文字查重系统使用说明书
采集器说明书

ZD1000图书数据采集器说明书目录第一部分采集器的基本使用 (2)1.如何开关机? (2)2.关于充电 (2)3.外接U盘、鼠标、键盘 (2)4.如何在PDA和电脑之间拷贝文件 (3)5.如果使PDA一开机,就自动运行《PDA采集查重盘点系统》? (3)第二部分图解《PDA采集查重盘点系统》 (3)1.功能介面 (3)2.查重采集功能 (4)3.盘点功能 (6)4.休眠 (6)5.退出 (6)6.关于 (6)7.系统设置 (7)8.输入法 (7)第三部分外部软件的使用 (7)DB=》EXCEL、ACCESS (7)EXCEL、ACCESS==》DB (7)MARC文件(.ISO)==》DB (7)第一部分采集器的基本使用1.如何开关机?2.关于充电每次电池电力用完时,请及时充电。
充满需用时大约8小时(或充至PDA右下方的绿色电源指示灯不再闪烁)。
3.外接U盘、鼠标、键盘ZD1000型数据采集器的综合数据线提供了3个USB接口和1个串口,可以同时外接U盘、鼠标和键盘。
接上这些外设后,ZD1000型数据采集器就是一个微型的电脑了,可以使用外接的鼠标来执行移动指针、选择、点击等操作,也可以使用外接的键盘进行打字输入,接入U盘后,在PDA“我的设备”里多了一个“硬盘”。
说明:PDA 内部的盘和外接的盘(U盘)同属闪存盘,保存在这些盘内的数据,不会因为没电而消失。
外接U盘后,在“我的设备”里多了一个“硬盘”图标。
电源指示灯。
4.如何在PDA和电脑之间拷贝文件“复制、粘贴”的操作与普通电脑上的操作是一样的(即在PDA 中选择需复制的文件或文件夹,执行“复制”,然后进入需复制到的目录,执行“粘贴”。
)。
使用外接U盘,可以方便地实现PDA和电脑之间拷贝文件。
5.如果使PDA一开机,就自动运行《PDA采集查重盘点系统》?初次运行《PDA采集查重盘点系统》程序,会自动设置为一开机就自动运行《PDA采集查重盘点系统》。
易撰查重使用方法

易撰查重使用方法
易撰查重使用方法
一、前言
在学术界,抄袭是一个严重的问题。
为了避免不必要的麻烦,我们需要使用查重工具来检测我们的文章是否存在抄袭行为。
易撰是一款非常优秀的查重工具,本文将介绍易撰查重使用方法。
二、注册账号
首先,我们需要注册一个易撰账号。
打开易撰官网,在首页右上角找到“注册”按钮,填写相关信息并进行验证即可完成注册。
三、上传文档
登录后,点击“上传文档”按钮,选择要检测的文件并上传。
等待上传完成后,系统会自动开始检测。
四、等待检测结果
在文件上传之后,系统会自动开始检测,并在几分钟内返回结果。
如果您的文件很大,则可能需要更长时间才能完成检测。
您可以在“我的文档”页面中查看已上传文件的状态,并获得有关其检测进度和结果的详细信息。
五、分析报告
当系统完成检测后,您将收到一份详细报告。
该报告将显示与其他网络资源相似或完全相同的部分,并提供有关每个匹配项的详细信息。
六、修改文章
如果您发现自己的文章存在抄袭行为,则需要修改文章以消除相似之处。
您可以使用易撰提供的建议来修改文章,以确保文章不会被视为抄袭。
七、再次检测
在修改文章后,您可以再次上传并检测文件以确保已消除所有相似之处。
如果检测结果显示没有相似之处,则说明您已经成功地消除了抄袭行为。
八、总结
易撰是一款非常优秀的查重工具,它可以帮助我们避免不必要的麻烦,并确保我们的文章符合学术规范。
通过本文所介绍的易撰查重使用方法,您将能够轻松地使用该工具来检测和修正您的文章。
怎么免费查重

怎么免费查重
要免费查重,可以通过以下几种方法:
1. 使用免费在线查重工具:现在有许多免费的在线查重
工具可供使用。
你可以在搜索引擎中输入关键词“免费在线查重工具”,然后选择一个可信赖的网站。
将你想要查重的文本粘贴到输入框中,点击“查重”按钮,系统将自动检测文本的相似度并给出结果。
2. 使用文字处理软件的查重功能:许多文字处理软件都
具有查重功能,比如微软Office套件中的Word软件,可以通过点击“审阅”选项卡下的“查重”功能来进行查重。
将文本粘贴到文档中,点击查重按钮,系统将给出相似度报告。
3. 借助互联网搜索引擎:将要查重的文本片段选取部分
连同引号一起在搜索引擎中检索,系统将给出相似的文本结果。
这种方法适用于短文本的查重,但如果文本过长,则需要分段检索。
总之,以上方法都可以帮助你免费查重,选择一种适合
自己的方法即可。
如果你对以上方法还不了解,建议你阅读相关使用教程或者咨询专业人士的帮助。
gscan使用手册

gscan使用手册
GScan 使用手册
欢迎使用 GScan!GScan 是一款功能强大的扫描工具,可帮助您快速、准确地扫描和处理文档。
本手册将详细介绍 GScan 的各项功能和操作步骤,帮助您更好地使用该工具。
目录
1. 安装和启动
1.1 系统要求
1.2 安装步骤
1.3 启动 GScan
2. 扫描文档
2.1 连接扫描仪
2.2 设置扫描参数
2.3 执行扫描
2.4 保存扫描结果
3. 文档处理
3.1 图像处理
3.1.1 裁剪
3.1.2 旋转
3.1.3 调整亮度和对比度
3.2 OCR(光学字符识别)
3.2.1 识别文字
3.2.2 导出为文本文件
3.3 PDF 转换
3.3.1 将扫描结果保存为 PDF 文件
3.3.2 合并多个 PDF 文件
4. 高级功能
4.1 批量处理
4.2 自动识别文档类型
4.3 设置快捷键
4.4 自定义输出设置
5. 常见问题解答
5.1 如何解决扫描仪连接问题?
