第06讲 输入模型处理
3500系列_中文手册

1.13.3 程序概要页 .................................................................................................... 29
1.13.4 报警概要......................................................................................................... 31
2.
2.1.1 2.1.2 2.1.3 2.2
第 2 章 访问更多的参数 .................................................33
等级 3(Level 3)......................................................................................... 33 配置等级......................................................................................................... 33 选择不同的访问等级................................................................................... 34 访问菜单中的参数 .........................................................................................35
1.1 这是什么样的仪表? .........................................................................................9
PowerMILL2010公司原厂教程-DOC
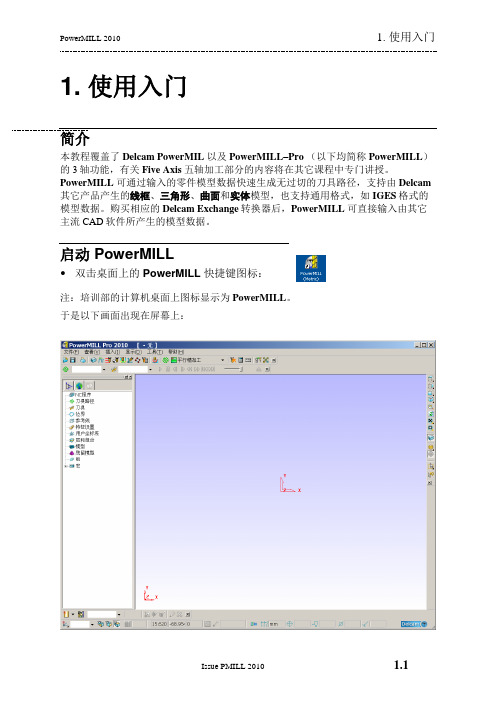
1. 使用入门简介本教程覆盖了Delcam PowerMIL 以及PowerMILL–Pro(以下均简称PowerMILL)的3轴功能,有关Five Axis五轴加工部分的内容将在其它课程中专门讲授。
PowerMILL可通过输入的零件模型数据快速生成无过切的刀具路径,支持由Delcam 其它产品产生的线框、三角形、曲面和实体模型,也支持通用格式,如IGES格式的模型数据。
购买相应的Delcam Exchange转换器后,PowerMILL可直接输入由其它主流CAD软件所产生的模型数据。
启动 PowerMILL双击桌面上的PowerMILL 快捷键图标:注:培训部的计算机桌面上图标显示为PowerMILL。
于是以下画面出现在屏幕上:可将屏幕划分为以下几个主要区域:1) 菜单栏–点击菜单栏中的某个菜单名称 (例如文件) ,打开相关的下拉菜单列表以及子菜单命令。
菜单文本右边如果有一小箭头,表示该菜单下包含子菜单 (例如文件-新近项目 >)。
将鼠标置于该箭头旁,屏幕上即弹出该子菜单中所包含的命令/名称(例如,文件-新近项目将显示出新近打开过的项目文件,点击这些文件可直接打开这些项目。
)2) 主工具栏–在此可快速访问PowerMILL中最常用的一些命令。
3) 浏览器–提供控制选项和用来保存PowerMILL运行过程中产生的元素。
4) 图形视窗–浏览器右边的一个大的直观显示和工作区域(参看上页图像)。
5) 查看工具栏–快速访问标准查看以及PowerMILL的阴影选项。
6) 信息工具栏 -此区域提供了一些激活设置选项的信息。
7) 刀具工具栏 - PowerMILL快速刀具生成工具。
除以上系统缺省工具栏外,PowerMILL还提供了一些其它非缺省工具栏,这些工具栏在PowerMILL启动后不会显示在屏幕上。
使用查看-工具栏下的相应选项可显示这些工具栏,例如选取查看-工具栏-刀具路径即可显示刀具路径工具栏:选取工具-自定义颜色并选取查看背景,可改变背景颜色。
盈建科—建模用户手册

YJK 建筑结构设计软件
模型及荷载输入
用户手册
北京盈建科软件有限责任公司 2012.6
目录
目录
第一章 软件主要功能 ....................................................................................................................... 1
第三节 轴线网格...................................................................................................................... 20 一、轴线网格的基本概念................................................................................................ 20 二、轴网输入.................................................................................................................... 21 三、绘图基本操作和工具................................................................................................ 26 四、形成网点.................................................................................................................... 31 五、轴线命名.................................................................................................................... 32 六、正交轴网.................................................................................................................... 32 七、圆弧轴网.................................................................................................................... 33 八、轴网编辑.................................................................................................................... 33
深度学习技术中的输入数据预处理技巧分享

深度学习技术中的输入数据预处理技巧分享深度学习技术在各个领域的应用日益广泛,它能够通过神经网络的训练和学习,实现对复杂数据模式的识别和分析。
然而,深度学习的性能很大程度上依赖于输入数据的质量和准确性。
为了确保深度学习模型的稳定性和高效性,数据预处理步骤尤为重要。
本文将分享一些在深度学习技术中常用的输入数据预处理技巧,以帮助读者提升模型的性能。
1. 数据清洗与去噪在深度学习中,输入数据通常不是完美的,可能包含一些噪声和错误。
因此,在进行模型训练之前,应首先进行数据清洗和去噪的处理。
一些常见的数据清洗技术包括删除重复数据、处理缺失值和异常值等。
对于图像数据,在处理之前可以先进行降噪处理,如使用图像滤波器进行平滑或者去除图像中的噪点。
2. 数据标准化与归一化深度学习模型对输入数据的尺度和分布很敏感,因此需要对数据进行标准化或归一化操作。
标准化可以将数据转化为均值为0、标准差为1的标准正态分布,而归一化则可以将数据缩放到0和1之间。
常用的数据标准化方法包括Z-score标准化和MinMaxScaler归一化等。
选择适当的标准化方法取决于数据的特征和分布。
3. 特征提取与降维在深度学习中,高维度的输入数据可能会导致训练时间过长和模型复杂度过高的问题。
因此,对于高维数据,可以使用特征提取和降维的方法来减少数据维度并提取最有用的特征。
常用的降维方法包括主成分分析(PCA)和线性判别分析(LDA)等。
这些方法可以帮助保留大部分信息的同时减少数据的维度,提高模型的效率和准确性。
4. 数据增强与扩充数据增强是一种通过对原始数据进行变换和处理,生成新的训练样本来扩充数据集的技术。
数据增强可以帮助模型更好地泛化和适应不同的场景。
对于图像数据,常用的数据增强方法包括旋转、平移、缩放、翻转和亮度调整等。
这些操作可以增加数据的多样性,提高模型的鲁棒性和泛化能力。
5. 数据划分与交叉验证在深度学习模型的训练中,数据划分和交叉验证是非常重要的步骤。
第06讲 SA法

