统计学贾俊平第四版第七章课后答案目前最全
统计学贾俊平_第四版课后习题答案
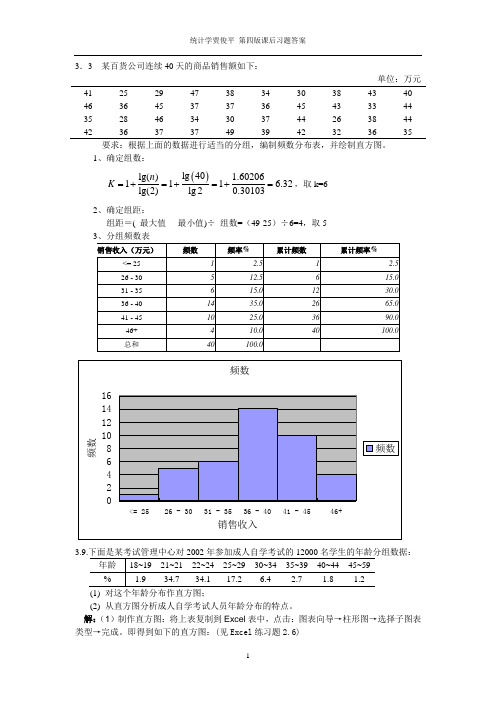
3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
1、确定组数: ()l g 40l g () 1.60206111 6.32l g (2)l g 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取5(1) 对这个年龄分布作直方图;(2) 从直方图分析成人自学考试人员年龄分布的特点。
解:(1)制作直方图:将上表复制到Excel 表中,点击:图表向导→柱形图→选择子图表类型→完成。
即得到如下的直方图:(见Excel 练习题2.6)(2)年龄分布的特点:自学考试人员年龄的分布为右偏。
解:(1)根据上面的数据,画出两个班考试成绩的对比条形图和环形图。
3.14 已知1995—2004年我国的国内生产总值数据如下(按当年价格计算):要求:(2)绘制第一、二、三产业国内生产总值的线图。
4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量N Valid 10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.0075 12.50种是所有颐客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。
统计学贾俊平_第四版课后习题答案第七章

7.11 (1) 解:已知n=50,1a -=0.9522,ss x z xz nn a aæö-×+×ç÷èø=81.822981.8229101.491.966,101.491.9665050æö-´+´ç÷èø= (100.89,101.91)(2)解:已知n=50,1a -=0.95,2z a =00.0225z =1.96,样本比率p=(50-5)/50=0.9 则食品合格率的95%的置信区间:()()2211,p p p p p zp z nna aæö--ç÷-×+×ç÷èø=()()0.910.90.910.90.9 1.91.966,0.9 1.91.9665050æö---´+´ç÷èø=(0.8168,0.9832)7.22 (1)由题知,该题为大样本,方差已知,则有21m m -的95%的置信区间为:176.12100201001696.1)2325()(2221212/21±=+´±-=+±-n s n s z x x a即(0.824,3.176)(2m m -的95%的置信区间为:()()64.42112212212/21±=÷÷øöççèæ+-+±-n n s n ntxxpa 即(—2.64,6.64) (3)由题知,该题为小样本,方差不同, 则有21m m -的95%的置信区间为:()()64.42112212212/21±=÷÷øöççèæ+-+±-n n s n n tx x p a 即(—2.64,6.64) (4)由题知,该题为小样本,样本量不等,方差相等,则合并估计量为()()713128524211212222112==-+-+-=n n s n s n s p 则有21m m -的95%的置信区间为:()()02.42112212212/21±=÷÷øöççèæ+-+±-n n s n n tx x p a 即(—2.02,6.02) ,2z a =00.0225z =1.96。
统计学(第四版)袁卫 庞皓 贾俊平 杨灿 统计学 第七章练习题参考解答

STATISTICS
单击练此习处题编第部辑七分母章版参标考题解样答式
练习题7.1
1. 设销售收入 为自变量,销售成本 为因变量。现已根据某百货
公司某年12个月的有关资料计算出以下数据:(单位:万元)
(xt x)2 425053.73 x 647.88
(yt y)2 262855.25
F (k 1, n k) F0.05 (1, 26) 2.91
F=17.70503 F0.05 (1, 26) 2.91
所以y和 联合起来对最终消费有显著影响,即回归方 程整体上是显著的。
练习题7.7
下表给出y对x2和x3回归的结果:
离差来源
平方和(SS) 自由度(df)
由F=58.20479,大于临界值 F0.05 (4 1, 22 4) 3.16 ,
说明模型在整体上是显著的。
练习题7.5
为进一步研究前期的消费对本期消费的影响,准备拟合以下
形式的消费函数: ct 1 yt 2ct1 ut
式中:ct 为t 期的消费;ct1 为 t-1期的消费;yt 为国民总收入。
t 2 (n 2) t0.025 (10) 2.2281 t 245.71875 t0.025 (8) 2.2281
H0 : 0 ,检验说明x对y有显著影响.
