可视化第五章排序
Excel的高级数据处理技巧

Excel的高级数据处理技巧第一章:数据筛选和排序在Excel中,数据筛选和排序是常见的操作,可以帮助我们从大量数据中找到需要的信息。
在本章中,将介绍一些高级的数据筛选和排序技巧。
1.1 高级筛选:通过设置多个条件来筛选数据,可以使用逻辑运算符(如AND、OR)结合多个条件进行精确筛选。
1.2 高级排序:除了基本的排序功能外,Excel还提供了多列排序的功能,可以通过设置多个排序条件对数据进行更精细的排序。
1.3 自定义排序:在排序选项中,可以选择自定义排序顺序,例如按照自定义的顺序对月份进行排序。
第二章:数据透视表数据透视表是Excel中一个非常强大的工具,可以帮助我们对大量数据进行汇总和分析。
在本章中,将介绍一些高级的数据透视表技巧。
2.1 数据透视表筛选:可以通过设置条件来筛选数据透视表中的数据,只显示满足条件的数据。
2.2 合并数据透视表:可以将多个数据透视表合并在一起,形成一个更全面的数据透视表,方便数据分析和比较。
2.3 透视表字段排序:可以对数据透视表中的字段进行排序,例如按照销售额从高到低进行排序。
第三章:数据清洗和转换在 Excel 中,我们常常需要对原始数据进行清洗和转换,以保证数据的准确性和一致性。
在本章中,将介绍一些高级的数据清洗和转换技巧。
3.1 文本清洗:可以使用文本函数和正则表达式等工具对文本数据进行清洗和提取。
3.2 数据转换:可以使用数据透视表和函数等工具对原始数据进行转换,以满足不同需求的分析。
3.3 多表数据合并:可以使用数据连接和合并工具将多个表格中的数据合并在一起,方便数据分析。
第四章:高级函数和公式应用Excel提供了许多强大的函数和公式,可以帮助我们进行复杂的数据处理和计算。
在本章中,将介绍一些常用的高级函数和公式应用技巧。
4.1 ARRAY公式:ARRAY公式可以处理数组数据,可以进行多个单元格的计算和处理。
4.2 数据的动态更新:通过使用函数和公式,可以使数据在源数据更新后自动更新。
算法可视化演示软件开发毕业设计

算法可视化演示软件开发毕业设计目录前言 (1)第一章绪论 (2)第一节课题背景 (2)第二节课题的目的与意义 (2)第三节论文结构 (3)第二章相关知识概述 (4)第一节 Java知识相关概述 (4)一、Java的发展史 (4)二、Java的主要特性 (4)三、JDK 平台相关信息 (5)第二节 Java图形界面技术概述 (5)一、 Java Swing相关概述 (5)二、容器和布局 (7)三、事件处理 (8)第三节相关算法的介绍 (9)一、冒泡排序 (9)二、插入排序 (10)三、选择排序 (12)四、二叉查找树 (12)第四节本章小结 (15)第三章需求分析 (17)第一节系统功能需求 (17)一、系统设计目标 (17)二、系统功能需求 (17)第二节系统运行环境 (18)第三节本章小结 (18)第四章系统设计 (19)第一节系统总体描述 (19)第二节模块设计 (20)一、算法模块设计 (20)二、界面模块设计 (22)第三节系统流程图 (25)第四节本章小结 (26)第五章系统实现 (27)第一节可视化主界面的实现 (27)第二节排序算法界面所实现的功能 (28)第三节二叉查找树可视化功能的实现 (31)第四节本章小结 (33)第六章系统测试 (34)第一节问题解决及测试结果 (34)一、遇到的问题 (34)二、解决的方法 (34)三、测试结果 (34)第二节本章小结 (41)结论 (42)致谢 (43)参考文献 (44)附录 (45)一、英文原文 (45)二、英文翻译 (52)前言可视化( Visualizations)计算机图形学和图像处理技术,将数据转换成图形或图像在屏幕上显示出来,并进行交互处理的理论、方法和技术。
此次设计算法可视化( Algorithm Visualizations)就是利用可视化技术将算法可视化[1]。
排序是计算机程序设计中的一种重要操作,其功能是一个数据元素(或者记录)的任意序列,从新排列成一个按关键字有序的序列。
PowerBI数据分析与数据可视化 第5章 数据视图和管理关系

5.1.3 新建列
• 可先通过下列方式执行“新建列”命令。
在“建模”选项卡中单击“新建列”命令。 在数据视图中,用鼠标右键单击数据表格,在快捷菜单中选择“新建列”命令。 在“字段”窗格中,用鼠标右键单击表名称,在快捷菜单中选择“新建列”命令。
• 执行“新建列”命令会激活公式编辑器,然后在公式编辑器中输入公式创建新列。 新建列始终属于当前表。
2.交叉筛选器方向
• 两个建立关系相当于两个表的笛卡尔积(交叉),然后按关联列的值匹配(筛选) 两个表中的行。建立关系后,两个表可当作一个表来用。交叉筛选器方向则指在一 个表中根据关联列查找另一个表中的匹配行。
• 在创建关系时,交叉筛选器方向可设置为“双向”(两个)或“单向”(单个)。 交叉筛选器方向设置为“双向”意味着从关联的两个表中的任意一个表,均可根据 关联列查找另一个表中的匹配行。交叉筛选器方向设置为“单向”则意味着只能从 一个表根据关联列查找另一个表中的匹配行,反之则不行。
第5章 数据视图和管理关系
• 数据视图除了显示数据表数据之外,还可为数据表添加列、修改列名、排序等各种 操作。
• 关系视图用于查看和管理数据表之间的关系。 • 本章主要内容:
数据视图基本操作 管理关系
5.1 数据视图基本操作
• 数据视图用于检查和浏览Power BI Desktop模型中的数据,它与在查询编辑器中查看表、列 和数据的方式有所不同。数据视图中的数据是已加载到模型之后的数据,也是最终在报表中 使用的数据。
一对一(1:1):这意味着两个表中的关联列中的值是一一对应关系。例如,在“报名信息” 表和“成绩数据”表中,每个学生的数据只出现一次,两个表按bmh(报名号)列建立的关 系就是“一对一”关系。
可视化标准管理手册

