无符号数词法分析程序
词法分析程序实验报告

词法分析程序实验报告篇一:词法分析器_实验报告词法分析器实验报告实验目的:设计、编制、调试一个词法分析子程序-识别单词,加深对词法分析原理的理解。
实验要求:该程序要实现的是一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分界符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
(一)实验内容(1)功能描述:对给定的程序通过词法分析器弄够识别一个个单词符号,并以二元式(单词种别码,单词符号的属性值)显示。
而本程序则是通过对给定路径的文件的分析后以单词符号和文字提示显示。
(2)程序结构描述:函数调用格式:参数含义:String string;存放读入的字符串 String str; 存放暂时读入的字符串 char ch; 存放读入的字符 int rs 判断读入的文件是否为空 char []data 存放文件中的数据 int m;通过switch用来判断字符类型,函数之间的调用关系图:函数功能:Judgement()判断输入的字符并输出单词符号,返回值为空; getChar() 读取文件的,返回值为空;isLetter(char c) 判断读入的字符是否为字母的,返回值为Boolean类型; switch (m) 判断跳转输出返回值为空;isOperator(char c)判断是否为运算符的,返回值为Boolean类型; isKey(String string)判断是否为关键字的,返回值为Boolean类型; isDigit(char c) 判断读入的字符是否为数字的,返回值为Boolean类型。
(二)实验过程记录:本次实验出错3次,第一次无法输出双运算符,于是采用双重if条件句进行判断,此方法失败,出现了重复输出,继续修改if语句,仍没有成功。
然后就采用了直接方法调用解决此问题。
对于变量的判断,开始忘了考虑字母和数字组成的变量,结果让字母和数字分家了,不过改变if语句的条件,解决了此问题。
词法分析

实验题目:无符号数的词法分析一、实验目的:1、培养学生初步掌握编译原理的实验技能。
2、验证所学理论、巩固所学知识并加深理解。
3、对学生进行实验研究的基本训练。
二、实验内容:掌握词法分析的基本思想,并用高级语言编写无符号数的词法分析程序。
三、实验要求:从键盘上输入一字符串(包括字母、数字等),最后以";"结束,编写程序识别出其中的无符号数。
无符号数文法规则可定义如下:<无符号数>→<无符号实数>|<无符号整数><无符号实数>→<无符号整数>.<数字串>[E<比例因子>]|<无符号整数>E<比例因子><比例因子>→<有符号整数><有符号整数>→[+|-]<无符号整数><无符号整数>→<数字串><数字串>→<数字>{<数字>}<数字>→0|1|2……8|9读无符号数的程序流程图见下图:三、实验代码#include "iostream.h"#include <string.h>#define N 200int main(void){char b;do{int w=0,p=0,j=0,e=1;int i,n;int d;char a[N];cout<<"请输入数据:";cin>>a;n=strlen(a);//for( i=0 ;i<n;i++)// cout<<a[i];if((a[0]<'0')||(a[0]>'9'))cout<<"您输入的数据不正确!"<<endl;elsefor(i=0;i<n;i++){if((a[i]>='0')&&(a[i]<='9')){d=a[i]-48;w=w*10+d;}else if(a[i]=='.'){if((a[i+1]<'0')||(a[i+1]>'9'))cout<<"数据有错!"<<endl;elsefor(i=i+1;i<n;i++){if((a[i]>='0')&&(a[i]<='9')){d=a[i]-48;w=10*w+d;j=j+1;}elseif(a[i]=='E'||'e'){if(a[i+1]=='-'){e=-1;if((a[i+2]<'0')||(a[i+2]>'9'))cout<<"数据有错!"<<endl;elsefor(i=i+1;i<n;i++){if((a[i]>='0')&&(a[i]<='9')){d=a[i]-48;p=p*10+d;}}}else if(a[i+1]=='+'){if((a[i+1]<'0')||(a[i+1]>'9'))cout<<"数据有错!"<<endl;else for(i=i+1;i<n;i++){if((a[i]>='0')&&(a[i]<='9')){d=a[i]-48;p=p*10+d;}}}else{if((a[i+1]<'0')||(a[i+1]>'9'))cout<<"数据有错!"<<endl;else for(i=i+1;i<n;i++){if((a[i]>='0')&&(a[i]<='9')){d=a[i]-48;p=p*10+d;}}}}}}else if(a[i]=='E'||'e'){if(a[i+1]=='-'){if((a[i+2]<'0')||(a[i+2]>'9'))cout<<"数据有错!"<<endl;else for(i=i+1;i<n;i++){if((a[i]>='0')&&(a[i]<='9')){d=a[i]-48;p=p*10+d;}}}else if(a[i+1]=='+'){if((a[i+1]<'0')||(a[i+1]>'9'))cout<<"数据有错!"<<endl;else for(i=i+1;i<n;i++){if((a[i]>='0')&&(a[i]<='9')){d=a[i]-48;p=p*10+d;}}}else{if((a[i+1]<'0')||(a[i+1]>'9'))cout<<"数据有错!"<<endl;else for(i=i+1;i<n;i++){if((a[i]>='0')&&(a[i]<='9')){d=a[i]-48;p=p*10+d;}}}}}cout<<"经运行,数据的输出为:"<<w<<"E"<<e*p-j<<endl; cout<<"您如果想继续运行请输入y或Y:";cin>>b;cout<<endl;} while(b='y'||'Y');}:五、实验结果三、实验要求:。