(4) 假定下年1月销售收入为800万元,利用拟合的回归方 程预测其销售成本,并给出置信度为95%的预测区间
y 549.8
(xt x)(yt y) 334229.09
(1)拟合简单线性回归方程,并对方程中回归系数的经济意义作 出解释。
统计学(第四版) 贾俊平 课后习题答案

第 2 章 统计数据的描述——练习题
●1. 为评价家电行业售后服务的质量,随机抽取了由 100 家庭构成的一个样本。服务质量的 等级分别表示为:A. 好;B.较好;C. 一般;D. 差;E. 较差。调查结果如下: B E C C A D C B A E D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C D E A B D D C A D B C C A E D C B C B C E D B C C B C (1) 指出上面的数据属于什么类型; (2) 用 Excel 制作一张频数分布表;
(3)条形图的制作:将上表 (包含总标题,去掉合计栏)复制到 Excel 表中,点击:图 表向导→条形图→选择子图表类型→完成(见 Excel 练习题 2.1)。即得到如下的条形图:
E D C B A 0 20 40
服务质量等 级评价的频 数分布 频 率% 服务质量等 级评价的频 数分布 家庭 数(频数)
25
30
35
40
●4. 为了确定灯泡的使用寿命(小时) ,在一批灯泡中随机抽取 100 只进行测试,所得结果 如下: 700 716 728 719 685 709 691 684 705 718 706 715 712 722 691 708 690 692 707 701 708 668 706 694 688 701 693 729 710 692 690 689 671 697 694 693 691 736 683 718 664 681 697 747 689 685 707 681 695 674 699 696 702 683 721 685 658 682 651 741 717 720 706 698 698 673 698 733 677 661 666 700 749 713 712 679 735 696 710 708 676 683 695 665 698 722 727 702 692 691
统计学第四版第七章答案

6.5
6.6
6.7
6.8
7.1
7.3
7.4
7.7
7.7
7.7
方式2
4.2
5.4
5.8
6.2
6.7
7.7
7.7
8.5
9.3
10
要求:
(1)构建第一种排队方式等待时间标准差的95%的置信区间。
解:估计统计量
经计算得样本标准差 =3.318
置信区间:
=0.95,n=10, = =19.02, = =2.7
7.11某企业生产的袋装食品采用自动打包机包装,每袋标准重量为l00g。现从某天生产的一批产品中按重复抽样随机抽取50包进行检查,测得每包重量(单位:g)如下:
每包重量(g)
包数
96~98
98~100
100~102
102~104
104~106
2
3
34
7
4
合计
50
已知食品包重量服从正态分布,要求:
(1)确定该种食品平均重量的95%的置信区间。
(2)抽样平均误差:
重复抽样: = =1.61/6=0.268
不重复抽样: = =
=0.268× =0.268×0.998=0.267
(3)置信水平下的概率度:
=0.9,t= = =1.645
=0.95,t= = =1.96
=0.99,t= = =2.576
(4)边际误差(极限误差):
=0.9, =
第四章抽样分布与参数估计
7.2某快餐店想要估计每位顾客午餐的平均花费金额。在为期3周的时间里选取49名顾客组成了一个简单随机样本。
(1)假定总体标准差为15元,求样本均值的抽样标准误差。
统计学第四版第七章答案

第四章 抽样分布与参数估计7.2 某快餐店想要估计每位顾客午餐的平均花费金额。
在为期3周的时间里选取49名顾客组成了一个简单随机样本。
(1)假定总体标准差为15元,求样本均值的抽样标准误差。
x σ===2.143 (2)在95%的置信水平下,求边际误差。
x x t σ∆=⋅,由于是大样本抽样,因此样本均值服从正态分布,因此概率度t=2z α 因此,x x t σ∆=⋅x z ασ=⋅0.025x z σ=⋅=1.96×2.143=4.2 (3)如果样本均值为120元,求总体均值 的95%的置信区间。
置信区间为:(),x x x x -∆+∆=()120 4.2,120 4.2-+=(115.8,124.2)7.4 从总体中抽取一个n=100的简单随机样本,得到x =81,s=12。
要求:大样本,样本均值服从正态分布:2,xN n σμ⎛⎫ ⎪⎝⎭或2,s xN n μ⎛⎫⎪⎝⎭置信区间为:22x z x z αα⎛-+ ⎝(1)构建μ的90%的置信区间。
2z α=0.05z =1.645,置信区间为:()81 1.645 1.2,81 1.645 1.2-⨯+⨯=(79.03,82.97)(2)构建μ的95%的置信区间。
2z α=0.025z =1.96,置信区间为:()81 1.96 1.2,81 1.96 1.2-⨯+⨯=(78.65,83.35)(3)构建μ的99%的置信区间。
2z α=0.005z =2.576,置信区间为:()81 2.576 1.2,81 2.576 1.2-⨯+⨯=(77.91,84.09)7.7 某大学为了解学生每天上网的时间,在全校7 500名学生中采取重复抽样方法随机抽取36人,调查他们每天上网的时间,得到下面的数据(单位:小时):解:(1)样本均值x =3.32,样本标准差s=1.61; (2)抽样平均误差: 重复抽样:x σ≈不重复抽样:x σ≈=0.268×0.998=0.267(3)置信水平下的概率度: 1α-=0.9,t=2z α=0.05z =1.645 1α-=0.95,t=2z α=0.025z =1.96 1α-=0.99,t=2z α=0.005z =2.576 (4)边际误差(极限误差): 2x x x t z ασσ∆=⋅=⋅1α-=0.9,2x x x t z ασσ∆=⋅=⋅=0.05x z σ⋅重复抽样:2x x z ασ∆=⋅=0.05x z σ⋅=1.645×0.268=0.441 不重复抽样:2x