药物基因组学相关大数据库
kegg使用方法

kegg使用方法摘要:1.KEGG 简介2.KEGG 的使用方法3.KEGG 的优点与局限性正文:1.KEGG 简介KEGG(Kyoto Encyclopedia of Genes and Genomes) 是一个综合性的基因组学数据库,提供了大量的基因组信息和代谢通路数据。
KEGG 数据库包括了基因组、代谢通路、化合物、药物等多个方面的信息,并且以一种高度结构化的方式呈现,方便用户进行查询和使用。
2.KEGG 的使用方法KEGG 的使用方法非常简单,用户只需要在网站上进行注册并登录,就可以使用KEGG 数据库。
KEGG 的主页提供了多种查询方式,例如通过基因、化合物、代谢通路等进行查询。
用户可以根据自己的需求选择不同的查询方式。
在查询时,用户可以通过输入基因或化合物的名字,或者输入代谢通路的名称来进行查询。
例如,如果用户想要了解某个基因的信息,可以在搜索框中输入该基因的名字,然后点击搜索按钮。
搜索结果会以列表的形式展示,用户可以在列表中选择自己感兴趣的基因,并查看其详细的信息。
除了查询功能外,KEGG 还提供了许多工具和应用程序,例如基因注释、代谢通路分析、蛋白质互作网络等。
这些工具和应用程序可以帮助用户更深入地研究基因组学和代谢通路。
3.KEGG 的优点与局限性KEGG 是一个非常优秀的基因组学数据库,具有以下几个优点:(1)KEGG 提供了大量的基因组信息和代谢通路数据,可以为用户提供全面的参考。
(2)KEGG 的数据库结构非常清晰,用户可以方便地查询和使用数据。
(3)KEGG 还提供了许多有用的工具和应用程序,可以帮助用户更深入地研究基因组学和代谢通路。
但是,KEGG 也存在一些局限性:(1)KEGG 的数据库主要侧重于基因组学和代谢通路,对于其他方面的信息可能不够全面。
(2)KEGG 的数据库虽然很大,但是有些数据可能不是最新的。
生物信息学中的数据库和计算工具

生物信息学中的数据库和计算工具生物信息学是一门综合性学科,应用范围十分广泛。
生物信息学研究的是生物体内的遗传信息的获取、存储、分析和应用。
它结合了生物学、信息学、计算机科学、数学等多个学科,旨在解决生物大数据的存储、分析和挖掘问题。
本文将介绍生物信息学中的数据库和计算工具,以及它们在生物信息学中的应用。
一、生物信息学中的数据库生物信息学中的数据库是受到生物学家和计算机科学家制作和维护的存储和组织生物数据的资源。
这些数据库包括基因组、蛋白质、代谢、信号转导、基因表达谱等生物信息学数据库。
生物信息学中的数据库已经成为研究生物学的常规工具,研究人员可以通过分析数据库中的信息来更好地理解生物学现象。
1. 基因组数据库基因组数据库是生物信息学中最重要的数据库之一。
它存储了各种物种的基因组信息。
基因组数据库的应用包括基因预测、基因注释、基因功能鉴定、基因组进化分析等。
最知名的基因组数据库包括 GenBank、EMBL、Ensembl 等。
其中 GenBank 是最大的公共基因组数据库之一,它由美国国家生物技术信息中心(NCBI)维护。
2. 蛋白质数据库蛋白质数据库是存储蛋白质结构和序列信息的数据库。
其中,PDB是最著名的蛋白质数据库之一,它提供了大量的蛋白质三维结构的信息。
此外,UniProt 是另一重要的蛋白质数据库,它整合了多个独立的蛋白质数据库,提供了关于蛋白质序列、结构和功能的详细信息。
3. 引用数据库引用数据库存储了生物学家在论文、会议和其他出版物中发表的研究结果。
它们经常被生物信息学家用于构建生物信息学算法的基础,并分析特定领域的研究趋势。
PubMed 和 Web of Science 是引文数据库的代表性例子。
二、生物信息学中的计算工具随着数据量的增加和分析复杂度的提高,生物信息学中出现了大量的计算工具用于帮助生物科学家完成各种分析任务。
这些工具包括序列比对、序列拼接、批量序列处理、统计分析、数据可视化、机器学习等。
药物基因组学究竟是何方神圣?PharmGkb数据库又如何使用?

药物基因组学究竟是何⽅神圣?PharmGkb数据库⼜如何使⽤?药物基因组学是近年来国内外的研究热点。
发表药物基因⽅⾯的⽂章实验费时费⼒少、见刊迅速,也成为⼴⼤临床医⽣⼼中⼀个理想的研究⽅向。
⼩⾄1-2分⽂章,⼤到5-10分的⽂章,均可见到药物基因组学研究的影⼦。
以药物华法林在⼼⾎管领域的研究为例(华法林是临床常见的抗凝药,⼴泛⽤于房颤、⼼脏瓣膜置换术后、下肢深静脉⾎栓的抗凝治疗中),笔者在PubMed上检索“warfarin,gene”关键词,就⼀共检索出1057篇相关⽂献,其中不乏Heart,Blood等⼼⾎管领域顶级杂志上发表的⽂章。
⽬前,以药物基因组学命名的SCI杂志有两个“Pharmacogenomics Journal”(IF=3.812)和“Pharmacogenomics”(IF=2.302),专门接受药物基因组学领域的⽂章。
那么,药物基因组学的研究究竟是何⽅神圣?研究为何颇受国外杂志的青睐?下⾯,笔者以华法林为例介绍药物基因组学两个重要基本概念和它具体的研究内容。
研究华法林的药物基因组学,就不得不提到两个重要的概念,药物代谢动⼒学(pharmacokinetics,PK)和药物效应动⼒学(pharmacodynamics,PD);前者,以华法林为例,它的PK是这样的:简单来说,就是华法林在⼈体肝脏内通过各种CYP酶(统称为细胞⾊素P450酶)代谢成各种⽆活性的产物并排泄出体外,这是药物华法林在体内代谢的过程;⽽各种CYP基因严格调控着CYP酶的活性。
它的PD则较为复杂,是这样的:简单来说,就是华法林通过作⽤于VKORC1、EPHX1、GGCX、CYP4F2等酶来发挥它的抗凝效应,⽽VKORC1,EPHX1,GGCX,CYP4F2等基因也严格调控这些酶的活性。
这样⼀来,药物基因组学的研究内容也就清晰了许多,即研究基因多态性(就是遗传学上所指的突变型、纯合型、杂合型)对药物代谢(基本上就是CYP⼀族)和药物效应(就是图3上的各种椭圆形)的影响。
引用jgi数据库中数据 参考文献

