疾病诊断的问题模型分析.
疾病诊断研究

合。 2.4 问题四 在问题三的基础上,选取就诊人员的关键元素含量,应用相关的 matlab 程 序或 SPSS 统计软件即可得到相关的判断结果。 2.5 问题五 为了对第二问和第四问的结果进行分析,我们汇总了费希尔判别方法和 BP 神经网络判别方法在全部元素和三种重要指标所得的结果, 进而定义了衡量两种 算法差异的稳定性检验公式。
(2)
(1) ( 2) (1) ( 2) 式中 D j X J , Dj X J 分别是患病者类和健康人类第 j 个 XJ XJ
指标的均数 ( j 1,2,, m) ;
Sij 是 X1 , X 2 ,
ห้องสมุดไป่ตู้
, X m 的合并协方差阵的元素。
S ij
(X
(1) i
X i(1) )( X (j1) X (j1) ) ( X i( 2) X i( 2) )( X (j 2) X (j 2) ) n1 n2 2
(2) 把协方差矩阵代入方程组(2) ,可求得:
第2页
1880C 1 10C2 - 60C3 5400C 4 690C 5 - 2150C 6 - 2690C 7 -43.5 - 10C 290C - 480C 11990C 1820C - 330C - 1450C -9.59 1 2 3 4 5 6 7 - 60C1 480C2 2970C 3 14090C 4 3310C5 700C 6 3460C 7 -38.95 .97 5400C 1 11990C 2 14090C 3 844990C 4 90190C 5 9340C 6 50850C 7 -1812 690C 1820C 3310C 90190C 16860C 1510C 11750C -181.74 1 2 3 4 5 6 7 - 2150C .76 1 330C 2 700C 3 9340C 4 1510C 5 35060C 6 35360C 7 110 .62 1 1450C 2 3460C 3 50850C 4 11750C 5 35360C 6 75000C 7 -159 - 2690C
医用疾病预测模型

医用疾病预测模型近年来,随着医疗技术的不断进步和人工智能的快速发展,医用疾病预测模型逐渐成为研究的热点。
这种模型基于大数据和机器学习算法,可以通过分析患者的症状、病史以及其他相关因素,预测患者可能患上的疾病类型和风险程度。
本文将深入探讨医用疾病预测模型的意义、方法以及应用前景。
一、医用疾病预测模型的意义疾病的早期预测对于疾病的治疗和管理至关重要。
通过医用疾病预测模型,我们可以在患者还未出现明显症状之前,就能够预测其可能患上的疾病。
这样一来,医生可以采取针对性的干预措施,早期治疗和管理患者,以减轻疾病带来的风险和痛苦。
二、医用疾病预测模型的方法医用疾病预测模型的建立通常需要以下几个关键步骤。
1.数据收集:医用疾病预测模型需要大量的数据作为依据。
医生可以通过患者的病历记录、实验室检查结果以及影像学资料等来收集数据。
同时,还可以结合公共卫生部门的统计数据和疾病数据库的信息。
2.特征选择:医用疾病预测模型需要从海量的数据中挑选出具有预测能力的特征。
在特征选择过程中,可以借助统计学方法和机器学习算法,在保留重要特征的同时减少冗余特征,提高模型的准确性和可解释性。
3.模型构建:医用疾病预测模型可以采用多种机器学习算法,如逻辑回归、支持向量机、决策树等。
根据数据的特点和需求,选择合适的算法,并通过训练和优化模型,使之能够更好地预测患者的疾病风险。
4.模型评估:建立好的预测模型需要进行评估,以验证其准确性和可靠性。
可以采用交叉验证、ROC曲线等方法来评估模型的性能,并不断优化和改进模型。
三、医用疾病预测模型的应用前景医用疾病预测模型在临床实践和公共卫生领域有着广阔的应用前景。
1.早期诊断:医用疾病预测模型可以帮助医生提前发现疾病风险,实现早期诊断和干预。
例如,针对高血压、糖尿病等慢性疾病,可以通过监测患者的生理指标和生活习惯,预测其疾病的发生概率,并采取相应的治疗措施。
2.个体化治疗:医用疾病预测模型可以帮助医生制定个性化的治疗方案。
疾病诊断模型

我们仔细阅读了中国大学生数学建模竞赛的竞赛规则.我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。
我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。
我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。
如有违反竞赛规则的行为,我们将受到严肃处理。
我们参赛选择的题号是(从A/B/C/D 中选择一项填写):我们的参赛报名号为(如果赛区设置报名号的话):所属学校(请填写完整的全名):广东商学院参赛队员(打印并签名):1. 邓思文2. 苏境财3. 吴妙指导教师或指导教师组负责人(打印并签名):戴宏亮日期:2012 年8 月18 日赛区评阅编号(由赛区组委会评阅前进行编号)2010 高教社杯全国大学生数学建模竞赛编号专用页赛区评阅编号(由赛区组委会评阅前进行编号):赛区评阅记录(可供赛区评阅时使用):全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号):疾病诊断问题摘要随着就医压力增加,在降低误诊率的前提下提高诊断效率是非常重要的,本文利用确诊样本数据建立判别模型,并利用模型筛选出主要元素,对就诊人员进行诊断。
针对问题(1),利用确诊数据建立Fisher判别模型、Logistic 回归模型和BP神经网络模型,运用matlab、spss求解,定出判别标准,并进行显著性检验和回代检验,判别模型的准确率。
结果显示Fisher 判别模型的准确率为%,Logistic回归模型和BP神经网络模型准确率均为100%,Logistic 回归模型相对简便。
针对问题(2),选择问题一中检验准确率为100%的Logistic 回归模型和BP神经网络模型对40 名就诊人员进行诊断,结果如下表:针对问题(3),建立Logistic 逐步回归模型对元素进行筛选,利用spss 软件求解,确定Ca和Fe 是影响人们患这种病的主要因素,因此在建立诊断模型时,其他元素不作为参考指标。
临床诊断模型构建

