哈工大模式识别课程期末总结分解
模式识别学习心得体会

模式识别学习心得体会篇一:最新模式识别与智能系统专业毕业自我总结最模式识别与智能系统专业大学生毕业自我总结优秀范文个人原创欢迎下载模式识别与智能系统专业毕业论文答辩完成之际,四年大学生活也即将划上一个句号,而我的人生却仅仅是个逗号,我即将开始人生的又一次征程。
作为×××大学(改成自己模式识别与智能系统专业所在的大学)毕业生的我即将告别大学生活,告别亲爱的模式识别与智能系统专业的同学和敬爱的老师,告别我的母校——×××大学。
回顾在×××大学模式识别与智能系统专业的求学生涯,感慨颇多,有酸甜苦辣,有欢笑和泪水,有成功和挫折!大学——是我由幼稚走向成熟的地方,在此,我们认真学习模式识别与智能系统专业知识,拓展自己的知识面,培养自己的模式识别与智能系统实践活动能力。
在思想道德上,×××大学(改成自己就读模式识别与智能系统专业所在的大学)学习期间我系统全面地学习了思政课程的重要思想,不断用先进的理论武装自己的头脑,热爱祖国,热爱人民,坚持四项基本原则,树立了正确的人生观、价值观、世界观,使自己成为思想上过硬的模式识别与智能系统专业合格毕业生。
在模式识别与智能系统专业学习上,我严格要求自己,刻苦钻研篇二:最新模式识别与智能系统专业毕业自我个人小结优秀范文原创最模式识别与智能系统专业大学生毕业个人总结优秀范文个人原创欢迎下载在×××(改成自己模式识别与智能系统就读的大学)模式识别与智能系统专业就读四年青春年华时光,匆匆而过。
四年的时间足以证明了,我爱上了×××(改成自己模式识别与智能系统就读的大学)的一草一木,一人一事。
回想四年里有过多少酸甜苦辣、曾经模式识别与智能系统班级里的欢声笑语,曾经期末考试备战中的辛勤汗水……所有的一切都历历在目。
模式识别考试总结

1.对一个染色体分别用一下两种方法描述:(1)计算其面积、周长、面积/周长、面积与其外接矩形面积之比可以得到一些特征描述,如何利用这四个值?属于特征向量法,还是结构表示法?(2)按其轮廓线的形状分成几种类型,表示成a、b、c等如图表示,如何利用这些量?属哪种描述方法?(3)设想其他的描述方法。
(1)这是一种特征描述方法,其中面积周长可以体现染色体大小,面积周长比值越小,说明染色体越粗,面积占外接矩形的比例也体现了染色体的粗细。
把这四个值组成特征向量可以描述染色体的一些重要特征,可以按照特征向量匹配方法计算样本间的相似度。
可以区分染色体和其它圆形、椭圆细胞结构。
(2)a形曲线表示水平方向的凹陷,b形表示竖直方向的凹陷,c形指两个凹陷之间的突起,把这些值从左上角开始,按顺时针方向绕一圈,可以得到一个序列描述染色体的边界。
它可以很好的体现染色体的形状,用于区分X和Y染色体很合适。
这是结构表示法。
(3)可以先提取待识别形状的骨架,在图中用蓝色表示,然后,用树形表示骨架图像。
2. 设在一维特征空间中两类样本服从正态分布,,两类先验概率之比,试求按基于最小错误率贝叶斯决策原则的决策分界面的x值。
答:由于按基于最小错误率的贝叶斯决策,则分界面上的点服从3、设两类样本的类内离散矩阵分别为,试用fisher准则求其决策面方程,并与第二章习题二的结构相比较。
答:由于两类样本分布形状是相同的(只是方向不同),因此应为两类均值的中点。
4,设在一个二维空间,A类有三个训练样本,图中用红点表示,B类四个样本,图中用蓝点表示。
试问:(1)按近邻法分类,这两类最多有多少个分界面(2)画出实际用到的分界面(3) A1与B4之间的分界面没有用到下图中的绿线为最佳线性分界面。
答:(1)按近邻法,对任意两个由不同类别的训练样本构成的样本对,如果它们有可能成为测试样本的近邻,则它们构成一组最小距离分类器,它们之间的中垂面就是分界面,因此由三个A类与四个B类训练样本可能构成的分界面最大数量为3×4=12。
模式识别与机器学习期末总结

哈工大 模式识别总结

非监督学习方法
与监督学习 方法的区别
