Smartcare融合大数据平台
智能医疗大数据管理平台的设计与实现

智能医疗大数据管理平台的设计与实现随着科技的不断进步,生活中的许多方面都受到了影响,其中医疗领域也是如此。
在过去,医疗是一项比较复杂而且繁琐的行业,但是在如今,随着智能医疗大数据管理平台的不断推广和应用,医疗行业发生了翻天覆地的变化。
在本文中,我们将着重探讨智能医疗大数据管理平台的设计和实现。
一、概述智能医疗大数据管理平台是一种用于管理医疗数据的平台,利用大数据分析技术将医疗数据进行整合,提供快速、准确和高效的服务。
它为医生、患者和医院提供了一种透明的模式,让他们能够更好地了解和管理医疗数据。
二、架构设计智能医疗大数据管理平台的架构设计非常重要,它直接决定了平台的功能和性能。
一个好的架构设计应该具有以下特征:1、可扩展性平台需要能够随着业务发展而快速扩展,同时能够保持高效率。
2、高可用性平台是用于处理医疗数据的,所以需要保证平台的高可用性,同时能够对数据进行及时的备份和恢复。
3、安全性医疗数据对于患者来说是非常敏感的,平台应该能够保护患者的隐私,并防止数据泄露。
4、易于维护平台应该具有良好的代码结构和文档,使得开发人员能够快速定位问题、修复,降低维护的难度。
三、主要功能智能医疗大数据管理平台主要提供以下功能:1、医疗数据采集平台可以从多个输入源收集医疗数据,包括病人住院记录、手术、检查结果、药品使用记录和其他相关信息。
2、数据整合和分析平台通过大数据技术将医疗数据进行整合,生成相关的报告、图表和指标,帮助医生和患者更加了解自己的身体状况,正确的制定治疗计划。
3、数据可视化平台通过数据可视化技术将数据呈现为图表和报表,使医生和患者能够更加方便、直观的了解数据。
4、远程医疗平台可以通过网络提供远程医疗服务,在需要时让医生和患者远程交流,提高医疗服务的效率。
5、疾病预测平台基于机器学习技术,对患者的医疗数据进行预处理和分析,给出未来可能发生疾病的预测,从而帮助医生和患者更好地预防疾病。
四、关键技术智能医疗大数据管理平台要实现以上功能,需要采用一些关键技术:1、大数据分析技术对于海量的医疗数据,需要采用分布式计算技术来加快数据分析和报表生成的速度,从而实现近实时的服务。
临床观察下的Smartcare智能化脱机安全性探讨

临床观察下的Smartcare智能化脱机安全性探讨我想明确一下什么是Smartcare智能化脱机系统。
它是一种基于云计算和大数据分析技术的医疗设备管理系统,可以帮助医院实现对设备的远程监控和管理,提高设备的使用效率和安全性。
具体来说,它可以实时收集和分析设备的运行数据,预测设备可能出现的问题,并在设备出现故障时及时发出警报,以便医护人员及时采取措施,确保患者的安全。
在我们的临床观察中,我们选取了100名使用了Smartcare智能化脱机系统的患者,并对他们的治疗过程进行了详细的记录和分析。
结果显示,使用Smartcare智能化脱机系统不仅可以提高设备的使用效率,减少设备的停机时间,更重要的是,它可以大大提高患者的安全性。
以一位患有心脏病的患者为例,他在接受心脏手术过程中,使用了我们的智能化脱机系统。
系统实时监控了他的心脏设备的运行状态,并及时预测了他可能会出现的心律失常问题。
在出现问题前,系统就发出了警报,医护人员及时采取了措施,避免了可能出现的严重后果。
然而,尽管Smartcare智能化脱机系统在提高患者安全性方面有着显著的优势,但也存在着一些潜在的风险。
例如,由于系统依赖于网络和大数据分析技术,因此可能会受到网络攻击和数据泄露的风险。
系统的准确性和可靠性也可能会受到数据质量和算法的影响。
为了解决这些问题,我们采取了一系列的措施。
我们加强了系统的网络安全防护,确保了系统的安全稳定运行。
我们优化了系统的算法,提高了系统的准确性和可靠性。
我们对医护人员进行了系统的培训,提高了他们对系统的理解和使用能力。
总的来说,通过对Smartcare智能化脱机系统的临床观察,我们认为它是一种具有巨大潜力的医疗技术。
它可以提高患者的安全性,提高设备的使用效率,但它也面临着一些挑战。
我们需要不断改进和完善这项技术,以确保它能够发挥出最大的作用。
重点和难点解析在上述文档中,我提到了Smartcare智能化脱机系统在提高患者安全性方面的优势,以及我们为解决可能出现的风险所采取的措施。
医疗行业大数据健康管理平台搭建方案

医疗行业大数据健康管理平台搭建方案第一章:项目概述 (2)1.1 项目背景 (2)1.2 项目目标 (3)1.3 项目范围 (3)第二章:需求分析 (3)2.1 用户需求分析 (3)2.2 功能需求分析 (4)2.3 技术需求分析 (5)第三章:平台架构设计 (5)3.1 系统架构设计 (5)3.1.1 整体架构 (5)3.1.2 技术架构 (6)3.2 数据库设计 (6)3.2.1 表结构设计 (6)3.2.2 索引设计 (6)3.2.3 数据安全策略 (7)3.3 网络架构设计 (7)3.3.1 网络拓扑结构 (7)3.3.2 网络安全策略 (7)3.3.3 数据传输协议 (7)第四章:数据采集与处理 (7)4.1 数据采集方式 (7)4.1.1 物联网设备采集 (8)4.1.2 电子病历系统采集 (8)4.1.3 医疗机构数据交换 (8)4.1.4 用户主动输入 (8)4.2 数据处理流程 (8)4.2.1 数据接收 (8)4.2.2 数据预处理 (8)4.2.3 数据存储 (8)4.2.4 数据分析 (8)4.2.5 数据应用 (8)4.3 数据清洗与整合 (8)4.3.1 数据清洗 (9)4.3.2 数据整合 (9)第五章:数据存储与管理 (9)5.1 数据存储方案 (9)5.2 数据安全管理 (9)5.3 数据备份与恢复 (10)第六章:数据分析与挖掘 (10)6.1 数据分析方法 (10)6.2 数据挖掘算法 (11)6.3 数据可视化展示 (11)第七章:健康管理服务 (11)7.1 健康评估与监测 (12)7.1.1 健康评估 (12)7.1.2 健康监测 (12)7.2 健康干预与指导 (12)7.2.1 健康干预 (12)7.2.2 健康指导 (12)7.3 健康教育与宣传 (13)7.3.1 健康教育 (13)7.3.2 健康宣传 (13)第八章:平台开发与实施 (13)8.1 技术选型与开发 (13)8.1.1 技术选型 (13)8.1.2 开发流程 (14)8.2 系统测试与优化 (14)8.2.1 测试策略 (14)8.2.2 优化策略 (14)8.3 项目实施与管理 (14)8.3.1 项目计划 (14)8.3.2 风险管理 (15)第九章:安全保障与合规 (15)9.1 数据安全策略 (15)9.2 信息安全法规 (16)9.3 用户隐私保护 (16)第十章:项目评估与展望 (16)10.1 项目评估指标 (16)10.2 项目效益分析 (17)10.3 未来发展展望 (17)第一章:项目概述1.1 项目背景科技的发展和医疗行业的数字化转型,大数据技术在健康管理领域中的应用日益广泛。
智慧医院智慧医疗大数据一体化管理平台解决方案

