统计学第七章第八章课后题答案
《统计学》-第7章-习题答案

第七章思考与练习参考答案1.答:函数关系是两变量之间的确定性关系,即当一个变量取一定数值时,另一个变量有确定值与之相对应;而相关关系表示的是两变量之间的一种不确定性关系,具体表示为当一个变量取一定数值时,与之相对应的另一变量的数值虽然不确定,但它仍按某种规律在一定的范围内变化。
2.答:相关和回归都是研究现象及变量之间相互关系的方法。
相关分析研究变量之间相关的方向和相关的程度,但不能确定变量间相互关系的具体形式,也无法从一个变量的变化来推测另一个变量的变化情况;回归分析则可以找到研究变量之间相互关系的具体形式,并可变量之间的数量联系进行测定,确定一个回归方程,并根据这个回归方程从已知量推测未知量。
3.答:单相关系数是度量两个变量之间线性相关程度的指标,其计算公式为:总体相关系数,样本相关系数。
复相关系数是多元线性回归分析中度量因变量与其它多个自变量之间的线性相关程度的指标,它是方程的判定系数2R 的正的平方根。
偏相关系数是多元线性回归分析中度量在其它变量不变的情况下两个变量之间真实相关程度的指标,它反映了在消除其他变量影响的条件下两个变量之间的线性相关程度。
4.答:回归模型假定总体上因变量Y 与自变量X 之间存在着近似的线性函数关系,可表示为t t t u X Y ++=10ββ,这就是总体回归函数,其中u t 是随机误差项,可以反映未考虑的其他各种因素对Y 的影响。
根据样本数据拟合的方程,就是样本回归函数,以一元线性回归模型的样本回归函数为例可表示为:tt X Y 10ˆˆˆββ+=。
总体回归函数事实上是未知的,需要利用样本的信息对其进行估计,样本回归函数是对总体回归函数的近似反映。
两者的区别主要包括:第一,总体回归直线是未知的,它只有一条;而样本回归直线则是根据样本数据拟合的,每抽取一组样本,便可以拟合一条样本回归直线。
第二,总体回归函数中的0β和1β是未知的参数,表现为常数;而样本回归直线中的0ˆβ和1ˆβ是随机变量,其具体数值随所抽取的样本观测值不同而变动。
统计学第七章课后题及答案解析

第七章一、单项选择题1.按指数所包括的范围不同, 可以把它分为( )A .个体指数和总指数B .数量指标指数和质量指标指数C .综合指数和平均指数D .定基指数和环比指数2.某集团公司为了反映所属各企业劳动生产率水平的提高情况,需要编制( ) A.质量指标综合指数 B.数量指标综合指数 C.可变构成指数 D.固定构成指数3.在一般情况下,商品销售量指数和工资水平指数的同度量因素分别为( ) A .商品销售量、平均工资水平 B .商品销售量、职工人数C .单位商品销售价格、职工人数D .单位商品销售价格、平均工资水平 4.下列指数中属于数量指标指数的是( )A .产品价格指数B .单位成本指数C .产量指数D .劳动生产率指数 5.下面属于价格指数的是( ) A .1101PQ P Q ∑∑ B .1100PQ P Q ∑∑ C .0100P Q P Q ∑∑ D .1000PQ P Q ∑∑ 6.某商品价格发生变化,现在的100元只值原来的90元,则价格指数为( ) A .10% B .90% C .110% D .111% 7.固定构成指数的公式是( )A .001110X F X F F F ∑∑÷∑∑ B .010010X F X F F F ∑∑÷∑∑ C .011111X F X F F F ∑∑÷∑∑ D .011010X F X F F F ∑∑÷∑∑ 二、多项选择题1.下列属于数量指标指数的有( )A .产量指数B .销售量指数C .价格指数D .单位产品成本指数E .职工人数指数 2.下列表述正确的是( )A .综合指数是先综合后对比B .平均数指数是先对比后综合C .平均数指数必须使用全面资料D .平均数指数可以使用固定权数E .固定构成指数受总体结构影响 3.同度量因素的作用有( )A .同度量作用B .联系作用C .权数作用D .比较作用E .平衡作用4.对某商店某时期商品销售额的变动情况进行分析,其指数体系包括( ) A .销售量指数 B .销售价格指数C .总平均价格指数D .销售额指数E .个体指数5.若用某企业职工人数和劳动生产率的分组资料来进行分析时,该企业总的劳动生产率的变动主要受到( )A.企业全部职工人数变动的影响 B.企业劳动生产率变动的影响C.企业各类职工人数在全部职工人数中所占比重的变动影响D.企业各类工人劳动生产率的变动影响E.受各组职工人数和相应劳动生产率两因素的影响6.下列指数中,属于拉氏指数的有()A.∑∑1QpQpB.∑∑11QpQPC.∑∑1pQpQD.∑∑111QpQpE.∑∑111pQpQ7.某企业产品总成本报告期为183150元,比基期增长10%,单位成本综合指数为104%,则()A.总成本指数110% B.产量增长了5.77% C.基期总成本为166500元D.单位成本上升使总成本增加了7044元 E.产量增产使总成本增加了9606元三、判断题1.综合指数的编制方法是先综合后对比。
统计学原理 第七章课后习题及答案

第七章 相关和回归一、单项选择题1.相关关系中,用于判断两个变量之间相关关系类型的图形是( )。
(1)直方图 (2)散点图 (3)次数分布多边形图 (4)累计频率曲线图 2.两个相关变量呈反方向变化,则其相关系数r( )。
(1)小于0 (2)大于0 (3)等于0 (4)等于13.在正态分布条件下,以2yx S (提示:yx S 为估计标准误差)为距离作平行于回归直线的两条直线,在这两条平行直线中,包括的观察值的数目大约为全部观察值的( )。
(1)68.27% (2)90.11% (3)95.45% (4)99.73% 4.合理施肥量与农作物亩产量之间的关系是( )。
(1)函数关系 (2)单向因果关系 (3)互为因果关系 (4)严格的依存关系 5.相关关系是指变量之间( )。
(1)严格的关系 (2)不严格的关系(3)任意两个变量之间关系 (4)有内在关系的但不严格的数量依存关系 6.已知变量X 与y 之间的关系,如下图所示:其相关系数计算出来放在四个备选答案之中,它是( )。
(1)0.29 (2)-0.88 (3)1.03 (4)0.997.如果变量z 和变量Y 之间的相关系数为-1,这说明两个变量之间是( )。
(1)低度相关关系 (2)完全相关关系 (3)高度相关关系 (4)完全不相关 8.若已知2()x x -∑是2()y y -∑的2倍,()()x x y y --∑是2()y y -∑的1.2倍,则相关系数r=( )。
(1)21.2 2(3)0.92 (4)0.65 9.当两个相关变量之问只有配合一条回归直线的可能,那么这两个变量之间的关系是( )。
(1)明显因果关系 (2)自身相关关系(3)完全相关关系 (4)不存在明显因果关系而存在相互联系 10.在计算相关系数之前,首先应对两个变量进行( )。
(1)定性分析 (2)定量分析 (3)回归分析 (4)因素分析 11.用来说明因变量估计值代表性高低的分析指标是( )。
统计学课后习题答案(全)

<<统计学>>课后习题参考答案第四章1. 计划完成相对指标==⨯++%100%51%81102.9% 2. 计划完成相对指标=%9.97%100%41%61=⨯-- 3.4.5.解:(1)计划完成相对指标=%56.115%1004513131214=⨯+++(2)从第四年二季度开始连续四季的产量之和为:10+11+12+14=47天完成任务。
