分块查找算法
查找排序
解:① 先设定3个辅助标志: low,high,mid, 显然有:mid= (low+high)/2 ② 运算步骤:
(1) low =1,high =11 ,故mid =6 ,待查范围是 [1,11]; (2) 若 S[mid] < key,说明 key[ mid+1,high] , 则令:low =mid+1;重算 mid= (low+high)/2;. (3) 若 S[mid] > key,说明key[low ,mid-1], 则令:high =mid–1;重算 mid ; (4)若 S[ mid ] = key,说明查找成功,元素序号=mid; 结束条件: (1)查找成功 : S[mid] = key (2)查找不成功 : high<low (意即区间长度小于0)
while(low<=high)
{ mid=(low+high)/2; if(ST[mid].key= = key) return (mid); /*查找成功*/
else if( key< ST[mid].key) high=mid-1; /*在前半区间继续查找*/ else } return (0); /*查找不成功*/
4 5 6 7
0
1
2
90
10
(c)
20
40
K=90
80
30
60
Hale Waihona Puke 25(return i=0 )
6
讨论:怎样衡量查找效率?
——用平均查找长度(ASL)衡量。
如何计算ASL?
c语言数据结构查找算法大全

printf("This number does not exist in this array.\n");
else
printf("a[%d]=%d\n",p,x);
}
9.2.2 折半查找(二分查找)
使用折半查找必须具备两个前提条件:
(1)要求查找表中的记录按关键字有序(设,从小到大有序) (2)只能适用于顺序存储结构
}
※折半查找算法性能分析:
在折半查找的过程中,每经过一次比较,查找范围都要缩小一半,所 以折半查找的最大查找长度为
MSL=[log2 n]+1
当n足够大时,可近似的表示为log2(n)。可见在查找速度上,折半查找 比顺序查找速度要快的多,这是它的主要优点。
结论:折半查找要求查找表按关键字有序,而排序是一 种很费时的运算;另外,折半查找要求表是顺序存储的,为 保持表的有序性,在进行插入和删除操作时,都必须移动大 量记录。因此,折半查找的高查找效率是以牺牲排序为代价 的,它特别适合于一经建立就很少移动、而又经常需要查找 的线性表。
查找技术分为: 1 静态查找表技术 顺序查找、折半查找、索引顺序查找 2 动态查找表技术 二叉查找树 3哈希表技术 哈希表技术
※查找算法的衡量指标
在查找一个记录时所做的主要操作是关键字的比较, 所以通常把查找过程中对关键字的平均比较次数作为衡量 一个查找算法效率优劣的标准,并称平均比较次数为平均 查找长度(Average Search Length)。平均查找长度的 定义为:
high2=N-1;
/*N为查找表的长度,high2为块在表中的末地址*/
else
high2=ID[low1+1].addr-1;
查找表结构——精选推荐

查找表结构查找表介绍在⽇常⽣活中,⼏乎每天都要进⾏⼀些查找的⼯作,在电话簿中查阅某个⼈的电话号码;在电脑的⽂件夹中查找某个具体的⽂件等等。
本节主要介绍⽤于查找操作的数据结构——查找表。
查找表是由同⼀类型的数据元素构成的集合。
例如电话号码簿和字典都可以看作是⼀张查找表。
⼀般对于查找表有以下⼏种操作:在查找表中查找某个具体的数据元素;在查找表中插⼊数据元素;从查找表中删除数据元素;静态查找表和动态查找表在查找表中只做查找操作,⽽不改动表中数据元素,称此类查找表为静态查找表;反之,在查找表中做查找操作的同时进⾏插⼊数据或者删除数据的操作,称此类表为动态查找表。
关键字在查找表查找某个特定元素时,前提是需要知道这个元素的⼀些属性。
例如,每个⼈上学的时候都会有⾃⼰唯⼀的学号,因为你的姓名、年龄都有可能和其他⼈是重复的,唯独学号不会重复。
⽽学⽣具有的这些属性(学号、姓名、年龄等)都可以称为关键字。
关键字⼜细分为主关键字和次关键字。
若某个关键字可以唯⼀地识别⼀个数据元素时,称这个关键字为主关键字,例如学⽣的学号就具有唯⼀性;反之,像学⽣姓名、年龄这类的关键字,由于不具有唯⼀性,称为次关键字。
如何进⾏查找?不同的查找表,其使⽤的查找⽅法是不同的。
例如每个⼈都有属于⾃⼰的朋友圈,都有⾃⼰的电话簿,电话簿中数据的排序⽅式是多种多样的,有的是按照姓名的⾸字母进⾏排序,这种情况在查找时,就可以根据被查找元素的⾸字母进⾏顺序查找;有的是按照类别(亲朋好友)进⾏排序。
在查找时,就需要根据被查找元素本⾝的类别关键字进⾏排序。
具体的查找⽅法需要根据实际应⽤中具体情况⽽定。
顺序查找算法(C++)静态查找表既可以使⽤顺序表表⽰,也可以使⽤链表结构表⽰。
虽然⼀个是数组、⼀个链表,但两者在做查找操作时,基本上⼤同⼩异。
顺序查找的实现静态查找表⽤顺序存储结构表⽰时,顺序查找的查找过程为:从表中的最后⼀个数据元素开始,逐个同记录的关键字做⽐较,如果匹配成功,则查找成功;反之,如果直到表中第⼀个关键字查找完也没有成功匹配,则查找失败。
数据结构中的查找算法总结

