层次分析法模型
层次分析法及模糊综合评价建模方法

否则,k:=k+1, 转2
5) 计算 max
1 n
n i 1
w(k 1) i w(k ) i
关于如何确定成对比较矩阵 A (aij )nn 中元素 aij 的值,
Saaty等建议试用1~9尺度,即 aij 的取值范围是1,2,…,9 以及倒数是1,1\2,…,1\9, 判断矩阵的元素一般采用1~9及 其倒数的标度方法。
科研C2
w1(3)=(w11(3),w12(3),w13(3),0)T P1
P2
P3
P4
w2(3)=(0,0,w23(3),w24(3)T已得 讨论由w(2),W(3)=(w1(3), w2(3)) 计算第3层对第1层权向量
P1,P2只作教学, P4只作科研, P3兼作教学、科研。
w(3)的方法
C1,C2支配元素的数目不等
间
业 业 业 靠 通 C8
C1
C3 C4 C5 C6 C7
舒进 美
适出 化
C9
方 便
C11
C1
0
桥梁 D1
隧道 D2
渡船 D3
(1)过河效益层次结构
例3 横渡 江河、海峡 方案的抉择
经济代价 B1
过河的代价 A
社会代价 B2
环境代价 B3
投 操 冲冲 交 居 汽 对 对
入 作 击击 通 民 车 水 生
一致性指标
CI max n
n 1
随机一致性指标
判断 矩阵 1 2 3 4 5 6 7 8 9 10 阶数n
RI 0 0 0.58 0.9 1.12 1.24 1.32 1.41 1.45 1.49
一致性比率
CR
CI RI
层次分析法
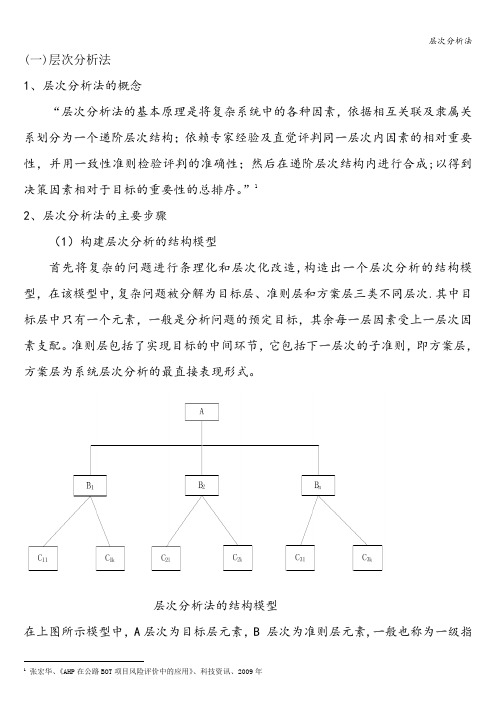
(一)层次分析法1、层次分析法的概念“层次分析法的基本原理是将复杂系统中的各种因素,依据相互关联及隶属关系划分为一个递阶层次结构;依赖专家经验及直觉评判同一层次内因素的相对重要性,并用一致性准则检验评判的准确性;然后在递阶层次结构内进行合成;以得到决策因素相对于目标的重要性的总排序。
”12、层次分析法的主要步骤(1)构建层次分析的结构模型首先将复杂的问题进行条理化和层次化改造,构造出一个层次分析的结构模型,在该模型中,复杂问题被分解为目标层、准则层和方案层三类不同层次.其中目标层中只有一个元素,一般是分析问题的预定目标,其余每一层因素受上一层次因素支配。
准则层包括了实现目标的中间环节,它包括下一层次的子准则,即方案层,方案层为系统层次分析的最直接表现形式。
层次分析法的结构模型在上图所示模型中,A层次为目标层元素,B 层次为准则层元素,一般也称为一级指1张宏华、《AHP在公路BOT项目风险评价中的应用》、科技资讯、2009年标,C层次为方案层元素,也可称为二级指标。
(2)专家评分建立层次分析法判断矩阵为了建立指标权重评判标准和构造判断矩阵,Saaty提出相对重要性比例标度,即1~9 层次比例标度,相对重要性比例标度的含义如表2—3所示。
假设有n个元素C1、C2,。
,C n给定一个准则,利用上表所给的相对重要性比例标度方,对元素C i和C j做两两比较判断,获得相对重要度的值a ij,构成矩阵。
专家根据评判准则对各个因素的权重两两比较并进行了打分之后,经过整理,可以得到因素权重的判断矩阵A:矩阵 A 中的各元素a ij 表示行指标A i 对列指标A j 相对重要性的比例标度,则判断矩阵A 中指标两两比较的特点有a ij >0,a ij =1,a ij =1/a ji (i ,j=1,2,。
..。
..n )。
如果a ij <1,表示A j 比A i 重要; 如果a ij >1,表示A i 比A j 重要; 如果a ij =1,表示A j 与A i 同样重要.根据判断矩阵A 在选择上的一致性要求,理想情况下,a ik*a jk =a ij (代表相对重要性所具有的传递性原理,满足该性质的矩阵A 称为一致矩阵),虽然在构造判断矩阵A 时并不要求判断具有一致性,但判断偏离一致性过大也是不允许的。
层次分析法AHP法建模

通过一致
一致性比率CR=0.018/1.12=0.016<0.1
性检验
正互反阵最大特征根和特征向量的简化计算
• 精确计算的复杂和不必要
• 简化计算的思路——一致阵的任一列向量都是特征向量,
一致性尚好的正互反阵的列向量都应近似特征向量,可取
其某种意义下的平均。
二、层次分析法的基本原理
层次分析法根据问题的性质和要达到的总目标,将问题分解为不同的 组成因素,并按照因素间的相互关联影响以及隶属关系将因素按不同 层次聚集组合,形成一个多层次的分析结构模型,从而最终使问题归 结为最低层(供决策的方案、措施等)相对于最高层(总目标)的相对重 要权值的确定或相对优劣次序的排定。
对总目标Z的排序为
A1
A2
Am
a1, a2,, am
B层n个因素对上层A中因素为Aj
B1
B2
Bn
的层次单排序为
b1 j ,b2 j ,,bnj ( j 1,2,, m)
B 层的层次总排序为:
即 B 层第 i 个因素对总目标
的权值为: m
a jbij
(影响加和)j 1
B1 : a1b11 a2b12 amb1m B2 : a1b21 a2b22 amb2m
是对难于完全定量的复杂系统作出决策的模型和方 法。
决策是指在面临多种方案时需要依据一定的标准选 择某一种方案。日常生活中有许多决策问题。举例
1. 在海尔、新飞、容声和雪花四个牌号的电冰箱 中选购一种。要考虑品牌的信誉、冰箱的功能、价 格和耗电量。
2. 在泰山、杭州和承德三处选择一个旅游点。要 考虑景点的景色、居住的环境、饮食的特色、交通 便利和旅游的费用。
层次分析法数学建模

在某些情况下,层次分析法可能无法合理地分配权重,导致决策结果 与实际情况存在较大偏差。
无法处理动态变化
层次分析法主要用于静态决策问题,对于动态变化的决策问题处理能 力较弱。
05 结论与展望
结论
层次分析法是一种有效的决策分析方法,能够将复杂问题 分解为多个层次和因素,通过比较和判断各因素之间的相 对重要性,为决策提供依据。
实例三:风险评估问题
总结词
层次分析法在风险评估问题中,能够综合考虑风险的多种来源和影响因素,确定各因素之间的权重关 系,为风险的有效控制提供科学的依据。
详细描述
风险评估问题涉及到如何识别、评估和控制各种潜在的风险。层次分析法可以将风险的多种来源和影 响因素进行比较和判断,确定各因素之间的权重关系,为风险的有效控制提供科学的依据。同时,层 次分析法还可以用于制定风险应对策略和预案,提高组织的抗风险能力。
层次单排序与一致性检验
层次单排序
根据判断矩阵的性质和计算方法,计 算出各组成元素的权重值,并按照权 重值的大小进行排序。
一致性检验
对判断矩阵的一致性进行检验,以确 保各组成元素之间的相对重要性关系 符合逻辑和实际情况。
层次总排序与一致性检验
层次总排序
根据各层次的权重值和组成元素的权重值,计算出整个层次结构模型的权重值, 并进行总排序。
确定层次
根据问题的复杂程度和组 成元素的性质,将层次结 构划分为不同的层次,以 便于分析和计算。
判断矩阵的建立
确定判断标准
根据问题的特点和要求,确定判 断各组成元素之间相对重要性的 标准和方法。
构造判断矩阵
根据判断标准,构造出一个判断 矩阵,用于表示各组成元素之间 的相对重要性关系。
层次分析法模型