个月零该产品总共提前天完成的天数已提前完成任务,提前该产品到第五年第一季1510459010144514121110∴=--+++=6.解:计划完成相对指标=%75.126%100%1.0102005354703252795402301564=⨯⨯⨯++++++(2)156+230+540+279+325+470=2000(万吨) 所以正好提前半年完成计划。
7.8.略第五章 平均指标与标志变异指标1.甲X =.309343332313029282726=++++++++乙X =44.319403836343230282520=++++++++ AD 甲=}22.29303430333032303130303029302830273026=-+-+-+-+-+-+-+-+-AD 乙=}06.594044.313844.313644.313444.313244.313044.312844.312544.3120=-+-+-+-+-+-+-+-+-R 甲=34-26=8 R 乙=40-20=20σ甲 =9)3334()3033()3032()3031()3030()3029()3028()3027()3026(222222222-+-+-+-+-+-+-+-+-=2.58 σ乙=9)44.3140()44.3138()44.3136()44.3134()44.3132()44.3130()44.3128()44.3125()44.3120(222222222-+-+-+-+-+-+-+-+-=6.06V 甲=1003058.2⨯%=8.6% V 乙=%3.19%10044.3106.6=⨯ 所以甲组的平均产量代表性大一些. 2.解:计算过程如下表:甲X =.)(5.101780元= 乙X =(元)9708077600= 3.解:计算过程如下表:甲X =.4.11980=(件) 乙X =8.120809660=(件) σ甲=06.98075.6568=(件) σ乙=81.10809355=(件) V 甲=1004.11906.9⨯%=7.58% V 乙=%94.8%1008.12081.10=⨯ 所以甲厂工人的平均产量的代表性要高些.4. 解:()()94.761018102457047.7610121871871870775121873595128518757653550=⨯-+==⨯-+--+==++++⨯+⨯+⨯+⨯+⨯=e M M X 5.解:(1)上期的平均计划完成程度为:()()第六章元解解度为下期的平均计划完成程tH V P X P P P P /3.2884102950943.5062900255.3212800604.43210943.506255.321604.432:.7%1.32%1009067.0291.0291.0%67.901%67.90%67.90%67.90%10030028300:.6%37.103%1031400%1011200%107810%110961400120081096:)2(%67.99%1001500100070080%951500%1001000%108700%1108044=⨯⎪⎭⎫ ⎝⎛++⨯++==⨯==-⨯====⨯-==++++++=⨯+++⨯+⨯+⨯+⨯σ1.()())(7.788%67.41500:2000%67.41500600:.6)(6.62126907106557306806702650600269071061527106556552655730620273068060026806706402670650:2)(7.62327107006907206806202680610271070062527006906452690720640272068062026806206002620680:)1(:.5%63.79%10026206005802580257646245002435:.4%85.105%100%113385%102350%97463%120485%105412%112410%98368%106350%105310%110324%102306%101303385350463485412410368350310324306303::.3872232122221030980329809002290010201210208402284067022670600.2104万吨年该县粮食产量为平均增长速度解元工人的月平均工资为乙工区上半年建筑安装元工人的月平均工资为甲工区上半年建筑安装解解度为全年月平均计划完成程解=+⨯=-==++++++⨯++⨯++⨯++⨯++⨯++⨯+=++++++⨯++⨯++⨯++⨯++⨯++⨯+=⨯++++++==⨯++++++++++++++++++++++=+++++⨯++⨯++⨯++⨯++⨯++⨯+=C a 7解:计算过程如下表:)(94.6653.444.45:1994:3.46025844.4594092万元年的地方财政支出额为则直线趋势方程为=⨯++=======∑∑∑bta y t tyb ny a二次曲线方程为:y = 0.0108x 2 + 4.1918x + 24.143(过程略) 指数曲线方程为:y = 26.996e 0.0978x8.解:计算过程如下表:9.解:(1)同季平均法求季节比率的过程如下表:(2)趋势剔除法测定的季节变动如下表:第七章 统计指数()()()()01001011111175000124000081138.44%5000012350008750002540000182138.03%500002535000181075000940000390.98%127500084000022750002540000425qqzpk q z q zq p q p q z kq z p q k p q⨯+⨯===⨯+⨯⨯+⨯===⨯+⨯⨯+⨯===⨯+⨯⨯+⨯==∑∑∑∑∑∑∑∑111111110102.12%75000184000015602.108.8%1200360110%105%pp q p q k p q p q p p=⨯+⨯====+∑∑∑∑11111560.135.65%1150135.65%124.68%108.8%.120%1800115%90096%6003.114.27%330042003300111.38%114.27%.pqpq qpqpq p qp q k p qk k k q q p q p q k q p q pkk k======⨯+⨯+⨯=======∑∑∑∑∑∑ 110101001013200005.100%128%250000128%123.1%14%320000307692.3104%307692.325000057692.3320000307692.312307.pq pqq PpK K K p qp q K p q p qq p q =⨯====+===-=-=-=-=∑∑∑∑∑∑1解:K 零售量变动对零售额变动影响的绝对值为:(万元)零售物价变动对零售总额变动影响的绝对值为:p 1110010000107350000120%120%180000110%110%116%116%17.6%107.6%350000291666.67120%180000163636.36.110%1pq pq q q pq pq q q K q K q p q Kq p q K p q p q ==+===+==+==+========⨯=∑∑∑∑∑∑∑∑城1城农城农1农1城城城1农农农城城城(万元)6.解:已知p ,,p ,,K ,K p 则p K 0010111101001116%291666.67338333.33107.6%163636.36176072.72350000180000103.03%338333.33176072.723%q pp q p q p q q q k p q p q p q ⨯==⨯=⨯=++====++∴∑∑∑∑∑∑∑∑农农农11城农城农K p p 该地区城乡价格上涨了。
