SPSS数据整理及t检验
SPSS数据处理小结:T检验、相关、二分类、散点图、箱图
!!立立。
接下来我们看一一下这一一组数据:NLR和HbA1c的相关性
! 图2-‐4
(ps:SPSS中有11种曲线可以选择,我会简单概述一一下在不用用直线作图
!时,怎样选择曲线)
!例子子:为了研究糖化血血红蛋白白上升时,NLR的上升趋势,试做直线拟合。
1.打开数据库“.sav”文文件
2.分析→回归→曲线估计
!
!图!!!!!!!!!! 3-‐1
首首先r=0.509,说明他们的相关是很密切的,而而p<0.001,说明相关是成立立 的。然后在“.509”右上角角现在是有两个*号,说明是显著相关的,假如说是一一
!!!!!个*号,说明只是p值小小于0.05,相关成立立,但是没有0.000显著。
!
!三. 回归分析(regression)
!(一一).曲线估计(curve estimation)
我们在刚刚的相关性中,做出了NLR和糖化血血红蛋白白是明显相关的,相关系
数是0.509,p是小小于0.001的,但是假如说在一一个图上,它又是怎样表现出
来的呢?所以我们现在就来学习一一下,如何用用曲线方方程描述糖化血血红蛋白白和
NLR的关系。
!!0.001)
假如你的分组有三个或者更多个,那么你就要做单方方向方方差分析(one-‐way ANOVA) 因为过程大大概和t检验类似,我就只简叙述一一下: 1.分析→均数比比较→单向方方差分析 2.把需要比比较均值的变量放到上面面因变量表列中,在下面面“因子子”中添加分组 (PS:可能很多同学在分组上会遇到困难,简单介绍一一下吧,你在需要分组 的那一一列数据的旁边插入入一一列数据,在插入入的新的数据中把所需要分组的数 据分别标上1,2,3……组) 3.然后在选项中选择“描述性”然后点击继续,然后点击主面面板的确定导出数 据。 4.数据的p值读取方方法和独立立样本t检验差不多的
使用SPSS做t检验和方差分析

4
2 两独立样本的t检验
P(Sig.)值的意义: 通常我们在计算出t的值后,通过查表得tα(n-1),然后比较t和tα(n1) 决定接受H0还是拒绝H0.
这里假设检验的判断采取另外一种形式:即直接计算检验统计量样本 实现的临界概率P值(也称为检验的P值)。 P值的含义:利用样本实现能够做出拒绝原假设的最小显著水平。 利用临界P值下结论:若P≤α,则拒绝H0;若P>α,则接受H0。P 的计算是复杂的,因为这将会设计抽样分布。现在的统计软件都有 此功能,可以直接比较。
Levene's Test for Equality of Variances
血磷值
Equal variances assumed
Equal variances not assumed
F .038
Sig. .847
Independent Samples Test
t 2.539
2.540
t-test for Equality of Means
3
1 单样本的t检验
One-Sample Statistics
结果:假设H0,样本总体均数=100
打包 的质量
N 9
Mean Std. Deviation
99.978
1.2122
Std. Error M ea n .4041
从左到右依次为t值,自由度(df), P值(Sig.2-tailed), 两均值误差(Mean Difference)、差值95%置信区间
2
1 单样本的t检验
例:某工厂用自动打包机打包,每包标准质量为100kg。 为了保证生产出的正常运行,每天开工后需要先行试 机,检查打包机是否有系统偏差,以便及时调整。某 日开工后在试机中共打了9个包,测得9包质量(kg)为 :99.3, 98.7, 100.5, 101.2, 98.3, 99.7, 99.5, 102.1,100.5。现在需要做出判断,今天的打包机是否 需要作出调整? 假设H0:μ=100; H1: μ≠100
SPSS简明教程(X2检验和T检验)

S P S S简明教程(X2检验和T检验)-CAL-FENGHAI.-(YICAI)-Company One1SPSS最适用的统计学方法(X2检验和T检验)1.SPSS的启动(1)在windows[开始]→[程序]→[spss20],进入SPSS for Windows对话框,2.创建一个数据文件三个步骤:(1)选择菜单【文件】→【新建】→【数据】新建一个数据文件。
(2)单击左下角【变量视窗】标签进入变量视图界面,定义每个变量类型。
(3)单击【数据视窗】标签进入数据视窗界面,录入数据库单元格内。
3.读取外部数据当前版本的SPSS可以很容易地读取Excel数据,步骤如下:(1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话框,在文件类型下拉列表中选择数据文件,如图所示。
图 Open File对话框(2)选择要打开的Excel文件,单击“打开”按钮,调出打开Excel数据源对话框,如图所示。
对话框中各选项的意义如下:工作表下拉列表:选择被读取数据所在的Excel工作表。
范围输入框:用于限制被读取数据在Excel工作表中的位置。
