第2章一维索引组织结构.
第2章数据库系统结构

一些基本术语(续)
• 元组:表中的每一行称作是一个元组,它 相当于一个记录值。 • 属性:表中的每一列是一个属性值的集合, 列可以命名,称为属性名。 • 主码:表中用于惟一地确定一个元组的一 个属性或最小的属性组。 • 域:属性的取值范围。如性别的域为: (‘男’,‘女’)
主码示例 • 学生基本信息表: (学号,姓名,年龄,性别,所在系) • 学生修课信息表: (学号,课程号,成绩)
2014年2月26日1时52分
7
2.1.2 数据模型
• 对于模型,人们并不陌生。
• 建筑模型 飞机模型
• 计算机中的模型是对事物、对象、过程等 客观系统中感兴趣的内容的模拟和抽象表 达,是理解系统的思维工具 • 数据模型(data model)也是一种模型,它 是对现实世界数据特征的抽象。
2014年2月26日1时52分 8
实体-联系模型
• 实体 • 属性 • 联系
实体
• 具有公共性质的可相互区分的现实世界 对象的集合。 • 可以是具体的事物,也可以是抽象的概 念或联系 • 具体的事物:学生、课程、职工
• 抽象的联系:学生选课
实体的表示方式
• 在E-R图中用矩形框表示实体,把实体 名写在框内,比如学生实体可以表示 为:
学号 9512101 姓名 李勇 性别 男 年龄 19 所在系 计算机系
9512102 9512103
9521101 9521102
刘晨 王敏
张立 吴宾
男 女
男 女
20 20
22 21
计算机系 计算机系
信息系 信息系
一些基本术语
• 关系 :关系就是二维表。并满足如下性质:
关系表中的每一列都是不可再分的基本属性; 表中的行、列次序并不重要。
数据仓库与数据挖掘技术 第二章 数据仓库

第2章数据仓库2.1数据仓库的基本概念1. 数据仓库的数据是面向主题的数据仓库与数据挖掘技术图2-1主题间的重叠关系2. 数据仓库的数据是集成的3. 数据仓库的数据是不可更新的数据仓库与数据挖掘技术4. 数据仓库的数据是随时间不断变化的图2-2数据仓库体系结构2.2数据仓库的体系结构数据仓库与数据挖掘技术图2-3数据仓库数据组织结构2.2.1元数据1. 元数据在数据仓库中的作用2. 元数据的使用3. 元数据的分类4. 元数据的内容2.2.2粒度的概念1. 按时间段综合数据的粒度2. 样本数据库2.2.3分割问题1. 分割的优越性2. 数据分割的标准3. 分割的层次2.2.4数据仓库中的数据组织形式1. 简单堆积结构图2-4简单堆积结构数据组织形式2. 轮转综合结构数据仓库与数据挖掘技术图2-5轮转综合结构数据组织形式3. 简单直接结构图2-6简单直接结构数据组织形式4. 连续结构图2-7连续结构数据组织形式数据仓库与数据挖掘技术2.3数据仓库的数据模型2.3.1概念数据模型图2-8商品、顾客和供应商E-R图2.3.2逻辑数据模型2.3.3物理数据模型2.3.4高层数据模型、中间层数据模型和低层数据模型1. 高层数据模型2. 中间层数据模型3. 低层数据模型数据仓库与数据挖掘技术2.4数据仓库设计步骤图2-9数据仓库设计步骤2.4.1概念模型设计1. 界定系统边界2. 确定主要的主题域3. 实例2.4.2技术准备工作2.4.3逻辑模型设计1. 分析主题域2. 划分粒度层次3. 确定数据分割策略4. 定义关系模式5. 定义记录系统2.4.4物理模型设计1. 确定数据的存储结构数据仓库与数据挖掘技术2. 确定索引策略3. 确定数据存放位置4. 确定存储分配2.4.5数据仓库的生成1. 接口设计2. 数据装入2.4.6数据仓库的使用和维护1. 开发DSS应用图2-10DSS应用开发步骤2. 进一步理解需求,改善系统,维护数据仓库图2-11William H.Inmon数据仓库设计步骤数据仓库与数据挖掘技术2.5利用SQL Server 2005构建数据仓库图2-12使用Visual Studio 2005系统新建项目图2-13新建Analysis Services项目图2-14新建数据源数据仓库与数据挖掘技术图2-15新建数据源向导图2-16选择如何连接数据源图2-17连接管理器图2-18连接管理器连接测试成功窗口图2-19选择已经连接的数据库作为数据源图2-20选择连接数据源的凭证图2-21新建数据源向导完成图2-22右击新建数据源视图图2-23新建数据源视图向导图2-24选择视图的数据源图2-25选择表和视图图2-26完成新建数据源视图向导图2-27新建多维数据集图2-28多维数据集向导图2-29选择生成多维数据集的方法图2-30选择多维数据集的数据源视图图2-31检测事实数据表和维度表图2-32标示事实表和维度表图2-33选择度量值图2-34扫描维度图2-35查看维度结构图2-36完成多维数据集向导图2-37创建完成数据仓库界面习题21. 如何理解数据仓库是面向主题的、集成的、不可更改的和是随时间不断变化的。
数据结构考试要点

