作业二基于Fisher准则线性分类器设计
线性分类器设计fisher准则
线性分类器设计(fisher准则)一、数据来源参考文献:《车辆类型自动分类器的研究》农业装备与车辆工程,2007年9月,总第149期二、设计分析众所周知,最简单的判别函数是线性函数,最简单的分界面是超平面,采用线性判别函数所产生的错误率或风险虽然可能比贝叶斯分类器来得大。
不过,它简单,容易实现,而且需要的计算量和存储量小。
故在不要求太高精确度情况下,小样本时可采用此法。
采用上面文献中的数据集,利用fisher准则我们设计了一个线性的分类器。
因为线性分类器只能处理两类问题,所以把原问题做了初步的处理。
选取的特征:长高比( 汽车总长/汽车高度) : x1=L/H顶篷相对位置( ( 车头坐标- 顶篷中心坐标) /汽车总长) : x2=l1 /L顶长比( 顶蓬长度/汽车总长) : x3=l /L样本空间:sample=[2.6522,0.5021,0.8951;2.6240,0.4923,0.9823;%客车训练样本2.9825,0.1922,0.3217;3.0124,0.1596,0.1972;%货车训练样本3.3345,0.6896,0.4217;3.6532,0.6482,0.4576];%轿车训练样本三、程序见fisher.m文件四、结果分析原文章中采用的的改进的BP神经网络算法,能很好的实现分类的效果。
而在这里我们挑了6个训练集样本和3个测试集样本,也很好的实现了分类效果。
但是,若对于大样本来说,贝叶斯分类器的效果更好。
下图就是采用线性分类器的效果图。
客车样本和非客车样本1 1.2 1.4 1.6 1.82 2.2 2.4 2.6 2.83客车样本和非客车样本1 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.92。
机器学习实验1-Fisher线性分类器设计

一、实验意义及目的掌握Fisher分类原理,能够利用Matlab编程实现Fisher线性分类器设计,熟悉基于Matlab算法处理函数,并能够利用算法解决简单问题。
二、算法原理Fisher准则基本原理:找到一个最合适的投影周,使两类样本在该轴上投影之间的距离尽可能远,而每一类样本的投影尽可能紧凑,从而使分类效果为最佳。
内容:(1)尝试编写matlab程序,用Fisher线性判别方法对三维数据求最优方向w的通用函数(2)对下面表1-1样本数据中的类别w1和w2计算最优方向w(3)画出最优方向w 的直线,并标记出投影后的点在直线上的位置(4)选择决策边界,实现新样本xx1=(-0.7,0.58,0.089),xx2=(0.047,-0.4,1.04)的分类三、实验内容(1)尝试编写matlab程序,用Fisher线性判别方法对三维数据求最优方向w的通用函数程序清单:clcclear all%10*3样本数据w1=[-0.4,0.58,0.089;-0.31,0.27,-0.04;-0.38,0.055,-0.035;-0.15,0.53,0.011;-0.35,.47,0.034;0.17,0.69,0.1;-0.011,0.55,-0.18;-0.27,0.61,0.12;-0.065,0.49,0.0012;-0.12,0.054,-0.063];w2=[0.83,1.6,-0.014;1.1,1.6,0.48;-0.44,-0.41,0.32;0.047,-0.45,1.4;0.28,0.35,3.1;-0.39,-0.48,0.11;0.34,-0.079,0.14;-0.3,-0.22,2.2;1.1,1.2,-0.46;0.18,-0.11,-0.49];W1=w1';%转置下方便后面求s1W2=w2';m1=mean(w1);%对w1每一列取平均值结果为1*3矩阵m2=mean(w2);%对w1每一列取平均值结果为1*3矩阵S1=zeros(3);%有三个特征所以大小为3S2=zeros(3);for i=1:10%1到样本数量ns1=(W1(:,i)-m1)*(W1(:,i)-m1)';s2=(W2(:,i)-m2)*(W2(:,i)-m2)';S1=S1+s1;S2=S2+s2;endsw=S1+S2;w_new=transpose(inv(sw)*(m1'-m2'));%这里m1m2是行要转置下3*3 X 3*1 =3*1 这里提前转置了下跟老师ppt解法公式其实一样%绘制拟合结果数据画图用y1=w_new*W1y2=w_new*W2;m1_new=w_new*m1';%求各样本均值也就是上面y1的均值m2_new=w_new*m2';w0=(m1_new+m2_new)/2%取阈值%分类判断x=[-0.7 0.0470.58 -0.40.089 1.04 ];m=0; n=0;result1=[]; result2=[];for i=1:2%对待观测数据进行投影计算y(i)=w_new*x(:,i);if y(i)>w0m=m+1;result1(:,m)=x(:,i);elsen=n+1;result2(:,n)=x(:,i);endend%结果显示display('属于第一类的点')result1display('属于第二类的点')result2figure(1)scatter3(w1(1,:),w1(2,:),w1(3,:),'+r'),hold onscatter3(w2(1,:),w2(2,:),w2(3,:),'sg'),hold onscatter3(result1(1,:),result1(2,:),result1(3,:),'k'),hold onscatter3(result2(1,:),result2(2,:),result2(3,:),'bd')title('样本点及实验点的空间分布图')legend('样本点w1','样本点w2','属于第一类的实验点','属于第二类的实验点')figure(2)title('样本拟合结果')scatter3(y1*w_new(1),y1*w_new(2),y1*w_new(3),'b'),hold onscatter3(y2*w_new(1),y2*w_new(2),y2*w_new(3),'sr')(2)对下面表1-1样本数据中的类别w1和w2计算最优方向w(3)画出最优方向w 的直线,并标记出投影后的点在直线上的位置最优方向w 的直线投影后的位置(4)选择决策边界,实现新样本xx1=(-0.7,0.58,0.089),xx2=(0.047,-0.4,1.04)的分类决策边界取法:分类结果:四、实验感想通过这次实验,我学会了fisher线性判别相关的分类方法,对数据分类有了初步的认识,尽管在过程中有不少中间量不会算,通过查阅网络知识以及模式识别专业课ppt等课件帮助,我最终完成了实验,为今后继续深入学习打下良好基础。
6-线性分类器设计-第六章