二、模型的假设1、假设我们所统计和分析的数据,都是客观真实的;2、在考虑影响毕业生就业的因素时,假设我们所选取的样本为简单随机抽样,具有典型性和普遍性,基本上能够集中反映毕业生就业实际情况;3、在数据计算过程中,假设误差在合理范围之内,对数据结果的影响可以忽略.三、符号说明四、模型的分析与建立1、问题背景的理解随着我国改革开放的不断深入,经济转轨加速,社会转型加剧,受高校毕业生总量的增加,劳动用工管理与社会保障制度,劳动力市场的不尽完善,以及高校的毕业生部分择业期望过高等因素的影响,如今的毕业生就业形势较为严峻.为了更好地解决广大学生就业中的问题,就需要客观地、全面地分析和评价毕业生就业的若干主要因素,并将它们从主到次依秩排序.针对不同专业的毕业生评价其就业情况,并给出某一专业的毕业生具体的就业策略.2、方法模型的建立 (1)层次分析法层次分析法介绍:层次分析法是一种定性与定量相结合的、系统化、层次化的分析方法,它用来帮助我们处理决策问题.特别是考虑的因素较多的决策问题,而且各个因素的重要性、影响力、或者优先程度难以量化的时候,层次分析法为我们提供了一种科学的决策方法.通过相互比较确定各准则对于目标的权重,及各方案对于每一准则的权重.这些权重在人的思维过程中通常是定性的,而在层次分析法中则要给出得到权重的定量方法.我们现在主要对各个因素分配合理的权重,而权重的计算一般用美国运筹学家T.L.Saaty 教授提出的AHP 法. (2)具体计算权重的AHP 法AHP 法是将各要素配对比较,根据各要素的相对重要程度进行判断,再根据计算成对比较矩阵的特征值获得权重向量k W .Step1. 构造成对比较矩阵 假设比较某一层k 个因素12,,,k C C C 对上一层因素ο的影响,每次两个因素i C 和j C ,用ij C 表示i C 和j C 对ο的影响之比,全部比较结果构成成对比较矩阵C ,也叫正互反矩阵.*()k k ij C C =, 0ij C >,1ij jiC C=, 1ii C =.若正互反矩阵C 元素成立等式:* ij jk ik C C C = ,则称C 一致性矩阵.标度ij C含义1i C 与j C 的影响相同 3 i C 比j C 的影响稍强 5i C 比j C 的影响强 7 i C 比j C 的影响明显地强 9i C 比j C 的影响绝对地强2,4,6,8i C 与j C 的影响之比在上述两个相邻等级之间11,,29i C 与j C 影响之比为上面ij a 的互反数Step2. 计算该矩阵的权重通过解正互反矩阵的特征值,可求得相应的特征向量,经归一化后即为权重向量12 = [ , ,..., ]T kkkkkQ q qq ,其中的ikq 就是i C 对ο的相对权重.由特征方程A-I=0λ,利用Mathematica 软件包可以求出最大的特征值max λ和相应的特征向量.Step3. 一致性检验1)为了度量判断的可靠程度,可计算此时的一致性度量指标CI :max 1kCI k λ-=-其中maxλ表示矩阵C 的最大特征值,式中k 正互反矩阵的阶数,CI 越小,说明权重的可靠性越高.2)平均随机一致性指标RI ,下表给出了1-14阶正互反矩阵计算1000次得到的平均随机一致性指标:3)当0.1CR RI=<时,(CR 称为一致性比率,RI 是通过大量数据测出来的随机一致性指标,可查表找到)可认为判断是满意的,此时的正互反矩阵称之为一致性矩阵.进入Step4. 否则说明矛盾,应重新修正该正互反矩阵.转入Step2. Step4. 得到最终权值向量将该一致性矩阵任一列或任一行向量归一化就得到所需的权重向量.计算出来的准则层对目标层的权重即不同因素的最终权重,这样一来,我们就可以按权重大小将进行排序了.(3)组合权向量的计算成对比较矩阵显然非常好体现了我们研究对象——各个因素之间权重的比较状态,能够有效地全面而深刻地表现出有关的数据信息,显然也是矩阵数学模型的重要应用价值. 因素往往是有层次的,我们经常在进行决策分析时,要进行多方面、多角度、多层次的分析与研究,把我们的决策选择建立在深刻而广泛的分析研究基础之上的.一个总的指标下面可以有第一层次的各个方面的指标、因素、成份、特征性质、组成成分等等,而每个这种因素又有新的成份在里面.这就是决策分析的数学模型的真正的意义之所在.定理1:对于三决策问题,假设第一层只有一个因素,即这是总的目标,决策总是最后要集中在一个总目标基础之上的东西,然后才能进行最后的比较.又假设第二层和第三层因素各有n 、m 个,并且记第二层对第一层的权向量(即构成成份的数量大小、成份的比例、影响程度的大小的数量化指标的量化结果、所拥有的这种属性的程度大小等等多方面的事情的量化的结果)为:(2)(2)(2)(2)12(,,,)Tn w w w w =, 而第3层对第2层的全向量分别是:(3)(3)(3)(3)12(,,,)Tk k k km w w w w =,这表示第3层的权重大小,具体表示的是第2层中第k 个因素所拥有的面对下一层次的m 个同类因素进行分析对比所产生的数量指标.那么显然,第三层的因素相对于第一层的因素而言,其权重应当是:先构造矩阵,用 (3)k w 为列向量构造一个方阵 (3)(3)(3)(3)12(,,)nWw w w=,这个矩阵的第一行是第3层次的m 个因素中的第1个因素,通过第2层次的n 个因素传递给第1层次因素的权重,故第3层次的m 个因素中的第i 个因素对第1层次的权重为 (2)(3)1nkkik w w=∑,从而可以统一表示为:(1)(3)(2)wWw=,它的每一行表示的就是三层(一般是方案层)中每一个因素相对总目标的量化指标.定理2:一般公式如果共有s 层,则第k 层对第一层(设只有一个因素)的组合权向量为()()(1),3,4,k k k k s wWw-==,其中矩阵 ()k W的第i 行表示第k 层中的第i 个因素,相对于第1k -层中每个因素的权向量;而列向量 (1)k w-则表示的是第1k -层中每个因素关于第一层总目标的权重向量.于是,最下层对最上层的的组合权向量为:()()(1)(3)(2)s s s wWWW w-=,实际上这是一个从左向右的递推形式的向量运算.逐个得出每一层的各个因素关于第一层总目标因素的权重向量. (4)灰色关联度综合评价法灰色系统的关联分析主要是对系统动态发展过程的量化分析,它是根据因素之间发展态势的相似或相异程度,来衡量因素间接近的程度,实质上就是各评价对象与理想对象的接近程度,评价对象与理想对象越接近,其关联度就越大.关联序则反映了各评价对象对理想对象的接近次序,即评价对象与理想对象接近程度的先后次序,其中关联度最大的评价对象为最优.因此,可利用关联序对所要评价的对象进行排序比较.利用灰色关联度进行综合评价的步骤如下:1)用表格方式列出所有被评价对象的指标.2)由于指标序列间的数据不存在运算关系,因此必须对数据进行无量纲化处理.3)构造理想对象,即把无量纲化处理后评价对象中每一项指标的最佳值作为理想对象的指标值.4)计算指标关联系数.其计算公式为:min max imax()()ik k ρρξ+=+∆∆∆∆其中min()()minminiikk k x x =-∆,max()()maxmaxiikk k x x =-∆,()ik ∆=0()()ik k x x -,1,2,i n =,1,2,k m =.式中n 为评价对象的个数;m 为评价对象指标的个数;()ik ξ为第i 个对象第k 个指标对理想对象同一指标的关联系数;A 表示在各评价对象第k 个指标值与理想对象第k 个指标值的最小绝对差的基础上,再按1,2,,i n =找出所有最小绝对差中的最小值;max ∆表示在评价对象第k 个指标值与理想对象第k 个指标值的最大绝对差的基础上,再按1,2,,i n =找出所有最大绝对差中的最大值;min ∆为评价对象第k 个指标值与理想对象第k 个指标值的绝对差.ρ为分辨系数,ρ越小分辨力越大,一般ρ的取值区间[0,1],更一般地取ρ=0.5.5)确立层次分析模型.6)确定判断矩阵,计算各层次加权系数及加权关联度,加权关联度的计算公式为:()mk iikk γξω=∑,式中7为第i 个评价对象对理想对象的加权关联度,kω为第k 个指标的权重.7)依加权关联度的大小,对各评价对象进行排序,建立评价对象的关联序,从而可以得出关联度较大的对象,关联度越大其综合评价结果也越好. (5)线性回归分析法假如对象(因变量)y 与p 个因素(自变量)12,,,p x x x 的关系是线性的,为研究他们之间定量关系式,做n 次抽样,每一次抽样可能发生的对象之值为12,,ny y y它们是在因素(1,2,,)i i p x =数值已经发生的条件下随机发生的.把第j 次观测的因素数值记为:12,,,jjpj x xx (1,2,j n =)那么可以假设有如下的结构表达式:1111011212201213011p pp pn nppy x x y x x y x xβββεβββεβββε⎧=++++⎪⎪=++++⎪⎨⎪⎪=++++⎪⎩其中,01,,,pβββ是1p +个待估计参数,12,,,n εεε是n 个相互独立且服从同一正态分布2(0,)N σ的随机变量.这就是多元线性回归的数学模型.若令12n y y y y ⎛⎫ ⎪ ⎪ ⎪= ⎪ ⎪ ⎪⎝⎭,111212122212111p p n n np x xx x x x x xxx ⎛⎫ ⎪ ⎪= ⎪ ⎪ ⎪⎝⎭,012p βββββ⎛⎫⎪ ⎪ ⎪ ⎪= ⎪ ⎪ ⎪ ⎪⎝⎭,12n εεεε⎛⎫ ⎪ ⎪= ⎪ ⎪ ⎪⎝⎭则上面多元线性回归的数学模型可以写成矩阵形式:y x βε=+在实际问题中,我们得到的是实测容量为n 的样本,利用这组样本对上述回归模型中的参数进行估计,得到的估计方法称为多元线性回归方程,记为011p p y b b x b x =+++式中,012,,,,p b b b b 分别为01,,,pβββ的估计值.(6)主成分分析法 1)主成分的定义 设有p 个随机变量12,,,p x x x ,它们可能线性相关,通过某种线性变换,找到p 个线性无关的随机变量12,,,pz z z,称为初始向量的主成分.设12(,,,)Tp αααα=为p 维空间pR 中的单位向量,并记所有单位向量的集合为{}0|1T R ααα==,且记X =12(,,,)Tp X X X .2)用相关矩阵确定的主成分令*i E X -=,**(,),ij i j E r X X =1,2,,j p =.*X=***12(,,)Tp X X X ,则1212121211()1pp ij p p R r r r rr r r⎛⎫ ⎪⎪== ⎪ ⎪ ⎪⎝⎭为*X 的协方程.类似地,我们可对R 进行相应的分析.3)主成分分析的一般步骤 第一步、选择主成分设X 的样本数据经过数据预处理后计算出的样本相关矩阵为121*21212111*()11()()pT p p p R ij n r rr rr X X r r⎛⎫ ⎪ ⎪=== ⎪- ⎪ ⎪⎝⎭. 由特征方程0R I λ-=,求出p 个非负实根,并按值从大到小进行排列:120p λλλ≥≥≥≥.将iλ带入下列方程组,求出单位特征向量iα()0,1,2,,i i R I i m λα-==确定m 的方法是使前m 个主成分的累计贡献率达到85%左右. 第二步、利用主成分进行分析在实际分析时,通常把特征向量的各个分量的取值大小和符号(正负)进行对照比较,往往能对主成分的直观意义作出合理的解释.利用主成分可以进行以下分析:a)对原指标进行分类;b)对原指标进行选择;c)对样品进行分类;d)对样品进行排序;e)预测分析.。
层次分析法模型

