生物信息学课程作业
生物信息学课后题及答案

生物信息学课后习题及答案(由10级生技一、二班课代表整理)一、绪论1.你认为,什么是生物信息学?采用信息科学技术,借助数学、生物学的理论、方法,对各种生物信息(包括核酸、蛋白质等)的收集、加工、储存、分析、解释的一门学科。
2.你认为生物信息学有什么用?对你的生活、研究有影响吗?(1)主要用于:在基因组分析方面:生物序列相似性比较及其数据库搜索、基因预测、基因组进化和分子进化、蛋白质结构预测等在医药方面:新药物设计、基因芯片疾病快速诊断、流行病学研究:SARS、人类基因组计划、基因组计划:基因芯片。
(2)指导研究和实验方案,减少操作性实验的量;验证实验结果;为实验结果提供更多的支持数据等材料。
3.人类基因组计划与生物信息学有什么关系?人类基因组计划的实施,促进了测序技术的迅猛发展,从而使实验数据和可利用信息急剧增加,信息的管理和分析成为基因组计划的一项重要的工作。
而这些数据信息的管理、分析、解释和使用促使了生物信息学的产生和迅速发展。
4简述人类基因组研究计划的历程。
通过国际合作,用15年时间(1990-2005)至少投入30亿美元,构建详细的人类基因组遗传图和物理图,确定人类DNA的全部核苷酸序列,定位约10万基因,并对其他生物进行类似研究。
1990,人类基因组计划正式启动。
1996,完成人类基因组计划的遗传作图,启动模式生物基因组计划。
1998完成人类基因组计划的物理作图,开始人类基因组的大规模测序。
Celera公司加入,与公共领域竞争启动水稻基因组计划。
1999,第五届国际公共领域人类基因组测序会议,加快测序速度。
2000,Celera公司宣布完成果蝇基因组测序,国际公共领域宣布完成第一个植物基因组——拟南芥全基因组的测序工作。
2001,人类基因组“中国卷”的绘制工作宣告完成。
2003,中、美、日、德、法、英等6国科学家宣布人类基因组序列图绘制成功,人类基因组计划的.目标全部实现。
2004,人类基因组完成图公布。
生物信息学作业(一)

生物信息学实验作业一1、了解NCBI、DDBJ、EMBL上网的方法自学各网站相关介绍。
答:(1)、NCBI: (National Center of Biotechnology Information,简称NCBI)美国国立生物技术信息中心。
其主页为:。
NCBI 是在NIH的国立医学图书馆(NLM)的一个分支。
NLM是因为它在创立和维护生物信息学数据库方面的经验被选择的,而且这可以建立一个内部的关于计算分子生物学的研究计划。
NCBI的任务是发展新的信息学技术来帮助对那些控制健康和疾病的基本分子和遗传过程的理解。
NCBI有一个多学科的研究小组包括计算机科学家,分子生物学家,数学家,生物化学家,实验物理学家,和结构生物学家,集中于计算分子生物学的基本的和应用的研究。
他们一起用数学和计算的方法研究在分子水平上的基本的生物医学问题。
这些问题包括基因的组织,序列的分析,和结构的预测。
在1992年10月,NCBI承担起对GenBank DNA序列数据库的责任。
NCBI 受过分子生物学高级训练的工作人员通过来自各个实验室递交的序列和同国际核酸序列数据库(EMBL和DDBJ)交换数据建立起数据库。
同美国专利和商标局的安排使得专利的序列信息也被整合。
BLAST是一个NCBI开发的序列相似搜索程序,还可作为鉴别基因和遗传特点的手段。
BLAST能够在小于15秒的时间内对整个DNA数据库执行序列搜索。
NCBI提供的附加的软件工具有:开放阅读框寻觅器(ORF Finder),电子PCR,和序列提交工具,Sequin和BankIt。
所有的NCBI数据库和软件工具可以从WWW 或FTP来获得。
NCBI还有E-mail服务器,提供用文本搜索或序列相似搜索访问数据库一种可选方法。
主要任务:(1)建立关于分子生物学,生物化学,和遗传学知识的存储和分析的自动系统(2)实行关于用于分析生物学重要分子和复合物的结构和功能的基于计算机的信息处理的,先进方法的研究(3)加速生物技术研究者和医药治疗人员对数据库和软件的使用。
生物信息学作业

生物信息学试题
1、构建分子系统树的主要方法有哪些?并简要说明构建分子进化树
的一般步骤。
(20分)
答:(1)构建进化树的方法包括两种:一类是序列类似性比较,主
要是基于氨基酸相对突变率矩阵(常用PAM250)计算不同序列差异性积分作为它们的差异性量度(序列进化树);另一类在难以通过序
列比较构建序列进化树的情况下,通过蛋白质结构比较包括刚体结构
叠合和多结构特征比较等方法建立结构进化树
(2)序列比对——选取所需序列——软件绘制
具体如下:
a测序获取序列或者在NCBI上搜索所需的目的序列
b在NCBI上做blast:比对相似度较高的基因,并以fast格式下载,整合在*txt文档中。
c比对序列,比对序列转化成*meg格式
d打开保存的*meg格式文件,构建系统进化树
2、氨基酸序列打分矩阵PAM和BLOSUM中序号有什么意义?它们各自
的规律是什么?(10分)
(1)PAM矩阵:基于进化的点突变模型,如果两种氨基酸替换频繁,说明
自然界接受这种替换,那么这对氨基酸替换得分就高。
一个PAM就是一个进化的变异单位, 即1%的氨基酸改变。
BLOSUM矩阵:首先寻找氨基酸模式,即有意义的一段氨基酸片断,分别比
较相同的氨基酸模式之间氨基酸的保守性(某种氨基酸对另一种氨基酸的取代数据),然后,以所有60%保守性的氨基酸模式之间的比较数据为根据,产生BLOSUM60;以所有80%保守性的氨基酸模式之间的比较数据为根据,产生。
生物信息学作业
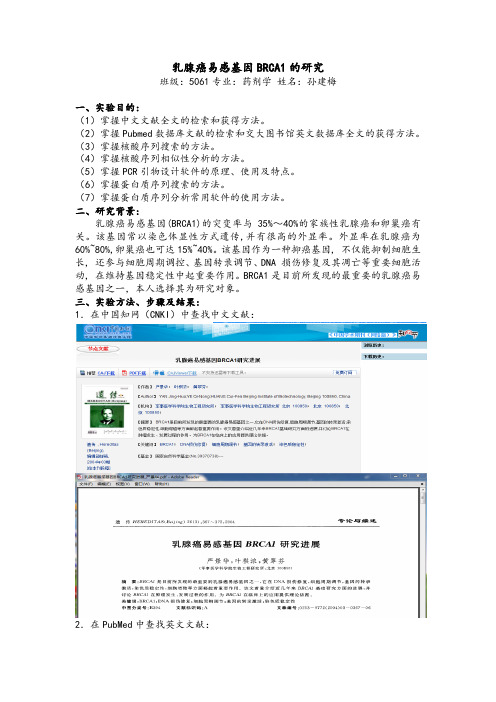
乳腺癌易感基因BRCA1的研究班级:5061专业:药剂学姓名:孙建梅一、实验目的:(1)掌握中文文献全文的检索和获得方法。
(2)掌握Pubmed数据库文献的检索和交大图书馆英文数据库全文的获得方法。
(3)掌握核酸序列搜索的方法。
(4)掌握核酸序列相似性分析的方法。
(5)掌握PCR引物设计软件的原理、使用及特点。
(6)掌握蛋白质序列搜索的方法。
(7)掌握蛋白质序列分析常用软件的使用方法。
二、研究背景:乳腺癌易感基因(BRCA1)的突变率与35%~40%的家族性乳腺癌和卵巢癌有关。
该基因常以染色体显性方式遗传,并有很高的外显率。
外显率在乳腺癌为60%~80%,卵巢癌也可达15%~40%。
该基因作为一种抑癌基因, 不仅能抑制细胞生长, 还参与细胞周期调控、基因转录调节、DNA 损伤修复及其凋亡等重要细胞活动, 在维持基因稳定性中起重要作用。
BRCA1是目前所发现的最重要的乳腺癌易感基因之一,本人选择其为研究对象。
三、实验方法、步骤及结果:1.在中国知网(CNKI)中查找中文文献:2.在PubMed中查找英文文献:3 在Genbank中查找BRCA1基因及其序列:登陆NCBI主页,网址:/guide/,选择gene数据库4. 使用NCBI网站中的BLAST工具进行序列比对登陆/,选择核酸序列比对nucleotide BLAST,界面显示如下,输入登录号,NM-007294.3,点击“BLAST”。
