回归分析练习题(有答案)
第七章回归与相关分析练习及答案

第七章回归与相关分析一、填空题1.现象之间的相关关系按相关的程度分为、和;按相关的形式分为和;按影响因素的多少分为和。
2.两个相关现象之间,当一个现象的数量由小变大,另一个现象的数量,这种相关称为正相关;当一个现象的数量由小变大,另一个现象的数量,这种相关称为负相关。
3.相关系数的取值X围是。
4.完全相关即是关系,其相关系数为。
5.相关系数,用于反映条件下,两变量相关关系的密切程度和方向的统计指标。
6.直线相关系数等于零,说明两变量之间;直线相关系数等1,说明两变量之间;直线相关系数等于—1,说明两变量之间。
7.对现象之间变量的研究,统计是从两个方面进行的,一方面是研究变量之间关系的,这种研究称为相关关系;另一方面是研究关于自变量和因变量之间的变动关系,用数学方程式表达,称为。
8.回归方程y=a+bx中的参数a是,b是。
在统计中估计待定参数的常用方法是。
9. 分析要确定哪个是自变量哪个是因变量,在这点上它与不同。
10.求两个变量之间非线性关系的回归线比较复杂,在许多情况下,非线性回归问题可以通过化成来解决。
11.用来说明回归方程代表性大小的统计分析指标是。
12.判断一条回归直线与样本观测值拟合程度好坏的指标是。
二、单项选择题1.下面的函数关系是( )A销售人员测验成绩与销售额大小的关系 B圆周的长度决定于它的半径C家庭的收入和消费的关系 D数学成绩与统计学成绩的关系2.相关系数r的取值X围( )A -∞<r<+∞B -1≤r≤+1C -1<r<+1D 0≤r≤+13.年劳动生产率z(干元)和工人工资y=10+70x,这意味着年劳动生产率每提高1千元时,工人工资平均( )A增加70元 B减少70元 C增加80元 D减少80元4.若要证明两变量之间线性相关程度是高的,则计算出的相关系数应接近于( )A+1 B 0 C 0.5 D [1]5.回归系数和相关系数的符号是一致的,其符号均可用来判断现象( ) A线性相关还是非线性相关 B正相关还是负相关C完全相关还是不完全相关 D单相关还是复相关6.某校经济管理类的学生学习统计学的时间(x)与考试成绩(y)之间建=a+b x。
回归分析练习试题和参考答案解析

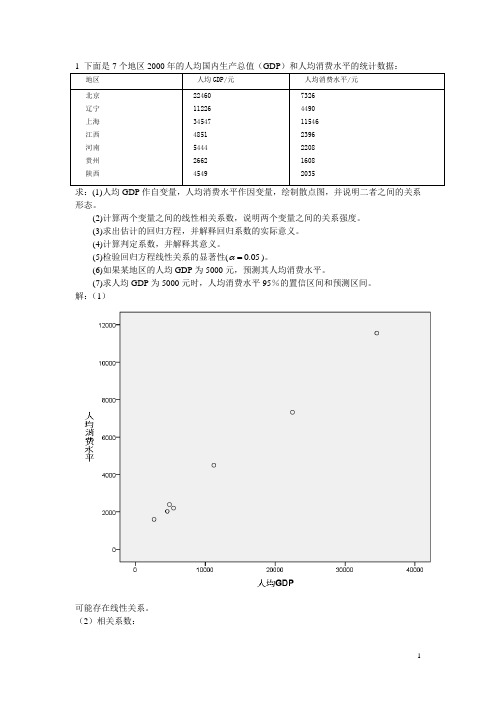
1 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据:求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
α=)。
(5)检验回归方程线性关系的显著性(0.05(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)可能存在线性关系。
(2)相关系数:系数a模型非标准化系数标准系数t Sig.相关性B标准误差试用版零阶偏部分1(常量).003人均GDP.309.008.998.000.998.998.998 a. 因变量: 人均消费水平有很强的线性关系。
(3)回归方程:734.6930.309y x=+系数a模型非标准化系数标准系数t Sig.相关性回归系数的含义:人均GDP没增加1元,人均消费增加元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t显著性B标准误Beta1(常量)人均GDP(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(4)模型汇总模型R R 方调整 R 方标准估计的误差1.998a.996.996a. 预测变量: (常量), 人均GDP。
人均GDP对人均消费的影响达到%。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
模型摘要模型R R 方调整的 R 方估计的标准差1.998(a)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(5)F检验:Anova b模型平方和df均方F Sig.1回归.6801.680.000a 残差5总计.7146a. 预测变量: (常量), 人均GDP。
回归分析练习题及参考答案
1 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据:地区人均GDP/元人均消费水平/元北京辽宁上海江西河南贵州陕西 224601122634547485154442662454973264490115462396220816082035求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)可能存在线性关系。
(2)相关系数:(3)回归方程:734.6930.309y x=+回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t 显著性B 标准误Beta1 (常量)734.693 139.540 5.265 0.003人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(4)模型汇总模型R R 方调整 R 方标准估计的误差1 .998a.996 .996 247.303a. 预测变量: (常量), 人均GDP。
人均GDP对人均消费的影响达到99.6%。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
回归分析时间序列分析答案

回归分析时间序列分析答案一、单项选择题1、下面的关系中不是相关关系的是(D )A、身高与体重之间的关系B、工资水平与工龄之间的关系C、农作物的单位面积产量与降雨量之间的关系D、圆的面积与半径之间的关系2、具有相关关系的两个变量的特点是(A )A、一个变量的取值不能由另一个变量唯一确定B、一个变量的取值由另一个变量唯一确定C、一个变量的取值增大时另一个变量的取值也一定增大D、一个变量的取值增大时另一个变量的取值肯定变小3、下面的假定中,哪个属于相关分析中的假定(B)A、两个变量之间是非线性关系B、两个变量都是随机变量C、自变量是随机变量,因变量不是随机变量D、一个变量的数值增大,另一个变量的数值也应增大4、如果一个变量的取值完全依赖于另一个变量,各观测点落在一条直线上,则称这两个变量之间为(A )A、完全相关关系B、正线性相关关系C、非线性相关关系D、负线性相关关系 5、根据你的判断,下面的相关系数取值哪一个是错误的( C )A、–0.86B、0.78C、1.25D、0x6、某校经济管理类的学生学习统计学的时间()与考试成绩(y)之间建立线性回归方程yx=a+b。
经计算,方程为y =200—0.8x,该方程参数的计算(C) ccA a值是明显不对的B b值是明显不对的C a值和b值都是不对的D a值和b值都是正确的 7、在回归分析中,描述因变量y如何依赖于自变量x和误差项ε的方程称为(B)A、回归方程B、回归模型C、估计回归方程D、经验回归方程,,,x,,8、在回归模型y=中,ε反映的是(C ) 01A、由于x的变化引起的y的线性变化部分B、由于y的变化引起的x的线性变化部分C、除x和y的线性关系之外的随机因素对y的影响D、由于x和y的线性关系对y的影响9、如果两个变量之间存在负相关关系,下列回归方程中哪个肯定有误(B),,A、=25–0.75xB、= –120+ 0.86x yy,,C、=200–2.5xD、= –34–0.74x yy10、说明回归方程拟合优度的统计量是(C )A、相关系数B、回归系数C、判定系数D、估计标准误差211、判定系数R是说明回归方程拟合度的一个统计量,它的计算公式为(A ) SSRSSRSSESSTA、 B、 C、 D、 SSTSSESSTSSR12、为了研究居民消费(C)与可支配收入(Y)之间的关系,有人运用回归分析的方法,得到以下方程:在该方程中0.76的含义是(B ) LnC,2.36,0.76LnY,A、可支配收入每增加1元,消费支出增加0.76元B、可支配收入每增加1%,消费支出增加0.76%C、可支配收入每增加1元,消费支出增加76%D、可支配收入每增加1%,消费支出增加76%13、年劳动生产率z(千元)和工人工资y=10+70x,这意味着年劳动生产率每提高1千元时,工人工资平均(A)A增加70元 B减少70元 C增加80元 D减少80元14、下列回归方程中哪个肯定有误(A),,A、y=15–0.48x,r=0.65B、y= –15 - 1.35x,r=-0.81,,C、yy=-25+0.85x,r=0.42D、=120–3.56x,r=-0.96215、若变量x与y之间的相关系数r=0.8,则回归方程的判定系数R为(C )A、0.8B、0.89C、0.64D、0.40 16、对具有因果关系的现象进行回归分析时(A)A、只能将原因作为自变量B、只能将结果作为自变量C、二者均可作为自变量D、没有必要区分自变量二、多项选择题1(下列哪些现象之间的关系为相关关系(ACD)A家庭收入与消费支出关系 B圆的面积与它的半径关系C广告支出与商品销售额关系 D单位产品成本与利润关系E在价格固定情况下,销售量与商品销售额关系2(相关系数表明两个变量之间的(DE)A线性关系 B因果关系 C变异程度 D相关方向 E相关的密切程度3、如下的现象属于负相关的有(BCD)。
专题05 回归分析(解析版)

