oracle_to_mysql工具
Oracle向Mysql迁移方案

Oracle向Mysql迁移方案一、可自动迁移部分;1、表这个部分的移植是最容易用工具实现的部分,因为很多MySQL的图形管理工具都自带这样的移植工具,比如SQL Yog,MySQL Administrator等。
但是,这些工具的移植能力各有不同,对字段类型转换﹑字符集等问题都有自己的处理方式,使用时请注意。
笔者使用“SQL Yog Migration Toolkit”工具按提示步骤移植后,表的主要结构和数据将成功移植,主要包括表的字段类型(经过映射转换,比如number会转换为int,Varchar2会转换为Varchar,date转换为datetime等,请小心处理日期字段的默认值等),表的主键,表的索引(Oracle的位图索引会被转成BTree索引,另外表和字段的注释会丢失)等信息。
注意的是,Oracle的自增字段的处理。
大家知道,Oracle通常使用序列sequence 配合触发器实现自增字段,但是MySQL和SQL Server等一样,不提供序列,而直接提供字段自增属性。
所以,请把Oracle里面的自增字段实现直接改为MySQL的字段属性,而且,这个字段必须是主键(key)并且不能有默认值。
还有一个问题,如果您的应用要直接使用Oracle的某个序列,那么您只能在MySQL里面模拟实现一个,具体方法就是利用MySQL的自增字段实现的。
二、不可自动迁移部分;视图、过程、函数、触发器以上对象都是写sql语句进行编程的,两个数据库的有些语法是不一新的,所以这些都要开发人员进行人工修改在mysql中重新创建;语法区别如下:视图:mysql中视图不能有子查询,可以把字查询再建一个视图;触发器:mysql中触发器中before或after的触发事件(insert、update、delete)只能有一个,oracle可以有多个;字符串拼接:oracle直接用’||’,mysql只能用函数’concat’;判断是否为空:oracle用nvl;mysql用ifnull;变量定义:oracle可以只写一次DECLARE,Mysql需要在每句前面加DECLARE变量赋值:oracle用’:=’,mysql用’=’;三、Oracle与Mysql几个主要根本区别1、oracle中的包在mysql中不存在,要全部改成普通的存储过程;2、用户及权限在oracle中是包含在各自的数据库里,而在mysql是数据库的用户及权限在一个单独的数据库中(information_schema);3、Oracle是没有敏感字段,是mysql有,如果有要修改成长非敏感名字;4、系统架构区别:oracle有主备库,和集群架构(RAC)且RAC是基共享存储的,Mysql有主从复制,和集群架构(ndbcluster),但ndbcluster是非共享存储的。
Oracle到mysql转换的问题总结

Oracle到mysql转换的问题总结常用字段类型区别Oracle number(10,0)number(10,2)varchar2datecolbmysqlintdecimal(10,2)varchardatetimetext编写单个语句时的差异1.oracle里只可以用单引号包起字符串,mysql里可以用双引号和单引号。
2.mysql在select*from()....,from后面是一个结果集时,括号后面必须加上别名。
3.MySQL在删除数据时不能向表中添加别名,例如从表1中删除twhere,会报告错误,但可以这样写:从表1中删除twhere。
4.mysql不支持在同一个表中先查这个表在更新这个表,举个例子说明一下,insertintotable1values(字段1,(select字段2fromtable1where...)),但是可以在后面那个table1加上别名就没有问题了。
insertintotable1values(字段1,(selectt.字段2fromtable1twhere...))5.mysql有自动增长的数据类型,插入记录时不用操作此字段,会自动获得数据值。
oracle没有自动增长的数据类型,需要建立一个自动增长的序列号,插入记录时要把序列号的下一个值赋于此字段。
也可以自定义函数实现oracle的nextval。
6.翻页SQL语句处理。
MySQL处理翻页SQL语句相对简单。
使用limit的起始位置记录数字,例如:从表格limit中选择*N,这意味着从M+1中取N。
常见的函数替换1.日期转换函数oraclemysql到char(date,'yyyyy-mm-ddhh24:mi:ss')到date (str,'yyyyy-mm-ddhh24:mi:ss')到date(str,'yyyyyy-mm-ddhh24:mi:ss')到char ()、到number()日期+数据格式(date,%y-%m%d%h:%i:%s')str到date(str,%y-%y-%m-%d%h:%i:%s')相应的时间格式。
Oracle到mysql的迁移步骤及各种注意事项_数据库

最近公司一个项目需要将数据库进行一次迁移,从oracle到mysql,网上资料甚少,现将我本次迁移过程中所遇到的一些问题总结于此(主要是存储过程的迁移),希望能给自己做一个日后的参考,如果有幸能帮助到大家更好。
-- mysql中没有包的概念,因此迁移的时候将存储过程命名为'包名。
存储过程名'的格式mysql存储过程格式:DELIMITER $$ -- 分隔符-- CREATE PROCEDURE([[IN |OUT ] 参数名数据类型…]) ,IN和OUT写在最前面,其中IN可以省略CREATE PROCEDURE `pkg_ypgl.prc_ypsc`(prm_ypbm VARCHAR (20),OUT prm_AppCode VARCHAR (20),-- 程序执行代码OUT prm_ErrorMsg VARCHAR (100)-- 程序执行错误信息)/*变量定义*/DECLARE n_count DECIMAL (8) ;DECLARE done INT(10);/*设置游标结束标志*/DECLARE CONTINUE HANDLER FOR NOT FOUND SET done=1; -- 如果NOT FOUND,取不到值,则将done赋值1,并且程序继续执行SET done=0;/*定义一个区块lavel_error,逻辑错误处理*/label_error : BEGIN/*定义游标*/DECLARE cur_bdjl CURSOR FORSELECT ……/*打开游标*/OPEN cur_bdjl ;REPEATFETCH cur_bdjl INTO v_aaz001…IF NOT done THEN -- 如果结束标志done为0则继续循环……END IF;/*结束循环,关闭游标*/UNTIL done -- 直到NOT FOUNDEND REPEAT ;CLOSE cur_bdjl ;SET prm_AppCode = 'noerror' ; -- 将prm_AppCode设为正确SET prm_ErrorMsg = '' ;END;END$$DELIMITER ;数据类型:Oracle:varchar2 Mysql:varchar(20) (参数自设)Oracle:number() Mysql:decimal()Oracle:date Mysql:datetime定义变量:Mysql需要在每句前面加DECLARE给变量赋值:Oracle:v_string := 'asdas'; Mysql: SET string := 'asdas'; (等号前面的冒号可以有也可以没有)异常处理:Oracle:EXCEPTION WHEN OTHERS THEN…Mysql: DECLARE { EXIT | CONTINUE } HANDLERFOR { error-number |{ SQLSTATE error-string } | condition } SQL statement;SQLWARNING 代表所有以01开头的错误代码NOT FOUND 代表所有以02开头的错误代码,也包括游标结束的时候SQLEXCEPTION 代表除了SQLWARNING和NOT FOUND 的所有错误代码eg. DECLARE EXIT HANDLER FORSQLEXCEPTION,SQLWARNING,NOT FOUND SET a = 1;注:一个begin…end里面只能声明一个HANDLER,EXIT表示遇到这种异常时就执行SET a = 1然后结束这个存储过程,CONTINUE表示遇到这种异常时就SET a = 1,然后继续执行之后的存储过程跳转:Oracle: GOTO label_error;……《label_error 》Mysql:初始化错误代码prm_AppCode为"错误",定义一个区块label_error,在区块的最后将prm_AppCode set为'noerror',中间触发条件,将GOTO label_error;改写成leave label_error;跳出区块游标:Mysql只有静态游标,没有动态游标,用存储过程代替定义游标的语句为DECLAREcur_bdjl CURSOR FOR ……Mysql不支持rec_curname.aaz001这种写法,所以必须将游标取得的所有字段FETCH INTO 到变量里循环:Mysql里有三种循环方式(1)。
oracle转MYSQL表

create or replace function fnc_table_to_mysql( i_owner in string,i_table_name in string,i_number_default_type in string := 'decimal',i_auto_incretment_column_name in string := '%ID')/*功能:ORACLE表生成MYSQL建表DDL作者:叶正盛 2013-07-27新浪微博:@yzsind-叶正盛参数说明:i_owner:schema名i_table_name:表名i_number_default_type:NUMBER默认转换的类型,缺省是decimali_auto_incretment_column_name:自增属性字段名称规则,默认是%ID已知问题:1.不支持分区2.不支持函数索引,位图索引等特殊索引定义3.不支持自定义数据类型,不支持ROWID,RAW等特殊数据类型4.不支持外键5.不支持自定义约束6.不支持与空间、事务相关属性7.DATE与TIMESTAMP转换成datetime,需注意精度8.超大NUMBER直接转换为bigint,需注意精度9.auto incretment 是根据字段名规则加一些判断,设置不一定准确,需检查*/return clob isResult clob;cnt number;data_type varchar2(128);column_str varchar2(4000);pk_str varchar2(4000);table_comments varchar2(4000);is_pk_column number := 0;beginselect count(*)into cntfrom all_tableswhere owner = i_ownerand table_name = i_table_name;if (cnt = 0) thenRAISE_APPLICATION_ERROR(-20000,'can''t found table,please check input!');elseResult := 'CREATE TABLE `' || lower(i_table_name) || '`(';--columnfor c in (select a.column_name,a.data_type,a.data_length,a.data_precision,a.data_scale,a.nullable,a.data_default,MENTSfrom all_tab_cols a, all_col_comments bwhere a.owner = i_ownerand a.table_name = i_table_nameand a.HIDDEN_COLUMN = 'NO'and a.owner = b.OWNERand a.TABLE_NAME = b.TABLE_NAMEand a.COLUMN_NAME = b.COLUMN_NAMEorder by a.column_id) loopif (c.data_type = 'VARCHAR2'or c.data_type = 'NVARCHAR2') thendata_type := 'varchar(' || c.data_length || ')';elsif (c.data_type = 'CHAR'or c.data_type = 'NCHAR') thendata_type := 'char(' || c.data_length || ')';elsif (c.data_type = 'NUMBER') thenif (c.column_name like'%ID'and c.data_scale is null) thendata_type := 'bigint';elsif (c.data_precision<3and c.data_scale = 0) thendata_type := 'tinyint';elsif (c.data_precision<5and c.data_scale = 0) thendata_type := 'smallint';elsif (c.data_precision<10and c.data_scale = 0) thendata_type := 'int';elsif (c.data_precision is not null and c.data_scale = 0) then data_type := 'bigint';elsif(c.data_precision is not null and c.data_scale is not null) thendata_type := 'decimal(' || c.data_precision || ',' ||c.data_scale || ')';elsedata_type := i_number_default_type;end if;elsif(c.data_type = 'DATE'or c.data_type like'TIMESTAMP%') then data_type := 'datetime';elsif (c.data_type = 'CLOB'or c.data_type = 'NCLOB'orc.data_type = 'LONG') thendata_type := 'text';elsif (c.data_type = 'BLOB'or