归并排序算法及演示(Pascal语言)
5. 5排序算法--快速与归并 课件-2021-2022学年浙教版(2019)高中信息技术选修1

快速排序算法
·快速排序算法(用栈实现)
代码:
def quick_sort(array, l, r): if l >= r: return stack = [] stack.append(l) stack.append(r) while stack: low = stack.pop(0) hight = stack.pop(0) if hight - low <= 0: continue k = array[hight] i = low - 1 for j in range(low, hight):
选修1《数据与数据结构》
第五章 数据结构与算法
5.5 排序算法 --快速与归并
学习目标
快速排序算法 归并排序算法
排序算法
快速排序算法
排序算法
·快速排序的基本思路
快速排序使用分治法策略来把一个串行(list)分为两个子串行(sub-lists)。
算法步骤:
1、 在数组中选一个基准数(通常为数组第一个)。 2、将数组中小于基准数的数据移到基准数左边,大于基准数的移到右边。 3、对于基准数左、右两边的数组,不断重复以上两个过程,直到每个子集只 有一个元素,即为全部有序。
排序算法
k = l #归并子数组的索引 while i < n1 and j < n2:
if L[i] <= R[ j]: arr[k] = L[i] i += 1
else: arr[k] = R[ j] j += 1
k += 1 while i < n1:
arr[k] = L[i] i += 1 k += 1 while j < n2: arr[k] = R[ j] j += 1 k += 1
《归并排序》教学设计

《归并排序》教学设计归并排序教学设计介绍归并排序归并排序是一种高效的排序算法,它基于分治的思想。
它将待排序的序列不断地分割成较小的子序列,直到每个子序列只有一个元素,然后将这些子序列两两合并,使得合并后的序列有序。
归并排序的时间复杂度为O(nlogn),所以在处理大规模数据排序时非常有效。
教学目标通过本教学设计,学生将能够:1. 理解归并排序的原理和过程;2. 掌握归并排序的实现方法;3. 熟练应用归并排序解决实际问题;4. 分析和评估归并排序的时间复杂度和空间复杂度。
教学内容理论讲解1. 归并排序的基本思想和过程;2. 归并排序的时间复杂度和空间复杂度分析;3. 归并排序的应用场景和优缺点。
算法实现1. 递归实现归并排序;2. 非递归实现归并排序。
实例分析通过一些实际例子,演示如何使用归并排序算法解决实际问题,例如对整数数组进行排序、对学生成绩进行排名等。
思考题和练为了加深学生对归并排序的理解和应用能力,设计一些思考题和练题,例如给定一组数据让学生手动执行归并排序算法、设计一些需要应用归并排序的问题等。
教学方法1. 理论讲解与实例分析相结合,既让学生理解归并排序的原理,又让他们看到归并排序在实际问题中的应用;2. 引导学生通过自主实践,编写归并排序的代码,并测试其正确性和效果。
评估方法1. 设计一份归并排序的小测试,包括选择题和编程题,以评估学生对归并排序的掌握程度;2. 观察学生在实践中的表现,评估其在应用归并排序解决实际问题时的能力。
参考资料- 归并排序的原理与实现方法- 《算法导论》本教学设计旨在通过理论讲解、实例分析和实践操作,帮助学生全面了解归并排序算法,掌握其实现方法,并能够应用归并排序解决实际问题。
请根据实际情况进行适当调整和补充。
freepascal语言与基础算法

freepascal语言与基础算法1. 引言1.1 概述本文将探讨Freepascal语言与基础算法的关系和应用。
Freepascal是一种强大且灵活的编程语言,被广泛应用于各个领域的软件开发中。
而基础算法则是计算机科学的核心内容,对于解决问题和优化程序至关重要。
通过结合这两者,我们可以深入理解Freepascal语言以及在实际项目中如何使用算法来提高效率和性能。
1.2 文章结构本文共分为五个部分。
首先,我们将介绍Freepascal语言的背景与发展历程,探讨其特性和优势,并列举一些应用领域和案例。
接着,我们会概述基础算法的基本概念和分类,并介绍算法设计与分析原则。
然后,我们会详细介绍几种常见的基础算法,并给出示例加以说明。
在第四部分中,我们将探讨Freepascal语言在基础算法中的具体应用,包括数据结构支持与实现方式、排序算法实现示例与性能分析以及查找算法实现示例与应用场景讨论。
最后,在结论部分,我们将总结Freepascal语言与基础算法的关系,并讨论其发展前景和实践意义,同时展望未来研究的方向。
1.3 目的本文的目的在于给读者提供有关Freepascal语言与基础算法之间联系的深入理解。
通过阐述Freepascal语言作为一种强大且广泛应用的编程语言以及基础算法作为解决问题和优化程序所必不可少的工具,我们希望读者能够了解如何利用Freepascal语言来实现各种常见的基础算法,并在实际项目中应用这些算法来提高效率和性能。
此外,本文还将探讨Freepascal语言与基础算法之间的潜在联系,以及可能产生的新思路和研究方向。
2. Freepascal语言介绍:2.1 背景与发展Freepascal是一种高级编程语言,最初由Anders Hejlsberg 发起并于1995年首次发布。
它是一种免费的、开源的、跨平台的编程语言,主要用于快速开发可靠、高效且易于维护的软件应用。
自推出以来,Freepascal得到了广泛的采用和用户社区支持。
算法—4.归并排序(自顶向下)

