weka开发文档5
weka中文教程

WEKA 3-5-5 Explorer 用户指南原文版本 3.5.5翻译王娜校对 C6H5NO2Pentaho 中文讨论组QQ 群:12635055论坛:/bipub/index.asp/目录1 启动WEKA (3)Explorer (5)2 WEKA2.1 标签页 (5)2.2 状态栏 (5)按钮 (5)2.3 Log状态图标 (5)2.4 WEKA3 预处理 (6)3.1 载入数据 (6)3.2 当前关系 (6)3.3 处理属性 (7)3.4 使用筛选器 (7)4 分类 (10)4.1 选择分类器 (10)4.2 测试选项 (10)4.3 Class属性 (11)4.4 训练分类器 (11)4.5 分类器输出文本 (11)4.6 结果列表 (12)5 聚类 (13)5.1 选择聚类器(Clusterer) (13)5.2 聚类模式 (13)5.3 忽略属性 (13)5.4 学习聚类 (14)6 关联规则 (15)6.1 设定 (15)6.2 学习关联规则 (15)7 属性选择 (16)7.1 搜索与评估 (16)7.2 选项 (16)7.3 执行选择 (16)8 可视化 (18)8.1 散点图矩阵 (18)8.2 选择单独的二维散点图 (18)8.3 选择实例 (19)参考文献 (20)启动WEKAWEKA中新的菜单驱动的 GUI 继承了老的 GUI 选择器(类 weka.gui.GUIChooser)的功能。
它的MDI(“多文档界面”)外观,让所有打开的窗口更加明了。
这个菜单包括六个部分。
1.Programz LogWindow打开一个日志窗口,记录输出到stdout或stderr的内容。
在 MS Windows 那样的环境中,WEKA 不是从一个终端启动,这个就比较有用。
z Exit关闭WEKA。
2.Applications 列出 WEKA 中主要的应用程序。
z Explorer 使用 WEKA 探索数据的环境。
WEKA数据分析实验共10页word资料