统计学第五版课后练答案(7-8章)

第七章 参数估计7.1 (1)x σ==(2)2x z α∆= 1.96=1.54957.2 某快餐店想要估计每位顾客午餐的平均花费金额。
在为期3周的时间里选取49名顾客组成了一个简单随机样本。
(1)假定总体标准差为15元,求样本均值的抽样标准误差。
x σ==(2)在95%的置信水平下,求估计误差。
x x t σ∆=⋅,由于是大样本抽样,因此样本均值服从正态分布,因此概率度t=2z α 因此,x x t σ∆=⋅2x z ασ=⋅0.025x z σ=⋅=1.96×2.143=4.2 (3)如果样本均值为120元,求总体均值 的95%的置信区间。
置信区间为:2x z x z αα⎛-+ ⎝=()120 4.2,120 4.2-+=(115.8,124.2)7.322x z x z αα⎛-+ ⎝=104560±(87818.856,121301.144) 7.4 从总体中抽取一个n=100的简单随机样本,得到x =81,s=12。
要求:大样本,样本均值服从正态分布:2,x N n σμ⎛⎫ ⎪⎝⎭ 或2,s x N n μ⎛⎫⎪⎝⎭置信区间为:22x z x z αα⎛-+ ⎝=1.2 (1)构建μ的90%的置信区间。
2z α=0.05z =1.645,置信区间为:()81 1.645 1.2,81 1.645 1.2-⨯+⨯=(79.03,82.97)(2)构建μ的95%的置信区间。
2z α=0.025z =1.96,置信区间为:()81 1.96 1.2,81 1.96 1.2-⨯+⨯=(78.65,83.35)(3)构建μ的99%的置信区间。
2z α=0.005z =2.576,置信区间为:()81 2.576 1.2,81 2.576 1.2-⨯+⨯=(77.91,84.09)7.5 (1)2x z α±=25 1.96±=(24.114,25.886)(2)2x z α±119.6 2.326±=(113.184,126.016)(3)2x z α± 3.419 1.645±(3.136,3.702)7.6 (1)2x z α±=8900 1.96±=(8646.965,9153.035)(2)2x z α±8900 1.96±=(8734.35,9065.65)(3)2x z α±8900 1.645±=(8761.395,9038.605)(4)2x z α±8900 2.58±=(8681.95,9118.05)7.7 某大学为了解学生每天上网的时间,在全校7 500名学生中采取重复抽样方法随机抽取36人,调解:(1)样本均值x =3.32,样本标准差s=1.611α-=0.9,t=2z α=0.05z =1.645,x z α± 3.32 1.645±=(2.88,3.76)1α-=0.95,t=z α=0.025z =1.96,x z α± 3.32 1.96±(2.79,3.85)1α-=0.99,t=z α=0.005z =2.576,2x z α± 3.32 2.76±(2.63,4.01)7.82x t α±=10 2.365±7.9 某居民小区为研究职工上班从家里到单位的距离,抽取了由16个人组成的一个随机样本,他们到单位的距离(单位:km)分别是:10 3 14 86 9 12 117 5 1015 9 16 13 2假定总体服从正态分布,求职工上班从家里到单位平均距离的95%的置信区间。
统计学原理 第七章课后习题及答案

第七章 相关和回归一、单项选择题1.相关关系中,用于判断两个变量之间相关关系类型的图形是( )。
(1)直方图 (2)散点图 (3)次数分布多边形图 (4)累计频率曲线图 2.两个相关变量呈反方向变化,则其相关系数r( )。
(1)小于0 (2)大于0 (3)等于0 (4)等于13.在正态分布条件下,以2yx S (提示:yx S 为估计标准误差)为距离作平行于回归直线的两条直线,在这两条平行直线中,包括的观察值的数目大约为全部观察值的( )。
(1)68.27% (2)90.11% (3)95.45% (4)99.73% 4.合理施肥量与农作物亩产量之间的关系是( )。
(1)函数关系 (2)单向因果关系 (3)互为因果关系 (4)严格的依存关系 5.相关关系是指变量之间( )。
(1)严格的关系 (2)不严格的关系(3)任意两个变量之间关系 (4)有内在关系的但不严格的数量依存关系 6.已知变量X 与y 之间的关系,如下图所示:其相关系数计算出来放在四个备选答案之中,它是( )。
(1)0.29 (2)-0.88 (3)1.03 (4)0.997.如果变量z 和变量Y 之间的相关系数为-1,这说明两个变量之间是( )。
(1)低度相关关系 (2)完全相关关系 (3)高度相关关系 (4)完全不相关 8.若已知2()x x -∑是2()y y -∑的2倍,()()x x y y --∑是2()y y -∑的1.2倍,则相关系数r=( )。
(1)1.2 (3)0.92 (4)0.65 9.当两个相关变量之问只有配合一条回归直线的可能,那么这两个变量之间的关系是( )。
(1)明显因果关系 (2)自身相关关系(3)完全相关关系 (4)不存在明显因果关系而存在相互联系 10.在计算相关系数之前,首先应对两个变量进行( )。
(1)定性分析 (2)定量分析 (3)回归分析 (4)因素分析 11.用来说明因变量估计值代表性高低的分析指标是( )。
统计学原理 第七章课后习题及答案
第七章 相关和回归一、单项选择题1.相关关系中,用于判断两个变量之间相关关系类型的图形是( )。
(1)直方图 (2)散点图 (3)次数分布多边形图 (4)累计频率曲线图 2.两个相关变量呈反方向变化,则其相关系数r( )。
(1)小于0 (2)大于0 (3)等于0 (4)等于13.在正态分布条件下,以2yx S (提示:yx S 为估计标准误差)为距离作平行于回归直线的两条直线,在这两条平行直线中,包括的观察值的数目大约为全部观察值的( )。
(1)68.27% (2)90.11% (3)95.45% (4)99.73% 4.合理施肥量与农作物亩产量之间的关系是( )。
(1)函数关系 (2)单向因果关系 (3)互为因果关系 (4)严格的依存关系 5.相关关系是指变量之间( )。
(1)严格的关系 (2)不严格的关系(3)任意两个变量之间关系 (4)有内在关系的但不严格的数量依存关系 6.已知变量X 与y 之间的关系,如下图所示:其相关系数计算出来放在四个备选答案之中,它是( )。
(1)0.29 (2)-0.88 (3)1.03 (4)0.997.如果变量z 和变量Y 之间的相关系数为-1,这说明两个变量之间是( )。