(k)称为收敛因子.
1 SA原理--Robbins-Monro算法(2/3)
可以证明,若收敛因子(k)满足下列条件
ρ(k ) 0 k Lim ρ(k ) 0 k ρ( k ) k 1 ρ 2 (k ) k 1
上述Robbins-Monro算法是求解随机方程(9)的根. 后来 ,Kiefer 和 Wolfowitz 将它应用到求解回归函数 h(x) 的 极值,提出求解随机函数数值优化的Kiefer-Wolfowitz算法. Kiefer-Wolfowitz算法的思想为: 如果h(x)存在极值,那么在极值处的x应使 dh(x)/dx=0. 根据Robbins-Monro算法,Kiefer和Wolfowitz给出了如 下求回归函数h(x)的极值的迭代算法 x(k+1)=x(k)-(k)dy/dx|x(k) (12)
(18) (19)
不难证明,只要被辨识系统的观测数据向量(k)不以指数 规律衰减,SA算法(18)~(19)的收敛因子(k)=1/r(k-1)必满 足SA法的收敛条件(11).
2 SA参数估计法(6/5)
ˆ (k ) θ ˆ (k -1) φ(k -1) [ y(k ) - φ τ (k -1)θ ˆ (k -1)] θ r (k 1) r (k - 1) r (k - 2) φ τ (k - 1)φ(k - 1), r (-1) 0 (18) (19)
第六讲 SA法(1/3)
第六讲 随机逼近法
前面讨论的辨识算法均属于LS类的估计算法,
其优点是 收敛速度快,
精度高等,
但其计算量大且占用计算机系统的内存较多等严重影响 了其在实时辨识和在自适应系统中的运用.
基于大语言模型知识增强和多特征融合的中文命名实体识别方法

基于大语言模型知识增强和多特征融合的中文命名实体识别方法目录一、内容概括 (2)二、背景知识介绍 (2)1. 中文命名实体识别概述 (3)2. 大语言模型知识增强技术 (4)3. 多特征融合技术 (5)三、基于大语言模型的知识增强技术细节 (6)1. 数据预处理 (7)2. 模型选择与训练 (8)3. 知识增强策略设计 (10)4. 模型优化与性能提升 (11)四、多特征融合策略的实现细节 (12)1. 特征选择和提取 (13)2. 特征融合方法选择 (13)3. 特征融合策略的优化和改进 (15)五、基于大语言模型和多特征融合的中文命名实体识别方法的具体实施步骤161. 数据集准备与处理 (17)2. 构建和训练大语言模型 (17)3. 特征提取与融合策略设计 (18)4. 模型训练和评估流程 (19)一、内容概括采用多特征融合的方法,将多种特征信息融合在一起,包括词性特征、结构特征、上下文特征等。
这些特征有助于模型更全面地捕捉命名实体的特征,提高识别准确性。
通过构建训练集和验证集,并在训练集上进行迭代训练,不断优化模型参数。
在验证集上评估模型的性能,根据评估结果调整模型结构或参数,以达到最佳识别效果。
本文提出的方法通过结合大语言模型的知识增强和多特征融合技术,有效提高了中文命名实体识别的性能,为中文自然语言处理领域的发展提供了有益的参考。
二、背景知识介绍随着自然语言处理技术的不断发展,中文命名实体识别(Named Entity Recognition, NER)作为其中的重要分支,在信息抽取、知识图谱构建、机器翻译等领域发挥着越来越重要的作用。
命名实体识别旨在从文本中识别出具有特定意义的实体,如人名、地名、机构名等,这些实体通常携带大量丰富的语义信息和业务价值。
传统的中文命名实体识别方法主要依赖于基于规则的方法和统计学习方法。
随着大规模预训练模型(如BERT、GPT等)的出现,基于深度学习的命名实体识别方法逐渐成为研究热点。
AMOS中文图解

SEM 的 AMOS 实现——以 CSI 为例
©2007 RUAN Jing
Email:ruanjing@
Structure RELationship)。与其他多元统计方法相比,结构方程模型具有以下几 个显著的特点: 第一,隐变量可以通过一个或多个显变量进行测量。在结构方程模型中,不 可观测的隐变量往往是通过可以观测的显变量来综合测量的, 可以理解为隐变量 可以从可测度的若干个方面来考察。 隐变量是事先可以根据研究目的确定下来的 研究对象的特征, 研究人员只要根据相关理论找出这些特征可以从哪些方面进行 测度或反映即可, 该过程是一个自上而下的研究过程; 而我们常见的因子分析中, 通过可观测的显变量我们同样也可以提取出变量之间的共同信息作为因子来对 研究对象进行分析, 但是通过因子分析提取的因子事先是不确定的,其所对应的 显变量也不是根据现有相关理论得来的, 而是通过数理上的特征根或方差贡献率 大小进行判断的,该过程是一个自下而上的过程。 第二,根据可观测的显变量可以计算出不可观测的隐变量之间的相互关系。 回归分析主要研究的是显变量之间的关系,对于隐变量而言,通常是通过设计若 干显变量去间接测量隐变量, 进而根据结构方程模型的具体计算方法产出隐变量 的所谓观测值,然后再将计算出来的隐变量作为显变量去进行回归分析。 第三,结构方程模型允许自变量和因变量含测量误差。对于一些诸如态度、 行为、感知等隐变量往往含有误差,也不能简单地用单一指标来测量,在结构方 程模型中则允许这些自变量和因变量均含测量误差来进行测度, 并可以通过显变 量与隐变量之间的测量方程排除这些误差。 第四, 结构方程模型可以同时估计隐变量与显变量的关系及隐变量之间的关 系。 隐变量与其对应的显变量之间的关系可以称之为因子结构,主要衡量了各个 显变量对它们共同反映的隐变量的影响; 隐变量之间的关系也可称之为因子关系, 主要考察经过显变量计算出来的隐变量之间的相互关系, 这种关系包括相关关系 和因果关系。 第五, 结构方程模型既可以用图形也可以用数学模型进行描述。用来表示结 构方程模型的图形称作路径图, 标示有变量之间相互影响程度大小的路径图即为 路径系数图;此外结构方程模型还可以用方程组来表示。 本文档主要从结构方程模型的设定、模型求解方法、模型拟合以及模型修正 等方面来介绍结构方程模型的基本方法,通过实际的顾客满意度(CSI)测评案
PDMS教程指导