WEKA 数据分析实验1.实验简介借助工具Weka 3.6 ,对数据样本进行测试,分类测试方法包括:朴素贝叶斯、决策树、随机数三类,聚类测试方法包括:DBScan,K均值两种;2.数据样本以熟悉数据分类的各类常用算法,以及了解Weka的使用方法为目的,本次试验中,采用的数据样本是Weka软件自带的“Vote”样本,如图:3.关联规则分析1)操作步骤:a)点击“Explorer”按钮,弹出“Weka Explorer”控制界面b)选择“Associate”选项卡;c)点击“Choose”按钮,选择“Apriori”规则d)点击参数文本框框,在参数选项卡设置参数如:e)点击左侧“Start”按钮2)执行结果:=== Run information ===Scheme: weka.associations.Apriori -I -N 10 -T 0 -C 0.9 -D 0.05 -U 1.0 -M 0.5 -S -1.0 -c -1 Relation: voteInstances: 435Attributes: 17handicapped-infantswater-project-cost-sharingadoption-of-the-budget-resolutionphysician-fee-freezeel-salvador-aidreligious-groups-in-schoolsanti-satellite-test-banaid-to-nicaraguan-contrasmx-missileimmigrationsynfuels-corporation-cutbackeducation-spendingsuperfund-right-to-suecrimeduty-free-exportsexport-administration-act-south-africaClass=== Associator model (full training set) ===AprioriMinimum support: 0.5 (218 instances)Minimum metric <confidence>: 0.9Number of cycles performed: 10Generated sets of large itemsets:Size of set of large itemsets L(1): 12Large Itemsets L(1):handicapped-infants=n 236adoption-of-the-budget-resolution=y 253physician-fee-freeze=n 247religious-groups-in-schools=y 272anti-satellite-test-ban=y 239aid-to-nicaraguan-contras=y 242synfuels-corporation-cutback=n 264education-spending=n 233crime=y 248duty-free-exports=n 233export-administration-act-south-africa=y 269Class=democrat 267Size of set of large itemsets L(2): 4Large Itemsets L(2):adoption-of-the-budget-resolution=y physician-fee-freeze=n 219adoption-of-the-budget-resolution=y Class=democrat 231physician-fee-freeze=n Class=democrat 245aid-to-nicaraguan-contras=y Class=democrat 218Size of set of large itemsets L(3): 1Large Itemsets L(3):adoption-of-the-budget-resolution=y physician-fee-freeze=n Class=democrat 219Best rules found:1. adoption-of-the-budget-resolution=y physician-fee-freeze=n 219 ==> Class=democrat 219 conf:(1)2. physician-fee-freeze=n 247 ==> Class=democrat 245 conf:(0.99)3. adoption-of-the-budget-resolution=y Class=democrat 231 ==> physician-fee-freeze=n 219 conf:(0.95)4. Class=democrat 267 ==> physician-fee-freeze=n 245 conf:(0.92)5. adoption-of-the-budget-resolution=y 253 ==> Class=democrat 231 conf:(0.91)6. aid-to-nicaraguan-contras=y 242 ==> Class=democrat 218 conf:(0.9)3)结果分析:a)该样本数据,数据记录数435个,17个属性,进行了10轮测试b)最小支持度为0.5,即至少需要218个实例;c)最小置信度为0.9;d)进行了10轮搜索,频繁1项集12个,频繁2项集4个,频繁3项集1个;4.分类算法-随机树分析1)操作步骤:a)点击“Explorer”按钮,弹出“Weka Explorer”控制界面b)选择“Classify ”选项卡;c)点击“Choose”按钮,选择“trees” “RandomTree”规则d)设置Cross-validation 为10次e)点击左侧“Start”按钮2)执行结果:=== Run information ===Scheme:weka.classifiers.trees.RandomTree -K 0 -M 1.0 -S 1Relation: voteInstances:435Attributes:17handicapped-infantswater-project-cost-sharingadoption-of-the-budget-resolutionphysician-fee-freezeel-salvador-aidreligious-groups-in-schoolsanti-satellite-test-banaid-to-nicaraguan-contrasmx-missileimmigrationsynfuels-corporation-cutbackeducation-spendingsuperfund-right-to-suecrimeduty-free-exportsexport-administration-act-south-africaClassTest mode:10-fold cross-validation=== Classifier model (full training set) ===RandomTreeel-salvador-aid = n| physician-fee-freeze = n| | duty-free-exports = n| | | anti-satellite-test-ban = n| | | | synfuels-corporation-cutback = n| | | | | crime = n : republican (0.96/0)| | | | | crime = y| | | | | | handicapped-infants = n : democrat (2.02/0.01) | | | | | | handicapped-infants = y : democrat (0.05/0)| | | | synfuels-corporation-cutback = y| | | | | handicapped-infants = n : democrat (0.79/0.01)| | | | | handicapped-infants = y : democrat (2.12/0)| | | anti-satellite-test-ban = y| | | | adoption-of-the-budget-resolution = n| | | | | handicapped-infants = n : democrat (1.26/0.01)| | | | | handicapped-infants = y : republican (1.25/0.25)| | | | adoption-of-the-budget-resolution = y| | | | | handicapped-infants = n| | | | | | crime = n : democrat (5.94/0.01)| | | | | | crime = y : democrat (5.15/0.12)| | | | | handicapped-infants = y : democrat (36.99/0.09)| | duty-free-exports = y| | | crime = n : democrat (124.23/0.29)| | | crime = y| | | | handicapped-infants = n : democrat (16.9/0.38)| | | | handicapped-infants = y : democrat (8.99/0.02)| physician-fee-freeze = y| | immigration = n| | | education-spending = n| | | | crime = n : democrat (1.09/0)| | | | crime = y : democrat (1.01/0.01)| | | education-spending = y : republican (1.06/0.02)| | immigration = y| | | synfuels-corporation-cutback = n| | | | religious-groups-in-schools = n : republican (3.02/0.01)| | | | religious-groups-in-schools = y : republican (1.54/0.04)| | | synfuels-corporation-cutback = y : republican (1.06/0.05)el-salvador-aid = y| synfuels-corporation-cutback = n| | physician-fee-freeze = n| | | handicapped-infants = n| | | | superfund-right-to-sue = n| | | | | crime = n : democrat (1.36/0)| | | | | crime = y| | | | | | mx-missile = n : republican (1.01/0)| | | | | | mx-missile = y : democrat (1.01/0.01)| | | | superfund-right-to-sue = y : democrat (4.83/0.03)| | | handicapped-infants = y : democrat (8.42/0.02)| | physician-fee-freeze = y| | | adoption-of-the-budget-resolution = n| | | | export-administration-act-south-africa = n| | | | | mx-missile = n : republican (49.03/0)| | | | | mx-missile = y : democrat (0.11/0)| | | | export-administration-act-south-africa = y| | | | | duty-free-exports = n| | | | | | mx-missile = n : republican (60.67/0)| | | | | | mx-missile = y : republican (6.21/0.15)| | | | | duty-free-exports = y| | | | | | aid-to-nicaraguan-contras = n| | | | | | | water-project-cost-sharing = n| | | | | | | | mx-missile = n : republican (3.12/0)| | | | | | | | mx-missile = y : democrat (0.01/0)| | | | | | | water-project-cost-sharing = y : democrat (1.15/0.14)| | | | | | aid-to-nicaraguan-contras = y : republican (0.16/0)| | | adoption-of-the-budget-resolution = y| | | | anti-satellite-test-ban = n| | | | | immigration = n : democrat (2.01/0.01)| | | | | immigration = y| | | | | | water-project-cost-sharing = n| | | | | | | mx-missile = n : republican (1.63/0)| | | | | | | mx-missile = y : republican (1.01/0.01)| | | | | | water-project-cost-sharing = y| | | | | | | superfund-right-to-sue = n : republican (0.45/0)| | | | | | | superfund-right-to-sue = y : republican (1.71/0.64)| | | | anti-satellite-test-ban = y| | | | | mx-missile = n : republican (7.74/0)| | | | | mx-missile = y : republican (4.05/0.03)| synfuels-corporation-cutback = y| | adoption-of-the-budget-resolution = n| | | superfund-right-to-sue = n| | | | anti-satellite-test-ban = n| | | | | physician-fee-freeze = n : democrat (1.39/0.01)| | | | | physician-fee-freeze = y| | | | | | water-project-cost-sharing = n : republican (1.01/0)| | | | | | water-project-cost-sharing = y : democrat (1.05/0.05)| | | | anti-satellite-test-ban = y : democrat (1.13/0.01)| | | superfund-right-to-sue = y| | | | education-spending = n| | | | | physician-fee-freeze = n| | | | | | crime = n : democrat (0.09/0)| | | | | | crime = y| | | | | | | handicapped-infants = n : democrat (1.01/0.01)| | | | | | | handicapped-infants = y : democrat (1/0)| | | | | physician-fee-freeze = y| | | | | | immigration = n| | | | | | | export-administration-act-south-africa = n : democrat(0.34/0.11)| | | | | | | export-administration-act-south-africa = y| | | | | | | | crime = n : democrat (0.16/0)| | | | | | | | crime = y| | | | | | | | | mx-missile = n| | | | | | | | | | handicapped-infants = n : republican (0.29/0) | | | | | | | | | | handicapped-infants = y : republican (1.88/0.87) | | | | | | | | | mx-missile = y : democrat (0.01/0)| | | | | | immigration = y : republican (1.01/0)| | | | education-spending = y| | | | | physician-fee-freeze = n| | | | | | handicapped-infants = n : democrat (1.51/0.01)| | | | | | handicapped-infants = y : democrat (2.01/0)| | | | | physician-fee-freeze = y| | | | | | crime = n : republican (1.02/0)| | | | | | crime = y| | | | | | | export-administration-act-south-africa = n| | | | | | | | handicapped-infants = n| | | | | | | | | immigration = n| | | | | | | | | | mx-missile = n| | | | | | | | | | | water-project-cost-sharing = n : democrat (1.01/0.01)| | | | | | | | | | | water-project-cost-sharing = y : republican (1.81/0)| | | | | | | | | | mx-missile = y : democrat (0.01/0)| | | | | | | | | immigration = y| | | | | | | | | | mx-missile = n : republican (2.78/0)| | | | | | | | | | mx-missile = y : democrat (0.01/0)| | | | | | | | handicapped-infants = y| | | | | | | | | mx-missile = n : republican (2/0)| | | | | | | | | mx-missile = y : democrat (0.4/0)| | | | | | | export-administration-act-south-africa = y| | | | | | | | mx-missile = n : republican (8.77/0)| | | | | | | | mx-missile = y : democrat (0.02/0)| | adoption-of-the-budget-resolution = y| | | anti-satellite-test-ban = n| | | | handicapped-infants = n| | | | | crime = n : democrat (2.52/0.01)| | | | | crime = y : democrat (7.65/0.07)| | | | handicapped-infants = y : democrat (10.83/0.02)| | | anti-satellite-test-ban = y| | | | physician-fee-freeze = n| | | | | handicapped-infants = n| | | | | | crime = n : democrat (2.42/0.01)| | | | | | crime = y : democrat (2.28/0.03)| | | | | handicapped-infants = y : democrat (4.17/0.01)| | | | physician-fee-freeze = y| | | | | mx-missile = n : republican (2.3/0)| | | | | mx-missile = y : democrat (0.01/0)Size of the tree : 143Time taken to build model: 0.01seconds=== Stratified cross-validation ====== Summary ===Correctly Classified Instances 407 93.5632 %Incorrectly Classified Instances 28 6.4368 %Kappa statistic 0.8636Mean absolute error 0.0699Root mean squared error 0.2379Relative absolute error 14.7341 %Root relative squared error 48.8605 %Total Number of Instances 435=== Detailed Accuracy By Class ===TP Rate FP Rate Precision Recall F-Measure ROC Area Class0.955 0.095 0.941 0.955 0.948 0.966 democrat0.905 0.045 0.927 0.905 0.916 0.967 republicanWeighted Avg. 0.936 0.076 0.936 0.936 0.935 0.966=== Confusion Matrix ===a b <-- classified as255 12 | a = democrat16 152 | b = republican3)结果分析:a)该样本数据,数据记录数435个,17个属性,进行了10轮交叉验证b)随机树长143c)正确分类共407个,正确率达93.5632 %d)错误分类28个,错误率6.4368 %e)测试数据的正确率较好5.分类算法-随机树分析1)操作步骤:a)点击“Explorer”按钮,弹出“Weka Explorer”控制界面b)选择“Classify ”选项卡;c)点击“Choose”按钮,选择“trees” “J48”规则d)设置Cross-validation 为10次e)点击左侧“Start”按钮2)执行结果:=== Run information ===Scheme:weka.classifiers.trees.J48 -C 0.25 -M 2Relation: voteInstances:435Attributes:17handicapped-infantswater-project-cost-sharingadoption-of-the-budget-resolutionphysician-fee-freezeel-salvador-aidreligious-groups-in-schoolsanti-satellite-test-banaid-to-nicaraguan-contrasmx-missileimmigrationsynfuels-corporation-cutbackeducation-spendingsuperfund-right-to-suecrimeduty-free-exportsexport-administration-act-south-africaClassTest mode:10-fold cross-validation=== Classifier model (full training set) ===J48 pruned treephysician-fee-freeze = n: democrat (253.41/3.75)physician-fee-freeze = y| synfuels-corporation-cutback = n: republican (145.71/4.0)| synfuels-corporation-cutback = y| | mx-missile = n| | | adoption-of-the-budget-resolution = n: republican (22.61/3.32)| | | adoption-of-the-budget-resolution = y| | | | anti-satellite-test-ban = n: democrat (5.04/0.02)| | | | anti-satellite-test-ban = y: republican (2.21)| | mx-missile = y: democrat (6.03/1.03)Number of Leaves : 6Size of the tree : 11Time taken to build model: 0.06seconds=== Stratified cross-validation ====== Summary ===Correctly Classified Instances 419 96.3218 %Incorrectly Classified Instances 16 3.6782 %Kappa statistic 0.9224Mean absolute error 0.0611Root mean squared error 0.1748Relative absolute error 12.887 %Root relative squared error 35.9085 %Total Number of Instances 435=== Detailed Accuracy By Class ===TP Rate FP Rate Precision Recall F-Measure ROC Area Class0.97 0.048 0.97 0.97 0.97 0.971 democrat0.952 0.03 0.952 0.952 0.952 0.971 republicanWeighted Avg. 0.963 0.041 0.963 0.963 0.963 0.971=== Confusion Matrix ===a b <-- classified as259 8 | a = democrat8 160 | b = republican3)结果分析:a)该样本数据,数据记录数435个,17个属性,进行了10轮交叉验证b)决策树分6级,长度11c)正确分类共419个,正确率达96.3218 %d)错误分类16个,错误率3.6782 %e)测试结果接近随机数,正确率较高6.分类算法-朴素贝叶斯分析1)操作步骤:a)点击“Explorer”按钮,弹出“Weka Explorer”控制界面b)选择“Classify ”选项卡;c)点击“Choose”按钮,选择“bayes” “Naive Bayes”规则d)设置Cross-validation 为10次e)点击左侧“Start”按钮2)执行结果:=== Stratified cross-validation ====== Summary ===Correctly Classified Instances 392 90.1149 %Incorrectly Classified Instances 43 9.8851 %Kappa statistic 0.7949Mean absolute error 0.0995Root mean squared error 0.2977Relative absolute error 20.9815 %Root relative squared error 61.1406 %Total Number of Instances 435=== Detailed Accuracy By Class ===TP Rate FP Rate Precision Recall F-Measure ROC Area Class0.891 0.083 0.944 0.891 0.917 0.973democrat0.917 0.109 0.842 0.917 0.877 0.973republicanWeighted Avg. 0.901 0.093 0.905 0.901 0.902 0.973 === Confusion Matrix ===a b <-- classified as238 29 | a = democrat14 154 | b = republican3)结果分析a)该样本数据,数据记录数435个,17个属性,进行了10轮交叉验证b)正确分类共392个,正确率达90.1149 %c)错误分类43个,错误率9.8851 %d)测试正确率较高7.分类算法-RandomTree、决策树、朴素贝叶斯结果比较:根据以上对比结果,三类分类算法对样板数据Vote测试准确率类似;。
WEKA教程完整版(新)