可视化标准管理手册第一章:引言本管理手册旨在为企业提供可视化标准管理的参考指南,并帮助企业建立和维护高效的可视化标准管理系统。
通过合理的可视化标准管理,企业可以提高工作效率、降低错误率,并为各个部门提供一个统一的标准操作框架。
第二章:可视化标准的概念和原则2.1 可视化标准的定义可视化标准是指将工作过程中的重要信息以图形、图表等形式呈现,以提高信息的可理解程度和决策效果的一种管理方法。
2.2 可视化标准管理的原则- 准确性:可视化标准应准确反映实际工作情况,信息内容应真实可靠。
- 简洁性:可视化标准应以简洁的形式呈现,避免信息过于繁杂,使人无法理解。
- 一致性:可视化标准应统一于企业的整体形象和风格,以便于员工的识别和理解。
- 及时性:可视化标准应根据实际情况进行及时更新,保持与工作流程的同步。
- 易于操作:可视化标准应易于制作、传播和使用,避免过于复杂的技术要求。
第三章:可视化标准管理的实施步骤3.1 确定关键指标首先,企业需确定关键的业务指标,如生产效率、质量指标、销售额等。
这些指标应与企业的战略目标相一致,为整个管理系统提供支持。
3.2 设计可视化标准基于确定的关键指标,企业需设计出适合自身的可视化标准,可以采用图表、仪表盘等形式进行呈现。
在设计过程中,需考虑到员工的理解能力和信息获取的便利性。
3.3 制作和发布可视化标准根据设计好的可视化标准,企业可以通过各种工具和软件进行制作,确保制作出的标准能够清晰明了地展示关键指标。
完成制作后,需要将标准发布给相关部门和员工,以便大家能够及时了解和使用。
3.4 标准执行和监控一旦可视化标准发布,相关部门和员工需按照标准进行工作。
管理层需要对标准的执行情况进行监控,并及时反馈和改进。
在监控过程中,可以采用可视化的方式展示标准的执行情况,以便于对比和分析。
3.5 持续改进可视化标准管理是一个持续改进的过程。
企业应根据实际情况,随时对可视化标准进行调整和优化,以适应和促进企业的发展。
python数据可视化第五章实训

python数据可视化第五章实训Python数据可视化第五章实训介绍本文将介绍Python数据可视化第五章实训,主要包括以下内容:1. 实验目的和背景2. 实验环境和工具3. 实验步骤和操作4. 实验结果分析和总结实验目的和背景本次实验的主要目的是了解如何使用Python进行数据可视化,掌握Matplotlib库的基本使用方法。
通过对实验数据进行处理和分析,学习如何绘制各种类型的图表,并能够根据需要对图表进行自定义设置。
实验环境和工具本次实验需要使用到以下工具和环境:1. Python 3.x版本2. Jupyter Notebook或其他Python IDE3. Matplotlib库Matplotlib是Python中用于绘制各种类型图表的一个常用库,它提供了简单易用的API接口,支持多种图表类型,并且可以进行自定义设置。
实验步骤和操作1. 安装Matplotlib库在Jupyter Notebook或其他Python IDE中打开命令行窗口,输入以下命令安装Matplotlib库:```pip install matplotlib```2. 导入Matplotlib库并加载数据集在代码文件中导入Matplotlib库并加载需要处理的数据集。
例如:```pythonimport matplotlib.pyplot as pltimport pandas as pd# 加载数据集data = pd.read_csv("data.csv")```3. 绘制折线图使用Matplotlib库绘制折线图,可以使用plot()函数实现。
例如:```python# 绘制折线图plt.plot(data['x'], data['y'])# 显示图表plt.show()```4. 绘制散点图使用Matplotlib库绘制散点图,可以使用scatter()函数实现。
第五章-层次与网络数据可视化

层次数据的可视化
层次数据的展现方式
按数据的理解方式不同,层次数据的构建分: 自上而下和自下而上
层次数据可视化的核心:
1、如何表达层次关系的树形结构 2、如何表达树形结构中的父结点和子结点 3、如何表现父子结点、具有相同父结点的兄弟结 点之间的关系等
层次数据的展现方式 按布局策略,主流方法可分为:
– 避免边相交
– 相似的子树用相似(或镜像)进行表达
– 表达紧凑
• 基本方法:
尤其注重布局的对称性和紧凑性
– 自底向上递归计算
– 对于每个父节点,确保子树已完全绘制
– 尽可能紧致地包装子树
– 将父节点放在子树的中心位置
Reingold-Tilford树算法
• 自底向上递归计算:
– 对树进行后序遍历 • 这样对于父节点,在遍历到的时候可以确保其 左右子树都已经布局完毕。
– 根据树的深度将空间沿纵轴平均分成等高的区域。每个区域对 应树的一层。树中相同深度的节点属于同一层。 – 根据叶节点的数量,将对应的区域沿横轴平均分成等宽的区域。 – 将节点布置在每个区域的中心。 – 在节点和它的父节点之间连线。
Reingold-Tilford树算法
• 标准:
– 所有节点按照在树中的层次进行分层绘制
缺点 操控不是很容易,非线性映射使得 准确控制节点的空间位置变得困难
节点链图的问题
节点数随着深度增加呈几何级数增长 解决方案——交互
使用变形 对节点进行汇总、过滤
鱼眼变形
DOI树(节点过滤)
8.1.2 空间嵌套填充法
一种基于区域的可视化方法, 直接采用显示空间中的分块区域表示数据中的个体。 三个可计算的评价指标:可读性、距离相关性、稳定性
PowerBI数据分析与数据可视化第5章数据视图和管理关系课件

