SQL2005引入的四个排名函数
总结SQL Server窗口函数、排名函数的简单使用

总结SQL Server窗口函数、排名函数的简单使用前言:我一直十分喜欢使用SQL Server2005/2008的窗口函数,排名函数ROW_NUMBER()尤甚。
今天晚上我在查看SQL Server开发的相关文档,整理收藏夹发现了两篇收藏已久的好文,后知后觉,读后又有点收获,顺便再总结一下。
一、从一个熟悉的示例说起我们熟知的数据库分页查询,以这一篇介绍过的为例吧。
分页查询Person表中的人,可以这么写SQL语句:?1 2 3 4 5 6 7 8 9101112131415161718192021 WITH Record AS(SELECTRow_Number() OVER (ORDER BY Id DESC) AS RecordNumber, Id,FirstName,LastName,Height,WeightFROMPerson (NOLOCK))SELECTRecordNumber,(SELECT COUNT(0) FROM Record) AS TotalCount,Id,FirstName,LastName,Height,WeightFROM RecordWHERE RecordNumber BETWEEN1 AND10其中,ROW_NUMBER()是排名函数,而紧随其后的OVER()函数就是窗口函数。
你还在用二次top方式的分页查询吗?可以考虑尝试使用排名函数配合CTE实现分页。
二、窗口函数本文介绍窗口函数,以下面的学生成绩表为例:?1 2 3 4 CREATE TABLE[StudentScore]([Id] [int] IDENTITY(1,1) NOT NULL,[StudentId] [int] NOT NULL CONSTRAINT[DF_StudentScore_StudentId] DEFAULT((0)), [ClassId] [int] NOT NULL CONSTRAINT[DF_StudentScore_ClassId] DEFAULT((0)),5 6 7 8 [CourseId] [int] NOT NULL CONSTRAINT[DF_StudentScore_CourseId] DEFAULT((0)), [Score] [float] NOT NULL CONSTRAINT[DF_StudentScore_Score] DEFAULT((0)),[CreateDate] [datetime] NOT NULL CONSTRAINT[DF_StudentScore_CreateDate] DEFAULT (getdate())) ON[PRIMARY]其中,Id是自增Id,CreateDate是录入时间,StudentId 学生,ClassId 班级,CourseId 课程,Score 分数。
mssqlsqlserver分组排序函数row_number、rank、dense_ran。。。

mssqlsqlserver分组排序函数row_number、rank、dense_ran。
在实际的项⽬开发中,我们经常使⽤分组函数,对组内数据进⾏群组后,然后进⾏组内排序:如:1:取出⼀个客户⼀段时间内,最⼤订单数的⾏记录2: 取出⼀个客户⼀段时间内,最后⼀次销售记录的⾏记录————————————————下⽂将讲述三个分组函数 row_number rank dense_rank的⽤法 ,以上三个函数的功能为:返回⾏数据在”分组数据内”的排列值1:row_number() over() 函数简介row_number() over(partition by [分组列] order by [排序列])分组列:这⾥放⼊我们需要群组的列,可以为⼀列也可以为多列,之间采⽤逗号分隔排序列:分组后,排序依据列通过row_number() over()排序后,依次⽣成分组后,⾏数据在分组内的排序值(1,2,3 …)2:rank() over(partition by [分组列] order by [排序列]) 函数简介分组列和排序列同上rank的群组内的排名⽅法为如果出现两个相同的排序列时,那么下⼀个排序值为会⾃动加⼀(1,1,3…)3:dense_rank() over(partition by [分组列] order by [排序列]) 函数简介分组列和排序列同上dense_rank的群组内的排名⽅法为如果出现两个相同的排序列时,那么下⼀个排序值不会出现跳跃例(1,1,2,3 ..)——————————————————例:create table A ([姓名] nvarchar(20),[订单数] int,[订单⽇期] datetime )goinsert into A ([姓名],[订单数],[订单⽇期]) values ('',1900,'2014-5-6')insert into A ([姓名],[订单数],[订单⽇期]) values ('',1800,'2018-5-6')insert into A ([姓名],[订单数],[订单⽇期]) values ('',1800,'2018-5-6')insert into A ([姓名],[订单数],[订单⽇期]) values ('⼩张',100,'2013-5-6')insert into A ([姓名],[订单数],[订单⽇期]) values ('⼩明',2600,'2013-1-6')insert into A ([姓名],[订单数],[订单⽇期]) values ('⼩明',1800,'2013-5-6')insert into A ([姓名],[订单数],[订单⽇期]) values ('⼩李',888,'2017-3-6')go/*row_number 返回分组后的连续排序,不会出现重复的排序值*/select row_number() over(partition by [姓名] order by [订单⽇期] desc ) as keyId,* from A/*rank 返回分组后的连续排序,会出现跳跃排序值*/select rank() over(partition by [姓名] order by [订单⽇期] desc ) as keyId,* from A/*dense_rank 返回分组后的连续排序,不会出现跳跃排序值,但是会出现重复的排序值*/select dense_rank() over(partition by [姓名] order by [订单⽇期] desc ) as keyId,* from Agotruncate table Adrop table A。
SQL常见函数以及使用

