OrientX A Schema-based Native XML Database System ABSTRACT
图数据库专业知识介绍

图数据库专业知识介绍图数据库是以点、边为基础存储单元,以高效存储、查询图数据为设计原理的数据管理系统。
图概念对于图数据库的理解至关重要。
图是一组点和边的集合,“点”表示实体,“边”表示实体间的关系。
在图数据库中,数据间的关系和数据本身同样重要,它们被作为数据的一部分存储起来。
这样的架构使图数据库能够快速响应复杂关联查询,因为实体间的关系已经提前存储到了数据库中。
图数据库可以直观地可视化关系,是存储、查询、分析高度互联数据的最优办法。
图数据库属于非关系型数据库(NoSQL)。
图数据库对数据的存储、查询以及数据结构都和关系型数据库有很大的不同。
图数据结构直接存储了节点之间的依赖关系,而关系型数据库和其他类型的非关系型数据库则以非直接的方式来表示数据之间的关系。
图数据库把数据间的关联作为数据的一部分进行存储,关联上可添加标签、方向以及属性,而其他数据库针对关系的查询必须在运行时进行具体化操作,这也是图数据库在关系查询上相比其他类型数据库有巨大性能优势的原因。
图数据库(graph database)不同于图引擎(graph engine)。
图数据库主要应用为联机事务处理OLTP(on-line transaction processing),针对数据做事务(ACID)处理。
图引擎用于联机分析处理OLAP(On-Line Analytical Processing),进行数据的批量分析。
发展历史图数据库发展有着非常长的历史。
早在1960年代,IBM的IMS导航型数据库已经支持了层次模型以及树状结构,这些都是特殊形式的图。
在1960年代后期的网络模型数据库(Network model Databases)已经可以支持图结构,CODASYL(Conference/Committee on ata SystemsLanguages)于 1959 年定义了COBOL,1969 年定义了网络数据库语言。
由于当时的硬件的性能无法支持复杂的查询需求,没有大范围的推广使用。
数据管理模块DataManager新增功能说明书-中国人民大学

数据管理模块(Data Manager)新增功能说明书文档负责人:朱金清文档编写人:朱金清文档系统版本号:OrientX Version 3.0文档完成时间:2007/8/25开发单位:中国人民大学IDKE实验室XML工作组1.概述本模块介绍数据在OrientX系统中的管理,包括数据的存储方法,数据的导入导出,数据的存取等。
向上层查询模块提供接口的是DataManager类。
它通过调用Schema类实现模式文档的解析和数据集的建立,通过调用ImportHandler 类实现XML格式的文档的导入,上层模块利用它的导航接口可以提取想要的数据对象。
由于原来讲schema绑定到数据集中,造成了接下来要完成的更新功能的不便,本文档应运而生。
在schema和数据集分开的前提下,自然也就达到操作上的松耦合。
Schema 的创建和DataSet的创建是两个独立的步骤,同样的删除一个DataSet不再涉及Schema的删除。
所以现在将修改(包括添加)的函数在下面第二部分中陈述。
2.数据结构描述2.1 NxdbDataManager 类NxdbDataManager类可以说是这个模块的主要接口的类,它的功能主要有向上层提供管理数据接口,包括:1)数据集的建立、删除2)Schema的注册、删除3)数据文件的导入导出4)存取查询需要的数据NxdbDataManager类就是封装了这些功能的接口,下面是NxdbDataManager类的具体实现1.数据成员2.成员函数(2) int ImportDoc(char* dataSetName,char* docName ,char* URL,StorageMode2007-07-22CDEBStorageMode(1)ElementNode* CDEBStorageMode::GetParent( ElementNode* cele )实现步骤:1.获取cele的父亲结点,如果父亲节点为ElementNode,则返回,否则执行下一步骤2.获取父亲结点(为RecordNode),然后读出父亲结点的parent Code Buffer,3.对CodeBuffer进行解析(ReadDEBRecIndexKey函数)4.对解析出来的Code的IndexKey(RegionCode32对应的m_start),如果是0,那么当前结点为根节点,那么根节点的父亲结点为空NULL。
SQL Server 权限管理手册说明书

