spss精选整理笔记
SPSS知识学习记录文本

Spss 学习笔记(1)在spss中,数据文件的管理功能基本上都集中在data和transform菜单上,其中transform主要实现变量级别的数据管理,如计算新变量、变量取值重新编码等,data的功能主要是实现文件级别的数据管理,如变量排序,文件合并、拆分等。
Transform菜单说明:计算新变量:compute变量转换:recode,visual bander,count,rank cases,automatic recode五个过程,可以看成是compute再某一方面的强化和打包。
专用过程:建立时间序列、缺失值代替和设定随机种子三个过程,前两个专用于时间序列模型。
设定随机种子的功能主要影响伪随机函数的使用。
数据分析中,将连续变量转换为等级变量,或将分类变量不同的变量等级进行合并是常见的工作。
而recode可以很好的完成这个任务。
Recode提供了精确的分组功能,但是如果希望进行的分组是有规律的,比如等距分组或者等样本量分组,使用recode过程进行操作就显得非常麻烦,而且可视化程度不高,可以使用visual bander过程进行可视化分段。
在数据分析中,将字符变量转换为数值变量是非常实用的一个功能,除了使用recode过程手工设定转换规则外,还可以使用automatic recode过程自动按照原变量的大小或者字母排序生成新变量,而变量值就是原值的大小次序。
Automatic recode的排序功能和rank cases类似,不同在于,automatic recode可以用于字符型变量。
所谓变量的秩序,就是对记录按照某个变量值得大小来排序。
Rank cases就是用来排序的专用过程。
Count:该过程用来表示某个变量的取值中是否出现某个值,可以使单个数值,也可以指定区间,并且可以仅给出条件,而不必对整个数据集进行操作。
该过程可以直接使用recode过程来实现。
Random number seed:默认情况下,随机种子随时间不停改变,这样计算出的随机数值无法重复,可以用该过程人为指定一个种子,以后所有的伪随机函数在计算时都会以该种子开始计算,即结果可以重现。
SPSS学习笔记

SPSS学习笔记课(1)数据输⼊第三种输⼊法:开始——运⾏——“edit”课(2)数据检查(1)简单检查:排序观察(右击数据名——Sort Ascending/Descending)(2)极端值处理:将要检查的变量转换为Z分数(Descriptive Statistics---Descriptive---选中变量,在save standardized values as variables上打勾)——Data--Select Cases—选if condition is satisfied---定义条件:-2<=za1&za1<=2(两个标准差之内)----filtered/Deleted(3)缺失值处理:Transform---Replace Missing Values---选中处理的数据和处理⽅式课(3)数据整理(1)⽂件的合并(merge files):打开被合并的⽂件------Data------merge files-----Add variables (2)⾏列转置(transpose):Data------transpose-----选⼊Variable(s)⼩贴⼠:①时不时按下ctrl+s快捷键存盘②记事本和run edit.exe⽐较适合于中⼩型数据③重复相同命令,点击如下按键课(4)⾮连续性变量的描述统计Bar 直条图,⾮连续性变量(名称变量或顺序变量)Pie 饼图,⾮连续性变量课(5)连续性变量的描述统计Histogram 直⽅图,连续性变量,还可要求绘制正态曲线Frequencies/Descriptive/ExploreExplore在⼀般描述性统计指标的基础上,增加有关数据的其他特征的⽂字与图形描述,显得更加细致与全⾯,有助于⽤户思考对数据进⾏进⼀步分析的⽅案。
Plots对话框:Normality plot with test: 结果中Q—Q图,⽽且有变量正态分布的检验、Kolmogorov-Smirnov 检验和Shapiro—Wilk检验(样本量少于50时适⽤),如果P<.05,说明变量服从正态分布Spread-versus-Level with levene test:变异数同质性检验。
spss学习笔记之主成分分析

spss学习笔记:因子分析因子分析(主成分分析法)Analyse—>data reduction—>Factor除了variables对话框外,还有五个对话框。
descriptive对话框:提供描述性统计量与相关矩阵有关的统计量。
这个对话框关键是以下一些选项:1)statistics选项Initial solution:输出有comunalities(公因子方差),Total variance explained(提供特征值、各因子解释的方差比例和累计比例等信息)。