词法分析程序生成实验

无符号数的词法分析程序一、实验课程的性质、目的和任务1.培养学生初步掌握编译原理实验的技能。
2.验证所学理论、巩固所学知识并加深理解。
3.对学生进行实验研究的基本训练。
二、实验内容掌握词法分析的基本思想,并用高级语言编写无符号数的词法分析程序。
三、实验要求从键盘上输入一串字符(包括字母、数字等),最后以“;”结束,编写程序识别出其中的无符号数。
四、无符号数语法规则<无符号数>→<无符号实数>│<无符号整数><无符号实数>→<无符号整数>.<数字串>[E<比例因子>]│<无符号整数>E<比例因子><比例因子>→<有符号整数><有符号整数>→[+│-]<无符号整数><无符号整数>→<数字串><数字串>→<数字>{<数字>}<数字>→0 1 2 3 (9)五、实验流程图六、实验源代码#include<stdio.h>#include<stdlib.h>#include <errno.h>#include<ctype.h>#include<math.h>#define N 50char UnsignedNumber[N] ;/*用来储存提取出来的无符号数字符串*/ /*识别已经提取出来的无符号数字符串*/void ReadUnsignedNumber(){int w=0 ;int p=0 ;int j=0 ;int i=0 ;short e=1 ;short d=0 ;double DataValue ;while(isdigit(UnsignedNumber[i])){d=UnsignedNumber[i]-48 ;w=w*10+d ;i++ ;}if(UnsignedNumber[i]=='.'){i++ ;while(isdigit(UnsignedNumber[i])){d=UnsignedNumber[i]-48 ;w=w*10+d ;j++ ;i++ ;}if(UnsignedNumber[i]=='\0'){DataValue=w*pow(10,e*p-j) ;printf("The value of %s is %f\n",UnsignedNumber,DataV alue) ;}else if(UnsignedNumber[i]=='e'||UnsignedNumber[i]=='E'){i++ ;if(UnsignedNumber[i]=='-'){e=-1 ;i++ ;}else if(UnsignedNumber[i]=='+'){i++;}do{d=UnsignedNumber[i]-48 ;p=p*10+d ;i++ ;}while(isdigit(UnsignedNumber[i]));DataValue=w*pow(10,e*p-j) ;printf("The value of %s is %f\n",UnsignedNumber,DataV alue) ;}}else if(UnsignedNumber[i]=='e'||UnsignedNumber[i]=='E'){ i++ ;if(UnsignedNumber[i]=='-'){e=-1 ;i++ ;}else if(UnsignedNumber[i]=='+'){i++;}do{d=UnsignedNumber[i]-48 ;p=p*10+d ;i++;}while(isdigit(UnsignedNumber[i])) ;DataValue=w*pow(10,e*p-j) ;printf("The value of %s is %f\n",UnsignedNumber,DataV alue) ; }else{DataValue=w ;printf("The value of %s is %f\n",UnsignedNumber,DataV alue) ;}if (errno == ERANGE){printf("Overflow condition occurred!\n");}}int main(){char ch ;int i ;int flag=0 ;printf("Please input the data with ';' to end!\n") ;ch=getchar() ;/*扫描输入的字符串,从中提取无符号数字符串*/while(ch!=';'){i=0 ;while(!isdigit(ch)){if(ch==';'){break ;}ch=getchar() ;}while(isdigit(ch)){UnsignedNumber[i]=ch ;i++ ;ch=getchar() ;}if(ch=='.'){UnsignedNumber[i]=ch ;i++ ;ch=getchar() ;while(isdigit(ch)){UnsignedNumber[i]=ch ;i++ ;ch=getchar() ;}if(ch=='e'||ch=='E'){UnsignedNumber[i]=ch ;i++ ;ch=getchar() ;if(!isdigit(ch)){if(ch=='+'||ch=='-'){UnsignedNumber[i]=ch ;i++ ;ch=getchar();if(!isdigit(ch)){i-- ;UnsignedNumber[i]='\0' ;}else{do{UnsignedNumber[i]=ch ;i++ ;ch=getchar() ;}while(isdigit(ch)) ;if(ch=='.'){printf("The data you input is wrong!\n") ;exit(1) ;}else{UnsignedNumber[i]='\0' ;}}}else{i-- ;UnsignedNumber[i]='\0' ;}}else{do{UnsignedNumber[i]=ch ;i++ ;ch=getchar() ;}while(isdigit(ch)) ;if(ch=='.'){printf("The data you input is wrong!