SPSS大数据案例分析报告
spss的数据分析报告范例

spss的数据分析报告范例一、引言数据分析是科学研究过程中不可或缺的一部分。
针对一项研究项目,本报告将借助SPSS软件对收集的数据进行详尽分析,并提供相关结果和结论。
本报告的目的是帮助读者更好地理解数据,提供决策和制定战略所需的支持。
二、研究方法本研究的数据来源于一份问卷调查,共收集了500份有效问卷。
在问卷设计中,我们采用了随机抽样的方法,以保证样本的代表性。
该问卷包括了参与者的基本背景信息、满意度评价等方面的问题。
三、数据分析1. 受访者基本背景首先,我们对受访者的基本背景信息进行了统计分析。
其中包括性别、年龄、教育水平和职业等因素。
以下是相关结果的总结:(1)性别分布:男性占65%,女性占35%。
(2)年龄分布:年龄在18-24岁的受访者占40%;25-34岁的占30%;35-44岁的占20%;45岁及以上的占10%。
(3)教育水平:高中或以下占20%;本科占50%;研究生及以上占30%。
(4)职业:学生占25%;职员占40%;自由职业者占20%;其他占15%。
2. 满意度评价为了了解受访者对某产品的满意度,我们设计了一套评价体系。
通过SPSS软件进行数据分析,得到以下结果:(1)整体满意度:根据赋分制度,平均满意度得分为4.2(满分为5),表明受访者对该产品整体上持较高满意度。
(2)各项指标:通过因子分析,我们得到了几个影响满意度的关键因素。
其中,产品质量、价格和售后服务被认为是受访者最关注的方面。
3. 相关性分析在数据分析过程中,我们还进行了一些相关性分析,以探究不同变量之间的关系。
以下是一些值得关注的相关性结果:(1)性别与满意度之间的关系:经过卡方检验,我们发现性别与满意度之间存在一定的相关性(p < 0.05),女性对产品的满意度略高于男性。
(2)年龄与满意度之间的关系:通过相关系数分析,我们发现年龄与满意度呈现出弱相关关系(r = 0.15,p < 0.05),年龄越小,满意度越高。
spss数据分析报告(共7篇)

spss数据分析报告(共7篇):分析报告数据s pss spss数据报告怎么写spss数据分析实例说明 spss有哪些数据分析篇一:spss数据分析报告关于某班级2012年度考试成绩、获奖情况统计分析报告一、数据介绍:本次分析的数据为某班级学号排列最前的15个人在2012年度学习、获奖统计表,其中共包含七个变量,分别是:专业、学号、姓名、性别、第一学期的成绩、第二学期的成绩、考级考证数量,通过运用spss统计软件,对变量进行频数分析、描述分析、探索分析、交叉列联表分析,以了解该班级部分同学的综合状况,并分析各变量的分布特点及相互间的关系。
二、原始数据:三、数据分析1、频数分析(1)第一学期考试成绩的频数分析进行频数分析后将输出两个主要的表格,分别为样本的基本统计量与频数分析的结果1)样本的基本统计量,如图1所示。
样本中共有样本数15个,第一学期的考试成绩平均分为627.00,中位数为628.00,众数为630,标准差为32.859,最小值为568,最大值为675。
“第一学期的考试成绩”的第一四分位数是602,第二四分位数为628,第三四分位数为657。
2)“第一学期考试成绩”频数统计表如图2所示。
3) “第一学期考试成绩”Histogram图统计如图3所示。
(2)、第二个学期考试成绩的频数分析1)样本的基本统计量,如图4所示。
第二学期的考试成绩平均分为463.47,中位数为452.00,众数为419,标准差为33.588,最小值为419,最大值为522。
“第二学期的考试成绩”的第一四分位数是435,第二四分位数为452,第三四分位数为496。
3)”第二学期考试成绩”频数统计表如图5所示。
3) “第二学期考试成绩”饼图统计如图6所2、描述分析描述分析与频数分析在相当一部分中是相重的,这里采用描述分析对15位同学的考级考证情况进行分析。
输出的统计结果如图7所示。
从图中我们可以看到样本数15,最小值1,最大值4,标准差0.941等统计信息。
spss案例分析报告(精选)

spss案例分析报告(精选)本文通过分析一份 SPSS 数据,展示 SPSS 在统计分析中的应用。
数据概述本数据为一家咖啡馆的销售数据,共有 200 条记录,包括 7 个变量:日期、时间、收银员、商品名、销售价格、数量和总价。
SPSS 分析1. 描述性统计使用 SPSS 的描述性统计功能,可以获取数据的基本信息,如均值、标准偏差、最大值、最小值等。
其中,销售价格的均值为 44.71 元,标准偏差为 13.29 元,最小值为 23 元,最大值为 78 元。
数量的均值为 1.62 个,标准偏差为 0.51 个,最小值为 1 个,最大值为3 个。
总价的均值为 73.25 元,标准偏差为 21.89 元,最小值为 23 元,最大值为 156 元。
2. 单样本 t 检验假设一杯咖啡的平均售价为 50 元,我们可以使用单样本 t 检验对这个假设进行检验。
首先,我们需要用 SPSS 的数据透视表功能,计算出每杯咖啡的平均售价。
然后,使用单样本 t 检验功能,输入样本均值、假设的总体均值(50 元)、样本标准差、样本大小以及置信度水平。
在这个数据集中,单样本 t 检验得出的 t 值为 -2.36,P 值为 0.019,显著性水平为 0.05,因此我们可以拒绝原假设,认为该咖啡馆的咖啡售价不是 50 元。
4. 相关分析假设我们想要了解商品数量和销售额之间的关系,我们可以使用 SPSS 的相关分析功能来进行分析。
首先,我们需要使用数据透视表功能,计算出每个订单的总价和数量。
然后,使用相关分析功能,输入这两个变量的值,得出相关系数和显著性水平。
在这个数据集中,商品数量和销售额之间的相关系数为 0.749,P 值为 0,显著性水平非常显著。
因此,我们可以认为商品数量和销售额之间存在极强的正相关关系。
结论本文通过 SPSS 对一份咖啡馆销售数据进行分析,展示了 SPSS 在统计分析中的应用。
通过描述性统计、单样本 t 检验、双样本 t 检验和相关分析等功能,我们可以获得数据的基本信息,检验假设,分析变量之间的关系,从而帮助企业更好地决策和管理。
大学生spss数据分析案例