k 此法可收敛于W值。W满足: XT(XW-b)=0
令 ρk =
ρ1
其中 ρ 1 为任意常数
因此下降算法不论XTX是否奇异,总能产生一个解。 若训练样本无限的重复出现,则简化为 W1任意 Wk+1=Wk+ρk(bk-WkTXk) Xk k+1
取 ρK
=
ρ1
k
ρk随迭代次数k而减少,以保证算法收敛于满意的W值
其中N/N1有N1个,N/N2有N2个
四 韦—霍氏法(LMS法)迭代法
上节得到MSE法的W解为:W=X+b
伪逆 X + =
(
XT X
)
−1
X
T
计算量很大
在计算X+时, 1. 要求XTX矩阵为非奇异 2 2. 由于计算量太大而引入比较大误差 所以要用迭代法来求 求J(W)的梯度 ▽J(W) =2XT(XW-b) 代入迭代公式 W1任意设定 Wk+1 = Wk-ρkXT(XWk-b)
H wk+1 ρk x
权值修正过程
例题:有两类样本 ω1=(x1,x2)={(1,0,1),(0,1,1)} ω2=(x3,x4)={(1,1,0),(0,1,0)} 解:先求四个样本的增值模式 x1=(1,0,1,1) x2=(0,1,1,1) x3=(1,1,0,1) x4=(0,1,0,1) 假设初始权向量 w1=(1,1,1,1) ρk=1 第一次迭代: w1Tx1=(1,1,1,1) (1,0,1,1)T=3>0 所以不修正 w1Tx2=(1,1,1,1) (0,1,1,1)T=3>0 所以不修正 w1Tx3=(1,1,1,1) (1,1,0,1)T=3>0 所以修正w1 w2=w1-x3=(0,0,1,0) w2Tx4=(0,0,1,0)T (0,1,0,1) =0 所以修正w2 w3=w2-x4=(0,-1,1,-1) 第一次迭代后,权向量w3=(0,-1,1,-1),再进行第2,3,…次迭代 如下表
基于Fisher判别分析的贝叶斯分类器

类别的所何条件概率 中最大者为应 I属的类 ,这样做可以使 J ] 识别决策 的错误率最小 , 一 这一 准则称 为最夫 后验概率准则 。 利用著名的贝 叶斯公式 P∞ I) ( :
pk x)
,注意到分母
() 在比较表达式 中足一个常数 ,经过 一 系列的推 导,呵以 把决策 式() 1表述为 :
D :1 9 9 s . 0 4 82 1.00 5 OI 036 /i n1 03 2 . 1.5 js 0 01
1 概述
分类是机器 学 习、模 式识 别和人工智能 等相 关领 域广 泛 研究的问题。近年来 ,随着相 关领 域中新技 术的不断涌现 , 分类 疗法也得到 了新的发展 。针对不同的分 类问题 ,分类方 , 法多种多样 ,如决策树分类、支持向量机分类、神经 网络分 类。 在众多的分类方法中 , 贝叶斯分类器受 到了极大地重视 。 贝叶斯分类器是基于最大后验概率准则的 ,即利用某对 象的 先验概率计算其后验概率 ,并选择具有最大后验概率 的类作 为该对象所属 的类 I 。在贝叶斯模型 中,模型 分别模 拟每 一 个类的类条件联合概率分布 ,然后基于贝叶斯定理构建后验 概率分类器 J 而,经典的贝叶斯分类器 并未 利用类与类 。然 之 问的信息 ,而这种信息正是分类所需要 的。本文在分析贝 叶 斯模 型 结 构 特 点 以及 构造 分 类 器 方法 的基础 上 ,结 合 Fse i r线性 判别分析 ,给出一种基于 Fse h i r线性判别分析 h (i e ier i r n n A ayi F D 的贝叶斯分类器。 Fs r na s i at n ls , L A) h L D c mi s
i f r t n e e tv l I r e o s v hi p o e n o ma i f c i e y n o d r t ol e t s r bl m,a mp o e l o i m fBa e i n c a s f r c o n i r v d a g rt h o y sa ls ii omb n d wi ih r Li e r Dic i i a t e i e t F s e n a s rm n n h
5第五章 线性分类器(几何分类器)