\n") ;exit(1) ;}else{UnsignedNumber[i]='\0' ;}}}else{UnsignedNumber[i]='\0' ;}}else if(ch=='e'||ch=='E'){UnsignedNumber[i]=ch ;i++ ;ch=getchar() ;if(!isdigit(ch)){if(ch=='+'||ch=='-'){UnsignedNumber[i]=ch ;i++ ;ch=getchar();if(!isdigit(ch)){i-- ;UnsignedNumber[i]='\0' ;}else{do{UnsignedNumber[i]=ch ;i++ ;ch=getchar() ;}while(isdigit(ch)) ;if(ch=='.'){printf("The data you input is wrong!\n") ;exit(1) ;}else{UnsignedNumber[i]='\0' ;}}}else{UnsignedNumber[i]='\0' ;}}else{do{UnsignedNumber[i]=ch ;i++ ;ch=getchar() ;}while(isdigit(ch)) ;if(ch=='.'){printf("The data you input is wrong!\n") ;exit(1) ;}else{UnsignedNumber[i]='\0' ;}}}else{UnsignedNumber[i]='\0' ;}if(i!=0){ReadUnsignedNumber() ;flag=1 ;}if(flag==0){printf("Sorry!There is no unsigned number in your data!\n") ;}}return 0 ;}七、实验结果。
实验3--识别无符号数的词法分析器设计实现c++

实验三识别无符号数的词法分析器程序设计一、实验目的与要求通过编写并上机调试一个词法分析程序,掌握在对程序设计语言的源程序进行扫描的过程中,将源程序分解成各类单词的词法分析方法。
二、实验重难点DFA无符号数的词法分析器编码实现三、实验内容与要求1.阅读实验案例,明确实验要求和程序实现方案;2.参考实验案例,完善该无符号数的词法分析器设计程序。
四、实验学时2课时五、实验设备与环境C语言编译环境六、实验案例1.无符号数的词法分析器原理(1)正规式表示:Unsigned digital: d…d…d…dESd…d, it includes four regular expressions: dd* 如:5 56 567d*.dd* 如:.5 5.6 5.67d*ESdd* 如:E5 E+56 5E-67d*.dd*ESdd* 如:.5E5 5.65E+56 5.4E-67whileV T={0, ···,9, ·,+,-,E}d =0|1| ···|9S = +|-|ε(2)NFA表示:(3)经过NFA转DFA和DFA的化简后得到无符号数的DFA表示:2.设计要求选取无符号数的算术四则运算中的各类单词为识别对象,要求将其中的各个单词识别出来。
输入:由无符号数和+,-,*,/, ( , ) 构成的算术表达式,如1.5E+2-100。
输出:对识别出的每一单词均单行输出其类别码。
3 (对应-)1 (对应100)3、程序源代码:1.cp p4、运行结果:测试用例1:0.23E-12-E12结论:(1)案例中的程序只给出了A到B\C及其后续通路的程序,没有给出A到D及其后续通路的程序。
因此不能识别E12是一个无符号数。
测试用例2:0.23E*12/a(0.23E-12)结论:(2)案例中的程序只给出了若输入的字符串符合无符号数的DFA语法规则,将该无符号数识别出来,并没有给出当输入的字符串不符合无符号数的DFA语法规则时,如何处理。
无符号数的识别

无符号数的词法分析程序一、实验目的和要求(1)初步掌握编译原理的实验的技能;(2)验证所学理论、巩固所学知识并加深理解。
二、实验内容和原理内容:掌握词法分析的基本思想,并用高级语言编写无符号数(包括整数和实数)的词法分析程序。
要求:从键盘中输入一字符串(包括字母、数字等),编写程序识别出其中的无符号数。
无符号数的文法规则课定义如下:<无符号数> <无符号实数>|<无符号整数><无符号实数> <无符号整数>.<数字串>[E<比例因子>]<比例因子> <有符号整数><有符号整数> [+|-]<无符号整数><无符号整数> <数字串><数字串> <数字>{<数字>}<数字> 0 1 2 3 4 5 6 7 8 9本实验中我利用了状态转化图的思想,下面是试验中用到构造的状态转化图:字描述状态机的代码格式如下:int state = S0 ;while(1){Switch(state){case S0 :if(T0转移条件满足) {状态转移到满足T0的次态;操作;}if(T1转移条件满足) {状态转移到满足T1的次态;操作;}if(T2转移条件满足) {状态转移到满足T2的次态;操作;}…Break ;case S1 ://插入S1状态下的操作;break ;…}}实验代码://本程序主要实现实数的识别import java.io.BufferedReader ;import java.io.IOException ;import java.io.InputStreamReader ;public class RealNumberIdentified {/*---------------------------------成员变量的定义---------------------------------------*/private final int S_0 = 0 ;private final int S_1 = 1 ;private final int S_2 = 2 ;private final int S_3 = 3 ;private final int S_4 = 4 ;private final int S_5 = 5 ;private final int