临床诊断模型构建在医学领域中,临床诊断是医生根据患者的症状和体征,通过系统的思维和判断,最终确定疾病的过程。
为了提高临床诊断的准确性和效率,研究者们不断探索和构建各种临床诊断模型。
本文将介绍一种常用的临床诊断模型构建方法,并探讨其应用和局限性。
临床诊断模型的构建是一个复杂而系统的过程。
首先,医生需要收集患者的详细病史,并进行全面的体格检查。
这些信息将作为构建临床诊断模型的基础数据。
在收集到足够的患者数据后,医生需要进行数据预处理,包括数据清洗、缺失值处理和异常值处理等。
接下来,医生需要选择合适的特征来构建临床诊断模型。
特征是指从患者数据中提取出的能够反映疾病特点的变量。
在选择特征时,医生需要考虑其与疾病的相关性和可解释性。
常用的特征选择方法有相关系数分析、主成分分析和递归特征消除等。
选择好特征后,医生需要选择合适的算法来构建临床诊断模型。
常用的算法有逻辑回归、决策树、支持向量机和人工神经网络等。
不同的算法有不同的应用场景和优缺点,医生需要根据具体情况选择合适的算法。
在构建临床诊断模型时,医生还需要进行模型的训练和评估。
模型的训练是指使用已知的患者数据来优化模型参数,以提高模型的预测准确性。
模型的评估是指使用独立的测试数据来评估模型的性能,包括准确率、召回率和F1值等指标。
医生需要将构建好的临床诊断模型应用于实际临床实践中。
通过输入患者的症状和体征,模型可以给出一定的患病概率或诊断结果。
然而,临床诊断模型并非万能的,它仅仅是医生的辅助工具,最终的诊断结果仍需要医生结合自身经验和专业知识来判断。
尽管临床诊断模型在提高诊断准确性和效率方面有着不可忽视的作用,但也存在一些局限性。
首先,临床诊断模型的构建需要大量的患者数据,而且不同的疾病可能需要不同的数据量。
其次,临床诊断模型的构建需要医生具备一定的编程和数据分析能力,这对于一些临床医生来说可能是一项挑战。
临床诊断模型的构建还需要考虑到伦理和隐私问题。
医疗数据具有高度敏感性和隐私性,医生在使用患者数据时需要遵守相关的法律法规和伦理要求。
minitab 分类模型案例

minitab 分类模型案例Minitab是一种常用的统计分析软件,它可以用于各种分类模型的建立和分析。
下面列举了10个基于Minitab的分类模型案例,来说明其在实际应用中的作用和效果。
1. 疾病诊断模型:医院收集了大量患者的临床数据和诊断结果,利用Minitab建立了一个疾病诊断模型。
该模型可以根据患者的临床指标,如血压、血糖、血脂等,预测患者是否患有某种疾病,并给出相应的诊断建议。
2. 信用评分模型:银行通过Minitab分析了大量客户的信用记录和还款情况,建立了一个信用评分模型。
该模型可以根据客户的个人信息、财务状况和信用历史等因素,预测客户的还款能力和风险等级,并据此决定是否给予贷款。
3. 市场细分模型:一家电商公司利用Minitab分析了大量用户的购物行为和偏好数据,建立了一个市场细分模型。
该模型可以根据用户的购买记录、浏览行为和兴趣标签等,将用户分为不同的市场细分群体,并据此进行个性化推荐和营销策略。
4. 员工离职预测模型:一家公司利用Minitab分析了员工的离职记录和个人信息,建立了一个员工离职预测模型。
该模型可以根据员工的职位、工龄、绩效等因素,预测员工是否有离职倾向,并据此采取相应的人力资源管理措施。
5. 欺诈检测模型:一家保险公司利用Minitab分析了保单的理赔记录和客户信息,建立了一个欺诈检测模型。
该模型可以根据保单的理赔金额、申请时间、客户的历史记录等因素,预测保单是否存在欺诈嫌疑,并据此采取相应的调查和处理措施。
6. 产品质量分类模型:一家制造公司利用Minitab分析了产品的质量数据和生产参数,建立了一个产品质量分类模型。
该模型可以根据产品的生产批次、工艺参数、质量指标等因素,预测产品的合格率和质量等级,并据此进行质量控制和改进。
7. 股票市场预测模型:一家投资公司利用Minitab分析了股票市场的历史数据和宏观经济指标,建立了一个股票市场预测模型。
该模型可以根据股票的历史价格、交易量、市场情绪等因素,预测股票的涨跌趋势,并据此进行投资决策和风险管理。
最新数学建模题目及其答案(疾病的诊断)

