生物信息学作业
小学生物生物信息学小测验

- A. GenBank
- B. RefSeq
- C. Ensembl
- D. UniProt
7.生物信息学中,将大量生物数据进行比较分析,以寻找生物学规律的方法称为____。
- A.数据挖掘
- B.统计分析
- C.机器学习
- D.比较基因组学
8.生物信息学中的生物标记物主要应用于____。
- A.疾病诊断
- B.疾病治疗
- C.疾病预防
- D.药物研发
9.生物信息学中的模式识别主要基于____。
- A.机器学习
- B.统计学
- C.计算机视觉
- D.人工智能
10.生物信息学中的数据标准化主要是为了解决____问题。
- A.数据质量
- B.数据重复
- C.数据异构
- D.数据缺失
##二、判断题(每题2分,共10分)
- B.疾病治疗
- C.疾病预防
- D.药物研发
8.生物信息学中的数据标准化主要是为了解决____问题。
- A.数据质量
- B.数据重复
- C.数据异构
- D.数据缺失
9.生物信息学中的同义词消歧主要是为了____。
- A.提高数据一致性
- B.提高数据多样性
- C.降低数据冗余
- D.增加数据噪声
小学生物生物信息学小测验
#小学生物信息学小测验
##一、选择题(每题2分,共20分)
1.生物信息学的定义是利用计算机技术对生物信息进行____。
- A.采集
- B.存储
- C.分析
- D.传播
2.下列哪个不属于生物信息学的研究领域?
生物信息学习题

一:名词解释1.生物信息学2.NCBI3.PubMed4.生物芯片5.BLAST6.UniProt7.电子克隆8.EMBL二:填空题1.基因芯片可以分为2. 人类基因组全序列分析分两大步骤即制图和测序,并最终绘制出四张图谱:3. 分子系统发生分析主要分为三个步骤即4. 国际上最主要的三大核酸序列数据库分别是5. 蛋白质得分矩阵有7. 文献是掌握科研进展的最直接方式,目前由NCBI维护的大型文献资源是。
3. 用于核酸序列比对中常见的三种得分矩阵,分别为4. 根据生物芯片探针分子类型的不同,可以将生物芯片哪三种,5. 核酸序列分析所获得的信息主要有(举例说明四个)6. 限制性酶切分析是分子生物学实验中的日常工作之一,这方面最好的限制酶数据库是三:选择题1、如果试图确定一个新蛋白质序列属于哪一个蛋白质家族,或该序列可能包含何种结构域或功能位点,应使用:()A: PROSITE数据库 B: DDBJ数据库C: PIR数据库 D: PDB数据库2、构建序列进化树的一般步骤不包括:()A:建立DNA文库 B:建立数据模型 C:建立取代模型 D:建立进化树3、BLAST教案所程序中,哪个方法是不存在的?()A:BLASTP B:BLASTN C:BLASTX D:BLASTQ4. 以下常见的几个物种,哪一个目前还没有完成全基因组测序:()A: 茶树 B: 玉米 C: 水稻 D: 小鼠5、向核酸序列数据库(GenBank/EMBL/DDBJ)提交数据,应该使用下面哪个软件:()。
A: Blast B:Sequin C:SRS D:Swiss-Model6、在蛋白质序列数据库中比较查询手头未知的蛋白质序列,应使用Blast中哪个具体的算法:()。
A:BLASTX B:tBLASTN C:BLASTP D:BLASTN7、下列中属于一级蛋白质结构数据库的是:()A:EMBL B:DDBJ C:PDB D:SWISS-PROT8、下面不属于SWISS-PROT蛋白质数据库的注释范畴的是:()A: 与其它蛋白质的相似性 B: 蛋白质的二级结构C: 由于缺乏该蛋白质而引起的疾病 D: 核酸的功能描述9、下列属于蛋白质二级结构预测的软件程序是()A: BLASTX B:SOPMA C:DNAstar D:GO10. 如果做DNA结构分析,应该考虑用下面哪个数据库:()A:GenBank B: PIR C:NDB D:UniProt四:简单题1.简述Entrez的设计概念和使用方法?2. 简述生物大分子PDB存储的生物分子种类和数据结构特点?3.简述生物信息学的研究意义?4 简述蛋白质序列分析的基本内容以及常用的软件?5. 简述Swiss-Prot的数据结构?6、简述序列多重比对的意义?7、简述生物信息学的发展历史?五:论述题1.论述蛋白质相互作用研究的意义,传统的实验方法和计算预测方法的应用?2.论述后基因组时代生物信息学面临的挑战和研究策略?3.论述生物信息学的应用?4. 论述如何利用基因芯片数据做聚类分析。
生物信息学作业(一)

生物信息学实验作业一1、了解NCBI、DDBJ、EMBL上网的方法自学各网站相关介绍。
答:(1)、NCBI: (National Center of Biotechnology Information,简称NCBI)美国国立生物技术信息中心。
其主页为:。
NCBI 是在NIH的国立医学图书馆(NLM)的一个分支。
NLM是因为它在创立和维护生物信息学数据库方面的经验被选择的,而且这可以建立一个内部的关于计算分子生物学的研究计划。
NCBI的任务是发展新的信息学技术来帮助对那些控制健康和疾病的基本分子和遗传过程的理解。
NCBI有一个多学科的研究小组包括计算机科学家,分子生物学家,数学家,生物化学家,实验物理学家,和结构生物学家,集中于计算分子生物学的基本的和应用的研究。
他们一起用数学和计算的方法研究在分子水平上的基本的生物医学问题。
这些问题包括基因的组织,序列的分析,和结构的预测。
在1992年10月,NCBI承担起对GenBank DNA序列数据库的责任。
NCBI 受过分子生物学高级训练的工作人员通过来自各个实验室递交的序列和同国际核酸序列数据库(EMBL和DDBJ)交换数据建立起数据库。
同美国专利和商标局的安排使得专利的序列信息也被整合。
BLAST是一个NCBI开发的序列相似搜索程序,还可作为鉴别基因和遗传特点的手段。
BLAST能够在小于15秒的时间内对整个DNA数据库执行序列搜索。
NCBI提供的附加的软件工具有:开放阅读框寻觅器(ORF Finder),电子PCR,和序列提交工具,Sequin和BankIt。
所有的NCBI数据库和软件工具可以从WWW 或FTP来获得。
NCBI还有E-mail服务器,提供用文本搜索或序列相似搜索访问数据库一种可选方法。
主要任务:(1)建立关于分子生物学,生物化学,和遗传学知识的存储和分析的自动系统(2)实行关于用于分析生物学重要分子和复合物的结构和功能的基于计算机的信息处理的,先进方法的研究(3)加速生物技术研究者和医药治疗人员对数据库和软件的使用。
生物信息学习题