数据清洗
对原始数据进行清洗和整 合,去除重复和无效数据 。
数据整合
将多源数据进行整合,形 成统一的数据格式和标准 。
数据处理流程
数据分析
采用统计学方法和数据挖掘技术对数据 进行深入分析,发现数据的潜在规律和
价值。
数据应用
提供各类数据应用,包括临床决策支 持、患者管理、科研分析等。
通过智慧医疗大数据一体化管 理平台,医院可以快速、准确 地处理大量的医疗数据,从而 提高医疗服务的质量和效率。
精准的决策支持
平台利用先进的数据分析和机器学 习技术,为医院管理层提供准确、 及时的数据支持,帮助他们做出更 明智的决策。
提升患者满意度
通过优化患者就诊流程,降低患者 等待时间,提高医疗服务透明度, 从而提升患者满意度。
当前医疗行业存在信息孤岛、 资源分散、数据冗余等问题, 限制了医疗服务的提升和优化 。
大数据技术的出现为解决这些 问题提供了新的思路和方法。
平台建设目标
实现医疗数据一体化
通过建设智慧医疗大数据平台,整合医院各科室的数据,打破信 息孤岛,实现数据一体化管理。
提高医疗服务质量
通过对海量医疗数据的分析挖掘,为医生提供更加精准的诊断和治 疗方案,提高医疗服务质量。
提升医院管理效率
通过数据分析和智能化应用,提高医院各项工作的协同效率,优化 资源配置,降低运营成本。
平台应用场景
临床决策支持
科研数据分析
利用大数据分析技术,为医生提供实时、 精准的病人数据分析报告,辅助医生进行 诊断和治疗方案制定。
精细化运营管理
通过对海量医疗数据的挖掘和分析,为科 研人员提供研究方向、实验设计等方面的 支持。
青年融合大数据平台理后台操作手册

爱+平台管理后台操作手册目录1.进入应用.................................................................................................错误!未定义书签。
2.主要功能概述.........................................................................................错误!未定义书签。
2.1登录..............................................................................................错误!未定义书签。
2.2首页..............................................................................................错误!未定义书签。
2.3基础管理......................................................................................错误!未定义书签。
3爱+婚恋...........................................................................................错误!未定义书签。
1.进入应用通过以下链接进入爱+平台管理后台:2.主要功能概述2.1登录登录方式:输入用户名、密码即可进行登录1)点击管理员激活进行管理员激活输入手机号码后点击获取验证码即可在手机上收到验证码,验证通过后点击激活按钮完成激活流程。
2)点击忘记密码进行重新设置密码输入手机号后点击获取验证码后输入新密码再点击确定即可完成修改密码。
金融保险行业大数据整体解决方案智慧保险大数据平台建设方案

金融保险行业大数据整体解决方案智慧保险大数据平台建设方案标题:金融保险行业大数据整体解决方案——智慧保险大数据平台建设方案随着科技的快速发展,大数据已经成为我们时代的重要组成部分,对各行各业产生了深远的影响。
特别是在金融保险行业,大数据的运用已经成为创新和竞争优势的关键。
本文将提出一种金融保险行业的大数据整体解决方案,即智慧保险大数据平台建设方案。
一、理解大数据在保险行业的应用大数据在保险行业的应用无所不在,从风险评估、产品设计、营销策略到理赔处理等各个环节。
通过大数据,保险公司可以更准确地评估风险,了解客户需求,提供个性化产品,精准营销,以及快速、准确地处理理赔。
二、智慧保险大数据平台建设方案1、数据采集与存储:首先,平台需要从各种来源(包括内部系统、外部公共数据源、社交媒体等)采集和存储海量的数据。
这包括结构化数据(如交易历史)和非结构化数据(如文本、图像等)。
2、数据清洗与整合:由于数据来源广泛,数据质量参差不齐,因此需要进行数据清洗,消除噪音和错误。
同时,将不同来源的数据整合到一个统一的数据仓库中,以便后续的分析和处理。
3、数据挖掘与分析:利用机器学习、数据挖掘等技术,对数据进行深入分析。
这包括分类、聚类、关联规则挖掘等,以发现隐藏在数据中的模式和价值。
4、风险评估与决策支持:通过分析客户的历史行为、信用记录、职业等信息,进行风险评估,为个性化保险产品设计和风险控制提供决策支持。
5、个性化推荐与服务:基于客户的个人信息和行为,进行个性化推荐,提供定制化的保险产品和服务。
这可以提高客户满意度,同时降低客户流失率。
6、智能理赔处理:通过自动化和智能化的理赔流程,可以快速、准确地处理理赔申请,提高客户体验,同时降低运营成本。
7、持续优化与迭代:最后,平台应能够收集和分析用户反馈,持续优化和迭代,以适应不断变化的市场需求和业务环境。
三、技术架构智慧保险大数据平台的技术架构应包含以下几个部分:1、数据源:包括内部系统、外部数据源、互联网数据等。
大数据健康云SaaS平台商业计划书

健康云SaaS平台-系统架构
健康云SaaS平台-应用场景
• 如居民与社区医院签署了家庭医生服务,社区的全科医生(健康管理师)作为家庭医生,为居民提 供如下服务: ✓ 免费的基础服务 ✓ 合理收费的增值服务 ✓ 针对高端用户的定制服务(VIP服务)
• 对于老人或慢性病患者,需配置一些医疗监测设备医疗监测设备(医疗传感器),这些医疗监测设 备包括可穿戴医疗设备、家用医疗设备,通过这些设备,实现对用户的基本体征参数的监测,如心 跳、血压、心电等;根据需要也可以配备基于物联网的监控设备、安全设备等,与智慧家居、智慧 小区结合。
• 通信方式包括: ✓ 公共通信:利用移动网络传输,设备需要插SIM卡; ✓ 蓝牙:通过蓝牙—手机APP传输; ✓ USB:通过USB—PC—INTERNET传输; ✓ WIFI:通过WIFI—家庭智能网关—INTERNET传输
健康云SaaS平台-产业链定位
健康云SaaS平台-SaaS架构
• 云健康平台以SaaS模式提供服务以及整体解决方案,不直接提供软、硬件产品 。即面向客户提供 的租赁服务,客户(如社区医院)按需购买;平台统一部署在数据中心的服务器上,客户通过互联 网(包括移动互联网)方式获取服务。这样,客户就不需要花费大量投资用于硬件、软件、人员培 训,业务部署的时间大大缩减,降低客户使用门槛。
智慧医疗大数据综合服务解决方案

智慧医疗大数据综合服务解决方案随着科技和医疗行业的不断发展,智慧医疗大数据的应用越来越广泛。
而为了更好地利用这些数据,提供综合服务解决方案是至关重要的。
本文将介绍智慧医疗大数据综合服务解决方案的概念、优势和主要组成部分。
一、概述智慧医疗大数据综合服务解决方案是一种基于人工智能和大数据技术的应用系统,旨在为医疗机构、医生和患者提供全方位的数据支持和服务。
通过收集、整合和分析医疗相关的大数据,综合服务解决方案可以提供个性化的医疗信息、辅助决策和预测疾病风险,从而实现医疗资源的优化和医患关系的改善。
二、优势智慧医疗大数据综合服务解决方案具有以下优势:1. 数据整合和分析能力:通过综合不同来源的医疗数据,并利用人工智能技术进行分析,可以为决策者提供全面的医疗信息和指导意见。
2. 个性化服务:综合服务解决方案可以根据患者的个人状况和需求,提供定制化的医疗服务,使患者获得更好的治疗效果和体验。
3. 疾病预测和风险评估:通过对大数据的分析,综合服务解决方案可以预测和评估患者未来的疾病风险,从而采取相应的预防和干预措施。
4. 医患交流加强:通过综合服务解决方案,患者和医生可以更加方便地进行交流和沟通,减少信息不对称和误解,提高医疗效率和满意度。
三、主要组成部分智慧医疗大数据综合服务解决方案由以下几个主要组成部分组成:1. 数据采集与存储:通过医疗设备、电子病历等手段,收集和存储医疗相关的大数据,包括患者信息、疾病诊断、治疗方案等。
2. 数据整合与清洗:对采集到的数据进行整合和清洗,消除数据中的噪音和错误,保证数据的准确性和完整性。
3. 数据分析与挖掘:利用数据挖掘和机器学习算法,对整合后的数据进行分析,发现潜在的规律和模式,并提供相应的决策支持。
4. 服务平台与应用:将数据分析的结果和预测的模型应用到服务平台上,为医生和患者提供相应的个性化服务和决策支持。
5. 安全与隐私保护:针对医疗数据的敏感性,综合服务解决方案需要具备强大的安全和隐私保护能力,确保数据的保密性和完整性。
智慧医疗大数据平台及专病数据库系统

