Analysis分析方法
Horizontal analysis

Horizontal analysis(水平分析):将本期报表与前期报表的相同项目进行比较的一种财务分析方法。
Ideal standards(理想标准):只有在没有时间浪费、没有机器故障、没有材料损耗的理想经营状况下才能达到的标准。
也称为理论标准。
Income from operations (operating income)(营业利润):一个利润中心或投资中心的收入减去经营费用和服务部门费用。
Income statement(损益表):总括列示一个企业在某一特定期间(如一个月或一年)收入与费用项目的报表。
Income summary(收益汇总):期末将收入账户和费用账户余额转入的账户。
Indirect method(间接法):报告经营活动现金流量的一种方法,这种方法在净利润的基础上进行调整来计算经营活动现金流量,调整项目包括过去现金收付的递延项目和未来现金收付的应计项目。
Inflation(通货膨胀):总物价水平上升并且货币购买力下降的期间。
Initial public offering (IPO)(首次公开招股):公司第一次向投资公众发行普通股。
Intangible assets(无形资产):对企业经营有用的、非待售的且没有实物形态的长期资产。
Internal controls(内部控制):用来保护企业资产、确保企业信息的准确性以及确保企业遵守有关法规的政策和程序。
Internal rate of return method(内含回报率法):运用现值概念来计算投资项目预计未来现金流量的收益率的一种评价备选投资项目的方法。
Inventory shrinkage(存货损耗):存货账户记录的可供销售商品金额大于实际盘点商品金额的部分。
Inventory turnover(存货周转率):用于衡量销售商品和存货数量关系,等于商品销售成本除以平均存货。
Investment center(投资中心):一个分权单位,其负责人有权利和责任做出决策从而影响该中心的收入、成本以及可获得的固定资产。
自顶向下分析方法

自顶向下分析方法
自顶向下分析方法(Top-Down Analysis Method)是一种从高层次抽象开始到底层实现的分析方法。
该方法首先从系统总体要求出发,逐步分解为较小的模块,然后再对每个模块进行更为具体的分析和设计。
该方法的一般流程为:先确定需求,确定功能模块,进行每个功能模块的详细分析和设计,最后实现代码。
自顶向下分析方法的优点是能够充分地体现系统层次结构和模块化设计思想,能够有效地实现开发过程的可控性和可维护性。
由于该方法从高层次抽象开始,能够明确系统的总体要求,避免了后期因需求变更而导致的繁琐修改。
但是该方法的缺点也很明显,由于其是从高层次抽象开始分解,因此可能导致底层实现的设计不够充分和优化。
此外,该方法需要系统需求已经明确,如果需求不明确,则需要先进行需求分析,否则不便于进行系统的分解和设计。
Analysis 分析结果
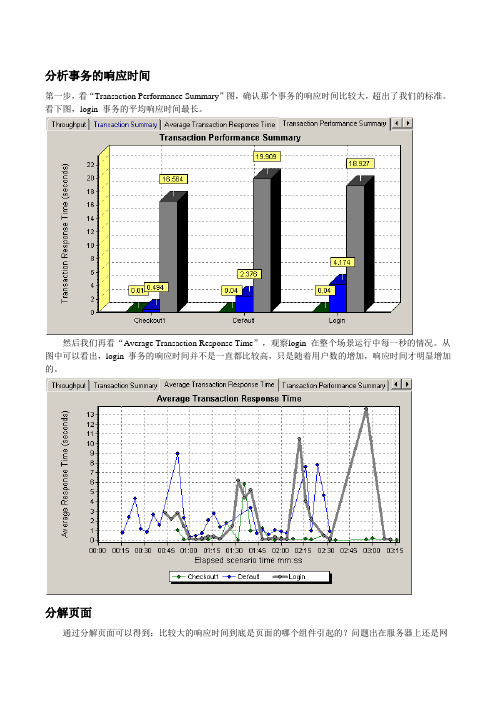
分析事务的响应时间第一步,看“Transaction Performance Summary”图,确认那个事务的响应时间比较大,超出了我们的标准。
看下图,login 事务的平均响应时间最长。
然后我们再看“Average Transaction Response Time”,观察login 在整个场景运行中每一秒的情况。
从图中可以看出,login 事务的响应时间并不是一直都比较高,只是随着用户数的增加,响应时间才明显增加的。
分解页面通过分解页面可以得到:比较大的响应时间到底是页面的哪个组件引起的?问题出在服务器上还是网络传输上。
下面简单说一下浏览器从发送一个请求到最后显示的全过程。
1. 浏览器向Web Server 发送请求,一般情况下,该请求首先发送到DNS Server 把DNS名字解析成IP 地址。
解析的过程的时间就是。
这个度量时间可以确定DNS 服务器或者DNS 服务器的配置是否有问题。
如果DNS Server 运行情况比较好,该值会比较小。
2. 解析出Web Server 的IP 地址后,请求被送到了Web Server,然后浏览器和Web Server 之间需要建立一个初始化连接,建立该连接的过程就是。
这个度量时间可以简单的判断网络情况,也可以判断Web Server 是否能够响应这个请求。
如果正常,该值会比较小。
3. 建立连接后,从Web Server 发出第一个数据包,经过网络传输到客户端,浏览器成功接受到第一字节的时间就是。
这个度量时间不仅可以表示Web Server 的延迟时间,还可以表示出网络的反应时间。
4. 从浏览器接受到第一个字节起,直到成功收到最后一个字节,下载完成止,这段时间就是。
这个度量时间可以判断网络的质量(可以用size/time 比来计算接受速率)其他的时间还有SSL Handshaking(SSL 握手协议,用到该协议的页面比较少)、Client Time(请求在客户端浏览器延迟的时间,可能是由于客户端浏览器的think time 或者客户端其他方面引起的延迟)、Error Time (从发送了一个HTTP 请求,到Web Server 发送回一个HTTP 错误信息,需要的时间)。
框架分析法