2)Correlation matrix选项:Coefficients输出观察变量的相关系数矩阵;Reproduced输出重构的相关系数矩阵(我用的spss版本显示的residual和produced correlation是分开的);KMO and Bartlett’s test ofsphericity:KMO测度和巴特里特球体检验。
KMO 值的可接受区间0.5~1。
球体检验则看显著性水平。
其他一般不必用。
Extraction对话框:Method选Principal components主成分分析法(系统默认)Analyse 选correlation matrix即可。
Display下的两个选项都选中。
分别输出未经旋转的因子矩阵和碎石图。
Extract决定提取因子的个数,有两种情况。
Eigenvalue over指定要提取因子的最小特征值;Number of factors直接指定要提取的因子数。
Rotation 对话框:Method下选择旋转方法:最常用的是varimax方差最大法;Direct Oblimin斜交旋转,在变量之间的相关性比较大时使用。
Display下:Rotated solution 输出旋转后的因子矩阵。
Loading Plots输出因子负载图(觉得这个东东没什么用,因子大于二时估计就已经看不清了)。
SPSS学习笔记非参数检验

学习必备欢迎下载总体分布未知,不会涉及有关总体分布的参数1.单样本非参数检验:卡方分布,二项分布,K-S检验,变量值随机性检验2.两独立样本非参数检验:两独立样本所来自的总体分布是否存在显著差异3.两配对样本非参数检验4.多独立样本非参数检验5.多配对样本非参数检验得到样本数据后,判断总体分布:直方图、P-P图、Q-Q图,或非参数检验1.1 卡方检验:根据样本数据,推断总体分布于期望分布或某一理论分布是否存在显著性差异,是一种吻合性检验,离散型数据。
原假设:样本来自总体的分布与期望分布或某一理论分布无显著性差异。
Eg:心脏病猝死人数与日期。
1.2二项分布检验:检验总体是否服从指定概率为P的二项分布,原假设:样本来自的总体与指定的二项分布无显著差异。
用于:二值型数据,性别,是否合格,是否为三好学生,硬币正反面等,用01表示。
注:检验概率值(检验比例)1.3单样本K-S检验:样本来自的总体是否与某一理论分布有显著差异,是一种拟合优度的检验方法。
用于:探索连续性变量的分布。
正态分布(normal)、均匀分布(uniform)、指数分布(ex.)、泊松分布。
原假设:样本来自的总体与指定的理论分布无显著差异。
另外,对于数据量很大的连续型变量,可以用图形直观判断。
P-P图:数据与理论分布一致时,各个数据点应落在对角线上。
Q-Q图:如果数据与理论分布无显著差异,点应分布在0横线附近。
(没找到啊?)2 Test type:Mann-Whitney: 秩:变量值排序的名次或位置K-S检验:游程检验Wald-wolfwitz Runs极端反应检验Moses Extreme Reactions:踢出极端值前后P值变化情况,是否踢出。
注:不同分析方法对同批数据的分析,结论可能不相同,要反复进行探索性分析,还要注意方法本身侧重点上的差异性。
4 中位数检验强调位置,Kruskal-Wallis检验侧重分析平均秩,Jonckheere比较同相对数。
SPSS个人笔记,顺序有点乱

9章 SPSS的多元统计分析9章 SPSS的多元统计分析1、针对变量作因子分析,R型因子分析;对样品作因子分析,Q型因子分析;2、X是可 实测的随机向量,F是因子,A是因子载荷矩阵,通过对变量的相关系数矩阵内部结构的分析,从中找出少数几个能控制原始变量的随机变量fi,以F代替X,用它再现原始变量X的信息,达到简化变量降低维数的目的;3、样品聚类——Q型聚类;变量聚类(观察指标)——R型聚类;4、马氏距离:既排除了各项指标之间相关性的干扰,而且还不受各指标量纲的影响;5、聚类中——收敛标准:如果是0.02,表示当两次迭代计算的最小的类中心的变化距离小于初始类中心距离的百分之2时,迭代停止;6、7、●Between-groups linkage:组间平均距离法。
系统默认选项。
合并两类的结果使所有的两类的平均距离最小。
●Within-groups linkage:组内平均距离法。
当两类合并为一类后,合并后的类中的所有项之间的平均距离最小。
●Nearest neighbor:最近距离法。
采用两类间最近点间的距离代表两类间的距离。
●Furthest Neighbor:最远距离法。
用两类之间最远点的距离代表两类之间的距离。
●Centroidclustering:重心法。
定义类与类之间的距离为两类中各样品的重心之间的距离。
●Median clustering:中位数法。
定义类与类之间的距离为两类中各样品的中位数之间的距离。
●Ward’s method:最小离差平方和法。
聚类中使类内各样品的离差平方和最小,类间的离差平方和尽可能大。
