1基于网格的数据流聚类算法
大数据建模练习(习题卷2)

大数据建模练习(习题卷2)第1部分:单项选择题,共39题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]在黑盒测试方法中,设计测试用例的主要根据是A)程序流程图B)程序内部逻辑C)程序外部功能D)程序数据结构答案:C解析:2.[单选题]以下关于字典类型的描述,正确的是:A)字典类型可迭代,即字典的值还可以是字典类型的对象B)表达式 for x in d: 中,假设d是字典,则x是字典中的键值对C)字典类型的值可以是任意数据类型的对象D)字典类型的键可以是列表和其他数据类型答案:C解析:3.[单选题]已知数据中时间字段的格式为2021-01-01 00:00:00,如果使用过滤算子,过滤出2021年5月1日以来的数据,以下哪个是正确的设置A)大于2021-05-01 00:00:00B)小于2021-05-01 00:00:00C)大于等于2021-05-01 00:00:00D)小于等于2021-05-01 00:00:00答案:C解析:4.[单选题]Jupyter notebook的记事本文件扩展名为:A)mB)pyC)pycD)ipynb答案:D解析:5.[单选题]修改数据库表结构用以下哪一项( )A)UPDATEB)CREATEC)UPDATEDD)ALTER答案:D解析:C)ORDER BY NAME DESCD)ORDER BY DESC NAME答案:A解析:7.[单选题]个栈的初始状态为空。
现将元素 1、2、3、4、5、A、B、C、D、E依次入栈,然后再依次出栈,则元素出栈的顺序是A)12345ABCDEB)EDCBA54321C)54321EDCBAD)ABCDE12345答案:B解析:8.[单选题]在Excel中,数据透视表是汇总、分析、浏览和呈现汇总数据的方法。
插入数据透视表之后,选择一个(),可以实现单元格区域的验证A)单元格B)表/区域C)公式D)文件答案:B解析:9.[单选题]在select语句的where子句中,使用正则表达式过滤数据的关键字是( )A)likeB)againstC)matchD)regexp答案:D解析:10.[单选题]如果要统计某家店铺当天的收益总和,需要按照日期分组,且对收益的统计方式是A)最大B)最小C)总数D)总和答案:D解析:11.[单选题]耦合性和内聚性是对模块独立性度量的两个标准。
基于网格和MST的混合属性流数据聚类算法

abt r hp . ov ep o lm, riaysa eToslet rbe GTMSi p o o e o ls r gsra d t wi x dd t y e, d a dmii m pn igte r h s rp sd frc ti tem aa t mie a tp s 鲥 n nmu sa nn e u en h a r tcnq e i u e ea oi ms s ga ido o t c d cn y a di oma o a u do xn a m l i . p f r eh iu ss s i t g r h , i kn f e me i aj e c f r t n gi f n nmii dt s i r y x e me d nh l t u n g r a n n i no g a i a t E i  ̄l
挖 掘 引起 人们 很 大 兴趣 。 与传 统 的 静 态数 据 仓库 不 同 , 流数 据 具 有 高速 、 时 序 到 达 、 时变 化 和 无 限 的特 点 。 于 流数 据 的这 些 特 按 实 基 点, 流数 据 挖 掘要 求 尽 可 能快 地 处 理 数 据 , 仅使 用 固定 数 量 的 内存 , 且 只 能单 遍 扫 描数 据 。 而
h t : w w.n sn g t / w d z .蠛 n p/ T h 8— 5 一 6 O 6 5 99 4 e + 6 5 l 5 99 3 6 0 6
基于网格的数据流聚类算法