二、模型的假设1、假设我们所统计与分析的数据,都就是客观真实的;2、在考虑影响毕业生就业的因素时,假设我们所选取的样本为简单随机抽样,具有典型性与普遍性,基本上能够集中反映毕业生就业实际情况;3、在数据计算过程中,假设误差在合理范围之内,对数据结果的影响可以忽略、三、符号说明四、模型的分析与建立1、问题背景的理解随着我国改革开放的不断深入,经济转轨加速,社会转型加剧,受高校毕业生总量的增加,劳动用工管理与社会保障制度,劳动力市场的不尽完善,以及高校的毕业生部分择业期望过高等因素的影响,如今的毕业生就业形势较为严峻、为了更好地解决广大学生就业中的问题,就需要客观地、全面地分析与评价毕业生就业的若干主要因素,并将它们从主到次依秩排序、针对不同专业的毕业生评价其就业情况,并给出某一专业的毕业生具体的就业策略、2、方法模型的建立(1)层次分析法层次分析法介绍:层次分析法就是一种定性与定量相结合的、系统化、层次化的分析方法,它用来帮助我们处理决策问题、特别就是考虑的因素较多的决策问题,而且各个因素的重要性、影响力、或者优先程度难以量化的时候,层次分析法为我们提供了一种科学的决策方法、通过相互比较确定各准则对于目标的权重,及各方案对于每一准则的权重、这些权重在人的思维过程中通常就是定性的,而在层次分析法中则要给出得到权重的定量方法、我们现在主要对各个因素分配合理的权重,而权重的计算一般用美国运筹学家T、L、Saaty教授提出的AHP法、(2)具体计算权重的AHP 法AHP法就是将各要素配对比较,根据各要素的相对重要程度进行判断,再根据W、计算成对比较矩阵的特征值获得权重向量kStep1、 构造成对比较矩阵假设比较某一层k 个因素12,,,k C C C L 对上一层因素ο的影响,每次两个因素i C 与j C ,用ij C 表示i C 与j C 对ο的影响之比,全部比较结果构成成对比较矩阵C ,也叫正互反矩阵、*()k k ij C C =,0ij C >,1ij jiC C=, 1ii C =、若正互反矩阵C 元素成立等式:* ij jk ik C C C = ,则称C 一致性矩阵、标度ij C含义1i C 与j C 的影响相同 3 i C 比j C 的影响稍强 5 i C 比j C 的影响强 7 i C 比j C 的影响明显地强 9i C 比j C 的影响绝对地强2,4,6,8i C 与j C 的影响之比在上述两个相邻等级之间11,,29Li C 与j C 影响之比为上面ij a 的互反数 Step2、 计算该矩阵的权重通过解正互反矩阵的特征值,可求得相应的特征向量,经归一化后即为权重向量12 = [ , ,..., ]T kkkkkQ q qq ,其中的ikq 就就是i C 对ο的相对权重、由特征方程A-I=0λ,利用Mathematica 软件包可以求出最大的特征值max λ与相应的特征向量、Step3、 一致性检验1)为了度量判断的可靠程度,可计算此时的一致性度量指标CI :max1kCI k λ-=-其中maxλ表示矩阵C 的最大特征值,式中k 正互反矩阵的阶数,CI 越小,说明权重的可靠性越高、2)平均随机一致性指标RI ,下表给出了1-14阶正互反矩阵计算1000次得到3)当0.1CR RI=<时,(CR 称为一致性比率,RI 就是通过大量数据测出来的随机一致性指标,可查表找到)可认为判断就是满意的,此时的正互反矩阵称之为一致性矩阵、进入Step4、 否则说明矛盾,应重新修正该正互反矩阵、转入Step2、 Step4、 得到最终权值向量将该一致性矩阵任一列或任一行向量归一化就得到所需的权重向量、计算出来的准则层对目标层的权重即不同因素的最终权重,这样一来,我们就可以按权重大小将进行排序了、 (3)组合权向量的计算成对比较矩阵显然非常好体现了我们研究对象——各个因素之间权重的比较状态,能够有效地全面而深刻地表现出有关的数据信息,显然也就是矩阵数学模型的重要应用价值、 因素往往就是有层次的,我们经常在进行决策分析时,要进行多方面、多角度、多层次的分析与研究,把我们的决策选择建立在深刻而广泛的分析研究基础之上的、一个总的指标下面可以有第一层次的各个方面的指标、因素、成份、特征性质、组成成分等等,而每个这种因素又有新的成份在里面、这就就是决策分析的数学模型的真正的意义之所在、定理1:对于三决策问题,假设第一层只有一个因素,即这就是总的目标,决策总就是最后要集中在一个总目标基础之上的东西,然后才能进行最后的比较、又假设第二层与第三层因素各有n 、m 个,并且记第二层对第一层的权向量(即构成成份的数量大小、成份的比例、影响程度的大小的数量化指标的量化结果、所拥有的这种属性的程度大小等等多方面的事情的量化的结果)为:(2)(2)(2)(2)12(,,,)Tn w w w w =L , 而第3层对第2层的全向量分别就是:(3)(3)(3)(3)12(,,,)Tk k k km w w w w =L ,这表示第3层的权重大小,具体表示的就是第2层中第k 个因素所拥有的面对下一层次的m 个同类因素进行分析对比所产生的数量指标、那么显然,第三层的因素相对于第一层的因素而言,其权重应当就是:先构造矩阵,用 (3)k w 为列向量构造一个方阵 (3)(3)(3)(3)12(,,)nWw w w=L,这个矩阵的第一行就是第3层次的m 个因素中的第1个因素,通过第2层次的n 个因素传递给第1层次因素的权重,故第3层次的m 个因素中的第i 个因素对第1层次的权重为 (2)(3)1nkkik w w=∑,从而可以统一表示为:(1)(3)(2)wWw=,它的每一行表示的就就是三层(一般就是方案层)中每一个因素相对总目标的量化指标、定理2:一般公式如果共有s 层,则第k 层对第一层(设只有一个因素)的组合权向量为()()(1),3,4,k k k k s wWw-==L ,其中矩阵 ()k W的第i 行表示第k 层中的第i 个因素,相对于第1k -层中每个因素的权向量;而列向量 (1)k w-则表示的就是第1k -层中每个因素关于第一层总目标的权重向量、于就是,最下层对最上层的的组合权向量为:()()(1)(3)(2)s s s wWWWw-=L ,实际上这就是一个从左向右的递推形式的向量运算、逐个得出每一层的各个因素关于第一层总目标因素的权重向量、 (4)灰色关联度综合评价法灰色系统的关联分析主要就是对系统动态发展过程的量化分析,它就是根据因素之间发展态势的相似或相异程度,来衡量因素间接近的程度,实质上就就是各评价对象与理想对象的接近程度,评价对象与理想对象越接近,其关联度就越大、关联序则反映了各评价对象对理想对象的接近次序,即评价对象与理想对象接近程度的先后次序,其中关联度最大的评价对象为最优、因此,可利用关联序对所要评价的对象进行排序比较、利用灰色关联度进行综合评价的步骤如下:1)用表格方式列出所有被评价对象的指标、2)由于指标序列间的数据不存在运算关系,因此必须对数据进行无量纲化处理、3)构造理想对象,即把无量纲化处理后评价对象中每一项指标的最佳值作为理想对象的指标值、4)计算指标关联系数、其计算公式为:min max imax()()ik k ρρξ+=+∆∆∆∆其中min()()minminiikk k x x =-∆,max()()maxmaxiikk k x x =-∆,()ik ∆=()()ik k x x -,1,2,i n =L ,1,2,k m =L 、式中n 为评价对象的个数;m 为评价对象指标的个数;()ik ξ为第i 个对象第k 个指标对理想对象同一指标的关联系数;A 表示在各评价对象第k 个指标值与理想对象第k 个指标值的最小绝对差的基础上,再按1,2,,i n =L 找出所有最小绝对差中的最小值;max ∆表示在评价对象第k 个指标值与理想对象第k 个指标值的最大绝对差的基础上,再按1,2,,i n =L 找出所有最大绝对差中的最大值;min ∆为评价对象第k 个指标值与理想对象第k 个指标值的绝对差、ρ为分辨系数,ρ越小分辨力越大,一般ρ的取值区间[0,1],更一般地取ρ=0、5、5)确立层次分析模型、6)确定判断矩阵,计算各层次加权系数及加权关联度,加权关联度的计算公式为:()mk iikk γξω=∑,式中7为第i 个评价对象对理想对象的加权关联度,kω为第k 个指标的权重、7)依加权关联度的大小,对各评价对象进行排序,建立评价对象的关联序,从而可以得出关联度较大的对象,关联度越大其综合评价结果也越好、 (5)线性回归分析法假如对象(因变量)y 与p 个因素(自变量)12,,,p x x x L 的关系就是线性的,为研究她们之间定量关系式,做n 次抽样,每一次抽样可能发生的对象之值为12,,ny y yL它们就是在因素(1,2,,)i i p x =L 数值已经发生的条件下随机发生的、把第j 次观测的因素数值记为:12,,,jjpj x xx L (1,2,j n =L )那么可以假设有如下的结构表达式:1111011212201213011p p p p n np p y x x y x x y x x βββεβββεβββε⎧=++++⎪⎪=++++⎪⎨⎪⎪=++++⎪⎩L L L L L L L L L L L L L L L L L L 其中,01,,,pβββL 就是1p +个待估计参数,12,,,n εεεL 就是n 个相互独立且服从同一正态分布2(0,)N σ的随机变量、这就就是多元线性回归的数学模型、若令12n y y y y ⎛⎫ ⎪ ⎪ ⎪= ⎪ ⎪ ⎪⎝⎭M ,111212122212111p p n n np x xx x xx x xxx ⎛⎫ ⎪ ⎪=⎪ ⎪⎪⎝⎭L L L LLL L L,012p βββββ⎛⎫⎪ ⎪ ⎪ ⎪= ⎪ ⎪ ⎪ ⎪⎝⎭M ,12n εεεε⎛⎫ ⎪ ⎪= ⎪ ⎪ ⎪⎝⎭M则上面多元线性回归的数学模型可以写成矩阵形式:y x βε=+在实际问题中,我们得到的就是实测容量为n 的样本,利用这组样本对上述回归模型中的参数进行估计,得到的估计方法称为多元线性回归方程,记为%011p p y b b x b x =+++L式中,012,,,,p b b b b L 分别为01,,,p βββL 的估计值、 (6)主成分分析法1)主成分的定义设有p 个随机变量12,,,p x x x L ,它们可能线性相关,通过某种线性变换,找到p 个线性无关的随机变量12,,,pz z zL ,称为初始向量的主成分、设12(,,,)Tp αααα=L为p 维空间pR 中的单位向量,并记所有单位向量的集合为{}0|1TR ααα==,且记X =12(,,,)Tp X X X L 、2)用相关矩阵确定的主成分令*i E X -=,**(,),ij i j E r X X =1,2,,j p =L 、*X=***12(,,)Tp X X X L ,则1212121211()1pp ij p p R r r r rr r r⎛⎫ ⎪⎪== ⎪ ⎪ ⎪⎝⎭L LL L LLL 为*X 的协方程、类似地,我们可对R 进行相应的分析、3)主成分分析的一般步骤 第一步、选择主成分设X 的样本数据经过数据预处理后计算出的样本相关矩阵为121*21212111*()11()()pT p p p R ij n r r r rr XX r r⎛⎫ ⎪ ⎪=== ⎪- ⎪ ⎪⎝⎭L LL L LLL %%、 由特征方程0R I λ-=,求出p 个非负实根,并按值从大到小进行排列:120p λλλ≥≥≥≥L 、将iλ带入下列方程组,求出单位特征向量iα()0,1,2,,i i R I i m λα-==L确定m的方法就是使前m个主成分的累计贡献率达到85%左右、第二步、利用主成分进行分析在实际分析时,通常把特征向量的各个分量的取值大小与符号(正负)进行对照比较,往往能对主成分的直观意义作出合理的解释、利用主成分可以进行以下分析:a)对原指标进行分类;b)对原指标进行选择;c)对样品进行分类;d)对样品进行排序;e)预测分析、。
层次分析法的原理