(1)低度相关关系 (2)完全相关关系 (3)高度相关关系 (4)完全不相关 8.若已知2()x x -∑是2()y y -∑的2倍,()()x x y y --∑是2()y y -∑的1.2倍,则相关系数r=( )。
(1)1.2 (3)0.92 (4)0.65 9.当两个相关变量之问只有配合一条回归直线的可能,那么这两个变量之间的关系是( )。
(1)明显因果关系 (2)自身相关关系(3)完全相关关系 (4)不存在明显因果关系而存在相互联系 10.在计算相关系数之前,首先应对两个变量进行( )。
(1)定性分析 (2)定量分析 (3)回归分析 (4)因素分析 11.用来说明因变量估计值代表性高低的分析指标是( )。
统计学原理 第七章课后习题及答案
第七章 相关和回归一、单项选择题1.相关关系中,用于判断两个变量之间相关关系类型的图形是( )。
(1)直方图 (2)散点图 (3)次数分布多边形图 (4)累计频率曲线图 2.两个相关变量呈反方向变化,则其相关系数r( )。
(1)小于0 (2)大于0 (3)等于0 (4)等于13.在正态分布条件下,以2yx S (提示:yx S 为估计标准误差)为距离作平行于回归直线的两条直线,在这两条平行直线中,包括的观察值的数目大约为全部观察值的( )。
(1)68.27% (2)90.11% (3)95.45% (4)99.73% 4.合理施肥量与农作物亩产量之间的关系是( )。
(1)函数关系 (2)单向因果关系 (3)互为因果关系 (4)严格的依存关系 5.相关关系是指变量之间( )。
(1)严格的关系 (2)不严格的关系(3)任意两个变量之间关系 (4)有内在关系的但不严格的数量依存关系 6.已知变量X 与y 之间的关系,如下图所示:其相关系数计算出来放在四个备选答案之中,它是( )。
(1)0.29 (2)-0.88 (3)1.03 (4)0.997.如果变量z 和变量Y 之间的相关系数为-1,这说明两个变量之间是( )。
(1)低度相关关系 (2)完全相关关系 (3)高度相关关系 (4)完全不相关 8.若已知2()x x -∑是2()y y -∑的2倍,()()x x y y --∑是2()y y -∑的1.2倍,则相关系数r=( )。
(1)21.2 2(3)0.92 (4)0.65 9.当两个相关变量之问只有配合一条回归直线的可能,那么这两个变量之间的关系是( )。
(1)明显因果关系 (2)自身相关关系(3)完全相关关系 (4)不存在明显因果关系而存在相互联系 10.在计算相关系数之前,首先应对两个变量进行( )。
(1)定性分析 (2)定量分析 (3)回归分析 (4)因素分析 11.用来说明因变量估计值代表性高低的分析指标是( )。
统计学课后练答案

第七章 参数估计(1)x σ==(2)2x z α∆==1.96=某快餐店想要估计每位顾客午餐的平均花费金额。
在为期3周的时间里选取49名顾客组成了一个简单随机样本。
(1)假定总体标准差为15元,求样本均值的抽样标准误差。
x σ=== (2)在95%的置信水平下,求估计误差。
x x t σ∆=⋅,由于是大样本抽样,因此样本均值服从正态分布,因此概率度t=z α 因此,x x t σ∆=⋅x z ασ=⋅0.025x z σ=⋅=×=(3)如果样本均值为120元,求总体均值 的95%的置信区间。
置信区间为:2x z x z αα⎛-+ ⎝=()120 4.2,120 4.2-+=(,)2x z x z αα⎛-+ ⎝=104560±(,) 从总体中抽取一个n=100的简单随机样本,得到x =81,s=12。
要求:大样本,样本均值服从正态分布:2,x N n σμ⎛⎫ ⎪⎝⎭:或2,s x N n μ⎛⎫⎪⎝⎭:置信区间为:22x z x z αα⎛-+ ⎝, (1)构建μ的90%的置信区间。
2z α=0.05z =,置信区间为:()81 1.645 1.2,81 1.645 1.2-⨯+⨯=(,) (2)构建μ的95%的置信区间。
2z α=0.025z =,置信区间为:()81 1.96 1.2,81 1.96 1.2-⨯+⨯=(,) (3)构建μ的99%的置信区间。
2z α=0.005z =,置信区间为:()81 2.576 1.2,81 2.576 1.2-⨯+⨯=(,)(1)2x z α±=25 1.96±(,) (2)2x z α±=119.6 2.326±=(,) (3)2x z α±=3.419 1.645±(,) (1)2x z α±=8900 1.96±=(,)(2)2x z α±=8900 1.96±=(,) (3)2x z α±=8900 1.645±=(,)(4)2x z α±=8900 2.58±=(,) 某大学为了解学生每天上网的时间,在全校7 500名学生中采取重复抽样方法随机抽取36人,调查解:(1)样本均值x =,样本标准差s=1α-=,t=z α=0.05z =,xz α±=3.32 1.645±(,) 1α-=,t=z α=0.025z =,x z α±=3.32 1.96±(,)1α-=,t=z α=0.005z =,x zα±=3.32 2.76±(,)2x t α±=10 2.365±=,某居民小区为研究职工上班从家里到单位的距离,抽取了由16个人组成的一个随机样本,他们到单位的距离(单位:km)分别是:10 3 14 8 6 9 12 11 7 5 10 15 9 16 13 2假定总体服从正态分布,求职工上班从家里到单位平均距离的95%的置信区间。
统计学第四版第七章课后题最全答案

配对号
来自总体A得样本
来自总体B得样本
1
2
3
4
2
5
10
8
0
7
6
5
(1)计算A与B各对观察值之差,再利用得出得差值计算与。
=1、75,=2、62996
(2)设分别为总体A与总体B得均值,构造得95%得置信区间。
解:小样本,配对样本,总体方差未知,用t统计量
均值=1、75,样本标准差s=2、62996
(2)已知:E=0、1,=0、8,=0、05,=1、96
应抽取得样本量为:=≈62
7.20
(1)构建第一种排队方式等待时间标准差得95%得置信区间。
解:估计统计量
经计算得样本标准差=3、318
置信区间:
=0、95,n=10,==19、02,==2、7
==(0、1075,0、7574)
因此,标准差得置信区间为(0、3279,0、8703)
(3)已知=0、01,=2、58
由于n=100为大样本,所以总体均值得99%得置信区间为:
=812、58*813、096,即(77、94,84、096)
7、5(1)已知=3、5,n=60,=25,=0、05,=1、96
由于总体标准差已知,所以总体均值得95%得置信区间为:
=251、96*250、89,即(24、11,25、89)
7、4(1)已知n=100,=81,s=12, =0、1,=1、645
由于n=100为大样本,所以总体均值得90%得置信区间为:
=811、645*811、974,即(79、026,82、974)
(2)已知=0、05,=1、96
由于n=100为大样本,所以总体均值得95%得置信区间为:
统计学课后答案第七八章汇总

6.1 调理一个装瓶机使其对每个瓶子的灌装量均值为盎司,经过察看这台装瓶机对每个瓶子的灌装量听从标准差 1.0 盎司的正态散布。
随机抽取由这台机器灌装的9 个瓶子形成一个样本,并测定每个瓶子的灌装量。