5.2 如何调整图像的亮度和对比度?
5.3 如何使用 OCR 功能识别文字?
5.4 如何将扫描结果保存为 PDF 文件?
5.5 如何合并多个 PDF 文件?
6. 技术支持和反馈
6.1 联系我们
6.2 提交反馈
请注意,本手册只是 GScan 的简要介绍和操作指南。
如需更详细的信息和操作步骤,请参阅 GScan 的官方文档或联系我们的技术支持团队。
感谢您选择使用 GScan,祝您使用愉快!
版权所有© GScan。
查重报告怎么弄出来

查重报告怎么弄出来
要制作查重报告,可以按照以下步骤进行操作:
1. 确定文档类型:首先要确定需要查重的文档类型,比如论文、文章、报告等。
2. 选择查重工具:根据所需查重的文档类型,选择一款合适的查重工具。
常用的查重工具包括Turnitin、Copyscape、Grammarly等。
在选择工具时要考虑工具的准确性、方便程度
以及费用等因素。
3. 上传文档:使用选定的查重工具,将需要查重的文档上传到该工具的平台。
4. 进行查重:根据工具的操作指引,开始进行查重操作。
工具会对文档进行与现有文献或网络资源的比对,找出相似或重复的内容。
5. 生成报告:查重工具通常会生成一份查重报告,其中会标注出与已有文献或网络资源相似的内容,并给出相似度的百分比。
可以将该报告保存为PDF或其他常见文档格式。
6. 分析和处理报告:仔细分析查重报告,注意标注出的相似内容并与原文进行对比。
如果发现有未注明的引用或引用格式不正确,应及时进行修改。
7. 编辑和完善文稿:根据查重报告的结果,对文档进行必要的
修改和完善,确保不会出现抄袭问题。
总之,制作查重报告需要先选择合适的查重工具进行操作,然后根据生成的报告进行分析和处理,最后对文稿进行修改和完善。
这样才能确保文档的原创性和避免抄袭问题。
学术不端文献检测系统50简明使用手册【模板】

学术不端文献检测系统5.0简明使用手册中国知网学术出版分社学位论文采编部二零一六年十二月目录目录 (1)第一章上传论文 (3)1.1文件夹管理 (3)1.1.1创建和修改文件夹 (4)1.1.2删除文件夹 (4)1.2上传检测文献 (4)1.2.1上传单篇/多篇文献 (5)1.2.2上传压缩文献 (5)1.2.3手工录入 (6)第二章检测结果 (6)2.1文献操作 (6)2.1.1选中文献报告单与下载报告单 (6)2.1.2文件夹报告单 (6)2.1.3导出Excel (6)2.1.4选择报告单 (7)2.2检测结果 (7)2.2.1 加入问题库及个人对比库 (8)2.2.2 文献分段浏览及修改 (8)第三章结果查询 (8)3.1文献查询及操作 (8)3.2查看检测结果 (9)第四章辅助功能 (9)4.1引文核对 (9)4.2两两比对 (9)4.3问题库 (10)第五章信息统计 (10)5.1文件夹信息统计 (10)5.2专业信息统计 (10)5.3年度报表 (11)第六章管理员中心 (11)6.1会员管理 (11)6.1.1 新增子账号 (11)6.1.2管理员账号信息 (11)6.2文献管理 (12)6.3会员查询 (12)6.4文献转移 (12)第七章设置 (13)7.1修改密码 (13)7.2 文件夹管理 (13)7.3个人比对库 (13)7.4一键清空 (14)7.5提建议 (14)第一章上传论文进入TMLC系统(【网址】)后,点击导航条“上传论文”进入上传论文页面。
注:也可以从检测结果页面点击“上传论文”进入上传论文页面。
1.1文件夹管理文件夹是用户管理论文的重要工具,用户可以根据实际需求创建文件夹、设置文件夹的属性。
合理的文件夹设置能有效的减轻用户的工作量。
1.1.1创建和修改文件夹用户可以在上传论文页面、检测结果页面左侧或设置——文件夹管理页面创建文件夹和修改文件夹信息。
用户可在文件夹信息页面根据实际需要选择对比库类型与范围,之后所有上传至该文件夹的文献都默认按照该对比库范围进行检测。
手写文字识别软件详细教程

手写文字识别软件详细教程第一章:介绍手写文字识别软件的背景和概述手写文字识别软件是一种能够将手写文字转换为电子化格式的工具。
随着移动设备的普及和人们对数字化办公的需求增加,手写文字识别软件逐渐受到人们的关注和需求。
本章将对手写文字识别软件的背景和概述进行介绍。
第二章:手写文字识别软件的应用领域手写文字识别软件在多个领域有着广泛的应用。
本章将围绕教育、商务、文化娱乐等方面展开,详细介绍手写文字识别软件的应用场景和实际效果。
第三章:选择和安装手写文字识别软件在市场上有众多手写文字识别软件可供选择,用户需要根据自己的需求和设备的系统选择合适的软件。
本章将介绍几种主流的手写文字识别软件,并详细阐述如何进行安装和设置。
第四章:手写文字识别软件的基本操作本章将详细介绍手写文字识别软件的基本操作流程和功能使用。
从打开软件、创建新文件、导入手写文字图片、识别文字等方面进行逐步讲解,使读者能够轻松上手使用手写文字识别软件。
第五章:提升手写文字识别准确度的技巧与建议手写文字识别软件在识别准确度方面存在一定的局限性,但通过一些技巧和建议可以提高识别的准确度。
本章将介绍一些常用的技巧和建议,如选择清晰的手写文字图片、调整软件设置和优化手写输入等,帮助用户更好地使用手写文字识别软件。
第六章:手写文字识别软件的高级功能除了基本的手写文字识别功能外,很多手写文字识别软件还提供一些高级功能,如手写文字翻译、手写笔记编辑等。
本章将结合具体例子,详细介绍手写文字识别软件的高级功能及其使用方法。
第七章:手写文字识别软件的未来发展趋势随着科技的不断进步和人工智能的发展,手写文字识别软件将会有更加广阔的应用前景。
本章将对手写文字识别软件的未来发展趋势进行展望,如更高的识别准确度、更多的应用场景等。