PDMS教程指导Pipework Modelling管道设计通常是一个大型项目中最费时的工作,也是产生问题最多的部分。
在PDMS中,管道建模是系统中最强大的功能之一,它最大可能地避免了设计错误的产生。
(database hierarchy)每个管道(PIPE)可以有多个分支(BRANCH),在分支下面才是具体的管件,分支与管道的不同在于分支只有两个端点,而管道可以有多个端点,这要看它有几个分支。
Branch 1Branch 2Tee? ??Branches分支有两个用途:1(定义管道的起点和终点,在PDMS 中称为Head 和Tail。
2(用分支管理管道上的所有管件。
当你定义分支的头和尾时,它会在两点之间出现一个虚线。
VANTAGE PDMS 培训手册 1HeadTail在分支下面的管件位置和顺序决定了管道的铺设。
在PDMS 中,不用添加管道,只须考虑管件,因为管道是根据管件的等级在两个相邻管件中自动生成的。
Heads and Tails所有的分支必须有起点和终点,它可以是空间的一点,嘴子的法兰面,三通或者设计中的其它点。
分支的方向必须是管道的流向。
而分支中的管件顺序同样重要,它决定了管道的最终走向。
????Nozzle 1Gasket 1Flange 1Elbow 2Nozzle 2Flange 2Gasket 2Head is at start position of Gasket 1Tail is at end of Gasket 2Elbow 1生成管件都要完成下面的步骤:1(从管道等级中选择管件。
2(定义管件位置。
3(指定出口方向。
:HPOS 分支起点的位置HCON 分支起点的连接形式(用三个字母代表法兰,对焊,螺纹等等)HDIR 分支起点的方向HBOR 分支起点管道直径HREF 与分支起点连接的元件,一般为管嘴,例如C1101-N1。
如果这个属性没有设置,那末这个分支可能是放空或排凝。
Omega学习手册

