医学统计学(李晓松主编 第2版 高等教育出版社)附录 第3章思考与练习答案
医学统计学(第二版)思考与练习答案

第四章 定量资料的统计描述【习题解析】一、思考题1. 均数、中位数、几何均数三者的相同点是都用于描述定量资料的集中趋势,。
不同点:①均数用于单峰对称分布,特别是正态分布或近似正态分布的资料;②几何均数用于变量值间呈倍数关系的偏态分布资料,特别是变量经过对数变换后呈正态分布或近似正态分布的资料;③中位数用于不对称分布资料、两端无确切值的资料、分布不明确的资料。
2. 同一资料的标准差不一定小于均数。
均数描述的是一组同质定量变量的平均水平,而标准差是描述单峰对称分布资料离散程度最常用的指标。
标准差大,表示观察值之间变异大,即一组观察值的分布较分散;标准差小,表示观察值之间变异小,即一组观察值的分布较集中。
若标准差远大于均数表明数据离散程度较大,可能为偏态分布,此时应考虑改用其他指标来描述资料的集中趋势。
3. 极差、四分位数间距、标准差、变异系数四者的相同点是都用于描述资料的离散程度。
不同点:①极差可用于描述单峰对称分布小样本资料的离散程度,或用于初步了解资料的变异程度;②四分位数间距可用于描述偏态分布资料、两端无确切值或分布不明确资料的离散程度;③标准差用于描述正态分布或近似正态分布资料的离散程度;④变异系数用于比较几组计量单位不同或均数相差悬殊的正态分布资料的离散程度。
4. 正态分布的特征:①正态曲线在横轴上方均数处最高;②正态分布以均数为中心,左右对称;③正态分布有两个参数,即位置参数μ和形态参数σ;④正态曲线下的面积分布有一定的规律,正态曲线与横轴间的面积恒等于1。
曲线下区间( 2.58, 2.58)μσμσ-+内的面积为95.00%;区间( 2.58, 2.58)μσμσ-+内的面积为99.00%。
5.①通过大量调查证实符合正态分布的变量或近似正态分布的变量,可按正态分布曲线下面积分布的规律制定医学参考值范围;服从对数正态分布的变量,可对观察值取对数后按正态分布法算出医学参考值范围的对数值,然后求其反对数即可;②对于经正态性检验不服从正态分布的变量,应采用百分位数法制定医学参考值范围。
医学统计学李晓松主编第2版高等教育出版社附录第3章思考与练习答案.doc

第三章实验研究设计【思考与练习】一、思考题1. 实验设计根据对象的不同可分为哪几类?2. 实验研究中,随机化的目的是什么?3. 什么是配对设计?它有何优缺点?4. 什么是交叉设计?它有何优缺点?5. 临床试验中使用安慰剂的目的是什么?二、案例辨析题“三联药物治疗士兵消化性溃疡”一文中,对2000~2006年在某卫生所采用三联药物治疗的38例消化性溃疡患者进行分析。
内镜检测结果显示,痊愈13人,显效14人,进步7人,无效4人,有效率达89.5%。
据此认为该三联疗法的疗效较好,且由于其价格适中,可在部队卫生所中推广。
该结论是否正确?如果不正确,请说明理由。
三、最佳选择题1. 实验设计的三个基本要素是A. 处理因素、实验效应、实验场所B. 处理因素、实验效应、受试对象C. 受试对象、研究人员、处理因素D. 受试对象、干扰因素、处理因素E. 处理因素、实验效应、研究人员2. 实验设计的三个基本原则是A. 随机化、对照、重复B. 随机化、对照、盲法C. 随机化、重复、盲法D. 均衡、对照、重复E. 盲法、对照、重复3. 实验组与对照组主要不同之处在于A. 处理因素B. 观察指标C. 抽样误差D. 观察时间E. 纳入、排除受试对象的标准4. 为了解某疗法对急性肝功能衰竭的疗效,用12头健康雌性良种幼猪建立急性肝功能衰竭模型,再将其随机分为两组,仅实验组给予该疗法治疗,对照组不给予任何治疗。
7天后观察两组幼猪的存活情况。
该研究采用的是A. 空白对照B. 安慰剂对照C. 实验对照D. 标准对照E. 自身对照5. 观察指标应具有A. 灵敏性、特异性、准确度、精密度、客观性B. 灵敏性、变异性、准确度、精密度、客观性C. 灵敏性、特异性、变异性、均衡性、稳定性D. 特异性、准确度、稳定性、均衡性、客观性E. 灵敏性、变异性、准确度、精密度、均衡性6. 比较两种疗法对乳腺癌的疗效,若两组患者的乳腺癌分期构成不同可造成A. 选择性偏倚B. 测量性偏倚C. 混杂性偏倚D. 信息偏倚E. 失访性偏倚7. 将两个或多个处理因素的各水平进行组合,对各种可能的组合都进行实验,该实验设计方案是A. 随机区组设计B. 完全随机设计C. 析因设计D. 配对设计E. 交叉设计8. 在某临床试验中,将180例患者随机分为两组,实验组给予试验药+对照药的模拟剂,对照给予对照药+试验药的模拟剂,整个过程中受试对象和研究者均不知道受试对象的分组。
医学统计学课后习题答案解析

医学统计学第一章 绪论答案名词解释:(1) 同质与变异:同质指被研究指标的影响因素相同,变异指在同质的基础上各观察单位(或个体)之间的差异。
(2) 总体和样本:总体是根据研究目的确定的同质观察单位的全体。
样本是从总体中随机抽取的部分观察单位。
(3) 参数和统计量:根据总体个体值统计算出来的描述总体的特征量,称为总体参数,根据样本个体值统计计算出来的描述样本的特征量称为样本统计量。
(4) 抽样误差:由抽样造成的样本统计量和总体参数的差别称为抽样误差。
(5) 概率:是描述随机事件发生的可能性大小的数值,用p 表示(6) 计量资料:由一群个体的变量值构成的资料称为计量资料。
(7) 计数资料:由一群个体按定性因数或类别清点每类有多少个个体,称为计数资料。
(8) 等级资料:由一群个体按等级因数的级别清点每类有多少个体,称为等级资料。
是非题:1. ×2. ×3. ×4. ×5. √6. √7. ×单选题:1. C2. E3. D4. C5. D6. B第二章 计量资料统计描述及正态分布答案名词解释:1. 平均数 是描述数据分布集中趋势(中心位置)和平均水平的指标2. 标准差 是描述数据分布离散程度(或变量变化的变异程度)的指标3. 标准正态分布 以μ服从均数为0、标准差为1的正态分布,这种正态分布称为标准状态分布。
4. 参考值范围 参考值范围也称正常值范围,医学上常把把绝大多数的某指标范围称为指标的正常值范围。
填空题:1. 计量,计数,等级2. 设计,收集资料,分析资料,整理资料。