智慧医疗大数据平台及专病数据库系统1.1系统概述系统采用了基于大数据和机器研究的相关技术,对医院多源异构数据进行清洗和整合,形成了标准化大数据平台,并基于大数据平台建设专病数据中心,实现了专病库管理、数据质控、数据导出、统计分析等功能,解决了科研人员在专病库建立及统计建模等方面的难题。
近年来,大数据、人工智能等计算机技术的迅猛发展,对临床科研模式的巨大影响正日益受到各界关注。
国家先后出台了《国务院办公厅关于印发深化医药卫生体制改革2016年重点工作任务的通知》《国务院办公厅关于促进和规范健康医疗大数据应用发展的指导意见》等政策文件,鼓励推进科研大数据应用,提升医学科研及应用效能,进而推动智慧医疗的发展。
与此同时,传统科研模式中存在的“科研构思难、数据获取难、想法验证难、数据处理难”等弊端,已严重阻碍临床研究水平的进一步发展,亟待利用新的技术手段予以解决。
因此,基于大数据及人工智能技术进行临床研究的新模式应运而生。
新技术和新思路的引入,将帮助医生从数据中发现问题,实时进行数据质控,并行验证研究问题,从而实现数据驱动的一体化科研工作模式。
本系统采用了基于大数据和机器研究的相关技术,对病院多源异构数据进行清洗和整合,形成了标准化大数据平台,并基于大数据平台建设专病数据中心,实现了专病库管理、数据质控、数据导出、统计分析等功能,解决了科研人员在专病库建立及统计建模等方面的难题。
通过建设一体化科研大数据平台和专病数据库,系统可以大幅提升医疗科研的效力,使得医生和科研人员能够高效、高质地完成科研工作。
系统的建设可以大幅提升医疗科研的质量及效力,加快科研成果转化,从而间接促进医疗质量的提高。
1.2系统具备如下特性:1)基于双模式的数据集成2)十亿级记录的亚秒级搜索相应3)统一的临床科研专病平台4)科研病例资料收集的自动化和智能化5)统一并规范化专病科研数据集6)规范化科研病例报告CRF表单界说。
智能医疗大数据分析平台的设计与实现

智能医疗大数据分析平台的设计与实现随着智能医疗的广泛应用,医疗大数据分析平台的设计与实现已经成为医疗科技领域的一大热点。
本文将从平台的需求分析入手,探讨如何构建一套完整的智能医疗大数据分析平台。
一、需求分析智能医疗大数据分析平台,顾名思义,就是利用人工智能技术对医疗数据进行分析的平台。
在构建这样一个平台之前,首先需要做好需求分析工作。
1. 数据来源智能医疗大数据分析平台需要汇集来自多个来源的医疗数据,包括病人的就诊记录、医生的诊断意见、医学文献数据等。
这些数据涉及的范围非常广泛,需要有一个统一的数据标准和处理方式。
2. 数据存储数据存储是智能医疗大数据分析平台的重要组成部分。
数据存储需要具备以下特点:(1)可靠性高:医疗数据极其重要,需要有一个高可靠性的数据存储系统,确保数据不会因为系统崩溃或其他原因丢失。
(2)安全性好:为了保护患者隐私,存储系统需要有较高的安全性,只有授权人员才能对数据进行访问。
(3)扩展性强:医疗数据增长非常快,存储系统需要具备较强的扩展性,以应对不断增长的数据量。
3. 数据分析数据分析是智能医疗大数据分析平台的核心功能,需要利用人工智能技术对医疗数据进行处理和分析。
具体可以包括以下方面:(1)自然语言处理:将诊断报告等文本数据进行分析和处理,提取出其中的关键信息。
(2)图像处理:对影像学图像进行分析,提取特征信息,辅助医生诊断。
(3)机器学习:通过机器学习技术,对医疗数据进行分类和预测,辅助医生进行诊断和治疗决策。
二、平台设计在需求分析的基础上,可以开始进行平台设计。
平台设计需要考虑以下几个方面:1. 数据架构设计数据架构设计决定了数据在平台中的存储方式和处理方式。
为了保证数据的可靠性和安全性,可以考虑采用分布式存储系统和加密存储技术。
同时,为了提高数据的处理效率,可以采用数据预处理技术,提前对数据进行处理和清洗,以减少后续的计算负担。
2. 系统架构设计系统架构设计决定了平台的组成和交互方式。
创新创业计划书十大痛点

创新创业计划书十大痛点一、创业项目名称:SmartCare智能养老二、创业项目的背景:随着我国人口老龄化加速,养老领域面临着巨大的挑战。
传统的家庭养老模式已经无法满足老年人对安全、健康、便利的需求。
而且,随着互联网、大数据、人工智能等技术的发展和应用,智慧养老正成为未来的发展趋势。
在这样的背景下,我们创立了SmartCare智能养老项目,致力于打造智慧、人性化、全方位的养老服务平台,为老年人提供更好的生活质量。
三、创业项目的市场需求:1.高龄化社会必将带来养老服务需求的急剧增长。
据统计,我国60岁及以上的老年人口已达到2.5亿,占总人口的18%,预计到2050年将达到40%。
而且,随着“一带一路”和城市化进程的推进,老年人口将会越来越多地集中在城市。
这意味着,城市养老服务市场将迎来巨大的机遇。
2.老年人对于养老服务的需求呈多样化趋势,不仅要求养老机构提供基本的生活照料,还需要关注心理健康、社交活动、文化娱乐、医疗护理等方面的服务。
而且,由于高龄群体中老年人的教育水平和经济实力普遍较高,他们对于服务的品质和体验也有更高的要求。
3.智能科技的发展为养老服务提供了新的可能性。
智能化、信息化、数据化等技术已经在智慧养老领域得到了广泛的应用,但目前市场上尚未出现一款满足老年人全方位需求的智能养老服务平台。
因此,我们认为,开发一款智能、人性化、全方位的养老服务平台将大有可为。
四、创业项目的创新点和优势:1. 全方位服务:SmartCare智能养老平台不仅提供基本的生活照料,还将为老年人提供心理健康、社交活动、文化娱乐、医疗护理等方面的服务。
我们将建立一个包括家庭养老、社区养老、机构养老等在内的全方位的养老服务网络,为老年人提供个性化、定制化的服务。
2. 智能化管理:通过互联网、传感器、大数据等技术,我们将实现老年人的健康监测、生活照料、社交活动等方面的信息化管理。
同时,我们将提供智能助手、健康咨询、健康教育等智能化服务,帮助老年人更好地管理自己的生活。
智能医疗健康管理平台和智慧医院系统