数据结构中的查找算法总结静态查找是数据集合稳定不需要添加删除元素的查找包括:1. 顺序查找2. 折半查找3. Fibonacci4. 分块查找静态查找可以⽤线性表结构组织数据,这样可以使⽤顺序查找算法,再对关键字进⾏排序就可以使⽤折半查找或斐波那契查找等算法提⾼查找效率,平均查找长度:折半查找最⼩,分块次之,顺序查找最⼤。
顺序查找对有序⽆序表均适⽤,折半查找适⽤于有序表,分块查找要求表中元素是块与块之间的记录按关键字有序动态查找是数据集合需要添加删除元素的查找包括: 1. ⼆叉排序树 2. 平衡⼆叉树 3. 散列表 顺序查找适合于存储结构为顺序存储或链接存储的线性表。
顺序查找属于⽆序查找算法。
从数据结构线形表的⼀端开始,顺序扫描,依次将扫描到的结点关键字与给定值k相⽐较,若相等则表⽰查找成功 查找成功时的平均查找长度为: ASL = 1/n(1+2+3+…+n) = (n+1)/2 ; 顺序查找的时间复杂度为O(n)。
元素必须是有序的,如果是⽆序的则要先进⾏排序操作。
⼆分查找即折半查找,属于有序查找算法。
⽤给定值value与中间结点mid的关键字⽐较,若相等则查找成功;若不相等,再根据value 与该中间结点关键字的⽐较结果确定下⼀步查找的⼦表 将数组的查找过程绘制成⼀棵⼆叉树排序树,如果查找的关键字不是中间记录的话,折半查找等于是把静态有序查找表分成了两棵⼦树,即查找结果只需要找其中的⼀半数据记录即可,等于⼯作量少了⼀半,然后继续折半查找,效率⾼。
根据⼆叉树的性质,具有n个结点的完全⼆叉树的深度为[log2n]+1。
尽管折半查找判定⼆叉树并不是完全⼆叉树,但同样相同的推导可以得出,最坏情况是查找到关键字或查找失败的次数为[log2n]+1,最好的情况是1次。
时间复杂度为O(log2n); 折半计算mid的公式 mid = (low+high)/2;if(a[mid]==value)return mid;if(a[mid]>value)high = mid-1;if(a[mid]<value)low = mid+1; 折半查找判定数中的结点都是查找成功的情况,将每个结点的空指针指向⼀个实际上不存在的结点——外结点,所有外界点都是查找不成功的情况,如图所⽰。
基本查找方法