算法—4.归并排序(⾃顶向下)1.基本思想将两个有序的数组归并成⼀个更⼤的有序数组,很快⼈们就根据这个操作发明了⼀种简单的递归排序算法:归并排序。
要将⼀个数组排序,可以先(递归地)将它分成两半分别排序,然后将结果归并起来。
你将会看到,归并排序最吸引⼈的性质是它能够保证将任意长度为N的数组排序所需时间和NlogN成正⽐;它的主要缺点则是它所需的额外空间和N成正⽐。
简单的归并排序如下图所⽰:原地归并的抽象⽅法:实现归并的⼀种直截了当的办法是将两个不同的有序数组归并到第三个数组中,实现的⽅法很简单,创建⼀个适当⼤⼩的数组然后将两个输⼊数组中的元素⼀个个从⼩到⼤放⼊这个数组中。
public void merge(Comparable[] a, int lo, int mid, int hi){int i = lo, j = mid+1;//将a[lo..hi]复制到aux[lo..hi]for (int k = lo; k <= hi; k++) {aux[k] = a[k];}//归并回到a[lo..hi]for (int k = lo; k <= hi; k++) {if(i > mid){a[k] = aux[j++];}else if(j > hi){a[k] = aux[i++];}else if(less(aux[j], aux[i])){a[k] = aux[j++];}else{a[k] = aux[i++];}}}以上⽅法会将⼦数组a[lo..mid]和a[mid+1..hi]归并成⼀个有序的数组并将结果存放在a[lo..hi]中。
在归并时(第⼆个for循环)进⾏了4个条件判断:左半边⽤尽(取右半边的元素)、右半边⽤尽(取左半边的元素)、右半边的当前元素⼩于左半边的当前元素(取右半边的元素)以及右半边的当前元素⼤于等于左半边的当前元素(取左半边的元素)。
2.具体算法/*** ⾃顶向下的归并排序* @author huazhou**/public class Merge extends Model{private Comparable[] aux; //归并所需的辅助数组public void sort(Comparable[] a){System.out.println("Merge");aux = new Comparable[a.length]; //⼀次性分配空间sort(a, 0, a.length - 1);}//将数组a[lo..hi]排序private void sort(Comparable[] a, int lo, int hi){if(hi <= lo){return;}int mid = lo + (hi - lo)/2;sort(a, lo, mid); //将左半边排序sort(a, mid+1, hi); //将右半边排序merge(a, lo, mid, hi); //归并结果}} 此算法基于原地归并的抽象实现了另⼀种递归归并,这也是应⽤⾼效算法设计中分治思想的最典型的⼀个例⼦。
二分归并排序的时间复杂度以及递推式

一、简介二分归并排序是一种常见的排序算法,它通过将问题分解为子问题,并将子问题的解合并来解决原始问题。
该算法的时间复杂度非常重要,因为它直接影响算法的效率和性能。
在本文中,我们将深入探讨二分归并排序的时间复杂度,并通过递推式来进一步分析算法的性能。
二、二分归并排序的时间复杂度1. 分析在二分归并排序中,时间复杂度可以通过以下三个步骤来分析:- 分解:将原始数组分解为较小的子数组。
- 解决:通过递归调用来对子数组进行排序。
- 合并:将排好序的子数组合并为一个整体有序的数组。
2. 时间复杂度在最坏情况下,二分归并排序的时间复杂度为O(nlogn)。
这是因为在每一层递归中,都需要将数组分解为两个规模近似相等的子数组,并且在每一层递归的最后都需要将这两个子数组合并起来。
可以通过递推式来进一步证明算法的时间复杂度。
3. 递推式分析我们可以通过递推式来分析二分归并排序的时间复杂度。
假设对规模为n的数组进行排序所需的时间为T(n),则可以得到以下递推式:T(n) = 2T(n/2) +其中,T(n/2)表示对规模为n/2的子数组进行排序所需的时间表示将两个子数组合并所需的时间。
根据递推式的定义,我们可以得到二分归并排序的时间复杂度为O(nlogn)。
三、结论与个人观点通过以上分析,我们可以得出二分归并排序的时间复杂度为O(nlogn)。
这意味着该算法在最坏情况下也能保持较好的性能,适用于大规模数据的排序。
我个人认为,二分归并排序作为一种经典的排序算法,其时间复杂度的分析对于理解算法的工作原理和性能至关重要。
通过深入研究递推式,可以更加直观地理解算法的性能表现,为进一步优化算法提供了重要的参考依据。
四、总结在本文中,我们探讨了二分归并排序的时间复杂度,通过分析和递推式的方式深入理解了该算法的性能表现。
通过对时间复杂度的分析,我们对算法的性能有了更深入的认识,并且能够更好地理解算法在实际应用中的表现。
相信通过本文的阅读,读者能够对二分归并排序有更全面、深刻和灵活的理解。
算法21--内部排序--归并排序