SQL常见函数以及使用1.COUNT函数:COUNT函数用于统计符合一些条件的行数,常用于查询一些表中一些列的行数。
示例:SELECT COUNT(*) FROM table_name;SELECT COUNT(column_name) FROM table_name WHERE condition;2.AVG函数:AVG函数用于计算一些数值字段的平均值,常用于统计一些表中一些列的平均值。
示例:SELECT AVG(column_name) FROM table_name;3.SUM函数:SUM函数用于计算一些数值字段的总和,常用于统计一些表中一些列的总和。
示例:SELECT SUM(column_name) FROM table_name;4.MAX函数:MAX函数用于返回一些字段的最大值,常用于查找一些表中一些列的最大值。
示例:SELECT MAX(column_name) FROM table_name;5.MIN函数:MIN函数用于返回一些字段的最小值,常用于查找一些表中一些列的最小值。
示例:SELECT MIN(column_name) FROM table_name;6.UPPER函数:UPPER函数用于将一些字段的值转换为大写。
示例:SELECT UPPER(column_name) FROM table_name;7.LOWER函数:LOWER函数用于将一些字段的值转换为小写。
示例:SELECT LOWER(column_name) FROM table_name;8.CONCAT函数:CONCAT函数用于连接多个字符串,将它们串联在一起。
示例:SELECT CONCAT(column1, column2) FROM table_name;9.SUBSTRING函数:SUBSTRING函数用于提取一些字段的子字符串。
示例:SELECT SUBSTRING(column_name, start_position, length) FROM table_name;10.DATE函数:DATE函数用于提取日期类型字段的日期部分。
Sql四大排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介

Sql四⼤排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介排名函数是Sql Server2005新增的功能,下⾯简单介绍⼀下他们各⾃的⽤法和区别。
我们新建⼀张Order表并添加⼀些初始数据⽅便我们查看效果。
CREATE TABLE [dbo].[Order]([ID] [int] IDENTITY(1,1) NOT NULL,[UserId] [int] NOT NULL,[TotalPrice] [int] NOT NULL,[SubTime] [datetime] NOT NULL,CONSTRAINT [PK_Order] PRIMARY KEY CLUSTERED([ID] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY]GOSET IDENTITY_INSERT [dbo].[Order] ONGOINSERT [dbo].[Order] ([ID], [UserId], [TotalPrice], [SubTime]) VALUES (1, 1, 100, CAST(0x0000A419011D32AF AS DateTime))GOINSERT [dbo].[Order] ([ID], [UserId], [TotalPrice], [SubTime]) VALUES (2, 2, 500, CAST(0x0000A419011D40BA AS DateTime))GOINSERT [dbo].[Order] ([ID], [UserId], [TotalPrice], [SubTime]) VALUES (3, 3, 300, CAST(0x0000A419011D4641 AS DateTime))GOINSERT [dbo].[Order] ([ID], [UserId], [TotalPrice], [SubTime]) VALUES (4, 2, 1000, CAST(0x0000A419011D4B72 AS DateTime))GOINSERT [dbo].[Order] ([ID], [UserId], [TotalPrice], [SubTime]) VALUES (5, 1, 520, CAST(0x0000A419011D50F3 AS DateTime))GOINSERT [dbo].[Order] ([ID], [UserId], [TotalPrice], [SubTime]) VALUES (6, 2, 2000, CAST(0x0000A419011E50C9 AS DateTime))GOSET IDENTITY_INSERT [dbo].[Order] OFFGOALTER TABLE [dbo].[Order] ADD CONSTRAINT [DF_Order_SubTime] DEFAULT (getdate()) FOR [SubTime]GO 附上表结构和初始数据图:⼀、ROW_NUMBER row_number的⽤途的⾮常⼴泛,排序最好⽤他,⼀般可以⽤来实现web程序的分页,他会为查询出来的每⼀⾏记录⽣成⼀个序号,依次排序且不会重复,注意使⽤row_number函数时必须要⽤over⼦句选择对某⼀列进⾏排序才能⽣成序号。
sql四大排名函数---(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介
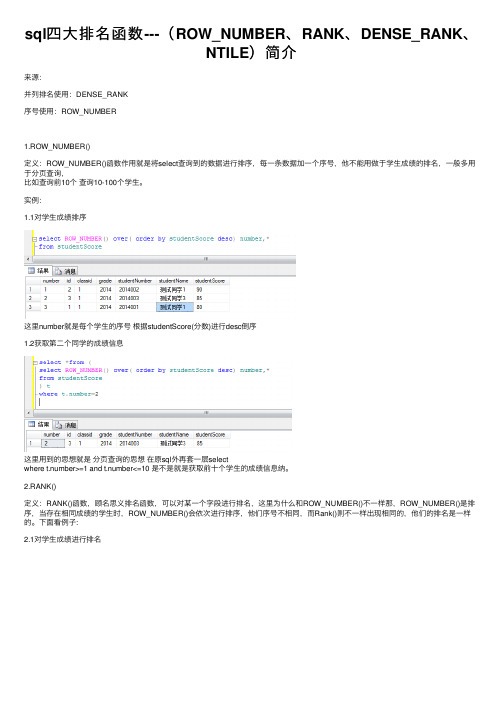
sql四⼤排名函数---(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介来源:并列排名使⽤:DENSE_RANK序号使⽤:ROW_NUMBER1.ROW_NUMBER()定义:ROW_NUMBER()函数作⽤就是将select查询到的数据进⾏排序,每⼀条数据加⼀个序号,他不能⽤做于学⽣成绩的排名,⼀般多⽤于分页查询,⽐如查询前10个查询10-100个学⽣。
实例:1.1对学⽣成绩排序这⾥number就是每个学⽣的序号根据studentScore(分数)进⾏desc倒序1.2获取第⼆个同学的成绩信息这⾥⽤到的思想就是分页查询的思想在原sql外再套⼀层selectwhere t.number>=1 and t.number<=10 是不是就是获取前⼗个学⽣的成绩信息纳。
2.RANK()定义:RANK()函数,顾名思义排名函数,可以对某⼀个字段进⾏排名,这⾥为什么和ROW_NUMBER()不⼀样那,ROW_NUMBER()是排序,当存在相同成绩的学⽣时,ROW_NUMBER()会依次进⾏排序,他们序号不相同,⽽Rank()则不⼀样出现相同的,他们的排名是⼀样的。
下⾯看例⼦:2.1对学⽣成绩进⾏排名这⾥发现 ROW_NUMBER()和RANK()怎么⼀样?因为学⽣成绩都不⼀样所以排名和排序⼀样,下⾯改⼀下就会发现区别。
当出现两个学⽣成绩相同是⾥⾯出现变化。
RANK()是 1 2 2,⽽ROW_NUMBER()则还是1 2 3,这就是RANK()和ROW_NUMBER()的区别了3.DENSE_RANK()定义:DENSE_RANK()函数也是排名函数,和RANK()功能相似,也是对字段进⾏排名,那它和RANK()到底有什么不同那?看例⼦:实例:DENSE_RANK()密集的排名他和RANK()区别在于,排名的连续性,DENSE_RANK()排名是连续的,RANK()是跳跃的排名,所以⼀般情况下⽤的排名函数就是RANK()。
SQL Server系统函数大全