Omega学习手册Omega学习手册 0前言 (9)第一章陆地观测系统定义 (10)1.0 技术讨论 (10)1.1 模块简介 (10)1.2 Database and Line Information 观测系统和测线信息 (15)1.3 Geometry Database Creation 观测系统数据库创建 (15)1.4 Primary and Secondary Data Tables (16)1.5 Pattern Specifications (16)1.6 Field Statics Corractions (16)1.7 Trace Editing 道编辑 (19)第二章静校正 (24)第一节2-D 折射静校正(EGRM) (24)1.0 技术讨论 (24)1.1 简介 (24)1.2 第一步——对拾取值进行处理 (25)1.3 第二阶段---建立折射模型 (37)1.4 第3步——计算静校正 (46)1.5 特别选件 (49)1.6 海洋资料处理要考虑的因素 (53)1.7 控制手段 (53)参考文献: (63)3.0 道头总汇: (63)第二节三维折射波静校正 (64)1.0 技术讨论 (64)2.0 二维与三维折射静校正方法 (64)1.2 折射静校正计算原理 (65)1.3 初始值的给定 (67)1.4 最小二乘法延迟时的计算 (67)1.5 iterations (75)1.6 Diving Waves (81)1.7 建立折射模型 (84)1.8 uphole options (86)1.9 water uphole corrections (87)1.10 用井口信息修正风化层速度 (88)1.11 静校正量的计算 (89)1.12 地表基准面和剩余折射静校正 (90)1.13 定义偏移距范围 (91)1.14 定义速度 (91)1.15 延迟时控制 (92)1.16 观测系统、辅助观测系统和一些道头字的输入要求 (92)1.17 输出的库文件和道头字 (96)第三节反射波剩余静校正(miser) (97)2.0 地表一致性剩余静校正 (98)3.0 非地表一致性静校正 (102)第四节反射波最大叠加能量静校正计算 (103)1.0 模块简介: (104)2.0 应用流程: (105)3.0 分子动力模拟法的理论基础: (106)4.0 模块中参数的设计 (106)5.0 应用实例及效果分析 (110)第五节波动方程基准面校正 (113)1.0 技术讨论 (113)1.1 理论基础 (115)1.2 波动方程层替换的应用 (117)1.4 模块算法 (118)1.5 应用的方法 (120)第三章地表一致性振幅补偿 (127)第一节地表一致性振幅补偿–拾取(1) (127)1.0 技术讨论 (127)1.1 概况 (127)1.2 地表一致性振幅补偿流程 (128)1.3 振幅统计 (128)1.4 预处理/道编辑 (129)1.5 自动道删除 (129)1.6 模块输出 (130)1.7 分析时窗 (130)2.0 道头字总结 (131)3.0 参数设置概要 (131)4.0 参数设置 (131)4.3 Amplitude Reject Limits (132)第二节地表一致性振幅补偿–分解(2) (133)目录 (133)一、技术讨论 (134)二、道头字总结 (148)三、参数设置概述 (148)四、参数设置(简) (148)第三节地表一致性振幅补偿–应用(3) (149)目录 (149)一、技术讨论 (150)1.1 背景 (150)1.2 SCAC处理过程的流程图 (150)1.2.1 HIDDEN SPOOLING (151)1.3 模块概论 (152)二、道头字总结 (152)三、参数设置概述 (152)五、参数设置(略) (153)5.1 General (153)5.2 SCAC Term Application (153)5.3 Printout Options (153)第四节剩余振幅分析与补偿 (153)1.0 技术讨论: (153)1.1 背景 (154)1.2 模块的输入和输出 (155)1.3 分析过程概述 (155)1.4 分析参数表 (159)1.5 设置网格范围 (164)1.6 分析用时间门参数设定 (166)1.7 时空域加权 (167)1.8 打印选项参数设置 (168)1 .9 应用过程综述 (168)1.10 应用参数设置 (171)1.11 应用时间门参数设置 (173)1.12 RAC函数的质量控制 (174)1.13 在振幅随偏移距变化(A VO)处理中的注意事项 (175)1.14 背景趋势推算 (176)2.0 道头字总结 (176)3.0 参数设置摘要 (176)4.0 设置参数 (176)4.1 Units (176)4.2 General (176)4.3 Analysis (177)Primary Auto Range: (180)Secondary Auto Range: (180)4.6 Primary Manual Range 用于划分面元的首排序范围确定(手动设置) (180)4.7 Secondary Auto Range:用于划分面元的次排序范围确定(手动设置)1804.8 Analysis Time Gates :分析时间门参数(可选) (181)4.9 Temporal Smoothing Weights at Top of Data (可选) (181)4.10 Temporal Smoothing Weights at Bottom of Data(可选) (181)4.11 Primary Spatial Smoothing Weights(可选) (182)4.12 Secondary Spatial Smoothing Weights(可选) (182)4.13 Application (182)4.14 Application Time Gates (183)5.0 参考流程 (183)第四章 (185)第一节瞬时增益 (185)1.0 技术讨论 (185)第二节指数函数增益 (188)1.1 背景 (188)1.2 梯度平滑 (189)2.0 道头总结 (191)3.0 参数设置概要 (191)4.0 参数设置 (191)4.1 General (191)5.0 应用实例 (192)第四章反褶积 (195)第一节地震子波处理(SWP)指导 (195)辅导班Tutorial (195)辅导班1 快速漫游(Quick Tour) (195)概要 (195)快速漫游: 基本训练 (195)辅导班2 –a 为信号反褶积准备一个子波 (203)辅导班2 –b 从野外信号中消除原始的仪器响应影响 (204)辅导班2–c 建立新的仪器响应和新的整形算子 (209)辅导班2– d 将滤波器保存到带通滤波作业文件中 (211)辅导班3用尖脉冲的逆做特征信号反褶积 (213)第二节子波转换应用指导 (215)子波训练 (215)第三节地表一致性反褶积分析 (218)地表一致性谱分解 (225)地表一致性反褶积算子设计 (249)反褶积算子的应用 (255)第四节谱分析 (273)第五节地表一致性反褶积分析 (297)第六节地表一致性谱分解 (302)第八节地表一致性反褶积算子设计 (320)第九节反褶积算子的应用 (325)第六章动校正 (345)第一节视各向异性动校正 (345)第七章各种理论方法简介 (355)第一节层速度反演方法简介 (355)1.1 层速度反演的几种方法 (355)1.1.1 相干反演 (356)1.1.2 旅行时反演 (357)1.1.3 叠加速度反演 (358)2.1 二维层速度反演 (359)2.1.1 相干反演计算的偏移距范围 (359)2.1.2 单个CMP位置超道集的选择 (359)2.1.3 相干反演中的互相关 (360)2.1.4 不确定值 (360)2.1.5 速度的横向变化 (360)3.1 三维层速度反演 (361)3.1.1 方位角范围 (361)3.1.2 相干反演 (362)3.1.3 叠加速度反演 (363)3.1.4 方位角 (364)3.1.5 DMO (364)3.1.6 射线追踪 (364)第二节射线偏移方法简介 (365)1.1 射线偏移 (365)1.2 向射线偏移与成像射线偏移 (367)第三节层位正演方法简介 (368)1.1 层位正演 (368)1.2 零偏移距正演 (369)1.3 成像射线追踪-从深度域到时间偏移域的零偏移距正演 (369)1.4 CMP射线追踪 (371)1.5 CRP正演 (371)1.6 3D正演 (372)1.7 速度正演 (372)1.8 浮动基准面与静校正的处理 (372)第四节扩展STOLT--FK 偏移 (373)概述 (373)1.0 技术讨论 (373)1.1 背景 (374)1.2 扩展STOLT算法 (374)1.3 扩展STOLT偏移的推荐参数 (376)1.4 截断速度和W因子 (377)1.5 框架速度(frame velocity) (378)1.6 速度的横向变化 (378)1.7 速度输入 (378)1.8 三维偏移 (379)1.9 反偏移 (379)1.10 反偏移到零偏移距的处理 (379)1.11 充零方式镶边 (380)1.12 边界处理 (380)1.13 频率内插 (381)1.14 随机波前衰减 (381)1.15 三维偏移中少道的情形 (381)1.16 时间内插 (381)第五节DMO 准备模块 (381)概述: (382)1.0 技术讨论: (382)1.1 理论基础 (382)1.2 递进叠加文件 (382)1.3 速度监控和非矩形网格 (383)1.4 倾角加权表 (383)1.5 统计分析 (383)1.6 层位属性分析 (384)1.7 位图化(Bitmapping) (384)1.8 均衡DMO (384)1.9 限定边界DMO (385)1.10 随意边界DMO (386)1.11 3D DMO Monitor (389)DMO 倾角校正 (390)(DMO X-T STACK)(2) (390)概述: (390)1.0 技术讨论 (390)1.1 简介 (390)1.2 递进叠加 (390)1.3 倾角时差校正(Dip Moveout)-DMO (391)1.4 处理类型 (392)1.5 DMO应用模式 (392)1.6 算子设计 (393)1.7 递进叠加文件 (393)1.8 固定边界和随意边界中的分片段叠加 (393)1.9 运行时间 (394)1.10 DMO处理流程 (394)DMO 输出模块 .............................................................................................................. - 396 - (DMO X-T OUT)(3)........................................................................................................ - 396 - 第八章多波多分量................................................................................................................ - 397 - 第一节多分量相互均衡.............................................................................................. - 397 -1.0 技术讨论......................................................................................................... - 397 -1.1 引言................................................................................................................. - 397 -1.2 数据的输入/输出............................................................................................ - 397 -1.3 背景介绍......................................................................................................... - 398 -1.4 原理................................................................................................................. - 398 -1.5 道头字集......................................................................................................... - 400 -1.6 三维实例......................................................................................................... - 401 -1.7 操作指南......................................................................................................... - 404 -第二节S波两分量旋转合成....................................................................................... - 408 -1.1 引言................................................................................................................. - 408 -1.2 背景介绍......................................................................................................... - 409 -1.3 输入数据......................................................................................................... - 410 -1.4 旋转的应用..................................................................................................... - 412 -1.5 测算水平方向................................................................................................. - 416 -第三节转换波速度比(Vp/Vs)计算 ..................................................................... - 417 -1.0 技术讨论......................................................................................................... - 418 -1.1 引言................................................................................................................. - 418 -1.2 输入速度和Vp/Vs文件 ................................................................................ - 418 -1.3 输出速度和Vp/Vs文件 ................................................................................ - 420 -1.4 有效Vp/Vs比值计算 .................................................................................... - 420 -1.5 S波速度计算(Vs) .......................................................................................... - 421 -1.6 平均Vp/Vs比值计算 .................................................................................... - 424 -第四节共转换点计算(CCP_BIN) ............................................................................. - 424 -1.0 技术简介......................................................................................................... - 425 -1.1 基础原理......................................................................................................... - 425 -1.2 更新道头字..................................................................................................... - 427 -1.3 输入速度和Vp/Vs比率文件 ........................................................................ - 427 -1.4 共转换点的计算方法..................................................................................... - 428 -1.5 时窗................................................................................................................. - 430 -1.6 操作指导......................................................................................................... - 431 -1.7 有关提高运行效率的指导............................................................................. - 433 - 第九章模型建立.................................................................................................................. - 435 - 第一节地震岩性模型建立.......................................................................................... - 435 -1.0 技术讨论......................................................................................................... - 435 -SLIM处理 ............................................................................................................... - 435 -1.2 概述................................................................................................................. - 436 -1.3 SLIM模型研究 .............................................................................................. - 437 -1.4 输入层的细分................................................................................................. - 441 -第二节地震岩性模拟属性分析.............................................................................. - 442 -1. 0 技术讨论........................................................................................................ - 442 -1.1 地震模拟模型处理......................................................................................... - 442 -1.2 概要............................................................................................................... - 442 -1.3 地震记录输入................................................................................................. - 443 -1.4 合成地震记录剖面图..................................................................................... - 443 -1.5 地球物理属性................................................................................................. - 444 -1.6 测井记录数据................................................................................................. - 445 -1.7 显示................................................................................................................. - 445 -第三节地震正演模拟模型生成................................................................................ - 445 -1.0 技术讨论......................................................................................................... - 445 -1.1 地震正演模拟模型处理................................................................................. - 446 -1.2 概要................................................................................................................. - 446 -1.3 SLIM模型讨论 .............................................................................................. - 446 -1.4 输入层的细分................................................................................................. - 450 -1.5 井记录............................................................................................................. - 451 -1.6 密度是速度的函数......................................................................................... - 451 - 第四节地震岩性模型优化.......................................................................................... - 453 - 技术讨论.................................................................................................................. - 453 -1.1 地震岩性模拟过程......................................................................................... - 453 -1.2 概要................................................................................................................. - 453 -1.3 问题的公式化................................................................................................. - 453 -1.4 计算方法......................................................................................................... - 455 -1.5 影响区域......................................................................................................... - 462 - 第五节地震岩性模拟控制点定义.............................................................................. - 464 -1.0 技术讨论......................................................................................................... - 464 -1.1 概要................................................................................................................. - 464 -1.2 二维控制点组................................................................................................. - 465 -1.3 三维控制点组................................................................................................. - 467 -前言自西方地球物理公司Omega处理系统引进以来,通过我院处理人员的不断开发,目前已成为西北分院的主力处理系统。
湖南心泽变频器 通用说明书