智能医疗健康管理平台和智慧医院系统随着科技的不断进步和人们健康意识的逐步提高,智能医疗健康管理平台和智慧医院系统逐渐成为医疗领域的热门话题。
智能医疗健康管理平台是一种基于互联网技术和大数据分析的检测、预防、治疗和康复管理平台。
智慧医院系统则是将信息技术、工业控制技术等运用于医院管理和医疗服务中,以提升效率和质量。
智能医疗健康管理平台的出现为医疗健康管理带来了极大的便利和帮助。
通过与各种传感器和设备的联动,智能医疗健康管理平台可以自动化地读取和分析用户的健康数据,并对用户的身体状况和病情进行预测和跟踪。
例如,通过智能穿戴设备采集用户的健康数据和生理数据,医疗机构可以生成个性化的健康档案,并对疾病的预防和治疗提供更加精准的服务。
同时,智能医疗健康管理平台还可以为医疗机构提供数字化医疗解决方案,为医疗机构实现全面数字化管理提供支持。
通过智能化的ER、ICU管理系统、电子病历、预约挂号、社交化医疗和家庭医疗等服务,医疗机构可以更加高效地管理医疗资源和服务,提高服务质量和医疗效率,进而提升医患关系和医院的口碑。
当然,智能医疗健康管理平台也面临着一些挑战,如数据隐私安全、数据互通等问题,需要政府和行业主管部门的积极监管和引导。
智慧医院系统同样是一个创新性的解决方案。
它把新兴的技术应用于医疗服务,可以实现信息化、网络化、数字化和智能化的医院管理和医疗服务,大大提高了医院服务的效率、质量和安全。
例如,智慧医院系统的数字化医疗记录功能可以提高病人就诊的流畅度、减少病人排队的时间和医生任务的重复性工作,有效提高了医疗服务的效率。
此外,智慧医院系统还能进一步优化医疗服务,如通过医疗服务咨询和预约,提高病人就医的难度,减少了就医过程的焦虑和疑虑;通过智能化的派单系统、超时提醒、医生排班、医疗设备和药品库房管理系统等,实现了全方位的医院管理。
这种智慧医院系统不仅可以提升医生的工作效率和工作质量,提高医院的服务质量和口碑,还可以为病人提供更加全面、优质和高效的医疗服务。
Smartcare—用户体验为王

由通信行业的精英人才傅晓先生规划和 参与 设 计 的 Smartcare解 决 方 案 一 经 推 出就 获 得 了极 高的关注 。该方案突破了传统思维的限制 ,以更 加 科 学 的 理 念 和 更 加 先 进 的 技 术 帮 助运 营商 建 设 面 向用 户 感 知 的 运 维 评 价 体 系 及 监 测平 台 。
通信 行业将 走 向体 验 为王 的新时 代
傅 晓 先 生 规 划 并 参 与设 计 了Smartcare解 决 方案 的设计工作 ,在他看来 ,优良的用户体验是 Smartcare解决方案的绝对优势 。推出这样具有 现实意 义的解 决方案 ,就是为 了成就 客户 ,助 力运营商走上现代 化发展之路 。以Smartcare解 决 方 案 为 先 驱 ,通 信 行 业 将 走 向体 验 为 王 的 新 时 代 。
Smartcare解 决 方 案 具 有 以 下 几 个特 色 : 首 先 是可 评 。众 所周 知 ,KPI指标 是 运营 商 在 开 展 管 理 工 作 时 所 参 考 的 重 要 标 准 。 在 移 动 网络 普及之初 ,KPI指标确实起 到了非常关键 的 作 用 。 但 是 随 着 用 户 要 求 的 提 升 ,这 种 传 统 管 理 模 式 的 弊 端 开 始 显 现 出 来 ,例 如 ,运 营 商 根 据 KPI指 标 判 断 出 网 络 质 量 良好 ,一 切 正 常 , 但 是 用 户 所 反 馈 出 来 的 却 大 不 相 同 , 频 繁 的 投 诉 ,对 网 络 质 量 的 抱 怨 ,极大 地 影 响 了运 营 商 的 信 誉 。实 际 上 ,KPI指 标 显 示 的 是 网络 整 体 统 计 值 ,它 无 法 将 每 一 位 用 户 的 真 实 体 验 都 反 应 出 来 。SmartCare解 决 方 案 就 有 针 对 }生地 解 决 了 这 一 问 题 。 该 体 系 建 立 了 一 套 完 善 的 业 务 指 标 衡 量 体 系 , 将 终 端 侧 和 网 络 侧 作 为 基 础 , 引 入 了 KQI——关 键质量指 标 ,这个指标 能够表征客观 业务质量。这种多维度 的衡量方式 ,弥补了传统 KPI指 标 的 不 完 整 性 ,使 运 营 商 能 够 更 加 客 观地 评价客户 的感知和 体验 ,实现 了传统 KPI} ̄标向 QoE衡 量 体 系 的 演 变 。 其 次 是 可视 。准 确 对 问题 进 行 定 位 ,才 能及 肘解决 问题 ,提高客户的满意度 ,此时监控 体系 的建立就显得至关重要 。SmartCare解决方案就 能 够 完 成 对 数 据 源 的 统 一 检 测 、分 析 ,获 取 用 户 的感知 ,发现业务质量问题。整个 监测分析过程 采用端到端的业务质量监测平台和 方法 ,不仅能 够集成现有的监测工具 ,实现 资源 的高效利用 , 同时还能保护投资 。在这种模式 的支持下 .运营
健康医疗大数据分析与服务平台搭建方案