Top Level Server PermissionsDatabase Level PermissionsALTER ANY APPLICATION ROLE ALTER ANY ASSEMBLY ALTER ANY ASYMMETRIC KEY ALTER ANY CERTIFICATE ALTER ANY CONTRACTALTER ANY DATABASE AUDIT ALTER ANY DATABASE DDL TRIGGERALTER ANY DATABASE EVENT NOTIFICATION ALTER ANY DATASPACEALTER ANY FULLTEXT CATALOGALTER ANY MESSAGE TYPEALTER ANY REMOTE SERVICE BINDING ALTER ANY ROLE ALTER ANY ROUTE ALTER ANY SCHEMA ALTER ANY SERVICE ALTER ANY SYMMETRIC KEYALTER ANY USER –See Connect and Authentication –Database Permissions ChartCREATE AGGREGATE CREATE DEFAULT CREATE FUNCTION CREATE PROCEDURE CREATE QUEUE CREATE RULE CREATE SYNONYM CREATE TABLE CREATE TYPE CREATE VIEWCREATE XML SCHEMA COLLECTIONTop Level Database PermissionsCONTROL ON DATABASE::<name>CREATE ASSEMBLY CREATE ASYMMETRIC KEY CREATE CERTIFICATE CREATE CONTRACTCREATE DATABASE DDL EVENT NOTIFICATIONCREATE FULLTEXT CATALOG CREATE MESSAGE TYPECREATE REMOTE SERVICE BINDING CREATE ROLE CREATE ROUTE CREATE SCHEMA CREATE SERVICE CREATE SYMMETRIC KEYAUTHENTICATE BACKUP DATABASE BACKUP LOG CHECKPOINTCONNECT REPLICATION DELETE EXECUTE INSERT REFERENCES SELECT UPDATEVIEW DEFINITION TAKE OWNERSHIP SHOWPLANSUBSCRIBE QUERY NOTIFICATIONS VIEW DATABASE STATECONTROL SERVERCONNECT DATABASESTATEMENTS:CREATE DATABASE AUDIT SPECIFICATION CREATE/ALTER/DROP database triggersPARTITION & PLAN GUIDE statementsSTATEMENTS:Combined with TRUSTWORTHY allows delegation of authentication BACKUP DATABASE BACKUP LOG CHECKPOINTCREATE ANY DATABASE ALTER ANY DATABASEALTER ANY SERVER AUDIT ALTER ANY EVENT NOTIFICATIONAUTHENTICATE SERVERVIEW ANY DEFINITIONALTER TRACEVIEW SERVER STATE STATEMENTS:Applies to subordinate objects in the database. See Database Permissions –Schema Objects chart.TAKE OWNERSHIP ON OBJECT|TYPE|XML SCHEMA COLLECTION::<name>RECEIVE ON OBJECT::<queue name>SELECT ON OBJECT::<queue name>VIEW CHANGE TRACKING ON OBJECT::<name> SELECT ON OBJECT::<table |view name>INSERT ON OBJECT::< table |view name> UPDATE ON OBJECT::< table |view name> DELETE ON OBJECT::< table |view name>EXECUTE ON OBJECT|TYPE|XML SCHEMA COLLECTION::<name> REFERENCES ON OBJECT|TYPE|XML SCHEMA COLLECTION:<name> VIEW DEFINITION ON OBJECT|TYPE|XML SCHEMA COLLECTION::<name>ALTER ON OBJECT|TYPE|XML SCHEMA COLLECTION::<name>TAKE OWNERSHIP ON SCHEMA::<name>VIEW CHANGE TRACKING ON SCHEMA::<name>SELECT ON SCHEMA::<name>INSERT ON SCHEMA::<name>UPDATE ON SCHEMA::<name>DELETE ON SCHEMA::<name>EXECUTE ON SCHEMA::<name>REFERENCES ON SCHEMA::<name>VIEW DEFINITION ON SCHEMA::<name>ALTER ON SCHEMA::<name>CREATE SEQUENCESELECT ON DATABASE::<name>INSERT ON DATABASE::<name>UPDATE ON DATABASE::<name>DELETE ON DATABASE::<name>EXECUTE ON DATABASE::<name>REFERENCES ON DATABASE::<name>VIEW DEFINITION ON DATABASE::<name>TAKE OWNERSHIP ON DATABASE::<name>ALTER ON DATABASE::<name>ALTER ANY SCHEMACREATE SCHEMACREATE AGGREGATE CREATE DEFAULT CREATE FUNCTION CREATE PROCEDURE CREATE QUEUE CREATE RULE CREATE SYNONYM CREATE TABLE CREATE TYPE CREATE VIEWCREATE XML SCHEMA COLLECTIONVIEW ANY DEFINITIONVIEW ANY DATABASEALTER ANY DATABASEServer PermissionsDatabase PermissionsSchema PermissionsObject Permissions Type PermissionsXML Schema Collection PermissionsDatabase Permissions –Schema ObjectsNotes:•To create a schema object (such as a table) you must have CREATE permission for that object type plus ALTER ON SCHEMA::<name> for the schema of the object. Might require REFERENCES ON OBJECT::<name> for any referenced CLR type or XML schema collection.•To alter an object (such as a table) you must have ALTER permission on the object (or schema ),or CONTROL permission on the object.CONTROL ON SERVERCONTROL ON DATABASE::<name>CONTROL ON SCHEMA ::<name>CONTROL ON OBJECT|TYPE|XML SCHEMA COLLECTION ::<name>OBJECT permissions apply to the following database objects:AGGREGATE DEFAULT FUNCTION PROCEDURE QUEUE RULE SYNONYM TABLE VIEW(All permissions do not apply to all objects. For example UPDATE only applies to tables and views.)•To drop an object (such as a table) you must have ALTER permission on the schema or CONTROL permission on the object.•To create an index requires ALTER OBJECT::<name> permission on the table or view.•To create or alter a trigger on a table or view requires ALTER OBJECT::<name> on the table or view.•To create statistics requires ALTER OBJECT::<name> on the table or view.CONTROL SERVERVIEW ANY DEFINITIONALTER ANY DATABASECONTROL ON DATABASE::<name>VIEW DEFINITION ON DATABASE::<name>REFERENCES ON DATABASE::<name>ALTER ON DATABASE::<name>ALTER ANY FULLTEXT CATALOGCREATE FULLTEXT CATALOG Certificate PermissionsFull-text PermissionsAssembly PermissionsQuestions and comments to ************************Server Role PermissionsCONTROL SERVERVIEW ANY DEFINITIONALTER ANY SERVER ROLEVIEW DEFINITION ON SERVER ROLE::<name>TAKE OWNERSHIP ON SERVER ROLE::<name>ALTER ON SERVER ROLE::<name>CONTROL ON SERVER ROLE::<name>Most permission statements have the format :AUTHORIZATION PERMISSION ON SECURABLE::NAME TO PRINCIPAL•AUTHORIZATION must be GRANT, REVOKE or DENY.•PERMISSION is listed in the charts below.•ON SECURABLE::NAME is the server, server object, database, or database object and its name. Some permissions do not require ON SECURABLE::NAME.•PRINCIPAL is the login, user, or role which receives or loses the permission. Grant permissions to roles whenever possible.Sample grant statement: GRANT UPDATE ON OBJECT::Production.Parts TO PartsTeam Denying a permission at any level, overrides a related grant.To remove a previously granted permission, use REVOKE, not DENY.NOTES:•The CONTROL SERVER permission has all permissions on the instance of SQL Server.•The CONTROL DATABASE permission has all permissions on the database.•Permissions do not imply role memberships and role memberships do not grant permissions. (E.g. CONTROL SERVER does not imply membership in the sysadmin fixed server role. Membership in the db_owner role does not grant the CONTROL DATABASE permission.) However, it is sometimes possible to impersonate between roles and equivalent permissions.•Granting any permission on a securable allows VIEW DEFINITION on that securable. It is an implied permissions and it cannot be revoked, but it can be explicitly denied by using the DENY VIEW DEFINITION statement.Server Level PermissionsNotes:•Creating a full-text index requires ALTER permission on the table and REFERENCES permission on the full-text catalog.•Dropping a full-text index requires ALTER permission on the table.STATEMENTS:DROP DATABASEMarch 28, 2014How to Read this Chart•Most of the more granular permissions are included in more than one higher level scope permission. So permissions can be inherited from more than one type of higher scope.•Black, green, and blue arrows and boxes point to subordinate permissions that are included in the scope of higher a level permission.•Brown arrows and boxes indicate some of the statements that can use the permission.CREATE SERVER ROLEAvailability Group PermissionsCONTROL SERVERVIEW ANY DEFINITIONALTER ANY AVAILABILITY GROUPVIEW DEFINITION ON AVAILABILITY GROUP::<name>TAKE OWNERSHIP ON AVAILABILITY GROUP::<name>ALTER ON AVAILABILITY GROUP::<name>CONTROL ON AVAILABILITY GROUP::<name>CREATE AVAILABILITY GROUPADMINISTER BULK OPERATIONSALTER ANY AVAILABILITY GROUP –See Availability Group PermissionsCREATE AVAILABILTY GROUPALTER ANY CONNECTION ALTER ANY CREDENTIALALTER ANY DATABASE –See Database Permission ChartsCREATE ANY DATABASE –See Top Level Database PermissionsALTER ANY ENDPOINT –See Connect and AuthenticationCREATE ENDPOINT –See Connect and AuthenticationALTER ANY EVENT NOTIFICATIONCREATE DDL EVENT NOTIFICATION CREATE TRACE EVENT NOTIFICATIONALTER ANY EVENT SESSION ALTER ANY LINKED SERVERALTER ANY LOGIN –See Connect and Authentication ALTER ANY SERVER AUDITALTER ANY SERVER ROLE –See Server Role PermissionsCREATE SERVER ROLE –See Server Role PermissionsALTER RESOURCES (Not used. Use diskadmin fixed server role instead.)ALTER SERVER STATEVIEW SERVER STATEALTER SETTINGS ALTER TRACEAUTHENTICATE SERVERCONNECT SQL –See Connect and Authentication CONNECT ANY DATABASE IMPERSONATE ANY LOGIN SELECT ALL USER SECURABLES SHUTDOWN UNSAFE ASSEMBLYEXTERNAL ACCESS ASSEMBLYVIEW ANY DEFINITIONVIEW ANY DATABASE –See Database Permissions –Schema* NOTE:The SHUTDOWN statement requires the SQL Server SHUTDOWN permission. Starting, stopping, and pausing the Database Engine from SSCM, SSMS, or Windows requires Windows permissions, not SQL Server permissions.STATEMENTS:CREATE/ALTER/DROP server triggers OPENROWSET(BULK….KILL CREATE/ALTER/DROP CREDENTIAL DBCC FREE…CACHE and SQLPERF SELECT on server-level DMV’s sp_configure, RECONFIGURE sp_create_traceAllows server-level delegationCONTROL SERVERSTATEMENTS:CREATE/ALTER/DROP server triggers OPENROWSET(BULK …KILLServer scoped event notifications Server scoped DDL event notifications Event notifications on trace events Extended event sessions sp_addlinkedserverDBCC FREE…CACHE and SQLPERF SELECT on server-level DMV’s sp_configure, RECONFIGURE sp_trace_create Allows server-level delegation SHUTDOWN*CREATE/ALTER/DROP SERVER AUDIT and SERVER AUDIT SPECIFICATION CONTROL SERVERVIEW ANY DEFINITION ALTER ANY LOGINCONNECT SQLCONTROL ON LOGIN::<name>Connect and Authentication –Server PermissionsVIEW ANY DEFINITIONALTER ANY ENDPOINTCREATE ENDPOINTCONNECT ON ENDPOINT::<name>TAKE OWNERSHIP ON ENDPOINT::<name>VIEW DEFINITION ON ENDPOINT::<name>ALTER ON ENDPOINT::<name>CONTROL ON ENDPOINT::<name>Notes:•The CREATE LOGIN statement creates a login and grants CONNECT SQL to that login.•Enabling a login (ALTER LOGIN <name> ENABLE) is not the same as granting CONNECT SQL permission.•To map a login to a credential, see ALTER ANY CREDENTIAL.•When contained databases are enabled, users can access SQL Server without a login. See database user permissions.•To connect using a login you must have :o An enabled login o CONNECT SQLoCONNECT for the database (if specified)VIEW DEFINITION ON LOGIN::<name>IMPERSONATE ON LOGIN::<name>ALTER ON LOGIN::<name>STATEMENTS:ALTER LOGIN, sp_addlinkedsrvlogin DROP LOGIN CREATE LOGINSTATEMENTS:ALTER ENDPOINT DROP ENDPOINTCREATE ENDPOINTSTATEMENTS:ALTER SERVER ROLE <name> ADD MEMBER DROP SERVER ROLECREATE SERVER ROLESTATEMENTS:ALTER AVAILABILITY GROUP DROP AVAILABILITY GROUPCREATE AVAILABILITY GROUPCONTROL ON FULLTEXT CATALOG::<name>VIEW DEFINITION ON FULLTEXT CATALOG::<name>REFERENCES ON FULLTEXT CATALOG::<name>TAKE OWNERSHIP ON FULLTEXT CATALOG::<name>ALTER ON FULLTEXT CATALOG::<name>STATEMENTS:ALTER FULLTEXT CATALOG CREATE FULLTEXT CATALOGDatabase Role PermissionsCONTROL SERVERVIEW ANY DEFINITIONALTER ANY DATABASEVIEW DEFINITION ON DATABASE::<name>ALTER ON DATABASE::<name>ALTER ANY ROLE CREATE ROLE CONTROL ON DATABASE::<name>VIEW DEFINITION ON ROLE::<name>TAKE OWNERSHIP ON ROLE::<name>ALTER ON ROLE::<name>CONTROL ON ROLE::<name>STATEMENTS:ALTER ROLE <name> ADD MEMBER DROP ROLECREATE ROLESymmetric Key PermissionsCONTROL SERVERVIEW ANY DEFINITIONALTER ANY DATABASEVIEW DEFINITION ON DATABASE::<name>REFERENCES ON DATABASE::<name>ALTER ON DATABASE::<name>ALTER ANY SYMMETRIC KEYCREATE SYMMETRIC KEY CONTROL ON DATABASE::<name>VIEW DEFINITION ON SYMMETRIC KEY::<name>REFERENCES ON SYMMETRIC KEY::<name>TAKE OWNERSHIP ON SYMMETRIC KEY::<name>ALTER ON SYMMETRIC KEY::<name>CONTROL ON SYMMETRIC KEY::<name>STATEMENTS:ALTER SYMMETRIC KEY DROP SYMMETRIC KEY CREATE SYMMETRIC KEYNote: OPEN SYMMETRIC KEY requires VIEW DEFINITION permission on the key (implied by any permission on the key), and requires permission on the key encryption hierarchy.Asymmetric Key PermissionsCONTROL SERVERVIEW ANY DEFINITIONALTER ANY DATABASEVIEW DEFINITION ON DATABASE::<name>REFERENCES ON DATABASE::<name>ALTER ON DATABASE::<name>ALTER ANY ASYMMETRIC KEYCREATE ASYMMETRIC KEYCONTROL ON DATABASE::<name>VIEW DEFINITION ON ASYMMETRIC KEY::<name>REFERENCES ON ASYMMETRIC KEY::<name>TAKE OWNERSHIP ON ASYMMETRIC KEY::<name>ALTER ON ASYMMETRIC KEY::<name>CONTROL ON ASYMMETRIC KEY::<name>STATEMENTS:ALTER ASYMMETRIC KEY DROP ASYMMETRIC KEYCREATE ASYMMETRIC KEYNote: ADD SIGNATURE requires CONTROL permission on the key, andrequires ALTER permission on the object.CONTROL SERVERVIEW ANY DEFINITIONALTER ANY DATABASEVIEW DEFINITION ON DATABASE::<name>REFERENCES ON DATABASE::<name>ALTER ON DATABASE::<name>ALTER ANY CERTIFICATE CREATE CERTIFICATE CONTROL ON DATABASE::<name>VIEW DEFINITION ON CERTIFICATE::<name>REFERENCES ON CERTIFICATE::<name>TAKE OWNERSHIP ON CERTIFICATE::<name>ALTER ON CERTIFICATE::<name>CONTROL ON CERTIFICATE::<name>STATEMENTS:ALTER CERTIFICATE DROP CERTIFICATECREATE CERTIFICATENote: ADD SIGNATURE requiresCONTROL permission on the certificate, and requires ALTER permission on the object.CONTROL SERVERVIEW ANY DEFINITIONALTER ANY DATABASEVIEW DEFINITION ON DATABASE::<name>REFERENCES ON DATABASE::<name>ALTER ON DATABASE::<name>ALTER ANY ASSEMBLY CREATE ASSEMBLYCONTROL ON DATABASE::<name>VIEW DEFINITION ON ASSEMBLY::<name>REFERENCES ON ASSEMBLY::<name>TAKE OWNERSHIP ON ASSEMBLY::<name>ALTER ON ASSEMBLY::<name>CONTROL ON ASSEMBLY::<name>STATEMENTS:ALTER ASSEMBLYDROP ASSEMBLYCREATE ASSEMBLYEvent Notification PermissionsCONTROL SERVERALTER ANY EVENT NOTIFICATIONCREATE DDL EVENT NOTIFICATIONCREATE TRACE EVENT NOTIFICATIONALTER ON DATABASE::<name>ALTER ANY DATABASE EVENT NOTIFICATION CREATE DATABASE DDL EVENT NOTIFICATIONCONTROL ON DATABASE::<name>Database scoped event notificationsDatabase scoped DDL event notificationsEvent notifications on trace eventsNote: EVENT NOTIFICATION permissions also affect service broker. See the service broker chart for more into.Connect and Authentication –Database PermissionsCONTROL SERVERVIEW ANY DEFINITIONALTER ANY DATABASEVIEW DEFINITION ON DATABASE::<name>ALTER ON DATABASE::<name>ALTER ANY USER CONNECT ON DATABASE::<name>CONTROL ON DATABASE::<name>VIEW DEFINITION ON USER::<name>IMPERSONATE ON USER::<name>ALTER ON USER::<name>CONTROL ON USER::<name>STATEMENTS:ALTER USER DROP USER CREATE USERNOTES:•When contained databases are enabled, creating a database user that authenticates at the database, grants CONNECT DATABASE to that user,and it can access SQL Server without a login.•Granting ALTER ANY USER allows a principal to create a user based on a login, but does not grant the server level permission to view information about logins.Replication PermissionsCONTROL SERVERCONTROL ON DATABASE::<name>CONNECT REPLICATION ON DATABASE::<name>CONNECT ON DATABASE::<name>Application Role PermissionsCONTROL SERVERVIEW ANY DEFINITION ALTER ANY DATABASE CONTROL ON DATABASE::<name>VIEW DEFINITION ON DATABASE::<name>ALTER ON DATABASE::<name>ALTER ANY APPLICATION ROLECONTROL ON APPLICATION ROLE::<name>VIEW DEFINITION ON APPLICATION ROLE::<name>ALTER ON APPLICATION ROLE::<name>STATEMENTS:ALTER APPLICATION ROLE DROP APPLICATION ROLE CREATE APPLICATION ROLESTATEMENTS:DROP FULLTEXT CATALOG DROP FULLTEXT STOPLISTDROP FULLTEXT SEARCH PROPERTYLISTCONTROL ON FULLTEXT STOPLIST::<name>VIEW DEFINITION ON FULLTEXT STOPLIST::<name>REFERENCES ON FULLTEXT STOPLIST::<name>TAKE OWNERSHIP ON FULLTEXT STOPLIST::<name>ALTER ON FULLTEXT STOPLIST::<name>STATEMENTS:ALTER FULLTEXT STOPLIST CREATE FULLTEXT STOPLISTCONTROL ON SEARCH PROPERTY LIST::<name>VIEW DEFINITION ON SEARCH PROPERTY LIST::<name>REFERENCES ON SEARCH PROPERTY LIST::<name>TAKE OWNERSHIP ON SEARCH PROPERTY LIST::<name>ALTER ON SEARCH PROPERTY LIST::<name>STATEMENTS:ALTER SEARCH PROPERTY LIST CREATE SEARCH PROPERTY LISTService Broker PermissionsNotes:•The user executing the CREATE CONTRACT statement must have REFERENCES permission on all message typesspecified.•The user executing the CREATE SERVICE statement must have REFERENCES permission on the queue and allcontracts specified.•To execute the CREATE or ALTER REMOTE SERVICE BINDING the user must have impersonate permission forthe principal specified in the statement.•When the CREATE or ALTER MESSAGE TYPE statement specifies a schema collection, the user executing thestatement must have REFERENCES permission on the schema collection specified.•See the ALTER ANY EVENT NOTIFICATION chart for more permissions related to Service Broker.•See the SCHEMA OBJECTS chart for QUEUE permissions.•The ALTER CONTRACT permission exists but at this time there is no ALTER CONTRACT statement.CONTROL ON REMOTE SERVICE BINDING::<name>VIEW DEFINITION ON REMOTE SERVICE BINDING::<name>TAKE OWNERSHIP ON REMOTE SERVICE BINDING::<name>ALTER ON REMOTE SERVICE BINDING::<name>STATEMENTS:ALTER REMOTE SERVICE BINDINGDROP REMOTE SERVICE BINDINGCREATE REMOTE SERVICE BINDINGCONTROL SERVERVIEW ANY DEFINITIONALTER ANY DATABASECONTROL ON DATABASE::<name>VIEW DEFINITION ON DATABASE::<name>ALTER ON DATABASE::<name>ALTER ANY REMOTE SERVICE BINDINGCREATE REMOTE SERVICE BINDINGCONTROL ON CONTRACT::<name>VIEW DEFINITION ON CONTRACT::<name>REFERENCES ON CONTRACT::<name>TAKE OWNERSHIP ON CONTRACT::<name>ALTER ON CONTRACT::<name>STATEMENTS:DROP CONTRACTCREATE CONTRACTCONTROL SERVER VIEW ANY DEFINITIONALTER ANY DATABASECONTROL ON DATABASE::<name>VIEW DEFINITION ON DATABASE::<name>REFERENCES ON DATABASE::<name>ALTER ON DATABASE::<name>ALTER ANY CONTRACTCREATE CONTRACTCONTROL ON SERVICE::<name>VIEW DEFINITION ON SERVICE::<name>SEND ON SERVICE::<name>TAKE OWNERSHIP ON SERVICE::<name>ALTER ON SERVICE::<name>STATEMENTS:ALTER SERVICE DROP SERVICECREATE SERVICECONTROL SERVERVIEW ANY DEFINITION ALTER ANY DATABASE CONTROL ON DATABASE::<name>VIEW DEFINITION ON DATABASE::<name>ALTER ON DATABASE::<name>ALTER ANY SERVICECREATE SERVICESTATEMENTS:ALTER ROUTE DROP ROUTE CREATE ROUTECONTROL SERVERVIEW ANY DEFINITIONALTER ANY DATABASECONTROL ON DATABASE::<name>VIEW DEFINITION ON DATABASE::<name>ALTER ON DATABASE::<name>ALTER ANY ROUTECREATE ROUTE CONTROL ON ROUTE::<name>VIEW DEFINITION ON ROUTE::<name>TAKE OWNERSHIP ON ROUTE::<name>ALTER ON ROUTE::<name>STATEMENTS:ALTER MESSAGE TYPEDROP MESSAGE TYPE CREATE MESSAGE TYPECONTROL SERVER VIEW ANY DEFINITIONALTER ANY DATABASECONTROL ON DATABASE::<name>VIEW DEFINITION ON DATABASE::<name>REFERENCES ON DATABASE::<name>ALTER ON DATABASE::<name>ALTER ANY MESSAGE TYPECREATE MESSAGE TYPECREATE QUEUECONTROL ON MESSAGE TYPE::<name>VIEW DEFINITION ON MESSAGE TYPE::<name>REFERENCES ON MESSAGE TYPE::<name>TAKE OWNERSHIP ON MESSAGE TYPE::<name>ALTER ON MESSAGE TYPE::<name>Permission SyntaxCREATE DATABASE **ALTER ON DATABASE::<name>STATEMENTS: CREATE DATABASE, RESTORE DATABASE** NOTE:CREATE DATABASE is a database level permissionthat can only be granted in the master database.STATEMENTS:EXECUTE ASSTATEMENTS:EXECUTE ASSTATEMENTS:ALTER AUTHORIZATIONNotes:•ALTER AUTHORIZATION for any object might also require IMPERSONATE or membership in a role or ALTER permission on a role.•ALTER AUTHORIZATION exists at many levels in the permission model but is never inherited from ALTER AUTHORIZATION at a higher level.Note: CREATE and ALTER ASSEMBLY statements sometimes require server level EXTERNAL ACCESS ASSEMBLY and UNSAFE ASSEMBLY permissions, and can require membership in the sysadmin fixed server role.NOTES:Only members of the db_owner fixed database role can add or remove members from fixed database roles.NOTES:To add a member to a fixed server role, you must be a member of that fixed server role, or be a member of the sysadmin fixed server role.© 2014 Microsoft Corporation. All rights reserved.Database Engine PermissionsMicrosoft SQL Server 2014。
Native XML数据库——dbXML的存储策略的改进