层次分析法的原理层次分析法(Analytic Hierarchy Process,简称AHP)是一种用于多准则决策的数学模型。
它由美国数学家Thomas L. Saaty于20世纪70年代提出,被广泛应用于各个领域的决策分析中。
层次分析法基于人们在决策过程中常常需要考虑多个因素及其相对重要性的观点,通过对这些因素进行定量化和比较,帮助决策者做出理性决策。
层次分析法的原理主要包括层次结构、成对比较和权重计算三个部分。
一、层次结构:在层次分析法中,我们首先需要构建一个层次结构,将决策问题划分为不同的层次。
层次结构由目标层、准则层、子准则层和方案层组成。
目标层:决策问题的最终目标,通常只有一个。
准则层:实现目标所需的准则或评价指标,可以有多个。
子准则层:对每个准则进行细分或进一步评价的子指标,根据实际情况确定是否需要。
方案层:候选方案或决策选项,可以有多个。
二、成对比较:通过成对比较来确定各个层次之间的重要性或优先级。
成对比较是指将两个层次中的元素逐一配对,并根据它们之间的重要性进行比较。
在成对比较中,使用1-9的数值尺度,其中1表示相等重要,3表示略微重要,5表示中等重要,7表示强烈重要,9表示绝对重要。
通过比较各个元素对的重要性,可以建立一个判断矩阵。
例如,在准则层中,假设有三个准则A、B、C,那么我们需要进行三次成对比较,得到一个3x3的判断矩阵。
同样,在子准则层或方案层中,也需要进行成对比较,得到相应的判断矩阵。
三、权重计算:通过计算判断矩阵的特征向量,可以得到各个层次的权重,用于确定决策的最终结果。
特征向量是指矩阵的一个列向量,使得该矩阵与特征向量的乘积等于特征值乘特征向量。
通过对判断矩阵的特征向量进行归一化处理,可以得到各个层次的权重,用于计算总体权重或方案的优先级。
最后,根据权重计算的结果,可以得到最优的决策选择。
层次分析法的原理基于多个准则、多个层次的权重计算,旨在帮助决策者以合理的方式处理决策问题,并提供一种定量化的决策分析方法。
第九章 层次分析法模型