5.1.5 排序和筛选
• 在数据视图的数据表格中,单击列标题右侧的下拉图标,可打开排序和筛选菜单 • 实例5-2 按专业名称排序和筛选
5.1.6 更改数据类型和格式
• 在数据视图中,可以更改列的数据类型和显示格式。 • 要更改列的数据类型,需先在数据表格中选中列,然后在“建模”选项卡中单击
“数据类型”图标打开快捷菜单,在菜单中选中要应用的类型即可。 • 要更改列的显示格式,同样需先在数据表格中选中列,然后在“建模”选项卡中单
• 如果要刷新单个表,可用鼠标右键单击“字段”窗格中的表名,然后在快捷菜单中 选择“刷新数据”命令;或者在数据视图中右键单击数据表格,然后在快捷菜单中 选择“刷新数据”命令。
• 在“开始”选项卡中单击“刷新”图标,可对所有数据表执行刷新操作。
5.2 管理关系
• 当报表使用多个数据表时,正确建立表之间的关系才能保证分析的准确性。 • 本节主要内容
击“格式”图标打开快捷菜单,在菜单中选中要应用的格式即可。 • 实例5-3 修改“报名信息”表中zy列的数据类型
5.1.7 数据刷新
• Power BI Desktop采用不同连接模式获取数据源数据时,只有实时连接不需要刷新 (详见2.1.2)。通过数据刷新操作,Power BI Desktop才能从数据源获取最新的数 据。
5.2.4 编辑关系
• 要编辑关系,可在“管理关系”对话框中选中关系,然后单击“编辑”图标打开 “编辑关系”对话框。
• 在关系视图中,如果想修改关系设置,可双击关系连线打开“编辑关系”对话框进 行修改。
5.2.5 删除关系
• 要删除关系,可在“管理关系”对话框中选中关系,然后单击“删除”图标打开 “删除关系”对话框。
• 在“开始”选项卡中单击“管理关系”图标,打开“管理关系”对话框。在对话框 中单击“自动检测”图标可自动检测关系
高教社2024Python数据可视化教学课件05章Matplotlib绘图高阶设置

二、刻度标签和刻度线个性化设置
画布上的任何内容都是一个Artist对象,可以获取这些对象做进一步设置。下面绘制一条余弦曲线,然后获 取x轴的刻度标签和刻度线进行设置,这样可实现灵活的个性化设置,具体代码如下:
plt.figure(facecolor='pink')
x = np.linspace(-5,5,50)
以利用双Y轴图形实现。双Y轴图形由两个共享x轴的彼此重叠的子图构成,代码如下:
fig, ax1 = plt.subplots()
t = np.arange(0.05, 10.0, 0.01)
s1 = np.exp(t)
# 指数函数
ax1.plot(t, s1, c="b", ls="-", lw=3) # 在ax1绘制指数函数,蓝色
plt.plot(a, np.sin(2*np.pi*a), 'r-.') plt.xlabel('横轴:时间', fontproperties='SimHei', fontsize=18)
# 黑体
plt.ylabel('纵轴:振幅', fontproperties='Simsun', labelpad=5, fontsize=18) # 宋体
# 设置x轴范围
plt.ylim(-6, 6)
# 设置y轴范围
plt.title('图2指定轴范围为6', fontsize=16)
ax3 = fig.add_subplot(133)
plt.plot(x, y, color='m')
plt.axis([-1, 1, -1, 1])
python数据可视化第五章实训