广东外语外贸大学 杜剑峰
WEKA教程
1. 2. 3.
4.
5. 6.
7.
8. 9.
WEKA简介 数据格式 数据准备 属性选择 可视化分析 分类预测 关联分析 聚类分析 扩展WEKA
课程的总体目标和要求: 熟悉WEKA的基本操作,了 解WEKA的各项功能 掌握数据挖掘实验的流程
2、数据格式(续)
字符串属性 字符串属性中可以包含任意的文本。这种类型的属性在文本挖掘 中非常有用。 示例: @ATTRIBUTE LCC string 日期和时间属性 日期和时间属性统一用―date‖类型表示,它的格式是 @attribute <name> date [<date-format>] 其中<name>是这个属性的名称,<date-format>是一个字符串, 来规定该怎样解析和显示日期或时间的格式,默认的字符串是 ISO-8601所给的日期时间组合格式―yyyy-MM-ddTHH:mm:ss‖。 数据信息部分表达日期的字符串必须符合声明中规定的格式要求 (下文有例子)。
2、数据格式(续)
WEKA支持的<datatype>有四种
numeric <nominal-specification> string date [<date-format>]
数值型 标称(nominal)型 字符串型 日期和时间型
其中<nominal-specification> 和<date-format> 将在下 面说明。还可以使用两个类型―integer‖和―real‖,但是 WEKA把它们都当作―numeric‖看待。注意―integer‖, ―real‖,―numeric‖,―date‖,―string‖这些关键字是区分 大小写的,而―relation‖、“attribute ‖和―data‖则不区分。
weka使用