研究目的和意义
5.1 几何分类器的基本概念
03
内容纲要
研究目的和意义
一个模式通过某种变换映射成一个特征向量后, 该特征向量可以理解为特征空间的一个点。
O { f1, f 2 ,, f n }
06
内容纲要
研究目的和意义
在特征空间中,属于一个类的点集,在某种程 度上总是与属于另一个类的点集相分离,各个类之 间是确定可分的,
10
内容纲要
研究目的和意义
几何分类法按照分界函数的形式可以分为
线性判别函数 和 非线性判别函数 两大类。
11
1.若已知类的所有特征向量都可以用线性分类器正确 研究目的和意义 分类,我们将研究其相应的线性函数的计算方法。
内容纲要
线性可分情况
12
内容纲要 2.对于不能将所有向量正确分类的线性分类器,我们 研究目的和意义 将通过采用相应的优化规则来寻找设计最优线性分类 器的方法。
有多个判别函数的值大于0,第一种情况下只有一个判
别函数的值大于0。
30
内容纲要
研究目的和意义
31
内容纲要 若可用以上几种情况中的任一种线性判别函数来进行分类, 则这些模式类称为线性可分的。总结如表所示。 研究目的和意义
32
内容纲要 第五章 几何分类器专题
研究目的和意义
5.3 线性判别函数的实现
02
内容纲要
研究目的和意义
还记得吗?
第二章到第四章在概率密度和概率函数的基础 上设计分类器。
04
内容纲要
研究目的和意义
直接使用Bayes决策首先需要知道有关样品总体 分布的知识,包括各类先验概率 P(1 ) 、
类条件概率密度函数和样品的后验概率 P(1 | X ) , 并以此作为产生判别函数的必要依据,设计出相应 的判别函数与决策面,这种方法称为参数判别方法。
FISHER分类

Fisher 线性判别分类器成员姓名: 学号:莫文敏 201111921217 赵越 201111921229 顾瑞煌 201111921104一、实验目的1.实现基于FISHER 分类的算法程序;2.能够根据自己的设计加深对FISHER 分类的认识;3.掌握FISHER 分类的原理、特点。
二、实验设备1.手提电脑2.MATLAB三、FISHER 算法原理线性判别函数的一般形式可表示成0)(w X W X g T +=其中⎪⎪⎪⎭⎫ ⎝⎛=d x x X 1 ⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=d w w w W 21但是,在应用统计方法解决模式识别的问题时,经常会遇到“维数风暴”的问题,因此压缩特征空间的维数在此时十分重要,FISHER 方法实际上是涉及维数压缩的问题。
把多为特征空间的点投影到一条直线上,就能把特征空间压缩成一维,这在数学上是很容易做到的。
但是在高维空间里很容易一分开的样品,把它们投射到任意一条直线上,有可能不同类别的样品就混在一起,无法区分了,如图5-16(a )所示,投影1x 或2x 轴无法区分。
若把直线绕原点转动一下,就有可能找到一个方向,样品投射到这个方向的直线上,各类样品就能很好地分开,如图5-16(b )所示。
因此直线方向的选择是很重要的。
一般来说总能找到一个最好的方向,使样品投射到这个方向的直线上很容易分开。
如何找到这个最好的直线方向以及如何实现向最好方向投影的变换,这正是FISHER 算法要解决的基本问题,这个投影变换正是我们寻求的解向量*W 。
样品训练集以及待测样品的特征总数目为n ,为找到最佳投影方向,需要计算出各类样品的均值、样品类内离散度矩阵i S 和总类间矩阵w S 、样品类间离散度矩阵b S ,根据FISHER 准则找到最佳投影向量,将训练集内所有样品进行投影,投影到一维Y 空间,由于Y 空间是一维的,则需要求出Y 空间的划分边界点,找到边界点后,就可以对待测样品进行一维Y 空间的投影,判断它的投影点与分界点的关系将其归类。
基于Fisher的线性判别回归分类算法

基于Fisher的线性判别回归分类算法曾贤灏;石全民【摘要】To improve the robustness of the linear regression classification (LRC) algorithm, a linear discrimi⁃nant regression classification algorithm based on Fisher criterion is proposed. The ratio of the between-classre⁃construction error over the within-class reconstruction error is maximized by Fisher criterion so as to find an opti⁃mal projection matrixfor the LRC. Then, all testing and training images are projected to each subspace by the op⁃timal projection matrix and Euclidean distances between testing image and all training images are computed. Fi⁃nally, K-nearest neighbor classifier is used to finish face recognition . Experimental results on AR face databases show that proposed method has better recognition effects than several other regression classification approaches.%为了提高线性回归分类(LRC)算法的鲁棒性,提出了一种基于Fisher准则的线性判别回归分类算法。
模式识别答案