主要任务:数据分析 数据分析的典型类型:聚类分析 直接方法:按概率密度划分 投影法 基 于 对 称性 质 的 单 峰 子集 分 离方法 间接方法:按数据相似度划分 动态聚类 方法 C-均值 算法 ISODATA 算法 分级聚类 算法
第三章 判别函数及分类器的设计
(1)非参数分类决策方法的定义;与贝叶斯决策方法进行比 较,分析非参数分类方法的基本特点。 (2)线性分类器。说明这种分类器的定义及其数学表达式, 进一步分析数学表达式的各种表示方法,从而导出典型的线 性分类器设计原理:Fisher准则函数、感知准则函数。 (3)非线性判别函数。从样本的线性不可分例子说明线性判 别函数的局限性,从而引入分段线性判别函数概念及相应计 算方法。 (4)近邻法的定义及性能分析。从近邻法的优缺点导入改进 的近邻法;
非参数判别分类方法原理----有监督学习方法
线性分类器
近邻法: 最近邻法,K近邻法
Fisher 准则
扩展:分段 线性分类器 方法实现非 线性分类器
感知准则 函数
多层感知器 (神经网络)
支持向量机
SVM
改进的近邻法: --剪辑近邻法 --压缩近邻法
特征映射方法实 现非线性分类器
错误修正算法 可实现最小分段数的局部训练算法
特征空间优化:概念、目的及意义
两种优化方法:特征选择、特征提取 评判标准:判据 ------基于距离的可分性判据 -----基于概率的可分性判据 特征提取 特征选择 KL变换 产生矩阵 包含在类平 均信息中判 别信息的最 优压缩 最优方法 分支 定界 算法 次优方法 顺序前 进法, 广义顺 序前进 法 顺序后 退法, 广义顺 序后退 法
模式识别期末复习总结

1、贝叶斯分类器贝叶斯分类器的定义:在具有模式的完整统计知识的条件下,按照贝叶斯决策理论进行设计的一种最优分类器。
贝叶斯分类器的分类原理:通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。
贝叶斯分类器是各种分类器中分类错误概率最小或者在预先给定代价的情况下平均风险最小的分类器。
贝叶斯的公式:什么情况下使用贝叶斯分类器:对先验概率和类概率密度有充分的先验知识,或者有足够多的样本,可以较好的进行概率密度估计,如果这些条件不满足,则采用最优方法设计出的分类器往往不具有最优性质。
2、K近邻法kNN算法的核心思想:如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
假设有N个已知样本分属c个类,考察新样本x在这些样本中的前K个近邻,设其中有个属于类,则类的判别函数就是决策规则:若则∈什么情况下使用K近邻法:kNN只是确定一种决策原则,在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别,并不需要利用已知数据事先训练出一个判别函数,这种方法不需要太多的先验知识。
在样本数量不足时,KNN法通常也可以得到不错的结果。
但是这种决策算法需要始终存储所有的已知样本,并将每一个新样本与所有已知样本进行比较和排序,其计算和存储的成本都很大。
对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
3、PCA和LDA的区别Principal Components Analysis(PCA):uses a signal representation criterionLinear Discriminant Analysis(LDA):uses a signal classification criterionLDA:线性判别分析,一种分类方法。
它寻找线性分类器最佳的法线向量方向,将高维数据投影到一维空间,使两类样本在该方向上的投影满足类内尽可能密集,类间尽可能分开。
哈工大模式识别实验报告
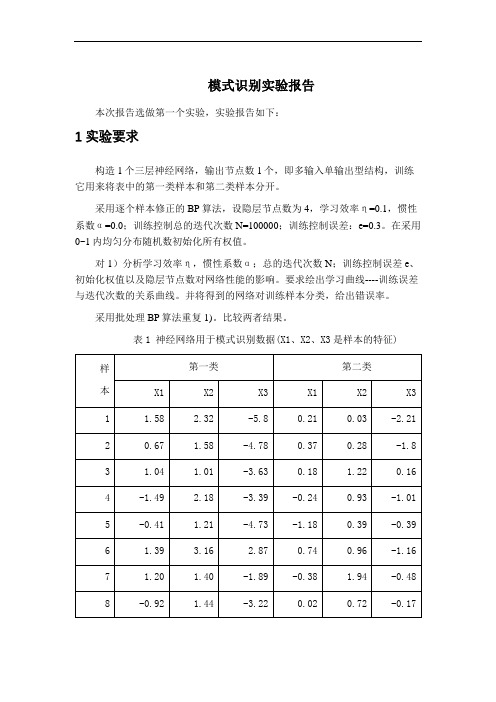