第六章 分子系统发生分析(问题与练习)
1、构建系统发生树,应使用
A、BLAST
B、FASTA
C、UPGMA
D、Entrez
2、构建系统树的主要方法有
、
、
等。
3、根据生物分子数据进行系统发生分析有哪些优点?
4、在 5 个分类单元所形成的所有可能的有根系统发生树中,随机抽取一棵树是反映真实关
系的树的可能性是多少?从这些分类单元所有可能的无根系统发生树中,随机选择一棵
库
8、TreeBASE 系统主要用于
A、发现新基因 B、系统生物学研究 C、类群间系统发育关系研究 D、序列比对
二、 问答题
1、 为什么说 SWISS-PROT 是最重要的蛋白质一级数据库?
2、 构建蛋白质二级数据库的基本原则是什么?
3、 构建蛋白质二级数据库的主要方法有哪些?
4、 叙述 SCOP 数据库对蛋白质分类的主要依据
第八章 后基因组时代的生物信息学(问题与练习)
1、 比较生物还原论与生物综合论的异同 2、 简述“后基因组生物信息学”的基本研究思路 3、 后基因组生物信息学的主要挑战是什么? 4、 功能基因组系统学的基本特征是什么? 5、 说明后基因组生物信息学对信息流动的最新理解 6、 列举几种预测蛋白质-蛋白质相互作用的理论方法 7、 解释从基因表达水平关联预测蛋白质-蛋白质相互作用的理论方法 8、 解释基因保守近邻法预测蛋白质-蛋白质相互作用的理论方法 9、 解释基因融合法预测蛋白质-蛋白质相互作用的理论方法 10、解释种系轮廓发生法预测蛋白质-蛋白质相互作用的理论方法
1、蛋白质得分矩阵类型有 、
、、
和
等。
2、对位排列主要有局部比对和 三、运算题 1、画出下面两条序列的简单点阵图。将第一条序列放在 x 坐标轴上,将第二条序列放在 y
生物信息学作业

生物信息学试题
1、构建分子系统树的主要方法有哪些?并简要说明构建分子进化树
的一般步骤。
(20分)
答:(1)构建进化树的方法包括两种:一类是序列类似性比较,主
要是基于氨基酸相对突变率矩阵(常用PAM250)计算不同序列差异性积分作为它们的差异性量度(序列进化树);另一类在难以通过序
列比较构建序列进化树的情况下,通过蛋白质结构比较包括刚体结构
叠合和多结构特征比较等方法建立结构进化树
(2)序列比对——选取所需序列——软件绘制
具体如下:
a测序获取序列或者在NCBI上搜索所需的目的序列
b在NCBI上做blast:比对相似度较高的基因,并以fast格式下载,整合在*txt文档中。
c比对序列,比对序列转化成*meg格式
d打开保存的*meg格式文件,构建系统进化树
2、氨基酸序列打分矩阵PAM和BLOSUM中序号有什么意义?它们各自
的规律是什么?(10分)
(1)PAM矩阵:基于进化的点突变模型,如果两种氨基酸替换频繁,说明
自然界接受这种替换,那么这对氨基酸替换得分就高。
一个PAM就是一个进化的变异单位, 即1%的氨基酸改变。
BLOSUM矩阵:首先寻找氨基酸模式,即有意义的一段氨基酸片断,分别比
较相同的氨基酸模式之间氨基酸的保守性(某种氨基酸对另一种氨基酸的取代数据),然后,以所有60%保守性的氨基酸模式之间的比较数据为根据,产生BLOSUM60;以所有80%保守性的氨基酸模式之间的比较数据为根据,产生。
生物信息学作业
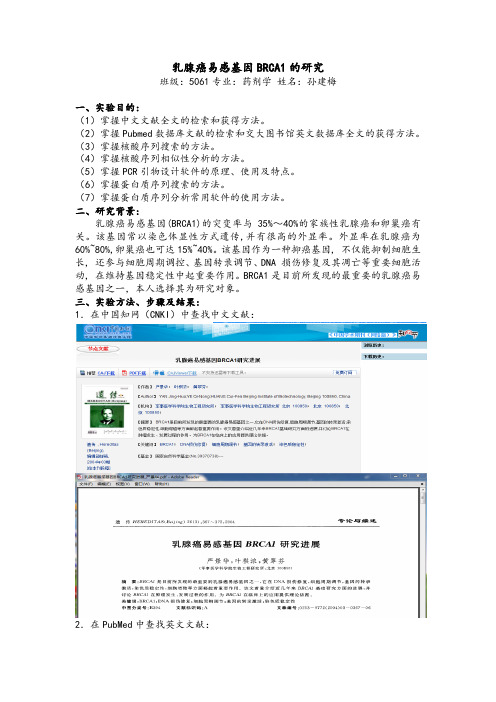
乳腺癌易感基因BRCA1的研究班级:5061专业:药剂学姓名:孙建梅一、实验目的:(1)掌握中文文献全文的检索和获得方法。
(2)掌握Pubmed数据库文献的检索和交大图书馆英文数据库全文的获得方法。
(3)掌握核酸序列搜索的方法。
(4)掌握核酸序列相似性分析的方法。
(5)掌握PCR引物设计软件的原理、使用及特点。
(6)掌握蛋白质序列搜索的方法。
(7)掌握蛋白质序列分析常用软件的使用方法。
二、研究背景:乳腺癌易感基因(BRCA1)的突变率与35%~40%的家族性乳腺癌和卵巢癌有关。
该基因常以染色体显性方式遗传,并有很高的外显率。
外显率在乳腺癌为60%~80%,卵巢癌也可达15%~40%。
该基因作为一种抑癌基因, 不仅能抑制细胞生长, 还参与细胞周期调控、基因转录调节、DNA 损伤修复及其凋亡等重要细胞活动, 在维持基因稳定性中起重要作用。
BRCA1是目前所发现的最重要的乳腺癌易感基因之一,本人选择其为研究对象。
三、实验方法、步骤及结果:1.在中国知网(CNKI)中查找中文文献:2.在PubMed中查找英文文献:3 在Genbank中查找BRCA1基因及其序列:登陆NCBI主页,网址:/guide/,选择gene数据库4. 使用NCBI网站中的BLAST工具进行序列比对登陆/,选择核酸序列比对nucleotide BLAST,界面显示如下,输入登录号,NM-007294.3,点击“BLAST”。
结果如下:与其匹配的核苷酸序列和基因组序列如下:1, mRNA”,登录号:NM_007294.3。
variant 2, mRNA”,登录号:NM_007300.3。
5.蛋白质序列的比对检索页面:结果输出:6. 根据序列,设计PCR引物:(1)利用peimer3进行引物设计登陆引物设计软件primer3网址/primer3/。
输入FASTA格式的核苷酸序列,运算得到:上游引物:5’caccctctgctctgggtaaa 3’下游引物:5’aagctcattcttggggtcct 3’产物:5680bp。
生物信息学作业1.doc