模式识别答案模式识别试题⼆答案问答第1题答:在模式识别学科中,就“模式”与“模式类”⽽⾔,模式类是⼀类事物的代表,概念或典型,⽽“模式”则是某⼀事物的具体体现,如“⽼头”是模式类,⽽王先⽣则是“模式”,是“⽼头”的具体化。
问答第2题答:Mahalanobis距离的平⽅定义为:其中x,u为两个数据,是⼀个正定对称矩阵(⼀般为协⽅差矩阵)。
根据定义,距某⼀点的Mahalanobis距离相等点的轨迹是超椭球,如果是单位矩阵Σ,则Mahalanobis距离就是通常的欧⽒距离。
问答第3题答:监督学习⽅法⽤来对数据实现分类,分类规则通过训练获得。
该训练集由带分类号的数据集组成,因此监督学习⽅法的训练过程是离线的。
⾮监督学习⽅法不需要单独的离线训练过程,也没有带分类号(标号)的训练数据集,⼀般⽤来对数据集进⾏分析,如聚类,确定其分布的主分量等。
就道路图像的分割⽽⾔,监督学习⽅法则先在训练⽤图像中获取道路象素与⾮道路象素集,进⾏分类器设计,然后⽤所设计的分类器对道路图像进⾏分割。
使⽤⾮监督学习⽅法,则依据道路路⾯象素与⾮道路象素之间的聚类分析进⾏聚类运算,以实现道路图像的分割。
问答第4题答:动态聚类是指对当前聚类通过迭代运算改善聚类;分级聚类则是将样本个体,按相似度标准合并,随着相似度要求的降低实现合并。
问答第5题答:在给定观察序列条件下分析它由某个状态序列S产⽣的概率似后验概率,写成P(S|O),⽽通过O求对状态序列的最⼤似然估计,与贝叶斯决策的最⼩错误率决策相当。
问答第6题答:协⽅差矩阵为,则1)对⾓元素是各分量的⽅差,⾮对⾓元素是各分量之间的协⽅差。
2)主分量,通过求协⽅差矩阵的特征值,⽤得,则,相应的特征向量为:,对应特征向量为,对应。
这两个特征向量即为主分量。
3) K-L变换的最佳准则为:对⼀组数据进⾏按⼀组正交基分解,在只取相同数量分量的条件下,以均⽅误差计算截尾误差最⼩。
4)在经主分量分解后,协⽅差矩阵成为对⾓矩阵,因⽽各主分量间相关消除。
《模式识别》课程实验 线性分类器设计实验

《模式识别》课程实验线性分类器设计实验一、实验目的:1、掌握Fisher 线性分类器设计方法;2、掌握感知准则函数分类器设计方法。
二、实验内容:1、对下列两种情况,求采用Fisher 判决准则时的投影向量和分类界面,并做图。
12{(2,0),(2,2),(2,4),(3,3)}{(0,3),(2,2),(1,1),(1,2),(3,1)}T T T T T T T T T ωω⎧=⎪⎨=-----⎪⎩ 12{(1,1),(2,0),(2,1),(0,2),(1,3)}{(1,2),(0,0),(1,0),(1,1),(0,2)}T T T T T T T T T T ωω⎧=⎪⎨=-----⎪⎩ 2、对下面的两类分类问题,采用感知准则函数,利用迭代修正求权向量的方法求两类的线性判决函数及线性识别界面,并画出识别界面将训练样本区分的结果图。
12{(1,1),(2,0),(2,1),(0,2),(1,3)}{(1,2),(0,0),(1,0),(1,1),(0,2)}T T T T T T T T T T ωω⎧=⎪⎨=-----⎪⎩ 三、实验原理:(1)Fisher 判决准则投影方向:*112()w w S μμ-=-(2)感知准则函数:()()kT p z Z J v v z ==-∑当k Z为空时,即()0J v ,*v即为所求p四、解题思路:1、fisher线性判决器:A.用mean函数求两类样本的均值B.求两类样本的均值的类内离散矩阵SiC.利用类内离散矩阵求总类内离散矩阵SwD.求最佳投影方向WoE.定义阈值,并求得分界面2、感知准则函数分类器:A.获得增广样本向量和初始增广权向量B.对样本进行规范化处理C.获得解区,并用权向量迭代修正错分样本集,得到最终解区五、实验结果:1、fisher线性判决分类器:条件:取pw1=pw2=0.5,阈值系数为0.5A.第一种情况B.第二种情况2、感知准则函数判决:条件:取步长row为1判决结果:六、结果分析:1、fisher线性判决器中,调整阈值系数时,分界面会随之平行上下移动,通过调整阈值系数的大小,就能比较合理的得到分界面。
fisher线性判别

