标。
常见的离散程度统计指标有标准差、方差和极差等。
标准差衡量数据与平均值的离散程度,数值越大表示数据越分散;方差是标准差的平方,也可以用于衡量数据的离散程度;极差是最大值与最小值之间的差异,可以反映数据的全局差异。
此外,还可以对数据的分布形态进行分析,以了解数据分布的形状。
常见的分布形态统计指标有偏度和峰度。
偏度反映数据分布的对称性,偏度为正表示数据右偏,为负表示左偏;峰度衡量数据分布的尖锐程度,峰度为正表示数据分布较为陡峭,为负表示较为平缓。
最后,还可以进行变量的相关性分析,以了解变量之间的相关关系。
常见的相关性统计指标有皮尔逊相关系数和斯皮尔曼等级相关系数。
皮尔逊相关系数是衡量变量之间线性相关关系的指标,取值范围为-1到1,数值越接近于1或-1表示相关性越强;斯皮尔曼等级相关系数则可以反映变量之间的单调相关关系,适用于非线性关系的变量。
在SPSS中进行描述性统计分析非常简单。
首先,打开SPSS软件并导入数据文件。
然后,在"分析(Analyze)"菜单中选择"描述性统计(Descriptive Statistics)",再选择"统计量(Descriptives)"。
在该对话框中,选择要进行统计分析的变量,并选择所需的统计指标,最后点击"确定"按钮即可。
SPSS的变量设置和基本操作

SPSS的变量设置和基本操作SPSS(Statistical Package for the Social Sciences)是一款常用的统计分析软件,可帮助研究者在社会科学领域进行数据分析。
在使用SPSS进行分析之前,需要对变量进行设置和进行一些基本操作。
本文将介绍SPSS的变量设置和基本操作。
一、变量设置在使用SPSS之前,必须先进行变量设置,包括变量属性和数据类型的定义。
变量属性可以是数值型、字符型或日期型;数据类型可以是连续型、离散型或自定义型。
以下是一些常见的变量设置步骤:1. 打开SPSS软件并新建数据文件(Data Editor)。
2. 在数据文件中选择“变量视图”(Variable View),可以看到一个表格,每一行代表一个变量。
3.在第一列输入变量名。
变量名应具有描述性且易于理解。
4. 在第二列选择变量类型。
可以选择数值型(Numeric)、字符型(String)或日期型(Date)。
5. 在第三列选择变量宽度(Width),即变量所占的字符数或数字位数。
根据实际需要进行设置。
6. 在第四列选择小数位数(Decimals)。
对于数值型变量,可以设置其精度。
二、变量操作除了变量设置之外,还需要进行一些基本的变量操作,如变量输入、导入、导出、修改和删除等。
以下是一些常见的变量操作步骤:2. 变量导入:可以将数据从其他文件导入到SPSS中进行分析。
选择“文件”(File)→“打开”(Open),然后选择需要导入的数据文件。
3. 变量导出:可以将分析结果导出到其他文件格式中,如Excel、CSV等。
选择“文件”→“导出”→“数据”(Export)。
5. 变量删除:可以删除不需要的变量。
选择相应的变量列,右键点击,并选择“删除”(Delete)。
三、变量操作技巧除了基本的变量设置和操作之外,还有一些变量操作的技巧可以提高效率和准确性。
2. 变量筛选:对于大量变量的数据文件,可以使用变量筛选功能,只显示需要的变量。
spss操作步骤讲解系列--描述统计及个案加权和多选题的频率分析

描述统计及数据个案加权1.个案加权及描述统计分析个案加权:常出现在实验、医学类。
对观测量进行加权,体现出该数值不是数而是个案数。
描述统计分析:主要用来对连续变量做描述性分析,可以输出很多类型的统计量。
一般展示:个案数、最小值、最大值、平均值、标准差、偏度和峰度。
平均数:也称为均值,是一组数据相加后除以数据的个数的结果。
标准差:方差的平方根。
方差:是各个变量值与其平均数离差平方的平均数。
偏度:对数据分布对称性的测量。
