新浪博客文章采集器
如何把整个网页下载下来

如何把整个网页下载下来有的时候,我们在浏览网页的时候,感觉这整个网页内容还不错,想要把其下载下来,这个时候应该怎么办呢,特别是要下载多个网页的时候,一个一个去复制下载特别的浪费时间。
其实可以使用八爪鱼采集器批量下载网页内容。
下面以csdn网页举例为大家介绍如何把整个网页下载下来。
第一步:打开客户端,选择自定义采集,进入采集界面以后,输入网址并保存第二步:根据需要确定采集范围,这里我们以采集“Java”相关的博客为例,鼠标选中博客,然后右边的弹窗中选择“点击该元素”再把鼠标滚动到页面底部,点中翻页符号,选择“循环点击下一页”,创建翻页循环如下图,选中绿框内容,所有适配的元素会变成粉色,然后在右边的框中选择“选中子元素”,接着选择“选中全部”第三步:修改字段名称,如下图,选中编辑标志,更改字段名称,把不要的字段删除,然后选中采集数据,就可以保存启动采集了。
导出的数据如下图:这就是使用八爪鱼采集CSDN博客的过程。
相关采集教程:点评数据采集/tutorial/hottutorial/shfw/xfdp分类信息采集教程/tutorial/hottutorial/shfw/fenleixinxi网站文章采集/tutorial/hottutorial/qita网易新闻数据采集方法/tutorial/wycj_7新浪微博评论数据的抓取与采集方法 /tutorial/wbplcj-7新浪微博博主信息采集教程/tutorial/wbbzcj_7知乎信息采集详细教程,以知乎发现话题为例/tutorial/zh-ht知乎回答内容采集方法以及详细步骤 /tutorial/zh-hd-7美团商家数据采集/tutorial/meituansjpl八爪鱼——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
如何实现搜索关键词的新浪微博信息采集与监控

搜索新浪微博指定信息的采集与监控之前我们已经讲过如何采集新浪微博博主信息的采集与监控,但是也听很多朋友说,我需要监控特定关键词的相关微博最新信息,那么我们应该如何采集呢,下面的教程就主要实现我们对搜索出来的微博信息采集与监控。
众所周知,微博微信作为时下最火热的社交平台,如果能对这两个平台上的数据进行深入分析挖掘,那么价值将非常巨大,但是在采集过程中,很多朋友也因为新浪的防采集很是头痛,笔者通过多方比较尝试,笔者最终顺利完成了整个数据采集过程,要采集的数据为指定城市的所有微博用户的相关信息。
比如微博内容、微博评论数、微博转发数等等,进入正题,看看具体一步一步怎么操作来实现的。
此次的教程需要用到的是熊猫采集软件,这是新一代的智能采集器,操作非常简单容易,不需要专业基础,新手首选。
且功能特别强悍复杂,只要是浏览器能看到的内容,都可以用熊猫批量的采集下来。
如各种电话号码邮箱,各种网站信息搬家,网络信息监控、网络舆情监测、股票资讯实时监控等等。
熊猫采集器是唯一拥有子页面嵌套访问功能的采集软件,对于本案例涉及到的微博的信息获取,需要利用这个功能,轻松获取到js加载的信息内容。
如果有兴趣的看官们,可以百度熊猫采集软件下载即可,熊猫的免费版就已经包含我下面演示所以功能。
那么我就进入本次教程的演示环节吧!首先,我们打开我们这次采集需要的工具,也就是熊猫采集器,点击新建项目(标准)这个时候是进入我们的基础设置,在这里,我们可以给我们创建的项目命名一个名称已方便我们以后好区分我们之前设置过的项目,当然,我们不设置也是可以的,因为我这里是采集搜索出来的新浪微博信息,我就去了一个新浪微博收索的名称。
直接点击下一步设置,进入到标题列表页及其翻页设置,列表页是包含我们要采集内容的链接网址的页面,比如百度搜索一个关键词,会列出来很多网页,这些网页我们就可以认为是标题列表页面。
我们在新浪微博搜索的地方需要我们要监控的关键词,比如我要监控“财经行业”这个关键词的微博信息,那么我们就需要这个关键词点击搜索就会出来我们需要的标题列表页面。
文章采集软件使用方法
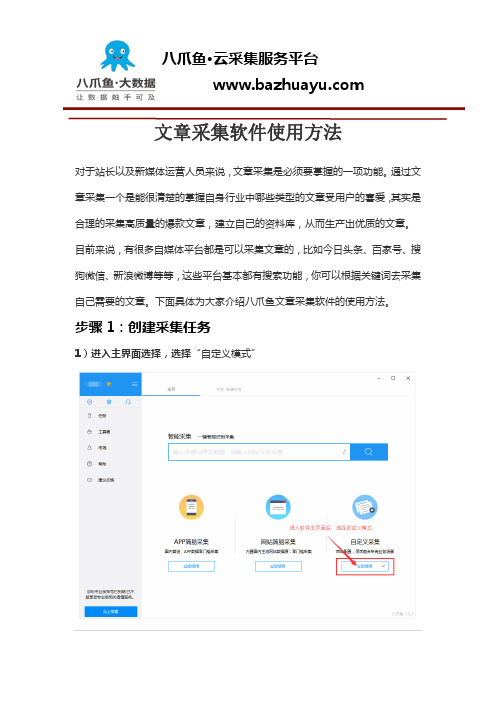