种一次性扫描 的方法 和算法 , 如文[-4等等 , 1 - 1 但它们 的聚类 结果通 常是球形 的, 不能支持对任意形状类的聚类[ 。 5 ]
Gr d b s d Da a S r a u t rng Al o ih i - a e t t e m Cl se i g r t m LI QigB o DAI a F n DENG u Z U n — a o a Ch - S HANG e- ig W i n M
称为 p rmi t r e的结 构储存 下 来 。同时 , ya d i f me a m 使用 另一 个离线的 mar c se 过程 , 据用户 的具 体要求 对 m co co l tr - u 根 i r- c se 聚类 的结果 进行 再分析 。但 它采用 距 离作 为度 量参 l tr u 数, 聚类结果通 常是球 形 的, 不能 支持对 任意形状 类 的聚类 。
( le eo n om ain S se a d M a a e n ,N ain lUnv r i fDee eTe h oo y, a g h 1 0 3 Colg fI f r to y tm n n g me t to a iest o fns c n lg Ch n s a4 0 7 ) y
噪 声干扰 下发现任 意形状 的类, 而且有效地解决 了聚类算 法参数敏感和聚 类结果无法区分密度差异等 问题。
关键词
Ab ta t W i to g a i t rd s o e i g a b t a y s a e cu t r n a d i g n i e g i— a e a as r a cu t — sr c t s r n b l y f ic v rn r ir r h p l s e sa d h n l o s , rd b s d d t t e m l s e h i o n r g ag rt m f ce ty r s l e h s r b e o en e y s n ii e t h s r d f e a a e e s a d d fiu t t i lo ih ef in l e o v st e e p o lm fb i g v r e st o t e u e - e i d p r m t r n i c l o n i v n f d s ig ih t e d n iy d s i c in o l s e s it u s h e st it to f u t r . n n c Ke wo d Cl s e i g,Da a s r a ,Cl s e i a a t r y rs u t rn t te m u t rn p r me e ,Re ai e d n i g ltv e st y
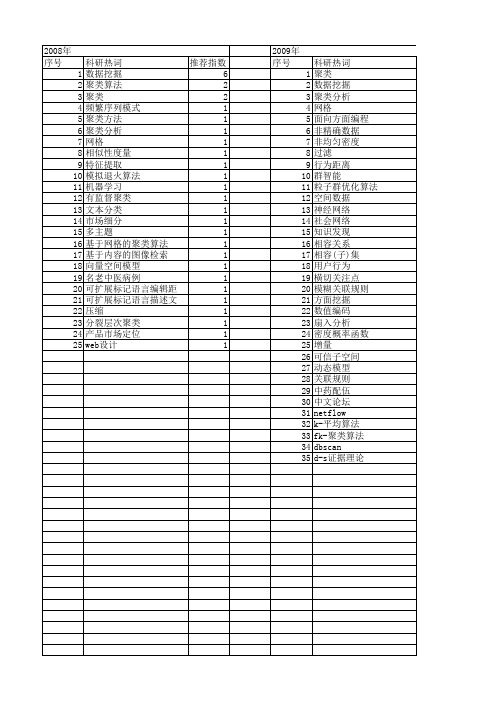
【计算机应用研究】_聚类数据挖掘_期刊发文热词逐年推荐_20140726
推荐指数 7 7 3 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
科研热词 数据挖掘 预处理数据 蚁群聚类 聚类 网格 维数灾 粒子群优化 混合粒子群聚类 并行算法 分布式 分层聚类 入侵检测 主成分分析 web聚类 k均值聚类
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
科研热词 聚类 数据挖掘 聚类分析 网格 面向方面编程 非精确数据 非均匀密度 过滤 行为距离 群智能 粒子群优化算法 空间数据 神经网络 社会网络 知识发现 相容关系 相容(子)集 用户行为 横切关注点 模糊关联规则 方面挖掘 数值编码 扇入分析 密度概率函数 增量 可信子空间 动态模型 关联规则 中药配伍 中文论坛 netflow k-平均算法 fk-聚类算法 dbscan d-s证据理论
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
推荐指数 3 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2014年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14
聚类算法的分类

聚类算法的分类
聚类算法是一种机器学习算法,其目的是将数据集中的对象分成不同的组或簇,使得同一簇内的对象相似度高,不同簇之间的相似度低。
聚类算法的分类可以根据不同的算法思想和应用场景进行划分。
1. 基于原型的聚类算法:该类算法将每个簇表示为一个原型,
如质心、中心点或者最典型的对象,然后通过计算每个对象到原型的距离来确定其所属簇。
常见的算法包括K-means、K-medoids等。
2. 基于层次的聚类算法:该类算法将对象逐层进行分组,直到
达到某个终止条件。
常见的算法包括凝聚层次聚类和分裂层次聚类等。
3. 基于密度的聚类算法:该类算法将簇定义为密度相连的对象,可以处理噪声和离群点。
常见的算法包括DBSCAN、OPTICS等。
4. 基于网格的聚类算法:该类算法将数据集划分为网格,并在
每个网格内进行聚类操作。
常见的算法包括CLIQUE、STING等。
5. 基于模型的聚类算法:该类算法假设数据集由多个组成成分
混合而成,每个组成成分对应一个簇。
常见的算法包括高斯混合模型、潜在狄利克雷分配等。
聚类算法在许多领域都有广泛的应用,如生物学、社交网络分析、文本挖掘等。
选择适合的聚类算法可以有效地提高数据分析的效率和准确性。
- 1 -。
基于网格和密度的数据流聚类算法

whc o i e h p r a h b s d o e st n r .B a so e mo e o o b e—l y rc n t cin,t e ih c mb n d te a p o c a e n d n i a d g d y i y me n ft d l f u l h d a e o s u t r o h
A b t a t Ac o d n o t e c a a trsiso h aa sr a , i p r p e e td a n w l se n lo t m s r c : c r i g t h h r ce it ft e d t te m h spa e r s n e e c u tr g a g r h GTCS c i i
数据流的挖掘要在有限的内存 中完成对数据的及时处理. 通过单次扫描机制 , 在内存中保存数据流的概要信
息 ,以支持后 续 的计 算 , 成挖掘 结果 的近似性 . 形 数据 流是一 个连续 、 在线 的过程 , 传统 的聚类 算法 无法 在数 据 流 中直接 应用 , 因此数 据流 的聚类对 数 据挖 掘 领域 提 出了前 所 未 有 的新 挑 战 , 也成 为许 多学 者 研究 的热
基于动态网格的数据流聚类分析