sql server 系统函数大全一、字符转换函数1、ASCII()返回字符表达式最左端字符的ASCII 码值。
在ASCII()函数中,纯数字的字符串可不用‘’括起来,但含其它字符的字符串必须用‘’括起来使用,否则会出错。
2、CHAR()将ASCII 码转换为字符。
如果没有输入0 ~ 255之间的ASCII 码值,CHAR()返回NULL 。
3、LOWER()和UPPER()LOWER()将字符串全部转为小写;UPPER()将字符串全部转为大写。
4、STR()把数值型数据转换为字符型数据。
STR (<float_expression>[,length[,<decimal>]])length 指定返回的字符串的长度,decimal 指定返回的小数位数。
如果没有指定长度,缺省的length 值为10,decimal 缺省值为0。
当length 或者decimal 为负值时,返回NULL;当length 小于小数点左边(包括符号位)的位数时,返回length 个*;先服从length ,再取decimal ;当返回的字符串位数小于length ,左边补足空格。
二、去空格函数1、LTRIM() 把字符串头部的空格去掉。
2、RTRIM() 把字符串尾部的空格去掉。
三、取子串函数1、left()LEFT (<character_expression>,<integer_expression>)返回character_expression 左起integer_expression 个字符。
2、RIGHT()RIGHT (<character_expression>,<integer_expression>)返回character_expression 右起integer_expression 个字符。
3、SUBSTRING()SUBSTRING (<expression>,<starting_ position>,length)返回从字符串左边第starting_ position 个字符起length个字符的部分。
sql常用的五个函数

sql常用的五个函数SQL是一种用于管理关系型数据库的语言,它可以用来查询、插入、更新和删除数据。
在SQL中,函数是一种特殊的语句,它可以用来处理数据并返回结果。
在本文中,我们将介绍SQL常用的五个函数。
一、COUNT函数COUNT函数用于统计某个表中符合条件的记录数。
其基本语法如下:SELECT COUNT(column_name) FROM table_name WHERE condition;其中,column_name表示要统计的列名,table_name表示要统计的表名,condition表示统计条件。
例如,在一个学生信息表中,我们想要统计出性别为男性的学生人数,则可以使用如下语句:SELECT COUNT(*) FROM student WHERE gender='male';这条语句会返回一个数字,即男性学生人数。
二、SUM函数SUM函数用于对某个列进行求和操作。
其基本语法如下:SELECT SUM(column_name) FROM table_name WHERE condition;其中,column_name表示要求和的列名,table_name表示要求和的表名,condition表示求和条件。
例如,在一个销售记录表中,我们想要统计出所有销售额的总和,则可以使用如下语句:SELECT SUM(sales_amount) FROM sales_record;这条语句会返回一个数字,即所有销售额的总和。
三、AVG函数AVG函数用于对某个列进行求平均值操作。
其基本语法如下:SELECT AVG(column_name) FROM table_name WHERE condition;其中,column_name表示要求平均值的列名,table_name表示要求平均值的表名,condition表示求平均值条件。
例如,在一个学生成绩表中,我们想要统计出所有学生的平均成绩,则可以使用如下语句:SELECT AVG(score) FROM student_score;这条语句会返回一个数字,即所有学生的平均成绩。
2005提示row_number不是可以识别的函数名mssqlserv