峰度:对数据分布平峰或者尖峰程度的测量。
图1描述统计在spss软件中勾选情况2.描述统计第一步,将数据导入spss软件后点击分析、描述统计、描述。
图2描述统计分析步骤一第二步,将对应变量放入对应变量框中,点击选项勾选分布里的偏度和峰度。
图3描述统计分析第二步然后描述统计的结果就出来了。
图4描述统计结果展示将结果粘贴复制到Excel表格中进行整理,后将整理好的结果粘贴复制到Word文档中进行表格的制作和文字描述。
图5描述统计结果整理3.个案加权个案加权:如果说数据为总合结果数据时,如图6所示,这样情况下还需进行数据分析就应进行个案加权操作。
图6数据形式第一步、点击数据、个案加权。
图7个案加权步骤一第二步、图中人数为个案数因此需要对人数进行加权处理,将人数放入频率变量框中点击确定,出现图中下方语法表明个案加权成功,可以进行接下的数据分析了。
图8个案加权第二步4.多重响应分析第一步、首先需要定义变量集,点击分析、多重响应、定义变量集。
图9多重响应分析第一步第二步、进入下方对话框后、将多选题选项题项放入集合中的变量框中、后在二分法后的值里填入1,定义好变量名称。
图10多重响应分析第二步第三步、定义完成后就可以进行多重响应分析:点击分析、多重响应、频率。
图11多重响应分析第三步进入图中对话框后将定义好的变量放入点击确定图12多重响应分析第四步然后多重响应分析的结果就出来了图13多重响应分析结果将结果粘贴赋值到Excel表格中进行整理,后将整理好的结果粘贴到Word 文档中进行表格的制作和文字解释。
SPSS统计描述几个重要的统计指标

均值(平均值、平均数):表示的是某变量所有取值的集中趋势或平均水平。
例如,学生某门学科的平均成绩、公司员工的平均收入、某班级学生的平均身高等。
计算公式如下。
中位数:定义:把一组数据按递增或递减的顺序排列,处于中间位置上的变量值就是中位数。
它是一种位置代表值,所以不会受到极端数值的影响,具有较高的稳健性计算公式:一个大小为的数列,要求其中位数,首先应把该数列按大小顺序排列好,如果为奇数,那么该数列的中位数就是位置上的数;如果N为偶数,中位数则是该数列中第与第+1位置上两个数值的平均数众数:定义:众数是指一组数据中,出现次数最多的那个变量值。
众数在描述数据集中趋势方面有一定的意义。
例如,制鞋厂可以根据消费者所需鞋的尺码的众数来安排生产。
计算公式:手工计算众数比较麻烦,需要统计数据的次数分布。
全距:定义:全距也称为极差,是数据的最大值与最小值之间的绝对差。
在相同样本容量情况下的两组数据,全距大的一组数据要比全距小的一组数据更为分散。
计算公式:最大值-最小值。
方差(Variance)和标准差(Standard Deviation):定义:方差是所有变量值与平均数偏差平方的平均值,它表示了一组数据分布的离散程度的平均值。
标准差是方差的平方根,它表示了一组数据关于平均数的平均离散程度。
方差和标准差越大,说明变量值之间的差异越大,距离平均数这个“中心”的离散趋势越大。
频数(Frequency):定义:频数就是一个变量在各个变量值上取值的个案数。
如要了解学生某次考试的成绩情况,需要计算出学生所有分数取值,以及每个分数取值有多少个人,这就需要用到频数分析。
变量的频数分析正是实现上述分析的最好手段,它可以使人们非常清楚地了解变量取值的分布情况。
峰度(Kurtosis):定义:峰度是描述某变量所有取值分布形态陡缓程度的统计量。
这个统计量是与正态分布相比较的量,峰度为0表示其数据分布与正态分布的陡缓程度相同;峰度大于0表示比正态分布高峰要更加陡峭,为尖顶峰;峰度小于0表示比正态分布平顶峰。
SPSS软件的操作与应用第2讲 描述性统计 (1)

直方图
1. 用面积表示各组频数的多少,矩形的高度表示每一组的频数或频率 宽度表示各组的组距; 2. 由于分组数据具有连续性,各矩形通常是连续排列; 3. 主要用于展示数值型数据。