数据库具有 一般数据库 的特性 , 内部存储是基 于 但 X L数据 的树形 结 构, 存储 的 X L数 据 都通过 M 所 M
X L相关 的技 术进 行 访 问 。但 它 并 不 是一 个独 立 的 M
。
一
个 良好 的底层存储是 N t e M av L数据库进行 i X
高效的查询和读 写的关键 。本文 以 dX L为对象 , bM
0 引 言
N teX ai ML数 据库是 随 着 X L的广泛 应 用 而产 v M 生 的 , 专 门用来 存 储 和管理 X 它 ML数 据 。N teX av ML i
行时间和 存储空间上优化了文档表存储模型。 1 d XnL存 储 策 略研 究 b
底层存储是 N teX L数据 库 的核 心技 术 之 av M i
维普资讯
计
20 0 8年第 7期
文 章 编 号 :0 62 7 ( 0 8 0 -0 60 10 -4 5 2 0 ) 702 -3
算
机
与
现 代
化
总 第 15期 5
JS A J Y IN AHU IU N I U XA D I A
N t eX av ML数 据 库— — dX i b ML的存 储 策 略 的改 进
王汉林 , 谢荣传
( 安徽 大学计 算智能与信 号处理教育部重点 实验室 , 安徽 合肥 2 0 3 3 09) 摘要 : a v ML数据库是 当前数 据库领域的研 究热点之一。X L文档在 N t eX N f eX i M a v ML数据 库 中的存储和 索 引策略 是 首 i 要关心 的问题 。本 文以一 个开放源代码的 N t eX a v ML数 据库 产 ̄- d X i - b ML为对象, 分析 了它的 页面存储 策略 ; 然后 , 针 对其 页面存储 策略 在“ 空闲” 页面管理上存在的不足 , 出并 实现 了新 的策略 , 提 有效地释 放 了“ 闲”页面 占用 的磁 盘 空 空 闻, 高了系统 对磁 盘资源的利用率。 提
聚簇方法在Native XML数据库中的应用

l bl l/ / al e f g d
Ⅺ 文档树
S L聚簇
图 1 S 聚簇和 S L P聚簇
) ^ 数据是半结构化 的 , (L ^ 不像 关系数据那样 是严 格的结构 化数据 , 这样就给 N teX 数 据库 中的存 ai ML v 储 系统带 来更 大 的灵 活性 , 当然 , 也带 来 了更 大 的挑 战。如 何提高 X 数据 库的 查询效 率一 直是 一个 棘 ML
容 易实现 , 也可 以通过数据向导 ( 具有相同路 径的结 点 作为一个 目标集合来管 理 ) 实现 。当新的聚 簇分配 绝
对路径时 , 聚簇 的数量 与数据 向导 的数量 一样。具 有 同样 标签 的结点 由于绝 对路 径 的不 同 , 而存储在不 同 的聚 簇中。图 1 , 中 由于 结点 3和 结点 1 有 不同 的绝 1
一
2 基本 的聚簇方法
一
基本的聚 簇 算法 有两 种 ( 1 示 ) 图 所 。一 种是 S L
(a a e) 簇 , S meLb 1聚 就是具有 相 同标 签 的结点聚 簇在
块, 每个 聚簇 中的数据结点是根 据文档 的顺序和每
口圃 团
1
// c a b/ // c a h/
绝对路径也存储其 中。这种方法可 以通过路径 索引很
和 ‘ D B C’ / / / 。当查 询 ‘/ 请 求 时 , /C’ 存在 s ls 2和 p 、p s3的数据可返 回, p 因而 S P聚簇安排的顺序在查询过
程 中对 页 面 I 没 有 影 响 。 另 一 方 面 , 查 询 ‘i / / O 当 l B
魏东平 刘树 涛 张 静 ( 中国石油大 学 计算机 与通信工程学院 2 7 6 ) 50 ]
FME 使用手册

简介(注意并非针对本文,可能有差异) 改为二维圆弧,圆弧的形状由参数控制,例 如常数或属性值 改为二维矩形,矩形的最大最小坐标为指定 的常数或原始要素的属性值 根据参数创建二维要素,并输入转换流程 改为二维椭圆,椭圆的形状由参数控制 改为二维要素(删除Z坐标) 按格网方式生成一批二维点状要素,须指定 原点和间距 将输入的一批要素改为按格网方式生成的二 维点状要素,格网的范围(至少)覆盖全部 输入要素的外接矩形,格网间距须指定 给要素增加一个二维的节点(最后一个节 点),其坐标由原始要素的属性获得 改为二维的点,其坐标由原始要素的属性获 得 改为二维圆弧(注:原文如此),圆弧的形 状由参数控制,例如常数或属性值 根据参数创建三维要素,并输入转换流程 改为三维要素,Z坐标由指定的属性或常数 获得 三维插值:沿着一个线状要素、根据起始值 和结束值内插高程 给要素增加一个三维的节点(最后一个节 点),其坐标由原始要素的属性获得 改为三维的点,其坐标由原始要素的属性获 得 坐标仿射变换 仿射纠正,用于纠正一批要素使之最接近参 考要素 聚合过滤:根据图形是否为聚合类型而分别 输出
简介注意并非针对本文可能有差异2darcreplacer改为二维圆弧圆弧的形状由参数控制例如常数或属性值2dboxreplacer改为二维矩形矩形的最大最小坐标为指定的常数或原始要素的属性值2dcreator根据参数创建二维要素并输入转换流程2dellipsereplacer改为二维椭圆椭圆的形状由参数控制2dforcer改为二维要素删除z坐标2dgridcreator按格网方式生成一批二维点状要素须指定原点和间距将输入的一批要素改为按格网方式生成的二维点状要素格网的范围至少覆盖全部输入要素的外接矩形格网间距须指定给要素增加一个二维的ห้องสมุดไป่ตู้点最后一个节点其坐标由原始要素的属性获得改为二维的点其坐标由原始要素的属性获得2dgridreplacer2dpointadder2dpointreplacer3darcreplacer改为二维圆弧注
一种基于XMLSchema的异构资源数据库整合中间件