引用jgi数据库中数据参考文献全文共四篇示例,供读者参考第一篇示例:JGI(Joint Genome Institute)是一个致力于基因组学研究的重要数据库,为科学家提供了大量高质量的基因组数据和相关的研究资源。
JGI数据库包含了来自各种类型生物的基因组序列和相关信息,为科学家在生物领域的研究提供了强大的支持。
引用JGI数据库中的数据在科学研究中扮演着重要的角色。
科学家们可以通过JGI数据库获取到大量的基因组数据,这些数据包括了各种类型生物的基因组序列、基因功能信息、生物通路数据等。
这些数据可以帮助科学家们进行基因结构分析、基因功能注释、基因组比对等工作,为他们的研究提供了重要的参考依据。
JGI数据库中的数据也可以用于分析生物多样性、进化关系等方面的研究。
通过比对不同物种的基因组序列数据,科学家们可以揭示出物种之间的亲缘关系、进化路径等信息,为生物学领域的研究提供了重要的参考依据。
在研究论文中引用JGI数据库中的数据,不仅可以为研究提供可靠的数据支持,还可以让读者更好地理解研究结果的来源和依据。
在引用JGI数据库中的数据时,科学家们需要遵循相关的引用规范,包括注明数据来源、提供数据访问链接等信息,以确保数据的可追溯性和透明性。
JGI数据库中的数据对科学研究具有重要的意义,为科学家们提供了丰富的基因组资源和研究工具,促进了生物学领域的发展和进步。
引用JGI数据库中的数据在科学研究中起着重要的作用,为研究提供了可靠的数据支持和重要的参考依据。
希望科学家们能够充分利用JGI数据库中的数据资源,推动科学研究的进步和发展。
【字数不足,继续努力】第二篇示例:JGI数据库是一个重要的基因组信息数据库,为研究人员提供了丰富的基因组数据资源。
在科研工作中,我们常常需要引用JGI数据库中的数据,以支撑我们的研究工作。
本文将从JGI数据库的特点、使用方法和引用规范等方面详细介绍如何在学术论文中引用JGI数据库中的数据。
kegg 解读

kegg 解读Kegg(Kyoto Encyclopedia of Genes and Genomes)是一个广泛被应用于生物信息学领域的数据库。
它的主要目标是将基因组、化学物质和其他生物大分子有机地整合在一起,为生物学家、生物信息学家和医学研究人员提供有关代谢途径、生物网络和相关信息的详细数据。
本文将对Kegg数据库进行解读,介绍其功能和应用。
一、Kegg数据库简介Kegg数据库是由日本京都大学生物信息中心创建和维护的一个综合性数据库。
它通过整合基因组、代谢物和附加信息,提供了生物学大分子的全面知识库。
Kegg数据库的内容包括基因功能、生物化学途径、代谢物结构和化学反应等。
目前,Kegg数据库涵盖了大量的物种,包括人类、动物、植物、微生物等。
二、Kegg数据库的功能1. 基因功能注释Kegg数据库提供了基因功能注释的工具和资源,帮助研究人员从大量的基因序列中识别和注释功能。
可以通过Kegg的基因分类方式,将基因按照功能进行分类,并提供详细的注释信息和功能预测。
2. 代谢途径分析Kegg数据库中包含了大量的代谢途径信息,可以帮助研究人员理解生物体代谢的整体框架。
通过Kegg的图谱展示和路径分析工具,可以可视化地展示代谢途径,并分析其中的关键代谢步骤和相互作用。
3. 疾病相关信息Kegg数据库还提供了与疾病相关的信息,包括疾病的发病机制、相关基因和蛋白质等。
对于研究人员来说,这意味着可以通过Kegg数据库寻找潜在的药物靶点和疾病相关的代谢通路,以及潜在的治疗策略。
4. 生物网络分析Kegg数据库中的生物网络信息可用于研究基因、蛋白质和代谢物之间的相互作用。
通过分析这些生物网络,可以揭示基因调控网络、蛋白质相互作用和信号转导途径等重要生物学过程。
三、Kegg数据库的应用1. 基因组学研究Kegg数据库为基因组学研究提供了宝贵的资源和工具。
研究人员可以利用Kegg的代谢途径信息,推断基因在代谢网络中的功能和相互作用,帮助揭示生物的生理和代谢特征。
生物学基因组学数据库的发展及其应用前景