二、频数分析
4. SPSS操作及案例 例一:各门成绩统计 结果保存为:3-StudentScore.spo
二、频数分析
5. SPSS操作及案例分析 根据方差齐性检验结果可以看出,语文成绩按照男女分开的样 本显著性水平Sig.值都大于0.05,表明方差的差异不显著,也就是 说方差是齐性的。
四、探索性分析
5. SPSS操作及案例分析 例五:操作步骤(数据文件:4-Explore.sav ) Analyze→Descriptive Statistics→Explore...
平均值(Mean):即算术平均值(=(X1+X2+…+Xn)/n)。 易受极端值影响。 中位数(Median):把变量的值有序排列,位于中间位置的值即中位数。 是位置平均置,不易受极端值的影响。 众数(Mode):样本中出现次数最多的值,代表数据的集中程序。 求和(Sum):所有变量之和,反映变量的总体水平。
三、基本描述统计量
4. 描述分布形态的统计量 考察数据分布形态特征的统计量,例如,数据分布是否对称、偏 斜程度以及陡缓程度,主要有如下两种统计量: 偏度(Skewness):
偏度值>0,为正偏或右偏;偏度值<0,为负偏或左偏。偏度绝对值越大,偏斜越大。
峰度(Kurtosis):
峰度值>0,数据分布比标准正态分布更陡峭,为尖峰分布;峰度值<0,数据分布比 标准正态分布更平缓,为平峰分布。
四、探索性分析
2. 通过茎叶图(Stem-and-Leaf Plots)描述频度分布
SPSS描述性分析统计操作步骤

SPSS描述性分析统计操作步骤SPSS是一个非常强大的数据处理和统计分析软件,它广泛应用于社会科学、医学、生物、商业等领域。
描述性分析是SPSS中常用的数据分析方法之一,具体涉及的操作步骤可以分为如下几个部分:一、数据录入和数据检查在运行SPSS前,需要先进行数据录入,将现场采集的数据输入到计算机中。
在录入数据之后,需要对数据进行检查,确认数据的完整性、正确性和一致性。
具体包括以下几个方面:1.检查数据是否按照规定的格式录入,比如数值型数据是否为数字,字符型数据是否为字符等;2.检查数据是否有重复、缺失、异常等情况,并针对这些情况进行相应处理;3.检查变量的名称、标签是否与实际意义一致,需要根据实际情况进行修改。
二、数据分布分析1.单变量分析单变量分析是指针对单个变量进行分析,主要关注该变量的基本统计信息和分布情况。
常用的描述性统计指标包括均值、中位数、众数、标准差、方差、最大值、最小值等。
如需对单个变量作更加细致的分析,可以生成直方图、箱线图、概率密度图等图形。
在SPSS 中,可以通过点和菜单或者语法来进行单变量分析。
三、数据检验1.正态性检验正态性检验是指检验变量是否符合正态分布,通常采用Kolmogorov-Smirnov检验、Shapiro-Wilk检验、Anderson-Darling检验等方法。
在SPSS中,可以通过点和菜单或者语法来进行正态性检验。
2.均值比较均值比较是指比较两个或多个组的均值是否存在显著差异,通常采用t检验和方差分析等方法。
在SPSS中,可以通过点和菜单或者语法来进行均值比较。
四、分组分析分组分析是指将数据按照某一变量进行分组,比较不同组之间的差异。
常用的分组变量包括性别、年龄、学历、职业等。
在SPSS中,可以通过点和菜单或者语法来进行分组分析。
以上就是SPSS描述性分析统计操作步骤的一些基本内容,因为需要考虑数据的来源、数据类型、研究目的等多方面的因素,所以具体操作步骤可能会有所不同。
如何使用SPSS进行数据统计分析

如何使用SPSS进行数据统计分析数据统计分析在各个领域中都扮演着重要的角色。
而SPSS(Statistical Package for the Social Sciences)作为一款功能强大且广为使用的数据分析软件,被广泛应用于社会科学研究、市场调研、医学研究等领域。
本文将向您介绍如何使用SPSS进行数据统计分析。
第一步:数据准备与导入首先,我们需要将待分析的数据准备好并导入到SPSS中。
SPSS支持导入多种数据格式,如Excel、CSV等。
选择"文件"->"导入数据"->"从文件",然后选择数据文件所在的路径,点击"打开"即可将数据导入到SPSS中。
第二步:数据清理与变量设置对于初步导入的数据,我们需要进行数据清理与变量设置。