用户可查看经过修改后的功能参数
用户可根据需要,确定特定故障发生后,变频器的动作方式: 自由停机、减速停机、继续运行。也可选择继续运行时的 频率。 具备两组 PID 参数,可通过端子切换或根据偏差自动切换
-2-
A380 系列通用变频器用户手册
简介
功能 PID 反馈丢失检测 DIDO 正反逻辑 DIDO 响应延迟
1.1 安全事项 .......................................................................................................................14 1.2 注意事项 .......................................................................................................................15 第二章 产品信息 ................................................................................................................... 20
_________________________________________
_________________________________________
_________________________________________
_________________________________________
2.1 产品命名与铭牌标识 .....................................................................................................20 2.2 A 380 系列变频器各部分名称.....................................................................................20 2.3 基本技术规格................................................................................................................22 2.4 外围电气元件及系统构成..............................................................................................24
第04讲 RLS法

(1) 选取^(0)各元素为零或较小的参数 ,P(-1)=2I,其中 为充分大的实数;
(2) 先将大于所需辨识的参数个数的 L组数据 ,利用成批 型的LS法求取参数估计值 LS和协方差阵P(L-1),并将 这些量作为递推估计的初值.
1 递推算法--LS法和RLS法的比较(1/1)
第四讲 RLS法(2/5)
时变参数辨识 故障监测与诊断
仿真等.
如对时变系统斌是,需要 以采样频率实时更新模型 充分利用过去的辨识模型(参数值),减少在线计算量 递推算法辨识值要尽可能等效为成批算法辨识值 计算机计算技术的发展,为发展这种能在线辨识、在线控 制和预报的算法提供了强有力的工具.
B. LS法和RLS法的比较
LS法和RLS法的比较
LS法是一次完成算法 , 适于离线辩识 , 要记忆全部测量数 据,程序长;
RLS法是递推算法,适于在线辩识和时变过程,只需要记忆 n+1步数据,程序简单;
RLS法用粗糙初值时 ,如若 N( 即样本数少 )较小时, 估计精 度不如LS法.
1 递推算法--信号充分丰富与系统充分激励(1/2)
C. 信号充分丰富与系统充分激励 对于所有学习系统与自适应系统,信号充分丰富(系统充分激 励)是非常重要的. 若系统没有充分激励,则学习系统与自适应系统就不能一 致收敛.
不一致收敛则意味着所建模型存在未建模动态或模 型误差较大,这对模型的应用带来巨大隐患.
第四讲 RLS法(3/5)
递推辨识算法的思想可以概括成 新的参数估计值=旧的参数估计值+修正项 (1) 即新的递推参数估计值是在旧的递推估计值的基础上修正而成, 这就是递推的概念. 递推算法不仅可减少计算量和存储量 ,而且能实现在线实 时辨识.
神经网络算法及模型

神经网络算法及模型思维学普遍认为,人类大脑的思维分为抽象(逻辑)思维、形象(直观)思维和灵感(顿悟)思维三种基本方式。
人工神经网络就是模拟人思维的第二种方式。
这是一个非线性动力学系统,其特色在于信息的分布式存储和并行协同处理。
虽然单个神经元的结构极其简单,功能有限,但大量神经元构成的网络系统所能实现的行为却是极其丰富多彩的。
神经网络的研究内容相当广泛,反映了多学科交叉技术领域的特点。
主要的研究工作集中在以下几个方面:(1)生物原型研究。
从生理学、心理学、解剖学、脑科学、病理学等生物科学方面研究神经细胞、神经网络、神经系统的生物原型结构及其功能机理。
(2)建立理论模型。
根据生物原型的研究,建立神经元、神经网络的理论模型。
其中包括概念模型、知识模型、物理化学模型、数学模型等。
(3)网络模型与算法研究。
在理论模型研究的基础上构作具体的神经网络模型,以实现计算机模拟或准备制作硬件,包括网络学习算法的研究。
这方面的工作也称为技术模型研究。
(4)人工神经网络应用系统。
在网络模型与算法研究的基础上,利用人工神经网络组成实际的应用系统,例如,完成某种信号处理或模式识别的功能、构作专家系统、制成机器人等等。
纵观当代新兴科学技术的发展历史,人类在征服宇宙空间、基本粒子,生命起源等科学技术领域的进程中历经了崎岖不平的道路。
我们也会看到,探索人脑功能和神经网络的研究将伴随着重重困难的克服而日新月异。
神经网络和粗集理论是智能信息处理的两种重要的方法,其任务是从大量观察和实验数据中获取知识、表达知识和推理决策规则。
粗集理论是基于不可分辩性思想和知识简化方法,从数据中推理逻辑规则,适合于数据简化、数据相关性查找、发现数据模式、从数据中提取规则等。
神经网络是利用非线性映射的思想和并行处理方法,用神经网络本身的结构表达输入与输出关联知识的隐函数编码,具有较强的并行处理、逼近和分类能力。
在处理不准确、不完整的知识方面,粗集理论和神经网络都显示出较强的适应能力,然而两者处理信息的方法是不同的,粗集方法模拟人类的抽象逻辑思维,神经网络方法模拟形象直觉思维,具有很强的互补性。
ANSYS高级分析之-APDL 基础

APDL 基础
…概述
• 这一章的目的是向您介绍APDL的基本功能使您能够:
– 定义并使用标量参数
Training Manual
INTRODUCTION TO ANSYS
– 从 ANSYS 数据库中获取信息
• 您可以从在线帮助的APDL手册中获得更多的信息。 • 我们将就以下问题展开讨论:
A. 定义参数
数组参数
...怎样定义数组
• 对字符数组, 不能以图形方式填充字符串
– 使用 “=”命令键入值, 接着用 *STAT 显 示字符串 – 每个字符串必须用单引号括起来 – 例如: dofs(1) = ‘ux’, ‘uy’, ‘uz’, ‘rotx’, ‘roty’, ‘rotz’ *stat,dofs
INTRODUCTION TO ANSYS
• 参数值可以是一个数值,一个以前定义过的参数,一个函数,一个
参数表达式,或者一个字符串。
• 利用 *GET 命令或函数从 ANSYS 数据库中获取信息。 • ANSYS 存储的是参数的实际值(数字或字符串), 而不是参数名。
2. 数组参数
• 数组参数 是能够容纳多个值的参数 • 数组参数可以是 1-D, 2-D, or 3-D.
! 作业名
! 杨氏模量 ! 2号关键点的力 ! 6号关键点的力
APDL 基础
C. 从数据库中获取信息
Training Manual
• 从数据库中获取信息并给参数赋值, 使用 *GET 命令或 Utility Menu > Parameters > Get Scalar Data...
INTRODUCTION TO ANSYS
Training Manual
优化模型