生物信息学实验作业试验一一.找到编码拟南芥(arabidopsis)phyA(光敏色素A)基因的核酸序列编号, 并记录查找过程。
GI:224576211步骤1.进入NCBI主页2.搜索arabidopsis phyA3.Arabidopsis thaliana phytochrome A (PHYA) gene, partial cds4.VERSION:GI:224576211二.以phyA为检索词,在pubmed数据库中分别检索在题目和关键词字段中含有该检索词的文献,记录检索出的条目数目。
Results: 614三.仔细阅读所查询核酸序列在NCBI和EMBL数据库中格式的解释,理解各字段的含义,并比较NCBI 与EMBL中序列格式的异同。
实验二一.分析你感兴趣核酸序列的分子质量、碱基组成。
Composition 35 A; 25 C; 35 G; 15 T; 0 OTHERPercentage: 32% A; 23% C; 32% G; 14% T; 0%OTHERMolecular Weight (kDa): ssDNA: 34.26 dsDNA: 67.8二.列出你所分析核酸序列(或部分序列)的互补序列、反向序列、反向互补序列、DNA双链序列和RNA 序列。
R S1 ACTACTCGAG AAGCAGCGAC AGAGGCGTTA GCCCGCTCAG CAGACTGGCA GTTCTCTACC61 GACAAAAAAG AGGTAGGAGG CACAGTAATG ATACAGGCGT AGCAGGAGGGC S1 CCCTCCTGCT ACGCCTGTAT CATTACTGTG CCTCCTACCT CTTTTTTGTC GGTAGAGAAC61 TGCCAGTCTG CTGAGCGGGC TAACGCCTCT GTCGCTGCTT CTCGAGTAGTR C S1 TGATGAGCTC TTCGTCGCTG TCTCCGCAAT CGGGCGAGTC GTCTGACCGT CAAGAGATGG61 CTGTTTTTTC TCCATCCTCC GTGTCATTAC TATGTCCGCA TCGTCCTCCCD DNA S1 GGGAGGACGA TGCGGACATA GTAATGACAC GGAGGATGGA GAAAAAACAG CCATCTCTTGCCCTCCTGCT ACGCCTGTAT CATTACTGTG CCTCCTACCT CTTTTTTGTC GGTAGAGAAC61 ACGGTCAGAC GACTCGCCCG ATTGCGGAGA CAGCGACGAA GAGCTCATCATGCCAGTCTG CTGAGCGGGC TAACGCCTCT GTCGCTGCTT CTCGAGTAGTRNA S1 GGGAGGACGA UGCGGACAUA GUAAUGACAC GGAGGAUGGA GAAAAAACAG CCAUCUCUUG61 ACGGUCAGAC GACUCGCCCG AUUGCGGAGA CAGCGACGAA GAGCUCAUCA三.列出核酸序列的限制性酶切位点分析结果(酶及识别位点)。
生物信息学习题

1单选(以下哪位科学家获得了两次诺贝尔奖?A.桑格(Frederick Sanger)B.沃森(James Waston)C.霍利(Robert W.Holley)D.克里克(Francis Crick)2单选(被称为“DNA之父”的是哪位科学家?A.摩尔根(Thomas H.Morgen)B.沃森(James Waston)C.查加夫(Erwin Chargaff)D.桑格(Frederick Sanger)3单选(被称为“计算机之父,人工智能之父”的是哪位科学家?A.莱布尼兹(Gottfried W Leibniz)B.图灵(Alan Mathison Turing)C.帕斯卡(Blaise Pascal)D.桑格(Frederick Sanger)4单选(被称为“现代实验生物学奠基人”的是哪位科学家?A.摩尔根(Thomas H.Morgen)B.达尔文(Charles Darwin)C.桑格(Frederick Sanger)D.孟德尔(Gregor J.Mendel)5单选(被称为“遗传学的奠基人,现代遗传学之父”的是哪位科学家A.孟德尔(Gregor J.Mendel)B.沃森(James Waston)C.查加夫(Erwin Chargaff)D.摩尔根(Thomas H.Morgen)1单选(从GenBank的哪一项注释中可以找到关于编码蛋白的信息?A.CDSB.SOURCEC.RBSD.ORIGIN2单选(以下关于GenBank的描述,哪个是正确的?A.GenBank里的一条数据库记录对应一个完整的基因。
B.真核生物的基因经常是分段存储在多条GenBank数据库记录里。
C.真核生物的基因都是整个存储在GenBank的一条数据库记录里。
D.原核生物的基因都是分片段存储在多条GenBank数据库记录里。
3多选(以下关系式正确的是?A.1T=1,000GB.1G=1,000MC.1G=1,000,000KD.1T=1,000,000M4(GenBank数据库中的检索号(Accession)和基因座名(Locus)指的都是一条序列在数据库中的编号,他们永远都是相同的。
生物信息学作业10

调和序列
1 Ⅰ Ⅱ Ⅲ Ⅳ Ⅴ Y Y F F Y y 2 D D E D E d 3 G G G G G 4 G G G G G G 5 A I I A A/I 6 V L L V 7 V V V 8 E E E Q Q 9 A A A A A 1 L L L V L
多序列比对的方法
同源性分析中常常要通过多序列比对来找出序列之间的相 互关系,和blast的局部匹配搜索不同,多序列比对大多 都是采用全局比对的算法。这样对于采用计算机程序的自 动多序列比对是一个非常复杂且耗时的过程,特别是序列 数目多,且序列长的情况下。
Clustal程序有许多版本。 Clustal是免费软件,很容易从互联网上下载,和其它软 件一起,广泛用于序列分析。Clustal所支持的数据格式包 括EMBL/SWISSPROT、PIR、Pearson/FastA以及 Clustal本身定义的格式。它的输出格式是Clustal格式。
FASTA格式
以上这个FASTA文件中包含了gi号码、GenBank检索号码、LOCUS名称、 以及GenBank记录中的DEFINATION字段。 第一行( 〉)表示一个新的序列文件的开始,为标记符。后面可以加上文 字说明, gi号码、GenBank检索号码、LOCUS名称等信息。 第二行 序列本身,为DNA或蛋白质的标准符号。通常核苷酸符号大小写 均可,而氨基酸一般用大写字母。
正因为存在这样的关系,很多时候对序列的相似性和 同源性就没有做很明显的区分,造成经常等价混用两个 名词。所以有出现A序列和B序列的同源性为80%一说。 不能把相似性和同源性混为一谈。所谓“具有50%同 源性”,或“这些序列高度同源”等说法,都是不确切 的,应该避免使用。
序列相似性比较和序列同源性分析
《生物信息学》题集

《生物信息学》题集一、选择题(每题3分,共30分)1.生物信息学的主要研究对象是什么?A. 蛋白质结构B. 基因序列C. 生态系统D. 细胞代谢2.下列哪项技术不是生物信息学中常用的数据库技术?A. BLASTB. GenBankC. PubMedD. SWISS-PROT3.在生物信息学中,进行多序列比对时常用的软件是什么?A. MATLABB. ClustalWC. ExcelD. PowerPoint4.哪种算法常用于基因表达数据的聚类分析?A. K-meansB. DijkstraC. A*D. Floyd5.生物信息学中,下列哪项不是常用的序列分析技术?A. PCRB. 测序C. 质谱分析D. 芯片技术6.下列哪项不是生物信息学在医学领域的应用?A. 疾病诊断B. 药物设计C. 天气预报D. 个性化医疗7.下列哪项技术常用于生物大分子的结构预测?A. NMRB. X射线衍射C. 同源建模D. 质谱分析8.在生物信息学中,下列哪项不是基因注释的内容?A. 基因功能B. 基因表达水平C. 基因在染色体上的位置D. 基因的长度9.下列哪项技术不是高通量测序技术?A. Sanger测序B. Illumina测序C. 454测序D. SOLiD测序10.下列哪项不是生物信息学在农业领域的应用?A. 作物育种B. 病虫害防治C. 土壤成分分析D. 农产品品质改良二、填空题(每题2分,共20分)1.生物信息学是一门交叉学科,它主要涉及______、计算机科学和数学等领域。
2.在生物信息学中,______技术常用于基因序列的相似性搜索。
3.生物信息学在药物研发中的主要应用包括______和药物靶点的预测。
4.在基因表达数据分析中,______是一种常用的数据标准化方法。
5.生物信息学中,______技术常用于蛋白质结构的预测和分析。
6.在生物信息学数据库中,GenBank主要存储的是______数据。
生物信息学作业2