收稿日期:20030225基金项目:国家863基金项目(2002AA414210)资助作者简介:周竞涛(1976-),男(汉),辽宁,博士研究生E 2mail :zhoujtnet @.cn周竞涛文章编号:100328728(2004)0520627204一种基于X M L Schema 的异构资源数据库整合中间件周竞涛,张树生,王明微,孙宏伟,和延立,高俊杰(西北工业大学C AD/C AM 国家专业实验室,西安 710072)摘 要:将异构资源数据库整合到数字图书馆系统中所面对的首要问题是异构问题,主要包括系统异构、语法异构和语义异构三个方面。
本文以W3C 的X M L Schema 标准作为异构数据源的全局模式,借助X M L Schema 强的数据描述能力,通过实现关系模式的提取、关系模式到X M L Schema 的转化和附加语义约束,实现了异构资源数据库数据的整合。
关 键 词:资源整合;X M L Schema ;语义;模式转化;数字图书馆中图分类号:TP311 文献标识码:AA Method for Merging X ML Schem aB ased H eterogeneous R esource DatabasesZH OU Jing 2tao ,ZH ANG Shu 2sheng ,W ANG Ming 2wei ,S UN H ong 2wei ,HE Y an 2li ,G AO Jun 2jie (State K ey Laboratory of C AD/C AM ,N orthwestern P olytechnical University ,X i ′an 710072)Abstract :A digital library (D L )needs interoperation between diverse information services.In order to use the legacy heterogeneous res ource databases in one single D L ,their in formation requires merging into one comm on virtual m odel to facilitate the operation and interoperation.Heterogeneity ,structure and semantic relationship extension are the main challenges in the process of merging.T o s olve these problems ,we define a directed 2graph data m odel as the comm on data m odel and propose a merging approach based on X M L Schema which cap 2tures the full structures and semantic constraints in relational schema ,translates them into the global X M L Schema representations and merges the result through adding semantic content constraints.In addition ,a secu 2rity m odel that allows for authentication and authorization are im plemented for the method to satis fy the autho 2rization required in the merging process.K ey w ords :X M L schema ;Semantics ;C onstraints extension ;Schema trans formation ;Digital library 异构问题是实现数字图书馆资源数据库整合所要解决的首要问题,其主要表现在以下三个方面:(1)系统异构。
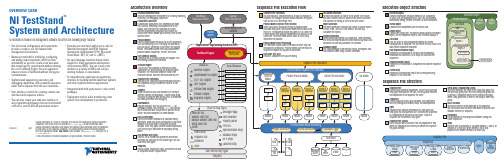
National Instruments TestStand序列编辑器用户手册说明书
Execution Object StructureExecution ObjectContains information TestStand needs to run a sequence, its steps, and any subsequences it calls. You can suspend,interactively debug, resume, terminate, or abort executions.Thread ObjectRepresents an independent path of control flow.Report ObjectContains the report text. The process model updates the Report object, and the sequence editor or user interface displays it.Call StackLists the chain of active sequences waiting for nestedsubsequences to complete. The first item in the call stack is the most-nested sequence invocation.Root SequenceContext ObjectRepresents the execution of the least-nested sequence invocation that contains a list of steps and calls to other sequences.SequenceContext ObjectRepresents the execution of a sequence that another sequence called.Current StepRepresents the executing step of the currently executingsequence in the call stack.Architecture OverviewTestStand Sequence EditorTestStand development environment for creating, modifying,executing, and debugging sequences.Custom User InterfacesCustomizable applications that, depending on mode,edit, execute, and debug test sequences on a test station. User interfaces are available in several different programming languages and include fullsource code, which allows you to modify them to meet specific needs.Process ModelsDefine the operations that occur for all test sequences,such as identifying the UUT, notifying the operator of pass/fail status, generating a test report, and logging results. TestStand includes three fully customizable process models: Sequential, Parallel, and er Interface ControlsA powerful set of ActiveX controls and support APIs for creating custom user interfaces.TestStand EngineA set of DLLs that provides an extensive ActiveX Automation API for controlling and interacting with TestStand. The TestStand Sequence Editor, User Interface Controls, and user interfaces use this API.Sequence File ExecutionsCreated by the TestStand Engine when you execute a test sequence using the sequence editor or a user interface.AdaptersAllow TestStand to call code modules in a variety of different formats and languages. Adapters also allow TestStand to integrate with various ADEs to streamline test code generation and debugging.Code ModulesProgram modules, such as LabVIEW VIs (.vi ) or Windows Dynamic Link Libraries (.dll ), that contain one or more functions that perform a specific test or action. TestStand adapters call code modules. Built-In Step TypesDefine the standard behaviors for common testing operations. Some step types use adapters to call code modules that return data to TestStand for furtheranalysis. Other step types perform standard operations,such as calling an executable or displaying dialog boxes.User-Defined Step TypesDefine a set of custom step properties and default behaviors for each step of that custom type. You can also define data types.TemplatesCreate custom sequences, steps, and variables to use as templates to build sequence files.OVERVIEW CARDNI TestStandTMSystem and ArchitectureNI TestStand is flexible test management software that offers the following major features:•Out-of-the-box configuration and components provide a ready-to-run, full-featured test management environment.•Numerous methods for modifying, configuring,and adding new components, which provide extensibility so you can create a test executive that meets specific requirements without altering the core TestStand Engine. You can upgrade to newer versions of TestStand without losing your customizations.•Sophisticated sequencing, execution, anddebugging capabilities, and a powerful sequence editor that is separate from the user interfaces.•User interface controls for creating custom user interfaces and sequence editors.•You can also create your own user interface in any programming language that can host ActiveX controls or control ActiveX automation servers.•Example user interfaces with source code for National Instruments LabVIEW, National Instruments LabWindows ™/CVI ™, Microsoft Visual Basic .NET, C#, and C++ (MFC).•An open language interface that provides support for many application development environments (ADEs). You can create code modules in a variety of ADEs and call pre-existing modules or executables.• A comprehensive application programminginterface for building multithreaded test systems and other sophisticated test applications.•Integration with third-party source code control packages.•Deployment tools to aid in transferring a test system from development to production.TestStand Sequence EditorCode ModulesResultsResultsResultsResultsResultsResultsResultsResultsCustom User InterfacesUser Interface (UI)ControlsApplication Programming Interface (API) TestStand EngineSequence File ExecutionsUser-Defined Step TypesSequence File ExecutionsNo ModelTest Socket 0Execution UUTUUTUUTTest Socket 1Execution UUTUUT TestSocket nExecution UUTUUTUUT UUT UUTUUTUUTUUTProcess Model Result ProcessingSchema DefinitionsDatabase LoggerReport GeneratorADO/ODBCThread Object 0Thread Object n Sequence File GlobalsStepsMain Step GroupStepsCleanup Step GroupParametersSequencesLocal VariablesAdapters.VI.DLL, .OBJ, .LIB, .C.DLL .DLL, .EXE .DLL, .EXE.PRG .SEQLabVIEW Adapter LabWindows/CVI Adapter C/C++ DLL Adapter .NET Adapter ActiveX/COM Adapter HTBasic Adapter Sequence AdapterTypesSequence FileParallel Process ModelBatch Process ModelSequential Process ModelProcess Model Sequence File ExecutionTestSocket nExecution Test Socket 1Execution TestSocket 0Execution Oracle . . .SQL ServerReport ObjectExecution ObjectCall StackRootSequenceContextObject 0SequenceContextObject 1SequenceContextObject nStep Object 0Step Object n. . .Current StepMicrosoft Access Process Models. ... ..XMLHTMLASCII-Text. . .Sequence File Execution FlowSequence File ExecutionsYou can execute a sequence directly, or you can execute a sequence file through a process model Execution entry point,such as Test UUTs and Single Pass.Process Model Sequence File ExecutionWhen you start an execution through a process modelExecution entry point, the process model defines how to test the UUTs. The Sequential model tests one UUT at a time. The Parallel model tests multiple independent test sockets at the same time. The Batch model tests a batch of UUTs using dependent test sockets.Process Model Result ProcessingThe TestStand Engine collects the results of each step that executes into a result list. Process models use the result list to generate reports and log data to databases. Unit Under Test (UUT)Device or component that you are testing.Test Socket ExecutionFor each test socket, or fixture, in the system, the Parallel and Batch models launch a separate test socket execution that controls the testing of UUTs in that test socket.Report GeneratorThe report generator traverses test results to create reports in XML, HTML, and ASCII-text formats. You can fully customize the reports.Schema DefinitionsSchema definitions define SQL statements, table definitions,and TestStand expressions that define how to log results to a database. You can fully customize the schemas.Database LoggerThe database logger traverses test results and exports data into database tables using schema definitions.Sequence File StructureSequence FileContains any number of sequences, a set of data types and step types the sequence file uses, and any global variables that sequences in the sequence file share.SequencesContain groups of steps, local variables, and parameters used for passing data between steps and subsequences.TypesSequence files contain definitions of all data types and step types that its sequences use. Variables and properties in a sequence are instances of data types. Steps in a sequence are instances of step types.Sequence File GlobalsStore data you want to access from any sequence or step within the sequence file in which you define the sequence file global variable.Setup, Main, Cleanup Step GroupsTestStand executes the steps in the Setup step group first,the Main step group next, and the Cleanup step group last.By default, a sequence moves to the Cleanup step group when a step generates an error in the Setup or Main step group.Local VariablesStore data relevant to the execution of the sequence. You can access local variables from within steps and code modules defined in a sequence.ParametersUse parameters to exchange data between calling and called sequences.StepsPerform built-in operations or call code modules. A step is an instance of a step type, which defines a set of step properties and default behaviors for each step.373457B-01 Apr07. . .. . .. . .National Instruments, NI, , NI TestStand, and LabVIEW are trademarks of National Instruments Corporation. Refer to the Terms of Use section on /legal for more information aboutNational Instruments trademarks. Other product and company names mentioned herein are trademarks or trade names of their respective companies. For patents covering National Instruments products,refer to the appropriate location: Help»Patents in your software, the patents.txt file on your CD, or /patents .© 2003–2007 National Instruments Corporation. All rights reserved.Printed in Ireland.StepsSetup Step GroupTemplatesFlow Control Sequence Call Statement LabelMessage Popup Call Executable Property Loader FTP FilesSynchronization Steps Database Steps IVI-C Steps LabVIEW UtilityPass/Fail Test Numeric Limit Test Multiple Numeric Limit Test String Value Test Action Built-In Step TypesYou can use the fully customizable TestStand developmentenvironment to create, modify, execute, and debug sequences. You can also use the sequence editor to modify step types and process models. You can customize the environment by docking, auto-hiding, and floating panes to optimize your development tasks. TheDevelopment EnvironmentOVERVIEW CARD NI TestStand TMSystem and ArchitectureTestStand includes separate user interface applications developed in LabVIEW, LabWindows/CVI, Microsoft Visual Basic .NET,C#, and C++ (MFC). Because TestStand includes the source code for each user interface, you can fully customize the userinterfaces. You can also create your own user interface using any programming language that can host ActiveX controls orcontrol ActiveX automation servers. With the user interfaces in operator mode, you can start multiple concurrent executions, set breakpoints, and single-step. In editor mode, you can modify sequences, display sequence variables, sequence parameters,step properties, and so on.TestStand Sequence Editor Overview User Interface OverviewPrinted DocumentationNI TestStand Quick Start GuideUse this document for system requirements andinstallation instructions. This document also contains information about the different TestStand licensing options.NI TestStand Release NotesUse this document to learn about new features and upgrade information.Using TestStandUse this manual to familiarize yourself with the TestStand environment and the basic features you use to build and run test sequences.Using LabVIEW with TestStandUse this manual in conjunction with the Using TestStand manual to learn how to use LabVIEW with ing LabWindows/CVI with TestStandUse this manual in conjunction with the Using TestStand manual to learn how to use LabWindows/CVI with TestStand.NI TestStand Reference ManualUse this manual to learn about TestStand concepts,architecture, and features.Online HelpNI TestStand HelpUse this help file to learn more about the TestStand environment and the TestStand User Interface Controls and Engine APIs. The NI TestStand Help also includes basic information about using an ActiveX automation server.NI TestStand VIs and Functions HelpUse this help file to learn more about TestStand-specific VIs and functions. This help file is accessible only from LabVIEW.Cards and PostersNI TestStand User Interface Controls Reference Poster Use this poster to learn about the controls available for writing custom user interfaces for TestStand.NI TestStand API Reference PosterUse this poster as an overview of the TestStand API. This poster lists the properties, objects, methods, and APIinheritance of the TestStand API.L i s t B a r Lists the currentlyopen sequence files and executions.S e q u e n c e F i l e W i n d o wE x e c u t i o n V i e wR e p o r t V i e wS e q u e n c e V i e wLists steps in the sequence and step group for the sequence file you select in the list bar.Displays the threads,call stack, and steps for the execution you select.Displays the report for the execution you select.Displays sequences and other items in a sequence Displays the threads,call stack, and stepsthat an execution runs.When executioncompletes, displays thereport for theexecution.User Manager WindowAdministers groups, users,login names, pass-words, and privi-leges.UsersDisplays users for the test station. Output Pane Displays output messages that expressions and code modules post to theTestStand Engine.Call Stack Pane Displays the nested sequence invocations for the thread you select.sequence editor provides familiar LabVIEW, LabWindows/CVI, and Microsoft Visual Studio .NET debugging tools, including breakpoints, single-stepping, stepping into or over function calls, tracing, a Variables pane, and a Watch View pane. In the TestStand Sequence Editor, you can start multiple concurrent executions, execute multiple instances of the same sequence, and execute different sequences at the same time. Separate Execution windows display each execution. In trace mode, the Execution window displays the steps in the currently executing sequence. When you suspend an execution, the Execution window displays the next step to execute and provides single-stepping options.Templates List Organizes custom sequences, steps,and variables you can use as templates for building sequence files.Step Settings PaneSpecifies the settings for the step, such as code module parameters, switching, flow control, and post actions.Variables Pane Displays the variables andproperties, including the values, that steps can access at run time.StepPerforms built-in operations or calls code modules.ProjectOrganizes sequence files and code module files in folders.Workspace PaneManages projects for source code control (SCC) integration and deployment. TestStand inte-grates with third-party SCC pack-ages to add files, obtain the lat-est versions of files, and check files in and out.Watch View Pane Monitors the values of specifiedvariables, properties,and expressions during an execution.Threads Pane Contains a list of threads in the current execution.Insertion Palette Displays step types and templates you can insert into sequence files.GroupsDisplays groups that users belong to.。
XML Schema相关的应用技术