框架分析法
框架分析法(FrameworkAnalysis)是一种研究方法,它着重于分析数据,以改善个人或组织的决策能力。
这种分析方法的重要性是从收集的数据中发现可用的有用信息,以支持管理决策,它是将大量的数据转换为有价值的信息的重要工具。
框架分析法可以帮助快速收集、处理和解释数据,以支持有效的决策和行动计划。
框架分析法可以用来帮助组织提高其决策能力,它提供了一种提取有用数据的结构方法,从而使组织可以更充分地利用这些数据。
它是一种模式,用于分析数据以证明论点并发现解决方案,使组织可以获得更好的机会,制定出更佳的计划,以应对和处理变化。
它是一种研究方法,有助于提高组织的决策效率,明确其未来的发展方向,提高实现利益的重要性,并从现有资源中实现最大化回报。
框架分析法包括数据收集、建模、实施和报告几个步骤。
首先,进行数据收集,以便正确理解要求分析的问题;其次,进行建模,为了确定数据收集的方式;然后,进行实施,以确定所需的步骤和步骤的完成度;最后,报告分析的结果,以适当地实施决策,行动计划和改善全球业务流程。
框架分析法在管理决策中发挥着重要作用。
它不仅可以帮助公司有效地处理数据,还可以更全面地了解市场,确定参与战略决策的合理方式,并帮助公司处理复杂和多变的市场概念,以实现最佳绩效。
此外,框架分析法还可以用于模拟管理条件,改善战略决策,满足公司的策略要求,提高公司的效率和产出,减少决策的风险,提高公司
的最终盈利能力。
总之,框架分析法是一种重要的研究方法,它可以帮助组织更有效地分析数据,以改善管理决策,提高业务绩效,有效地发掘和利用数据资源,提高公司的竞争力和效率,最终以实现最佳的绩效为目的。
python中analysis的用法

python中analysis的用法
Python中的analysis是一种数据分析工具,它能够帮助我们对数据进行探索和分析。
在Python中,我们可以使用pandas库来处理数据,并使用其内置的analysis功能来分析数据。
具体来说,我们可以使用以下方法:
1. describe()方法:该方法可以输出数据集的统计信息,包括均值、标准差、最小值、最大值等。
2. corr()方法:该方法可以计算数据集中各列之间的相关性系数,用于探索不同变量之间的关系。
3. value_counts()方法:该方法可以统计数据集中每个值的频率,用于分析数据的分布情况。
4. groupby()方法:该方法可以按照指定的列对数据集进行分组,并对每个组进行聚合操作,用于探索不同组之间的差异。
除了以上方法外,Python中还有许多其他的analysis工具,例如numpy库、matplotlib库等,它们能够帮助我们更加深入地理解和分析数据。
- 1 -。
因素分析法

因素分析法因素分析法(Factor Analysis)是一种统计分析方法,用于研究变量之间的关系,揭示潜在的影响因素。
这种方法基于隐变量模型,通过统计数据降维和数据描述,帮助我们理解数据背后的结构和关联。
因素分析法最初由心理学家斯皮尔曼(C. Charles Spearman)于1904年提出,旨在研究智力的因素结构。
随后,这种方法被逐渐应用于其他学科领域,如经济学、社会学、市场研究等。
在实践中,因素分析法被广泛用于数据挖掘、模式识别、变量选择和数据降维等领域。
因素分析法的基本原理是假设多个观测变量与少数几个潜在因素相关联,且这些潜在因素无法直接观测到。
通过因素分析,我们可以发现这些潜在因素,从而帮助我们理解变量之间的关系。
一般来说,因素分析法包括两个步骤:因子提取和因子旋转。
因子提取是指从观测变量中提取出少数几个解释变量的因子。
常用的因子提取方法有主成分分析法(Principal Component Analysis)和主因子分析法(Principal Factor Analysis)。
主成分分析法将变量与因子之间的关系表示为线性组合,将原始变量转化为几个无关的主成分,保留了原始数据的总方差的大部分信息。
主因子分析法在主成分分析的基础上,进一步提取出与原始变量更相关的因子,以更好地解释变量之间的关系。
因子旋转是指调整因子所带的权重,使得因子之间的相关性更小,更容易解释。
常用的因子旋转方法有正交旋转和斜交旋转。
正交旋转方法(如Varimax旋转)使得因子之间没有相关性,从而更容易解释各个因子的特征。
斜交旋转方法(如Oblique旋转)允许因子之间存在相关性,适用于因子之间存在关联的情况。
因素分析法的应用范围广泛,涵盖了许多领域。
在社会科学研究中,因素分析法可以用于研究心理学测试中的潜在因素,如人格特征、态度、价值观等。
在市场研究中,因素分析法可以用于揭示消费者行为背后的因素,如购买决策、品牌选择等。
SPSS因子分析法