分块查找算法
int blksearch (sqlist r,index idx,int k,bn) /*bn为块的个数*/ {
int i,high=bn,low=1,mid,j,find=0; while (low<=high&& !find) { /*二分查找索引表*/
mid=(low+high)/2; if(k<idx[mid].key)
查找
图8.1 线性表与索引表
查找
索引表的定义
struct indexterm {
keytype key; int low,high; }; typedef struct indexterm index[MAXITEM]; 这里的keytype可以是任何相应的数据类型, 如int、float、或char等,在算法中,我们规 定keytype缺省是int类型。
查找
二分查找算法
int binsearch(sqlist r,int k,n) {
int i,low=1,high=n,m,find=0; /*low和high分别表示查找范围的起始单元下标和终止
单元下标,find为查找成功的标志变量*/ while (low<=high && !find) {
m=(low+high)/2; if(k<r[m].key)
数据结构
1.1 顺序查找
顺序查找(Sequential search)也称为线性查找, 是采用线性表作为数据的存储结构,对数据 在表中存放的先后次序没有任何要求。
顺序查找是最简单的查找方法,它的基本思 想是:查找从线性表的一端开始,顺序将各 单元的关键字与给定值k进行比较,直至找 到与k相等的关键字,则查找成功,返回该 单元的位置序号;如果进行到表的另一端, 仍未找到与k相等的关键字,则查找不成功, 返回0作为查找失败的信息。
链表的分块查找-原理及C++示例代码.

一个快两年没有联系的高中同学突然跟我发消息要我帮忙写个算法设计的作业,其实本来不是很闲,只是觉得自己很久没有认真的写过专业课的作业了,就答应了,顺便温习一下链表...事实上我学的不是很好吧。
晚上就不会寝室睡觉了,呆在实验室就来看题目。
要求是用分块查找法找到创建的链表的某个数据。
分块查找?好像我们老师没讲啊!无奈百度一圈下来,看得不是很明白,也不是完全不明白。
最后理解为,给链表分块,当然可以为不等大小的,这里我就用等大小的来直接处理,这样就可以从控制台直接输入块的大小来查找。
其次,还要输入被查找的块。
如果这个数在此块以外,就无法找到。
最后,把找到的数字的节点数输出来。
首先看看原理图,这个是在网上看的,不过原图有点不准确,用fireworks(不要鄙视我古董,我依然喜欢它)处理了下贴上来。
分块查找的思路是:1、首先查找索引表索引表是有序表,可采用二分查找或顺序查找,以确定待查的结点在哪一块。
这里我定义了一个我认为比较雷人的数组用于存放节点的地址。
#define N 30int *add[N];每次添加数据时,分配的地址会被保存到这里。
add[++i]=(struct Node *)p1;然后数组的下表自增移动。
2、然后在已确定的块中进行顺序查找由于块内无序,只能顺序查找。
for(i=block * BLK ; i<(block+1)* BLK && add[i]!=0 ;i++)这个范围就是由块得大小和第几个来确定的,当然,不能超过范围,这里用的add[i]!=0来作条件,因为add[]数组是在全局定义的,编译时全部初始化为零,自然,越界的就是零了。
这里注意,虽然数组存的值是地址,但是不能直接用,需要转化为结构体的地址才行struct Node *t;t=add[i];if(t->id==key) printf("找到第%d个数是%d\n",i,key);OK,我的思路大概就是这样,不知道是不是和标准的分块查找算法一样啊。
常见的查找算法(六):分块查找