实现这种递归调用的关键是为过程建立递归调用工作栈。通 常,在一个过程中调用另一过程时,系统需在运行被调用过 程之前先完成3件事:
(1)将所有实参指针,返回地址等信息传递给被调用过程; (2)为被调用过程的局部变量分配存储区; (3)将控制转移到被调用过程的入口。 在从被调用过程返回调用过程时,系统也相应地要完成3件事: (1)保存被调用过程的计算结果; (2)释放分配给被调用过程的数据区; (3)依照被凋用过程保存的返回地址将控制转移到调用过程.
实际的意义:可以把一个长度为n 的无序序列看成 是 n 个长度为 1 的有序子序列 ,首先做两两归 并,得到 n/2 个长度为 2 的子序列;再做两两 归并,…,如此重复,直到最后得到一个长度为 n
的有序序列。
归并排序
初始序列
[49] [38] [65] [97 [76] [13] [27]
第一步 第二步
T(1)=1 T(n)=kT(n/m)+f(n)
2019/10/20
归并排序时间复杂性分析
• 合并趟数: log2n • 每趟进行比较的代价 n • 总的代价为 T(n) = O ( nlog2n ) • 在一般情况下:
c
n=1
T(n) =
T( n/2 ) + T( n/2 ) + cn n>1
优缺点:Ω的这个定义的优点是与O的定义对称,缺点 是当 f(N) 对自然数的不同无穷子集有不同的表达式, 且有不同的阶时,未能很好地刻画出 f(N)的下界。
2019/10/20
f(n) cg(n)
n0
n
2019/10/20
代入法解递归方程
方法的关键步骤在于预先对解答作出推测,然后用 数学归纳法证明推测的正确性。
二叉树的快速排序、归并排序方法

二叉树的快速排序、归并排序方法一、快速排序快速排序采用的是分治法策略,其基本思路是先选定一个基准数(一般取第一个元素),将待排序序列抽象成两个子序列:小于基准数的子序列和大于等于基准数的子序列,然后递归地对这两个子序列排序。
1. 递归实现(1)选定基准数题目要求采用第一个元素作为基准数,因此可以直接将其取出。
(2)划分序列接下来需要将待排序序列划分成两个子序列。
我们定义两个指针 i 和 j,从待排序序列的第二个元素和最后一个元素位置开始,分别向左和向右扫描,直到 i 和 j 相遇为止。
在扫描过程中,将小于等于基准数的元素移到左边(即与左侧序列交换),将大于基准数的元素移到右边(即与右侧序列交换)。
当 i=j 时,扫描结束。
(3)递归排序子序列完成划分后,左右两个子序列就确定了下来。
接下来分别对左右两个子序列递归调用快速排序算法即可。
2. 非递归实现上述方法是快速排序的递归实现。
对于大量数据或深度递归的情况,可能会出现栈溢出等问题,因此还可以使用非递归实现。
非递归实现采用的是栈结构,将待排序序列分成若干子序列后,依次将其入栈并标注其位置信息,然后将栈中元素依次出栈并分割、排序,直至栈为空。
二、归并排序归并排序同样采用的是分治思想。
其基本思路是将待排序序列拆分成若干个子序列,直至每个子序列只有一个元素,然后将相邻的子序列两两合并,直至合并成一个有序序列。
1. 递归实现(1)拆分子序列归并排序先将待排序序列进行拆分,具体方法是将序列平分成两个子序列,然后递归地对子序列进行拆分直至每个子序列只剩下一个元素。
(2)合并有序子序列在完成子序列的拆分后,接下来需要将相邻的子序列两两合并为一个有序序列。
我们先定义三个指针 i、j 和 k,分别指向待合并的左侧子序列、右侧子序列和合并后的序列。
在进行合并时,从两个子序列的起始位置开始比较,将两个子序列中较小的元素移动到合并后的序列中。
具体操作如下:- 当左侧子序列的第一个元素小于等于右侧子序列的第一个元素时,将左侧子序列的第一个元素移动到合并后的序列中,并将指针 i 和 k 分别加 1。
pascal常见算法整理

3、归并排序
program gbpx;
const maxn=7;
type arr=array[1..maxn] of integer;
var a,b,c:arr;
i:integer;
procedure merge(r:arr;l,m,n:integer;var r2:arr);
a[i+d]:=t;
end;
end;
write('output data:');
for i:=1 to n do write(a[i]:6);
writeln;
end.
程序2:(子序列是冒泡排序)
program xepx;
const n=7;
type
arr=array[1..n] of integer;
while (i<n) and bool do
begin
bool:=false;
for j:=n downto i+1 do
if a[j-1]<a[j] then
begin t:=a[j-1];a[j-1]:=a[j];a[j]:=t;bool:=true end;
for i:=1 to n do write(a[i]:6);
writeln;
end.
i,j,k,t:integer;
begin
write('Enter date:');
for i:= 1 to n do read(a[i]);
writeln;
for i:=2 to n do
begin
k:=a[i];j:=i-1;
知识点归并排序和基数排序