图 Open Excel Data Source对话框4.数据编辑在SPSS中,对数据进行基本编辑操作的功能集中在Edit和Data菜单中。
5.SPSS数据的保存SPSS数据录入并编辑整理完成以后应及时保存,以防数据丢失。
保存数据文件可以通过【文件】→【保存】或者【文件】→【另存为】菜单方式来执行。
在数据保存对话框(如图所示)中根据不同要求进行SPSS数据保存。
图 SPSS数据的保存5. 数据分析在SPSS中,数据整理的功能主要集中在【数据】和【分析】两个主菜单下6.语言切换:编辑(E)—选项(N)--用户界面-语言--简体中文第六章:描述性统计分析(X2检验)完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。
6.1.1界面说明界面如下所示:分析—描述统计—频率用于定义需要计算的其他描述统计量。
SPSS数据的整理与分析
数据的整理与分析chy一、数据收集-问卷星1、检查与剔除不合格问卷,比如答题时间太短、年龄不符合、问卷填写不完整等。
2、应答率/回收率:是指定的或者抽中的需要作答的对象中,最终完成作答的百分比。
3、合格率:合格数量/作答数量。
4、一般的,访问问卷的回收率最高,回收率一般要求在90%以上;邮寄问卷的回收率低,回收率在50%左右就可以了;发送式自填问卷的回收率一般,回收率要求在67%以上。
5、如果不高尽量不要写入,反而起反作用。
6、可以运用问卷星中的图与表描述,直观描述。
二、数据整理-Excel1、结果导出方式:文本、数字、分数,保存excel原版。
2、再另存一版你用于SPSS分析的表格。
3、注意反向计分的题目。
4、如果量表分为几个维度,可以单独列出来进行分析。
(如我发到群里的表格,可以用总分与其他条目分析,也可以用这个量表包括的几个维度分别与其他条目分析,观察其关联)。
5、如果分不清楚,可以标注一下变量的类型,如分类变量还是数据变量(如我的Excel的第二行,但是导入到SPSS中时需要删除)。
三、数据录入-SPSSSPSS中“变量视图”输入各变量如下:1、“类型”尽量都转换为“数字”;(选中右边的…)(点击“数字”即可)3、“值”的标记:(用于计数资料的标记,在结果中易于观察)点击…,分别输入对应的值和代表的标签,点击“添加”和确定即可4、“测量”分为三类:(1)标度:指计数资料,如年龄、108总分等;(2)有序:指等级资料,如年级等;(3)名义:指计数资料,如性别、性格等。
5、如何把计数资料转换为计量资料,即赋值(以“拖延总分为例”)步骤:(注意填写名称和标签,点击“变化量”) ----点击“旧值和新值”进行赋值:0-20赋值为1:--添加--20.1-40赋值为2:--添加--40.1-60赋值为3:--添加--然后“变量视图”最后一行就会出现新的变量“拖延分数三分类”,可以把“名义”改为“有序”,也可不改。
Spss实验总结

本学期一共学习了七项spss使用方法,分别是数据整理、数据的转换、t检验、方差分析、卡方检验、相关分析与回归方程、图表的制作与编辑。
我觉得spss对我用处非常大,就平时学习来说,我用它计算了几道生物统计题,完成了spss作业和数学建模作业。
因为实验指导书有几个实验实验方法与步骤很不详细,我还练习了写实验方法与步骤,但在写实验感受方面还有所欠缺。
统计学是一门研究随机事件的学科,这类偶然现象是遵循统计规律的,当随机现象是由大量的成份组成,或者随机现象出现大量的次数时,就能体现统计平均规律。
我们只有对数据资料作统计处理,才可能发现它们的内在规律,掌握现象的特征,检验研究的假设,才能得出准确的、可靠的研究结果。
每次实验我开始时都觉得很难,很多时候是因为不知道怎么做表格,比如做卡方检验的时候要交叉值表,一开始我都一直是认为应该把不同因素和不同水平放到不同列里,之后才发现同一因素要写在同一列里,然后在另一列里些他们的水平,这样就会被自动分开。
相关分析我到现在还有一点不明白。
相关分析和回归方程里的那几道题那些应该用相关分析做,那些应该用回归方程做,当然这是统计学方面的问题了。
我以后还要加强对实验结果的解读能力,spss给出的计算结果往往有双侧sig.值等,而我还不太会查表(有个别不清楚查那个表),所以一些题目没有写最终分析。
Spss作为一个工具,本身并无太多原理可言,主要是掌握它的使用方法。
数据输入主要是分为数据列表和变量列表。
和excel最不一样的是变量列表。
变量列表可以对变量名,变量类型作出规定。
而这些尤其是变量类型对后续的统计分析工作有很大影响。
数据整理很重要的一点是排序。
Spss可以先按一个变量排,再在此基础上按另一个变量排。
这是我以前不了解的一个功能。
1.在数据文件中单击菜单项“Data→Sort Cases”,在变量列表中选定按哪(几)个变量的值排序,并用箭头按钮将其移入Sort by矩形框中,单击按纽即会对数据文件中的case进行排序。
第八章 t检验与SPSS(发)

▲ t 统计量: t= | x1 − x 2 |
S x1 − x 2
Sx1 − x2 =
Sc2
(
1 n1
+
1) n2
Sc2
=