专题5 回归分析例1.已知回归方程y=5x+1,则该方程在样本(1,4)处的残差为()A.﹣2B.1C.2D.5【解析】解:当x=1时,y=5x+1=6,∴方程在样本(1,4)处的残差是4﹣6=﹣2.故选:A.例2.研究变量x,y得到一组样本数据,进行回归分析,有以下结论①残差平方和越小的模型,拟合的效果越好;②用相关指数R2来刻画回归效果,R2越小说明拟合效果越好;③在回归直线方程y=−0.2x+0.8中,当解释变量x每增加1个单位时,预报变量y平均减少0.2个单位;④若变量y和x之间的相关系数为r=﹣0.9462,则变量y和x之间的负相关很强.以上正确说法的是①③④.【解析】解:①可用残差平方和判断模型的拟合效果,残差平方和越小,模型的拟合效果越好,故①正确;②用相关指数R2来刻画回归效果,R2越大说明拟合效果越好,故②错误;③在回归直线方程y=−0.2x+0.8中中,当解释变量x每增加1个单位时,预报变量y平均减少0.2个单位,故③正确;④若变量y和x之间的相关系数为r=﹣0.9462,r的绝对值趋向于1,则变量y和x之间的负相关很强,故④正确.故答案为:①③④.例3.下列命题中,正确的命题有②③.①回归直线y=b x+a恒过样本点中心(x,y),且至少过一个样本点;②用相关指数R2来刻画回归效果,表示预报变量对解释变量变化的贡献率,R2越接近于1说明模型的拟合效果越好;③残差图中残差点比较均匀的落在水平的带状区域中,说明选用的模型比较合适;④两个模型中残差平方和越大的模型的拟合效果越好.【解析】解:①回归直线y=b x+a恒过样本点中心(x,y),不一定过样本点,故①正确;②用相关指数R2来刻画回归效果,表示预报变量对解释变量变化的贡献率,R2越接近于1说明模型的拟合效果越好,正确;③残差图中残差点比较均匀的落在水平的带状区域中,说明选用的模型比较合适,正确;④两个模型中残差平方和越大的模型的拟合效果越差.故④错误,故正确的是②③,故答案为:②③例4.下列命题:①相关指数R2越小,则残差平方和越大,模型的拟合效果越好.②对分类变量X与Y的随机变量K2的观测值k来说,k越小,“X与Y有关系”可信程度越大.③残差点比较均匀地落在水平带状区域内,带状区域越宽,说明模型拟合精度越高.④两个随机变量相关性越强,则相关系数的绝对值越接近0.其中错误命题的个数为4.【解析】解:对于①,相关指数R2越小,则残差平方和越大,此时模型的拟合效果越差,所以①错误;对于②,对分类变量X与Y的随机变量K2的观测值k来说,k越小,“X与Y有关系”可信程度越小,所以②错误;对于③,残差点比较均匀地落在水平带状区域内,带状区域越宽,说明模型拟合精度越低,所以③错误;对于④,两个随机变量相关性越强,则相关系数的绝对值越接近1,所以④错误.综上知,错误命题的序号是①②③④,共4个.故答案为:4.例5.垃圾是人类日常生活和生产中产生的废弃物,由于排出量大,成分复杂多样,且具有污染性,所以需要无害化、减量化处理.某市为调査产生的垃圾数量,采用简单随机抽样的方法抽取20个县城进行了分析,得到样本数据(x i,y i)(i=1,2,……,20),其中x i和y i分别表示第i个县城的人口(单位:万人)和该县年垃圾产生总量(单位:吨),并计算得∑20i=1x i=80,∑20i=1y i=4000,∑20i=1(x i−x)2=80,∑20i=1(y i−y)2=8000,∑20i=1(x i−x)(y i−y)=7000.(1)请用相关系数说明该组数据中y与x之间的关系可用线性回归模型进行拟合;(2)求y关于x的线性回归方程;(3)某科研机构研发了两款垃圾处理机器,如表是以往两款垃圾处理机器的使用年限(整年)统计表:1年2年3年4年5年使用年限台数款式甲款520151050乙款152010550某环保机构若考虑购买其中一款垃圾处理器,以使用年限的频率估计概率.根据以往经验估计,该机构选择购买哪一款垃圾处理机器,才能使用更长久?参考公式:相关系数r=∑n i=1i−x)(y i−y)√∑i=1(x i−x)∑i=1(y i−y)2.对于一组具有线性相关关系的数据(x i,y i)(i=1,2,……,n),其回归直线y=b x+a的斜率和截距的最小二乘估计分别为:b=∑ni=1(x i−x)(y i−y)∑n i=1(x i−x)2,a=y−b x.【解析】解:(1)由题意知相关系数r=∑20i=1i−x)(y i−y)√∑i=1(x i−x)2∑i=1(y i−y)2=√80×8000=78=0.875,因为y与x的相关系数接近1,所以y与x之间具有较强的线性相关关系,可用线性回归模型进行拟合.(2)由题意可得,b=∑20i=1(x i−x)(y i−y)∑20i=1(x i−x)2=70080=8.75,a=y−b x=400020−8.75×8020=200−8.75×4=165,所以y=8.75x+165.(3)以频率估计概率,购买一台甲款垃圾处理机器节约政府支持的垃圾处理费用X(单位:万元)的分布列为X﹣50050100P0.10.40.30.2E(X)=﹣50×0.1+0×0.4+50×0.3+100×0.2=30(万元)购买一台乙款垃圾处理机器节约政府支持的垃圾处理费用Y(单位:万元)的分布列为:Y﹣302070120P0.30.40.20.1E(Y)=﹣30×0.3+20×0.4+70×0.2+120×0.1=25(万元)因为E(X)>E(Y),所以该县城选择购买一台甲款垃圾处理机器更划算.例6.某基地蔬菜大棚采用水培、无土栽培方式种植各类蔬菜.据统计该基地的西红柿增加量y(百斤)与使用某种液体肥料x(千克)之间对应数据为如图所示的折线图.(1)依据数据的折线图,请计算相关系数r(精确到0.01),并以此判定是否可用线性回归模型拟合y 与x的关系?若是请求出回归直线方程,若不是请说明理由;(2)过去50周的资料显示,该地周光照量X(小时)都在30小时以上,其中不足50小时的周数有5周,不低于50小时且不超过70小时的周数有35周,超过70小时的周数有10周.蔬菜大棚对光照要求较大,某光照控制仪商家为该基地提供了部分光照控制仪,但每周光照控制仪最多可运行台数受周光照量X限制,并有如表关系:周光照量X(单位:小时)30<X<5050≤X≤70n≥2光照控制仪最多可运行台数542若某台光照控制仪运行,则该台光照控制仪周利润为3000元;若某台光照控制仪未运行,则该台光照控制仪周亏损1000元.若商家安装了5台光照控制仪,求商家在过去50周每周利润的平均值.附:对于一组数据(x1,y1),(x2,y2),……,(x n,y n),其相关系数公式r=∑n i=1i−x)(y i−y)√∑i=1i−x)2∑i=1i−y)2,回归直线y=b x+a的斜率和截距的最小二乘估计分别为:b=∑ni=1(x i−x)(y i−y)∑n i=1(x i−x)2=∑ni=1x i y i−nxy∑n i=1(x i−x)2,a=y−b x,参考数据√0.3≈0.55,√0.9≈0.95.【解析】解:(1)由已知数据可得x=2+4+5+6+85=5,y=3+4+4+4+55=4,因为∑5i=1(x i−x)(y i−y)=(−3)×(−1)+0+0+0+3×1=6,√∑5i=1(x i−x)2=√(−3)2+(−1)2+02+12+32=2√5,√∑5i=1(y i−y)2=√(−1)2+02+02+02+12=√2.所以相关系数r=∑n i=1i−x)(y i−y)√∑i=1i −x)2√∑i=1i−y)2=2√5⋅√2=√910≈0.95,因为r>0.75,所以可用线性回归模型拟合y与x的关系,因为b=∑ni=1(x i−x)(y i−y)∑n i=1(x i−x)2=620=0.3,a=y−b x=2.5,所以回归直线方程y=0.3x+2.5.(2)记商家周总利润为Y元,由条件可得在过去50周里:X>70时,共有10周,只有2台光照控制仪运行,周总利润Y=2×3000﹣3×1000=3000元,当50≤X≤70时,共有35周,有4台光照控制仪运行,周总利润Y=4×3000﹣1×1000=11000元,当X<50时,共有5周,5台光照控制仪都运行,周总利润Y=5×3000=15000元,所以过去50周每周利润的平均值Y=3000×10+11000×35+15000×550=9800元,所以商家在过去50周每周利润的平均值为9800元.例7.湖南省从2021年开始将全面推行“3+1+2”的新高考模式,新高考对化学、生物、地理和政治等四门选考科目,制定了计算转换T分(即记入高考总分的分数)的“等级转换赋分规则”(详见附1和附2),具体的转换步骤为:①原始分Y等级转换;②原始分等级内等比例转换赋分.某校的一次年级统考中,政治、生物两选考科目的原始分分布如表:等级A B C D E比例约15%约35%约35%约13%约2%政治学科各等级对应的原始分区间[81,98][72,80][66,71][63,65][60,62]生物学科各等级对应的原始分区间[90,100][77,89][69,76][66,68][63,65]现从政治、生物两学科中分别随机抽取了20个原始分成绩数据,作出茎叶图:(1)根据茎叶图,分别求出政治成绩的中位数和生物成绩的众数;(2)该校的甲同学选考政治学科,其原始分为82分,乙同学选考生物学科,其原始分为91分,根据赋分转换公式,分别求出这两位同学的转化分;(3)根据生物成绩在等级B的6个原始分和对应的6个转化分,得到样本数据(Y i,T i),请计算生物原始分Y i与生物转换分T i之间的相关系数,并根据这两个变量的相关系数谈谈你对新高考这种“等级转换赋分法”的看法.附1:等级转换的等级人数占比与各等级的转换分赋分区间等级A B C D E原始分从高到低排序的等级人数占比约15% 约35% 约35% 约13% 约2%转换分T 的赋分区间[86,100] [71,85][56,70] [41,55] [30,40]附2:计算转换分T 的等比例转换赋分公式:Y 2−Y Y−Y 1=T 2−T T−T 1.(其中:Y 1,Y 2别表示原始分Y 对应等级的原始分区间下限和上限;T 1,T 2分别表示原始分对应等级的转换分赋分区间下限和上限.T 的计算结果按四舍五入取整).附3:∑ 6i=1(Y i −Y )(T i −T )=74,√∑ 6i=1(Yi −Y)2∑ 6i=1(T i −T)2=√5494≈74.12,r =∑n i=1i −Y)(T i −T)√∑i=1i −Y)2∑i=1i −T)2.