x z ασ∆=⋅=0.05x z σ⋅=1.645×0.267=0.4391α-=0.95,2x x x t z ασσ∆=⋅=⋅=0.025x z σ⋅重复抽样:2x x z ασ∆=⋅=0.025x z σ⋅=1.96×0.268=0.525 不重复抽样:2x x z ασ∆=⋅=0.025x z σ⋅=1.96×0.267=0.5231α-=0.99,2x x x t z ασσ∆=⋅=⋅=0.005x z σ⋅重复抽样:2x x z ασ∆=⋅=0.005x z σ⋅=2.576×0.268=0.69 不重复抽样:2x x z ασ∆=⋅=0.005x z σ⋅=2.576×0.267=0.688(5)置信区间:(),x x x x -∆+∆1α-=0.9,重复抽样:(),x x x x -∆+∆=()3.320.441,3.320.441-+=(2.88,3.76)不重复抽样:(),x x x x -∆+∆=()3.320.439,3.320.439-+=(2.88,3.76)1α-=0.95,重复抽样:(),x x x x -∆+∆=()3.320.525,3.320.525-+=(2.79,3.85) 不重复抽样:(),x x x x -∆+∆=()3.320.441,3.320.441-+=(2.80,3.84)1α-=0.99,重复抽样:(),x x x x -∆+∆=()3.320.69,3.320.69-+=(2.63,4.01) 不重复抽样:(),x x x x -∆+∆=()3.320.688,3.320.688-+=(2.63,4.01)7.9 某居民小区为研究职工上班从家里到单位的距离,抽取了由16个人组成的一个随机样本,他们到单位的距离(单位:km)分别是:10 3 14 8 6 9 12 11 7 5 10 15 9 16 13 2假定总体服从正态分布,求职工上班从家里到单位平均距离的95%的置信区间。
统计学贾俊平课后习题答案完整版

统计学贾俊平课后习题答案HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】附录:教材各章习题答案第1章统计与统计数据1.1(1)数值型数据;(2)分类数据;(3)数值型数据;(4)顺序数据;(5)分类数据。
1.2(1)总体是“该城市所有的职工家庭”,样本是“抽取的2000个职工家庭”;(2)城市所有职工家庭的年人均收入,抽取的“2000个家庭计算出的年人均收入。
1.3(1)所有IT从业者;(2)数值型变量;(3)分类变量;(4)观察数据。
1.4(1)总体是“所有的网上购物者”;(2)分类变量;(3)所有的网上购物者的月平均花费;(4)统计量;(5)推断统计方法。
1.5(略)。
1.6(略)。
第2章数据的图表展示2.1(1)属于顺序数据。
(2)频数分布表如下(4)帕累托图(略)。
2.2(1)频数分布表如下2.3频数分布表如下2.5(1)排序略。
(2)频数分布表如下2.6(3)食品重量的分布基本上是对称的。
2.72.8(1)属于数值型数据。
2.9(1)直方图(略)。
(2)自学考试人员年龄的分布为右偏。
2.10A 班分散,且平均成绩较A 班低。
2.11 (略)。
2.12 (略)。
2.13 (略)。
2.14 (略)。
2.15 箱线图如下:(特征请读者自己分析) 第3章 数据的概括性度量3.1(1)100=M ;10=e M ;6.9=x 。
(2)5.5=L Q ;12=U Q 。
(3)2.4=s 。
(4)左偏分布。
3.2(1)190=M ;23=e M 。
(2)5.5=L Q ;12=U Q 。
(3)24=x ;65.6=s 。
(4)08.1=SK ;77.0=K 。
(5)略。
3.3 (1)略。
(2)7=x ;71.0=s 。
(3)102.01=v ;274.02=v 。
(4)选方法一,因为离散程度小。
3.4 (1)x =(万元);M e= 。
统计学(贾俊平四版)七练习题详细答案

第七章 练习题参考答案7.1 (1)已知σ=5,n=40,x =25,α=0.05,z205.0=1.96样本均值的抽样标准差σx=nσ=79.0405=(2)估计误差(也称为边际误差)E=z 2αnσ=1.96*0.79=1.557.2(1)已知σ=15,n=49,x =120,α=0.05,z205.0=1.96(2)样本均值的抽样标准差σx=nσ==4915 2.14估计误差E=z 2αnσ=1.96*=4915 4.2(3)由于总体标准差已知,所以总体均值μ的95%的置信区间为: nx z σα±=120±1.96*2.14=120±4.2,即(115.8,124.2)7.3(1)已知σ=85414,n=100,x =104560,α=0.05,z205.0=1.96由于总体标准差已知,所以总体均值μ的95%的置信区间为: nx z σα±=104560±1.96*=10085414104560±16741.144即(87818.856,121301.144)7.4(1)已知n=100,x =81,s=12,α=0.1,z 21.0=1.645由于n=100为大样本,所以总体均值μ的90%的置信区间为:ns x z 2α±=81±1.645*=1001281±1.974,即(79.026,82.974)(2)已知α=0.05,z205.0=1.96由于n=100为大样本,所以总体均值μ的95%的置信区间为:ns x z 2α±=81±1.96*=1001281±2.352,即(78.648,83.352)(3)已知α=0.01,z201.0=2.58由于n=100为大样本,所以总体均值μ的99%的置信区间为:ns x z 2α±=81±2.58*=1001281±3.096,即(77.94,84.096)7.5(1)已知σ=3.5,n=60,x =25,α=0.05,z205.0=1.96由于总体标准差已知,所以总体均值μ的95%的置信区间为: nx z σα±=25±1.96*=60.5325±0.89,即(24.11,25.89)(2)已知n=75,x =119.6,s=23.89,α=0.02,z 202.0=2.33由于n=75为大样本,所以总体均值μ的98%的置信区间为:ns x z 