1)Explorer用来进行数据实验、挖掘的环境,它提供了分类,聚类,关联规则,特征选择,数据可视化的功能。
(An environment for exploring data with WEKA)2)Experimentor用来进行实验,对不同学习方案进行数据测试的环境。
(An environment for performing experiments and conducting statistical tests between learning schemes.)3)KnowledgeFlow功能和Explorer差不多,不过提供的接口不同,用户可以使用拖拽的方式去建立实验方案。
另外,它支持增量学习。
(This environment supports essentially the same functions as the Explorer but with a drag-and-drop interface. One advantage is that it supports incremental learning.)4)SimpleCLI简单的命令行界面。
(Provides a simple command-line interface that allows direct execution of WEKA commands for operating systems that do not provide their own command line interface.)二、实验内容1.选用数据文件为:2.在WEKA中点击explorer 打开文件3.对数据整理分析4.将数据分类:单机classify ——在test options 中 选择第一项(Use training set )——点击classifier 下面的choose 按钮 选择trees 中的J48由上图可知该树有5个叶子是否出去游玩由天气晴朗(sunny)、天气预报(overcast)以及阴雨天(rainy)因素决定5.关联规则我们打算对前面的“bank-data”数据作关联规则的分析。
web开发文档
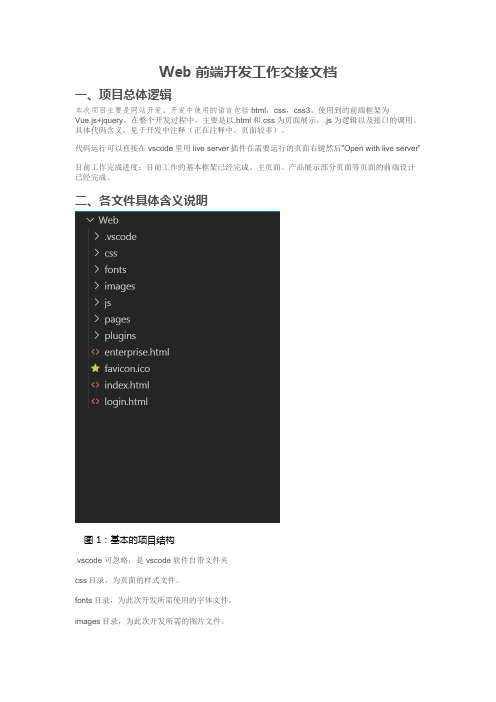
Web前端开发工作交接文档一、项目总体逻辑本次项目主要是网站开发。
开发中使用的语言包括html,css,css3。
使用到的前端框架为Vue.js+jquery。
在整个开发过程中,主要是以.html和.css为页面展示,.js为逻辑以及接口的调用。
具体代码含义,见于开发中注释(正在注释中,页面较多)。
代码运行可以直接在vscode里用live server插件在需要运行的页面右键然后”Open with live server”目前工作完成进度:目前工作的基本框架已经完成。
主页面、产品展示部分页面等页面的前端设计已经完成。
二、各文件具体含义说明图 1:基本的项目结构.vscode 可忽略,是vscode软件自带文件夹css目录,为页面的样式文件。
fonts目录,为此次开发所需使用的字体文件。
images目录,为此次开发所需的图片文件。
js目录,为项目的js文件,逻辑和接口调用都在里。
pages目录,为项目的展示页面,大部分页面的展示都在此文件夹。
plugins目录,为项目的插件所在地。
enterprise.html,为项目的专业版。
index.html,为项目的首页。
login.html,为项目的登录页三、各文件具体含义说明(1)pages文件夹图 2:pages文件夹里面的内容Act文件夹: 1.askforprice.html 主要是IoT物联网市场模板,暂时未调用接口只有页面Cart文件夹:主要是购物车模块1.cartbuy.html 是用来选择购买时支付的选择,选择支付宝支付或微信支付2.buycode.html是上一文件选择购买后跳转的页面,跳转到微信支付或支付宝支付3.cart.html是购物车页面,有两个模块,自营类和撮合类,商品加入购物车后,可以通过下单按钮下单,通过点击顶部购物车按钮跳转到这个页面,在店铺详情页面通过点击侧边栏的购物车按钮跳转这个页面4.ordersubmit.html是下单页面,购物车下单后跳转这个页面,主要是用来提交订单的5.orderpay.html支付页面,用来支付订单,在下单的时候会弹出是否支付按钮,还有订单列表在出现支付按钮,在点击支付按钮会跳转这个页面6.neworder.html询价单下单页面,作用与ordersubmit.html类似,不过是通过询价单里“生成采购单”跳转到此页面Civil文件夹:主要是商品模块和江苏版1.detail.html是商品详细页面,主要是用来展示商品的详细信息,比如价格,库存,商品图片,商品介绍,评价,售后保障等。
weka二次开发

本科毕业设计论文课题名称 基于JAVA的WEKA数据挖掘平台分析及二次开发学生姓名 林莉莉 学号 20032311 专业名称 计算机科学与技术指导教师姓名 陈 慧 萍申请学位级别 工学学士学位授予单位 河海大学论文提交日期 2007年6月计算机及信息工程学院(常州)河海大学本科毕业设计(论文)任务书(理工科类)Ⅰ、毕业设计(论文)题目:基于JA V A的WEKA数据挖掘平台分析及二次开发Ⅱ、毕业设计(论文)工作内容(从综合运用知识、研究方案的设计、研究方法和手段的运用、应用文献资料、数据分析处理、图纸质量、技术或观点创新等方面详细说明):数据挖掘是目前计算机科学中活跃的研究领域之一,所谓数据挖掘就是采用机器学习算法从大量数据中提取和挖掘知识,因此广泛用于智能数据分析和处理中。
WEKA是基于java的数据挖掘平台,其中集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,聚类,关联规则,属性选择以及在新的交互式界面上的可视化。
由于其源码的开放性,WEKA不仅可以用于完成常规的数据挖掘任务,也可以用于数据挖掘的二次开发中。
本课题属研究性课题,要求学生阅读大量资料,自学数据挖掘方面的知识,分析WEKA 数据挖掘的平台,写出全面的文献综述。
并综合利用数据结构、算法设计与分析、JA V A 语言等知识,进行基于WEKA平台的二次开发。
具体任务如下:①阅读国内外文献,了解数据挖掘技术的基本方法与应用;对数据挖掘的方法之一如分类或聚类算法作更深入的了解。
②WEKA数据挖掘平台的分析:阅读WEKA数据挖掘平台的大量文档,分析其实现机理,了解WEKA进行数据挖掘的基本过程。
结合①和②写出WEKA数据挖掘工具的文献综述。
③WEKA平台的数据挖掘实验:分析WEKA的数据挖掘过程,分析WEKA所要求的数据集的格式和WEKA Explorer的功能模块,并准备典型的数据集,在WEKA平台上做大量数据挖掘测试实验,并分析其实现机理及存在问题。
Weka开发----在代码中使用Weka

Weka开发----在代码中使用Weka最常用的组件(components)是:l Instances 你的数据l Filter 对数据的预处理l Classifiers/Clusterer 被建立在预处理的数据上,分类/聚类l Evaluating 评价classifier/clustererl Attribute selection 去除数据中不相关的属性下面将介绍如果在你自己的代码中使用WEKA,其中的代码可以在上面网址的尾部找到。
InstancesARFF文件3.5.5和3.4.X版本从ARFF文件中读取是一个很直接的import weka.core.Instances;import java.io.BufferedReader;import java.io.FileReader;...Instances data = new Instances(new BufferedReader(new FileReader("/some/where/data.arff")));// setting class attributedata.setClassIndex(data.numAttributes() - 1);Class Index是指示用于分类的目标属性的下标。
在ARFF文件中,它被默认为是最后一个属性,这也就是为什么它被设置成numAttributes-1.你必需在使用一个Weka函数(ex: weka.classifiers.Classifier.buildClassifier(data))之前设置Cl ass Index。
3.5.5和更新的版本DataSource类不仅限于读取ARFF文件,它同样可以读取CSV文件和其它格式的文件(基本上Weka可以通过它的转换器(converters)导入所有的文件格式)。
import weka.core.converters.ConverterUtils.DataSource;...DataSource source = new DataSource("/some/where/data.arff");Instances data = source.getDataSet();// setting class attribute if the data format does not provide this//information// E.g., the XRFF format saves the class attribute information as wellif (data.classIndex() == -1)data.setClassIndex(data.numAttributes() - 1);数据库从数据库中读取数据稍微难一点,但是仍然是很简单的,首先,你需要修改你的DatabaseUtils. props(自己看一下原文,基本上都有链接)重组(resemble)你的数据库连接。
WEKA教程完整版(新)
2、数据格式(续)
数据信息 数据信息中―@data‖标记独占一行,剩下的是各个实例 的数据。 每个实例占一行。实例的各属性值用逗号―,‖隔开。如果 某个属性的值是缺失值(missing value),用问号―?‖ 表示,且这个问号不能省略。例如: @data sunny,85,85,FALSE,no ?,78,90,?,yes
准备数据 选择算法和参数运行 评估实验结果
了解或掌握在WEKA中加入 新算法的方法
1、WEKA简介
WEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),其源代码可 从/ml/weka/得到。同时 weka也是新西兰的一种鸟名,而WEKA的主要开发者 来自新西兰。
2、数据格式(续)
字符串属性和标称属性的值是区分大小写的。若值中含 有空格,必须被引号括起来。例如:
@relation LCCvsLCSH @attribute LCC string @attribute LCSH string @data
AG5, 'Encyclopedias and dictionaries.;Twentieth century.' AS262, 'Science -- Soviet Union -- History.'
2、数据格式(续)
数值属性 数值型属性可以是整数或者实数,但WEKA把它们都当作实数看 待。
标称属性 标称属性由<nominal-specification>列出一系列可能的类别名称并 放在花括号中:{<nominal-name1>, <nominal-name2>, <nominal-name3>, ...} 。数据集中该属性的值只能是其中一种类 别。 例如如下的属性声明说明―outlook‖属性有三种类别:―sunny‖,― overcast‖和―rainy‖。而数据集中每个实例对应的―outlook‖值必是 这三者之一。 @attribute outlook {sunny, overcast, rainy} 如果类别名称带有空格,仍需要将之放入引号中。
【精品文档】weka案例-范文word版 (18页)