3. σμχ-=u (变量变换)标准正态分布、0、1 4. σ± σ96.1± σ58.2± 68.27% 95% 99%5. 47.5%6.均数、标准差7. 全距、方差、标准差、变异系数8. σμ96.1± σμ58.2±9. 全距 R10. 检验水准、显著性水准、0.05、 0.01 (0.1)11. 80% 90% 95% 99% 95%12. 95% 99%13. 集中趋势、离散趋势14. 中位数15. 同质基础,合理分组16. 均数,均数,μ,σ,规律性17. 标准差18. 单位不同,均数相差较大是非题:1. ×2. √3. ×4. ×5. ×6. √7. √8. √9. √ 10. √11. √ 12. √ 13. × 14. √ 15. √ 16. × 17. × 18. × 19. √ 20. √21. √单选题:1. B2. D3. C4. A5. C6. D7. E8. A9. C 10. D11. B 12. C 13. C 14. C 15. A 16. C 17. E 18. C 19. D 20. C21. B 22. B 23. E 24. C 25. A 26. C 27. B 28. D 29. D 30. D31. A 32. E 33. D 34. A 35. D 36. D 37. C 38. E 39. D 40. B41. C 42. B 43. D 44. C 45. B问答题:1.均数﹑几何均数和中位数的适用范围有何异同?答:相同点,均表示计量资料集中趋势的指标。
医学统计学课后习题答案解析

医学统计学第一章 绪论答案名词解释:(1) 同质与变异:同质指被研究指标的影响因素相同,变异指在同质的基础上各观察单位(或个体)之间的差异。
(2) 总体和样本:总体是根据研究目的确定的同质观察单位的全体。
样本是从总体中随机抽取的部分观察单位。
(3) 参数和统计量:根据总体个体值统计算出来的描述总体的特征量,称为总体参数,根据样本个体值统计计算出来的描述样本的特征量称为样本统计量。
(4) 抽样误差:由抽样造成的样本统计量和总体参数的差别称为抽样误差。
(5) 概率:是描述随机事件发生的可能性大小的数值,用p 表示(6) 计量资料:由一群个体的变量值构成的资料称为计量资料。
(7) 计数资料:由一群个体按定性因数或类别清点每类有多少个个体,称为计数资料。
(8) 等级资料:由一群个体按等级因数的级别清点每类有多少个体,称为等级资料。
是非题:1. ×2. ×3. ×4. ×5. √6. √7. ×单选题:1. C2. E3. D4. C5. D6. B第二章 计量资料统计描述及正态分布答案名词解释:1. 平均数 是描述数据分布集中趋势(中心位置)和平均水平的指标2. 标准差 是描述数据分布离散程度(或变量变化的变异程度)的指标3. 标准正态分布 以μ服从均数为0、标准差为1的正态分布,这种正态分布称为标准状态分布。
4. 参考值范围 参考值范围也称正常值范围,医学上常把把绝大多数的某指标范围称为指标的正常值范围。
填空题:1. 计量,计数,等级2. 设计,收集资料,分析资料,整理资料。
3. σμχ-=u (变量变换)标准正态分布、0、1 4. σ± σ96.1± σ58.2± 68.27% 95% 99%5. 47.5%6.均数、标准差7. 全距、方差、标准差、变异系数8. σμ96.1± σμ58.2±9. 全距 R10. 检验水准、显著性水准、0.05、 0.01 (0.1)11. 80% 90% 95% 99% 95%12. 95% 99%13. 集中趋势、离散趋势14. 中位数15. 同质基础,合理分组16. 均数,均数,μ,σ,规律性17. 标准差18. 单位不同,均数相差较大是非题:1. ×2. √3. ×4. ×5. ×6. √7. √8. √9. √ 10. √11. √ 12. √ 13. × 14. √ 15. √ 16. × 17. × 18. × 19. √ 20. √21. √单选题:1. B2. D3. C4. A5. C6. D7. E8. A9. C 10. D11. B 12. C 13. C 14. C 15. A 16. C 17. E 18. C 19. D 20. C21. B 22. B 23. E 24. C 25. A 26. C 27. B 28. D 29. D 30. D31. A 32. E 33. D 34. A 35. D 36. D 37. C 38. E 39. D 40. B41. C 42. B 43. D 44. C 45. B问答题:1.均数﹑几何均数和中位数的适用范围有何异同?答:相同点,均表示计量资料集中趋势的指标。
《卫生统计学》课后思考题答案

《卫生统计学》课后思考题答案《卫生统计学》思考题参考答案第一章绪论1、统计资料可以分为那几种类型?举例说明不同类型资料之间是如何转换的?答:(1)1定量资料(离散型变量、连续型变量)、2无序分类资料(二项分类资料、无序多项分类资料)、3有序分类资料(即等级资料);(2)例如人的健康状况可分为“非常好、较好、一般、差、非常差”5个等级,应归为等级资料,若将该五个等级赋值为5、4、3、2、1,就可按定量资料处理。
2、统计工作可分为那几个步骤?答:设计、收集资料、整理资料、分析资料四个步骤。
3、举例说明小概率事件的含义。
答:某人打靶100次,中靶次数少于等于5,那么该人一次打中靶的概率≤0.05,即可称该人一次打中靶的事件为小概率事件,可以视为很可能不发生。
第二章调查研究设计1、调查研究有何特点?答:(1)不能人为施加干预措施(2)不能随机分组(3)很难控制干扰因素(4)一般不能下因果结论2、四种常用的抽样方法各有什么特点?答:(1)单纯随机抽样:优点是操作简单,统计量的计算较简便;缺点是当总体观察单位数量庞大时,逐一编号繁复,有时难以做到。
(2)系统抽样:优点是易于理解、操作简便,被抽到的观察单位在总体中分布均匀,抽样误差较单纯随机抽样小;缺点是在某些情况下会出现偏性或周期性变化。
(3)分层抽样:优点是抽样误差小,各层可以独立进行统计分析,适合大规模统计;缺点是事先要进行分层,操作麻烦。
(4)整群抽样:优点是易于组织和操作大规模抽样调查;缺点是抽样误差大。
3、调查设计包括那些基本内容?答:(1)明确调查目的和指标(2)确定调查对象和观察单位(3)选择调查方法和技术(4)估计样本大小(5)编制调查表(6)评价问卷的信度和效度(7)制定资料的收集计划(8)指定资料的整理与分析计划(9)制定调查的组织措施4、调查表中包含那几种项目?答:(1)分析项目直接整理计算的必须的内容;(2)备查项目保证分析项目填写得完整和准确的内容;(3)其他项目大型调查表的前言和表底附注。
医学统计学第二版高等教育出版社课后习题答案

第一章绪论1.举例说明总体和样本的概念。
研究人员通常需要了解和研究某一类个体,这个类就是总体。
总体是根据研究目的所确定的所有同质观察单位某种观察值(即变量值)的集合,通常有无限总体和有限总体之分,前者指总体中的个体是无限的,如研究药物疗效,某病患者就是无限总体,后者指总体中的个体是有限的,它是指特定时间、空间中有限个研究个体。
