统计学第四版答案(贾俊平)
统计学第四版答案(贾俊平)知识分享

统计学第四版答案(贾俊平)请举出统计应用的几个例子:1、用统计识别作者:对于存在争议的论文,通过统计量推出作者2、用统计量得到一个重要发现:在不同海域鳗鱼脊椎骨数量变化不大,推断所有各个不同海域内的鳗鱼是由海洋中某公共场所繁殖的3、挑战者航天飞机失事预测请举出应用统计的几个领域:1、在企业发展战略中的应用2、在产品质量管理中的应用3、在市场研究中的应用④在财务分析中的应用⑤在经济预测中的应用你怎么理解统计的研究内容:1、统计学研究的基本内容包括统计对象、统计方法和统计规律。
2、统计对象就是统计研究的课题,称谓统计总体。
3、统计研究方法主要有大量观察法、数量分析法、抽样推断法、实验法等。
④统计规律就是通过大量观察和综合分析所揭示的用数量指标反映的客观现象的本质特征和发展规律。
举例说明分类变量、顺序变量和数值变量:分类变量:表现为不同类别的变量称为分类变量,如“性别”表现为“男”或“女”,“企业所属的行业”表现为“制造业”、“零售业”、“旅游业”等,“学生所在的学院”可能是“商学院”、“法学院”等顺序变量:如果类别有一定的顺序,这样的分类变量称为顺序变量,如考试成绩按等级分为优、良、中、及格、不及格,一个人对事物的态度分为赞成、中立、反对。
这里的“考试成绩等级”、“态度”等就是顺序变量。
数值变量:可以用数字记录其观察结果,这样的变量称为数值变量,如“企业销售额”、“生活费支出”、“掷一枚骰子出现的点数”。
定性数据和定量数据的图示方法各有哪些:1、定性数据的图示:条形图、帕累托图、饼图、环形图2、定量数据的图示:a、分组数据看分布:直方图b、未分组数据看分布:茎叶图、箱线图、垂线图、误差图c、两个变量间的关系:散点图d、比较多个样本的相似性:雷达图和轮廓图直方图与条形图有何区别:1、条形图中的每一个矩形表示一个类别,其宽度没有意义,而直方图的宽度则表示各组的组距。
2、由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。
最新统计学第四版答案(贾俊平)

请举出统计应用的几个例子:1、用统计识别作者:对于存在争议的论文,通过统计量推出作者2、用统计量得到一个重要发现:在不同海域鳗鱼脊椎骨数量变化不大,推断所有各个不同海域内的鳗鱼是由海洋中某公共场所繁殖的3、挑战者航天飞机失事预测请举出应用统计的几个领域:1、在企业发展战略中的应用2、在产品质量管理中的应用3、在市场研究中的应用④在财务分析中的应用⑤在经济预测中的应用你怎么理解统计的研究内容:1、统计学研究的基本内容包括统计对象、统计方法和统计规律。
2、统计对象就是统计研究的课题,称谓统计总体。
3、统计研究方法主要有大量观察法、数量分析法、抽样推断法、实验法等。
④统计规律就是通过大量观察和综合分析所揭示的用数量指标反映的客观现象的本质特征和发展规律。
举例说明分类变量、顺序变量和数值变量:分类变量:表现为不同类别的变量称为分类变量,如“性别”表现为“男”或“女”,“企业所属的行业”表现为“制造业”、“零售业”、“旅游业”等,“学生所在的学院”可能是“商学院”、“法学院”等顺序变量:如果类别有一定的顺序,这样的分类变量称为顺序变量,如考试成绩按等级分为优、良、中、及格、不及格,一个人对事物的态度分为赞成、中立、反对。
这里的“考试成绩等级”、“态度”等就是顺序变量。
数值变量:可以用数字记录其观察结果,这样的变量称为数值变量,如“企业销售额”、“生活费支出”、“掷一枚骰子出现的点数”。
定性数据和定量数据的图示方法各有哪些:1、定性数据的图示:条形图、帕累托图、饼图、环形图2、定量数据的图示:a、分组数据看分布:直方图b、未分组数据看分布:茎叶图、箱线图、垂线图、误差图c、两个变量间的关系:散点图d、比较多个样本的相似性:雷达图和轮廓图直方图与条形图有何区别:1、条形图中的每一个矩形表示一个类别,其宽度没有意义,而直方图的宽度则表示各组的组距。
2、由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。
统计学贾俊平-第四版课后习题答案

3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图. 1、确定组数:()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103n K =+=+=+=,取k=62、确定组距:组距=< 最大值 - 最小值>÷ 组数=〔49-25〕÷6=4,取5(1) 对这个年龄分布作直方图;(2) 从直方图分析成人自学考试人员年龄分布的特点. 解:〔1〕制作直方图:将上表复制到Excel 表中,点击:图表向导→柱形图→选择子图表类型→完成.即得到如下的直方图:<见Excel 练习题2.6>〔2〕年龄分布的特点:自学考试人员年龄的分布为右偏. 解:3.12 甲乙两个班各有40名学生,期末统计学考试成绩的分布如下:要求:<1>根据上面的数据,画出两个班考试成绩的对比条形图和环形图.3.14 已知1995—20##我国的国内生产总值数据如下<按当年价格计算>:<2>绘制第一、二、三产业国内生产总值的线图.4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量<单位:台>排序后如下:2 4 7 10 10 10 12 12 14 15要求:〔1〕计算汽车销售量的众数、中位数和平均数.<2>根据定义公式计算四分位数.<3>计算销售量的标准差.<4>说明汽车销售量分布的特征.解:Statistics汽车销售数量N Valid 10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.0075 12.504.3 某银行为缩短顾客到银行办理业务等待的时间.准备采用两种排队方式进行试验:一种是所有颐客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待.为比较哪种排队方式使顾客等待的时间更短.两种排队方式各随机抽取9名顾客.得到第一种排队方式的平均等待时间为7.2分钟,标准差为1.97分钟.第二种排队方式的等待时间<单位:分钟>如下:5.5 6.6 6.7 6.8 7.1 7.3 7.4 7.8 7.8要求:<1>画出第二种排队方式等待时间的茎叶图.第二种排队方式的等待时间<单位:分钟> Stem-and-Leaf PlotFrequency Stem & Leaf1.00 Extremes <=<5.5>3.00 6 . 6783.00 7 . 1342.00 7 . 88Stem width: 1.00Each leaf: 1 case<s><2>计算第二种排队时间的平均数和标准差.Mean7Std. Deviation0.714143Variance0.51<3>比较两种排队方式等待时间的离散程度.第二种排队方式的离散程度小.<4>如果让你选择一种排队方式,你会选择哪—种?试说明理由.选择第二种,均值小,离散程度小.要求:<1>计算120家企业利润额的平均数和标准差.<2>计算分布的偏态系数和峰态系数.