S P S S因子分析法本页仅作为文档封面,使用时可以删除This page is only the cover as a document 2021year因子分析因子分析(Factor analysis ):用少数几个因子来描述许多指标或因素之间的联系,以较少几个因子来反映原资料的大部分信息的统计学分析方法。
从数学角度来看,主成分分析是一种化繁为简的降维处理技术。
主成分分析(Principal component analysis ):是因子分析一个特例,是使用最多的因子提取方法。
它通过坐标变换手段,将原有的多个相关变量,做线性变化,转换为另外一组不相关的变量。
选取前面几个方差最大的主成分,这样达到了因子分析较少变量个数的目的,同时又能与较少的变量反映原有变量的绝大部分的信息。
两者关系:主成分分析(PCA )和因子分析(FA )是两种把变量维数降低以便于描述、理解和分析的方法。
特点(1)因子变量的数量远少于原有的指标变量的数量,因而对因子变量的分析能够减少分析中的工作量。
(2)因子变量不是对原始变量的取舍,而是根据原始变量的信息进行重新组构,它能够反映原有变量大部分的信息。
(3)因子变量之间不存在显著的线性相关关系,对变量的分析比较方便,但原始部分变量之间多存在较显著的相关关系。
(4)因子变量具有命名解释性,即该变量是对某些原始变量信息的综合和反映。
在保证数据信息丢失最少的原则下,对高维变量空间进行降维处理(即通过因子分析或主成分分析)。
显然,在一个低维空间解释系统要比在高维系统容易的多。
类型根据研究对象的不同,把因子分析分为R 型和Q 型两种。
当研究对象是变量时,属于R 型因子分析;当研究对象是样品时,属于Q 型因子分析。
但有的因子分析方法兼有R 型和Q 型因子分析的一些特点,如因子分析中的对应分析方法,有的学者称之为双重型因子分析,以示与其他两类的区别。
分析原理假定:有n 个地理样本,每个样本共有p 个变量,构成一个n ×p 阶的地理数据矩阵 :当p 较大时,在p 维空间中考察问题比较麻烦。
相关性分析的五种方法

相关性分析的五种⽅法相关分析(Analysis of Correlation)是⽹站分析中经常使⽤的分析⽅法之⼀。
通过对不同特征或数据间的关系进⾏分析,发现业务运营中的关键影响及驱动因素。
并对业务的发展进⾏预测。
本篇⽂章将介绍5种常⽤的分析⽅法。
在开始介绍相关分析之前,需要特别说明的是相关关系不等于因果关系。
相关分析的⽅法很多,初级的⽅法可以快速发现数据之间的关系,如正相关,负相关或不相关。
中级的⽅法可以对数据间关系的强弱进⾏度量,如完全相关,不完全相关等。
⾼级的⽅法可以将数据间的关系转化为模型,并通过模型对未来的业务发展进⾏预测。
下⾯我们以⼀组⼴告的成本数据和曝光量数据对每⼀种相关分析⽅法进⾏介绍。
以下是每⽇⼴告曝光量和费⽤成本的数据,每⼀⾏代表⼀天中的花费和获得的⼴告曝光数量。
凭经验判断,这两组数据间应该存在联系,但仅通过这两组数据我们⽆法证明这种关系真实存在,也⽆法对这种关系的强度进⾏度量。
因此我们希望通过相关分析来找出这两组数据之间的关系,并对这种关系进度度量。
1,图表相关分析(折线图及散点图)第⼀种相关分析⽅法是将数据进⾏可视化处理,简单的说就是绘制图表。
单纯从数据的⾓度很难发现其中的趋势和联系,⽽将数据点绘制成图表后趋势和联系就会变的清晰起来。
对于有明显时间维度的数据,我们选择使⽤折线图。
为了更清晰的对⽐这两组数据的变化和趋势,我们使⽤双坐标轴折线图,其中主坐标轴⽤来绘制⼴告曝光量数据,次坐标轴⽤来绘制费⽤成本的数据。
通过折线图可以发现,费⽤成本和⼴告曝光量两组数据的变化和趋势⼤致相同,从整体的⼤趋势来看,费⽤成本和⼴告曝光量两组数据都呈现增长趋势。
从规律性来看费⽤成本和⼴告曝光量数据每次的最低点都出现在同⼀天。
从细节来看,两组数据的短期趋势的变化也基本⼀致。
经过以上这些对⽐,我们可以说⼴告曝光量和费⽤成本之间有⼀些相关关系,但这种⽅法在整个分析过程和解释上过于复杂,如果换成复杂⼀点的数据或者相关度较低的数据就会出现很多问题。
实证分析方法