试确立样本均值偏离整体均值不超出0.3 盎司的概率。
解:整体方差知道的状况下,均值的抽样散布听从N , 2的正态散布,由正态散布,n标准化获得标准正态散布:z= x~ N 0,1 ,所以,样本均值不超出整体均值的概率P n为:P x 0.3 =P x 0.3= P0.3 x 0.3n n 1 9 n 1 9= P 0.9 z 0.9 =2 0.9 -1,查标准正态散布表得0.9 =0.8159所以, P x 0.3 =0.63186.2 在练习题 6.1 中,我们希望样本均值与整体均值的偏差在 0.3 盎司以内的概率达到0.95,应该抽取多大的样本?解: P xx 0.3= P0.3 x 0.30.3 =Pn n 1 n n 1 n= 2 (0.3 n) 1 0.95 (0.3 n) 0.9750.3 n 1.96 n 42.68288 n 436.3 Z1,Z2 ,,Z6表示从标准正态整体中随机抽取的容量,n=6 的一个样本,试确立常数b,使得6P Z i2b0.95i 1解:因为卡方散布是由标准正态散布的平方和构成的:设 Z1, Z2,,Z n是来自整体N(0,1)的样本,则统计量2 Z12 Z 22 Z n2听从自由度为2 2~ 2n 的χ散布,记为χχ( n)6 6 62所以,令2Z i2,则 2 Z i2 2 6 ,那么由概率 P Z i b0.95 ,可知:i 1 i 1 i 120.95 6 ,查概率表得: b=12.59b= 1121 6.4 在习题 6.1 中,假定装瓶机对瓶子的灌装量听从方差 的标准正态散布。
假定我们计划随机抽取 10 个瓶子构成样本,观察每个瓶子的灌装量,获得 10 个观察值,用这1n10 个观察值我们能够求出样本方差S 2 (S 2(Y i Y )2 ) ,确立一个适合的范围使得有n 1 i 1较大的概率保证 S 2落入此中是实用的,试求 b 1, b 2 ,使得p(b 1 S 2 b 2 ) 0.90解:更为样本方差的抽样散布知识可知,样本统计量:(n 1s)22(n 1 ) 2~此处, n=10,21 ,所以统计量(n 1)s 2(10 1)s 22~ 2(n 1)21 9s依据卡方散布的可知:P b 1 S 2 b 2P 9b 1 9S 29b 20.90又因为:2n122 n11P 1 29S2所以:P 9b 129b 2P2n 19S 22n1 10.909S122P 9b 12P222n 19S 9b 2 12 n 1 9S2P2922 9 0.900.959S0.05则:222 9299b 19b 10.95, b 20.050.959 ,9b 2 0.0599查概率表: 2 9 =3.325 ,2 9 =19.919 ,则0.950.052 92 90.95=0.369, b 20.05=1.88b 19927.1 从一个标准差为 5 的整体中采纳重复抽样方法抽出一个样本容量为40 的样本,样本均值为 25。
统计学课后习题答案(全章节)(精品).docx
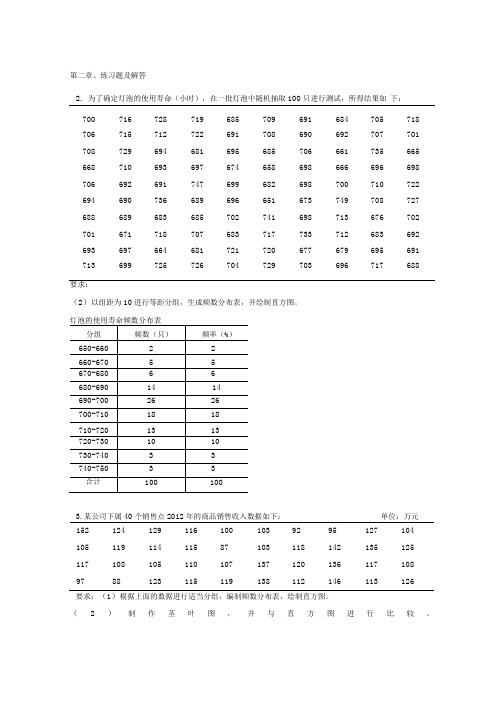
第二章、练习题及解答2.为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果如下:700 716 728 719 685 709 691 684 705 718 706 715 712 722 691 708 690 692 707 701 708 729 694 681 695 685 706 661 735 665 668 710 693 697 674 658 698 666 696 698 706 692 691 747 699 682 698 700 710 722 694 690 736 689 696 651 673 749 708 727 688 689 683 685 702 741 698 713 676 702 701 671 718 707 683 717 733 712 683 692 693 697 664 681 721 720 677 679 695 691 713 699 725 726 704 729 703 696 717 688要求:(2)以组距为10进行等距分组,生成频数分布表,并绘制直方图。
3.某公司下属40个销售点2012年的商品销售收入数据如下:单位:万元152 124 129 116 100 103 92 95 127 104 105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 10897 88 123 115 119 138 112 146 113 126要求:(1)根据上面的数据进行适当分组,编制频数分布表,绘制直方图。
(2)制作茎叶图,并与直方图进行比较。
1.已知下表资料:25 20 10 500 2.5 30 50 25 1500 7.5 35 80 40 2800 14 40 36 18 1440 7.2 4514 7 630 3. 15 合 计200100687034. 35_y xf 6870根据频数计算工人平均日产量:〒=金^ =北* = 34.35 (件)£f 200结论:对同一资料,采用频数和频率资料计算的变量值的平均数是一致的。
统计学第七章课后题及答案解析

第七章 一、单项选择题1.按指数所包括的范围不同, 可以把它分为( )A.个体指数和总指数 B .数量指标指数和质量指标指数C.综合指数和平均指数 D.定基指数和环比指数2. 某集团公司为了反映所属各企业劳动生产率水平的提高情况 ,需要编制(A.质量指标综合指数B.数量指标综合指数C.可变构成指数D.固定构成指数3.在一般情况下,商品销售量指数和工资水平指数的同度量因素分别为( 商品销售量、平均工资水平 单位商品销售价格、职工人数 下列指数中属于数量指标指数的是 产品价格指数 产量指数 下面属于价格指数的是(B .商品销售量、职工人数D.单位商品销售价格、平均工资水平 )B .单位成本指数 D.劳动生产率指数5. A.工RQ 1 氓Q 1B -F 1Q 1ZFO Q OC.QZP0QoD E pQ oZP0Q O6. A.7. 某商品价格发生变化,现在的10%B. 90% 固定构成指数的公式是(100元只值原来的 C. 110%)90元,则价格指数为(D. 111%A. C.1. A. D.2. A. C. E.3. A. D.4.A. C. ZX i F i ZF iZX 1F 1ZF I... ZX P F O 1F0 D. ZX O F^ IXo F oIX 0F 1ZF iZFoIX 1F 0ZF O、多项选择题下列属于数量指标指数的有( 产量指数单位产品成本指数 下列表述正确的是( 综合指数是先综合后对比 平均数指数必须使用全面资料 固定构成指数受总体结构影响 同度量因素的作用有( 同度量作用 B.比较作用E. )B.销售量指数E.职工人数指数C.价格指数B .平均数指数是先对比后综合 D.平均数指数可以使用固定权数联系作用平衡作用c.权数作用对某商店某时期商品销售额的变动情况进行分析,其指数体系包括( 销售量指数B.销售价格指数总平均价格指数 D.销售额指数 E.个体指数若用某企业职工人数和劳动生产率的分组资料来进行分析时,该企业总的劳动生产率的A.C.4.A.C.变动主要受到()A.企业全部职工人数变动的影响B.企业劳动生产率变动的影响C.企业各类职工人数在全部职工人数中所占比重的变动影响D.企业各类工人劳动生产率的变动影响E.受各组职工人数和相应劳动生产率两因素的影响6.下列指数中,属于拉氏指数的有()' Q1P01 0 1 01 1 1 1P0Q0 P0Q1 C X Q0 P0 P0Q1 Q0 P1 7.某企业产品总成本报告期为183150元,比基期增长10%单位成本综合指数为104%则()A.总成本指数110%B.产量增长了5.77%C.基期总成本为166500元D.单位成本上升使总成本增加了7044元E.产量增产使总成本增加了9606元三、判断题1.综合指数的编制方法是先综合后对比。
