第三章回归模型的估计概论(高级计量经济学-清华大学
高级计量经济学导论复习资料

第一章高级计量经济学4 1.数据类型:42.经验经济分析的步骤:4 第二章简单回归模型41.回归分析(regression analysis):42.回归分析的主要内容包括:43.变量间的关系:44.变量关系的描述:45.相关关系的类型:46.线性相关的程度:57.回归分析的意义:58.总体回归线(population regression line )/总体回归曲线(population regression curve ):在给定解释变量Xi 条件下被解释变量Yi 的期望轨迹。
59.总体回归函数(PRF):E (y ∣x )=β0+β1x,510.随机干扰项(stochastic disturbance )或随机误差项(stochastic error ):511.样本回归方程(SRF ):01ˆˆˆi i y x =β+β 512.拟合值:当x=i 时,y 通过样本回归方程算出来的值。
即01ˆˆˆi i y x =β+β 5 13.样本回归模型(sample regression model ):01ˆˆˆi i i iY Y u X e =+=β+β+ 5 14.回归分析的主要目的:根据样本回归函数SRF ,估计总体回归函数PRF 。
6 第三章:简单回归方程分析61.简单回归方程:62.线性的含义:63.OLS 斜率估计,β0和β1的普通最小二乘估计值的推算:64.OLS 法是要找到一条直线,使残差平方和最小。
75.残差:是对误差项的估计,因此,它是拟合直线(样本回归函数)和样本点之间的距离。
76.OLS 统计量的代数性质:77.SST=SSE+SSR :88.拟合优度:来衡量样本回归线是否很好地拟合了样本数据的指标。
89.判定系数:解释变异与总变异之比。
即y 的样本变异中被x 解释的部分。
8 10.测量单位:811.在简单回归中加入非线性因素(因变量为对数):8 12.OLS 的基本假设:913.定理2.1: OLS 的无偏性:914.定理2.2 OLS 估计量的抽样方差:9 15.定理2.3:σ²的无偏估计1016.回归标准误差:ˆσ17.1ˆβ的标准误:11221ˆˆ()(())ni i se x x =σβ==-∑10第四章多元回归分析101.多元回归分析的优点:102.多元线性回归模型:103.多元线性回归的OLS估计值:104.SRF样本回归函数:115.拟合值和残差11ˆβ的计算116.偏效应以及17.比较简单回归和多元回归估计值:128.拟合优度(SST、SSR、SSE、R2):139.过原点的回归:1310.多元回归模型的假定及定理3.1、定理3.2:1411.多重共线性:两个或多个自变量之间高度(但不完全)相关。
第三章 回归模型的估计 概论(高级计量经济学-清华大学 潘文清)

2、极大似然估计
对具有pdf或pmf为f(Y;)的随机变量Y(其参数未知), 随机抽取一容量为n的样本Y=(Y1,Y2,…Yn)’其联合分布为:
gn(Y1,Y2,…Yn;)=if(Yi;) 可将其视为给定Y=(Y1,Y2,…Yn)’时关于的函数,称其为关于 的似然函数(likelihood function),简记为L() : L()= gn(Y1,Y2,…Yn;)=if(Yi;) 对离散型分布,似然函数L()就是实际观测结果的概率。 极大似然估计就是估计参数,以使这一概率最大; 对连续型分布,同样也是通过求解L()的最大化问题,来 寻找的极大似然估计值的。
二、类比估计法(The Analogy Principle)
1、基本原理
• 总体参数是关于总体某特征的描述,估计该参数, 可使用相对应的描述样本特征的统计量。 (1)估计总体矩,使用相应的样本矩
(2)估计总体矩的函数,使用相应的样本矩的函数 对线性回归模型: Y=0+1X+u
上述方法都是通过样本矩估计总体矩,因此,也 称为矩估计法(moment methods, MM)。 (3)类比法还有: • 用样本中位数估计总体中位数; • 用样本最大值估计总体最大值; • 用样本均值函数mY|X估计总体期望函数Y|X,等