Python数据可视化第五章实训一、简介本实训将介绍Python数据可视化中的第五章内容。
本章主要讲解了如何使用Python进行图表的定制化,以及如何将多个图表合并到一个画布中。
通过对本章内容的学习和实践,我们可以更好地掌握Python数据可视化的技巧,实现更加美观和有吸引力的数据可视化效果。
二、图表的定制化在数据可视化的过程中,我们经常需要对图表进行定制化,以满足我们的特定需求。
本章介绍了一些常用的图表定制化技巧,包括修改图表的颜色、字体、线条样式等。
下面分别介绍这些技巧的具体内容。
1. 修改颜色通过修改颜色,我们可以让图表更加生动和美观。
Python提供了多种方法来修改图表的颜色,包括使用预定义的颜色、使用RGB或RGBA颜色模式以及使用自定义的颜色映射。
下面是一些常用的修改颜色技巧:•使用预定义的颜色:可以使用Python的内置颜色名称,如red、green、blue等。
另外,还可以使用HTML颜色名称或十六进制颜色代码,例如#FF0000代表红色。
•使用RGB或RGBA颜色模式:RGB颜色模式使用红、绿、蓝三个通道来定义颜色,RGBA颜色模式除了三个通道外,还包含透明度通道。
使用这种颜色模式可以精确地定义图表的颜色。
•使用自定义的颜色映射:可以根据数据的特点使用自定义的颜色映射。
例如,可以使用深浅不同的蓝色来表示温度的高低。
2. 修改字体通过修改字体,我们可以让图表更加清晰和易读。
Python提供了多种方法来修改图表的字体,包括修改标题字体、坐标轴标签字体、图例字体等。
下面是一些常用的修改字体技巧:•修改标题字体:可以使用set_title()方法来修改标题的字体。
可以指定字体的名称、大小和样式。
•修改坐标轴标签字体:可以使用set_xlabel()方法和set_ylabel()方法来修改坐标轴标签的字体。
可以指定字体的名称、大小和样式。
•修改图例字体:可以使用legend()方法来设置图例的字体。
vtk文档:第五章总结
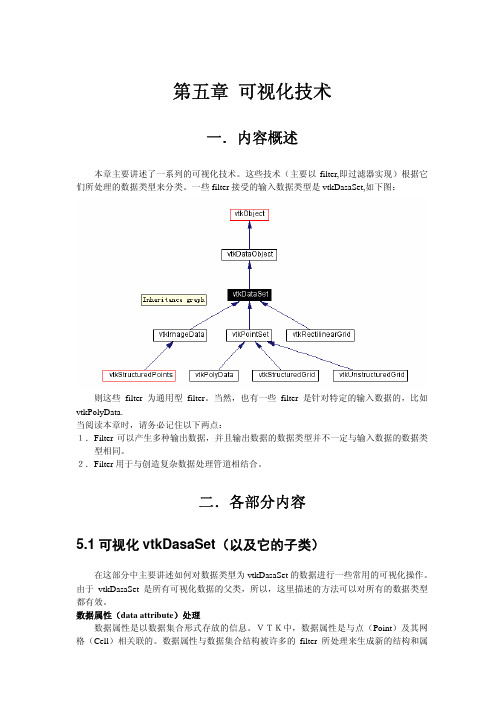
第五章可视化技术一.内容概述本章主要讲述了一系列的可视化技术。
这些技术(主要以filter,即过滤器实现)根据它们所处理的数据类型来分类。
一些filter接受的输入数据类型是vtkDasaSet,如下图:则这些filter为通用型filter。
当然,也有一些filter是针对特定的输入数据的,比如vtkPolyData.当阅读本章时,请务必记住以下两点:1.Filter可以产生多种输出数据,并且输出数据的数据类型并不一定与输入数据的数据类型相同。
2.Filter用于与创造复杂数据处理管道相结合。
二.各部分内容5.1可视化vtkDasaSet(以及它的子类)在这部分中主要讲述如何对数据类型为vtkDasaSet的数据进行一些常用的可视化操作。
由于vtkDasaSet是所有可视化数据的父类,所以,这里描述的方法可以对所有的数据类型都有效。
数据属性(data attribute)处理数据属性是以数据集合形式存放的信息。
VTK中,数据属性是与点(Point)及其网格(Cell)相关联的。
数据属性与数据集合结构被许多的filter所处理来生成新的结构和属性。
下图为与数据集合中的点和网格所关联的各种数据属性。
如上图所示,数据属性可以被归为标量,矢量,张量,法向量或者结构坐标。
数据属性就是以vtkDataArray来表示,每一个与vtkDasaSet相关联的vtkDataArray即为一个vtkDataArray的具体子类,例如vtkFloatArray或者vtkIntArray。
下图为vtkDataArray的继承图:这些数组可以被认识是存放相应数据的连续的内存空间,在这片空间中,数据数组可以被想像成由一系列小的数组组成。
创建属性数据由下面一系列动作组成:1.以需要的数据类型初始化一个一个数组2.声明每个属性元素的大小3.将它与一个数据集合相关联创建过程中要注意,与点相关联的属性的数目一定要等于数据集合中点的数目,同理,与网格相关联的属性数目一定要等于数据集合中网格的数目。
计算机软件使用技巧的发展趋势

计算机软件使用技巧的发展趋势第一章:智能化计算机软件使用技巧的发展趋势已经朝着智能化的方向发展。
随着人工智能技术的快速发展,计算机软件在各个领域都开始具备自主学习和决策的能力。
例如,大数据分析软件已经能够根据数据自动发现可行的解决方案,并帮助用户进行决策。
智能化的计算机软件将能够更好地满足用户需求,并提供更高效、准确的解决方案。
第二章:自动化自动化是计算机软件使用技巧的另一个发展趋势。
随着机器学习和自然语言处理技术的进步,计算机软件已经能够实现自动化的任务。
例如,自动化测试软件能够自动执行测试用例并生成测试报告,大大提高了软件质量和开发效率。
自动化技术的应用还可以扩展到其他领域,如自动化运维、自动化运输等,通过减少人工干预,提高工作效率和准确性。
第三章:可视化可视化是计算机软件使用技巧的另一个重要发展趋势。
随着数据量的快速增长,人们需要更直观、易于理解的方式来展示和分析数据。
数据可视化软件的出现满足了这一需求,它能够将复杂的数据通过图表、地图、仪表盘等形式进行可视化展示,帮助用户更好地理解数据,并从中发现隐藏的规律和趋势。
可视化技术的发展也将进一步提高数据分析和决策的效率。
第四章:云计算云计算是计算机软件使用技巧的又一重要发展趋势。
随着互联网的普及,用户对计算资源和存储空间的需求越来越大。
云计算通过提供可扩展的计算和存储服务,满足了这一需求。
云计算软件的使用技巧使用户能够在云上部署和管理应用程序,从而实现资源的弹性使用和快速扩展。
云计算技术的应用还包括大数据分析、人工智能等领域,为用户提供更强大、灵活的计算能力。
第五章:安全性在计算机软件使用技巧的发展趋势中,安全性是一个不可忽视的因素。
随着互联网的快速发展,网络安全威胁日益增加。
计算机软件必须具备一定的安全性能,以保护用户的数据和隐私不受攻击。
安全性技巧的发展包括数据加密、访问控制、漏洞修复等方面,以确保软件的可靠性和用户的信息安全。
总结:计算机软件使用技巧在智能化、自动化、可视化、云计算和安全性等方面都有着明显的发展趋势。
可视化标准手册