统计学人教版第五版7,8,10,11,13,14章课后题答案

统计学人教版第五版7,8,10,11,13,14章课后题答案第七章 参数估计7.1 (1)79.0405===nx σσ (2)由于1-α=95% α=5% 96.12=αZ所以 估计误差55.140596.12≈⨯=nZ σα7.2 (1)14.24915===nx σσ (2)因为96.12=αZ 所以20.4491596.12≈⨯=nZ σα(3)μ的置信区间为20.41202±=±nZ x σα7.3 由于96.12=αZ 104560=x 85414=σ n=100所以μ的95%置信区间为14.167411045601008541496.11045602±=⨯±=±nZ x σα7.4(1)μ的90%置信区间为97.18110012645.1812±=⨯±=±n s Z x α(2)μ的95%置信区间为35.2811001296.1812±=⨯±=±n s Z x α(3)μ的99%置信区间为096.3811001258.2812±=⨯±=±n s Z x α7.5 (1)89.025605.396.1252±=⨯±=±nZ x σα(2)416.66.1197589.23326.26.1192±=⨯±=±n s Z x α(3)283.0419.332974.0645.1419.32±=⨯±=±n s Z x α7.6 (1)035.25389001550096.189002±=⨯±=±nZ x σα(2)650.16589003550096.189002±=⨯±=±nZ x σα(3)028.139890035500645.189002±=⨯±=±n s Z x α(4)583.196890035500326.289002±=⨯±=±n s Z x α7.7 317.31==∑i x nx ()609.1113612=--=∑=i ix x n s 90%置信区间为441.0317.336609.1645.1317.32±=⨯±=±n s Z x α95%置信区间为526.0317.336609.196.1317.32±=⨯±=±n s Z x α99%置信区间为6908.0317.336609.1576.2317.32±=⨯±=±n s Z x α7.8 101==∑i x nx ()464.311812=--=∑=i ix x n s 所以95%置信区间为()896.2108464.33646.21012±=⨯±=±-n s t x n α7.9 375.91==∑i x n x 由于()131.2)15(025.012==-t t n α ()113.4112=--=∑x x n s i 所以95%置信区间为()191.2375.916113.4131.2375.912±=⨯±=±-n s t x n α7.10 (1)63.05.1493693.196.15.1492±=⨯±=±n s Z x α(2)中心极限定理 7.11 (1)132.10150665011=⨯==∑i x nx ()641.188.131491112=⨯=--=∑x x n s i 455.032.10150641.196.132.1012±=⨯±=±n s Z x α(2)由于9.05045==p 所以 合格率的95%置信区间为()083.09.0501.09.096.19.012±=⨯⨯±=-±n p p Z p α7.12 由于128.161==∑i x n x ()745.3)24(005.012==-t t n α ()8706.0112=--=∑x x n s i所以99%置信区间为653.028.161258706.0745.328.161)1(2±=⨯±=-±n s n t x α 7.13 7396.1)17()1(05.02==-t n t α 556.131==∑i x nx ()800.7112=--=∑x x n s i所以90%置信区间为198.3556.13188.77396.1556.13)1(2±=⨯±=-±n s n t x α 7.14(1)()194.051.04449.051.0576.251.012±=⨯⨯±=-±n p p Z p α(2)()0435.082.030018.082.096.182.012±=⨯⨯±=-±n p p Z p α(3)()024.048.0115052.048.0645.148.012±=⨯⨯±=-±n p p Z p α7.15(1)90%置信区间为()049.023.020077.023.0645.123.012±=⨯⨯±=-±n p p Z p α(2)95%置信区间为()058.023.020077.023.096.123.012±=⨯⨯±=-±n p p Z p α7.16 89.1652001000576.222222222=⨯=⎪⎪⎭⎫ ⎝⎛=⇒=E Z n nZ E σδαα所以n 为166 7.17(1)()13.25302.06.04.0054.2122222=⨯⨯=-⎪⎪⎭⎫⎝⎛=E Z n ππα 所以n 为254 (2)()0625.15004.05.05.096.1122222=⨯⨯=-⎪⎪⎭⎫⎝⎛=E Z n ππα 所以n 为151(3)()89.26705.045.055.0645.1122222=⨯⨯=-⎪⎪⎭⎫⎝⎛=E Z n ππα 所以n 为268 7.18(1)64.05032==p (2)()46.611.02.08.096.1122222=⨯⨯=-⎪⎪⎭⎫⎝⎛=E Z n ππα 所以n 为62 7.19(1)()()339.661501205.022=-=-χχαn()()930.331501295.0221=-=--χχαn ()()2212222211ααχσχ--≤≤-s n s n所以()()40.272.1293.33492339.66491122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n(2)()()6848.231151205.022=-=-χχαn()()5706.61151295.0221=-=--χχαn()()043.0015.002.05.61470602.06848.23141122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n (3)()()6706.321221205.022=-=-χχαn()()5913.111221295.0221=-=--χχαn ()()725.4185.24315913.112131706.36211122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n 