1、主要菜单项:data数据;transform转换;2、基本原理:a) 单项选择题的编码b) 多项选择题的编码c) 排序题的编码d) 开放式问题的编码e) 缺失值的编码f) “不适用情况”的编码g) 数据转换3、调查问卷的信度分析:可靠性和有效性的试测;分析————度量————可靠性分析:把需要分析的项目都填入“项目”中,例子中的“科学素质”+“文化素质”+“经济素质”+“道德素质”,选择模型“阿尔法a”————4、克朗巴哈信度系数,由于在0.8-0.9之间,说明问卷调查中的题目具有较强的内在一致性;5、多重响应(Multiple Response)是指对同一个问题被调查者可能有多个答案,它是调查研究中十分常见的数据形式。
SPSS学习笔记之——相关分析

SPSS学习笔记:探索相关分析方法(包括Pearson、Spearman 和卡方检验),了解如何运用这些统计工具揭示变量间的关联与独立性。
一、相关分析方法的选择及指标体系连续变量的两个相关分析1、Pearson相关系数最常用的相关系数,又称积差相关系数,取值-1到1,绝对值越大,说明相关性越强。
该系数的计算和检验为参数方法,适用条件如下:(1)两变量呈直线相关关系,如果是曲线相关可能不准确。
极端值会对结果造成较大影响。
(3)两变量符合双变量联合正态分布。
2、Spearman秩相关系数优化语序后的文本:对原始变量的分布不做要求、适用范围广泛,该方法不仅适用于等级资料,且对Pearson相关系数的应用场景有所扩展。
然而,作为非参数方法,它在检验效能上相较于基于参数的方法可能略显不足。
二:有序分类变量相关分析有序分类变量的相关性,即一致性,指的是:行变量等级高时,列变量等级亦高;反之,若行变量等级较高但列变量等级较低,则表现为不一致。
常用的统计量包括Gamma、Kendall的tau-b与tau-c。
(三)无序分类变量的相关分析最常用的为卡方检验,用于评价两个无序分类变量的相关性。
根据卡方值衍生出来的指标还有列联系数、Phi、Cramer的V、Lambda系数、不确定系数等。
OR、RR也是衡量两变量之间的相关程度的指标。
二、SPSS相关操作SPSS的相关分析散布在交叉表和相关分析两个模块中。
(1)交叉表过程如下图:以上的指标很全面,解释如下:(1)“卡方”复选框:为常用的卡方检验,适用于两个无序分类变量的检验。
相关性复选框适用于两个连续性变量的相关分析,提供两变量的Pearson及Spearman相关系数。
有序复选框组仅适用于两变量皆为有序分类变量,包含评估一致性指标。
(4)“名义”复选框组:包含一组分类变量相关性的指标,有序和无序分类时都可使用,但变量为有序时,检验效能没有“有序”复选框组中的统计量高。
SPSS学习笔记-图文

SPSS学习笔记---------------------------------------1. SPSS学习笔记之——常用统计方法的选择汇总2. SPSS学习笔记之——多因素方差分析3. SPSS学习笔记之——协方差分析4. SPSS学习笔记之——重复测量的多因素方差分析5.SPSS学习笔记之——二项Logistic回归分析6.SPSS学习笔记之——两配对样本的非参数检验(Wilcoxon符号秩检验)7.SPSS学习笔记之——两独立样本的非参数检验(Mann-Whitney U秩和检验)8.SPSS学习笔记之——多个独立样本的非参数检验(Cruskal-Wallis秩和检验)9.SPSS学习笔记之——生存分析的Cox回归模型(比例风险模型)10.SPSS学习笔记之——相关分析(Pearson、Spearman、卡方检验)11.SPSS学习笔记之——配对logistic回归分析12.SPSS学习笔记之——单样本非参数检验13.SPSS学习笔记之——ROC曲线14.SPSS学习笔记之——Kaplan-Meier生存分析15.SPSS学习笔记之——多相关样本的非参数检验(Friedman检验)16.R×C列联表(分类数据)的统计分析方法选择与SPSS实现17.SPSS学习笔记之——OR值与RR值----------------------------------------价SPSS学习笔记之——多因素方差分析问题:对小白鼠喂以三种不同的营养素,目的是了解不同营养素增重的效果。
采用随机区组设计方法,以窝别作为划分区组的特征,以消除遗传因素对体重增长的影响。
现将同品系同体重的24只小白鼠分为8个区组,每个区组3只小白鼠。
三周后体重增量结果(克)列于下表,问小白鼠经三种不同营养素喂养后所增体重有无差别?区组号营养素1营养素2营养素3150.1058.2064.50247.8048.5062.40353.1053.8058.60463.5064.2072.50571.2068.4079.30641.4045.7038.40761.9053.0051.20842.2039.8046.20SPSS软件版本:18.0中文版。
SPSS笔记

1、信度分析(指标及其降维与量表的可靠性关系,即Cronbachα系数) (2)2分析——频率分析(把握数据分布特征) (3)3、分析——探索 (4)4、P-P图 (4)5、制图 (5)附加内容:参数估计 (5)6、t检验(student t检验)——均值的差异性 (6)附加:非参数检验 (6)7、方差F检验 (6)8、单因素ANONA检验(亦是方差检验,即一维方差分析) (7)9、分析→一般线性模型→单变量 (8)10、卡方分析(Kappa)——表示观测值A t与理论值p t间的偏离程度。