第一章:数据结构包含:逻辑结构,数据的存储结构,对数据进行的操作。
数据元素:相对独立的基本单位,即可简单也可复杂,简单的数据元素只有一个数据项,数据项是数据的不可分割的最小单位。
数据对象:性质相同的数据元素的集合。
数据结构:相互存在一种或者多种特定关系的数据元素的集合(集合,线性结构,树结构,图结构)。
顺序存储结构:数据元素按照逻辑顺序依次存放在存储器的一段连续存储单元中。
链式存储结构:存储在存储空间的任意位置上,包含一个数据域和至少一个指针域,要访问,必须从第一个元素开始查找。
数据类型:一组值加一组操作。
第二章:线性表:有限多个性质相同的数据元素构成的一个序列,数据元素的个数就是长度。
线性表的顺序存储结构:用一组地址连续的存储单元能随机存取的结构。
链式存储结构:具有链式存储结构的线性表称为链表,是用一组地址任意的存储单元来存线性表中的数据元素。
每个数据元素存储结构包括数据元素信息域和地址域,存放一个数据元素的存储结构称为结点,每个结点只定义一个指针域,存放的是当前结点的直接后记结点的地址(直接后继结点),线性表的最后一个结点指针域存放空(0,NULL)标志结束。
不支持随机存取,访问必须从第一个结点开始,一次访问。
双向链表:每个结点设置两个方向的指针(直接前驱和直接后继)。
第三章:栈:堆栈的简称,限定在表尾进行插入和删除的线性表。
特点是后进先出。
当栈定指针指向栈底时,为空栈。
队列:限定只能在一端进行插入和在另一端进行删除的线性表,进行插入的是队尾,删除的是队头。
特点是先进先出。
队列的链式结构:用一个链表依次存放从队头到队尾的所有的数据元素。
存放队头地址(队头指针)队尾地址(队尾指针),空链队列:有头结点,空队列条件是头结点存放0,无头结点为队头指针指向空。
队列的顺序存储结构:用一组地址连续的存储空间依次存放从队头到队尾的所有数据元素,再用队头指针和队尾指针记录队头和队尾的位置。
队头指针指向队头元素前一个数组元素的位置,队尾始终指向队尾,当队尾和队头指向同一位置,空队列。
计算固体力学 第2章 一维Lagrangian和Eulerian有限元

Xa
uA0 P, X u, X
A0 PdX
Xb
Xb
Xa
u A0 P , X dX uA0 n 0 P uA0 t x0
Xb Xa
t
Xa
u , X A0 P dX
u , X A0 P dX
在指定位移边界处变分项 u 消失,第二行服从边界互补条件 和力边界条件。
b-单位质量的力-体力 应力在坐标方向的分量
如果初始横截面面积在空间保持常数,则动量方程成为
( P),X 0b 0u
2 完全的Lagrangian格式
不计惯性力,则动量方程成为平衡方程
平衡方程 能量守恒
( A0 P),X 0 A0b 0
平衡意味着物体处于静止或者以匀速运动
尽管TL和UL表面看来有很大区别,两种格式的力学本质 是相同的;因此,TL可以转换为UL,反之亦然。
TSINGHUA UNIVERSITY
1 引言
对于每一种公式,将建立动量方程的弱形式,已知为虚 功原理(或虚功)。这种弱形式是通过对变分项与动量方程 的乘积进行积分来建立。在 TL格式中,积分在所有材料坐标 上进行;在 Eulerian 和 UL格式中,积分在空间坐标上进行。 也将说明如何处理力边界条件,因此近似(试)解不需要满 足力边界条件。这个过程与在线性有限元分析中的过程是一 致的,在非线性公式中的主要区别是需要定义积分赋值的坐 标系和确定选择应力和应变的度量。 推导有限元近似计算的离散方程。对于考虑加速度(动 力学)或那些包含率相关材料的问题,推导离散有限元方程 为普通微分方程( ODEs )。这个空间的离散过程称为半离散 化,因为有限元仅将空间微分运算转化为离散形式,而没有 对时间导数进行离散。对于静力学与率无关材料问题,离散 方程独立于时间,有限元离散将导致一组非线性代数方程。
材料的组织结构.pptx