可见,总体均值的极大似然估计就是样本均值,总 体方差的极大似然估计就是样本方差。
3、极大似然估计的统计性质
由数理统计学知识: (n-1)s*2/2~2(n-1)
因此, Var[(n-1)s*2/2]=2(n-1)
Var(S*2)=24/(n-1)
§3.2 估计总体关系 Estimating a Population Relation 一、问题的引入(Introduction)
计量经济学中级教程(潘省初清华大学出版社)课后习题答案

计量经济学中级教程(潘省初清华大学出版社)课后习题答案计量经济学中级教程习题参考答案第一章绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说)(2)建立计量经济模型(3)收集数据(4)估计参数(5)假设检验(6)预测和政策分析 1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3 时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YYn==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章经典线性回归模型2.1 判断题(说明对错;如果错误,则予以更正)(1)对(2)对(3)错只要线性回归模型满足假设条件(1)~(4),OLS 估计量就是BLUE 。
(4)错R 2 =ESS/TSS 。
(5)错。
我们可以说的是,手头的数据不允许我们拒绝原假设。
(6)错。
因为∑=22)?(tx Var σβ,只有当∑2t x 保持恒定时,上述说法才正确。
2.2 应采用(1),因为由(2)和(3)的回归结果可知,除X 1外,其余解释变量的系数均不显著。
高级计量经济学 广义回归模型PPT共140页

▪
27、只有把抱怨环境的心情,化为上进的力量,才是成功的保证。——罗曼·罗兰
▪
28、知之者不如好之者,好之者不如乐之者。——孔子
▪
29、勇猛、大胆和坚定的决心能够抵得上武器的精良。——达·芬奇
▪
30、意志是一个强壮的盲人,倚靠在明眼的跛子肩上。——叔本华
谢谢!
140
▪
26、要使整个人生都过得舒适、愉快,这是不可能的,因为人类必须具备一种能应付逆境的态度。——卢梭
高级计量经济学模型与应用

高级计量经济学模型与应用导言计量经济学是一门应用数学和统计学原理来研究经济学理论的学科。
随着数据科学和计量经济学的发展,高级计量经济学模型的重要性日益凸显。
这些模型可以帮助经济学家和决策者更准确地理解经济现象,并做出有根据的政策建议。
本文将介绍几种常见的高级计量经济学模型,并探讨它们在实际中的应用。
ARMA模型ARMA模型(自回归滑动平均模型)是一种时间序列模型,用于描述时间序列的相关性和趋势。
ARMA模型结合了自回归(AR)模型和滑动平均(MA)模型的特点。
在实际应用中,ARMA模型经常被用来分析和预测金融时间序列数据,如股票价格、汇率和利率等。
通过估计ARMA模型的参数,我们可以对未来数据进行预测,从而帮助投资者做出更明智的决策。
面板数据模型面板数据模型是一种经济计量学中常用的模型,用于分析横截面数据和时间序列数据的交叉样本。
面板数据模型具有较强的灵活性,可以用来处理包含多个观察单元和时间点的复杂数据。
在实践中,面板数据模型广泛应用于诸如教育经济学、劳动经济学和区域经济学等领域的研究中。
例如,研究人员可以使用面板数据模型来评估教育政策对学生学习成果的影响,或分析劳动市场的供求关系。
VAR模型VAR模型(向量自回归模型)是一种多元时间序列模型,用于描述多个经济变量之间的动态关系。
VAR模型可以帮助我们了解不同变量之间的相互作用,并预测它们可能的未来走势。
在经济学领域,VAR模型被广泛应用于宏观经济预测、货币政策分析和金融风险管理等方面。
例如,央行可以利用VAR模型,基于过去的经济数据来预测未来的通货膨胀率,从而制定相应的货币政策。