(8)11、相关分析(不确定性关系分析)——方向与大小方面的关联 (9)附加:二元变量相关分析:(两个及以上变量零假设的相关性分析) (9)12、偏相关分析:(控制可能影响性变量) (10)13、回归分析基础(确定性关系的分析) (10)附加:线性回归分析(R2、F(方差)、Sig.) (10)14、主成分分析与因子分析 (15)15、因子分析 (17)16、分析→分类 (19)分类概述(非分层的) (19)附加:K-means聚类过程:(用变量来实现样品的动态分类) (20)附加:系统聚类(分层聚类) (20)两步聚类:(置信度Confidence level区别其是否有差异) (21)1、信度分析(指标及其降维与量表的可靠性关系,即Cronbachα系数)信度界定:人们在衡量某事物的某种综合特征时,往往要从影响该事物该种特征的多个方面进行分析。
例如评价某人的身体素质,就要从他的身高、胸围、脉搏、血压及肺活量等多个方面进行考虑。
由这些指标的聚集构成的表称为量表。
量表的结构是否合理,或者说所选择的指标是否全面反映对应事物的性质,以及指标取值的可信程度等等,需要作出判断。
可靠性分析就是一种对上面几个问题进行解决的方法。
基本功能:通过研究测量数值和组成研究指标的特性,剔除无效的或者对研究对象作用较小的指标,从而达到将一个多维的研究对象进行降维的目的,正是由于对分析数据进行了降维,发现了反映研究对象的数据结构,从而提高数据的可靠性。
spss自学笔记

相关性分析1.双变量目的:判定变量间相互关系的密切程度(可多个变量)一般选择:pearson, 双侧检验结果重点:相关性,显著性2.偏变量目的:控制某个变量,判定其他变量间的密切程度一般选择:双侧检验,零阶相关系数(不控制变量)结果重点:相关性,显著性3.距离分析目的:不同数据之间的相似性测试回归分析1.线性回归目的:建立线性方程式结果重点:F检验值,SIG值2.曲线回归目的:建立线性方程式结果重点:F检验值,SIG值3.二项logistic回归(只有两种定性的选择,例如,是或不是)目的:建立logistic方程一般选择:方法—》前方进入选项:拟合度结果重点:模型综合检验:sig值拟合度检验:sig值(越接近1为好)方程中的变量:得到方程公式4.多项logistic回归(多于两种分类的定性选择,例如4种消费行为)目的:建立logistic方程一般选择:进行回归预测前要对频数进行权重配比,因子—分类变量协变量—连续性变量或者称自变量模型—步进式统计量—模型拟合度信息,拟合度,似然比测试结果重点:模型拟合信息-SIG值拟合优度:SIG值(越大越好)似然比:sig判断变量是否有意义观测值和预估值对比形式:因变量没大小顺序关系,要加入频数选项(有序logistic回归就是有大小顺序关系,并且加上平行线检验,此项检验类似拟合优度检验,其他雷同)对数线性模型1.常规对数线性模型目的:验证模型拟合优度(大样本时,调整残差近似服从正态分布)一般选择:频数加权调整残差对应散点图结果重点:拟合优度理想状态下的调整残差绝对值《=2散点图(理想状态是分布在横轴两端)。
spss笔记
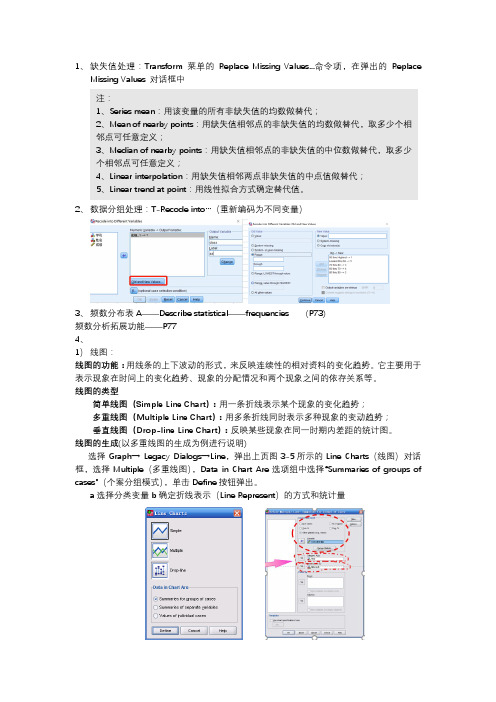
1、缺失值处理:Transform菜单的Replace Missing Values...命令项,在弹出的ReplaceMissing Values 对话框中2、数据分组处理:T-Re code into…(重新编码为不同变量)3、频数分布表A——Describe statistical——frequencies (P73)频数分析拓展功能——P774、1)线图:线图的功能:用线条的上下波动的形式,来反映连续性的相对资料的变化趋势。
它主要用于表示现象在时间上的变化趋势、现象的分配情况和两个现象之间的依存关系等。
线图的类型简单线图(Simple Line Chart):用一条折线表示某个现象的变化趋势;多重线图(Multiple Line Chart):用多条折线同时表示多种现象的变动趋势;垂直线图(Drop-line Line Chart):反映某些现象在同一时期内差距的统计图。
线图的生成(以多重线图的生成为例进行说明)选择Graph→ Legacy Dialogs→Line,弹出上页图3-5所示的Line Charts(线图)对话框,选择Multiple(多重线图),Data in Chart Are选项组中选择“Summaries of groups of cases”(个案分组模式),单击Define按钮弹出。
a选择分类变量b确定折线表示(Line Represent)的方式和统计量注:1、Series mean:用该变量的所有非缺失值的均数做替代;2、Mean of nearby points:用缺失值相邻点的非缺失值的均数做替代,取多少个相邻点可任意定义;3、Median of nearby points:用缺失值相邻点的非缺失值的中位数做替代,取多少个相邻点可任意定义;4、Linear interpolation:用缺失值相邻两点非缺失值的中点值做替代;5、Linear trend at point:用线性拟合方式确定替代值。
SPSS笔记