数学建模疾病的诊断现要你给出疾病诊断的一种方法。
胃癌患者容易被误诊为萎缩性胃炎患者或非胃病者。
从胃癌患者中抽取5人(编号为1-5),从萎缩性胃炎患者中抽取5人(编号为6-10),以及非胃病者中抽取5人(编号为11-15),每人化验4项生化指标:血清铜蓝蛋白(X)、1蓝色反应(X)、尿吲哚乙酸(3X)、中性硫化物(4X)、测得数据如表1 2所示:表1. 从人体中化验出的生化指标根据数据,试给出鉴别胃病的方法。
论文题目:胃病的诊断摘要在临床医学中,诊断试验是一种诊断疾病的重要方法。
好的诊断试验方法将对临床诊断的正确性和疾病的治疗效果起重要影响。
因此,对于不同疾病不断发现新的诊断试验方法是医学进步的重要标志。
传统的诊断试验方法有生化检测、DNA检测和影像检测等方法。
而本文则通过利用多元统计分析中的判别分析及SPSS软件的辅助较好地解决了临床医学中胃病鉴别的问题。
在临床医学上,既提高了临床诊断的正确性,又对疾病的治疗效果起了重要效果,同时也减轻了病人的负担。
判别分析是在分类确定的条件下,根据某一研究对象的各种特征值判别其类型归属问题的一种多变量统计分析方法。
其基本原理是按照一定的判别准则,建立一个或多个判别函数,用研究对象的大量资料确定判别函数中的待定系数,并计算判别指标。
首先,由判别分析定义可知,只有当多个总体的特征具有显著的差异时,进行判别分析才有意义,且总体间差异越大,才会使误判率越小。
因此在进行判别分析时,有必要对总体多元变量的均值进行是否不等的显著性检验。
其次,利用判别分析中的费歇判别和贝叶斯判别进行判别函数的建立。
最后,利用所建立的判别函数进行回判并测得其误判率,以及对其修正。
本文利用SPSS软件实现了对总体间给类变量的均值是否不等的显著性检验并根据样本建立了相应的费歇判别函数和贝叶斯判别函数,最后进行了回判并测得了误判率,从而获得了在临床诊断中模型,给临床上的诊断试验提供了新方法和新建议。
智能医疗中的疾病预测模型研究

智能医疗中的疾病预测模型研究随着互联网和人工智能技术的不断发展,智能医疗开始受到越来越多的关注。
智能医疗是指利用大数据、人工智能等技术,在医疗保健领域实现更精准、更高效的服务。
其中,疾病预测模型是智能医疗最重要也是最核心的一部分。
本文将深入探讨智能医疗中的疾病预测模型研究,包括现状、挑战和发展趋势等方面。
一、疾病预测模型现状疾病预测模型是基于机器学习、深度学习等技术,通过分析和处理大量的临床数据,建立疾病预测模型,预测人们在未来可能患上的疾病。
目前,美国、欧洲和中国等地的医疗机构和科技公司都在积极研发疾病预测模型,其中以美国为代表的发达国家在该领域的研究最具备领先优势。
目前,已经有很多研究机构和公司开发了各种类型的疾病预测模型,如心血管疾病、癌症、糖尿病等。
这些模型都经常运用在临床实践中,通过早期诊断和预测来帮助医生更准确地诊断和治疗病人。
二、疾病预测模型挑战虽然疾病预测模型已经在一些领域得到了广泛应用,但是仍然面临着许多挑战和问题。
1.数据的质量和数量疾病预测模型需要基于大量的、高质量的临床数据,但是现实情况是,各医疗机构的数据质量和数量千差万别,这就给模型训练带来了很大的困难。
有些医疗机构的电子病历数据不完整,有些数据则波动很大,这使得模型训练不充分,结果难以达到预期效果。
2.隐私保护临床数据涉及到病人隐私,为了保护病人的隐私权,医疗机构不能轻易将数据共享出去。
这就使得数据的共享和交换变得更加困难,阻碍了疾病预测模型的发展。
3.模型的可解释性许多疾病预测模型在建模过程中采用的是复杂的算法,比如深度学习模型,这种模型虽然具有更好的预测准确性,但是对于医生和患者来说,很难理解这些模型是如何得出预测结果的,从而影响了模型的可靠性和使用率。
三、疾病预测模型发展趋势尽管疾病预测模型面临在许多难题,但是随着技术的逐步发展和应用的不断推广,疾病预测模型也将会发生很大的变化,未来疾病预测模型的发展趋势主要包括以下几个方面:1.多源数据的融合通过结合不同类型、不同来源的临床数据,将有助于提升模型的预测准确性和实用性。
预训练模型在医疗领域中的疾病诊断应用案例分享(四)