结语:手写文字识别软件是一个方便实用的工具,能够将手写文字转化为电子化格式,大大提高了办公和学习的效率。
希望通过本文的介绍和教程,读者对手写文字识别软件有更加深入的了解,并能够更好地使用该类软件进行工作和学习。
Paperpass使用手册

PaPerPass使用手册 2012年1月9日 为帮助更多的同学、学术朋友们,能有效使用Paperpass 这一论文检测系统,学会使用Paperpass检测报告进行有效的论文修改,降低重复率、提高通过率,笔者根据自己的一些浅薄经验编写了该本电子书,希望能对大家有所帮助。
目 录 1、Paperpass介绍 (4)2、Paperpass使用 (5)3、读懂Paperpass检测报告 (7)4、论文、文章重复率修改方法 (9)5、Paperpass系统和其它检测系统比较 (10)1、Paperpass介绍 1.1关于PaperPass2007年,是全球首个中文文献相似度比对系统,运营最可信赖的中文原创性检查和预防剽窃的在线网站。
目前在用检测版本是汲取了大量的用户意见后开发的,更新了比对算法,比对的效率和准确率大大提高,另外还增加了上传文件、下载报告、引用率统计等实用功能。
我们将继续贴近用户需求,升级比对算法,为用户提供更为专业的论文原创性检测服务。
1.2PaperPass的宗旨 多年来,教育工作者和广大学生都强烈要求论文抄袭检测系统的出现。
教育工作者不断告诉我们,他们的学生总是不知道该如何处理手中拥有的论文参考资料。
对于许多学生来说,一份能清楚展示自己论文中存在的问题的分析报告,可以帮助他们很清晰地理解在论文写作过程中犯下的错误。
用户使用PaperPass的初衷是:把它作为写作辅助工具,而不是作为一种逃避自己任务的工作方式。
1.3自建库 用户可以在提交论文检测之前首先构建属于自己的自建资源库,即用户可以把写论文时重点借鉴的那些文章或片段上传到系统里作为一个比对对象。
系统会将您提交的论文优先与您的自建库进行比对,随后再进入PaperPass的数据库进行扫描比对,这样可以提高论文检测报告的质量,给用户修改论文带来了极大的方便。
1.4特点1.4.1优秀的算法 系统采用自主研发的动态指纹越级扫描技术,检测主要步骤有:文本预处理、语义挖掘、深度识别、全局扫描等,检测速度快并且检测准确率达到了99%以上。
论文查重系统使用说明
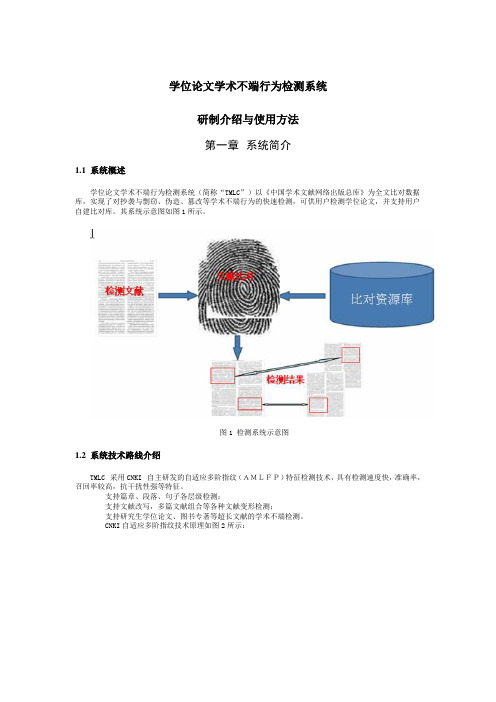
学位论文学术不端行为检测系统研制介绍与使用方法第一章系统简介1.1 系统概述学位论文学术不端行为检测系统(简称“TMLC”)以《中国学术文献网络出版总库》为全文比对数据库,实现了对抄袭与剽窃、伪造、篡改等学术不端行为的快速检测,可供用户检测学位论文,并支持用户自建比对库。
其系统示意图如图1所示。
图1 检测系统示意图1.2 系统技术路线介绍TMLC采用CNKI自主研发的自适应多阶指纹(AMLFP)特征检测技术,具有检测速度快,准确率,召回率较高,抗干扰性强等特征。
支持篇章、段落、句子各层级检测;支持文献改写,多篇文献组合等各种文献变形检测;支持研究生学位论文、图书专著等超长文献的学术不端检测。
CNKI自适应多阶指纹技术原理如图2所示:图2 CNKI自适应多阶指纹技术原理图对任意一篇需要检测的文献,系统首先对其进行分层处理,按照篇章、段落、句子等层级分别创建指纹,而比对资源库中的比对文献,也采取同样技术创建指纹索引。
这样的分层多阶指纹结构,不仅可以满足我们对超长文献的快速检测,而且,因为我们的最小指纹粒度为句子,因此,也满足了系统对检准率和检全率的高要求。
原则上,只要检测文献与比对文献存在一个相同的句子,就能被检测系统发现。
1.3 系统功能概述系统主要功能包括:已发表文献检测、论文检测、问题库查询、自建比对库管理等。
◆已发表文献检测:指检测系统能够自动将属于用户的已正式发表的学位论文检索出来,并对每一篇已发表文献进行实时检测,快速给出检测结果。
◆论文检测:主要实现论文实时在线检测功能。
◆问题库查询:指用户可以将检测结果中确认有问题的文献放入到问题库,便于用户集中管理。
◆自建比对库:指管理人员可以选择将检测文献放入个人比对库或者批量上传文献作为个人比对库,该个人比对库即可作为以后学术不端文献检测的比对数据库,该自建个人比对库完全属于用户,其他用户无权使用。
1.4 系统目的TMLC的目的是辅助各研究生培养单位对学位论文质量进行评估,为审查论文提供技术服务。
查重科技KQB2系列应用管说明书
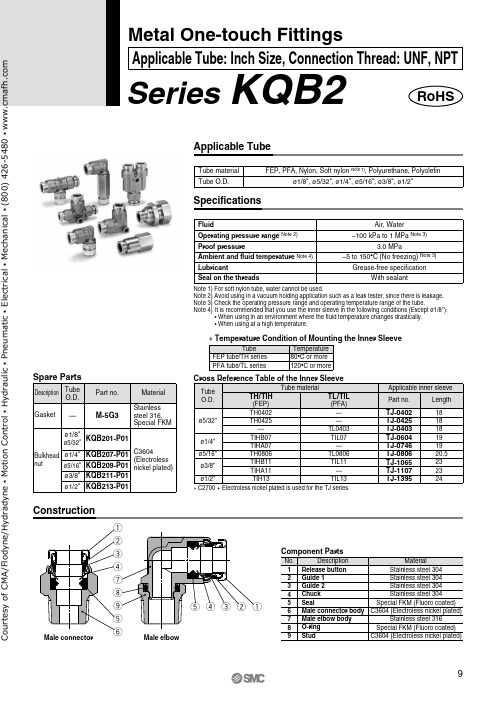
qu w e r t yt o i r e w q Series KQB2Applicable TubeTube material Tube O.D.FEP, PFA, Nylon, Soft nylon Note 1), Polyurethane, Polyolefinø1/8", ø5/32", ø1/4", ø5/16", ø3/8", ø1/2"TubeFEP tube/TH series PFA tube/TL seriesTemperature 80°C or more 120°C or more SpecificationsConstructionFluidOperating pressure range Note 2)Proof pressureAmbient and fluid temperature Note 4)LubricantSeal on the threadsAir, Water–100 kPa to 1 MPa Note 3)3.0 MPa–5 to 150°C (No freezing) Note 3)Grease-free specificationWith sealant∗ Temperature