Chapter 2:1.名义尺度,定序尺度,,间隔尺度(定距尺度,定比尺度)2.变量类型(点型每隔三位以一个圆点分隔)3.编辑(选项)货币4.日期变量:h:hour m:minute5.字符变量:系统默认为8位,大小写不同。
6.值:变量值标签视图:值标签可显示变量值标签。
7.菜单显示工作信息查看变量。
8.编辑(转至个案)编辑(查找变量值)9.编辑(插入变量)10.数据:数据排序11.增加变量,数据(合并文件)12.数据的转置数据-转置Chapter31.基本统计分析包括报告分析和描述性统计分析两项功能。
2.样本方差用N-13.偏度(Skewness)样本的三阶中心矩与样本方差的3/2次方的比值而得,来自正太总体偏度为-4.峰度(Kutosis)是描述变量等于0是正太分布。
5.分析报告选择统计量个案汇总比较简单6.频数分析:描述性统计—频数可作图7.描述性分析标准化8.峰度和偏度的标准误只和N有关9.探索性分析分组数据M均值的四种估计方法。
界边值方便寻找极值。
正太性检验分别利用K-S检验和S-W检验;Sig代表显著性水平一般来说大于0.05则代表接受原假设;DF表示自由度,Q-Q图和Q-Q趋势图,可以查看数据是否服从正太分布。
10.研究离散变量的名义变量可以采用列联表的卡方检验步骤:描述性统计交叉表列变量必须是数值型或者字符型等分类变量卡方检验:皮尔逊卡方检验常用在二维表中对行变量和列变量进行独立性假设显著性水平小雨0.05则拒绝原假设相关似然比卡方检验(Linear-by-linear)可以用于对数线形模型的检验其它两种见书P87相关性-1 . 0 .1相依系数不可能达到1Phi and Cramer’s v 也是用来刻画相关性Lambda 1表示自变量完全预测因变量系数为0时,预测完全没有效果不定性系数表示用一个变量来预测其它变量时降低错误的比率。
Kappa 两个评估人对同一对象的评估是否有一致性。
spss精选整理笔记

1、spss的三种输出结果: 表格格式格式文本格式标准图与交互图2、变量名的定义与保留字不同,同时变量名不能一数字开头。
变量名不能与spss保留字相同,spss的保留字有ALL、END、BY、EQ、GE、GT、LE、LT、NE、NOT、OR、TO、WITH。
3、字符型:字符型数据的默认显示宽度为8个字符位,系统不区分变量名中的大小写字母,并且不能进行数学运算。
注意:在输入数据时不应输入引号,否则双引号将会作为字符型数据的一部分。
4、(1)定类尺度(Nominal Measurement):定类尺度是对事物的类别或属性的一种测度,按照事物的某种属性对其进行分类或分组。
离散型特点:其值仅代表了事物的类别和属性,即能测度类别差异,不能比较各类之间的大小,所以各类之间没有顺序和等级。
对定类尺度的变量只能计算频数和频率。
在spss中,能适用定类尺度的数据可以是数值型,也可以是字符型变量。
使用定类变量对事物进行分类时,必须符合穷尽原则和互斥原则。
(2)定序尺度(Ordinal Measurement):定序尺度是对事物之间的等级或顺序差别的一种测度,可比较优劣或排序。
离散型特点:由于定序变量只能侧度类别之间的顺序,无法测出类别之间的准确差值,即测量数值不代表绝对的数量大小,所以其测量结果只能排序,不能进行运算。
(3)定矩尺度(Interval Measurement):定矩尺度是对事物类别或次序之间间距的测度。
特点:不仅能将事物区分为不同类型并进行排序,而且可能准确指出类别之间的差距是多少;定矩变量通常以自然或物理单位为计量尺度,因此测量结果往往表现为数值,所以计量结果可以进行加减运算。
(4)定比尺度(Scale Measurement):定比尺度是能够测算两个测度值之间比值的一种计量尺度,它的测量结果同定距变量一样表现为数值。
特点:定比变量是测量尺度的最高水平,它除了具有其他三种测量尺度的全部特点外,还具有可计算两个测度之间比值的特点,因此它可以进行加、减、乘、除运算,而定矩变量值可进行加减运算。
spss学期笔记总结

学期笔记总结一、基本掌握1.研究要注意的问题2.题目的输入编码(各种题型的输入方法)3.数据的筛选:Data--select casesA.simple size(百分比和个数)B.If条件(复杂条件的筛选)4.简单编码5.新变量的产生:transform--compute--variable6.重新编码:transform--recode into different variable7.数据合并:Data--Merge files--1.Add Cases纵向合并(样本量增加) (注意ID码的重要性) 2.Add Variables横向合并(变量增加)二、描述统计(Analyze)类型:频率分析,描述分析,相关分析,图标分析,交叉分析等等1.连续变量统计:均值,标准差,众数,中数,平均数A.频率:Analyze--Descriptive statistics--123 FrequencyB.交叉分析:Analyze--Descriptive statistics--crosstabsC.多变量交叉分析--加层Analyze--Descriptive statistics--crosstabs(next加层)D.