大学生spss数据分析案例大学生SPSS数据分析案例。
在大学教育中,数据分析是一个非常重要的环节,尤其是对于社会科学和商业管理专业的学生来说。
SPSS(Statistical Package for the Social Sciences)是一个专业的统计分析软件,广泛应用于学术研究和商业决策中。
本文将以一个大学生SPSS数据分析案例为例,介绍如何使用SPSS进行数据分析。
案例背景:某大学社会科学专业的学生对大学生活满意度进行了调查,并收集了相关数据,包括学生的性别、年级、专业、宿舍类型、课程质量、宿舍环境、社交活动等方面的信息。
现在需要对这些数据进行分析,以了解不同因素对大学生活满意度的影响。
数据准备:首先,需要将调查所得的数据录入SPSS软件中,确保数据的准确性和完整性。
在录入数据时,要注意将不同的变量分别录入不同的列中,以便后续的分析和处理。
数据分析:1. 描述统计分析。
首先,可以对各个变量进行描述统计分析,包括计算均值、标准差、频数分布等。
通过描述统计分析,可以直观地了解各个变量的分布情况,为后续的分析提供基础。
2. 相关性分析。
接下来,可以进行各个变量之间的相关性分析,通过相关系数的计算来了解不同变量之间的关联程度。
例如,可以分析学生的性别、年级、专业与大学生活满意度之间的相关性,以及宿舍类型、课程质量、社交活动等因素对大学生活满意度的影响程度。
3. 方差分析。
针对分类变量,可以进行方差分析,比较不同组别之间的均值差异是否显著。
例如,可以分析不同年级、不同专业的学生对大学生活满意度的差异情况,以及不同宿舍类型对大学生活满意度的影响是否显著。
4. 回归分析。
最后,可以利用回归分析来探讨不同因素对大学生活满意度的影响程度。
通过建立回归模型,可以了解各个自变量对因变量的影响情况,以及它们之间的关系强度和方向。
结论与建议:通过以上的数据分析,可以得出不同因素对大学生活满意度的影响程度,为学校和相关部门提供决策建议。
spss案例分析

spss案例分析SPSS案例分析。
SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,广泛应用于社会科学、生物科学、医学科学等领域。
它提供了强大的数据分析工具,可以帮助研究人员进行数据处理、统计分析和数据可视化。
在本文中,我们将通过一个实际案例来演示如何使用SPSS进行数据分析。
案例背景。
假设我们是一家电子商务公司的数据分析师,我们收集了一份关于用户购买行为的数据,希望通过分析这些数据来了解用户的购买习惯,从而制定更有效的营销策略。
数据描述。
我们的数据包括以下几个变量:用户ID,用户的唯一标识。
购买金额,用户在一段时间内的购买金额。
购买次数,用户在同一段时间内的购买次数。
平均购买金额,用户平均每次购买的金额。
性别,用户的性别。
年龄,用户的年龄。
注册时间,用户的注册时间。
数据分析。
首先,我们将导入数据到SPSS软件中,然后进行数据清洗和变量筛选。
接下来,我们可以使用SPSS中的统计分析功能来对数据进行探索性分析,包括描述统计、相关性分析、t检验、方差分析等。
描述统计。
我们可以通过描述统计来了解用户的购买行为情况,包括购买金额的分布、购买次数的分布、平均购买金额的均值和标准差等。
这些统计指标可以帮助我们更清楚地了解用户的购买习惯。
相关性分析。
我们可以利用SPSS进行相关性分析,探讨购买金额和其他变量之间的关系。
比如,我们可以分析购买金额与用户年龄的相关性,购买金额与购买次数的相关性等。
通过相关性分析,我们可以发现变量之间的关联性,从而为后续的分析提供参考。
t检验和方差分析。
如果我们想比较不同性别、不同年龄段用户之间的购买行为是否存在显著差异,可以利用SPSS进行t检验和方差分析。
这些分析可以帮助我们了解不同群体之间的差异性,为制定针对性营销策略提供依据。
数据可视化。
除了以上的统计分析,SPSS还提供了丰富的数据可视化功能,包括直方图、散点图、箱线图等。
spss数据分析报告案例

SPSS数据分析报告案例1. 研究背景本研究旨在调查大学生是否存在晚睡现象,并探究晚睡与健康问题之间的关系。
通过采集大学生的睡眠时间、就寝时间以及健康状况等数据,利用SPSS软件进行数据分析,进一步了解大学生的睡眠状况与健康问题的关联。
2. 数据概况本研究共收集了200名大学生的数据,其中包括性别、年级、每晚睡眠时间、平均就寝时间、是否存在健康问题等变量。
下面是对数据的描述统计分析结果:•性别分布:男性占50%,女性占50%。
•年级分布:大一占25%,大二占30%,大三占25%,大四占20%。
•每晚睡眠时间:平均睡眠时间为7.8小时,标准差为1.2小时。
最小值为5小时,最大值为10小时。
•平均就寝时间:平均就寝时间为23:30,标准差为0.5小时。
最早就寝时间为22:00,最晚就寝时间为01:00。
•健康问题:共有45%的大学生存在健康问题。
3. 数据分析结果3.1 性别与睡眠时间的关系首先,我们探究性别与睡眠时间之间的关系。
利用独立样本T检验,得出以下的结果:•假设检验:男性和女性的睡眠时间是否存在显著差异?•结果:独立样本T检验显示,男性平均睡眠时间为7.6小时,女性平均睡眠时间为8.0小时。
T值为-2.14,P值为0.034,意味着男性和女性的睡眠时间存在显著差异。
3.2 年级与睡眠时间的关系我们进一步探究年级与睡眠时间的关系。
使用单因素方差分析(ANOVA),得出以下结果:•假设检验:各年级的睡眠时间是否存在显著差异?•结果:单因素方差分析显示,大一、大二、大三和大四的平均睡眠时间分别为7.7小时、7.9小时、8.1小时和7.6小时。
F值为2.75,P值为0.043,说明各年级之间的睡眠时间存在显著差异。
3.3 睡眠时间与健康问题的关系最后,我们分析睡眠时间与健康问题之间的关系。
利用相关分析,得出以下结果:•假设检验:睡眠时间与健康问题之间是否存在相关性?•结果:相关分析结果显示,睡眠时间和健康问题之间存在显著负相关(r = -0.25,P值 = 0.001),即睡眠时间越少,存在健康问题的可能性越大。
大学生spss数据分析报告