但是,研究整个总体一般并不实际,通常能研究的只是它的一部分,这个部分就是样本。
例如在一项关于2007年西藏自治区正常成年男子的红细胞平均水平的调查研究中,该地2007年全部正常成年男子的红细胞数就构成一个总体,从此总体中随即抽取2000人,分别测的其红细胞数,组成样本,其样本含量为2000人。
2.简述误差的概念。
误差泛指实测值与真实值之差,一般分为随机误差和非随机误差。
随机误差是使重复观测获得的实际观测值往往无方向性地围绕着某一个数值左右波动的误差;非随机误差中最常见的为系统误差,系统误差也叫偏倚,是使实际观测值系统的偏离真实值的误差。
3.举例说明参数和统计量的概念。
某项研究通常想知道关于总体的某些数值特征,这些数值特征称为参数,如整个城市的高血压患病率。
根据样本算得的某些数值特征称为统计量,如根据几百人的抽样调查数据所算得的样本人群高血压患病。
统计量是研究人员能够知道的,而参数是他们想知道的。
一般情况下,这些参数是难以测定的,仅能够根据样本估计。
显然,只有当样本代表了总体时,根据样本统计量估计的总体参数才是合理的。
4.简述小概率事件原理。
当某事件发生的概率小于或等于0.05时,统计学上习惯称该事件为小概率事件,其含义是该事件发生的可能性很小,进而认为它在一次抽样中不可能发生,这就是所谓的小概率事件原理,它是进行统计推断的重要基础。
第二章调查研究设计1.调查研究主要特点是什么?调查研究的主要特点是:①研究的对象及其相关因素(包括研究因素和非研究因素)是客观存在的,不能人为给予干预措施②不能用随机化分组来平衡混杂因素对调查结果的影响。
医学统计学第二版高等教育出版社课后习题答案剖析

第一章绪论1.举例说明总体和样本的概念。
研究人员通常需要了解和研究某一类个体,这个类就是总体。
总体是根据研究目的所确定的所有同质观察单位某种观察值(即变量值)的集合,通常有无限总体和有限总体之分,前者指总体中的个体是无限的,如研究药物疗效,某病患者就是无限总体,后者指总体中的个体是有限的,它是指特定时间、空间中有限个研究个体。
但是,研究整个总体一般并不实际,通常能研究的只是它的一部分,这个部分就是样本。
例如在一项关于2007年西藏自治区正常成年男子的红细胞平均水平的调查研究中,该地2007年全部正常成年男子的红细胞数就构成一个总体,从此总体中随即抽取2000人,分别测的其红细胞数,组成样本,其样本含量为2000人。
2.简述误差的概念。
误差泛指实测值与真实值之差,一般分为随机误差和非随机误差。
随机误差是使重复观测获得的实际观测值往往无方向性地围绕着某一个数值左右波动的误差;非随机误差中最常见的为系统误差,系统误差也叫偏倚,是使实际观测值系统的偏离真实值的误差。
3.举例说明参数和统计量的概念。
某项研究通常想知道关于总体的某些数值特征,这些数值特征称为参数,如整个城市的高血压患病率。
根据样本算得的某些数值特征称为统计量,如根据几百人的抽样调查数据所算得的样本人群高血压患病。
统计量是研究人员能够知道的,而参数是他们想知道的。
一般情况下,这些参数是难以测定的,仅能够根据样本估计。
显然,只有当样本代表了总体时,根据样本统计量估计的总体参数才是合理的。
4.简述小概率事件原理。
当某事件发生的概率小于或等于0.05时,统计学上习惯称该事件为小概率事件,其含义是该事件发生的可能性很小,进而认为它在一次抽样中不可能发生,这就是所谓的小概率事件原理,它是进行统计推断的重要基础。
第二章调查研究设计1.调查研究主要特点是什么?调查研究的主要特点是:①研究的对象及其相关因素(包括研究因素和非研究因素)是客观存在的,不能人为给予干预措施②不能用随机化分组来平衡混杂因素对调查结果的影响。
医学统计学课后习题答案解析
医学统计学第一章 绪论答案名词解释:(1) 同质与变异:同质指被研究指标的影响因素相同,变异指在同质的基础上各观察单位(或个体)之间的差异。
(2) 总体和样本:总体是根据研究目的确定的同质观察单位的全体。
样本是从总体中随机抽取的部分观察单位。
(3) 参数和统计量:根据总体个体值统计算出来的描述总体的特征量,称为总体参数,根据样本个体值统计计算出来的描述样本的特征量称为样本统计量。
(4) 抽样误差:由抽样造成的样本统计量和总体参数的差别称为抽样误差。
(5) 概率:是描述随机事件发生的可能性大小的数值,用p 表示(6) 计量资料:由一群个体的变量值构成的资料称为计量资料。
(7) 计数资料:由一群个体按定性因数或类别清点每类有多少个个体,称为计数资料。
(8) 等级资料:由一群个体按等级因数的级别清点每类有多少个体,称为等级资料。
是非题:1. ×2. ×3. ×4. ×5. √6. √7. ×单选题:1. C2. E3. D4. C5. D6. B第二章 计量资料统计描述及正态分布答案名词解释:1. 平均数 是描述数据分布集中趋势(中心位置)和平均水平的指标2. 标准差 是描述数据分布离散程度(或变量变化的变异程度)的指标3. 标准正态分布 以μ服从均数为0、标准差为1的正态分布,这种正态分布称为标准状态分布。
4. 参考值范围 参考值范围也称正常值范围,医学上常把把绝大多数的某指标范围称为指标的正常值范围。
填空题:1. 计量,计数,等级2. 设计,收集资料,分析资料,整理资料。
3. σμχ-=u (变量变换)标准正态分布、0、1 4. σ± σ96.1± σ58.2± 68.27% 95% 99%5. 47.5%6.均数、标准差7. 全距、方差、标准差、变异系数8. σμ96.1± σμ58.2±9. 全距 R10. 检验水准、显著性水准、0.05、 0.01 (0.1)11. 80% 90% 95% 99% 95%12. 95% 99%13. 集中趋势、离散趋势14. 中位数15. 同质基础,合理分组16. 均数,均数,μ,σ,规律性17. 标准差18. 单位不同,均数相差较大是非题:1. ×2. √3. ×4. ×5. ×6. √7. √8. √9. √ 10. √11. √ 12. √ 13. × 14. √ 15. √ 16. × 17. × 18. × 19. √ 20. √21. √单选题:1. B2. D3. C4. A5. C6. D7. E8. A9. C 10. D11. B 12. C 13. C 14. C 15. A 16. C 17. E 18. C 19. D 20. C21. B 22. B 23. E 24. C 25. A 26. C 27. B 28. D 29. D 30. D31. A 32. E 33. D 34. A 35. D 36. D 37. C 38. E 39. D 40. B41. C 42. B 43. D 44. C 45. B问答题:1.均数﹑几何均数和中位数的适用范围有何异同?答:相同点,均表示计量资料集中趋势的指标。
