第二章第一课百度算法-蜘蛛爬行原理解析
搜索引擎spider爬虫(蜘蛛)原理

搜索引擎spider爬⾍(蜘蛛)原理做SEO的⼈应该要对搜索引擎的基本原理有⼀些了解,从搜索引擎发现⽹址到该页⾯拥有排名,以及后续更新整个过程中,搜索引擎到底是怎么⼯作的?你都需要了解。
对于专业的算法不必进⾏深⼊的研究,但是对于搜索引擎⼯作中的⽣命⼒和算法原理要有个简单的认知,这样才能更有效地开展SEO⼯作,知其然也要知其所以然;当然也有⼀些朋友不懂这些,照样做昨有声有⾊,但是有对搜索引擎⼯作原理,懂总⽐不懂好⼀点。
以往的SEO书藉中对这内容讲解都⽐较简单,希望在些能够尝试结合SEO实际⼯作和现象,更进⼀步剖析⼀下搜索引擎的⼯作原理,其实当你了解了搜索引擎的⼯作流程、策略和基本算法后,就可以在⼀定程序上避免因为不当操作⽽带来的不必要处罚,同也可以快速分析出很多搜索引擎搜索结果异常的原因。
有搜索⾏为的地⽅就有搜索引擎,站内搜索、全⽹搜索、垂直搜索等都⽤到搜索引擎;接下来,本⽂会根据从业认知,讨论⼀下全⽂搜索引擎的基本架构。
百度、⾕歌等综合搜索巨头肯定有着更为复杂的架构和检索技术,但宏观上基本原理都差不多的。
搜索引擎的⼤概架构如图2-1所⽰。
可以分成虚线左右两个部分:⼀部分是主动抓取⽹页进⾏⼀系列处理后建⽴索引,等待⽤户搜索;另⼀部分是分析⽤户搜索意图,展现⽤户所需要的搜索结果。
搜索引擎主动抓取⽹页,并进⾏内容处理、索引部分的流程和机制⼀般如下:1.派出spider按照⼀定策略把⽹页抓回到搜索引擎服务器;2.对抓回的⽹页进⾏链接抽离、内容处理,削除噪声、提取该页主题⽂本内容等;3.对⽹页的⽂本内容进⾏中⽂分词、去除停⽌词等;4.对⽹页内容进⾏分词后判断该页⾯内容与已索引⽹页是否有重复,剔除重复页,对剩余⽹页进⾏倒排索引,然后等待⽤户的检索。
当有⽤户进⾏查询后,搜索引擎⼯作的流程机制⼀般如下:1.先对⽤户所查询的关键词进⾏分词处理,并根据⽤户的地理位置和历史检索特征进⾏⽤户需求分析,以便使⽤地域性搜索结果和个性化搜索结果展⽰⽤户最需要的内容;2.查找缓存中是否有该关键词的查询结果,如果有,有为最快地呈现查询,搜索引擎会根据当下⽤户的各种信息判断其真正需求,对缓存中的结果进⾏微调或直接呈现给⽤户;3.如果⽤户所查询的关键词在缓存中不存在,那么就在索引库中的⽹页进⾏调取排名呈现,并将该关键词和对应的搜索结果加⼊到缓存中;4.⽹页排名是⽤户的搜索词和搜索需求,对索引库中⽹页进⾏相关性、重要性(链接权重分析)和⽤户体验的⾼低进⾏分析所得出的。
百度蜘蛛爬行原理

百度蜘蛛爬行原理百度蜘蛛,是百度搜索引擎的一个自动程序。
它的作用是访问收集整理互联网上的网页、图片、视频等内容,然后分门别类建立索引数据库,使用户能在百度搜索引擎中搜索到您网站的网页、图片、视频等内容。
(1)通过百度蜘蛛下载回来的网页放到补充数据区,通过各种程序计算过后才放到检索区,才会形成稳定的排名,所以说只要下载回来的东西都可以通过指令找到,补充数据是不稳定的,有可能在各种计算的过程中给k掉,检索区的数据排名是相对比较稳定的,百度目前是缓存机制和补充数据相结合的,正在向补充数据转变,这也是目前百度收录困难的原因,也是很多站点今天给k了明天又放出来的原因。
(2)深度优先和权重优先,百度蜘蛛抓页面的时候从起始站点(即种子站点指的是一些门户站点)是广度优先抓取是为了抓取更多的网址,深度优先抓取的目的是为了抓取高质量的网页,这个策略是由调度来计算和分配的,百度蜘蛛只负责抓取,权重优先是指反向连接较多的页面的优先抓取,这也是调度的一种策略,一般情况下网页抓取抓到40%是正常范围,60%算很好,100%是不可能的,当然抓取的越多越好。
百度蜘蛛在从首页登陆后抓取首页后调度会计算其中所有的连接,返回给百度蜘蛛进行下一步的抓取连接列表,百度蜘蛛再进行下一步的抓取,网址地图的作用是为了给百度蜘蛛提供一个抓取的方向,来左右百度蜘蛛去抓取重要页面,如何让百度蜘蛛知道那个页面是重要页面?可以通过连接的构建来达到这个目的,越多的页面指向该页,网址首页的指向,副页面的指向等等都能提高该页的权重,地图的另外一个作用是给百度蜘蛛提供更多的链接来达到抓去更多页面的目的,地图其实就是一个链接的列表提供给百度蜘蛛,来计算你的目录结构,找到通过站内连接来构建的重要页面。
补充数据到主检索区的转变:在不改变板块结构的情况下,增加相关连接来提高网页质量,通过增加其他页面对该页的反向连接来提高权重,通过外部连接增加权重。
如果改变了板块结构将导致seo的重新计算,所以一定不能改变板块结构的情况下来操作,增加连接要注意一个连接的质量和反向连接的数量的关系,短时间内增加大量的反向连接将导致k站,连接的相关性越高,对排名越有利。
蜘蛛爬行原理