结果如下:与其匹配的核苷酸序列和基因组序列如下:1, mRNA”,登录号:NM_007294.3。
variant 2, mRNA”,登录号:NM_007300.3。
5.蛋白质序列的比对检索页面:结果输出:6. 根据序列,设计PCR引物:(1)利用peimer3进行引物设计登陆引物设计软件primer3网址/primer3/。
输入FASTA格式的核苷酸序列,运算得到:上游引物:5’caccctctgctctgggtaaa 3’下游引物:5’aagctcattcttggggtcct 3’产物:5680bp。
生物信息学习题(2010-7)

生物信息学练习题(2009-2010学年第2学期)姓名:性别:班级:学号:说明:(1)此作业主要是让大家熟悉一下生物信息学的基本知识点,并真正练习一下生物信息软件的使用。
(2)此作业将作为我们的成绩,不交者将没有成绩,请认真对待;(3)作业统一用A4纸打印,并装订;(4)在7月10日前,各班学委收起后,交到新生化大楼C615房间;(5)如有问题可与我联系,一.问答题:1. 当今世界上主要的三大生物数据库是指哪些数据库?答:当今世界上主要的三大生物数据库是美国国家生物技术信息中心NCBI(National Center for Biotechnology Information),EBI(European Bioinformatics Institute)欧洲生物信息研究所,DDBJ(DNA Data Bank of Japan)日本核酸数据库2. 人类基因组计划的完成将绘制出“四张图“,请问这四张图是指哪些图?答:人类基因组计划的完成将绘制出“四张图“是指:1遗传图谱,又称连锁图谱(linkage map),它是以具有遗传多态性(在一个遗传位点上具有一个以上的等位基因,在群体中的出现频率皆高于1%)的遗传标记为“路标”,以遗传学距离(在减数分裂事件中两个位点之间进行交换、重组的百分率,1%的重组率称为1cM)为图距的基因组。
2物理图谱,是以一段已知核酸序列的片段STS序列为路标,以碱基对数目的多少为图距来表示两个遗传标记之间的物理距离[基本单位是Mb、kb、bp]的图谱。
3序列图谱,是分别将各染色体全部碱基序列绘制的图谱。
包括转录序列和非转录序列。
4转录图谱谱也叫基因表达图谱,以表达序列标签(expressed sequence tag , EST )为位标,反映基因在不同条件下的表达情况的图谱。
3. 生物信息学的定义有狭义与广义之分,请问狭义的生物信息学定义是什么?答:目前生物信息学可以狭义地定义为:将计算机科学和数学应用于生物大分子信息的获取、加工、存储、分类、检索与分析,以达到理解这些生物大分子信息的生物学意义的交叉学科。
生物信息学作业1.doc

生物信息学实验作业试验一一.找到编码拟南芥(arabidopsis)phyA(光敏色素A)基因的核酸序列编号, 并记录查找过程。
GI:224576211步骤1.进入NCBI主页2.搜索arabidopsis phyA3.Arabidopsis thaliana phytochrome A (PHYA) gene, partial cds4.VERSION:GI:224576211二.以phyA为检索词,在pubmed数据库中分别检索在题目和关键词字段中含有该检索词的文献,记录检索出的条目数目。
Results: 614三.仔细阅读所查询核酸序列在NCBI和EMBL数据库中格式的解释,理解各字段的含义,并比较NCBI 与EMBL中序列格式的异同。
实验二一.分析你感兴趣核酸序列的分子质量、碱基组成。
Composition 35 A; 25 C; 35 G; 15 T; 0 OTHERPercentage: 32% A; 23% C; 32% G; 14% T; 0%OTHERMolecular Weight (kDa): ssDNA: 34.26 dsDNA: 67.8二.列出你所分析核酸序列(或部分序列)的互补序列、反向序列、反向互补序列、DNA双链序列和RNA 序列。
R S1 ACTACTCGAG AAGCAGCGAC AGAGGCGTTA GCCCGCTCAG CAGACTGGCA GTTCTCTACC61 GACAAAAAAG AGGTAGGAGG CACAGTAATG ATACAGGCGT AGCAGGAGGGC S1 CCCTCCTGCT ACGCCTGTAT CATTACTGTG CCTCCTACCT CTTTTTTGTC GGTAGAGAAC61 TGCCAGTCTG CTGAGCGGGC TAACGCCTCT GTCGCTGCTT CTCGAGTAGTR C S1 TGATGAGCTC TTCGTCGCTG TCTCCGCAAT CGGGCGAGTC GTCTGACCGT CAAGAGATGG61 CTGTTTTTTC TCCATCCTCC GTGTCATTAC TATGTCCGCA TCGTCCTCCCD DNA S1 GGGAGGACGA TGCGGACATA GTAATGACAC GGAGGATGGA GAAAAAACAG CCATCTCTTGCCCTCCTGCT ACGCCTGTAT CATTACTGTG CCTCCTACCT CTTTTTTGTC GGTAGAGAAC61 ACGGTCAGAC GACTCGCCCG ATTGCGGAGA CAGCGACGAA GAGCTCATCATGCCAGTCTG CTGAGCGGGC TAACGCCTCT GTCGCTGCTT CTCGAGTAGTRNA S1 GGGAGGACGA UGCGGACAUA GUAAUGACAC GGAGGAUGGA GAAAAAACAG CCAUCUCUUG61 ACGGUCAGAC GACUCGCCCG AUUGCGGAGA CAGCGACGAA GAGCUCAUCA三.列出核酸序列的限制性酶切位点分析结果(酶及识别位点)。
生物信息学习题

1单选(以下哪位科学家获得了两次诺贝尔奖?A.桑格(Frederick Sanger)B.沃森(James Waston)C.霍利(Robert W.Holley)D.克里克(Francis Crick)2单选(被称为“DNA之父”的是哪位科学家?A.摩尔根(Thomas H.Morgen)B.沃森(James Waston)C.查加夫(Erwin Chargaff)D.桑格(Frederick Sanger)3单选(被称为“计算机之父,人工智能之父”的是哪位科学家?A.莱布尼兹(Gottfried W Leibniz)B.图灵(Alan Mathison Turing)C.帕斯卡(Blaise Pascal)D.桑格(Frederick Sanger)4单选(被称为“现代实验生物学奠基人”的是哪位科学家?A.摩尔根(Thomas H.Morgen)B.达尔文(Charles Darwin)C.桑格(Frederick Sanger)D.孟德尔(Gregor J.Mendel)5单选(被称为“遗传学的奠基人,现代遗传学之父”的是哪位科学家A.孟德尔(Gregor J.Mendel)B.沃森(James Waston)C.查加夫(Erwin Chargaff)D.摩尔根(Thomas H.Morgen)1单选(从GenBank的哪一项注释中可以找到关于编码蛋白的信息?A.CDSB.SOURCEC.RBSD.ORIGIN2单选(以下关于GenBank的描述,哪个是正确的?A.GenBank里的一条数据库记录对应一个完整的基因。