S12 (n1 − 1) + S22 (n2 n1 + n2 − 2
− 1)
自由度 = n1+n2 – 2
▲ 适用条件:
(1)已知/可计算两个样本均数及它们的标准差 ;
(2)两个样本之一的例数少于100;
12名儿童分别用两种结核菌素的皮肤浸润反应结果(mm)
编号 1 2 3
标准品 12.0 14.5 15.5
新制品 10.0 10.0 12.5
差值d 2.0 4.5 3.0
4 5 6 7 8 9 10 11 12 合计
12.0 13.0 12.0 10.5
7.5 9.0 15.0 13.0 10.5
pare Means- One sample t test
3.test variable(s):d 4.test Value:0
5.OK
与总体均数 为0作比较
结果:
Sig.(2-tailed): 双侧的P值
第三节 两样本均数的比较
◆两样本均数比较的t检验 ◆两样本几何均数比较的t检验
两独立样本t检验(independent sample t test)
⑤. 统计结果与结论:因为p < 0.05,故拒绝检验假 设H0,接受H1,可认为两种方法皮肤浸润反应结果 的差别有统计学意义。
SPSS实现
配对资料数据格式
配对资料的操作模块
3
Pair 标准品
1
新制品
Paired Samples Statistics
SPSS统计分析第四章均值比较与T检验

N 258 216
Mean $41441.8 $26031.9
Std. Dev iation $19,499.214 $7,558.021
Std. Error Mean $1213.97
$514.258
左第一栏为分析变量标签和分类变量标签 N观测量数目 Mean均值 Std. Deviation标准差 Std. Error Mean标准误
三、配对样本T检验
配对样本T检验(Paired Sample T test)用 于检验两个相关的样本是否来自具有相同均 值的总体。这种相关的或配对的样本常常来 自这样的实验结果,在实验中被观测对象在 实验前后均被观测。两个变量可以是before after,配对分析的测度也不是必须来自同一 个观测对象。一对可以两者组合而成。
练习题
已知某水样中含CaCO3的真值为20.7mg/L, 现用某方法重复测定该水样11次CaCO3的含 量(mg/L)为:20.99,20.41,20.10, 20.00,20.91,22.60,20.99,20.41, 20.00,23.00,22.00。问该方法测得的均值 是否偏高?
2、Independent Sample T test(独立样本T检验)
例题一
现有银行雇员工资为例,检验男女雇员现工 资是否有显著差异。一个是要比较salary变量 的均值,另一个是gender变量作为分水平变 量。 (data09--03) 。
分析变量的简单描述性统计量
Gender Current Salary Male
F emale
Group Statistics
如果你试图比较的变量明显不是正态分布的,则应该 考虑使用一种非参数检验过程(Nonparametric test)。 如果想比较的变量是分类变量,应该使用Crosstabs 功能。
SPSS-t检验

数据输入
1)启动SPSS,进入定义变量工作表,分别命名 两变量:组别、鱼产量。其中组别1表示A料,组 别2表示B料。
2)进入数据视图工作表,输入数据
统计பைடு நூலகம்析
Analyze---compare mean----indendent samples T test
Test variable(输入):产鱼量
2、选择检验方法和计算检验统计量 因为总体标准差σ未知,所以采用t检验。 Analyze →Compare Means→One-Sample T Test出现如下对话框:
•把x移入到Test Variable(s) 的变量列表; •在Test Value后输入需要 比较的总体均数20; •OK
3、根据检验统计量的结果做出统计推断 基本统计量信息:
T检验
(一)单个总体均数的t检验 (二)独立样本成组t检验 (三)成对样本t检验
(一)单个总体均数的t检验
计算公式
样本平均数与总体平均数差异显著性检验
例:成虾的平均体重为21克,在配合饲料中添加 0.5%的酵母培养物饲养成虾时,随机抽取16只对 虾,体重为20.1、21.6、22.2、23.1、20.7、19.9、 21.3、21.4、22.6、22.3、20.9、21.7、22.8、 21.7、21.3、20.7。试检验添加添加0.5%的酵母 培养物是否提高了成虾体重。
从结果中可以看出,统计量t=3.056,P=0.012<α=0.05,因此拒 绝H0,接收H1,即用该方法测量所得结果与标准浓度值有所不 同。认为该方法测量结果所对应总体均数μ与标准浓度μ0间的差 异有统计学意义。
(二)独立样本成组t检验
独立样本:又称非配对样本或成组样本。是指一组数据与另一 组数据没有任何关系,也就是说,两样本资料是相互独立的。 两组的样本容量尽可能相同,可以提高检验的精确度。其均 数差异显著性的t检验,又分为两总体方差相等(方差齐性)和 方差不等两种检验方法。