蜘蛛爬行原理搜索引擎蜘蛛我们通常称它为机器人,是一种能够自己抓取网站,下载网页的程序。
它可以访问互联网上的网页、图片、视频等内容,喜欢收集对用户有用的内容。
百度蜘蛛,它的作用是访问互联网上的HTML网页,建立索引数据库,使用户能在百度搜索引擎中搜索到您网站的网页。
可见,SEO技术网站优化少不了蜘蛛的爬行,而蜘蛛的爬行原理,爬行习惯,从一个链接访问,到所有很多人认为的是搜索引擎的爬行,是越靠近左上角的链接权重越高。
其实这个也有一定的误区,链接越靠前也算是蜘蛛越容易爬行,这是对的,但是在与网站的管理网站的分布,布局来说很多方面上没有做到这一点,其中最为流行的div+css是可以实现的,从右到左,从下到上的布局。
而蜘蛛对与新站老站的爬行习惯爬行的深度是不一样的,新站可以说爬行的非常浅,但是对于一个权重很高的网站爬行的深度抓取的信息越来越多,这对于新站竞争老站有一定的难度。
可见,对于蜘蛛每次来爬行你的网站的时候,其中他们的深度与内容都是一致的,这会导致蜘蛛爬行的频率越来越低,权重也不会上去,你知道权重的提升也是蜘蛛爬行的次数。
如何改进,改进层次结构低层次,内容的改变,所以这一点需要网站的更新来完成,每次蜘蛛来网站的时候收录的情况爬行的内容是不一样的,文字的数量,文字的不同文章的增多,内容的丰富越多给你一定的权重。
完成每一个页面都有一个较高的权重。
一般来说百度搜索引擎是每周更新,网页重要性有不同的更新频率,频率在几天至一月之间,baiduspider会重新访问和更新一个网页。
上面内容的整理和分析,内链和目录调整,达到收录率提升,也会蜘蛛更好的访问到你的网站。
搜索引擎是人为的技术。
我们也是需要的这些数据的分析,应能更好的分析数据,完成我们站长的需求,百度蜘蛛的再次爬行,可以促进你网站的价值观,一个网站的完成的网站需要做的就是这些。
蜘蛛的爬行完全是需要新奇的东西,新奇的首页,蜘蛛才会经常来到你的网站,也会给你一定的排名。
搜索引擎Web Spider(蜘蛛)爬取的原理分享

搜索引擎Web Spider(蜘蛛)爬取的原理分享一、网络蜘蛛基本原理网络蜘蛛即WebSpider,是一个很形象的名字。
把互联网比方成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。
网络蜘蛛是通过网页的链接地址来寻觅网页,从网站某一个页面(通常是首页)开头,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻觅下一个网页,这样向来循环下去,直到把这个网站全部的网页都抓取完为止。
假如把囫囵互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上全部的网页都抓取下来。
对于搜寻引擎来说,要抓取互联网上全部的网页几乎是不行能的,从目前公布的数据来看,容量最大的搜寻引擎也不过是抓取了囫囵网页数量的百分之四十左右。
这其中的缘由一方面是抓取技术的瓶颈,薹ū槔械耐常行矶嗤澄薹ù悠渌车牧唇又姓业剑涣硪桓鲈蚴谴娲⒓际鹾痛砑际醯奈侍猓绻凑彰扛鲆趁娴钠骄笮∥0K计算(包含),100亿网页的容量是100×2000G字节,即使能够存储,下载也存在问题(根据一台机器每秒下载20K计算,需要340台机器不停的下载一年时光,才干把全部网页下载完毕)。
同时,因为数据量太大,在提供搜寻时也会有效率方面的影响。
因此,许多搜寻引擎的网络蜘蛛只是抓取那些重要的网页,而在抓取的时候评价重要性主要的依据是某个网页的链接深度。
在抓取网页的时候,网络蜘蛛普通有两种策略:广度优先和深度优先(如下图所示)。
广度优先是指网络蜘蛛会先抓取起始网页中链接的全部网页,然后再挑选其中的一个链接网页,继续抓取在此网页中链接的全部网页。
这是最常用的方式,由于这个办法可以让网络蜘蛛并行处理,提高其抓取速度。
深度优先是指网络蜘蛛会从起始页开头,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。
这个办法有个优点是网络蜘蛛在设计的时候比较简单。
两种策略的区分,下图的解释会越发明确。
百度蜘蛛爬行原理

百度蜘蛛爬行原理百度蜘蛛,是百度搜索引擎的一个自动程序。
它的作用是访问收集整理互联网上的网页、图片、视频等内容,然后分门别类建立索引数据库,使用户能在百度搜索引擎中搜索到您网站的网页、图片、视频等内容蜘蛛抓取第一步爬行和抓取爬行到你的网站网页,寻找合适的资源。
蜘蛛它有一个特性,那就是他的运动轨迹通常都是围绕着蜘蛛丝而走的,而我们之所以将搜索引擎的机器人命名为蜘蛛其实就是因为这个特性。
当蜘蛛来到你的网站之后,它就会顺着你网站中的链接(蜘蛛丝)不断的进行爬行,因此如何让蜘蛛能够更好的在你的网站中进行爬行就成为了我们的重中之重。
抓取你的网页。
引导蜘蛛的爬行这只是一个开始,一个好的开始意味着你将有一个高起点。
通过自己的内链设计,使得网站中不存在任何死角,蜘蛛可以轻松的到达网站中的每一个页面,这样蜘蛛在进行第二步工作——抓取的时候,将会事半功倍。
而在这一步抓取的过程中我们又需要注意的就是要精简网站的结构,将那些不必要、不需要的多余代码去掉,因为这些都将会影响蜘蛛抓取网页的效率与效果。
另外还需要大家注意的事情就是通过我们都不建议网站中放入FLASH,因为蜘蛛对于FLASH是不好抓取的,过多的FLASH会导致蜘蛛放弃抓取你网站的页面。
蜘蛛抓取第二步存储抓取了链接所对应的页面,会把这些页面的内容存储到搜索引擎的原始数据库里面。
会抓取一些文本内容。
网站在优化的时候不要盲目的给网站添加一些图片或者动画flash文件。
这样不利搜索引擎的抓取。
这类对排没有太大价值,应该多做内容。
抓取到搜索引擎原始数据中,不代表你的网站内容就一定会被百度采纳。
搜索引擎还需要再进行下一步处理。
蜘蛛抓取第三步预处理搜索引擎主要还是以(文字)为基础。
JS,CSS程序代码是无法用于排名。
蜘蛛将第一步中提取的文字进行拆分重组,组成新的单词。
去重处理(去掉一些重复的内容,搜索引擎数据库里面已经存在的内容)要求我们在做SEO优化的人员在优化网站内容的不能完全抄袭别人的站点内容。
蜘蛛强引的原理