V0 . 5 No 1 12 . 1 NO . 2 0 V 0 8
基 于 动 态 网格 的数 据 流 聚 类分 析
何
摘
勇, 刘青宝
( 国防科 学技 术 大 学 信 息 系统 与 管理 学院 , 沙 40 7 ) 长 103 要 :提 出的增 量式数 据流 聚类 算 法 D C S结合 网格 和 密度技 术 , GD 能够得 到任 意形状 的聚 类 , 通过 改进 网格
密度的计算方式, 解决了现有网格算法中丢失数据空间影响信息的问题 , 并且实现了关键参数的 自适应设置, 减 小 了 工参数对聚类结果的影响。 人 关键词 :动态网格 ;网格密度 ; 数据流聚类; 聚类参数
中图分 类号 :T 3 1 P9 文献标 志码 :A 文 章编 号 :10 —6 5 20 ) 138.4 0 139 (0 8 1-2 10
提出的增量式数据流聚类算法dgcds结合网格和密度技术能够得到任意形状的聚类通过改进网格密度的计算方式解决了现有网格算法中丢失数据空间影响信息的问题并且实现了关键参数的自适应设置减小了人工参数对聚类结果的影响
第 2 第 1 期 5卷 1
20 0 8年 1 1月
计 算 机 应 用 研 究
Ap l ain Ree rh o mp tr p i t sac fCo ues c o
Dy a c g i — a e l se i g o e aa sra n mi rd b s d cu trn v rd t t m e
HEY n , igbo o g HU Qn —a
( o eefI o a o y e &M n gm n , a o l n e i D e eT hooy C agh 10 3 C i ) Clg n r t n sm l o fm i S t a a e et N t n i rt o e n e nl , h nsa 0 7 , h a i a U v sy f fs c g 4 n
一种基于网格密度的聚类算法

一种基于网格密度的聚类算法作者:刘敏娟,于景茹,张西芝来源:《软件导刊》2012年第12期摘要:提出了一种基于网格密度的聚类算法(DGCA)。
该算法主要利用网格技术去除数据集中的部分孤立点或噪声数据,对类的边缘节点使用一种边缘节点判断函数进行提取,最后利用相近值的方法进行聚类。
实验表明,DGCA算法能够很好地识别出孤立点或噪声,聚类结果可以达到一个较高的精度。
关键词:网格聚类;边界点;网格密度中图分类号:TP312文献标识码:A文章编号:1672-7800(2012)012-0056-020引言聚类是把一组数据按照相似性归成若干类别,它的目的是使得属于同一类别的个体之间的距离尽可能地小而不同类别上的个体间的距离尽可能地大。
聚类的结果可以得到一组数据对象的集合,称其为簇或类。
簇中的对象彼此相似,而与其它簇中的对象相异。
迄今为止,已经提出了许多聚类算法,大体上这些算法可以分为基于距离的方法、基于层次的方法、基于密度的方法、基于网格的方法和基于模型的方法等。
基于网格的聚类算法首先将d维数据空间的每一维平均分割成等长的区间段,即把数据空间分割成一些网格单元。
若一个网格单元中所含数据量大于给定的值,则将其定为高密度单元;否则将其视为低密度单元。
如果一个低密度网格单元的相邻单元都是低密度的,则视这个低密度单元中的节点为孤立点或噪声节点。
网格聚类就是这些相邻的高密度单元相连的最大集合。
1基本概念1.1相近值网格单元内节点之间的相近值是利用节点间的距离来计算的。
节点间的相近值越大,它们就越相似。
即对这些网格单元内的节点进行聚类时,它们属于同一个类的可能性就越大。
定义1节点集:设P=(U,K),我们用P表示n条记录的集合。
U={U1,U2,…,Un}代表网格单元内的节点集K={K1,K2,…,Kr}代表网格单元内节点的属性其中,,i∈(1,2,…,n),,m∈(1,2,…,r)代表节点Ui的第m个属性Km,因此,用Km代表一个r维的向量(ki1,ki2,…,kir),i∈(1,2,…,n)。
基于网格和密度的随机样例的聚类算法

( col f l t ncIfr ao nier g Taj n esy Taj 0 02, hn ) Sh o o e r i nom tnE gnei , i i U i r t, in n30 7 C i E co i n nn v i i a
维普资讯
第 3 卷 第 5期 9 20 0 6年 5月
天
津
大 学
学
报
V 1 3 No 5 o. 9 . Ma 0 6 v2 0
Ju n l f ini nvri o r a aj U iesy oT n t
基 于 网格 和 密 度 的 随机样 例 的聚 类算 法
Absr c : To i r v fiin y o e st— a e lse n loih sa d d a t h o sr iso o —p — ta t mp o eefce c fd n i b s d cu t r g ag rtm n e l h te c n tan fn n s a y i wi tm trb t s o e p ta l se n g rt m ald GDRS i p o o e . I i a e n gi n e st ih i at ue ,an v ls ailcu tr ga o h c e i i l i l s rp s d t sb s d o rd a d d n i w t y
的参考点; 然后随机选择没有分类的参考点, 并测试其邻域的稀疏状况、 与其他聚类的关系以及非空间属性的约束 来决定加入、 合并聚类或形成新的聚类; 最后把参考点映射回数据. 把此算法和 D S A B C N及 D R 算法进行了理论 BS
数据挖掘考试习题汇总