解:Statistics企业利润组中值Mi〔万元〕N Valid 120Missing 0Mean 426.6667Std. Deviation 116.48445Skewness 0.208Std. Error of Skewness 0.221Kurtosis -0.625Std. Error of Kurtosis 0.4384.7 为研究少年儿童的成长发育状况,某研究所的一位调查人员在某城市抽取100名7~17岁的少年儿童作为样本,另一位调查人员则抽取了1 000名7~17岁的少年儿童作为样本.请回答下面的问题,并解释其原因.<1>两位调查人员所得到的样本的平均身高是否相同?如果不同,哪组样本的平均身高较大?<2>两位调查人员所得到的样本的标准差是否相同?如果不同,哪组样本的标准差较大?<3>两位调查人员得到这l 100名少年儿童身高的最高者或最低者的机会是否相同?如果不同,哪位调查研究人员的机会较大?解:〔1〕不一定相同,无法判断哪一个更高,但可以判断,样本量大的更接近于总体平均身高.〔2〕不一定相同,样本量少的标准差大的可能性大.〔3〕机会不相同,样本量大的得到最高者和最低者的身高的机会大.4.8 一项关于大学生体重状况的研究发现.男生的平均体重为60kg,标准差为5kg;女生的平均体重为50kg,标准差为5kg.请回答下面的问题:<1>是男生的体重差异大还是女生的体重差异大?为什么?女生,因为标准差一样,而均值男生大,所以,离散系数是男生的小,离散程度是男生的小.<2>以磅为单位<1ks=2.2lb>,求体重的平均数和标准差.都是各乘以2.21,男生的平均体重为60kg×2.21=132.6磅,标准差为5kg×2.21=11.05磅;女生的平均体重为50kg×2.21=110.5磅,标准差为5kg×2.21=11.05磅.<3>粗略地估计一下,男生中有百分之几的人体重在55kg一65kg之间?计算标准分数:Z1=x xs-=55605-=-1;Z2=x xs-=65605-=1,根据经验规则,男生大约有68%的人体重在55kg一65kg之间.<4>粗略地估计一下,女生中有百分之几的人体重在40kg~60kg之间?计算标准分数:Z1=x xs-=40505-=-2;Z2=x xs-=60505-=2,根据经验规则,女生大约有95%的人体重在40kg一60kg之间.4.9 一家公司在招收职员时,首先要通过两项能力测试.在A项测试中,其平均分数是100分,标准差是15分;在B项测试中,其平均分数是400分,标准差是50分.一位应试者在A项测试中得了115分,在B项测试中得了425分.与平均分数相比,该应试者哪一项测试更为理想?解:应用标准分数来考虑问题,该应试者标准分数高的测试理想.Z A=x xs-=11510015-=1;Z B=x xs-=42540050-=0.5因此,A项测试结果理想.4.10 一条产品生产线平均每天的产量为3 700件,标准差为50件.如果某一天的产量低于或高于平均产量,并落人士2个标准差的X围之外,就认为该生产线"失去控制〞.下面是4.13 在金融证券领域,一项投资的预期收益率的变化通常用该项投资的风险来衡量.预期收益率的变化越小,投资风险越低;预期收益率的变化越大,投资风险就越高.下面的两个直方图,分别反映了200种商业类股票和200种高科技类股票的收益率分布.在股票市场上,高收益率往往伴随着高风险.但投资于哪类股票,往往与投资者的类型有一定关系.<1>你认为该用什么样的统计量来反映投资的风险? 标准差或者离散系数.<2>如果选择风险小的股票进行投资,应该选择商业类股票还是高科技类股票? 选择离散系数小的股票,则选择商业股票.<3>如果进行股票投资,你会选择商业类股票还是高科技类股票? 考虑高收益,则选择高科技股票;考虑风险,则选择商业股票. 解:〔1〕方差或标准差;〔2〕商业类股票;〔3〕〔略〕.7.1 从一个标准差为5的总体中抽出一个容量为40的样本,样本均值为25.(1) 样本均值的抽样标准差x σ等于多少?(2) 在95%的置信水平下,允许误差是多少?解:已知总体标准差σ=5,样本容量n =40,为大样本,样本均值x =25, 〔1〕样本均值的抽样标准差x σσ5=0.7906 〔2〕已知置信水平1-α=95%,得 α/2Z =1.96,于是,允许误差是E =α/2σZ =1.96×0.7906=1.5496. 7.2 某快餐店想要估计每位顾客午餐的平均花费金额.在为期3周的时间里选取49名顾客组成了一个简单随机样本.<1>假定总体标准差为15元,求样本均值的抽样标准误差.x σ===2.143 <2>在95%的置信水平下,求边际误差.x x t σ∆=⋅,由于是大样本抽样,因此样本均值服从正态分布,因此概率度t=2z α因此,x x t σ∆=⋅2x z ασ=⋅0.025x z σ=⋅=1.96×2.143=4.2 <3>如果样本均值为120元,求总体均值 的95%的置信区间. 置信区间为:(),x x x x -∆+∆=()120 4.2,120 4.2-+=〔115.8,124.2〕7.107.11 某企业生产的袋装食品采用自动打包机包装,每袋标准重量为l00g.现从某天生产的一每包重量〔g 〕 包数 96~98 98~100 100~102 102~104 104~106 2 3 34 7 4 合计50<1>确定该种食品平均重量的95%的置信区间. 解:大样本,总体方差未知,用z 统计量样本均值=101.4,样本标准差s=1.829 置信区间:1α-=0.95,z α=0.025z =1.96=101.4 1.96 1.965050⎛-+ ⎝=〔100.89,101.91〕 <2>如果规定食品重量低于l00g 属于不合格,确定该批食品合格率的95%的置信区间.解:总体比率的估计大样本,总体方差未知,用z 统计量 样本比率=〔50-5〕/50=0.9 置信区间:1α-=0.95,z α=0.025z =1.96=()()0.910.90.910.90.9 1.96,0.9 1.965050⎛-- -+ ⎝=〔0.8168,0.9832〕 7.13 一家研究机构想估计在网络公司工作的员工每周加班的平均时间,为此随机抽取了18个员工.得到他们每周加班的时间数据如下<单位:小时>: 6 321 817 1220 117 90 218 2516 1529 16置信区间.解:小样本,总体方差未知,用t 统计量均值=13.56,样本标准差s=7.801 置信区间:1α-=0.90,n=18,()21t n α-=()0.0517t =1.7369=13.56 1.7369 1.7369⎛-+ ⎝=〔10.36,16.75〕 7.15 在一项家电市场调查中.随机抽取了200个居民户,调查他们是否拥有某一品牌的电视机.其中拥有该品牌电视机的家庭占23%.求总体比例的置信区间,置信水平分别为90%和95%.解:总体比率的估计大样本,总体方差未知,用z 统计量 样本比率=0.23 置信区间:1α-=0.90,z α=0.025z =1.645=0.23 1.645 1.645⎛ -+ ⎝ =〔0.1811,0.2789〕1α-=0.95,z α=0.025z =1.96=0.23 1.96 1.96⎛ -+ ⎝=〔0.1717,0.2883〕7.28 某超市想要估计每个顾客平均每次购物花费的金额.