预训练模型在医疗领域中的疾病诊断应用案例分享近年来,随着人工智能技术的不断发展,预训练模型在医疗领域中的应用逐渐引起人们的关注。
其中,预训练模型在疾病诊断方面发挥着越来越重要的作用。
本文将结合实际案例,探讨预训练模型在医疗领域中的疾病诊断应用。
一、肺部疾病诊断在医学影像诊断领域,预训练模型已经取得了显著的成果。
以肺部疾病诊断为例,研究人员利用预训练模型对X光片和CT影像进行分析,以协助医生诊断肺部疾病,尤其是在肺结核、肺炎和肺癌等疾病的早期筛查和诊断中取得了令人瞩目的效果。
预训练模型可以快速而准确地识别影像中的病灶,为医生提供重要参考信息,有助于提高疾病的诊断准确性和效率。
二、心脏疾病诊断除了肺部疾病,预训练模型在心脏疾病诊断方面也展现出了巨大潜力。
通过对心脏超声图像和心电图等医学影像数据的分析,预训练模型能够帮助医生快速发现心脏疾病,如心肌梗塞、心律失常等。
此外,预训练模型还可以利用患者的临床数据和生理参数,辅助医生进行心血管疾病的风险评估和预后预测,为临床决策提供科学依据。
三、神经系统疾病诊断在神经系统疾病诊断方面,预训练模型同样发挥着重要作用。
例如,针对脑部MRI和CT影像数据,预训练模型可以帮助医生快速定位和分析脑卒中、脑肿瘤等疾病的病变部位和大小,为临床治疗提供重要参考。
此外,预训练模型还可以结合患者的临床症状和病史,辅助医生进行神经系统疾病的诊断和鉴别诊断,提高医疗诊断的准确性和精准性。
四、临床应用挑战与展望尽管预训练模型在医疗领域的疾病诊断应用取得了显著的成就,但仍面临着一些挑战。
首先,医学影像数据的质量和数量对于预训练模型的性能有着重要影响,因此如何积累和共享高质量的医学影像数据是当前亟待解决的问题。
其次,预训练模型的可解释性和适应性也是当前的研究热点,如何让模型的决策过程更加可解释和可信是未来的发展方向。
此外,医学领域的伦理和法律问题也需要引起重视,如何保护患者隐私和数据安全是当前亟待解决的问题。
疾病诊断数学模型1
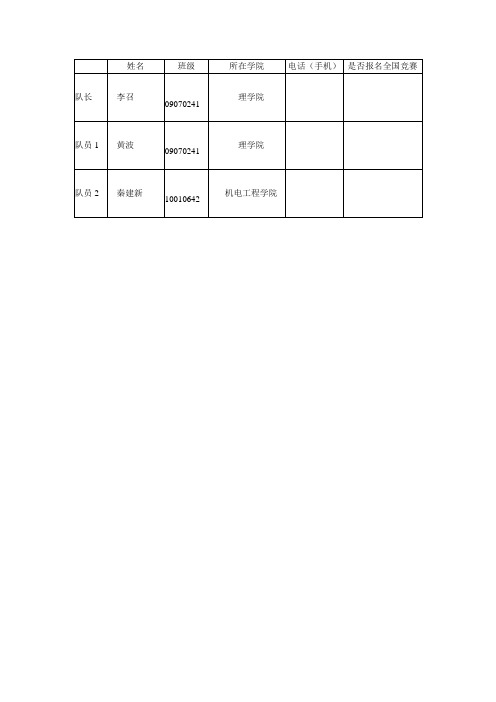
姓名班级所在学院电话(手机)是否报名全国竞赛队长李召理学院09070241理学院队员1黄波09070241机电工程学院队员2秦建新10010642疾病诊断数学模型摘要本文解决的是如何根据就诊者体内各元素含量判别某人是否患有某种疾病和确定哪些指标是影响人们患该疾病的关键因素的问题。
通过分析可知此类问题为典型的分析判别,在此我们采用元素判别和Bayes 判别并应用Excel 和SAS 软件来对某人是否患病进行判别,并通过主成分分析法来确定患该疾病的关键因素。
对于问题一,我们采用元素判别和Bayes 判别进行前60人是否患病的判别,并对其结果进行对比。
对于元素判别,我们用Excel 对化验结果数据进行统计并通过折线图得出其分界值,然后与是否患病的真实情况进行对比,得出其准确度为95%;对于Bayes 判别,通过编写SAS 程序来进行判别,并得出其准确度为93.33%;考虑到诊断的实际情况和简便性最终确定Bayes 判别为本文所要使用的判别方法。
对于问题二,我们利用问题一中建立的判别模型对表2中的15名就诊人员的化验结果进行检验,检验结果为:9个人为患病者,6 个人为健康人员。
对于问题三,为了确定影响人们患该病的关键或主要因素,我们选取表1中的数据作为样本,建立主成分分析模型,通过对表1中的数据进行标准化并确定相关系数矩阵,接着,求出相关矩阵的特征值和特征向量,然后通过前m 个主成分的累计贡献率满足%8511≥∑∑==pk kik kλλ来确定主成分的个数,最后通过主成份载荷分析得出最能代表主成分的原指标即所要求的主要因素为Fe 、Ca 、Mg 、Cu 。
在此基础上,得到去掉K 、Na 、Zn 的化检结果的新样本,利用Bayes 判别,再对表2中的15名就诊人员的化验结果进行判别,判别结果:9个人为患病者,6 个人为健康人员。
关键词: 元素判别,Bayes 判别,主成分分析法,Excel ,SAS 软件一 问题重述.人们到医院就诊时,通常要化验一些指标来协助医生诊断。
数学建模题目及其答案(疾病的诊断)

数学建模疾病的诊断现要你给出疾病诊断的一种方法。
胃癌患者容易被误诊为萎缩性胃炎患者或非胃病者。
从胃癌患者中抽取5人(编号为1-5),从萎缩性胃炎患者中抽取5人(编号为6-10),以及非胃病者中抽取5人(编号为11-15),每人化验4项生化指标:血清铜蓝蛋白(X)、蓝色1反应(X)、尿吲哚乙酸(3X)、中性硫化物(4X)、测得数据如表1所示:2根据数据,试给出鉴别胃病的方法。
论文题目:胃病的诊断摘要在临床医学中,诊断试验是一种诊断疾病的重要方法。
好的诊断试验方法将对临床诊断的正确性和疾病的治疗效果起重要影响。
因此,对于不同疾病不断发现新的诊断试验方法是医学进步的重要标志。
传统的诊断试验方法有生化检测、DNA检测和影像检测等方法。
而本文则通过利用多元统计分析中的判别分析及SPSS软件的辅助较好地解决了临床医学中胃病鉴别的问题。
在临床医学上,既提高了临床诊断的正确性,又对疾病的治疗效果起了重要效果,同时也减轻了病人的负担。
判别分析是在分类确定的条件下,根据某一研究对象的各种特征值判别其类型归属问题的一种多变量统计分析方法。
其基本原理是按照一定的判别准则,建立一个或多个判别函数,用研究对象的大量资料确定判别函数中的待定系数,并计算判别指标。
首先,由判别分析定义可知,只有当多个总体的特征具有显著的差异时,进行判别分析才有意义,且总体间差异越大,才会使误判率越小。
因此在进行判别分析时,有必要对总体多元变量的均值进行是否不等的显著性检验。
其次,利用判别分析中的费歇判别和贝叶斯判别进行判别函数的建立。
最后,利用所建立的判别函数进行回判并测得其误判率,以及对其修正。
本文利用SPSS软件实现了对总体间给类变量的均值是否不等的显著性检验并根据样本建立了相应的费歇判别函数和贝叶斯判别函数,最后进行了回判并测得了误判率,从而获得了在临床诊断中模型,给临床上的诊断试验提供了新方法和新建议。
关键词:判别分析;判别函数;Fisher判别;Bayes判别一问题的提出在传统的胃病诊断中,胃癌患者容易被误诊为萎缩性胃炎患者或非胃病患者,为了提高医学上诊断的准确性,也为了减少因误诊而造成的病人死亡率,必须要找出一种最准确最有效的诊断方法。
数学建模题目及其答案(疾病诊断)