c.data_type = 'LONG RAW') thendata_type := 'blob';elsif (c.data_type = 'BINARY_FLOAT') thendata_type := 'float';elsif (c.data_type = 'BINARY_DOUBLE') thendata_type := 'double';elsedata_type := c.data_type;end if;column_str := ' `' || lower(c.column_name) || '` ' || data_type;if (c.column_name like i_auto_incretment_column_name and(c.data_scale is null or c.data_scale = 0)) thenselect count(*)into is_pk_columnfrom all_constraints a, all_cons_columns bwhere a.owner = i_ownerand a.table_name = i_table_nameand a.constraint_type = 'P'and a.OWNER = b.OWNERand a.TABLE_NAME = b.TABLE_NAMEand a.CONSTRAINT_NAME = b.CONSTRAINT_NAMEand b.COLUMN_NAME = c.column_name;if is_pk_column > 0thencolumn_str := column_str || ' AUTO_INCREMENT';end if;end if;if c.nullable = 'NO'thencolumn_str := column_str || ' NOT NULL';end if;if (trim(c.data_default) is not null) thencolumn_str := column_str || ' DEFAULT ' ||trim(replace(replace(c.data_default, chr(13), ''),chr(10),''));end if;if ments is not null thencolumn_str := column_str || ' COMMENT ''' || ments || '''';end if;Result := Result || chr(10) || column_str || ',';end loop;--pkfor c in (select a.constraint_name, wm_concat(a.column_name)pk_columnsfrom (select a.CONSTRAINT_NAME,'`' || b.COLUMN_NAME || '`' column_namefrom all_constraints a, all_cons_columns bwhere a.owner = i_ownerand a.table_name = i_table_nameand a.constraint_type = 'P'and a.OWNER = b.OWNERand a.TABLE_NAME = b.TABLE_NAMEand a.CONSTRAINT_NAME = b.CONSTRAINT_NAMEorder by b.POSITION) agroup by a.constraint_name) loopResult := Result || chr(10) || ' PRIMARY KEY (' ||lower(c.pk_columns) || '),';end loop;--uniquefor c in (select a.constraint_name, wm_concat(a.column_name)uk_columnsfrom (select a.CONSTRAINT_NAME,'`' || b.COLUMN_NAME || '`' column_namefrom all_constraints a, all_cons_columns bwhere a.owner = i_ownerand a.table_name = i_table_nameand a.constraint_type = 'U'and a.OWNER = b.OWNERand a.TABLE_NAME = b.TABLE_NAMEand a.CONSTRAINT_NAME = b.CONSTRAINT_NAMEorder by b.POSITION) agroup by a.constraint_name) loopResult := Result || chr(10) || ' UNIQUE KEY `' ||lower(c.constraint_name) || '`('|| lower(_columns) || '),';end loop;-- indexfor c in (select a.index_name, wm_concat(a.column_name) ind_columns from (select a.index_name,'`' || a.COLUMN_NAME || '`' column_namefrom all_ind_columns awhere a.table_owner = i_ownerand a.TABLE_NAME = i_table_nameand not exists(select index_namefrom all_constraints bwhere a.TABLE_OWNER = b.ownerand a.TABLE_NAME = b.TABLE_NAMEand a.INDEX_NAME = b.INDEX_NAME)order by a.COLUMN_POSITION) agroup by a.index_name) loopResult := Result || chr(10) || ' KEY `' || lower(c.index_name) || '`(' ||lower(c.ind_columns) || '),';end loop;Result := substr(Result, 1, length(result) - 1) || chr(10) || ')';--table commentsselect max(MENTS)into table_commentsfrom all_tab_comments awhere owner = i_ownerand table_name = i_table_name;if (table_comments is not null) thenResult := Result || 'COMMENT=''' || table_comments || '''';end if;Result := Result || ';';end if;return(Result);end fnc_table_to_mysql;/。
通过oracle11g连接mysql
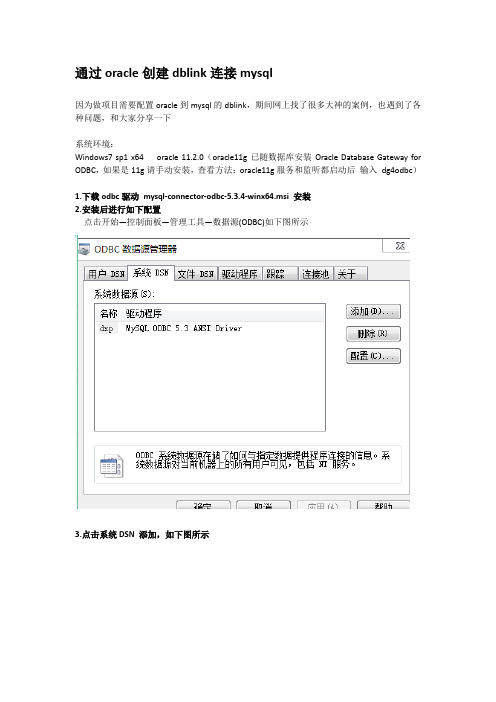