2005 提示'row_number' 不是可以识别的函数名- MS-SQL Serv...ROW_NUMBER、RANK、DENSE_RANK的用法(爱新觉罗.毓华(十八年风雨,守得冰山雪莲花开) 2007-12-16 广东深圳)SQL Server 2005 引入几个新的排序(排名)函数,如ROW_NUMBER、RANK、DENSE_RANK 等。
这些新函数使您可以有效地分析数据以及向查询的结果行提供排序值。
--------------------------------------------------------------------------ROW_NUMBER()说明:返回结果集分区内行的序列号,每个分区的第一行从1 开始。
语法:ROW_NUMBER () OVER ( [ ] order_by_clause> ) 。
备注:ORDER BY 子句可确定在特定分区中为行分配唯一ROW_NUMBER 的顺序。
参数:partition_by_clause> :将FROM 子句生成的结果集划入应用了ROW_NUMBER 函数的分区。
order_by_clause>:确定将ROW_NUMBER 值分配给分区中的行的顺序。
返回类型:bigint 。
示例:/*以下示例将根据年初至今的销售额,返回AdventureWorks 中销售人员的ROW_NUMBER。
*/USE AdventureWorksGOSELECT c.FirstName,stName, ROW_NUMBER() OVER(ORDER BY SalesYTD DESC) AS 'Row Number', s.SalesYTD, a.PostalCodeFROM Sales.SalesPerson s JOIN Person.Contact c on s.SalesPersonID = c.ContactIDJOIN Person.Address a ONa.AddressID = c.ContactIDWHERE TerritoryID IS NOT NULL AND SalesYTD 0/*FirstName LastName Row Number SalesYTD PostalCode--------- ---------- ---------- ------------ ----------------------------Shelley Dyck 1 5200475.2313 98027Gail Erickson 2 5015682.3752 98055Maciej Dusza 3 4557045.0459 98027Linda Ecoffey 4 3857163.6332 98027Mark Erickson 5 3827950.238 98055Terry Eminhizer 6 3587378.4257 98055Michael Emanuel 7 3189356.2465 98055Jauna Elson 8 3018725.4858 98055Carol Elliott 9 2811012.7151 98027Janeth Esteves 10 2241204.0424 98055Martha Espinoza 11 1931620.1835 98055Carla Eldridge 12 1764938.9859 98027Twanna Evans 13 1758385.926 98055(13 行受影响)*//*以下示例将返回行号为50 到60(含)的行,并以OrderDate 排序。
MS SQL 2005 四个排序函数ROW_NUMBER、RANK、DENSE_RANK 和 NTILE简介用法结果排名排序

MS SQL 2005 四个排序函数ROW_NUMBER、RANK、DENSE_RANK 和 NTILE 简介用法/结果排名排序2010-11-01 10:30在SQL 2005中存在四种排名函数: ROW_NUMBER、RANK、DENSE_RANK 和 NTILE。
这些新函数可以有效地分析数据以及向查询的结果行提供排序值。
您可能发现这些新函数有用的典型方案包括:将连续整数分配给结果行,以便进行表示、分页、计分和绘制直方图。
下面通过具体的方案将用来讨论和演示不同的函数和它们的子句。
十一位演讲者在会议中发表演讲,并且为他们的讲话获得范围为 1 到 9 的分数。
结果被总结并存储在下面的 SpeakerStats 表中:CodeCREATE TABLE SpeakerStats(speaker VARCHAR(10) NOT NULL PRIMARY KEY, track VARCHAR(10) NOT NULL, score INT NOT NULL, pctfilledevals INT NOT NULL, numsessions INT NOT NULL)SET NOCOUNT ONINSERT INTO SpeakerStats VALUES(‗Dan‘, ‗Sys‘, 3, 22, 4)INSERT INTO SpeakerStats VALUES(‗Ron‘, ‗Dev‘, 9, 30, 3)INSERT INTO SpeakerStats VALUES(‗Kathy‘, ‗Sys‘, 8, 27, 2)INSERT INTO SpeakerStats VALUES(‗Suzanne‘, ‗DB‘, 9, 30, 3)INSERT INTO Spe akerStats VALUES(‗Joe‘, ‗Dev‘, 6, 20, 2)INSERT INTO SpeakerStats VALUES(‗Robert‘, ‗Dev‘, 6, 28, 2)INSERT INTO SpeakerStats VALUES(‗Mike‘, ‗DB‘, 8, 20, 3)INSERT INTO SpeakerStats VALUES(‗Michele‘, ‗Sys‘, 8, 31, 4)INSERT INTO SpeakerStats VALUES(‗Jessica‘, ‗Dev‘, 9, 19, 1)INSERT INTO SpeakerStats VALUES(‗Brian‘, ‗Sys‘, 7, 22, 3)INSERT INTO SpeakerStats VALUES(‗Kevin‘, ‗DB‘, 7, 25, 4)每个演讲者都在该表中具有一个行,其中含有该演讲者的名字、议题、平均得分、填写评价的与会者相对于参加会议的与会者数量的百分比以及该演讲者发表演讲的次数。
sqlserver序号函数

sqlserver序号函数SQL Server序号函数序号函数是SQL Server中对数据行进行排序(按某个给定值排序)的一种方法,它的最终结果是按照某个字段的增序排列,并且可以按照序号的大小从小到大进行排序。
SQL Server中的序号函数和Oracle中的ROW_NUMBER函数类似。
下面就SQL Server序号函数的使用方法做一个简单介绍。
SQL Server序号函数共有三种,分别是ROW_NUMBER、RANK、DENSE_RANK,这三个函数都用于排序,并且可以按某个字段的值进行排序。
ROW_NUMBER函数:ROW_NUMBER函数用于对查询结果进行排序,每行表示一个序号,序号从1开始,每行表示一个序号,序号从1开始,每行数据的序号自动递增。
使用语法:ROW_NUMBER() OVER ( order by 字段1[ASC,DESC],字段2[ASC,DESC]……)RANK函数:RANK函数的结果是从1开始的递增数字,并且当有多行结果相同时,每行的排名都相同,例如第一行排名为1,第二行和第三行排名也为1,第四行排名为2,以此类推。
使用语法:RANK() OVER ( order by 字段1[ASC,DESC],字段2[ASC,DESC]……)DENSE_RANK函数:DENSE_RANK函数的结果于RANK函数相似,但是多行值相同时,它会给出连续的排名。
例如第一行排名为1,第二行和第三行排名也都为1,第四行排名为2,以此类推。
使用语法:DENSE_RANK() OVER (order by 字段1[ASC,DESC],字段2[ASC,DESC]……)实例:假设有表employee,其中有字段name、age、sal(薪水),查询表中每行的age(年龄)字段的序号,要求从小到大排序,则可以使用ROW_NUMBER函数进行排序,具体语句如下:SELECT ROW_NUMBER() OVER (ORDER BY age) AS AgeSequence,name,ageFROM employee以上就是有关SQL Server序号函数的介绍,希望对大家有所帮助。
SQL中row_number()和over()