蜘蛛强引的原理蜘蛛强引的原理一、什么是蜘蛛强引?蜘蛛强引(Spider Trapping)是指一种通过对搜索引擎爬虫的行为进行干扰,从而达到改善网站排名的一种黑帽SEO技术。
二、为什么要使用蜘蛛强引?在SEO优化中,网站的排名是非常重要的。
而搜索引擎爬虫(也称为“蜘蛛”)会根据一些算法来评估网站的质量和价值,从而决定其排名。
因此,如果能够通过干扰爬虫行为来提高网站质量和价值的评估结果,就可以改善网站排名。
三、如何实现蜘蛛强引?1. 重定向重定向是指将一个URL地址重定向到另一个URL地址。
在实现重定向时,可以将搜索引擎爬虫重定向到一个与用户所看到内容不同的页面上,从而干扰其对页面内容进行评估。
2. 隐藏链接隐藏链接是指将链接放置在页面代码中但不显示出来。
这样做可以让搜索引擎爬虫认为该页面包含更多有用信息,并提高其对页面内容进行评估的分数。
3. 动态页面动态页面是指通过动态生成HTML代码来呈现页面内容。
在实现动态页面时,可以将搜索引擎爬虫重定向到一个静态页面上,从而干扰其对页面内容进行评估。
4. 伪造内容伪造内容是指将一些与原始内容无关的信息添加到页面中,例如关键词堆砌、隐藏文本等。
这样做可以让搜索引擎爬虫认为该页面包含更多有用信息,并提高其对页面内容进行评估的分数。
四、蜘蛛强引的原理蜘蛛强引的原理是通过干扰搜索引擎爬虫对网站的评估来改善网站排名。
具体实现方式包括重定向、隐藏链接、动态页面和伪造内容等。
这些技术可以让搜索引擎爬虫认为该网站包含更多有用信息,并提高其对网站质量和价值进行评估的分数,从而改善网站排名。
五、蜘蛛强引的风险尽管蜘蛛强引可以改善网站排名,但它也存在一定的风险。
首先,使用这种技术可能会违反搜索引擎的规则,从而导致被惩罚或封禁。
其次,蜘蛛强引可能会降低网站的用户体验和可用性,从而影响网站的流量和转化率。
六、如何避免蜘蛛强引的风险?为了避免蜘蛛强引的风险,建议网站管理员应该尽量遵守搜索引擎的规则,并采用正规的SEO优化技术来改善网站排名。
网络爬行蜘蛛定义及原理讲解

网络爬行蜘蛛定义及原理讲解当“蜘蛛”程序出现时,现代意义上的搜索引擎才初露端倪。
它实际上是一种电脑“机器人”(),电脑“机器人”是指某个能以人类无法达到的速度不间断地执行某项任务的软件程序。
由于专门用于检索信息的“机器人”程序就象蜘蛛一样在网络间爬来爬去,反反复复,不知疲倦。
所以,搜索引擎的“机器人”程序就被称为“蜘蛛”程序。
网络蜘蛛什么是网络蜘蛛呢?网络蜘蛛即,是一个很形象的名字。
把互联网比喻成一个蜘蛛网,那么就是在网上爬来爬去的蜘蛛。
网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
这样看来,网络蜘蛛就是一个爬行程序,一个抓取网页的程序。
起源发展要说网络蜘蛛的起源,我们还得从搜索引擎说起,什么是搜索引擎呢?搜索引擎的起源是什么,这和网络蜘蛛的起源密切相关。
搜索引擎指自动从英特网搜集信息,经过一定整理以后,提供给用户进行查询的系统。
英特网上的信息浩瀚万千,而且毫无秩序,所有的信息象汪洋上的一个个小岛,网页链接是这些小岛之间纵横交错的桥梁,而搜索引擎,则为你绘制一幅一目了然的信息地图,供你随时查阅。
搜索引擎从年原型初显,到现在成为人们生活中必不可少的一部分,它经历了太多技术和观念的变革。
十四年前年的一月份,第一个既可搜索又可浏览的分类目录上线了。
在它之后才出现了雅虎,直至我们现在熟知的、百度。
但是他们都不是第一个吃搜索引擎这个螃蟹的第一人。
从搜索上的文件开始,搜索引擎的原型就出现了,那时还未有万维网,当时人们先用手工后用蜘蛛程序搜索网页,但随着互联网的不断壮大,怎样能够搜集到的网页数量更多、时间更短成为了当时的难点和重点,成为人们研究的重点。
爬行及练习
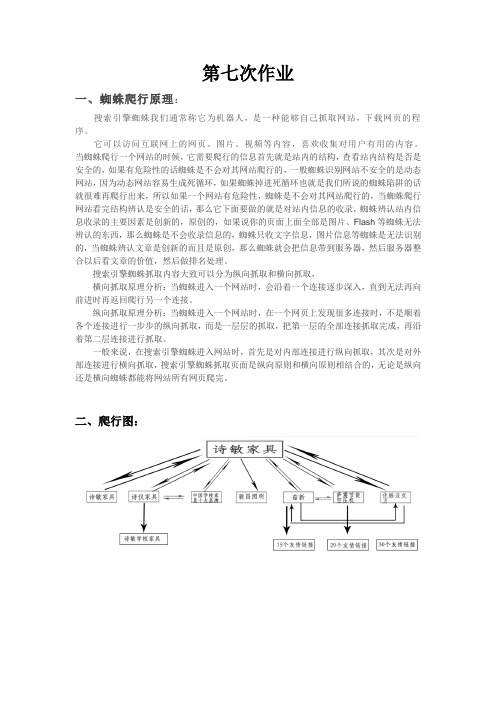
第七次作业
一、蜘蛛爬行原理:
搜索引擎蜘蛛我们通常称它为机器人,是一种能够自己抓取网站,下载网页的程序。
它可以访问互联网上的网页、图片、视频等内容,喜欢收集对用户有用的内容。
当蜘蛛爬行一个网站的时候,它需要爬行的信息首先就是站内的结构,查看站内结构是否是安全的,如果有危险性的话蜘蛛是不会对其网站爬行的,一般蜘蛛识别网站不安全的是动态网站,因为动态网站容易生成死循环,如果蜘蛛掉进死循环也就是我们所说的蜘蛛陷阱的话就很难再爬行出来,所以如果一个网站有危险性,蜘蛛是不会对其网站爬行的,当蜘蛛爬行网站看完结构辨认是安全的话,那么它下面要做的就是对站内信息的收录,蜘蛛辨认站内信息收录的主要因素是创新的,原创的,如果说你的页面上面全部是图片、Flash等蜘蛛无法辨认的东西,那么蜘蛛是不会收录信息的,蜘蛛只收文字信息,图片信息等蜘蛛是无法识别的,当蜘蛛辨认文章是创新的而且是原创,那么蜘蛛就会把信息带到服务器,然后服务器整合以后看文章的价值,然后做排名处理。
搜索引擎蜘蛛抓取内容大致可以分为纵向抓取和横向抓取,
横向抓取原理分析:当蜘蛛进入一个网站时,会沿着一个连接逐步深入,直到无法再向前进时再返回爬行另一个连接。
纵向抓取原理分析:当蜘蛛进入一个网站时,在一个网页上发现很多连接时,不是顺着各个连接进行一步步的纵向抓取,而是一层层的抓取,把第一层的全部连接抓取完成,再沿着第二层连接进行抓取。
一般来说,在搜索引擎蜘蛛进入网站时,首先是对内部连接进行纵向抓取,其次是对外部连接进行横向抓取,搜索引擎蜘蛛抓取页面是纵向原则和横向原则相结合的,无论是纵向还是横向蜘蛛都能将网站所有网页爬完。
二、爬行图:
三、练习搜索引擎高级指令:。
搜索引擎(百度)工作原理——蜘蛛爬行和抓取