CARL ZEISS-Standard Visual ManagementCARL ZEISS-Standard Visual Management第一章颜色线条的标准第二章空间地名的标准第三章地面通道的标准第四章设备电器的标准第五章物品材料的标准第六章工具器具的标准第七章安全警示的标准第八章外围环境的标准第九章办公部门的标准第十章管理看板的标准第十一章标识更换标准第十二章个人责任区域标准第一章颜色线条的标准1.1 工厂基本颜色标准1.1.1 厂房颜色1.1.2 办公室颜色1.1.3 动力管道颜色1.1.4 动力设备颜色1.1.5 其他1.2 常用线条颜色宽度规格(油漆或胶带)第二章空间地名的标准2.1工厂房间命名方法2.2仓库区域名牌标示方法2.3楼梯引导标示方法第三章地面通道的标准3.1 通道地面标示方法3.2 室内通行线标示方法3.3 步行方向标示方法3.4 地面导向标示方法3.5 门区域线标示方法3.6 出入门牌标示方法3.7 房间门管理责任者标示方法第四章设备电器的标准4.1 螺栓、螺母松紧状态标示方法4.2 空调风口标示方法4.3 管道颜色标示方法4.4 管道流向标示方法4.5 物流运行方向标示方法4.6 旋转体旋转方向标示方法4.7 电机旋转方向标示方法4.8 计量器界限范围标示方法4.9 流量表界限标示方法4.10 空压油壶界限标示方法4.11 扳手型阀门标示方法4.12 轮式阀门标示方法第四章设备电器的标准4.13 检查部位标示方法4.14 注油点标示方法4.15 油桶种类标示方法4.16 换件周期标示方法4.17 设备修理中标示方法4.18 设备备用/运行标示方法4.19 不运转设备现况标示方法4.20 设备名牌标示方法4.21 电气控制箱标示方法4.22 电气警示灯标示方法4.23 额定电压标示方法4.24 开关控制范围标示方法第五章物品材料的标准5.1 零件放置区标示方法5.2 半成品区标示方法5.3 物料底盘颜色标示方法5.4 物品原位置标示方法5.5 垃圾分类回收标示方法5.6 垃圾桶定位定量标示方法5.7 瓶装药品保管标示方法5.8 小物件定位标示方法第五章物品材料的标准5.9 私物柜标示方法5.10 台阶形架台保管标示方法5.11 保管柜标示方法5.11.1 保管柜的标示方法补充说明(1)5.11.2 保管柜的标示方法补充说明(2)5.12 物品现况标示方法5.13 物品定量标示方法5.14 零件堆放限高线标示方法5.15 物料定货卡管理标示方法第六章工具器具的标准6.1 一般工具的标示方法(工具陈列柜)6.2 撬棍类工具的标示方法(兵器架)6.3 胶管电缆类的保管标示方法(转盘)6.4 清扫工具保管标示方法6.5 砂轮片、碟片保管标示方法6.6 手套保管标示方法6.7 绳索保管标示方法6.8 搬运工具标示方法第七章安全警示的标准7.1 消防设施管理标示方法7.2 消防设施位置标示方法7.3 旋转部安全防护罩的设置方法7.4 安全FENCE工事栏的设置方法7.5 安全防护围栏的设置方法7.6 安全隔离网的设置方法7.7 固定梯子的设置方法7.8 悬挂传送带地面标示7.9 旋转移载设备的隔离方法7.10 墙角墩柱标示方法第七章安全警示的标准7.11 反射镜的设置方法7.12 通道上方障碍物高度标示7.13 保护性指令标示方法7.14 警示性标示方法7.15 消防提示性标示方法7.16 禁令性标示方法7.17 电力安全标示方法7.18 消防紧急疏散图的标示方法7.19 危险物品保管标示方法第八章外围环境的标准8.1 室外通行线标示方法8.2 汽车库位标示方法8.3 自行车库标示方法8.4 道路路沿标示方法8.5 市政井盖设施的标示方法8.6 树木花草的标示方法第九章办公部门的标准9.1 电话机原位置标示方法9.2 台历原位置标示方法9.3 水杯保管方法9.4 办公文具的保管方法9.5 抽屉标示方法9.6 文件状态标示方法9.7 文件夹摆放标示方法9.8 资料柜/物品柜标示方法9.9 参考资料标示方法9.10 管理责任人标示方法9.11 岗位牌的标示方法9.12 报纸架的标示方法第十章管理看板的标准10.1 车间方针看板的标示方法10.2 主要指标看板的标示方法10.3 改善提案看板的标示方法10.4 优秀员工看板的标示方法10.5 公告栏看板的标示方法10.6 学习园地看板的标示方法10.7 办公室看板的标示方法10.8 “我的区域”标示方法10.9 “我的设备”标示方法10.10 问题揭示牌的标示方法第一章颜色线条的标准1.1 工厂基本颜色标准1.1.1 厂房颜色项目颜色名称标准色样围墙栅栏黑色及绿化植物厂房内墙乳白色,蔡司蓝厂房外墙米黄色,蔡司蓝厂房地面自定义,淡灰色厂房墙裙淡灰色厂房踢脚线虎纹线1.1 工厂基本颜色标准1.1.2 办公室颜色项目颜色名称标准色样内墙白色踢脚线羊皮纸色过道羊皮纸色地面自定义门浅黄楼梯扶手不锈钢色楼梯踢脚线灰色楼梯地面深紫大理石色1.1 工厂基本颜色标准1.1.3 动力管道颜色项目颜色名称标准色样生产、生活自来水管绿色消防水管红色冷却水管蓝色纯水管白蓝一般工业废水淡蓝高温水管粉色工业酸液管大黄工业碱液管紫色生活污水管黑色电源、网络线管米黄空气管道银灰色1.1 工厂基本颜色标准1.1.4 动力设备颜色项目颜色名称标准色样冷冻机本休自定义储气罐、真空罐、干燥机自定义配电柜、风机土黄变压器灰色消防设备、消防器材红色发电机、水泵及电机黄色暖器自定义空压机,压力容器自定义散热器自定义1.1 工厂基本颜色标准1.1.5 其他项目颜色名称标准色样隔栏、安全网、罩黄色货架自定义液压手推车黄色安全通道、扶手黄色VIP通道绿色手推车不锈钢色斑马线黄黑间隔色1.2 常用线条颜色宽度规格(油漆或胶带)适用项目基准规格(mm)基准颜色色例仓库/车间主通道线800黄色室内一般通道线480黄色车间/仓库区域线480黄色辅助通道线480黄色可移动物(工具车等)480黄色清扫工具类200黄色门开闭线80黄色所有生产使用设备、仪器及桌椅200黄色工具定位地面200黑色所有桌面物品定位线80根据标准1.2 常用线条颜色宽度规格(油漆或胶带)适用项目基准规格(mm)基准颜色色例合格品区域线地面200;桌面80绿色不合格区域线地面200;桌面80大红废弃物地面200;桌面80大红闲置物地面200;桌面80红白待处理品/待返工地面200;桌面80红白灭火器地面200;桌面80虎纹线消防栓地面200;桌面80虎纹线垃圾桶地面200;桌面80大黄危险区域地面200;桌面80虎纹线回风口地面200;桌面80大黄警告警示地面200;桌面80虎纹线配电柜地面200;桌面80虎纹线突出物地面200;桌面80虎纹线坑道周围地面200;桌面80虎纹线第二章空间地名的标准2.2工厂房间命名方法1.由主体和嵌条两部分组成。
chap5空间数据可视化(上)