Condition of Mounting the Inner SleeveNo.12345678Description Release button Guide 1Guide 2Chuck Seal Male connector body Male elbow body O-ring Stainless steel 304Stainless steel 304Stainless steel 304Stainless steel 304Special FKM (Fluoro coated)C3604 (Electroless nickel plated)Stainless steel 316Special FKM (Fluoro coated)Material Note 1) For soft nylon tube, water cannot be used.Note 2) Avoid using in a vacuum holding application such as a leak tester, since there is leakage. Note 3) Check the operating pressure range and operating temperature range of the tube.Note 4) It is recommended that you use the inner sleeve in the following conditions (Except ø1/8"):• When using in an environment where the fluid temperature changes drastically.• When using at a high temperature.Component PartsMetal One-touch FittingsApplicable Tube: Inch Size, Connection Thread: UNF, NPTDescription Tube O.D.GasketBulkhead nut Part no.Material M-5G3KQB201-P01KQB207-P01KQB209-P01KQB211-P01KQB213-P01ø1/8"ø5/32"ø1/4"ø5/16"ø3/8"ø1/2"Stainless steel 316,Special FKMC3604(Electrolessnickel plated)Spare Parts—Tube O.D.ø5/32"ø1/4"ø5/16"ø3/8"ø1/2"Tube materialTH/TIH(FEP)Applicable inner sleeveTH0402TH0425—TIHB07TIHA07TH0806TIHB11TIHA11TIH13TL/TIL(PFA)——TL0403TIL07—TL0806TIL11—TIL13Part no.TJ-0402TJ-0425TJ-0403TJ-0604TJ-0746TJ-0806TJ-1065TJ-1107TJ-1395Length 18 18 18 19 19 20.523 23 24Cross Reference Table of the Inner SleeveRoHSo u r t e s y o f C M A /F l o d y n e /H y d r a d y n e ▪ M o t i o n C o n t r o l ▪ H y d r a u l i c ▪ P n e u m a t i c ▪ E l e c t r i c a l ▪ M e c h a n i c a l ▪ (800) 426-5480 ▪ w w w .c m a f h .c o mStraight Union: Note 1) øD is maximum diameter.Note 2) Value of FEP tube.o u r t e s y o f C M A /F l o d y n e /H y d r a d y n e ▪ M o t i o n C o n t r o l ▪ H y d r a u l i c ▪ P n e u m a t i c ▪ E l e c t r i c a l ▪ M e c h a n i c a l ▪ (800) 426-5480 ▪ w w w .c m a f h .c o mNote 1) øD is maximum diameter.Note 2) Value of FEP tube.Note 1) øD is maximum diameter.Note 2) Value of FEP tube.Union Elbow: o u r t e s y o f C M A /F l o d y n e /H y d r a d y n e ▪ M o t i o n C o n t r o l ▪ H y d r a u l i c ▪ P n e u m a t i c ▪ E l e c t r i c a l ▪ M e c h a n i c a l ▪ (800) 426-5480 ▪ w w w .c m a f h .c o mUnion Tee: Union “Y”:ourtesyofCMA/Flodyne/Hydradyne▪MotionControl▪Hydraulic▪Pneumatic▪Electrical▪Mechanical▪(8)426-548▪www.cmafh.co mNote 2) Value of FEP tube.Note 1) øD is maximum diameter.Note 2) Value of