搜索引擎(百度)工作原理——蜘蛛爬行和抓取引擎的工作过程一般分为三个阶段:爬行和抓取:通过引擎蜘蛛跟踪链接和访问页面,抓取内容,存入数据库。
预处理:引擎抓取的数据,会进行文字提取,中文分词,索引,倒排索引,方便日后排名程序调用。
排名:用户输入查询关键以后,排名程序会调用索引库数据,按相关性生成结果页面。
一、蜘蛛爬行和抓取是引擎的第一步,收集数据的过程。
引擎是爬行和访问页面的自动程序收集数据,这种程序也叫蜘蛛或者机器人。
引擎蜘蛛访问网站类似于我们浏览网站,也可以理解蜘蛛爬行就像司令部放出去的收集情报员一样。
引擎蜘蛛访问网站是和普通用户基本一致的,蜘蛛程序访问页面以后,服务器会返回HTML代码,蜘蛛程序会把代码,出入原始页面数据库,引擎会同时使用很多蜘蛛程序提高抓取数据的效率。
引擎为了提高爬行和抓取速度,都使用多个蜘蛛进行发布和爬行,情报员多了,自然信息收集的就会更多,工作效率也就更高了。
蜘蛛访问网站时,会先访问网站的robots.txt文件,如果robots.txt文件里头有止访问的文件或者目录,蜘蛛就不会抓取。
其实就是入乡随俗,比如:回族人不吃猪肉,你虽然是客人,去了回族地域,也需要遵守当地习俗,就是这个意思。
引擎蜘蛛也是有自己的用户代理名称的,就好像警察的工作证一样,执行公务的时候都要先把证件拿出来,蜘蛛也是一样的,站长可以通过日志文件看到蜘蛛的用户代理,从而识别出到底是什么网站的引擎蜘蛛。
360蜘蛛:Mozilla5.0(Windows;U;Windows NT5.1;zh-CN;)Firefox/1.5.0.11;360Spider二、跟踪链接为了爬取更多的页面蜘蛛,都是靠跟踪网页的的链接爬取的,从一个页面到另一个页面,蜘蛛从任何一个页面出发都能爬取到网上所有的页面,不过,网站的机构复杂,信息太多,所有蜘蛛爬行也是有一定策略的,一般是2中深度优先和广度优先。
从理论上讲,只要给蜘蛛足够的时间,就能爬完所有网络内容。
搜索引擎蜘蛛爬行原理和规律分析

搜索引擎蜘蛛爬行原理和规律分析搜索引擎蜘蛛爬行原理和规律分析网站的收录前期工作是要让搜索引擎蜘蛛到网站上来抓取内容,如果搜索引擎蜘蛛都不来网站,那网站的内容再多在丰富也是没有用的。
整个互联网是有连接组成的,形如一张网,儿搜索引擎的抓取程序就是通过这些一个一个的连接来抓取页面内容的,所以形象的叫做蜘蛛。
(网络爬虫)。
是搜索引擎的一个自动的抓取页面的程序。
搜索引擎蜘蛛通过跟踪连接访问页面。
获得页面HTML代码存入数据库。
爬行和抓取是搜索引擎工作的第一步,也是全成数据收集的任务。
然后就是预处理以及排名,这些都依赖非常机密的算法规则来完成。
对于站长来说,网站的第一步就是解决收录问题,我们每天都在更新,可有时就是不收录。
我们要想得到收录和蜘蛛的青睐,你就要懂得蜘蛛的爬行原理和规律。
一般搜索引擎蜘蛛抓取内容的时候,大致可以分为纵向抓取和横向抓取两种。
纵向抓取原理分析:3、从网站运营维护的角度来说,网站运营人员则可以对网站方便的进行管理维护,有利于各种网络营销方法的应用,并且可以积累有价值的网络营销资源,因为只有经过网站优化公司设计的企业网站才能真正具有网络营销导向,才能与网络营销策略相一致。
SEO网络优化具体操作步骤第一步关键词分析根据企业行情,分析相关关键词的搜索热度,筛选出最合适您网站的热门关键词第二步网站诊断针对网站结构,网站功能,网站内容等基本要素进行全面分析,提出问题以及该井建议第三步网站优化根据诊断结果,确定核心关键词对网站进行整体搜索引擎优化第四步网站登录向国内外各大搜索引擎提交您的网站第五步搜索排名优化采取专业SEO优化策略,提高您网站在搜索引擎上的排名第六步搜索排名维护根据搜索排名算法的变化,做出相应调整维护您网站的排名原创文章不收录的原因文章的可看性需要注意一下几点:1、切记内容原创但不独特。
搜索引擎不是你原创就会一定收录,你写的文章和网络上的文章相同的地方太多了,搜索引擎也是能分析出来的,是在做不出原创伪原创也可以,以适应独特的内容为铺。
蜘蛛爬行原理