对于站长以及新媒体运营人员来说,文章采集是必须要掌握的一项功能。
通过文章采集一个是能很清楚的掌握自身行业中哪些类型的文章受用户的喜爱,其实是合理的采集高质量的爆款文章,建立自己的资料库,从而生产出优质的文章。
目前来说,有很多自媒体平台都是可以采集文章的,比如今日头条、百家号、搜狗微信、新浪微博等等,这些平台基本都有搜索功能,你可以根据关键词去采集自己需要的文章。
下面具体为大家介绍八爪鱼文章采集软件的使用方法。
步骤1:创建采集任务1)进入主界面选择,选择“自定义模式”文章采集软件使用步骤12)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”文章采集软件使用步骤23)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容,即为今日头条最新发布的热点新闻。
文章采集软件使用步骤3步骤2:设置ajax页面加载时间●设置打开网页步骤的ajax滚动加载时间●找到翻页按钮,设置翻页循环●设置翻页步骤ajax下拉加载时间1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定文章采集软件使用步骤4注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量。
文章采集软件使用步骤5步骤3:采集新闻内容创建数据提取列表1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色 然后点击“选中子元素”文章采集软件使用步骤6注意:点击右上角的“流程”按钮,即可展现出可视化流程图。
2)然后点击“选中全部”,将页面中需要需要采集的信息添加到列表中文章采集软件使用步骤7注意:在提示框中的字段上会出现一个“X”标识,点击即可删除该字段。
文章采集软件使用步骤83)点击“采集以下数据”文章采集软件使用步骤9 4)修改采集字段名称,点击下方红色方框中的“保存并开始采集”文章采集软件使用步骤10步骤4:数据采集及导出1)根据采集的情况选择合适的采集方式,这里选择“启动本地采集”文章采集软件使用步骤11说明:本地采集占用当前电脑资源进行采集,如果存在采集时间要求或当前电脑无法长时间进行采集可以使用云采集功能,云采集在网络中进行采集,无需当前电脑支持,电脑可以关机,可以设置多个云节点分摊任务,10个节点相当于10台电脑分配任务帮你采集,速度降低为原来的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导出操作。
网站文章标题采集

网站文章标题采集当我们在网站优化,或分析词频权重,研究站点内哪些类型的文章标题是频繁出现时,快速的获取站点内全部的文章标题就必不可少了。
量少或许还能通过复制粘贴解决,但量若上来了,有成千甚至上万的文章标题需要获取。
那手动复制粘贴简直就是噩梦!此时必然要寻求更快的解决方案。
如通过爬虫工具快速批量获取文章标题。
以下用做网易号文章例演示,通过八爪鱼这个爬虫工具去获取数据,不单单获取文章标题,还能获取文章内容。
步骤1:创建网易号文章采集任务1)进入主界面,选择“自定义采集”2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”步骤2:创建循环点击加载更多1)打开网页之后,打开右上角的流程按钮,从左边的流程展示界面拖入一个循环的步骤,如下图2)然后拉到页面底部,看到加载更多按钮,因为想要查看更多内容就需要循环的点击加载更多,所以我们就需要设置一个点击“加载更多”的循环步骤。
注意:采集更多内容就需要加载更多的内容,本篇文章仅做演示,所以选择执行点击“加载更多”20次,根据自己实际需求加减即可。
步骤3:创建循环点击列表采集详情1)点击文章列表的第一个和第二个标题,然后选择“循环点击每个元素”按钮,这样就创建了一个循环点击列表命令,当前列表页的内容就都能在采集器中看到了。