连续变量分析的数据分组Analyze--Descriptive statistics--123 Frequency--statisticsa.等分点:cut point for __equal groupsb.百分比:percentileC.重新编码和数据分组的综合运用2.多选题选项的分析:Analyze--multiple response--frequencies三、推断统计(Analyze)A.包括参数估计和假设估计B.用样本统计量推断(估计)总体参数采用标准误C.假设检验检验组间差异检验组内差异检验变量之间的关系1.单样本T检验:Analyze--Compare means--One sample T test一组数据和平均数进行比较(平均数自己输,可以设置置信度)结果:采用单样本T检验,结果发现T=5.63(p<.05)。
spss复习资料整理1

spss复习资料整理1第⼀章1.SPSS是软件英⽂名称的⾸字母缩写,其最初为Statistical Package for the Social Sciences的缩写,即“社会科学统计软件包”。
2.SPSS系统运⾏管理⽅式(SPSS的⼏种基本运⾏⽅式)有:(1)完全窗⼝菜单运⾏⽅式(2)程序运⾏管理⽅式(3)混合运⾏管理⽅式3.SPSS的界⾯提供的五个窗⼝:数据编辑窗⼝、结果管理窗⼝、结果编辑窗⼝、语法编辑窗⼝、脚本窗⼝。
第⼆章1.SPSS的⽂件类型:语法⽂件(*.sps)、数据⽂件(*.sav)、结果输出⽂件(*.spv)。
2.SPSS数据编辑器的每⼀⾏数据称为⼀个个案(Case),每⼀个数据代表个体的属性,即变量(V ariable)。
3.SPSS变量名的命名规则:1)必须以英⽂字母开头,其他部分可以含有字母、数字、下划线(即“-”);2)变量名尽量避免和SPSS已有的关键字重复,例如sum、compute、anova等;3)SPSS13及以后版本⽀持变量名最长为64Byte,即变量名最长为64个英⽂字符,或者32个中⽂字符;4)SPSS变量名不区分⼤⼩写,即SPSS认为Name、name、nAme这三个变量名没有区别。
4.变量度量类型:定量(个数、⾼度、温度等)、定序(“⼗分重要”、“重要”、“⼀般”、“不重要”)、定类(名字、地址、电话等)。
5.列和宽度的区别:变量宽度:对字符型变量,该数值决定了你能输⼊的字符串的长度;列:设定该变量数据视图中列的宽度。
6.变量的值标签:即对数值含义的解释。
例如:值标签1 2 男⼥7.默认的缺失值类型:数值型类型(.)、字符串类型(空格)。
8.数据⽂件的合并包括:纵向合并和横向合并(合并个案和合并变量),合并变量包括⼀对⼀合并和⼀对多合并。
9.SPSS⽤“(*)”表⽰变量来⾃于当前活动数据⽂件中的变量,⽽⽤“(+)”表⽰将要和当前数据⽂件进⾏合并的数据⽂件中的变量。
spss笔记

SPSS理论知识1、抽样要具体(小)online survey2、问卷●Quantitative study定性研究●Qualititative study定量研究(一)关于统计的适度应用问题1、定量研究一个好的定量研究,一般用推断统计来做。
推断统计至少要有t检验、卡方检验,方差分析、回归检验。
***《心理评定量表手册》:从中选取一个量表,再自己加一个小量表EFA(详细步骤见(一))CFA要做定量研究,问卷来源有两个。
问卷研究可以是自拟,也可以选择一个具有良好信度效度的问卷,自拟的问卷测量信度和效度比较难(也不是不可用),因此最好是选择一个良好信度效度的问卷。
2、定性研究访谈(难度一般较大,在做时,需要一定是学科背景、访谈经验以及一定的编制方法)。
3、混合研究定性研究与定量研究相结合(量表做完后,在最后选择其中的几个被试,进行访谈)。
4、描述统计(descriptive statistic)、推断统计(inferential statistic)5、全国比较著名的期刊SCI(《课程与教材教法》、《教育研究》、《教师教育研究》、《北大教育评论》、《清华大学教育研究》)6、问卷的忌讳(常见量表的选择)(1)切记网上选择(2)最好不要自制问卷(3)最好应用一个现成的问卷,再进行访谈辅助(4)两个问卷同时应用也可以7、老师推荐书目:《常用心理测评量表手册》《心理评定量表手册》《量化研究与统计分析》(是关于EFA的书本)8、数据做出来以后,数据应该如何分析和规范表述,有以下推荐书目:《量化研究与统计分析》重庆大学出版社《统计分析从零开始》清华大学出版社9、教育写作中常用的统计方法:T TESTANOV AREGRESSIONEFA10、混合研究在实证研究中,定量研究、定性研究和混合研究是经常用到的三种方法。
一般来说,一个严格的定量研究,应该是以较好信效度的问卷为基础,对问卷中的某些维度进行推断统计分析。
在心理学上,有时也用两个问卷或三个问卷,一起进行调查,然后看他们的相关性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1、spss的三种输出结果: 表格格式格式文本格式标准图与交互图2、变量名的定义与保留字不同,同时变量名不能一数字开头。