(3)是否支持名域(命名空间)
XML Schema利用名域将文档中特殊的节点与Schema说明相
联系,一个XML文件可以对应有多个不同的Schema(各个 Schema通过命名空间进行相互区分)命名空间。 而如果是使用DTD,一个XML文件只能有一个与之相对应的 DTD文件。
在命名空间声明中,等号右边的命名空间名虽说要求 是一个URI,但其目的并不是要直接获取一个Schema或DTD 文件,而在于标识特定的命名空间。
#PCDATA为字符串
如何解决这个问题? (4)DTD的主要问题 DTD 的语法相当复杂同时在数据类型的支持方面比较 差,不支持多种多样的数据类型; 并且它不符合 XML 文件的标准,自成一个体系。也就 是说 DTD 文档本身并不是一个良好形式的 XML 文档,用 了非XML的语法规则; DTD 无法简化子元素基数性的规范(可以简洁地指定 “一个或多个”子元素,但不能指定“二到五个之 间”,扩展性较差。 在 DTD 中,符号: ? 、 * 和 + 分别指定“零或 一”、“零或多个”、“一个或多个”,其中一个量化了 基数性;即,除了问号有能力说:“有或没有”以外, DTD语法中似乎没有可以限制给定模式出现次数的东西
您应该知道这个要求吧!
(1)XML文档有“格式良好”和“有效性”两种约束 其中的格式良好适合于所有的XML文档,即满足XML标准中 对于格式的规定 ; 而当XML文档满足一定的语义约束则称该XML文档为有效的 XML文档 (2)为什么要对XML文档 加以约束 因为在特定的应用 中,数据本身有“语义限 制”。也就是有下面的要 求: 含义上 数据类型上 数据关联上的限制
5、XML Schema的用法应用示例 (1)XML文档(emp如下(employees.dtd)
Data_Manager

数据管理模块(Data Manager)概要设计说明书负责人:罗道峰,安靖编写人:安靖系统版本号:OrientX Version 1.5完成时间:2004/2/20开发单位:中国人民大学IDKE实验室XML工作组1.引言编写本说明书是为了向用户介绍OrientX系统中,数据管理模块的设计思路及使用方法。
本模块重点在数据在系统中的存储模型,数据模式的建立,数据的导入、导出和和如何向上层提供数据。
下面各章节的具体安排:第2节概述,介绍相关的背景知识,此模块的功能,以及此模块在整个系统中的地位和作用。
第3节总体设计,介绍整个模块的处理思想,模块内部由哪些小模块构成,以及它们之间的关系。
第4节接口设计为上层模块提供服务的接口,第5节数据结构设计,包括逻辑结构设计和物理结构设计两部分。
第6节介绍出错处理。
2.概述本模块介绍数据在OrientX系统中的管理,包括数据的存储方法,数据的导入导出,数据的存取等。
向上层查询模块提供接口的是DataManager类。
它通过调用Schema类实现模式文档的解析和数据集的建立,通过调用ImportHandler 类实现XML格式的文档的导入,上层模块利用它的导航接口可以提取想要的数据对象。
3.总体设计3.1XML解析的相关知识XML文档有自己的格式,要经过相应的软件进行转换,转换成应用需要的文件格式。
其中语法分析器和应用程序之间有两种接口:DOM 和SAX3.1.1 DOM接口DOM(Document Object Model)节点有Document、Element、Comment、Type等等节点类型,其中每一个DOM文档必须有一个Document节点,并且为节点树的根节点。
它可以有子节点,或者叶子节点如Text节点、Comment节点等。
作为基于对象的接口,DOM通过在内存中显示的构建对象树来与应用程序通信,对象树是XML文件中元素树的精确映射。
3.1.2 SAX接口SAX的全称是Simple APIs for XML,也即XML简单应用程序接口。
OrientStore+: 一种支持高效更新的Native XML存储方法

OrientStore+:一种支持高效更新的Native XML存储方
法
张新;孟小峰;朱金清;王伟;黄静
【期刊名称】《计算机研究与发展》
【年(卷),期】2007(044)0z3
【摘要】XML数据在数据库中的存储模式对XML数据的查询、索引及更新有重要的影响.而目前许多XML存储方法在更新上都需要较高的代价.提出一种Native XML存储方法OrientStore+,可以完全保留XML树结构信息,同时还具有如下特点:1)易于对XML数据建立各种索引; 2)存储记录间相互独立,进行更新时,可以减少对XML存储及索引的修改,减小了更新的代价; 3)在Native XML数据库系统OrientX中实现了这种存储模式.另外,在这种存储模式基础上提出一种基于空间利用率的XML存储更新算法.并通过实验比较了在不同存储方法上的查询与更新效率.【总页数】6页(P368-373)
【作者】张新;孟小峰;朱金清;王伟;黄静
【作者单位】中国人民大学信息学院,北京,100872;中国人民大学信息学院,北京,100872;中国人民大学信息学院,北京,100872;中国人民大学信息学院,北
京,100872;中国人民大学信息学院,北京,100872
【正文语种】中文
【中图分类】TP391
【相关文献】
1.一种全面支持XML动态更新的扩展BSC编码 [J], 庄景彬;郭朝珍
2.一种基于XML的图像高效存储方法 [J], 郝伟
3.一种支持更新的XML编码方法 [J], 覃遵跃;黄云;梁平元
4.一种支持更新的有序XML文档编码方法 [J], 朱长城;梁平元
5.一种新的支持XML文档更新的编码方法 [J], 付鹏;蒋夏军;皮德常
因版权原因,仅展示原文概要,查看原文内容请购买。
更新概要设计说明书

更新概要设计说明书负责人:安靖编写人:安靖系统版本号:OrientX Version 1.5完成时间:2004/09/08开发单位:中国人民大学IDKE实验室XML工作组1.引言本说明书介绍OrientX系统中更新模块的设计。
第2部分介绍模块的背景知识,模块的功能,以及此模块在整个系统中的地位和作用。
第3部分介绍整个模块的处理思想,模块内部由哪些小模块构成,以及它们之间的关系。
第4部分介绍本系统使用的更新语言。
第5部分讲述模块内的数据结构的设计和主要成员函数的功能。
最后第6部分介绍该模块的错误处理机制。
2.概述背景知识:数据库应该提供增删改等更新功能,允许用户更新数据库中的内容。
目前更新关于XML数据更新的研究有:设计更新语言,定义XML数据的完整性约束,更新操作的约束检查等。
这三方面目前都正在讨论阶段,还没有官方的标准,所以作者借鉴他人的研究成果,从可能的应用出发,针对本系统的具体情况,粗略地实现了对XML数据的更新。
OrientX2.0通过对XQuery的扩展定义丰富易学易用的更新语言。
针对越来越多的应用使用有模式约束的XML文档这一事实,提出了快捷先验性地检查XML更新约束的方法,能过滤不符合模式约束的更新请求。
针对本系统的存储特征,实现XML文档的更新。
模块功能:向用户提供更新语句,实现对OrientX数据库中存储的数据文档的增删改操作,包括增加、删除、修改元素、属性和值。
增加的元素可以是同一文档中符合某些谓词的元素,也可以是其他文档中的元素。
此模块在整个系统中的地位和作用:图1 系统框架图3.总体设计本模块包括更新操作的有效性检查模块,数据操作模块。
有效性检查模块有效性检查模块负责检查更新请求的合法性,过滤不合法的更新请求,执行合法的更新请求。
经过检查的有效的更新请求才会被继续处理,会被数据操作子模块处理。
XML 文档分成有模式约束和无约束两种,更新操作执行完后的文档如果仍然符合模式约束的话,则此更新操作是合法的更新操作,否则是非法的。
面向对象数据库

年龄 19 20 18 20
OODBS
关系模式 元组
5
11.4 面对对象数据模型
➢ 关系模型旳数据构造 — 二维表 外关键字
OODBS
学号 S1001 S1001 S1001 S1003 S1002 S1003 S1004
课程编号 C101 C102 C103 C101 C101 C102 C101
➢ 面对对象数据库管理系统(OODBMS)除了具有面对 对象旳概念与措施外,还必需具有老式数据库管理系 统旳全部功能,是面对对象技术与老式数据库技术旳 结合体。
➢ 1989年12月在日本京都第一届‘演绎与面对对象数据 库’国际会议上(DOOD’89)刊登了著名旳面对对象 数据库宣言,在该宣言中明确提出了OODBMS需要满 足旳条件。其中又分为三类: ▪ 第一类:必需满足旳条件(15条)。7条是有关面 对对象旳概念与原理旳,另8条是老式数据库管理 系统所必需旳条件。 ▪ 第二类:希望满足旳条件(5条)。 ▪ 第三类:仅供参照旳4个条件。
➢ OODM旳数据操作 — 措施 与 消息
➢ OODM旳数据约束 — 措施 与 消息
▪ 实体完整性 – 无 ▪ 引用完整性 – 无 ▪ 顾客自定义完整性约束条件 – 完整性约束措施
12
OODBS
11.4 面对对象数据模型
➢ 面对对象数据模型就是一种由类及类旳继承与合成关 系所构成旳类层次构造图。例如:
S1002
C101
76
C101
C++
T02
C102
OS
T01
S1003
C102
87
C103
DB
T02
S1004
C101
88
orientdb

orientdbOrientDB: A Powerful Graph Database for Modern ApplicationsIntroductionIn today's digital age, managing and analyzing data efficiently is crucial for businesses and organizations. Traditional relational databases have long been the go-to solution, but with the rise of complex and interconnected data, there is a growing need for more versatile and scalable database solutions. This is where OrientDB comes into play. OrientDB is a multi-model and native graph database that combines the flexibility of a document database with the power of a graph database, making it an ideal choice for modern applications. In this document, we will explore the features and benefits of OrientDB and how it can revolutionize data management in various industries.What is OrientDB?OrientDB is an open-source, NoSQL (non-relational) database management system that can handle complex data structures,including graphs, documents, key-value pairs, columns, and more. It was first released in 2010 and has since gained popularity due to its ability to manage large-scale distributed graphs and handle high levels of concurrency. Unlike traditional SQL databases, OrientDB does not require a fixed schema, allowing for more flexibility and agility in data modeling.Key Features and Benefits1. Native Graph Database: Unlike other databases that add graph capabilities as an afterthought, OrientDB is designed from the ground up as a native graph database. This means that it excels at handling interconnected data and querying complex relationships, making it a natural fit for applications such as social networks, recommendation engines, and fraud detection systems.2. Multi-Model Support: OrientDB supports multiple data models, including graphs, documents, key-value pairs, columns, and more. This versatility allows developers to use the most suitable data model for their specific use cases, without the need for multiple database systems. It also simplifies the integration of different data sources, reducing the complexity and maintenance overhead.3. ACID Compliance: ACID (Atomicity, Consistency, Isolation, Durability) compliance ensures that database transactions are reliable and maintain data integrity. OrientDB provides strong ACID guarantees, making it a reliable choice for mission-critical applications, where data consistency is of utmost importance.4. Distributed Architecture: OrientDB's distributed architecture allows it to scale horizontally across multiple machines, providing fault-tolerance and high availability. This makes it ideal for applications that require high performance and handle massive amounts of data.5. Easy Integration: OrientDB provides rich APIs and drivers for major programming languages, including Java, Python, and JavaScript. This makes it easy to integrate OrientDB into existing applications and frameworks, speeding up development and reducing learning curves.6. Powerful Query Language: OrientDB uses a SQL-like query language called OrientSQL, which supports both graph and document queries. It allows developers to express complex relationships and search patterns easily, and it providespowerful indexing and query optimization capabilities, ensuring high performance even with large datasets.Use Cases1. Social Networks: OrientDB's native graph database capabilities make it an excellent choice for building social network applications. It can efficiently handle user relationships, friend recommendations, news feeds, and other social features, providing a seamless and immersive user experience.2. Recommendation Systems: OrientDB's ability to handle complex relationships and perform graph traversals makes it an ideal platform for recommendation systems. By analyzing user behavior, preferences, and interconnected data, OrientDB can generate highly accurate recommendations for products, services, or content, enhancing customer satisfaction and driving revenue.3. Fraud Detection: OrientDB's graph database capabilities play a crucial role in fraud detection. By modeling and analyzing connections between users, transactions, and suspicious behaviors, OrientDB can identify patterns and anomalies that indicate fraudulent activities, helpingbusinesses prevent financial losses and protect their customers.4. Content Management Systems: OrientDB's multi-model support enables it to handle both structured and unstructured data, making it a perfect fit for content management systems. With OrientDB, developers can efficiently store, search, and retrieve various content types, such as articles, images, videos, and metadata, delivering fast and personalized content to users.ConclusionOrientDB provides a powerful and versatile solution for modern applications that deal with complex and interconnected data. Its native graph database capabilities, combined with multi-model support, ACID compliance, distributed architecture, and easy integration, make it a compelling choice for various industries and use cases. Whether you are building a social network, recommendation system, fraud detection system, or content management system, OrientDB offers the performance, scalability, and flexibility needed to handle the most demanding data challenges. Invest in OrientDB and unlock the true potential of your data.。
Native XML数据库技术及实现