生物学基因组学数据库的发展及其应用前景近年来,随着生物技术的快速发展,生物学基因组学数据库在生物学研究中起着越来越重要的作用。
基因组学数据库是存储和共享生物学基因组学数据的重要平台,通过整合、组织和分析大量的基因组数据,为研究者提供了研究基因功能和遗传变异的重要资源。
在本文中,我们将探讨生物学基因组学数据库的发展历程以及它们在生物学研究中的应用前景。
生物学基因组学数据库的发展可以追溯到上世纪80年代,当时人类基因组计划的启动为这一领域的快速发展奠定了基础。
自那时以来,越来越多的基因组学数据库相继建立起来。
其中最著名的数据库包括GenBank、EMBL和DDBJ等。
这些数据库收集了全球各地研究者提交的大量基因组数据,为研究人员提供了查找和共享基因组数据的重要工具。
此外,还有一些专门致力于特定物种的数据库,如Ensembl和NCBI的基因数据库,它们提供了特定物种的详细基因组信息,帮助研究者更深入地了解不同物种的基因功能和结构。
随着高通量测序技术的广泛应用,大量的基因组序列数据不断产生,这给基因组学数据库带来了巨大的挑战,即如何有效存储和处理这些大规模的数据。
为了应对这一问题,不断涌现出新的生物学基因组学数据库,包括GEO、ArrayExpress和SRA等。
这些数据库主要存储和管理生物学实验中获得的基因组数据,如基因表达数据、甲基化数据和复杂疾病的基因变异数据。
同时,还有一些数据库专门用于存储和共享人类疾病相关的基因组数据,如ClinVar和GWAS Catalog等。
这些数据库提供了研究人员进行生物学实验数据的挖掘和分析的重要资源,进一步促进了生物学研究的发展。
生物学基因组学数据库的发展不仅在基础生物学研究中发挥着重要作用,还在医学研究和临床实践中得到广泛应用。
基因组学数据库为研究人员提供了参考标准,帮助他们理解基因组中的变异,并研究它们与疾病之间的关联。
通过比较患者和正常人基因组数据的差异,研究人员可以发现特定基因变异与疾病之间的关系,从而推动精准医学的发展。
基于整合的TCGA数据库探索基因组学与临床数据关系

基于整合的TCGA数据库探索基因组学与临床数据关系一、本文概述随着生物信息学和临床研究的不断深入,基因组学与临床数据之间的关联日益成为生物医学领域的研究热点。
本文旨在通过整合和分析公开的The Cancer Genome Atlas(TCGA)数据库,探索基因组学与临床数据之间的关系。
我们将系统介绍如何利用TCGA数据库的资源,运用生物信息学方法,挖掘基因组学数据中的潜在信息,并与临床数据进行整合分析,以期揭示癌症发生、发展过程中的关键基因和分子机制,为癌症的诊断、治疗和预后评估提供新的思路和方法。
本文将首先介绍TCGA数据库的概况和数据特点,阐述选择TCGA 数据库作为研究基础的原因。
随后,我们将详细介绍基因组学数据的处理方法,包括数据清洗、基因表达分析、基因变异检测等,并阐述如何将这些方法与临床数据进行有效整合。
在结果展示部分,我们将通过图表和统计分析,展示基因组学与临床数据之间的关联,并解释这些关联在癌症研究中的意义。
我们将讨论本文的局限性,并对未来的研究方向进行展望。
通过本文的研究,我们期望能够为深入理解癌症的基因组学特征和临床表型提供新的视角和工具,为癌症的精准医疗提供科学支持。
我们也希望本文的研究方法和结果能够为其他领域的生物医学研究提供借鉴和参考。
二、TCGA数据库概述The Cancer Genome Atlas (TCGA) 是一个由美国国家癌症研究所(NCI)和国家人类基因组研究所(NHGRI)共同发起的项目,旨在通过应用高通量的基因组测序技术,对多种类型的人类癌症进行深入的基因组学研究。
自2006年启动以来,TCGA已经产生了海量的多维度数据,包括基因组、转录组、表观组、蛋白质组以及临床数据等,涵盖了超过33种不同类型的癌症,总计数千个患者的样本。
TCGA数据库不仅提供了丰富的原始测序数据,还通过严格的数据处理和分析流程,生成了大量的二级和三级数据,如基因变异注释、基因表达量统计、生存分析等。
Drugbank:最强大的综合性药物数据库,收藏

Drugbank:最强⼤的综合性药物数据库,收藏DrugBank数据库是阿尔伯塔⼤学将详细的药物数据和全⾯的药物⽬标信息结合起来,真实可靠的⽣物信息学和化学信息学数据库。
DrugBank包含13791种药物条⽬,其中包括2653种经批准的⼩分⼦药物、1417种经批准的⽣物技术(蛋⽩质/肽)药物、131种营养品和6451种实验药物。
此外,5236个⾮冗余蛋⽩(即药物靶标/酶/转运体/载体)序列与这些药物条⽬相关联。
每个DrugCard条⽬包含200多个数据字段,其中⼀半⽤于药物/化学数据,另⼀半⽤于药物靶标或蛋⽩质数据。
总的来说,DrugBank的⾓⾊主要有两个:①临床导向的药品百科全书。
DrugBank能够提供关于药品,药品靶点和药物作⽤的⽣物或⽣理结果的详细、最新、定量分析或分⼦量的信息。
②化学导向的药品数据库。
提供计算机检索药物、药物“复原”、计算机检索药物结构数据、药物对接或筛选、药物代谢预测、药物靶点预测功能。
DrugBank接下来看看如何使⽤这个数据库吧。
从主页⾯我们可以看出,检索⽅式有两种,⼀种是专门的search模块,⼀种是主页快速搜索。
Search模块给出的搜索模式很丰富(包括但不限于化学机构、分⼦量、药理学的专业搜索),如下:其中Chemical structure允许⽤户绘制(使⽤Marvin Sketch⼩程序或Chem Sketch⼩程序)或写下(SMILES字符串)化合物,右侧可以设置检索相似值等,对结构式进⾏模糊检索,可以找到与⽬标结构式相近的药物。
主页的搜索包括四种,分别为“Drugs(药品名)”、“Targets(靶点)”、“Pathways(作⽤途径)”、“Indications(适应症)”,由于篇幅的原因,以下对Drugs进⾏介绍吧。
这⾥我们以DRUGBANK的热门药物“Morphine”吗啡为例进⾏搜索,点击enter,结果如下:01 01 IDENTIFICATION这⾥可以看到对药物的名称、描述、类型、结构体同位素、化学式等内容,⽐如这⾥描述说到吗啡是鸦⽚的主要⽣物碱,于1805年⾸次从罂粟种⼦中获得。
TCGA数据库介绍