2α±=119.6±2.33*=759.823119.6±6.43,即(113.17,126.03)(3)已知x =3.419,s=0.974,n=32,α=0.1,z21.0=1.645由于n=32为大样本,所以总体均值μ的90%的置信区间为:ns x z 2α±=3.419±1.645*=3274.90 3.419±0.283,即(3.136,3.702)7.6(1)已知:总体服从正态分布,σ=500,n=15,x =8900,α=0.05,z205.0=1.96由于总体服从正态分布,所以总体均值μ的95%的置信区间为:nx z σα2±=8900±1.96*=155008900±253.03,即(8646.97,9153.03)(2)已知:总体不服从正态分布,σ=500,n=35,x =8900,α=0.05,z205.0=1.96虽然总体不服从正态分布,但由于n=35为大样本,所以总体均值μ的95%的置信区间为:nx z σα2±=8900±1.96*=355008900±165.65,即(8734.35,9065.65)(3)已知:总体不服从正态分布,σ未知, n=35,x =8900,s=500,α=0.1,z 21.0=1.645虽然总体不服从正态分布,但由于n=35为大样本,所以总体均值μ的90%的置信区间为:ns x z 2α±=8900±1.645*=355008900±139.03,即(8760.97,9039.03)(4)已知:总体不服从正态分布,σ未知, n=35,x =8900,s=500,α=0.01,z 01.0=2.58虽然总体不服从正态分布,但由于n=35为大样本,所以总体均值μ的99%的置信区间为:ns x z 2α±=8900±2.58*=355008900±218.05,即(8681.95,9118.05)7.7 已知:n=36,当α=0.1,0.05,0.01时,相应的z21.0=1.645,z205.0=1.96,z201.0=2.58根据样本数据计算得:x =3.32,s=1.61由于n=36为大样本,所以平均上网时间的90%置信区间为:ns x z 2α±=3.32±1.645*=361.61 3.32±0.44,即(2.88,3.76)平均上网时间的95%置信区间为:ns x z 2α±=3.32±1.96*=361.61 3.32±0.53,即(2.79,3.85)平均上网时间的99%置信区间为:ns x z 2α±=3.32±2.58*=361.61 3.32±0.69,即(2.63,4.01)7.8 已知:总体服从正态分布,但σ未知,n=8为小样本,α=0.05,)(18t05.0-=2.365根据样本数据计算得:x =10,s=3.46 总体均值μ的95%的置信区间为:ns x t α±=10±2.365*=83.4610±2.89,即(7.11,12.89)7.9 已知:总体服从正态分布,但σ未知,n=16为小样本,α=0.05,)(116t205.0-=2.131根据样本数据计算得:x =9.375,s=4.113从家里到单位平均距离的95%的置信区间为:ns x t α±=9.375±2.131*=144.1139.375±2.191,即(7.18,11.57)7.10 (1)已知:n=36,x =149.5,α=0.05,z205.0=1.96由于n=36为大样本,所以零件平均长度的95%的置信区间为:ns x z 2α±=149.5±1.96*=361.93149.5±0.63,即(148.87,150.13)(2)在上面的估计中,使用了统计中的中心极限定理。
贾俊平统计学第六、七章课后习题答案

贾俊平统计学第六、七章课后习题答案6.1解:设每个瓶子的灌装量为X,X?为样本均值,样本容量为n。
由于总体X服从正态分布,样本均值X?也服从正态分布,且均值相同,标准差为σ√n =1√9=13所以P(|X??μ|≤0.3)=P(|X??μ|13≤0.313)=2Φ(0.9)?1=2?0.8159?1=0.6318 7.1(1)已知σ=500,n=15,x=8900,1-α=95%,Z2α=1.96x+Z2αnσ=8900+1.96×15500=(8647,9153)(2)已知σ=500,n=35,x=8900,1-α=95%,Z2α=1.96x+Z2αnσ=8900+1.96×35500=(8734,9066)(3)已知n=35,x=8900,s=500,由于总体方差未知,但为大样本,所以可用样本方差来代替总体方差。
置信水平1-α=90%,Z2α=1.645x+Z2αns=8900+1.645×35500=(8761,9039)(4)已知n=35,x=8900,s=500,由于总体方差未知,但为大样本,所以可用样本方差来代替总体方差。
置信水平1-α=99%,Z2α=2.58x +Z2αn s =8900+2.58×35500=(8682,9118)7.2已知n=36,x =3.3167,s=1.6093(1)当置信水平为90%时,Z 2α=1.645x +Z 2αn s =3.3167+1.645×366093.1=3.3167+0.4532=(2.88,3.76)(2)当置信水平为95%时,Z 2α=1.96x +Z 2αn s =3.3167+1.96×366093.1=3.3167+0.544=(2.80,3.84)(3)当置信水平为99%时,Z 2α=2.58Z2αn s =3.3167+2.58×366093.1=3.3167+0.7305=(2.63,4.01)7.3(1)已知总体服从正态分布,但σ未知,n=50为大样本,α=0.05,Z 2α=1.96,根据样本计算可知x =101.32,s=1.63x +Z 2αn s =101.32+1.96×5063.1=101.32+0.45=(100.87,101.77)(2)由所给样本数据可知样本合格率:p=5045=0.9p +Z2αnp p )1(-=0.9+1.9650)9.0-19.0(=0.9+0.08=(0.82,0.98)7.4由样本数据得x =16.13,σ=0.8706,置信水平1-α=99%,Z 2α=2.58x +Zαn σ=16.13+2.58×58706.0=16.13+0.45=(15.68,16.58)7.5、(1)n=44,p=0.51,置信水平为99%由题意,已知n=44,置信水平1-α=99%,因此检验统计量为:,代入数值计算,总体比例π的置信区间为(31.6%,70.4%) (2)n=300,p=0.82,置信水平为95%由题意可得知96.12=αZ检验统计量为:,代入数值计算,总体比例π的置信区间为(77.7%,86.3%) (3)n=1150,p=0.48,置信水平为90%由题意可得知检验统计量为:,代入数值计算,58.22=αZ np p Z P )1(2-±α)704.0,316.0(194.051.044)51.01(51.058.251.0=+=-??p p Z P )1(2-±α)863.0,777.0(043.082.0300)82.01(82.096.182.0=+=-?