2 3 2
2 4 4
INSERT INTO Person VALUES ('John',40,'M')
INSERT INTO Person VALUES ('George',6,'M')
INSERT INTO Person VALUES ('Mary',11,'F')
INSERT INTO Person VALUES ('Sam',17,'M')
8 Marty 23
9 Sue 29
FirstName,
Age
FROM Person
出现的数据如下
Row Number by Age FirstName Age
-------------------------- ---------- --------
6 Sam 17
7 Ted 23
FirstName,
Age,
Gender
FROM Person这里是按性别划分区间了,同一性别再按年龄来排序,输出结果如下
Partition by Gender FirstName Age Gender
-------------------- ---------- ----------- ------
-------------------- ---------- ----------- ------
1 Doris 6 F
2 Mary 11 F
3 George 6
4 Mary 11
5 Sherry 11
1、select row_number()over(order by xxxx) from xxxx;
SQL函数使用大全

SQL函数使用大全SQL是一种用于管理和操作关系型数据库的语言,它提供了许多内置函数来进行数据查询、计算和转换等操作。
下面是一些常用的SQL函数及其用法。
1.COUNT函数:用于统计一些列的行数,可用于查询一些表或一些列的记录数量。
例如:SELECT COUNT(*) FROM table_name;2.SUM函数:用于计算一些列的总和,可用于计算数值型列的总和。
例如:SELECT SUM(column_name) FROM table_name;3.AVG函数:用于计算一些列的平均值,可用于计算数值型列的平均值。
例如:SELECT AVG(column_name) FROM table_name;4.MAX函数:用于找出一些列的最大值,可用于查找数值型列的最大值。
例如:SELECT MAX(column_name) FROM table_name;5.MIN函数:用于找出一些列的最小值,可用于查找数值型列的最小值。
例如:SELECT MIN(column_name) FROM table_name;6.CONCAT函数:用于将多个字符串合并成一个字符串。
例如:SELECT CONCAT(column1, ' ', column2) FROM table_name;7.SUBSTRING函数:用于截取字符串的一部分。
例如:SELECT SUBSTRING(column_name, start_position, length) FROM table_name;8.UPPER函数:用于将字符串转换为大写。
例如:SELECT UPPER(column_name) FROM table_name;9.LOWER函数:用于将字符串转换为小写。
例如:SELECT LOWER(column_name) FROM table_name;10.TRIM函数:用于去除字符串两端的空格或指定字符。
例如:SELECT TRIM(column_name) FROM table_name;11.LTRIM函数:用于去除字符串左边的空格或指定字符。
sql 计算成绩排名 语句

SQL 计算成绩排名语句
在SQL中,我们可以使用SELECT语句来选择要排名的数据表和列名,然后使用ORDER BY子句按照成绩从高到低或从低到高进行排序,并使用LIMIT子句限制返回的行数,以获得排名前几名的数据。
下面是一个示例SQL语句:
```sql
SELECT student_name, score
FROM student_scores
ORDER BY score DESC
LIMIT 10;
```
这个语句选择了名为"student_scores"的数据表中的"student_name"和"score"两列。
然后使用ORDER BY子句按照成绩从高到低(DESC)进行排序。
最后,使用LIMIT子句限制返回的行数为10,以获得排名前10名的数据。
如果你想按照成绩从低到高进行排序,可以将ORDER BY子句改为"ASC",如下所示:
```sql
SELECT student_name, score
FROM student_scores
ORDER BY score ASC
LIMIT 10;
```
这个语句将返回排名前10名的数据,按照成绩从低到高进行排序。
你可以根据需要修改LIMIT子句中的数字来获取不同的排名数据。
sql 四分位的函数

sql 四分位的函数
SQL中并没有专门用于计算四分位数的内置函数,但是可以通过SQL语句来计算。
通常可以使用NTILE函数来实现四分位数的计算。
NTILE函数将结果集中的行分成指定数量的桶,并为每个桶分配一个数字,从1到指定的桶的数量。
通过将数据集分成四个桶,然后分别计算每个桶的最小值、最大值或中位数,就可以得到四分位数的值。
举个例子,假设我们有一个名为sales的表,包含了销售额的数据,我们可以使用NTILE函数来计算四分位数。
假设我们想要计算销售额的第一四分位数(25th百分位数),可以使用以下SQL语句:
sql.
SELECT NTILE(4) OVER (ORDER BY sales_amount) AS quartile.
FROM sales;
这将返回一个结果集,其中quartile列包含了每行数据所属的
四分位数桶的编号。
然后我们可以根据这个结果集进一步计算每个
四分位数的具体值。
除了NTILE函数,有些数据库系统还提供了一些特定的函数来
计算四分位数,比如Oracle数据库中的PERCENTILE_CONT和PERCENTILE_DISC函数,可以用来计算指定百分位数的值。
在使用
这些函数时,需要根据具体的数据库系统来查阅相应的文档和语法
规则。
综上所述,虽然SQL中没有专门用于计算四分位数的函数,但
是可以通过一些内置函数和窗口函数来实现四分位数的计算。
通过
合理地利用这些函数,我们可以在SQL中计算出所需的四分位数值。
sql排序函数