根据过去的经验,标准差大约为120元,现要求以95%的置信水平估计每个顾客平均购物金额的置信区间,并要求边际误差不超过20元,应抽取多少个顾客作为样本? 解:2222xz n ασ⋅=∆,1α-=0.95,2z α=0.025z =1.96,2222xz n ασ⋅=∆2221.9612020⨯==138.3,取n=139或者140,或者150.8. 18.2 一种元件,要求其使用寿命不得低于700小时.现从一批这种元件中随机抽取36件,测得其平均寿命为680小时.已知该元件寿命服从正态分布,σ=60小时,试在显著性水平0.05下确定这批元件是否合格. 解:H 0:μ≥700;H 1:μ<700已知:x =680 σ=60由于n=36>30,大样本,因此检验统计量:x z==-2 当α=0.05,查表得z α=1.645.因为z <-z α,故拒绝原假设,接受备择假设,说明这批产品不合格.8.4 糖厂用自动打包机打包,每包标准重量是100千克.每天开工后需要检验一次打包机工作是否正常.某日开工后测得9包重量<单位:千克>如下:99.3 98.7 100.5 101.2 98.3 99.7 99.5 102.1 100.5已知包重服从正态分布,试检验该日打包机工作是否正常<a =0.05>? 解:H 0:μ=100;H 1:μ≠100经计算得:x =99.9778 S =1.21221 检验统计量:x t =-0.055 当α=0.05,自由度n -1=9时,查表得()9t α=2.262.因为t <2t α,样本统计量落在接受区域,故接受原假设,拒绝备择假设,说明打包机工作正常.8.5 某种大量生产的袋装食品,按规定不得少于250克.今从一批该食品中任意抽取50袋,发现有6袋低于250克.若规定不符合标准的比例超过5%就不得出厂,问该批食品能否出厂<a =0.05>?解:解:H 0:π≤0.05;H 1:π>0.05已知: p =6/50=0.12 检验统计量:Z ==2.271当α=0.05,查表得z α=1.645.因为z >z α,样本统计量落在拒绝区域,故拒绝原假设,接受备择假设,说明该批食品不能出厂.8.7 某种电子元件的寿命x<单位:小时>服从正态分布.现测得16只元件的寿命如下: 159 280 101 212 224 379 179 264 222 362 168 250 149 260 485 170问是否有理由认为元件的平均寿命显著地大于225小时<a =0.05>? 解:H 0:μ≤225;H 1:μ>225经计算知:x =241.5 s =98.726 检验统计量:x t=0.669 当α=0.05,自由度n -1=15时,查表得()15t α=1.753.因为t <t α,样本统计量落在接受区域,故接受原假设,拒绝备择假设,说明元件寿命没有显著大于225小时. 9.19.2 9.3 9.410.210.410.7 某企业准备用三种方法组装一种新的产品,为确定哪种方法每小时生产的产品数量最多,随机抽取了30名工人,并指定每个人使用其中的一种方法.通过对每个工人生产的产品数进行方差分析得到下面的结果;<1>完成上面的方差分析表.<2>若显著性水平a=0.05,检验三种方法组装的产品数量之间是否有显著差异?解:〔2〕P=0.025>a=0.05,没有显著差异.11.311.411.9 某汽车生产商欲了解广告费用<x>对销售量<y>的影响,收集了过去12年的有关数据.通过计算得到下面的有关结果:方差分析表要求:<1>完成上面的方差分析表.<2>汽车销售量的变差中有多少是由于广告费用的变动引起的?<3>销售量与广告费用之间的相关系数是多少?<4>写出估计的回归方程并解释回归系数的实际意义.<5>检验线性关系的显著性<a=0.05>.解:〔2〕R2=0.9756,汽车销售量的变差中有97.56%是由于广告费用的变动引起的.〔3〕r=0.9877.〔4〕回归系数的意义:广告费用每增加一个单位,汽车销量就增加1.42个单位.〔5〕回归系数的检验:p=2.17E—09<α,回归系数不等于0,显著.回归直线的检验:p=2.17E—09<α,回归直线显著.11.1013.1 下表是1981年—1999年国家财政用于农业的支出额数据年份支出额〔亿元〕年份支出额〔亿元〕1981 110.21 1991 347.571982 120.49 1992 376.021983 132.87 1993 440.451984 141.29 1994 532.981985 153.62 1995 574.931986 184.2 1996 700.431987 195.72 1997 766.391988 214.07 1998 1154.761989 265.94 1999 1085.761990 307.84〔1〕绘制时间序列图描述其形态.〔2〕计算年平均增长率.〔3〕根据年平均增长率预测20##的支出额.详细答案:〔1〕时间序列图如下:从时间序列图可以看出,国家财政用于农业的支出额大体上呈指数上升趋势.〔2〕年平均增长率为:.〔3〕.13.2 下表是1981年—20##我国油彩油菜籽单位面积产量数据〔单位:kg / hm2〕年份单位面积产量年份单位面积产量1981 1451 1991 12151982 1372 1992 12811983 1168 1993 13091984 1232 1994 12961985 1245 1995 14161986 1200 1996 13671987 1260 1997 14791988 1020 1998 12721989 1095 1999 14691990 1260 2000 1519〔1〕绘制时间序列图描述其形态.〔2〕用5期移动平均法预测20##的单位面积产量.〔3〕采用指数平滑法,分别用平滑系数a=0.3和a=0.5预测20##的单位面积产量,分析预测误差,说明用哪一个平滑系数预测更合适?详细答案:〔1〕时间序列图如下:〔2〕20##的预测值为:| 〔3〕由Excel输出的指数平滑预测值如下表:年份单位面积产量指数平滑预测a=0.3 误差平方指数平滑预测a=0.5误差平方1981 14511982 1372 1451.0 6241.0 1451.0 6241.0 1983 1168 1427.3 67236.5 1411.5 59292.3 1984 1232 1349.5 13808.6 1289.8 3335.1 1985 1245 1314.3 4796.5 1260.9 252.0 1986 1200 1293.5 8738.5 1252.9 2802.4 1987 1260 1265.4 29.5 1226.5 1124.3 1988 1020 1263.8 59441.0 1243.2 49833.6 1989 1095 1190.7 9151.5 1131.6 1340.8 1990 1260 1162.0 9611.0 1113.3 21518.4 1991 1215 1191.4 558.1 1186.7 803.51992 1281 1198.5 6812.4 1200.8 6427.7 1993 1309 1223.2 7357.6 