常见的查找算法(六):分块查找 分块查找⼜称索引顺序查找,它是顺序查找的⼀种改进⽅法。
算法流程:先选取各块中的最⼤关键字构成⼀个索引表;查找分两个部分:先对索引表进⾏⼆分查找或顺序查找,以确定待查记录在哪⼀块中;然后,在已确定的块中⽤顺序法进⾏查找。
注:算法的思想是将n个数据元素"按块有序"划分为m块(m ≤ n)。
每⼀块中的结点不必有序,但块与块之间必须"按块有序",每个块内的的最⼤元素⼩于下⼀块所有元素的任意⼀个值。
所以,给定⼀个待查找的key,在查找这个key值位置时,会先去索引表中利⽤顺序查找或者⼆分查找来找出这个key所在块的索引开始位置,然后再根据所在块的索引开始位置开始查找这个key所在的具体位置。
下⾯给出⼀段分块查找的代码,其思想和上⾯描述的⼀样,都是通过索引表来找key的位置。
先给出主表和索引表:1// 主表,size=302static int[] mainList = new int[]{3 101, 102, 103, 104, 105, 0, 0, 0, 0, 0,4 201, 202, 203, 204, 0, 0, 0, 0, 0, 0,5 301, 302, 303, 0, 0, 0, 0, 0, 0, 06 };78// 索引表9static IndexItem[] indexItemList = new IndexItem[]{10new IndexItem(1, 0, 5),11new IndexItem(2, 10, 4),12new IndexItem(3, 20, 3)13 }; 索引表类:static class IndexItem {public int index; //值⽐较的索引public int start; //开始位置public int length;//块元素长度(⾮空)public IndexItem(int index, int start, int length) {this.index = index;this.start = start;this.length = length;}//... getter and setter} 索引查找算法:1public static int indexSearch(int key) {2 IndexItem indexItem = null;34//建⽴索引规则5int index = key / 100;67//遍历索引表8for(int i = 0;i < indexItemList.length; i++) {9//找到索引项10if(indexItemList[i].index == index) {11 indexItem = indexItemList[i];12break;13 }14 }1516//索引表中不存在该索引项17if(indexItem == null)18return -1;1920//根据索引项,在主表中查找21for(int i = indexItem.start; i < indexItem.start + indexItem.length; i++) {22if(mainList[i] == key)23return i;24 }2526return -1;27 } 时间复杂度分析:先按⼆分查找去找key在索引表为⼤概位置(所给出代码是顺序查找),然后在主表中的可能所在块的位置开始按顺序查找,所以时间复杂度为O(log₂(m)+N/m),m为分块的数量,N为主表元素的数量,N/m 就是每块内元素的数量。
《数据结构》课程标准

《数据结构》课程标准一、课程定位《数据结构》是大数据技术与应用专业的一门专业基础课程,本课程所涵盖的知识和技能是作为大数据技术与应用专业学生其他专业课程的核心基础课程之一。
通过本课程的学习,使学生能够获得学习后续专业课程所需的编程算法、数据结构方面的基础知识。
通过本课程及其实践环节教学,使学生能够培养良好的编程习惯,锻炼计算机软件算法思想,并培养学生分析问题和解决问题的能力。
为以后进行实际的软件开发工作打下良好的专业知识和职业技能基础。
二、课程目标通过本课程的学习,培养和提高计算机软件技术专业学生的职业核心能力和素质。
使学生能够具备良好的职业素养,具备团队协作、与人沟通等多方面的能力;使学生具有较强的编程专业基础知识和技能,并具备进行自我拓展的能力。
让学生能够具备深厚的专业基础,为今后的长足发展提供厚实而强大的动力。
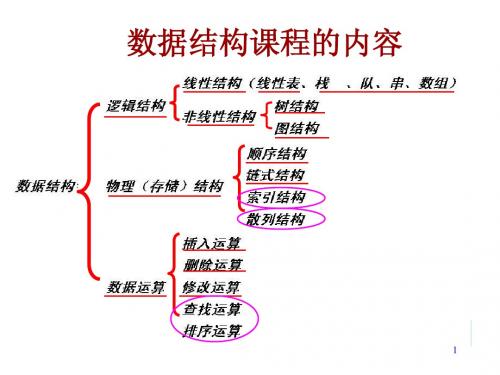
1、知识目标本课程涵盖了以下知识目标:(1)掌握算法设计的基本度量方法;(2)掌握线性表、栈、队列、数组和二叉树抽象数据类型的实现及其基本的操作实现;(3)理解图抽象数据类型的实现及其基本的操作特点;(4)掌握常见查找算法和排序算法的特点和实现方法。
2、能力目标(1)能查阅英文版的相关技术手册;(2)能正确地实现常用的抽象数据类型,并能实现常见的基本操作;(3)能针对现实问题选择正确的数据结构,并能在所选择的数据结构基础上编写相应算法以解决该问题;(4)能够对所编写的算法进行简单的度量和评估。
3、素质目标(1)具有良好的心理素质,顽强的意志力,勇于克服困难;(2)具有较强的身心素质,适应艰苦工作需要;(3)具有较扎实的业务基础,并能不断进行创新和自我超越。
三、课程设计1、设计思想教学内容框架按照知识和技能递进的关系,本课程的内容框架设计如下图所示:教学内容框架示意图本课程教学内容按照线性表、栈、队列、数组、树及二叉树和图等基本数据结构的顺序来实施教学,最后将前面的基本数据结构应用于查询算法和排序算法的设计和实现。
算法的魅力