数据结构
二、空间性能 指的是排序过程中所需的辅助空间大小
1. 所有的简单排序方法(包括:直接插入、
起泡和简单选择) 和堆排序的空间复杂度为O(1);
2. 快速排序为O(logn),为递归程序执行过程中,
栈所需的辅助空间;
数据结构
容易看出,对 n 个记录进行归并排序的时间 复杂度为Ο(nlogn)。即:
每一趟归并的时间复杂度为 O(n), 总共需进行 log2n 趟。
数据结构
10.6 基 数 排 序
数据结构
基数排序是一种借助“多关键字排序” 的思想来实现“单关键字排序”的内部 排序算法。
多关键字的排序
链式基数排序
一、多关键字的排序 n 个记录的序列 { R1, R2, …,Rn} 对关键字 (Ki0, Ki1,…,Kid-1) 有序是指:
对于序列中任意两个记录 Ri 和 Rj (1≤i<j≤n) 都满足下列(词典)有序关系: (Ki0, Ki1, …,Kid-1) < (Kj0, Kj1, …,Kjd-1) 其中: K0 被称为 “最主”位关键字
数据结构
10.5 归 并 排 序(知识点三)
数据结构
归并的含义是将两个或两个以上的有序表组 合成一个新的有序表。
归并排序可分为两路归并排序,或多路归并 排序,既可用于内排序,也可用于外排序。这 里仅对内排序的两路归并方法进行讨论。
数据结构
两路归并排序算法思路:
假设初始序列含有n个记录,首先把n个记录 看成n个长度为1的有序序列,进行两两归并, 得到 n/2个长度为2的关键字有序序列, 再两两归并直到所有记录归并成一个长度为n 的有序序列为止。
归并排序求逆序对
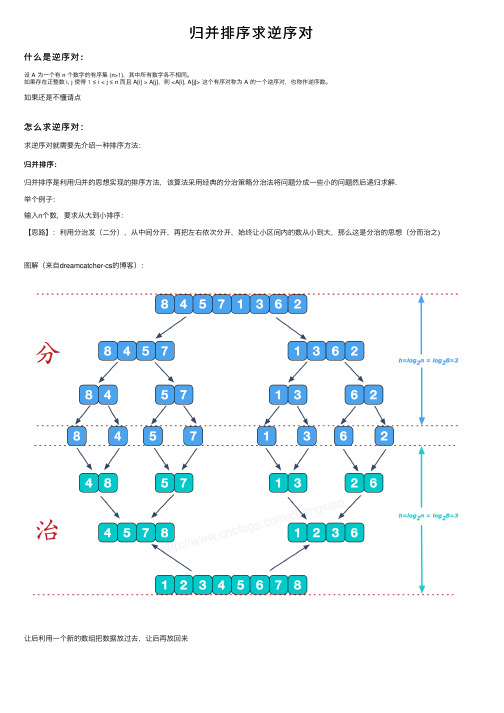
归并排序求逆序对什么是逆序对:设 A 为⼀个有 n 个数字的有序集 (n>1),其中所有数字各不相同。
如果存在正整数 i, j 使得1 ≤ i < j ≤ n ⽽且 A[i] > A[j],则 <A[i], A[j]> 这个有序对称为 A 的⼀个逆序对,也称作逆序数。
如果还是不懂请点怎么求逆序对:求逆序对就需要先介绍⼀种排序⽅法:归并排序:归并排序是利⽤归并的思想实现的排序⽅法,该算法采⽤经典的分治策略分治法将问题分成⼀些⼩的问题然后递归求解.举个例⼦:输⼊n个数,要求从⼤到⼩排序:【思路】:利⽤分治发(⼆分),从中间分开,再把左右依次分开,始终让⼩区间内的数从⼩到⼤,那么这是分治的思想(分⽽治之)图解(来⾃dreamcatcher-cs的博客):让后利⽤⼀个新的数组把数据放过去,让后再放回来代码:#include<iostream>#include<cstdio>#include<algorithm>#include<cmath>#include<queue>#include<stack>#include<vector>#include<map>#include<string>#include<cstring>using namespace std;const int maxn=999999999;const int minn=-999999999;inline int read() {char c = getchar();int x = 0, f = 1;while(c < '0' || c > '9') {if(c == '-') f = -1;c = getchar();}while(c >= '0' && c <= '9') x = x * 10 + c - '0', c = getchar(); return x * f;}int n,a[100152],b[100250];void doit(int l,int mid,int r) {int i,j,k;int n1=mid-l+1;int n2=r-mid;int L[n1],R[n2];for (i=0; i<n1; i++)L[i]=a[l+i];for (j=0; j<n2; j++)R[j]=a[mid+j+1];i=0;j=0;k=l;while(i<n1&&j<n2) {if(L[i]<=R[j]) {a[k]=L[i];i++;} else {a[k]=R[j];j++;}k++;}while(i<n1) {a[k]=L[i];i++;k++;}while(j<n2) {a[k]=R[j];j++;k++;}}void my_sort(int l,int r) { //分if(l<r) {int mid=(l+r)/2;my_sort(l,mid);my_sort(mid+1,r);doit(l,mid,r);}}int main() {cin>>n;for(int i=0; i<n; ++i) {cin>>a[i];}my_sort(0,n-1);for(int i=0; i<n; ++i) {cout<<a[i]<<"";}return0;}接下来终于到逆序对了:放两个题⽬:【题⽬描述】Prince对他在这⽚⼤陆上维护的秩序感到满意,于是决定启程离开艾泽拉斯。
二路归并排序算法