蜘蛛爬行原理蜘蛛的原理蜘蛛是机器人,但是不了解蜘蛛最喜欢的是什么?其实要想和蜘蛛打好关系,只要知道它们喜欢什么就可以了,因为蜘蛛是机器人,所以在它们的眼里所有的规矩都是定死的,所以就不会像人一样需要各种方法和它打好关系,所以只要了解蜘蛛的脾性就可以有方法与蜘蛛打好关系,当蜘蛛爬行一个网站的时候,它需要爬行的信息首先就是站内的结构,查看站内结构是否是安全的,如果有危险性的话蜘蛛是不会对其网站爬行的,一般蜘蛛识别网站不安全的是**站,因为**站容易生成死循环,如果蜘蛛掉进死循环也就是我们所说的蜘蛛陷阱的话就很难再爬行出来,所以如果一个网站有危险性,蜘蛛是不会对其网站爬行的,当蜘蛛爬行网站看完结构辨认是安全的话那么它下面要做的就是对站内信息的收录,蜘蛛辨认站内信息收录的主要因素是创新的,原创的,如果说你的页面上面全部是图片、Flash等蜘蛛无法辨认的东西,那么蜘蛛是不会收录信息的,大家要记住蜘蛛只收文字信息,图片信息等蜘蛛是无法识别的,当蜘蛛辨认文章是创新的而且是原创,那么蜘蛛就会把信息带到服务器,然后服务器整合以后看文章的价值,然后做排名处理,其实蜘蛛爬行的时候就这么简单,所以只要我们知道它在爬行的时候有什么样的习惯和脾性,那么我们让蜘蛛喜欢自己的网站也是很容易的,所以不要觉得吸引蜘蛛有多么难,其实这一切就这么简单,下面就说一下蜘蛛主要喜欢的东西.1安全的静态网站是蜘蛛最喜欢的,**站有时蜘蛛可能不会收录其中的文字信息.2蜘蛛喜欢原创文章,如果文章在服务器上有重复的,蜘蛛就不会对其收录的.3蜘蛛喜欢站内明确的表明关键词、权重网页等信息,明确这些不会误导蜘蛛.4蜘蛛喜欢定点来访,所以蜘蛛一般都会每天固定时间段对网站进行爬行.蜘蛛的原理就是这样的,就像我上面所说的,蜘蛛不会像人一样有多面性,因为蜘蛛是机器人,所以在它们的世界里什么都是服务器定死的,所以它们只会遵命去办事,没有什么其他情绪和爱好。
蜘蛛是怎样爬行的

蜘蛛的肌肉位于表皮细胞之下,构成皮肌囊。
而且蜘蛛的肌肉已脱离表皮,形成独立的肌肉束,并附着在外骨骼的内表面或骨骼的内突上。
蜘蛛的肌肉均为横纹肌,靠收缩牵引骨板弯曲或伸直,以产生运动。
肌肉与骨骼以杠杆作用产生运动的原理与脊椎动物运动的原理是相同的。
所不同的是蜘蛛的肌肉是附着在外骨骼的内表面,而脊椎动物的肌肉是附着在内骨骼的外表面。
蜘蛛运动主要是利用其分节附肢,附肢中的肌肉是按节分布的,构成颉颃作用。
伸肌与屈肌成对排列。
运动时步足成对地交替进行作用。
即一侧的足举起,另一侧的足与地面接触,牵引身体向前移动,然后两侧的步足交换进行。
在变化的过程中,蜘蛛的步足变得细长,并向腹部中线靠拢,运动时足的跨度加长,重叠性减少,机械干扰降低,运动时迅速快捷。
SEO优化之百度蜘蛛爬行规律?

百度蜘蛛,英文名是“Baiduspider”是百度搜索引擎的一个自动程序。
它的作用是访问互联网上的网页、图片、视频等内容,建立索引数据库,使用户能在百度搜索引擎中搜索到您网站的网页、图片、视频等内容。
Baiduspider是一套人自己编制的程序,百度蜘蛛的爬行有一定的规律可寻,以下来看看百度蜘蛛到底是如何爬行的呢?一、爆发式爬行不知百度蜘蛛是不是喜欢高效率的爬行,有时百度蜘蛛能在一两分钟内爬行几百次。
因为蜘蛛机器人,它爬行一段时间过后,蜘蛛机器人再去运算程序,看是否是原来收录过的,是否是原创什么的,是否应该收录等等。
毕竟这样的爬行不会经常出现,只是偶有现身。
二、稳定式爬行稳定式爬行,指的是每天24小时,每一个小时的爬行量相差不大。
稳定式爬行往往是对新站才会出现,对于百度认为你站是成熟期的,如果出现了这种爬行方式,你可一定要小心了,这种爬行方式,你的站多半会被降权。
第二天就能看出来,首页的快照日期,一定不会给你更新的。
就好比一个人做任何事情时的,没有了激情,也就没有了爆发力,当然不会卖力干事的,不卖力干事,你说效果会有多好。
三、确认式爬行什么是确认式爬行呢?就是指你网站更新一个内容过后,百度第一次爬行过后,一定不会给你放出收录来,百度蜘蛛还要进行第二次爬行再运算、比较计算的,如果认为你这个更新内容有必要收录,百度蜘蛛会进行第三次爬行,正常情况下百度蜘蛛不会进行第四次爬行。
第三次确认过后,百度蜘蛛就会慢慢的给你放出收录。
这种确认式爬行方式,就有点类似与谷歌的爬行方式。
百度蜘蛛机器人爬行首页的方式还是同原来一样,一天不知要爬行多少次首页,其它页面,如果百度认为有必要进行计算的话,就会进行第二次确认爬行。
以上说了这么多,大家可能有疑问了,百度蜘蛛来没有,我怎么知道,这个很简单你可以去查看服务器的记录日志。
你如果查看不了记录日志的话,看一下网站后台有没有记录蜘蛛爬行记录的。
做百度优化的朋友都知道,百度相对Google而言是比较难做的,但“世上无难事,只怕有心人。
蜘蛛爬原理