模式识别实验报告本次报告选做第一个实验,实验报告如下:1 实验要求构造1个三层神经网络,输出节点数1个,即多输入单输出型结构,训练它用来将表中的第一类样本和第二类样本分开。
采用逐个样本修正的BP算法,设隐层节点数为4,学习效率η=0.1,惯性系数α=0.0;训练控制总的迭代次数N=100000;训练控制误差:e=0.3。
在采用0~1内均匀分布随机数初始化所有权值。
对1)分析学习效率η,惯性系数α;总的迭代次数N;训练控制误差e、初始化权值以及隐层节点数对网络性能的影响。
要求绘出学习曲线----训练误差与迭代次数的关系曲线。
并将得到的网络对训练样本分类,给出错误率。
采用批处理BP算法重复1)。
比较两者结果。
表1 神经网络用于模式识别数据(X1、X2、X3是样本的特征)2 BP 网络的构建三层前馈神经网络示意图,见图1.图1三层前馈神经网络①网络初始化,用一组随机数对网络赋初始权值,设置学习步长η、允许误差ε、网络结构(即网络层数L 和每层节点数n l );②为网络提供一组学习样本; ③对每个学习样本p 循环a .逐层正向计算网络各节点的输入和输出;b .计算第p 个样本的输出的误差Ep 和网络的总误差E ;c .当E 小于允许误差ε或者达到指定的迭代次数时,学习过程结束,否则,进行误差反向传播。
d .反向逐层计算网络各节点误差)(l jp δ如果l f 取为S 型函数,即xl e x f -+=11)(,则 对于输出层))(1()()()()(l jp jdp l jp l jp l jp O y O O --=δ 对于隐含层∑+-=)1()()()()()1(l kj l jp l jp l jp l jp w O O δδe .修正网络连接权值)1()()()1(-+=+l ip l jp ij ij O k W k W ηδ式中,k 为学习次数,η为学习因子。
η取值越大,每次权值的改变越剧烈,可能导致学习过程振荡,因此,为了使学习因子的取值足够大,又不至产生振荡,通常在权值修正公式中加入一个附加动量法。
模式识别总结

模式识别总结第一章1、 定义模式识别:对表征事物或现象的各种形式的(数值的、文字的和逻辑关系的)信息进行处理和分析,以对事物或现象进行描述、辨认、分类和解释的过程。
2、 模式识别的主要方法解决模式识别问题的主要方法可以归纳为基于知识的方法和基于数据的方法。
所谓基于知识的方法,主要是指专家系统为代表的方法,一般归在人工智能的范畴中,其基本思想是,根据人们已知的(从专家那里收集整理的)关于研究对象的知识,整理出若干描述特征与类别间关系的准则,建立一定的计算机推理系统,对未知样本通过这些知识推理决策其类别。
基于数据的方法是模式识别最主要的方法,在无特殊说明的情况下,人们说模式识别通常就是指这一类方法,其任务可以描述为:在类别标号y 与特征向量x 存在一定的未知依赖关系、但已知的信息只有一组训练数据对{(x,y )}的情况下,求解定义在x 上的某一函数y’=f(x),对未知样本进行预测。
这一函数就叫做分类器。
3、 模式识别的分类模式识别可分为监督模式识别与非监督模式识别。
监督模式识别:已知要划分的类别,并且能够获得一定数量的类别已知的训练样本,这种情况下建立分类器的问题属于监督学习的问题。
非监督模式识别:事先不知道要划分的是什么类别,更没有类别已知的样本用作训练,很多情况下我们甚至不知道有多少类别。
我们要做的是根据样本特征讲样本聚成几个类,是属于同一类的样本在一定意义上是相似的,而不同类之间的样本则有较大差异。
这种学校过程称作非监督模式识别,在统计中通常被称为聚类,所得到的类别也称为聚类。
● 分类和聚类的概念分类(监督学习):通过给定的已知类别标号的样本、训练某种学习机器,使他能够对未知泪别进行分类。
聚类(无监督学习):是将数据分类到不同的类或者簇的过程,是探索学习的分析,在分类过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。
简单来说,分类就是按照某种标准给对象标签,再根据标签来分类,对未知数据的预测。