spss均值检验(均数分析单样本t检验独立样本t检验)

在统计学中,我们往往从样本的特性推知随机变量总体的特性。
但由于总体中个体之间存在差异,样本的统计量和总体的参数之间往往会有误差。
因此,均值不相等的样本未必来自不同分布的总体,而均值相等的样本未必来自有相同分布的总体。
也就是说,如何从样本均值的差异推知总体的差异,这就是均值比较的内容。
SPSS提供了均值比较过程,在主菜单栏单击“Analyze”菜单下的“Compare Means”项,该项下有5个过程,如图4-1。
平均数比较Means过程用于统计分组变量的的基本统计量。
这些基本统计量包括:均值(Mean)、标准差(Standard Deviation)、观察量数目(Number of Cases)、方差(Variance)。
Means过程还可以列出方差表和线性检验结果。
[例子]调查了棉铃虫百株卵量在暴雨前后的数量变化,统计暴雨前和暴雨后的统计量,其数据如下:暴雨前 110 115 133 133 128 108 110 110 140 104 160 120 120暴雨后 90 116 101 131 110 88 92 104 126 86 114 88 112该数据保存在“DATA4-1.SAV”文件中。
1)准备分析数据在数据编辑窗口输入分析的数据,如图4-2所示。
或者打开需要分析的数据文件“DATA4-1.SAV”。
图4-2 数据窗口2)启动分析过程在SPSS主菜单中依次选择“Analyze→Compare Means→Means”。
出现对话框如图4-3。
图4-3 Means设置窗口3)设置分析变量从左边的变量列表中选中“百株卵量”变量后,点击变量选择右拉按钮,该变量就进入到因子变量列表“Dependent List:”框里,用户可以从左边变量列表里选择一个或多个变量进行统计。
从左边的变量列表中选中“调查时候”变量,点击“Independent List”框左边的右拉按钮,该变量就进入分组变量“IndependentList”框里,用户可以从左边变量列表里选择一个或多个分组变量。
SPSS对数据进行T检验统计分析

SPSS对数据进行T检验统计分析下面将做此项目的最后一个环节,即使用SPSS进行统计分析。
先用SPSS来做组设计两样本均数比较的T检验,其步骤如下。
(1)执行Analyze/Compare Means/Independent-Samples T test命令,打开如图1-43所示的对话框。
(2)在该对话框中选择X放入TEST列表框中,选择Group放入Grouping Variable文本框中,如图1-44所示。
图1-43 打开T检验对话框图1-44 选择入列表(3)单击Define Groups按钮,系统弹出比较组定义对话框,如图1-45所示。
(4)在该对话框中的两个值框中分别输入1和2,然后单击Continue按钮,如图1-46所示。
图1-45 比较组定义对话框图1-46 输入值(5)单击T检验对话框中的OK按钮,如图1-47所示。
图1-47 进行T检验(6)系统经过计算后,会弹出结果浏览窗口。
首先给出的是两组的基本情况描述,如样本量、均数等,然后是T检验的结果,如图1-48所示。
图1-48 T检验结果从上图中可见,结果分为两大部分:第一部分为Levene's方差检验,用于判断两体方差是否齐,这里的检验结果为F=0.032,p=0.860,可见在本例中方差齐;第二部分则分别给出两组所在部体方差齐和方差不齐时的T检验结果,即上面一行列出的T=2.542,V=22,p=0.019。
从而最终的统计结论为按=0.05水准,拒绝H0,认为克山病患者与健康人的血磷值是不同的。
从样本均数来看,可以确定克山病患者的血磷值较高。
《证券理论与实务》模块八考试精要(证券市场基础知识)模块八考试精要一、单项选择题1、涉及证券市场的法律、法规第一个层次是指()。
A、法律B、行政法规C、厂纪厂规D、部门规章2、涉及证券市场的法律、法规第二个层次是指()。
A、法律B、行政法规C、厂纪厂规D、部门规章3、涉及证券市场的法律、法规第三个层次是指()。
SPSS数据处理小结:T检验、相关、二分类、散点图、箱图
!!!!图1-‐12 !! 图1-‐13
!二二.相关性
!(一一).双变量相关分析(Bivariate)
!当分析两个变量之间是否存在相关关系时,使用用双变量相关分析。
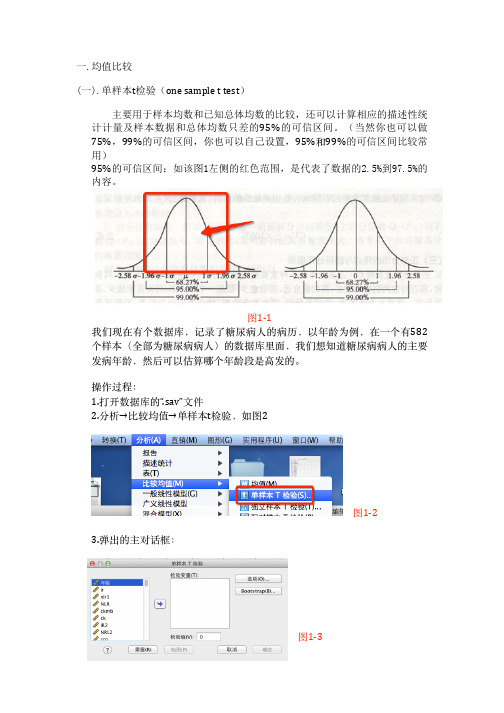
这个结果就是r=0.022,p等于0.603. 要在r大大于0.5的情况下,表示示两组的关系密切;而而p值要小小于0.05相关才成
!!立立。
接下来我们看一一下这一一组数据:NLR和HbA1c的相关性
! 图2-‐4
首首先r=0.509,说明他们的相关是很密切的,而而p<0.001,说明相关是成立立 的。然后在“.509”右上角角现在是有两个*号,说明是显著相关的,假如说是一一
!!!!!个*号,说明只是p值小小于0.05,相关成立立,但是没有0.000显著。
!
!三. 回归分析(regression)
! 图1-‐8 图1-‐9
!!!!!!!