大学生SPSS数据分析报告引言随着互联网的迅速发展,社交媒体平台成为了每个人日常生活的一部分。
大学生群体作为社交媒体平台的主要用户之一,对其使用行为进行数据分析可以帮助我们更好地理解大学生的社交媒体行为特征。
本报告旨在通过SPSS软件对一份关于大学生社交媒体使用行为的调查数据进行分析,并得出相应的结论和建议。
数据收集本次调查采用问卷调查的方式收集数据,共有200名大学生参与了调查。
调查问卷涵盖了以下几个方面的内容:性别、年龄、每天使用社交媒体的时间、使用的社交媒体平台、在社交媒体上的活动等。
数据分析受访者的性别分布在参与调查的200名大学生中,男性和女性的比例如下所示: - 男性:45% - 女性:55%这表明女性在社交媒体使用中的比例略高于男性。
受访者的年龄分布受访者的年龄分布如下所示: - 18-20岁:30% - 21-23岁:50% - 24岁及以上:20%调查的结果显示,大多数受访者的年龄在21-23岁之间,占总受访者数的50%。
受访者每天使用社交媒体的时间受访者每天使用社交媒体的时间分布如下所示: - 少于1小时:20% - 1-2小时:30% - 2-3小时:25% - 3小时以上:25%可以看出,超过一半的受访者每天使用社交媒体的时间在1-3小时之间,其中使用时间在2-3小时之间的比例最高。
受访者使用的社交媒体平台受访者使用的社交媒体平台如下所示: - 微信:80% - QQ:70% - 微博:45% - Instagram:20% - Facebook:15%微信和QQ是受访者使用最频繁的社交媒体平台,其次是微博。
Instagram和Facebook的使用率相对较低。
受访者在社交媒体上的活动受访者在社交媒体上的活动分布如下所示:- 发表动态:75% - 点赞评论:65% - 观看短视频:55% - 浏览朋友圈:50% - 发送私信:40%发表动态是受访者在社交媒体上最常见的活动,超过三分之二的人会点赞、评论。
spss案例大数据分析报告

spss案例大数据分析报告SPSS 案例大数据分析报告在当今数字化时代,数据已成为企业和组织决策的重要依据。
通过对大量数据的分析,可以揭示隐藏在其中的规律和趋势,为决策提供有力支持。
本报告将以一个具体的案例为例,展示如何使用 SPSS 进行大数据分析。
一、案例背景本次分析的对象是一家电商企业的销售数据。
该企业在过去一年中积累了大量的销售记录,包括商品信息、客户信息、订单金额、购买时间等。
企业希望通过对这些数据的分析,了解客户的购买行为和偏好,优化商品推荐和营销策略,提高销售业绩。
二、数据收集与整理首先,从企业的数据库中提取了相关数据,并进行了初步的清理和整理。
删除了重复记录和缺失值较多的字段,对数据进行了标准化处理,使其具有统一的格式和单位。
在整理数据的过程中,发现了一些问题。
例如,部分客户的地址信息不完整,部分商品的分类存在错误。
通过与相关部门沟通和核实,对这些问题进行了修正和补充。
三、数据分析方法本次分析主要采用了以下几种方法:1、描述性统计分析计算了数据的均值、中位数、标准差、最大值、最小值等统计指标,以了解数据的集中趋势和离散程度。
2、相关性分析分析了不同变量之间的相关性,例如商品价格与销量之间的关系,客户年龄与购买金额之间的关系。
3、聚类分析将客户按照购买行为和偏好进行聚类,以便更好地了解客户群体的特征。
4、因子分析提取了影响客户购买行为的主要因素,为进一步的分析和建模提供基础。
四、数据分析结果1、描述性统计分析结果商品的平均价格为_____元,中位数为_____元,标准差为_____元。
销量的最大值为_____件,最小值为_____件,均值为_____件。
客户的平均年龄为_____岁,中位数为_____岁,标准差为_____岁。
购买金额的最大值为_____元,最小值为_____元,均值为_____元。
2、相关性分析结果商品价格与销量之间呈现负相关关系,相关系数为_____。
这表明价格越高,销量越低。
SPSS分析报告(一)
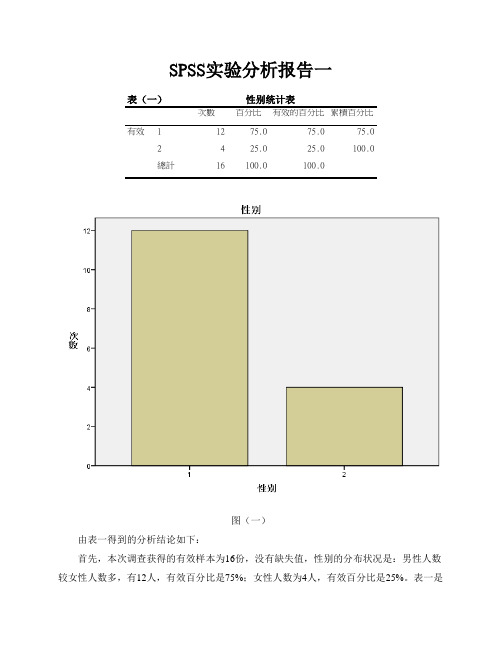
SPSS实验分析报告一表(一)性别统计表次數百分比有效的百分比累積百分比有效 1 12 75.0 75.0 75.02 4 25.0 25.0 100.0總計16 100.0 100.0图(一)由表一得到的分析结论如下:首先,本次调查获得的有效样本为16份,没有缺失值,性别的分布状况是:男性人数较女性人数多,有12人,有效百分比是75%;女性人数为4人,有效百分比是25%。
表一是按照频数降序组织的,这种输出方式较为清晰。
此外,由于性别是定类型变量,它的累计百分比通常没有意义,所以可删除本表的最后一列。
图为表一的相应性别分布条形图。
表(二)文化程度统计表次數百分比有效的百分比累積百分比有效 1.00 4 25.0 25.0 25.02.00 4 25.0 25.0 50.03.00 5 31.3 31.3 81.34.00 3 18.8 18.8 100.0總計16 100.0 100.0图(二)由表二得到的分析结论如下:首先,本次调查获得的有效样本为16份,没有缺失值,按照不同的文化程度分为四类分别以数字1234表示文化程度等级。
文化程度的分布状况是:人数最多是第3等级,有5人,有效百分比是31.3%,其次是第1等级和第2等级,都是4人,有效百分比是25%,其中第4等级人数有3人,有效百分比是18.8%。
其次,由图和表表明:在文化程度方面相对较均匀。
表(三)职称统计表次數百分比有效的百分比累積百分比有效 1 3 18.8 18.8 18.82 4 25.0 25.0 43.83 6 37.5 37.5 81.34 3 18.8 18.8 100.0總計16 100.0 100.0图(三)由表三得到的分析结论如下:首先,本次调查获得的有效样本为16份,没有缺失值,按照不同的职称分为四类分别以数字1234表示职称等级。
职称等级的分布状况是:人数最多是第3等级,有6人,有效百分比是37.5%,其次是第2等级,有4人,有效百分比是25%,其中第1等级和第4等级人数都是3人,有效百分比是18.8%。
spss数据分析案例