健康医疗大数据分析与服务平台搭建方案第一章引言 (2)1.1 背景介绍 (2)1.2 目的和意义 (2)第二章健康医疗大数据概述 (3)2.1 健康医疗大数据定义 (3)2.2 健康医疗大数据类型 (3)2.3 健康医疗大数据应用领域 (4)第三章数据采集与整合 (4)3.1 数据来源与采集方法 (4)3.1.1 数据来源 (4)3.1.2 数据采集方法 (5)3.2 数据清洗与预处理 (5)3.2.1 数据清洗 (5)3.2.2 数据预处理 (5)3.3 数据整合与标准化 (5)3.3.1 数据整合 (5)3.3.2 数据标准化 (6)第四章数据存储与管理 (6)4.1 数据存储技术选择 (6)4.2 数据库设计与优化 (6)4.3 数据安全与隐私保护 (7)第五章数据分析与挖掘 (7)5.1 数据分析方法选择 (7)5.2 数据挖掘算法应用 (8)5.3 结果可视化与解释 (8)第六章平台架构设计与实现 (9)6.1 系统架构设计 (9)6.1.1 整体架构 (9)6.1.2 技术架构 (9)6.2 关键技术与组件 (9)6.2.1 数据清洗与转换 (9)6.2.2 分布式存储 (10)6.2.3 数据分析与挖掘 (10)6.3 平台开发与部署 (10)6.3.1 开发环境 (10)6.3.2 部署过程 (10)第七章应用场景与案例分析 (11)7.1 医疗健康管理与决策支持 (11)7.1.1 应用场景概述 (11)7.1.2 案例分析 (11)7.2 疾病预测与诊断 (11)7.2.1 应用场景概述 (11)7.2.2 案例分析 (11)7.3 个性化医疗与精准治疗 (12)7.3.1 应用场景概述 (12)7.3.2 案例分析 (12)第八章数据质量控制与评估 (12)8.1 数据质量评估指标 (12)8.2 数据质量控制方法 (13)8.3 数据质量改进策略 (13)第九章法律法规与伦理规范 (13)9.1 相关法律法规概述 (13)9.2 数据安全与隐私保护法规 (14)9.3 伦理规范与道德责任 (14)第十章项目管理与推进策略 (15)10.1 项目组织与管理 (15)10.2 风险评估与管理 (15)10.3 项目推进与可持续发展 (16)第一章引言1.1 背景介绍信息技术的飞速发展,大数据技术在各个行业中的应用日益广泛。
HUAWEI SmartCare介绍
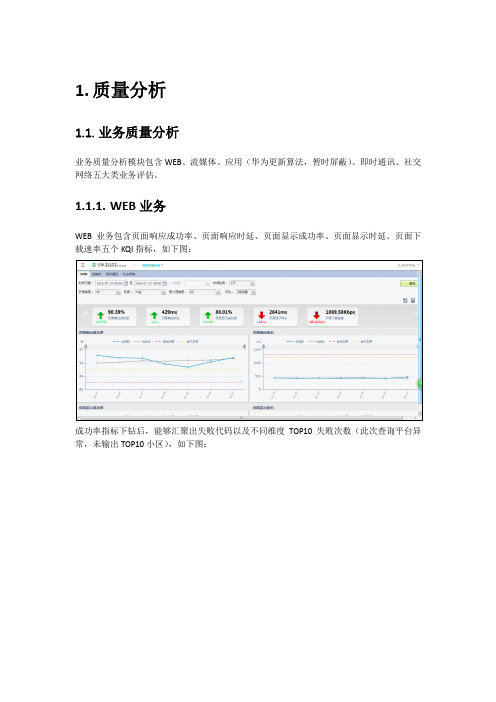
1.质量分析1.1.业务质量分析业务质量分析模块包含WEB、流媒体、应用(华为更新算法,暂时屏蔽)、即时通讯、社交网络五大类业务评估。
1.1.1.WEB业务WEB业务包含页面响应成功率、页面响应时延、页面显示成功率、页面显示时延、页面下载速率五个KQI指标,如下图:成功率指标下钻后,能够汇聚出失败代码以及不同维度TOP10失败次数(此次查询平台异常,未输出TOP10小区),如下图:时延类指标输出为时延区间的业务次数汇聚,如下图(此次查询平台异常,未正常输出指标):速率类指标输出与时延类似,同样为区间汇聚,如下图:1.1.2.流媒体流媒体业务包含视频流媒体播放成功率、视频流媒体初始缓存时延、视频流媒体停顿频次、视频流媒体停顿占比、视频流媒体下载速率五个KQI(流媒体指标下钻后的呈现,与WEB 指标下钻界面呈现一样),如下图:1.1.3.即时通讯即时通讯的指标包含流量、信令次数、服务器侧RTT、终端侧RTT(即时通讯类指标无法下钻),如下图:1.1.4.社交网络社交网络的指标包含流量、信令次数、上行速率、下行速率、服务器侧RTT、终端侧RTT(社交网络类指标无法下钻),如下图:1.2.网络性能分析网络性能分析模块是呈现各接口的信令面消息,具体接口见下图:以S1-MME为例,呈现的为S1-MME接口的各类信令面指标,并针对部分成功率指标进行下钻,汇聚失败代码,如下图:S1-MME接口附着失败代码:1.3.业务流量分析业务流量分析模块是汇聚不同维度的流量情况,分为用户、区域、业务、总体、接入网、APN、网站7个维度进行分析,其中用户与网站维度仅能查询TOP流量。
以业务流量分析为例,输出结果为不同业务类型的流量情况,如下图:1.4.问题定界问题定界模块与网络性能模块功能一致,差距在于问题定界模块中的接口更多,具体接口见下图:以S1-MME接口为例,输出结果与网络性能一致,如下图:1.5.网站KQI分析网站KQI分析模块输出的KQI为WEB业务5大指标(见1.1.1)、TCP时延与流量。
智慧医养结合健康管理服务平台系统解决方案

智慧医养结合健康管理服务平台系统解决方案概述智慧医养结合健康管理服务平台系统是一个为医疗和养老机构提供综合管理和健康监护的解决方案。
该系统通过整合医疗和养老资源,提供智能化的健康管理服务,以提升老年人的生活质量和医疗护理水平。
功能特点1. 健康档案管理:系统实现了老年人的健康档案电子化管理,可以存储和共享患者的个人信息、病历记录、医学影像等数据,方便医护人员快速查阅和分析。
2. 健康监测和警报:通过智能设备和传感器,系统可以监测老年人的健康指标,如心率、血压、体温等,及时发出警报,提醒医护人员关注高风险患者。
3. 远程医疗服务:系统支持远程医疗功能,老年人可以通过平台与医生进行线上咨询、诊断和处方,在减少出行和等待时间的同时,获得及时的医疗服务。
4. 健康管理方案:系统根据老年人的健康状况和特点,提供个性化的健康管理方案,包括饮食、运动、用药等方面的建议和跟踪。
5. 社交和娱乐功能:系统提供多种社交和娱乐功能,如社区讨论、在线活动、健康教育内容等,促进老年人之间的交流和心理健康。
技术架构该平台系统基于云计算和大数据技术,以及人工智能和物联网技术为支撑,实现以下核心功能:- 前端开发:采用现代化的前端开发框架,如Vue.js或React.js,提供直观和友好的用户界面。
- 后端开发:使用Java或Python等主流编程语言,结合Spring Boot或Django等框架来构建后台服务。
- 数据存储:利用云数据库服务,如AWS RDS或阿里云RDS,实现高可用和安全的数据存储。
- 数据分析:通过应用商店的分析工具,如Google Analytics或百度统计,分析用户行为和平台数据,为用户提供更好的服务。
- 安全性和隐私保护:采用加密技术和权限管理机制,保证用户数据的安全和隐私。
优势和价值通过智慧医养结合健康管理服务平台系统,医疗和养老机构可以获得以下优势和价值:1. 提高医疗质量和效率:系统的健康监测和远程医疗功能可以及时发现和诊断疾病,提高医疗水平,并减少不必要的门诊和住院。
健康医疗大数据管理与应用平台建设方案

健康医疗大数据管理与应用平台建设方案第1章引言 (2)1.1 项目背景 (2)1.2 项目目标 (2)1.3 项目意义 (3)第2章健康医疗大数据概述 (3)2.1 健康医疗大数据定义 (3)2.2 健康医疗大数据类型 (3)2.3 健康医疗大数据应用领域 (4)第3章平台架构设计 (4)3.1 技术架构 (4)3.1.1 架构概述 (4)3.1.2 基础设施层 (4)3.1.3 数据存储层 (5)3.1.4 数据处理层 (5)3.1.5 服务接口层 (5)3.1.6 应用展现层 (5)3.2 数据架构 (5)3.2.1 数据来源 (5)3.2.2 数据分类 (5)3.2.3 数据存储与管理 (6)3.3 应用架构 (6)3.3.1 应用模块划分 (6)3.3.2 应用流程 (6)3.3.3 技术选型 (6)第四章数据采集与存储 (7)4.1 数据采集方式 (7)4.2 数据存储策略 (7)4.3 数据安全与隐私保护 (7)第五章数据处理与分析 (8)5.1 数据清洗与预处理 (8)5.1.1 数据清洗 (8)5.1.2 数据预处理 (8)5.2 数据挖掘与分析 (9)5.2.1 数据挖掘方法 (9)5.2.2 数据分析方法 (9)5.3 数据可视化与展示 (9)5.3.1 数据可视化方法 (9)5.3.2 数据展示方式 (9)第6章平台功能模块设计 (10)6.1 数据管理模块 (10)6.1.1 数据采集与清洗 (10)6.1.2 数据存储与备份 (10)6.1.3 数据权限管理 (10)6.1.4 数据维护与更新 (10)6.2 数据分析模块 (10)6.2.1 数据预处理 (10)6.2.2 数据挖掘 (10)6.2.3 数据可视化 (11)6.2.4 模型评估与优化 (11)6.3 应用服务模块 (11)6.3.1 数据查询与检索 (11)6.3.2 数据分析与报告 (11)6.3.3 应用集成与拓展 (11)6.3.4 用户管理与反馈 (11)第7章平台关键技术 (11)7.1 云计算技术 (11)7.2 分布式存储技术 (12)7.3 机器学习与深度学习技术 (12)第8章平台建设与实施 (13)8.1 项目实施计划 (13)8.2 项目组织与管理 (13)8.3 项目风险与应对措施 (14)第9章应用案例分析 (14)9.1 案例一:疾病预测与防控 (14)9.2 案例二:医疗资源优化配置 (14)9.3 案例三:个性化医疗与健康服务 (15)第十章总结与展望 (15)10.1 项目总结 (15)10.2 未来发展趋势与展望 (16)第1章引言1.1 项目背景信息技术的飞速发展,大数据技术在各个领域的应用日益广泛。
智慧医疗中的智能随访系统