模式识别期末大作业报告

模式识别期末作业——BP_Adaboost分类器设计目录1 BP_ Adaboost分类器设计 (1)1.1 BP_ Adaboost模型 (1)1.2 公司财务预警系统介绍 (1)1.3模型建立 (1)1.4编程实现 (3)1.4. 1数据集选择 (3)1.4.2弱分类器学习分类 (3)1.4.3强分类器分类和结果统计 (4)1.5结果今析 (5)1 BP_ Adaboost分类器设计1.1 BP_ Adaboost模型Adaboost算法的思想是合并多个“弱”分类器的输出以产生有效分类。
其主要步骤为:首先给出弱学习算法和样本空间((x, y),从样本空间中找出m组训练数据,每组训练数据的权重都是1 /m。
.然后用弱学习算法迭代运算T次,每次运算后都按照分类结果更新训练数据权重分布,对于分类失败的训练个体赋予较大权重,下一次迭代运算时更加关注这些训练个体.弱分类器通过反复迭代得到一个分类函数序列f1 ,f2,...,fT,每个分类函数赋予一个权重,分类结果越好的函数,其对应权重越大.T次迭代之后,最终强分类函数F由弱分类函数加权得到。
BP_Adaboost模型即把BP神经网络作为弱分类器.反复训练BP神经网络预测样本输出.通过Adaboost算法得到多个BP神经网络弱分类器组成的强分类器。
1.2 公司财务预警系统介绍公司财务预警系统是为了防止公司财务系统运行偏离预期目标而建立的报瞥系统,具有针对性和预测性等特点。
它通过公司的各项指标综合评价并顶测公司财务状况、发展趋势和变化,为决策者科学决策提供智力支持。
财务危机预警指标体系中的指标可分为表内信息指标、盈利能力指标、偿还能力指标、成长能力指标、线性流量指标和表外信息指标六大指标,每项大指标又分为若干小指标,如盈利能力指标又可分为净资产收益率、总资产报酬率、每股收益、主营业务利润率和成本费用利润率等。
在用于公司财务预瞥预测时,如果对所有指标都进行评价后综合,模型过于复杂,并且各指标间相关性较强,因此在模型建立前需要筛选指标。
模式识别总结

监督学习与非监督学习的区别:监督学习方法用来对数据实现分类,分类规则通过训练获得。
该训练集由带分类号的数据集组成,因此监督学习方法的训练过程是离线的。
非监督学习方法不需要单独的离线训练过程,也没有带分类号(标号)的训练数据集,一般用来对数据集进行分析,如聚类,确定其分布的主分量等。
(实例:道路图)就道路图像的分割而言,监督学习方法则先在训练用图像中获取道路象素与非道路象素集,进行分类器设计,然后用所设计的分类器对道路图像进行分割。
使用非监督学习方法,则依据道路路面象素与非道路象素之间的聚类分析进行聚类运算,以实现道路图像的分割。
1、写出K-均值聚类算法的基本步骤,算法:第一步:选K个初始聚类中心,z1(1),z2(1),…,zK(1),其中括号内的序号为寻找聚类中心的迭代运算的次序号。
聚类中心的向量值可任意设定,例如可选开始的K个模式样本的向量值作为初始聚类中心。
第二步:逐个将需分类的模式样本{x}按最小距离准则分配给K个聚类中心中的某一个zj(1)。
假设i=j时,,则,其中k为迭代运算的次序号,第一次迭代k=1,Sj表示第j个聚类,其聚类中心为zj。
第三步:计算各个聚类中心的新的向量值,zj(k+1),j=1,2,…,K求各聚类域中所包含样本的均值向量:其中Nj为第j个聚类域Sj中所包含的样本个数。
以均值向量作为新的聚类中心,可使如下聚类准则函数最小:在这一步中要分别计算K个聚类中的样本均值向量,所以称之为K-均值算法。
第四步:若,j=1,2,…,K,则返回第二步,将模式样本逐个重新分类,重复迭代运算;若,j=1,2,…,K,则算法收敛,计算结束。
线性分类器三种最优准则:Fisher准则:根据两类样本一般类内密集, 类间分离的特点,寻找线性分类器最佳的法线向量方向,使两类样本在该方向上的投影满足类内尽可能密集,类间尽可能分开。