30
等值面提取算法
_ _ + _ + _ _ + _ + _ _ _ _ _ + _ _ + + + + + _ +
_
顶点状态反转
_
_
_
_
_
旋转对称性
+
31
等值面提取算法
移动立方体面在简化后分为15种情况
32
等值面提取算法
歧义性问题
(a)
(b)
(c)
(d)
(a)和(b)两个数据相容的立方体用15种情形中的第3种和经过顶点 值逆转变换后的第6种得出不连续的等值面;(c)和(d)给出 二维上的例子,两个有相同顶点值的方块由于划分为三角形的方 式不同而生成不同的轮廓
24
空间标量数据可视化
三维数据
医学影像数据
CT, MRI
大气数值模拟数据
体绘制方法
核桃的CT数据光线投射体绘制效果
等值面绘制方法
直接体绘制方法
25
体绘制算法
等值面绘制
基于几何体采样
直接体绘制
图像空间方法
数据空间方法
传输函数设计
26
三维数据体绘制
等值面绘制
体绘制
27
等值面提取算法
38
直接体绘制
直接计算最终可视化里的每一个像素 方法
图像空间方法 数据空间方法
39
图像空间方法
图像空间方法,对每个投影平面的像素,从视点(人眼) 到像素之间连一条光线,并将这条光线投射到数据空间。在 光线遍历的路径上进行数据采样、重建、数据映射和着色等 操作。这种方法,通常称为光线投射法。
第五章空间数据的可视化表达

2
2)地理信息的可视化表示
是利用各种数学模型,把各类统计数 据、实验数据、观察数据、地理调查资 料等进行分级处理,然后选择适当的视 觉变量以专题地图的形式表示出来,如 分级统计图、分区统计图、直方图等。 这种类型的可视化体现了科学计算可视 化的初始含义。
查看分类 方法
分级属性中默认要素的分级方案是Natual Breaks,它是在分级数确定的情况下,通 过聚类分析将相似性最大的数据分在同 一级,差异性大的分在不同级,这种方 法可以保持较好数据的统计特性,但分 级界限往往是任意数,不符合常规制图 需要。
23
选择分类方法 为手动;
在中断值中依 次输入数值
查看分类符号属性
双击红框中的线 符号改变线类型;
单击类型红框中 的名称改变标注 名称;
查看符号化后的 公路,以及内容 列表中的变化;
1.3、分级色彩
将要素属性数值按照一定的分级方法分成若干级别之后, 用不同的颜色来表示不同级别。每个级别用来表示数值的 一个范围,从而可以明确反映制图要素的定量差异。
第五章 空间数据的可视化表达
可视化,也称作科学计算可视化,它将符号或数据转 换为直观的几何图形,便于研究人员观察其模拟和计 算过程。可视化包括了图像综合,这就是说,可视化 是用来解释输入到计算机中的图像数据,并从复杂的 多维数据中生成图像的一种工具。是地图数据的屏幕 显示。
1
1)地图数据的可视化表示
5
符号化有两个含义:在地图设计中,地 图数据的符号化是指利用符号将连续的 数据进行分类分级、概括化、抽象化的 过程。在数字地图转换为模拟地图过程 中,地图的符号化指的是将已处理好的 地图数据恢复成连续图形,并附之以不 同符号表示的过程。
数据可视化软件的图表设计与交互效果展示技巧