层次分析法模型
层次分析模型
y
离散模型
• 离散模型:差分方程(第7章)、
整数规划(第4章)、图论、对策 论、网络流、… … • 分析社会经济系统的有力工具
• 只用到代数、集合及图论(少许)
的知识
层次分析模型
背 景
• 日常工作、生活中的决策问题
• 涉及经济、社会等方面的因素 • 作比较判断时人的主观选择起相当 大的作用,各因素的重要性难以量化
1/ 2 1 1/ 7 1/ 5 1/ 5 4 7 1 2 3 3
3 5 5 A~成对比较阵 1 / 2 1 / 3 A是正互反阵 1 1 1 1
要由A确定C1,… , Cn对O的权向量
成对比较阵和权向量 成对比较的不一致情况
1 A 2
1/ 2 1
准则层对目标的成对比较阵
1 2 A 1/ 4 1/ 3 1/ 3 1/ 2 1 1/ 7 1/ 5 1/ 5 4 7 1 2 3 3 5 5 1 / 2 1 / 3 1 1 1 1 3
权向量(特征向量)w =(0.263,0.475,0.055,0.090,0.110)T
…Cn
…Bn … n
最大特征根 1
2
w2(3)
权向量
w1(3)
… wn(3)
组合权向量
k 1
第3层对第2层的计算结果 2 3 4 5
w
( 3) k
0.595 0.277 0.129
3.005 0.003
0.082 0.236 0.682
3.002 0.001
0.429 0.429 0.142
4)计算组合权向量(作组合一致性检验*)
数学建模(层次分析法(AHP法))

判断矩阵元素a 判断矩阵元素 ij的标度方法
标度 1 3 5 7 9 2 , 4 , 6, 8 倒数 含义 表示两个因素相比, 表示两个因素相比,具有同样重要性 表示两个因素相比, 表示两个因素相比,一个因素比另一个因素稍微重要 表示两个因素相比, 表示两个因素相比,一个因素比另一个因素明显重要 表示两个因素相比, 表示两个因素相比,一个因素比另一个因素强烈重要 表示两个因素相比, 表示两个因素相比,一个因素比另一个因素极端重要 上述两相邻判断的中值
层次分析法在经济、科技、文化、军事、 环境乃至社会发展等方面的管理决策中都 有广泛的应用。 常用来解决诸如综合评价、选择决策方案、 估计和预测、投入量的分配等问题。
层次分析法建模
一 、问题的提出 日常生活中有许多决策问题。 日常生活中有许多决策问题。决策是指 在面临多种方案时需要依据一定的标准选择 某一种方案。 某一种方案。 例1 某人准备选购一台电冰箱 他对市场上的6 他对市场上的6种不同类型的电冰箱进行了解 选取一些中间指标进行考察。例如电冰 指标进行考察 后,选取一些中间指标进行考察。例如电冰 箱的容量、制冷级别、价格、型式、耗电量、 箱的容量、制冷级别、价格、型式、耗电量、 外界信誉、售后服务等 外界信誉、售后服务等。
目标层
O(选择旅游地 选择旅游地) 选择旅游地
准则层
C1 景色
C2 费用
C3 居住
C4 饮食
C5 旅途
要比较各准则C1,C2,… , Cn对目标O的重要性 要比较各准则 对目标 的重要性
Ci :Cj ⇒aij
选 择 C1 旅 C2 游 C 3 地
C4 C5 C1
层次分析法(AHP法 层次分析法(AHP法)
Analytic Hierarchy Process
多目标决策模型:层次分析法(AHP)、代数模型、离散模型

程中常是定性的。 例如:经济好,身体好的人:会将景色好作为第一选择; 中老年人:会将居住、饮食好作为第一选择; 经济不好的人:会把费用低作为第一选择。 而层次分析方法则应给出确定权重的定量分析方法。 (S3)将方案后对准则层的权重,及准则后对目标层的权重进行综合。 (S4)最终得出方案层对目标层的权重,从而作出决策。 以上步骤和方法即是 AHP 的决策分析方法。 三、确定各层次互相比较的方法——成对比较矩阵和权向量 在确定各层次各因素之间的权重时,如果只是定性的结果,则常常不容易被别人接受,因 而 Santy 等人提出:一致矩阵法 ..... 即:1. 不把所有因素放在一起比较,而是两两相互比较 2. 对此时採用相对尺度,以尽可能减少性质不同的诸因素相互比较的困难,提高准确度。 因素比较方法 —— 成对比较矩阵法: 目的是,要比较某一层 n 个因素 C1 , C 2 , , C n 对上一层因素 O 的影响(例如:旅游决策解 中,比较景色等 5 个准则在选择旅游地这个目标中的重要性) 。 採用的方法是:每次取两个因素 C i 和 C j 比较其对目标因素 O 的影响,并用 aij 表示,全部 比较的结果用成对比较矩阵表示,即:
分析:
W1 W2 若重量向量 W 未知时, 则可由决策者对物体 M 1 , M 2 , , M n 之间两两相比关系, W n 主观作出比值的判断,或用Delphi(调查法)来确定这些比值,使 A 矩阵(不一定有一致性)
为已知的,并记此主观判断作出的矩阵为(主观)判断矩阵 A ,并且此 A (不一致)在不一致 的容许范围内,再依据: A 的特征根或和特征向量 W 连续地依赖于矩阵的元素 aij ,即当 aij 离 一致性的要求不太远时, A 的特征根 i 和特征值(向量)W 与一致矩阵 A 的特征根 和特征向 量 W 也相差不大的道理:由特征向量 W 求权向量 W 的方法即为特征向量法,并由此引出一致 性检查的方法。 问题:Remark 以上讨论的用求特征根来求权向量 W 的方法和思路,在理论上应解决以下问题: 1. 一致阵的性质 1 是说:一致阵的最大特征根为 n (即必要条件) ,但用特征根来求特征向量 时, 应回答充分条件: 即正互反矩阵是否存在正的最大特征根和正的特征向量?且如果正互 反矩阵 A 的最大特征根 max n 时, A 是否为一致阵? 2. 用主观判断矩阵 A 的特征根 和特征向量 W 连续逼近一致阵 A 的特征根 和特征向量 W 时,即: 由 lim k
层次分析法