通过oracle创建dblink连接mysql因为做项目需要配置oracle到mysql的dblink,期间网上找了很多大神的案例,也遇到了各种问题,和大家分享一下系统环境:Windows7 sp1 x64 oracle 11.2.0(oracle11g已随数据库安装Oracle Database Gateway for ODBC,如果是11g请手动安装,查看方法:oracle11g服务和监听都启动后输入dg4odbc)1.下载odbc驱动mysql-connector-odbc-5.3.4-winx64.msi 安装2.安装后进行如下配置点击开始—控制面板—管理工具—数据源(ODBC)如下图所示3.点击系统DSN 添加,如下图所示4.在D:\SysFiles\Oracle11g\product\11.2.0\dbhome_1\hs\admin下建立initude.ora文件(注意oracle10g为hsodbc)注意:默认会有一个initdg4odbc.ora 需要复制后修改成init+数据库实例名.ora修改后打开输入:HS_FDS_CONNECT_INFO = dxpHS_FDS_TRACE_LEVEL = 05.在D:\SysFiles\Oracle11g\product\11.2.0\dbhome_1\NETWORK\ADMIN下修改listener.ora输入:(SID_DESC =(SID_NAME = ude)(ORACLE_HOME = D:\SysFiles\Oracle11g\product\11.2.0\dbhome_1)(PROGRAM = dg4odbc))注意此处括号填写:否则监听起不来。
6.修改tnsnames.ora输入:UDE=(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 127.0.0.1)(PORT = 1521)))(CONNECT_DATA =(SID = ude))(HS=OK))7.创建dblink 注意大小写否则会报错create public database link mysqllinkconnect to "ude"identified by"ude" using 'mysqltest';8.访问mysql库中的表user 注意需要添加双引号select "ID", "O_ID", "NAME" from "ude_task"@mysqllink另外:如果以下方式访问会报错。
Oracle数据库迁移到MySQL(kettle,navicate,sqldeveloper等工具

Oracle数据库迁移到MySQL(kettle,navicate,sqldeveloper等⼯具Oracle 数据库迁移到MySQL (kettle,navicate,sql developer等⼯具1 kettle--第⼀次使⽤kettle玩迁移,有什么不⾜之处和建议,请⼤家指正和建议。
下载软件,官⽹⽐较慢,国内有⼀些镜像下载完成,解压pdi-ce-7.0.0.0-25.zipG:\download\pdi-ce-7.0.0.0-25\data-integration双击Spoon.bat 运⾏提⽰找不到javaw.exe下载jdk安装(这⾥在oracle官⽹上选择相应的进⾏下载安装jdk-8u191-windows-x64.exe),路径C:\Program Files\Java\jdk1.8.0_191添加环境变量 C:\Program Files\Java\jdk1.8.0_191在双击Spoon.bat 运⾏--整库转移数据ojdbc5.jar ojdbc6.jar mysql-connector-java-5.1.47.jar拷贝到kettle的lib路径 G:\download\pdi-ce-7.0.0.0-25\data-integration\lib在启动kettle之前拷贝进去,这⾥重新运⾏--mysql连接--连接oralce,由于oralce是11g r2 rac环境,之前⼀直报错Error connecting to database: (using class oracle.jdbc.driver.OracleDriver)Listener refused the connection with the following error:ORA-12505, TNS:listener does not currently know of SID given in connect descriptor--所以这⾥直接指定⼀个sid,即bol1,选择第⼀个节点,ip是scan ip新建⼀个job,创建2个db的连接,source,target,在菜单中找到[复制多表导向],点击进⾏关联操作⼯具--向导--复制多表导向--点击 finish--开始执⾏--⽇志--登录mysql进⾏查询,发现数据和表已经同步--问题,oracle迁移到mysql的表,字段是number类型,迁移到mysql之后,变成了double类型,数据存储的是整数。
如何从Oracle迁移到MySQL数据库

如何从Oracle迁移到MySQL数据库从Oracle迁移到MySQL数据库简介:Oracle和MySQL都是目前广泛使用的关系型数据库管理系统(RDBMS)。
尽管两者在一些方面有所不同,但随着MySQL的快速发展和成熟,许多企业开始考虑从Oracle迁移到MySQL。
本文将探讨从Oracle迁移到MySQL的一些关键问题和最佳实践。
一、数据兼容性分析:在迁移过程中,首要任务是分析Oracle数据库和MySQL之间的数据兼容性。
由于Oracle和MySQL使用不同的SQL语法和数据类型,可能存在某些表、字段或查询存在差异的情况。
因此,在迁移之前,必须仔细检查数据库结构和数据,以确保在MySQL中正确创建和导入数据。
Oracle和MySQL之间的差异通常涉及以下方面:1. 数据类型:Oracle和MySQL支持不同的数据类型。
在转换时,需要注意数据类型的映射和兼容性。
2. 约束和索引:Oracle和MySQL的约束和索引有一些差异,需要逐个检查并调整。
3. 存储过程和触发器:Oracle和MySQL的存储过程和触发器语法也有所不同,需要做相应的调整。
二、数据迁移方法:1. 导出和导入数据:一种常见的迁移方法是使用Oracle的导出工具(如expdp)将数据导出为可移植的数据文件(例如,使用XML格式)。
然后使用MySQL的导入工具(如mysqlimport)将数据导入到MySQL数据库中。
这种方法简单直接,但可能会导致一些数据类型的兼容性问题。
2. 数据库连接工具:如果Oracle和MySQL之间的网络连接可用,可以使用数据迁移工具,如Oracle的Gateway或MySQL的Federated引擎,直接在两个数据库之间进行数据交换。
这种方法可以实现实时数据同步,并且具有较低的延迟。
3. 自定义脚本:对于一些复杂的数据迁移任务,可能需要编写自定义的脚本来处理数据转换和迁移过程。
这需要深入了解Oracle和MySQL的SQL语法和函数,以及相关的数据处理操作。
oggoracletomysql_借助OGG完成Oracle到MySQL的数据迁移

oggoracletomysql_借助OGG完成Oracle到MySQL的数据迁移现在有个任务是需要把Oracle的数据迁移到MySQL,因为就涉及到了⼏个表,所以我最先想到了使⽤spool把Oracle的数据导成txt⽂件,然后再load 进去MySQL。
⾮常遗憾的是,我的有⼀个表有110个字段,并且有160万的数据,始终就只能倒进⼀部分数据,最后由于时间问题,没有继续尝试,然后打算⽤golden gate完成任务。