FEP tube.o u r t e s y o f C M A /F l o d y n e /H y d r a d y n e ▪ M o t i o n C o n t r o l ▪ H y d r a u l i c ▪ P n e u m a t i c ▪ E l e c t r i c a l ▪ M e c h a n i c a l ▪ (800) 426-5480 ▪ w w w .c m a f h .c o mNote 2) Value of FEP tube. Plug: KQB2PourtesyofCMA/Flodyne/Hydradyne▪MotionControl▪Hydraulic▪Pneumatic▪Electrical▪Mechanical▪(8)426-548▪www.cmafh.co m。
关于申报指南查重的说明范文模板

关于申报指南查重的说明范文模板尊敬的[相关人员/部门]:今天来给大家唠唠咱们申报指南查重这事儿。
一、为啥要查重呢?您想啊,申报指南就像是一场比赛的规则说明书,如果里面有大量重复的内容,就好比比赛规则这儿抄一点那儿抄一点,那多乱套啊。
而且,没有独特性的申报指南可能会让申请者迷惑,也显示不出咱们项目或者工作的独特价值和要求。
比如说,要是大家看到一模一样的指南,都不知道到底是哪个才是针对咱们这个事儿的准确要求,就像到了一个岔路口,路标都一样,那可就抓瞎了。
二、查重查些啥?咱们这个查重可不是随便看看那么简单。
就是查那些文字表述。
像那些大段大段描述项目目标、要求、流程的话,要是和其他地方的指南差不多,那可不行。
这就好比您写作文,不能抄别人的好词好句还当成自己原创的一样。
其次呢,那些关键概念的解释也得查。
要是概念解释都千篇一律,那可能说明咱们没有深入思考这个项目自己的特点。
比如说,咱们这个项目里的“创新点”这个概念,要是解释和其他项目没差别,那申请者怎么能准确理解咱们的特殊要求呢?三、查重的标准是啥?四、如果查重不过会怎样呢?要是查重那可就像火车跑错了轨道,得赶紧调整。
咱们得重新审视申报指南,把那些重复的部分修改得既能准确表达意思,又有咱们自己的特色。
这可能会耽误一点时间,但总比让申请者拿着一份混乱、不专业的指南要好得多。
而且,如果带着查重不过的指南就发布出去,万一被人发现了,那咱们的信誉可就像气球被扎了个洞,一下子就瘪了,以后大家对咱们的项目或者工作可能就没那么信任了。
五、怎么避免查重不过呢?这就需要咱们编写申报指南的时候多花点心思啦。
在动笔之前,要把这个项目的方方面面都研究透彻,找出那些真正独特的地方。
就像寻宝一样,先知道自己宝藏的独特之处,才能准确描述给别人。
然后呢,多参考不同的资料,但不是直接抄袭,而是把那些有用的东西消化吸收,再用自己的话表达出来。
这就好比做菜,看了很多菜谱,但最后做出来的是有自己独特风味的菜肴。
维普系统查重操作指南

维普系统查重操作指南(港航院、力材院、理学院、马院、外语院等适用)一、学生提交论文定稿及查重1.论文查重的流程:学生提交论文定稿—指导教师审核(退回修改\允许查重)(1)当教师选择了“退回修改”,则学生重新修改论文,重新提交,教师重新审核(退回修改\允许查重)(2)当教师选择了“允许查重”,则学生页面定稿页面会出现查重的按钮,可以进行查重。
查重完获取结果提交给教师后,指导教师进行审核(退回修改\审核评分);查重环节系统设置2次查重机会,请慎重使用。
查重结果出来,教师点击“退回修改”后,学生重新提交论文,教师重新审核(退回修改\允许查重,可进行第二次查重)。
查重后教师点击“审核评分”后,老师就正常的给学生录入评分,正常的往后续走流程。
当指导教师审核通过并且评完分之后,学生就不能再次提交论文查重。
2.文档解析失败:如果学生页面查重显示状态为空,相似率为0%,且获取检查结果按钮是灰色的,则文档上传检测系统解析失败(如下图)。
解决办法:学生联系导师审核“回退修改“,重新选择文档上传(第二次上传前原文档格式另存为doc/docx的另外一种。
注意:转化格式不是直接修改文档后缀,而是“另存为”)二、常见问题(1)定稿阶段有2次查重机会,为什么我只用了一次,就显示无法查重了?在第一次查重,学生点击确认后提交论文给指导教师审核,如指导教师审核通过,则无法进行后续查重;如指导教师审核不通过,才可进行第二次查重;(2)学生提交了论文,但是指导老师页面无法看到,为什么?学生端要经过查重,并确认提交,指导教师页面才可查看。
如出现指导老师无法查看的情况,请检查学生的论文状态是否为“已暂存,待提交”,如果是此状态,需要学生点击确认按钮后,提交论文,指导教师才能在系统中查看并审阅。
(3)单篇论文检测的时间3-10分钟,检测速度与文件大小及网速有关。
学生提交查重后,不要重复点击提交查重检测,通过点击“获取检测结果”刷新页面获取报告。
中国知网大学生论文检测系统使用说明

中国知网大学生论 文检测系统使用说明
2021/4/9
1
论文检测须知
• 每个学院检测的篇数已经分配,请按照分配的篇数检 测。
• 检测过的文章,即使删除检测结果,检测名额也已经
减少,切忌删除检测结果。
以对已检测文献进行查询,查看详细的检测数据。选
择导出excel,可导出详细信息。
•
2021/4/9
5
谢谢观赏
实践教学科
2021/4/9
6
2021/4/9
2
检测步骤
• 登陆网址:
• 进入高级版,选择管理部门 入口
• 选择上传论文
• 输入用户名,密码: 12345678,登陆后请修改密 码,否则责任自负
2021/4/9
3
选择上传压缩文件,点 击上传按钮,论文自动 检测。
2021/4/9
4
•
点击导航条“结果查询”进入结果查询页面,可
大雅相似度使用说明——个人单篇检测