医学统计学(高等教育出版社第二版)思考与练习答案

第四章 定量资料的统计描述【习题解析】一、思考题1. 均数、中位数、几何均数三者的相同点是都用于描述定量资料的集中趋势,不同点:①均数用于单峰对称分布,特别是正态分布或近似正态分布的资料;②几何均数用于变量值间呈倍数关系的偏态分布资料,特别是变量经过对数变换后呈正态分布或近似正态分布的资料;③中位数用于不对称分布资料、两端无确切值的资料、分布不明确的资料。
2. 同一资料的标准差不一定小于均数。
均数描述的是一组同质定量变量的平均水平,而标准差是描述单峰对称分布资料离散程度最常用的指标。
标准差大,表示观察值之间变异大,即一组观察值的分布较分散;标准差小,表示观察值之间变异小,即一组观察值的分布较集中。
若标准差远大于均数表明数据离散程度较大,可能为偏态分布,此时应考虑改用其他指标来描述资料的集中趋势。
3. 极差、四分位数间距、标准差、变异系数四者的相同点是都用于描述资料的离散程度。
不同点:①极差可用于描述单峰对称分布小样本资料的离散程度,或用于初步了解资料的变异程度;②四分位数间距可用于描述偏态分布资料、两端无确切值或分布不明确资料的离散程度;③标准差用于描述正态分布或近似正态分布资料的离散程度;④变异系数用于比较几组计量单位不同或均数相差悬殊的正态分布资料的离散程度。
4. 正态分布的特征:①正态曲线在横轴上方均数处最高;②正态分布以均数为中心,左右对称;③正态分布有两个参数,即位置参数μ和形态参数σ;④正态曲线下的面积分布有一定的规律,正态曲线与横轴间的面积恒等于1。
曲线下区间( 2.58, 2.58)μσμσ-+内的面积为95.00%;区间( 2.58, 2.58)μσμσ-+内的面积为99.00%。
5.①通过大量调查证实符合正态分布的变量或近似正态分布的变量,可按正态分布曲线下面积分布的规律制定医学参考值范围;服从对数正态分布的变量,可对观察值取对数后按正态分布法算出医学参考值范围的对数值,然后求其反对数即可;②对于经正态性检验不服从正态分布的变量,应采用百分位数法制定医学参考值范围。
医学统计学课后习题答案解析
医学统计学第一章 绪论答案名词解释:(1) 同质与变异:同质指被研究指标的影响因素相同,变异指在同质的基础上各观察单位(或个体)之间的差异。
(2) 总体和样本:总体是根据研究目的确定的同质观察单位的全体。
样本是从总体中随机抽取的部分观察单位。
(3) 参数和统计量:根据总体个体值统计算出来的描述总体的特征量,称为总体参数,根据样本个体值统计计算出来的描述样本的特征量称为样本统计量。
(4) 抽样误差:由抽样造成的样本统计量和总体参数的差别称为抽样误差。
(5) 概率:是描述随机事件发生的可能性大小的数值,用p 表示(6) 计量资料:由一群个体的变量值构成的资料称为计量资料。
(7) 计数资料:由一群个体按定性因数或类别清点每类有多少个个体,称为计数资料。
(8) 等级资料:由一群个体按等级因数的级别清点每类有多少个体,称为等级资料。
是非题:1. ×2. ×3. ×4. ×5. √6. √7. ×单选题:1. C2. E3. D4. C5. D6. B第二章 计量资料统计描述及正态分布答案名词解释:1. 平均数 是描述数据分布集中趋势(中心位置)和平均水平的指标2. 标准差 是描述数据分布离散程度(或变量变化的变异程度)的指标3. 标准正态分布 以μ服从均数为0、标准差为1的正态分布,这种正态分布称为标准状态分布。
4. 参考值范围 参考值范围也称正常值范围,医学上常把把绝大多数的某指标范围称为指标的正常值范围。
填空题:1. 计量,计数,等级2. 设计,收集资料,分析资料,整理资料。
3. σμχ-=u (变量变换)标准正态分布、0、1 4. σ± σ96.1± σ58.2± 68.27% 95% 99%5. 47.5%6.均数、标准差7. 全距、方差、标准差、变异系数8. σμ96.1± σμ58.2±9. 全距 R10. 检验水准、显著性水准、0.05、 0.01 (0.1)11. 80% 90% 95% 99% 95%12. 95% 99%13. 集中趋势、离散趋势14. 中位数15. 同质基础,合理分组16. 均数,均数,μ,σ,规律性17. 标准差18. 单位不同,均数相差较大是非题:1. ×2. √3. ×4. ×5. ×6. √7. √8. √9. √ 10. √11. √ 12. √ 13. × 14. √ 15. √ 16. × 17. × 18. × 19. √ 20. √21. √单选题:1. B2. D3. C4. A5. C6. D7. E8. A9. C 10. D11. B 12. C 13. C 14. C 15. A 16. C 17. E 18. C 19. D 20. C21. B 22. B 23. E 24. C 25. A 26. C 27. B 28. D 29. D 30. D31. A 32. E 33. D 34. A 35. D 36. D 37. C 38. E 39. D 40. B41. C 42. B 43. D 44. C 45. B问答题:1.均数﹑几何均数和中位数的适用范围有何异同?答:相同点,均表示计量资料集中趋势的指标。
医学统计学课后习题答案解析
医学统计学第一章 绪论答案名词解释:(1) 同质与变异:同质指被研究指标的影响因素相同,变异指在同质的基础上各观察单位(或个体)之间的差异。
(2) 总体和样本:总体是根据研究目的确定的同质观察单位的全体。
样本是从总体中随机抽取的部分观察单位。
(3) 参数和统计量:根据总体个体值统计算出来的描述总体的特征量,称为总体参数,根据样本个体值统计计算出来的描述样本的特征量称为样本统计量。
(4) 抽样误差:由抽样造成的样本统计量和总体参数的差别称为抽样误差。
(5) 概率:是描述随机事件发生的可能性大小的数值,用p 表示(6) 计量资料:由一群个体的变量值构成的资料称为计量资料。
(7) 计数资料:由一群个体按定性因数或类别清点每类有多少个个体,称为计数资料。
(8) 等级资料:由一群个体按等级因数的级别清点每类有多少个体,称为等级资料。
是非题:1. ×2. ×3. ×4. ×5. √6. √7. ×单选题:1. C2. E3. D4. C5. D6. B第二章 计量资料统计描述及正态分布答案名词解释:1. 平均数 是描述数据分布集中趋势(中心位置)和平均水平的指标2. 标准差 是描述数据分布离散程度(或变量变化的变异程度)的指标3. 标准正态分布 以μ服从均数为0、标准差为1的正态分布,这种正态分布称为标准状态分布。