【解析】解:(1)根据茎叶图知,政治成绩的中位数为72,生物成绩的众数为73; (2)甲同学选考政治学科的等级为A ,由转换赋分公式:98−8282−81=100−T T−86,解得T =87;乙同学选考生物学科的等级为A ,由赋分转换公式:100−9191−90=100−T T−86,解得T =87;所以甲、乙两位同学的转换分都是87分. (3)由题意知,r =∑n i=1i −Y)(T i −T)√∑ i=1(Y i −Y)2∑ i=1(T i −T)2=7474.12≈0.998, 说法1:等级转换赋分公平,因为相关系数十分接近1,接近函数关系,因此高考这种“等级转换赋分”具有公平性与合理性.说法2:等级转换赋分法不公平,在同一等级内,原始分与转化分是确定的函数关系,理论上原始分与转化分的相关系数为1,在实际赋分过程中由于数据的四舍五入,使得实际的转化分与应得的转化分有一定的误差,极小部分同学赋分后会出现偏高或偏低的现象. (只要说法有道理,都可以得分).例8.某市房管局为了了解该市市民2018年1月至2019年1月期间买二手房情况,首先随机抽样其中200名购房者,并对其购房面积m (单位:平方米,60≤m ≤130)进行了一次调查统计,制成了如图1所示的频率分布直方图,接着调查了该市2018年1月至2019年1月期间当月在售二手房均价y (单位:万元/平方米),制成了如图2所示的散点图(图中月份代码1﹣13分别对应2018年1月至2019年1月).(Ⅰ)试估计该市市民的购房面积的中位数m0;(Ⅱ)现采用分层抽样的方法从购房面积位于[110,130]的40位市民中随机抽取4人,再从这4人中随机抽取2人,求这2人的购房面积恰好有一人在[120,130]的概率;(Ⅲ)根据散点图选择y=a+b√x和y=c+d lnx两个模型进行拟合,经过数据处理得到两个回归方程,分别为y=0.9369+0.0285√x和y=0.9554+0.0306lnx,并得到一些统计量的值如表所示:y=0.9369+0.0285√x y=0.9554+0.0306lnx ∑13i=1(y i−y i)20.0005910.000164∑13i=1(y i−y)20.006050请利用相关指数R2判断哪个模型的拟合效果更好,并用拟合效果更好的模型预测出2019年12月份的二手房购房均价(精确到0.001).【参考数据】ln2≈0.69,ln3≈1.10,ln23≈3.14,ln25≈3.22,√2≈141,√3≈1.73,√23≈4.80.【参考公式】R2=1−∑ni=1(y i−y i)2∑n i=1(y i−y)2.【解析】解:(I)由频率分布直方图,可得,前三组频率和为0.05+0.1+0.2=0.35,前四组频率和为0.05+0.1+0.2+025=0.6,故中位数出现在第四组,且m0=90+10×0.150.25=96.(Ⅱ)设从位于[110,120)的市民中抽取x人,从位于[120,130]的市民中抽取y人,由分层抽样可知:440=x30=y10,则x=3,y=1,在抽取的4人中,记3名位于[11,120)的市民为A1,A2,A3,位于[120,130]的市民为B则所有抽样情况为:(A1,A2),(A1,A3),(A1,B),(A2,A3),(A2,B),(A3,B)共6种.而其中恰有一人在位于购房面积[120,130]的情况共有3种,故所求概率P=36=12,(III)设模型y=0.9369+0.0285√x和y=0.955+0.0306lnx的相关指数分别为R12,R22,则R12=1−0.0005910.006050,R22=1−0.0001640.006050,显然R12<R22,故模型y=0.9554+0.0306lnx的拟合效果更好.由2019年12月份对应的代码为24,则y=0.9554+0.0306ln24=0.9554+0.0306(3ln2+ln3)≈1.052万元/平方米.例9.某汽车公司拟对“东方红”款高端汽车发动机进行科技改造,根据市场调研与模拟,得到科技改造投入x(亿元)与科技改造直接收益y(亿元)的数据统计如表:x2346810132122232425y1322314250565868.56867.56666当0<x≤16时,建立了y与x的两个回归模型:模型①:y=4.1x+11.8;模型②:y=21.3√x−14.4;当x>16时,确定y与x满足的线性回归方程为:y=−0.7x+a.(Ⅰ)根据下列表格中的数据,比较当0<x≤16时模型①、②的相关指数R2,并选择拟合精度更高、更可靠的模型,预测对“东方红”款汽车发动机科技改造的投入为16亿元时的直接收益.回归模型模型①模型②回归方程y=4.1x+11.8y=21.3√x−14.4∑7i=1(y i−y i)2182.479.2(附:刻画回归效果的相关指数R2=1−∑n i=1(y i−y i)2∑n i=1(y i−y)2.)(Ⅱ)为鼓励科技创新,当科技改造的投入不少于20亿元时,国家给予公司补贴收益10亿元,以回归方程为预测依据,比较科技改造投入16元与20亿元时公司实际收益的大小;(附:用最小二乘法求线性回归方程y=b x+a的系数公式b=∑ni=1x i y i−nx⋅y∑n i=1x i2−nx2=∑ni=1(x i−x)(y i−y)∑n i=1(x i−x)2;a=y−b x)(Ⅲ)科技改造后,“东方红”款汽车发动机的热效率X大幅提高,X服从正态分布N(0.52,0.012),公司对科技改造团队的奖励方案如下:若发动机的热效率不超过50%但不超过53%,不予奖励;若发动机的热效率超过50%但不超过53%,每台发动机奖励2万元;若发动机的热效率超过53%,每台发动机奖励4万元.求每台发动机获得奖励的数学期望.(附:随机变量ξ服从正态分布N(μ,σ2),则P(μ﹣σ<ξ<μ+σ)=0.6827,P(μ﹣2σ<ξ<μ+2σ)=0.9545.)【解析】解:(Ⅰ)由表格中的数据,有182.4>79.2,即182.4∑7i=1(y i−y)2>79.2∑7i=1(y i−y)2,∴模型①的R2小于模型②的R2,说明模型②的刻画效果更好.∴当x=16亿元时,科技改造直接收益的预测值为y=21.3×√16−14.4=70.8(亿元);(Ⅱ)由已知可得,x−20=0.5+2+3.5+4+55=3,则x=23,y−60=8.5+8+7.5+6+65=7.2,则y=67.2,∴a=y−0.7x=67.2+0.7×23=83.3,∴当x>16亿元时,y与x满足线性回归方程y=−0.7x+83.3,当x=20亿元时,科技改造直接收益的预测值为y=−0.7×20+83.3=69.3.∴当x=20亿元时,实际收益的预测值为69.3+10=79.3亿元>70.8亿元.∴科技改造投入20亿元时,公司的实际收益更大;(Ⅲ)∵P(0.52﹣0.02<X<0.52+0.02)=0.9545,∴P(X>0.50)=1+0.95452=0.97725,P(X≤0.50)=1−0.95452=0.02275,∵P(0.52﹣0.01<X<0.52+0.01)=0.6827,∴P(X>0.53)=1−0.68272=0.15865,∴P(0.50<X≤0.53)=0.97725﹣0.15865=0.8186.设每台发动机获得的奖励为Y(万元),则Y的分布列为:Y024P0.022750.81860.15865∴每台发动机获得的奖励的数学期望为:E(Y)=0×0.02275+2×0.8186+4×0.15865=2.2718(万元).例10.某高中数学建模兴趣小组的同学为了研究所在地区男高中生的身高与体重的关系,从若干个高中男学生中抽取了1000个样本,得到如下数据.数据一:身高在[170,180)(单位:cm)的体重频数统计体重(kg)[50,55)[55,60)[60,65)[65,70)[70,75)[75,80)[80,85)[85,90)人数206010010080201010数据二:身高所在的区间含样本的个数及部分数据身高x(cm)[140,150)[150,160)[160﹣170)[170﹣180)[180﹣190)平均体重y(kg)4553.66075(Ⅰ)依据数据一将下面男高中生身高在[170﹣180)(单位:cm)体重的频率分布直方图补充完整,并利用频率分布直方图估计身高在[170﹣180)(单位:cm)的中学生的平均体重;(保留小数点后一位)(Ⅱ)依据数据一、二,计算身高(取值为区间中点)和体重的相关系数约为0.99,能否用线性回归直线来刻画中学生身高与体重的相关关系,请说明理由;若能,求出该回归直线方程;(Ⅲ)说明残差平方和或相关指数R2与线性回归模型拟合效果之间关系.(只需写出结论,不需要计算)参考公式:b=∑ni=1(x i−x)(y i−y)∑n i=1(x i−x)2=∑ni=1x i y i−nx⋅y∑n i=1x i2−nx2,a=y−b x.参考数据:(1)145×45+155×53.6+165×60+185×75=38608;(2)1452+1552+1652+1752+1852﹣5×1652=1000.(3)663×175=116025,664×175=116200,665×175=116375.(4)728×165=120120.【解析】解:(1)身高在[170,180)的总人数为:20+60+100+100+80+20+10+10=400,体重在[55﹣60)的频率为:60400=0.15,体重在[70﹣75)的 频率为:80400=0.2,平均体重为:52.5×0.05+57.5×0.15+62.5×0.25+67.5×0.25+72.5×0.2 +77.5×0.05+82.5×0.025+87.5×0.025≈66.4,(2)因为 r =0.99→1,线性相关很强,故可以用线性回归直线来 刻画中学生身高与体重的相关, x =145+155+165+175+1855=165,y =45+75+60+53.6+66.45=60,b =∑ 8i=1x i y i −8x⋅y ∑ 8i=1x i 2−8x2=38608+175×66.4−5×165×601000=0.728, a =y −b x =60−0.728×165=−60.12, 所以回归直线方程为:y =0.728x −60.12,(3)残差平方和越小或相关指数 R 2 越接近于1,线性回归模型拟合效果越好.