2.3 金属的结晶与细晶强化
晶粒大小对力学性能的影响
晶粒的大小及其控制
1. 增加过冷度,提高形核率 2. 变质处理,促进非自发形核浇
注前向金属液体中加入一些促进生核或 作为晶核的物质使金属晶粒细化的方法。
3. 振动,打碎枝晶
金属在结晶时,对液态金属附加振动、 超声波振动和电磁振动等措施,使结晶 的金属经振动而破碎,增加了生核率, 从而使晶粒细化。
亚晶界
面缺陷是位错运动的
障碍,晶粒、亚晶越细
小,界面越多,晶格畸
变越大,位错阻力越大, 金属强度越高。
晶界
晶界
2.1.3 金属材料的结构特点
(一)、基本概念
1、合金:两种或两种以上的金属元
素或金属元素与非金属元素组成的具有金
属性质的新金属。
2、组元:组成合金最基本、能独立
存在的物质(可以是化学元素也可以是稳
2.4 材料的同素异构现象
2.4 材料的同素异构现象
金属的同素异构 转变与液态金属的结 晶过程相似,遵循液 体结晶的一般规律:
1、恒温转变;
2、转变时有过冷
现象;
3、转变过程由生
核和长大两个基本过
程组成。
2.5 铁碳合金相图
2.5.1 二元合金相图 凝固:一切物质从液态到固态的
转变过程。若凝固后形成晶体结构, 该转变过程称为结晶。
当溶质原子代替了
溶剂晶格的某些结点原
子而形成的固溶体。
形成无限固溶体的
条件:两组元具有相同
的晶格,原子直径相差
很小。
2.1.3 金属材料的结构特点
(2)间隙固溶体
溶质原子分布在溶剂晶格 间隙处而形成的晶体相。
形成条件:两组元直径相 差较大。
第2章 一维定常流动的基本方程(Part4.临界状态和气体动力学函数)

中国民航大学航空工程学院发动机系
8
气体动力学(Aerodynamics)
临界状态和临界参数
对于一个绝能等熵加速流动,
T
*
P
* * c T( ) *
出口截面马赫数等于 1 的喷管, 出口截面即为临界截面,它的 参数也是整个流管的临界参数 马赫数小于1的截面上的气流 状态参数、滞止参数和临界参 数的关系
2016/3/30
0.2 0 0.4 0.8 1.2 发动机系
气体动力学(Aerodynamics)
2016/3/30
中国民航大学航空工程学院发动机系
18
气体动力学(Aerodynamics)
2016/3/30
中国民航大学航空工程学院发动机系
19
( Ma <1 )
P T( c ) Pcr
cr
Tcr ( ccr )
s
滞止状态、临界状态和实际状态
2016/3/30
中国民航大学航空工程学院发动机系
9
气体动力学(Aerodynamics)
速度系数:λ
V ccr
——无量纲的速度,气流速度与临界声速之比
思考:已经定义了Ma,为什么还要引入速度系数λ?
2 p A q z k 1 p A f
qm AV
2016/3/30
中国民航大学航空工程学院发动机系
22
气体动力学(Aerodynamics)
2016/3/30
中国民航大学航空工程学院发动机系
23
气体动力学(Aerodynamics)
2016/3/30
中国民航大学航空工程学院发动机系
24
§2.1一维能量本征态的一般性质

第2章 一维势场中的粒子教材第2章P27~49§ 2.1一维能量本征态的一般性质§ 2.2方势§ 2.3 一维谐振子§ 2.1一维能量本征态的一般性质质量为m 的粒子在一维势)(x V 中运动,能量本征方程为)()(ˆx E x Hψ=ψ )(2ˆ222x V xm H +-=d d 或写成)()()(2222x E x x V x m ψ=ψ+-⎪⎪⎪⎭⎫ ⎝⎛d d注意)(x V 为实。
问题一般分为两类:给定)(x V 求E 和ψ,给定)(x V 和E 求ψ。
下面讨论能量本征方程解的一般性质定理1 . 设)(x ψ是能量本征方程的一个解,对应的能量本征值为E ,则)(*x ψ也是方程的一个解,对应的能量也是E 。
证明:设)(x ψ是能量本征方程的一个解,方程两边取复共轭,因E 和)(x V 为实,则)()()(2**222x E x x V x m ψ=ψ+-⎪⎪⎪⎭⎫ ⎝⎛d d即)(*x ψ也是方程的一个解,对应的能量也是E 。
若能量的某一本征值E 无简并,即只有一个独立的本征波函数)(x ψ,则)(x ψ可取为实函数。
这是因为:由定理1,)(x ψ和)(*x ψ均为与E 对应的本征波函数。
因E 无简并,则)()(*x C x ψ=ψ其中C 为常数。
上式取复共轭)()()(2**x C x C x ψ=ψ=ψ 12=C αi C e =,α为实若取0=α,则)()(*x x ψ=ψ,即)(x ψ可取为实函数。
对于能级有简并情况,有定理2 定理2 . 对应于能量的某个本征值E ,总可以找到能量本征方程的一组实解,属于E 的任何解均可表示为这一组实解的线性叠加。
证明:设)(x ψ是对应能量E 的一个解,若为实解,则可归入实解的集合中去。
若为复解,按定理1, )(*x ψ也是方程的一个解,同属于能量E 。
由线性方程解的叠加定理,实函数)()()(*x x x ψ+ψ=ϕ)]()([)(*x x i x ψ-ψ-=χ也是方程的解,同属于能量E ,并彼此独立。
数据结构知识点总结归纳整理