TCGA数据库介绍TCGA(The Cancer Genome Atlas)是由美国国立癌症研究所(NCI)和美国国立人类基因组研究所(NHGRI)共同发起的一个大型国际性癌症基因组计划。
该计划的目标是通过对人类癌症进行全面的基因组学分析,以帮助科学家更好地理解癌症的发生机制,识别潜在的治疗靶点,并为个性化医疗提供关键信息。
TCGA数据库提供了多种类型的基因组数据,包括基因组测序数据、表达谱数据、DNA甲基化数据、蛋白质表达数据等。
每个样本都经过详细的基因组学分析,使得科学家可以探索癌症的发生机制、转录组表达变化、基因突变和表达、DNA甲基化等方面的信息。
除了数据规模之外,TCGA数据库的另一个显著特点是其数据的多样性。
由于TCGA采集了全球范围内的癌症样本,包括不同类型的癌症和不同种族、性别和年龄的患者,因此其数据库中的数据具有一定的代表性和覆盖性。
这使得科学家在比较不同类型的癌症、寻找特定变异或基因表达的相关性时具有更高的可靠性。
TCGA数据库对于癌症研究以及相关领域的研究有着重要的意义。
首先,它为癌症研究提供了宝贵的资源和参考。
科学家可以利用TCGA数据库中的数据与自己的研究进行验证和比较,进一步加深对癌症的认识。
其次,TCGA数据库还为研究人员提供了一个共享和交流的平台。
任何人都可以访问TCGA数据库并使用其中的数据进行自己的研究,促进了全球范围内的合作和共同进展。
最后,TCGA数据库的开放性和透明度也为临床医生和患者提供了一个参考资源,帮助他们做出更准确的医疗决策和制定个性化的治疗方案。
然而,需要注意的是,TCGA数据库也存在一些限制和挑战。
首先,由于大规模基因组数据的复杂性和多样性,对于非专业研究人员来说,理解和解释TCGA数据可能是一项挑战。
其次,基因组数据的分析和解释需要一定的专业知识和技能,并且需要使用适当的分析工具和软件进行处理。
此外,由于TCGA数据库只包含了限定数量和类型的癌症数据,所得到的研究结果可能并不适用于所有类型的癌症或个体患者。
DataBase肿瘤药物敏感性基因组学数据库GDSC

DataBase肿瘤药物敏感性基因组学数据库GDSChttps:///Genomics of Drug Sensitivity in Cancer (GDSC),提供免费公开的肿瘤治疗基因组数据,致⼒于发现潜在的肿瘤治疗靶点以改善肿瘤治疗,是全球最⼤的同类型公共数据库。
⾸页可见,GDSC数据库⽀持化合物(药物)、细胞系和癌基因三种检索⽅式。
化合物的相关信息由⾏业、学术合作伙伴或供应商处获取;癌基因组突变信息来⾃COSMIC数据库。
GDSC数据库基本上每年会有⼀个⼤版本的更新,年中会有不定期的⼩版本更新。
截⾄本稿,最新版本是Release 8.1 (Oct 2019) ,数据统计可见,共收录453种药物,988个细胞系,以及38万+组检测IC50值:注:数据量并⾮持续增加的,与TCGA⼀样,对于新的质控标准下,不满⾜QC阈值的数据将被移除。
GDSC⽬前提供两个数据集:GDSC1是该⽹站上可⽤的原始数据集(2009-2015年间收集)的扩展。
⽽GDSC2则基于改进的技术、设备和程序等所得的最新的数据(2015-⾄今)。
例如:GDSC1使⽤DNA染料(Syto60),⽽GDSC2使⽤代谢测定法(Resazurin / CellTiter-Glo)来确定细胞活⼒。
GDSC2中已经重复了许多来⾃GDSC1的实验,官⽅建议使⽤GDSC2!【但实际选哪个⽤,由你⾃⼰决定,实际上有些基因的数据在GDSC1中有,在GDSC2中则不存在...】注:类似于现⾏TCGA的GDC Legacy 和 GDC Portal!GDSC数据库提供在线的数据分析和可视化。
其中,⽕⼭图(Volcano Plot)⽤于展⽰基因特征和药物敏感性之间的联系(ANOVA分析):Gene specific volcano plots represent the effect of a mutated gene (e.g. BRAF) on the responses to all drugs analysed. A drug-specificvolcano plot represents how genomic changes influence response to a specific drug (e.g. BRAF inhibitor PLX4720).IC50,半抑制浓度,即凋亡细胞与全部细胞数之⽐等于50%时所对应的药物浓度。
医疗研究中的生物信息学数据库与工具