例11.2019年的“金九银十”变成“铜九铁十”,国各地房价“跳水”严重,但某地二手房交易却“逆市”而行.如图是该地某小区2018年11月至2019年1月间,当月在售二手房均价(单位:万元/平方米)的散点图.(图中月份代码1~13分别对应2018年11月~2019年11月)根据散点图选择y =a +b √x 和y =c +dlnx 两个模型进行拟合,经过数据处理得到两个回归方程分别为y ^=0.9369+0.0285√x和y^=0.9554+0.0306lnx,并得到以下一些统计量的值:y^=0.9369+0.0285√x y^=0.9554+0.0306lnx ∑13i=1(y i−y^i)20.0005910.000164∑13i=1(y i−y)20.006050(1)请利用相关指数R2判断哪个模型的拟合效果更好;(2)某位购房者拟于2020年4月购买这个小区m(70≤m≤160)平方米的二手房(欲购房为其家庭首套房).若购房时该小区所有住房的房产证均已满2但未满5年,请你利用(1)中拟合效果更好的模型解决以下问题:(i)估算该购房者应支付的购房金额;(购房金额=房款+税费,房屋均价精确到0.001万元/平方米)(ii)若该购房者拟用不超过100万元的资金购买该小区一套二手房,试估算其可购买的最大面积.(精确到1平方米)附注:根据有关规定,二手房交易需要缴纳若干项税费,税费是按房屋的计税价格(计税价格=房款)进行征收的.房产证满2年但未满5年的征收方式如下:首套面积90平方米以内(含90平方米)为1%;首套面积90平方米以上且140平方米以内(含140平方米)1.5%;首套面积140平方米以上或非首套为3%.参考数据:ln2≈0.69,ln3≈1.10,ln17≈2.83,ln19≈2.94,√2≈1.41,√3≈1.73,√17≈4.12,√19≈4.36.参考公式:相关指数R2=1−∑ni=1(y i−y^i)2∑n i=1(y i−y)2.【解析】解:(1)模型一中,y=0.9369+0.0285√x的残差平方和为0.000591,相关指数为R21−0.0005910.006050≈0.923,模型二中,y=0.9554+0.0306lnx的残差平方和为0.000164,相关指数为 R 21−0.0001640.006050≈0.973,∴ 相关指数较大的模型二拟合效果好些. (2)通过散点图确定2020年4月对应的 x =18, 代入(1)中拟合效果更好的模型二,代入计算 y =0.9554+0.0306ln18 =0.9554+0.0306×(ln 2+2ln 3) =0.9554+0.0306×(0.69+2×1.10) ≈1.044 (万元/平方米),则2020年4月份二手房均价的预测值为1.044(万元/平方米).(i )设该购房者应支付的购房金额 h 万元,因为税费中淵方只需缴纳契税, ①当70⩽m ⩽90 时,契税为计税价格的 1%, 故h =m ×1.044×(1%+1)=1.05444m ; ②当90<m ⩽144 时,契税为计税价格的 1.5%, 故h =m ×1.044×(1.5%+1)=1.05966m ; ③当144<m ⩽160 时,契税为计税价格的 3%, 故h =m ×1.044×(3%+1)=1.07532m ;∴ℎ={1.05444m ,70⩽m ⩽901.05966m ,90<m ⩽1441.07532m ,144<m ⩽160;∴ 当 70⩽m ⩽90 时购房金额为 1.05444m 万元, 当 90<m ⩽144 时购房金额为 1.05966m 万元, 当 144<m ⩽160 时购房金额为 1.07532m 万元.(ii )设该购房者可购买该小区二手房的最大面积为 t 平方米,由(i ) 知,当70⩽m ⩽90时,应支付的购房金额为 1.05444t ,又1.05444t ⩽1.05444×90<100, 又因为房屋均价约为1.044万元/平方米,所以 t <100,所以90⩽t <100, 由1.05966t ⩽100,解得 t ⩽1001.05966,且1001.05966≈94.4,所以该购房者可购买该小区二手房的最大面积为94平方米.例12.某新兴科技公司为了确定新研发的产品下一季度的营销计划,需了解月宣传费x (单位:万元)对月销售量y(单位:千件)的影响,收集了2020年3月至2020年8月共6个月的月宣传费x和月销售量y的数据如表:月份345678宣传费x5678910月销售量y0.4 3.5 5.27.08.610.7现分别用模型①y=b x+a和模型②y=e m x+n对以上数据进行拟合,得到回归模型,并计算出模型的残差如表:(模型①和模型②的残差分别为e1和e2,残差=实际值﹣预报值)x5678910y0.4 3.5 5.37.08.610.7e1﹣0.60.540.280.12﹣0.24﹣0.1e2﹣0.63 1.71 2.10 1.63﹣0.7﹣5.42(1)根据上表的残差数据,应选择哪个模型来拟合月宣传费x与月销售量y的关系较为合适,简要说明理由;(2)为了优化模型,将(1)中选择的模型残差绝对值最大所对应的一组数据(x,y)剔除,根据剩余的5组数据,求该模型的回归方程,并预测月宣传费为12万元时,该公司的月销售量.(剔除数据前的参考数据:x=7.5,y=5.9,∑6i=1x i y i=299.8,∑6i=1x i2=355,z=lny.z≈−1.41,∑6i=1x i y i=−73.10,ln10.7≈2.37,e4.034≈56.49.)参考公式:b=∑ni=1x i y i−nxy∑n i=1x i2−nx2,a=y−b x.【解析】解:(1)应选择模型①,因为模型①每组数据对应的残差绝对值都比模型②的小,残差波动小,残差点比较均匀地落在水平的带状区域内,说明拟合精度高.(2)由(1)知,需剔除第一组数据,则剔除后的x=7.5×6−55=8,y=5.9×6−0.45=7,5xy=280,5x2=320,∑5i=1x i y i=299.8−5×0.4=297.8,∑5i=1x i2=355−25=330.∴b=∑5i=1x i y i−5xy∑5i=1x i2−5x2=297.8−280330−320=1.78,a=y−b x=7−1.78×8=−7.24.得①的回归方程为y=1.78x−7.24,则当x=12时,y=1.78×12−7.24=14.12.故月宣传费为12万元时,该公司的月销售量为14.12千件.例13.新型冠状病毒肺炎COVID﹣19疫情发生以来,在世界各地逐渐蔓延.在全国人民的共同努力和各级部门的严格管控下,我国的疫情已经得到了很好的控制.然而,小王同学发现,每个国家在疫情发生的初期,由于认识不足和措施不到位,感染人数都会出现快速的增长.如表是小王同学记录的某国连续8天每日新型冠状病毒感染确诊的累计人数.日期代码x12345678累计确诊人数y481632517197122为了分析该国累计感染人数的变化趋势,小王同学分别用两种模型:①y=bx2+a,②y=dx+c对变量x和y的关系进行拟合,得到相应的回归方程并进行残差分析,残差图如下(注:残差e î=y i−y î):经过计算得它∑8i=1(x i−x)(y i−y)=728,∑8i=1(x i−x)2=42,∑8i=1(z i−z)(y i−y)=6868,∑8i=1(z i−z)2=3570,其中z i=x i2,z=18∑8i=1z i.(1)根据残差图,比较模型①,②的拟合效果,应该选择哪个模型?并简要说明理由;(2)根据(1)问选定的模型求出相应的回归方程(系数均保留两位小数);(3)由于时差,该国截止第9天新型冠状病毒感染确诊的累计人数尚未公布.小王同学认为,如果防疫形势没有得到明显改善,在数据公布之前可以根据他在(2)问求出的回归方程来对感染人数做出预测,那么估计该地区第9天新型冠状病毒感染确诊的累计人数是多少?附:回归直线的斜率和截距的最小二乘估计公式分别为:b=∑8i=1(x i−x)(y i−y)∑8i=1(x i−x)2,a=y−b x.【解析】解:(1)选择模型①,理由如下:根据残差图可以看出,模型①的估计值和真实值相对比较接近,模型②的残差相对比较大,所以模型①的拟合效果相对较好;(2)由(1)可知y关于x的回归方程为y=bx2+a,令z=x2,则y=bz+a,由所给的数据可得:z=18(1+4+9+16+25+36+49+64)=25.5,y=18(4+8+16+31+51+71+97+122)=50,b=∑8i=1(z i−z)(y i−y)∑8i=1(z i−z)2=68683570≈1.92,则a=y−b z≈50﹣1.92×25.5=1.04,所以y关于x的回归方程为y=1.92x2+1.04;(3)将x=9代入回归方程,可得y=1.92×92+1.04=156.56≈157(人),所以预测该地区第9天新型冠状病毒感染确诊的累计人数约为157人.例14.H市某企业坚持以市场需求为导向,合理配置生产资源,不断改革、探索销售模式.下表是该企业每月生产的一种核心产品的产量x(吨)与相应的生产总成本y(万元)的五组对照数据.产量x(件)12345生产总成本y(万元)3781012(Ⅰ)根据上达数据,若用最小二乘法进行线性模拟,试求y关于x的线性回归方程y=b x+a;参考公式:b=∑ni=1x i y i−nxy∑n i=1x i2−nx2,a=y−b x.(Ⅱ)记第(Ⅰ)问中所求y与x的线性回归方程y=b x+a为模型①,同时该企业科研人员利用计算机根据数据又建立了y与x的回归模型②:y=12x2+1.其中模型②的残差图(残差=实际值﹣预报值)如图所示:请完成模型①的残差表与残差图,并根据残差图,判断哪一个模型更适宜作为y关于x的回归方程?并说明理由;(Ⅲ)根据模型①中y与x的线性回归方程,预测产量为6吨时生产总成本为多少万元?