在数据清理方面,我们可以使用SPSS的数据查看器功能进行数据观察,如查看数据的完整性、数据值是否有误、缺失值等。
如果发现异常数据,可以根据具体情况进行剔除或修正。
在变量设置方面,我们可以使用SPSS的变量视图功能进行变量属性的设置。
可以为每个变量指定变量类型(如数值、字符)、变量标签(用于标识变量含义)、缺失值编码等。
第三步:描述性统计分析描述性统计分析是一种基本的数据分析方法,用于对数据进行整体的概括与描述。
SPSS提供了多种描述性统计分析的方法,如频数分析、中心趋势与离散程度分析等。
频数分析可以帮助我们了解样本中每个变量的不同取值及其频率分布情况。
在SPSS中,我们可以通过选择"分析"->"描述统计"->"频数"来进行频数分析。
在对话框中选择需要进行频数分析的变量,点击"确定"即可生成频数表。
中心趋势与离散程度分析可以帮助我们了解变量的平均水平、中位数、标准差等统计指标,从而对变量进行整体的描述。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Data菜单练习
打开体检表.sav 练习插入(删除)cases或者variables 先对性别排升序,再对身高排降序 按照 性别 = ‘男’ & 身高>120的条件选择观 测 (注意不要在中文输入状态下敲单引号) 分性别保存数据文件 打开男生数据,追加女生数据 (注意进行了删除添加操作后,要另存..)
SPSS软件概述
公卫学院流行病与统计学系 易伟宁 讲师 82801619 yiweining@
SPSS是什么?
美国SPSS公司 公司()产品 美国 公司 产品 社会科学统计软件包(曾经 曾经) 社会科学统计软件包 曾经 Statistical Package for Social Sciences 统计产品和服务解决方案(现在的解释 现在的解释) 统计产品和服务解决方案 现在的解释 Statistical Product and Service Solutions 主要功能:专业的统计分析, 主要功能:专业的统计分析,强大的数 据管理, 据管理,一定的制表绘图功能
正态分布
有一类特殊的连续型随机变量,具有正 态分布(normal distribution)的分布特点 例如:106名儿童的身高和体重值 总体和样本、参数和统计量的概念 正态分布两个重要参数:均数、标准差 正态分布曲线的形状由这两个参数决定 查表可知正态曲线下任意区间所围面积 SP布资料 集中趋势 X =
− −
∑X
n
,离散趋势s =
( X − X )2 ∑ n −1
偏态分布资料 集中趋势M = P50,离散趋势Q = P75 − P25
SPSS操作
对身高、肺活量列频数表、绘制直方图 由于身高是对称(正态)分布的,所以选 择均数、标准差来进行描述 而肺活量是偏态分布的,所以选中位数 和四分位间距进行统计描述 还可作箱式图、茎叶图和正态Q-Q图 在explore命令里定义性别为因素factor 可以对身高等指标分性别描述
讨论
哪些变量命名方式是SPSS不接受的 Help -> Topics -> Data editor -> Variable view -> Variable names -> The following rules apply …
SPSS整理编辑功能
公卫学院流行病与统计学系 易伟宁 讲师 82801619 yiweining@
作业
对全部学生的体重指标编频数表,选择适合的 统计指标进行描述。 分性别对体重进行描述,编写统计表 从理论上说大部分(95%)的学生的体重在什 么范围内?为什么? 应如何估计这些学生肺活量的95%参考值范围? (注意:要写公式,表格要符合统计学要求)
关于考试
开卷上机考试 两个小时的考试时间,不允许延长 只能带入一本课本,可以带入课件。不 能带入u盘,目的是让大家专心答题, 不要把大部分时间花在翻书找答案上 基本上每次课会布置一些小作业,上交 后用于计算平时成绩,和考试成绩汇总 在一起,构成大家的最后成绩。
SPSS常用窗口介绍
数据编辑窗口 Data Editor,类似Excel 表格形式,每一行代表一个个体(case) 每一列代表该个体的一个属性。 语法编辑窗口 Syntax Editor,将窗口操 作以文本形式记录,便于调试和重复。 结果浏览窗口 Output Viewer,可编辑 和导出为word或html等格式。 对应扩展名为SAV, SPS, SPO的文件