数据可视化软件的图表设计与交互效果展示技巧第一章:引言数据可视化是将复杂的数据转化为具有图形形式的信息展示方式。
随着科技的不断进步,数据分析和可视化正变得越来越重要。
数据可视化软件的图表设计和交互效果对于用户的体验和理解至关重要。
本文将重点讨论数据可视化软件的图表设计和交互效果展示技巧。
第二章:图表设计技巧1. 确定合适的图表类型:根据数据类型和目标,选择合适的图表类型。
例如,使用饼图来表示不同类别的分布,柱状图来比较不同组的数据。
2. 清晰简洁的图表布局:图表布局应该简洁明了,不应有任何多余的装饰,以免分散用户的注意力。
使用明确的标题和标签,确保读者能够快速理解图表内容。
3. 使用适当的颜色:颜色可以帮助突出重要的数据和信息。
选择适当的颜色配色方案,避免使用过多的颜色,以免造成视觉混乱。
4. 合理的刻度标记和轴线:刻度标记和轴线应该清晰可读,确保精确度和一致性。
避免使用冗长和拥挤的刻度标记,限制轴线的长度和密度。
第三章:交互效果展示技巧1. 提供交互功能:数据可视化软件应该提供交互功能,允许用户自定义视图并与数据进行互动。
例如,通过拖动滑块控制时间范围,获取特定时间段的数据。
2. 高互动性的过滤器和控件:为用户提供各种过滤器和控件,以便根据需要筛选和操作数据。
例如,添加下拉菜单,滑块或复选框,用于选择特定的数据维度或指标。
3. 动画和过渡效果:使用动画和过渡效果可以帮助用户更好地理解数据的变化和趋势。
例如,通过渐变效果或眨眼动画来突出显示不同数据点或数据集之间的变化。
4. 提供工具提示和交互说明:为用户提供工具提示和交互说明,解释图表的各个部分和交互功能的作用。
这样可以确保用户在使用软件时能够充分理解并正确操作。
第四章:案例分析1. 数据可视化软件A的图表设计和交互效果展示技巧案例分析:通过对数据可视化软件A的图表设计和交互效果进行案例分析,分析其在图表设计和交互方面的优点和不足之处。
2. 数据可视化软件B的图表设计和交互效果展示技巧案例分析:对数据可视化软件B的图表设计和交互效果进行案例分析,探讨其在图表设计和交互方面的成功之处和可以改进的地方。
信息可视化设计基础教程