蜘蛛爬原理蜘蛛是一类十分神奇的昆虫,它们以其独特的捕食方式和灵活的行动方式而闻名于世。
蜘蛛爬行的原理是什么呢?让我们一起来探究一下蜘蛛爬行的奥秘。
蜘蛛的爬行能力主要依赖于它们身体表面的微结构和特殊的生理机制。
首先,蜘蛛的脚趾上覆盖着大量微小的毛发,这些毛发能够产生静电力,使得蜘蛛能够在垂直或倾斜的表面上行走,甚至在天花板上自如地爬行。
其次,蜘蛛的脚趾上还有微小的刺状结构,这些结构能够增加蜘蛛与地面之间的接触面积,提供更好的附着力。
此外,蜘蛛的脚趾下覆盖着一层特殊的黏液,能够在蜘蛛行走时产生粘附力,使得蜘蛛能够在光滑的表面上行走。
除了脚部结构的优势之外,蜘蛛的身体结构也为其爬行提供了便利。
蜘蛛的身体由头胸部和腹部组成,头胸部连接着四对腿,腹部则连接着蜘蛛的丝腺。
蜘蛛通过腹部的丝腺分泌出丝线,利用丝线进行攀爬和捕食。
蜘蛛的丝线具有很高的韧性和粘附力,能够支撑蜘蛛的身体重量,使得蜘蛛能够在空中自由悬挂,甚至在丝线上快速移动。
此外,蜘蛛还利用丝线构建巢穴和捕食网。
蜘蛛的巢穴和捕食网不仅能够提供蜘蛛安全的居所,还能够帮助蜘蛛捕获猎物。
蜘蛛在构建巢穴和捕食网时,会利用自己的丝线技巧,将丝线拉扯成不同的形状和结构,从而构建出坚固耐用的巢穴和精密有效的捕食网。
总的来说,蜘蛛的爬行原理是多方面的,它们利用身体结构、脚部结构和丝线技巧,实现了在各种复杂环境中的灵活爬行和捕食。
蜘蛛的爬行原理不仅是一种生物学奇迹,也为人类科学技术的发展提供了宝贵的启示,例如仿生学领域就曾受到蜘蛛爬行原理的启发,开发出了许多具有前瞻性的科技产品。
通过对蜘蛛爬行原理的深入了解,我们不仅能够更加欣赏蜘蛛这一生物的独特魅力,也能够从中汲取灵感,为人类科学技术的发展注入新的动力。
希望本文所述能够帮助读者更好地理解蜘蛛的爬行原理,并对生物学和科技发展产生更多的思考和探索。
蜘蛛爬行与抓取工作原理及优化技巧

蜘蛛爬行与抓取工作原理及优化技巧1:先了解蜘蛛爬行抓取特征主要是以“快”“全”“准”,呼和浩特杨进东说下来会详细介绍他原理,蜘蛛我相信大家都知道,可以比喻成现实生活中蜘蛛,蜘蛛爬行需要蜘蛛网,蜘蛛网可以理解互联网,呼和浩特杨进东说是所有网站与网站形成非常大互联网,呼和浩特杨进东说我们就知道想让蜘蛛喜欢快速爬行抓取你网站尽可能在建站时注意模版/列表/文章页简单和用户体验.2:蜘蛛爬行原理特征:呼和浩特杨进东说一种是深度优先,另一种是宽度优先:呼和浩特杨进东说(1)为什么深度优先:我们可以了解成像小孩刚学走路前肯定先会爬行,爬路径越长越累甚至爬一半就累了想休息就回去,呼和浩特杨进东说那我们想到网站列表/文章路劲如很长的话蜘蛛爬一半就走,呼和浩特杨进东说走时候什么内容都没带走。
(上面就提到蜘蛛爬行一个特征“快”在这个高速发展时代什么都是快,呼和浩特杨进东说效率,结果,当在你网站爬半天都没找到内容蜘蛛觉得还不如爬其他网站)(2)另一种是宽度优先:这个更容易理解同一样层次页面蜘蛛比较喜欢内容好优先爬行抓取。
3:快速引蜘蛛:呼和浩特杨进东说做SEO优化外链专员挑选一些我们资源当中高权重/IP浏览用户多/百度天天快照/不会删除文章平台发一些网址让百度知道我这个网站已经建好了,呼和浩特杨进东说很多人投票投分数给网站,(投票投分数越多越好,说明网站曝光度广)告诉百度蜘蛛你的快来爬行抓取我网站内容。
4:重复内容检测:呼和浩特杨进东说{建站时因注意事项(动态地址静态化)(对于优化来讲url直径越短越重要)}(1):动态地址静态化我们可以简单理解成重复内容检测如一个动态页面入口链接(URL)如地址指向不同一个地方,蜘蛛会觉得你这个动态页面入口里面这么多重复链接(URL)地址不知道那个链接(URL)地址是你想要让他抓取,呼和浩特杨进东说蜘蛛会觉得抓取耗我这么长时间,就不想抓取.5:地址库:可以理解成地址与库概念,蜘蛛“快”“全”“准”爬行抓取互联网所有URL ,呼和浩特杨进东说然后URL地址蜘蛛抓取地址放到他想存储库里面去.这就叫地址库。
揭秘:百度蜘蛛爬行方式