该种度量通过类内离散矩阵Sw和类间离散矩阵Sb实现。
感知准则函数:准则函数以使错分类样本到分界面距离之和最小为原则。
哈尔滨工程大学 模式识别实验报告

实验报告实验课程名称:模式识别姓名:班级: 20120811 学号:注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和2、平均成绩取各项实验平均成绩3、折合成绩按照教学大纲要求的百分比进行折合2015年 4月实验1 图像的贝叶斯分类1.1 实验目的将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。
1.2 实验仪器设备及软件HP D538、MA TLAB1.3 实验原理1.3.1基本原理阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。
并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。
此过程中,确定阈值是分割的关键。
对一般的图像进行分割处理通常对图像的灰度分布有一定的假设,或者说是基于一定的图像模型。
最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。
而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。
类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。
上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。
这时如用全局阈值进行分割必然会产生一定的误差。
分割误差包括将目标分为背景和将背景分为目标两大类。
实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。
这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。
图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。
模式识别复习重点总结

1.什么是模式及模式识别?模式识别的应用领域主要有哪些?模式:存在于时间,空间中可观察的事物,具有时间或空间分布的信息; 模式识别:用计算机实现人对各种事物或现象的分析,描述,判断,识别。
模式识别的应用领域:(1)字符识别;(2) 医疗诊断;(3)遥感; (4)指纹识别 脸形识别;(5)检测污染分析,大气,水源,环境监测; (6)自动检测;(7 )语声识别,机器翻译,电话号码自动查询,侦听,机器故障判断; (8)军事应用。
2.模式识别系统的基本组成是什么?(1) 信息的获取:是通过传感器,将光或声音等信息转化为电信息;(2) 预处理:包括A\D,二值化,图象的平滑,变换,增强,恢复,滤波等, 主要指图象处理;(3) 特征抽取和选择:在测量空间的原始数据通过变换获得在特征空间最能反映分类本质的特征;(4) 分类器设计:分类器设计的主要功能是通过训练确定判决规则,使按此类判决规则分类时,错误率最低。
把这些判决规则建成标准库; (5) 分类决策:在特征空间中对被识别对象进行分类。
3.模式识别的基本问题有哪些? (1)模式(样本)表示方法:(a )向量表示;(b )矩阵表示;(c )几何表示;(4)基元(链码)表示;(2)模式类的紧致性:模式识别的要求:满足紧致集,才能很好地分类;如果不满足紧致集,就要采取变换的方法,满足紧致集(3)相似与分类;(a)两个样本x i ,x j 之间的相似度量满足以下要求: ① 应为非负值② 样本本身相似性度量应最大 ③ 度量应满足对称性④ 在满足紧致性的条件下,相似性应该是点间距离的 单调函数(b)用各种距离表示相似性(4)特征的生成:特征包括:(a)低层特征;(b)中层特征;(c)高层特征 (5) 数据的标准化:(a)极差标准化;(b)方差标准化4.线性判别方法(1)两类:二维及多维判别函数,判别边界,判别规则 二维情况:(a )判别函数: ( ) (b )判别边界:g(x)=0; (cn 维情况:(a )判别函数: 也可表示为: 32211)(w x w x w x g ++=为坐标向量为参数,21,x x w 12211......)(+++++=n n n w x w x w x w x g X W x g T =)(为增值模式向量。