B.真核生物的基因经常是分段存储在多条GenBank数据库记录里。
C.真核生物的基因都是整个存储在GenBank的一条数据库记录里。
D.原核生物的基因都是分片段存储在多条GenBank数据库记录里。
3多选(以下关系式正确的是?A.1T=1,000GB.1G=1,000MC.1G=1,000,000KD.1T=1,000,000M4(GenBank数据库中的检索号(Accession)和基因座名(Locus)指的都是一条序列在数据库中的编号,他们永远都是相同的。
生物信息学作业10

调和序列
1 Ⅰ Ⅱ Ⅲ Ⅳ Ⅴ Y Y F F Y y 2 D D E D E d 3 G G G G G 4 G G G G G G 5 A I I A A/I 6 V L L V 7 V V V 8 E E E Q Q 9 A A A A A 1 L L L V L
多序列比对的方法
同源性分析中常常要通过多序列比对来找出序列之间的相 互关系,和blast的局部匹配搜索不同,多序列比对大多 都是采用全局比对的算法。这样对于采用计算机程序的自 动多序列比对是一个非常复杂且耗时的过程,特别是序列 数目多,且序列长的情况下。
Clustal程序有许多版本。 Clustal是免费软件,很容易从互联网上下载,和其它软 件一起,广泛用于序列分析。Clustal所支持的数据格式包 括EMBL/SWISSPROT、PIR、Pearson/FastA以及 Clustal本身定义的格式。它的输出格式是Clustal格式。
FASTA格式
以上这个FASTA文件中包含了gi号码、GenBank检索号码、LOCUS名称、 以及GenBank记录中的DEFINATION字段。 第一行( 〉)表示一个新的序列文件的开始,为标记符。后面可以加上文 字说明, gi号码、GenBank检索号码、LOCUS名称等信息。 第二行 序列本身,为DNA或蛋白质的标准符号。通常核苷酸符号大小写 均可,而氨基酸一般用大写字母。
正因为存在这样的关系,很多时候对序列的相似性和 同源性就没有做很明显的区分,造成经常等价混用两个 名词。所以有出现A序列和B序列的同源性为80%一说。 不能把相似性和同源性混为一谈。所谓“具有50%同 源性”,或“这些序列高度同源”等说法,都是不确切 的,应该避免使用。
序列相似性比较和序列同源性分析
生物信息学作业1.doc
生物信息学实验作业试验一一.找到编码拟南芥(arabidopsis)phyA(光敏色素A)基因的核酸序列编号, 并记录查找过程。
GI:224576211步骤1.进入NCBI主页2.搜索arabidopsis phyA3.Arabidopsis thaliana phytochrome A (PHYA) gene, partial cds4.VERSION:GI:224576211二.以phyA为检索词,在pubmed数据库中分别检索在题目和关键词字段中含有该检索词的文献,记录检索出的条目数目。
Results: 614三.仔细阅读所查询核酸序列在NCBI和EMBL数据库中格式的解释,理解各字段的含义,并比较NCBI 与EMBL中序列格式的异同。
实验二一.分析你感兴趣核酸序列的分子质量、碱基组成。
Composition 35 A; 25 C; 35 G; 15 T; 0 OTHERPercentage: 32% A; 23% C; 32% G; 14% T; 0%OTHERMolecular Weight (kDa): ssDNA: 34.26 dsDNA: 67.8二.列出你所分析核酸序列(或部分序列)的互补序列、反向序列、反向互补序列、DNA双链序列和RNA 序列。
R S1 ACTACTCGAG AAGCAGCGAC AGAGGCGTTA GCCCGCTCAG CAGACTGGCA GTTCTCTACC61 GACAAAAAAG AGGTAGGAGG CACAGTAATG ATACAGGCGT AGCAGGAGGGC S1 CCCTCCTGCT ACGCCTGTAT CATTACTGTG CCTCCTACCT CTTTTTTGTC GGTAGAGAAC61 TGCCAGTCTG CTGAGCGGGC TAACGCCTCT GTCGCTGCTT CTCGAGTAGTR C S1 TGATGAGCTC TTCGTCGCTG TCTCCGCAAT CGGGCGAGTC GTCTGACCGT CAAGAGATGG61 CTGTTTTTTC TCCATCCTCC GTGTCATTAC TATGTCCGCA TCGTCCTCCCD DNA S1 GGGAGGACGA TGCGGACATA GTAATGACAC GGAGGATGGA GAAAAAACAG CCATCTCTTGCCCTCCTGCT ACGCCTGTAT CATTACTGTG CCTCCTACCT CTTTTTTGTC GGTAGAGAAC61 ACGGTCAGAC GACTCGCCCG ATTGCGGAGA CAGCGACGAA GAGCTCATCATGCCAGTCTG CTGAGCGGGC TAACGCCTCT GTCGCTGCTT CTCGAGTAGTRNA S1 GGGAGGACGA UGCGGACAUA GUAAUGACAC GGAGGAUGGA GAAAAAACAG CCAUCUCUUG61 ACGGUCAGAC GACUCGCCCG AUUGCGGAGA CAGCGACGAA GAGCUCAUCA三.列出核酸序列的限制性酶切位点分析结果(酶及识别位点)。
生物信息学作业

作业个人感觉entrez系统查询序列比SRS更精准,推荐用entrez完成作业。
1.Do a search for the 16S ribosomal RNA gene from Aeromonas hydrophila strainAE7.a.Give the search details that you used to find this sequence.b.What is the accession number?c.How many base pairs are in this sequence?d.When was the entry last modified?e.Is there another organism that produces the same gene? If so, name theorganism and show your evidence.答案:a.进入网址/Entrez,在搜索栏中输入“16Sribosomal RNA gene from Aeromonas hydrophila strain AE7”点击GO,在Nucleotide就能找到结果。