揭秘:百度蜘蛛爬行方式大家都知道,做网站的百度优化,是比较困难的,但是“世上无难事,只怕有心人”,要更好网站的百度优化,就得知道百度蜘蛛平时是怎样活动的。
只有揣摩清楚了蜘蛛的爬行规律,然后按照它的规律进行优化,必能事半功倍。
建议还是选择像凡科网此类做网站优化服务,给自己的网站提供一个保障。
以下就来看看百度蜘蛛是怎样爬行的吧。
第一、爆发式爬行。
有时候,百度蜘蛛会在一两分钟内,光顾你的网站好几次。
不用怕,这种爆发式的爬行,一般是很少出现的。
有些时候,它爬行一段时间以后,需要去运算程序,看看原来有没有来体验过,判断网站的内容是否为原创等等。
所以,在很短的时间内,它可能多次光顾你的网站,这也是不足为奇的。
网站的内容,可能会经受蜘蛛的多次考验,所以,千万不要直接复制粘贴别处的资料过来。
第二、稳定式爬行。
稳定式爬行,就是每天,每个小时的爬行量都差不多。
这种爬行,往往是在新站才会出现。
如果一个网站已经建成好久了,并且有了不错的排名、权重,这时候,如果蜘蛛来你的网站爬行,还出现这种爬行方式,你就要小心了。
出现这种爬行方式,多是蜘蛛对你的网站有不满之处,要找原因,及时应对,否则就等着蜘蛛给你降权吧。
第三、确认式爬行。
确认式爬行,就是蜘蛛爬行体验网站更新的内容以后,不一定就会马上收录,还要经过程序的运算等,然后再次进行爬行体验,再确认是否要收录,是否有必要收录。
通常情况下,蜘蛛不会爬行四次,如果三次爬行以后,还没有被收录,也就没有多大的希望能被收录了。
这种爬行方式,多见于网站的首页。
一个网站,其首页,每天不知道要被蜘蛛爬行体验多少次,但是其他的内页,则要等蜘蛛进行计算,觉得有必要收录的话,才会再次爬行体验,看看是否有收录的必要。
由此可见,网站的首页是网站优化建设的重中之重,一定要做好网站的首页优化。
搜索引擎蜘蛛爬虫原理

搜索引擎蜘蛛爬虫原理:1、聚焦爬虫工作原理及关键技术概述网络爬虫是一个自动提取网页的程序,它为搜索引擎从Internet网上下载网页,是搜索引擎的重要组成。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。
然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止,另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:(1) 对抓取目标的描述或定义;(2) 对网页或数据的分析与过滤;(3) 对URL的搜索策略。
抓取目标的描述和定义是决定网页分析算法与URL搜索策略如何制订的基础。
而网页分析算法和候选URL排序算法是决定搜索引擎所提供的服务形式和爬虫网页抓取行为的关键所在。
这两个部分的算法又是紧密相关的。
2、抓取目标描述现有聚焦爬虫对抓取目标的描述可分为基于目标网页特征、基于目标数据模式和基于领域概念3种。
基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。
根据种子样本获取方式可分为:(1)预先给定的初始抓取种子样本;(2)预先给定的网页分类目录和与分类目录对应的种子样本,如Yahoo!分类结构等; (3)通过用户行为确定的抓取目标样例,分为:a) 用户浏览过程中显示标注的抓取样本;b) 通过用户日志挖掘得到访问模式及相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。
现有的聚焦爬虫对抓取目标的描述或定义可以分为基于目标网页特征,基于目标数据模式和基于领域概念三种。
爬行动作的原理和应用