实证分析方法实证分析方法(Empirical Analysis Method)是一种基于实际数据和经验观察的科学研究方法。
它通过收集和分析实际数据,从而为研究问题提供定量或定性的证据和证据支持。
实证分析方法的核心目标是使用可验证的实证数据来验证或推翻特定的研究假设,并从中得出结论。
实证分析方法主要有两种类型:定量分析和定性分析。
定量分析是一种基于数值数据的实证研究方法。
它使用统计分析和数学模型来解释现象和问题,并从中得出结论。
定量分析通常涉及收集和处理大量数据,因此需要使用统计方法和计算工具进行分析。
定量分析的一个常见应用是市场调研,用于测量和分析消费者行为、市场趋势和产品偏好等。
定性分析是一种以文字描述和解释为基础的实证研究方法。
它通过收集和分析非数值的数据,如文本、访谈和观察记录,来揭示现象和问题背后的含义和动态。
定性分析通常涉及对文本和内容进行分类和分类,并通过比较和解释来识别模式和主题。
定性分析的一个常见应用是社会科学,如人类行为和社会动态的研究。
实证分析方法可以带来许多好处。
首先,它能够提供客观的证据和数据支持,有助于验证或否定研究假设。
其次,实证分析方法可以提供详细和深入的研究结果,帮助研究人员理解和解释现象和问题的根本原因。
另外,实证分析方法还可以为政策制定者和实践者提供有用的指导和建议,有助于制定决策和解决问题。
虽然实证分析方法具有很多优点,但也有一些限制和挑战。
首先,实证分析方法需要高质量的数据和样本,以确保研究的可靠性和有效性。
其次,实证分析方法可能受到研究设计和研究者的个人偏见的影响,影响分析结果的准确性和可解释性。
最后,实证分析方法需要时间和资源的投入,以收集和处理大量数据,因此需要研究人员具备一定的技能和专业知识。
总之,实证分析方法是一种基于实际数据和经验观察的科学研究方法。
它通过收集和分析数据来验证或推翻研究假设,并从中得出结论。
实证分析方法有定量分析和定性分析两种类型,可以提供客观的证据和深入的研究结果。
analysis的几种形式

analysis的几种形式
【最新版】
目录
1.引言:分析分析的几种形式
2.分析的几种形式概述
3.形式 1:定性分析
4.形式 2:定量分析
5.形式 3:比较分析
6.形式 4:因果分析
7.形式 5:系统分析
8.结论:分析的各种形式的应用和优缺点
正文
分析是我们理解和解决问题的重要手段,它可以帮助我们从不同的角度和深度理解事物。
分析的几种形式包括定性分析、定量分析、比较分析、因果分析和系统分析。
定性分析是一种基于描述和解释的分析方法,它主要通过文字和图表来描述和解释事物的特性和关系。
定性分析通常用于研究初始阶段,它可以帮助我们理解问题的性质和范围。
定量分析则是一种基于数学和统计的分析方法,它通过收集和分析数据来描述和解释事物。
定量分析可以提供更精确和客观的分析结果,但它需要大量的数据支持。
比较分析是通过比较两个或多个事物来分析它们的相同和不同之处,从而理解它们的本质和特性。
比较分析可以帮助我们理解事物的相对优劣,从而做出更明智的决策。
因果分析则是通过分析事物之间的因果关系来理解事物的发展和变化。
因果分析可以帮助我们确定问题的根本原因,从而提供有效的解决方案。
系统分析则是一种整体性的分析方法,它通过分析事物的各个部分和它们之间的关系来理解事物。
系统分析可以帮助我们理解事物的整体性和系统性,从而提供更全面和深入的分析结果。
总的来说,分析的各种形式都有其独特的优点和应用,我们需要根据问题的性质和需要选择合适的分析方法。
analysis的用法总结大全

analysis的用法总结大全(学习版)编制人:__________________审核人:__________________审批人:__________________编制学校:__________________编制时间:____年____月____日序言下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!并且,本店铺为大家提供各种类型的经典范文,如英语单词、英语语法、英语听力、英语知识点、语文知识点、文言文、数学公式、数学知识点、作文大全、其他资料等等,想了解不同范文格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor.I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!In addition, this shop provides various types of classic sample essays, such as English words, English grammar, English listening, English knowledge points, Chinese knowledge points, classical Chinese, mathematical formulas, mathematics knowledge points, composition books, other materials, etc. Learn about the different formats and writing styles of sample essays, so stay tuned!analysis的用法总结大全analysis的意思analysis的简明意思n. 分析;解析英式发音 [ə'næləsɪs] 美式发音 [ə'næləsɪs]analysis的词态变化为:名词复数: analysesanalysis的详细意思在英语中,analysis不仅具有上述意思,还有更详尽的用法,analysis作名词 n. 时具有分析,解析;分解;【化】解析,分解,分析;精神分析;分析结果,分析报告;梗概,要略,纲领;【数】解析;《分析》双月刊;【化】验定,检验;用词序和非语法变化的词语来表示句法关系等意思,analysis的具体用法用作名词 n.analysis的基本意思是“分析”,指对事物的各个组成部分及其性质、结构和相互关系的研究,有时还有有意识地去发现或揭示事物的性质、原因、效果、动机或可能性并以此作为作出判断或采取行动的基础之意。
常见的9种大数据分析方法