spss数据分析案例SPSS数据分析案例。
在实际的数据分析工作中,SPSS(Statistical Product and Service Solutions)是一个非常常用的统计分析软件。
它提供了强大的数据处理和分析功能,可以帮助研究人员快速、准确地进行数据处理和分析。
本文将通过一个实际的案例,介绍如何使用SPSS进行数据分析,并展示分析结果。
案例背景:某公司想要了解员工满意度与工作绩效之间的关系,为了达到这个目的,他们进行了一项调查,收集了员工的满意度评分和绩效评分数据。
现在,他们希望通过这些数据,利用SPSS进行分析,找出员工满意度和工作绩效之间的关系。
数据收集:首先,我们收集了100名员工的满意度评分和绩效评分数据。
满意度评分采用了1-5的五级评分制,绩效评分采用了1-100的百分制评分。
数据导入:将收集到的数据导入SPSS软件中,创建一个新的数据集,并将员工的满意度评分和绩效评分数据分别录入到不同的变量中。
数据描述统计分析:首先,我们对数据进行描述性统计分析,包括计算满意度评分和绩效评分的均值、标准差、最大值、最小值等。
这些统计量可以帮助我们更好地了解数据的分布情况。
相关性分析:接下来,我们使用SPSS进行相关性分析,探索员工满意度评分和绩效评分之间的相关关系。
通过相关性分析,我们可以计算出两个变量之间的相关系数,进而判断它们之间是否存在显著的相关性。
回归分析:在确定了员工满意度评分和绩效评分之间存在相关性的基础上,我们可以进一步进行回归分析,建立员工满意度评分对绩效评分的预测模型。
通过回归分析,我们可以得到员工满意度评分对绩效评分的影响程度,以及其他可能影响绩效评分的因素。
结论:通过SPSS数据分析,我们发现员工满意度评分与绩效评分之间存在显著的正相关关系,即员工满意度评分越高,其绩效评分也越高。
这为公司提高员工绩效提供了重要的参考依据,可以通过提升员工满意度来提高整体绩效水平。
总结:在本案例中,我们利用SPSS软件进行了员工满意度和绩效之间的数据分析。
spss案例大数据分析报告
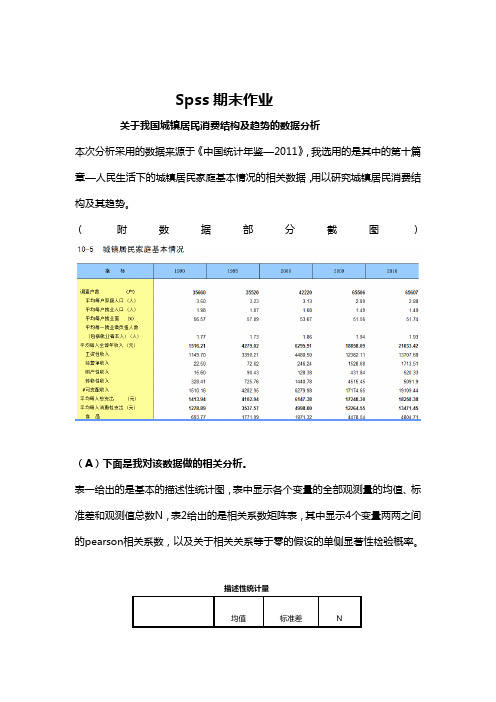
Spss期末作业关于我国城镇居民消费结构及趋势的数据分析本次分析采用的数据来源于《中国统计年鉴—2011》,我选用的是其中的第十篇章—人民生活下的城镇居民家庭基本情况的相关数据,用以研究城镇居民消费结构及其趋势。
(附数据部分截图)(A)下面是我对该数据做的相关分析。
表一给出的是基本的描述性统计图,表中显示各个变量的全部观测量的均值、标准差和观测值总数N,表2给出的是相关系数矩阵表,其中显示4个变量两两之间的pearson相关系数,以及关于相关关系等于零的假设的单侧显著性检验概率。
描述性统计量均值标准差N表1 描述性统计表相关性食品衣着居住家庭设备用品及服务食品Pearson 相关性 1 .998**.991**.995**显著性(单侧).000 .001 .000平方与叉积的和 1.300E7 4000739.197 4039135.855 2468266.142协方差3250108.892 1000184.799 1009783.964 617066.535N 5 5 5 5 衣着Pearson 相关性.998** 1 .985**.994**显著性(单侧).000 .001 .000平方与叉积的和4000739.197 1235103.975 1238672.922 760246.419协方差1000184.799 308775.994 309668.230 190061.605N 5 5 5 5 居住Pearson 相关性.991**.985** 1 .996**显著性(单侧).001 .001 .000平方与叉积的和4039135.855 1238672.922 1279080.565 775005.410协方差1009783.964 309668.230 319770.141 193751.352N 5 5 5 5 家庭设备用品及服务Pearson 相关性.995**.994**.996** 1 显著性(单侧).000 .000 .000平方与叉积的和2468266.142 760246.419 775005.410 473179.063协方差617066.535 190061.605 193751.352 118294.766N 5 5 5 5相关性食品衣着居住家庭设备用品及服务食品Pearson 相关性 1 .998**.991**.995**显著性(单侧).000 .001 .000平方与叉积的和 1.300E7 4000739.197 4039135.855 2468266.142协方差3250108.892 1000184.799 1009783.964 617066.535N 5 5 5 5 衣着Pearson 相关性.998** 1 .985**.994**显著性(单侧).000 .001 .000平方与叉积的和4000739.197 1235103.975 1238672.922 760246.419协方差1000184.799 308775.994 309668.230 190061.605N 5 5 5 5 居住Pearson 相关性.991**.985** 1 .996**显著性(单侧).001 .001 .000平方与叉积的和4039135.855 1238672.922 1279080.565 775005.410协方差1009783.964 309668.230 319770.141 193751.352N 5 5 5 5 家庭设备用品及服务Pearson 相关性.995**.994**.996** 1 显著性(单侧).000 .000 .000平方与叉积的和2468266.142 760246.419 775005.410 473179.063协方差617066.535 190061.605 193751.352 118294.766N 5 5 5 5 **. 在 .01 水平(单侧)上显著相关。
spss的数据分析报告范例