+645.12=αZ np p Z P )1(2-±α总体比例π的置信区间为(45.6%,50.4%)7.6、(1)由题意已知n=200,当置信水平为90%时,,检验统计量为代入数据计算可得:置信区间为(18.10%,27.90%) (2)当置信水平为95%时,96.12=αZ ,检验统计量为代入数据计算可得:置信区间为(17.17%,28.83%)7.7、由题意已知置信水平为99%,即1-α=99%,则,估计误差E=200,=1000504.0,456.0(024.048.01150)48.01(48.0645.148.0=+=-?+645.12=αZ np p Z P )1(2-±α%)90.27%,10.18(%90.4%23200%)231%(23645.1%23=±=-?±np p Z P )1(2-±α%)83.28%,17.17(%83.5%23200%)231%(2396.1%23=+=-?+58.22=αZ σ则,即应该取样本量为1677.8、(1)由题意可知n=50,p=32/50=0.64,α=0.05,96 .12=αZ 总体中赞成该项改革的户数比例的置信区间为,代入数据计算:即置信区间为(51%,77%)(2)如果小区管理者预计赞成的比例能达到80%,即π=0.80,估计误差不超过10%,即E=10%,α=0.05,96.12=αZ ,应抽取的样本量为即应该抽取62户进行调查7.9(1)x?=21,s=2,n=50,α=0.1χ0.12?2(50?1)=66.3387,χ1?0.12?2(50?1)=33.9303∴(n?1)s 2χα22≤σ2≤(n?1)s 2χ1?α22(50?1)×2266.3387≤σ2≤(50?1)×2233.9303即2.95≤σ2≤5.78.标准差的置信区间为1.72≤σ≤2.4 (2)x?=1.3,s=0.02,n=15,α=0.1167200100058.22222222≈?==E Z n σαnp p Z P )1(2-±α)77.0,51.0(13.064.050)64.01(64.096.164.0=±=-±621.0)80.01(80.096.1)1(22222=-?=-?=E Z n ππαχ0.12?2(15?1)=23.6848,χ1?0.12?2(15?1)=6.5706∴(n?1)s 2χα22≤σ2≤(n?1)s 2χ1?α22(15?1)×0.02223.6848≤σ2≤(15?1)×0.0226.5706标准差的置信区间为0.015≤σ≤0.029 (3)x?=167,s=31,n=22,α=0.1χ0.12?2(22?1)=32.6706,χ1?0.12?2(22?1)=11.5913∴(n?1)s 2χα22≤σ2≤(n?1)s 2χ1?α22(22?1)×312≤σ2≤(22?1)×312标准差的置信区间为24.85≤σ≤41.73。
统计学第四版(贾俊平)课后思考题答案

统计课后思考题答案第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学_贾俊平_第4版_课后答案(优选.)
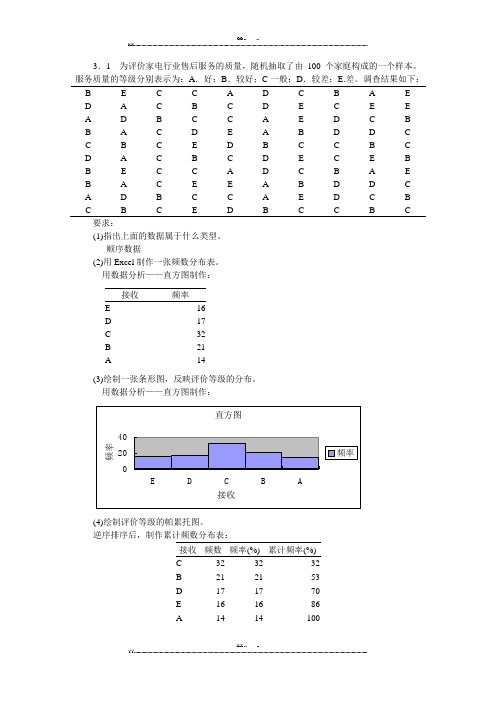
3.1 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C一般;D.较差;E.差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB AC E E A BD D CA DBC C A ED C BC B C ED B C C B C要求:(1)指出上面的数据属于什么类型。
顺序数据(2)用Excel制作一张频数分布表。
用数据分析——直方图制作:接收频率E16D17C32B21A14(3)绘制一张条形图,反映评价等级的分布。
用数据分析——直方图制作:(4)绘制评价等级的帕累托图。
逆序排序后,制作累计频数分布表:接收频数频率(%)累计频率(%)C 32 32 32B 21 21 53D 17 17 70E 16 16 86A 14 14 1005101520253035CDBAE204060801001203.2 某行业管理局所属40个企业2002年的产品销售收入数据如下: 152 124 129 116 100 103 92 95 127 104 105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 108 9788123115119138112146113126要求:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。
1、确定组数:()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(152-87)÷6=10.83,取10 3(2)按规定,销售收入在125万元以上为先进企业,115~125万元为良好企业,105~115 万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
统计学课后习题答案第四版贾俊平

统计学课后习题答案-(第四版)-贾俊平《统计学》第四版 第四章练习题答案4.1 (1)众数:M 0=10; 中位数:中位数位置=n+1/2=5.5,M e =10;平均数:6.91096===∑n x x i(2)Q L 位置=n/4=2.5, Q L =4+7/2=5.5;Q U 位置=3n/4=7.5,Q U =12(3)2.494.1561)(2==-=∑-n i s x x(4)由于平均数小于中位数和众数,所以汽车销售量为左偏分布。