sql排序函数SQL排序函数是指按照指定的规则对查询结果中的记录进行排序的函数,可以说是SQL语言中的基础操作,是要掌握的必备技能之一。
在实际的应用中,SQL排序函数的功能可以大大的提高程序的可读性,从而简化程序的编写和实现目标任务。
SQL查询语句中的排序函数包括ORDER BY子句,它是查询语句中必不可少的。
ORDER BY子句可以指定要对查询出来的记录进行排序,并指定排序依据,可以按照日期、数值、字符串等一系列规则来进行排序,从而让结果更加有序。
ORDER BY子句有两种模式,一种是升序模式,即无论是数值还是字符串排列,都是从小到大进行排列,通常使用ASC模式;另一种是降序模式,即从大到小进行排列,通常使用DESC模式,在使用ORDER BY子句指定排序依据时,可以使用这两种模式中的任意一种。
ORDER BY子句可以指定多个排序依据,如果排序依据有多个,则可以按照列表中的次序依次进行排序,例如多条记录按照日期进行排序,然后按照数值进行排序,这种排序方式可以使用列表的方式实现,如:SELECT * FROM mytable ORDER BY date ASC, value DESC;以上语句表示按照日期升序排列,数值降序排序,当两个排序依据的排序规则是一致的时候,也可以简写成:SELECT * FROM mytable ORDER BY date, value;以上语法表示按照日期和数值的默认排序,一般情况下日期是升序排列,数值也是升序排列。
此外,SQL中还提供了统计函数,可以实现对结果记录的统计,但此类函数不具备排序功能,但如果将它们与ORDER BY子句结合起来使用,就可以达到排序的目的。
通常,我们将要查询的字段放在SELECT语句中,然后在ORDER BY 子句中指定排序的依据。
例如,要查询某个表中的日期和金额,并将记录按照日期升序排列,则可以使用如下语句:SELECT date, amount FROM mytable ORDER BY date ASC;此外,如果要查询某个表中所有的记录,并将记录按照某个字段的值从大到小进行排序,这种情况可以使用如下语句:SELECT * FROM mytable ORDER BY amount DESC;以上就是SQL排序函数的基本用法,它可以帮助我们把结果记录进行有序排序,从而使程序更加易读。
SQL 生成序号的四种方式

sql四个排名函数生成记录序号排名函数是SQL Server2005新加的功能。
在SQL Server2005中有如下四个排名函数:1. row_number顺序生成序号2. rank 相同的序值序号相同,但序号会跳号3. dense_rank相同的序值序号相同,序号顺充递增4. ntile 装桶,把记录分成指的桶数,编序号下面分别介绍一下这四个排名函数的功能及用法。
在介绍之前假设有一个t_table表,表结构与表中的数据如图1所示:图1其中field1字段的类型是int,field2字段的类型是varchar一、row_numberrow_number函数的用途是非常广泛,这个函数的功能是为查询出来的每一行记录生成一个序号。
row_number函数的用法如下面的SQL语句所示:select row_number() over(order by field1) as row_number,* from t_tabl e上面的SQL语句的查询结果如图2所示。
图2其中row_number列是由row_number函数生成的序号列。
在使用row_number 函数是要使用over子句选择对某一列进行排序,然后才能生成序号。
实际上,row_number函数生成序号的基本原理是先使用over子句中的排序语句对记录进行排序,然后按着这个顺序生成序号。
over子句中的order by子句与SQL语句中的order by子句没有任何关系,这两处的order by 可以完全不同,如下面的SQL语句所示:select row_number() over(order by field2 desc) as row_number,* from t _table order by field1 desc上面的SQL语句的查询结果如图3所示。
图3我们可以使用row_number函数来实现查询表中指定范围的记录,一般将其应用到Web应用程序的分页功能上。
SQL中的查询排序

SQL中的查询排序⼀、SQL基础查询1、select语句格式:select字段from表名;2、where ⽤于限制查询的结果3、查询条件> < >= <= = !=4、与或(AND,OR)5、在不在(IN,NOT IN)6、在[a,b] (between val1 and val2)7、空⾮空(NULL,NOT NULL)8、全部任⼀(ALL,ANY)不能单独使⽤,必须与关系运算符配合9、排重DISTINCT⽤在字段之前⼆、排序1、使⽤ ORDER BY 语句格式:select 字段 from 表名 where 条件 ORDER BY 字段;2、设置升序降序(ASC,DESC)格式:select 字段 from 表名 where 条件 ORDER BY 字段 ASC|DESC3、多项排序格式:select 字段 from 表名 where 条件 ORDER BY 字段 ASC|DESC,字段ASC|DESC三、聚合函数注意:在使⽤⽐较运算符时NULL为最⼤值,在排序时也会受影响把 select 语句的查询结果汇聚成⼀个结果,这样的函数叫聚合函数1、MAX\MIN获取最⼤值和最⼩值,可以是任何数据类型,但只能获取⼀个字段2、AVG\SUM获取平均值、总和nvl(salary,0)3、COUNT统计记录的数量四、分组1、GROUP BY格式:select 组函数 from 表 group by 字段2、HAVING 组判断条件它的真假决定⼀组数据是否返回五、查询语句的执⾏顺序1、格式:select sum(salary) from 表名 where bool order by group by a、from 表名,先确定数据的来源 b、where 确定表中的哪些数据有效 c、group by 字段名,确定分组的依据 d、having 确定组数据是否返回 e、order by 对组数据进⾏排序六、关联查询1、多表查询select 字段 from 表1,表2 where;2、多表查询时有相同字段怎么办 1、表名.字段名 2、表名如果太长,可以给表起别名(from 表别名)3、笛卡尔积 a、8条数据 b、9条数据在多表查询时,⼀定要设置where 条件,否则将得到笛卡尔积七、连接查询当使⽤多表进⾏关联查询时,根据设置的条件会得到不同的结果1、内连接查询:左右两边能匹配上的select last_name ,name from s_emp,s_dept where dept_id=s_dept.id2、外连接:左右两边不能匹配的数据select last_name ,name from s_emp left|right|full outer join s_dept on dept_id=s_dept.id 3、左外连接匹配成功的数据+左表不能匹配的数据4、右外连接匹配成功的数据+右表不能匹配的数据5、全外连接匹配成功的数据+左右表不能匹配的数据。
mysql中的排名函数rank()、dense_rank()、row_number()