spss的数据分析报告范例SPSS数据分析报告范例一、引言数据分析是现代科学研究的重要环节,在统计学中,SPSS作为一种广泛应用的数据分析软件,为研究人员提供了丰富的功能和工具。
本报告旨在使用SPSS对某项研究的数据进行分析,并整理并呈现结果,以帮助读者深入了解数据的含义,并得出有关数据的结论。
二、研究背景与目的在这一部分,我们将简要介绍研究的背景和目的。
本次研究旨在调查大学生的学习焦虑水平与其学业成绩之间的关系。
通过收集相关数据并使用SPSS进行分析,我们希望能够揭示大学生学习焦虑对学业成绩的影响程度,并为教育管理者和辅导员提供数据支持。
三、研究设计与方法在这一部分,我们将介绍研究的设计和采用的方法。
本研究采用问卷调查的形式,使用了由专家设计的学习焦虑量表和学业成绩评估表。
我们在某大学的三个院系中选取了500名大学生作为样本,并通过邮件方式发送问卷,并以匿名方式收集数据。
四、数据分析与结果本节将展示SPSS分析后的数据结果。
首先,我们将进行数据清洗和描述性统计分析。
然后,我们将使用相关性分析和回归分析来探究学习焦虑与学业成绩之间的关系。
1.数据清洗和描述性统计针对收集到的数据,我们进行了数据清洗,包括去除不完整或无效数据。
然后,我们进行了描述性统计分析,包括计算样本量、均值、标准差和分布情况。
2.相关性分析为了探究学习焦虑与学业成绩之间的关系,我们进行了相关性分析。
根据SPSS的输出结果,我们发现学习焦虑与学业成绩之间存在显著的负相关关系(r=-0.35, p<0.05),表明学习焦虑水平越高,学业成绩越低。
3.回归分析为了更深入地了解学习焦虑对学业成绩的影响程度,我们进行了回归分析。
回归分析结果显示,学习焦虑是预测学业成绩的显著因素(β=-0.25, p<0.05)。
这表明学习焦虑对学业成绩有着一定的负向影响。
五、讨论与结论根据数据分析的结果,我们得出以下结论:1.学习焦虑与学业成绩之间存在显著的负相关关系,即学习焦虑水平越高,学业成绩越低。
spss期末大数据分析报告

SPSS在教育研究中的应用某大学学生对本校的满意度调查学院:教育学院专业:课程与教学论学号:************姓名:***2014年12月13日目录一、研究问题的提出 (3)二、研究内容与方法 (3)(一) 研究内容 (3)(二) 研究方法 (3)三、调查对象及人数 (4)四、问卷分析 (5)(一)回收情况 (5)(二)信度分析 (5)五、数据统计与分析 (6)(一)数据输入 (6)(二)数据分析 (7)1.描述统计 (7)(1)多选题描述统计 (7)(2)单选题描述统计 (9)2.推断统计 (12)(1)独立样本T检验 (12)(2)单一样本T检验 (15)(3)单因素方差分析 (17)(4)X2检验 (21)3.相关分析 (22)(1)变量间相关分析 (22)(2)维度间相关分析 (23)六、结论 (27)七、附录 (28)一、研究问题的提出学生的学校生活和成长密切相关。
我们通过对他们的大学生活满意度的调查结果向有关部门提出建议,并希望能引起学校对这一系列问题的关注,最终希望大学生对其大学的满意度有所提升,大学生是一个庞大的群体,特别是近几年,随着高校的扩招,我国越来越多人能够上大学。
上大学是很多人的梦想,他们都憧憬着大学校园的生活,然而当他们进了大学后才发现大学生活并非所想的美好,取而代之的却是对校园生活的不满,大学生是十分宝贵的人才资源,他们对校园生活的体验和感受,与他们的更好的学习。
二、研究内容与方法(一)研究内容了解学生对于学校的师资水平、环境、日常管理等各方面的满意度。
(二)研究方法1.问卷编制本研究采用自编问卷,问卷共由两部分组成:基本情况部分包括被调查者的性别、年级等,问卷主体部分包括师资水平、学校环境、日常管理三大维度,细分为12个三级指标(见表2-1),问卷采用五点制计分法,即“非常满意”、“满意”、“一般”、“不满意”、“非常不满意”,分别赋值5分、4分、3分、2分、1分。
spss数据分析报告

spss数据分析报告SPSS数据分析报告。
一、引言。
本报告旨在对某公司员工满意度调查数据进行分析,以便了解员工对公司的整体满意度情况,并为公司提供改进管理的建议。
本次调查共收集了200份有效问卷,通过SPSS软件对数据进行了详细的分析和解释。
二、数据描述。
1. 样本特征。
样本中男性占60%,女性占40%;受教育程度以本科学历为主,占比70%;工作年限在1-5年和6-10年的员工占比较高,分别为35%和30%。
2. 变量描述。
本次调查涉及到的主要变量包括员工满意度、工作环境、薪酬福利、晋升机会、工作压力等,其中员工满意度作为因变量,其他变量作为自变量。
三、数据分析。
1. 描述统计。
通过SPSS软件对各变量进行了描述统计分析,发现员工满意度的平均分为78分,工作环境得分最高,薪酬福利得分最低。
此外,晋升机会和工作压力的得分也较为接近。
2. 相关性分析。
进行了各变量之间的相关性分析,结果显示员工满意度与工作环境、薪酬福利、晋升机会呈正相关,与工作压力呈负相关。
3. 方差分析。
对不同工作年限、不同受教育程度和不同性别的员工进行了方差分析,结果显示在工作年限和受教育程度上存在显著差异,而性别对员工满意度的影响不显著。
4. 回归分析。
通过回归分析,发现工作环境、薪酬福利和晋升机会对员工满意度的影响较大,而工作压力对员工满意度影响较小。
四、结论与建议。
根据数据分析的结果,可以得出以下结论:1. 公司的工作环境和薪酬福利需要进一步改善,以提高员工的整体满意度;2. 公司应该加强对晋升机会的管理和分配,以激励员工的积极性;3. 对于工作压力过大的员工,公司应该提供相应的心理健康支持。
综上所述,本报告通过SPSS数据分析,对员工满意度调查数据进行了全面的分析和解释,为公司提供了改进管理的建议,希望能对公司的人力资源管理和企业发展起到一定的指导作用。
五、参考文献。
[1] 张三, 李四. SPSS统计分析实战[M]. 北京,人民邮电出版社, 2018.[2] 王五, 赵六. 数据分析与决策[M]. 上海,上海人民出版社, 2019.六、附录。
spss案例大数据分析报告