2)然后就可以提取我们需要的文本数据了,下图提取了文本的标题、时间、正文等三个部分的文字内容,还需要其他的信息可以自由删减编辑。
然后就可以点 击保存,开始本地采集。
3)点击开始采集后,采集器就开始提取数据。
4)采集结束后导出即可。
相关采集教程:新浪新闻采集/tutorial/xlnewscjBBC英文文章采集/tutorial/englisharticlecj新浪博客文章采集/tutorial/sinablogcjuc头条文章采集/tutorial/ucnewscj百家号爆文采集/tutorial/bjharticlecj自媒体文章怎么采集/tutorial/zmtwzcj微信文章爬虫使用教程/tutorial/wxarticlecrawl 八爪鱼采集原理/tutorial/spcjyl八爪鱼采集器7.0简介/tutorial/70js八爪鱼——90万用户选择的网页数据采集器。
微博数据获取方法

微博数据获取方法
要获取微博数据,可以通过以下几种方法:
1. 使用微博的开放平台API:微博提供了一系列的接口,可以通过API获取用户个人信息、用户的微博内容、用户的关注关系等数据。
你可以从微博开放平台申请开发者账号,并获取API的访问权限,然后使用相应的API进行数据获取。
2. 使用爬虫工具:你可以使用网络爬虫工具,如Python的Scrapy框架或BeautifulSoup库,来爬取微博网页的内容。
通过分析微博网页的结构,可以提取需要的数据,如用户的微博内容、用户的关注列表等。
3. 使用第三方微博数据采集工具:市面上有一些第三方工具可以帮助你采集微博数据,这些工具通常提供了简化的操作界面,可以帮助你方便地设置爬取的范围和条件,并提供自动化的数据采集功能。
无论使用哪种方法,都需要注意遵守微博的使用条款和开放平台的规定,确保数据获取的合法性和合规性。
此外,由于微博的页面结构和API接口可能会有变动,你还需要及时跟踪微博的更新和调整,以确保数据获取的稳定性和准确性。
利用博客备份工具BlogDown备份新浪博客

很想把自己写的博客制作成电子书,作为留恋珍藏,怎么办?使用博客备份工具BlogDown 轻松完成。
只需要几个步骤即可:步骤一:添加博客用户,例如著名足球评论员李承鹏的新浪博客:lichengyong图一添加用户在用户名填写“lichengpeng”即可。
其他都不要选择,否则很慢。
步骤二:点击【备份】按钮,即可下载博客文章。
图二下载博客步骤三:点击【导出】按钮,即可制作博客电子书了。
图三导出博客可以进行导出设置,一般用默认即可。
最后导出的文件包括各种格式,其中chm格式是最流行的电子书格式,他可以包括文字和图片,全部打包在一个文件之中,方便保存。
双击左边的博客用户"lichengpeng",打开备份的文件夹。
里面有各种格式的备份文件。
其中,chm文件格式(使用网页内容) 是推荐文件格式。
如图。
图五备份为chm电子书格式也可以使纯文本格式和网页格式图六备份为纯文本格式图七备份为网页格式博客备份工具BlogDown简介:BlogDown是强大的博客备份工具,支持多种博客,支持多种导出格式,多线程下载,纯绿色软件,解压即可运行。
主要功能和特点介绍:**多线程博客备份真正多线程博客下载备份,可以同时下载多个不同网站不同用户的博客,实时查看每个博客内容。
**强大的博客备份功能可以解析博客文章的标题,正文,发表时间,分类,文章地址。
**支持众多的博客网站支持国内所有大型的博客网站,例如新浪博客,网易博客,百度空间,QQ空间,搜狐博客等等。
目前总共支持49个博客,详细目录附后。
**丰富的导出格式可以把下载的博客文章导出为流行的文档格式,包括经典的电子书chm格式(里面可以包含图片),纯文本txt格式(单个或者多个文件),网页html格式(单个或者多个文件),Web文档mht格式(可以包含图片),RSS格式。
**备份博客图片可以备份博客文章中的图片,可以单独备份,也可以跟文章一起备份。
也可以在导出的备份文章中保存,例如chm,mht格式。
10个适用于WordPress的RSS采集插件大全