算法的魅力刘诗蓉学号:1167007118 提要:算法是一种逐步解决问题或完成任务的方法,有顺序、判断、循环三种结构。
基本算法有求和、乘积、排序、查找等。
递归与迭代则作为子算法,使程序更容易理解。
关键词:算法结构、排序、查找、递归、迭代引言:算法是计算机科学领域最重要的基石之一,计算机语言和开发平台日新月异,但万变不离其宗的便是那些算法。
今天,让我们深入算法,共同领略它的独特魅力。
一、算法的结构算法有以下三种结构,仅仅使用这三种结构就可以使程序或算法容易理解、调试或修改。
1.顺序算法(终是程序)都是指令的序列。
指令可是简单指令或是其他两种结构之一。
2.判断有些问题只用顺序结构是不能解决的,有时候需要检查条件是否满足。
假如测试的结果为真,即条件满足,则可以继续顺序往下执行命令;加入结果为假,程序将从另外一个顺序结果的指令继续执行。
这就是判断(分支)结构。
3.循环在有些问题中,相同的一系列顺序指令需要重复,那么就可以用重复或循环结构来解决这个问题。
从指定的数据集中找到最大数的算法就是循环结构的例子。
二、基本算法1.求和求和算法可分为三个逻辑部分:1)将和初始化。
2)循环,在每次迭代中将一个新数加到和上。
3)退出循环后返回结果。
2.乘积乘法算法有三个逻辑部分:1)讲乘积初始化。
2)循环,在每次迭代中将一个新数与乘积相乘。
3.最大和最小通过判断结构找到两个数中的较大值,再把这个结构放到循环中的思想找出最大值。
1)将最大值设为负无穷。
2)如果当前比最大值大,将最大值设为当前数。
….n)如果当前数比最大值大,将最大值设为当前数。
求解最小值与求解最大值不同之处为:初始值设为正无穷。
4.排序排序中我们介绍三种基本排序,它们都是快速排序的基础。
a.选择排序在选择排序中,数字列表可以分为两个子列表,一个已排序,一个未排序,他们通过家乡的一堵墙分开。
找到未排序子列表中最小的元素并把它和未排序数据中第一个元素进行交换,经过每次选择和交换,两个子列表中假想的这堵墙向前移动一个元素,这样每次排序列表中将增加一个元素而未排序列表中将减少一个元素,每次把一个元素从未排序列表移到已排序列表就完成了一次分类扫描。
数据结构与算法学习情境8查找与演示项目开发

学习情境8 查找与演示项目开发
private JLabel jLabel32 = null; private JLabel jLabel33 = null; private JLabel jLabel34 = null; private JLabel jLabel35 = null; private JLabel jLabel36 = null; private JLabel jLabel37 = null; private JLabel jLabel4 = null; private JTextField jTextField = null; private JButton jButton = null; private JButton jButton1 = null; private JButton jButton2 = null; private JButton jButton3 = null; private JLabel label1[] = new JLabel[8]; private int array[] = {21, 4, 5, 74, 85, 12, 43, 32};
学习情境8 查找与演示项目开发
8.1 任务一 认识查找 查找(search)就是在数据集中寻找指定数 据。如日常生活中的查字典、 号码、图书等, 以及高考考生在考试后通过网络信息系统查询
成绩和录取情况等。 1.查找
查找:对给定的一个关键字的值,在数据 表中搜索出一个关键字的值等于该值的记录或 数据。假设找到了指定的数据,那么称之为查
分解为规模更小的子问题,分而治之,逐一解决。
学习情境8 查找与演示项目开发
2.折半查找算法分析 折半查找其实是一棵二叉判定树,树高为k = int(lb n) + 1, 查找成功的比较次数为1~k次,查找不成功的比较次数为k-1 或k次,平均查找长度为O(lb n)。 在顺序表长度相同的情况下,虽然折半查找算法效率比顺序 查找算法效率高,但是折半查找算法要求数据必须是已排序 的。 顺序查找和折半查找均适用于数据量较小的情况。 3.演示程序的实现 以下程序实现图形界面显示折半查找的过程,文件名为, 代码量为400行,以下是完整代码(供参考):
数据结构第九章:查找