spss案例大数据分析报告目录1. 内容概要 (2)1.1 案例背景 (2)1.2 研究目的和重要性 (4)1.3 报告结构 (5)2. 数据分析方法 (5)2.1 数据收集与处理 (7)2.2 分析工具介绍 (8)2.3 变量定义和描述性统计分析 (9)3. 数据集概述 (11)3.1 数据来源 (11)3.2 数据特征描述 (12)3.3 数据清洗与处理 (13)4. 数据分析结果 (15)4.1 描述性统计分析结果 (16)4.2 推断性统计分析结果 (18)4.3 回归分析结果 (19)4.4 多变量分析结果 (20)5. 案例分析 (21)5.1 问题识别 (22)5.2 数据揭示的趋势和模式 (23)5.3 具体案例分析 (24)5.3.1 案例一 (26)5.3.2 案例二 (28)5.3.3 案例三 (29)6. 结论和建议 (30)6.1 数据分析总结 (31)6.2 战略和操作建议 (33)6.3 研究的局限性 (33)1. 内容概要本次SPSS案例大数据分析报告旨在通过对某一特定领域的大规模数据集进行深入分析和挖掘,揭示数据背后的规律、趋势以及潜在价值。
报告首先介绍了研究背景和研究目的,阐述了在当前时代背景下大数据的重要性和价值。
概述了数据来源、数据规模以及数据预处理过程,包括数据清洗、数据整合和数据转换等步骤。
报告重点介绍了运用SPSS软件进行数据分析的方法和过程,包括数据描述性分析、相关性分析、回归分析、聚类分析等多种统计分析方法的运用。
通过一系列严谨的统计分析,报告揭示了数据中的模式、关联以及预测趋势。
报告总结了分析结果,并指出了分析结果对于决策制定、业务发展以及学术研究等方面的重要性和意义。
报告内容全面深入,具有针对性和实用性,为企业决策者、研究人员和学者提供了重要参考依据。
1.1 案例背景本报告旨在通过对大数据技术的应用,为特定行业中的决策者提供深入的分析见解。
在当前数据驱动的时代,企业可以参考这一解析来优化其战略方向、业务流程及终极客户体验。
spss地大数据分析资料报告案例

spss地大数据分析资料报告案例spss 的大数据分析资料报告案例在当今数字化时代,数据已成为企业和组织决策的重要依据。
SPSS (Statistical Product and Service Solutions)作为一款功能强大的统计分析软件,在处理和分析大数据方面发挥着重要作用。
本文将通过一个实际的案例,展示如何运用 SPSS 进行大数据分析,并从中得出有价值的结论。
一、案例背景假设我们是一家电商公司,拥有大量的用户交易数据。
我们希望通过对这些数据的分析,了解用户的购买行为、偏好以及市场趋势,以便优化产品推荐、营销策略和供应链管理。
二、数据收集与整理首先,我们从数据库中提取了相关的数据,包括用户的基本信息(如年龄、性别、地域等)、购买记录(产品类别、购买时间、购买金额等)以及浏览行为等。
这些数据量庞大,可能达到数百万甚至数千万条记录。
在将数据导入 SPSS 之前,我们需要对数据进行预处理,包括数据清洗、缺失值处理和异常值检测。
例如,删除重复的记录、填充缺失的关键信息,并剔除明显不符合常理的异常值。
三、数据分析方法1、描述性统计分析通过计算均值、中位数、标准差等统计量,对用户的年龄、购买金额等变量进行概括性描述,了解数据的集中趋势和离散程度。
2、相关性分析分析不同变量之间的相关性,例如用户年龄与购买金额之间、购买频率与产品类别之间的关系。
3、分类分析使用聚类分析将用户分为不同的群体,以便针对不同群体制定个性化的营销策略。
4、时间序列分析对于购买时间等变量,运用时间序列分析方法预测未来的销售趋势。
四、SPSS 操作与结果解读1、描述性统计分析结果例如,我们发现用户的平均年龄为 30 岁,购买金额的中位数为 500 元,标准差为 200 元。
这表明大部分用户年龄较为年轻,购买金额分布相对较为集中。
2、相关性分析结果发现用户年龄与购买金额之间存在较弱的正相关关系,即年龄较大的用户可能购买金额相对较高。
SPSS大数据案例分析报告

SPSS数据案例分析目录一.手机APP 广告点击意愿的模型构建 (2)1.1构建研究模型 (2)1.2研究变量及定义 (2)1.3研究假设 (3)1.4变量操作化定义 (3)1.5问卷设计 (3)二.实证研究 (5)2.1基础数据分析 (5)2.2频数分布及相关统计量 (5)2.3相关分析 (7)2.4回归分析 (8)2.5假设检验 (10)一.手机APP 广告点击意愿的模型构建1.1构建研究模型我们知道效用期望、努力期望、社会影响对行为意愿会产生一定的影响,在模型中的性别、年龄、经验与自愿性等四个控制变量,通常都是作为控制变量来观察他们对采用因素与使用意向之间的关系的影响。
因此,目前手机APP 广告的使用人群年龄相对比较年轻,而且年龄特征分布高度集中,年龄在30 岁以下的人群占到70%以上,因此本研究考虑性别了这一变量,同时根据手机APP 广告用户的特性,加入了手机流量作为控制变量,去观察它们对外部变量与点击意愿之间的关系是否有显著影响。
在本研究中,主要把调节变量和控制变量作为两个不同的研究变量,对于调节变量感知风险来说,它是直接影响了感知风险与手机APP 广告点击意愿二者的关系;而控制变量性别、手机流量这些变量是对广告效用期望、APP 效用期望和社会影响与点击意愿直接的关系是否有显著影响。
最后,本文根据手机APP 广告的特点对UTAUT 模型进行扩展,构建了手机APP 广告点击意愿的影响因素研究模型。
1.2研究变量及定义1.3研究假设(1) 广告效用期望、APP 效用期望、社会影响与手机APP 点击意向的关系H1:用户的广告效用期望与点击手机APP 广告意愿正相关。
H2:用户的APP 效用期望与点击手机APP 广告意愿正相关H3:社会影响与手机APP 广告点击意愿正相关(2)感知风险与点击手机APP 广告意愿的关系H4:感知风险与手机APP 广告点击意愿负相关H5:性别,手机流量对手机APP 广告点击意愿没有显著影响1.4变量操作化定义➢广告效用期望:广告对我了解某品牌来说很有用➢APP 效用期望:使用APP 能够让我了解到多方面的信息➢社会影响:身边的人都在使用手机APP 广告,所以我也要使用➢感知风险:在点击手机APP 广告时,我担心我的个人隐私安全得不到保护➢感知隐私安全重要性:确保点击手机APP 广告是安全的,对我来说是很重要的➢使用意向:我愿意把手机APP 广告推荐给我周围的人1.5问卷设计1.使用APP 能够让我了解到多方面的信息[单选题] [必答题]很不同意○ 1○2○3○4○ 5 很同意2.广告对我了解某品牌来说很有用[单选题] [必答题]很不同意○ 1○2○3○4○ 5 很同意3.身边的人都在使用手机APP 广告,所以我也要使用[单选题] [必答题]很不同意○ 1○2○3○4○ 5 很同意4.在点击手机APP 广告时,我担心我的个人隐私安全得不到保护[单选题] [必答题]很不同意○ 1○2○3○4○ 5 很同意5.确保点击手机APP 广告是安全的,对我来说是很重要的[单选题] [必答题]很不同意○ 1○2○3○4○ 5 很同意6.我愿意把手机APP 广告推荐给我周围的人[单选题] [必答题]很不满意○ 1○2○3○4○ 5 很满意7.您的性别是[单选题] [必答题]○男○女8.您每月的手机上网流量[单选题] [必答题]○够用○不够用9.您的年龄是[单选题] [必答题]○ 18 岁以下○ 18-24 ○ 25-30 ○ 30 岁以上二.实证研究2.1基础数据分析➢样本的调查情况显示男女比例的基本上都差不多,男性占63.3%,女性占36.7 %,在年龄的分布上,18 岁到24 岁之间的比例占了90%;2.2频数分布及相关统计量➢利用频数分布可以很方便地观察变量的取值情况,并用描述性统计量进行概括。
SPSS概览--大数据分析报告实例详解