ARCH/GARCH模型ARCH模型(自回归条件异方差模型)和GARCH模型(广义自回归条件异方差模型)是一类用来研究时间序列波动性的模型。
它们被广泛应用于金融风险管理和资产组合优化等领域。
通过建立ARCH/GARCH模型,我们可以对金融数据中的波动性进行建模和预测。
计量经济学第3章参考答案

(3) = TSS
RSS 480 = = 750 2 1− R 1 − 0.36
7. 答: (1) cov( = x, y )
1 2 2 ( xt − x )( y = r σx σ y = 0.9 × 16 ×10 =11.38 ∑ t − y) n −1
∑ ( x − x )( y − y )=
即表明截距项也显著不为 0,通过了显著性检验。 (3)Yf=2.17+0.2023×45=11.2735
2 1 (x f − x ) 1 (45 − 29.3) 2 ˆ 1+ + = × × + = 4.823 t0.025 (8) × σ 1.8595 2.2336 1+ n ∑ ( x −x ) 2 10 992.1
3
2
五、综合题 1. 答: (1)建立深圳地方预算内财政收入对 GDP 的回归模型,建立 EViews 文件,利用地方预 算内财政收入(Y)和 GDP 的数据表,作散点图
可看出地方预算内财政收入(Y)和 GDP 的关系近似直线关系,可建立线性回归模型:
Yt = β1 + β 2 GDPt + u t
第 3 章参考答案
一、名词解释 1. 高斯-马尔可夫定理:在古典假定条件下,OLS 估计量是模型参数的最佳线性无偏估计 量,这一结论即是高斯-马尔可夫定理。 2. 总变差(总离差平方和) :在回归模型中,被解释变量的观测值与其均值的离差平方和。 3. 回归变差(回归平方和) :在回归模型中,因变量的估计值与其均值的离差平方和,也就 是由解释变量解释的变差。 4. 剩余变差(残差平方和) :在回归模型中,因变量的观测值与估计值之差的平方和,是不 能由解释变量所解释的部分变差。 5. 估计标准误差:在回归模型中,随机误差项方差的估计量的平方根。 6. 样本决定系数:回归平方和在总变差中所占的比重。 7. 拟合优度:样本回归直线与样本观测数据之间的拟合程度。 8. 估计量的标准差:度量一个变量变化大小的测量值。 9. 协方差:用 Cov(X,Y)表示,度量 X,Y 两个变量关联程度的统计量。 10. 显著性检验:利用样本结果,来证实一个虚拟假设的真伪的一种检验程序。 11. 拟合优度检验:检验模型对样本观测值的拟合程度,用 R 2 表示,该值越接近 1,模型 对样本观测值拟合得越好。 12. t 检验:是针对每个解释变量进行的显著性检验,即构造一个 t 统计量,如果该统计量 的值落在置信区间外,就拒绝原假设。 13. 点预测:给定自变量的某一个值时,利用样本回归方程求出相应的样本拟合值,以此作 为因变量实际值均值的估计值。
清华大学计量经济学课件
二、经济预测
• 计量经济学模型作为一类经济数学模型,是从 用于经济预测,特别是短期预测而发展起来的。
• 计量经济学模型是以模拟历史、从已经发生的 经济活动中找出变化规律为主要技术手段。
• 对于非稳定发展的经济过程,对于缺乏规范行 为理论的经济活动,计量经济学模型预测功能 失效。
• 模型理论方法的发展以适应预测的需要。
ln(人均食品需求量)=-2.0+0.5ln(人均收 入)-0.8ln(食品价格) +0.8ln(其它商品价格)
⑵ 统计检验 由数理统计理论决定 包括拟合优度检验 总体显著性检验 变量显著性检验
⑶ 计量经济学检验 由计量经济学理论决定 包括异方差性检验 序列相关性检验 共线性检验
⑷ 模型预测检验 由模型的应用要求决定 包括实际
例如:ln(人均食品需求量)=α+βln(人均收入) +γln(食品价格) +δln(其它商品价格)+ε
其中α 、β、γ、δ的符号、大小、 关系
二、样本数据的收集
⑴ 几类常用的样本数据 时间序列数据 截面数据 虚变量离散数据 联合应用
⑵ 数据质量 完整性 准确性 可比性 一致性
三、模型参数的估计
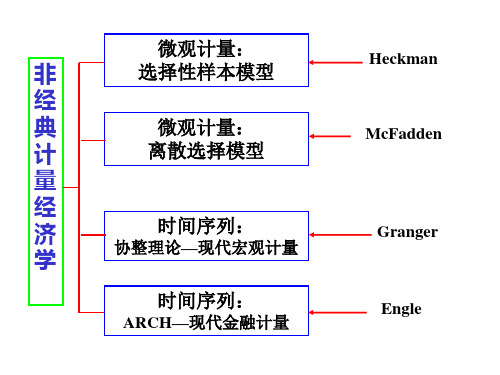