⼆路归并排序算法将两个按值有序序列合并成⼀个按值有序序列,则称之为⼆路归并排序,下⾯有⾃底向上和⾃顶向下的两种排序算法,⾃顶向下的排序在本⽂末讲述,使⽤递归实现,代码较简洁,经供参考。
1. 归并⼦算法:把位置相邻的两个按值有序序列合并成⼀个按值有序序列。
例如把序列 X[s..u] = {3, 12, 23, 32}和序列 X[u+1..v] = {2, 5, 8, 99} 合并成序列Z[s..v] = {2, 3, 5, 8, 12, 23, 32, 99}, 注意合并前的元素都位于同⼀个有序序列的相邻位置,合并后的有序序列的下标与合并前的序列总的起始下标相同。
算法过程中需要三个整型变量,i ⽤来遍历归并的前⼀个有序序列,其初始位置是s;j ⽤来遍历归并的后⼀个有序序列,其初始值是u+1;q ⽤来指出归并后得到的有序序列的末尾元素的位置,其初始值是s。
当遍历完成其中的⼀个有序序列之后,只需把另⼀个未结束有序序列的剩余元素复制到合并后的有序序列的末尾。
看代码:[cpp]1. //将有序的X[s..u]和X[u+1..v]归并为有序的Z[s..v]2. void merge(int X[], int Z[], int s, int u, int v)3. {4. int i, j, q;5. i = s;6. j = u + 1;7. q = s;8.9. while( i <= u && j<= v )10. {11. if( X[i] <= X[j] )12. Z[q++] = X[i++];13. else14. Z[q++] = X[j++];15. }16.17. while( i <= u ) //将X中剩余元素X[i..u]复制到Z18. Z[q++] = X[i++];19. while( j <= v ) //将X中剩余元素X[j..v]复制到Z20. Z[q++] = X[j++];21. }2. ⼀趟归并扫描⼦算法:将参加排序的序列分成若⼲个长度为 t 的,且各⾃按值有序的⼦序列,然后多次调⽤归并⼦算法merge将所有两两相邻成对的⼦序列合并成若⼲个长度为2t 的,且各⾃按值有序的⼦序列。
归并排序-PPT优秀课件

堆排序
O(1)
归并排序
O(n)
空间复杂度
30
排序方法 直接插入排序 希尔排序 冒泡排序 快速排序 简单选择排序 堆排序 归并排序
辅助空间
稳定 不稳定 稳定 不稳定 稳定 不稳定 稳定
算法稳定性
31
10.6 内部排序方法的比较讨论
❖ 简单性
一类是简单算法,包括直接插入排序、直接 选择排序和冒泡排序,
另一类是改进后的算法,包括希尔排序、堆 排序、快速排序和归并排序,这些算法较复杂
32
10.6 内部排序方法的比较讨论
❖ 待排序记录个数比较
n越小,采用简单排序方法越合适。 n越大,采用改进的排序方法越合适。
因为n越小,O(n2)同O(nlog2n)的差距越小, 并且输入和调试简单算法比 高效算法要容易
关键码的分布情况29排序方法平均情况最好情况最坏情况时间复杂度30排序方法辅助空间空间复杂度31排序方法辅助空间稳定算法稳定性32简单性一类是简单算法包括直接插入排序直接选择排序和冒泡排序另一类是改进后的算法包括希尔排序堆排序快速排序和归并排序这些算法较复杂106内部排序方法的比较讨论33106内部排序方法的比较讨论待排序记录个数比较n越小采用简单排序方法越合适
33
10.6 内部排序方法的比较讨论
❖ 数据的信息量比较
信息量越大,移动记录所花费的时间就越多, 所以对记录的移动次数较多的算法不利。
排序方法
直接插入排序 冒泡排序
直接选择排序
最好情况 O(n) 0 0
最坏情况 O(n2) O(n2) O(n)
平均情况 O(n2) O(n2) O(n)
34
10.6 内部排序方法的比较讨论
❖ 数据的分布情况比较
pascal-经典算法

动态规划(一)
• 0-1背包 • 完全背包 • 乘法问题 • 数塔问题 • 装箱问题
动态规划(二)
• 最长上升序列(LIS) • 最长公共子串(• 归并排序 • 最近点对问题 • 求最大子序列和的O(nlogn)算法 • Hanoi塔问题及其变种 • 棋盘覆盖问题 • 循环赛日程表问题
贪心
• 最优装载问题 • 部分背包问题 • 独立区间的选择 • 覆盖区间的选择 • 区间的最小点覆盖 • 点的最小区间覆盖
递推
• Fibonacci数的若干应用 • Catalan数的若干应用 • 拆分数 • 差分序列
数据结构(二)
• ★平衡二叉树 • ★树状数组 • ★线段树 • ★块状链表
排列与组合
• 生成所有排列 • 生成所有组合 • 生成下一个排列 • 生成下一个组合
计算几何(一)
• 计算斜率 • 计算点积 • 计算余弦 • 计算平面两点的距离 • 计算空间两点的距离 • ★计算广义空间两点的距离 • 判断三点是否共线
语言与计算机
• 递归调用 • 向前引用 • 随机化 • 指针类型 • 按位运算
排序(一)
• 冒泡排序(起泡排序) • 选择排序 • 插入排序 • ★ Shell排序 • 快速排序
排序(二)
• 线性时间排序 • 查找第k大元素 • 带第二关键字的排序
数论(一)
• 素性判断 • 筛选建立素数表 • 分解质因数 • 进制转换 • 二分取幂 • ★二分求解线性递推方程
图论:二分图
• 验证二分图 • 匈牙利算法 • ★KM算法 • ★稳定婚姻系统
树
• 求树的最短链 • 二叉树的四种遍历 • 已知先序中序求后序 • 已知中序后序求先序 • ★已知先序后序求中序 • ★LCA问题的Tarjan离线算法 • ★Huffman编码
归并排序怎么操作方法