以“%”开始的行是注释,WEKA将忽略这些行。如果你看到的“weather.arff”文件多了或少了些“%”开始的行,是没有影响的。
除去注释后,整个ARFF文件可以分为两个部分。第一部分给出了头信息(Head information),包括了对关系的声明和对属性的声明。第二部分给出了数据信息(Data information),即数据集中给出的数据。从“@data”标记开始,后面的就是数据信息了。 关系声明
sunny,85,85,FALSE,no
?,78,90,?,yes
字符串属性和分类属性的值是区分大小写的。若值中含有空格,必须被引号括起来。例如:
@relation LCCvsLCSH
@attribute LCC string
@attribute LCSH string
@data
AG5, 'Encyclopedias and dictionaries.;Twentieth century.'
WEKA存储数据的格式是ARFF(Attribute-Relation File Format)文件,这是一种ASCII文本文件。图1所示的二维表格存储在如下的ARFF文件中。这也就是WEKA自带的“weather.arff” 文件,在WEKA安装目录的“data”子目录下可以找到。
需要注意的是,在Windows记事本打开这个文件时,可能会因为回车符定义不一致而导致分行不正常。推荐使用UltraEdit这样的字符编辑软件察看ARFF文件的内容。 下面我们来对这个文件的内容进行说明。
例如如下的属性声明说明“outlook”属性有三种类别:“sunny”,“ overcast”和“rainy”。而数据集中每个实例对应的“outlook”值必是这三者之一。
weka操作介绍讲解学习

标变量,直方图中的每个长方形
就会按照该变量的比例分成不同
颜色的段。默认地,分类或回归
任务的默认目标变量是数据集的
最后一个属性。要想换个分段的
依据,即目标变量,在区域7上 方的下拉框中选个不同的分类属
性就可以了。下拉框里选上
“No Class”或者一个数值属性会 变成黑白的直方图。
wekቤተ መጻሕፍቲ ባይዱ操作介绍
在KnowledgeFlow 窗口顶部有八个标签: DataSources--数据载入器 DataSinks--数据保存器 Filters--筛选器 Classifiers--分类器 Clusterers--聚类器 Associations—关联器 Evaluation—评估器 Visualization—可视化
关联运行结果
此课件下载可自行编辑修改,仅供参考! 感谢您的支持,我们努力做得更好!谢谢
3 4
5 8
1 2
6 7
1.区域1的几个选项卡是用来切换不同的 挖掘任务面板。
Preprocess(数据预处理) Classify(分类) Cluster(聚类) Associate(关联分析) Select Attributes(选择属性) Visualize(可视化)
2. 区域2是一些常用按钮。包括打开数据, 保存及编辑功能。我们可以在这里把 “bank-data.csv”,另存为“bank-data.arff”
Cluster
主要算法包括: SimpleKMeans — 支持分类属性的K均值算法 DBScan — 支持分类属性的基于密度的算法 EM — 基于混合模型的聚类算法 FathestFirst — K中 心点算法 OPTICS — 基于密度的另一个算法 Cobweb — 概念聚类算法 sIB — 基于信息论的聚类算法,不支持分类属性 XMeans — 能自动确定簇个数的扩展K均值算法,不 支持分类属性
数据挖掘工具Weka API使用文档说明书

Evaluation
weka.classifiers.trees weka.associations
Business Intelligence Lab
Option handling
5
Either with get/set methods
Every action overwrites the previous ones
Weka Knowledge Flow documents the process, but …
it is time-consuming to experiment with many variants
(algs, params, inputs, …)
Split into x% training and (100-x)% test
Stratified sampling, where x range in [20-80]
For which x accuracy is maximized?
Business Intelligence Lab
BUSINESS INTELLIGENCE LABORATORY
Weka API
Salvatore Ruggieri
Computer Science Department, University of Pisa
Business Informatics Degree
Why API?
2
Weka Explorer does not keep track of experimental settings
E.g., selection of customers in marketing campaigns can be suggested to the marketer by a decision-support system which exploits data mining models
Weka使用文档(1)
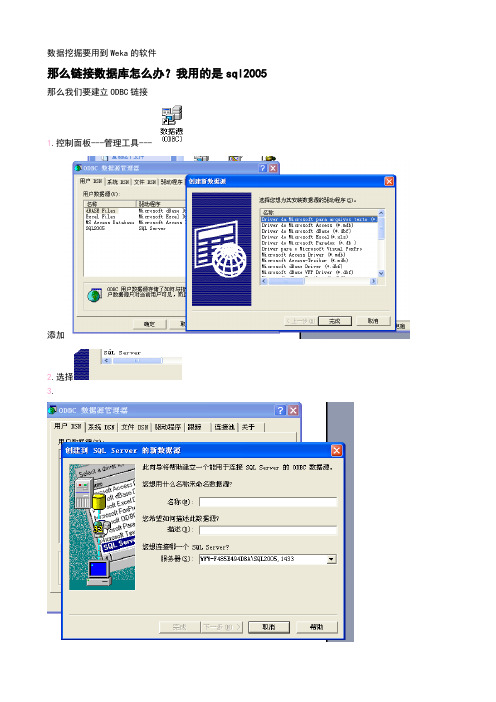
数据挖掘要用到Weka的软件那么链接数据库怎么办?我用的是sql2005 那么我们要建立ODBC链接1.控制面板---管理工具---添加2.选择3.1433是sql服务的端口4.下一步我们来进行安装文件。
在官网上/projects/weka/能够下载到最新版本。
我用的是3.6版本。
安装后请解压weka.jar文件,找到文件名DatabaseUtils.props一下是java数据类型Java type Java method Identifier Weka attribute type VersionString getString() 0 nominalboolean getBoolean() 1 nominaldouble getDouble() 2 numericbyte getByte() 3 numericshort getByte() 4 numericint getInteger() 5 numericlong getLong() 6 numericfloat getFloat() 7 numericdate getDate() 8 datetext getString() 9 string >3.5.5time getTime() 10 string >3.5.8In the props file one lists now the type names that the database returns and what Java type it represents (via the identifier), e.g.:CHAR=0VARCHAR=0CHAR and VARCHAR are both String types, hence they are interpreted as String (identifier 0)Note: in case database types have blanks, one needs to replace those blanks with an underscore, e.g., DOUBLE PRECISION must be listed like this:DOUBLE_PRECISION=2对应你的文件添加修改类型和他的值(注意大小写)修改文件DatabaseUtils.props.odbcjdbcURL=jdbc:odbc:SQL2005(SQL2005是建立连接池的名称)最后把修改后的文件添加到压缩文件中。
WEKA中文详细教程