b.DQ855289c. 992 bpd. 21-AUG-2006e. there are a few organisms like Drosophila melanogaster and it was published onScience 316 (5831), 1625-1628 (2007)2.Search for the nucleotide sequence with accession number NM_013161.a.What organism is this sequence from?b.What is the accession number of the protein linked to this sequence?c.What is the function of this protein?d.Find a reference by Hjorth, et al, related to this protein. What is the PubMedID for this article?e.In your own words, briefly describe what the researchers reported in thearticle.答案:a.Rattus norvegicus (Norway rat)b. NP_037293.1c.The protein named Pancreatic triglyceride lipase (胰甘油三酯脂酶, PTL), is an enzyme ofdigestive system, which plays very important roles in the digestion and absorption of lipids. And there has new data suggested that PTL may be involved in the pathophysiology of TBI (脑外伤) and that PTL may be implicated in the proliferation (增殖) of astrocytes (星形胶质细胞) and the recovery of neurological outcomes.d. 8490016 Pancreatic lipase structure-function relationships by domain exchange (通过改变结构域来研究胰脂酶三级结构与功能的关系).e.试验通过交换古典人类胰脂肪酶(HPL)和几内亚猪胰脂肪酶相关蛋白2(GPLRP2)帽子区域设计嵌合突变体,测定两种嵌合体C-端磷脂酶与脂肪酶活性发现脂肪分解酵素在界面锚定和稳定的效应,这个嵌合体的动力学特性首次揭示了胰脂肪酶的界面稳定性取决于它的C端结构域的结构。
生物信息学作业题

生物信息学作业题生物信息学作业题绪论1.什么是生物信息学?2.生物信息学有哪些主要研究领域?第一章生物信息学的分子生物学基础1.DNA的双螺旋结构要点是什么?2.什么是基因组和蛋白质组?对它们的研究有何意义?第二章生物信息学的计算机基础1.简述网络操作系统的类型。
第三章核酸序列分析1.什么是全局比对?2.什么是局部比对?有哪些优点?第四章分子进化分析1.分子进化分析具有哪些优点?2. 简述分子进化的中性学说。
第五章基因组分析1. 什么是基因组学?其主要研究内容是什么?2.简述基因预测分析的一般步骤。
第六章蛋白质组分析1. 蛋白质组学的概念和主要研究的大致方向是什么?2. 蛋白质组功能预测的程序是怎样的?第七章生物芯片数据分析1. 什么是生物芯片?2. 生物芯片有哪些方面的应用?第八章核酸与蛋白质结构预测1. RNA二级结构典型的预测方法有哪些?2. 基于统计学的预测蛋白质二级结构的方法有哪些?第九章生物信息学平台与工具软件1. 请利用Clustal X软件对下列6条蛋白质序列进行多重比对(比对结果用BioEdit软件打开,用“截图”方式显示比对结果)。
>1mqngkvkwfn sekgfgfiev eggedvfvhf saiqgegfkt leegqevtfe veqgnrgpqatnvnkk>2mqgkvkwfnn ekgfgfieie gaddvfvhfs aiqgegykal eegqevsfdi tegnrgpqaanvvkl>3mqngkvkwfn sekgfgfiev eggedvfvhf saiqgegfkt leegqevtfe veqgnrgpqatnvnkk>4mqgkvkwfnn ekgfgfieie gaddvfvhfs aiqgegykal eegqevsfdi tegnrgpqaanvvkl>5mqngkvkwfn sekgfgfiev eggedvfvhf saiqgegfkt leegqevtfe veqgnrgpqatnvnkk>6mqgkvkwfnn ekgfgfieie gaddvfvhfs aiqgegykal eegqevsfdi tegnrgpqaanvvkl2. 现有一ZmPti1b蛋白质序列,请用DNAMAN软件分析其二级结构,给出分析结果。
生物信息学作业题目郝柏林

《生物信息学》作业题目(郝柏林)1、试估计地球上出现智人以来,人们所讲过的“字”的总和不超过10的多少次方?2、试计算10µg大肠杆菌基因组DNA样品中包含多少个DNA大分子?已知1个E. coli. 基因组DNA=4.64×106bp,1bp650 dalton(分子量);1molH 原子=N A个H原子=1g,N A =6×1023。
3、正态分布下,1-4个标准差()范围所覆盖的(即±1~4)概率分别为多少?4、假设赌场的骰子中99%是好的,即P(D fair)=99/100,1%是做过手脚的,即P(D load)=1/100,如果使用的是做过手脚的骰子,则出6点的概率为1/2。
问:(1)在投骰子时连续出了3个6点,你有多大把握说所用的骰子是做过手脚的?(2)如果你要用99%的把握说骰子是做过手脚的,则在投骰子时需要连续出多少个6点?5、某一序列为gtgcaatcagactgataattgccacgatcag(L=31),问该序列是否为CpG island?已知下列转移矩阵:a+ c+ g+ t+P (+)a+ 0.180 0.274 0.426 0.120c+ 0.171 0.367 0.274 0.188g+ 0.161 0.339 0.375 0.125t+ 0.079 0.355 0.384 0.1826、 从地点A 到地点B 有多条路线,每条路线都要收取(或得到)一定的过路费(如图):试问从地点A 到地点B 的哪条路线得钱最多?7、 请分别用动态规划法(dynamic programming )Needleman-Wunsch 和Smith-Waterman 算法对下列两条蛋白质序列进行联配,并写出联配方案: P1=HEAGAWGHEE, P2=PAWHEAE其中替换矩阵选用BLOSUM50(女生)和BLOSUM62(男生)(见下表,其中括号中的数字属于BLOSUM62),空位(gap)罚分设定为8(女生)和9(男生)。