归并排序怎么操作方法归并排序是一种分治算法,它的操作方法如下:1. 将待排序的数组分成两个子数组,每次将数组拆分成两半,直到每个子数组只有一个元素为止。
2. 对每个子数组进行递归排序,直到排序完成。
3. 将排好序的子数组合并,合并时比较两个子数组的第一个元素,将较小的元素放在结果数组中,并将对应子数组的指针向后移动一个位置。
4. 重复步骤3,直到合并完成。
5. 返回合并后的结果数组。
归并排序的操作方法可以用以下的伪代码表示:def merge_sort(arr):if len(arr) <= 1:return arrmiddle = len(arr) 2left = merge_sort(arr[:middle]) # 递归排序左半部分right = merge_sort(arr[middle:]) # 递归排序右半部分return merge(left, right) # 合并左右两个排好序的子数组def merge(left, right):result = []i, j = 0, 0while i < len(left) and j < len(right):if left[i] <= right[j]:result.append(left[i])i += 1else:result.append(right[j])j += 1result += left[i:] # 将剩余的元素添加到结果数组中result += right[j:]return result以上就是归并排序的操作方法。
它的时间复杂度为O(nlogn),其中n为待排序数组的长度。
我最喜欢的排序算法快速排序和归并排序

我最喜欢的排序算法快速排序和归并排序我最喜欢的排序算法--快速排序和归并排序2011-02-05 20:35摘要:一般评判排序算法的标准有时刻代价,空间代价和稳固性。
本文主要讨论性质相对比较好且作者喜欢的快速排序算法和归并排序算法,并对此这做了必然比较。
正文:常见的排序算法大致分为四类:1.插入排序:直接插入排序,Shell排序2.选择排序:直接选择排序,堆排序3.互换排序:冒泡排序,快速排序4.归并排序而对排序算法的一般评判标准有:时刻代价:比较次数、移动次数空间代价:额外空间、堆栈深度稳固性:存在多个具有相同排序码的记录排序后这些记录的相对顺序维持不变下面咱们先用这些评判标准对这些算法做一下大体评价:从那个表中能够看出,快速排序、归并排序和堆排序的时刻代价是比较小的,而其他几个的时刻代价相对比较大。
咱们明白时刻复杂度是评判一个算法的最主要标准。
程序运行速度直接关系着算法的可行性。
而真正美好的算法也一定是运行速度比较快的。
但是,由于此刻运算机硬件的进展,尤其是多级缓存的引入,致使堆排序在实际运行中并非快。
而且堆排序算法相对比较难理解,程序实现也相对困难,如此的算法显然不是美好的算法。
至少在快速排序眼前很难找到优势。
而对于快速排序和归并排序,咱们先做一简单介绍,然后别离分析,最后对比分析。
快速排序:算法思想:以第一个元素为准,小于该元素的放在左侧,不小于该元素的放在右边,然后对双侧元素递归排序。
算法:void quicksort(int l,int u){int i,m;if(l=u)return;m=l;for(i=l+1;i=u;i++)if(x[i]x[l])swap(++m,i);swap(l,m);quicksort(l,m-1);quicksort(m+1,u);}这里假设x为全局变量。
改良:快速排序有一个专门大不足就是对于比较有序的数组排序效率很低,而且当数组较短时快速排序并非是最快的。
[教案]PASCAL教程(整理版)
![[教案]PASCAL教程(整理版)](https://img.taocdn.com/s3/m/4c1b453ae2bd960591c6770b.png)
第一章简单程序 (2)第一节Pascal程序结构和基本语句 (2)第二节顺序结构程序与基本数据类型 (6)第二章分支程序 (10)第一节条件语句与复合语句 (10)第二节情况语句与算术标准函数 (11)第三章循环程序 (15)第一节for循环 (15)第二节repeat循环 (21)第三节While循环 (25)第四章函数与过程 (31)第一节函数 (31)第二节自定义过程 (34)第五章Pascal的自定义数据类型 (38)第一节数组与子界类型 (38)第二节二维数组与枚举类型 (45)第三节集合类型 (54)第四节记录类型和文件类型 (58)第五节指针类型与动态数据结构 (64)第六章程序设计与基本算法 (69)第一节递推与递归算法 (69)第二节回溯算法 (76)第七章数据结构及其应用 (82)第一节线性表 (82)第二节队列 (86)第三节栈 (89)第四节数组 (92)第八章搜索 (96)第一节深度优先搜索 (96)第二节广度优先搜索 (106)第九章其他常用知识和算法 (110)第一节图论及其基本算法 (110)第二节动态规划 (117)第一章简单程序无论做任何事情,都要有一定的方式方法与处理步骤。
计算机程序设计比日常生活中的事务处理更具有严谨性、规范性、可行性。
为了使计算机有效地解决某些问题,须将处理步骤编排好,用计算机语言组成“序列”,让计算机自动识别并执行这个用计算机语言组成的“序列”,完成预定的任务。
将处理问题的步骤编排好,用计算机语言组成序列,也就是常说的编写程序。
在Pascal语言中,执行每条语句都是由计算机完成相应的操作。
编写Pascal 程序,是利用Pascal语句的功能来实现和达到预定的处理要求。
“千里之行,始于足下”,我们从简单程序学起,逐步了解和掌握怎样编写程序。
第一节Pascal程序结构和基本语句在未系统学习Pascal语言之前,暂且绕过那些繁琐的语法规则细节,通过下面的简单例题,可以速成掌握Pascal程序的基本组成和基本语句的用法,让初学者直接模仿学习编简单程序。
排序精讲之pascal