Weka可以将分析结果导出为多种格式,如CSV、ARFF、LaTeX等,用户可以通过“文件”菜单 选择“导出数据”来导出数据。
数据清理
缺失值处理
Weka提供了多种方法来处理缺失值, 如删除含有缺失值的实例、填充缺失 值等。
异常值检测
Weka提供了多种异常值检测方法, 如基于距离的异常值检测、基于密度 的异常值检测等。
Weka中文详细教程
目录
• Weka简介 • 数据预处理 • 分类算法 • 关联规则挖掘 • 回归分析 • 聚类分析 • 特征选择与降维 • 模型评估与优化
01
Weka简介
Weka是什么
01 Weka是一款开源的数据挖掘软件,全称是 "Waikato Environment for Knowledge Analysis",由新西兰怀卡托大学开发。
解释性强等优点。
使用Weka进行决策树 分类时,需要设置合 适的参数,如剪枝策 略、停止条件等,以 获得最佳分类效果。
决策树分类结果易于 理解和解释,能够为 决策提供有力支持。
贝叶斯分类器
贝叶斯分类器是一种 基于概率的分类算法, 通过计算不同类别的 概率来进行分类。
Weka中的朴素贝叶斯 分类器是一种基于贝 叶斯定理的简单分类 器,适用于特征之间 相互独立的场景。
08
模型评估与优化
交叉验证
01
交叉验证是一种评估机器学习模型性能的常用方法,通过将数据集分成多个子 集,然后使用其中的一部分子集训练模型,其余子集用于测试模型。
02
常见的交叉验证方法包括k-折交叉验证和留出交叉验证。在k-折交叉验证中, 数据集被分成k个大小相近的子集,每次使用其中的k-1个子集训练模型,剩余 一个子集用于测试。
使用Weka进行数据挖掘的的基本方法手册与心得

简介和回归简介什么是数据挖掘?您会不时地问自己这个问题,因为这个主题越来越得到技术界的关注。
您可能听说过像 Google 和 Yahoo! 这样的公司都在生成有关其所有用户的数十亿的数据点,您不禁疑惑,“它们要所有这些信息干什么?”您可能还会惊奇地发现 Walmart 是最为先进的进行数据挖掘并将结果应用于业务的公司之一。
现在世界上几乎所有的公司都在使用数据挖掘,并且目前尚未使用数据挖掘的公司在不久的将来就会发现自己处于极大的劣势。
那么,您如何能让您和您的公司跟上数据挖掘的大潮呢?我们希望能够回答您所有关于数据挖掘的初级问题。
我们也希望将一种免费的开源软件 Waikato Environment for Knowledge Analysis (WEKA) 介绍给您,您可以使用该软件来挖掘数据并将您对您用户、客户和业务的认知转变为有用的信息以提高收入。
您会发现要想出色地完成挖掘数据的任务并不像您想象地那么困难。
此外,本文还会介绍数据挖掘的第一种技术:回归,意思是根据现有的数据预测未来数据的值。
它可能是挖掘数据最为简单的一种方式,您甚至以前曾经用您喜爱的某个流行的电子数据表软件进行过这种初级的数据挖掘(虽然 WEKA 可以做更为复杂的计算)。
本系列后续的文章将会涉及挖掘数据的其他方法,包括群集、最近的邻居以及分类树。
(如果您还不太知道这些术语是何意思,没关系。
我们将在这个系列一一介绍。
)回页首什么是数据挖掘?数据挖掘,就其核心而言,是指将大量数据转变为有实际意义的模式和规则。
并且,它还可以分为两种类型:直接的和间接的。
在直接的数据挖掘中,您会尝试预测一个特定的数据点—比如,以给定的一个房子的售价来预测邻近地区的其他房子的售价。
在间接的数据挖掘中,您会尝试创建数据组或找到现有数据的模式—比如,创建“中产阶级妇女”的人群。
实际上,每次的美国人口统计都是在进行数据挖掘,政府想要收集每个国民的数据并将它转变为有用信息。
引用 Weka学习五(ROC简介)讲课讲稿

引用W e k a学习五(R O C简介)引用 Weka学习五(ROC简介)智能信息处理 2010-07-11 22:13:11 阅读3 评论0 字号:大中小订阅 .引用其实的 Weka学习五(ROC简介)今天我们来介绍一下ROC(Receiver operating characteristics)国内复旦张文彤老师在《SPSS统计分析基础教材》中将其翻译成“受试者工作特征”,也有按字面意思译成“接受者操作特征曲线”。
到底选择哪一个大家自便吧。
ROC曲线是有TP(True positive rate)、FP(Flase positive rate)构成的,以TP作为Y轴,FP作为X轴。
对于一个离散型分类器(discrete classifier),每一个分类器仅仅对测试集生成一组(fp,tp)点。
这个结果对应着ROC空间上的一个点,例如上图中的A、B、C几个点。
那么如何让它们产生一个曲线就成了大家最关心的问题。
有一种方法通过对每一个样本集中的样本依次排序进入队列,来到一个样本就计算一次(fp,tp)值,直到样本集中样本全部进入为止。
这样我们就得到了一个与样本数量相同的(fp,tp)数组了。
然后我们通过这个二维数组我们就可以在ROC空间上做出一个ROC曲线了。
具体的算法大家可以参见《An introduction to ROC anslysis》Tom Fawcett, 2005。
这篇论文中对ROC曲面进行了很详细的讲解。
这样我们就可以得到一个如上图所示的ROC曲线。
我们可以看到上图中有很多条ROC曲线,但是到底哪一条ROC曲线代表对应的分类器的分类效果?这也是一个值得探讨的问题。
我们可以看到ROC曲线下面覆盖了一定的面积,不同的曲线覆盖的大小不同,于是一个通俗的想法就是比较它们覆盖面积的不同来判断分类器的效果。
当然这个通俗的想法也是有其缘由的,因为对于在ROC空间中的点来说,分类器的分类效果越好它所对应的TP值就越高,FP越低,那么这个对应的点就越靠近西北方向(及左上角)。
实验5:在weka中进行关联规则挖掘