20 0 7年 1 1月刊 ( 总第 9 9期 )
大 众 科 技
DA Z HO NG KE J
2 0 .1 0 7 1
(u u te o 9 C m l i lN . ) av y 9
N t e X L数据库技术及实现 a M i v
应 当根据相关 的标准独立于查询语言的表层语 法而存在 。 N D查 询的查询语言 的设计与它 的数据 模型是紧密相关 X
1存储机制 . 种是基于文本 方式 目前, X N D主流 的存储方式有两种
数据的存储和查询,并且能达到很好的效果。 个 比较确切 的 N D的定义 是 由 R B r e t提 出来得 , X . or n
一
指将数据 的概念模 型转换 成物理存储模型 。有些数据库将该 模型存储 于关 系型和面向对象 的数据库 中,例如 在关系型数
据库 中存储 DM时,就会有元 素、属性 、PDT 、实体 、实 O CA A 体引用等表格 。有 些数据库使用 了专 为这种 模型作 了优化的
它可以是任意维数。 F b i 索引是对X L arc M 结构和数据建立索 引的一种方法 ,是 从P t i i r e 发展来的。这种索 引很适合半结构数据特 arcatis 点 ,能够处理大量的字符串。这种索 引也有 不足 ,它只支持 从根结 点开始的路径 。
3查询 . N D的查询技术可 以分为三类 : 1查询语言之上的部分 , X ()
N t v M a ie X L数据库即 N D是专 门存储和管理 X L的数据 X M 库 。与 以往关系数据库不同的是,它充分考虑到 XL数据的 M 特 点,以一种 比较 自然的方式来处理 X L数据 ,保 持 X L文 M M
在SaaS中使用原生XML数据库

b e . r u e e p rme t n h e u t n i ae t a l s Ca r o tt x e i n s a d te r s l i dc t t y h s h NXD ,a h d a aa so a e f rXM L n we s t e i e d t t r g o l i b,i n a tr a i e c o c n sa e t b ie a d l n v
中 图分 类号 : P 1 . T 3 15 文献 标识码 : A 文 章编号 :6 3 6 9 2 1 ) 2 0 8 — 4 17 — 2 X( 0 10 — 0 6 0
.
Usn t e XM L n S fwa e a e v c i g Na i v DB i o t r sa S r ie
徐 从 娟 陈 维 良 ,
( . 东大学 控 制 学院 , 东 济 南 2 0 6 ; 1山 山 5 0 1 2 山东大 学 计 算机 科 学与技 术 学院 , 东 济南 2 0 0 ) . 山 5 1 1
摘 要: 多租户数 据存储 是软件 即服务 ( aS 的重要研 究点之 一 。现有 的解决 方案大 都是 基 于关 系数 据库 的模式 映 射技 Sa )
do o e p an t a a s ai e XM L n S a n t x li twe c n u n t h e v DB i a S.Att e Sll i . i e t e XM L tu t r ih i e u v l n l rv t a aTe t h me g v h sr cu wh c s q i ae t o t p i ae t- e t l
同时依据此 X L结构进 行 了相关 的 实验 , 果表 明 N D作 为理想 的 w b中 X 数据 存储 方式可 以成为 多租户数 据存 储 M 结 X e ML 的一 种解决 方案 , 并且 能够 有效地 支持 Sa 的 w b aS e 特性 、 据存储 灵活性 等特 点 。 数
一种基于XML的异构数据库集成方法