常见的9种大数据分析方法
一、机器学习(Machine Learning)
机器学习是一种以数据为基础的计算技术,它可以通过学习来获取数据,并能够从中提取出有用的信息。
它也可用于分析大量数据,以便发现
规律性和隐藏的模式,从而让机器以更高精度做出判断和决策。
机器学习
中包含了许多算法,如朴素贝叶斯,K-近邻,决策树,支持向量机(SVM)和人工神经网络(ANN)。
二、统计分析(Statistical Analysis)
统计分析是指从数据中提炼出有用的信息,以便分析机器学习模型的
预测能力的过程。
它包括多元统计分析,回归模型,T检验,卡方检验等
统计方法。
统计分析是一种用于分析大量数据的技术,它可以用于从大量
数据中提取有用信息,并用于机器学习模型的训练和优化。
三、模式发现(Pattern Discovery)
模式发现是一种可以从大量数据中找出有价值的模式的技术。
它可以
帮助机器学习模型从大量数据中发现有用的知识,从而更好地分析模型的
性能和可靠性。
常见的模式发现技术有关联规则,K-means聚类算法和Apriori算法等。
四、数据挖掘(Data Mining)
一种有效分析大量数据的技术,它可以帮助组织发现有价值的知识,
为管理决策提供指导。
判别分析四种方法

判别分析四种方法判别分析(Discriminant Analysis)是一种用于分类问题的统计方法, 它通过分析已知分类的样本数据,构造出一个判别函数,然后将未知类别的样本数据带入判别函数进行分类。
判别分析可以用于研究变量之间的关系以及确定分类模型等方面。
在判别分析中,有四种主要的方法,包括线性判别分析(Linear Discriminant Analysis, LDA)、二次判别分析(Quadratic Discriminant Analysis, QDA)、多重判别分析(Multiple Discriminant Analysis, MDA)和正则化判别分析(Regularized Discriminant Analysis, RDA)。
1.线性判别分析(LDA):线性判别分析是最常用的判别分析方法之一、它假设每个类别的样本数据都服从多元正态分布,并且各个类别具有相同的协方差矩阵。
基于这些假设,LDA通过计算类别间离散度矩阵(Sb)和类别内离散度矩阵(Sw),然后求解广义瑞利商的最大化问题,得到最佳的线性判别函数。
线性判别分析适用于样本类别数量较少或样本维度较高的情况。
2.二次判别分析(QDA):二次判别分析是基于类别的样本数据服从多元正态分布的假设构建的。
与LDA不同的是,QDA没有假设各个类别具有相同的协方差矩阵。
相反,QDA为每个类别计算一个特定的协方差矩阵,并将其带入到判别函数中进行分类。
由于QDA考虑了类内协方差矩阵的差异,因此在一些情况下可以提供比LDA更好的分类效果。
3.多重判别分析(MDA):4.正则化判别分析(RDA):正则化判别分析是近年来提出的一种改进的判别分析方法。
与LDA和QDA不同的是,RDA通过添加正则化项来解决维度灾难问题,以及对输入数据中的噪声进行抑制,从而提高分类的准确性。
正则化项的引入使得RDA可以在高维数据集上进行有效的特征选择,并获得更鲁棒的判别结果。
交叉分析法怎么分析

交叉分析法怎么分析交叉分析法(Cross-Analysis)是一种常用的统计分析方法,可以帮助我们深入了解不同因素之间的关联及影响程度。
通过对数据进行分层或分类,我们可以比较不同因素在不同层级或类别下的变化情况,从而得出关于相关性和差异性的结论。
本文将介绍交叉分析法的基本步骤,并以一个实际案例进行说明。
一、确定研究对象和目的交叉分析法适用于各种研究对象和目的,例如市场调研、客户满意度评估、产品质量改进等。
在开始分析之前,我们首先需要明确研究对象是什么,想要获得什么样的信息或结论。
二、收集和整理数据在进行交叉分析之前,我们需要收集和整理相关的数据。
数据来源可以包括调查问卷、销售报表、客户数据库等。
确保数据的准确性和完整性对于得出可靠的结论至关重要。
三、选择适当的分析方法交叉分析方法有很多种,选择适合自己研究对象和目的的方法非常重要。
下面是几种常见的交叉分析方法:1. 卡方检验卡方检验(Chi-Square Test)主要用于比较两个或多个分类变量之间是否存在显著差异。
通过计算实际观测值与期望理论值之间的差异,判断不同类别变量之间的关联性。
2. 相关分析相关分析(Correlation Analysis)用于衡量两个连续变量之间的线性关系。
通过计算协方差和相关系数,可以判断变量之间的正相关或负相关程度。
3. 方差分析方差分析(Analysis of Variance,ANOVA)常用于比较多个分类变量之间的均值是否存在显著差异。
通过计算组间方差和组内方差,来判断不同组别之间的差异性。
四、进行交叉分析在进行交叉分析时,我们可以按照以下步骤进行:1. 选择分析变量根据研究目的,选择需要进行交叉分析的变量。
可以是分类变量或连续变量,根据具体情况来决定。
2. 定义分类或分层标准根据所选变量,将数据进行分类或分层。
例如,如果我们想了解不同性别对某一产品的购买行为的影响,可以将数据按性别分类。
3. 进行统计计算根据选择的分析方法,进行相应的统计计算。
5种常用的分析方法