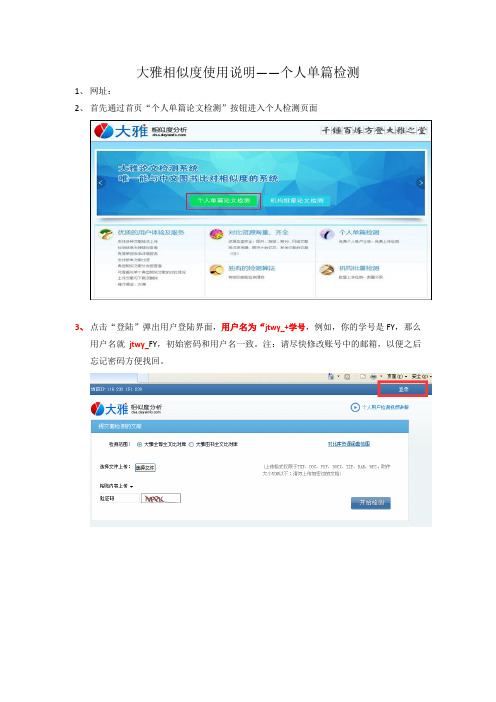
大雅相似度使用说明——个人单篇检测1、网址:2、首先通过首页“个人单篇论文检测”按钮进入个人检测页面3、点击“登陆”弹出用户登陆界面,用户名为“jtwy_+学号,例如,你的学号是FY,那么用户名就jtwy_FY,初始密码和用户名一致。
注:请尽快修改账号中的邮箱,以便之后忘记密码方便找回。
4、进入系统后,请尽快修改密码,以免用户名被盗用,你可以通过点击右上角的用户名进行查看历史记录,修改密码、退出操作。
另外请尽快修改账号中的邮箱,以便之后忘记密码方便找回。
5、先输入验证码,您可以在这里直接上传原文文档进行检测,也可以展开输入框直接粘贴待检测内容。
6、点击查看报告,会弹出提示信息,每个帐号一天最多免费检测3次,每个帐号共有5次免费检测的权限,点击确定即可以看到文章的相似度检测结果。
如果超过5次需按要求付费,是否继续查看同学们可以根据自己具体情况来定。
7、检测报告中,一些统计数据与学院论文审查要求的对应关系(这里看到的检测结果不包括你引用学院以前的毕业论文):a)毕业论文正文要求的字数:正文字数b)正文中累计文献引用比例(含中、英文):文献相似度c)正文中单篇文献引用字数(含中、英文):点击典型相似文献,详细情况见第8点同学们可以点击全文报告、详细报告和简单报告分别查看相关相似度详细报告8、点击典型相似文献后,弹出以下界面,图中显示相似图书列表,最上面即为图书相似度最高的图书,点击题名就可以看到重复字符数,该字符数就是单篇引用最多的图书字符数。
依此类推,分别可以查看相似报纸、相似期刊论文和其他网络文档的相似度检测结果。
这4类中单篇引用最多的就是论文正文单篇引用字符数例如:一篇论文4类相似度检查出来的重复字符数分别如下,那么这篇论文正文单篇引用字符数为:3900●相似图书:489●相似报纸:567●相似期刊论文:758●其他网络文档:3900。
论文查重说明

论文查重说明
论文查重说明
本论文经维普论文检测系统(大学生版)检测,自写率为88.76%、复写率为8.56%、引用率为2.68%,总相似比为11.24%。
系统检测有5个引用片段。
5个片段在论文中的分布情况为:摘要中一个,绪论中两个,讨论中两个。
引用目的在于介绍研究对象的研究背景和研究现状。
论文中有25个相似片段,在论文中的分布情况如下:
诚信声明中有3个相似片段,相似度分别为95.74%、64.84%、76.27%;中文摘要中有1个相似片段,相似度为76.27%;绪论中有9个相似片段,相似度在55%--85%之间。
以上相似片段为必要的背景介绍和专有名词相似,并非刻意摘抄相关文献。
材料和方法中有3个相似片段,相似度分别为60.71%、75%、59.77%,相似之处为实验操作方法和步骤。
讨论中有10个相似片段相似度在65%--85%之间,其中多数为70%--75%之间。
主要相似之处为相关研究的研究现状和展望。
结论部分相似度为0。
论文总相似度为11.24%,符合学校对大学生毕业论文相似程度的要求。
毕业设计说明书查重

毕业设计说明书查重毕业设计说明书查重【篇一:2015届毕业论文(设计)查重说明】附件6:2015届毕业论文(设计)查重说明一、检测办法与检测时间2015届所有毕业论文及部分毕业设计必须通过中国知网大学生论文学术诚信检测系统进行检测,检测工作由教务处负责,所有论文(设计)的检测工作必须在各专业答辩前两周完成。
二、论文提交要求1.文本格式:由各系统一提交学生毕业论文(设计)word格式电子文档,文字部分不能以图片形式出现。
2.文本大小:文本限8万字符以内,若超限,可去掉论文中过大的图、表、源程序及附录等。
3.文件命名方式:“班级+学生姓名+学号.doc”,如“房产l111班张三20110040.doc”,各系需将所有检测学生文件命名制成“查重信息一览表”(格式见附件6)。
4.各系于答辩前两周将相关论文(设计)电子版、2015届毕业设计(论文)一览表电子版及查重信息一览表电子版打包发至教务科研部邮箱:lushanjiaoxuebu@。
三、检测结果认定与处理方法对检测中发现的重复率过高涉嫌论文(设计)作假行为的,学校将依据教育部《学位论文作假行为处理办法》(教育部令第34号)、二、论文提交要求1.文本格式:由各系统一提交学生毕业论文(设计)文件扩展名为.doc 格式电子文档。
(注意:文字部分不能以图片、公示形式出现。
)2.文本大小:文本限8万字符以内,若超限,可去掉论文中过大的图、表、源程序及附录等。
3.文件命名方式:“班级+学生姓名+学号.doc”,如“房产l121班张三20120040.doc”,各系需将所有检测学生文件命名制成“查重信息一览表”(格式见附件6)。
(注意:文件命名必须准确无误)4.各系于答辩前两周将相关论文(设计)电子版、2016届毕业设计(论文)一览表电子版及查重信息一览表电子版打包发至教务部邮箱:lushanjiaoxuebu@。
三、检测结果认定与处理方法对检测中发现的重复率过高涉嫌论文(设计)作假行为的,学校将依据教育部《学位论文作假行为处理办法》(教育部令第34号)、《广西工学院鹿山学院普通高等教育本科毕业生学士学位授予办法》(院发?2012?12号)等文件规定进行严肃处理:1.复制比r≤35%的,视为检测通过,可参加答辩。
易撰查重使用方法

易撰查重使用方法1. 简介在学术界和写作领域,查重是一个非常重要的环节。
为了确保文章的原创性和学术诚信,我们需要使用一些工具来检测文本的相似度和可能存在的抄袭问题。
易撰查重是一款专业的查重工具,它可以帮助用户快速准确地检测文本的相似度,并给出相应的报告。
本文将介绍易撰查重的使用方法,帮助用户更好地利用该工具。
2. 注册与登录首先,用户需要在易撰查重官方网站上进行注册并创建账号。