1240.9 4635.8 1994 1296 1249.0 2213.1 1275.0 442.8 1995 1416 1263.1 23387.7 1285.5 17035.9 1996 1367 1308.9 3369.9 1350.7 264.4 1997 1479 1326.4 23297.7 1358.9 14431.3 1998 1272 1372.2 10031.0 1418.9 21589.8 1999 1469 1342.1 16101.5 1345.5 15260.3 2000 1519 1380.2 19272.1 1407.2 12491.7 合计——291455.2 —239123.0 20##a=0.3时的预测值为:a=0.5时的预测值为:比较误差平方可知,a=0.5更合适.13.3 下面是一家旅馆过去18个月的营业额数据月份营业额〔万元〕月份营业额〔万元〕1 295 10 4732 283 11 4703 322 12 4814 355 13 4495 286 14 5446 379 15 6017 381 16 5878 431 17 6449 424 18 660〔1〕用3期移动平均法预测第19个月的营业额.〔2〕采用指数平滑法,分别用平滑系数a=0.3、a=0.4和a=0.5预测各月的营业额,分析预测误差,说明用哪一个平滑系数预测更合适?〔3〕建立一个趋势方程预测各月的营业额,计算出估计标准误差.详细答案:〔1〕第19个月的3期移动平均预测值为:〔2〕月份营业额预测a=0.3误差平方预测a=0.4误差平方预测a=0.5误差平方1 2952 283 295.0 144.0 295.0 144.0 295.0 144.03 322 291.4 936.4 290.2 1011.2 289.0 1089.04 355 300.6 2961.5 302.9 2712.3 305.5 2450.35 286 316.9 955.2 323.8 1425.2 330.3 1958.16 379 307.6 5093.1 308.7 4949.0 308.1 5023.37 381 329.0 2699.4 336.8 1954.5 343.6 1401.68 431 344.6 7459.6 354.5 5856.2 362.3 4722.39 424 370.5 2857.8 385.1 1514.4 396.6 748.510 473 386.6 7468.6 400.7 5234.4 410.3 3928.711 470 412.5 3305.6 429.6 1632.9 441.7 803.112 481 429.8 2626.2 445.8 1242.3 455.8 633.513 449 445.1 15.0 459.9 117.8 468.4 376.914 544 446.3 9547.4 455.5 7830.2 458.7 7274.815 601 475.6 15724.5 490.9 12120.5 501.4 9929.416 587 513.2 5443.2 534.9 2709.8 551.2 1283.317 644 535.4 11803.7 555.8 7785.2 569.1 5611.718 660 567.9 8473.4 591.1 4752.7 606.5 2857.5 合计——87514.7—62992.5—50236由Excel输出的指数平滑预测值如下表:a=0.3时的预测值:,误差均方=87514.7.a=0.4时的预测值:,误差均方=62992.5..a=0.5时的预测值:,误差均方=50236.比较各误差平方可知,a=0.5更合适.〔3〕根据最小二乘法,利用Excel输出的回归结果如下:回归统计Multiple R 0.9673R Square 0.9356Adjusted R Square 0.9316标准误差31.6628观测值18方差分析df SS MS F Significance F回归分析 1 232982.5 232982.5 232.3944 5.99E-11残差16 16040.49 1002.53总计17 249022.9Coefficients 标准误差t Stat P-value Lower 95% Upper 95% Intercept 239.73203 15.57055 15.3965 5.16E-11 206.7239 272.7401 X Variable 1 21.928793 1.438474 15.24449 5.99E-11 18.87936 24.97822.估计标准误差.14.114.2。
统计学第四版(贾俊平)课后思考题答案

统计课后思考题答案第一章思考题1。
1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1。
2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1。
3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据.它也是有类别的,但这些类别是有序的.(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值. 统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的.实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据.时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1。
4解释分类数据,顺序数据和数值型数据答案同1.31。
5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1。
7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学 贾俊平第四版第四章课后答案(目前最全)

第四章统计数据的概括性描述4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:(1)(2)(3)(4)说明汽车销售分部的特征答:10名销售人员的在5月份销售的汽车数量较为集中。
4.2 随机抽取25个网络用户,得到他们的年龄数据如下:单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:1、排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄从频数看出,众数Mo有两个:19、23;从累计频数看,中位数Me=23。
(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652(4)计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线:分组:1、确定组数:()l g 25l g ()1.3981115.64l g (2)l g 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图:4.3 某银行为缩短顾客到银行办理业务等待的时间。