我们知道golden gate主要就在于⼏个进程的配置,安装很简单,解压缩就可以,下⾯重点讲解各个进程的配置问题。
整体迁移的思路以及注意事项:⾸先在oracle端和mysql端安装上OGG,安装很简单,然后在oracle源端和⽬标端配置好mgr(端⼝需要⼀致),然后在源端配置上抓取进程,在⽬标端配置上replicate进程(只运⾏⼀次即可),然后在源端使⽤DEFGEN命令做映射⽂件,并把⽂件传到mysql端相应⽬录下。
启动源端的抓取进程即可实现数据库初始化,也就完成了数据迁移。
注意事项和相关报错:1,oracle到mysql的ogg属于异构的ogg, 需要借助DEFGEN命令⽣成⼀个映射⽂件,也就是两个表的映射关系,并把⽂件放到⽬标端相应位置下。
否则会报错WARNING OGG-01194 EXTRACT task RINIG1 abended : Could not find definition forINFOSERVICE.T_MEMBER_INFO_SUM2,在源端配置抓取进程,需要注意的是:初始化数据库过程需要⼀个的抓取进程,之后保持数据同步也需要⼀个抓取进程,这两个抓取进程是有区别的,然后⽬的端也需要两个replicate进程,⼀个⽤来初始化数据库,⼀个⽤来实时同步数据 。
3,注意oracle字段默认是区分⼤⼩写的,但是mysql默认是不区分的。
如下:mysql> select login_id from T_MEMBER_INFO where login_id = 'SHFRONT';+----------+| login_id |+----------+| shfront || SHFRONT |+----------+2 rows in set (0.81 sec)需要这样修改,让mysql对⼤⼩写敏感。
powerdesigner oracle sql语句 转 mysql sql语句

powerdesigner oracle sql语句转mysql sql语句在 PowerDesigner 中将 Oracle SQL 语句转换为 MySQL SQL 语句的过程大致如下:首先,需要确保你已安装了相应的 PowerDesigner 插件,用于支持Oracle 和 MySQL 数据库的转换。
接下来,按照以下步骤操作:1. 打开 PowerDesigner 并进入数据模型设计环境。
2. 选择 "Database" 菜单,然后选择 "Open Database"。
3. 在弹出的文件选择对话框中,选择你想要转换的 Oracle SQL 文件。
4. 加载 SQL 文件后,你可以在 PowerDesigner 中看到一个 SQL 编辑器窗口。
5. 在 SQL 编辑器窗口中,你可以找到你的 Oracle SQL 语句。
6. 复制这些语句,并创建一个新的 MySQL SQL 文件。
7. 在新的 MySQL SQL 文件中,粘贴你复制的 Oracle SQL 语句。
8. 使用 MySQL 的语法和特性对语句进行修改和调整,以适应 MySQL 的语法和要求。
9. 一旦你对语句进行了必要的修改,就可以将其保存为新的 MySQL SQL 文件。
下面是一个简单的示例,展示如何将一个简单的 Oracle SQL 查询转换为MySQL SQL 查询:Oracle SQL 查询:```sqlSELECT * FROM employees WHERE department_id = 10 AND salary > 5000; ```转换为 MySQL SQL 查询:```sqlSELECT * FROM employees WHERE department_id = 10 AND salary > 5000; ```请注意,转换过程可能会因具体的 SQL 语句和数据模型而有所不同。
Oracle转Mysql

Oracle转Mysql过程记录1. 迁移数据库2. 改⽅⾔等配置⽂件3. 改sql(to_chat: date_format, ||: CONCAT())4. 改idjdbc.driverClassName=com.mysql.cj.jdbc.Driver注:Mysql版本⾼加cj,不⾼去掉jdbc.url=jdbc:mysql://10..165:3306/hc_busername=jdbc.password=***预告:Oracle数据库的序列(Seq)在Mysql中没有,是使⽤的⾃增值⼀般,得看主键⽣成策略Oracel数据库中数据表转换到Mysql是不能将视图转过去,需要将使⽤到的视图⼿动添加到Mysql数据库中Oracle⽅⾔import ng3.StringUtils;public class OracleDialect implements Dialect {public OracleDialect() {}public boolean supportsLimit() {return true;}public String getLimitString(String oldSql, int skipResults, int maxResults) {int endRownumber = skipResults + maxResults;String tmpSql = StringUtils.lowerCase(StringUtils.deleteWhitespace(oldSql));boolean sqlFlag = StringUtils.contains(tmpSql, "orderby") || StringUtils.contains(tmpSql, "groupby") || StringUtils.contains(tmpSql, "having") || StringUtils.contains(tmpSql, "union") || StringUtils.contains(tmpSql, "distinct") || StringUtils.c if (!sqlFlag) {if (StringUtils.contains(tmpSql, "where")) {tmpSql = null;return "select * from (select rownum as myrownum,c.* from (" + oldSql + " and rownum<=" + endRownumber + ") c) where myrownum>" + skipResults;} else {tmpSql = null;return "select * from (select rownum as myrownum,c.* from (" + oldSql + " where rownum<=" + endRownumber + ") c) where myrownum>" + skipResults;}} else {tmpSql = null;return "select * from (select rownum as myrownum,c.