第20卷 第1期茂名学院学报V ol.20 N o.1 2010年2月JOURNA L OF MAOMI NG UNI VERSITY Feb.2009一种基于X M L的异构数据库集成方法Ξ乔玮(西安文理学院,陕西西安710065)摘要:异构数据库的集成是当前数据库研究领域内的一个热点,它能更有效地利用信息资源及实现数据共享。
论述了一种基于X M L中间件的异构数据库集成方法。
首先介绍了异构数据库集成系统整体框架结构的层次模型和每一层的服务功能,然后对其中的关键问题,如关系数据模式到X M L Schema模式转换及查询分解方法进行了讨论,最后阐述了该异构数据库集成方法的优点。
关键词:X M L;中间件;数据集成;异构数据库中图分类号:TP311.13文献标识码:A文章编号:1671-6590(2010)01-0049-03现代企业普遍应用数据库技术来管理各种数据,多数企业在发展过程中积累了大量的数据,这些数据可为企业的业务发展和经营规划提供参考。
但由于数据库应用系统是在不同时期、根据不同的需求建立的,开发标准、数据库平台、数据格式等不同,因此在企业数据共享中形成了“信息孤岛”。
数据库中间件技术通过提供一个全局模式和对应各数据源的局部模式,集成来自不同数据源的数据,不需考虑数据库的模型和运行平台[1]。
X M L(eX tensible Markup Language)是SG M L(Standard G eneral Markup Language)的子集。
作为一种可扩展标记语言,其自描述性使得X M L本身非常适用于异构数据应用间的数据交换。
由于X M L 能够描述不规则数据,能够从不同的来源集成数据,因此将X M L作为数据的描述工具和转换工具来构造数据集成的中间件,是实现异构数据集成的较理想的解决方式[2]。
1 异构数据库集成方案本文中的异构数据库是指相关的多个数据库系统的集合,异构数据库的各个组成部分具有自身的自治性,每个局部数据库拥有自己的DBMS(可以是同为关系型数据库系统的Oracle、S Q L Server等,也可以是不同数据模型的数据库,如关系、模式、层次、面向对象数据库等),在实现数据的共享和透明访问的同时,每个数据库管理系统仍然保有自身的完整性控制和安全性控制。
法语音标详细介绍
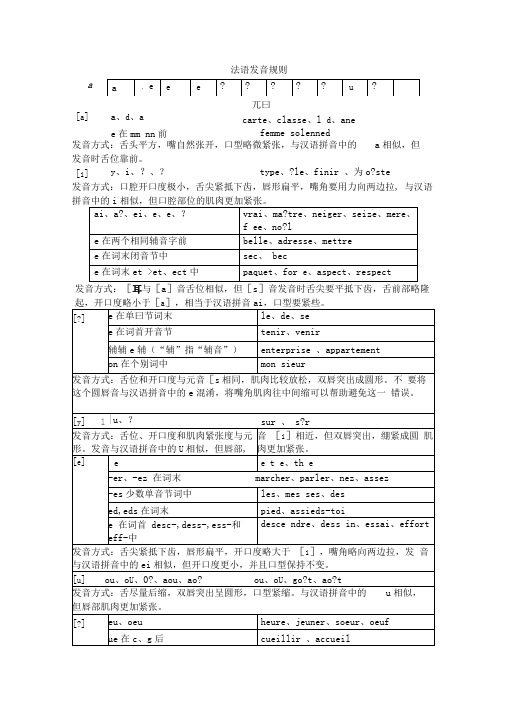
发音方式:舌头平方,嘴自然张开,口型略微紧张,与汉语拼音中的 a 相似,但 发音时舌位靠前。
发音方式:口腔开口度极小,舌尖紧抵下齿,唇形扁平,嘴角要用力向两边拉, 与汉语拼音中的相似,但口腔部位的肌肉更加紧张。
发音方式:[耳与[a ]音舌位相似,但[s ]音发音时舌尖要平抵下齿,舌前部略隆 起,开口度略小于a ,相当于汉语拼音,口型要紧些。
法语发音规则a兀曰[a ]a 、d 、a e 在mm nn 前carte 、classe 、l d 、anefemme solenned[i ]y 、i 、?、? type 、?le 、finir 、为o?stec 在个别词中 发音方式:发音方式同[k ],但声带必须振动并只有极少量的气流冲出口腔。
发音方式:舌尖抵下齿,舌后部略抬起,气流通过时小舌颤动,声带振动,发音 时关键要放松喉部,让气流通过时产生小舌振动。
second[r ]r 、rr 、r 在词末 rare 、rat 、verre 、voir [b ]b 、bb 、b 在少数词末 blond 、abb e 、club 发音方式:发音方式基本同[p ],但发音时声带振动,并只有极少量的气流冲出口腔。
发音方式:发音方式与[t ]相同,但声带必须振动并只有极少量的气流冲出口d 、dddiet e e 、addition [?]|gncampagne champagne peigne发音方式:舌尖抵上齿龈,软腭下降形成阻塞,气流同时从鼻腔和口腔冲出,同 时放下舌尖。
法语中辅音字母在词末一般不发音;除: 节奏长音:[v ]、[z ]、[r ]、[?]、[vr ]结尾的重读闭音节中,接着这些音前的元 音要读长音;这类长音受重音变化的影响;历史长音:[o ]、[?]、[至]、住]、[即、[引音在词末闭音节中有长音;这类长音 不受重音变化影响; [?] 一般无长音和重音;e 字母在词末时一般不发音;如果两个相同的辅音字母合在一起,一般合读成一个音;连颂:前一词是原来不发音的辅音,后一词是以原因开始,则前一辅音发音,并 与后一词合成一个音节; _ _ _ 连音:—代词主语后面的动词以元音或 h 开始,那么他们必须连音; 「X 的读法:一般读[ks ],如:texte ;在six 、dix 中读[s ];在deux 中不发音; 连颂时读[z ] c 、f 、l 、q 、r 、tc 在词末发音; ex ex 在辅音前ex 在兀曰前省音:少数以元音字母结尾的单音节词,常和下一词的词首元音合读成一个音节, 而省去词末的元音字母;连颂时S 、x 读[z ]音、d 读[t ]、f 读[v ]; 不发音的 e :词尾;元音前后;元辅 e 辅元;鼻化元音:元音字母加n 或m 在n 或m 后面不能再有元音字母或n 、m[?]在词末闭音节中有长音; 以[j ]结尾的重读闭音节中,紧接在[j ]前的元音读长音; [?]只出现在开音节中,永远不读重音或长音; 连词et 读[e ],他的字母t 不能和后面的词连颂; ti 的发音:ti 在元音字母前,而t 前又没有[S ]音时,读[si ]或[sj ],有[S ]时。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
OrientX:A Schema-based Native XML Database SystemXiaofeng Meng,Yu Wang,Daofeng Luo,Shichao Lu,Jing An,Y an Chen,Jianbo Ou,Yu JiangInformation SchoolRenmin University of China,Beijing,100872,Chinaxfmeng@ABSTRACTThe increasing number of XML repositories has provided the impetus to design and develop systems that can store and query XML data efficiently.Non-native XML method could not adequately be customized to support XML,native XML database will be more efficient.Most of existed XML database systems claimed that their systems are schema-independent.But we argue that schema plays an impor-tant role in managing XML data.In this paper,we intro-duce OrientX,a schema-based native XML database system. Schema information is fully investigated to enhance the effi-ciency and reliability in every module,including the multi-granularity native storage strategy,the cost-based XML op-timizer,the schema-based path index,the XML update, and the XML security,etc.KeywordsXML,database,native,schema1.INTRODUCTIONXML has self-describing characteristic,supports user de-fined tags,and is quickly becoming the new standard for data representation and exchange in the Internet.The in-creasing number of XML repositories has provided the im-petus to design and develop systems that can store and query XML data efficiently.Many alternatives to manage XML document collections are mapping the data into tradi-tional database systems[2].This introduces additional lay-ers between the logical data and its physical storage,slow-ing down both updates and query processing.None of the existing DBMS could adequately be customized to support XML,despite all claims of their vendors.Another alter-native approach for XML data management is designing a native XML database system.In native XML database, XML data is stored directly,retaining its natural tree struc-ture,and queried directly,processing query statements de-scribed by XML query languages such as XQuery/XPath on the tree structure.According to the XML schema from the bottom up,native method avoids the mapping operations Some native XML databases have appeared,for example, Timber[4],Natix[5]and so on.Most of these systems are schema-independent,that is to say,the schema of the data are not required of the system.But,OrientX believes that schema plays an important role in managing XML data and is indispensable.In fact,making good use of schema infor-mation could improve the efficiency of storing and retrieving XML a lot.In this paper,we describe OrientX,an effi-cient,schema-based native database for storing,querying and managing XML data.The key intellectual contribution of this system is to use XML schema in managing XML. We sufficiently use schema information in all the modules, including:•OrientX supports clustering storage strategy based on schema.The schema can also be used as a guide to choose the proper storage strategy automatically.•Path index is built according to the schema by sum-mering all paths in the data.•Optimizer collects the statistical information by inte-grating the schema with the histograms.•Schema information can be used to validate checking in query or updating processing.•OrientX supports role based access control.The tree of roles has the same structure with the schema in-formation,each role corresponding to a node in the schema.The rest of the paper is organized as follows.We give an overview of OrientX in Section2.In Section3,we de-scribe our multi-granularity native storage strategy.Section 4focus on path index of OrientX.Section5and section6 describe the query evaluator and query optimizor.Section 7describe a novel role based access control for OrientX.We review related work in Section8and conclude in Section9.2.ARCHITECTURE OF ORIENTXOrientX adopts client-server architecture.Client provides graphical interfaces for user managing and retrieving data. Server provides an API interface to access database.The communication between them is implemented by socket tech-nique.The overall architecture of OrientX is shown in Fig-ure1.We introduce in brief some modules here,and some important modules are focused on in the following sections.Figure1:OrientX Architecture.File Manager:The underlyingfile manager communicates withfile system to create,delete,open and close datafiles, in units offixed size such as8MB.Storage Manager:The storage manager manages the stor-age space of thefile in units of a physical page,which is set to8KB.The main tasks include:apply/free physical page, create/delete dataset,etc.Buffer Manager:There are two layers of our Buffer Mech-anism:the lower layer is page buffer,and the higher layer is record buffer.Like RDBMS,page buffer manager man-aging the physical pages with LRU(Least Recently Used) method.Unlike RDBMS,the record in OrientX is tree struc-ture,and need to be generated from the byte stream,which may cost some CPU time.Record buffer cached such tree structures to reduce the generating time.Another main tar-get of record buffer is to enable OrientX query large docu-ments.Through record buffer,documents can be read in peaces(records),and the unoccupied record can be freed to accommodate new records.In OirentX system,the record buffer is called tree-flog,which means the current cursor can jump from records to records on the XML tree.Access Manager:The access manager provides a uni-form access interface to data manager,index manager,and schema manager.Details of the buffer manager and storage manager are hidden.Data Manager:The data manager provides functions for importing,exporting,and retrieving the root of a document, etc.It formats a record(memory object)into(and from)a byte-stream.Schema Manager:Schema-independent system can im-port XML data without schema.But for accelerating query processing,the system need to extract the schema form the data.That may make the schema even more huge and com-plex than the data.Moreover,the schema has not the func-tion of constraining data,which will limit the use cases of schema,such as type checking in query and update.Like tra-ditional database,OrientX is schema-based.Schema strictly constraint the type and structure of data.So,data re-trieving,updating and storing are all under the schema’s guidance.Schema information can be used in data layout,in choice of index,in type checking,in user access control,andin query optimization.Schema in OrientX is consistent withthe XML Schema standard.Schema information is stored asa special data set in the database.Meanwhile,schema savedby tree structure is semi-structure itself,so it can restrict XML data without breaking features of XML data.Schema manager provides a uniform interface for other modules to access the schema information.Data Processor:The data processor includes query eval-uator and data updater.The former will be described in Section5.Now we introduce the later in brief.In RDBMS, relationship between the records is represented by foreign key,and in OODBMS,relationship between objects is rep-resented by object containment.While XML supports bothof them:identity reference and nesting structure.OrientX keeps the reference integrity within updating.While delet-ing a complex element,all of the nested elements and valueswill be removed.While deleting an element referenced by other elements,the corresponding reference will be found bythe value index and then deleted.The deleting of reference directly is also supported.In our storage prototype,the elements are stored as vari-able length records.Each record has its parent record’s or neighbor sibling record’s pointer.The records may change their address because of increase or decrease contents during update operations,thus leads to the changes of the pointer.In order to decrease the modification of the pointers we in-troduce the oid(object id).Each element has a unique id.We use the oid table to store the oid and its corresponding storage address.In the system the record stores its parentand children oid as the pointer rather than their storage address.Therefore if the storage address of one record is changed due to update,we just to update the oid table.To decrease the address modification of the updating record, we set a preserve factor of each page to preserve space for updating record.We supply garbage collection mechanismfor space reuse.3.ORIENTSTORE:A MULTI-GRANULARITYSTORAGE STRATEGYSeveral native storage strategies have been developed in [4,5,7,9,13].According to the granularity of the records, these storage methords can be classified into Element-Based (EB),Subtree-Based(SB)and Document-Based(DB).Boththe Lore system[7]and TIMBER[4]utilize the classic EB strategy,where each element is an atomic unit of storage andis organized in a depth-first traversal manner.Natix[5]is awell-known SB strategy.It divides the XML document treeinto subtrees according to the physical page size,such that each subtree is a record.The sizes of the subtrees are keptas close as possible to the size of the physical page.A split matrix is defined to ensure that correlated element nodes re-main clustered.Similar to the EB strategy,the records are stored in a depth-first traversal way.The storage modulein the Apache Xindice system[13]employs the DB strat-egy,whereby the entire XML document constitutes a single record.All the above native storage strategies are schema-independent,that is,they do not leverage the power ofFigure2:CSB Storage.Schema information(XML Schema or DTD)even when such information is available.The availability of schema informa-tion is crucial to data exchange applications,and query opti-mizations.We observe that schema information also plays a key role in designing efficient and effective storage strategies for XML management systems.OrientX exploits schema in-formation in the design and implementation of two storage strategies[8]:Clustering Element-Based(CEB),and Clus-tering Subtree-Based strategies.OrientX also implements the above schema-independent storage strategies:the strat-egy in Lore(We call it Depth-First Element-Based)and the strategy in Natix(We call it Depth-First Subtree-Based). Depth-First Element-Based:In Depth-First Element-Based(DEB)strategy,each element node is a record,and records are stored in Depth-First order.This is quite the same to Lore.Depth-First Subtree-Based:Depth-First Subtree-Based (DEB)strategy divides the XML document tree into sub-trees according to the physical page size,such that each subtree is a record.Records are stored in depth-first order. Clustering Element-Based:The Clustering Element-Based(CEB)storage strategy is similar to DEB as used in Lore and TIMBER in which each element node is a record. However,instead of storing the records in a depth-first traver-sal fashion,CEB clusters the element records such that records with the same TagName are placed close together. Clustering Subtree-Based:The Clustering Subtree-Based(CSB)storage strategyfirst partitions the schema graph into semantic blocks.A semantic block describes a relatively integrated logical unit.We use the following heuristic to obtain semantic blocks:A node in a schema graph is the root of a semantic block if:a).it is a root of the schema graph,or b).it has a cardinality of‘*’or‘+’,and it has children nodes.A record in the CSB storage strategy is an instance of a semantic block.All the instances of the same semantic block are clustered together.Figure2shows an example of semantic blocks and records.(a)is the Schema graph,and the dot line partitions the graph into two semantic blocks:vendor(name,book)and book(publisher,title).(b)is an instance document,and the dot line implies three records here:the records b1(p1, t1)and b2(p2,t2)are instances of the semantic block book (publisher,title),while the record v(n,b1,b2)is an instance of vendor(name,book).b1(p1,t1)and b2(p2,t2)will be clustered which implies fewer I/Os for a query.The storage strategy is chosen by the schema and the query requests.For instance,there must be few nodes hav-ing the same tag name in the documents having compa-rable size withthe schema.Then cluster-based methods will lead to high percentage of free space in pages.So the DEB or DSB strategies can save more storage space.OnFigure3:SUPEX Structure.the other hand,when the documents size is larger out than the schema,CSB and CEB methods may be more attrac-tive.Another example,if there are many text nodes in the schema,then most of query requests are location.In that case,the navigation on depth-first methods will be more efficient.Otherwise,if there are many value nodes in the schema,and most of query requests are range condition, then the system will prefer cluster-based methods.4.SUPEX:A SCHEMA-GUIDED PATH IN-DEX FOR XML DATAAn XML data set is a forest of rooted,ordered,labeled trees.Each node corresponding to an element and the edges represent elment-subelement relationships.A key issue in XML query processing is how to determine the ancestor-descendant relationship between any two elements.We adopt the numbering scheme proposed by[6].Every node in XML document tree is associated with an encode(DocIdOrder: SizeLevel).For any two given nodes n1(d1,o1:s1,l1)and n2(d2,o2:s2,l2)of a XML document tree,n1is an ancestor of n2if and only if d1=d2,o1<o2<o1+s1.This encoding scheme is applied to XML document tree and our index.As shown in Figure3,SUPEX[11]consists of two struc-tures:a structural graph(SG),and a element map(EM).SG is constructed according to the schema,and represents the structure summary of XML data.EM provides fast entries to the nodes in SG.SG is a structural summary of top level elements in the schema.So all possible path starting from the roots of XML documents conforming to special schema will appear in SG.EM is a B+tree.The key of EM is el-ement name defined in the schema,and the entries in leaf nodes include a pointer to the nodes in SG.EM is useful for finding all elements with the same tag.SG has one root node.Every node in SG except root node has a label which is a tag name defined in the schema,called E-Label.Except pointers to children nodes,every node has two pointers,one pointing to another node in SG which has the same E-Label called label pointer,another pointing to a set offixed-length records of elements having the same incoming label path from the root of the document tree as itself called element pointer.We call the recoreds set the extent of the corresponding node.Figure3shows the SUPEX structure,in which thin bro-ken line means label pointer,wide broken line means element pointer and real line means children pointer.SG is a tree when there is no cycle in the schema.When the schema is cyclic,SG is still like a tree by omitting the<results>{for $b in doc("bib.xml")/bib/book where $b/price > 50return<result>{ $b/title }{ $b//author }</result>}</results>Results( for $b in ( doc("bib.xml")), child::bib, child::book) returnLet tmp0:=( some $tmp1 in ($b, child::price)satisfiesreturn $tmp1 > 50 )returnif ( tmp0)thenresult(( $b, child::title),( $b, descendant::author) )else ( )(a) XQuery Exprssion Example(b) XAlgebra Expression Results( for $b in JOIN (name-index (bib), name-index(book) returnLet tmp0:= ( ( $b, child::price) > 50 )returnif ( tmp0)thenresult(( $b, child::title),( $b, descendant::author) )else ( )(C) Rewritten Query PlanFigure4:Query Processing Example.edges pointing to ancestor nodes.To keep the equivalence between the schema and SG,a tag is used to mark the cycle. To facilitate the query processing,we associate each node with a encode like(Order:Size,Tag:BeginOrder).Tag can be one of three values:0,1,or2.0indicates that the corresponding node is not in a cycle.1indicates that the node is in a cycle,and2means that the node is in a subtree rooted at a node of tag1.Base on this encoding scheme,we can judge whether any two nodes in SG have the ancestor-descendant relationship.SUPEX supports two basic queries:(1)given a tag,all elements with this tag can be obtained by the lookup of EM.