医疗研究中的生物信息学数据库与工具在现代医疗领域,生物信息学数据库与工具的应用已经变得越来越重要。
生物信息学数据库与工具是指用于存储、管理和分析生物学数据的软件系统和工具。
这些数据库和工具能够提供生物学研究人员和医学专业人员快速访问、挖掘和分析大规模的生物学数据,以便更好地理解和治疗疾病。
一、生物信息学数据库1. 基因组数据库基因组数据库是存储各种生物体基因组序列的集合。
其中,最著名的基因组数据库是基因组浏览器,如NCBI的GenBank和Ensembl。
这些数据库提供了大量的基因组序列、注释信息和相关的研究数据,为研究人员提供了基因组水平的信息。
2. 蛋白质数据库蛋白质数据库是用于存储蛋白质序列和结构的数据库。
蛋白质序列和结构数据的积累对于理解蛋白质的功能和特性至关重要。
常见的蛋白质数据库包括UniProt和PDB(蛋白数据银行),它们提供了全球各地研究人员所提交的海量蛋白质序列和结构信息。
3. 基因调控数据库基因调控数据库主要用于存储和分析基因调控元件(如启动子、增强子等)的序列和相关信息。
这些数据库对于理解基因的调控机制和功能方面起着重要的作用。
常见的基因调控数据库包括TRANSFAC、JASPAR和UCSC。
二、生物信息学工具1. 序列分析工具序列分析工具用于对DNA、RNA和蛋白质等生物序列进行分析和比对。
其中,最常用的序列比对工具是BLAST(基本局部序列比对工具)。
BLAST可以将输入的序列与已知序列数据库中的相似序列进行比对,快速找到相似序列和亲缘关系。
此外,还有如ClustalW、MUSCLE等多序列比对工具和MEME等序列模式分析工具。
2. 结构预测工具结构预测工具用于预测蛋白质的三维结构。
根据蛋白质序列,可以使用基于比较模型或折叠预测的方法进行蛋白质结构预测。
在比较模型方法中,SWISS-MODEL和Phyre2是常用的工具;而在折叠预测方法中,Rosetta和I-TASSER等被广泛使用。
生物数据库介绍——NCBI

⽣物数据库介绍——NCBINCBI(National Center for Biotechnology Information,美国国家⽣物技术信息中⼼)除了维护GenBank核酸序列数据库外,还提供数据分析和检索资源。
NCBI资源包括Entrez、Entrez编程组件、MyNCBI、PubMed、PudMed Central、PubReader、Gene、the NCBI Taxonomy Browser、BLAST、Pimer-Blast、COBALT、RefSeq、UniGene、HomoloGene、ProtEST、dbMHC、dbSNP、dbVar、Epigenomics、the Genetic Testing Registry、Genome和相关⼯具、⽐对查看器、跟踪存档、Sequence Read Archive、BioProject、BioSample、ClinVar、MedGen、HIV-1/⼈类蛋⽩质相互作⽤数据库、Gene Expression Omnibus、Probe、Online Mendelian Inheritance in Animals、the Molecular Modeling Database、the Conserved Domain Database、the Conserved Domain Architecture Retrieval Tool、Biosystem、Protein Clusters and thePubChem suite of small molecule databases,所有这些资源可以在NCBI主页找到。
Databases⼀个提供有关基因组组装结构,装配名称和其他元数据,统计报告以及基因组序列数据链接等信息的数据库。
⼀个有关培养物、动植物样本和其他⾃然样本的精选元数据集。
记录显⽰样本状态,有关馆藏的机构的信息,以及NCBI中相关数据链接。
NCBI数据库的使用与功能介绍

NCBI数据库的使用与功能介绍NCBI (National Center for Biotechnology Information)数据库是世界上最大的生物信息学数据库之一,旨在为全球科学家提供生物学、生物化学、生物物理学和生物医学研究的数据和工具。
该数据库包含了来自各种生物学研究领域的大量数据,包括基因组序列、蛋白质序列、文献引用、医学图像和结构信息等。
NCBI数据库的使用和功能非常多样化,本文将介绍其中的一些主要功能。
一、检索和浏览数据NCBI数据库提供了强大的功能,可以帮助用户检索和浏览各种生物学数据。
用户可以使用关键词、序列、ID或其他查询方式来感兴趣的信息。
例如,用户可以通过基因组序列、蛋白质序列或特定生物物种来查找相关的数据。
二、基因组和基因信息NCBI数据库中包含大量的基因组序列和基因信息,包括人类和其他生物物种的基因组数据。
用户可以使用NCBI数据库来特定基因的相关信息,如基因序列,基因表达数据,蛋白质序列,基因功能和遗传变异等。
此外,NCBI数据库还提供了对基因组浏览器的访问,可以帮助用户在特定基因组上查看和分析基因注释和结构信息。
三、蛋白质信息NCBI数据库也包含了大量的蛋白质序列和相关信息。
用户可以使用NCBI数据库来特定蛋白质的相关信息,如蛋白质序列,结构信息,功能注释,亚细胞定位和表达水平等。
此外,用户还可以使用NCBI数据库中提供的BLAST工具来进行蛋白质序列比对和相似性,以帮助识别新的蛋白质序列。
四、文献和引用NCBI数据库中包含了大量的科学文献引用和摘要信息。
用户可以使用PubMed工具来特定主题的科学文献,并查看摘要和全文。
此外,用户还可以使用PubMed工具来查找相关文献的引用信息,以帮助了解和分析科学研究领域的发展趋势。
五、医学图像和结构信息NCBI数据库还提供了医学图像和结构信息的访问,帮助用户了解各种疾病和病理过程的图像和结构特征。
用户可以使用NCBI数据库来和浏览医学图像数据库,如CT扫描、MRI图像和遗传学图像等。
生物信息学数据库的种类