!图1-‐2
3.弹出的主对话框:
!!!!!!!
图1-‐3
!
4.如果你想设置99的可信区间就去“选项里里面面设置”,系统默认95%的可信区
间。
5!!!!!!!!!!!!!!.接着就是开始做数据了:
!
图1-‐4
6.得到结果:
图1-‐5 首首 先 我 们 在 图 5 中 可 以 看 到 样 本 数 目目 是 N = 5 8 2 个 , 均 数 ± 标 准 差 是 62.69±9.669。 (PS:高高中统计学知识忘记了的我就不再这里里意义赘述了,自自行行补脑吧) 下面面的那个t我不是很了解是什么意思,一一般的文文章里里面面也没有用用到。重要 的是Sig.(双侧)值,就是在常在文文献中看到的p value,它要小小于0.05才是 有意义的。而而后面面的“差分的95%置信区间”的上下限,只要均值差值在可信 区间里里面面,并且置信区间没有包含0,就说明样本均数和总体均数的差异是
SPSS:数据分析3、T检验(TTest)方差分析(ANOVA)(Chi-squareTe。。。

SPSS:数据分析3、T检验(TTest)⽅差分析(ANOVA)(Chi-squareTe。
⽬录1、数据采集2、数据是否服从正态分布3、T检验(T Test)4、⽅差分析(ANOVA)5、卡⽅检验(Chi-square Test)6、灰⾊关联度分析(Grey Relation Analysis,GRA)7、弗⾥德曼检验(Friedman Test)8、箱图(Box)1、数据采集1、数据分类定性观察、访谈、调查定量⼿动测量、⾃动测量、问卷打分主观等级、排序、感觉、有⽤性客观时间、数量、错误率、分数⾃变量不同的实验条件因素,研究的因素因变量不同的实验条件所影响的、要观测的因素连续数量值(preference)时间、数量、错误率------离散数量值(usability问卷打分等级数量值(usability)等级、排序变量类型Norminal Data 定类变量 | 变量的不同取值仅仅代表了不同类的事物,这样的变量叫定类变量。
问卷的⼈⼝特征中最常使⽤的问题,⽽调查被访对象的“性别”,就是定类变量。
对于定类变量,加减乘除等运算是没有实际意义的。
Ordinal Data 定序变量 | 变量的值不仅能够代表事物的分类,还能代表事物按某种特性的排序,这样的变量叫定序变量。
问卷的⼈⼝特征中最常使⽤的问题“教育程度“,以及态度量表题⽬等都是定序变量,定序变量的值之间可以⽐较⼤⼩,或者有强弱顺序,但两个值的差⼀般没有什么实际意义。
Interval Data 定距变量 | 变量的值之间可以⽐较⼤⼩,两个值的差有实际意义,这样的变量叫定距变量。
有时问卷在调查被访者的“年龄”和“每⽉平均收⼊”,都是定距变量。
Ratio Data 定⽐变量 | 有绝对0点,如质量,⾼度。
定⽐变量与定距变量在市场调查中⼀般不加以区分,它们的差别在于,定距变量取值为“0”时,不表⽰“没有”,仅仅是取值为0。
定⽐变量取值为“0”时,则表⽰“没有”。
t检验使用条件及在SPSS中地应用

t检验使用条件及在SPSS中的应用t检验是对均值的检验,有三种用途,分别对应不同的应用场景:1)单样本t检验(One Sample T Test):对一组样本,检验相应总体均值是否等于某个值;2)相互独立样本t检验(Independent-Sample T Test):利用来自某两个总体的独立样本,推断两个总体的均值是否存在显著性差异;3)配对样本t检验:是采用配对设计方法观察以下几种情形,1,两个同质受试对象分别接受两种不同的处理;2,同一受试对象接受两种不同的处理;3,同一受试对象处理前后。
下文将分别介绍三种t检验的使用条件以及在SPSS中的实现。
一、单样本t检验1.1简介1)单样本t检验的目的利用来自某总体的样本数据,推断该总体的均值是否与指定的检验值之间存在显著性差异,它是对总体均值的检验。
2)单样本t检验的前提样本来自的总体应服从和近似服从正态分布,且只涉及一个总体。
如果样本不符合正态分布或不清楚总体分布的形状,就不能用单样本t检验,而要改用单样本的非参数检验。
3)单样本t检验的步骤a)提出假设单样本t检验需要检验总体的均值是否与指定的检验值之间存在显著性差异,为此,,提出假设:给定检验值μH0:μ= μ(原假设,null hypothesis)H1:μ≠μ(备择假设,alternative hypothesis,)b)选择检验统计量属于总体均值和方差都未知的检验采用t统计量:t =X ̅−μ0S ̂√n ⁄,其中,X ̅和S ̂分别为样本均值和方差,t 的自由度为n-1SPSS 中还将显示均值标准误差,计算公式为S ̂√n⁄,即t 统计量的分母部分。