数学建模疾病的诊断现要你给出疾病诊断的一种方法。
胃癌患者容易被误诊为萎缩性胃炎患者或非胃病者。
从胃癌患者中抽取5人(编号为1-5),从萎缩性胃炎患者中抽取5人(编号为6-10),以及非胃病者中抽取5人(编号为11-15),每人化验4项生化指标:血清铜蓝蛋白(X)、1蓝色反应(X)、尿吲哚乙酸(3X)、中性硫化物(4X)、测得数据如表1 2所示:表1. 从人体中化验出的生化指标根据数据,试给出鉴别胃病的方法。
论文题目:胃病的诊断摘要在临床医学中,诊断试验是一种诊断疾病的重要方法。
好的诊断试验方法将对临床诊断的正确性和疾病的治疗效果起重要影响。
因此,对于不同疾病不断发现新的诊断试验方法是医学进步的重要标志。
传统的诊断试验方法有生化检测、DNA检测和影像检测等方法。
而本文则通过利用多元统计分析中的判别分析及SPSS软件的辅助较好地解决了临床医学中胃病鉴别的问题。
在临床医学上,既提高了临床诊断的正确性,又对疾病的治疗效果起了重要效果,同时也减轻了病人的负担。
判别分析是在分类确定的条件下,根据某一研究对象的各种特征值判别其类型归属问题的一种多变量统计分析方法。
其基本原理是按照一定的判别准则,建立一个或多个判别函数,用研究对象的大量资料确定判别函数中的待定系数,并计算判别指标。
首先,由判别分析定义可知,只有当多个总体的特征具有显著的差异时,进行判别分析才有意义,且总体间差异越大,才会使误判率越小。
因此在进行判别分析时,有必要对总体多元变量的均值进行是否不等的显著性检验。
其次,利用判别分析中的费歇判别和贝叶斯判别进行判别函数的建立。
最后,利用所建立的判别函数进行回判并测得其误判率,以及对其修正。
本文利用SPSS软件实现了对总体间给类变量的均值是否不等的显著性检验并根据样本建立了相应的费歇判别函数和贝叶斯判别函数,最后进行了回判并测得了误判率,从而获得了在临床诊断中模型,给临床上的诊断试验提供了新方法和新建议。
最经典 数学建模 Fisher模型

疾病诊断问题疾病诊断问题摘要文中研究的是通过已给出的数据对其四项生化指标:血清铜蓝蛋白(X1)、蓝色反应(X2)、鸟吲哚乙酸(X3)、中型硫化物(X4)进行分析,得出健康综合指数的临界值,从而协助医生诊断就诊人员是癌症病人还是萎缩性胃炎病人及健康人。
首先,在合理的假设下,建立了Fisher判别分析模型,将表中的数据分为,A B,C三组,由其各自的离差矩阵求得每种指标对应的权重,并得到了健康综合指数的临界值,经过检验,用此模型诊断的正确率为100%此外,文中对所建立的模型做了检验,误差分析和评价,并将此模型做了推广和应用。
关键词综合指数临界值权重Fisher判别分析一、问题重述胃癌患者容易被误诊为萎缩性胃炎患者或非胃病者,据此,通常要化验人体内四项生化指标:血清铜蓝蛋白(X1)、蓝色反应(X2)、鸟吲哚乙酸(X3)、中型硫化物(X4),从而用这些指标协助医生诊断。
表中1-5号病例是已经确诊为胃癌的病人的化验结果;6-10号病例是已经确定为萎缩性胃炎病人的化验结果;11-15根据表中的数据,设想使用Fisher判别分析法,给出鉴别胃病的方法并对所给的数据进行检验,使问题得到有效的解决。
二、问题分析医生在诊断就诊人员是癌症病人还是萎缩性胃炎病人及健康人。
通常要化验人体内四项生化指标,从而用这些指标协助诊断。
由表中看出医生通常用血清铜蓝蛋白(X1)、蓝色反应(X2)、鸟吲哚乙酸(X3)、中型硫化物(X4)在人体内的含量作为指标进行诊断。
要判断就诊人员是ⅰ胃癌病人还是ⅱ萎缩性胃炎病人及ⅲ健康人,分别对①胃癌患者与非胃病者及②萎缩性胃炎患者与非胃病者以及③胃癌患者与萎缩性胃炎患者进行分析,分别得出其相对应的健康综合指数的临界值(H1,H2,H3)作为判别标准,这是一个判别分析问题。
通过表中的数据分析可得:如果就诊人员在情况①下由临界值H1判断为胃癌,则在第三种情况下分析,如果由临界值H3判断为胃癌,则认为此人患有胃癌;如果判断为萎缩性胃炎,则此人为萎缩性胃炎患者。
疾病诊断的问题模型分析