生物信息学实验三1.了解什么是BLAST,它有哪些应用。
BLAST (Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具。
BLAST程序能迅速与公开数据库进行相似性序列比较。
BLAST结果中的得分是对一种对相似性的统计说明。
BLAST对一条或多条序列(可以是任何形式的序列)在一个或多个核酸或蛋白序列库中进行比对。
BLAST还能发现具有缺口的能比对上的序列。
2.请在NCBI中查找你感兴趣的某一基因或蛋白,通过BLAST工具检索与其高度相似的序列,并将你查到的这一基因或蛋白与你检索到的与其相似的序列(其中一条)的比对结果列出来,简单说明序列比对评分和检索过程。
Homo sapiens coagulation factor VIII, procoagulant component(F8), transcript variant 1, mRNA Length=9048Score = 398 bits (212), Expect = 1e-108Identities = 214/215 (99%), Gaps = 0/215 (0%)Strand=Plus/PlusQuery 15 GGAGCTGAATATGATGATCAGACCAGTCAAAGGGAGAAAGAAGATGATAAAGTCTTCCCT 74||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 559 GGAGCTGAATATGATGATCAGACCAGTCAAAGGGAGAAAGAAGATGATAAAGTCTTCCCT 618Query 75 GGTGGAAGCCATACATATGTCAGGCAGGTCCTGAAAGAGAATGGTCCAATGGCCTCTGAC 134||||||||||||||||||||| ||||||||||||||||||||||||||||||||||||||Sbjct 619 GGTGGAAGCCATACATATGTCTGGCAGGTCCTGAAAGAGAATGGTCCAATGGCCTCTGAC 678Query 135 CCACTGTGCCTTACCTACTCATATCTTTCTCATGTGGACCTGGTAAAAGACTTGAATTCA 194||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 679 CCACTGTGCCTTACCTACTCATATCTTTCTCATGTGGACCTGGTAAAAGACTTGAATTCA 738Query 195 GGCCTCATTGGAGCCCTACTAGTATGTAGAGAAGG 229|||||||||||||||||||||||||||||||||||Sbjct 739 GGCCTCATTGGAGCCCTACTAGTATGTAGAGAAGG 773Homo sapiens chromosome X genomic contig, GRCh37.p5 Primary AssemblyLength=6178498Score = 451 bits (240), Expect = 2e-124Identities = 242/243 (99%), Gaps = 0/243 (0%)Strand=Plus/MinusQuery 1 TTCTTCCTGCTATAGGAGCTGAATATGATGATCAGACCAGTCAAAGGGAGAAAGAAGATG 60||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 5139376 TTCTTCCTGCTATAGGAGCTGAATATGATGATCAGACCAGTCAAAGGGAGAAAGAAGATG 5139317Query 61 ATAAAGTCTTCCCTGGTGGAAGCCATACATATGTCAGGCAGGTCCTGAAAGAGAATGGTC 120||||||||||||||||||||||||||||||||||| ||||||||||||||||||||||||Sbjct 5139316 ATAAAGTCTTCCCTGGTGGAAGCCATACATATGTCTGGCAGGTCCTGAAAGAGAATGGTC 5139257Query 121 CAATGGCCTCTGACCCACTGTGCCTTACCTACTCATATCTTTCTCATGTGGACCTGGTAA 180||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 5139256 CAATGGCCTCTGACCCACTGTGCCTTACCTACTCATATCTTTCTCATGTGGACCTGGTAA 5139197Query 181 AAGACTTGAATTCAGGCCTCATTGGAGCCCTACTAGTATGTAGAGAAGGTAAGTGTATGA 240||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 5139196 AAGACTTGAATTCAGGCCTCATTGGAGCCCTACTAGTATGTAGAGAAGGTAAGTGTATGA 5139137Query 241 AAG 243|||Sbjct 5139136 AAG 5139134Homo sapiens chromosome X genomic contig, alternate assemblyHuRef SCAF_1103279188170, whole genome shotgun sequence Length=869535Score = 451 bits (240), Expect = 2e-124Identities = 242/243 (99%), Gaps = 0/243 (0%)Strand=Plus/MinusQuery 1 TTCTTCCTGCTATAGGAGCTGAATATGATGATCAGACCAGTCAAAGGGAGAAAGAAGATG 60||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 406733 TTCTTCCTGCTATAGGAGCTGAATATGATGATCAGACCAGTCAAAGGGAGAAAGAAGATG 406674Query 61 ATAAAGTCTTCCCTGGTGGAAGCCATACATATGTCAGGCAGGTCCTGAAAGAGAATGGTC 120||||||||||||||||||||||||||||||||||| ||||||||||||||||||||||||Sbjct 406673 ATAAAGTCTTCCCTGGTGGAAGCCATACATATGTCTGGCAGGTCCTGAAAGAGAATGGTC 406614Query 121 CAATGGCCTCTGACCCACTGTGCCTTACCTACTCATATCTTTCTCATGTGGACCTGGTAA 180||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 406613 CAATGGCCTCTGACCCACTGTGCCTTACCTACTCATATCTTTCTCATGTGGACCTGGTAA 406554Query 181 AAGACTTGAATTCAGGCCTCATTGGAGCCCTACTAGTATGTAGAGAAGGTAAGTGTATGA 240||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 406553 AAGACTTGAATTCAGGCCTCATTGGAGCCCTACTAGTATGTAGAGAAGGTAAGTGTATGA 406494Query 241 AAG 243|||Sbjct 406493 AAG 4064911)于NCBI下载一条序列(FASTA格式)2)在BLAST中载入该序列文件3)调节各参数4)点击BLAST进行比对3.理解BLAST不同参数的含义,以及如何调整和适用情况。
生物信息学作业

作业个人感觉entrez系统查询序列比SRS更精准,推荐用entrez完成作业。
1.Do a search for the 16S ribosomal RNA gene from Aeromonas hydrophila strainAE7.a.Give the search details that you used to find this sequence.b.What is the accession number?c.How many base pairs are in this sequence?d.When was the entry last modified?e.Is there another organism that produces the same gene? If so, name theorganism and show your evidence.答案:a.进入网址/Entrez,在搜索栏中输入“16Sribosomal RNA gene from Aeromonas hydrophila strain AE7”点击GO,在Nucleotide就能找到结果。
b.DQ855289c. 992 bpd. 21-AUG-2006e. there are a few organisms like Drosophila melanogaster and it was published onScience 316 (5831), 1625-1628 (2007)2.Search for the nucleotide sequence with accession number NM_013161.a.What organism is this sequence from?b.What is the accession number of the protein linked to this sequence?c.What is the function of this protein?d.Find a reference by Hjorth, et al, related to this protein. What is the PubMedID for this article?e.In your own words, briefly describe what the researchers reported in thearticle.答案:a.Rattus norvegicus (Norway rat)b. NP_037293.1c.The protein named Pancreatic triglyceride lipase (胰甘油三酯脂酶, PTL), is an enzyme ofdigestive system, which plays very important roles in the digestion and absorption of lipids. And there has new data suggested that PTL may be involved in the pathophysiology of TBI (脑外伤) and that PTL may be implicated in the proliferation (增殖) of astrocytes (星形胶质细胞) and the recovery of neurological outcomes.d. 8490016 Pancreatic lipase structure-function relationships by domain exchange (通过改变结构域来研究胰脂酶三级结构与功能的关系).e.试验通过交换古典人类胰脂肪酶(HPL)和几内亚猪胰脂肪酶相关蛋白2(GPLRP2)帽子区域设计嵌合突变体,测定两种嵌合体C-端磷脂酶与脂肪酶活性发现脂肪分解酵素在界面锚定和稳定的效应,这个嵌合体的动力学特性首次揭示了胰脂肪酶的界面稳定性取决于它的C端结构域的结构。
生物信息学作业题