实用生物信息技术第一次作业

实用生物信息技术课程第1 次作业网络书籍、文档和文献资源检索和应用一、分子月报(Molecular of the Month):1) 按功能分类,网站的生物大分子分为哪几大类?1、DNA, RNA, and Protein Synthesis - building the molecules of life2、Enzymes - the cell's chemists3、Molecular Infrastructure - supporting cells, tissues and organisms4、Transport - delivering the cell's resources5、Biological Energy - capturing and converting sources of power6、Molecules and the Environment - proteins with global impact7、Photosynthesis - capturing energy from the sun8、Molecular Motors - directed motion at the molecular level9、Cellular Signaling - sending and receiving molecular message二、2000 年12 篇月报中描述的蛋白质分子,你熟悉的有哪些?Pepsin胃蛋白酶)Nucleosome 核小体DNA PolymeraseMyoglobin 肌红蛋白三、有关DNA、rRNA、tRNA 的月报有哪几篇?1、DNA2、Transfer Ribonucleic Acid (tRNA)3、Transfer-Messenger RNA四、该网站中和DNA 复制相关的蛋白质分子有哪些?1、DNA Helicase 解旋酶2、DNA Polymerase 聚合酶3、Sliding Clamps4、DNA ligase 连接酶五、该网站中介绍的病毒有哪些?HIVAdenovirus腺病毒Ebola Virus Proteins 埃博拉病毒Bacteriophage phiX174 噬菌体病毒Dengue Virus 登革病毒HIV艾滋病毒Poliovirus and Rhinovirus脊髓灰质炎病毒Simian Virus 40Tobacco Mosaic Virus烟草花叶病毒六、该网站中你熟悉的酶分子有哪些?DNA PolymeraseRNA PolymerasecAMP-dependent Protein Kinase (PKA)Acetylcholinesterase乙酰胆碱酯酶Pepsin胃蛋白酶Topoisomerases拓扑异构酶Aminoacyl-tRNA Synthetases氨酰tRNA合成酶DNA Ligase连接酶七、阅读该网站关于血红蛋白的短文,说明其结合和释放氧气时不同亚基之间如何协同作用。
生物信息学课堂操作练习

生物信息学课堂操作练习一、生物信息学科的发展和研究内容通过下列internet上的自教课程,初步了解不同的数据库和分析工具/2can/Education二、生物数据库1. 熟悉各种数据库。
2. 重点了解GenBank和SWISS-PROT所包含的各种功能和适用范围。
三、关键词或词组为基础的数据库检索1. 熟练掌握Entrez检索体系。
2. 查找与水稻抗病基因Xa21有关的资料(1) 由多少碱基构成?编码多少个氨基酸?(2) exon和intron的位置?(3) 是否有3-D structure数据?1) 由多少碱基构成?编码多少个氨基酸?4623b.p., 1025A.a.;2) exon和intron的位置?Exon: 24~2700,3543~3943 intron: remaining;3) 是否有3-D structure数据?没有.3. 查找C. elegans基因组的资料。
(1) chromosome I的测序是否已完成?(2) 已知的chromosome I的序列有多少碱基?序列发表在哪份杂志上?期号和页码?1) chromosome I的测序是否已完成?完成.2) 已知的chromosome I的序列有多少碱基? 序列发表在哪份杂志上? 期号和页码? 15.0724Mb.p.(15072421b.p.), Science 1999 Jan 1;283(5398):35.4. 查看人类基因组第1染色体上基因的分布。
/mapview/maps.cgi?ORG=hum&MAPS=ideogr,est,loc&LINKS= ON&VERBOSE=ON&CHR=15. 查看Arabidopsis的系谱树,以及Arabidopsis第1染色体上的序列。
比较Arabidopsis基因组的资料提供形式与人类基因组有什么不同(/Taxonomy/Browser/wwwtax.cgi?id=3701,/mapview/maps.cgi?taxid=3702&chr=1)貌似没什么区别……比较Arabidopsis基因组的资料提供形式与人类基因组有什么不同。
生物信息学作业
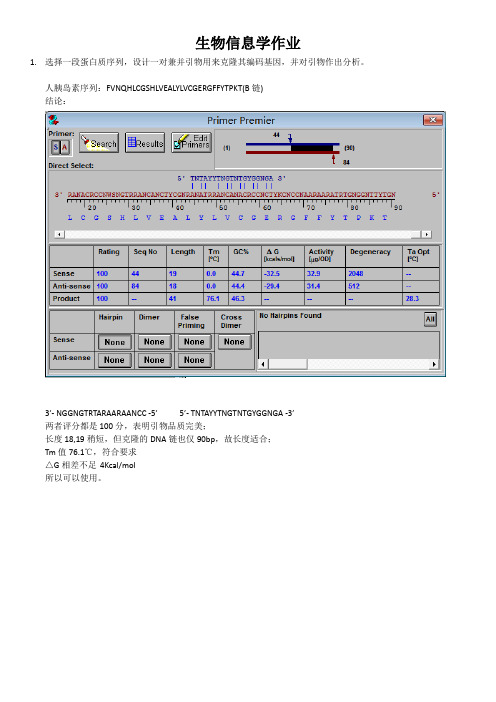
生物信息学作业1.选择一段蛋白质序列,设计一对兼并引物用来克隆其编码基因,并对引物作出分析。
人胰岛素序列:FVNQHLCGSHLVEALYLVCGERGFFYTPKT(B链)结论:3’- NGGNGTRTARAARAANCC -5’ 5’- TNTAYYTNGTNTGYGGNGA -3’两者评分都是100分,表明引物品质完美;长度18,19稍短,但克隆的DNA链也仅90bp,故长度适合;Tm值76.1℃,符合要求△G相差不足4Kcal/mol所以可以使用。
Step1:打开primer premier 5.0 输入蛋白质链,转化为DNA链。
获得DNA链。
2.选择一段基因,预测期编码RNA的二级结构,并分析功能。
取一段基因:ACGCG GGCGG GCATG TGGGC AGCTT TACCC AGTGC TACTG TGCTG GCCAGCACTG AAACA GGGGC ACTGG TTTGG GGTGG ATGAA GGGTA GAAGT GCAAGTTCCA TTGCC TGTGC AATCC CTGCC TTGCT CAGAC CCTGC TCACT CCTCAGGCCC CATCA GCCCC TCAAC TCTGC TAACC ATGGT GGTAG AAATC AGCTACAATA AACCC TGGAG CCAGT AAAAA AAAAA AAAAA AAAAA AAAAA AAAGT点击Fold as RNA点击START点击Draw Stuclture得到RNA二级结构RNA功能预测打开网址http://sidirect2.rnai.jp/输入DNA序列得出结论:。