else if a1<b1 then begin c[k]:=a1; i:=i+1; a1:=a[i]; end; else begin c[k]:=b1; j:=j+1; b1:=b[j]; end; k=n+m until ________; End; Begin n:=12;m:=8; for i:=1 to n do a[i]:=a0[i]; for i:=1 to m do b[i]:=b0[i]; paixu(a,n); paixu(b,m); guibing; for i:=1 to n+m do write(c[i]:3); End.
A
16 24
55 58
60
60 74
86 93
93 94
98
B
15 16
22 43
49
73 73
99
C
Program ex7_12; Type ad=array[1..20] of integer; Const a0:array[1..12] of integer=(60,98,55,94,93,16,86,74,60,24,58,93); b0:array[1..8] of integer=(22,99,73,49,73,15,43,16); Var a1,b1,n,m,i,j,k:integer; a,b,c:ab; Procedure paixu(var e:ab;n:integer); var p,s:integer; begin for i:=1 to n-1 do begin p:=I; for j:=i+1 to n do if e[j]<e[p] then p:=j; if p<>I then begin s:=e[p]; e[p]:=e[i]; e[i]:=s; end; end; end;
C语言实现归并排序算法

C语言实现归并排序算法C语言实现归并排序算法归并排序是创建在归并操作上的一种有效的排序算法。
下面店铺为大家整理了C语言实现归并排序算法,希望能帮到大家!归并排序(Merge sort)是创建在归并操作上的一种有效的排序算法。
该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
一个归并排序的例子:对一个随机点的链表进行排序算法描述归并操作的过程如下:申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列设定两个指针,最初位置分别为两个已经排序序列的起始位置比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置重复步骤3直到某一指针到达序列尾将另一序列剩下的所有元素直接复制到合并序列尾特点:归并排序是稳定的`排序.即相等的元素的顺序不会改变, 速度仅次于快速排序,但较稳定。
归并操作归并操作(merge),也叫归并算法,指的是将两个顺序序列合并成一个顺序序列的方法。
如:设有数列 [6,202,100,301,38,8,1]初始状态:6, 202, 100, 301, 38, 8, 1第一次归并后:[6, 202], [100, 301], [8, 38], [1],比较次数:3;第二次归并后:[6, 100, 202, 301],[1, 8, 38],比较次数:4;第三次归并后:[1, 6, 8, 38, 100, 202, 301],比较次数:4;总的比较次数为:3+4+4=11,;逆序数为14;算法实现// Completed on 2014.10.11 17:20// Language: C99//// 版权所有(C)codingwu (mail: ****************)// 博客地址:/archimedes/#include#includevoid merge_sort(int *list, const int first, const int last){ int len= last-first+1; int left_min,left_max; //左半区域边界 int right_min,right_max; //右半区域边界 int index; int i; int *tmp; tmp = (int *)malloc(sizeof(int)*len); if( tmp == NULL || len <= 0 ) return; for( i = 1; i < len; i *= 2 ) { for( left_min = 0; left_min < len - i; left_min = right_max) { int j; right_min = left_max = left_min + i; right_max = left_max + i; j = left_min; if ( right_max > len ) right_max = len; index = 0; while( left_min < left_max && right_min < right_max ) { tmp[index++] = (list[left_min] > list[right_min] ? list[right_min++] : list[left_min++]); } while( left_min < left_max ) { list[--right_min] = list[--left_max]; } while( index > 0 ) { list[--right_min] = tmp[--index]; } } } free(tmp);}int main(){ int a[] = {288, 52, 123, 30, 212, 23, 10, 233}; int n, mid; n = sizeof(a) / sizeof(a[0]); mid = n / 2; merge_sort(a, 0, n - 1); for(int k = 0; k < n; k++) printf("%d ", a[k]); printf("n"); return 0;}使用递归实现:// Completed on 2014.10.11 18:20// Language: C99//// 版权所有(C)codingwu (mail: ****************)// 博客地址:/archimedes/#include#includevoid merge(int *array,const int first, const int mid, const int last){ int i,index; int first1,last1; int first2,last2; int *tmp; tmp = (int *)malloc((last-first+1)*sizeof(int)); if( tmp == NULL ) return; first1 = first; last1 = mid; first2 = mid+1; last2 = last; index = 0; while( (first1 <= last1) && (first2 <= last2) ) { if( array[first1] < array[first2] ) { tmp[index++] = array[first1]; first1++; } else{ tmp[index++] = array[first2]; first2++; } } while( first1 <= last1 ) { tmp[index++]= array[first1++]; } while( first2 <= last2 ) { tmp[index++] = array[first2++]; } for( i=0; i<(last-first+1); i++) { array[first+i] = tmp[i]; } free(tmp);}void merge_sort(int *array, const int first, const int last){ int mid = 0; if(first < last) { mid = (first + last) / 2; merge_sort(array, first, mid); merge_sort(array, mid + 1, last); merge(array, first, mid, last); }}int main(){ int a[] = {288, 52, 123, 30, 212, 23, 10, 233}; int n, mid; n = sizeof(a) / sizeof(a[0]); mid = n / 2; merge_sort(a, 0, n - 1); for(int k = 0; k < n; k++) printf("%d ", a[k]); printf("n"); return 0;}【C语言实现归并排序算法】。
数据结构课程设计--二路归并排序说明书