fisher线性判别
fisher 判决⽅式是监督学习,在新样本加⼊之前,已经有了原样本。
原样本是训练集,训练的⽬的是要分类,也就是要找到分类线。
⼀⼑砍成两半!
当样本集确定的时候,分类的关键就在于如何砍下这⼀⼑!
若以⿊⾊的来划分,很明显不合理,以灰⾊的来划分,才是看上去合理的
1.先确定砍的⽅向
关键在于如何找到投影的向量u,与u的长度⽆关。
只看⽅向
找到样本点的中⼼均值m1,m2,以及在向量u上的投影的m1~,m2~。
因为u的⽅向与样本点都有关,所以需要考虑⼀个含有所有样本点的表达式
不妨算出离差阵
算出类内离差矩阵,两个都要求出来,并求和
并且投影的离差阵
根据聚类的理想情况,类内距离⼩,类间距离⼤,所以就⽤类间去处理类内,我们现在的变量是向量u,我们就对u求导,算出max存在的时后u的条件。
为了⽅便化简,引⼊⼀个参数不要以为下⾯除以是向量,(1*2)*(2*2)(2*1)=1 维度变成1,这是⼀个常数。
当求导公式
分⼦为0的时候,推出
所以
⽽且是(1*2)*(2*1)等于1,也是⼀个常数
到此为⽌,u的⽅向已经确定了
2.具体切哪⼀个点。
a,切
切投影均值的终点
2.
切贝叶斯概率的⽐例点
⽅向和具体点均已找到,分析完毕。
FISHER分类器(FISHER
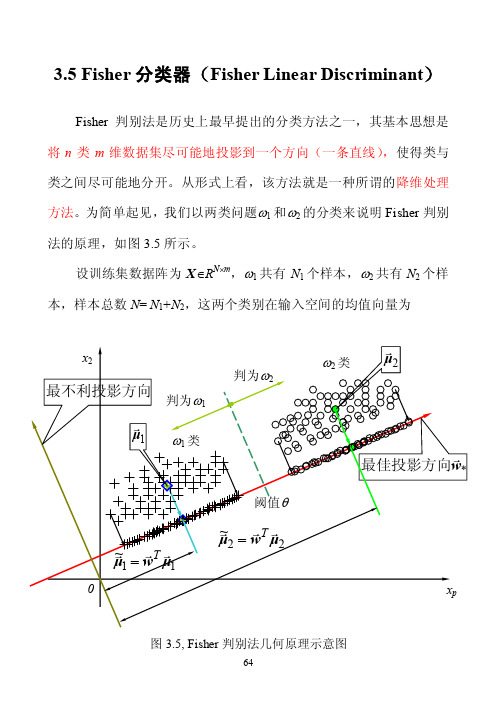
3.5 Fisher分类器(Fisher Linear Discriminant)Fisher判别法是历史上最早提出的分类方法之一,其基本思想是将n类m维数据集尽可能地投影到一个方向(一条直线),使得类与类之间尽可能地分开。
从形式上看,该方法就是一种所谓的降维处理方法。
为简单起见,我们以两类问题ω1和ω2的分类来说明Fisher判别法的原理,如图3.5所示。
设训练集数据阵为X∈R N⨯m,ω1共有N1个样本,ω2共有N2个样本,样本总数N= N1+N2,这两个类别在输入空间的均值向量为图3.5, Fisher判别法几何原理示意图)37.3(11212211⎪⎪⎩⎪⎪⎨⎧∈=∈=∑∑∈∈m p m p R N R N pp ωωx xx μx μ设有一个投影方向()mT m R w w w ∈=,...,,21w ,这两个均值向量在该方向的投影为)38.3(1~1~1222111121⎪⎪⎩⎪⎪⎨⎧∈==∈==∑∑∈∈R N R N pp p T T p T T ϖϖx xx w μw μx w μw μ(3-38)表示的是两个数。
在w方向,两均值之差为())39.3(~~2121μμw μμ -=-=∇T类似地,样本总均值向量在该方向的投影为)40.3(1~11R NNp p T T ∈==∑=x w μw μ定义类间散度(Between-class scatter )平方和SS B 为()()()()()()()()()[])41.3(~~~~~~222111222211221222211wS w w μμμμμμμμw μw μw μw μw μμμμμμ B T T T T T T T T j j j B N N N N N N N SS =--+--=-+-=-=-+-=∑=其中,类间散度阵为()()()()()())42.3(21222111∑=--=--+--=j T j j j TT B N N N μμμμμμμμμμμμS若将所有样本用所在类别的均值所代表,则类间散度平方和SS B 为这N 个均值到训练集总均值在最佳投影方向上投影之差的平方和。
线性判别函数-Fisher

任意x,在H上投影 xp X与xp距离r
多类的情况:
将c类问题转化为c个两类问题,有c个判别函数。
把ωi作为一类,其余作为一类,构建c个超平面
更复杂一些,用C(C-1)/2个线性判别函数进行判别。
判别函数和决策面:
超平面Hij的法向量 决策规则:对一切i ≠ j有gi(x)>gj(x),则把x归为ωi类。
线性判别函数的齐次简化
令x0=1则:
增广特征向量
增广权向量
一个三维增广特征空间y和增广权向量a(在原点)
这是广义线性判别函数的一个特例。y与x相比, 虽然增加了一维,但保持了样本间的欧式距离不变。
变换得到的y向量仍然都在d维的子空间中,即原X 空间中,方程aTy=0在Y空间确定了一个通过原点 的超平面H’,它对d维子空间的划分与原决策面 wTx+w0=0对原X空间的划分完全相同。
映射y把一条直线映射为三维空间中的一条抛物线01122123321xcyayyaacxyac????????????????????????????????????????????22gxccxcx令
线性判别函数
已知条件
贝叶斯决策
实际问题
条件未知
利用样本集直接设计分类器,即给定某个判别函 数类,然后利用样本集确定出判别函数中的未知 参数。
N个d维样本x , x ,...x ,
1
2
N
其中: X : N 个属于 的样本集
1
1
1
X : N 个属于 的样本集
2
2
2
对xn的分量作线性组合:
y wT x , n 1,2,..., N
n
Fisher分类算法