学士学位论文疾病诊断分析的问题模型作者单位西北民族大学指导老师 ***作者姓名 ***专业、班级数学与应用数学 2009级应数班提交时间2013年5月疾病诊断分析的问题模型专业:2009级数学与应用数学姓名:*** 指导教师:***摘要在对肾炎进行诊断时,医生通过测得到人体内元素的含量数据,进行肾炎的诊断.结合临床实际数据,根据测得体内元素Cu、Fe、Ca、Zn、Mg、K、Na的含量数据特征,分别建立了健康系数、距离判别、bp神经网络三种模型,介绍了三种模型的计算过程及结果,作为判别人们是否患病的依据.为了使医生减少化验时的数据,得出了影响人们患病的主要指标为Cu、Fe、Ca,使得检验即方便又节省化验费用.利用人体内各种元素含量协助医生对就诊人员进行诊断,通过对三种模型的比较,找出了最佳模型bp神经网络模型,使得诊断的结果比其他模型的准确度要高.关键字疾病诊断,健康系数,欧氏距离,神经网络,模型ABSTRACTNephritis diagnosis, the doctor can be measured to obtain the elements of the content data of the human body, the diagnosis of nephritis associated with the actual clinical data, according to the measured body elements Cu, Fe, Ca, Zn, Mg, K, Na content data definitionswere established health factor, distance discriminant, bp neural network of three models, the calculation process and results of the three models, come to influence doctors in order to reduce the data in the laboratory, as discrimination based on whether people are sick.the people sick indicators for Cu, Fe, Ca, making the test that is convenient and save laboratory costs. use the content of various elements of the human body to assist doctors in diagnosis treatment personnel, through the comparison of the three models to identify the bestmodel bp neural network model, the results of the diagnostic accuracy is higher than other models.Key word:disease diagnosis, health factors, Euclidean distance, neural network model目录摘要 (2)引言.................................... 错误!未定义书签。
医疗诊断辅助系统的使用教程与疾病预测模型

医疗诊断辅助系统的使用教程与疾病预测模型医疗诊断辅助系统是一种利用人工智能技术来辅助医生进行疾病诊断和预测的工具。
它能够根据患者的症状和医学数据提供可能的诊断结果,并给出相应的治疗建议。
本文将介绍医疗诊断辅助系统的使用教程以及其中的疾病预测模型。
1. 注册与登录首次使用医疗诊断辅助系统,用户需要进行注册。
注册过程往往需要提供基本的个人信息,例如姓名、性别、年龄等。
注册完成后,用户可以使用注册时填写的用户名和密码进行登录。
2. 患者症状输入登录后,用户进入系统的主界面。
在主界面上,用户可以看到一个症状输入框。
用户需要将患者的主要症状输入到该框中。
症状可以是患者的主观感受,例如头痛、咳嗽等,也可以是客观的检查结果,例如体温、血压等。
3. 数据分析与诊断一旦用户输入完患者的症状,系统会自动对输入的数据进行分析。
它会将症状与大量的医学数据进行比对,并找出与用户输入的症状相似的疾病。
系统会将疾病按照可能性进行排序,并给出每种疾病的匹配程度以及对应的治疗建议。
4. 疾病预测模型医疗诊断辅助系统中的疾病预测模型是其核心组成部分之一。
它是通过对大量的医学数据进行学习和分析,建立起来的一个能够预测疾病发生概率的模型。
疾病预测模型能够根据患者的症状和个人信息,评估患者患某种疾病的可能性,并给出相应的预测结果。
5. 模型训练与更新疾病预测模型的训练是一个关键的步骤。
医疗诊断辅助系统会不断收集和更新医疗数据,并使用这些数据来改进和优化疾病预测模型。
模型训练的过程一般由专业的数据科学家和医生共同完成,确保模型的准确性和可靠性。
6. 数据安全与隐私保护在使用医疗诊断辅助系统时,用户的个人信息和医疗数据是非常敏感的。
系统开发者必须采取各种措施来确保用户数据的安全性和隐私保护。
例如,使用加密技术来保护数据的传输和存储过程,限制对数据的访问权限,并定期审查系统的安全性。
7. 使用建议与注意事项使用医疗诊断辅助系统时,我们需要注意以下几点:7.1. 诊断辅助系统只是一个辅助工具,不能替代医生的判断和临床经验。
构建疾病预测模型的方法与步骤

构建疾病预测模型的方法与步骤构建疾病预测模型的方法与步骤【引言】疾病预测是医学领域中的重要研究方向,通过构建疾病预测模型,可以帮助医生和研究人员更早地发现和预测疾病的发生和发展。
本文将介绍构建疾病预测模型的一般方法与步骤,为读者提供一个全面的指南。
【1. 确定研究目标】在构建任何预测模型之前,首先需要明确研究目标。
确定预测的疾病类型、预测的时间窗口以及模型的性能指标是非常重要的。
【2. 数据收集与预处理】获得高质量的数据是构建准确预测模型的关键。
这包括患者的临床数据、生理参数、基因组学数据等。
数据质量需要得到保证,同时需要进行数据预处理,包括数据清洗,缺失值填充,异常值处理等。
【3. 特征选择与提取】选择合适的特征对于构建有效的预测模型至关重要。
特征选择可以通过统计方法、机器学习算法或领域知识进行。
根据特定领域的背景知识,还可以提取新的特征来增加模型的预测能力。
【4. 模型选择与训练】在选择合适的模型时,需要考虑多个因素,如数据类型、问题类型、特征数量等。
常用的疾病预测模型包括逻辑回归、支持向量机、决策树、神经网络等。
选定模型后,需要使用已标记的数据进行训练,并通过交叉验证来评估模型的性能。
【5. 模型评估与优化】评估模型的性能是确保预测准确性的关键。
常用的评估指标包括准确率、召回率、精确率和F1分数。
如果模型性能不满足要求,可以尝试调整模型参数、增加数据量、使用集成学习方法等来提高模型效果。
【6. 模型应用与验证】在模型开发完成后,需要对其进行进一步验证和应用。
这可以通过与独立数据集的比较来评估模型的泛化性能。
还可以将模型应用于临床实践中,通过预测患者的疾病风险,来提供个性化的医疗建议。
【7. 模型解释与可解释性】对于疾病预测模型,其解释性和可解释性也非常重要。
通过解释模型预测结果的原因,可以帮助医生和病人更好地理解预测的依据,从而增强信任度。
【8. 持续改进与更新】疾病预测模型需要不断改进和更新,以适应新的数据和新的挑战。
临床诊断模型构建