MIN 66.8x11+75.6x12+87x13+58.6x14 +… … +67.4x51+71 x52+83.8x53+62.4x54 SUBJECT TO x11+x12+x13+x14 <=1 …… x41+x42+x43+x44 <=1 x11+x21+x31+x41+x51 =1 …… x14+x24+x34+x44+x54 =1 END INT 20
最优化模型
主讲人
张兴永
1
最优化模型
在数学建模竞赛中,经常会遇到有关最优化问题, 下面介绍几个简单的最优化模型。 最优化模型是在解决实际问题中应用最广泛的模 型之一,它涉及面广、内容丰富,且随着计算机的发 展,解决问题的范围越来越宽。一般地,人们做的任 何一件事情,小的如日常生活、学习工作等,大的如 工农业生产,国防建设及科学研究等,为了达到预先 设想的目的,都要做计划,选择好的方案,进行优化 处理。最优化模型主要有线性规划模型、整数规划模 型、非线性规划模型、动态规划模型等。
这样把多目标规划变成一个目标的线性规划,下 面给出三个单目标优化模型:
24
1、在实际投资中,投资者承受风险的程度不一样, 若给定风险一个界限a,使最大的一个风险qixi/M≤a, 可找到相应的投资方案。 模型1 固定风险水平,优化收益 目标函数:Q=max (ri pi ) xi i 0 约束条件: q x ≤a
9
问题二 混合泳接力队的选拔
5名候选人的百米成绩
蝶泳 仰泳 蛙泳 自由泳 甲 1’06”8 1’15”6 1’27” 58”6 乙 57”2 1’06” 1’06”4 53” 丙 1’18” 1’07”8 1’24”6 59”4 丁 1’10” 1’14”2 1’09”6 57”2 戊 1’07”4 1’11” 1’23”8 1’02”4
深度学习模型的训练技巧与步骤详解

深度学习模型的训练技巧与步骤详解深度学习模型的训练技巧与步骤在实际应用中起着至关重要的作用。
深度学习模型的训练过程涉及选择合适的算法、数据预处理、超参数优化等多个方面。
本文将详细介绍深度学习模型的训练技巧与步骤,以帮助读者更好地理解和应用深度学习算法。
一、数据预处理数据预处理是深度学习模型训练的首要步骤。
它的目的是将原始数据转换为可供深度学习模型使用的合适形式。
数据预处理的常见技巧包括数据的归一化、标准化、缺失值填充、特征选择等。
通过数据预处理,可以提升深度学习模型的效果和收敛速度。
首先,数据的归一化和标准化非常重要。
归一化指将数据的取值范围缩放到统一的区间,常见的方法包括将数据缩放到[0,1]或[-1,1]的范围内。
标准化指将数据转化为均值为0,方差为1的标准正态分布。
这两种方法可以使得数据的特征在训练过程中更加平衡,避免某些特征对模型的训练结果产生过大的影响。
其次,对于存在缺失值的数据,需要进行缺失值的填充。
常见的方法包括使用平均值、中位数或众数填充缺失值,或者使用插值法进行填充。
填充缺失值的目的是保证数据集的完整性和一致性,避免缺失值对模型的训练造成干扰。
最后,特征选择是数据预处理的最后一步。
特征选择的目的是从原始数据中选择出对模型训练和预测有用的特征。
常见的特征选择方法包括相关系数分析、主成分分析等。
特征选择可以提高模型的泛化能力和训练速度。
二、模型选择在深度学习中,模型的选择对最终训练结果有着决定性的影响。
模型的选择需要考虑数据集的特点、任务的要求以及计算资源等因素。
常见的深度学习模型包括卷积神经网络(CNN)、循环神经网络(RNN)和生成对抗网络(GAN)等。
卷积神经网络适用于图像和语音等具有空间结构的数据,能够提取出数据的局部特征。
循环神经网络适用于序列数据,能够捕捉数据的时序关系。
生成对抗网络用于生成新的数据样本,能够模拟真实数据的分布特征。
在模型选择的过程中,可以根据任务的需求选择合适的模型架构,并根据实际情况进行调整和优化。
如何解决神经网络中的输入数据预处理问题

如何解决神经网络中的输入数据预处理问题神经网络作为一种强大的机器学习模型,已经在许多领域取得了显著的成果。
然而,神经网络的性能很大程度上依赖于输入数据的质量和预处理方式。
在这篇文章中,我将探讨如何解决神经网络中的输入数据预处理问题。
首先,我们需要明确输入数据预处理的目标是什么。
输入数据预处理的目标是将原始数据转换为适合神经网络模型的形式,以提高模型的性能和稳定性。
在实际应用中,输入数据可能具有不同的特点和问题,如缺失值、异常值、不平衡的类别分布等。
因此,我们需要采取一系列的预处理步骤来解决这些问题。
第一步是数据清洗。
数据清洗的目标是处理缺失值和异常值。
缺失值是指在数据采集过程中由于各种原因导致的数据缺失的情况。
处理缺失值的常用方法有删除缺失值、插补缺失值和使用特定的值来代替缺失值。
异常值是指与其他数据明显不同的数据点。
处理异常值的方法包括删除异常值、替换异常值和使用异常值检测算法。
第二步是数据标准化。
数据标准化的目标是将数据转换为具有相似尺度和分布的形式,以便神经网络模型更好地学习。
常用的数据标准化方法包括均值归一化、标准差归一化和最大最小值归一化。
均值归一化是将数据减去均值然后除以标准差,使得数据的均值为0,标准差为1。
最大最小值归一化是将数据按照最大值和最小值进行线性变换,使得数据的范围在0到1之间。
第三步是特征选择。
特征选择的目标是从原始数据中选择最相关和最有用的特征,以减少数据维度和模型复杂度。
特征选择的方法包括过滤法、包装法和嵌入法。
过滤法是根据特征和目标变量之间的统计关系进行选择。
包装法是通过反复训练模型并评估特征子集的性能来选择最佳特征子集。
嵌入法是将特征选择嵌入到模型训练过程中,通过正则化或其他方法来选择最佳特征子集。
第四步是样本平衡。
在某些情况下,输入数据可能存在类别不平衡的问题,即某些类别的样本数量远远大于其他类别。
类别不平衡会导致模型对多数类别的预测效果较好,而对少数类别的预测效果较差。
ple模型原理及实现