爬行动作的原理和应用1. 爬行动作的定义爬行动作是指通过物体表面的摩擦力和腿部或身体的运动来移动的一种动作方式。
在自然界中,许多生物,尤其是爬行动物,如蛇、蜥蜴和蜘蛛等,都采用爬行动作来移动。
这种移动方式被人工模仿并应用于机器人技术中。
2. 爬行动作的原理爬行动作的原理基于两个主要原理:摩擦力和身体的运动。
2.1 摩擦力爬行动作的前提是物体表面具有足够的摩擦力,这样爬行动物才能通过腿部或身体的运动施加足够的力量来克服重力和摩擦力。
在机器人中,通常使用特殊的材料或表面纹理来增加机器人与地面之间的摩擦力,从而实现爬行移动。
2.2 身体的运动爬行动物通过身体的运动来推动自身的移动。
最常见的是通过腿部的往复运动来完成移动,类似于人类行走的方式。
但也有一些爬行动物(如蛇)通过身体的扭动和蛇行的方式来实现移动。
在机器人中,通常使用电机和传动装置来模拟爬行动作。
通过控制电机的转动和传动装置的运动方式,可以实现类似于爬行动物的移动效果。
3. 爬行动作的应用爬行动作的应用非常广泛,涵盖了许多领域。
以下是一些典型的应用场景:3.1 探索与搜救机器人的爬行能力使其成为探索和搜救任务中的理想选择。
例如,在灾难现场,机器人可以通过狭窄的空间爬行,寻找被埋的幸存者或收集有用的信息。
爬行机器人还可以用于探索未知的地下或水下环境,帮助科学家研究和探索。
3.2 工业检测与维护爬行机器人可用于工业检测和维护任务。
例如,它们可以在高处的建筑物或桥梁上进行安全检查,避免人员受伤。
爬行机器人还可以在狭小的空间中执行维护工作,如管道或风扇的清洁和修理。
3.3 农业和农业爬行机器人在农业领域的应用正在迅速增长。
它们可以在农田中进行种植和收获作物,减轻农民的劳动力压力。
此外,爬行机器人还可以在农作物之间巡视,检查病虫害,并及时采取措施。
3.4 医疗和护理爬行机器人在医疗和护理领域也有广泛的应用。
它们可以用于手术中的辅助操作,如开腹手术中的器官移动和操作。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
扁平化与非扁平化区分
非扁平化设计:多达6层点击到达最终产品页
扁平化设计:最多三次点击即可找到想要的产品
利于搜索引擎权重传递从而提高网页排名,就与搜索引擎算法有关了。
3种蜘蛛爬行策略
1、最佳优先
搜索策略按照一定的网页分析算 法,预测候选URL与目标网页的 相似度,或与主题的相关性,并 选取评算法预测为“有用”的网页03
③PR优先策略
RP优先策略是一个非常注明的链接分析方法,它用 于衡量网页的重要性,通常它会计算一个页面上 URL的PR,按照从高到低的顺序进行抓取。
由于PR值的计算,需要不断的迭代更新,通常这里 所采用的都是非完全PageRank策略。
④反链策略
反链策略,并没有一个明确的官方文档说明,我认 为,它主要是基于反链的数量以及种子页面的权威 度,二者进行加权评估后,按照优先顺序抓取。
一般蜘蛛抓取的流程
一般蜘 蛛抓取
对于搜索引擎而言,常见的抓取流程包括:种子页URL提取->整
1.
理新的待抓取URL集合->合并更新链接(包括已经抓取过的链接)
->解析页面内容->进入链接总库(索引库)
其中,在解析页面内容,进入索引库的时候,它需要经过多层复
2.
杂的系统计算,评估目标URL的质量,从而决定是否进入低质量
存在的一个问题是,在爬虫抓取 路径上的很多相关网页可能被忽 略,因为最佳优先策略是一种局 部最优搜索算法,因此需要将最 佳优先结合具体的应用进行改进 ,以跳出局部最优点,据古月建 站博客的研究发现,这样的闭环 调整可以将无关网页数量降低 30%~90%
2、深度优先(层级)
深度优先是指蜘蛛沿着发现的链 接一直向前爬行,直到前面再也 没有其他链接,然后返回到第一 个页面,沿着另一个链接再一直 往前爬行。
URL使用关键词拼音对SEO优化有什么影响
在SEO优化中,URL起着很重要的作用,那么URL使用关键词拼音对SEO优化有什么影响,这里为大家详细介绍一下:
针对搜索引擎: 1、提高识别度 URL中使用关键词拼音,让搜索引擎蜘蛛更容易识别页面相关度。 2、突出页面主题 URL中使用关键词拼音,可以突出页面主题,提升页面相关度。 3、提升排名 URL中使用关键词拼音,利于关键词排名,在同等的页面质量下,URL中含有该关键词的页面更具有排名能力。
服务器的连通率是决定,搜 索引擎蜘蛛是否能够顺利抓 取的主要因素,如果你的网 站经常产生延迟,识别对抓 取与索引产生重要影响。
高权重的站点,更受搜索引 擎的亲睐,蜘蛛抓取的也相 对频繁,但这个评级,并不 是咱们SEO专对于合理引导蜘蛛爬行页面,具体常见的操作是以上几种
蜘蛛爬行原理
对于网站设计者来说,扁平化的网站结构设计有助于搜索引擎抓取其更多的网页。网络蜘蛛在访问网 站网页的时候,经常会遇到加密数据和网页权限的问题,有些网页是需要会员权限才能访问。 当然,网站的所有者可以通过协议让网络蜘蛛不去抓取,但对于一些出售报告的网站,他们希望搜索 引擎能搜索到他们的报告,但又不能完全免费的让搜索者查看,这样就需要给网络蜘蛛提供相应的用 户名和密码。网络蜘蛛可以通过所给的权限对这些网页进行网页抓取,从而提供搜索,而当搜索者点 击查看该网页的时候,同样需要搜索者提供相应的权限验证。
3种爬行策略
3、广度优先(平级)
广度优先是指蜘蛛在一个页面发 现多个链接时,不是顺着一个链 接一直向前,而是把页面上所有 链接都爬一遍,然后再进入第二 层页面沿着第二层上发现的链接 爬向第三层页面。
从理论上说,无论是深度优先还是 广度优先,只要给蜘蛛足够的时间, 都能爬完整个互联网。
在实际工作中,蜘蛛的带宽资源、 时间都不是无限的,也不能爬完所 有页面,实际上最大的搜索引擎也 只是爬行和收录了互联网的一小部 分,当然也并不是搜索引擎蜘蛛爬 取的越多越好。因此,为了尽量多 的抓取用户信息,深度优先和广度 优先通常是混合使用的,这样既可 以照顾到尽量多的网站,也能照顾 到一部分网站的内页。
总结
言外之意,如果你的URL最先没有在 网址提交,而是出现在社交媒体 中,比如:分享策略
社会化媒体分析策略,主要是指一个 URL在社交媒体中的流行度,它的转 载量,评论,转发量,综合指标的评 估。
05
01
常见 抓取
04
02
②宽度优先遍历策略
宽度优先便利策略,是早期搜索引擎常用的一 种抓取策略,主要流程是提取整个页面中的URL, 其中未被抓取的URL,就被放入待抓取列队,以 此循环。
库。
如何引蜘蛛爬行页面
内容更新频率
内容更新质量
网站页面稳定
整站目标权重
理论上,如果你的页面更新 频率相对较高,那么搜索引 擎自然爬虫就是频繁来访, 目的是抓取更多潜在的优质 内容。
言外之意,如果你长期频稀缺性的内容(独特的视 角)你会发现蜘蛛的来访频 率很高,并且经过一定周期 的信任度累积,很容易达到 “秒收录”
针对用户: 1、增加点击率 用户能从URL大致判断网页内容以及网站结构信息,并且可以预测将要看到的内容,会增加用户点击率。 2、提升用户搜索体验 部分用户搜索的时候,可能会使用拼音进行搜索,URL中使用拼音关键词利于用户搜索体验。
02 蜘蛛抓取的策略
常见蜘蛛抓取的策略
①深度优先遍历策略
深度优先遍历策略主要是指建立一个起点,按照这个起 点的顺序,顺序抓取链条上,没有被抓取的每个节点。 但有的时候,面对“无限循环”节点的时候,这一策略 便显得捉禁见理
目录/Contents
搜索引擎蜘蛛原理
01
蜘蛛抓取的策略
02
01
搜索引擎蜘蛛原理
搜索引擎蜘蛛访问网站页面时类似于普通用户使用浏览器,蜘 蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程 序把收到的代码存入原始页面数据库,搜索引擎为了提高爬行 和抓取的速度,都使用多个蜘蛛分布爬行。