注册时需要提供有效的邮箱地址,并设置密码以确保账号安全。
注册完成后,用户可以使用注册时填写的邮箱地址和密码进行登录。
3. 文本上传登录后,用户可以看到易撰查重的主界面。
要开始使用该工具进行查重,用户需要将待检测的文本上传到系统中。
用户可以选择直接粘贴文本内容或者上传文件(支持常见格式如doc、docx、pdf等)。
上传完成后,系统将自动对文本进行处理。
4. 查重设置在进行查重之前,用户可以根据自己的需求对查重设置进行调整。
点击界面上方的“设置”按钮,进入设置页面。
在设置页面中,用户可以选择查重算法、相似度阈值等参数。
不同的设置会对查重结果产生影响,用户可以根据自己的需求进行调整。
5. 开始查重设置完成后,用户可以点击界面上方的“开始查重”按钮,系统将开始对上传的文本进行查重分析。
易撰查重利用先进的文本处理技术和算法,能够非常快速地完成查重任务,并给出详细的结果报告。
6. 查重报告查重完成后,系统将生成一份详细的查重报告。
用户可以点击界面上方的“报告”按钮来查看报告内容。
报告中会显示文本相似度、可能存在的抄袭部分以及参考文献等信息。
用户可以根据报告内容来判断文本是否存在抄袭问题,并采取相应措施。
7. 结果解读与处理根据查重报告,用户可以了解到文本与其他已有文献或网络资源之间的相似度情况。
如果发现文本存在抄袭问题,用户需要重新修改并进行再次检测,直到确保文本原创性和学术诚信。
8. 其他功能除了基本的查重功能外,易撰查重还提供了其他一些实用功能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
文字查重系统使用说明书版本0.071. 安装1.1 准备1.1.1服务器准备LINUX Ubuntu 14 64位或 WINDOWS均可1.1.2安装gitLINUXsudo apt-get updatesudo apt-get install gitWINDOWS请参考https:///progit/progit/blob/master/zh/01-introduction/01-chapter1.markdown 1.1.3 安装jdk1.8LINUX$sudo add-apt-repository ppa:webupd8team/java$ sudo apt-get update$ sudo apt-get install oracle-java8-installerWINDOWS/technetwork/java/javase/downloads/jdk8-downloads-2133151.html1.1.4 安装gradleLINUXsudo apt-get install gradlesudogedit /usr/bin/../share/gradle/bin/gradle把下面一行注释掉:export JAVA_HOME=....WINDOWS/view/d109245c6c85ec3a87c2c58f.html1.2 获取git源码创建合适的目录,例如 xx然后到该目录下执行下面的命令git clone https:///lxh5147/Zeen会创建Zeen/PlagiarismChecker,该目录称之为安装目录1.3 使用DOCKER安装DOCKER请参考相关文档,例如https:///installation/ubuntulinux/ 然后执行:sudodocker pull lxh5147/plagiarism_checker2. 索引2.1 导出论文库新建一个目录,将论文库全文(用PDFBox提取的文本)导出到该目录下。
每篇论文对应一个文本文件,文件名规则为:[论文编号].txt。
论文编号为整数。
该目录称为PDF文本库目录。
可以新建多个PDF文本库目录,从而把论文PDF文本全文分布在多个目录下。
注意,此时要保证每个目录下的文件整数编号没有重复. 例如,可以建 articles2,然后把论文2PDF全文放入articles2中.2.2准备论文库打开终端,执行下面的命令:gradlebuildArticleRepository -PappArgs="['--pdfTextFileFolders','pdfTextFileFolder1,pdfTextFileFolder2','--articleRepositoryFolder', 'articles','--overwrite','--lowercase']"参数说明:pdfTextFileFolders:PDF文本库目录目录列表,多个PDF文本库目录目录用英语半角逗号分开。
articleRepositoryFolder': 论文库目录overwrite: 可选参数,如果指定该参数,则论文库目录下同名的文件将被改写lowercase: 可选参数,如果指定该参数,文本将转化为小写。
注意,用合适的参数替换上述命令行中的红色部分。
上述命令执行将对全部PDF文本库目录下的文本文件做段落提取操作,并将提取的结果保存为论文库目录下一个同名但无.txt扩展名的压缩的文本文件。