信息可视化设计基础教程第一章:信息可视化设计概述信息可视化设计是一门融合了图形设计、数据分析和可视化技术的学科。
它旨在通过图形化的方式,将庞杂的数据和信息转化为易于理解和解读的可视形式,帮助用户更好地理解和分析数据。
本章将介绍信息可视化设计的基本概念和原则,并引导读者加深对信息可视化的理解。
第二章:数据类型与可视化图形在信息可视化设计中,了解不同的数据类型以及如何选择合适的可视化图形是至关重要的。
本章将介绍常见的数据类型,如连续型、离散型和时间序列数据,并详细介绍各种类型数据适合的可视化图形,如折线图、柱状图、饼图等。
读者将学到如何根据不同的数据类型选择最适合的可视化方式。
第三章:数据收集与整理在进行信息可视化设计之前,首先需要收集和整理数据。
本章将介绍常用的数据收集方法,如问卷调查、用户行为分析等,并推荐一些常用的数据整理工具和技术,如Microsoft Excel和Python等。
读者将学到如何有效地收集和处理数据,为后续的可视化设计做好准备。
第四章:可视化设计原则与技巧好的可视化设计需要遵循一些基本的原则和技巧,以确保信息的准确传达和用户的良好体验。
本章将介绍常用的可视化设计原则,如简洁性、一致性和易读性,并分享一些实用的设计技巧,如颜色搭配、图形比例等。
读者将学到如何运用这些原则和技巧设计出高质量的可视化图形。
第五章:交互式可视化设计交互式可视化设计是信息可视化设计的重要发展方向。
本章将介绍什么是交互式可视化设计以及它的意义和应用。
读者将了解到交互式可视化设计的基本原理和技术,如用户交互、动画效果等,并学习一些常见的交互式可视化设计工具,如Tableau和D3.js等。
第六章:实际案例分析本章将通过实际案例分析来展示信息可视化设计的应用和效果。
案例将从不同领域选取,如商业分析、医疗数据分析等。
读者将通过分析这些案例,掌握信息可视化设计的实际应用技巧,并了解如何将设计原则和技巧应用到实际项目中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
12
插入排序main子图
13
插排look_for_position子图
14
插排move_to_new_position子图
15
冒泡排序
冒泡排序(Bubble Sort)的基本概念是: 将被排序的记录数组a[1..n]垂直排列,每个记录a[i]看作 是重量为a[i]所存数值的气泡 根据轻气泡不能在重气泡之下的原则,从下往上扫描数 组a[]:凡扫描到违反本原则的轻气泡,就使其向上"飘 浮“ 如此反复进行,直到最后任何两个气泡都是轻者在上, 重者在下为止
图书馆工作人员的重要工作,就是把归还的书,插入适
当的书架、层次、位置, 方便读者查阅
社会中排序:
会议代表名单的排序(按姓氏笔画);
联大会议的发言顺序(按国家名称字母排序)
3
计算机如何进行排序?
从”混沌”到有序:排序自身也是一种应用,同时也为快
速的查找提供必要的准备 在计算机科学中,排序(sorting)是研究最多的问题之 一 基本排序算法有5类:
当的改进
快速排序是由C. A. R. Hoare在1962年提出的
它采用了分治的策略,是一种划分交换排序算法
被誉为二十世纪“十大经典算法”之一
22
快速排序的基本思想
通过一趟排序将要排序的数据分割成独立的两部分 其中一部分的所有数据都比另外一部分的所有数据要小 然后再按此方法对这两部分数据分别进行快速排序 整个排序过程可以递归进行,从而使整个数据变为有
插入排序,例如,直接插入排序,二分插入排序等; 交换排序,例如,冒泡排序,快速排序等; 选择排序,例如,选择排序,堆排序等 归并排序,例如,归并排序,多相归并排序等 分布排序,例如,桶排序,基数排序等
4
排序术语和实现策略
自然的(natural) 如果某种排序算法对有序的数据排序速度较快(工作量 变小),对无序的数据排序速度却较慢(工作变量大),这 种算法被称为自然排序算法 如果数据已接近有序,就需要考虑选用自然的排序算法
序序列
23
24
快速排序main子图
25
快速排序QkSort子图
26
快速排序QkPass子图
27
RAPTOR中的快速排序
通过实际运行可知,这里实现的“快速排序”尽管可
以改善排序算法的时间复杂性,但由于全局变量问题, 实际上的空间复杂性很差 可以考虑使用非递归的实现来完成“快速排序”
28
9
如何在RAPTOR中实现排序
排序算法测试的数据来源 请回顾第2章提及的随机数生成和存储,以及使用文件 输入数据的方法 不仅可以节省用户与算法的交互时间
而且可以适当扩大数据集合,验证算法的效率
10
直接插入排序
直接插入排序与整理扑克牌的过程非常类似 第1张牌没有必要整理 以后每次从牌堆(无序区)的最上面摸出1张牌并插入左手 牌(有序区)中正确的位置上
当某个记录的关键字与给定值相等时,即找到所查的记
录,查找成功;
反之,若查到最后一个记录,其关键字和给定值的比较
都不相等,则表明表中没有所查的记录,查找失败。
30
顺序查找的算法设计
由于顺序查找的数据表,无需将节点实现排序,所以
可以直接使用随机数产生一张线形表,进行查找的实 验
31
二分查找 基本思想:
19
冒泡排序
bubble子图
20
冒泡算法如何改进?
假如待排序列已经是基本有序的(只有两个数字需要
换位),如何能够在n-1趟之前,结束排序?
提示:可以将已经排好的数据,有意调换一对,然后使
用改进后的算法实验(从文件读入待排数据)
21
快速排序
快速排序(Quick sort)是在冒泡排序基础上做了适
16
17
冒泡排序main子图
18
冒泡算法说明
初始状态: a[1..n]为无序区。
第一次扫描:从无序区底部向上依次比较相邻的 两个气泡的重量,若发现轻者在下、重者在上,
则交换二者的位置,第一次扫描完毕时,"最轻"的 气泡就飘浮到该区间的顶部,即关键字最小的记 录被放在最高位置a[1]上。 第二次扫描:扫描a[2..n]。扫描完毕时,"次轻"的 气泡飘浮到a[2]的位置上……。 最后,经过n-1 趟扫描可得到有序区a[1..n]
《可视化计算》
学习目标
如何在计算机中进行排序?
排序算法有那些分类? 如何实现常用的排序算法?
查找与排序有何关系?
查找算法有哪些分类? 如何实现常用的查找算法?
2
学习中的排序: 何为排序 ?
在一些教课书中,会将涉及到的所有术语排成索引,作
为附录,方便读者在需要时查找
查找
查找算法和排序算法有密切的联系,因为许多查找算
法依赖于要查找的数据集的有序程度 基本的查找算法有以下4种:
顺序查找;
比较查找也称二分查找; 基数查找也称分块查找;
哈希查找
29
顺序查找
顺序查找过程:
通常从表中的第一个(或最后一个)记比较
7
排序术语和实现策略
关键字排序(Key sort) 如果要对某班级学生的期末成绩表进行排序,表中给出 了每个学生的学号、姓名、单科成绩和总成绩等项目 按什么来排序?所选结果,就是关键字 本章所有案例中,只考虑关键字字段,而先将信息的其 他内容一概略去
8
排序术语和实现策略
数字化排序(digitized sort) 在排序过程中,可以按数值大小排序,有时候需要按字 符来排序,有时候需要按照时间的迟早来排序 实际上,计算机内的所有数据,无论属于哪种类型数据, 都可以转换成数字(二进制或十进制)表达 所以排序本身可以抽象为对数字进行排序
为了确定正确的插入位置,一般从左向右将摸上来的
牌与手中已有的牌逐一比较
11
直接插入排序
假设data.txt文件中存放着待排序的记录R[] ,则R[]可
以看成是一个长度为n的待排数组 首先从data.txt文件中保存的数组R[]读入一个数据到 a[1],生成一个有序数组 由于文件中的数组R[]呈无序状态,从i=2起至i=n为止, 依次将R[i]插入当前的有序数组a[1..i-1]中 最后生成含n个记录的有序数组
34
二分查找的算法分析
+折半查找法每执行一次,都可以将查找空间减少一
半,是计算机科学中分治思想的完美体现 -其缺点是要求待查表为有序表,而有序表的特点则是 插入删除困难
因此,折半查找方法适用于不经常变动而查找频繁的
有序列表
35
小结与回顾
查找策略则与数据的排序与否,数据自身的属性有重
二分查找的算法说明
子程序先将表中间位置记录的关键字与查找关键 字比较,如果两者相等,则查找成功;
否则利用中间位置记录将表分成前、后两个子表
如果中间位置记录的关键字大于查找关键字,则进一步
查找前一子表 否则将继续查找后一子表
重复以上过程,直至找到满足条件的记录,或者 根本查不到子表,此时查找失败
将n个元素分成个数大致相同的两半,取a[n/2]与欲查找
的x作比较,如果x=a[n/2]则找到x,算法终止 如果x>a[n/2],则需要在数组a的右半部继续搜索 直至找到x为止或得出关键字不存在的结论
算法实现的前提
1.必须采用顺序存储结构
2.必须按关键字大小有序排列
32
33
大关系。 顺序查找针对未排序数据,
二分查找针对已排序数据,
分块查找针对按块有序、块内无序的数据 而最能体现计算机科学精髓的查找方法则是哈希查找,
哈希查找是通过计算数据元素的存储地址进行查找的算 法
36
5
排序术语和实现策略
稳定的(stable) 如果能保持它认为相等的数据的前后顺序,这种算法被 称为稳定排序算法 稳定的排序算法可按主、次关键字对数据进行排序,例 如,按照姓氏和名字排序。
在具体实现时,就是先按主关键字排序,再按次关键字排序
6
排序术语和实现策略
内部排序和外部排序 待排数据全部在内存中的排序方法被称为内部排序,待 排数据在磁盘、磁带和其它外存中的排序方法被称为外 部排序 本节涉及的排序算法,全部针对内部排序进行讨论