mysql中的排名函数rank()、dense_rank()、row_number()1.rank()按照某字段的排序结果添加排名,但它是跳跃的、间断的排名,例如两个并列第⼀名后,下⼀个是第三名,1、1、3、4.SELECT Score,rank() over(ORDER BY Score desc) as 'Rank' FROM score;# 分组排序SELECT Score,rank() over(partition by xxx ORDER BY Score desc) as 'Rank' FROM score;2.row_number()它是将某字段按照顺序依次添加⾏号。
如1、2、3、4SELECT Score,row_number() over(ORDER BY Score desc) as 'Rank' FROM score;# 分组排序SELECT Score,row_number() over(partition by xxx ORDER BY Score desc) as 'Rank' FROM score;3.dense_rank()dense 英语中指“稠密的、密集的”。
dense_rank()是的排序数字是连续的、不间断。
当有相同的分数时,它们的排名结果是并列的,例如,1、2、2、3、4。
SELECT Score,dense_rank() over(ORDER BY Score desc) as 'Rank' FROM score;# 分组排序SELECT Score,dense_rank() over(partition by xxx ORDER BY Score desc) as 'Rank' FROM score;4.总结。
请解释SQL中RANK函数的用法并提供示例

SQL中的RANK()函数是一个窗口函数,用于为结果集中的每一行分配一个唯一的排名。
它通常与OVER()子句结合使用,以指定如何对行进行排名。
RANK()函数的语法:sql复制代码RANK() OVER ([PARTITION BY partition_expression, ... ]ORDER BY sort_expression [ASC | DESC], ...)•PARTITION BY:这是一个可选的子句,用于将结果集分成多个分区,并为每个分区的行分别分配排名。
•ORDER BY:这个子句指定了如何对行进行排序以生成排名。
RANK()函数的行为:•RANK()函数会为结果集中的每一行分配一个唯一的排名。
•如果两行或多行具有相同的排序值,则它们会获得相同的排名。
•下一个排名将跳过这些并列排名的数量。
例如,如果有两行并列排名第一,那么下一行的排名将是第三。
示例:假设我们有一个名为students的表,其中包含学生的姓名和分数。
我们想要根据分数为学生排名。
sql复制代码CREATE TABLE students (name VARCHAR(50),score INT);INSERT INTO students (name, score) VALUES('Alice', 90),('Bob', 85),('Charlie', 90),('David', 80),('Eve', 75);要为学生按分数排名,可以使用以下查询:sql复制代码SELECT name, score,RANK() OVER (ORDER BY score DESC) AS rankingFROM students;这将返回以下结果:diff复制代码name | score | ranking---------|-------|--------Alice | 90 | 1Charlie | 90 | 1Bob | 85 | 3David | 80 | 4Eve | 75 | 5注意,尽管Alice和Charlie的分数相同,但他们都获得了第一名,而Bob则是第三名。
sql top函数