第1章绪论1.1 数据结构的基本概念数据元是数据的基本单位,一个数据元素可由若干个数据项完成,数据项是构成数据元素的不可分割的最小单位。
例如,学生记录就是一个数据元素,它由学号、姓名、性别等数据项组成。
数据对象是具有相同性质的数据元素的集合,是数据的一个子集。
数据类型是一个值的集合和定义在此集合上一组操作的总称。
•原子类型:其值不可再分的数据类型•结构类型:其值可以再分解为若干成分(分量)的数据类型•抽象数据类型:抽象数据组织和与之相关的操作抽象数据类型(ADT)是指一个数学模型以及定义在该模型上的一组操作。
抽象数据类型的定义仅取决于它的一组逻辑特性,而与其在计算机内部如何表示和实现无关。
通常用(数据对象、数据关系、基本操作集)这样的三元组来表示。
#关键词:数据,数据元素,数据对象,数据类型,数据结构数据结构的三要素:1.逻辑结构是指数据元素之间的逻辑关系,即从逻辑关系上描述数据,独立于计算机。
分为线性结构和非线性结构,线性表、栈、队列属于线性结构,树、图、集合属于非线性结构。
2.存储结构是指数据结构在计算机中的表示(又称映像),也称物理结构,包括数据元素的表示和关系的表示,依赖于计算机语言,分为顺序存储(随机存取)、链式存储(无碎片)、索引存储(检索速度快)、散列存储(检索、增加、删除快)。
3.数据的运算:包括运算的定义和实现。
运算的定义是针对逻辑结构的,指出运算的功能;运算的实现是针对存储结构的,指出运算的具体操作步骤。
1.2 算法和算法评价算法是对特定问题求解步骤的一种描述,有五个特性:有穷性、确定性、可行性、输入、输出。
一个算法有零个或多个的输入,有一个或多个的输出。
时间复杂度是指该语句在算法中被重复执行的次数,不仅依赖于问题的规模n,也取决于待输入数据的性质。
一般指最坏情况下的时间复杂度。
空间复杂度定义为该算法所耗费的存储空间。
算法原地工作是指算法所需辅助空间是常量,即O(1)。
第2章线性表2.1 线性表的定义和基本操作线性表是具有相同数据类型的n个数据元素的有限序列。
计算机二级公共基础知识完整

第一章数据结构及算法经过对部分考生的调查以及对近年真题的总结分析,笔试部分常常考查的是算法困难度, 数据结构的概念, 栈, 二叉树的遍历, 二分法查找,读者应对此部分进行重点学习。
具体重点学习知识点:1.算法的概念, 算法时间困难度及空间困难度的概念2.数据结构的定义, 数据逻辑结构及物理结构的定义3.栈的定义及其运算, 线性链表的存储方式4.树及二叉树的概念, 二叉树的基本性质, 完全二叉树的概念, 二叉树的遍历5.二分查找法6.冒泡排序法1.1算法考点1 算法的基本概念考试链接:考点1在笔试考试中考核的几率为30%,主要是以填空题的形式出现,分值为2分,此考点为识记内容,读者还应当了解算法中对数据的基本运算。
计算机解题的过程事实上是在实施某种算法,这种算法称为计算机算法。
1.算法的基本特征:可行性, 确定性, 有穷性, 拥有足够的情报。
2.算法的基本要素:(1)算法中对数据的运算和操作一个算法由两种基本要素组成:一是对数据对象的运算和操作;二是算法的限制结构。
在一般的计算机系统中,基本的运算和操作有以下4类:算术运算, 逻辑运算, 关系运算和数据传输。
(2)算法的限制结构:算法中各操作之间的执行依次称为算法的限制结构。
描述算法的工具通常有传统流程图, N-S结构化流程图, 算法描述语言等。
一个算法一般都可以用依次, 选择, 循环3种基本限制结构组合而成。
考点2 算法困难度考试链接:考点2在笔试考试中,是一个常常考查的内容,在笔试考试中出现的几率为70%,主要是以选择的形式出现,分值为2分,此考点为重点识记内容,读者还应当识记算法时间困难度及空间困难度的概念。
1.算法的时间困难度算法的时间困难度是指执行算法所须要的计算工作量。
同一个算法用不同的语言实现,或者用不同的编译程序进行编译,或者在不同的计算机上运行,效率均不同。
这表明运用肯定的时间单位衡量算法的效率是不合适的。
撇开这些及计算机硬件, 软件有关的因素,可以认为一个特定算法"运行工作量"的大小,只依靠于问题的规模(通常用整数n表示),它是问题规模的函数。
第二章-搜索引擎的架构PPT课件

分布式
排序以分布式形式
将多个用户查询分派给不同的处理器,并负责将各处理
器返回的结果合在一起
.
27
2.3.4查询处理(Cont.)
日志
调整和改善搜索引擎系统的效果和效率
用户的查询日志可以用于拼写检查、相关查询词推荐、查询 缓存及其他任务
排序分析
对于大量的查询-文档对,给定日志数据和显示的相关性判定, 可以对排序算法的效果进行评估
- 使用tag定义文档元素,E.g. , <h2> Overview </h2>
- 文档解析器使用标记语言的句法知识识别文档的结构
.
16
2.3.2文本转换(Cont.)
停用词去除
不具有实际意义的功能词,去除后不影响搜索效果 - e.g., “and”, “or”, “the”, “in”
根据实际应用确定停用词表 - 避免“to be or not to be”
新的页面
- 能够高效处理互联网上大量出现的新网页 - 抓取任务可以限制在一个单独的站点 - 主题爬虫采用分类技术限制所访问的网页是同一 主题
.
10
2.3.1文本采集(Cont.)
爬虫(Cont.)
及时、高效的收集数量尽可能多的有用的万维网 页面,以及建立它们之间的超链接关系
侧重用户需求:及时、数量多、有用 侧重搜索引擎系统需求:高效 收集的内容:网页、链接关系
强调文档中的重要词和段落
对输出结果聚类以找到文档相关的类别
在结果显示中增加相应的广告
在涉及多语言的应用系统中,结果可能被翻译成 同一种语言
.
25
2.3.4查询处理(Cont.)
排序--打分机制
使用排序算法计算文档的分值
《数据结构教学》cha(2)