10个适用于WordPress的RSS采集插件大全作为一个强大的博客甚至说CMS内容管理系统,WordPress完全兼容RSS输出和输入。
这就意味着,如果需要,可以通过rss来采集网站信息,当然,鼓励适度而为之,不建议滥用采集。
具体的安装使用方法这里就不一一介绍了,请Google之.1、wordpress自动采集插件-FeedWordPress这个插件用的很不错,主要是读取feed来实现你的博文更新的,并且是以全文的形式。
优点是插件更新升级很及时!建议不要用汉化包,就用英文版WordPress和FeedWordPress原插件!插件下载后需要在后台控制面板激活,并根据需要定制功能。
2、wordpress自动采集插件-Caffeinated Content是一个非常强大的WordPress插件,根据关键词搜索Youtube、Yahoo Answer、Articles、Files 而获取相关内容,可保留原文也可翻译成多个国家语言,并可以定时定量自动发布到你的博客上的插件工具。
功能是十分强大的,只可惜没有针对中文设置几个比较好的信息源头,如果想自行做二次开发,用这个做基础是非常好的选择。
下载解压后上传到plugins根目录下,到后台激活即可,本插件需要注册后方能使用。
3、wordpress自动采集插件-WP-o-Matic是一款效果非常不错的WordPress采集插件,虽然少了自动分类功能,但该插件在各个方面都表现的尚佳,相对于wordpress采集插件Caffeinated Content来说,wp-o-matic是不错的选择,通过RSS完成blog的自动采集。
WP-o-Matic 插件是博客联盟见过的最狠的一个wordpress 采集插件――只需在后台设定Rss 源以及采集的时间,WP-o-Matic就会自动执行。
它甚至可以将对方网站的附件以及图片等都采集,跟国内的cms系统有得一拼,完全无需站长耗心耗力。
孤狼采集器是干什么的

孤狼采集器是干什么的做自媒体相关工作或者站长的朋友可能会听过孤狼采集器,通过孤狼采集器采集微信文章,然后发布到自己的网站上或者微信工作号上。
不过孤狼采集器只能采集文章,并且目前好像只能采集微信平台的。
如果要采集其它网站数据,或者采集其它平台的文章,那么可以考虑使用八爪鱼采集器。
八爪鱼采集器的优点1、功能强大。
八爪鱼采集器是一款通用爬虫,可应对各种网页的复杂结构(瀑布流等)和防采集措施(登录、验证码、封IP),实现百分之九十九的网页数据抓取。
2、操作简单。
模拟人浏览网页的操作,通过输入文字、点击元素、选择操作项等一些简单操作,即可完成规则配置,无需编写代码,对没有技术背景的用户极为友好。
3、流程可视化。
真正意义上实现了操作流程可视化,用户可打开“流程”按钮,直接可见操作流程,并对每一步骤,进行高级选项的设置(ajax/修改xpath 等)。
4、云采集。
数量庞大的企业云,24x7不间断运行,可定时采集、关机也可采集,同时支持任务拆分,可提高数据采集速度。
5、7.0版本推出的简易网页采集,内置主流网站大量数据源和已经写好的采集规则。
用户只需输入关键词,即可采集到大量所需数据。
八爪鱼采集器能采集平台文章数据目前绝大部分自媒体平台,八爪鱼采集器都是可以进行采集的,比如微信公众号,今日头条,新浪博客,UC头条,下面介绍具体的采集方法,大家可以根据自身需求查看相应的教程。
1、今日头条数据采集采集内容:标题、来源、评论、发布时间采集教程地址:/tutorialdetail-1/jrtt-7.html2、网易号文章采集采集内容:网易号文章标题,网易号文章发布时间,网易号文章正文。
采集教程地址:/tutorialdetail-1/wyhcj.html3、uc头条文章采集采集内容:标题、发布者、发布时间、文章内容、页面网址、图片URL 采集教程地址:/tutorialdetail-1/ucnewscj.html4、百家号爆文采集采集内容:文章标题,文章作者,发布时间,阅读数,文章正文采集教程地址:/tutorialdetail-1/bjharticlecj.html5、微信公众号热门文章采集(文本+图片)采集内容:文章标题、时间、来源和正文+图片URL采集教程地址:/tutorialdetail-1/wxcjimg.html6、新浪博客文章采集采集内容:博客文章正文,博客文章标题,文章标签,文章分类,文章发布日期。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