模式识别课程报告

模式识别实验报告学生姓名:班学号:指导老师:机械与电子信息学院2014年 6月基于K-means算法的改进算法方法一:层次K均值聚类算法在聚类之前,传统的K均值算法需要指定聚类的样本数,由于样本初始分布不一致,有的聚类样本可能含有很多数据,但数据分布相对集中,而有的样本集却含有较少数据,但数据分布相对分散。
因此,即使是根据样本数目选择聚类个数,依然可能导致聚类结果中同一类样本差异过大或者不同类样本差异过小的问题,无法得到满意的聚类结果。
结合空间中的层次结构而提出的一种改进的层次K均值聚类算法。
该方法通过初步聚类,判断是否达到理想结果,从而决定是否继续进行更细层次的聚类,如此迭代执行,生成一棵层次型K均值聚类树,在该树形结构上可以自动地选择聚类的个数。
标准数据集上的实验结果表明,与传统的K均值聚类方法相比,提出的改进的层次聚类方法的确能够取得较优秀的聚类效果。
设X = {x1,x2,…,xi,…,xn }为n个Rd 空间的数据。
改进的层次结构的K均值聚类方法(Hierarchical K means)通过动态地判断样本集X当前聚类是否合适,从而决定是否进行下一更细层次上的聚类,这样得到的最终聚类个数一定可以保证聚类测度函数保持一个较小的值。
具体的基于层次结构的K均值算法:步骤1 选择包含n个数据对象的样本集X = {x1,x2,…,xi,…,xn},设定初始聚类个数k1,初始化聚类目标函数J (0) =0.01,聚类迭代次数t初始化为1,首先随机选择k1个聚类中心。
步骤2 衡量每个样本xi (i = 1,2,…,n)与每个类中心cj ( j = 1,2,…,k)之间的距离,并将xi归为与其最相似的类中心所属的类,并计算当前聚类后的类测度函数值J (1) 。
步骤3 进行更细层次的聚类,具体步骤如下:步骤3.1 根据式(5)选择类半径最大的类及其类心ci :ri = max ||xj - ci||,j = 1,2,…,ni且xj属于Xj(5)步骤3.2 根据距离公式(1)选择该类中距离类ci最远的样本点xi1,然后选择该类中距离xi1最远的样本点xi2。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
【最大似然估计】
多元参数
【最大似然估计】
例子(梯度法不适合):
1 p( x | ) 2 1 0
,1 x 2 其它
1 p ( x , x ,..., x | , ) N 1 2 N 1 2 l ( ) 2 1 0
p( | x)
p( x | ) p( )
p( x | ) p( )d
p( , x) p( | x) p( x) p( x | ) p( )
R
E
d
ˆ, ) p ( | x) p ( x)d dx (
ˆ, ) p( | x)d dx d p( x) (
h( x) ln l ( x) ln p( x | 1 ) ln p( x | 2 ) ln P(1 ) P(2 )
x 1
x 2
【基于最小错误率的贝叶斯决策】
【基于最小错误率的贝叶斯决策】
【基于最小风险的贝叶斯决策】
概念
决策 决策空间 前面所讲的错误率达到最小。在某些实际应用中,最小错 误率的贝叶斯准则并不适合。以癌细胞识别为例,诊断中如 果把正常细胞判为癌症细胞,固然会给病人精神造成伤害, 但伤害有限;相反地,若把癌症细胞误判为正常细胞,将会 使早期的癌症患者失去治疗的最佳时机,造成验证的后果。
【基于最小风险的贝叶斯决策】