生物信息学作业题生物信息学作业题绪论1.什么是生物信息学?2.生物信息学有哪些主要研究领域?第一章生物信息学的分子生物学基础1.DNA的双螺旋结构要点是什么?2.什么是基因组和蛋白质组?对它们的研究有何意义?第二章生物信息学的计算机基础1.简述网络操作系统的类型。
第三章核酸序列分析1.什么是全局比对?2.什么是局部比对?有哪些优点?第四章分子进化分析1.分子进化分析具有哪些优点?2. 简述分子进化的中性学说。
第五章基因组分析1. 什么是基因组学?其主要研究内容是什么?2.简述基因预测分析的一般步骤。
第六章蛋白质组分析1. 蛋白质组学的概念和主要研究的大致方向是什么?2. 蛋白质组功能预测的程序是怎样的?第七章生物芯片数据分析1. 什么是生物芯片?2. 生物芯片有哪些方面的应用?第八章核酸与蛋白质结构预测1. RNA二级结构典型的预测方法有哪些?2. 基于统计学的预测蛋白质二级结构的方法有哪些?第九章生物信息学平台与工具软件1. 请利用Clustal X软件对下列6条蛋白质序列进行多重比对(比对结果用BioEdit软件打开,用“截图”方式显示比对结果)。
>1mqngkvkwfn sekgfgfiev eggedvfvhf saiqgegfkt leegqevtfe veqgnrgpqatnvnkk>2mqgkvkwfnn ekgfgfieie gaddvfvhfs aiqgegykal eegqevsfdi tegnrgpqaanvvkl>3mqngkvkwfn sekgfgfiev eggedvfvhf saiqgegfkt leegqevtfe veqgnrgpqatnvnkk>4mqgkvkwfnn ekgfgfieie gaddvfvhfs aiqgegykal eegqevsfdi tegnrgpqaanvvkl>5mqngkvkwfn sekgfgfiev eggedvfvhf saiqgegfkt leegqevtfe veqgnrgpqatnvnkk>6mqgkvkwfnn ekgfgfieie gaddvfvhfs aiqgegykal eegqevsfdi tegnrgpqaanvvkl2. 现有一ZmPti1b蛋白质序列,请用DNAMAN软件分析其二级结构,给出分析结果。
生物信息学作业题目郝柏林

《生物信息学》作业题目(郝柏林)1、试估计地球上出现智人以来,人们所讲过的“字”的总和不超过10的多少次方?2、试计算10µg大肠杆菌基因组DNA样品中包含多少个DNA大分子?已知1个E. coli. 基因组DNA=4.64×106bp,1bp650 dalton(分子量);1molH 原子=N A个H原子=1g,N A =6×1023。
3、正态分布下,1-4个标准差()范围所覆盖的(即±1~4)概率分别为多少?4、假设赌场的骰子中99%是好的,即P(D fair)=99/100,1%是做过手脚的,即P(D load)=1/100,如果使用的是做过手脚的骰子,则出6点的概率为1/2。
问:(1)在投骰子时连续出了3个6点,你有多大把握说所用的骰子是做过手脚的?(2)如果你要用99%的把握说骰子是做过手脚的,则在投骰子时需要连续出多少个6点?5、某一序列为gtgcaatcagactgataattgccacgatcag(L=31),问该序列是否为CpG island?已知下列转移矩阵:a+ c+ g+ t+P (+)a+ 0.180 0.274 0.426 0.120c+ 0.171 0.367 0.274 0.188g+ 0.161 0.339 0.375 0.125t+ 0.079 0.355 0.384 0.1826、 从地点A 到地点B 有多条路线,每条路线都要收取(或得到)一定的过路费(如图):试问从地点A 到地点B 的哪条路线得钱最多?7、 请分别用动态规划法(dynamic programming )Needleman-Wunsch 和Smith-Waterman 算法对下列两条蛋白质序列进行联配,并写出联配方案: P1=HEAGAWGHEE, P2=PAWHEAE其中替换矩阵选用BLOSUM50(女生)和BLOSUM62(男生)(见下表,其中括号中的数字属于BLOSUM62),空位(gap)罚分设定为8(女生)和9(男生)。
生物信息学考查作业