{ 其它省略 }
.
1.3 算法和算法的衡量
一、算法 二、算法设计的原则 三、算法效率的衡量方法和准则 四、算法的存储空间需求
.
应用例子
栈和队列的应用——迷宫问题 树的应用——哈夫曼编码 链表的应用——约瑟夫游戏 文件系统大都采用B-Tree或其变种 B+Tree作为索引结构。
.
1.1 数据结构讨论的范畴 1.2 基本概念 1.3 算法和算法的量度
.
1.1 数据结构讨论的范畴
Niklaus Wirth:
Algorithm + Data Structures = Programs
// 返回复数 Z 的实部值 float Getimag( cpmplex Z ); // 返回复数 Z 的虚部值 void add( complex z1, complex z2,
complex &sum ); // 以 sum 返回两个复数 z1, z2 的和
.
// -----基本操作的实现
void add( complex z1, complex z2, complex &sum ) {
则在数据元素 a1、a2 和 a3 之间存在着
“次序”关系 a1,a2、a2,a3
3214,6587,9345 ≠ 6587,3214,9345
a1 a2 . a3
a2 a1 a3
数据结构:带结构的数据元素的集合
又例,在2行3列的二维数组{a1, a2, a3, a4, a5, a6}
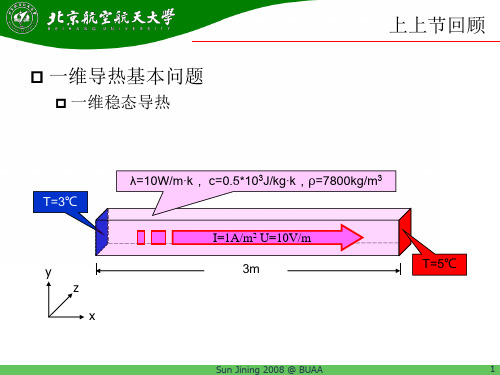
计算传热学第6节-第2章 一维导热3
TP1 =0.334T =0.334*4.64+2.118=3.67 P2+2.118
TP2 =0.602*5.24+1.49=4.64 TP3 =0.718*5.45+1.328=5.24
P4
P5 Pa Pb
代入可得 aP1=aP10 aP2=aP20 aP3=aP30 aP4=aP40 aP5=aP50
= = = = =
aE1(TP1,TP2)TP2+aW1(TP1)Tpa +6 aE2(TP2,TP3)TP3+aW2(TP2,TP1)TP1+6 aE3(TP3,TP4)TP4+aW3(TP3,TP2)TP2+6 aE4(TP4,TP5)TP5+aW4(TP4,TP3)TP3+6 aE5(TP5) TPb+aW5(TP5,TP4)TP4+6
解方程可得 TP1=TP11 TP2=TP21 TP3=TP31 TP4=TP41 TP5=TP51 代入可得 aP1=aP11 aP2=aP21 aP3=aP31 aP4=aP41 aP5=aP51
Pa Pb
TPa =3 TPb =5 解方程可得 TP1=TP1n TP2=TP2n TP3=TP3n TP4=TP4n TP5=TP5n
一维导热讨论问题
导热系数为x的函数λ
Pa P1 P2
λ=10W/m·k
(x)
P3
λ=50W/m·k P4 P5 Pb T=5℃
T=3℃
Δx=0.6m Δx=0.6m Δx=0.6m Δx=0.6m Δx=0.6m
数据结构导论知识点