【解析】解:(Ⅰ)计算x=15(1+2+3+4+5)=3,y=15(3+7+8+10+12)=8,∑5i=1x i2=12+22+32+42+52=55,∑5i=1x i y i=1⋅3+2⋅7+3⋅8+4⋅10+5⋅12=141,b=∑5i=1x i y i−nxy∑5i=1x i2−nx2=141−5×3×855−5×9=2.1,a=y−b x=8−2.1×3=1.7,因此,回归直线方程为y=2.1x+1.7.(Ⅱ)模型①的残差表为:x12345y3781012 y 3.8 5.9810.112.2 e﹣0.8 1.10﹣0.1﹣0.2画出残差图,如图所示;结论:模型①更适宜作为y关于x的回归方程,因为:理由1:模型①的4个样本点的残差点落在的带状区域比模型②的带状区域更窄;理由2:模型①的4个样本点的残差点比模型②的残差点更贴近进x轴..(不列残差表不扣分,写出一个理由即可得分.)(Ⅲ)根据模型①中y与x的回归直线方程,计算x=6时,y=2.1×6+1.7=14.3,所以预测产量为6吨时生产总成本为14.3万元.例15.为了解某企业生产的某产品的年利润与年广告投入的关系,该企业对最近一些相关数据进行了调查统计,得出相关数据见表:23456年广告投入x(万元)346811年利润y(十万元)根据以上数据,研究人员分别借助甲.乙两种不同的回归模型,得到两个回归方程,方程甲:方程甲:y(1)=b(x﹣1)2+2.75,方程乙:y(2)=c x﹣1.6.(1)求b(结果精确到0.01)与c的值.(2)为了评价两种模型的拟合效果,完成以下任务.①完成下表(备注:e î=y i−y î,e î称为相应于点(x i,y i)的残差;年广告投入x(万元)23456年利润y(十万元)346811模型甲估计值y î(1)残差e î(1)模型乙估计值y î(2)残差e î(2)②分别计算模型甲与模型乙的残差平方和Q1及Q2,并通过比较Q1,Q2的大小,判断哪个模型拟合效果更好.【解析】解:(1)设t=(x﹣1)2,则t=15(1+4+9+16+25)=11.∵y=6.4,∴6.4=b×11+2.75,解得b≈0.33.又x=4,∴6.4=c×4−1.6,即c=2.(2)①经计算,可得下表:年广告投入x(万元)23456年利润y(十万元)346811模型甲估计值y î(1) 3.08 4.07 5.728.0311残差e î(1)﹣0.08﹣0.070.28﹣0.030模型乙估计值y î(2) 2.4 4.4 6.48.410.4残差e î(2)0.6﹣0.4﹣0.4﹣0.40.6②Q1=(−0.08)2+(−0.07)2+0.282+(−0.03)2=0.0906.Q2=0.62×2+(−0.4)2×3=1.2.∵Q1<Q2,∴模型甲的拟合效果更好.。
相关分析与回归分析练习试卷1(题后含答案及解析)

相关分析与回归分析练习试卷1(题后含答案及解析) 题型有:1. 单选题 2. 多选题单项选择题以下每小题各有四项备选答案,其中只有一项是正确的。
1.根据散点图8-1,可以判断两个变量之间存在( )。
A.正线性相关关系B.负线性相关关系C.非线性关系D.函数关系正确答案:A 涉及知识点:相关分析与回归分析2.假设某品牌的笔记本市场需求只与消费者的收入水平和该笔记本的市场价格水平有关。
则在假定消费者的收入水平不变的条件下,该笔记本的市场需求与其市场价格水平的相关关系就是一种( )。
A.单相关B.复相关C.偏相关D.函数关系正确答案:C解析:在某一现象与多种现象相关的场合,假定其他变量不变,专门考察其中两个变量的相关关系称为偏相关。
在假定消费者的收入水平不变的条件下,该笔记本的市场需求与其市场价格水平的关系就是一种偏相关。
知识模块:相关分析与回归分析3.相关图又称( )。
A.散布表B.折线图C.散点图D.曲线图正确答案:C解析:相关图又称散点图,是指把相关表中的原始对应数值在乎面直角坐标系中用坐标点描绘出来的图形。
知识模块:相关分析与回归分析4.下列相关系数取值中错误的是( )。
A.-0.86B.0.78C.1.25D.0正确答案:C解析:相关系数r的取值介于-1与1之间。
知识模块:相关分析与回归分析5.如果相关系数r=0,则表明两个变量之间( )。
A.相关程度很低B.不存在任何关系C.不存在线性相关关系D.存在非线性相关关系正确答案:C解析:相关系数r是根据样本数据计算的度量两个变量之间线性关系强度的统计量。
如果相关系数r=0,说明两个变量之间不存在线性相关关系。
知识模块:相关分析与回归分析6.当所有观测值都落在回归直线上,则两个变量之间的相关系数为( )。
A.1B.-1C.+1或-1D.大于-1,小于+1正确答案:C解析:当所有观测值都落在回归直线上时,说明两个变量完全线性相关,所以相关系数为+1或-1。
《应用回归试分析》试题答案

一、一家保险公司十分关心其总公司营业部加班的程度,决定认真调查现状。
经十周时间,收集了每周加班时间的数据和签发的新保单数目,x 为每周签发的新保单数目,y 为每周加(3)设回归方程为01y x ββ∧∧∧=+11221(2637021717)0.0036(71043005806440)()ni ii nii x y n x yxn x --=-=--β===--∑∑01 2.850.00367620.1068y x ββ-∧-=-=-⨯=0.10680.0036y x∧∴=+可得回归方程为(4) 22n i=11()n-2i i y y σ∧∧=-∑ 2n01i=11(())n-2i y x ββ∧∧=-+∑=0.2305 σ∧=0.4801(5) 由于211(,)xxN L σββ∧t σ∧==服从自由度为n-2的t 分布。
因而/2|(2)1P t n αασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t t ααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为0.4801/⨯⨯(0.0036-1.8600.0036+1.860即为:(0.0028,0.0044)22001()(,())xxx N n L ββσ-∧+t ∧∧==服从自由度为n-2的t 分布。
因而/2(2)1P t n αα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1p βσββσα∧∧∧∧-<<+=- 095%0.3567,0.5703β∧-可得的置信度为的置信区间为()(6)x 与y 的决定系数 22121()()nii nii y y r y y ∧-=-=-==-∑∑16.8202718.525=0.908(7)ANOV Ax平方和 df均方F 显著性组间(组合) 1231497.500 7 175928.214 5.302.168 线性项 加权的1168713.036 1 1168713.036 35.222 .027 偏差62784.464 6 10464.077 .315.885组内 66362.500 2 33181.250 总数1297860.0009由于(1,9)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。
回归分析练习题及参考答案
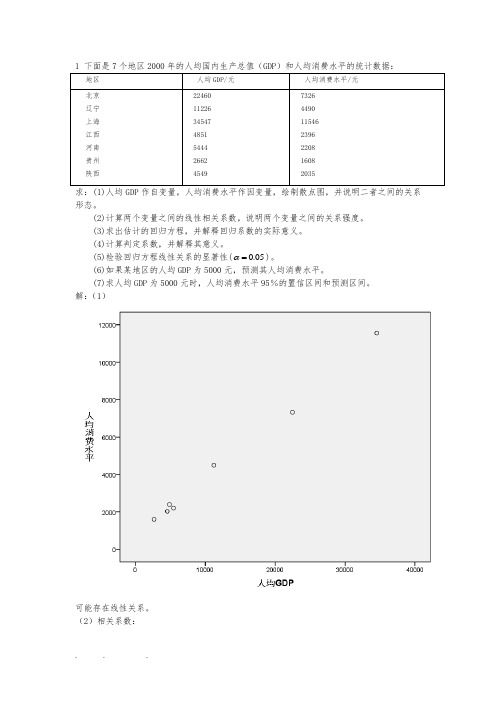
1 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据:地区人均GDP/元人均消费水平/元北京辽宁上海江西河南贵州陕西 224601122634547485154442662454973264490115462396220816082035求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)可能存在线性关系。
(2)相关系数:(3)回归方程:734.6930.309y x=+回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t 显著性B 标准误Beta1 (常量)734.693 139.540 5.265 0.003人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(4)模型汇总模型R R 方调整 R 方标准估计的误差1 .998a.996 .996 247.303a. 预测变量: (常量), 人均GDP。
人均GDP对人均消费的影响达到99.6%。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
回归分析习题及答案

回归分析习题及答案回归分析习题及答案回归分析是统计学中一种常用的分析方法,用于研究变量之间的关系。
它可以帮助我们了解变量之间的相关性,并预测未来的趋势。
在本文中,我们将提供一些回归分析的习题及其详细解答,帮助读者更好地理解和应用这一方法。
习题一:某公司想要了解其销售额与广告投入之间的关系。
公司收集了过去12个月的数据,包括每个月的广告投入(单位:万元)和当月的销售额(单位:万元)。
请利用这些数据进行回归分析,并给出相关的统计结果。
解答一:首先,我们需要将数据导入统计软件,比如SPSS或Excel。
然后,我们可以使用线性回归模型来分析销售额与广告投入之间的关系。
在SPSS中,可以选择“回归”分析,将销售额作为因变量,广告投入作为自变量,进行线性回归分析。
回归分析的结果包括回归方程、相关系数、显著性检验等。
回归方程可以用来描述销售额与广告投入之间的关系。
相关系数可以告诉我们这两个变量之间的相关程度,取值范围为-1到1,越接近1表示相关性越强。
显著性检验可以告诉我们回归方程是否显著,即广告投入是否对销售额有显著影响。
习题二:某研究人员想要了解学生的考试成绩与他们的学习时间之间的关系。
研究人员随机选择了100名学生,记录了他们的学习时间(单位:小时)和考试成绩(百分制)。
请利用这些数据进行回归分析,并给出相关的统计结果。