最新统计学第四版答案(贾俊平)资料

请举出统计应用的几个例子:1、用统计识别作者:对于存在争议的论文,通过统计量推出作者2、用统计量得到一个重要发现:在不同海域鳗鱼脊椎骨数量变化不大,推断所有各个不同海域内的鳗鱼是由海洋中某公共场所繁殖的3、挑战者航天飞机失事预测请举出应用统计的几个领域:1、在企业发展战略中的应用2、在产品质量管理中的应用3、在市场研究中的应用④在财务分析中的应用⑤在经济预测中的应用你怎么理解统计的研究内容:1、统计学研究的基本内容包括统计对象、统计方法和统计规律。
2、统计对象就是统计研究的课题,称谓统计总体。
3、统计研究方法主要有大量观察法、数量分析法、抽样推断法、实验法等。
④统计规律就是通过大量观察和综合分析所揭示的用数量指标反映的客观现象的本质特征和发展规律。
举例说明分类变量、顺序变量和数值变量:分类变量:表现为不同类别的变量称为分类变量,如“性别”表现为“男”或“女”,“企业所属的行业”表现为“制造业”、“零售业”、“旅游业”等,“学生所在的学院”可能是“商学院”、“法学院”等顺序变量:如果类别有一定的顺序,这样的分类变量称为顺序变量,如考试成绩按等级分为优、良、中、及格、不及格,一个人对事物的态度分为赞成、中立、反对。
这里的“考试成绩等级”、“态度”等就是顺序变量。
数值变量:可以用数字记录其观察结果,这样的变量称为数值变量,如“企业销售额”、“生活费支出”、“掷一枚骰子出现的点数”。
定性数据和定量数据的图示方法各有哪些:1、定性数据的图示:条形图、帕累托图、饼图、环形图2、定量数据的图示:a、分组数据看分布:直方图b、未分组数据看分布:茎叶图、箱线图、垂线图、误差图c、两个变量间的关系:散点图d、比较多个样本的相似性:雷达图和轮廓图直方图与条形图有何区别:1、条形图中的每一个矩形表示一个类别,其宽度没有意义,而直方图的宽度则表示各组的组距。
2、由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。
统计学贾俊平_第四版课后习题答案第七章

7.11 (1) 解:已知n=50,1a -=0.9522,ss x z xz nn a aæö-×+×ç÷èø=81.822981.8229101.491.966,101.491.9665050æö-´+´ç÷èø= (100.89,101.91)(2)解:已知n=50,1a -=0.95,2z a =00.0225z =1.96,样本比率p=(50-5)/50=0.9 则食品合格率的95%的置信区间:()()2211,p p p p p zp z nna aæö--ç÷-×+×ç÷èø=()()0.910.90.910.90.9 1.91.966,0.9 1.91.9665050æö---´+´ç÷èø=(0.8168,0.9832)7.22 (1)由题知,该题为大样本,方差已知,则有21m m -的95%的置信区间为:176.12100201001696.1)2325()(2221212/21±=+´±-=+±-n s n s z x x a即(0.824,3.176)(2m m -的95%的置信区间为:()()64.42112212212/21±=÷÷øöççèæ+-+±-n n s n ntxxpa 即(—2.64,6.64) (3)由题知,该题为小样本,方差不同, 则有21m m -的95%的置信区间为:()()64.42112212212/21±=÷÷øöççèæ+-+±-n n s n n tx x p a 即(—2.64,6.64) (4)由题知,该题为小样本,样本量不等,方差相等,则合并估计量为()()713128524211212222112==-+-+-=n n s n s n s p 则有21m m -的95%的置信区间为:()()02.42112212212/21±=÷÷øöççèæ+-+±-n n s n n tx x p a 即(—2.02,6.02) ,2z a =00.0225z =1.96。
统计学第四版答案(贾俊平)

请举出统计应用的几个例子:1、用统计识别作者:对于存在争议的论文,通过统计量推出作者2、用统计量得到一个重要发现:在不同海域鳗鱼脊椎骨数量变化不大,推断所有各个不同海域内的鳗鱼是由海洋中某公共场所繁殖的3、挑战者航天飞机失事预测请举出应用统计的几个领域:1、在企业发展战略中的应用2、在产品质量管理中的应用3、在市场研究中的应用④在财务分析中的应用⑤在经济预测中的应用你怎么理解统计的研究内容:1、统计学研究的基本内容包括统计对象、统计方法和统计规律。
2、统计对象就是统计研究的课题,称谓统计总体。
3、统计研究方法主要有大量观察法、数量分析法、抽样推断法、实验法等。
④统计规律就是通过大量观察和综合分析所揭示的用数量指标反映的客观现象的本质特征和发展规律。
举例说明分类变量、顺序变量和数值变量:分类变量:表现为不同类别的变量称为分类变量,如“性别”表现为“男”或“女”,“企业所属的行业”表现为“制造业”、“零售业”、“旅游业”等,“学生所在的学院”可能是“商学院”、“法学院”等顺序变量:如果类别有一定的顺序,这样的分类变量称为顺序变量,如考试成绩按等级分为优、良、中、及格、不及格,一个人对事物的态度分为赞成、中立、反对。
这里的“考试成绩等级”、“态度”等就是顺序变量。
数值变量:可以用数字记录其观察结果,这样的变量称为数值变量,如“企业销售额”、“生活费支出”、“掷一枚骰子出现的点数”。
定性数据和定量数据的图示方法各有哪些:1、定性数据的图示:条形图、帕累托图、饼图、环形图2、定量数据的图示:a、分组数据看分布:直方图b、未分组数据看分布:茎叶图、箱线图、垂线图、误差图c、两个变量间的关系:散点图d、比较多个样本的相似性:雷达图和轮廓图直方图与条形图有何区别:1、条形图中的每一个矩形表示一个类别,其宽度没有意义,而直方图的宽度则表示各组的组距。
2、由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。
统计学第四版(贾俊平著)中国人民大学出版社第四章课后答案PPT课件
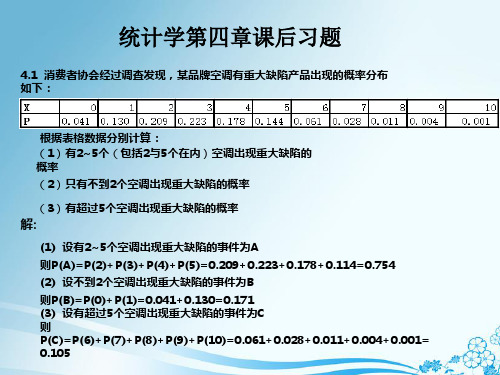
4.3 求标准正态分布的概率:
(1)P ( 0 ≤ Z ≤ 1.2) ; (2)P ( -0.48 ≤ Z ≤ 0); (3)P (Z > 1.33)。
解:
(1)P ( 0 ≤ Z ≤ 1.2) = P ( 1.2) -P ( 0 )= 0.3849 (2)P ( -0.48 ≤ Z ≤ 0 ) = P ( 0) -P (-0.48)= 0.1844 (3)P (Z > 1.33) = P ( -1.33) = 0.0918
统计学第四章课后习题
4.1 消费者协会经过调查发现,某品牌空调有重大缺陷产品出现的概率分布 如下:
根据表格数据分别计算: (1)有2~5个(包括2与5个在内)空调出现重大缺陷的 概率 (2)只有不到2个空调出现重大缺陷的概率
(3)有超过5个空调出现重大缺陷的概率
解:
(1) 设有2~5个空调出现重大缺陷的事件为A 则P(A)=P(2)+P(3)+P(4)+P(5)=0.209+0.223+0.178+0.114=0.754 (2) 设不到2个空调出现重大缺陷的事件为B 则P(B)=P(0)+P(1)=0.041+0.130=0.171 (3) 设有超过5个空调出现重大缺陷的事件为C 则 P(C)=P(6)+P(7)+P(8)+P(9)+P(10)=0.061+0.028+0.011+0.004+0.001= 0.105
用样本均值 X 估计总体均值
(1)X 的期望是多少? (2)X 的标准差是多少? (3)X 的概率分布是什么?
解:
(1) E(x) 200
(2)
x
统计学贾俊平第四版课后习题测验答案

3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
1、确定组数:()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取5(1) 对这个年龄分布作直方图;(2) 从直方图分析成人自学考试人员年龄分布的特点。
解:(1)制作直方图:将上表复制到Excel 表中,点击:图表向导→柱形图→选择子图表类型→完成。
即得到如下的直方图:(见Excel 练习题2.6)(2)年龄分布的特点:自学考试人员年龄的分布为右偏。
解:(1)根据上面的数据,画出两个班考试成绩的对比条形图和环形图。
3.14 已知1995—2004年我国的国内生产总值数据如下(按当年价格计算):要求:(2)绘制第一、二、三产业国内生产总值的线图。
4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量N Valid 10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.0075 12.50种是所有颐客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。
统计学第四版答案(贾俊平)

第1章统计和统计数据1.1 指出下面的变量类型。
(1)年龄。
(2)性别。
(3)汽车产量。
(4)员工对企业某项改革措施的态度(赞成、中立、反对)。
(5)购买商品时的支付方式(现金、信用卡、支票)。
详细答案:(1)数值变量。
(2)分类变量。
(3)数值变量。
(4)顺序变量。
(5)分类变量。
1.2 一家研究机构从IT从业者中随机抽取1000人作为样本进行调查,其中60%回答他们的月收入在5000元以上,50%的人回答他们的消费支付方式是用信用卡。
(1)这一研究的总体是什么?样本是什么?样本量是多少?(2)“月收入”是分类变量、顺序变量还是数值变量?(3)“消费支付方式”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。
(2)数值变量。
(3)分类变量。
1.3 一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。
(1)这一研究的总体是什么?(2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有的网上购物者”。
(2)分类变量。
1.4 某大学的商学院为了解毕业生的就业倾向,分别在会计专业抽取50人、市场营销专业抽取30、企业管理20人进行调查。
(1)这种抽样方式是分层抽样、系统抽样还是整群抽样?(2)样本量是多少?详细答案:(1)分层抽样。
(2)100。
第3章用统计量描述数据为7.2分钟,标准差为1.97分钟,第二种排队方式的等待时间(单位:分钟)如下:5.56.6 6.7 6.87.1 7.3 7.4 7.8 7.8(1)计算第二种排队时间的平均数和标准差。
(2)比两种排队方式等待时间的离散程度。
(3)如果让你选择一种排队方式,你会选择哪一种?试说明理由。
详细答案:(1)(岁);(岁)。
(2);。
第一中排队方式的离散程度大。
(3)选方法二,因为平均等待时间短,且离散程度小。
统计学第四版(贾俊平)课后思考题答案

统计课后思考题答案第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学第四版(贾俊平)课后所有题答案很全期末考试必备

统计课后思考题答案第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别姆鞘中褪荩嵌允挛锝蟹掷嗟慕峁荼硐治啾穑梦淖掷幢硎觯唬ǘㄐ允荩┧承蚴荩褐荒芄橛谀骋挥行蚶啾鸬姆鞘中褪荨K彩怯欣啾鸬模庑├啾鹗怯行虻摹#渴荩┦敌褪荩喊词殖叨炔饬康墓鄄熘担浣峁硐治咛宓氖怠?统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同 1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
1.8 统计应用实例人口普查,商场的名意调查等。
统计学第四版问题详解(贾俊平)
第1章统计和统计数据1.1 指出下面的变量类型。
(1)年龄。
(2)性别。
(3)汽车产量。
(4)员工对企业某项改革措施的态度(赞成、中立、反对)。
(5)购买商品时的支付方式(现金、信用卡、支票)。
详细答案:(1)数值变量。
(2)分类变量。
(3)数值变量。
(4)顺序变量。
(5)分类变量。
1.2 一家研究机构从IT从业者中随机抽取1000人作为样本进行调查,其中60%回答他们的月收入在5000元以上,50%的人回答他们的消费支付方式是用信用卡。
(1)这一研究的总体是什么?样本是什么?样本量是多少?(2)“月收入”是分类变量、顺序变量还是数值变量?(3)“消费支付方式”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。
(2)数值变量。
(3)分类变量。
1.3 一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。
(1)这一研究的总体是什么?(2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有的网上购物者”。
(2)分类变量。
1.4 某大学的商学院为了解毕业生的就业倾向,分别在会计专业抽取50人、市场营销专业抽取30、企业管理20人进行调查。
(1)这种抽样方式是分层抽样、系统抽样还是整群抽样?(2)样本量是多少?详细答案:(1)分层抽样。
(2)100。
第3章用统计量描述数据););=426.67;,,第五章1.23.4.5.6.7.5.8 (1)(3.02%,16.98%)。
(2)(1.68%,18.32%)。
5.9 详细答案:(4.06,24.35)。
5.10详细答案: 139。
5.11 详细答案: 57。
5.12 769。
第6章假设检验平看电,绝平,,绝,,绝在,,=100 =50=14.8 =10.4=0.8 =0.6对,,绝。
对设,。
统计学贾俊平_第四版课后习题答案