low high mid
8
1 5
2 13
3 19
4 21
5 37
6 56
7 64
8 75
9 80
10 88
11 92
high low 1 5 2 13 3 19 4 21 5 37 6 56 6 3 1 2
算法描述: 算法描述:ENTER
9
7 64
8 75
9 80
10 88
11 92
判定树: 判定树:
17
考试题型介绍: 考试题型介绍:
1. 填空题 若用链表存储一棵二叉树时,每个结点除数据域外, 若用链表存储一棵二叉树时,每个结点除数据域外,还有指向左孩子和右 孩子的两个指针。在这种存储结构中, 个结点的二叉树共有 个结点的二叉树共有________个 孩子的两个指针。在这种存储结构中,n个结点的二叉树共有 个 指针域,其中有________个指针域是存放了地址,有 指针域,其中有 个指针域是存放了地址, 个指针域是存放了地址 ________________个指针是空指针。 个指针是空指针。 个指针是空指针 2. 选择题 设有序表中有1000个元素,则用二分查找查找元素X最多需要比较( )次 个元素,则用二分查找查找元素 最多需要比较 最多需要比较( 设有序表中有 个元素 A. 25 3. 简答题 已知序列( , , , , , , , , , ) 已知序列(10,18,4,3,6,12,1,9,18,8)请用快速排序写出每一 趟排序的结果。 趟排序的结果。 4. 算法题 设计判断单链表中元素是否是递增的算法。 设计判断单链表中元素是否是递增的算法。 已知: 已知: 1. 单链表已存在,并带有头结点; 单链表已存在,并带有头结点; 2. 要求写出详细的算法步骤或画出详细的流程图; 要求写出详细的算法步骤或画出详细的流程图; B. 10 C. 7 D. 1
数据结构作业——分块查找算法

数据结构实验报告三题目:试编写利用折半查找确定记录所在块的分块查找算法。
提示:1)读入各记录建立主表;2)按L个记录/块建立索引表;3)对给定关键字k进行查找;测试实例:设主表关键字序列:{12 22 13 8 28 33 38 42 87 76 50 63 99 101 97 96},L=4 ,依次查找K=13, K=86,K=88算法思路题意要求对输入的关键字序列先进行分块,得到分块序列。
由于序列不一定有序,故对分块序列进行折半查找,找到关键字所在的块,然后对关键字所在的块进行顺序查找,从而找到关键字的位置。
故需要折半查找和顺序查找两个函数,考虑用C++中的类函数实现。
因为序列一般是用数组进行存储的,这样可以调用不同类型的数组,程序的可适用性更大一些。
折半查找函数:int s,d,ss,dd;//声明一些全局变量,方便函数与主函数之间的变量调用。
template <class T>int BinSearch(T A[],int low,int high,T key)//递归实现折半查找{int mid;// 初始化中间值的位置T midvalue;// 初始化中间值if (low>high){s=A[high];d=A[low];ss=high;dd=low;return -1;}// 如果low的值大于high的值,输出-1,并且将此时的low与high的值存储。
else{mid=(low+high)/2;// 中间位置为低位与高位和的一半取整。
midvalue=A[mid];if (midvalue==key)return mid;else if (midvalue < key) //如果关键字的值大于中间值return BinSearch(A,mid+1,high,key);// 递归调用函数,搜索下半部分elsereturn BinSearch(A,low,mid-1,key);// 否则递归调用哦个函数,搜索上半部分}}以上为通用的折半查找的函数代码,这里引入了几个全局变量,主要是方便在搜索关键字在哪一个分块中时,作为判断条件。
数据结构与算法(10):查找