m i 首先求各类样本均值向量N i xx,i 1,2i然后求各个样本的来内离散度矩阵再求出样本的总类内离散度根据公式1s m1m2再求出一维Y空间中各类样本均值S i x m ix W j求出把m is1 pX投影到m T,i 1,2S2Y的最好的投影方向。
y,i 1,2N i y i ,其中y实验二用身高和/或体重数据进行性别分类的实验一、实验目的1)加深对Fisher线性判别方法原理的理解和认识2)掌握Fisher线性判别方法的设计方法、实验数据训练样本集FAMALE.TXT 50个女生的身高、体重数据MALE.TXT 50个男生的身高、体重数据测试样本集test1.txt 35个同学的身高、体重、性别数据(15个女生、20个男生)test2.txt 300个同学的身高、体重、性别数据(50个女生、250个男生)三、实验内容试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分类器进行比较。
同时采用身高和体重数据作为特征,用Fisher线性判别方法求分类器,将该分类器应用到训练和测试样本,考察训练和测试错误情况。
将训练样本和求得的决策边界画到图上,同时把以往用Bayes方法求得的分类器(例如:最小错误率Bayes分类器)也画到图上,比较结果的异同。
四、原理简述、程序流程图1、Fisher线性判别方法Mm, N2m2'y o - -N1N2本次实验的分界阈值我们用如下方法得到:最后,将测试样本中的值代入,求出y,并将其与y0来进行比较来分类。
2、流程图五、实验结果时,其错误率较高,测试结果不好。
2、Fisher判别方法图像X分析:从图中我们可以直观的看出对训练样本Fisher判别比最大似然Bayes判别效果更好。
六、总结与分析本次实验使我们对加深Fisher判别法的理解。
通过两种分类方法的比较,我们对于同一种可以有很多不同的分类方法,各个分类方法各有优劣,所以我们更应该熟知这些已经得到充分证明的方法,在这些方法的基础上通过自己的理解,创造出更好的分类方法。
Fisher准则线性分类器设计

一 、基于F i s h e r 准则线性分类器设计1、 实验内容:已知有两类数据1ω和2ω二者的概率已知1)(ωp =0.6,2)(ωp =0.4。
1ω中数据点的坐标对应一一如下:数据:x =0.2331 1.5207 0.6499 0.7757 1.0524 1.1974 0.2908 0.2518 0.6682 0.5622 0.9023 0.1333 -0.5431 0.9407 -0.2126 0.0507 -0.0810 0.7315 0.3345 1.0650 -0.0247 0.1043 0.3122 0.6655 0.5838 1.1653 1.2653 0.8137 -0.3399 0.5152 0.7226 -0.2015 0.4070 -0.1717 -1.0573 -0.2099 y =2.3385 2.1946 1.6730 1.6365 1.7844 2.0155 2.0681 2.1213 2.4797 1.5118 1.9692 1.8340 1.8704 2.2948 1.7714 2.3939 1.5648 1.9329 2.2027 2.4568 1.7523 1.6991 2.4883 1.7259 2.0466 2.0226 2.3757 1.7987 2.0828 2.0798 1.9449 2.3801 2.2373 2.1614 1.9235 2.2604 z =0.5338 0.8514 1.0831 0.4164 1.1176 0.5536 0.6071 0.4439 0.4928 0.5901 1.0927 1.0756 1.0072 0.4272 0.4353 0.9869 0.4841 1.09921.02990.71271.01240.45760.85441.12750.77050.41291.00850.76760.84180.87840.97510.78400.41581.03150.75330.9548数据点的对应的三维坐标为2x2 =1.40101.23012.08141.16551.37401.18291.76321.97392.41522.58902.84721.95391.25001.28641.26142.00712.18311.79091.33221.14661.70871.59202.93531.46642.93131.83491.83402.50962.71982.31482.03532.60301.23272.14651.56732.9414 y2 =1.02980.96110.91541.49010.82000.93991.14051.06780.80501.28891.46011.43340.70911.29421.37440.93871.22661.18330.87980.55920.51500.99830.91200.71261.28331.10291.26800.71401.24461.33921.18080.55031.47081.14350.76791.1288 z2 =0.62101.36560.54980.67080.89321.43420.95080.73240.57841.49431.09150.76441.21591.30491.14080.93980.61970.66031.39281.40840.69090.84000.53811.37290.77310.73191.34390.81420.95860.73790.75480.73930.67390.86511.36991.1458数据的样本点分布如下图:1)请把数据作为样本,根据Fisher选择投影方向W的原则,使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求,求出评价投影方向W的函数,并在图形表示出来。
Fisher线性分类

Sw S1 S2
T
•
3.
样本类间离散度矩阵Sb:
Sb (m1 m2 )(m1 m2 )
离散矩阵在形式上与协方差矩阵很相似,但协方 差矩阵是一种期望值,而离散矩阵只是表示有限 个样本在空间分布的离散程度
一维Y空间样本分布的描述量
1. • 2. 各类样本均值
1 mi Ni
•
只要给出待分类的模式特征的数值, 看它在特征平面上落在判别函数的哪一 侧,就可以判别是男还是女了。
统计方法(判别分析)
判别分析—在已知研究对象分成若干类型, 并已取得各种类型的一批已知样品的观测数 据,在此基础上根据某些准则建立判别式, 然后对未知类型的样品进行判别分类。 距离判别法—首先根据已知分类的数据,分 别计算各类的重心,计算新个体到每类的距 离,确定最短的距离(欧氏距离、马氏距离) Fisher判别法—利用已知类别个体的指标构 造判别式(同类差别较小、不同类差别较 大),按照判别式的值判断新个体的类别.
的投影
中心
中心
Fisher准则的基本原理
找到一个最合适的投影轴,使两 类样本在该轴上投影之间的距离尽 可能远,而每一类样本的投影尽可 能紧凑,从而使两类分类效果为最 佳。
Fisher线性判别图例
x2 w
1
Fisher 判别
维空间样本分布的描述量fisherfisher判别判别离散矩阵在形式上与协方差矩阵很相似但协方差矩阵是一种期望值而离散矩阵只是表示有限个样本在空间分布的离散程度一维y空间样本分布的描述量fisherfisher判别判别以上定义描述d维空间样本点到一向量投影的分散情况因此也就是对某向量w的投影在w上的分布
fisher判别式