ple模型原理及实现
PLE (Pretraining with Language Modeling) 模型是一种预训练模型,通常用于自然语言处理领域。
其原理是通过大量的无标注数据来训练
一个基于语言模型的神经网络模型,然后将其用于目标任务的微调,从而
提高模型性能。
具体来说,PLE模型的训练过程包括以下几个步骤:
1.数据预处理:将原始的文本数据进行清洗、分词等处理,生成一个
包含大量的文本片段的数据集。
2. 语言模型训练:使用上述数据集训练一个语言模型,通常采用LSTM 或 Transformer 等深度学习模型。
语言模型的目标是学习最大化下
一个单词出现的概率与当前单词及其前面所有单词的条件概率。
3.微调训练:使用预训练的语言模型,在目标任务的数据集上进行微
调训练,例如文本分类、命名实体识别、机器翻译等任务。
PLE 模型的实现通常使用深度学习框架如 PyTorch 和 TensorFlow,
并使用大量的 GPU 资源进行训练。
常见的 PLE 模型包括 BERT、GPT 等。
这些模型通过调整不同的超参和微调技巧,可以在各种 NLP 任务上获得
优秀的性能。
输入-输出模型与传递函数

5 2t 4 t 1 e e (11sin 2t 3 cos 2t ). 12 15 20
如何求本例的阶跃响应?
u(t ) (t ), m 1, u(0) 1 0, 所以无法用卷积公式。
在 y' ' y'2 y u'3u 两侧取拉氏变换得:
s 2Y ( s) sy (0) y ' (0) sY ( s) y (0) 2Y ( s) sU ( s) u (0) 3U ( s)
2.3 组合系统的传递函数
一个系统往往由两个或两个以上子系统按某种方式连接而成, 称之为组合系统。组合方式有串联、并联和反馈三种连接方式。 设两个系统的传递函数分别为 G1( s), G2 ( s)
串联组合
U ( s)
G1 ( s ) Z ( s) G2 ( s ) Y ( s)
如图所示, 子系统 G1 ( s )和 G2 ( s ) 串联连接。子系统 G1 ( s )的输出 Z ( s) 作为子系统 G2 ( s )的输入;子系统 G1 ( s )的输入 U (s) 和子系统 G2 ( s ) 的 输出 Y ( s) 分别是整个组合系统的输入和输出。虚线框内是串联组 合系统.
肪冲响应
在零初始条件下,线性系统对单 位脉冲输入信号的输出响应,称 为该系统的肪冲响应.
由于 u(t ) (t ), L
-1[
卷积定理
在零初始条件下,系统的任一输入u(t ) 与相应的输出 y(t ) 之间有如下关系:
y (t ) g (t ) * u (t ) g (t )u ( )d
由于这些初始值有很大的随意性与系统的本性无关因此可令它们全为零为系统1的传递函数由传递函数的定义可知微分方程和其传递函数是一一对应的而且从其中任一形式能方便地写出另一形式
第 06 讲 实体认证

实体认证的模型
窜扰者
信源
认证编码器
认证译码器
信宿
密钥源
安全信道
PAP CHAP Kerberos X.509
身份认证协议
基于共享密钥的认证
基于共享密钥的认证方式是:通信双方以共享密钥作为相互 通信的依据,在相互通信过程中,为每一个新连接选择一个 随机生成的会话密钥。主要通信数据采用会话密钥来加密, 尽可能减少使用共享密钥加密的数据量,以减少窃听者获得 的使用共享密钥加密的消息数量,降低共享密钥被破译的可 能性。 基于共享密钥的常见认证协议有:
A,B,R,RA,KA(A,B,R,RA)
KA(A,B,R,RA), (2)
A
KB(A,B,R,RB)
K
B
(3)
KA(RA,kS)
D
C
(4)
KB(RB,kS)
基于公钥的认证
(1)A首先生成质询信息RA,RA是 一个随机数;接着A用B的公钥 KB加密会话信息{A, RA},然 后发给B。
B的公钥KB
(4)
RA
(5)
KAB(RA)
(6)A确认B的身份之后,选取一个会话密钥KS, 并且用KAB加密之后发送给B。
(6)
KAB(Ks)
使用密钥分发中心的认证协议
通信双方A和B依靠密钥分发中心KDC(Key Distribution Center)实现身份认证。KDC拥有A的 密钥KA和B的密钥KB。
(1)A准备一个会话信息,其中指明了B的身份标识及 会话密钥KS,使用A的密钥KA对会话信息进行加密, 然后再连同A的身份标识一起发给KDC。
(5)A收到消息后确认了B的身份,再向B发送KS (RB-1)。B收到消息后也可以确认A的身份。
多输入多输出预测模型的训练