智慧医疗中的智能随访系统智慧医疗(Smart Healthcare)是指运用先进信息技术、人工智能等手段来改善医疗服务与管理的新型医疗模式。
在智慧医疗中,智能随访系统(Intelligent Follow-up System)扮演着重要的角色。
智能随访系统利用大数据、云计算、物联网等技术,对患者进行个性化、远程化的随访,提供精准、高效的医疗服务和管理。
一、智能随访系统的概述智能随访系统是基于互联网和人工智能技术开发的一种医疗健康管理系统。
它通过搜集、分析患者的病历、生理指标、生活习惯等数据信息,结合医学知识和规则,为医生提供针对性的医疗方案,并通过智能化的方式实时监测患者的健康状况。
二、智能随访系统的优势1. 个性化随访:智能随访系统能根据不同患者的病情、需求等特点,提供个性化的医疗服务和健康管理方案。
通过患者输入的信息和系统分析,医生可以掌握患者的治疗进展,及时调整治疗方案,提高治疗效果。
2. 远程随访:智能随访系统利用互联网和物联网技术,使医生能够远程监测患者的健康状况。
患者不需要亲自前往医院,医生可以通过智能设备获取患者的生理指标数据,实时了解患者的健康情况。
3. 高效管理:智能随访系统可以大幅度提高医生对患者的管理效率。
系统自动根据患者信息和医学规则,生成随访计划,并为医生提供随访提醒和指引。
医生可以通过系统对多个患者的健康状况进行集中监测和管理,提高工作效率。
三、智能随访系统的应用场景1. 慢性病管理:智能随访系统在慢性病管理上有着广泛的应用。
例如,患有糖尿病的患者可以通过智能随访系统实时监测血糖水平,并将数据自动上传至系统中,医生可以实时查看和评估患者的病情。
2. 康复随访:智能随访系统在康复随访中也起到了重要作用。
通过智能设备和传感器,系统可以记录患者的康复训练过程,医生可以根据这些数据进行对症随访和调整治疗方案。
3. 老年人护理:智能随访系统可以实时监测老年人的生活习惯、生理指标等,通过智能化的方式提醒和指导老年人保持健康的生活方式,及时发现并处理老年人的健康问题。
Smartcare融合大数据平台