统计学贾俊平_第四版课后习题答案3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42 36 37 37 49 39 42 32 36 35 要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
1、确定组数:()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取54.8 一项关于大学生体重状况的研究发现.男生的平均体重为60kg,标准差为5kg;女生的平均体重为50kg,标准差为5kg。
请回答下面的问题:(1)是男生的体重差异大还是女生的体重差异大?为什么?女生,因为标准差一样,而均值男生大,所以,离散系数是男生的小,离散程度是男生的小。
(2)以磅为单位(1ks=2.2lb),求体重的平均数和标准差。
都是各乘以2.21,男生的平均体重为60kg×2.21=132.6磅,标准差为5kg ×2.21=11.05磅;女生的平均体重为50kg×2.21=110.5磅,标准差为5kg×2.21=11.05磅。
(3)粗略地估计一下,男生中有百分之几的人体重在55kg一65kg之间?计算标准分数:Z1=x xs-=55605-=-1;Z2=x xs-=65605-=1,根据经验规则,男生大约有68%的人体重在55kg一65kg之间。
(4)粗略地估计一下,女生中有百分之几的人体重在40kg~60kg之间?计算标准分数:Z1=x xs-=40505-=-2;Z2=x xs-=60505-=2,根据经验规则,女生大约有95%的人体重在40kg一60kg之间。
贾俊平统计学第四版课后答案
第三章节:数据的图表展示…………………………………………………1 第四章节:数据的概括性度量……………………………………………….15 第六章节:统计量及其抽样分布……………………………………………26 第七章节:参数估计………………………………………………. …………28 第八章节:假设检验……………………………………………….. …………38 第九章节:列联分析……………………………………………….. …………41 第十章节:方差分析……………………………………………….. …………43 3. 要求:(1)指出上面的数据属于什么类型。
顺序数据 3.31、确定组数: ()l g 40l g () 1.60206111 6.32l g (2)l g 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取53、分组频数表销售收入(万元)频数频率%累计频数累计频率%<= 25 1 2.5 1 2.5 26 - 30 5 12.5 6 15.0 31 - 35 6 15.0 12 30.0 36 - 40 14 35.0 26 65.0 41 - 45 10 25.0 36 90.0 46+ 4 10.0 40100.0总和40100.0频数246810121416<= 2526 - 3031 - 3536 - 4041 - 4546+销售收入频数频数3.4data605040302010data Stem-and-Leaf PlotFrequency Stem & Leaf3.00 1 . 889 5.00 2 . 01133 7.00 2 . 6888999 2.00 3 . 13 3.00 3 . 569 3.00 4 . 123 3.00 4 . 667 3.00 5 . 012 1.00 5 . 7Stem width: 10 Each leaf: 1 case(s)3.6解:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第1章统计和统计数据
指出下面的变量类型。
(1)年龄。
(2)性别。
(3)汽车产量。
(4)员工对企业某项改革措施的态度(赞成、中立、反对)。
(5)购买商品时的支付方式(现金、信用卡、支票)。
详细答案:(1)数值变量。
(2)分类变量。
(3)数值变量。
(4)顺序变量。
(5)分类变量。
一家研究机构从IT从业者中随机抽取1000人作为样本进行调查,其中60%回答他们的月收入在5000元以上,50%的人回答他们的消费支付方式是用信用卡。
(1)这一研究的总体是什么样本是什么样本量是多少(2)“月收入”是分类变量、顺序变量还是数值变量(3)“消费支付方式”是分类变量、顺序变量还是数值变量详细答案:(1)总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。
(2)数值变量。
(3)分类变量。
一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。
(1)这一研究的总体是什么
(2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值变量详细答案:
(1)总体是“所有的网上购物者”。
(2)分类变量。
某大学的商学院为了解毕业生的就业倾向,分别在会计专业抽取50人、市场营销专业抽取30、企业管理20人进行调查。
(1)这种抽样方式是分层抽样、系统抽样还是整群抽样(2)样本量是多少详细答案:(1)分层抽样。
(2)100。
第3章用统计量描述数据
排队方式各随机抽取9名顾客,得到第一种排队方式的平均等待时间为分钟,标准差为分钟,第二种排队方式的等待时间(单位:分钟)如下:
(1)计算第二种排队时间的平均数和标准差。
(2)比两种排队方式等待时间的离散程度。
(3)如果让你选择一种排队方式,你会选择哪一种试说明理由。
详细答案:
(1)(岁);(岁)。
(2);。
第一中排队方式的离散程度大。
(3)选方法二,因为平均等待时间短,且离散程度小。
在某地区随机抽取120家企业,按利润额进行分组后结果如下:按利润额分组(万元)企业数(个)
300以下19
300~40030
400~50042
500~60018
600以上11
合计120
计算120家企业利润额的平均数和标准差(注:第一组和最后一组的组距按相邻组计算)。
详细答案:
=(万元);(万元)。
一家公司在招收职员时,首先要通过两项能力测试。
在A项测试中,其平均分数是100分,标准差是15分;在B项测试中,其平均分数是400分,标准差是50分。
一位应试者在A项测试中得了115分,在B项测试中得了425分。
与平均分数相比,该位应试者哪一项测试更为理想
详细答案:
通过计算标准化值来判断,,,说明在A项测试中该应试者比平均分数高出1个标准差,而在B项测试中只高出平均分数个标准差,由于A项测试的标准化值高于B项测试,所以A项测试比较理想。
一种产品需要人工组装,现有3种可供选择的组装方法。
为检验哪种方法更好,随机抽取15个工人,让他们分别用3种方法组装。
下面是15个工人分别用3种方法在相同的时间内组装的产品数量(单位:个):方法A方法B方法C
164129125
167130126
168129126
165130127
170131126
165130128
164129127
168127126
164128127
离散系数最小,方法C最大;从分布的形状看,方法A和方法B的偏斜程
度都不大,方法C则较大。
(2)综合来看,应该选择方法A,因为平均水平较高且离散程度较小
第五章
1.