第一章1、数据仓库就是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合。
2、元数据是描述数据仓库内数据的结构和建立方法的数据,它为访问数据仓库提供了一个信息目录,根据数据用途的不同可将数据仓库的元数据分为技术元数据和业务元数据两类。
3、数据处理通常分成两大类:联机事务处理和联机分析处理。
4、多维分析是指以“维”形式组织起来的数据(多维数据集)采取切片、切块、钻取和旋转等各种分析动作,以求剖析数据,使拥护能从不同角度、不同侧面观察数据仓库中的数据,从而深入理解多维数据集中的信息。
5、ROLAP是基于关系数据库的OLAP实现,而MOLAP是基于多维数据结构组织的OLAP实现。
6、数据仓库按照其开发过程,其关键环节包括数据抽取、数据存储与管理和数据表现等。
7、数据仓库系统的体系结构根据应用需求的不同,可以分为以下4种类型:两层架构、独立型数据集合、以来型数据结合和操作型数据存储和逻辑型数据集中和实时数据仓库。
8、操作型数据存储实际上是一个集成的、面向主题的、可更新的、当前值的(但是可“挥发”的)、企业级的、详细的数据库,也叫运营数据存储。
9、“实时数据仓库”以为着源数据系统、决策支持服务和仓库仓库之间以一个接近实时的速度交换数据和业务规则。
10、从应用的角度看,数据仓库的发展演变可以归纳为5个阶段:以报表为主、以分析为主、以预测模型为主、以运营导向为主和以实时数据仓库和自动决策为主。
第二章1、调和数据是存储在企业级数据仓库和操作型数据存储中的数据。
2、抽取、转换、加载过程的目的是为决策支持应用提供一个单一的、权威数据源。
因此,我们要求ETL 过程产生的数据(即调和数据层)是详细的、历史的、规范的、可理解的、即时的和质量可控制的。
3、数据抽取的两个常见类型是静态抽取和增量抽取。
静态抽取用于最初填充数据仓库,增量抽取用于进行数据仓库的维护。
4、粒度是对数据仓库中数据的综合程度高低的一个衡量。
粒度越小,细节程度越高,综合程度越低,回答查询的种类越多。
数据挖掘——探索数据的奥秘智慧树知到课后章节答案2023年下青岛工学院

数据挖掘——探索数据的奥秘智慧树知到课后章节答案2023年下青岛工学院青岛工学院第一章测试1.数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
()A:对 B:错答案:对2.下面哪些是时空数据的应用()。
A:气象学家使用人造卫星和雷达观察飓风 B:从多媒体数据库中发现有趣的模式 C:机动车辆管理者把GPS安装在汽车上,以便更好地监管和引导车辆 D:动物学家把遥感设备安装在野生动物身上,以便分析生态行为答案:气象学家使用人造卫星和雷达观察飓风;机动车辆管理者把GPS安装在汽车上,以便更好地监管和引导车辆;动物学家把遥感设备安装在野生动物身上,以便分析生态行为3.数据挖掘生命周期的数据理解阶段,起于原始数据收集,止于熟悉数据、识别数据质量问题。
()A:对 B:错答案:错4.以下关于数据挖掘规律的描述中,不正确的是()。
A:业务知识是数据挖掘过程每一步的中心 B:对所有领域的每个数据挖掘问题,总有模式可循。
C:数据准备超过数据挖掘过程的3/4 D:给定应用的正确模型只能通过实验发现答案:数据准备超过数据挖掘过程的3/45.关于数据挖掘生命周期的部署阶段,说法正确的是()。
A:部署阶段要完成模型的创建 B:执行部署步骤的通常是数据分析师 C:部署通常是数据挖掘项目的终点 D:建立模型的目的不能仅仅是增加对数据的了解答案:部署阶段要完成模型的创建6.“8,000”和“10,000”表示:()。
A:数据 B:信息 C:知识 D:智慧答案:数据7.“8,000米是飞机飞行最大高度”与“10,000米的高山”表示:()。
A:数据 B:知识 C:信息 D:智慧答案:信息8.“飞机无法飞过高山”表示:()。
A:知识 B:智慧 C:数据 D:信息答案:知识9.数据取样时,除了要求抽样时严把质量关外,还要求抽样数据必须在足够范围内有代表性。
一种基于网格索引的数据聚类算法

E ma :j nl@1 3 o — i lu s li g 6.n c
L u S NG a ,I I J n,O K iJANG Xu -u . t c seig ag r h b sd o n e o r dn .o ue n ier g n e j nDaa l tr lo i m ae n id x f g i igC mp tr E gn e n a d u n t d i
A piain .0 8 4 ( 6 : 3 - 4 . p l t s 2 0 ,4 1 ) 1 9 1 1 c o
Abs r t I o d r o m p o e h e c e c o l t rng a g rt tac : n r e t i r v t e f i n y f cuse i i l o hm ba e o de st a a od e nd nt e r h n r c s i i sd n n iy nd v i r du a s a c i p o e sng,
tepp rp t f w r a m rvd sa a d t c s r g a oi m bsd o B C NT eagrh ssteme o fojc’ h ae u o a n i poe p t l a l t n l rh ae n D S A . lo tm ue h t d o bet s r d i a u e i g t h i h S
基于网格和最近邻居的聚类算法

连接 , 并尽 可能去 除噪 声点和孤 立 点.该 算法 可以 处理 包含 有 不 同密度 的簇 数 据 , 而且 在 处理 高 维 数 据 时具有较 低 的时 间复杂度 、实验 结果证 明 , 该算 法能有 效找 出不 同大小 、 状和 密度 的聚类. 形 关键 词 : 类算 法 ;相似 度 ;密度 ;网格 ; 近邻居 聚 最 中图分 类号 : P0 . T S 16 文献 标志码 :A
cut n a st w i oti c s r wt iee t e si rdsnusi daet ls r wt ls r gdt es hc cnan l t s i df rn dn ie o iig i n ajcn ut s i e i a h u e h f ts t hg c e h
n ih o r p e g b rg a h.I o e s s d ts t o ti i g cu t r t i e e td n i e n a o tme c m- tprc se aa es c na n n lse s wi df r n e st s a d h s lw i o h f i p e i l e i g wih h g i n in a a l xt whi d a n t ih d me so a d t .Th x e me tr s lsp o e t a h g rt m a f - y e l l e e p r n e u t r v h tt e a o ih c n ef i l i c e ty fn lse s wih dfe n h p s ie n e i e . in l d cu t r t i r g s a e ,sz sa d d nst s i fi i Ke r s:c u trng ag rt m ;smi rt y wo d l se i l o h i i li y;d n iy;g i a e st rd;n a e tn ih o e r s eg b r
聚类算法在医学诊断中的应用分析