层次分析法-061002116张西军—关于选拔干部的模型对三个干部候选人、、,按选拔干部的五个标准:品德、才能、资历、年龄和群众关系,构成如下层次分析模型:假设有三个干部候选人、、,按选拔干部的五个标准:品德,才能,资历,年龄和群众关系,构成如下层次分析模型二. 构造成对比较矩阵比较第 i 个元素与第 j 个元素相对上一层某个因素的重要性时,使用数量化的相对权重来描述。
设共有 n 个元素参与比较,则称为成对比较矩阵。
成对比较矩阵中的取值可参考 Satty 的提议,按下述标度进行赋值。
在 19 及其倒数中间取值。
∙元素 i 与元素 j 对上一层次因素的重要性相同;∙元素 i 比元素 j 略重要;∙元素 i 比元素 j 重要;∙元素 i 比元素 j 重要得多;∙元素 i 比元素 j 的极其重要;∙,元素 i 与 j 的重要性介于与之间;∙,当且仅当。
成对比较矩阵的特点:,,。
对例 2,选拔干部考虑5个条件:品德,才能,资历,年龄,群众关系。
某决策人用成对比较法,得到成对比较阵如下:=5 表示品德与年龄重要性之比为 5,即决策人认为品德比年龄重三. 作一致性检验从理论上分析得到:如果是完全一致的成对比较矩阵,应该有。
但实际上在构造成对比较矩阵时要求满足上述众多等式是不可能的。
因此退而要求成对比较矩阵有一定的一致性,即可以允许成对比较矩阵存在一定程度的不一致性。
由分析可知,对完全一致的成对比较矩阵,其绝对值最大的特征值等于该矩阵的维数。
对成对比较矩阵的一致性要求,转化为要求:的绝对值最大的特征值和该矩阵的维数相差不大。
检验成对比较矩阵 A 一致性的步骤如下:o计算衡量一个成对比矩阵 A ( >1 阶方阵)不一致程度的指标:其中是矩阵 A 的最大特征值。
注解o从有关资料查出检验成对比较矩阵 A 一致性的标准:称为平均随机一致性指标,它只与矩阵阶数有关。
o按下面公式计算成对比较阵 A 的随机一致性比率CR:。
层次分析法

一. 层次分析模型和一般步骤层次分析法是一种定性与定量分析相结合的多因素决策分析方法。
这种方法将决策者的经验判断给于数量化,在目标因素结构复杂且缺乏必要数据的情况下使用更为方便,因而在实践中得到广泛应用。
层次分析的四个基本步骤:(1)在确定决策的目标后,对影响目标决策的因素进行分类,建立一个多层次结构;(2)比较同一层次中各因素关于上一层次的同一个因素的相对重要性,构造成对比较矩阵;(3)通过计算,检验成对比较矩阵的一致性,必要时对成对比较矩阵进行修改,以达到可以接受的一致性;(4)在符合一致性检验的前提下,计算与成对比较矩阵最大特征值相对应的特征向量,确定每个因素对上一层次该因素的权重;计算各因素对于系统目标的总排序权重并决策。
二. 建立层次结构模型将问题包含的因素分层:最高层(解决问题的目的);中间层(实现总目标而采取的各种措施、必须考虑的准则等。
也可称策略层、约束层、准则层等);最低层(用于解决问题的各种措施、方案等)。
把各种所要考虑的因素放在适当的层次内。
用层次结构图清晰地表达这些因素的关系。
例1〕购物模型某一个顾客选购电视机时,对市场正在出售的四种电视机考虑了八项准则研究了统计分位数的一些性质 ,特别是它们与数学期望之间的关系 ,并归纳了统计分位数的求法 ,介绍了统计分位数的一些应用分位数有三种不同的称呼,即α分位数、上侧α分位数与双侧α分位数,它们的定义如下:当随机变量X的分布函数为 F(x),实数α满足0 <α<1 时,α分位数是使P{X< xα}=F(xα)=α的数xα,上侧α分位数是使P{X >λ}=1-F(λ)=α的数λ,双侧α分位数是使P{X<λ1}=F(λ1)=0.5α的数λ1、使P{X>λ2}=1-F(λ2)=0.5α的数λ2。
作为评估依据,建立层次分析模型如下:〔例2〕选拔干部模型对三个干部候选人、、,按选拔干部的五个标准:品德、才能、资历、年龄和群众关系,构成如下层次分析模型:假设有三个干部候选人、、,按选拔干部的五个标准:品德,才能,资历,年龄和群众关系,构成如下层次分析模型〔例3〕评选优秀学校某地区有三个学校,现在要全面考察评出一个优秀学校。
第三讲 层次分析法及差分方程模型

n 1
= n是A为一致阵的充要条件。
一致性指标 CI 定义合理
2. 正互反阵最大特征根和特征向量的简化计算
• 精确计算的复杂和不必要 • 简化计算的思路——一致阵的任一列向量都是特征向量, 一致性尚好的正互反阵的列向量都应近似特征向量,可取 其某种意义下的平均。 和法——取列向量的算术平均
Step 1:构造层次结构模型
目标层
O(选择旅游地)
准则层
C1 景色
C2 费用
C3 居住
C4 饮食
C5 旅途
方案层
P1 海南
P2 哈尔滨 层次结构模型
P3 莫高窟
Step 2:构造判别矩阵 Saaty等人提出1~9尺度——aij 取值 比较尺度aij 1,2,… , 9及其互反数1,1/2, … , 1/9 • 便于定性到定量的转化:
2 1 例 A 1 / 2 1 1 / 6 1 / 4
6 列向量 4 归一化 1
0.6 0.615 0.545 算术 0.587 0.3 0.308 0.364 平均 0.324 w 0.089 0.1 0.077 0.091
尺度
a ij
1 相同
2
3 稍强
4
5 强
6
7
8
9 绝对强
Ci : C j的重要性
明显强
aij = 1,1/2, ,…1/9 ~ Ci : C j 的重要性与上面相反
• 心理学家认为成对比较的因素不宜超过9个 • 用1~3,1~5,…1~17,…,1p~9p (p=2,3,4,5), d+0.1~d+0.9 (d=1,2,3,4)等27种比较尺度对若干实例构造成对比较 阵,算出权向量,与实际对比发现, 1~9尺度较优。
层次分析模型

计算判断矩阵的最大特征 值和特征向量,得出各因 素的权重值,并进行一致 性检验。
计算组合权向量,得出各 因素的组合权重值,并进 行一致性检验。
02 建立层次结构
目标层
01
目标层是层次分析模型的最顶层,代表要解决的问题或要实现 的目标。
02
在目标层中,需要明确问题的最终目标,并将其作为层次分析
模型的输出。
特点
简单明了、系统性、灵活性、所需定量数据信息较少、广泛的应用领域。
层次分析模型的应用领域
资源分配
在资源有限的条件下,合理分配资源以达到 最优的效果。
综合评价
对某个事物进行全面的评价。
方案选择
从多个备选方案中选出最优方案。
决策分析
对决策问题进行分析,得出最优的决策方案。
层次分析模型的基本步骤
01
层次分析法软件
使用专门开发的层次分析法软件,如 yaahp、Analytic Hierarchy
Process等,可以方便地构造判断矩 阵
判断矩阵的一致性检验
一致性检验的步骤
先计算判断矩阵的最大特征值λmax,然后根据公式CI=(λmax-n)/(n-1)计算一致性 指标CI,其中n为判断矩阵的阶数。接着查找相应的平均随机一致性指标RI(常见的 RI值有0、0.58、0.90、1.12等),最后计算一致性比例CR=CI/RI。
一致性检验的标准
当CR<0.1时,认为判断矩阵的一致性是可以接受的;当CR≥0.1时,需要对判断矩 阵进行调整。
04 层次单排序与层次总排序
层次单排序
确定比较判断矩阵
根据专家意见或数据,确定各因素之间的相对重 要性,构建比较判断矩阵。
计算权重向量
数学建模层次分析法