解答二:同样地,我们需要将数据导入统计软件,然后进行回归分析。
这次,我们将考试成绩作为因变量,学习时间作为自变量。
除了之前提到的回归方程、相关系数和显著性检验之外,我们还可以通过回归分析的结果来进行预测。
例如,我们可以利用回归方程来预测一个学生在给定学习时间下的考试成绩。
习题三:某研究人员想要了解一个人的身高与体重之间的关系。
研究人员随机选择了200名成年人,记录了他们的身高(单位:厘米)和体重(单位:千克)。
请利用这些数据进行回归分析,并给出相关的统计结果。
解答三:同样地,我们将数据导入统计软件,然后进行回归分析。
第七章 习题及答案

第七章 相关与回归分析一、单项选题题1、当自变量X 减少时,因变量Y 随之增加,则X 和Y 之间存在着( ) A 、线性相关关系 B 、非线性相关关系 C 、正相关关系 D 、负相关关系2、下列属于函数关系的有( )A 、身高与体重之间B 、广告费用支出与商品销售额之间C 、圆面积与半径之间D 、施肥量与粮食产量之间 3、下列相关程度最高的是( )A 、r=0.89B 、r=-0.93C 、r=0.928D 、r=0.8 4、两变量x 与y 的相关系数为0.8,则其回归直线的判定系数为( ) A 、0.80 B 、0.90 C 、0.64 D 、0.50 5、在线性回归模型中,随机误差项被假定服从( )A 、二项分布B 、t 分布C 、指数分布D 、正态分布6、物价上涨,销售量下降,则物价与销售量之间的相关属于( ) A 、无相关 B 、负相关 C 、正相关 D 、无法判断7、相关分析中所涉及的两个变量( )A 、必须确定哪个是自变量、哪个是因变量B 、都不能为随机变量C 、都可以是随机变量D 、不是对等关系 8、单位产品成本y (元)对产量x (千件)的回归方程为:t t x y 2.0100-=∧,其中“—0.2”的含义是( )A 、产量每增加1件,单位成本下降0.2元B 、产量每增加1件,单位成本下降20%C 、产量每增加1000件,单位成本下降20%D 、产量每增加1000件,单位成本平均下降0.2元E 、产量每增加1000件,单位成本平均下降20% 二、多项选择题1、下列说法正确的有( )A 、相关分析和回归分析是研究现象之间相关关系的两种基本方法B 、相关分析不能指出变量间相互关系的具体形式,也无法从一个变量的变化来推测另一个变量的变化情况 C、回归分析可以不必确定变量中哪个是自变量,哪个是因变量 D、相关分析必须事先研究确定具有相关关系的变量中哪个为自变量,哪个为因变量 E、相关分析中所涉及的变量可以都是随机变量,而回归分析中因变量是随机的,自变量是非随机的2、判定现象之间有无相关关系的方法有()A、计算回归系数B、编制相关表C、绘制相关图D、计算相关系数E、计算中位数3、相关关系按相关的形式可分为()A、正相关B、负相关C、线性相关D、非线性相关E、复相关4、在直线回归方程∧yt=∧β1+∧β2Xt中,回归系数∧β2的数值()A、表明两变量之间的平衡关系B、其正、负号表明两变量之间的相关方向C、表明两变量之间的密切程度D、表明两变量之间的变动比例E、在数学上称为斜率5、下列那些项目属于现象完全相关()A、r=0B、r= —1C、r= +1D、y的数量变化完全由X的数量变化所确定E、r=0.986、在回归分析中,要求所涉及的两个变量x和y()A、必须确定哪个是自变量、哪个是因变量B、不是对等关系C、是对等关系D、一般来说因变量是随机的,自变量是非随机变量E、y对x的回归方程与x对y的回归方程是一回事7、下列有相关关系的是()A、居民家庭的收入与支出B、广告费用与商品销售额C、产量与单位产品成本D、学生学习的时间与学习成绩E、学生的身高与学习成绩8、可决系数2r=86.49%时,意味着()A 、自变量与因变量之间的相关关系密切B 、因变量的总变差中,有80%可通过回归直线来解释 C 、因变量的总变差中,有20%可由回归直线来解释 D 、相关系数绝对值一定是0.93 E 、相关系数绝对值一定是0.8649 三、填空题1、相关系数r 的取值范围为 。
回归分析试题答案
诚信应考 考出水平 考出风格浙江大学城市学院2011 — 2012 学年第一学期期末考试卷《 回归分析 》开课单位: 计算分院 ;考试形式:开卷(A4纸一张);考试时间:2011年01月6日; 所需时间: 120 分钟一.计算题(10分。
)1,考虑过原点的线性回归模型1,1,2,...,i i i y x i n βε=+=误差1,...,n εε仍满足基本假定。
求1β的最小二乘估计。
并求出1β 的期望和方差,写出1β的分布。
1221111111121,1,2,...,ˆ()()2()0ˆi i i nni i i i i i ni i i i ni ii nii y x i n Q y yy x Qy x x x yxβεββββ======+==-=-∂=--=∂=∑∑∑∑∑解:第1页共 6 页二. 证明题(本大题共2小题,每小题7分,共14分。
)1,证明:(1)22()1var()[1]i i xxx x e n L σ-=--(2)2211ˆˆ()2n i ii y y n σ==--∑是2σ的无偏估计。
011111122ˆˆˆ()()1()()1var()var[()()]()1var()var((()))()12cov[,(())](1(i i i i i nn i i j j jj j xx ni i i j j j xx ni i j j j xx ni i j j j xxe y y y x x x x y y x x y n L x x e y x x y n L x x y x x y n L x x y x x y n L x n ββσσ======-=----=----=-+--=++---+-=++∑∑∑∑∑解(1):222122222221212211)()1())2()()()11(12()]()1[1]1ˆˆ(2)()(())21ˆ[()]2()111var()[1]2212n i i j j xx xxi i xx xxi xx ni i i ni i i n n i i i i xx x x x x x L n L x x x x n L n L x x n L E E y y n E y y n x x e n n n L n σσσσσ=====----+--=++-+-=--=--=---==----=-∑∑∑∑∑22(11)n σσ--=三.填空题.(每空2分,共46分)1.为了研究家庭收入和家庭消费的关系,通过调查得到数据如下:6.22893,29.12349,43008,97.29,5422=====∑∑∑xy yxy x1)用最小二乘估计求出线性回归方程的参数估计值0ˆβ= 。
回归分析作业参考答案

回归分析作业参考答案1 、数据文件“资产评估 1 ”提供了 35 家上市公司资产评估增值的数据。
num--- 公司序号pg---- 资产评估增值率gz---- 固定资产在总资产中所占比例fz---- 权益与负债比bc---- 总资产投资报酬率gm--- 公司资产规模(亿元)•建立关于资产评估增值率的四元线性回归方程,并通过统计分析、检验说明所得方程的有效性,解释各回归系数的经济含义。
•剔除 gz 变量,建立关于资产评估增值率的三元线性回归方程,与 a 中的模型相比较,那个更为实用有效,说明理由。
解:(1)、SPSS相关数据表如下:Model Summary(b)总资产投资报酬率b Dependent Variable: 资产评估增值率ANOVA(b)b Dependent Variable: 资产评估增值率Residuals Statistics(a)Minimum Maximum Mean Std. Deviation NPredicted Value -.084652 .494055 .172240 .1312429 35 Residual -.150002 .149380 .000000 .0739727 35Std. Predicted Value -1.957 2.452 .000 1.000 35Std. Residual -1.905 1.897 .000 .939 35a Dependent Variable: 资产评估增值率R为0.871,决定系数R2为0.759,校正决定系数为0.727。
拟合的回归模型F值为23.609,P值为0,所以拟合的模型是有统计意义的。
从系数的t检验可以看出,只有固定资产比重的相伴概率0.339>0.05,说明只有固定资产比重对资产评估增值率的影响是不显著的,其他自变量对固定资产增值的比率均有显著的影响。
线性回归方程为:pg=0.396+0.079gz+0.063fz+0.602bc-0.044gm表示,在权益与负债比、总资产投资报酬率和公司规模不变的条件下,固定资产比重每增加1个单位,资产评估增值率增加。
回归分析的初步应用(人教A版)(含答案)