聚类算法在医学诊断中的应用分析一、引言医学诊断是医生确定病人健康状态的过程,其准确性直接影响着病人的健康和生命。
为了提高诊断的准确性,医学界积极引入人工智能技术,聚类算法作为一种重要的数据挖掘技术,已成功地应用于医学诊断中。
本文将分析聚类算法在医学诊断中的应用情况以及其优缺点。
二、聚类算法简介聚类算法是数据挖掘中的一种重要技术,其目的是将数据集中的观察值分为多个组或类别,使得在同一组中的观察值相似度较高,在不同组中的观察值相似度较低。
聚类算法可以分为以下几类:1. 基于距离的聚类算法:如k-means、层次聚类(Hierarchical Clustering)等。
2. 基于密度的聚类算法:如DBSCAN、OPTICS等。
3. 基于网格的聚类算法:如STING、CLIQUE等。
三、聚类算法在医学诊断中的应用聚类算法可以对病人的多种数据进行分析,如病史、体检报告、影像学资料等,从而帮助医生诊断病情、制定治疗方案和预测治疗效果。
以糖尿病为例,聚类算法可以对病人的多个指标进行聚类分析,如血糖、体重、血压等,可将病人分为不同的簇,并根据簇的特征来描述不同类型的糖尿病患者。
这有助于医生根据特定的临床表现来提供有针对性的治疗。
此外,聚类算法还可以用于预测糖尿病患者的趋势和治疗效果,对病人的康复治疗也有一定的意义。
另外,聚类算法还可以应用于肺癌诊断中。
研究表明,随机森林聚类算法(Random Forest Clustering)可以对肺癌影像学数据进行聚类分类,准确率高达93.7%。
这为医生们提供了较为稳定、可靠的肺癌病情评估工具。
四、聚类算法的优缺点1. 优点(1)快速有效:聚类算法具有较高的计算效率,能够在短时间内对大量数据进行聚类分析。
(2)不受先验知识影响:聚类算法不需要特定的先验知识,可根据数据的特征自动分类。
(3)可视化结果:聚类算法将数据分为不同簇,结果易于理解和使用。
2. 缺点(1)对参数敏感:聚类算法中的聚类参数对于结果的影响较大,需要经过多次试验和调整才能得到较为准确的聚类结果。
数据聚类算法

数据聚类算法摘要:一、数据聚类算法概述1.定义与背景2.聚类算法的应用领域二、聚类算法的分类1.基于距离的聚类算法1.1 K-means 算法1.2 层次聚类算法2.基于相似性的聚类算法2.1 基于网格的聚类算法2.2 基于模型的聚类算法三、聚类算法的评估与选择1.评估指标2.选择方法四、聚类算法在各领域的应用案例1.数据挖掘2.生物信息学3.社交网络分析正文:一、数据聚类算法概述数据聚类算法是一种无监督学习方法,用于将相似的数据点归为一类。
这种方法可以用于发现数据集的潜在结构和模式,从而帮助我们更好地理解数据。
聚类算法广泛应用于数据挖掘、生物信息学、社交网络分析等多个领域。
二、聚类算法的分类根据聚类算法所依据的相似性度量方法,可以将其分为两大类:1.基于距离的聚类算法基于距离的聚类算法是最常见的聚类方法,它们根据数据点之间的距离来判断其相似性。
主要包括以下两种算法:1.1 K-means 算法K-means 算法是一种基于划分的聚类方法,通过计算数据点之间的距离,将距离最近的点归为一类。
该算法通过迭代计算来更新聚类中心,直至满足停止条件。
1.2 层次聚类算法层次聚类算法是一种基于层次结构的聚类方法,通过计算数据点之间的距离,构建一棵聚类树。
该算法可以发现数据集的层次结构,并计算不同层次的聚类结果。
2.基于相似性的聚类算法基于相似性的聚类算法是根据数据点的内部结构和特征进行聚类。
主要包括以下两种算法:2.1 基于网格的聚类算法基于网格的聚类算法将数据空间划分为网格结构,根据数据点在网格中的分布来进行聚类。
这类算法对于密集型数据和任意形状的数据集具有良好的适应性。
2.2 基于模型的聚类算法基于模型的聚类算法通过建立数据点的概率模型来进行聚类。
这类算法可以发现数据集的潜在结构和规律,并适用于高维数据集。
三、聚类算法的评估与选择在实际应用中,我们需要对聚类算法进行评估和选择。
常用的评估指标有内部评价指标(如轮廓系数、Calinski-Harabasz 指数)和外部评价指标(如兰德指数、准确率)。
基于网格的聚类方法研究