微观计量:
非
选择性样本模型
经
典
微观计量:
计
离散选择模型
量
经
济 学
时间序列:
协整理论—现代宏观计量
时间序列:
ARCH—现代金融计量
Heckman McFadden
Granger Engle
五、计量经济学在经济学科中的地位
△ 从现代西方经济学的特征看 △ 从西方经济学的发展历史看 △ 从世界一流大学经济学课程表看 △ 从国际经济学刊物论文看 △ 从经济学的“世界先进水平”看
[课件]数学建模 相关分析与回归分析 清华大学PPT
![[课件]数学建模 相关分析与回归分析 清华大学PPT](https://img.taocdn.com/s3/m/2492f4accc22bcd126ff0c9e.png)
r>0
** * * * ** **** * ** * *
**
***
r <0 表 示大体 上 Y随 着X增 加而递 减。
* * * * ** **** ** * * ** *** ** *
r<0
** **
* * * *
*** *
*** * * *
r0
*
*
*
*
* * * * * * * * *
1)假设回归方程不显著 H0:方程不显著 H1:方程显著
ˆy 2/1 y ˆ 2 / n 2 yy
2)计算回归方程的F统计量 F= 回归平方和/自由度(f1) 剩余平方和/自由度(f2)
3)给定显著性水平和两个自由度,查F分布表,得到相应临界值F
4)若F>F,拒绝H0,回归方程显著; 若FF,不能拒绝H0,x与y之间的关系不明显或无关系,回归方程不 显著
计算回归系数b的t值:
t
2
b
b
S
b
2 a y b xy / n 2 y S y S 2 2 b 2 n x x x x
1428879 ( 8 . 3 ) 4087 0 . 5175 2824500 / 12 2
模块BASE中的过程CORR可方便地用于计算变量之间的 相互关系:计算数据集FITNESS中OXYGEN,MAXPULSE, RSTPULSE三个变量和另三个变量RUNTIME,RUNPULSE, WEIGHT之间的相关系数。
以下可看出变量MAXPULSE和RUNPULSE有最大的正相关,OXYGEN 和RUNTIME负相关的绝对值最大,RSTPLUSE和WEIGHT的相关的绝 对值最小。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(2)在计量经济学中,除了精确分布已知的情况, 最佳渐近正态性,或称为渐近有效性(asymptotic efficiency),是最常选择的准则。
(3)渐近有效估计量的直观表述为
二、类比估计法(The Analogy Principle)
第三章 回归模型的估计: 概论
Regression Model Estimation: General Approaches
第二章指出,当联合概率分布p(X,Y)已知时,在 MSE最小化准则下,E(Y|X)是Y的最佳代表,被称 为是Y关于X的回归函数(regression function),也可 称为总体回归函数(population regression function)。
对于某一样本(Y1,Y2,…,Yn)’,则有一个估计值 (estimate):
t=h(Y1,Y2,…,Yn)
一、衡量参数估计量优劣的准则 Criteria for an Estimator
1、有限样本准则
记T为所选取的统计量,则T与参数的差异可用 均方误(mean square error, MSE)刻画:
1、基本原理 • 总体参数是关于总体某特征的描述,估计该参数,
可使用相对应的描述样本特征的统计量。 (1)估计总体矩,使用相应的样本矩
(2)估计总体矩的函数,使用相应的样本矩的函数 对线性回归模型: Y=0+1X+u
上述方法都是通过样本矩估计总体矩,因此,也 称为矩估计法(moment methods, MM)。
要寻找最佳估计量,则需在约束∑ci=1下求解 min ∑ci2
记 Q=∑ci2-(∑ci -1)
则 Q/ci=2ci -
(i=1,2,…,n)