作业分解
• 1、现有10条基因,全班分成10组,每组做 1条基因,每组4个人,每组16道题,每人 完成4道不同的题 • 2、要求:按照提供的gene accession number的分子质量、 碱基组成、碱基分布、酶切、简要过程 2.碱基同源性分析:网站如下:/BLAST/, 程序、参数、结果、简要过程 3.开放性阅读框分析:利用NCBI的ORF Finder程序对man做开放性阅读 框分析,网址如下: /projects/gorf/orfig.cgi要求:参数、结果、 简要过程 4.蛋白质序列的结构功能域分析:要求用简单模块构架搜索工具SMART 对上述ORF蛋白质序列进行结构功能域分析。网址如下: http://smart.embl-heidelberg.de/,要求结果、参数、简要过程 5.氨基酸同源分析:要求运用NCBI的BLAST程序对此蛋白质序列进行分 析:要求:参数、结果、过程 6.同源物种分析:要求根据上述分析列出该蛋白质的同源物种至少5个, 要求名称、学名 7.蛋白质一级序列的基本分析:要求运用BioEdit对该基因编码的蛋白质 基本信息如分子量、等电点、氨基酸组成等作出分析。 8.信号肽预测:要求利用signal p预测,分析结果、写出简要过程,网址 如下:http://www.cbs.dtu.dk/services/SignalP/
• • • • • •
• •
• •
• •
• •
nnpredict nnpredict 算法使用了一个双层、前馈神经网络去给每个氨基酸分配预测的类型(Kneller 等,1990)。在预测时,服务器使用 FASTA 格式的文件,其中 有单字符或三字符的序列以及蛋白质的折叠类(α 、β 或α /β )。残基被分为几类:α 螺旋(H)、β 叠片(E)或其它(-)。若无法对某残基给出预测, 则会标上问号(?),这说明无法做出可信的分配。若没有关于折叠类的信息,预测也能在不定折叠类的情况下进行,而且这是缺省的工作方式。 据报道,对于最佳实例的预测,nnpredict 的准确率超过了 65%。序列通过向 nnpredict@ 发送电子邮件或是填写网上的表提交给 nnpredict。 PredictProtein PredictProtein(Rost 等,1994)在预测中应用了略为不同的方法。首先,蛋白质序列被作为查询序列在 SWISS-PROT 库中搜索相似的序列。当相似的 序列被找到后,一个名为 MaxHom 的算法被用来进行一次基于特征简图的多序列比对(Sander 和 Schneider,1991)。 MaxHom 用迭代的方法来构造比对:当第一次搜索 SWISS-PROT 后,所有找到的序列与查询序列进行比对,并构造出一个比对后的特征简图。然后,这 个简图又被用来在SWISS-PROT 中搜索新的相似序列。由 MaxHom 产生的多序列比对随后被置入一个神经网络,用一套称为 PHD(Rost,1996)的方 法进行预测。PHD 这一套二级结构预测方法不仅仅给每个残基分配一个二级结构类型,它还对序列上每个位点的预测可信度给予统计分析。该方法的平均 准确率超过 72%,最佳残基预测准确率达 90%以上。 向 PredictProtein 提交数据可以通过电子邮件,也可以在网上提交。上交序列的时候可以有几种选择,序列可以是单个字母的氨基酸代码,也可以带 SWISS-PORT 标识符。另外,FASTA 格式的多序列比对或 PIR 比对也可以被提交,以进行二级结构预测。输入的序列发送给predictprotein@emblheidelberg.de。 输出结果内容很多并包含大量有关信息。其中有 MaxHom 搜索结果,并包括多序列比对的结果,它可以用于例如基于特征简图的搜索或物种谱系分析等 进一步研究。如果提交的序列在 PDB 库中有已知同源蛋白,则其 PDB标识号也会输出返回。随后是方法本身信息,最后是实际预测结果。输出结果还可 以被用户自己来指定。与 nnpredict 不同,PredictProtein 还返回每个位点的“预测可信度索引”,范围从 0 到 9,9 具有最高的可信度,也就是说该位点 所分配的二级结构类型是正确的 PREDATOR PREDATOR 算法通过对氨基酸序列中潜在的氢键残基的识别来预测二级结构。它使用源自数据库的统计数据,具体地说是对在不同种氢键结构中残基种 类出现的统计。这种方法的新特征是,它依靠局部的双序列比对来预测每个相关序列。这个程序的输入可以是单个序列,也可以是一组没经过比对的相关 序列。序列可以通过给predator@embl-heidelberg.de 发电子邮件或是在网上直接提交。输入序列可以是 FASTA、MSF 或 CLUSTER 格式。PREDATOR 对三种结构预测的平均准确率是,对单个序列为 68%,对一组相关的序列为 75%。 PSIPRED PSIPRED 方法是由英国 Warwick 大学开发的,使用 PSI-BLAST先在数据库中搜索序列的相似蛋白,构建多序列比对,然后进行预测。PSIPRED 用两 个前向神经网络对来自 PSI-BLAST 的特征图进行分析。序列可以通过互连网用简单的单字母格式或是 FASTA 格式提交,PSIPRED 的预测结果通过电 子邮件以文本文件形式发送回来。另外,在电子邮件中会给出一个网址,到那里可以看到被预测蛋白质的图象表示,可视化是用 JAVA 应用程序 PSIPREDview 实现的。PSIPRED 的平均预测准确率为 76.5%,比这里介绍的其它方法都要高。 SOPMA 位于法国里昂的 CNRS ( Centre National de la RechercheScientifique)使用独特的方法进行蛋白质二级结构预测。它不是用一种,而是5种相互独立的 方法进行预测,并将结果汇集整理成一个“一致预测结果”。这5种方法包括:Garnier-Gibrat-Robson(GOR)方法(Garnier等,1996)、Levin同源预 测方法(Levin等,1986)、双重预测方法(Deléage和Roux,1987)、作为前面PredictProtein一部分的PHD方法和CNRS自己的SOPMA方法 (Geourjon和Déleage,1995)。SOPMA这种自优化的预测方法简要的建立了已知二级结构序列的次级数据库,库中的每个蛋白质都经过基于相似性的 二级结构预测。然后用次级库中得到的信息去对查询序列进行二级结构预测。
生物信息学作业
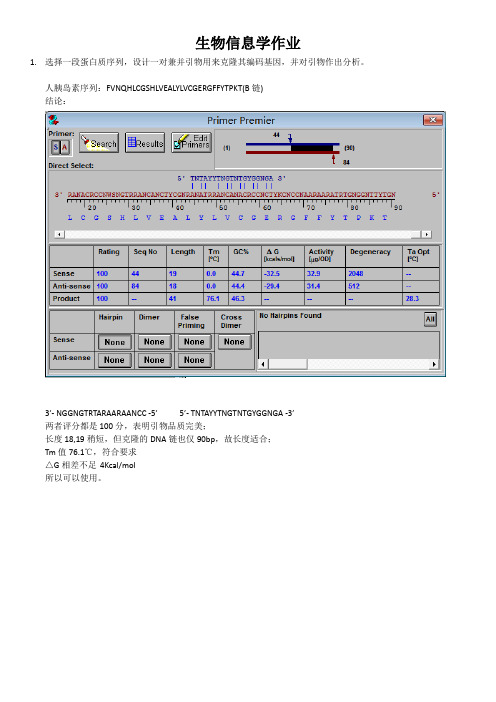
生物信息学作业1.选择一段蛋白质序列,设计一对兼并引物用来克隆其编码基因,并对引物作出分析。
人胰岛素序列:FVNQHLCGSHLVEALYLVCGERGFFYTPKT(B链)结论:3’- NGGNGTRTARAARAANCC -5’ 5’- TNTAYYTNGTNTGYGGNGA -3’两者评分都是100分,表明引物品质完美;长度18,19稍短,但克隆的DNA链也仅90bp,故长度适合;Tm值76.1℃,符合要求△G相差不足4Kcal/mol所以可以使用。
Step1:打开primer premier 5.0 输入蛋白质链,转化为DNA链。
获得DNA链。
2.选择一段基因,预测期编码RNA的二级结构,并分析功能。
取一段基因:ACGCG GGCGG GCATG TGGGC AGCTT TACCC AGTGC TACTG TGCTG GCCAGCACTG AAACA GGGGC ACTGG TTTGG GGTGG ATGAA GGGTA GAAGT GCAAGTTCCA TTGCC TGTGC AATCC CTGCC TTGCT CAGAC CCTGC TCACT CCTCAGGCCC CATCA GCCCC TCAAC TCTGC TAACC ATGGT GGTAG AAATC AGCTACAATA AACCC TGGAG CCAGT AAAAA AAAAA AAAAA AAAAA AAAAA AAAGT点击Fold as RNA点击START点击Draw Stuclture得到RNA二级结构RNA功能预测打开网址http://sidirect2.rnai.jp/输入DNA序列得出结论:。
《生物信息学》课程期末作业

山东大学生命科学学院2012~2013学年第一学期期末考试试卷(研究实践型)考试科目: 《生物信息学》适用类别: 本科院系:生命科学学院专业:年级:2010级姓名:kengnidiancom学号:第1页,共22页考试说明和要求1.试卷内容布局包括七部分:目录、引言、实践资源(使用的软件和数据库)、实践方法、实践结果和讨论、参考文献、心得与致谢。
(要求使用此论文模板创建规范统一答卷,详见模板使用说明,请从此模板第3页开始答卷;参考文献要求借助专业软件按《微生物学报》样式统一进行参考文献格式化;请于12月23日前提交电子版(发至邮箱:lzf-204@)和请于12月25-26日提交纸质版(微生物楼北楼玻璃房377室)答卷;团队讨论或受他人帮助请在致谢中说明体现)2.实践素材:完整目的基因groel被克隆入表达载体PET-32a的Nde I与Hind III酶切位点切点中,得到重组克隆PET-32a-groel,利用载体通用引物“T7 promoter”和“T7 terminator primer #69337-3”对重组克隆进行测序,得到序列采集结果“PET-32a-groel__T7.ab1”和“PET-32a-groel__T7ter.scf”。
3.实践要求:(实践方法和结果部分请提供说明问题的关键截图)●对序列采集结果“PET-32a-groel__T7.ab1”和“PET-32a-groel__T7ter.scf”进行基本处理,得到无污染的完整目的基因groel,结果中展示最终的contig装配截图;●设计合适的引物,实现将完整目的基因groel克隆插入表达载体PET-32a的Nde I与HindIII酶切位点的切点中,结果中展示引物参数信息及待送公司合成的引物序列订单;●参考“pET-32a”图谱及其序列文件,绘制(用作测序模板的)重组克隆PET-32a-groel的载体图谱,生成重组载体图谱PET-32a-groel.vec并在结果中展示导出的PET-32a-groel 图谱;●参考“groel information.txt”信息,将得到的完整目的基因groel模拟提交数据库,生成groel.sqn文件并在结果中展示完整的内容信息。
《生物信息学》上机作业