基于网格的聚类方法研究作者:高兵邹启杰来源:《软件工程师》2010年第03期摘要:已有的聚类算法对于发现任意形状的聚类和处理离群点效果不理想,分析了现有基于网格的聚类算法。
使用网格方法的数据分析方法将空间划分为由(超)矩形网格单元组成的网格,然后在网格单元上进行聚类。
最后,总结全文并提出基于网格的聚类需要进一步研究的方向。
关键词:数据挖掘;网格;聚类1 引言数据挖掘是指从大型数据库或数据仓库中提取隐含的、未知的及有应用价值的信息或模式。
它是数据库研究中的一个很有应用价值的领域,融合了数据库、机器学习、统计学等多个领域的理论和技术[1]。
聚类分析是数据挖掘中广为研究的课题之一,是从数据中寻找数据间的相似性,并依此对数据进行分类,从而发现数据中隐含的有用信息或知识。
目前已经提出了不少数据聚类算法,其中比较著名的有CLARANS[2]、BIRCH[3]、DBSCAN[4]和CLIQUE[5]等。
但对于高维、大规模数据库的高效聚类分析仍然是一个有待研究的开放问题。
网格方法是空间数据处理中常用的将空间数据离散化的方法。
基于网格的聚类算法由于易于增量实现和进行高维数据处理而被广泛应用于聚类算法中。
研究人员已经提出了很多基于网格的聚类算法,包括STING[6],它利用了存储在网格单元中的统计信息;WaveCluster[7]它用一种小波转换方法来聚类数据对象;CLIQUE在高维数据空间中基于网格和密度的聚类方法等。
本文对已有的基于网格的聚类算法进行了研究,从网格的表示,划分网格单元的方法,到统计网格内信息,搜索近邻网格单元,聚类超过指定阙值的网格单元的各个步骤进行了分析,最后对基于网格方法聚类的研究方向做了展望。
2 网格的定义与划分网格的基本概念,设A1, A2,…, Ar 是数据集O={O1, O2,…, On }中数据对象的r 个属性的有界定义域,那W=A1 ×A2 ×…×Ar 就是一个r 维空间, 将A1,A2 ,…, Ar 看成是W 的维( 属性、字段),则对于一个包含n 个数据点的r 维空间中的数据集O={O1 , O2 ,…, On },其中Oi ={Oi1 ,Oi2 ,…, Oir }( i=1, 2,…, n) , Oi 的第j 个分量Oij ∈Aj 。
halcon聚类算法

halcon聚类算法
(原创实用版)
目录
1.聚类算法概述
2.halcon 聚类算法介绍
3.halcon 聚类算法的特点
4.halcon 聚类算法的应用实例
5.halcon 聚类算法的优缺点
正文
聚类算法是数据挖掘和机器学习领域中一种重要的无监督学习算法,其主要目的是将相似的数据点划分到同一类别中,从而实现数据的分类。
halcon 聚类算法是众多聚类算法中的一种,它是基于网格结构和距离度量来对数据进行聚类的。
halcon 聚类算法的全称是"A 网格为基础的聚类算法",它是由Hartigan 和 Lemon 提出的。
该算法的主要思想是将数据空间划分为网格结构,然后根据数据点到网格节点的距离度量来对数据进行聚类。
具体来说,halcon 算法首先将数据空间划分为网格结构,然后计算每个数据点到网格节点的距离,最后将距离最近的数据点划分到同一类别中。
halcon 聚类算法具有以下特点:
1.可以处理任意形状的数据集,不仅仅局限于凸集;
2.可以处理大规模数据集,因为其时间复杂度为 O(n),其中 n 为数据点的数量;
3.可以灵活地设置聚类参数,如网格密度和距离度量等。
halcon 聚类算法在许多领域都有广泛应用,例如数据挖掘、模式识
别、图像处理等。
例如,在图像处理中,可以使用 halcon 聚类算法对图像中的颜色进行聚类,从而实现图像的彩色分割。
尽管 halcon 聚类算法具有许多优点,但也存在一些缺点,如对离群点和噪声敏感,以及在处理大规模数据集时计算量较大等。
基于密度的聚类和基于网格的两大聚类算法