变量名不能与spss保留字相同,spss的保留字有ALL、END、BY、EQ、GE、GT、LE、LT、NE、NOT、OR、TO、WITH。
3、字符型:字符型数据的默认显示宽度为8个字符位,系统不区分变量名中的大小写字母,并且不能进行数学运算。
注意:在输入数据时不应输入引号,否则双引号将会作为字符型数据的一部分。
4、(1)定类尺度(Nominal Measurement):定类尺度是对事物的类别或属性的一种测度,按照事物的某种属性对其进行分类或分组。
离散型特点:其值仅代表了事物的类别和属性,即能测度类别差异,不能比较各类之间的大小,所以各类之间没有顺序和等级。
对定类尺度的变量只能计算频数和频率。
在spss中,能适用定类尺度的数据可以是数值型,也可以是字符型变量。
使用定类变量对事物进行分类时,必须符合穷尽原则和互斥原则。
(2)定序尺度(Ordinal Measurement):定序尺度是对事物之间的等级或顺序差别的一种测度,可比较优劣或排序。
离散型特点:由于定序变量只能侧度类别之间的顺序,无法测出类别之间的准确差值,即测量数值不代表绝对的数量大小,所以其测量结果只能排序,不能进行运算。
(3)定矩尺度(Interval Measurement):定矩尺度是对事物类别或次序之间间距的测度。
特点:不仅能将事物区分为不同类型并进行排序,而且可能准确指出类别之间的差距是多少;定矩变量通常以自然或物理单位为计量尺度,因此测量结果往往表现为数值,所以计量结果可以进行加减运算。
(4)定比尺度(Scale Measurement):定比尺度是能够测算两个测度值之间比值的一种计量尺度,它的测量结果同定距变量一样表现为数值。
特点:定比变量是测量尺度的最高水平,它除了具有其他三种测量尺度的全部特点外,还具有可计算两个测度之间比值的特点,因此它可以进行加、减、乘、除运算,而定矩变量值可进行加减运算。
定类、定序、定距、定比变量的比较适用的运算形式=、‡›、‹+、- X、∕变量层次定类变量√定序变量√√定距变量√√√定比变量√√√√5、对变量进行操作的内容主要集中于Transform菜单中,包括新变量的生成、记录的排序、对变量进行计数等。
1)计算新变量:Compute用于给变量赋值,其特点如下:目标变量可以是新变量,也可以是已有的变量。
赋给变量的值可以是一个常数,也可以是从已有变量值或系统函数计算而来的值操作记录集可以是所有记录,也可以设定逻辑条件,只对满足条件记录加以赋值。
其余纪录的相应变量或保持原状,或被赋于缺失值。
2)变量转换:Recode——recode into different variables 在SPSS中可以将连续变量转换为离散(等级或定序)变量,按照某种一一对应的关系生成新变量值,可以将新值赋给原变量。
注意所有的范围都是包含了端点的,而前面设定的变换会优于后面的变换。
Recode过程也常用于合并某个分类变量的几个水平为一个水平3) Categorize variable用于将连续性变量自动按要求公成等间距的几组4) count过程如果用户需要对满足某项条件的数据进行计数,可以使用Count命令。
先在Target Variable中指定一个变量(可以是已经存在的变量或新变量),并定义变量标签,然后指定要统计的变量加到Numeric Variables框中,再单击Define Values按纽,打开Value to Count对话框。
Value:输入某个值为清点对象;System-missing:以系统的缺失值为清点对象;System-or user missing:以系统或用户指定的缺失值为清点对象;Range:指定数值的计数区域:其中包括:()through()在框内指定下限和上限lowest through(): 在框内只指定上限;()highest through: 在框内只指定下限。
5) 在数据表格的变量名处单击右键,弹出的右键菜单最后两项就是“sort Ascending”和“Sort Descending”。
对于多变量排序,则需要使用Sort Cases过程来进行多变量排序需要注意的三点:1)在多重排序中,制定排序变量名是很关键的,先指定的变量在排序时必然优先于后制订的变量。
2)可以指定按某变量值升序排序的同时按另一变量值降序排序,或相反。
3)排序以后,原来记录数据的排列次序将被打乱。
6) Split File 分割文件的功能是把当前工作分割成两个或两个以上的组,随后的分析将对每个组进行。
7) Select Cases:当用户不需要分析全部的数据,而是按要求分析其中的一部分,使用该选择。
All case:选择所有数据;If condition is satisfied: 按指定条件选择数据。
8) 所谓分类汇总就是按指定的分类变量对观测值进行分组,对每组记录的各变量求指定的描述统计量,结果可以存入新数据文件,也可以替换当前数据文件。
在左侧的源变量框中选择一个或多个变量作为分类变量进入分类变量(Break Variable[s])框中,在左侧的源变量框中选择一个或多个变量作为要求汇总的变量进入汇总变量(Aggregate Variable[s])框中,即要求这些变量的值进行分类汇总。