《生物信息学》上机作业

《生物信息学》上机作业题目:对人血红蛋白(HBA1)编码基因序列的生物信息分析目录引言 .............................................................................................................................................. - 1 -1 正文......................................................................................................................................... - 2 -1.1 NCBI上对相关核苷酸序列的查找............................................................................ - 2 -1.2 BLAST运行及其结果.................................................................................................. - 2 -1.3 BLASTX运行及其结果................................................................................................ - 6 -2 其他软件的运行及其结果..................................................................................................... - 8 -2.1 Clustal W运行及其结果 ............................................................................................. - 9 -2.2 MEGA4.0运行及其结果............................................................................................. - 10 -结论 ............................................................................................................................................ - 10 -引言血红蛋白又称血色素,是红细胞的主要组成部分,能与氧结合,运输氧和二氧化碳。
生物信息学作业2

生物信息学实验三1.了解什么是BLAST,它有哪些应用。
BLAST (Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具。
BLAST程序能迅速与公开数据库进行相似性序列比较。
BLAST结果中的得分是对一种对相似性的统计说明。
BLAST对一条或多条序列(可以是任何形式的序列)在一个或多个核酸或蛋白序列库中进行比对。
BLAST还能发现具有缺口的能比对上的序列。
2.请在NCBI中查找你感兴趣的某一基因或蛋白,通过BLAST工具检索与其高度相似的序列,并将你查到的这一基因或蛋白与你检索到的与其相似的序列(其中一条)的比对结果列出来,简单说明序列比对评分和检索过程。
Homo sapiens coagulation factor VIII, procoagulant component(F8), transcript variant 1, mRNA Length=9048Score = 398 bits (212), Expect = 1e-108Identities = 214/215 (99%), Gaps = 0/215 (0%)Strand=Plus/PlusQuery 15 GGAGCTGAATATGATGATCAGACCAGTCAAAGGGAGAAAGAAGATGATAAAGTCTTCCCT 74||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 559 GGAGCTGAATATGATGATCAGACCAGTCAAAGGGAGAAAGAAGATGATAAAGTCTTCCCT 618Query 75 GGTGGAAGCCATACATATGTCAGGCAGGTCCTGAAAGAGAATGGTCCAATGGCCTCTGAC 134||||||||||||||||||||| ||||||||||||||||||||||||||||||||||||||Sbjct 619 GGTGGAAGCCATACATATGTCTGGCAGGTCCTGAAAGAGAATGGTCCAATGGCCTCTGAC 678Query 135 CCACTGTGCCTTACCTACTCATATCTTTCTCATGTGGACCTGGTAAAAGACTTGAATTCA 194||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 679 CCACTGTGCCTTACCTACTCATATCTTTCTCATGTGGACCTGGTAAAAGACTTGAATTCA 738Query 195 GGCCTCATTGGAGCCCTACTAGTATGTAGAGAAGG 229|||||||||||||||||||||||||||||||||||Sbjct 739 GGCCTCATTGGAGCCCTACTAGTATGTAGAGAAGG 773Homo sapiens chromosome X genomic contig, GRCh37.p5 Primary AssemblyLength=6178498Score = 451 bits (240), Expect = 2e-124Identities = 242/243 (99%), Gaps = 0/243 (0%)Strand=Plus/MinusQuery 1 TTCTTCCTGCTATAGGAGCTGAATATGATGATCAGACCAGTCAAAGGGAGAAAGAAGATG 60||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 5139376 TTCTTCCTGCTATAGGAGCTGAATATGATGATCAGACCAGTCAAAGGGAGAAAGAAGATG 5139317Query 61 ATAAAGTCTTCCCTGGTGGAAGCCATACATATGTCAGGCAGGTCCTGAAAGAGAATGGTC 120||||||||||||||||||||||||||||||||||| ||||||||||||||||||||||||Sbjct 