第一个对象P进行扩张: Step 3.1:如果P不是核心节点.转Step 4;否则,对P 的E邻域内任一
未扩张的邻居q 进行如下处理 :如果q已在有序种子队列中且从P到 q的可达距离小于旧值,则更新q的
基于网格(dding-based)指将对象空间量化为有 限数目的单元,形成一个网格结构,所有聚类都 在这个网格结构上进行。
20
基于网格的聚类
基本思想是将每个属性的可能值分割成许多相邻 的区间,创建网格单元的集合(对于的讨论我们 假设属性值是序数的、区间的或者连续的)。
每个对象落入一个网格单元,网格单元对应的属 性区间包含该对象的值。
据点在邻域内的影响,被称为影响函数。 数据空间的整体密度(全局密度函数)可以被模拟为所有数据点的影响函数
的 总和; 聚类可以通过确定密度吸引点(density attractor)来得到,这里的密度吸引点
是全局密度函数的局部最大值。 一个点 x 是被一个密度吸引点 x*密度吸引的,如果存在一组点 x0,x1,
高层单元的统计参数可以很容易Fra bibliotek从低层单元的参数计算得到。
28
STING:统计信息网格
统计处理思想: 使用自顶向下的方法回答空间数据的查询
从一个预先选择的层次开始-通常包含少量的单 元,为当前层的每个单元计算置信区间 不相关的单元不再考虑 当检查完当前层,接着检查下一个低层次 重复这个过程直到达到底层
(1)对数据点占据的空间推导密度函数; (2)通过沿密度增长最大的方向(即梯度方向)移动,识别密度函数的局
部最大点(这是局部吸引点),将每个点关联到一个密度吸引点; (3)定义与特定的密度吸引点相关联的点构成的簇; (4)丢弃与非平凡密度吸引点相关联的簇(密度吸引点 x’称为非平凡密
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3)国家自然科学基金(60172012)。
刘青宝 博士生,副教授,主要研究方向为数据仓库技术和数据挖掘;戴超凡 博士,副教授,主要研究方向为数据仓库技术和数据挖掘;邓 苏 博士,教授,主要研究方向指挥自动化、信息综合处理与辅助决策;张维明 博士生导师,教授,主要研究方向为军事信息系统、信息综合处理与辅助决策。
计算机科学2007Vol 134№13基于网格的数据流聚类算法3)刘青宝 戴超凡 邓 苏 张维明(国防科学技术大学信息系统与管理学院 长沙410073)摘 要 本文提出的基于网格的数据流聚类算法,克服了算法CluStream 对非球形的聚类效果不好等缺陷,不仅能在噪声干扰下发现任意形状的类,而且有效地解决了聚类算法参数敏感和聚类结果无法区分密度差异等问题。
关键词 聚类,数据流,聚类参数,相对密度 G rid 2based Data Stream Clustering AlgorithmL IU Qing 2Bao DA I Chao 2Fan DEN G Su ZHAN G Wei 2Ming(College of Information System and Management ,National University of Defense Technology ,Changsha 410073)Abstract With strong ability for discovering arbitrary shape clusters and handling noise ,grid 2based data stream cluste 2ring algorithm efficiently resolves these problem of being very sensitive to the user 2defined parameters and difficult to distinguish the density distinction of clusters.K eyw ords Clustering ,Data stream ,Clustering parameter ,Relative density 随着计算机和传感器技术的发展和应用,数据流挖掘技术在国内外得到广泛研究。
它在网络监控、证券交易分析、电信记录分析等方面有着巨大的应用前景。
特别在军事应用中,为了获得及时的战场态势信息,大量使用了各种传感器,对这些传感器数据流的分析处理已显得极为重要。
针对数据流数据持续到达,且速度快、规模大等特点,数据流挖掘技术的研究重点是设计高效的单遍数据集扫描算法[12]。
数据流聚类问题一直是吸引许多研究者关注的热点问题,已提出多种一次性扫描的方法和算法,如文[1~4]等等,但它们的聚类结果通常是球形的,不能支持对任意形状类的聚类[5]。
本文提出的基于网格的数据流聚类算法,在有限内存条件下,以单遍扫描方式,不仅能在噪声干扰下发现任意形状的类,而且有效地解决了基于绝对密度聚类算法所存在的高密度聚类结果被包含在相连的低密度聚类结果中的问题。
本文第1节简要介绍数据流聚类相关研究,并引出基于网格的数据流聚类算法的思路及其与相关研究的异同;第2节给出基于网格的数据流聚类算法所使用到的基本概念;第3节给出一个完整的基于网格的数据流聚类算法,详细解析算法的执行过程;第4节进行算法性能分析对比;最后总结本文的主要工作和贡献,并指出需要进一步研究和改进的工作。
1 相关研究在有限内存约束下,一般方法很难对数据流进行任意形状的聚类。
第一个增量式聚类挖掘方法是文[6]提出的In 2crementalDBSCAN 算法,它是一个用于数据仓库环境(相对稳定的数据流)的有效聚类算法,可以在有噪声的数据集中发现任意形状的类。
但是,它为了形成任意形状的类,必须用类中的所有点来表示,要求获得整个数据流的全局信息,这在内存有限情况下是难以做到的。
而且,它采用全局一致的绝对密度作参数,使得聚类结果对参数值非常敏感,设置的细微不同即可能导致差别很大的聚类结果。
Aggarwal 在2003年提出的一个解决数据流聚类问题的框架CluStream [1]。
它使用了两个过程来处理数据流聚类问题:首先,使用一个在线的micro 2cluster 过程对数据流进行初级聚类,并按一定的时间跨度将micro 2cluster 的结果按一种称为pyramid time f rame 的结构储存下来。