(Analytic Hierarchy Process) 建模
数学建模
模型背景 基本步骤 应用实例
一、模型背景
❖ 美国运筹学家匹兹堡大学教授Saaty在20世纪70 年代初提出的一种层次权重决策分析方法。
❖层次分析法(Analytic Hierarchy Process简称AHP) 是一种定性和定量分析相结合的决策分析方法。
对总目标Z的排序为
A1
A2
Am
a1, a2 ,, am
B层n个因素对上层 A中因素为 Aj
其层次单排序为
B1
B2
Bn b1 j ,b2 j ,,bnj ( j 1,2,, m)
层次 A A1
层次 B a1
B1
b11
B2
b21
.
.
.
.
.
.
Bn
bn1
A2 … Am B 层次总
a2
… am 排序权值
RI 0i RIi 0.58 i 1
CR CI / RI 0.087 / 0.58 0.015 0.1
C5
0.118 0.166 0.166 0.668
层次P的 总排序
0.3 0.246 0.456
层次分析法的优点
系统性——将对象视作系统,按照分解、比较、判断、综合 的思维方式进行决策。成为成为继机理分析、统 计分析之后发展起来的系统分析的重要工具;
w(2) (0.263, 0.475, 0.055, 0.090, 0.110)T
同样求第3层(方案)对第2层每一元素(准则)的权向量
方案层对C1(景色)的 成对比较阵
方案层对C2(费用)的 成对比较阵
…Cn
层次分析法模型

层次分析法模型层次分析法模型(AHP)是指采用多角度分析综合决策问题的决策模型。
层次分析法模型也常被称为“综合衡量决策法AHP”,它可以清楚地显示决策问题中各个因素和各种决策目标之间的变化关系,从而协助决策者进行决策分析,尤其是在复杂多样的环境下,可以提供较为准确的分析和决策结果。
一、层次分析法模型的原理及概念层次分析法模型是一种有着多样度的决策方法,它可以帮助决策者从多角度的结果进行综合性的分析,从而有助于提升决策的准确性和鲁棒性。
层次分析法模型的核心思想是将决策问题分解为一系列级联的小问题,在组织问题越来越复杂的情况下,层次分析法模型可以更有效地进行管理。
层次分析法模型主要包括三个层次:目标层、指标层和子指标层。
1.目标层:目标层即分析的主题,是实际分析的核心问题,是总体分析的指导原则。
2.指标层:指标层由各种相关指标组成,用以检测目标层的实现状况。
3.子指标层:子指标层是指标层的进一步分解,包括客观指标与主观指标,用以更加准确地衡量目标层在实现过程中的困难程度。
二、层次分析法模型的特征1.简单易操作:层次分析法模型具有很高的计算简便性,操作简洁,只要决策者能够合理地组织数据,就可以运用层次分析法模型得出准确的结果。
2.易于计算:采用层次分析法模型进行综合性分析时,需要计算一系列不同层面之间的相对权重,这一点使得计算成本较低。
3.考虑多项条件:采用层次分析法模型,进行决策分析的同时可以考虑多个条件,从而利用这些条件完成更加准确的决策。
4.表达性强:层次分析法模型擅长表达决策者的思路,通过具体的分析过程可以更清楚地了解决策者的想法,从而使决策者更容易接受最终的决策结果。
三、层次分析法模型的应用1.组织治理:组织治理是组织管理的重要部分,其中重要的指标也是关键因素,层次分析法分析法模型可以帮助组织管理者准确掌握各个指标的变化,从而进行有效的组织治理。
2.市场营销:市场营销是一项复杂的技术活动,需要分析多个指标,如客户偏好、价格影响因素等,考虑这些因素之间的关系,层次分析法模型可以有效帮助企业发掘潜在市场需求,从而更有效地实现市场营销计划。
层次分析法建模举例

其中:maxN为单注封顶金额;minN为单注保底 金额;Qij为第 i 种方案得第 j 等奖的单项奖比例; M为当期销售总额;n为低项奖总额; Q为总奖金 比例。
三、层次分析
3.1层次分析模型分为四层:
目标层:即决策目标,在本问题中取彩票的销售规则 及其相应的奖金设置方案的合理性作为决策目标。 中间层:作为目标层的衡量准则,我们取彩票的高项 奖金,低项固定奖金,和中奖面三方面来衡量目标层。 指标层:其中包括高项奖金的3个评价标准(即一, 二,三等奖)和低项固定奖金的4个评价指标(即四, 五,六,七等奖),而位于中间层的中奖面衡量准则 可以单独作为目标层的一个评价指标(即中奖面)。 方案层: 需进行评估的各种分配方案
一、 问题的提出与概率计算
已给的29种方案分为两种类型 1、“传统型”采用“10选6+1”方案: 投注者从0~9十个号码中任选6个基本号码(可 重复),从0~4中选一个特别号码,构成一注 。根 据单注号码与中奖号码相符的个数多少及顺序确定 中奖等级;
表1: “传统型” 中奖办法
中 奖 等 级 10 选 6+1(6+1/10) 基本号码 特别号码 选7中
Roots: 多项式的零点可用命令roots求的。
例: >> r=roots(p) 得到 r= 0.2500 + 1.5612i 0.2500 - 1.5612i -1.0000 所有零点由一个列向量给出。
Poly: 由零点可得原始多项式的各系数,但可能相差一 个常数倍。 例: >> poly(r)
如“33选7”的方案:投注者从01~33个号码 中任选7个组成一注(不可重复),根据单注号 码与中奖号码相符的个数多少确定相应的中奖等 级,不考虑号码顺序。
层次分析法评价模型

层次分析法评价模型评价类数学模型是全国数学建模竞赛中经常出现的一类模型,如2005年全国赛A题长江水质的评价问题,2008年B题高校学费标准评价体系问题等。
主要介绍三种比较常用的评价模型:层次分析模型,模糊综合评价模型,灰色关联分析模型,以期帮助大家了解不同背景下不同评价方法的应用。
层次分析模型层次分析法(AHP)是根据问题的性质和要求,将所包含的因素进行分类,一般按目标层、准则层和子准则层排列,构成一个层次结构,对同层次内诸因素采用两两比较的方法确定出相对于上一层目标的权重,这样层层分析下去,直到最后一层,给出所有因素相对于总目标而言,按重要性程度的一个排序。
其主要特征是,它合理地将定性与定量决策结合起来,按照思维、心理的规律把决策过程层次化、数量化。
运用层次分析法进行决策,可以分为以下四个步骤:步骤1 建立层次分析结构模型深入分析实际问题,将有关因素自上而下分层(目标—准则或指标—方案或对象),上层受下层影响,而层内各因素基本上相对独立。
步骤2构造成对比较阵对于同一层次的各元素关于上一层次中某一准则的重要性进行两两比较,借助1~9尺度,构造比较矩阵;步骤3计算权向量并作一致性检验由判断矩阵计算被比较元素对于该准则的相对权重,并进行一致性检验,若通过,则最大特征根对应的特征向量做为权向量。
步骤4计算组合权向量(作组合一致性检验)组合权向量可作为决策的定量依据通过一个具体的例子介绍层次分析模型的应用。
例(选择旅游地决策问题)如何在桂林、黄山、北戴河3个目的地中按照景色、费用、居住条件、饮食、旅途条件等因素进行选择。
步骤1 建立系统的递阶层次结构将决策问题分为3个层次:目标层O,准则层C,方案层P;每层有若干元素,各层元素间的关系用相连的直线表示。
图1 选择旅游地的层次结构步骤2构造比较矩阵元素之间两两对比,对比采用美国运筹学家A.L.Saaty 教授提出的1~9比率标度法(表1)对不同指标进行两两比较,构造判断矩阵。
层次分析法