* from (" + oldSql + ") c)where myrownum<=" + endRownumber + " and myrownum>" + skipResults;}}}Mysql⽅⾔import ng3.StringUtils;public class MySQLDialect implements Dialect {public MySQLDialect() {}public boolean supportsLimit() {return true;}public String getLimitString(String oldSql, int skipResults, int maxResults) {int var10000 = skipResults + maxResults;String tmpSql = StringUtils.lowerCase(StringUtils.deleteWhitespace(oldSql));boolean sqlFlag = StringUtils.contains(tmpSql, "orderby") || StringUtils.contains(tmpSql, "groupby") || StringUtils.contains(tmpSql, "having") || StringUtils.contains(tmpSql, "union") || StringUtils.contains(tmpSql, "distinct") || StringUtils.c if (!sqlFlag) {return "(" + oldSql + ") LIMIT " + skipResults + "," + maxResults;} else {tmpSql = null;return "(" + oldSql + ") LIMIT " + skipResults + "," + maxResults;}}}PostgreSQL⽅⾔public class PostgreSQLDialect implements Dialect {public PostgreSQLDialect() {}public boolean supportsLimit() {return true;}public String getLimitString(String sql, int skipResults, int maxResults) {StringBuilder pageSql = (new StringBuilder()).append(sql);if (skipResults <= 0) {pageSql.append(" limit ").append(maxResults);} else {pageSql.append(" limit ").append(maxResults).append(" offset ").append(skipResults);}return pageSql.toString();}}项⽬:Mysql驱动包Maven配置,下载驱动包<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.23</version></dependency>数据源配置,四项缺⼀不可jdbc.driverClassName=com.mysql.cj.jdbc.Driverjdbc.url=jdbc:mysql://10.***.165:3306/***ername=***jdbc.password=***Hibernate映射⽂件中属性generator的值设置<hibernate-mapping><class name="com.yinhai.modules.security.spring.domain.po.TaonlinelogPo" table="TAONLINELOG"><id name="logid" type="ng.Long">//主键<column name="LOGID" precision="10" scale="0"/><generator class="native" />//主键⽣成策略</id><property name="clientsystem" type="ng.String">//普通字段<column name="CLIENTSYSTEM" length="50" /></property></class></hibernate-mapping>主键⽣成策略:常⽤的三种:uuid、native、assigned。
PHP将数据从Oracle向Mysql数据迁移实例
为什么要迁移?首先从运营成本考虑,用Mysql可以节约不少的费用。
另一方面,Mysql的稳定性及功能不断地提高与增强,基本上可以满足客户的需求,如支持多节点部署,数据分区等。
还有就是My sql使用方便,比Oracle简单易用。
故客户就要求将已有的Oracle数据表与内容迁移到Mysql来。
为什么要自己写脚本?迁移的表与数据都蛮多的,有几百张表。
因此手工完成不太方便。
也尝试了一些免费的迁移工具,如:MySQLMigrationTool等,发现转移的字段类型不太符合要求(可能是原来的Oracle 表设计得不太好),会导致数据不太完整,觉得不是太可靠,所以决定自己写迁移脚本放心一些,有不符合要求的也可立即调整,所以就开始吧。
所用到的技术支持1.php52.php oci83.mysql 5.1迁移表结构获取schema所有表用以下语句可以从Oracle中获得schema中所有的表名SELECT table_name FROM user_tables然后可以遍历所有表向mysql进行表结构的创建与数据的迁移工作。
获取单个表的所有字段与类型用以下语句可以从oracle中获得单个表的所有字段与类型SELECT COLUMN_NAME, DATA_TYPE, DATA_LENGTH, NULLABLE,DATA_DEFAULTFROM USER_TAB_COLUMNS WHERE TABLE_NAME =UPPER('{$table_name}') ORDER BY column_id ASC这样可以得知表字段的名称,类型,长度,是否允许为空,默认值。
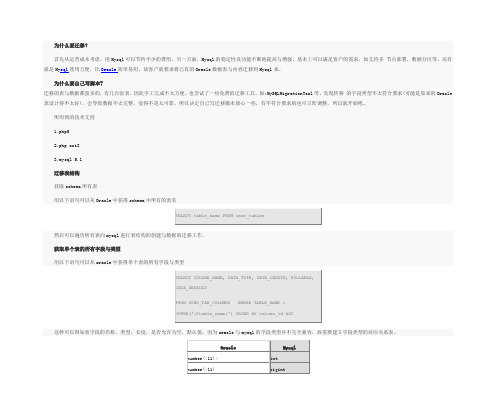
因为oracle与mysql的字段类型并不完全兼容,故需要建立字段类型的对应关系表。
Oracle Mysqlnumber(<11)> intnumber(>11) bigintvarchar varcharvarchar2(<255)> varcharvarchar2(>255) textclob textdate date获取单个表的Primary Foreign Unique Key用以下语句可以从oracle中获得单个表的Primary Foreign Unique KeySELECT C.CONSTRAINT_NAME, C.CONSTRAINT_TYPE,C.R_CONSTRAINT_NAME, C.DELETE_RULE,CC.COLUMN_NAME FROM USER_CONSTRAINTS C,USER_CONS_COLUMNS CCWHERE C.TABLE_NAME=upper('{$table_name}') ANDC.CONSTRAINT_TYPE!='C'AND C.CONSTRAINT_NAME=CC.CONSTRAINT_NAME ANDC.OWNER=CC.OWNER AND C.TABLE_NAME=CC.TABLE_NAMEORDER BY C.CONSTRAINT_TYPE, C.CONSTRAINT_NAME,CC.POSITION<="" key="" ?r?则取得表的所有foreign="" ;为="" ?u?则取得表的所有unique="" ?p?则取得表的所有primary="" 为="">获取单个表的索引用以下语句可以从oracle中获得单个表的索引SELECT T.INDEX_NAME,T.COLUMN_NAME,I.INDEX_TYPE FROMUSER_IND_COLUMNS T,USER_INDEXES IWHERE T.INDEX_NAME = I.INDEX_NAME AND T.TABLE_NAME =I.TABLE_NAME ANDT.TABLE_NAME = UPPER('{$table_name}')这样可以获知表的索引名称,被索引的字段。