多输入多输出预测模型的训练多输入多输出预测模型是一种能够同时处理多个输入和输出的机器学习模型。
在传统的机器学习中,通常只能处理一个输入和一个输出,而多输入多输出预测模型则具有更强大的能力,可以同时处理多个输入和多个输出。
这种模型在很多实际应用场景中非常有用。
例如,在自然语言处理中,我们可以使用多输入多输出预测模型来将一段文本转换成多个目标语言的翻译结果。
又如,在图像处理中,我们可以使用多输入多输出预测模型来将一张图片中的多个物体进行识别和标记。
那么,如何训练一个多输入多输出预测模型呢?首先,我们需要准备好训练数据。
对于每个输入和输出,我们都需要有大量的样本数据进行训练。
这些样本数据应该具有代表性,并且涵盖了各种不同的情况和变化。
接下来,我们需要选择合适的模型架构。
多输入多输出预测模型可以使用各种不同的架构,例如神经网络、决策树等。
我们需要根据具体的问题和数据特点选择合适的模型架构。
然后,我们需要进行模型的训练。
训练过程中,我们会使用训练数据来不断调整模型的参数,使得模型能够更好地拟合输入和输出之间的关系。
训练的目标是使得模型在训练数据上的预测结果与真实输出尽可能接近。
在训练过程中,我们可以使用各种不同的优化算法来最小化模型的误差。
常见的优化算法包括梯度下降、随机梯度下降等。
这些算法能够通过不断调整模型的参数来逐步改进模型的性能。
训练完成后,我们可以使用训练好的模型来进行预测。
对于给定的输入,模型会给出对应的输出。
这些输出可以是分类标签、连续值等,具体取决于问题的特点和模型的设计。
需要注意的是,训练一个多输入多输出预测模型可能会比较复杂和耗时。
这是因为模型需要处理多个输入和多个输出,这增加了模型的复杂度和计算量。
此外,训练数据的准备和标注也需要相应地增加。
在实际应用中,多输入多输出预测模型已经取得了很多成功的应用。
例如,在自动驾驶领域,我们可以使用多输入多输出预测模型来同时处理车辆的图像、雷达和传感器数据,实现智能驾驶的功能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
还可以单击“压缩对话框”按钮 ,选择工作表中的区域,然 后再次单击“压缩对话框”按钮返回到对话框。
13
2011年10月10日星期一
使用Excel直方图工具
4. 在“输入”下的“接收区域”框中,输入对包含一
组可选边界值(用于定义接收区域)的区域的单元 格引用。提示 如果使用的是示例工作表数据,则键 入 B1:B5。 5. 如果在选择输入和接收区域数据时包括了列标签, 则选中“标签”复选框。 6. 在“输出选项”下,执行以下操作之一:
10
2011年10月10日星期一
使用Excel直方图工具
按 Ctrl + C(复制) 在工作表中,选择单元格 A1,然后按 Ctrl + V(粘贴)
11
2011年10月10日星期一
使用Excel直方图工具
在工作表中,按以下方式输入自己的数据: 1.)在一列中,键入输入数据。注释:必须在输入列的每个单元 格中输入定量数值数据(例如项金额或测试分数)— 直方图 工具不处理定性数值数据(例如身份证号码)。 2.)在另一列中,键入要用于分析的接收区域数据。接收区域数 据必须按升序输入。 注释: 如果未在工作表上输入接收区 域数据,则直方图工具使用输入区域中的最小值和最大值作 为起始点和结束点来自动创建均匀分布的接收区域。但是, 这些区域可能无用 — 建议您使用自己的接收区域数据。 提示 如果需要,可以在这些列的第一个单元格中添加标签。
22
其中λ为该分布的均值。
17
2011年10月10日星期一
三、参数估计
三、参数估计 获得直方图的拟合曲线和参数λ的估计值,见 下图。从图上可以看出,λ为9.018,即选择的 指数分布密度函数pdf如下: 概率分布函数cdf如下: f ( x) 1 e x / 9.018
F( x) 1 e x / 9.018 x0 F ( x) 0 else
2011年10月10日星期一
仿真数据分析之输入模型处理 随机数据分布簇选择及其假设检验基本过程
1
2011年10月10日星期一
随机数据分布簇选择及其假设检验
基本过程: (参考书《离散事件系统仿真》P212) 一、 生成数据的直方图 (当然得先收集数据) 二、 根据直方图与各种pdf曲线对比,选择分布簇 (用数据辨识分布) 三、 进行参数估计 四、 进行假设检验,如果检验不通过重复步骤二 ☞四 (拟合优良度检验) 五、获得该数据的随机分布函数
14
2011年10月10日星期一
使用Excel直方图工具
要在同一工作表中粘贴输出表,请单击“输出区域”,再 输入输出表左上角单元格的单元格引用 (单元格引用:用 于表示单元格在工作表上所处位置的坐标集。例如,显示 在第 B 列和第 3 行交叉处的单元格,其引用形式为
“B3”。)。
注释 直方图工具会自动确定输出区域的大小并显示一条 消息,说明输出表是否替换现有数据。 要在当前工作簿中插入新的工作表并从新工作表的单元格 A1 开始粘贴输出表,请单击“新工作表组”。 提示 可以在“新工作表组”框中键入名称。 要创建新工作簿并在新工作簿的新工作表中粘贴输出表, 请单击“新工作簿”。
3
2011年10月10日星期一
随机数据分布簇选择及其假设检验
到达时间间隔数据表
4
2011年10月10日星期一
随机数据分布簇选择及其假设检验
求解过程: 一、 数据的直方图 使用excel生成数据直方图如下:
5
2011年10月10日星期一
一、 数据的直方图
6
2011年10月10日星期一
使用Excel直方图工具
9
2011年10月10日星期一
使用Excel直方图工具
直方图分析的输出会显示在一个新的工作表 (或新的工作簿)中,将显示一个直方图表和 一个反映直方图表中数据的柱形图。 步骤: 0. 将待处理工作表数据复制到您的工作表 创建一个空白工作簿或工作表,选择要处理的 工作表数据,注意不要选择行或列标题
9.018
x0 f ( x) 0 else
18
2011年10月10日星期一
三、参数估计
19
2011年10月10日星期一
四、Χ2检验
四、χ2检验 运用χ2检验如下假设: H0:x的概率密度函数服从式f(x)(上页公式)的 指数分布 χ2检验计算表
20
2011年10月10日星期一
8. 单击“确定”。
16
2011年10月10日星期一
二、选择分布簇
二、选择分布簇 对照pdf曲线图和上面的直方图,可以发现,该直方 图同指数分布曲线比较吻合,因此,假设顾客到达 时间间隔服从指数分布,及其概率密度函数pdf为:
f ( x) 1
e x / x 0
f ( x) 0(else)
四、Χ2检验
2 02.05 (k r 1) 0 .05 (6 1 1) 2 0 .05 ( 4) 9.488 2.162
21
2011年10月10日星期一
四、Χ2检验
故在水平0.05下接受H0,认为x服从均值为 9.018的指数分布。所以,该银行客户到达时 间间隔服从均值为9.018Min的指数分布。 H1?☺
12
2011年10月10日星期一
使用Excel直方图工具
1. 在“数据”选项卡上的“分析”组中,单击“数据 分析”。 2. 在“分析工具”框中单击“直方图”,再单击“确 定”。 3. 在“输入”下的“输入区域”框中,输入对要分析 的数据区域的单元格引用。 提示 如果使用的是示 例工作表数据,则键入 A1:A11。
要创建直方图,必须将数据组织到工作表上的两列 中。这些列应包含以下数据: 输入数据 要使用直方图工具分析的数据。 接收区域数据 这些数字指定了在进行数据分析时 您希望直方图工具度量输入数据的间隔。
7
2011年10月10日星期一
8
2011年10月10日星期一
使用Excel直方图工具
当您使用直方图工具时,Excel 会对每个数据区域中 的数据点 (数据点:在图表中绘制的单个值,这些值 由条形、柱形、折线、饼图或圆环图的扇面、圆点 和其他被称为数据标记的图形表示。相同颜色的数 据标记组成一个数据系列。)计数。如果数字大于 某区域的下限并且等于或小于该区域的上限,则对 应的数据点包括在该特定区域内。如果忽略接收区 域,Excel 将创建一个介于数据最小值和最大值之间 的均匀分布区域。
15
2011年10月10日星期一
使用Excel直方图工具
7. 在“输出选项”下,执行以下任意或全部操作:
要按频率的降序在输出表中显示数据,请选中“柏拉图” 复选框(柏拉图为经过排序的直方图)。 要在输出表中生成累积百分率列并在直方图中包括累积百 分率行,请选中“累积百分率”复选框。 要在生成带输出表的嵌入式直方图,请选中“图表输出” 复选框。
2
Hale Waihona Puke 2011年10月10日星期一
随机数据分布簇选择及其假设检验
☺ 指数分布数据处理范例 在对银行营业部客户服务水平的仿真过程中, 需要分析顾客到达时间间隔服从怎样的随机分 布函数。通过秒表测时收集了连续的100位顾 客到达营业厅的时刻点数据,处理得出到达时 间间隔数据如下表所示。 试分析顾客到达时间间隔服从什么分布?开发 并检验一个合适的模型。