Smartcare融合大数据平台
Contents
01 平台概述 02 解决方案关键技术 03 解决方案介绍
— 2—
华为移动网端到端支撑平台架构
应用层 共享层 采集层
应用
信令跟踪 和分析应
用
网络质量 评估和监
控
用户感知分 析专题应用
营销支撑
存量用 户维系
…
三方应 用
地理化定位
道路匹配
室内外 区分
道路匹 配
建筑物匹配 高速用户识别
多点聚合
电平特征
面定位 立体定位(2017Q3)
定位 场景
精度(米)
OTT
20-50
Only AGPS/MDT
20-50
城区
AGPS/MDT FeatureDB
50-80
FeatureDB
80~120 m
U
S1-
U
S11
③
②
G
X
⑤ S1-U单据与Mw接口单据通过**+时间关联
⑥ S1_MME与CHR、MR单据通过**+MMEC关联
PCRF
④
RX
SG I
LTE信令面数据流
VoLTE信令面数据 流
VoLTE用户面数据
Mw
流
ENODE B
⑥
S/P_G W
⑤
PCSCFS/SBC
①②③④ ⑤
XDR基础信息(IMSI、开始时间、结束时间、MOS、IPMOS、 Cause…)
等实时业务
•支持XDR字段的增加以及删减;
•多协议支持:FTP、SFTP、FTPS、TCP、SDTP
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Security Level:内部公开Smartcare融合大数据平台Contents01 平台概述02 解决方案关键技术03 解决方案介绍华为平台关键能力及技术优势100G大容量探针•NetProbe12U 探针•100 Gbps(处理能力)•60 TB (存储能力)复杂多接口拼接能力•跨CS,PS,IMS多域的接口关联能力;•具有120万条/秒流式数据、100MB/s文件数据采集能力强大的实时计算能力•实时流处理能力•实时事件规则定制•VVIP用户分钟级实时感知监控•海量数据存储能力•海量数据高效获取能力•后分析和离线挖掘能力海量数据存储计算能力•架构开放硬件虚拟化•平台开放Hadoop数据订阅•数据开放多租户管理架构灵活&开放能力华为平台关键能力1-架构灵活&开放能力数据开放架构开放平台开放平台能力开放给客户,易于平台的使用•第三方工具通过标准接口使用Hadoop 组件;•通过CEP 配置接口,开放实时CEP 能力;使用客户现有资产,易于平台的部署•使用第三方硬件:PC 服务器、存储•使用第三方的Cloud 环境各类数据灵活共享,数据价值最大化•实时事件数据,根据条件触发到第三方系统•通过多租户方式,客户可访问共享平台数据现网硬件虚拟化层功能现网云平台数据库权限控制DSI实时处理多租户视图SparkHadoopData MiningMachine Learning共享平台3方工具标准接口根据电信行业数据特点,采用最优的组件处理特定的数据。
Hadoop Distributed File System(HDFS)HBASE (投诉处理详单)IMPALA (接口详单)Spark(天粒度汇总计算)Hadoop 通用组件功能:•HDFS :提供可扩展的海量数据低成本存储。
•Spark :提供小批量流式处理、离线批处理、SQL 查询、数据挖掘,适合高优先级、迭代型计算任务。
•IMPALA :基于SQL 查询接口提供海量数据查询能力的新型查询引擎。
•HBASE :支持主键检索及简单事务,适合存储大表数据。
采用Huawei 自研的Hadoop 方案:兼容开源Hadoop ,便于开发者使用和技能复制;根据电信数据特点进行针对性的增强,更适合运营商部署;技术优势:在Hadoop 标准组件功能的基础上,增加以下功能•基于聚簇表/聚簇索引框架的HBase 增强:通过HBase 内部机制实现一个对象下多个用户表数据在物理上的相邻存放,从而达到查询时延相比传统方法5~100倍提升。
•基于二级索引的Hbase 增强:开源的Hbase 只提供单索引,Huawei 增强的二级索引,就是对于电信领域需要经常查询的列,建立这一列数据(例如用户号码)和RowKey 之间的索引;避免了直接在全数据表中的整表搜索,可以大大减少数据搜索量;华为平台关键能力3-海量数据存储计算能力(Hadoop )华为平台关键能力4-复杂多接口拼接能力复杂的多接口拼接能力:采集多接口探针上报数据,通过适配转换、单据关联回填,实现复杂的多接口单据拼接,生成XDR 详单。
技术优势:•跨CS ,PS ,IMS 多域的接口关联能力;•完成实时跟踪、链路监控、链路拓扑、协议分析等实时业务•支持XDR 字段的增加以及删减;•多协议支持:FTP 、SFTP 、FTPS 、TCP 、SDTP 和SNMP•具有120万条/秒流式数据、100MB/s 文件数据采集能力差异化特点:•独立实时通道,确保特定数据的实时性;多接口探针单据适配拼接●12U 探针:•100 Gbps (处理能力)•60 TB (存储能力)100Gpbs 探针是在未来LTE 时代满足数据大爆炸需求的关键能力华为平台关键能力5——100G 大容量探针●2U 探针:•10 Gbps (处理能力)•24 TB (存储能力)12U2UTecal E9000 采用OSCA 平台架构,用于大容量的MBB 探针。
完成原始信令的数据识别、解析和处理,生成xDR 。
技术优势:1、处理能力强,单机框最大处理流量100Gbps ;2、配置灵活:通过增加插板,可逐级增加处理能力;(每块业务板支持10G 流量)3、计算单板、存储单板根据需要配置;4、前插板提供计算、存储资源,后插板提供接口、交换能力;Tecal E9000Contents01 平台概述02 解决方案关键技术03 解决方案介绍关键技术1:高铁用户精准识别算法基于MR/CHR/xDR 多维大数据运算,通过合理的高铁用户识别算法,“四大步六小步”充分识别和定位高铁用户,从而达到评估高铁性能质量的能力。
工程参数预处理高铁用户识别标示高铁站点专网/非专网高铁站点小区清单,包含ECGI\小区类型\专网标记◆xDR 与软采数据拼接◆xDR 与CHR 数据拼接◆CHR 与MME CHR 拼接◆CHR 内通话间拼接高铁用户的MR 过滤与定位1、基于站点切换序列和时间,识别高速高铁用户。
2、识别同车高铁用户,获取小区切换序列和时间匹配的用户信息。
3、根据专公网切换信息和驻留时长,识别上下车用户。
4、基于上下车用户、站点和速度,识别低速高铁用户。
5、根据高低速用户的切换信息,识别高铁运行方向。
六步六识别(高铁用户/同车/上下车/运行方向/运行线路)多类数据源关联拼接1、按照识别的高铁用户,过滤出高铁MR2、通过地理化定位算法,定位每个高铁MR 的实际位置高铁用户识别准确率达到XX%。
数据拼接关键技术2:高精度的地理定位算法定位场景城区郊区/农村OTTOnly AGPS/MDTAGPS/MDT FeatureDBFeatureDBFast PositioningOTTOnly AGPS/MDTAGPS/MDT FeatureDBFeatureDBFast Positioning精度(米)20-5020-5050-8080~120 m 110~160 m 20-50?20-5060-100100~220 m 150~220 m多维数据源6大场景定位技术高精度定位OTT 数据MR 数据工程参数高精度地图快速定位立体定位道路匹配室内外区分OTT 定位特征库定位地理化定位电平特征工参特征立体特征库构建特征匹配特征库校准建筑物匹配高速用户识别多点聚合道路匹配电平特征呼叫特征邻区特征用户特征切换特征电平特征邻区特征仿真算法地物特征用户角色用户位置用户业务网络质量用户行为WiFi 信息平面定位立体定位(2017Q3)关键技术3:机器学习算法应用upperlower传统模式(故障告警思维管理性能问题):1、上区级性能告警门限一刀切->告警要么太多,要么太少->无法支撑生产运营2、用户投诉使用体验恶化->工程师分析,发现并解决问题->问题发现滞后,影响感知机器学习新模式(海量小区动态门限自动学习)几十万对象(小区/连接/IP …)1000+ 指标网络性能指标时序图c.多指相关度分析:a.时间序列聚类自学习算法:OutlierProbability Densityb.异常检测:d.指标间关联规则学习:1.基于聚类算法的海量对象长周期历史数据机器自学习获得动态门限;2.告警自动检测&多指标关联分析,问题闭环应用实例:Cell CQI页面下载速率Cell PRB 利用率Pokémon Go 流量监控:预警:恶化前兆告警:显著恶化对象:小区工程师分析:小区内Pokémon Go游戏新出现热点,用户痛点:海量对象门限如何管理?关键技术4:多数据源问题端到端定位PSPU ®每业务每用户●基于核心网定界算法,实现五元定界(终端、小区、IPRAN 、网元、SP )基于DPI 数据五元定界无线数据源深度定位SP 侧问题进一步定位●针对无线侧问题进一步深度定位,提供TOP 小区及无线根因分析(弱覆盖、干扰、负荷)●根据IP 流量流向配置信息,识别异网运营商IP ●识别DNS 跳数过多等问题小区栅格地理化分析●明确无线原因可进一步进行小区级栅格性能分析,输出优化方案。