数据加权练习
新建一个数据文件 在数据窗口里输入数据,包括6个1,6 个2,6个3共18个数。如何快速完成? Data -> Weight cases -> weight by f 用描述性统计菜单下的freq命令验证 23名病人,其中12名病人用A药治疗, 有效7名,无效5名;另外11名用B药治 疗,有效3名,无效8名。如何建立文件
SPSS作统计描述
公卫学院流行病与统计学系 易伟宁 讲师 82801619 yiweining@
数值变量的统计描述
统计描述是用统计指标和统计图表描述 资料的数量特征。常见变量类型包括数 值和分类变量,相应采用不同统计方法 数值变量特点,有单位,连续取值 描述数值变量的集中趋势,用均数 mean、中位数median、几何均数G。 描述其离散趋势,用全距range、四分 位数间距Interquartile range、方差 variance、标准差standard deviation和 变异系数等指标。
出生日期 日期
练习
将体检表输入SPSS,并在指定文件夹 保存 (SAV) 另存为excel97格式的文件(XLS),删除 姓名变量 用SPSS读取XLS文件。读之前要注意 关闭EXCEL窗口 如在点击“打开”或“确定”前 选”Paste”,操作过程用程序记录,点 之前不运行 打开文本数据文件(体检表.dat)
身高资料是对称(正态)分布的
身身 (Banded)
Frequency 1 5 4 14 21 20 16 15 6 3 1 106 Percent .9 4.7 3.8 13.2 19.8 18.9 15.1 14.2 5.7 2.8 .9 100.0 Valid Percent .9 4.7 3.8 13.2 19.8 18.9 15.1 14.2 5.7 2.8 .9 100.0 Cumulative Percent .9 5.7 9.4 22.6 42.5 61.3 76.4 90.6 96.2 99.1 100.0
106名学生身高(cm)的频数表
身高组段 102~ 105~ … 132~135 合计 频数 1 5 … 1 106 频率(%) 0.9 4.7 … 0.9 100.0 累计频率(%) 0.9 5.7 … 100.0 —
106名学生身高(cm)的均数表
性别组段 男 女 例数数 1 5 均数 0.9 4.7 标准差 0.9 5.7
Valid
<105.0 105.0 - 107.9 108.0 - 110.9 111.0 - 113.9 114.0 - 116.9 117.0 - 119.9 120.0 - 122.9 123.0 - 125.9 126.0 - 128.9 129.0 - 131.9 132.0+ Total
数据输入实例
某地区学龄儿童的体检表 学号:40025 姓名:李婷婷 年级: 1 性别:男 女√ 出生日期:04年3月31日 体检结果 身高120.0cm
体重19.5kg 肺活量883ml
变量清单
变量名 中文含义 类型 xh xm nj xb csrq sg tj fhl 学号 姓名 年级 性别 身高 体重 肺活量 数值 字符 数值 字符 数值 数值 数值 宽度 F8.0 A8 F8.0 A1 F8.1 F8.1 F8.0 m=男 f=女 厘米 千克 毫升 Date10 mm/dd/yyyy 备注
Data菜单
定义变量属性 复制数据属性 定义日期 插入变量√ 插入变量√ 插入个案√ 插入个案√ 跳至.. 跳至 排序√ 排序√ 转置 重构 合并文件√ 合并文件√ 数据汇总 发现重复数据 正交设计 分割文件 选择观测√ 选择观测√ 加权√ 加权√
Transform菜单
计算√ 计算 重编码√ 重编码 可视化分组√ 可视化分组 计数 数据编秩 自动编码
Transform菜单练习
打开OneCase.sav,计算年龄 Compute产生新变量now,值为02/15/2012 用now减去生日得出年龄(秒),再换算为年 打开体检表.sav, 从学号里提取班级信息(compute, substr) 将字符型变量--性别变换为数值型的(record) 身高<120, 120~130, 130+的学生各有多少 对身高进行每3岁一组分组 (Visual Bander )