7.20(1)15.71==∑i x n x ()4767.0112=--=∑x x n s i ()()0228.1911012025.022=-=-χχαn ()()7004.211012975.0221=-=--χχαn ()()87.0328.04767.07004.294767.00228.1991122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n(2)()()326.3253.1822.17004.29822.10228.1991122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n7.21 2)1()1(212222112-+-+-=n n s n s n s p=442.981910268.9613≈⨯+⨯ (1)21μμ-的90%置信区间为: 212122111)2()(n n s n n t x x p+-+±-α=⨯⨯±442.98729.18.971141+ =9411.78.9± (2)21μμ-的95%置信区间为: 212122111)2()(n n s n n t x x p+-+±-α=⨯⨯±442.9893.028.971141+ =13.698.9± (3)21μμ-的99%置信区间为: ⨯⨯±442.98609.828.971141+=40.1138.9± 7.22(1)2122121221)(n s n s z x x +±-α=36.096.12⨯±=176.12±(2)2)1()1(212222112-+-+-=n n s n s n s p=18209169⨯+⨯=18212122111)2()(n n s n n t x x p+-+±-α=5118.122⨯⨯±=8.932± (3)1)(1)()(222221212122122121-+-+=n n s n n s n s n s ν=17.78 2122121221)(t )(n s n s x x +±-να=6.31.22⨯±=98.32±(4)048.2)28(t 025.0=2)1()1(212222112-+-+-=n n s n s n s p=18.714 212122111)2()(n n s n n t x x p+-+±-α=20110114.71848.022+⨯⨯± =3.432±(5)1)(1)()(222221212122122121-+-+=n n s n n s n s n s ν1919.61)20201016(222++==20.05 086.2)(t =να2122121221)(t )(n s n s x x +±-να=1.61086.22+⨯±=64.332± 7.23(1)47d = 1)(2--=∑n d ds id =48332=917.6(2)n s n t d )1(d -±α=185.447± 7.24 6216.2)1(2=-n t α 11=d ,53197.6=d s d μ的置信区间为:ns n t d )1(d 2-±α=1053197.66216.211⨯±=4152.511±7.25(1)222111221)1()1()(p n p p n p p z p -+-±-α=25076.03.02506.04.0645.11.0⨯+⨯⨯±=0698.01.0± (2)222111221)1()1()(p n p p n p p z p -+-±-α=25076.03.02506.04.096.11.0⨯+⨯⨯±=0831.01.0± 7.26 241609.01=s 076457.02=s)1,1(21--n n F α=)20,20(025.0F =2.464 )20,20(975.0F =0.40576212221222122221αασσ-≤≤F s s F s s 40576.0986.9446.2986.92221≤≤σσ 611.240528.42221≤≤σσ7.27 222)1()(Ez n ππα-==2204.098.002.096.1⨯⨯=47.06 所以 n =487.282222)(E z n σα==2222012096.1⨯=138.30所以 n =139第8章 假设检验二、练习题(说明:为了便于查找书后正态分布表,本答案中,正态分布的分位点均采用了下侧分位点。
统计学原理 第七章课后习题及答案
第七章 相关和回归一、单项选择题1.相关关系中,用于判断两个变量之间相关关系类型的图形是( )。
(1)直方图 (2)散点图 (3)次数分布多边形图 (4)累计频率曲线图 2.两个相关变量呈反方向变化,则其相关系数r( )。
(1)小于0 (2)大于0 (3)等于0 (4)等于13.在正态分布条件下,以2yx S (提示:yx S 为估计标准误差)为距离作平行于回归直线的两条直线,在这两条平行直线中,包括的观察值的数目大约为全部观察值的( )。
(1)68.27% (2)90.11% (3)95.45% (4)99.73% 4.合理施肥量与农作物亩产量之间的关系是( )。
(1)函数关系 (2)单向因果关系 (3)互为因果关系 (4)严格的依存关系 5.相关关系是指变量之间( )。
(1)严格的关系 (2)不严格的关系(3)任意两个变量之间关系 (4)有内在关系的但不严格的数量依存关系 6.已知变量X 与y 之间的关系,如下图所示:其相关系数计算出来放在四个备选答案之中,它是( )。
(1)0.29 (2)-0.88 (3)1.03 (4)0.997.如果变量z 和变量Y 之间的相关系数为-1,这说明两个变量之间是( )。
(1)低度相关关系 (2)完全相关关系 (3)高度相关关系 (4)完全不相关 8.若已知2()x x -∑是2()y y -∑的2倍,()()x x y y --∑是2()y y -∑的1.2倍,则相关系数r=( )。
(1)1.2 (3)0.92 (4)0.65 9.当两个相关变量之问只有配合一条回归直线的可能,那么这两个变量之间的关系是( )。
(1)明显因果关系 (2)自身相关关系(3)完全相关关系 (4)不存在明显因果关系而存在相互联系 10.在计算相关系数之前,首先应对两个变量进行( )。
(1)定性分析 (2)定量分析 (3)回归分析 (4)因素分析 11.用来说明因变量估计值代表性高低的分析指标是( )。
《统计学》-第7章-习题答案

第七章思考与练习参考答案1 •答:函数关系是两变量之间的确定性关系,即当一个变量取一定数值时,另一个变量有确定值与之相对应;而相关关系表示的是两变量之间的一种不确定性关系,具体表示为当一个变量取一定数值时,与之相对应的另一变量的数值虽然不确定,但它仍按某种规律在定的范围内变化。
2•答:相关和回归都是研究现象及变量之间相互关系的方法。
相关分析研究变量之间相关的方向和相关的程度,但不能确定变量间相互关系的具体形式,也无法从一个变量的变化来推测另一个变量的变化情况;回归分析则可以找到研究变量之间相互关系的具体形式,并可变量之间的数量联系进行测定,确定一个回归方程,并根据这个回归方程从已知量推测未知量。
3•答:单相关系数是度量两个变量之间线性相关程度的指标,其计算公式为:总体相关系数二样本相关系数,「一】。