4.2 (1)从表中数据可以看出,年龄出现频数最多的是19和23,故有个众数,即M 0=19和M 0=23。
将原始数据排序后,计算中位数的位置为:中位数位置= n+1/2=13,第13个位置上的数值为23,所以中位数为M e =23(2)Q L 位置=n/4=6.25, Q L ==19;Q U 位置=3n/4=18.75,Q U =26.5(3)平均数==∑nx x i600/25=24,标准差65.612510621)(2=-=-=∑-n i s x x(4)偏态系数SK=1.08,峰态系数K=0.77 (5)分析:从众数、中位数和平均数来看,网民年龄在23-24岁的人数占多数。
由于标准差较大,说明网民年龄之间有较大差异。
从偏态系数来看,年龄分布为右偏,由于偏态系数大于1,所以,偏斜程度很大。
由于峰态系数为正值,所以为尖峰分布。
4.3 (1)茎叶图如下:(2)==∑n x x i63/9=7,714.0808.41)(2==-=∑-n i s x x(3)由于两种排队方式的平均数不同,所以用离散系数进行比较。
第一种排队方式:v 1=1.97/7.2=0.274;v 21>v 2,表明第一种排队方式的离散程度大于第二种排队方式。
(4)选方法二,因为第二种排队方式的平均等待时间较短,且离散程度小于第一种排队方式。
4.4 (1)==∑n x x i8223/30=274.1中位数位置=n+1/2=15.5,M e =272+273/2=272.5 (2)Q L 位置=n/4=7.5, Q L ==(258+261)/2=259.5;Q U 位置=3n/4=22.5,Q U =(284+291)/2=287.5 (3)17.211307.130021)(2=-=-=∑-n i s x x4.5 (1)甲企业的平均成本=总成本/总产量=41.193406600301500203000152100150030002100==++++乙企业的平均成本=总成本/总产量=29.183426255301500201500153255150015003255==++++原因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。
贾俊平统计学(四版)课后习题答案

第1章绪论1.什么是统计学?怎样理解统计学与统计数据的关系?2.试举出日常生活或工作中统计数据及其规律性的例子。
3..一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。
因此,他们开始检查供货商的集装箱,有问题的将其退回。
最近的一个集装箱装的是2 440加仑的油漆罐。
这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。
装满的油漆罐应为4.536 kg。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)描述推断。
答:(1)总体:最近的一个集装箱内的全部油漆;(2)研究变量:装满的油漆罐的质量;(3)样本:最近的一个集装箱内的50罐油漆;(4)推断:50罐油漆的质量应为4.536×50=226.8 kg。
4.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。
这场战役因影视明星、运动员的参与以及消费者对品尝试验优先权的抱怨而颇具特色。
假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝试验(即在品尝试验中,两个品牌不做外观标记),请每一名被测试者说出A品牌或B品牌中哪个口味更好。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)一描述推断。
答:(1)总体:市场上的“可口可乐”与“百事可乐”(2)研究变量:更好口味的品牌名称;(3)样本:1000名消费者品尝的两个品牌(4)推断:两个品牌中哪个口味更好。
第2章统计数据的描述——练习题●1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。
统计学(贾俊平 第四版)课后习题答案
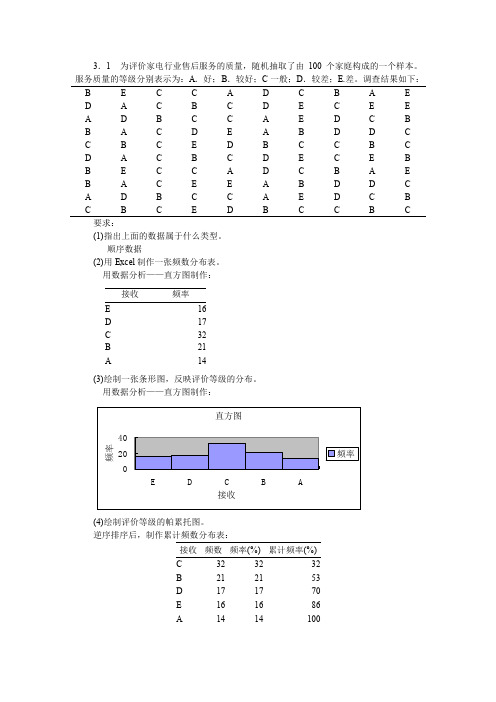
频数
2 3 9 12 7 4 2 1 40
频率%
5.0 7.5 22.5 30.0 17.5 10.0 5.0 2.5 100.0
要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
K 1
l g 4 0 l gn ( ) 1.60206 ,取 1 1 6.3 2 k=6 lg(2) lg 2 0.30103
2、确定组距: 组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取 5 3、分组频数表
要求: (1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。 1、确定组数:
K 1
l g 4 0 l gn ( ) 1.60206 ,取 1 1 6.3 2 k=6 lg(2) lg 2 0.30103
2、确定组距: 组距=( 最大值 - 最小值)÷ 组数=(152-87)÷6=10.83,取 10 3、分组频数表 销售收入
直方图:
组距4,小于等于
40
30
Frequency
20
10
Mean =4.06 Std. Dev. =1.221 N =100 0 0 2 4 6 8
组距4,小于等于
组距 5,上限为小于等于 频数 有效 <= 45.00 46.00 - 50.00 51.00 - 55.00 56.00 - 60.00 61.00+ 合计 12 37 34 16 1 100 百分比 12.0 37.0 34.0 16.0 1.0 100.0 累计频数 12.0 49.0 83.0 99.0 100.0 累积百分比 12.0 49.0 83.0 99.0 100.0
统计学第四版答案(贾俊平)

第1章统计和统计数据指出下面的变量类型。
(1)年龄。
(2)性别。
(3)汽车产量。