“name& label”(名称与标签):单击此按钮可以修改组合后所生成新变量名称以及标签:可以在name后面的矩形框中输入新变量名。
在Label后面的矩形框中输入新变量标签。
单击“continue”按钮继续。
、“Function”(函数)选择此项可以确定汇总变量的描述内容;系统默认函数为平均数。
6、纵向合并实质就是将两个数据文件的变量列,按照各个变量名的含义,一一对应的进行首尾相接。
Merge files——add cases纵向合并必须遵循两个条件:spss数据文件,其内容合并是有实际意义的。
spss数据文件的合并,在不同的数据文件中,最好起相同的名字,变量类型和变量长度也要尽量相同。
Unpaired variable:不匹配变量栏。
指变量名相同而变量定义不同的变量,或变量名不同的变量。
Variable in new working data:新工作数据变量栏。
Indicate case source as variable:指示记录来源的变量选项/7、横向合并的实质是将两个数据文件的记录,按照记录对应,一一进行左右对接。
横向合并遵循三个条件:merge files ——add variables数据文件必须至少有一个变量名相同的公共变量,这个变量是两个数据文件横向合并的依据,成为关键变量。
文件都必须事先按关键变量进行升序排列。
SPSS文件的合并,在不同的数据文件中,数据含义不相同的列,变量名不应取相同的名称。
Excluded Variables:拒绝变量名。
外部文件与当前数据的同变量,拒绝加到新工作区中。
New Working Data:新工作数据变量栏。
Match Case on Key Variable in sort:排序文件中按关键变量匹配记录选项。
Both files provide case:由外部文件和当前数据量两者提供记录。
External file is keyed table:外部文件为关键表,以当前数据为基准,外部文件匹配当前数据的关键变量值,如匹配成功,外部文件的新变量值加入到当前数据的新变量中,匹配不成功则不加入。
Working Data File is keyed table:当前数据为关键表。
Key Variables:关键变量栏,在拒绝变量选择某变量作为关键变量。
Indicate case source as variable:指示记录来源的变量选项。
8、集中趋势(Central Trend):均数(Mean)中位数(Median)众数(Mode)总合(Sum)离散趋势(Dispersion Trend):标准差(Std. Deviation)、方差(Variance)、全距(Range)最小值(Minimum)、最大值(Maximum)、标准误(S.E. Mean)分布特征(Distribution Tendency):偏度系数(Skewness)和峰度系数(Kurtosis)其他趋势:百分位数指标(Percentile)、极端值(Outlier)。
所用到的统计图则有:条图、饼图、直方图、箱式图、QQ图(用于判断正态性的)9、Spss的用于连续变量统计描述的过程,均集中在Descriptive Statistics子菜单中。
1)Frequencies:产生原始数据的频数表,并能计算各种百分位数。
对分类资料和定量资料都适用。
2)Descriptive,该过程用于一般性的统计描述,相对于Frequencies过程而言,它不能绘制统计图。
3)Explore,该过程用于对连续性资料分布状况不清楚时的探索性分析,它可以计算许多描述统计量,给出各种统计图,并进行简单的参数估计。
4)Ratio,用于对两个连续性变量计算相对比指标,当研究者关心A、B两个指标比值的变动情况时,该过程非常有用。
10、Chi-Square过程其分析目的是检验分类数据样本所在总体分布(各类别所占比例)是否与已知总体分布相同,是一个单样本检验。
11、分类变量的联合描述当一共有两个分类变量时,汇总因分类变量的各类别交叉而成的复合频数表被称为行*列表,也称列联表。
12、Crosstabs 过程既包括强大的描述功能,又提供了非常有力而实用的统计推断能力。
Crosstabs 过程不能产生一维频数表(单变量频数表),该功能由Frequencies过程实现。
AnalyzeDescriptive Statistics Crosstabs,如果是二维列联表分析,可以将行变量选择进入Row(s)中,将列变量选择进入Column(s)框中分类资料数据录入格式:具体的个体取值而已。
Weight Cases过程指定频数变量。
13、多选题的统计描述,多重二分法(multiple dichotomy method),多重分类法(multiple category method)多选题的描述指标体系在多选题分析中比较特别的描述指标有:(1)应答人数:是指选择了本项人数。
(2)应答人数百分比(Percent of Cases):选择该项的人占总人数的比例。
(3)应答人次:选择本选项的人次。
(4)应答次数百分比(Percent of Responses):在作出的选择中,选择该项的人数占总次数的比例。