临床诊断模型构建临床诊断模型是医学领域中的重要工具,它能够帮助医生更准确地诊断疾病并制定合理的治疗方案。
在临床实践中,医生常常需要面对各种病症和症状,而临床诊断模型的构建可以帮助医生系统地分析病情,并提供指导性的诊疗建议。
临床诊断模型的构建是一个复杂的过程,需要综合考虑多个因素,包括患者的临床表现、体征、实验室检查等。
首先,医生需要收集患者的病史信息,包括病症出现的时间、症状的严重程度、伴随症状等。
然后,医生会进行体格检查,观察患者的外貌、皮肤颜色、呼吸、心跳等指标。
此外,医生还会根据患者的实验室检查结果,如血液检查、尿液检查等,来进一步了解患者的病情。
在收集了足够的信息后,医生需要将这些信息组织起来,并进行分析。
临床诊断模型的构建通常基于两个主要的步骤:特征选择和模型建立。
特征选择是指从众多的临床特征中选择出最具有诊断价值的特征。
医生可以通过统计学方法,如卡方检验、t检验等,来评估特征与疾病之间的相关性,并选择出最相关的特征。
然后,医生可以利用机器学习算法或统计模型来建立临床诊断模型。
常用的模型包括逻辑回归、支持向量机、决策树等。
临床诊断模型的建立并非一成不变的,它需要不断地进行验证和更新。
医生可以将已有的病例数据分为训练集和测试集,利用训练集来建立模型,并利用测试集来评估模型的性能。
如果模型的性能不理想,医生可以调整模型的参数或重新选择特征,以提高模型的准确度和稳定性。
此外,医生还可以通过与其他医生的交流和共享经验来改进模型。
临床诊断模型的构建对于提高诊断准确性和治疗效果具有重要意义。
它可以帮助医生更好地理解疾病的本质,找到合适的治疗方法,并预测疾病的发展趋势。
然而,临床诊断模型也存在一些挑战和限制。
首先,模型的构建需要大量的病例数据和专业知识,这对于一些罕见病或特殊疾病来说可能存在困难。
其次,模型建立过程中可能存在误差和偏差,因此医生需要谨慎地评估模型的结果,并结合自己的临床经验进行判断。
癌症疾病预测与诊断模型的构建与效果评估