4. 参考值范围 参考值范围也称正常值范围,医学上常把把绝大多数的某指标范围称为指标的正常值范围。
填空题:1. 计量,计数,等级2. 设计,收集资料,分析资料,整理资料。
3. σμχ-=u (变量变换)标准正态分布、0、1 4. σ± σ96.1± σ58.2± 68.27% 95% 99%5. 47.5%6.均数、标准差7. 全距、方差、标准差、变异系数8. σμ96.1± σμ58.2±9. 全距 R10. 检验水准、显著性水准、0.05、 0.01 (0.1)11. 80% 90% 95% 99% 95%12. 95% 99%13. 集中趋势、离散趋势14. 中位数15. 同质基础,合理分组16. 均数,均数,μ,σ,规律性17. 标准差18. 单位不同,均数相差较大是非题:1. ×2. √3. ×4. ×5. ×6. √7. √8. √9. √ 10. √11. √ 12. √ 13. × 14. √ 15. √ 16. × 17. × 18. × 19. √ 20. √21. √单选题:1. B2. D3. C4. A5. C6. D7. E8. A9. C 10. D11. B 12. C 13. C 14. C 15. A 16. C 17. E 18. C 19. D 20. C21. B 22. B 23. E 24. C 25. A 26. C 27. B 28. D 29. D 30. D31. A 32. E 33. D 34. A 35. D 36. D 37. C 38. E 39. D 40. B41. C 42. B 43. D 44. C 45. B问答题:1.均数﹑几何均数和中位数的适用范围有何异同?答:相同点,均表示计量资料集中趋势的指标。
《医学统计学》资料整理:医学统计学课程思考题及答案

《医学统计学》资料整理:医学统计学课程思考题及答案医学统计学课程思考题及答案(注:红色字体表示已经改正,多余表示删除的内容)一.名词解释1.Population and Sample总体:根据研究目的确定的同质研究对象某观测值的集合。
样本:从总体中随机抽取的有代表性的部分研究对象其观测值的集合。
2.Cross-over design交叉设计:每个受试者随机地在两个或多个不同试验阶段分别接受指定的处理(试验药或对照药)。
3.Variance方差:离均差平方和的均数,反映一组同质计量资料的离散趋势大小。
4.Power of test检验效能:常用1-β表示,其意义是当两个总体存在差异时,使用统计检验发现总体间差异的能力,一般在0.8左右5.Relative ration相对数、相对比:二.选择题1、分析母亲体重与婴儿的出生体重的关系,宜绘制( C )A. 直方图B. 圆图C. 散点图D. 直条图2、统计推断包括( D )A、统计描述B、参数估计C、估计抽样误差D、参数估计和假设检验3、两样本率比较,经χ2检验,差别无显著性时,P值越大小,说明(B C )A.两样本率差别越大B.两总体率相同的可能性越大C.越有理由认为两总体率不同D.越有理由认为两样本率不同4、调查某地1000人,记录每人的血压值,所得的资料是一份( B A)。
A、计量资料B、计数资料C、还不能决定是计量资料还是计数资料D、可看作计量资料,也可看作计数资料5、某医师用A药治疗25例病人,治愈20人;用B药治疗30例病人,治愈10人;比较两药疗效时,可选用的最适当的方法是( A )。
A、χ2检验B、 u检验C、校正χ2检验D、确切概率法χ2检验:推断两个或两个以上总体率(或构成比)之间有无差别及两分类变量间有无相关关系等。
因为T=25*25/55>=5,n>=40,所以采用四格表专用公式。
u检验:两完全随机设计两总体均数比较,样本量很大,且总体的方差已知。
医学统计学(李晓松主编第2版高等教育提高出版社)附录思考与理解练习95%答案解析
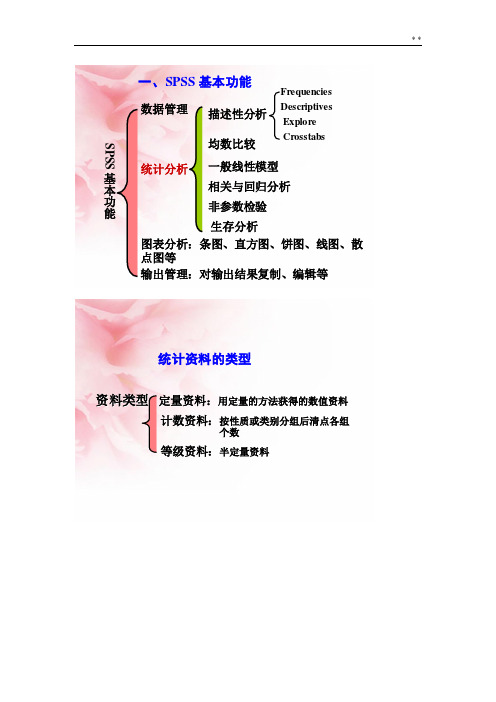
一、SPSS 基本功能SPSS基本功能数据管理统计分析图表分析:条图、直方图、饼图、线图、散点图等输出管理:对输出结果复制、编辑等描述性分析均数比较一般线性模型相关与回归分析非参数检验生存分析FrequenciesDescriptivesExploreCrosstabs 统计资料的类型资料类型定量资料:用定量的方法获得的数值资料计数资料:按性质或类别分组后清点各组个数等级资料:半定量资料定量资料的统计推断正态分布两组均数比较单样本设计t检验配对设计t检验成组设计t检验三组及以上均数比较完全随机设计方差分析随机区组设计方差分析重复测量方差分析析因设计方差分析偏态分布配对设计秩和检验单样本设计秩和检验成组设计秩和检验资料类型定量资料计数资料等级资料统计分析统计描述统计推断相对数总体率的估计假设检验u检验卡方检验4假设检验参数检验非参数检验正态分布等级资料偏态分布资料分布类型未知方差不齐,且不易变换达到齐性数据一端或两端不确定的资料1.参数检验:已知总体分布类型,对未知的总体参数做推断的假设检验方法。
故参数检验依赖于特定的分布类型,比较的是总体参数2.非参数检验:不依赖于总体分布类型、不针对总体参数的检验方法。
故非参数检验对总体的分布类型不做任何要求,不受总体参数的影响,比较的是分布或分布位置。
适用范围广,可适用于任何类型资料 参数检验➢ 优点:资料信息利用充分;检验效能较高 ➢ 缺点:对资料的要求高;适用范围有限 ➢ 优点:适用范围广,可适用于任何类型的资料 ➢ 缺点:检验效能低,易犯Ⅱ型错误 凡适合参数检验的资料,应首选参数检验对于符合参数检验条件者,采用非参数检验,其检验效能低,易犯Ⅱ型错误第一章绪论1.举例说明总体和样本的概念。
研究人员通常需要了解和研究某一类个体,这个类就是总体。
总体是根据研究目的所确定的所有同质观察单位某种观察值(即变量值)的集合,通常有无限总体和有限总体之分,前者指总体中的个体是无限的,如研究药物疗效,某病患者就是无限总体,后者指总体中的个体是有限的,它是指特定时间、空间中有限个研究个体。
医学统计学复习思考题及参考答案

预防医学第三篇复习思考题及参考答案第十三章医学统计学方法的基本概念和基本步骤1.举例说明总体与样本的关系。
总体是根据研究目的确定的同质的所有观察单位某项观察值(变量值)的集合。
例如研究某地2002年正常成人白细胞数,观察对象是该地2002年全部正常成人,观察单位是每个人,观察值是每人测得的白细胞数,则该地2002年全部正常成人的白细胞数就构成了一个总体;从总体中随机抽取部分观察单位其某项指标的实测值组成样本。
从上述的某地2002年正常成人中随机抽取150人,这150正常成人的白细胞数就是样本。