同时,使用另一个离线的macro 2cluster 过程,根据用户的具体要求对micro 2cluster 聚类的结果进行再分析。
但它采用距离作为度量参数,聚类结果通常是球形的,不能支持对任意形状类的聚类。
而且,它维护的是micro 2cluster 的聚类特征向量(CF 2x ;CF 1x ;CF 2t ;CF 1t ;n ),这在噪声情况下,会产生干扰误差。
2006年,Feng Cao 等人在文[5]中提出了针对动态进化数据流的DenStream 算法。
它相对CluStream 有很大的改进,继承了IncrementalDBSCAN 基于密度的优点,能够支持对有噪声的动态进化(非稳定)的数据流进行任意形状的聚类。
但由于采用全局一致的绝对密度作参数,使得聚类结果对参数值非常敏感。
同时,与CluStream 算法相比,它只能提供对当前数据流的一种描述,不能反映用户指定时间窗内的流数据的变化情况。
朱蔚恒等在文[13]中提出的基于密度与空间的ACluS 2tream 聚类算法,通过引入有严格空间的意义聚类块,在对数据流进行初步聚类的同时,尽量保留数据的空间特性,有效克服了CluStream 算法不能支持对任意形状聚类的缺陷。
但它在处理不属于已有聚类块的新数据点时,使用一种类似“抛硬币”的方法来猜测是否为该点创建一个新的聚类块,误差较大。
而且它以绝对密度做参考,所以在聚类结果中无法区分密度等级不同的簇[7]。
本文提出的基于网格的数据流聚类算法GClustream(Grid Based Data Stream Clustering Algorithm),借鉴算法CluStream的两阶段聚类思想和pyramid time f rame的快照储存结构,采用相对密度作为聚类参数,通过对数据空间进行网格化处理,提高了算法处理速度,并能在噪声干扰条件下发现任意形状的类,同时解决了基于绝对密度聚类算法所存在的高密度聚类结果被包含在相连的低密度聚类结果中的问题[7]。
2 基本概念定义1 网格单元在各维上定义一个单位格长,采用网格方式将n维空间划分为若干个网格单元。
一个网格单元是n维空间中各个维上具有单位格长的n维超立方体,即以n维向量o为起点,向各维的正方向延伸单位格长所形成的一个区间,记为Grid (o)。
定义2 聚合块由若干个网格单元组成的超立方体,称为聚合块,记为Cub(o, r),其中 r为聚合块的各维边长组成的向量。
采用衰变窗口模型[5],数据流上的数据对象,其权重随时间衰减,即w p(t c)=2-λ(t-t)cp,其中λ表示衰减速度,t c表示当前时间,t P表示数据对象p到达时间。
设数据流在时刻t0, t1,t2,…,t c到达的数据对象数n0,n1,n2,…,n c,则数据流的当前时刻t c权重W(t c)为W(t c)=∑c j=0n j2-λ(t c-t j)定义3 网格单元特征向量设起点为o i的网格单元包含n个分别在时刻t i1,t i2,…, t in到达的数据对象p i1,p i2,…,p in,在t c时刻网格单元的特征向量记为(o i,F1,F2,w,t c),其中F1=∑n j=1p ij2-λ(t c-t ij)F2=∑n j=1p2ij2-λ(t c-t ij)w=∑n j=12-λ(t c-t ij)定义4 密集网格单元和候选密集网格单元对于给定的密度阈值ξ(0<ξ<1),设网格单元的特征向量为(o i,F1,F2,w,t c)。
若w>ξW(t c),则称该网格单元在t c 时刻为密集网格单元,记为D—Grid(o i);若0<w<=ξW (t c),则称该网格单元在t c时刻为候选密集网格单元,记为C—Grid(o i)。
定义5 密集聚合块对于给定的密度阈值ξ(0<ξ<1),设聚合块的特征向量为(o i,F1,F2,w,t c, r),若有w>ξW(t c)∏r i,则称该聚合块在t c时刻为密集的。
3 基于网格的数据流聚类算法借鉴算法CluStream的思路[1],基于相对网格的数据流聚类算法GCluStream分为两个阶段:在线的进程和离线的进程。
记录当前数据流聚类特征的在线进程称为GMic2Clus2 ter,而离线的响应查询的进程称为GMac2Cluste。
3.1 G Mic2Cluster过程描述在线进程GMic2Cluster的具体步骤如下:(1)初始化初始时,对每个新到来的数据对象,计算出其所在网格单元的特征向量。
积累一定数量的数据对象后,区分密集网格单元集合和候选密集网格单元集合。
(2)加入数据对象对新到的数据对象p,若它属于一个已存在的密集网格单元或候选密集网格单元,则修改该网格单元的特征向量为(o i,F1+p,F2+p2,w+1,t c)。
否则,直接定位其所在的网格单元,计算该网格单元的特征向量,并把它加入到候选密集网格单元集合。
(3)生成密集聚合块在连续数据流条件下,非密集网格单元通过新数据对象的不断聚集,可以转换为密集网格单元。
在内存空间有限的条件下,随着密集网格单元的数目增大,须把相邻且密度相近的密集网格单元进行聚合,以节省空间消耗。
同样,可把相邻且密度相近的聚合块聚合为更大的块。
这一步的聚合条件是要求相邻、密度相近、同体积大小的两个密集网格单元或两个初级聚类块才能聚合。
(4)密集聚合块的切分聚合块在新数据对象的不断加入下,可能导致内部密度失衡。
在每次加入数据对象时,更新聚合块特征向量,并计算方差,判断失衡程度。
当超过一定阈值δ,则从失衡程度最大、边长超过1的那一维进行居中切分,对切分形成的两个新聚合块或两个新网格单元进行特征向量分割计算。
(5)密集聚合块、密集网格单元的退化由于引进了衰减因子2-λt,若没有新数据对象的加入,初级聚类块特征向量修改为(o i,F132-λΔt,F232-λΔt,w3 2-λΔt,t c, r),密集网格单元特征向量修改为(o i,F132-λΔt, F232-λΔt,w32-λΔt,t c),其中Δt为特征向量上次修改到当前修改的时间间隔。
一旦密集聚合块特征向量(o i,F1,F2, w,t c, r)的w<=ξW(t c)∏ri,则让该密集聚合块“土崩瓦解”成若干个候选密集网格单元。