5种常用的分析方法
数据分析是企业发展和管理最重要的方面,也是大多数企业广泛开展的一项工作。
它是以
数据为基础,通过分析和表达来获取有用信息、指导企业决策和提高经济效益的过程。
有多种数据分析方法,今天我们就来谈谈其中5种常用的:
1、数据挖掘(Data Mining):是从大量的历史数据中,发现有价值的、有用的信息的数
据分析方法。
使用各种算法和方法,从大量的数据中发现潜在的关系,从而让企业少走弯路,快速找到有效的解决方案。
2、统计分析(Statistical Analysis):它是一种通用分析方法,使用统计学原理和方法,从数据中发现有用的统计规律,从而得出有效的对策。
3、时序分析(Time-Series Analysis):它以时间序列的形式分析数据,通过对时间序列
的模型分析和推断,了解其发展趋势,从而更好的为企业做出决策和调整。
4、决策树分析(Decision Tree Analysis):它是一种用于建立决策的一种逻辑思维方式,通过对多个变量和决策的分析,建立一颗决策树,从而得出最优解,实现更好的决策。
5、因子分析(Factor Analysis):它是一种常用的数据分析方法,可以用来分析某一现
象或事件中不同变量之间的关系和影响,从而更好的了解数据的内在规律,并预测变量的
发展趋势。
以上是目前被广泛应用的5种常用的数据分析方法,但它们只能做到发现有价值、有用的
信息,最后企业还是要依靠自己的智慧,结合实际情况,使用最佳的方法,打造出更优秀
的数据分析模型。
数据分析永远是没有尽头的,需要企业持续不断地投入,持之以恒地努力,只有这样企业才能获得最大的收益。
析因法名词解释

"析因法"(Analysis of Covariance,简称ANCOVA)是一种统计学中用于分析数据的方法。
它结合了方差分析(ANOVA)和回归分析的特点,旨在比较两个或多个组之间的平均差异,并通过考虑一个或多个协变量(covariate)来控制其他因素的影响。
以下是对析因法的详细解释:1. 方差分析 (ANOVA):▪ANCOVA 最初是为了解决方差分析中的一个问题而提出的。
方差分析用于比较两个或多个组之间的平均值是否存在显著差异,但它对其他因素(协变量)的影响不敏感。
2. 回归分析:▪ANCOVA 引入了回归分析的思想,通过引入一个或多个协变量,即与因变量相关但不是独立变量的变量,来控制其他因素的影响。
这使得我们能够更精确地比较不同组之间的平均值,从而减小了误差的影响。
3. 协变量(Covariate):▪协变量是在研究中被认为可能影响因变量的一个或多个变量。
在ANCOVA 中,协变量用于控制其他因素的影响,从而更准确地测量组之间的差异。
协变量可以是连续的或分类的。
4. ANCOVA的基本模型:▪ANCOVA的基本模型可以表示为:Y ij=β0+β1X i+β2G j+ϵij▪Y ij:第i组、第j个观察值的因变量。
▪X i:第i组的协变量。
▪G j:第j个组的虚拟变量(例如,一个二元变量,表示是否属于该组)。
▪ϵij:误差项。
5. ANCOVA的目标:▪ANCOVA的主要目标是通过控制协变量来比较不同组的平均值,以确定组间的差异是否在控制了其他因素的影响后仍然存在。
6. 应用领域:▪ANCOVA广泛用于实验设计、社会科学研究和医学研究等领域,特别是在需要考虑其他因素对实验结果的影响时。
总体上说,ANCOVA是一种强大的统计方法,可以在考虑其他因素影响的情况下更准确地评估不同组之间的差异。
第一讲 Analysis结果分析

nalysis”。
Analysis使用基础(3)——启 动与界面2
本节课程内容
• Analysis使用基础
– 简介 – 启动与界面
• Analysis分析概要 • Analysis图
Analysis分析概要(1)
• 分析概要报告显示场景运行情况的一般信息,对判断是 否需要深入分析性能测试结果图有重要作用。
– 概要整体信息 – 统计信息概要 – N个执行情况最差的事务 – 随时间变化的场景行为 – 事务概要 – HTTP响应概要
403 资源不可用。服务器理解客户的请求, 但拒绝处理。通常是由于服务器上的 文件或目录权限设置导致的
404 要浏览的网页在服务器中不存在,该 网页可能已迁移
500 服务器遇到内部错误,不能够完成请 求
501 服务器不支持实现请求所需要的功能 503 服务器由于维护或负载过重未能应答
504 网关超时,表示不能及时从远程服务 器获得应答
Web Page Diagnostics图
• 1:事务细分树。 • 2:页面下载时间。 • 3:选择具体某一待细分的页面,区域2和4中信息会同
步更新。 • 4:通过切换四个选项,支持如下功能。 • 5:图例。显示所有页面。
Page Component Breakdown图
• 页面组件细分图,以饼状图显示各网页及页面组件的平 均下载时间(秒)。
本节课程内容
• Analysis使用基础
– 简介 – 启动与界面
• Analysis分析概要 • Analysis图
latent class analysis结果解释