2
3.
4.
5.
6.
7.
(1)(%,%)。
(2)(%,%)。
详细答案:(,)。
详细答案:139。
详细答案:57。
769。
第6章假设检验
一项包括了200个家庭的调查显示,每个家庭每天看电视的平均时间为小时,标准差为小时。
据报道,10年前每天每个家庭看电视的平均时间是小时。
取显着性水平,这个调查能否证明“如今每个家庭每天收看电视的平均时间增加了”
详细答案:
,=,,拒绝,如今每个家庭每天收看电视的平均时间显着地增加了。
为监测空气质量,某城市环保部门每隔几周对空气烟尘质量进行一次随机测试。
已知该城市过去每立方米空气中悬浮颗粒的平均值是82微克。
在最近一段时间的检测中,每立方米空气中悬浮颗粒的数值如下(单位:微克):
根据最近的测量数据,当显着性水平时,能否认为该城市空气中悬浮颗粒的平均值显着低于过去的平均值
详细答案:
,=,,拒绝,该城市空气中悬浮颗粒的平均值显着低于过去的平均值。
安装在一种联合收割机的金属板的平均重量为25公斤。
对某企业生产的20块金属板进行测量,得到的重量数据如下:
假设金属板的重量服从正态分布,在显着性水平下,检验该企业生产的金属板是否符合要求
详细答案:
,,,不拒绝,没有证据表明该企业生产的金属板不符合要求。
在对消费者的一项调查表明,17%的人早餐饮料是牛奶。
某城市的牛奶生产商认为,该城市的人早餐饮用牛奶的比例更高。
为验证这一说法,生产商随机抽取550人的一个随机样本,其中115人早餐饮用牛奶。
在
显着性水平下,检验该生产商的说法是否属实详细答案:
,,,拒绝,该生产商的说法属实。
某生产线是按照两种操作平均装配时间之差为5分钟而设计的,两种装配操作的独立样本产生如下结果:
操作A操作B
=100=50
==
==
对=,检验平均装配时间之差是否等于5分钟。
详细答案:
,=,,拒绝,两种装配操作的平均装配时间之差不等于5分钟。
某市场研究机构用一组被调查者样本来给某特定商品的潜在购买力打分。
样本中每个人都分别在看过该产品的新的电视广告之前与之后打分。
潜在购买力的分值为0~10分,分值越高表示潜在购买力越高。
原假设认为“看后”平均得分小于或等于“看前”平均得分,拒绝该假设就表明广告提高了平
均潜在购买力得分。
对=的显着性水平,用下列数据检验该假设,并对该广告给予评价。
购买力得分购买力得分个体看后看前个体看后看前
165535
264698
377775
443866
详细答案:
设,。
,=,,不拒绝,广告提高了平均潜在购买力得分。
某企业为比较两种方法对员工进行培训的效果,采用方法1对15名员工进行培训,采用方法2 对12名员工进行培训。
培训后的测试分数如下:方法1方法2
565145595753
475243525665
425352535553
504248546457
474444
两种方法培训得分的总体方差未知且不相等。
在显着性水平下,检验两种方法的培训效果是否有显着差异
详细答案:
,,,拒绝,两种方法的培训效果是有显着差异。
为研究小企业经理们是否认为他们获得了成功,在随机抽取100个小企业的女性经理中,认为自己成功的人数为24人;而在对95个男性经理的调查中,认为自己成功的人数为39人。
在的显着性水平下,检验男女经理认为自己成功的人数比例是否有显着差异
详细答案:
设,。
,,,拒绝,男女经理认为自己成功的人数比例有显着差异。
为比较新旧两种肥料对产量的影响,以便决定是否采用新肥料。
研究者选择了面积相等、土壤等条件相同的40块田地,分别施用新旧两种肥料,得到的产量数据如下:
旧肥料新肥料
1091019798100105109110118109
9898949910411311111199112
1038810810210610611799107119
97105102104101110111103110119
取显着性水平,检验:
(1)新肥料获得的平均产量是否显着地高于旧肥料假定条件为:
①两种肥料产量的方差未但相等,即。
②两种肥料产量的方差未且不相等,即。
(2)两种肥料产量的方差是否有显着差异
详细答案:
(1)设,。
,,,拒绝,新肥料获得的平均产量显着地高于旧肥料。
(2),拒绝,新肥料获得的平均产量显着地高于旧肥料。
(3),。
,,两种肥料产量的方差有显着差异。
生产工序中的方差是工序质量的一个重要测度,通常较大的方差就意味着要通过寻找减小工序方差的途径来改进工序。
某杂志上刊载了关于两部机器生产的袋茶重量的数据(单位:克)如下,检验这两部机器生产的袋茶重量的方差是否存在显着差异(a=)。
机器1
机器2
详细答案:
,。
=,,拒绝,两部机器生产的袋茶重量的方差存在显着差异。