5139316 ATAAAGTCTTCCCTGGTGGAAGCCATACATATGTCTGGCAGGTCCTGAAAGAGAATGGTC 5139257Query 121 CAATGGCCTCTGACCCACTGTGCCTTACCTACTCATATCTTTCTCATGTGGACCTGGTAA 180||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 5139256 CAATGGCCTCTGACCCACTGTGCCTTACCTACTCATATCTTTCTCATGTGGACCTGGTAA 5139197Query 181 AAGACTTGAATTCAGGCCTCATTGGAGCCCTACTAGTATGTAGAGAAGGTAAGTGTATGA 240||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 5139196 AAGACTTGAATTCAGGCCTCATTGGAGCCCTACTAGTATGTAGAGAAGGTAAGTGTATGA 5139137Query 241 AAG 243|||Sbjct 5139136 AAG 5139134Homo sapiens chromosome X genomic contig, alternate assemblyHuRef SCAF_1103279188170, whole genome shotgun sequence Length=869535Score = 451 bits (240), Expect = 2e-124Identities = 242/243 (99%), Gaps = 0/243 (0%)Strand=Plus/MinusQuery 1 TTCTTCCTGCTATAGGAGCTGAATATGATGATCAGACCAGTCAAAGGGAGAAAGAAGATG 60||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 406733 TTCTTCCTGCTATAGGAGCTGAATATGATGATCAGACCAGTCAAAGGGAGAAAGAAGATG 406674Query 61 ATAAAGTCTTCCCTGGTGGAAGCCATACATATGTCAGGCAGGTCCTGAAAGAGAATGGTC 120||||||||||||||||||||||||||||||||||| ||||||||||||||||||||||||Sbjct 406673 ATAAAGTCTTCCCTGGTGGAAGCCATACATATGTCTGGCAGGTCCTGAAAGAGAATGGTC 406614Query 121 CAATGGCCTCTGACCCACTGTGCCTTACCTACTCATATCTTTCTCATGTGGACCTGGTAA 180||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 406613 CAATGGCCTCTGACCCACTGTGCCTTACCTACTCATATCTTTCTCATGTGGACCTGGTAA 406554Query 181 AAGACTTGAATTCAGGCCTCATTGGAGCCCTACTAGTATGTAGAGAAGGTAAGTGTATGA 240||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||Sbjct 406553 AAGACTTGAATTCAGGCCTCATTGGAGCCCTACTAGTATGTAGAGAAGGTAAGTGTATGA 406494Query 241 AAG 243|||Sbjct 406493 AAG 4064911)于NCBI下载一条序列(FASTA格式)2)在BLAST中载入该序列文件3)调节各参数4)点击BLAST进行比对3.理解BLAST不同参数的含义,以及如何调整和适用情况。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
生物信息学作业1. Align the leghemoglobin protein from soy bean and myoglobin from human with global and local alignment software (ex. needle and water) respectively and interpret the results.ANSWER:(1)Use Needle to Align the two sequence:Aligned_sequences: 2# 1: CAA38024.1# 2: NP_001157488.1# Matrix: EBLOSUM62# Gap_penalty: 10.0# Extend_penalty: 0.5# Length: 203# Identity: 43/203 (21.2%)# Similarity: 58/203 (28.6%)# Gaps: 90/203 (44.3%)# Score: 30.0(2)Use Water to Align the two sequence:Aligned_sequences: 2# 1: CAA38024.1# 2: NP_001157488.1# Matrix: EBLOSUM62# Gap_penalty: 14# Extend_penalty: 4# Length: 32# Identity: 11/32 (34.4%)# Similarity: 15/32 (46.9%)# Gaps: 0/32 ( 0.0%)# Score: 35两种软件虽然使用同一罚分标准但得分不同。
因为Needle程序实现标准pairwise全局比对,而Water则是局部比对。
全局比对因为是比对全长序列,所以空位罚分多,得分较局部比对低。
2. Evaluate the significance of the local protein alignment score of question 1 with PRSS and interpret the result.参数如下:Statistics: (shuffled [200]) MLE statistics: Lambda= 0.1886; K=0.0575statistics sampled from 1 (1) to 200 sequencesParameters: VT160 matrix (16:-7), open/ext: -12/-2在两个不同网站选不同矩阵均未得到E值,原因可能是两条序列的同源性很低。
如果同源性高则得到的E值小,且前面的比对工作可性度大;反之则说明前置比对工作可性度低,两条序列的同源性低。
一般来说如果E值小于千分之一则证明序列同源性高。