(2)Simple label paths from the root of document can be matched by traversal of SG starting from the root.In addition to these basic structural relationships,our in-dex can support partial label path matching.For label paths like‘//E1/E2/.../En’,we needn’t traverse the index graph to get result nodes.By the lookup of EM,we can obtain the head node of lists with E-Lable E1.For each node in this list,the subtree rooted at it will be traversed tofind nodes matching‘E1/E2/.../E’.So only a part of SG will be traversed to get the result.This will greatly reduce the cost of partial label path matching.5.XALGEBRA BASED QUERY EV ALUA-TIONXML Query Enginee,the most important component in OrientX system,supports the Xquery1.0recommended by W3C Work Group.The query engine does not cover all the features of XQuery[12]but captures its essence.The Core syntax[1]defines the formal semantics of XQuery and provides a naive processing model.XAlgebra is similar to the XQuery formal semantics,but improves it in several aspects:a)Core syntax decomposes a path expression into a series of for-nest-loops,puts a distinct-operator after each evaluation of path expression.XAl gebra only decomposes a path expression onto a series of simple paths,which can be processed by matured path matching techniques,rather than naive nest-loop manner.b)Following Core syntax as the processing plan,nest-loop is the only choice for process-ing,and it is hard for Core syntax to take the advantages of storage,index,and optimization techniques on DBMS. Furthermore,it will show a inefficiency for evaluating a query on large XML documents.XAlgebra introduces some smart processing methods such as sort-merge join,predi-cate pushing-down,unnesting,etc,to improve the efficiency of processing.This will improve the efficiency a lot.c)Since OrientX is schema-dependent,the schema contains the in-formaiton of the document structure and the node type def-inition.These information can be helpful to improve theefficiency of type checking before query processing.More details about XAlgebra is out of the scope of this paper.For the reason of space,we only propose the sketchof query evaluation with a simple example.The query processingflow is as following.An input queryisfirst parsed into a syntax tree and transformed into an internal expression represented in XAlgebra in the parser analyzer.The query in internal expression is then passed tothe optimizer.In the optimizer,the original query plan is reorganized based on a set of rewriting rules and statistical information.The optimization result,a physical query planis constructed and it will be evaluated by the evaluation engine through a set of call to the index manager and data manager.At last,the evaluation result,an XML tree may beoffered to advance development through the OrientX API,or materialized to an XML document.Figure4(a)is an example of XQuery expression,which liststhe title and authors,grouped by result element for each book with price larger than100in the bibliography.After parsing and analyzing,the query is transformed into the internal expression shown in Figure4(b).Note that,eachpath expression in Figure4(a)is decomposed as a list of simple paths.Assuming name index for bib and book elements are avail-able,then all bib and book elements can be retrieved by index;and a containment join is used to match the parent-child relationships among the bib and book elements.Notethat only a document(bib.xml)is referred in the query, hence the simple path doc(‘bib.xml’)can be omitted here,for all the data to be accessed from the document root. Therefore the expression‘for$b in(doc(‘bib.xml’), child::bib,child::book)’in Figure4(b)can be rewrit-ten as‘for$b in JION(name-index(bib),name-index (book))’.Assume that there is one and only one price element existing under each book element,then the some-quantify expression can be optimized as‘($b,child::price) >50’.After optimization,the query plan infigure4(b)is rewritten as the one shown infigure4(c).6.HISTOPER:A HISTOGRAM BASED QUERYOPTIMIZERHistOper supports cost based query optimization.HistOperFigure5:Statistical Information Model.can estimate the cost of the paths or subpaths in the query, andfind an optimized execution plan.Selectivity estimation of path expressions in querying XML data plays an important role in query optimization.A path expression may contain multiple branches with predicates, each of which having its impact on the selectivity of the entire query.Previous methods of selectivity estimation have not taken into consideration the correlation between attribute values and their hierarchical positions,and assume instead that the selectivity of attribute values on different nodes and structures is independent and uniform.HistOper builds an novel statistical information integrat-ing the histograms into the schema information,which can capture the correlations in the XML data.Unlike most his-togram method that process the structure and the value in-dependently,we propose a novel method based on2-dimensional value histograms to estimate the selectivity of path expres-sions embedded with predicates.The value histograms cap-ture the correlation between the structures and the valuesin the XML data.Another type of histograms,coding his-tograms,keeps track of the position distribution.Figure5is an example of statistical information.Abstractly,our sta-tistical information model is a node-labeled,directed graph structure G=(N,E,D,R,L),where each node n∈N isan element or a value.Each element has an identity Eid. Each edge e∈E corresponds to the containment relation-ship between the nodes.D is a region maintains the countof the elements or the domain of the values.R is a recursive nesting tag marking if the node is in the recursive circle. Each element node has a link l∈L points to the coding histograms of the node,if the node have value as its child, the VH are also exist.A B+tree index is accepted tofind the histograms with an Eid.We define six basic operations on the value histograms as well as on the coding histograms:V,S,D,A,PA,and PD. Thefirst two,V and S,are used to study value correlation, and the rest are for hierarchical correlation.We then con-struct a cost tree based on such operations.The selectivityof any node(or branch)in a path expression can be esti-mated by executing the cost tree.Figure6shows an exam-ple cost tree for the selectivity of r in the path//r/d[price<100].First,we can get the preliminary coding histogram (SH)by applying the V operation on the VH of the value node and the value domain of the predicate.Then we can use the S operation on the SH and the original CH of the value node to get the new CH,which only counts the nodes satisfying the predicate ineach grid.At last,two Aopera-tions are used to get the selectivity of r inthe path.Thecost tree can be simplifiedby some rules if we know somenodes in the path are not self-nested through the schema information.CH(003)VH(003)Figure6:Cost Tree.<bookstore><book><name>xmlac</name><author><name>xxx</name></author></book><bookstore>Figure7:Mapping Role to Node.7.NODE-MAPPING ROLE BASED ACCESSCONTROLBecause of the different data model between relation data and XML data,the access control mechanism in relational database is not capable of managing XML data any more. Some important aspects need to be reconsidered,such as the granularity of access control,the semantic of authority,the relation among the rights on relative node in XML struc-ture and so on.At the same time,large data capacity and alteration of the data also should be care of.RBAC has just been approved to be the member of ANSI.It makes ac-cess control powerful and simple.We extend the RBAC for OrientX,calling Node-Mapping Role Based Access Control. We observed that role hierarchy and the XML data have some similarities.For example,there is an XML data section about a bookstore(Shown in Figure7).If we define that Manager role can access all the information of this section and Sailor role can access just the book name,then we can map the Manager role to the node bookstore and the Sailor role to the node name in the schema of the data(Shown in Figure7).In formalization,if role A is the superior of role B,the data set which role A can access should be the superset of the data set which role B can access.Then we can map the two roles to two nodes in XML structure which has ancestor-descendant relation(ancestor is the superior and descendant is the junior).A role defined the access rules of a subtree of the Schema.In this way we can be awarded both the excellence of Role and the convenience of XML data access controlling.For example,we have used the Dynamic Sep-aration of Duty Relation(DSD)characteristic to solve the problem of illegal association information accessing[3].A role is a set of3-uary tuples:R={Node,Context, Action},where Node denotes the tag name of the root of thesubtree in XML document;Context is a path and defines the unique position of the node in the schema,and the Action represents a collection of allowed operation on the node, includeing read,insert,delete and update.The roles can be awarded to the user in two ways:positive and negative.The positive roles assign the actions user can do,and the negative roles assign the actions user cannot do.Based on the compatibility,there are two kinds of roles: general roles and DSD roles.A user can choose many general roles during one session,and only one DSD role during one session.Introducing negative roles enable the user assigning the rulesflexibly.8.RELATED WORKThere are several Native XML Database systems,for ex-ample,Natix[5],Timber[4]and Tamino[9].Natix is attrac-tive of its storage model.XML documents are stored like thefile trees in operating system,and the size of subtrees can be limitedflexibly,XML data fragment insertion and deletion are also supported.But Natix does little support to XML schema.And its query performance maybe is inef-ficient,as it use D-Join step by step to match XPEs(also be limited with its index structure),which is time-consuming. Additional,Natix does not pay much attention to interme-diate result and nested query translation,which are pivotal for XQuery implementation.Timber is another mature Native XML Database,which brings forward the Pattern tree based XQuery processing method for thefirst time,and it proposed a proper log-ical algebra for XQuery.But its storage is borrowed from the Object-oriented database Shore,which reduces its query performance.Tamino is a leading commercial native XML database,yet descriptions of its architecture are fairly sketchy.Current native XML database systems are all schema-independented,so that they can not fully use schema to enhance the efficiency and ability of the system.OrientX is schema-based,and get the high overall performance of the system.9.CONCLUSION AND DISCUSSIONIn this paper,we described the system structure and de-sign of OrientX,a schema-based native XML database pro-posed by Renmin University of China.Right now,the stor-age,query and index parts mentioned in this paper have already been implemented,and the query optimization,ac-cess control and update parts are under developing and will befinished soon.Next,we will publish OrientX to several high-level applications,such as E-government,news(base on NewsML),medication management and civil aviation sys-tem.During the system developing,wefind some open problems for native XML databases:•Is XQuery suitable for native XML database?Set-at-a-time processing method embodies the efficiency of traditional database.But it is hard to apply any set-at-a-time processing method on XQuery and its core syntax for its programming language style.•Tree based algebra is a set-at-a-time method on XML data.But it is inadequate for expressing complex query request,especially for nesting query.•Cost-based optimization method is a hot research topic for native XML database.But works on logical opti-mization seems few.A set of heuristic rules for accel-erating the query is urgently needed.The availability of tradition rules such as predicate push down,need to be proved by a great deal of experiments.•Without the semantic constraint in the schema,up-dating XML data will become unsafe.On the other hand,a strict schema will limit theflexibility of XML data.How to keep the balance?After all,native XML database is a brand-new research field,and there are so many problems for us to deal with.10.REFERENCES[1]B.Choi,M.Fernandez and J.Simeon.The XQueryFormal Semantics:A Foundation for Implementationand Optimization.Technical Report MS-CIS-02-25,University of Pennsylvania,2002.[2]D.Florescu,D.Kossman(1999)Storing and queryingXML data using an RDBMS.IEEE Data Eng Bull22(3),27-34.[3]V.Gowadia,C.Farkas.RDF metadata for XMLaccess control.In Proc.of2003ACM workshop onXML security.39-48.[4]H.V.Jagadish,Shurug AL-Khalifa,et al.TIMBER:A Native XML Database.Technical Report,University of Michigan,April2002.[5]C.-C.Kanne and G.Moerkotte.Efficient Storage ofXML data.In Proc.of16th ICDE.San Diego,California,USA,February2000.198.[6]Q.Li,B.Moon.Indexing and Querying XML Data forRegular Path Expressions,In Proc.of27thVLDB,Roma,Italy,2001[7]J.McHugh,S.Abiteboul,R.Goldman,D.Quass,andJ.Widom.Lore:A Database Management System for Semistructured Data.SIGMOD Record,Vol.26(3):54-66,September1997.[8]X.Meng,D.Luo,M.Lee and J.An.OrientStore:ASchema Based Native XML Storage System.In:Proc.of VLDB2003.Berlin,Germany.1057-1060[9]H.Schoning.Tamino-A DBMS Designed for XML.In Proc.of17th ICDE.Heidelberg,Germany,April2001.149-154.[10]I.Tatarinov,Z.G.Ives,A.Y.Halevy,D.s.Weld.Updating XML.In Proc.of2001SIGMODInternational Conference on Management of Data,Santa Barbara,CA,USA,May2001.[11]J.Wang,X.Meng and S.Wang.SUPEX:ASchema-Guided Path Index for XML Data.DoctoralPoster.In:Proc.of28th VLDB Conf.Hong Kong,2002.[12]XQuery1.0:An XML Query Language,W3C WorkingDraft,April2002.Available At/TR/xquery/[13]Apache Xindice./xindice/。