oracle到mysql,oracle到oraclel的多表批量数据迁移,定期任务抽取数据。。。

oracle到mysql,oracle到oraclel的多表批量数据迁移,定期任务抽取数据。
⼀、背景上⼀篇⽂章(单表数据迁移)⽤kettle实现了⼀张表的数据迁移。
但实际情况中,数据库会有⼏百,⼏千张表,⽽kettle的表输⼊和表输出只能选择⼀张表,我们不可能⼀个个地填写表名。
这时候,我们要考虑通过循环实现多表的数据迁移。
⼆、前期准备与单表数据迁移类似准备好Oracle和MySQL的库,Oracle到Oracle也可以,转移,只是必须提前在kettle⽂件夹的lib⽬录下放⼊各个数据库的依赖。
电脑可以连接Oracle和MySQL。
下载好kettle,并把Oracle和MySQL的驱动包放在kettle⽂件夹的lib⽬录下。
如果第⼀次使⽤kettle,建议先看上⼀篇⽂章《单表数据迁移》,上⼀篇很详细地介绍了新建转换、新建节点、新建数据库连接等问题。
三、批量数据迁移1.读取需要迁移的表(转换)⽅法⼀:从数据库读取所有表// mysql查询该数据库的所有表select table_name from information_schema.tables where table_schema=当前数据库名 and table_type='base table';点击⽂件——新建——转换,在左侧的核⼼对象标签下选择输⼊下的表输⼊,双击添加到右侧的转换⾯板,再选择作业下的复制记录到结果,双击添加到右侧的转换⾯板。
接下来配置表输⼊,双击表输⼊的图标,橙⾊区域为必填项。
如果是两个库表结构⼀致,导⼊所有表,可⽤语句select table_name from user_tables //且千万不要在语句后⾯加分号,会报错。
如果只有部分表结构⼀致且要导⼊,可⽤语句来过滤掉源数据库没有的表,否则就会报错。
select table_name from user_tables where table_name!='T_XZQH'and table_name !='BASE_BUSINESS_INFO'新建mysql的数据库连接,数据库连接的配置参考上⼀篇⽂章(注意是mysql的连接),新建好连接,记得测试⼀下是否连接成功。
通过DataX从Oracle同步数据到MySQL-安装配置过程

通过DataX从Oracle同步数据到MySQL-安装配置过程DataXDataX 是阿⾥巴巴集团内被⼴泛使⽤的离线数据同步⼯具/平台,实现包括 MySQL、SQL Server、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间⾼效的数据同步功能。
FeaturesDataX本⾝作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向⽬标端写⼊数据的Writer插件,理论上DataX框架可以⽀持任意数据源类型的数据同步⼯作。
同时DataX插件体系作为⼀套⽣态系统, 每接⼊⼀套新System RequirementsLinuxJDK(1.8以上,推荐1.8)Python(推荐Python2.6.X)Apache Maven 3.X(Compile DataX)Quick Start⼯具部署⽅法⼀、直接下DataX⼯具包:,下载后解压⾄本地某个⽬录,进⼊bin⽬录,即可运⾏同步作业$ cd {YOUR_DATAX_HOME}/bin$ python datax.py {YOUR_JOB.json}⽅法⼆、下载DataX源码,⾃⼰编译:①.安装JDKtar xvf jdk-8u151-linux-x64.tar.gzmv jdk1.8.0_151vim /etc/profile.d/jdk.shexport JAVA_HOME=/usr/local/jdk1.8.0_151export JAVA_BIN=$JAVA_HOME/binexport PATH=$PATH:$JAVA_BINexport CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarsource /etc/profile.d/jdk.sh检测安装是否成功[root@oracle ~]# java -versionjava version "1.8.0_151"Java(TM) SE Runtime Environment (build 1.8.0_151-b12)Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)②.查看Python版本,如果不满⾜则需要⾃⾏安装[root@oracle ~]# python -VPython 2.6.6③.安装Maven下载地址:开始安装配置tar xvf apache-maven-3.6.1-bin.tar.gzmv apache-maven-3.6.1-bin.tar ../mavenvim /etc/profileM2_HOME=/usr/local/mavenexport PATH=${M2_HOME}/bin:/u01/mysql/bin:${PATH}验证Maven是否安装成功[root@oracle src]# mvn -vApache Maven 3.6.1 (bb52d8502b132ec0a5a3f4c09453c07478323dc5; 2015-11-11T00:41:47+08:00)Maven home: /usr/local/mavenJava version: 1.8.0_151, vendor: Oracle CorporationJava home: /usr/local/jdk1.8.0_151/jreDefault locale: en_US, platform encoding: UTF-8OS name: "linux", version: "3.10.0-862.el7.x86_64", arch: "amd64", family: "unix"系统需求已配置完成,开始源码安装DataX,下载⽅法⼆选其⼀下载地址:git clone git@:alibaba/DataX.git开始源码安装unzip DataX-master.zipmv DataX-master ../cd ../DataX-mastermvn -U clean package assembly:assembly -Dmaven.test.skip=true该过程⾮常⾮常的漫长,需要等待,打包成功,最终显⽰如下[INFO] BUILD SUCCESS[INFO]-----------------------------------------------------------------[INFO] Total time: 08:12min[INFO] Finished at: 2015-12-13T16:26:48+08:00[INFO] Final Memory: 133M/960M[INFO]-----------------------------------------------------------------打包成功后的DataX包位于{DataX_source_code_home}/target/datax/datax/,结构如下:cd /usr/local/Datax-master[root@oracle DataX-master]# ls -a ./target/datax/datax/. .. bin conf job lib log log_perf plugin script tmp配置⽰例:从stream读取数据并打印到控制台,第⼀步。