回归分析的初步应用(人教A版)一、单选题(共7道,每道14分)1.下列结论:①函数关系是一种确定性关系;②相关关系是一种非确定关系;③回归分析是对具有函数关系的两个变量进行统计分析的一种方法;④回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法.其中正确的是( )A.①②B.①②③C.①②④D.①②③④答案:C解题思路:试题难度:三颗星知识点:回归分析的初步应用2.在回归分析中,残差图中纵坐标为( )A.残差B.样本编号C. D.答案:A解题思路:试题难度:三颗星知识点:回归分析的初步应用3.在回归分析中,代表了数据点和它在回归直线上相应位置的差异的是( )A.总偏差平方和B.残差平方和C.回归平方和D.相关指数答案:B解题思路:试题难度:三颗星知识点:回归分析的初步应用4.给出下列结论:①在回归分析中,可用指数系数的值判断模型的拟合效果,越大,模型的拟合效果越好;②在回归分析中,可用残差平方和判断模型的拟合效果,残差平方和越大,模型的拟合效果越好;③在回归分析中,可用相关系数的值判断模型的拟合效果,越大,模型的拟合效果越好;④在回归分析中,可用残差图判断模型的拟合效果,残差点比较均匀地落在水平的带状区域内,说明这样的模型比较适合,带状区域的宽度越窄,说明模型的拟合精度越高.其中正确的共有( )A.1个B.2个C.3个D.4个答案:B解题思路:试题难度:三颗星知识点:回归分析的初步应用5.下列四个命题:①将一组数据中的每个数据都加上同一个常数,方差不变;②已知回归方程,则当变量增加一个单位时,平均减少5个单位;③将一组数据中的每个数据都加上一个常数,均值不变;④在回归分析中,我们常用来反映拟合效果,越大,残差平方和就越小,拟合的效果就越好.其中错误的共有( )A.0个B.1个C.2个D.3个答案:B解题思路:试题难度:三颗星知识点:回归分析的初步应用6.为了研究两个变量之间的线性相关性,甲、乙两位同学各自独立地做10次和15次试验,并且利用线性回归方法,求得回归直线分别为,已知两个人在试验中发现,变量的观测数据的平均值都是,变量的观测数据的平均值都是,那么下列说法正确的是( )A.必定平行B.必定重合C.有交点D.相交,但交点不一定是答案:C解题思路:试题难度:三颗星知识点:回归分析的初步应用7.某工厂为了对新研发的一种产品进行合理定价,将该产品按事先拟定的价格进行试销,得到如下数据:由表中数据,求得线性回归方程为.若在这些样本点中任取一点,则它在回归直线左下方的概率为( )A. B.C. D.答案:B解题思路:试题难度:三颗星知识点:回归分析的初步应用。
应用回归分析试题

应用回归分析试题(一)一、选择题1. 两个变量与x的回归模型中,通常用2R来刻画回归的效果,则正确的叙述是( D )A. 2R越小,残差平方和越小B. 2R越大,残差平方和越大C. 2R与残差平方和无关D. 2R越小,残差平方和越大2.下面给出了4个残差图,哪个图形表示误差序列是自相关的(B)(A) (B)(C)(D)3.在对两个变量x,y进行线性回归分析时,有下列步骤:i ,…,①对所求出的回归直线方程作出解释; ②收集数据(i x,i y),1,2n;③求线性回归方程; ④求未知参数; ⑤根据所搜集的数据绘制散点图如果根据可行性要求能够作出变量,x y具有线性相关结论,则在下列操作中正确的是( D )A.①②⑤③④ B.③②④⑤①C.②④③①⑤ D.②⑤④③①4.下列说法中正确的是(B )A.任何两个变量都具有相关关系B.人的知识与其年龄具有相关关系C.散点图中的各点是分散的没有规律 D.根据散点图求得的回归直线方程都是有意义的5. 下面的各图中,散点图与相关系数r不符合的是(B )二、填空题1. OLSE估计量的性质线性、无偏、最小方差。
2. 学习回归分析的目的是对实际问题进行预测和控制。
3. 检验统计量t 值与P 值的关系是P(|t |>|t 值|)=P 值,P 值越小,|t 值| 越大 ,回归方程越显著。
4. 在一元线性回归中,SST 自由度为n-1, SSE 自由度为n-2, SSR 自由度为1。
5. 在多元线性回归中,样本决定系数2R = 1SSR SSESSTSST =-。
三、叙述题1. 叙述一元线性回归模型中回归方程系数的求解过程及结果(OLSE 法)答案:定义离差平方和2^1)()(i ni i y y Q ∑=-=β最小二乘思想找出参数10,ββ的估计值^1^0,ββ。
使得离差平方和最小,使^1^0,ββ满足下述条件:∑∑==--=-=ni i i ni i i x y x y Q 1210,121^^010)(min ),(),(1ββββββββ根据微分中值定理可得:0)(2|0)(2|^11^01^11^11^00^00=---=∂∂=---=∂∂∑∑====i i n i i i n i i x x y Qx y Qββββββββββ求解正规方程组得到:⎪⎪⎪⎩⎪⎪⎪⎨⎧---=-=∑∑=-=----n i i n i i i x x y y x x xy 121^11^^0)())((βββ 令 --=-=--==--=--=-=-=∑∑∑∑y x n y x y y x x L xn x x x L ni i i i ni i xy ni ini i xx 1121212)()()(则一元线性回归模型中回归方程系数可表示为⎪⎪⎩⎪⎪⎨⎧=-=--xx xy L L x y ^1^1^0βββ2. 叙述多元线性回归模型的基本假设 答案:假设1.解释变量12,,,K X X X L 是非随机的 假设(i ε)=0;假设(i ε)=2σ,i =1,2,……ncov(,i j εε)=0,i j ≠, ,i j =1,2,……n; 假设4.解释变量12,,,K X X X L 线性无关;假设5.2(0,)i N εσ:3. 回归模型中随机误差项ε的意义是什么?答案:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y 与12,,px x x L 的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
回归分析练习题及参考答案
1 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据:地区人均GDP/元人均消费水平/元北京辽宁上海江西河南贵州陕西 224601122634547485154442662454973264490115462396220816082035求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)可能存在线性关系。
(2)相关系数:(3)回归方程:734.6930.309y x=+回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t 显著性B 标准误Beta1 (常量)734.693 139.540 5.265 0.003人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(4)模型汇总模型R R 方调整 R 方标准估计的误差1 .998a.996 .996 247.303a. 预测变量: (常量), 人均GDP。
人均GDP对人均消费的影响达到99.6%。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
应用回归分析试题(二)

应用回归分析试题(二)一、选择题1.对两个变量X和y进行线性回归分析时,有以下步骤:yii?2,1,①对所求出的回归直线方程作出解释;②收集数据(xi、),…,N③ 找出线性回归方程;④ 寻找未知参数;⑤ 根据收集的数据进行绘制散点图。
根据可行性要求,如果可以得出变量X和y具有线性相关性的结论,则以下操作中正确的变量为(d)a.①②⑤③④b.③②④⑤①c.②④③①⑤d.②⑤④③①2.下列说法中正确的是(b)a.任何两个变量都具有相关关系b.人的知识与其年龄具有相关关系c.散点图中的各点是分散的没有规律d、从散点图得到的回归线性方程是有意义的3.下面的各图中,散点图与相关系数r不符合的是(b)4.一位母亲记录了她3到9岁儿子的身高,并建立了身高和年龄之间的关系7.19x?73.93,归直线方程为y据此可以预测这个孩子10岁时的身高,正确的说法是(d)a.身高一定是145.83cmb.身高超过146.00cmc.身高低于145.00cmd.身高在145.83cm左右5.在画两个变量的散点图时,下面哪个叙述是正确的(b)(a)预报变量在x 轴上,解释变量在y轴上(b)解释变量在x轴上,预报变量在y轴上(c)可以选择两个变量中任意一个变量在x轴上(d)可以选择两个变量中任意一个变量二、填空题m21。
y变量是否存在m个可能的回归方程?1.2.h是帽子矩阵,则tr(h)=p+1。
3.回归分析可分为单变量和多变量。
4.回归模型的一般形式为y??0 1x1??2x2pxp5.冠状病毒(e)??2(I?H)(E是多元回归的残差矩阵)。
3、叙事问题1.引起异常值消除的方法(至少5个)?答案:异常值消除方法:(1)重新核实数据;(2)重新测量数据;(3)删除或重新观测异常值数据;(4)增加必要的自变量;(5)增加观测数据,适当扩大自变量的取值范围;(6)采用加权线性回归;(7)采用非线性回归模型;2.自相关引起的问题?答案:(1)参数的估计值不再具有最小方差线性无偏性;(2)均方差(mse)可能严重低估误差项的方差;(3) T值容易被高估,常用的F检验和T检验均失败;(4)当存在序列相关性时,?还无偏估计,但在任何特定样本中;?可能会被严重扭曲?也就是说,最小二乘估计对采样波动变得非常敏感;(5)如果不加处理的运用普通最小二乘估计模型参数,用此模型进行预测和结构分析会带来较大的方差甚至错误的解释。
整理回归分析练习题与参考答案

20 年 月 日
A4打印 / 可编辑
2019
年招收攻读硕士学位研究生入学
考试试题
2019年招收攻读硕士学位研究生入学考试试题
********************************************************************************************招生专业与代码:流行病与卫生统计学100401、劳动卫生与环境卫生学100402、营养与食品卫生学100403、儿少卫生与妇幼保健学100404、卫生毒理学100405、公共卫生(专业学位)105300考试科目名称及代码:卫生综合353
整理丨尼克
本文档信息来自于网络,如您发现内容不准确或不完善,欢迎您联系我修正;如您发现内容涉嫌侵权,请与我们联系,我们将按照相关法律规定及时处理。
Logistic_回归分析作业答案[3页]
![Logistic_回归分析作业答案[3页]](https://img.taocdn.com/s3/m/bfd1a26871fe910ef02df8a6.png)
第六章 Logistic回归练习题 (操作部分:部分参考答案)1. 下面问题的数据来自“ch6-logistic_exercise”,数据包含受访者的人口学特征、劳动经济特征、流动身份。