Q/= - (∑ci -1) 由极值求解条件得:
ci=/2, ∑ci =1 于是 ∑ci = n/2 =2/n, ci=1/n
Theorem. 从任何总体中进行简单随机抽样,样本均 值是总体期望的最小方差线性无偏估计量(minimum variance linear unbiased estimator,MVLUE)。
2、总体均值的估计 对E(Y)=,Var(Y)=2的某总体随机抽样,由类
比法(矩法)知:
记T=∑iciYi,ci为不全为0的常数。 E(T)=E(∑ciYi)=∑ciE(Yi)=∑ci Var(T)=∑ci2Var(Yi)=2∑ci2 于是,任何无截距项,系数和为1的Yi的线性组 合都是的无偏估计量。
2、无限样本准则(Asymptotic Criteria)
有限样本往往需要知道估计量的精确分布,而这是建立 在对总体分布已知的情况下的。
如果总体分布未知,则需要依赖无限样本准则:
注意: (1)一致性的充分条件是:lim E(Tn)=, 且 lim Var(Tn)=0 (2)同一参数可能会有多个一致估计量。如从对称分布的
而当上述总体回归函数呈现线性形式
E(Y|X)=X’0 时,则称回归模型 Y=X’+u 关于E(Y|X)正确设定,这时“真实”参数0等于最 佳线性最小二乘解*:
0=*=[E(XX’)]-1E(XY)
且
E(u|X)=0 E(Xu)=0
问题是:我们往往不知道总体的p(X,Y)。因此, 只能通过样本来估计总体的相关信息。
总体中抽样,则样本均值与样本中位数都是总体期望=E(Y) 的一致估计量。
在实践中,为了区分同一参数不同的一致估计量, 需要从退化极限分布(degenerate limiting distribution) 转向渐近分布(asymtotic distribution)
尤其是,一致估计量具有以参数真实值为中心的 渐近正态分布(asymptotic normal distribution)。
(3)类比法还有: • 用样本中位数估计总体中位数; • 用样本最大值估计总体最大值; • 用样本均值函数mY|X估计总体期望函数Y|X,等
Questions: Are analog estimator sensible from a statistical point of view?
How reliable are they? What shall we do when an analog estimator is unreliable?
定义: T is an unbiased estimator of iff E(T- )=0, for all .
对无偏估计量, MSE=Variance,因此,在实践 中还希望从无偏估计量中选择方差最小的。于是, 有如下最小方差无偏准则(minimum variance unbiasedness criterion)
定义: T is a minimum variance unbiased estimator, or MVUE, of iff
(a) E(T- )=0 for all , and (b) V(T)≤V(T*) for all T* such that E(T*- )=0
最小方差无偏估计量也称为无偏有效估计量 (Unbiased and efficient estimator)
E(T-)2 由于T关于的均方误有如下分解式
E(T- )2=Var(T)+[E(T)- ]2 记[E(T)- ]=E(T)- 为T关于的偏差(bias)。
Var(T)刻画了统计量T的真正的离散程度,如果它 较小,表明T不太受数据随机波动的影响;
如果E(T)-较小,表明T的分布密切围拢着。
根据样本估计总体构成了回归分析的主体内容。
§3.1 参数估计:概论 Parameter Estimation: General Approaches
设(Y1,Y2,…,Yn)’是从未知总体Y~f(Y)中随机抽取 的一个样本,并由此估计总体的特征,如参数。
我们可以寻找一个关于的估计量(estimator)T, 它是关于所抽样本Y的函数:T=h(Y)