c) 计算统计量的观测值和概率将样本均值、样本方差、μ0带入t 统计量,得到t 统计量的观测值,查t 分布界值表计算出概率P 值。
d) 给出显著性水平α,作出统计判断给出显著性水平α,与检验统计量的概率P 值作比较。
当检验统计量的概率值小于显著性水平时,则拒绝原假设,认为总体均值与检验值μ0之间有显著性差异;反之,如果检验统计量的概率值大于显著性水平,则接受原假设,认为总体均值与检验值μ0之间没有显著性差异。
SPSS检验步骤总结

检验步骤总结:1、t检验2、方差分析3、卡方检验4、秩和检验5、相关分析6、线性回归1、t检验(要求数据来自正态总体,可能需要先做正态检验)(1)单一样本t检验数据特征:单一样本变量均数与某固定已知均数进行比较方法:ANALYZE—COMPARE MEANS-ONE SAMPLE t TEST(2)独立样本t检验数据特征:两个独立、没有配对关系的样本(有专门变量表示组数)方法:ANALYZE—COMPARE MEANS-INDEPENDENT SAMPLES t TEST注意观察方差分析结果,判断查看的数据是哪一行!(3)配对样本t检验数据特征:两个不独立的,有配对关系的样本(没有专门变量表示组数)方法:ANALYZE—COMPARE MEANS—PAIRED SAMPLES t TEST不需要方差分析结果检验步骤:(1)正态性检验1(有同学推荐,老师没有强调,但依据理论应进行)(2)建立假设(H0:。
来自同一样本。
H1:。
.。
不来自同一样本)(3)确定检验水准(4)计算统计量(依据上面不同样本类型选择检验方法,注意独立样本t检验要先注明方差分析结果)(5)确定概率值P(6)得出结论2、方差分析(要求数据来自正态总体,可能需要先做正态检验)(1)单因素方差分析数据特征:相互独立、来自正态总体、随机、方差齐性的多样本(有专门变量表示组数,且组数大于2)方法:ANALYZE—COMPARE MEANS—ONE WAY ANOVA注意需要在options 里面选择homogeneity variance test 做方差分析符合方差齐性才可以得出结论!(〉0.1)(2)双因素方差分析1正态性检验方法:analyze-explore-plot里面选择normality test数据特征:有三列数据,1列是主要研究因素,1列是配伍组因素,1列是研究数据。
方法:GENERAL LINEAR MODEL—UNIVARIATE (注意选择model里的custom,type是main effect,注意把两个因素选择为fixed factor)检验步骤:(1)正态性检验(有同学推荐,老师没有强调,但依据理论应进行)(2)建立假设(H0:.。
SPSS数据分析 第四章 t检验

3. 被称为观察到的(或实测的)显著性水平
4. 决策规则:若p值<, 拒绝 H0
双侧检验的P 值
/2
拒绝H0
1/2 P 值
/2
拒绝H0
1/2 P 值
临界值 0
临界值
Z
计算出的样本统计量
计算出的样本统计量
左侧检验的P 值
抽样分布
拒绝H0
P值
异较大。其图形如下:
f(t)
ν─>∞(标准正态曲线)
ν=5
ν=1
-5.0
-4.0
-3.0
-2.0
-1.0
0.0
1.0
2.0
3.0
4.0
5.0
t
图3-3 不同自由度下的t 分布图
3.特征:
① 单峰分布,以 0 为中心,左右对称; ② 自由度 越小,则 t 值越分散,t 分布的峰部
越矮而尾部翘得越高; ③当 逼近, SX 逼近 X , t 分布逼近 u 分布,故标
解:研究者想收集证据予以证明的 假设应该是“生产过程不正常”。 建立的原假设和备择假设为
H0 : 10cm H1 : 10cm
【例】某品牌洗涤剂在它的产品说明书中声称: 平均净含量不少于500克。从消费者的利益出发, 有关研究人员要通过抽检其中的一批产品来验 证该产品制造商的说明是否属实。试陈述用于 检验的原假设与备择假设
行比较
3. 作出决策
双侧检验:统计量的绝对值 > 临界值,拒 绝H0
左侧检验:统计量 < 临界值,拒绝H0 右侧检验:统计量 > 临界值,拒绝H0
利用 P 值 进行决策
什么是P 值?