sql top函数SQLTop函数是一种非常有用的函数,用于在数据库中检索前几行数据。
Top函数的使用非常灵活,可以根据需要检索前n行,也可以按照指定的条件来检索前几行数据。
在数据分析和数据处理工作中,Top函数被广泛应用。
Top函数最常见的用法是检索前n条记录。
在SQL语句中使用Top 函数,只需在Select语句中添加Top子句即可。
例如,要检索第1行至第5行的数据,可以使用以下语句:SELECT TOP 5 * FROM table_name;这条语句将返回表table_name中的前5行数据。
如果要检索前10行,则将5改为10即可。
除了检索前n条记录之外,Top函数还可以按照指定的条件来检索前几行数据。
例如,可以按照某个字段的值来检索前几行数据。
在这种情况下,需要使用Order By子句来指定排序的字段。
例如:SELECT TOP 5 * FROM table_name ORDER BY column_name DESC;这条语句将返回表table_name中按照字段column_name降序排列的前5行数据。
需要注意的是,在使用Top函数时,如果没有指定排序字段,则返回的数据可能是随机的。
因此,在使用Top函数时,一定要指定排序字段。
除了Top函数之外,SQL还提供了其他一些类似的函数,如Bottom 函数和Rank函数。
Bottom函数与Top函数相似,用于检索最后几行数据。
Rank函数是用于计算排名的函数,可以根据指定的条件来计算每行数据的排名。
总之,SQL Top函数是一种非常实用的函数,可以用于检索前几行数据。
在数据分析和数据处理工作中,Top函数被广泛应用。
需要注意的是,在使用Top函数时,一定要指定排序字段,以避免返回随机数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
排名函数是SQL Server2005新加的功能。
在SQL Server2005中有如下四个排名函数:
1. row_number
2. rank
3. dense_rank
4. ntile
下面分别介绍一下这四个排名函数的功能及用法。
在介绍之前假设有一个t_table表,表结构与表中的数据如图1所示:
图1
其中field1字段的类型是int,field2字段的类型是varchar
一、row_number
row_number函数的用途是非常广泛,这个函数的功能是为查询出来的每一行记录生成一个序号。
row_number函数的用法如下面的SQL语句所示:
select row_number() over(order by field1) as row_number,*from t_table
上面的SQL语句的查询结果如图2所示。
图2
其中row_number列是由row_number函数生成的序号列。
在使用row_number 函数是要使用over子句选择对某一列进行排序,然后才能生成序号。
实际上,row_number函数生成序号的基本原理是先使用over子句中的排序语句对记录进行排序,然后按着这个顺序生成序号。
over子句中的order by子句与SQL语句中的order by子句没有任何关系,这两处的order by 可以完全不同,如下面的SQL语句所示:
select row_number() over(order by field2 desc) as row_number,*from t_table order b y field1 desc
上面的SQL语句的查询结果如图3所示。
图3
我们可以使用row_number函数来实现查询表中指定范围的记录,一般将其应用到Web应用程序的分页功能上。
下面的SQL语句可以查询t_table表中第2条和第3条记录:
with t_rowtable
as
(
select row_number() over(order by field1) as row_number,*from t_table
)
select*from t_rowtable where row_number>1and row_number <4order by field1
上面的SQL语句的查询结果如图4所示。
图4
上面的SQL语句使用了CTE,关于CTE的介绍将读者参阅《SQL Server2005杂谈(1):使用公用表表达式(CTE)简化嵌套SQL》。
另外要注意的是,如果将row_number函数用于分页处理,o ver子句中的order by 与排序记录的order by 应相同,否则生成的序号可能不是有续的。
当然,不使用row_number函数也可以实现查询指定范围的记录,就是比较麻烦。
一般的方法是使用颠倒Top来实现,例如,查询t_table表中第2条和第3条记录,可以先查出前3条记录,然后将查询出来的这三条记录按倒序排序,再取前2条记录,最后再将查出来的这2条记录再按倒序排序,就是最终结果。
SQL语句如下:
select*from (select top2*from( select top3*from t_table order by field1) a order by field1 desc) b order by field1
上面的SQL语句查询出来的结果如图5所示。
图5
这个查询结果除了没有序号列row_number,其他的与图4所示的查询结果完全一样。
二、rank
rank函数考虑到了over子句中排序字段值相同的情况,为了更容易说明问题,在t_table表中再加一条记录,如图6所示。
图6
在图6所示的记录中后三条记录的field1字段值是相同的。
如果使用rank 函数来生成序号,这3条记录的序号是相同的,而第4条记录会根据当前的记录数生成序号,后面的记录依此类推,也就是说,在这个例子中,第4条记录的序号是4,而不是2。
rank函数的使用方法与row_number函数完全相同,SQL语句如下:
select rank() over(order by field1),*from t_table order by field1
上面的SQL语句的查询结果如图7所示。
图7
三、dense_rank
dense_rank函数的功能与rank函数类似,只是在生成序号时是连续的,而rank函数生成的序号有可能不连续。
如上面的例子中如果使用dense_rank函数,第4条记录的序号应该是2,而不是4。
如下面的SQL语句所示:
select dense_rank() over(order by field1),*from t_table order by field1
上面的SQL语句的查询结果如图8所示。
图8
读者可以比较图7和图8所示的查询结果有什么不同
四、ntile
ntile函数可以对序号进行分组处理。
这就相当于将查询出来的记录集放到指定长度的数组中,每一个数组元素存放一定数量的记录。
ntile函数为每条记录生成的序号就是这条记录所有的数组元素的索引(从1开始)。
也可以将每一个分配记录的数组元素称为“桶”。
ntile函数有一个参数,用来指定桶数。
下面的SQL语句使用ntile函数对t_table表进行了装桶处理:
select ntile(4) over(order by field1) as bucket,*from t_table
上面的SQL语句的查询结果如图9所示。
图9
由于t_table表的记录总数是6,而上面的SQL语句中的ntile函数指定了桶数为4。
也许有的读者会问这么一个问题,SQL Server2005怎么来决定某一桶应该放多少记录呢?可能t_table表中的记录数有些少,那么我们假设t_table表中有59条记录,而桶数是5,那么每一桶应放多少记录呢?
实际上通过两个约定就可以产生一个算法来决定哪一个桶应放多少记录,这两个约定如下:
1. 编号小的桶放的记录不能小于编号大的桶。
也就是说,第1捅中的记录数只能大于等于第2桶及以后的各桶中的记录。
2. 所有桶中的记录要么都相同,要么从某一个记录较少的桶开始后面所有捅的记录数都与该桶的记录数相同。
也就是说,如果有个桶,前三桶的记录数都是10,而第4捅的记录数是6,那么第5桶和第6桶的记录数也必须是6。
根据上面的两个约定,可以得出如下的算法:
// mod表示取余,div表示取整
if(记录总数 mod 桶数 == 0)
{
recordCount = 记录总数 div 桶数;
将每桶的记录数都设为recordCount
}
else
{
recordCount1 = 记录总数 div 桶数 + 1;
int n = 1; // n表示桶中记录数为recordCount1的最大桶数
m = recordCount1 * n;
while(((记录总数 - m) mod (桶数 - n)) != 0 )
{
n++;
m = recordCount1 * n;
}
recordCount2 = (记录总数 - m) div (桶数 - n);
将前n个桶的记录数设为recordCount1
将n + 1个至后面所有桶的记录数设为recordCount2
}
根据上面的算法,如果记录总数为59,桶数为5,则前4个桶的记录数都是12,最后一个桶的记录数是11。
如果记录总数为53,桶数为5,则前3个桶的记录数为11,后2个桶的记录数为10。
就拿本例来说,记录总数为6,桶数为4,则会算出recordCount1的值为2,在结束while循环后,会算出recordCount2的值是1,因此,前2个桶的记录是2,后2个桶的记录是1。