抽取样本的目的是用样本的信息推论总体特征。
2.简述3种变量类型的特征。
(1)数值变量的变量值是用定量方法测量的,表现为数值的大小,一般有计量单位;(2)无序分类变量的变量值是用定性方法得到的,表现为互不相容的类别或属性,但各类别间无程度上的差别,包括二项分类和多项分类;(3)有序分类变量的变量值也是用定性方法得到的,也表现为互不相容的类别或属性,但各类别之间有程度上的差别。
第十四章数值变量的统计描述1.均数、几何均数和中位数的适用范围是什么?(1)均数适用于描述对称分布,特别是正态分布的数值变量资料的平均水平;(2)几何均数适用于描述原始数据呈偏态分布,但经过对数变换后呈正态分布或近似正态分布的数值变量资料的平均水平;(3)中位数适用于描述呈明显偏态分布(正偏态或负偏态),或分布情况不明,或分布的末端有不确切数值的数值变量资料的平均水平。
2.全距、四分位数间距、方差、标准差、变异系数各有何特点?(1)全距是一组观察值中最大值与最小值之差,计算简单,意义明了,但全距的不能反映组内其他观察值之间的离散情况,并且容易受个别特大值或特小值的影响,稳定性较差;(2)四分位数间距内包括了全部观察值的一半,可看作为中间一半观察值的全距,它比全距稳定,但仍未考虑每个观察值的离散度,它适用于描述偏态分布资料,特别是分布末端无确定数据资料的离散度;(3)方差是离均差平方和的均数,克服了全距和四分位数间距不能反映组内每个观察值离散度的缺点,但方差把观察值的原度量单位变成了平方单位,导致计算结果难于解释;(4)方差开方,即为标准差,它适宜于描述对称分布,特别是正态分布的数值变量资料的离散程度;(5)变异系数是标准差与均数之比,它适宜于描述度量单位不同的观察值的离散程度和度量单位相同但均数相差悬殊的观察值的离散程度。
医学统计学课后习题答案解析
医学统计学第一章 绪论答案名词解释:(1) 同质与变异:同质指被研究指标的影响因素相同,变异指在同质的基础上各观察单位(或个体)之间的差异。
(2) 总体和样本:总体是根据研究目的确定的同质观察单位的全体。
样本是从总体中随机抽取的部分观察单位。
(3) 参数和统计量:根据总体个体值统计算出来的描述总体的特征量,称为总体参数,根据样本个体值统计计算出来的描述样本的特征量称为样本统计量。
(4) 抽样误差:由抽样造成的样本统计量和总体参数的差别称为抽样误差。
(5) 概率:是描述随机事件发生的可能性大小的数值,用p 表示(6) 计量资料:由一群个体的变量值构成的资料称为计量资料。
(7) 计数资料:由一群个体按定性因数或类别清点每类有多少个个体,称为计数资料。
(8) 等级资料:由一群个体按等级因数的级别清点每类有多少个体,称为等级资料。
是非题:1. ×2. ×3. ×4. ×5. √6. √7. ×单选题:1. C2. E3. D4. C5. D6. B第二章 计量资料统计描述及正态分布答案名词解释:1. 平均数 是描述数据分布集中趋势(中心位置)和平均水平的指标2. 标准差 是描述数据分布离散程度(或变量变化的变异程度)的指标3. 标准正态分布 以μ服从均数为0、标准差为1的正态分布,这种正态分布称为标准状态分布。
4. 参考值范围 参考值范围也称正常值范围,医学上常把把绝大多数的某指标范围称为指标的正常值范围。
填空题:1. 计量,计数,等级2. 设计,收集资料,分析资料,整理资料。
3. σμχ-=u (变量变换)标准正态分布、0、1 4. σ± σ96.1± σ58.2± 68.27% 95% 99%5. 47.5%6.均数、标准差7. 全距、方差、标准差、变异系数8. σμ96.1± σμ58.2±9. 全距 R10. 检验水准、显著性水准、0.05、 0.01 (0.1)11. 80% 90% 95% 99% 95%12. 95% 99%13. 集中趋势、离散趋势14. 中位数15. 同质基础,合理分组16. 均数,均数,μ,σ,规律性17. 标准差18. 单位不同,均数相差较大是非题:1. ×2. √3. ×4. ×5. ×6. √7. √8. √9. √ 10. √11. √ 12. √ 13. × 14. √ 15. √ 16. × 17. × 18. × 19. √ 20. √21. √单选题:1. B2. D3. C4. A5. C6. D7. E8. A9. C 10. D11. B 12. C 13. C 14. C 15. A 16. C 17. E 18. C 19. D 20. C21. B 22. B 23. E 24. C 25. A 26. C 27. B 28. D 29. D 30. D31. A 32. E 33. D 34. A 35. D 36. D 37. C 38. E 39. D 40. B41. C 42. B 43. D 44. C 45. B问答题:1.均数﹑几何均数和中位数的适用范围有何异同?答:相同点,均表示计量资料集中趋势的指标。
医学统计学李晓松主编第2版高等教育出版社附录第3章思考与练习答案

第三章实验研究设计【思考与练习】一、思考题1. 实验设计根据对象的不同可分为哪几类?2. 实验研究中,随机化的目的是什么?3. 什么是配对设计?它有何优缺点?4. 什么是交叉设计?它有何优缺点?5. 临床试验中使用安慰剂的目的是什么?二、案例辨析题“三联药物治疗士兵消化性溃疡”一文中,对2000~2006年在某卫生所采用三联药物治疗的38例消化性溃疡患者进行分析。
内镜检测结果显示,痊愈13人,显效14人,进步7人,无效4人,有效率达89.5%。
据此认为该三联疗法的疗效较好,且由于其价格适中,可在部队卫生所中推广。
该结论是否正确?如果不正确,请说明理由。
三、最佳选择题1. 实验设计的三个基本要素是A. 处理因素、实验效应、实验场所B. 处理因素、实验效应、受试对象C. 受试对象、研究人员、处理因素D. 受试对象、干扰因素、处理因素E. 处理因素、实验效应、研究人员2. 实验设计的三个基本原则是A. 随机化、对照、重复B. 随机化、对照、盲法C. 随机化、重复、盲法D. 均衡、对照、重复E. 盲法、对照、重复3. 实验组与对照组主要不同之处在于A. 处理因素B. 观察指标C. 抽样误差D. 观察时间E. 纳入、排除受试对象的标准4. 为了解某疗法对急性肝功能衰竭的疗效,用12头健康雌性良种幼猪建立急性肝功能衰竭模型,再将其随机分为两组,仅实验组给予该疗法治疗,对照组不给予任何治疗。
7天后观察两组幼猪的存活情况。