(4.5-14)
L 对 w 求偏导数:
L( w, ) 2( Sb w S w w) w
令
L( w, ) 0 得到: w
Sb w* S w w*
(4.5-15)
S w 是 d 维特征的样本协方差矩阵, 它是对称的和半正定的。 当样本数目 n 从上述推导(4.5-10)~(4.5-12)可知,
(4.5-6)
m2 |2 || wT M 1 wT M 2 ||2 || wT ( M 1 M 2 ) ||2
wT ( M 1 M 2 )( M 1 M 2 )T w wT Sb w
(4.5-7) (4.5-8)
其中: Sb
( M 1 M 2 )( M 1 M 2 )T
Mi
1 ni 1 ni
xk X i
x
k
,i
1,2
(4.5-2)
通过变换 w 映射到一维特征空间后,各类的平均值为:
mi
y k Yi
y
k
,i
1,2
(4.5-3)
映射后,各类样本“类内离散度”定义为:
Si2 ( yk mi )2 , i 1,2
yk Yi
1
(4.5-4)
*
1,2,...., n) 其中 n1 个样本来自 wi 类型, n2 个样本来自 w j 类
n1 n2 。两个类型的训练样本分别构成训练样本的子集 X 1 和 X 2 。
令:
yk wT xk , k 1,2,..., n
(4.5-1)
yk 是向量 xk 通过变换 w 得到的标量,它是一维的。实际上,对于给定的 w , yk 就是判决函数的值。
模式识别习题集