生物信息学数据库的种类1.引言1.1 概述生物信息学数据库是由生物学和计算机科学相结合的一个重要领域。
随着高通量测序技术的快速发展, 生物学研究已经进入了“大数据”时代。
生物信息学数据库的出现, 解决了这些海量生物信息的存储和管理问题, 为生命科学研究提供了重要的工具和资源。
生物信息学数据库可以存储和管理各种类型的生物信息数据, 对于科学家和研究人员来说, 这些数据库包含了大量的基因组序列、蛋白质序列、基因表达数据等重要信息。
通过对这些数据的分析和挖掘, 科学家们可以更深入地研究生物体的组成、功能和进化等方面。
在当前的生物信息学数据库中, 可以根据数据类型进行分类。
常见的生物信息学数据库包括序列数据库、结构数据库、基因表达数据库、蛋白质互作数据库、药物数据库、多样性数据库、基因组数据库、疾病数据库和转录因子数据库等。
每种类型的数据库都有其独特的特点和应用领域。
随着生物学研究的不断深入和技术的不断进步, 生物信息学数据库也在不断发展。
未来的数据库将更加注重数据的互联互通, 提供更完整、准确和可靠的生物信息。
同时, 数据分析和挖掘的算法和工具也将不断更新和完善, 为科学家们的研究提供更加强大的支持。
总之, 生物信息学数据库是生物学研究中不可或缺的重要工具和资源。
通过这些数据库, 科学家们可以更加高效地存储、管理和分析生物信息,推动生命科学领域的发展。
未来, 随着生物学研究的不断进步, 生物信息学数据库将不断发展和完善, 为科学家们带来更多的可能性和突破。
1.2 文章结构本文将分为三个部分来详细介绍生物信息学数据库的种类。
首先,在引言部分,我们将提供对本文的概述,介绍生物信息学数据库的基本概念和作用,并说明文章的目的。
接下来,在正文部分,我们将详细介绍九种不同类型的生物信息学数据库,包括序列数据库、结构数据库、基因表达数据库、蛋白质互作数据库、药物数据库、多样性数据库、基因组数据库、疾病数据库和转录因子数据库。
NCBI所有数据库简介
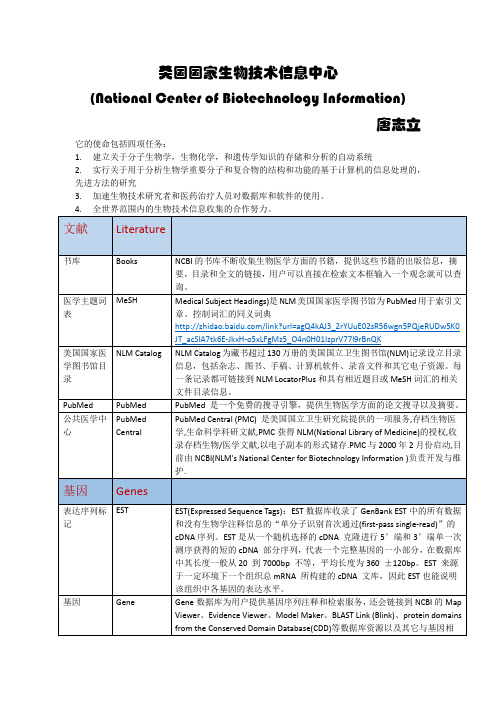
美国国家生物技术信息中心(National Center of Biotechnology Information)唐志立它的使命包括四项任务:1. 建立关于分子生物学,生物化学,和遗传学知识的存储和分析的自动系统2. 实行关于用于分析生物学重要分子和复合物的结构和功能的基于计算机的信息处理的,先进方法的研究3. 加速生物技术研究者和医药治疗人员对数据库和软件的使用。
山东师范大学2016年4月10日星期日30则留学生经典笑话,英语不好伤不起!凭你在国内口语练得多么娴熟,去了国外,照样有犯痴呆傻的时候!1、有次房东问我:did u eat anyting yet? 我说:no.她听后重复了一遍:so u didn’t eat anyting. 我说:yes.房东老太太犹豫了下又问:did u eat? 我说:no.她接着说:so u didn’t eat. 我说:yes. 估计她当时要崩溃了……2、刚上班不久,有个公司的A/R打电话来催支票,我循例问了一下他是哪间公司打来的,那男的很有礼貌的说:This is xxx calling from Beach Brother.听懂了很开心,不过由于对公司名字还不熟,心想先用笔记下来公司名,省得等下忘记了,正得意忘形之间,顺嘴开始拼写人家公司的名字,还说得一本正经:b.i.t.c.h.bitch, correct? 那男的终于还是没能忍住怒火,近似于怒吼似的对我喊道:NO!B.E.A.C.H.BEACH! 接下来的一年里,没再跟这间公司有过任何生意往来……3、我男朋友以前在温哥华乘skytrain 的时候,一个白人女人说:I am sorry. 他直接说:you are welcome. 对方都呆了。
4、第一次跟老外去打painball,玩的是抢旗的那种。
由于第一次玩,一直跟着个看起来很专业的队友跑,一路上躲着子弹跑到对方的base. 我们人都挂了,对方就剩一个人在看老家,就听那老外跟我说了一大堆术语,我也没听懂。
genbank数据库检索