《生物信息学》上机作业题目:对人血红蛋白(HBA1)编码基因序列的生物信息分析目录引言 .............................................................................................................................................. - 1 -1 正文......................................................................................................................................... - 2 -1.1 NCBI上对相关核苷酸序列的查找............................................................................ - 2 -1.2 BLAST运行及其结果.................................................................................................. - 2 -1.3 BLASTX运行及其结果................................................................................................ - 6 -2 其他软件的运行及其结果..................................................................................................... - 8 -2.1 Clustal W运行及其结果 ............................................................................................. - 9 -2.2 MEGA4.0运行及其结果............................................................................................. - 10 -结论 ............................................................................................................................................ - 10 -引言血红蛋白又称血色素,是红细胞的主要组成部分,能与氧结合,运输氧和二氧化碳。
《生物信息学》练习题及答案

《生物信息学》练习题及答案1、在Genbank中查找以下6个植物蛋白序列:protein1:NP_974673.2;protein2:NP_187969.1;protein3: NP_190855.1;protein4:NP_565618.1;protein5: NP_200511.1;protein6:NP_191407.1(以FASTA格式)。
(1)用EBI上的ClustalW2工具对其进行多序列比对,分析各蛋白序列之间的同源性。
序列比对结果比对结果表明:protein1:NP_974673.2和protein4: NP_565618.1的亲缘关系最近。
(2)利用Phylip软件,选择距离法构建其进化树(要求写出具体的建树步骤)。
1.将蛋白序列保存为FASTA格式,存于txt文档;2.用Clustalx打开txt文本,保存为*.phy文件;3.用seqboot程序打开phy文件,输出结果文件*_seqboot4.用protdist程序打开*_seqboot文件,输出为*_protdist文件5.用neighbor程序打开*_protdist文件,输出为*_neighbor 文件6.用consense程序打开*_neighbor文件,输出为*_consense 文件7.用dratree程序打开*_consense文件得到进化树。
(注:由于seqboot软见无法正常运行,因此进化树无法显示)(3)任意选取其中的一个蛋白进行蛋白质一级序列分析、二级结构预测及三维结构的模拟。
选择protein3:NP_190855.1一级结构网址:/doc/479b86d06edb6f1afe001f6e.html /tools/protparam.htmlNumber of amino acids:456氨基酸数目Molecular weight:51154.5相对分子质量Theoretical pI:8.69理论pI值Amino acid composition氨基酸组成Ala(A)306.6%Arg(R)286.1%Asn(N)153.3%Asp(D)275.9%Cys(C)51.1%Gln(Q)183.9%Glu(E)286.1%Gly(G)378.1%His(H)163.5%Ile(I)163.5%Leu(L)429.2%Lys(K)327.0%Met(M)51.1%Phe(F)173.7%Pro(P)163.5%Ser(S)4610.1%Thr(T)214.6%Trp(W)81.8%Tyr(Y)194.2%Val(V)306.6%Pyl(O)00.0%Sec(U)00.0%(B)00.0%(Z)00.0%(X)00.0%正/负电荷残基数Total number of negatively charged residues(Asp+Glu): 55Total number of positively charged residues(Arg+Lys): 60Atomic composition:原子组成Carbon C2270Hydrogen H3531Nitrogen N645Oxygen O686Sulfur S10Formula:C2270H3531N645O686S10分子式Total number of atoms:7142总原子数Extinction coefficients:消光系数Extinction coefficients are in units of M-1cm-1,at280 nm measured in water.Ext.coefficient72560Abs0.1%(=1g/l)1.418,assuming all pairs of Cys residues form cystines Ext.coefficient72310Abs0.1%(=1g/l) 1.414,assuming all Cys residues are reducedEstimated half-life:半衰期The N-terminal of the sequence considered is M(Met). The estimated half-life is:30hours(mammalian reticulocytes,in vitro).>20hours(yeast,in vivo).>10hours(Escherichia coli,in vivo).Instability index:不稳定系数The instability index(II)is computed to be48.99This classifies the protein as unstable.Aliphatic index:75.26脂肪系数Grand average of hydropathicity(GRAVY):-0.554总平均亲水性蛋白质亲疏水性分析所用氨基酸标度信息Ala:1.800Arg:-4.500Asn:-3.500Asp:-3.500Cys:2.500 Gln:-3.500Glu:-3.500Gly:-0.400His:-3.200Ile:4.500 Leu:3.800Lys:-3.900Met:1.900Phe:2.800Pro:-1.600 Ser:-0.800Thr:-0.700Trp:-0.900Tyr:-1.300Val: 4.200:-3.500:-3.500:-0.490分析所用参数信息Weights for window positions1,..,9,using linear weight variation model:1234567891.001.001.001.001.001.001.001.001.00edge center edge跨膜结构预测结果(没有跨膜结构)信号肽分析:二级结构预测三级结构预测网站/doc/479b86d06edb6f1afe001f6e.html/~phyre2、在拟南芥基因组数据库中(/doc/479b86d06edb6f1afe001f6e.ht ml/)查找编号分别为At4G33050,At3G13600,At3G52870或At2G26190基因,针对所查找的基因进行初步的生物信息学分析(每人任选其中一个基因)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
CDK2基因和蛋白质序列的生物信息学分析姓名:学号:专业:1前言细胞周期蛋白依赖激酶2(cyclin-dependent kinase 2,CDK2),又名细胞分裂激酶2(cell division kinase 2)或p33蛋白激酶(p33 protein kinase),其基因定位于人类基因组的12号染色体上的q13染色带上。
CDK2基因全长6013bp,这部分中有7个外显子和6个内含子,7个外显子的长度依次为353bp、78bp、121bp、171bp、102bp、204bp、1264bp(可依次记为外显子1-7)。
在翻译过程中,该基因转录成的mRNA的外显子1的前137bp和外显子7的后1159bp不进行翻译,属于调控序列。
mRNA上只有中间的部分编码蛋白质。
CDK2基因可以转录为两种mRNA。