实验5:在weka中进行关联规则挖掘实验五实验项目名称:在weka中进行关联规则挖掘实验要求:(1)熟悉weka软件;(2)掌握关联规则挖掘基本概念;(3)掌握在weka中进行关联规则挖掘的相关方法。
(4)本实验要求列出每个主要步骤,附上截图,对挖掘出的关联规则的结果进行详细的说明。
要求附上sql代码。
实验步骤:(1)首先对big_university数据集中的数据进行预处理。
注意:weka采用的算法只能对分类属性进行操作,因此需要对big_university数据集中的tj属性进行处理。
建议:●先将原始数据通过sql写入数据库表big_university,然后编写一个存储过程,对数据库表记录进行处理,删除tj属性,但数据库表所表达的含义不能改变。
●将表中的记录导出到EXCEL表中,转换成CSV文件●在weka中将big_university.csv存储为big_university.arff文件。
(2)对big_university.arff进行关联规则分析。
该分析没有使用到概念分层,属于低层的关联规则挖掘。
(3)编写一个存储过程,针对big_university数据库表中的字段值进行概念分层替换,然后对新产生的big_university.arff进行关联规则分析。
该分析使用到概念分层,属于高层的关联规则挖掘。
设最小支持度阈值为2%,最小置信度阈值为50%假定描述Big-University 大学学生的数据关系已被泛化为下表的泛化关系R。
设概念分层如下:status: {freshman, sophomore, junior, senior} ∈ undergraduate{M.Sc, M.A, Ph.D} ∈ graduatemajor: {physics, chemistry, math} ∈ science{CS, engineering} ∈ appl_scienceage: {16...20, 21-25} ∈ young{26...30, over_30} ∈ oldnationality: {Asia, Europe, Latin_America}∈ foreign{Canada, U.S.A.} ∈North_America泛化关系如下表所示:major status age nationality gpa tj French M.A over_30 Canada 2.8...3.2 3 CS junior 16...20 Europe 3.2...36 29 Physics M.S 26...30 Latin_America 3.2...3.6 18 Engineering Ph.D 26...30 Asia 3.6...4.0 78 Philosophy Ph.D 26...30 Europe 3.2...3.6 5 French senior 16...20 Canada 3.2...3.6 40 chemistry junior 21...25 U.S.A.3.6...4.0 25 CS senior 16...20 Canada 3.2...3.6 70 Philosophy M.S over_30 Canada 3.6...4.0 15 French junior 16...20 U.S.A. 2.8...3.2 8 Philosophy junior 26...30 Canada 2.8...3.2 9 Philosophy M.S 26...30 Asia 3.2...3.6 9 French junior 16...20 Canada 3.2...3.6 52 math senior 16...20 U.S.A. 3.6...4.0 32 CS junior 16...20 Canada 3.2...3.6 76 Philosophy Ph.D 26...30 Canada 3.6...4.0 14 Philosophy senior 26...30 Canada 2.8...3.2 19 French Ph.D over_30 Canada 2.8...3.2 1 Engineering junior 21...25 Europe 3.2...3.6 71 Math Ph.D 26...30 Latin_America 3.2...3.6 7 chemistry junior 16...20 U.S.A.3.6...4.0 46 engineering junior 21...25 Canada 3.2...3.6 96 French M.S over_30 Latin_America 3.2...3.6 4 Philosophy junior 21 (25)U.S.A. 2.8...3.2 8 Math junior 16...20 Canada 3.6...4.0 59。
Weka开发初步

Weka初步文章分类:JavaEye转载自/anqiang1984/archive/2009/04/01/4040571.aspx从前年开始使用weka最数据挖掘方面的研究,到现在有一年半的时间了。
看到我们同组的兄弟写了关于weka方面的总结,我也想整理一下。
因为网上的资料实在是太少,记得刚接手的时候,真是硬着头皮看代码。
不过到现在看来,也积累了很多的代码了。
希望能够在这里跟大家分享一下学习weka的乐趣与经验。
Weka是来之新西兰怀卡托大学的一款开源软件,主要是数据挖掘方面的一些算法的集合。
这款软件大概是当前数据挖掘领域最好的开源软件了,当然国外还有其它一些组织维护的有自己的开源软件,但是只有这款软件应用是比较广泛的了。
具体关于weka的信息可以到官网去查看/ml/weka/,软件的下载也可大家到官网去。
我是从weka3.4一直用到现在的3.6版本的,其间weka在图形界面上有一些变动,但是底层的框架结构没有太大的变化,主要是添加一些新的算法什么的。
总之大家可以放心的使用。
我现在积累的代码是从3.5版本积累下来的,到现在3.6版本,集成起来一点问题都没有,这大概也是我喜欢weka的一个原因。
数据挖掘的过程一般如下:1. 读入训练、测试样本2. 初始化分类器3. 使用训练样本训练分类器4. 使用测试样本测试分类器的学习效果5. 打印分类结果我们现在看看一个简单的实例Java代码package com.csdn;import java.io.File;import weka.classifiers.Classifier;import weka.classifiers.Evaluation;import weka.core.Instance;import weka.core.Instances;import weka.core.converters.ArffLoader;public class Test {/*** @param args*/public static void main(String[] args) {// TODO Auto-generated method stubInstances ins = null;Classifier cfs = null;try{/** 1.读入训练、测试样本* 在此我们将训练样本和测试样本作为同一个样本*/File file= new File("C:\\Program Files\\Weka-3-6\\data\\contact-lenses.arff");ArffLoader loader = new ArffLoader();loader.setFile(file);ins = loader.getDataSet();//在使用样本之前一定要首先设置instances的classIndex,否则在使用instances 对象是会抛出异常ins.setClassIndex(ins.numAttributes()-1);/** 2.初始化分类器* 具体使用哪一种特定的分类器可以选择,请将特定分类器的class名称放入forName函数* 这样就构建了一个简单的分类器*/cfs =(Classifier)Class.forName("weka.classifiers.bayes.NaiveBayes").newInstance();/** 3.使用训练样本训练分类器*/cfs.buildClassifier(ins);/** 4.使用测试样本测试分类器的学习效果* 在这里我们使用的训练样本和测试样本是同一个,在实际的工作中需要读入一个特定的测试样本*/Instance testInst;/** Evaluation: Class for evaluating machine learning models* 即它是用于检测分类模型的类*/Evaluation testingEvaluation = new Evaluation(ins);int length = ins.numInstances();for (int i =0; i < length; i++) {testInst = ins.instance(i);//通过这个方法来用每个测试样本测试分类器的效果testingEvaluation.evaluateModelOnceAndRecordPrediction(cfs, testInst);}/** 5.打印分类结果* 在这里我们打印了分类器的正确率* 其它的一些信息我们可以通过Evaluation对象的其它方法得到*/System.out.println( "分类器的正确率:" + (1- testingEvaluation.errorRate()));}catch(Exception e){e.printStackTrace();}}}package com.csdn;import java.io.File;import weka.classifiers.Classifier;import weka.classifiers.Evaluation;import weka.core.Instance;import weka.core.Instances;import weka.core.converters.ArffLoader;public class Test {/*** @param args*/public static void main(String[] args) {// TODO Auto-generated method stubInstances ins = null;Classifier cfs = null;try{/** 1.读入训练、测试样本* 在此我们将训练样本和测试样本作为同一个样本*/File file= new File("C:\\Program Files\\Weka-3-6\\data\\contact-lenses.arff");ArffLoader loader = new ArffLoader();loader.setFile(file);ins = loader.getDataSet();//在使用样本之前一定要首先设置instances的classIndex,否则在使用instances 对象是会抛出异常ins.setClassIndex(ins.numAttributes()-1);/** 2.初始化分类器* 具体使用哪一种特定的分类器可以选择,请将特定分类器的class名称放入forName函数* 这样就构建了一个简单的分类器*/cfs =(Classifier)Class.forName("weka.classifiers.bayes.NaiveBayes").newInstance();/** 3.使用训练样本训练分类器*/cfs.buildClassifier(ins);/** 4.使用测试样本测试分类器的学习效果* 在这里我们使用的训练样本和测试样本是同一个,在实际的工作中需要读入一个特定的测试样本*/Instance testInst;/** Evaluation: Class for evaluating machine learning models* 即它是用于检测分类模型的类*/Evaluation testingEvaluation = new Evaluation(ins);int length = ins.numInstances();for (int i =0; i < length; i++) {testInst = ins.instance(i);//通过这个方法来用每个测试样本测试分类器的效果testingEvaluation.evaluateModelOnceAndRecordPrediction(cfs, testInst);}/** 5.打印分类结果* 在这里我们打印了分类器的正确率* 其它的一些信息我们可以通过Evaluation对象的其它方法得到*/System.out.println( "分类器的正确率:" + (1- testingEvaluation.errorRate()));}catch(Exception e){e.printStackTrace();}}}通过这个实例,我们可以看到在weka上做开发非常简单的,每个模块weka都提供了很好的支持。
数据挖掘开源工具weka简明教程