实习二 SPSS计量描述与t检验

实习二 SPSS计量描述与t检验一、计量描述1.打开“例02-01.sav”数据,用frequencies菜单计算血清总胆固醇的均数、中位数、四分位数、标准差;用descriptives计算均数、标准差。
2.用explore计算均数、均数95%可信区间、中位数、四分位数间距、标准差等指标,并进行正态性检验。
二、t检验1.将P58【例7-1】数据输入SPSS,检验正态性,如正态性条件满足进行单样本的t检验。
【例7-1】某医生测量了36名从事铅作业男性工人的血红蛋白含量,算得其均数为130.83g/L,标准差为25.74g/L。
问从事铅作业工人的血红蛋白是否不同于正常成年男性平均值140g/L?36名从事铅作业男性工人的血红蛋白含量的数据如下:112,137,129,126,88,90,105,178,130,128,126,103,172,116,125,90,96,62,157,151,135,113,175,129,165,171,128,128,160,110,140,163,100,129,116,1272.将P61【例7-2】数据输入SPSS,检验配对差值的正态性,如正态性条件满足进行配对设计的t 检验。
【例7-2】为比较两种不同方法对乳酸饮料中脂肪含量测定结果是否不同,随机抽取了10份乳酸饮料制品,分别用脂肪酸水解法和哥特里-罗紫法测定其结果如下表第(1)-(3)栏。
问两种测定结果是否不同。
两法测定乳酸饮料中脂肪含量的结果编号(1) 哥特里-罗紫法(2)脂肪酸水解法(3)1 0.840 0.5802 0.591 0.5093 0.674 0.5004 0.632 0.3165 0.687 0.3376 0.978 0.5177 0.750 0.4548 0.730 0.5129 1.200 0.99710 0.870 0.506合计……3.将P63【例7-3】输入数据SPSS,分组检验正态性,并检验两组的方差齐性,如正态性和方差齐性条件满足,进行完全随机设计的t检验。
t检验使用条件及在SPSS中的应用

t 检验使用条件及在SPSS 中的应用t 检验是对均值的检验,有三种用途,分别对应不同的应用场景:1) 单样本t 检验(One Sample T Test ):对一组样本,检验相应总体均值是否等于某个值;2) 相互独立样本t 检验(Independent-Sample T Test ):利用来自某两个总体的独立样本,推断两个总体的均值是否存在显著性差异;3) 配对样本t 检验:是采用配对设计方法观察以下几种情形,1,两个同质受试对象分别接受两种不同的处理;2,同一受试对象接受两种不同的处理;3,同一受试对象处理前后。
下文将分别介绍三种t 检验的使用条件以及在SPSS 中的实现。
一、 单样本t 检验1.1简介1) 单样本t 检验的目的利用来自某总体的样本数据,推断该总体的均值是否与指定的检验值之间存在显著性差异,它是对总体均值的检验。
2) 单样本t 检验的前提样本来自的总体应服从和近似服从正态分布,且只涉及一个总体。
如果样本不符合正态分布或不清楚总体分布的形状,就不能用单样本t 检验,而要改用单样本的非参数检验。
3) 单样本t 检验的步骤a) 提出假设单样本t 检验需要检验总体的均值是否与指定的检验值之间存在显著性差异,为此,给定检验值μ0,提出假设:H 0:μ = μ0 (原假设,null hypothesis )H 1:μ ≠ μ0(备择假设,alternative hypothesis ,)b) 选择检验统计量属于总体均值和方差都未知的检验采用t 统计量:t =X ̅−μ0S ̂√n ⁄,其中,X ̅和S ̂分别为样本均值和方差,t 的自由度为n-1SPSS 中还将显示均值标准误差,计算公式为S ̂√n⁄,即t 统计量的分母部分。
c) 计算统计量的观测值和概率将样本均值、样本方差、μ0带入t 统计量,得到t 统计量的观测值,查t 分布界值表计算出概率P 值。
d) 给出显著性水平α,作出统计判断给出显著性水平α,与检验统计量的概率P 值作比较。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2016/5/19
研究生SPSS上机实习
29
2016/5/19
研究生SPSS上机实习
30
• 单击Charts按钮,打开Charts对话框,选择: • Histograms:直方图(对分类资料,可选用条图 Bar charts和圆图Pie charts)。 • With normal curve:加载正态曲线。
2016/5/19 研究生SPSS上机实习 38
• 从菜单选择AnalyzeDescriptive Statistics Frequencies,打开Frequencies对话框,将变量x 选入Variables栏。 • 单击Statistics按钮,打开Statistics对话框,选择:
2016/5/19
潜伏期(天) 人数
4~ 26
8~ 48
12 ~ 25
16 ~ 6
20 ~ 3
2016/5/19
研究生SPSS上机实习
37
• 用变量 f 进行加权。从菜单选择: DataWeight Cases , 打 开 Weight Cases对话框。单击OK按钮。加权后, 虽然数据窗的数据表面上没有改变,但 程序已经记住:有 26 个观察值为 6 , 48 个观察值为10,25个观察值为14,等。
SPSS数据文件的整理、转换、 合并及t检验
三峡大学医学院 邓 青
2016/5/19
研究生SPSS上机实习
1
一、数据文件的整理
(一)排序(Sort Cases) • 练习:将例1.1中的数据按“性别”和 “年龄”从小到大排序,观察到什么?