2.3建索引打开终端,执行下面的命令:gradlebuildIndex -PappArgs="['--articleRepositoryFolders','/home/lxh5147/git/PlagiarismChecker/articles','--contentAnalyzers','SimpleContentAnalizerWithSimpleTokenizer,SegmentContentAnalizerWithSimpleSeg mentSplitter','--indexPath','/home/lxh5147/git/PlagiarismChecker/indexes','--capability','100000','--batchSize','1000','--parallelism','2']"2.2.1 参数说明articleRepositoryFolders: 论文库目录列表,多个论文库目录用英文半角逗号分开(”,”),例如’/home/lxh5147/git/PlagiarismChecker/articles,/home/lxh5147/git/PlagiarismChecker/articles2'.论文库目录可以为绝对路径或者相对路径(相对于执行该命令时所在的目录)--contentAnalyzers:对段落进行的哪些种类的指纹提取,多个提取操作名称用英文半角逗号隔开.目前支持如下的指纹提取操作,其复杂程度依次递增. 测试阶段建议选取示例所给的两种做测试.SimpleContentAnalizerWithSimpleTokenizer:去掉段落中的空格、标点符号等,仅保留[a-zA-Z]和[1-9],然后抽取指纹。
每个段落生成一个指纹。
SimpleContentAnalizerWithOpenNLPTokenizer:基于最大熵模型把段落切分成单词、标点符号等,去掉它们之间的空格,然后抽取指纹。
每个段落生成一个指纹。
SegmentContentAnalizerWithSimpleSegmentSplitter:它基于“.”、”?”和”!“将段落切分成句子,为每个句子,去掉句子中的空格、标点符号等,仅保留[a-zA-Z]和[1-9],然后抽取指纹。
如果该句子少于16个单词,将从后续的句子中依次从头取若干单词,凑齐16个后再做指纹提取。
每个句子对应一个指纹。
ShallowContentAnalizerWithSimpleTokenizer:和SimpleContentAnalizerWithSimpleTokenizer类似,但在建指纹前,还会去掉停用词,例如a,the等,并把每个词转化为原型,例如living会转化为live。
ShallowContentAnalizerWithOpenNLPTokenizer:和SimpleContentAnalizerWithOpenNLPTokenizer类似,但在建指纹前,还会去掉停用词,例如a,the等,并把每个词转化为原型,例如living会转化为live。
BagOfWordsContentAnalizerWithSimpleTokenizer:去掉段落中的空格、标点符号等,提取单词和数字以及它们各自出现的次数,然后将单词和数字降序排序,根据排列的单词和数字及其次数建立指纹。
每个段落对应一个指纹。
BagOfWordsContentAnalizerWithOpenNLPTokenizer:基于最大熵模型把段落切分成单词、标点符号等,提取单词和数字以及它们各自出现的次数,然后将单词和数字降序排序,根据排列的单词和数字及其次数建立指纹。
每个段落对应一个指纹。
注意,上述指纹提取操作是大小写敏感的。
为了实现大小写不敏感的指纹提取操作,请在建准备论文库时指定“--lowercase” 选项。
--indexPath: 指纹索引保存的目录.将在该目录下为每种指纹提取类别,建一个同名的索引文件. 如果该文件已经存在,将被重写(先被清空)--capability: 和指纹提取种类对应的每个索引最多允许多少索引项.目前每篇论文的每个段落将占用一个索引项,后期一个段落可能占用多个索引项. 如果有100万论文,每篇论文平均100个段落,则该参数应设为 1亿。
--batchSize:批量进行索引的指纹数目,一般可设置为capability的百分之一或千分之一。
内存足够的情况下,可酌情增大该参数值。
--parallelism:将启用多少个线程同时对批量传入的指纹进行索引。
可将其设为服务器的内核总数-2,例如对8核的服务器,可将值设置为6.2.3.2 多服务器并行索引如果有多台服务器,可在每台服务器上同时执行索引操作。
这些服务器执行几乎完全一样的命令,但每个索引论文库的不同部分,例如:两台服务器A和服务器B:服务器A:gradlebuildIndex -PappArgs="['--articleRepositoryFolders','/home/lxh5147/git/PlagiarismChecker/articlesA','--contentAnalyzers','SimpleContentAnalizerWithSimpleTokenizer,BagOfWordsContentAnalizerWithOpenN LPTokenizer','--indexPath','/home/lxh5147/git/PlagiarismChecker/indexesA','--capability','100000','--batchSize','1000','--parallelism','2']"服务器B:gradlebuildIndex -PappArgs="['--articleRepositoryFolders','/home/lxh5147/git/PlagiarismChecker/articlesB','--contentAnalyzers','SimpleContentAnalizerWithSimpleTokenizer,SegmentContentAnalizerWithSimpleSeg mentSplitter','--indexPath','/home/lxh5147/git/PlagiarismChecker/indexesB','--capability','100000','--batchSize','1000','--parallelism','2']"说明,还有其他并行索引的方式,例如不同服务器共享同一个论文库,但执行不同的指纹提取。