× (high − low)
也就是将上述的比比例例参数1/2改进为自自适应的,根据关键字在整个有序表中所处的位置,让mid值 的变化更更靠近关键字key,这样也就间接地减少了了比比较次数。
基本思想:基于二二分查找算法,将查找点的选择改进为自自适应选择,可以提高高查找效率。当然, 插值查找也属于有序查找。
if __name__ == '__main__': LIST = [1, 5, 7, 8, 22, 54, 99, 123, 200, 222, 444] result = binary_search(LIST, 444) print(result)
3.3 斐波那契查找
在介绍斐波那契查找算法之前,我们先介绍一一下和它很紧密相连并且大大家都熟知的一一个概念—— ⻩黄金金金分割。 ⻩黄金金金比比例例又又称为⻩黄金金金分割,是指事物各部分间一一定的数学比比例例关系,即将整体一一分为二二,较大大部 分与较小小部分之比比等于整体与较大大部分之比比,其比比值约为1:0.618。 0.618倍公认为是最具有审美意义的比比例例数字,这个数值的作用用不不仅仅体现在诸如绘画、雕塑、 音音乐、建筑等艺术领域,而而且在管理理、工工程设计等方方面面有着不不可忽视的作用用。因此被称为⻩黄金金金分 割。 大大家记不不记得斐波那契数列列:1,1,2,3,5,8,13,21,34,55,89......(从第三个数开 始,后面面每一一个数都是前两个数的和)。然后我们会发现,随着斐波那契数列列的递增,前后两个 数的比比值会越来越接近0.618,利利用用这个特性,我们就可以将⻩黄金金金比比例例运用用到查找技术中。
分块查找求平均查找长度例题

分块查找求平均查找长度例题
摘要:
1.分块查找算法概述
2.求平均查找长度的公式
3.例题解析
正文:
一、分块查找算法概述
分块查找算法是一种线性表查找算法,其基本思想是将表分成若干个块,然后在各个块中进行查找。
分块查找算法能有效减小查找范围,提高查找效率。
二、求平均查找长度的公式
平均查找长度(ASL)是指在所有查找操作中,查找成功和查找失败的平均查找长度。
其计算公式为:
ASL = (成功查找次数×成功查找长度+ 失败查找次数×失败查找长度) / (成功查找次数+ 失败查找次数)
三、例题解析
假设有一个包含n 个元素的线性表,采用分块查找算法,将表分成k 个块,每个块的长度分别为s1, s2,..., sk。
在所有查找操作中,成功查找m 次,失败查找n-m 次。
每查找一次成功查找长度为l1, l2,..., lm,失败查找长度为a1, a2,..., an-m。
求该分块查找算法的平均查找长度。
根据公式,平均查找长度ASL = (m×(l1+l2+...+lm) + (n-
m)×(a1+a2+...+an-m)) / n。
平均查找长度详解

平均查找长度详解1.顺序查找:从表的一端开始,顺序扫描线性表,依次将扫描到的节点关键字和给定值k相比较。
等概率条件下...平均查找长度:ASL = (n+....+2+1)/n= (n+1)/2。
2.二分法查找:前提是线性表是有序表。
假设数据是按升序排序的,对于给定值x,从序列的中间位置开始比较,如果当前位置值等于x,则查找成功;若x小于当前位置值,则在数列的前半段中查找;若x大于当前位置值则在数列的后半段中继续查找,直到找到为止。
在等概率条件下...平均查找长度:ASL =(1/n)* ( j * 2^(j-1) )(j 是从1到h),ASL = log2(n+1)-1。
原因:用二叉树来描述,树的高度d与节点树的关系为:n=(1+2+4+...... 2^(d-1))=2^d - 1;所以d = log2(n+1),每一层只需要比较一次,所以最多需要比较log2(n+1)次。
3.分块查找:又称索引顺序查找,由分块有序(每一块中的关键字不一定有序,但是前一块中的最大关键字必须小于后一块中的最小关键字,即分块有序。
)的索引表和线性表组成。
例如把r【1....n】分为b 块,则前b-1 块节点数为 s = 【n/b】,最后一块允许小于或等于s。
索引表是一个递增有序表。
平均查找长度分为两部分,索引表的查找+块内的查找。
(索引表能够用二分法和顺序查找,块内无序,所以只能用顺序查找)如果以二分查找来确定块,则 ASL = log2(b+1)-1 + (s+1)/2。
如果以顺序查找来确定块,则 ASL = (b+1)/2 + (s+1)/2。
如果以哈希查找来确定块,则ASL=1 + (s+1)/2。
转载自:/jiary5201314/article/details/51125411。
分块查找算法