新浪博客文章采集器
新浪博客拥有很多博主,会发布很多高质量的文章,有时候,有些朋友看到这些文章之后想采集下来,但是一篇一篇文章去复制效率太慢了,这个时候该怎么办呢?使用八爪鱼采集器,只需做好规则,即可全自动地将我们的想要的文章采集下来。
本文介绍使用八爪鱼采集新浪博客文章的方法。
采集网站:
/s/articlelist_1406314195_0_1.html
采集的内容包括:博客文章正文,标题,标签,分类,日期。
步骤1:创建新浪博客文章采集任务
1)进入主界面,选择“自定义采集”
2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
步骤2:创建翻页循环
1)打开网页之后,打开右上角的流程按钮,使制作的流程可见状态。
点击页面下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。
(可在左上角流程中手动点击“循环翻页”和“点击翻页”几次,测试是否正常翻页。
)
2)由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“循环翻页”的高级选项里设置“ajax加载数据”,超时时间设置为5秒,点击“确定”。
步骤3:创建列表循环
)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。
1
由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“点击元素”的高级选项里设置“
ajax
加载数据”,AJAX 超时设置为3秒,点击“确定”。
3)数据提取,接下来采集具体字段,分别选中页面标题、标签、分类、时间,点击“采集该元素的文本”,并在上方流程中修改字段名称。
鼠标点击正文所在的地方,
点击提示框中的右下角图标,扩大选项范围,直至包
括全部正文内容。
(笔者测试点击2下就全部包括在内了)
同样选择“采集该元素的文本”,修改字段名称,数据提取完毕。
4)由于该网站网页加载速度非常慢,所以可在流程各个步骤的高级选项里设置“执行前等待”几秒时间,也可避免访问页面较快出现防采集问题。
设置后点击“确定”。
步骤4
:新浪博客数据采集及导出
1)点击左上角的“保存”,然后点击“开始采集”。
选择“启动本地采集”
2)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导出方式”,将采集好的数据导出, 这里我们选择excel作为导出为格式,这个时候新浪博客数据就导出来了,数据导出后如下图
相关采集教程:
蚂蜂窝旅游美食文章评论采集:
/tutorialdetail-1/mafengwoplcj.html
搜狗微信公众号文章采集:
/tutorialdetail-1/sgwxwzcj-7.html
uc头条文章采集:
/tutorialdetail-1/ucnewscj.html
网易自媒体文章采集:
/tutorialdetail-1/wyhcj.html
百度搜索结果抓取和采集:
/tutorialdetail-1/bdssjg-7.html
新浪微博评论数据的抓取与采集方法:
/tutorialdetail-1/wbplcj-7.html
八爪鱼——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。
配置好采集任务后可关机,任务可在云端执行。
庞大云采集集群24*7不间断运行,不用担心IP被封,网络中断。
4、功能免费+增值服务,可按需选择。
免费版具备所有功能,能够满足用户的基本采集需求。
同时设置了一些增值服务(如私有云),满足高端付费企业用户的需要。