latent class analysis结果解释
潜类别分析(latent class analysis)是一种统计分析方法,用于识别一个总体中
存在的潜在的、未观察到的类别。
这种方法基于一组观察到的指标或变量,通过模式识别来推断潜在的类别结构。
通过潜类别分析,我们可以了解总体中存在的不同群体,并研究它们在不同变量上的差异。
在进行潜类别分析时,我们首先收集一组观察到的指标或变量,例如人口统计
学特征(如性别、年龄、教育程度)或行为特征(如购买习惯、兴趣爱好)。
然后,我们使用统计模型来推断这些指标背后的潜在类别。
模型根据观察到的指标之间的关系,将样本划分到不同的潜在类别中,并计算每个样本属于每个类别的概率。
通过分析潜类别分析的结果,我们可以得到有关不同群体的重要信息。
例如,
我们可以得知总体中存在的类别数,并对每个类别进行描述,包括每个类别的特征和差异。
我们还可以研究每个类别在观察到的指标上的分布情况,如某个类别中不同性别的比例或各自年龄段的比例。
这些结果可以帮助我们理解总体的多样性,并在市场调研、社会科学等领域中提供有用的信息。
需要注意的是,潜类别分析只是一种描述性的方法,它不能确定因果关系或解
释观察到的变量之间的关系。
因此,在解释潜类别分析的结果时,我们应该谨慎并不过度解读。
同时,在应用潜类别分析时,我们应该选择合适的模型和变量,确保得到可靠而有效的结果。
总之,潜类别分析是一种有用的统计方法,可以帮助我们识别和理解总体中存
在的潜在类别。
通过分析潜类别分析的结果,我们可以得到关于不同群体特征和差异的信息,从而为决策和研究提供有益的指导。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
001289 12 Mar,2000 3-21
壳单元:
◦ 用于模拟薄板或曲面 ◦ “薄”的定义取决于实际应用,但一般的原则是,壳体结构 的主要尺寸至少是板厚的10倍
001289 12 Mar,2000 3-22
1. 创建有限元模型 – 创建或读入几何模型. – 定义材料属性. – 划分单元 (节点及单元). 2. 施加载荷进行求解 – 施加载荷及载荷选项. – 求解. 3. 查看结果
使用ANSYS分析一个工字悬壁梁,如图所示. P
Point A H L
求解在力P作用下点A处的变形,已 知条件如下: P = 4000 lb L = 72 in I = 833 in4 E = 29 E6 psi 横截面积 (A) = 28.2 in2 H = 12.71 in
在练习之后,数值解将与用弹性梁理 论计算的解析解进行对比.
变化的情况,刚度变化的主要原因是:
◦ 应变超出弹性范围(朔性) ◦ 大变形,如垂钓用的钓鱼竿 ◦ 两物体之间的接触
s
e
001289 12 Mar,2000 3-8
许多建模决策必须在建立分析模型前就应该决定:
◦ 模型中应该包含多少细节? ◦ 可否利用对称性?
◦ 模型中是否包含应力奇异性?
001289 12 Mar,2000 3-9
轴对称
轴对称是指关于某个中心轴的对称,如灯泡、直的圆管、锥体、圆 盘以及圆屋顶等 对称面可以是是任意位置的横截面,这样就可以用一个2-D的“切 片”来描述整个 360°圆周 — 一种简化模型规模的手段!
载荷通常应该也是轴对称的,不过如果 是一个线性分析,载荷不对称也没关系, 可以把载荷分解成正谐分量,依次得到 独立的解,然后进行叠加
制订分析方案 分析的基本步骤
001289 12 Mar,2000 3-1
在开始ANSYS分析以前,你必须做几个决策,如: 选择何种分析类型、采用何种模型等 本讲将和大家一起讨论在分析过程前需要做的决策, 目的是给大家提供几点个在进入分析之前规划和建 议。 讨论的主题:
◦ A. 选择何种分析类型? ◦ B. 如何建模? ◦ C. 选择何种单元类型?
A 1
– 查看分析结果. – 检验结果. (分析是否正确)
Y Z X
001289 12 Mar,2000 3-23
分析的三个主要步骤可在主菜单中得到明确体现.
主菜单 1. 建立有限元模型 2. 施加载荷求解 3. 查看结果
001289 12 Mar,2000 3-24
ANSYS GUI中的功能排列 按照一种动宾结构,以动 词开始(如Create), 随后 是一个名词 (如Circle).
001289 12 Mar,2000 3-19
这也是在开始分析前必须做的重要决定 典型的问题是:
◦ 选择哪一类单元? 实体单元(Solid), 壳单元(shell), 梁单元 (beam)等 ◦ 单元的阶次. 线性还是二阶 ◦ 网格密度. 这通常由分析的目的所决定
单元类别 • ANSYS提供了各种单元类型以适应不同的分析类型,常用的类型 有:
关于对称性 许多结构可能存在某种对称性,允许你只用模型的某 个部分或截面来描述整个模型的特性 利用对称建模的优点是:
◦ 通常能很方便地建立整个模型 ◦ 利用对称性可以把模型建的更精细,包含更多细节,因此可 以获得比用整个模型得到的结果更好
001289 12 Mar,2000 3-11
要利用对称性进行分析,必须使以下条件同时满足对 称性:
001289 12 Mar,2000 3-29
练习 - 悬壁梁
解释
i. 选取两个关键点. j. 在拾取菜单中选择OK.
注意弹出的拾取菜单,以及输入窗口中的操作提示.
3.
存储ANSYS数据库.
Toolbar: SAVE_DB