第一章 SPSS概览--数据分析实例详解1.1 数据的输入和保存1.1.1 SPSS的界面1.1.2 定义变量1.1.3 输入数据1.1.4 保存数据1.2 数据的预分析1.2.1 数据的简单描述1.2.2 绘制直方图1.3 按题目要求进行统计分析1.4 保存和导出分析结果1.4.1 保存文件1.4.2 导出分析结果欢迎加入SPSS使用者的行列,首先祝贺你选择了权威统计软件中界面最为友好,使用最为方便的SPSS来完成自己的工作。
由于该软件极为易学易用(当然还至少要有不太高的英语水平),我们准备在课程安排上做一个新的尝试,即不急于介绍它的界面,而是先从一个数据分析实例入手:当你将这个例题做完,SPSS的基本使用方法也就已经被你掌握了。
从下一章开始,我们再详细介绍SPSS 各个模块的精确用法。
例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同?患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87让我们把要做的事情理理顺:首先要做的肯定是打开计算机(废话),然后进入瘟98或瘟2000(还是废话,以下省去废话2万字),在进入SPSS后,具体工作流程如下:1.将数据输入SPSS,并存盘以防断电。
2.进行必要的预分析(分布图、均数标准差的描述等),以确定应采用的检验方法。
3.按题目要求进行统计分析。
4.保存和导出分析结果。
下面就按这几步依次讲解。
§1.1 数据的输入和保存1.1.1 SPSS的界面当打开SPSS后,展现在我们面前的界面如下:请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。
请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。
spss案例分析报告