EMBL数据库
01
数据来源
EMBL数据库主要来源于欧洲分 子生物学实验室(EMBL),提 供高质量的DNA序列数据。
数据特点
02
03
检索方式
EMBL数据库的数据质量较高, 但相对较小,主要服务于欧洲的 科研机构。
提供多种检索方式,如关键词、 序列ID等,支持高级检索功能。
DDBJ数据库
数据来源
DDBJ数据库主要来源于日本,提供大量的DNA序列 数据。
总结词
高级检索功能提供了更灵活的检索方式,支 持多字段、多条件的组合检索。
详细描述
高级检索允许用户根据多个字段进行筛选, 如物种、基因类型、基因组位置等,并支持 逻辑运算符(AND、OR、NOT)进行组合。 高级检索功能可以帮助用户更精确地定位目 标序列记录,提高检索效率。
04
GenBank数据库与其他数据库的比较
序列相似性检索
总结词
通过序列相似性检索可以找到与已知序列相似的其他序列,适用于未知基因名称和功能 的情况。
详细描述
用户可以将已知序列输入到相似性检索中,GenBank数据库将返回与输入序列相似度 较高的相关序列记录。相似性检索基于序列比对算法,可以帮助用户发现潜在的同源基
因和相关物种中的基因。
高级检索功能
准确性和可靠性。
04
检索功能强大
GenBank数据库提供多种检索方 式,支持高级检索功能,方便用
户快速找到所需数据。
05
GenBank数据库的应用
基因组学研究
基因组测序
GenBank数据库包含了大量基因 组序列数据,为基因组测序提供 了重要的参考信息。
基因定位与注释
通过比对和分析GenBank中的基 因序列,可以对新测序的基因组 进行定位和注释,揭示基因的功 能和表达。
NCBI数据库集

NCBI数据库集生物信息学 2010-08-20 16:08:59 阅读202 评论0字号:大中小订阅NCBI数据库集/?p=20049一综合数据库NCBI数据库集美国国立生物技术信息中心(National Center for Biotechnology Information),即我们所熟知的NCBI是由美国国立卫生研究院(NIH)于1988年创办。
创办NCBI的初衷是为了给分子生物学家提供一个信息储存和处理的系统。
除了建有GenBank核酸序列数据库(该数据库的数据资源来自全球几大DNA数据库,其中包括日本DNA数据库DDBJ、欧洲分子生物学实验室数据库EMBL以及其它几个知名科研机构)之外,NCBI还可以提供众多功能强大的数据检索与分析工具。
目前,NCBI提供的资源有Entrez、Entrez Programming Utilities、My NCBI、PubMed、PubMed Central、Entrez Gene、NCBI Taxonomy Browser、BLAST、BLAST Link (BLink)、Electronic PCR等共计36种功能,而且都可以在NCBI的主页上找到相应链接,其中多半是由BLAST功能发展而来的。
1 NCBI最新进展1.1 PubMed搜索功能的增强去年,NCBI对PubMed进行了几项改进工作,改动最大的是搜索界面和摘要浏览界面。
其中,搜索界面中新增了“Advanced Search”选项(这实际上是对以往“Limits”和“Preview/Index”功能的整合),并且增加了一个新的窗口,用户可以在此窗口下通过“论文作者名”、“论文所属杂志名称”、“论文出版日期”等限定条件进行搜索。
而且,“论文作者名”和“论文所属杂志名称”还设有文本框自动填充功能。
现在,在PubMed数据库中进行文本搜索的同时还可以立即通过两个“内容传感器(content sensors)”进行分析。
PubChem数据库挖掘