分块查找算法
分块查找算法是一种高效的查找数据的方法。
它将数据分成若干块,并对每一块进行预处理,使得在查找时可以快速定位目标数据所在的块。
然后再在目标块中进行二分查找,以获得目标数据。
分块查找算法的时间复杂度为O(sqrt(n)+log(m)),其中n为数据总量,m为块的数量。
其空间复杂度为O(n)。
分块查找算法的优点是在具有大量数据的情况下,可以快速查找目标数据,同时保证查找的效率和准确性。
它适用于静态数据集合,即数据集合不随时间变化而改变的情况。
需要注意的是,分块查找算法的实现过程中需要对数据进行预处理,因此在数据集合进行较频繁的改变时,其效率可能会下降。
因此,如果数据集合需要频繁改变,可以考虑其他的查找算法实现。
- 1 -。
数据库索引原理及优化——查询算法

数据库索引原理及优化——查询算法 我们知道,数据库查询是数据库的最主要功能之⼀。
我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的⾓度进⾏优化。
那么有哪些查询算法可以使查询速度变得更快呢?顺序查找(linear search )最基本的查询算法当然是顺序查找(linear search),也就是对⽐每个元素的⽅法,不过这种算法在数据量很⼤时效率是极低的。
数据结构:有序或⽆序队列复杂度:O(n)实例代码://顺序查找int SequenceSearch(int a[], int value, int n){int i;for(i=0; i<n; i++)if(a[i]==value)return i;return -1;}⼆分查找(binary search)⽐顺序查找更快的查询⽅法应该就是⼆分查找了,⼆分查找的原理是查找过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜素过程结束;如果某⼀特定元素⼤于或者⼩于中间元素,则在数组⼤于或⼩于中间元素的那⼀半中查找,⽽且跟开始⼀样从中间元素开始⽐较。
如果在某⼀步骤数组为空,则代表找不到。
数据结构:有序数组复杂度:O(logn)实例代码://⼆分查找,递归版本int BinarySearch2(int a[], int value, int low, int high){int mid = low+(high-low)/2;if(a[mid]==value)return mid;if(a[mid]>value)return BinarySearch2(a, value, low, mid-1);if(a[mid]<value)return BinarySearch2(a, value, mid+1, high);}⼆叉排序树查找⼆叉排序树的特点是:1. 若它的左⼦树不空,则左⼦树上所有结点的值均⼩于它的根结点的值;2. 若它的右⼦树不空,则右⼦树上所有结点的值均⼤于它的根结点的值;3. 它的左、右⼦树也分别为⼆叉排序树。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
分块查找算法
分块查找(Blocking Search)又称索引顺序查找。
它是一种性能介于顺序查找和二分查找之间的查找方法。
1、分块查找表存储结构
分块查找表由"分块有序"的线性表和索引表组成。
(1)"分块有序"的线性表
表R[1..n]均分为b块,前b-1块中结点个数为,第b块的结点数小于等于s;每一块中的关键字不一定有序,但前一块中的最大关键字必须小于后一块中的最小关键字,即表是"分块有序"的。
(2)索引表
抽取各块中的最大关键字及其起始位置构成一个索引表ID[l....b],即:
ID[i](1≤i≤b)中存放第i块的最大关键字及该块在表R中的起始位置。
由于表R是分块有序的,所以索引表是一个递增有序表。
【例】下图就是满足上述要求的存储结构,其中R只有18个结点,被分成3块,每块中有6个结点,第一块中最大关键字22小于第二块中最小关键字24,第二块中最大关键字48小于第三块中最小关键字49。
2、分块查找的基本思想
分块查找的基本思想是:
(1)首先查找索引表
索引表是有序表,可采用二分查找或顺序查找,以确定待查的结点在哪一块。
(2)然后在已确定的块中进行顺序查找
由于块内无序,只能用顺序查找。
3、分块查找示例
【例】对于上例的存储结构:
(1)查找关键字等于给定值K=24的结点
因为索引表小,不妨用顺序查找方法查找索引表。
即首先将K依次和索引表中各关键字比较,直到找到第1个关键宇大小等于K的结点,由于K<48,所以关键字为24的结点若存在的话,则必定在第二块中;然后,由ID[2].addr找到第二块的起始地址7,从该地址开始在R[7..12]中进行顺序查找,直到R[11].key=K为止。
(2)查找关键字等于给定值K=30的结点
先确定第二块,然后在该块中查找。
因该块中查找不成功,故说明表中不存在关键字为30的结点。