数据结构导论知识点第一章概论数据结构:是相互之间存在一种或多种关系的数据元素的集合。
和该集合中数据元素之间的关系组成。
数据结构包括数据的逻辑结构、数据的存储结构和数据的基本运算。
简单地说,数据结构是计算机组织数据和存储数据的方式。
更进一步地说,数据结构是指一组相互之间存在一种或多种特定关系的数据的组织方式和它们在计算机内的存储方式,以及定义在该组数据上的操作。
合理的数据结构可降低程序设计的复杂性,提高程序执行的效率。
1.1 引言计算机解决一个具体问题时,一般需要经过以下几个步骤:①从具体的问题抽象出一个适当的数学模型;②设计一个求解该数学模型的算法;③用某种计算机语言编写实现该算法的程序,调试和运行程序直至最终得到问题的解答。
数据的逻辑结构:数据和数据的组织方式称为数据的逻辑结构。
为了能用计算机加工处理,逻辑结构还必须转换为能被计算机存储的存储结构。
1976年瑞士计算机科学家尼克劳斯·维尔特提出公式:算法+数据结构=程序。
该公式简洁的描述了数据结构和程序之间关系。
1.2 基本概念和术语1.2.1 数据、数据元素和数据项数据:所有被计算机存储、处理的对象。
数据元素:简称元素(又称为结点),数据的基本单位,在程序中作为一个整体而加以考虑和处理。
数据元素是运算的基本单位,通常具有完整确定的实际意义。
数据元素由数据项组成。
数据项:在数据库中数据项又称为字段或域,是数据的不可分割的最小标识单位,组成数据元素。
关系:数据、数据元素和数据项实际上反映了数据组织的三个层次,数据可由若干个数据元素组成,而数据元素又可由若干个数据项组成。
表格(逻辑结构),行=记录=数据元素,列=数据项。
1.2.2 数据的逻辑结构数据的逻辑结构:是指数据元素之间的逻辑关系。
逻辑关系:是指数据元素之间的关联方式或邻接关系。
逻辑结构示意图中的小圆圈称为结点,一个结点代表一个数据元素(记录)。
根据数据元素之间关系的不同特性,通常有集合、线性结构、树形结构和图结构四类基本逻辑结构,反映了四类基本的数据组织形式。
第2章--DEM数据组织与管理

镶嵌数据模型
规则格网数据模型的两个理解
适用于什么地形?
格网栅格的观点:格网单元的数值即其中所有点的值,对 应实地单元区域内高程为均一高程。 点栅格观点:格网单元的数值是格网中心点的数值,其它 任意点高程通过内插方式确定
镶嵌数据模型
不规则镶嵌数据模型
概念:是指用来进行镶嵌的小面块具有不规则的形状和边界, 如图。
不规则三角网DEM的优点是: • 能充分利用地貌的特征点和特征线,较好地表示
复杂地形; • 可根据不同的地形,选取合适的采样点数; • 进行地形分析和绘制立体图也很方便。
其缺点是:由于数据结构复杂,因而不便于规 范化管理,难以与矢量和栅格数据进行联合分析。
规则格网DEM和TIN的对比
规则格网DEM
拓扑关系
5
TIN 文件组成
4 3
C
B
D
6
A
E
2
坐标表
节点 1 2 3 4 5 6
坐标
X1,Y1,Z1 X2,Y2,Z2 X3,Y3,Z3 X4,Y4,,Z4 X5,Y5,Z5 X6,Y6,Z6
1 三角形/节点关系表
三角形
拓扑关系隐含
A
B
C
D
E
TIN 模型基本链表结构
节点 1,5,6 4,5,6 3,4,6 2,3,6 1,2,6
2023最新整理收集 do something
第2章 DEM数据组织与管理
主要内容
概述 DEM数据模型 DEM数据结构 DEM数据库管理
2.0 概述
空间对象建立过程
DEM建立的一般过程
• 数字高程模型是地形曲面的数字化表达,也就是说,DEM是 在计算机存储介质上科学、真实地描述、表达和模拟地形曲 面实体,因此它的建立实际上是一种地形数据的建模过程。
数据结构练习题 第二章 线性表 习题及答案

while(________________)
{ p=p->next; j++; }
if(i==j) return(p);
else return(NULL);
}
26.以下为单链表的定位运算,分析算法,请在____处填上正确的语句。
int locate_lklist(lklist head,datatype x)
if(________)return(i);
else return(0);
}
15.对于顺序表的定位算法,若以取结点值与参数X的比较为标准操作,平均时间复杂性量级为________。求表长和读表元算法的时间复杂性为________。
16.在顺序表上,求表长运算LENGTH(L)可通过输出________实现,读表元运算
36.当且仅当两个串的______相等并且各个对应位置上的字符都______时,这两个串相等。一个串中任意个连续字符组成的序列称为该串的______串,该串称为它所有子串的______串。
37.串的顺序存储有两种方法:一种是每个单元只存一个字符,称为______格式,另一种是每个单元存放多个字符,称为______格式。
2.为了满足运算的封闭性,通常允许一种逻辑结构出现不含任何结点的情况。不含任何结点的线性结构记为______或______。
3.线性结构的基本特征是:若至少含有一个结点,则除起始结点没有直接______外,其他结点有且仅有一个直接______;除终端结点没有直接______外,其它结点有且仅有一个直接______.
① 数据元素 ② 数据项 ③ 数据 ④ 数据结构
4.顺序表是线性表的 ( )
①链式存储结构 ②顺序存储结构 ③ 索引存储结构 ④ 散列存储结构
数据的组织结构--一维数组