其中,变体1长度为2325bp,编码298个氨基酸;变体2长度为2223bp,编码264个氨基酸。
这两种蛋白质为CDK2的同型蛋白,功能相同,具有调控细胞分裂的功能,主要在G1期到S期和S期到G2期这两个阶段起作用。
CDK2广泛分布在生物体的各种细胞的胞质溶胶和细胞核质中,但只在进行分裂的细胞中行使功能,这是因为CDK2只有与不同的细胞周期蛋白(cyclin)结合后才具有活性。
CDK2可以与细胞周期蛋白A、B1、B3、E等结合后,参与细胞周期调控。
由于CDK2在细胞内的数量变化有可能导致细胞周期异常而产生癌症,故CDK2基因可以被看作癌基因,其活性和表达量可以作为衡量癌症的指标。
CDK2与周期蛋白E的复合体不仅能直接参与中心体复制的起始调控,还能与类Rb蛋白p107或转录因子E2F结合,促进细胞从G1期向S期转化或调控DNA复制有关的基因转录。
而CDK2与周期蛋白A的复合体可以增强DNA复制因子RF-A的活性。
在CDK2分子中,被称为T环的氨基酸环阻断了活性部位,妨碍激酶履行它的酶功能,而且活性部位的氨基酸形成一种难于为蛋白质结合的形状。
CDK2与周期蛋白结合时,周期蛋白将T环转出2nm以上,又将CDK2中的PSTAIRE螺旋部分转了, 并把活性部位氨基酸变成能与底物蛋白结合的正确构象。
CDK2的活性不仅与周期蛋白有关,还与其上的Thr-15、Tyr-15、Thr-160三个位点是否磷酸化有关。
一般情况下,与周期蛋白结合的CDK2的上述三个位点被Wee/Mik1和CAK激酶磷酸化,但此时复合体还没有活性,只有当Cdc25c将Thr-15、Tyr-15两个位点去磷酸化后,复合体才有活性。
细胞中存在多种因子对CDK2进行修饰调节,此外还存在对其活性起负性调控的蛋白质,即CDK激酶抑制物,例如p21CIP/WAF1、p27KIP2等。
前面提到,CDK2基因转录的产物有两种。
这两种mRNA的不同之处在于变体1由全部7个外显子组成,而变体2缺失外显子5,由剩余的6个外显子组成。
这样翻译成的两种同型蛋白的长度就相差34个氨基酸。
2 材料和方法:2.1序列数据来源采用蛋白质名称对NCBI非冗余蛋白质数据库进行检索,CDK2蛋白的记录有1013个。
而采用基因名称对NCBI非冗余核酸数据库进行检索,CDK2蛋白的记录有680个。
采用人(Homo sapiens)的CDK2蛋白序列进行BLAST搜索。
2.2序列分析方法2.2.1 序列比对方法将以上序列数据以fasta格式作成一个文件后,用ClustalX2进行全序列自动比对。
比对过程中采取自动比对和手动比对相结合,输出格式为Clustal格式(.aln)。
2.2.2分子系统发育分析方法用MEGA4.0(Molecular Evolutionary Genetics Analysis 4.0)进行系统发育分析。
采用MEGA4.0的邻接法(Neighbor-joining method, NJ)和最大简约法(Maximum parsimony method, MP)建树。
NJ方法中采用Poission校正的氨基酸取代模型,在MP方法中采用CNI的方法搜索最简约树。
在两种方法中对空位的处理都采取全部删除(Complete deletion)策略,同时采用自举检验(bootstrap test,重抽样500次)估计系统树中结点的置信值(BCL值)。
2.2.3蛋白质家族和基序与结构域分析方法所研究蛋白质在PFAM、PROSITE等蛋白质二次数据库中的分类情况2.2.4蛋白质三级结构与结构分类分析所研究蛋白质在蛋白质结构数据库中的分类情况3 结果3.1 序列的查询情况CDK2在HomoloGene数据库中只有1条记录,即:HomoloGene:74409. Gene conserved in Eukaryota,其中有18个物种的19条蛋白质序列。
3.2 序列的比对情况从19条蛋白质序列的比对结果可以看出,这些序列的高度同源区较多,大致可分为7个区域。
这些区域的序列有较高的保守性,是蛋白质的功能区。
个别序列有十几到几十个长度不等的插入序列,这可能与蛋白质的外显子剪接或编码基因的突变有关,这一区域在功能上的作用较小。
以蛋白质的起始氨基酸为例,19条序列的起始氨基酸均为甲硫氨酸,但比对的结果却是有5条序列的的前几个氨基酸被认为是插入的。
这可能的原因是如果认为19条序列的起始氨基酸均为甲硫氨酸,则其中有5个因为会给比对体系带来过多的空位,从而降低了整个体系的评分。
3.3 序列之间的遗传距离DescriptionData Type : Amino acid Analysis : Pairwise distance calculation ->Compute : Distances only Include Sites : ->Gaps/Missing Data : Complete DeletionSubstitution Model : ->Model : Amino: Poisson correction ->Substitutions to Include : All ->Pattern among Lineages : Same (Homogeneous) ->Rates among sites : Uniform ratesNo. of Sites : 284 d : Estimate[1] Homo_sapiens [2] Pan_troglodytes [3] Canis_familiaris [4] Bos_taurus [5] Mus_musculus [6] Rattus_norvegicus [7] Danio_rerio [8] Drosophila_melanogaster [9] Anopheles_gambiae [10] Schizosaccharomyces_pombe[11] Saccharomyces_cerevisiae [12] Kluyveromyces_lactis [13] Ashbya_gossypii [14] Magnaporthe_grisea[15] Neurospora_crassa [16] Arabidopsis_thaliana [17]Oryza_sativa_1 [18]Oryza_sativa_2 [19] Plasmodium_falciparum[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18][ 1][ 2] 0.000[ 3] 0.011 0.011[ 4] 0.014 0.014 0.011[ 5] 0.011 0.011 0.007 0.004[ 6] 0.011 0.011 0.007 0.004 0.000[ 7] 0.100 0.100 0.088 0.092 0.092 0.092[ 8] 0.423 0.423 0.434 0.434 0.434 0.434 0.439[ 9] 0.507 0.507 0.501 0.507 0.501 0.501 0.496 0.429[10] 0.391 0.391 0.402 0.402 0.397 0.397 0.413 0.519 0.606[11] 0.456 0.456 0.456 0.450 0.456 0.456 0.450 0.568 0.568 0.413[12] 0.484 0.484 0.484 0.478 0.484 0.484 0.478 0.549 0.580 0.407 0.124[13] 0.462 0.462 0.462 0.462 0.462 0.462 0.450 0.561 0.586 0.407 0.136 0.088[14] 0.391 0.391 0.402 0.402 0.397 0.397 0.423 0.531 0.586 0.351 0.331 0.321 0.297[15] 0.381 0.381 0.386 0.381 0.386 0.386 0.407 0.519 0.580 0.361 0.316 0.326 0.316 0.104[16] 0.366 0.366 0.366 0.366 0.366 0.366 0.356 0.525 0.531 0.445 0.467 0.473 0.467 0.423 0.402[17] 0.361 0.361 0.361 0.371 0.371 0.371 0.366 0.543 0.549 0.434 0.456 0.467 0.445 0.381 0.381 0.173[18] 0.407 0.407 0.402 0.397 0.397 0.397 0.402 0.599 0.561 0.439 0.467 0.473 0.456 0.423 0.402 0.164 0.168[19] 0.462 0.462 0.462 0.467 0.462 0.462 0.467 0.612 0.638 0.574 0.543 0.543 0.549 0.537 0.561 0.434 0.439 0.4563.4 序列/物种之间的系统发生重建结果分子系统发育分析结果中NJ法和MP法分析结果见图1及2。
Homo sapiensPan troglodytesMus musculusRattus norvegicusBos taurusCanis familiarisDanio rerioDrosophila melanogasterAnopheles gambiaeSchizosaccharomyces pombeMagnaporthe griseaNeurospora crassaSaccharomyces cerevisiaeKluyveromyces lactisAshbya gossypiiOryza sativa 1Arabidopsis thalianaOryza sativa 2Plasmodium falciparum 图1:CDK2蛋白分子进化树:NJ(Neighbor joining)分析,分枝上显示的数字是Bootstap检验获得的BCL (bootstrap confidence level) 值。