癌症疾病预测与诊断模型的构建与效果评估近年来,癌症已成为全球范围内最为严重的疾病之一,给人们的健康和生活带来了巨大的威胁。
因此,早期癌症预测与诊断的准确性和及早性变得尤为重要。
随着人工智能和机器学习技术的迅猛发展,建立有效的癌症预测与诊断模型成为一种有前景的研究方向。
本文将针对癌症疾病预测与诊断模型的构建与效果评估进行探讨。
首先,构建癌症疾病预测与诊断模型的关键在于数据的选择和处理。
癌症疾病的研究数据通常来自于临床医院、医学研究机构和生物样本库等。
这些数据包括了患者的基本信息、临床表现、检查结果以及病理检查结果等多种类型的数据。
在构建模型之前,需对采集到的数据进行规范化和预处理,包括数据清洗、特征提取和特征选择等过程,以确保数据的准确性和一致性,同时减少模型的复杂度。
其次,选择合适的机器学习算法或深度学习模型对构建好的数据进行训练。
机器学习算法包括监督学习和无监督学习等多种方法,如决策树、支持向量机、逻辑回归等。
而深度学习模型如卷积神经网络(CNN)、循环神经网络(RNN)和长短时记忆网络(LSTM)等则适用于大规模数据集的训练与预测。
根据不同类型的癌症和数据特点,选择合适的算法模型进行训练,以提高预测的准确性和可靠性。
针对癌症疾病预测与诊断模型的效果评估,可以采用以下几种方法进行:1. 精确度评估:精确度是衡量模型分类性能的重要指标之一。
在癌症预测与诊断中,可根据模型的准确率、召回率、F1值等来评估模型的表现。
准确率指模型正确分类的样本数量与总样本数量之比,召回率指模型正确识别的癌症样本数量与实际癌症样本数量之比,F1值是综合准确率和召回率的综合评价指标。
2. ROC曲线:ROC曲线是评估二分类模型的性能的常用方法之一,反映了模型在不同阈值下假正例率和真正例率之间的平衡情况。
通过绘制ROC曲线并计算曲线下面积(AUC值),可以评估模型的分类能力,AUC值越接近1,模型的性能越好。
3. 交叉验证:交叉验证是一个常用的模型评估方法,通过将数据集分成多个训练集和测试集的组合进行多次训练和测试,以提高评估结果的准确性和稳定性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
疾病诊断的问题模型分析
答辩人:*** 导 师:*** 院 系:数学与计算机科学学院 日 期:2013.05.26
LOGO
疾病的背景及意义 1 背景
本科生论文报告
肾炎是一种免疫性疾病,是不同的抗原产生不 同的抗体,组合成不同的免疫复合物,在肾脏的 不同部位,造成的病理损伤,形成不同的肾炎类 型。随着医学技术的不断壮大,对疾病研究的专 业人才是越来越多,大量医学界的人士对疾病的 研究有了更多的认识,据统计100万人中大约有 上近百人是由于肾炎而危机生命,因此找出治疗 前正确的诊断方法是迫不眉睫的,诊断无论是对 医学还是对诊断的病人来说都是至关重要的。
论文的结构和主要内容 4主因素的选取
本科生论文报告
得出主要指标为Cu、Fe、Ca 回归模型方程式为 y 0.0164x2 0.0020x3 0.0004x3 0.9424
论文的结构和主要内容
本科生论文报告
பைடு நூலகம்结果验证
通过对表二进行分析可以看出,以7中元素为 样本数据和所得三种主要指标为样本,进行结果的 判别,与前面的相比,得到的还是有个别的差异. 虽然找出了影响人们患病的主要指标,可以使 医生化验的量减少,节约了很多的人力和物力,但 却简化后的模型难免会使模型的精度有所下降.例 如,对于33号待测数据,二中均确定为患病,但在 这问题四中却被判定为健康,这容易造成判别上的 误差,造成不可挽回的错误.这样就得到了一个比 较实用模型,即pc神经网络模型.
疾病的背景及意义 意义 有利于快速的检测出结果
本科生论文报告
有利于治疗的费用减少 有利于对医生辅助治疗
论文的目的
本科生论文报告
大夫给人们诊断是否患病时,一般都是要获 得人体的各种元素的含量. 附件一是对60个人的 诊断结果,前30个诊断为患者,后30个诊断为健 康者. 附件二测得的各元素的含量,并未诊断. 根据数据建立模型,能判别诊断的结果,检查 真确性及可行性; 对附件二的40组数据判别; 通过数据找出患病的主要指标; 通过主要指标诊断附件二的数据; 经过分析找出最好的模型。
X G1 , X G2 ,
当d 2 ( X , G1 ) d 2 ( X , G2 ) 当d 2 ( X , G1 ) d 2 ( X , G2 )
特别, 当时,则判的归属是无效的 . d 2 ( X , G1 ) d 2 ( X , G 2) 7 其中 i 1,2, K ,40 d ( X i , G ) ( xij ij ) 2 ( X i )( X i )'
论文的结构和主要内容
本科生论文报告
1 健康系数模型 样本到健康样本总体平均距离的1‰为该 样本的健康系数,即第个样本的健康系数为:
1 ki 1000
示意图
(x
j 1
7
ij
)
2
k
论文的结构和主要内容 2距离判别模型
本科生论文报告
设和为两总体,对于给定的样本,即7种元素的含量记作样本点,k 1,2 计算个 d ( X , Gi ), i欧氏距离,找出两者中小的一个,则判定 X样本来 自 , Gi0 , i0 1,2 即
j 1
示意图
G1总体 d(X,G1)
G2总体
d(X,G2)
样本点X
论文的结构和主要内容 3神经网络模型
本科生论文报告
BP算法叫误差反向向后神经网络算法,主要是通 过输出后的误差对输出层的直接前导层的误差进行估计 ,继续用此法来估计更前层的误差,如此一层一层的估 计下去,就得到了其他各层的误差估计,这样形成了正 向输入的方向与输出层估计得到误差有相反的方向,逐 级向网络的输入层递进的过程。
论文的结构和主要内容
第一部分 问题假设 第二部分 健康系数模型 第三部分 距离判别模型 第四部分 神经网络模型 第五部分 主元素的选取
本科生论文报告
论文的结构和主要内容 问题假设 在诊断所建立之前要所说明的情况:
本科生论文报告
论文里所提供的数据都是无疑义的; 除了在数据中的所需要的指标外,没有其他的元 素对之影响; 外部因素对患病的影响不计; 在这只有患肾炎的和健康的,其他的病不影响; 在这患病的各元素的含量不受其他病的影响; 在这测得数据的准确度很高,误差可以不计.
论文总结 1模型结果
本科生论文报告
由以上分析可得,三种模型检验准确率可以达到 86%以上,特别是通过pc神经网络模型,则检验准 确高达100%,可行度还是比较好的.一般的传统检 验方法不稳定,对诊断的结果有很大的影响,最坏 的是结局是还能诊断出错误的结果,因此需要诊断 的准确比较高的模型来进行诊断,基于欧氏距离判 别和神经网络就可以消除很大一部分误差.虽然建立 的模型较为简单,但是在模型的建立过程中,用剩 余的确定的数据样本来进行检验,从而保证了模型 的实用性和接近现实性,在这七种元素中,通过逐 步回归,求出主要元素,可以减少就诊过程中一些 繁琐的步骤,无论是给诊断的病人还是给大夫都带 来了很大的方便.为医生进行诊断有个很好的参考.
输入信号
连接权 链接权 W11 w1 W22 w2 激活函数 输出 激活函数 yk f ()
示意图
C1 C1 C2 C2
求和 求和
C7 C7 W77 w3
uk
bk
阈值或偏置
论文的结构和主要内容
本科生论文报告
3模型的比较
通过三种模型的比较,健康系数模型与距离判别模 型结果的吻合度 36/40=90%,距离判别模型与神经 网络模型结果的吻合度为39/40=97.5%,健康系数 模型与神经网络模型结果的吻合度为 35/40=87.5%,通过三种模型所得结果的比较与检 验的正确率判断可以得到神经网络模型最适合,且该 模型的效果也比较明显,故采用bp神经网络模型, 舍弃健康系数模型和距离判别模型.下面通过神经网 络来得到患病中的主要指标.
论文总结
本科生论文报告
2存在的问题 在这模型的运算过程中,由于数据量的限 制性,抽取的是总体中的部分样本量少来参 与模型的建立,用剩余的数据来进行验证, 难免会出现误判概率,而且建立的模型比较 简单,其适用复杂情行不太适合.所以建立的 模型在实际运用的过程中,会出现误差要慎 之又慎,不能盲目的得出结论,由此以模型 的诊断不能作为最终的结果,要从多角度的 来诊断.