数据的变量及其定义如下:变量名变量的定义age 年龄,连续测量degree 受教育程度:1=未上过学;2=小学;3=初中;4=高中;5=大专;6=大学;7=研究生girl 性别:1=女性;0=男性hanzu 民族:1=汉族;0=少数民族hetong 劳动合同:1=固定合同;2=非固定合同;3=无合同income 月收入ldhour 每周劳动时间married 婚姻状态:1=在婚;0=其他(未婚、离异、再婚、丧偶,等)migtype4 流动身份:1=本地市民;2=城-城流动人口;3=乡-城流动人口pid IDss_jobloss 失业保险:1=有;0=无ss_yanglao 养老保险:1=有;1=无这里的研究问题是,流动人口与流入地居民在社会保障、劳动保护和居住环境等方面是否存在显著差别。
流动人口被区分为城-城流动人口(即具有城镇户籍、但离开户籍地半年以上之人)和乡-城流动人口(即具有农村户籍、且离开户籍地半年以上之人)。
因此,样本包含三类人群:本地市民、城-城流动人口、乡-城流动人口及相应特征。
说明:(1)你需要对数据进行一些必要的处理,才能正确回答研究问题;(2)将变量hetong的缺失数据作为一个类别;(3)将degree合并为四类:<=小学,初中、高中、>高中. use "D:\course\integration of theory andmethod\8_ordered\chapter8-logistic_exercise.dta", clear*重新三个社会保障变量. gen ss_jobl=ss_jobloss==1. gen ss_ylao=ss_yanglao==1. gen ss_yili=ss_yiliao ==1*重新code受教育程度. recode degree (1/2=1) (3=2) (4=3)(5/7=4)*将劳动合同的缺失作为一个分类. recode hetong (.=4)请基于该数据,完成以下练习,输出odds ratio的分析结果:其一,运用二分类Logistic模型,探讨流动人口的社会保障机会。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.1回归分析的基本思想及其初步应用
一、选择题 1. 某同学由x 与y 之间的一组数据求得两个变量间的线性回归方程为y bx a =+,已知:数据x 的平
均值为2,数据
y 的平均值为3,则 ( )
A .回归直线必过点(2,3)
B .回归直线一定不过点(2,3)
C .点(2,3)在回归直线上方
D .点(2,3)在回归直线下方
2. 在一次试验中,测得(x,y)的四组值分别是A(1,2),B(2,3),C(3,4),D(4,5),则Y 与X 之间的回归直线方程为( )A .y
x 1=+ B .y x 2=+ C .y 2x 1=+ D.y x 1=-3. 在对两个变量x ,y 进行线性回归分析时,有下列步骤:
①对所求出的回归直线方程作出解释; ②收集数据(i x 、
i y ),1,2i =,…,n ;
③求线性回归方程; ④求未知参数; ⑤根据所搜集的数据绘制散点图
如果根据可行性要求能够作出变量,x y 具有线性相关结论,则在下列操作中正确的是( ) A .①②⑤③④ B .③②④⑤① C .②④③①⑤ D .②⑤④③①
4. 下列说法中正确的是( )
A .任何两个变量都具有相关关系
B .人的知识与其年龄具有相关关系
C .散点图中的各点是分散的没有规律
D .根据散点图求得的回归直线方程都是有意义的
5. 给出下列结论:
(1)在回归分析中,可用指数系数2
R 的值判断模型的拟合效果,2
R 越大,模型的拟合效果越好; (2)在回归分析中,可用残差平方和判断模型的拟合效果,残差平方和越大,模型的拟合效果越好; (3)在回归分析中,可用相关系数r 的值判断模型的拟合效果,r 越小,模型的拟合效果越好;
(4)在回归分析中,可用残差图判断模型的拟合效果,残差点比较均匀地落在水平的带状区域中,说明这样的模型比较合适.带状区域的宽度越窄,说明模型的拟合精度越高. 以上结论中,正确的有( )个.
A .1
B .2
C .3
D .4 6. 已知直线回归方程为2 1.5y x =-,则变量x 增加一个单位时(
)
A.y 平均增加1.5个单位
B.y 平均增加2个单位
C.y 平均减少1.5个单位
D.
y 平均减少2个单位
7. 下面的各图中,散点图与相关系数r 不符合的是( )
8. 一位母亲记录了儿子3~9岁的身高,由此建立的身高与年龄的回归直线方程为ˆ7.1973.93y
x =+,据此可以预测这个孩子10岁时的身高,则正确的叙述是( )
A .身高一定是145.83cm
B .身高超过146.00cm
C .身高低于145.00cm
D .身高在145.83cm 左右
9. 在画两个变量的散点图时,下面哪个叙述是正确的( ) (A)预报变量在x 轴上,解释变量在
y 轴上 (B)解释变量在x 轴上,预报变量在y 轴上 (C)可以选择两个变量中任意一个变量在x 轴上 (D)可以选择两个变量中任意一个变量在y 轴上
10. 两个变量
y 与x 的回归模型中,通常用2R 来刻画回归的效果,则正确的叙述是( )
A. 2R 越小,残差平方和小
B. 2R 越大,残差平方和大
C. 2
R 于残差平方和无关 D. 2
R 越小,残差平方和大 11. 两个变量
y 与x 的回归模型中,分别选择了4个不同模型,它们的相关指数2R 如下 ,其中拟合效果
最好的模型是( )
A.模型1的相关指数2R 为0.98
B.模型2的相关指数2R 为0.80
C.模型3的相关指数2
R 为0.50 D.模型4的相关指数2
R 为0.25
12. 在回归分析中,代表了数据点和它在回归直线上相应位置的差异的是( ) A.总偏差平方和 B.残差平方和 C.回归平方和 D.相关指数R 2
13.工人月工资(元)依劳动生产率(千元)变化的回归直线方程为ˆ6090y x =+,下列判断正确的是( ) A.劳动生产率为1000元时,工资为50元 B.劳动生产率提高1000元时,工资提高150元 C.劳动生产率提高1000元时,工资提高90元 D.劳动生产率为1000元时,工资为90元
14. 下列结论正确的是( )
①函数关系是一种确定性关系;②相关关系是一种非确定性关系;③回归分析是对具有函数关系的两个变量进行统计分析的一种方法;④回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法. A.①② B.①②③ C.①②④ D.①②③④
15. 已知回归直线的斜率的估计值为1.23,样本点的中心为(4,5),则回归直线方程为( ) A. 1.234y x =+ B. 1.235y x =+ C. 1.230.08y x =+ D.0.08 1.23y x =+
二、填空题
16. 在比较两个模型的拟合效果时,甲、乙两个模型的相关指数2
R 的值分别约为0.96和0.85,则拟合效果好的模型是 .
17. 在回归分析中残差的计算公式为 .
18. 线性回归模型y bx a e =++(a 和b 为模型的未知参数)中,e 称为 .
19. 若一组观测值(x 1,y 1)(x 2,y 2)…(x n ,y n )之间满足y i =bx i +a+e i (i=1、2.…n)若e i 恒为0,则R 2
为_____
三、解答题
20. 调查某市出租车使用年限x 和该年支出维修费用
y (万元)
,得到数据如下: 使用年限x 2 3 4 5 6 维修费用y
2.2
3.8
5.5
6.5
7.0
(1) 求线性回归方程;
(2)由(1)中结论预测第10年所支出的维修费用.(1
21()()()n
i i i n
i i x x y y b x x a y bx
==⎧
-⋅-⎪
⎪=⎨-⎪⎪=-⎪⎩∑∑)
21. 以下是某地搜集到的新房屋的销售价格
y 和房屋的面积x 的数据:
(1)画出数据对应的散点图;
(2)求线性回归方程,并在散点图中加上回归直线; (3)据(2)的结果估计当房屋面积为2
150m 时的销售价格. (4)求第2个点的残差。
答案
一、选择题 1. A 2. A 3. D 4. B 5. B 6. C 7. B 8. D
9. 解析:通常把自变量x 称为解析变量,因变量y 称为预报变量.选B
10. D 11. A 12. B 13. C 14. C 15. C
二、填空题 16. 甲
17. 列联表、三维柱形图、二维条形图 18. 随机误差
19. 解析: e i 恒为0,说明随机误差对y i 贡献为0.
答案:1.
三、解答题
20. 解析: (1
于是23.14
5905
453.112552
2
51
25
1=⨯-⨯⨯-=
--=
∑∑==x
x y
x y
x b i i i i
i , 08.0423.15=⨯-=-=bx y a
∴线性回归方程为:08
.023.1^
+=+=x a bx y (2)当x=10时,
38.1208.01023.1^=+⨯=y (万元)
即估计使用10年时维修费用是1238万元 回归方程为: 1.230.08y x =+
(2) 预计第10年需要支出维修费用12.38 万元.
21. 解析:(1)数据对应的散点图如图所示:
(2)1095151==∑=i i x x ,1570)(2
5
1
=-=∑=x x l i i xx ,
308))((,2.235
1
=--==∑=y y x x l y i i i xy
设所求回归直线方程为a bx y +=
,
则1962.01570
308
≈=
=
xx
xy l l b 8166.11570
308
1092.23≈⨯
-=-=x b y a 故所求回归直线方程为8166.11962.0+=x y
(3)据(2),当2
150x m =时,销售价格的估计值为:
2466.318166.11501962.0=+⨯=y
(万元)。