ANSYS数据库是当用户在建模求解时ANSYS保存在内 存中的数据。由于在ANSYS初始对话框中定义的工作 文件名为beam,因此存储的数据库的到名为beam.db 的文件中。经常存储数据库文件名是必要的。这样在进 行了误操作后,可以恢复上次存储的数据库文件. 存储 及恢复操作,可以点取工具条,也可以选择菜单: Utility Menu:File.
001289 12 Mar,2000 3-6
线性 vs. 非线性分析 线性分析假设载荷引起的对结构刚度的变化是可 以忽略,它的特征是:
◦ 小变形 ◦ 应变与应力的变化在弹性极限内 ◦ 无刚度突变,如两个物体发生接触或分离
s
弹性模量 (E)
001289 12 Mar,2000 3-7
e
非线性分析主要用于那些由于载荷引起的结构刚度
001289 12 Mar,2000 3-18
实际结构不存在应力奇异性,这是由于对实际模型简 化后产生的 那么如何来处理应力奇异性问题呢?
◦ 如果它们离我们关心的区域比较远,只需在显示结果时简单 地把这个区域排除在外 ◦ 如果它们离所关心的区域内,这时就必须采用正确的方法, 如:
在尖角处加一个倒角(实际情况也如此),并重新进行分析 用与点力等效的分布压力替代 将点约束“扩大”倒一组节点约束
001289 12 Mar,2000 3-4
静态 vs. 动态分析 静态分析假设刚度引起的力占主导地位 动态分析是考虑三种类型的力的作用
比如,考虑跳水板的分析
◦ 如果跳水运动员静态地站在上面时,那用静 态分析已足够了 ◦ 但如果跳水运动员在上面跳动时,您就要做 动态分析
001289 12 Mar,2000 3-5
001289 12 Mar,2000 3-31
练习 - 壁梁
解释
5. 设定单元类型相应 选项.
a. Main Menu: Preprocessor > Element Type > Add/Edit/Delete b. 选择 Add . . . c. 左边单元库列表中选 择 Beam. d. 在右边单元列表中选 择 2D elastic (BEAM3).
◦ 几何 ◦ 材料属性 ◦ 载荷条件
ANSYS可处理以下几种对称类型:
◦ ◦ ◦ ◦ 轴对称(Axisymmetry) 旋转对称(Rotational) 平面或反射(Planar or reflective) 重复或平移对称(Repetitive or translational)
001289 12 Mar,2000 3-12
001289 12 Mar,2000 3-2
ANSYS可以应用的分析类型可以是:
结构(Structural)
固体的运动,作用在固体上的压 力或固体之间的接触等 热(Thermal) 施加于固体上热,高温或温度的变化等 电磁场 传输电流(AC/DC)、电磁波以及电压 或电荷激励的 (Electromagnetic) 设备 流场(Fluid) 气体/流体的流动或容器内气体/流体 耦合场(Coupled-Field)以上几种物理场的偶合作用
本模型既是反射对 称也是旋转对称
001289 12 Mar,2000 3-15
重复对称或平移对称 每个重复段沿直线排列,如一个长的管子上均匀排列 着冷却片 载荷也假定沿模型长度“重复”加载
本模型既是重复对称也是反射对称
001289 12 Mar,2000 3-16
载有些情况下,由于几个小的细节而破坏了整个结构的对称性, 有时你可以忽略这些细节(即当作对称处理)以便利用较小的模型。 不过,由次造成的精度上的损失很难估计,因此应小心使用。
关于细节 某些小的细节对分析来讲是不重要的,就不应该包含在 分析模型中,如果你的模型是用其它CAD软件建的模 型,那么在传到ANSYS之前就把这些特征去掉 然而,对有些结构,一些如倒角、圆孔之类的“小”细 节,它们可能就是发生最大应力的部位,这时就不能忽 略。这取决于你的分析目的
001289 12 Mar,2000 3-10
对于任何分析,您必须单元类型库中选择一个或几个适 合您的分析的单元类型. 单元类型决定了辅加的自由度 (位移、转角、温度等)。许多单元还要设置一些单元 的选项,诸如单元特性和假设,单元结果的打印输出选 项等。对于本问题,只须选择 BEAM3 并默认单元选项 即可.
001289 12 Mar,2000 3-27
练习 - 悬壁梁
解释
1. 启动 ANSYS. 以交互模式进入ANSYS, 工作文件名为beam.
2.
a. Main Menu: Preprocessor > Modeling- Create > Keypoints > In Active CS...
创建基本模型
001289 12 Mar,2000 3-17
应力奇异性 应力奇异性是指有限元模型中应力值无限大的位置, 如:
◦ 点载荷, 如集中力或集中力矩 ◦ 一个孤立的约束点,此处的约束反力呈点载荷 ◦ 一个很尖的凹角(倒角半径为零)
P s = P/A 当网格密度在应力奇异点加密时,应力值急剧加大 当 A 0, s 并且永远不收敛
菜单的排列,按照由前到后 、由简单到复杂的顺序,与 典型分析的顺序相同.
001289 12 Mar,2000 3-25
Exercise
依照如下循序渐进的求解指导,进行一个悬壁梁的静力分析. 注意在此分析中采用的ANSYS分析步骤,以及几次将内存中 的数据存到文件中的操作.
001289 12 Mar,2000 3-26
如果施加的载荷随时间变化很快,惯性力和阻 尼力都是不可忽略的 可以根据载荷和时间的依赖关系来确定选择静 态还是动态分析
◦ 如果载荷在一个很长的时间内变化缓慢,甚至是常量, 可以选择静态分析