(4)员工对企业某项改革措施的态度(赞成、中立、反对)。
(5)购买商品时的支付方式(现金、信用卡、支票)。
详细答案:(1)数值变量。
(2)分类变量。
(3)数值变量。
(4)顺序变量。
(5)分类变量。
一家研究机构从IT从业者中随机抽取1000人作为样本进行调查,其中60%回答他们的月收入在5000元以上,50%的人回答他们的消费支付方式是用信用卡。
(1)这一研究的总体是什么?样本是什么?样本量是多少?(2)“月收入”是分类变量、顺序变量还是数值变量?(3)“消费支付方式”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。
(2)数值变量。
(3)分类变量。
一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。
(1)这一研究的总体是什么?(2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有的网上购物者”。
(2)分类变量。
某大学的商学院为了解毕业生的就业倾向,分别在会计专业抽取50人、市场营销专业抽取30、企业管理20人进行调查。
(1)这种抽样方式是分层抽样、系统抽样还是整群抽样?(2)样本量是多少?详细答案:(1)分层抽样。
(2)100。
第3章用统计量描述数据分钟,标准差为1.97分钟,第二种排队方式的等待时间(单位:分钟)如下:5.56.6 6.7 6.87.1 7.3 7.4 7.8 7.8(1)计算第二种排队时间的平均数和标准差。
(2)比两种排队方式等待时间的离散程度。
(3)如果让你选择一种排队方式,你会选择哪一种?试说明理由。
详细答案:(1)(岁);(岁)。
(2);。
第一中排队方式的离散程度大。
(3)选方法二,因为平均等待时间短,且离散程度小。
在某地区随机抽取120家企业,按利润额进行分组后结果如下:按利润额分组(万元)企业数(个)300以下19300~400 30400~500 42500~600 18600以上11合计120计算120家企业利润额的平均数和标准差(注:第一组和最后一组的组距按相邻组计算)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
7.1从一个标准差为5的总体中抽出一个容量为40的样本,样本均值为25。
(1) 样本均值的抽样标准差x σ等于多少?(2) 在95%的置信水平下,允许误差是多少?解:已知总体标准差σ=5,样本容量n =40,为大样本,样本均值x =25, (1)样本均值的抽样标准差x σ=n σ=405=0.7906 (2)已知置信水平1-α=95%,得 α/2Z =1.96, 于是,允许误差是E =nα/2σZ =1.96×0.7906=1.5496。
7.2 某快餐店想要估计每位顾客午餐的平均花费金额。
在为期3周的时间里选取49名顾客组成了一个简单随机样本。
(1)假定总体标准差为15元,求样本均值的抽样标准误差。
x nσ=49==2.143 (2)在95%的置信水平下,求边际误差。
x x t σ∆=⋅,由于是大样本抽样,因此样本均值服从正态分布,因此概率度t=2z α 因此,x x t σ∆=⋅2x z ασ=⋅0.025x z σ=⋅=1.96×2.143=4.2 (3)如果样本均值为120元,求总体均值 的95%的置信区间。
置信区间为:(),x x x x -∆+∆=()120 4.2,120 4.2-+=(115.8,124.2) 7.37.4 从总体中抽取一个n=100的简单随机样本,得到x =81,s=12。
要求:大样本,样本均值服从正态分布:2,xN n σμ⎛⎫ ⎪⎝⎭或2,s xN n μ⎛⎫⎪⎝⎭置信区间为:2x z x z n n αα⎛-+ ⎝n 100=1.2 (1)构建μ的90%的置信区间。
2z α=0.05z =1.645,置信区间为:()81 1.645 1.2,81 1.645 1.2-⨯+⨯=(79.03,82.97)(2)构建μ的95%的置信区间。
2z α=0.025z =1.96,置信区间为:()81 1.96 1.2,81 1.96 1.2-⨯+⨯=(78.65,83.35)(3)构建μ的99%的置信区间。
2z α=0.005z =2.576,置信区间为:()81 2.576 1.2,81 2.576 1.2-⨯+⨯=(77.91,84.09)7.57.67.7 某大学为了解学生每天上网的时间,在全校7 500名学生中采取重复抽样方法随机抽取36人,3.3 3.1 6.2 5.8 2.34.15.4 4.5 3.2 4.4 2.0 5.4 2.66.4 1.8 3.5 5.7 2.3 2.1 1.9 1.2 5.1 4.3 4.2 3.6 0.8 1.5 4.71.41.22.93.52.40.53.62.5求该校大学生平均上网时间的置信区间,置信水平分别为90%,95%和99%。
解:(1)样本均值x =3.32,样本标准差s=1.61; (2)抽样平均误差: 重复抽样:x σnn ≈不重复抽样:x σ1N n N n--1N n N n -≈-7500367500136--=0.2680.995×0.998=0.267(3)置信水平下的概率度: 1α-=0.9,t=z α=0.05z =1.645 1α-=0.95,t=2z α=0.025z =1.96 1α-=0.99,t=2z α=0.005z =2.576 (4)边际误差(极限误差): 2x x x t z ασσ∆=⋅=⋅1α-=0.9,2x x x t z ασσ∆=⋅=⋅=0.05x z σ⋅重复抽样:2x x z ασ∆=⋅=0.05x z σ⋅=1.645×0.268=0.441 不重复抽样:2x x z ασ∆=⋅=0.05x z σ⋅=1.645×0.267=0.4391α-=0.95,2x x x t z ασσ∆=⋅=⋅=0.025xz σ⋅重复抽样:2x x z ασ∆=⋅=0.025x z σ⋅=1.96×0.268=0.525 不重复抽样:2x x z ασ∆=⋅=0.025x z σ⋅=1.96×0.267=0.5231α-=0.99,2x x x t z ασσ∆=⋅=⋅=0.005x z σ⋅重复抽样:2x x z ασ∆=⋅=0.005x z σ⋅=2.576×0.268=0.69 