全量DPI 数据MR/CHR配置信息(IPRAN 、IP 流量流向)HW E///NOKIA ZTEMore关键技术5:VOLTE 多接口拼接及分析定界LTE 信令面数据流VoLTE 信令面数据流VoLTE 用户面数据流ENODE BS/P_G WMMEPCRFP-CSCFS/SBCS-CSCFS/I-CSCFU US1-US1-MMES11G XRXSG IMw①②④③⑤⑥XDR 基础信息(IMSI 、开始时间、结束时间、MOS 、IPMOS 、Cause…)关联后的CHR 、MR 信息(IMSI 、CAllID 、开始时间、结束时间、频点、PCI 、RSRP 、SINR…)XDR 基础信息(IMSI 、开始时间、结束时间、MOS 、IPMOS 、Cause )CHR 信息(CALLID 、频点、PCI…)MR 信息(RSRP 、SINR 、TA…)⑤⑥IMSI 、开始时间、结束时间S1-MME 单据与S11接口单据通过**+时间关联S11单据与S1-U 接口单据通过**+IP 关联S11单据与GX 接口单据通过**+时间关联RX 单据与GX 接口单据通过**+时间关联S1-U 单据与Mw 接口单据通过**+时间关联S1_MME 与CHR 、MR 单据通过**+MMEC 关联P-CSCFS/SBC①②③④⑤⑥适配大区制和NFV 架构•跨5域23+接口单据拼接•大区及省内关联分析•他省冗余信息过滤五元五阶四环质量分析•第一失败现场进行失败归属现场定界•IMS/EPC/无线关联•呼损鱼骨概念实现流程化指标拆分中移动25省及全球实践•提供完整的8元16阶指标体系•浙江(移动标杆)供应商,搬迁X 省Contents01 平台概述02 解决方案关键技术03 解决方案介绍北京电信上线UC列表序号UC名称1VVIP用户感知洞察2区域业务质量监控3区域业务质量分析4测试APP关联分析5管理者视图6重大活动保障7重点场景保障8规划支撑:感知建网评估9覆盖&干扰:上(下)行覆盖分析、异运营商覆盖对比、LTE过覆盖分析10话务分析:LTE上(下)行负荷分析、LTE上(下)行空口数传质量分析11性能分析:接入分析、掉话分析、切换分析、重定向分析12网络评估:高铁评估、LTE重点道路评估、LTE问题区域识别业务感知监控与分析业务感知监控与分析1.1-管理者视图2.1面向中高层管理人员,聚焦集团优良率考核指标,单天和本月指标实时可视,省市区指标可逐层下钻1刷新粒度:天存储周期:2个月地理化精度:全省、地市、行政区数据源:DPI 、测试APP关联:测试APP 关联分析(可选)跳转:测试APP 关联分析2与集团考核指标规范一致:浏览、视频、IM 、游戏与集团考核规则对齐:集成DPI+APP ,区分三高/非三高,考核门限&指标占比可调可配3集团考核指标实时可视2.22.32.42.52.1面向中层维护人员,聚焦集团DPI优良率考核指标,实时刷新,省市区指标逐层下钻1刷新粒度:15分钟存储周期:2个小时地理化精度:全省、地市、行政区数据源:DPI跳转:区域业务质量分析2与集团考核指标规范一致:浏览、视频、IM、游戏与集团考核规则对齐:考核门限&指标占比可调可配3区域级业务质量直观呈现快速发现网络问题2.32.52.22.42.1面向业务分析工程师,聚焦集团DPI 优良率考核指标,实现质差自动定界,定位、定因,结合地理化及TOP 网元进行分析1查询时间粒度:15分钟、小时、天呈现时间周期:3小时/12小时/2周查询范围粒度:省/市/区/网元/小区数据源:DPI跳转:覆盖分析(MR 栅格)2五段定界:终端/无线/IPRAN/核心网/SPTOP 定位:按网元、失败次数、指标进行TOP 排序定位质差定因:结合失败码等给出质差原因3端到端业务质量分析定界2.33.12.22.52.43.22.1面向业务分析工程师,聚焦集团DPI+APP 优良率考核指标,通过多数据源关联分析,结合“UC:区域业务质量分析”,给出双差小区1查询时间粒度:天、多天、本月呈现时间周期:多天、本月查询范围粒度:省/市/区/三高(非)数据源:DPI 、APP关联&跳转:区域业务质量分析2与集团考核指标规范一致:浏览、视频、IM 、游戏与集团考核规则对齐:考核门限&指标占比可调可配无线问题可地理化下钻,输出双差小区3APP+DPI 关联分析,快速评估双差小区2.33.22.23.32.43.1 2.5业务感知监控与分析1.5-重点场景保障2.1面向业务分析工程师,聚焦三高场景,以DPI 优良率为牵引,通过多数据源进行监控与分析1查询时间粒度:小时、天、多天呈现时间周期:多天、本月查询范围粒度:省/市/区/三高(非)数据源:DPI/MR/PM(北向-华为)/FM2提供重点场景小区组的感知优良率,直观呈现与集团考核规则对齐:考核门限&指标占比可调可配感知、性能、覆盖多数据源多维呈现3多数据源针对重点场景进行多维监控与分析2.33.22.23.32.43.1 3.3业务感知监控与分析1.6-重大活动保障2.12.32.23.3面向业务分析工程师,聚焦自定义的重大活动场景,以DPI优良率为牵引,通过多数据源进行实时监控与分析1时间刷新粒度:5分钟/1小时呈现时间周期:1小时/10小时查询范围粒度:自定义的小区数据源:DPI/PM(北向-华为)/FM2提供可自定义小区组的感知优良率,直观呈现与集团考核规则对齐:考核门限&指标占比可调可配感知、性能多数据源多维实时呈现3多数据源针对重大活动保障场景进行多维监控与实时分析2.4业务感知监控与分析1.7-VVIP 用户感知洞察2.1面向业务分析工程师,聚焦VVIP 用户感知,针对单用户,用户群实时进行感知洞察以及异常感知告警输出,通过地理化等手段进行呈现和分析1刷新时间粒度:5分钟呈现时间周期:12小时用户组:1000卡片式管理:200数据源:DPI2与集团考核指标规范一致:浏览、视频、IM 、游戏5分钟告警呈现,实时分析用户号码脱敏,保障信息安全小区地理化位置呈现3APP+DPI 关联分析,快速评估双差小区2.3 2.23.33.42.52.4网络性能评估与优化网络性能评估与优化特性总览网络评估网络分析用户分析⏹网络健康度评估⏹问题区域识别⏹重点道路评估-加强北向&MDT ⏹高铁评估⏹覆盖分析-加强首界面&异运营商&北向&MDT⏹话务分析-加强首界面⏹导频污染分析⏹邻区分析⏹网络性能分析-加强首界面&重定向⏹用户组分析(RAN)⏹单用户分析(RAN)—已调用该功能⏹终端存量分析(RAN)⏹PCI 核查⏹频率分析⏹上行干扰分析-加强首界面⏹网元配置核查网络性能评估与优化2.1-下行覆盖&上行覆盖&过覆盖面向网优工程师,通过对MR 数据的采集和栅格定位,将覆盖性能直观量化呈现,指导高效、精准、低成本覆盖评估1查询时间粒度:天(首界面)&天/小时(分析界面)呈现时间周期:14天数据源:MR&MDT (U2000-华为、北向-中兴、50*50&20*20)跳转:网络性能分析(栅格界面)2首界面直观呈现关键覆盖指标分析界面指标近20种覆盖评估项可分频点进行栅格覆盖分析区分室内外3利用MR 进行栅格化分析,量化评估网络覆盖性能注1:过覆盖没有MDT 功能网络性能评估与优化2.1-下行覆盖&上行覆盖&过覆盖-2面向网优工程师,通过对异网频点MR 数据的采集、数据清洗、栅格定位,指导不同运营商覆盖对比评估1查询时间粒度:天/周(首界面);小时/天/周(分析界面)呈现时间周期:7天存储:一年内有有效数据的30天数据源:MR(U2000-华为、北向-中兴、50*50)跳转:网络性能分析(栅格界面)2首界面直观呈现覆盖率、覆盖差值、覆盖走势指标分析界面通过多窗口实现不同运营商、覆盖差值等指标对比分析可分频点进行栅格覆盖分析区分室内外3通过本网终端采集异网MR 数据,实现三网覆盖评估面向网优工程师,通过对MR/CHR 数据的采集和栅格定位,将话务性能直观量化呈现,指导高效、精准、低成本网络话务评估1查询时间粒度:天/周(首界面)&天/小时(分析界面)呈现时间周期:24小时/7天;数据源:MR&CHR(U2000-华为/50*50&20*20)跳转:网络性能分析(栅格界面)2首界面直观呈现关键话务负荷指标分析界面指标近20种话务评估项可分频点进行栅格覆盖分析区分室内外3利用MR/CHR 进行话务栅格化定位,量化评估网络话务性能面向网优工程师,通过对MR/CHR 数据的采集和栅格定位,将接入性、移动性、保持性性能直观量化呈现,指导高效、精准、低成本网络承载能力评估1查询时间粒度:天/周(首界面)&天/小时(分析界面)呈现时间周期:24小时/7天;数据源:MR&CHR(U2000-华为/50*50)跳转:网络性能分析(栅格界面)2首界面直观呈现关键性能指标分析界面指标20+种性能评估项可分频点进行栅格覆盖分析区分室内外3利用MR/CHR 进行事件栅格化定位,量化评估网络承载能力面向网优工程师,通过对MR/CHR 数据的采集和栅格定位,将4G 回落3G 的性能直观量化呈现,指导高效、精准、低成本网络重定向评估1查询时间粒度:天/周(首界面)&天/小时(分析界面)呈现时间周期:24小时/7天;数据源:MR&CHR(U2000-华为/50*50)跳转:网络性能分析(栅格界面)2首界面直观呈现关键性能指标重定向比例走势分析高重定向小区TOP30列表可分频点进行栅格覆盖分析区分室内外3利用MR/CHR 进行重定向栅格化定位,量化评估网络重定向性能面向网优工程师,利用核心网与无线数据拼接识别高铁用户,针对高铁区域以及用户进行高效、精准、低成本的覆盖以及性能评估1查询时间粒度:小时/天/周数据存储周期:≤14天(不含当天)高铁规模:10条/5000KM 数据源:MR&CHR&XDR or MME CHR (仅华为)离散粒度/定位规格:10~50米/0.5~1倍间距2高铁用户查准率达90%,识全率达40%区分频点、路段、上下行、用户组指标树拖拽分析/分析图表用户轨迹回放分析详单和信令流程分析3高铁虚拟路测面向网优工程师,提供道路级的覆盖地理化和事件地理化,提供统计和钻取分析,支撑关键道路的RF 问题的保障1查询时间粒度:小时/天数据存储周期:≤14天(不含当天)道路规模:10万条/5000KM 数据源:MR&CHR&MDT (覆盖&干扰类指标支撑北向-中兴)离散粒度/定位规格:10~50米2区分频点、路段、用户速度、仅MDT 、终端类型指标树拖拽分析/分析图表用户轨迹回放分析详单和信令流程分析3道路虚拟路测面向网优工程师,快速的发掘出基于不同指标的栅格级问题区域,识别出需要优化的问题区域。