数据的组织结构--一维数组数据的组织结构一维数组在我们日常使用计算机处理各种信息和任务的过程中,数据的组织和管理是至关重要的环节。
其中,一维数组作为一种常见的数据结构,扮演着不可或缺的角色。
想象一下,你有一排整齐排列的盒子,每个盒子里都装着一个特定的数据。
这排盒子就是我们所说的一维数组。
它是一组相同类型的数据元素的有序集合。
比如说,我们要记录一个班级学生的语文考试成绩。
如果这个班级有 50 个学生,我们可以创建一个包含 50 个元素的一维数组。
每个元素就对应着一个学生的成绩。
一维数组的最大特点之一就是其元素的顺序性。
这意味着数组中的元素是按照特定的顺序排列的,并且每个元素都可以通过一个唯一的索引来访问。
就好像每个盒子都有一个编号,我们通过这个编号就能准确地找到对应的盒子,并获取里面的数据。
在编程中,一维数组的索引通常从 0 开始。
假设我们有一个名为“scores”的一维数组来存储学生成绩,那么第一个学生的成绩可以通过“scores0”来获取,第二个学生的成绩就是“scores1”,以此类推。
那么,一维数组是如何在内存中存储的呢?其实,它是连续存储的。
这就好比那些装着数据的盒子是一个紧挨着一个排列的,没有任何空隙。
这种连续存储的方式使得计算机在访问数组元素时非常高效,因为它可以根据索引快速计算出元素的存储位置,从而节省了查找的时间。
但是,一维数组也有其局限性。
比如,它的长度在创建时通常就需要确定,并且在后续的使用过程中难以动态地改变。
如果我们一开始创建了一个只能存储 50 个成绩的数组,但后来班级里又新来了 5 个学生,这时候就会出现问题。
为了解决这个问题,在实际编程中,我们可能会使用一些动态数据结构,如链表或者动态数组。
但这并不意味着一维数组就失去了其价值。
在很多情况下,当我们确切知道数据的数量并且不需要频繁地进行插入和删除操作时,一维数组仍然是一个非常好的选择。
再举个例子,假设我们要编写一个程序来计算一周内每天的平均气温。
概率与数理统计第2章一维随机变量习题及答案