层次分析法(AHP )评价模型1.层次分析法简介层次分析法简称AHP (The analytic hierarchy process),由美国的运筹学家T.L.Saaty 提出。
层次分析法要求明确项目的总目标,将其分解为各层子目标、准则层、指标层甚 至指标,构建一种递阶层次结构;构造两两判断矩阵,求解判断矩阵的特征向量,得到 每层的元素相对于上一层次的权重;采用加权的方法确定方案层各指标对总F1标的权 重,反映不同指标的相对重要性。
层次分析法通过制定标准,对难以量化的定性指标标 准化数学运算处理,转化为可以量化的数据,是一个定性和定量结合的方法。
2.层次分析法的一般步骤(1)确定评价目标和范围,构造递阶层次结构。
(2) 构造两两比较矩阵(判断矩阵)对于同一层次的各因素关于上一层中对应准则(目标)的重要性进行两两比较,构造出两两比较的判断矩阵。
用标度法表示比较结果。
如表所示:判断矩阵标注及其含义注:ij C ={2,4,6,8,1/2,1/4,1/6,1/8}表示重要性等级介于 ij C ={l,3,5,7,9,l/3,l/5,l/7,l/9}。
根据此表可以得到对于同一层次指标的判断矩阵mm A ,mm ij m a a a a A )(},...,,{21==A 的性质如下: ①0>ij a ②ijij a a 1=③1==ij a j i 时, (3)由比较矩阵计算被比较因素对上一层对应准则的相对权重(归一化特征向量),并进行判断矩阵的一致性检验。
(4)计算指标层对总目标的组合权重和组合一致性检验,得出各指标对总目标的影响权重。
3.一致性检验由于指标采用的两两比较,有可能出现甲的重要性大于乙、乙的重要性大于两、丙 的重要性却大于甲的情况,因此,确定计算相对权重后要进行組阵一致性判断,矩阵一 致性指标记为CI1max --=n nCI λRICI CR =RI 是平均随机一致性指标,判断矩阵的阶数不同,RI 的取值也不同,RI 的取值见表平均随机一致性指标的取值当时,判断矩阵通过一致性检验,得到的权重具有可信性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
通过相互比较确定各准则对于目标的权重,及各方案对于每一准则的权重. 这些权重在人的思维过程中通常是定性的,而在层次分析法中则要给出得到权 重的定量方法.
又假设第二层和第三层因素各有 n 、 m 个,并且记第二层对第一层的权向量
(即构成成份的数量大小、成份的比例、影响程度的大小的数量化指标的量化
结果、所拥有的这种属性的程度大小等等多方面的事情的量化的结果)为:
w(2) (w1(2),w(22),L ,w(n2))T ,
而第 3 层对第 2 层的全向量分别是:
的随机一致性指标,可查表找到)可认为判断是满意的,此时的正互反
矩阵称之为一致性矩阵.进入Step4. 否则说明矛盾,应重新修正该正互
反矩阵.转入Step2.
Step4. 得到最终权值向量
将该一致性矩阵任一列或任一行向量归一化就得到所需的权重向量.
计算出来的准则层对目标层的权重即不同因素的最终权重,这样一来,我们就
Step2. 计算该矩阵的权重
通过解正互反矩阵的特征值,可求得相应的特征向量,经归一化后即为权重向
Q q q q q C 量 = [ , ,..., ]T ,其中的 就是 对 的相对权重.由特征方程
k
1k
2k
kk
ik
i
A-I=0 ,利用Mathematica软件包可以求出最大的特征值 和相应的特征向 max
w(3) k
(w(k31),
w(k32),L
可以按权重大小将进行排序了.
(3)组合权向量的计算
成对比较矩阵显然非常好体现了我们研究对象——各个因素之间权重的比
较状态,能够有效地全面而深刻地表现出有关的数据信息,显然也是矩阵数学
模型的重要应用价值. 因素往往是有层次的,我们经常在进行决策分析时,要
进行多方面、多角度、多层次的分析与研究,把我们的决策选择建立在深刻而
广泛的分析研究基础之上的.一个总的指标下面可以有第一层次的各个方面的指
标、因素、成份、特征性质、组成成分等等,而每个这种因素又有新的成份在
里面.这就是决策分析的数学模型的真正的意义之所在.
定理 1:对于三决策问题,假设第一层只有一个因素,即这是总的目标,
决策总是最后要集中在一个总目标基础之上的东西,然后才能进行最后的比较.
ij
jk
ik
标度 Cij 1 3 5 7 9
含义 Ci 与 C j 的影响相同 Ci 比 C j 的影响稍强 Ci 比 C j 的影响强 Ci 比 C j 的影响明显地强 Ci 比 C j 的影响绝对地强
2, 4, 6,8
1 ,L
1 ,
29
Ci 与 C j 的影响之比在上述两个相邻 等级之间 Ci 与 C j 影响之比为上面 aij 的互反数
Ci 层次分析法中的第 i 个因素
C 正互反矩阵
max
正互反矩阵的最大特征值
Q 模型中第三层每个方案对第二层中每个因素的权向量构成的矩阵
CR 一致性比率
Q 归一化权向量 k
x
(k
0
)
参照列
(k) i 关联系数
x
(k
i
)
第 i 行第 k 列的元素
(k
i
)
即
x
(k
0
)
xi(k)
灰色关联度模型
max
我们现在主要对各个因素分配合理的权重,而权重的计算一般用美国运筹 学家T.L.Saaty教授提出的AHP法. (2)具体计算权重的AHP 法
AHP法是将各要素配对比较,根据各要素的相对重要程度进行判断,再根据
W 计算成对比较矩阵的特征值获得权重向量 . k Step1. 构造成对比较矩阵
假设比较某一层 k
二、模型的假设
1、假设我们所统计和分析的数据,都是客观真实的; 2、在考虑影响毕业生就业的因素时,假设我们所选取的样本为简单随机抽 样,具有典型性和普遍性,基本上能够集中反映毕业生就业实际情况; 3、在数据计算过程中,假设误差在合理范围之内,对数据结果的影响可以 忽略.
三、符号说明
层次分析法 模型
CI 一致性度量指标
业生总量的增加,劳动用工管理与社会保障制度,劳动力市场的不尽完善,以 及高校的毕业生部分择业期望过高等因素的影响,如今的毕业生就业形势较为 严峻.为了更好地解决广大学生就业中的问题,就需要客观地、全面地分析和评 价毕业生就业的若干主要因素,并将它们从主到次依秩排序.
针对不同专业的毕业生评价其就业情况,并给出某一专业的毕业生具体的 就业策略. 2、方法模型的建立 (1)层次分析法
maxmax
x
(k
0
)
x
(kiBiblioteka )ikmin
minmin
x
(k
0
)
xi(k)
i
k
k 第 k 个指标的权重
m
加权关联度,即
i
(k)
i
k
k
X EXi
i 的期望值
主成分分析模型
DX i
X i 的方差
R0 所有单位向量的集合
R 样本相关矩阵
i 单位特征向量
四、模型的分析与建立
1、问题背景的理解 随着我国改革开放的不断深入,经济转轨加速,社会转型加剧,受高校毕
个因素
C
,
1
C
,L
2
C, 对上一层因素 的影响,每次两个 k
C C C C C 因素 和 ,用 表示 和 对 的影响之比,全部比较结果构成成
i
j
ij
i
j
对比较矩阵 C ,也叫正互反矩阵.
C C C C C C ( )ij k*k ,
0, 1 , 1.
ij
ij
ii
ji
C C C 若正互反矩阵 C 元素成立等式: * ,则称 C 一致性矩阵.
量. Step3. 一致性检验
1)为了度量判断的可靠程度,可计算此时的一致性度量指标 CI :
k
CI max k 1
其中 表示矩阵 C 的最大特征值,式中 k 正互反矩阵的阶数, CI 越小,说明 max
权重的可靠性越高. 2)平均随机一致性指标 RI ,下表给出了1-14阶正互反矩阵计算1000次得
到的平均随机一致性指标:
阶 1 2 3 4 5 6 7 8 9 10 11 12 13 14
数
RI
0
0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58
3)当 CR CI 0.1时,( CR 称为一致性比率, RI 是通过大量数据测出来 RI