基于概率模型的分类方法,如Naive Bayes,适用于特征之间独立性较强的数据集。
贝叶斯
基于规则的分类方法,如JRip、OneR等,适用于可解释性要求较高的场景。
规则学习
支持多类别的分类问题,如SVM、Logistic回归等。
多类分类
分类算法
经典的聚类算法,将数据划分为K个簇,使每个数据点与其所在簇的中心点距离之和最小。
与Java集成
Weka是用Java编写的,因此可以方便地与Java集成,用户可以通过Java调用Weka的功能,或使用Weka提供的Java API进行二次开发。
与Excel集成
05
CHAPTER
实践案例
通过使用Weka的分类算法,可以有效地识别出信用卡交易中的欺诈行为,提高银行的风险管理能力。
总结词
客户细分是市场营销中的重要环节,能够帮助企业更好地了解客户需求和行为特征。Weka提供了多种聚类算法,如K-means、层次聚类等,可以对客户数据进行聚类分析,将客户群体划分为不同的细分市场。企业可以根据这些细分市场的特点和需求,制定更有针对性的市场策略,提高客户满意度和忠诚度。
详细描述
总结词
使用Weka进行股票价格预测
THANKS
感谢您的观看。
通过使用Weka的时间序列预测算法,可以对股票价格进行短期预测,帮助投资者做出更明智的投资决策。
详细描述
股票价格预测是投资者关注的焦点之一,但由于市场复杂性和不确定性,预测难度较大。Weka提供了多种时间序列预测算法,如ARIMA、指数平滑等,可以对历史股票价格数据进行学习和预测,为投资者提供参考。当然,股票价格预测存在风险,投资者需要结合其他因素和市场情况做出决策。
使用Weka进行数据挖掘
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
●
Test and training data may differ in nature
●
To estimate performance of classifier from town A in completely new town, test it on data from B
Data Mining: Practical Machine Learning Tools and Techniques (Chapter 5)
● ●
Estimated success rate: 75% With 80% confidence p in [69.1,80.1]
Data Mining: Practical Machine Learning Tools and Techniques (Chapter 5)
10
Mean and variance
6
Note on parameter tuning
It is important that the test data is not used in any way to create the classifier ● Some learning schemes operate in two stages:
♦ ♦ ♦
Success: instance’s class is predicted correctly Error: instance’s class is predicted incorrectly Error rate: proportion of errors made over the whole set of instances
●
However: (labeled) data is usually limited
♦
Data Mining: Practical Machine Learning Tools and Techniques (Chapter 5)
3
Issues in evaluation
●
●
Statistical reliability of estimated differences in performance (→ significance tests) Choice of performance measure:
●
●
Dilemma: ideally both training set and test set should be large!
Data Mining: Practical Machine Learning Tools and Techniques (Chapter 5)
8
Predicting performance
Data Mining: Practical Machine Learning Tools and Techniques (Chapter 5)
9
Confidence intervals
We can say: p lies within a certain specified interval with a certain specified confidence ● Example: S=750 successes in N=1000 trials
5
Training and testing II
●
Test set: independent instances that have played no part in formatioumption: both training data and test data are representative samples of the underlying problem Example: classifiers built using customer data from two different towns A and B
●
●
Resubstitution error: error rate obtained from training data Resubstitution error is (hopelessly) optimistic!
Data Mining: Practical Machine Learning Tools and Techniques (Chapter 5)
♦
Data Mining: Practical Machine Learning Tools and Techniques (Chapter 5)
4
Training and testing I
●
Natural performance measure for classification problems: error rate
Confidence limits
●
Confidence limits for the normal distribution with 0 mean and a variance of 1: z Pr[X ≥ z]
0.1% 0.5% 1% 5% 10% 20% 40% 3.09 2.58 2.33 1.65 1.28 0.84 0.25
Mean and variance for a Bernoulli trial: p, p (1–p) ● Expected success rate f=S/N ● Mean and variance for f : p, p (1–p)/N ● For large enough N, f follows a Normal distribution ● c% confidence interval [–z ≤ X ≤ z] for random variable with 0 mean is given by:
●
Pr [− z ≤ X ≤ z ]= c
●
With a symmetric distribution:
Pr [− z ≤ X ≤ z ]= 1−2× Pr [ x ≥ z ]
Data Mining: Practical Machine Learning Tools and Techniques (Chapter 5) 11
●
Assume the estimated error rate is 25%. How close is this to the true error rate?
♦
Depends on the amount of test data “Head” is a “success”, “tail” is an “error”
Data Mining
Practical Machine Learning Tools and Techniques
Slides for Chapter 5 of Data Mining by I. H. Witten, E. Frank and M. A. Hall
Credibility: Evaluating what’s been learned
●
● ●
Stage 1: build the basic structure Stage 2: optimize parameter settings
The test data can’t be used for parameter tuning! ● Proper procedure uses three sets: training data, validation data, and test data
Data Mining: Practical Machine Learning Tools and Techniques (Chapter 5)
2
Evaluation: the key to success
● ●
How predictive is the model we learned? Error on the training data is not a good indicator of performance on future data
●
●
Validation data is used to optimize parameters
Data Mining: Practical Machine Learning Tools and Techniques (Chapter 5)
7
Making the most of the data
Once evaluation is complete, all the data can be used to build the final classifier ● Generally, the larger the training data the better the classifier (but returns diminish) ● The larger the test data the more accurate the error estimate ● Holdout procedure: method of splitting original data into training and test set
●
Prediction is just like tossing a (biased!) coin
♦
●
In statistics, a succession of independent events like this is called a Bernoulli process
♦
Statistical theory provides us with confidence intervals for the true underlying proportion