第2章一维随机变量 习题2一. 填空题:1.设 离 散 型 随 机 变 量 ξ 的 分 布 函 数 是 (){}x P x F ≤=ξ, 则 用 F (x) 表 示 概 {}0x P =ξ = __________。
解:()()000--x F x F2.设 随 机 变 量 ξ 的 分 布 函 数 为 ()()+∞<<∞-+=x arctgx x F π121 则 P{ 0<ξ<1} = ____14_____。
解: P{ 0<ξ<1} = =-)0(F )1(F 143.设 ξ 服 从 参 数 为 λ 的 泊 松 分 布 , 且 已 知 P{ ξ = 2 } = P{ ξ = 3 },则 P{ ξ = 3 }= ___2783e - 或 3.375e -3____。
4.设 某 离 散 型 随 机 变 量 ξ 的 分 布 律 是 {}⋅⋅⋅===,2,1,0,!k k C k P Kλξ,常 数 λ>0, 则 C 的 值 应 是 ___ e -λ_____。
解:{}λλλλξ-∞=∞=∞==⇒=⇒=⇒=⇒==∑∑∑e C Ce k C k Ck P KK KK K 11!1!105 设 随 机 变 量 ξ 的 分 布 律 是 {}4,3,2,1,21=⎪⎭⎫⎝⎛==k A k P kξ则⎭⎬⎫⎩⎨⎧<<2521ξP = 0.8 。
解:()A A k P k 161516181412141=⎪⎭⎫ ⎝⎛+++==∑=ξ 令15161A = 得 A =1615()()212521=+==⎪⎭⎫ ⎝⎛<<ξξξp p P 8.041211516=⎥⎦⎤⎢⎣⎡+=6.若 定 义 分 布 函 数 (){}x P x F ≤=ξ, 则 函 数 F(x)是 某 一 随 机 变 量 ξ 的 分 布 函 数 的 充 要 条 件 是F ( x ) 单 调 不 减 , 函 数 F (x) 右 连 续 , 且 F (- ∞ ) = 0 , F ( + ∞ ) = 17. 随机变量) ,a (N ~2σξ,记{}σ<-ξ=σa P )(g ,则随着σ的增大,g()σ之值 保 持 不 变 。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• 顺序文件
– 按关系中指定的一个或多个字段组合值(键)排序的数 据文件;
• 索引文件
– 为方便检索数据文件中元组,而建立的一个独立的辅助 文件或辅助关系; – 索引项或索引记录通常包含两个字段:键和指针; – 索引表通常很小; – 按索引项(记录或元组) 与关系中元组的对应方式, 可将索引分为稠密索引和稀疏索引两类。
18
2018年10月9日
2.2 辅助索引 —基本特点与设计
• 如果查找键的值的顺序与主文件的顺序不一致,那 么这种索引称为辅助索引,或非聚集索引。 • 辅助索引总是稠密索引,通常有重复值 • 辅助索引的索引项按键值排序 • 辅助索引的指针不是指向一个或几个连续存储块, 而是指向很多不同的块。 例:k=20 要查找两个索引块,还要访问指针指向的三个 不同的数据块
17
2018年10月9日
2.2 辅助索引 —基本特点与设计
• • 辅助索引的特点
– 可能存在重复键; – 数据文件一般不按辅助索引键排序;
辅助索引设计
– – – – 必须是稠密的索引结构; 索引文件中索引项按键值排序; 可根据需要建立二级或多级索引 存在空间浪费,如某个键在数据文件中出 现n次,那么这个键值将在索引文件中出 现n次。
– 索引数据块通常比数据块少,I/0次数少,如果索 引足够小,甚至可以将整个索引放在内存缓冲区 中,则只需一次性读入索引的I/O,就可以定位任 意的记录; – 由于索引文件中键被排序,可用二分法快速查找, 若有n个索引项,最多只需要查log2n个块;
2018年10月9日
10
2.1顺序文件上的索引—稀疏索引
– 是一个独立文件,占用系列存储块,块中仅存 放记录键和指向记录的指针; – 每个索引项对应相应数据文件中的一条记录; – 通常其大小要明显小于数据文件;
• 稠密索引的查找 • 使用稠密索引文件的好处
2018年10月9日
8
2.1顺序文件上的索引—稠密索引
• 稠密索引的数据结构组织形式 • 稠密索引文件的特点 • 稠密索引的查找
• • • • 稀疏索引的数据结构组织形式 稀疏索引文件的特点 稀疏索引的查找 与稠密索引比较
(1)节省了存储空间 (2)查找给定值的记录需要更多时间 例:查询“是否存在键值为K的记录?” 稠密索引只需考虑键K在索引中的存在 稀疏索引要执行I/O操作去检索可能存在键值为K的记录的块
2018年10月9日
2018年10月9日
6
2.1顺序文件上的索引—稠密索引
• 稠密索引的数据结构组织形式 • 稠密索引文件的特点 • 使用稠密索引文件的好处
索引文件
数据文件:元组按主键排序
7 每个存储块只存放两个记录 2018年10月9日
2.1顺序文件上的索引—稠密索引
• 稠密索引的数据结构组织形式 • 稠密索引文件的特点
• 稀疏索引的数据结构组织形式
• 稀疏索引文件的特点
11
2018年10月9日
2.1顺序文件上的索引—稀疏索引
• 稀疏索引的数据结构组织形式 • 稀疏索引文件的特点
– 为每个存储块设一个键-指针对 – 键值是每个数据块中第一个记录的对应值
• 稀疏索引的查找 • 与稠密索引比较
2018年10月9日
12
2.1顺序文件上的索引—稀疏索引
• 稀疏索引的数据结构组织形式 • 稀疏索引文件的特点 • 稀疏索引的查找
找出键值为K的记录
(1)在索引中查找键值小于或等于K的最大键值 (2)根据指针找到相应数据块 (3)搜索数据块以找到键值为K的记录
• 与稠密索引比较
2018年10月9日
13
2.1顺序文件上的索引—稀疏索引
16
2018年10月9日
2.2 辅助索引 —应用背景
在实际的DB应用中,经常需要进行针对非主属性的 查询,为了加快查询的速度,也可以对非主属性建立 索引: SELECT name, address FROM movieStar WHERE birthDate=DATE(‘1995-01-01’); 可在属性上建立索引: CREATE INDEX i_birthDate ON movieStar(birthDate) 相对与主键索引,我们称之为辅助索引。
2018年10月9日
4
引言
• 查找键---建立索引的字段 • 索引方法 (1)顺序文件上的简单索引 (2)非排序文件上的辅助索引 (3)B树, 一种可以在任何文件上建立索引的 常用方法 (4)散列表
2018年10月9日
5
2.1顺序文件上的索引—相关概念
• 数据文件
– 存放一个关系所有元组数据的文件;
高级数据库课程
第一部分 数据库系统基础 第二部分 数据库的数据存储管理 第三部分 数据库查询处理
第2章:一维索引组织结构
2018年10月9日
1
引言
整个关系在储存中如何存储与表示?以 及怎样才能有效检索与定位? 比如,如何回答象 SELECT * FROM R 这样一个简单查询?
2018年10月9日
2
引言
• 我们可能不得不检索辅存中的与数据库 文件对应的每个存储块,且还得依赖块 首部中存在足够得信息来表明该块记录 从什么地方开始,块中记录属于什么关 系;
•
有效的解决方案――-采用索引结构;
3
2018年10月9日
索引:索引是一种数据结构,它以记录的特征(通常是一 个或多个字段的值)为输入,并能“快速地”找出具有该 特征的记录
14
2.1顺序文件上的索引—多级索引
• 在索引的基础上,再建索引
15
2018年10月9日
2.1顺序文件上的索引—多级索引
• 如对主索引再建立一级稀疏索引,即对每个索引 块建立一个索引记录,就形成了二级索引· 此时 外层索引块可常驻内存,在查找记录时内层索引 块只要读1次就行· • 如果外层索引块的数目太多,不能全部进内存, 那么可对最外层索引再外建一层索引,这就形成 了多级索引技术。 • 二级以上索引肯定是稀疏索引; • 一级索引通常是稠密的; • 多级索引的性能及管理的方便性不如B树结构;
支持按给定键值查找相应记录的查询 给定一个键值K (1)现在索引块中查找K (2)找到K后,按照K所对应的指针到数据文件中寻 找相应的记录
• 使用稠密索引文件的好处Leabharlann 2018年10月9日9
2.1顺序文件上的索引—稠密索引
• • • • 稠密索引的数据结构组织形式 稠密索引文件的特点 稠密索引的查找 使用稠密索引文件的好处