3. Obtain two sequences from Genbank with the accession number P0A7G6 and P25454. align them with LALIGN (EBI or virginia university sever). First try gap penalties of -12 and -2. Note the length of the alignment, E-value, the percent identity, and the score of the alignment, then repeat the alignment with gap penalties of -5 and -1 and note the features of the alignment. Describe what happened when the gap penalties were reduced, and why?ANSWER:(1)First try gap penalties of -12 and -2:Visual output:Alignment:Waterman-Eggert score: 214; 58.4 bits; E(1) < 3.7e-1328.7% identity (57.4% similar) in 230 aa overlap (34-241:153-375)Waterman-Eggert score: 62; 20.7 bits; E(1) < 0.08230.3% identity (55.1% similar) in 89 aa overlap (25-111:178-256)Waterman-Eggert score: 46; 16.7 bits; E(1) < 0.7427.5% identity (56.9% similar) in 51 aa overlap (15-64:9-59)Waterman-Eggert score: 45; 16.4 bits; E(1) < 0.823.0% identity (53.3% similar) in 135 aa overlap (15-148:1-125)Waterman-Eggert score: 41; 15.4 bits; E(1) < 0.9636.4% identity (63.6% similar) in 22 aa overlap (148-169:55-76)Waterman-Eggert score: 39; 14.9 bits; E(1) < 0.9930.0% identity (62.5% similar) in 40 aa overlap (16-55:178-213)Waterman-Eggert score: 36; 14.2 bits; E(1) < 124.3% identity (59.5% similar) in 37 aa overlap (76-112:313-349)Waterman-Eggert score: 35; 14.0 bits; E(1) < 150.0% identity (80.0% similar) in 10 aa overlap (259-268:10-19)353 residues in 1 query sequences400 residues in 1 library sequences(2)repeat the alignment with gap penalties of -5 and -1:Visual output:Alignment;Waterman-Eggert score: 402; 30.1 bits; E(1) < 0.0001231.5% identity (56.6% similar) in 311 aa overlap (2-274:123-394)Waterman-Eggert score: 270; 18.9 bits; E(1) < 0.2524.7% identity (50.0% similar) in 446 aa overlap (15-352:1-399)Waterman-Eggert score: 225; 15.0 bits; E(1) < 0.9826.3% identity (50.8% similar) in 388 aa overlap (17-351:5-326)Waterman-Eggert score: 214; 14.1 bits; E(1) < 126.3% identity (44.9% similar) in 323 aa overlap (8-303:164-396)Waterman-Eggert score: 211; 13.9 bits; E(1) < 123.4% identity (46.7% similar) in 418 aa overlap (2-332:33-395)353 residues in 1 query sequences400 residues in 1 library sequences当罚分较高时,图像中线条多且短;罚分较低时,图像中线条少且长。
原因是罚分高时,为了得到最优分,系统比对时会选取局部序列,尽量避免空位罚分。
罚分较低时,不会去避免空位,而是尽量全局比对。
4. A complex sample contains DNA from many species of bacteria. The species can be divided into two broad categories: (a) High GC content, (b) Low GC content.In (a) the probability that a GC-rich sequence be obtained by randomly sequencing part of the genome is 0.8In (b), it is 0.1. Assume that the sample contains both bacterial types in the proportion of 1:3 (prior knowledge)Suppose that a sequence obtained randomly from the sample is observed GC-rich. What is the probability that it came from (a) and (b)?Answer:假设事件X:observe GC-rich from (a)事件Y: observe GC-rich from (b)事件Z: observe GC-rich from the sample contains both bacterial types in the proportionP(Z/X)=P(X)P(X/Z)/P(Z)=0.25×0.8/(0.25×0.8+0.75×0.1)=72.72%P(Z/Y)=P(Y)P(Y/Z)/P(Z)=0.75×0.1/(0.25×0.8+0.75×0.1)=27.27%。