04
CATALOGUE
pubchem数据库的应用场景
化学物质发现和筛选
化合物筛选
pubchem数据库包含了大量的化合物 信息,可用于筛选出具有特定活性或 性质的化合物,为新药发现和化学研 究提供候选物质。
结构-活性关系研究
通过pubchem数据库中化合物的结构 信息和活性数据,可以研究化合物的 结构与活性之间的关系,为药物设计 和优化提供理论支持。
提供新的候选分子。
促进化学和生物学研究
数据库挖掘可以为化学和生物学研究 提供大量的数据支持和分析工具,促
进相关领域的研究进展。
发现化合物间的关联
通过分析化合物之间的相似性、化学 反应关系等,可以发现化合物之间的 关联和潜在的化学反应途径。
提高数据利用效率
通过数据库挖掘,可以快速、准确地 获取和分析数据,提高科研工作的效 率和质量。
pubchem数据库将进一步开放数据访问,允许用户自由查询和下载数据,促进数据的 共享和交流。
社区共建共享
pubchem数据库将鼓励用户参与数据的共建和共享,通过社区的力量共同完善和丰富 数据库内容,提高数据的质量和可用性。
06
CATALOGUE
结论
数据库挖掘的重要性和价值
发现新知识
通过数据库挖掘,可以从大量数据中发现隐藏的模式、关联和规 律,为科学研究和应用提供新的知识和洞见。
02
CATALOGUE
pubchem数据库的特性
数据库的结构和特点
大型化学物质数据
库
PubChem 是一个大型的化学物 质数据库,包含了数百万的化学 物质信息。
多种数据类型
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
药物基因组学数据库
1、Drugbank
.drugbank.ca/
2、dgidb
/
3、pharmGKB
https:///
4、cancercommon
cancercommon./
5、ChEMBL
https:///chembldb/
6、mycancergenome
/
7、TTD
.sg/group/cjttd/
8、guidetopharmcology
/
9、clearityfoundation
/
10、CIViC
https:///#/home
11、DoCM
/
1 Drugbank
药物和药物靶标资源库。
DrugBank是一个独特的生物信息学/化学信息学资源,它结合了详细的药物(例如化学制品)数据和综合的药物靶点(即:蛋白质)信息。
该数据库包含了超过4100个药物条目,包括超过800个FDA认可的小分子和生物技术药物,以及超过3200个试验性药物。
此外,超过1.4万条蛋白质或药物靶序列被到这些药物条目。
每个DrugCard条目包含超过80个数据域,其中一半信息致力于药物/化学制品数据,另一半致力于药物靶点和蛋白质数据。
许多数据域超到其他数据库(KEGG、PubChem、ChEBI、Swiss-Prot和GenBank)和各种结构查看小应用程序。
该数据库是完全可搜索的,支持大量的文本、序列、化学结构和关系查询搜索。
DrugBank的潜在应用包括模拟药物靶点发现、药物设计、药物对接或筛选、药物代谢预测、药物相互作用预测和普通药学教育。
DrugBank可以在www.drugbank.ca使用。
广泛应用于计算机辅助的药物靶标的发现、药物设计、药物分子对接或筛选、药物活性和作用预
测等。
在查询中,每一种药物对应1个DrugCard,即我们所得到的检索结果。
每一个DrugCard都包含的数据信息分为药物、靶标和酶三部分。
药物信息包括了该药物的CAS号、商品名、分子式、分子量、SMILES、2D和3D结构、logP、logS、pKa、熔点、吸收性、Caco-2细胞穿透性、药物类别和临床使用、性质描述、剂型与给药途径、半衰期、体的生物转化、毒性、作用于哪些生物体、食物对服用的影响、与其它药物的相互作用、作用机理、代谢途径、药理学特征、与蛋白质的结合情况、溶解度、物质形态、同义词、关于合成的相关文献等,还与ChEBI、GenBank、PubChem等外部数据库有。
靶标的信息包括ID、名称、靶标基因的名称、蛋白质序列、残基数目、分子量、等电点、功能和活性、参与的代谢途径和反应、体分布、靶标信号、跨膜区域、靶标基因序列及其在GenBank、HGNC等外部数据库中的ID和、参考文献,以及在GenBank和Swiss-Prot中的。
酶的信息包括名称、蛋白质序列、基因名称、在Swiss-Prot 等数据库中的。
在DrugBank的主界面上,在Browse菜单下可以浏览数据库的容,其中PharmaBrowse为用户提供了分类浏览的功能。
这为药剂师、医生以及寻找潜在药物的研究人员提供了方便。
在Search下拉菜单下,就是Drug Bank的4类检索方式。
ChemQuery允许用户通过绘制结构图或书写SMILES、分子式进行结构搜索。
在检索过程中还可以对搜索药物类型、分子量围、搜索结果相似度、结果数量最大值等进行设置。
TextQuery则为文本检索功能。
文本检索支持逻辑运算符连接及在特定领域搜索。
例如,在“dextromethorphan”中检索混合物,可以键入“mixtures:dextromethorphan”,即用分号在后面输入领域,同时可以加入逻辑运算符,例如,在“dextrome thorphan”和“doxylamine”2个领域进行检索,可以键入“mixtures:dextromethorphan AND mixtures:doxylamine”。
SeqSearch为用户提供了通过序列检索蛋白质的功能。
Data Extractor是1个组合检索工具。
用户可以对DrugCard所包含的信息进行选择性的组合检索(1) Browse按钮:Drug Browse、Category Browse、Geno Browse、Reaction Browse、Pathway Browse、Class Browse、Target Browse;
(2) Search按钮:ChemQuery Structure Search、Interax Interaction Search、Sequence Search、Advanced Search、MS Search、MS/MS Search、GC/MS Search、1D NMR Search、2D NMR Search;
(3)其他Tool按钮:HMDB、T3DB、SMPDB、FooDB、PPT-DB、CSF、Serum Metabolome、CCDB、YMDB、BMDB、ECMDB、MarkerDB、BacMap、Ref-DB。
Drug Browse:小分子药物、生物技术药物、显示药物在DrugBank中的ID、药物名称、分子量、化学式、化学结构、药物类型、治疗症状。
Drugs:显示ID、药物名称、治疗疾病
Drugs and T argets:显示ID、药物名称、作用位点(靶标)、靶标类型
总结:可以查找药物名称、分子量、化学式、分子结构、药物所属类型、靶标、靶标类型、治疗疾病、代谢途径等,还可到相关。
(较实用)
Drug Browse:药名、分子量、化学式、化学结构、药物分类、药效
Geno Browse:药物名称,相互作用的基因/酶,SNP位点、等位基因名称、碱基变化、副作用
Pathway Browse:可查看代谢通路
Classification Browse:药物分类
Target Browse:查靶标及靶标分类和详细细节(药物分类、药理学等)
2ChEMBL
生物活性药物类小分子数据库。
总结:输入分子结构或已知靶标描述或靶标蛋白,每条记录都包括分子的分类、名称、ChEMBI ID、功能、毒性、亚细胞定位、结构、序列、参考文献等。
(偏向于化学)
3 clearityfoundation
关于卵巢癌的公益。
治疗卵巢癌复发、有关肿瘤分子信息、临床试验、卵巢癌诊断和治疗分析、新型靶向制剂的临床开发、治疗结果。
(基本无用)
4 DoCM
位点突变数据库,
总结:查找染色体、基因、疾病、突变类型、氨基酸、起始位置、参考文献(稍微简单了点)
5 CIViC
Search:查找描述、疾病名称、疾病DOID、药物PubChem ID、药物名称、证据水平、基因名、PubChem ID、突变位点等查找相关信息。
总结:evidence ID、基因、氨基酸变化、描述、病名、药物、evidence level(A:经过验证的;B:临床;C:临床前;D:个体研究;E:推理的)、evidence type (predictive、diagnostic、prognostic)、evidence direction(supports、dose not support)、clinical significance(sensitivice/resistance or non-response/better outcome/poor outcome/positive/negative)、variant origin(somatic/germline)、trust
rating(1/2/3/4/5 stars),可到代谢途径及下载。
(比较实用)
Search:可按不同类型搜索
输入要搜索的单词,如“breast cancer”
点击一个基因/疾病
单击“View Full Detials from MyGene info”,查基因介绍、蛋白结构域、通路。