2016/5/19
研究生SPSS上机实习
2
• 方法:从菜单选择Data Sort Cases,打开Sort Cases对话框,将变量“性别”和“年龄”分别选 入Sort by 栏,默认升序排列(Ascending),单击 OK按钮。
研究生SPSS上机实习
39
结果解释
S t a ti s t i c s X N 108 0 Median 10.44a Percentiles 95 18.53b a. Calculated from grouped data. b. Percentiles are calculated from grouped data. Valid Missing
研究生SPSS上机实习
2016/5/19
25
SPSS之统计描述
Frequencies、Descriptives、
Means和Case Summaries程序
2016/5/19
研究生SPSS上机实习
26
• Frequencies、Descriptives、Means和 Case Summaries这4个命令都可以计算均 数、标准差、标准误等主要指标。 • 如果只计算上述3个主要指标,选用 Descriptives命令较为方便; • 如果需计算中位数、百分位数和绘制频数分 布图,应选用Frequencies命令; • 如果需分组计算均数、中位数、几何均数、 标准差、标准误等指标,应选用Means命令 (必须有分组变量); • 如果计算几何均数,选用Case Summaries 命令较为方便。
2016/5/19
研究生SPSS上机实习
23
2016/5/19
研究生SPSS上机实习
24
• 单 击 “ 打 开 ” ; 单 击 Match cases on key variables in sorted files(在已排序 的数据文件中匹配关键变量值相等的观察 单位 ) ,激活它下面的三个选项,本例选 择Both files provide cases,将“病人 编 号 ” 选 入 Key Variables 栏 ; 单 击 “ OK” ,将合并后的新工作文件另存为 数据文件e.sav。
2016/5/19
研究生SPSS上机实习
19
2016/5/19
研究生SPSS上机实习
20
(二)增加变量(Add Variables)
• 从外部数据文件中增加变量(variable) 到当前数据文件中,称为横向合并。横向 合并不仅要求两个需要合并的数据文件必 须有一个共同的变量,如病人编号(变量 名和数据类型都相同),称为关键变量, 还要求两个文件中关键变量的部分变量值 是相等的,如病人编号是相同的。
• 最小值和最大值分别为95.3和124.0厘米, 均数和标准差分别为110.11和5.803厘米。
研究生SPSS上机实习
2016/5/19
36
三、频数表资料与Weight(加权)
• 例:某种传染病的潜伏期(天)如下。求平 均潜伏期M和潜伏期的第95百分位数P95
表 3.4 某种传染病的潜伏期(天)
32
2.5 25 50 75 97.5
研究生SPSS上机实习
2016/5/19
身高值
20
10
Frequency
Std. Dev = 5.80 Mean = 110.1 0 96.0 100.0 98.0 104.0 108.0 112.0 116.0 120.0 124.0 102.0 106.0 110.0 114.0 118.0 122.0 N = 120.00
• 练习 将图2-9数据文件中的体重指数bmi 变量值重新编码:0:<24;1:≥24; 并赋值给新变量“肥胖”。
2016/5/19
研究生SPSS上机实习
13
• 从菜单选择Transform RecodeInto Different Variables,打开Recode into Different Variables 对话框,将“bmi”选 入Numeric Variable栏,在Output Variable栏输入新变量肥胖 ,单击 Change 按钮,单击Old and New Values 按钮。
2016/5/19
研究生SPSS上机实习
17
练习:将数据文件a.sav和b.sav合并为 c.sav。
a
c
2016/5/19
b
研究生SPSS上机实习
18
• 打开数据文件a.sav,作为工作文件 (Working Data File )。 • 从菜单选择:DataMerge files Add Cases。选定数据文件b.sav为外部文件, 单击“打开” ,单击“OK” ,将合并后 的新工作文件(New Working Data File) 另存为数据文件c.sav。
研究生SPSS上机实习
7
2016/5/19
研究生SPSS上机实习
8
二、数据文件的转换
• 用赋值方法生成新变量(Compute) • 对变量值重新划分(Recode)
2016/5/19
研究生SPSS上机实习
9
(一)用赋值方法生成新变量 (Compute)
• 练习1 根据已建数据库中的入院日期 date_in和出院日期 date_out,计算住院天 数,并生成新变量住院天数day
2016/5/19
研究生SPSS上机实习
14
2016/5/19
研究生SPSS上机实习
15
四、数据文件的合并
(一)增加观察单位(Add Cases) (二)增加变量(Add Variables)
2016/5/19
研究生SPSS上机实习
16
(一)增加观察单位(Add Cases)
• 从外部数据文件中增加案例(cases)到当 前数据文件中,称为纵向合并。纵向合并 要求两个需要合并的数据文件必须有一个 共同的变量,如病人编号、住院天数(变 量名和数据类型都相同),称为关键变量。
2016/5/19
研究生SPSS上机实习
31
Statistics 身 高值 N Mean Std. Error of Mean Median Std. Deviation Percentiles Valid Missing 120 0 110.1100 .5298 109.6000 5.8032 99.1100 105.7250 109.6000 114.7000 120.4925
2016/5/19 研究生SPSS上机实习 21
练习:将数据文件c.sav和d.sav合并为e.sav。
c
d
2016/5/19
研究生SPSS上机实习
e
22
• 分别对数据文件 c.sav 和 d.sav 按关键变量 “ 病 人 编 号 ” 升 序 排 列 (DataSort Cases)。 • 打 开 数 据 文 件 c.sav , 作 为 工 作 文 件 (Working Data File )。 • 从菜单选择: DataMerge files Add Variables 。选定数据文件 d.sav 为外部文 件;
2016/5/19
研究生SPSS上机实习
3
(二)选择观察单位(Select Cases)
• 练习:将已建数据文件中“男性”及 “年龄”在 65 岁以下的观察单位选择出 来。观察到什么?
2016/5/19
研究生SPSS上机实习
4
• 方法:从菜单选择Data Select Cases, 打开Select对话框,选择if condition is satisfied,单击 if 按钮,在条件栏中输入 sex = 1 & age < 65 ,单击Continue按钮, 单击OK按钮。
2016/5/19
研究生SPSS上机实习
34
2016/5/19
研究生SPSS上机实习
35
结果解释
Descriptive Statistics N 身 高值 Valid N (listwise) 120 120 Minimum 95.30 Maximum 124.00 Mean 110.1100 Std. Deviation 5.8032