数学描述
【基于最小风险的贝叶斯决策】
条件期望损失:
R(i | x) EP( j | x), i 1, 2,..., a
j 1 c
期望风险:
R R ( ( x) | x) p ( x)dx
目的:期望风险最小化
【基于最小风险的贝叶斯决策】
最小风险贝叶斯决策规则:
R( k | x) min R( i | x)
i 1,2,..., a
a k
【基于最小风险的贝叶斯决策】
算法步骤:
【基于最小风险的贝叶斯决策】
例题2:
【基于最小风险的贝叶斯决策】
【基于最小错误率的贝叶斯决策与最小风险的贝 叶斯决策的关系】
E E
ˆ | x) p( x)dx d R(
【贝叶斯估计】
采用最小风险贝叶斯决策
R(i | x) E (i , j ) (i , j ) P( j | x), i 1, 2,..., a
j 1 c
【贝叶斯估计】
R
E
d
ˆ, ) p( x, )d dx (
p( x | ) p( ) p ( x)
P i x
P x i
• 贝叶斯公式:
P i x
P x i P i P x
基于最小错误率的贝 叶斯决策
【基于最小错误率的贝叶斯决策】
(4) h( x) ln l ( x) ln p( x | 1 ) ln p( x | 2 ) ln P(1 ) P(2 )
第2章 贝叶斯决策理论
哈尔滨工业大学
概率论基础知识 贝叶斯决策基础知识 基于最小错误率的贝叶斯决策
基于最小风险的贝叶斯决策
贝叶斯分类器设计
正态分布时的统计决策
小结
贝叶斯决策基础知识
【贝叶斯决策基础知识】
贝叶斯决策理论
• 先验概率:
• 后验概率: • 类条件概率:
P i
课程总复习
哈尔滨工业大学
1. 关于期末考试/考察 2. 章节知识点整理
2
1. 关于期末考试/考察
3
【关于期末考试】
1. 确认考试人员名单; 2. 考试/考察方式 • 学位课:考试70%+报告30%; • 选修课:报告100%(不用考试)。 3. 报告形式(见word文档) 4. 考试题目(100分) • 1.简答题(35分) 7*5’=35分 • 2.推导题(8分) • 3.证明题(8分) • 4.问答题(24分)3*8’=24分 • 5.计算题(25分) 9’+8’+8’=25分 (记得要带尺子,铅笔,橡皮擦)
H( ) Nln 2 1
H( ) 1 N 1 2 1
, 1 x 2 其它
H( ) 1 N 2 2 1
不成功!
1 x ' x x '' 2
x ', x '' 1 2
2 x '',1 x '
定理:0-1风险
第3章 概率密度函数估计
哈尔滨工业大学
引言 参数估计 正态分布的参数估计
非参数估计
本章小结
参数估计
【参数估计】
最大似然估计
贝叶斯估计
贝叶斯学习
【最大似然估计】
基本假设
【最大似然估计】
基本概念
【最大似然估计】
基本原理
【最大似然估计】
估计量
估计值
【最大似然估计】
4
2.章节知识点整理
5
第1章 模式识别绪论
哈尔滨工业大学
模式识别基本概念 模式识别系统组成 模式识别基本问题
应用领域
小结
模式识别系统组成
【模式识别系统组成】
信息 获取 预处理
特征提取 与选择
模式识别系统组成框图
分类 决策
后处理
4. 分类决策:在特征空间中用统计方法把被识别对象归为某一类。 5.信息的获取:通过测量、采样、量化并用矩阵或向量表示。通常 后处理:针对决策采取相应的行动。 1. 基本作法是在样本训练集基础上确定某个判决规则,使按这种判决 输入对象的信息有三个类型:二维图像(文字、指纹、地图、照片 2. 预处理:去除噪声,加强有用的信息,并对输入测量仪器或其它 规则对被识别对象进行分类所造成的错误识别率最小或引起的损失 等)、一维波形(脑电图、心电图、机械震动波形等)、物理参量 3. 特征提取与选择:为了实现有效的识别分类,要对原始数据进行 因素造成的干扰进行处理。 最小。 和逻辑值(体检中的温度、血化验结果等) 变换得到最能反映分类本质的特征,此过程为特征提取和选择。