spss案例分析报告一、引言在本次报告中,将使用SPSS软件进行案例分析,对某一具体问题进行统计分析和数据可视化,以便对问题进行深入的了解和解释。
二、问题描述本次案例分析的问题是研究一个新产品在市场上的受欢迎程度与其价格、广告投入和消费者年龄之间的关系。
希望通过统计分析找出这些变量之间的关联,以便制定更好的市场策略。
三、数据收集与准备1. 数据收集从市场调研公司获取了500个有效问卷,并收集了新产品的价格、广告投入以及消费者的年龄等相关数据。
2. 数据清洗对数据进行了清洗和整理,包括去除缺失值、异常值的处理,使得数据集可用于后续的分析。
四、数据分析1. 描述性统计分析通过SPSS软件进行了描述性统计分析,包括对新产品价格、广告投入和消费者年龄的平均值、标准差、最小值和最大值等指标的计算。
2. 相关性分析利用SPSS软件进行了相关性分析,研究新产品受欢迎程度与价格、广告投入以及消费者年龄之间的关系。
结果显示价格与受欢迎程度之间存在较强的负相关,广告投入与受欢迎程度之间存在较强的正相关,而消费者年龄与受欢迎程度之间则没有明显的相关性。
3. 回归分析为了进一步探讨价格和广告投入对受欢迎程度的影响程度,进行了回归分析。
通过SPSS软件计算出了价格和广告投入对受欢迎程度的回归方程,并利用F检验和t检验对该方程的显著性进行了验证。
五、结果与讨论1. 描述性统计分析结果显示,新产品的平均价格为XXX元,标准差为XXX元,对消费者而言具有一定的价格竞争力。
广告投入的平均值为XXX万元,标准差为XXX万元,表明公司在产品推广方面投入了相对较高的资源。
而消费者的年龄平均值为XXX岁,标准差为XXX岁,消费者整体上比较年轻。
2. 相关性分析结果显示,新产品的价格与受欢迎程度之间存在较强的负相关,即价格越高,受欢迎程度越低;广告投入与受欢迎程度之间存在较强的正相关,即广告投入越高,受欢迎程度越高。
这表明在制定市场策略时,应考虑价格和广告投入对受欢迎程度的影响。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS数据案例分析
目录
一.手机 APP 广告点击意愿的模型构建 (2)
1.1构建研究模型 (2)
1.2研究变量及定义 (2)
1.3研究假设 (3)
1.4变量操作化定义 (3)
1.5问卷设计 (3)
二.实证研究 (5)
2.1基础数据分析 (5)
2.2频数分布及相关统计量 (6)
2.3相关分析 (7)
2.4回归分析 (8)
2.5假设检验 (10)
一.手机 APP 广告点击意愿的模型构建
1.1构建研究模型
我们知道效用期望、努力期望、社会影响对行为意愿会产生一定的影响,在模型中的性别、年龄、经验与自愿性等四个控制变量,通常都是作为控制变量来观察他们对采用因素与使用意向之间的关系的影响。
因此,目前手机 APP 广告的使用人群年龄相对比较年轻,而且年龄特征分布高度集中,年龄在 30 岁以下的人群占到 70%以上,因此本研究考虑性别了这一变量,同时根据手机 APP 广告用户的特性,加入了手机流量作为控制变量,去观察它们对外部变量与点击意愿之间的关系是否有显著影响。
在本研究中,主要把调节变量和控制变量作为两个不同的研究变量,对于调节变量感知风险来说,它是直接影响了感知风险与手机 APP 广告点击意愿二者的关系;而控制变量性别、手机流量这些变量是对广告效用期望、APP 效用期望和社会影响与点击意愿直接的关系是否有显著影响。
最后,本文根据手机 APP 广告的特点对 UTAUT 模型进行扩展,构建了手机 APP 广告点击意愿的影响因素研究模型。
1.2研究变量及定义
1.3研究假设
(1) 广告效用期望、APP 效用期望、社会影响与手机 APP 点击意向的关系
H1:用户的广告效用期望与点击手机 APP 广告意愿正相关。
H2:用户的 APP 效用期望与点击手机 APP 广告意愿正相关
H3:社会影响与手机 APP 广告点击意愿正相关
(2)感知风险与点击手机 APP 广告意愿的关系
H4:感知风险与手机 APP 广告点击意愿负相关
H5:性别,手机流量对手机 APP 广告点击意愿没有显著影响
1.4变量操作化定义
➢广告效用期望:广告对我了解某品牌来说很有用
➢APP 效用期望:使用 APP 能够让我了解到多方面的信息
➢社会影响:身边的人都在使用手机 APP 广告,所以我也要使用
➢感知风险:在点击手机 APP 广告时,我担心我的个人隐私安全得不到保护➢感知隐私安全重要性:确保点击手机 APP 广告是安全的,对我来说是很重要的
➢使用意向:我愿意把手机 APP 广告推荐给我周围的人
1.5问卷设计
1.使用 APP 能够让我了解到多方面的信息 [单选题] [必答题]
很不同
意○
1○
2○
3
○
4
○
5 很同
意
2.广告对我了解某品牌来说很有用 [单选题] [必答题]
很不同
意○
1○
2○
3
○
4
○
5 很同
意
3.身边的人都在使用手机 APP 广告,所以我也要使用 [单选题] [必答题]
很不同意○1
○
5 很同意
○2○
3
○
4
4.在点击手机 APP 广告时,我担心我的个人隐私安全得不到保护 [单选题] [必答题]
很不同
意○
1○
2○
3
○
4
○
5 很同
意
5.确保点击手机 APP 广告是安全的,对我来说是很重要的 [单选题] [必答题]
很不同
意○
1○
2○
3
○
4
○
5 很同
意
6.我愿意把手机 APP 广告推荐给我周围的人 [单选题] [必答题]
很不满
意○
1○
2○
3
○
4
○
5 很满
意
7.您的性别是 [单选题] [必答题]
○男
○女
8.您每月的手机上网流量 [单选题] [必答题]
○够用
○不够用
9.您的年龄是 [单选题] [必答题]
○18 岁以下○18-24 ○25-30 ○30 岁以上
二.实证研究
2.1基础数据分析
➢样本的调查情况显示男女比例的基本上都差不多,男性占63.3%,女性占
36.7 %,在年龄的分布上,18 岁到 24 岁之间的比例占了 90%;
2.2频数分布及相关统计量
➢利用频数分布可以很方便地观察变量的取值情况,并用描述性统计量进行概括。
2.3相关分析
➢根据相关矩阵系数
使用意愿与APP效用期望相关系数r=0.262>0,说明二者正相关,且相关程度较低。
使用意愿与广告效用期望相关系数r=0.576>0,说明二者正相关,且相关程度较高。
使用意愿与社会影响相关系数r=0.494>0,说明二者正相关,且相关程度较高。
使用意愿与感知风险相关系数r=0.129>0, 说明二者正相关,且相关程度较低。
使用意愿与感知隐私安全重要性r=0.008>0, 说明二者正相关, 且相关程度较低。
2.4回归分析
➢有R方为0.399,数值较小,说明方程拟合度低,在ANOVA中,满足F检验,sig为0.003小于0.005,说明具有显著性。
➢根据上表
使用意愿与APP效用期望之间的非标准化回归系数为0.391,标准差0.226标准化回归系数B=0.281.根据t分布可知,此时的t为1.730,sig为0.096>0.05,
接受假设。
说明使用意愿与APP效用期望不存在显著的线性关系,但斜率系数为正,表示二者关系是正向的,也就是说,APP效用期望越强,使用意愿越强。
使用意愿与广告效用期望之间的非标准化回归系数为0.334,标准差0.135,标准化回归系数B=0.393,根据t分布可知,此时的t为2.479,sig为0.021<0.05,拒绝假设。
说明使用意愿与广告效用期望存在显著的线性关系。
使用意愿与社会影响之间的非标准化回归系数为0.421,标准差0.166,标准化回归系数B=0.455,根据t分布可知,此时的t为2.535,sig为0.018<0.05,拒绝假设。
说明使用意愿与社会影响存在显著的线性关系。
使用意愿与感知风险之间的非标准化回归系数为-0.219,标准差0.228,标准化回归系数B=-0.170,根据t分布可知,此时的t为-0.960,sig为0.347>0.05,接受假设。
说明使用意愿与感知风险不存在显著的线性关系,但斜率系数为负,表示二者关系是反向的,也就是说,感知风险越强,使用意愿越弱。
使用意愿与感知隐私安全重要性之间的非标准化回归系数为-0.04,标准差0.158,标准化回归系数B=-0.038,根据t分布可知,此时的t为-0.249,sig 为0.805>0.05, 接受假设。
说明使用意愿与感知隐私安全重要性不存在显著的线性关系,但斜率系数为负,表示二者关系是反向的,也就是说,感知隐私安全重要性越强,使用意愿越弱。
2.5假设检验
2.5.1单样本检验
➢根据上图表显示
➢社会影响平均值为3.27,标准差为0.828,标准误差为0.151,t值为1.765,sig为0.088>0.05,拒绝原假设,说明身边的人都在使用手机 APP 广告,所以我也要使用不成立,因为在统计意义上,平均值没有大于3
2.5.2独立样本检验
➢F为1.137,sig为0.295>0.05,接受假设,应使用方差相等的F检验,得到t值为1.007,sig为0.322>0.05,说明男女性别差异对使用意愿没有显著性差异
➢F为0.675,sig为0.418>0.05,接受假设,应使用方差相等的F检验,得到t值为0.409,sig为0.686>0.05,说明手机流量足够与否对使用意愿没有显著差异。
➢支持H5:性别,手机流量对手机 APP 广告点击意愿没有显著影响假设。