该研究采用的是A. 空白对照B. 安慰剂对照C. 实验对照D. 标准对照E. 自身对照5. 观察指标应具有A. 灵敏性、特异性、准确度、精密度、客观性B. 灵敏性、变异性、准确度、精密度、客观性C. 灵敏性、特异性、变异性、均衡性、稳定性D. 特异性、准确度、稳定性、均衡性、客观性E. 灵敏性、变异性、准确度、精密度、均衡性6. 比较两种疗法对乳腺癌的疗效,若两组患者的乳腺癌分期构成不同可造成A. 选择性偏倚B. 测量性偏倚C. 混杂性偏倚D. 信息偏倚E. 失访性偏倚7. 将两个或多个处理因素的各水平进行组合,对各种可能的组合都进行实验,该实验设计方案是A. 随机区组设计B. 完全随机设计C. 析因设计D. 配对设计E. 交叉设计8. 在某临床试验中,将180例患者随机分为两组,实验组给予试验药+对照药的模拟剂,对照给予对照药+试验药的模拟剂,整个过程中受试对象和研究者均不知道受试对象的分组。
医学统计学李晓松主编 第2版 高等教育出版社附录 思考与练习95%答案

一、SPSS 基本功能SPSS基本功能数据管理统计分析图表分析:条图、直方图、饼图、线图、散点图等输出管理:对输出结果复制、编辑等描述性分析均数比较一般线性模型相关与回归分析非参数检验生存分析FrequenciesDescriptivesExploreCrosstabs 统计资料的类型资料类型定量资料:用定量的方法获得的数值资料计数资料:按性质或类别分组后清点各组个数等级资料:半定量资料定量资料的统计推断正态分布两组均数比较单样本设计t检验配对设计t检验成组设计t检验三组及以上均数比较完全随机设计方差分析随机区组设计方差分析重复测量方差分析析因设计方差分析偏态分布配对设计秩和检验单样本设计秩和检验成组设计秩和检验资料类型定量资料计数资料等级资料统计分析统计描述统计推断相对数总体率的估计假设检验u检验卡方检验4假设检验参数检验非参数检验正态分布等级资料偏态分布资料分布类型未知方差不齐,且不易变换达到齐性数据一端或两端不确定的资料1.参数检验:已知总体分布类型,对未知的总体参数做推断的假设检验方法。
故参数检验依赖于特定的分布类型,比较的就是总体参数2.非参数检验:不依赖于总体分布类型、不针对总体参数的检验方法。
故非参数检验对总体的分布类型不做任何要求,不受总体参数的影响,比较的就是分布或分布位置。
适用范围广,可适用于任何类型资料 参数检验➢ 优点:资料信息利用充分;检验效能较高 ➢ 缺点:对资料的要求高;适用范围有限 2.非参数检验➢ 优点:适用范围广,可适用于任何类型的资料 ➢ 缺点:检验效能低,易犯Ⅱ型错误 凡适合参数检验的资料,应首选参数检验对于符合参数检验条件者,采用非参数检验,其 检验效能低,易犯Ⅱ型错误研究人员通常需要了解与研究某一类个体,这个类就就是总体。
总体就是根据研究目的所确定的所有同质观察单位某种观察值(即变量值)的集合,通常有无限总体与有限总体之分,前者指总体中的个体就是无限的,如研究药物疗效,某病患者就就是无限总体,后者指总体中的个体就是有限的,它就是指特定时间、空间中有限个研究个体。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第三章实验研究设计【思考与练习】一、思考题1. 实验设计根据对象的不同可分为哪几类?2. 实验研究中,随机化的目的是什么?3. 什么是配对设计?它有何优缺点?4. 什么是交叉设计?它有何优缺点?5. 临床试验中使用安慰剂的目的是什么?二、案例辨析题“三联药物治疗士兵消化性溃疡”一文中,对2000~2006年在某卫生所采用三联药物治疗的38例消化性溃疡患者进行分析。
内镜检测结果显示,痊愈13人,显效14人,进步7人,无效4人,有效率达89.5%。
据此认为该三联疗法的疗效较好,且由于其价格适中,可在部队卫生所中推广。
该结论是否正确?如果不正确,请说明理由。
三、最佳选择题1. 实验设计的三个基本要素是A. 处理因素、实验效应、实验场所B. 处理因素、实验效应、受试对象C. 受试对象、研究人员、处理因素D. 受试对象、干扰因素、处理因素E. 处理因素、实验效应、研究人员2. 实验设计的三个基本原则是A. 随机化、对照、重复B. 随机化、对照、盲法C. 随机化、重复、盲法D. 均衡、对照、重复E. 盲法、对照、重复3. 实验组与对照组主要不同之处在于A. 处理因素B. 观察指标C. 抽样误差D. 观察时间E. 纳入、排除受试对象的标准4. 为了解某疗法对急性肝功能衰竭的疗效,用12头健康雌性良种幼猪建立急性肝功能衰竭模型,再将其随机分为两组,仅实验组给予该疗法治疗,对照组不给予任何治疗。
7天后观察两组幼猪的存活情况。
该研究采用的是A. 空白对照B. 安慰剂对照C. 实验对照D. 标准对照E. 自身对照5. 观察指标应具有A. 灵敏性、特异性、准确度、精密度、客观性B. 灵敏性、变异性、准确度、精密度、客观性C. 灵敏性、特异性、变异性、均衡性、稳定性D. 特异性、准确度、稳定性、均衡性、客观性E. 灵敏性、变异性、准确度、精密度、均衡性6. 比较两种疗法对乳腺癌的疗效,若两组患者的乳腺癌分期构成不同可造成A. 选择性偏倚B. 测量性偏倚C. 混杂性偏倚D. 信息偏倚E. 失访性偏倚7. 将两个或多个处理因素的各水平进行组合,对各种可能的组合都进行实验,该实验设计方案是A. 随机区组设计B. 完全随机设计C. 析因设计D. 配对设计E. 交叉设计8. 在某临床试验中,将180例患者随机分为两组,实验组给予试验药+对照药的模拟剂,对照给予对照药+试验药的模拟剂,整个过程中受试对象和研究者均不知道受试对象的分组。
本试验中采用的控制偏倚的方法有A. 单盲、多中心B. 随机化、多中心C. 随机化、单盲D. 随机化、双盲双模拟E. 双盲双模拟、多中心9. 临床试验的统计分析应主要包括A. 可比性分析、疗效评价、安全性评价B. 可比性分析、优效性分析、劣效性分析C. 可比性分析、安全性评价、可行性分析D. 优效性分析、等效性分析、安全性评价E. 疗效评价、安全性评价、可行性分析10. 药品上市后应用阶段进行的临床试验属于A. I期临床试验B. II期临床试验C. III期临床试验D. IV临床试验E. 现场试验四、综合分析题1. 欲将16只豚鼠随机分为两组,某研究员闭上眼睛从笼中抓了8只豚鼠作为实验组,剩下8只作为对照组。
该分组方法是否正确?若不正确,请说明理由。
2. 某研究人员欲将12只小鼠按月龄、体重相近的原则配成对,然后将每一对中的小鼠随机分配到实验组和对照组,应如何分组?3. 某研究欲了解褪黑素(MEL)和通心络超微粉(TXL)对糖尿病模型大鼠血管紧张素的影响,并欲分析两药联合应用是否更为有效。
(1) 你认为该研究最好采用何种实验设计方案?并说明理由。
(2) 请帮该研究者实现32只大鼠的随机分组。
【习题解析】一、思考题1. 根据受试对象不同,实验可以分为动物实验、临床试验和现场试验三类。