MySQL与Orcale数据库迁移工具方法

The Method of MySQL and Orcale Database Migration Tools
1 数据库迁移概述
数据库迁移前的准备工作,主要包括:找出原系统与目 标系统字段的对应关系,及做好数据备份。在使用数据库迁 移工具中会由于字段不匹配、格式不正确而影响 MySQL、 Oracle 数据迁移的完整性,因此,需要备份数据,避免在迁 移过程中因数据丢失而影响系统的正常运行。
2 数据迁移的工具方法
MySQL 与 Orcale 的 数 据 迁 移 方 法 主 要 包 括:(1) 使 用 DB Convert Studio 工具进行数据库迁移;(2)使用 ETLKettle 工具进行数据库迁移;(3)在1 DB Convert Studio 工具
2.1.1 添加连接
首先,添加数据库连接并配置它们。要添加一个新的连 接,点击连接→添加连接,或者点击连接窗口右上角的连接 按钮。在“新建连接”窗口中,从支持的数据库列表中选择 所需的数据库类型。通常需要 IP 地址、端口、用户名和密码 作为建立数据库连接的必要信息。点击测试连接按钮。应用 程序尝试使用指定的参数连接到服务器。连接成功建立后会 出现确认消息。单击“保存”按钮,使连接可用作源节点或 目标节点。在主窗口中,可以根据需要添加任意数量的连接。 即使在关闭该程序后,它们仍将保留在这个列表中 [1]。
Lu Yeshan, Wu Qiuyu
(School of Computer and Electronic Information, Guangxi University, Nanning Guangxi 530001, China)
oracle转mysql工具使用方法

Oracle迁移mysql工具使用方法目录文档修改历史....................................... 错误!未定义书签。
1. 工具使用简介 (3)1.1. 前言 (3)1.2.使用环境 (3)2. MySQL Migration Toolkit工具 (4)2.1.安装MySQL Migration Toolkit (4)2.2. 第一次运行加载jar包 (4)2.3. 填写oracle数据库的连接信息 (4)2.4. 填写mysql数据库的连接信息 (5)2.5.选择oracle中需要迁移的数据库 (5)2.6.选择需要迁移的表 (6)2.7.设置数据库编码参数 (7)2.8.修改建表脚本 (7)2.9.选择脚本存储目录 (8)2.10.建表sql完成 (8)2.11.选择目录存储表中数据 (9)2.12.数据sql创建完毕 (10)2.13.完成 (10)3. MySQL Workbench工具 (11)3.1.安装MySQL Workbench (11)3.2.选择数据库实例 (11)3.3.执行sql脚本 (12)4. Oracle序列的迁移 (14)4.1.迁移介绍 (14)4.2.迁移方法 (14)1.工具使用简介所使用的工具包含:①使用MySQL Migration Toolkit产生create、insert的脚本文件②使用MySQL Workbench导入脚本文件。
1.1.前言很多项目是基于Oracle数据库的,Oracle功能强大,但是部署和管理较复杂,更重要的是,购买Oracle的费用不是每个客户都愿意承担的。
因此,不少企业迫切需要把项目所用数据库移植到一个简单好用的数据库上。
当然,如您所料,选择了广受欢迎的MySQL。
作为一个开源数据库,MySQL用无数案例证明了她的可用性,因此让我们把重点放在如何将Oracle移植到MySQL上。
已经有很多的文章和专题介绍了Oracle 移植到MySQL的方法和步骤,也有相当多的工具可以辅助这种移植过程。
python将oracle中的数据导入到mysql中。

python将oracle中的数据导⼊到mysql中。
⼀.导⼊表结构。
使⽤⼯具:navicate premium 和PowerDesinger1. 先⽤navicate premium把oracle中的数据库导出为oracle脚本。
2. 在PowerDesinger⾥找到 File -->> Reverse Engineer --->> Database 将数据库导⼊到模型。
3 在.PowerDesinger⾥找到Database”--->“Change Current DBMS” 将数据库由oracle转换为mysql4. 在PowerDesinger⾥按快捷键ctrl+G导出mysql的sql⽂件5 ⽤navicate premium 将脚本⽂件导⼊到mysql中。
⼆.导⼊数据。
使⽤⼯具python 2.7 cx_Oracle mysql-python在本例中oracle字符集为gbk, mysql字符集为 utf-8 在导⼊过程中进⾏了字符集转换。
导⼊程序代码如下:#encoding:utf-8import sysimport MySQLdbimport mysqlHelperimport cx_Oracleimport oracleHelperreload(sys)sys.setdefaultencoding( "utf-8" )def mig_database():sql="select table_name from user_tables"oraHelper=oracleHelper.OracleHelper()rows=oraHelper.queryAll(sql)for row in rows:print row["TABLE_NAME"]mig_table(row["TABLE_NAME"])def mig_table(table_name):file_object = open('log.txt','a+')print"开始迁移"+table_name+"......"file_object.write("开始迁移"+table_name+"......\n")myhelper=mysqlHelper.MySQLHelper()oraHelper=oracleHelper.OracleHelper()myhelper.selectDb("nap")myhelper.query("delete from "+table_name)rows=oraHelper.queryAll("select * from "+table_name)n=0try:for row in rows:dict=convertDict(row)myhelper.selectDb("nap")myhelper.insert(table_name,dict)n=n+1mit()print table_name+"迁移完毕,共导⼊%d条数据。