不重复抽样:2x x z ασ∆=⋅=0.005x z σ⋅=2.576×0.267=0.688(5)置信区间:(),x x x x -∆+∆1α-=0.9,重复抽样:(),x x x x -∆+∆=()3.320.441,3.320.441-+=(2.88,3.76) 不重复抽样:(),x x x x -∆+∆=()3.320.439,3.320.439-+=(2.88,3.76)1α-=0.95,重复抽样:(),x x x x -∆+∆=()3.320.525,3.320.525-+=(2.79,3.85) 不重复抽样:(),x x x x -∆+∆=()3.320.441,3.320.441-+=(2.80,3.84)1α-=0.99,重复抽样:(),x x x x -∆+∆=()3.320.69,3.320.69-+=(2.63,4.01) 不重复抽样:(),x x x x -∆+∆=()3.320.688,3.320.688-+=(2.63,4.01)7.8从一个正态总体中随机抽取容量为8 的样本,各样本值分别为:10,8,12,15,6,13,5,11。
求总体均值95%的置信区间。
解:(7.1,12.9)。
7.9 某居民小区为研究职工上班从家里到单位的距离,抽取了由16个人组成的一个随机样本,他们到单位的距离(单位:km)分别是:10 3 14 8 6 9 12 11 7 5 10 15 9 16 13 2假定总体服从正态分布,求职工上班从家里到单位平均距离的95%的置信区间。
解:小样本,总体方差未知,用t 统计量x t s n=()1t n -均值=9.375,样本标准差s=4.11 置信区间:()()221,1x t n x t n n n αα⎛--⋅+-⋅ ⎪⎝⎭1α-=0.95,n=16,()21t n α-=()0.02515t =2.13()()221,1x t n x t n n n αα⎛--⋅+-⋅ ⎪⎝⎭=9.375 2.13,9.375 2.131616⎛-⨯+⨯ ⎪⎝⎭=(7.18,11.57) 7.107.11 某企业生产的袋装食品采用自动打包机包装,每袋标准重量为l00g 。
现从某天生产的一批每包重量(g ) 包数 96~98 98~100 100~102 102~104 104~106 2 3 34 7 4 合计50已知食品包重量服从正态分布,要求:(1)确定该种食品平均重量的95%的置信区间。
解:大样本,总体方差未知,用z 统计量x z s n=()0,1N样本均值=101.4,样本标准差s=1.829 置信区间:x z x z n n αα⎛-+ ⎝1α-=0.95,2z α=0.025z =1.9622,x z x z n n αα⎛-⋅+⋅ ⎪⎝⎭=101.4 1.96,101.4 1.965050⎛-⨯+⨯ ⎪⎝⎭=(100.89,101.91) (2)如果规定食品重量低于l00g 属于不合格,确定该批食品合格率的95%的置信区间。
解:总体比率的估计大样本,总体方差未知,用z 统计量()1z p p n=-()0,1N样本比率=(50-5)/50=0.9 置信区间:()()2211,p p p p p z p z n n αα⎛⎫-- ⎪-⋅+⋅ ⎪⎝⎭ 1α-=0.95,2z α=0.025z =1.96()()2211,p p p p p z p z n n αα⎛⎫-- ⎪-⋅+⋅ ⎪⎝⎭=()()0.910.90.910.90.9 1.96,0.9 1.965050⎛⎫-- ⎪-⨯+⨯⎪⎝⎭=(0.8168,0.9832) 7.127.13 一家研究机构想估计在网络公司工作的员工每周加班的平均时间,为此随机抽取了18个员工。
得到他们每周加班的时间数据如下(单位:小时): 6 321 817 1220 117 90 218 2516 1529 16间。
解:小样本,总体方差未知,用t 统计量x t s n=()1t n -均值=13.56,样本标准差s=7.801 置信区间:()()221,1x t n x t n n n αα⎛--⋅+-⋅ ⎪⎝⎭1α-=0.90,n=18,()21t n α-=()0.0517t =1.7369()()221,1x t n x t n n n αα⎛--⋅+-⋅ ⎪⎝⎭=13.56 1.7369,13.56 1.73691818⎛-⨯+⨯ ⎪⎝⎭=(10.36,16.75) 7.147.15 在一项家电市场调查中.随机抽取了200个居民户,调查他们是否拥有某一品牌的电视机。
其中拥有该品牌电视机的家庭占23%。
求总体比例的置信区间,置信水平分别为90%和95%。
解:总体比率的估计大样本,总体方差未知,用z 统计量()1z p p n=-()0,1N样本比率=0.23 置信区间:()()2211,p p p p p z p z n n αα⎛⎫-- ⎪-⋅+⋅ ⎪⎝⎭ 1α-=0.90,2z α=0.025z =1.645()()2211,p p p p p z p z n n αα⎛⎫-- ⎪-⋅+⋅ ⎪⎝⎭=()()0.2310.230.2310.230.23 1.645,0.23 1.645200200⎛⎫-- ⎪-⨯+⨯⎪⎝⎭=(0.1811,0.2789)1α-=0.95,2z α=0.025z =1.96()()2211,p p p p p z p z n n αα⎛⎫-- ⎪-⋅+⋅ ⎪⎝⎭=()()0.2310.230.2310.230.23 1.96,0.23 1.96200200⎛⎫-- ⎪-⨯+⨯⎪⎝⎭=(0.1717,0.2883) 7.16、7.177.187.197.20 顾客到银行办理业务时往往需要等待一段时间,而等待时间的长短与许多因素有关,比如,银行业务员办理业务的速度,顾客等待排队的方式等。
为此,某银行准备采取两种排队方式进行试验,第一种排队方式是:所有顾客都进入一个等待队列;第二种排队方式是:顾客在三个业务窗口处列队三排等待。
为比较哪种排队方式使顾客等待的时间更短,银行各随机抽取10名顾客,他们在办理业务时所等待的时间(单位:分钟)如下:方式1 6.5 6.6 6.7 6.87.17.37.47.77.77.7方式2 4.2 5.4 5.8 6.2 6.77.77.78.59.310要求:(1)构建第一种排队方式等待时间标准差的95%的置信区间。