动物实验的受试对象为动物,也可以是器官、细胞或血清等生物材料;临床试验的受试对象通常为患者,持续时间可以较长,目的在于评价药物或治疗方法的疗效;现场试验的受试对象通常是未患某种疾病的人群,持续时间一般较长,目的是通过干扰某些危险因素或施加某些保护性措施,了解其在人群中产生的预防效果。
2. 实验研究中,随机化的目的在于使非处理因素在实验组和对照组中的影响相当,提高对比组间的可比性,使实验结论的外推具有科学性和可靠性。
随机化是对资料进行统计推断的前提。
3. 配对设计是将受试对象按一定条件配成对子,再将每对中的两个受试对象随机分配到不同处理组。
用以配对的因素应为可能影响实验结果的主要混杂因素。
在动物实验中,常将窝别、性别、体重等作为配对因素;在临床试验中,常将病情、性别、年龄等作为配对因素。
配对设计和完全随机设计相比,其优点在于可增强处理组间的均衡性、实验效率较高;其缺点在于配对条件不易严格控制,当配对失败或配对欠佳时,反而会降低效率。
在临床试验中,配对的过程还可能延长实验时间。
4. 交叉设计是一种特殊的自身对照设计。
其中2 2交叉设计首先是将同质个体随机分为两组,每组先接受一种处理措施,待第一阶段结束后,两组交换处理措施进行第二阶段的实验,这样每个个体都接受了两种处理。
当然阶段数和处理数都可以扩展,成为多种处理多重交叉实验。
交叉设计一般不适于具有自愈倾向或病程较短的疾病研究。
交叉设计的优点有:①节约样本含量;②能够控制个体差异和时间对处理因素的影响;③在临床试验中同等地考虑了每个患者的利益。
其缺点有:①处理时间不能太长;②当受试对象的状态发生根本变化时,后一阶段的处理将无法进行;③受试对象一旦在某一阶段退出试验,就会造成数据缺失。
5. 临床试验中使用安慰剂,目的在于消除由于受试对象和试验观察者的心理因素引起的偏倚,还可控制疾病自然进程的影响,显示试验药物的效应。
二、案例辨析题该结论不正确。
研究某治疗方案对某病患者的治疗效果需进行临床试验,应遵循实验设计的三个基本原则,即对照、随机化和重复。
只有设立了对照才能较好地控制非处理因素对实验结果的影响,不设立对照往往会误将非处理因素造成的偏倚当成处理效应,从而得出错误的结论。
此研究仅纳入38例消化性溃疡患者,并未设立相应的对照组。
而且这38例患者接受治疗的时间为2000年至2006年,时间跨度太大,可能对研究结果造成影响的因素很多,在没有对照的情况下,不能控制非处理因素对试验结果的影响,其研究结论不具有说服力。
三、最佳选择题1.B2.A 3A. 4.A 5.A 6.C 7.C 8.D 9.A 10.D四、综合分析题1. 解:该分组方法不正确。
随机不等于随便,随机的含义是指每只动物都有相同机会进入实验组或对照组,而该分组方法由于豚鼠活跃程度不相同,进入各组的机会就不同,较活跃的豚鼠进入实验组的机会增大,因此破坏了随机化原则。
2. 解:先将6对小鼠按体重从小到大的顺序编号。
再从随机数字表中任一行,如第18行最左端开始横向连续取12个两位数字。
事先规定,每一对中,随机数较小者序号为1,对应于A组,随机数较大者序号为2,对应于B组。
分配结果见表3-1。
表3-1 配对设计的12只小鼠随机分组的结果对子数 1 2 3 4 5 6动物编号 1.1 1.2 2.1 2.2 3.1 3.2 4.1 4.2 5.1 5.2 6.1 6.2 随机数12 96 88 17 31 65 19 69 02 83 60 75 序号 1 2 2 1 1 2 1 2 1 2 1 2组别 A B B A A B A B A B A BSPSS操作数据录入:打开SPSS Data Editor窗口,点击Variable View标签,定义要输入的变量number和pair,再点击Data View标签,录入数据(见图3-1,图3-2)。
图3-1 Variable View窗口内定义要输入的变量number和pair图3-2 Data View窗口内录入数据分析:Transform→Random Number Generators …Active Generator InitializationSet Starting PointFixed ValueValue: 键入20071222 设定随机种子为20071222Transform→Compute…Target Valuable: 键入randomNumeric Expression: RV.Uniform(0,1) 产生范围在0~1之间的伪随机数Transform→Rank Cases…Variables(s): randomBy: pair 对每个对子中的两个伪随机数进行排序注:当样本量较大时,最好编程实现,以免除数据录入的不便。
以下为SPSS的Syntax窗口中用编程来完成本题。
File→New→Syntax,打开Syntax窗口,键入如下程序:input program. 开始数据录入程序段numeric k b n number pair (F8.0)/random(F8.6).string treat(A1).compute k=2. 处理组为2compute b=6. 对子数为6compute n=b*k.loop number=1 to n.compute pair=rnd((number-1)/k+0.5).end case.compute k=lag(k).end loop.end file.end input program. 结束数据录入程序段set seed 20071222. 设定随机种子为20071222compute random=uniform(1). 产生范围在0~1之间的伪随机数rank variables=random by pair. 对伪随机数排序formats rrandom(F3.0).compute根据伪随机数的序号进行分组treat=substr("ABCDEFGHIJKLMN",rrandom,1).list number pair treat. 结果中显示受试对象编号及被分到的处理组在Syntax窗口中选择Run→All 提交运行。
注:程序中的b(即对子数)可根据实际情况赋予不同的值。
随机区组设计受试对象的分配也可以用此程序来实现,仅需将k值设为处理组数,b值设为相应的区组数。
结果及解释Data View窗口图3-3 SPSS编程实现受试对象随机分配结果Output窗口Listnumber pair treat11A21B32A42B53B63A74A84B95B105A116B126A编程实现随机分配的结果见data view窗口(图3-3)或output 窗口。
可以看出12只小鼠被随机分配到A组和B组。
在用此程序进行随机分组前,规定A组表示实验组,B组表示对照组。