前言1.1排序的重要性生活中,无时不刻不充满这排序,比如:班级同学的成绩排名问题,公司产值高低的问题等等,解决这些问题的过程中,都涉及到了一个数据结构的构造思想过程。
数据结构中的排序,也有很多种,如:插入排序、交换排序、选择排序等等,此时我们就要注意选择具有优解的算法,将一个数据元素(或记录)的任意序列,重新排列成一个有序的排列,便于我们查找。
假设含有n个记录的序列为{R1,R2,Rn},其相应的关键字序列为{K1,K2,…,Kn}需确定1,2…n的一种排序P1,P2…Pn,使其相应的关键字满足如下的非递减的关系:Kp1≤Kp2≤…≤Kpn,即按关键字{Rp1,Rp2,…,Rpn}有序的排列,这样的一种操作称为排序。
一般情况下,排序又分为内部排序和外部排序。
而在内部排序中又含有很多排序方法,就其全面性能而言,很难提出一种被认为是最好的方法,因为每一种方法都有它的优缺点,适合在不同的环境下使用。
我们学习的排序有:直接插入排序、折半插入排序、希尔排序、快速排序、基数排序、归并排序等。
本次课题研究中,我主要进行了二路归并排序的研究和学习。
1.2设计的背景和意义排序是计算机领域的一类非常重要的问题,计算机在出来数据的过程中,有25%的时间花在了排序上,有许多的计算机设备,排序用去计算机处理数据时间的一半以上,这对于提高计算机的运行速度有一定的影响。
此时排序算法的高效率显得尤为重要。
在排序算法汇中,归并排序(Merging sort)是与插入排序、交换排序、选择排序不同的另一类排序方法。
归并的含义是将两个或两个以上的有序表组合成一个新的有序表。
归并排序可分为多路归并排序,两路归并排序,既可用于内排序,也可以用于外排序。
这里仅对内排序的两路归并排序进行讨论。
而我们这里所探究学习的二路归并排序,设计思路更加清晰、明了,程序本身也不像堆结构那样复杂,同时时间复杂度仅为0(N),同时在处理大规模归并排序的时候,排序速度也明显优于冒泡法等一些排序算法,提高排序算法的效率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
归并排序示意图
Mergesort(1,9)
递归分治
Mergesort(1,3)
Mergesort(1,5)
Mergesort(6,9)
Mergesort(4,5)
Mergesort(6,7)
Mergesort(8,9)
Mergesort(1,2)
Mergesort(3,3)
Mergesort(4,4)
Mergesort(5,5)
Mergesort(6,6)
Mergesort(7,7)
Mergesort(8,8)
Mergesort(9,9)
Mergesort(1,1)
Mergesort(2,2)
Merge(1,1,2)
合并子序列
Merge(1,2,3) Merge(4,4,5) Merge(6,6,7) Merge(8,8,9)
78 55 30 27 25 23 16 12
归并排序
归并排序是将两个(或两个以上) 归并排序是将两个(或两个以上)有序 表合并成一个新的有序表, 表合并成一个新的有序表,即把待排序 序列分为若干个子序列, 序列分为若干个子序列,每个子序列是 有序的。 有序的。然后再把有序子序列合并为整 体有序序列。 体有序序列。
归并排序(分治法)
//将两个有序子序列合并成一个 procedure merge(left,p,right:longint); var i,j,k:longint; begin i:=left; j:=p+1; k:=left; while (i<=p) and (j<=right) do begin if a[i] >a[j] then begin tmp[k]:=a[i]; inc(i); end else begin tmp[k]:=a[j]; inc(j); end; inc(k); end; while i<=p do begin tmp[k]:=a[i];inc(i);inc(k); end; while j<=right do begin tmp[k]:=a[j];inc(j);inc(k); end; for i:=left to right do a[i]:=tmp[i]; end; //归并排序过程:递归分治 procedure mergesort(left,right:longint); var mid:longint; begin if left<right then begin mid:=(left+right) div 2; mergesort(left,mid); mergesort(mid+1,right); merge(left,mid,right); end; end;
Merge(1,3,5)
Merge(6,7,9)
Merge(1, 5,9)
递归分治
12 23 78
6
25 16 27 55 30
12 23 78
6
25
16 27 55 30
12 23 78 12 23
6 25
16 27
55 30
12
23
78
6
பைடு நூலகம்25
16
27
55
30
23 12 78 23 12 78 25 23 12 合并子序列 25 6 6 27 16 55 30 27 16 6 55 30