复相关系数是多元线性回归分析中度量因变量与其它多个自变量之间的线性相关程度的指标,它是方程的判定系数R2的正的平方根。
偏相关系数是多元线性回归分析中度量在其它变量不变的情况下两个变量之间真实相关程度的指标,它反映了在消除其他变量影响的条件下两个变量之间的线性相关程度。
4.答:回归模型假定总体上因变量Y与自变量X之间存在着近似的线性函数关系,可表示为Y^ 11X t u t,这就是总体回归函数,其中u t是随机误差项,可以反映未考虑的其他各种因素对Y的影响。
根据样本数据拟合的方程,就是样本回归函数,以一元线性回归模型的样本回归函数为例可表示为:Y?=耳+弭x t。
总体回归函数事实上是未知的,需要利用样本的信息对其进行估计,样本回归函数是对总体回归函数的近似反映。
两者的区别主要包括:第一,总体回归直线是未知的,它只有一条;而样本回归直线则是根据样本数据拟合的,每抽取一组样本,便可以拟合一条样本回归直线。
第二,总体回归函数中的-0和-1是未知的参数,表现为常数;而样本回归直线中的'?Q和?i是随机变量,其具体数值随所抽取的样本观测值不同而变动。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
=1.96 ×0.7906=1.5496 。
n
2. 某快餐店想要估计每位顾客午餐的平均花费金额,在为期
3
周的时间里选取 49 名顾客组成了一个简单随机样本。
1) 假定总体标准差为 15 元,求样本均值的抽样标准误差。
2) 在 95% 的置信水平下,求估计误差。
3) 如果样本均值为 120 元,求总体均值 μ的 95% 的置信区间 。
统计学复习笔记
第七章 参数估计
一、 思考题
1. 解释估计量和估计值
在参数估计中, 用来估计总体参数的统计量称为 估计量 。估计量也是随机变 量。如样本均值,样本比例、样本方差等。
根据一个具体的样本计算出来的估计量的数值称为 估计值 。
2. 简述评价估计量好坏的标准
( 1)无偏性:是指估计量抽样分布的期望值等于被估计的总体参数。 ( 2)有效性:是指估计量的方差尽可能小。对同一总体参数的两个无偏估 计量,有更小方差的估计量更有效。 ( 3)一致性:是指随着样本量的增大,点估计量的值越来越接近被估总体 的参数。
解:( 1)已假定总体标准差为 σ =15 元,
则样本均值的抽样标准误差为
σ 15
σx =
=
=2.1429
n 49
2 / 26
( 2)已知置信水平 1-α=95%,得 Z α/2 =1.96 ,
于是,允许误差是 E = Zα /2 σ =1.96 ×2.1429=4.2000 。 n
( 3)已知样本均值为 x =120 元,置信水平 1-α =95%,得 Zα /2 =1.96 ,
3. 怎样理解置信区间
在区间估计中,由样本统计量所构造的总体参数的估计区间称为置信区间。 置信区间的论述是由区间和置信度两部分组成。 有些新闻媒体报道一些调查结果 只给出百分比和误差 (即置信区间),并不说明置信度, 也不给出被调查的人数, 这是不负责的表现。因为降低置信度可以使置信区间变窄(显得“精确”) ,有 误导读者之嫌。 在公布调查结果时给出被调查人数是负责任的表现。 这样则可以 由此推算出置信度(由后面给出的公式) ,反之亦然。
4. 从总体中抽取一个 n =100 的简单随机样本, 得到x =81,s=12。 要求:
1) 构建 μ的 90% 的置信区间。 2) 构建 μ的 95% 的置信区间。 3) 构建 μ的 99% 的置信区间。 解:由于是正态总体,但总体标准差未知。总体均值 在 1- 置信水 平下的置信区间公式为
3 / 26
解: 已知 n =100,x =104560,σ= 85414,1- =95% , 由于是正态总体,且总体标准差已知。总体均值 在 1- 置信水
平下的置信区间为
10
x z 22 n 10150.3465610.9±6 12.956 × 85414÷√ 100
105.36 3.92
=
11001.4454,61009.±2816741.144
1) 总体服从正态分布,且已知 σ= 500 ,n = 15 ,x =8900,置信
2) 在 95% 的置信水平下,估计误差是多少?
解: 已知总体标准差σ =5,样本容量 n=4x0,为大样本,样本均值 x =25,
( 1)样本均值的抽样标准差 σx = σ = 5 =0.7906 n 40
( 2)已知置信水平 1-α=95%,得 Z α/2 =1.96 ,
σ
于是,允许误差是 E = Zα /2
2) x =119,s =23.89,n =75,置信水平为 98%
3) x =3.149,s =0.974,n =32,置信水平为 90%
解:∵
x
z 22
或x n
∴ 1) 1- =95% ,
s
z 22
( n
未知 )
其置信区间为: 25±1.96 ×3.5÷√ 60
= 25
±0.885
2 ) 1- =98% ,则 =0.02, /2=0.01, 1- /2=0.99, 查标准
4. 解释 95% 的置信区间的含义是什么
置信区间 95%仅仅描述用来构造该区间上下界的统计量 ( 是随机的 ) 覆盖总体 参数的概率。也就是说,无穷次重复抽样所得到的所有区间中有 95%(的区间) 包含参数。
不要认为由某一样本数据得到总体参数的某一个 95%置信区间,就以为该区 间以 0.95 的概率覆盖总体参数。
81± ×12÷√ 100 = 81 ±
1)1- =90%,
1.65
其置信区间为 81 ± 1.98
2)1- =95% , 其置信区间为 81 ± 2.352
3) 1- =99%,
2.58
其置信区间为 81 ± 3.096
×1.2
5. 利用下面的信息,构建总体均值的置信区间。
1) x = 25,σ= 3.5,n =60,置信水平为 95%
这时总体均值的置信区间为
σ
124.2
x Zα /2
=120± 4.2=
n
115.8
可知,如果样本均值为 120 元,总体均值 95%的置信区间为( 115.8 , 124.2 )元。
3. 从一个总体中随机抽取 n =100 的随机样本,得到 x =104560,
假定总体标准差 σ= 85414,试构建总体均值 μ的 95% 的置信区间。
5. 简述样本量与置信水平、总体方差、估计误差的关系。
1. 估计总体均值时样本量 n 为
n
( z 22 ) 22 22 E 22
其中:
E z2 n
2. 样本量 n 与置信水平 1- α、总体方差 、估计误差 E 之间的关系为
1 / 26
? 与置信水平成正比, 在其他条件不变的情况下, 置信水平越大, 所 需要的样本量越大;
正态分布表 , 可知 :
2.33
其置信区间为 : 119 ±2.33 ×23.89 ÷√ 75
= 119
±6.345
3) 1- =90%,
1.65
其置信区间为 :3.149 ±1.65 ×0.974 ÷√ 32
4 / 26
= 3.149
± 0.284
6. 利用下面的信息,构建总体均值 μ的置信区间:
? 与总体方差成正比,总体的差异越大,所要求的样本量也越大; ? 与与总体方差成正比, 样本量与估计误差的平方成反比, 即可以接
受的估计误差的平方越大,所需的样本量越小。
二、 练习题
1. 从一个标准差为 5 的总体中采用重复抽样方法抽出一个样本 量为 40 的样本,样本均值为 25。
1) 样本均值的抽样标准差 xx 等于多少?