模式识别习题Part 2CH41.线性分类器的分界面是超平面,线性分类器设计步骤是什么?2.Fisher线性判别函数是研究这类判别函数中最有影响的方法之一,请简述它的准则.3.感知器的准则函数是什么?它通过什么方法得到最优解?4.(1)指出从x到超平面g(x)=(w T x+w0=0)的距离r=|g(x)|是在||w|| g(x q)=0的约束条件下,使||x−x q||2达到极小解;w(2)指出在超平面上的投影是x p=x−g(x)||w||2(《模式识别》第二版,边肇祺,pp.117 4.1) 5.设有一维空间二次判别函数g(x)=5+7x+9x2(1)试映射成广义齐次线性判别函数;(2)总结把高次函数映射成齐次线性函数的方法。
(《模式识别》第二版,边肇祺,pp.117 4.2) 6.(1)通过映射把一维二次判别函数g(x)=a1+a2x+a3x2映射成三维广义线性判别函数;(2)若x在一维空间具有分布密度p(x),说明三维空间中的分布退化成只在一条曲线上有值,且曲线上值无穷大。
(《模式识别》第二版,边肇祺,pp.117 4.3)7.对于二维线性判别函数g(x)=x1+2x2−2(1)将判别函数写成g(x)=w T x+w0的形式,并画出g(x)=0的几何图形;(2)映射成广义齐次线性函数g(x)=a T y;(3)指出上述X空间实际是Y空间的一个子空间,且a T y=0对于X子空间的划分和原空间中w T+w0=0对原X空间的划分相同,并在图上表示出来。
8.指出在Fisher线性判别中,w的比例因子对Fisher判别结果无影响。
9.证明在正态等方差条件下,Fisher线性判别等价于贝叶斯判别。
10.考虑准则函数J(a)=∑(a T y−b)2y∈Y(a)其中Y(a)是使a T y≤b的样本集合。
设y1是Y(a)中的唯一样本,则J(a)的梯度为∇J(a)=2(a k T y1−b)y1,二阶偏导数矩阵D=2y1y1T。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
作业二 F i s h e r
线性判别分类器
一 实验目的 本实验旨在让同学进一步了解分类器的设计概念,能够根据自己的设计对线性分类器有更深刻地认识,理解Fisher 准则方法确定最佳线性分界面方法的原理,以及Lagrande 乘子求解的原理。
二 实验条件
Matlab 软件
三 实验原理
线性判别函数的一般形式可表示成
0)(w X W X g T
+= 其中
根据Fisher 选择投影方向W 的原则,即使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求,用以评价投影方向W 的函数为:
)(211*m m S W W -=- 上面的公式是使用Fisher 准则求最佳法线向量的解,该式比较重要。
另外,该式这种形式的运算,我们称为线性变换,其中21m m -式一个向量,1-W S 是W S 的逆矩阵,如21m m -是d 维,W S 和1
-W S 都
是d ×d 维,得到的*W 也是一个d 维的向量。
向量*W 就是使Fisher 准则函数)(W J F 达极大值的解,也就是按Fisher 准则将d 维X 空间投影到一维Y 空间的最佳投影方向,该向量*W 的各分量值是对原d 维特征向量求加权和的权值。
以上讨论了线性判别函数加权向量W 的确定方法,并讨论了使Fisher 准则函数极大的d 维向量*
W 的计算方法,但是判别函数中的另一项0W 尚未确定,一般可采用以下几种方法确定0W 如 或者 m N N m N m N W ~~~2
122110=++-= 或当1)(ωp 与2)(ωp 已知时可用
当W 0确定之后,则可按以下规则分类,
201
0ωω∈→-<∈→->X w X W X w X W T T
四 实验程序及结果分析
%w1中数据点的坐标
x1 =[
];
x2 =[
];
x3 =[
];
%将x1、x2、x3变为行向量
x1=x1(:);x2=x2(:);x3=x3(:);
%计算第一类的样本均值向量m1
m1(1)=mean(x1);m1(2)=mean(x2);m1(3)=mean(x3);
%计算第一类样本类内离散度矩阵S1
S1=zeros(3,3);
for i=1:36
S1=S1+[-m1(1)+x1(i) -m1(2)+x2(i) -m1(3)+x3(i)]'*[-m1(1)+x1(i) -m1(2)+x2(i)
-m1(3)+x3(i)];
end
%w2的数据点坐标
x4 =[
];
x5 =[
];
x6 =[
];
x4=x4(:);x5=x5(:);x6=x6(:);
%计算第二类的样本均值向量m2
m2(1)=mean(x4);m2(2)=mean(x5);m2(3)=mean(x6);
%计算第二类样本类内离散度矩阵S2
S2=zeros(3,3);
for i=1:36
S2=S2+[-m2(1)+x4(i) -m2(2)+x5(i) -m2(3)+x6(i)]'*[-m2(1)+x4(i) -m2(2)+x5(i) -m2(3)+x6(i)];
end
%总类内离散度矩阵Sw
Sw=zeros(3,3);
Sw=S1+S2;
%样本类间离散度矩阵Sb
Sb=zeros(3,3);
Sb=(m1-m2)'*(m1-m2);
%最优解W
W=Sw^-1*(m1-m2)'
%将W变为单位向量以方便计算投影
W=W/sqrt(sum(W.^2));
%计算一维Y空间中的各类样本均值M1及M2
for i=1:36
y(i)=W'*[x1(i) x2(i) x3(i)]';
end
M1=mean(y)
for i=1:36
y(i)=W'*[x4(i) x5(i) x6(i)]';
end
M2=mean(y)
%利用当P(w1)与P(w2)已知时的公式计算W0
p1=;p2=;
W0=-(M1+M2)/2+(log(p2/p1))/(36+36-2);
%计算将样本投影到最佳方向上以后的新坐标
X1=[x1*W(1)+x2*W(2)+x3*W(3)]';
X2=[x4*W(1)+x5*W(2)+x6*W(3)]';%得到投影长度
XX1=[W(1)*X1;W(2)*X1;W(3)*X1];
XX2=[W(1)*X2;W(2)*X2;W(3)*X2];%得到新坐标
%绘制样本点
figure(1)
plot3(x1,x2,x3,'r*') %第一类
hold on
plot3(x4,x5,x6,'bp') %第二类
legend('第一类点','第二类点')
title('Fisher 线性判别曲线')
W1=5*W;
%画出最佳方向
line([-W1(1),W1(1)],[-W1(2),W1(2)],[-W1(3),W1(3)],'color','b');
%判别已给点的分类
a1=[1,,]';a2=[,,]';a3=[,,]';a4=[,,]';a5=[,,]';
A=[a1 a2 a3 a4 a5]
n=size(A,2);
%下面代码在改变样本时都不必修改
%绘制待测数据投影到最佳方向上的点
for k=1:n
A1=A(:,k)'*W;
A11=W*A1;%得到待测数据投影
y=W'*A(:,k)+W0;%计算后与0相比以判断类别,大于0为第一类,小于0为第二类 if y>0 plot3(A(1,k),A(2,k),A(3,k),'go'); %点为"rp"对应第一类
plot3(A11(1),A11(2),A11(3),'go'); %投影为"r+"对应go 类
else
plot3(A(1,k),A(2,k),A(3,k),'m+'); %点为"bh"对应m+类
plot3(A11(1),A11(2),A11(3),'m+'); %投影为"b*"对应m+类
end
end
%画出最佳方向
line([-W1(1),W1(1)],[-W1(2),W1(2)],[-W1(3),W1(3)],'color','k');
view([,30]);
axis([-2,3,-1,3,,]);
grid on
hold off
实验结果和数据:
首先根据求出最佳投影方向,然后按照此方向,将待测数据进行投影 。
数据的样本点分布如下: 其中,红色的*是给出的第一类样本点,蓝色的五角星是第二类样本点。
下方的实直线是最佳投影方向。
待测数据投影在其上,圆圈是被分为第一类的样本点,十字是被分为第二类的样本点。
使)(w J F 取极大值的W =( , , )
实验分析:
W 的比例因子对于Fisher 判别函数没有影响的原因:
在本实验中,最需要的是W 的方向,或者说是在此方向上数据的投影,那么W 的比例因子,即它是单位向量的多少倍长就无关紧要了,不管比例因子有多大,在最后求投影时都会被消掉而起不到实际作用。