S_6 = 6 ;private final int S_7 = 7 ;private char originNumber[ ] ; //用来记录原始的数字串private String resultNumber = new String( ) ;private int realnumberAmount = 0 ; //用来记录识别出的实数的个数private int realnumberFlag = 0 ; //用于标识该实数是正数还是负数private int eFlag = 0 ; //用来标识该实数是不是指数实数private int pointFlag = 0 ; //用来标识该实数是否是小数private int basePlusMinus = 1 ; //用来标识底数的符号private int count = 0 ; //用来记录已经识别数字串的位数private int currentState = S_0 ; //用来记录当前所处于的状态/*---------------------------------------------------------------------------------------*//*-------------------------该方法用来初始化一些参数------------------------------------*/private void init( ){resultNumber = new String( ) ;basePlusMinus = 1 ;eFlag = 0 ;pointFlag = 0 ;}/*----------------------------------------------------------------------------------------* //*---------------------init( )方法用于去除实数串开始和结尾的无效的空格----------------*/private void initOriginNumber( String str ){str = str.trim( ) ;str += '#' ;originNumber = str.toCharArray( ) ;}/*-----------------------------------------------------------------------------------------*//*---------------------------printResult()方法用来输出识别的结果------------------------*/private void printResult( ){if( realnumberFlag == 0 )System.out.println( "\n识别结束,您所输入的字符串中不包含任何实数!" ) ;else{realnumberAmount ++ ;if( realnumberAmount == 1 )System.out.println( "\n识别结束,您所输入的字符串中所包含的实数如下:" ) ;if( resultNumber.length( ) != 0 ){if( eFlag == 1 )if( basePlusMinus == 1 )System.out.println( "正指数实数:" + Double.parseDouble( resultNumber ) ) ;elseSystem.out.println( "负指数实数:" + Double.parseDouble( resultNumber ) ) ;elseif( pointFlag == 1 )System.out.println( " 小数:" + Double.parseDouble( resultNumber ) ) ;else{if( basePlusMinus == 1 )System.out.println( " 正整数:" + Long.parseLong( resultNumber ) ) ;elseSystem.out.println( " 负整数:" + Long.parseLong( resultNumber ) ) ;}}}}/*-----------------------------------------------------------------------------------------*//*--------------------------------识别该实数串的过程-------------------------------------*/private void identifiedProcess( String str ){initOriginNumber( str ) ;while( count < originNumber.length ){switch( currentState ){case S_0 : {if( originNumber[ count ] == '+' ){resultNumber = resultNumber + originNumber[ count ] ;currentState = S_1 ;}else{if( originNumber[ count ] == '-' ){resultNumber = resultNumber + originNumber[ count ] ;basePlusMinus = 0 ;currentState = S_1 ;}elseif( originNumber[ count ] >=48 && originNumber[ count ] <=57 ){resultNumber = resultNumber + originNumber[ count ] ;realnumberFlag = 1 ;currentState = S_2 ;}else{currentState = S_0 ;}}count ++ ;break ;}case S_1 : {if( originNumber[ count ] >=48 && originNumber[ count ] <=57 ){resultNumber = resultNumber + originNumber[ count ] ;realnumberFlag = 1 ;currentState = S_2 ;}else{resultNumber = resultNumber.substring( 0 , resultNumber.length( ) - 1 ) ;currentState = S_0 ;}count ++ ;break ;}case S_2 : {if( originNumber[ count ] == '.' ){resultNumber = resultNumber + originNumber[ count ] ;currentState = S_3 ;}elseif( originNumber[ count ] >=48 && originNumber[ count ] <=57 ){resultNumber = resultNumber + originNumber[ count ] ;currentState = S_2 ;}elseif( originNumber[ count ] == 'E' || originNumber[ count ] == 'e' ){resultNumber = resultNumber + originNumber[ count ] ;currentState = S_5 ;}else{if( originNumber[ count ] == '+' || originNumber[ count ] == '-' )count -- ;printResult( ) ;init( ) ;currentState = S_0 ;}count ++ ;break ;}case S_3 :{if( originNumber[ count ] >=48 && originNumber[ count ] <=57 ){resultNumber = resultNumber + originNumber[ count ] ;pointFlag = 1 ;currentState = S_4 ;}else{resultNumber.length( ) - 1 ) ;printResult( ) ;init( ) ;currentState = S_0 ;}count ++ ;break ;}case S_4 : {if( originNumber[ count ] >=48 && originNumber[ count ] <=57 ){resultNumber = resultNumber + originNumber[ count ] ;currentState = S_4 ;}else{if( originNumber[ count ] == 'E' || originNumber[ count ] == 'e' ){originNumber[ count ] ;currentState = S_5 ;}else{if( originNumber[ count ] == '+' || originNumber[ count ] == '-' )count -- ;printResult( ) ;init( ) ;currentState = S_0 ;}}count ++ ;break ;}case S_5 : {if( originNumber[ count ] == '+' ){resultNumber = resultNumber + originNumber[ count ] ;currentState = S_6 ;}elseif( originNumber[ count ] == '-' ){resultNumber = resultNumber + originNumber[ count ] ;currentState = S_6 ;}elseif( originNumber[ count ] >= 49 && originNumber[ count ] <= 57 ){resultNumber = resultNumber + originNumber[ count ] ;eFlag = 1 ;currentState = S_7 ;}else{resultNumber = resultNumber.substring( 0 , resultNumber.length( ) - 1 ) ;printResult( ) ;init( ) ;currentState = S_0 ;count -- ;}count ++ ;break ;}case S_6 : {if( originNumber[ count ] >= 49 && originNumber[ count ] <= 57 ){resultNumber = resultNumber + originNumber[ count ] ;eFlag = 1 ;currentState = S_7 ;}else{resultNumber = resultNumber.substring( 0 , resultNumber.length( ) - 2 ) ;printResult( ) ;init( ) ;currentState = S_0 ;count -= 2 ;}count ++ ;break ;}case S_7 : {if( originNumber[ count ] >= 48 && originNumber[ count ] <= 57 ){resultNumber = resultNumber + originNumber[ count ] ;currentState = S_7 ;}else{if( originNumber[ count ] == '+' ||originNumber[ count ] == '-' )count -- ;printResult( ) ;init( ) ;currentState = S_0 ;}count ++ ;break ;}}}printResult( ) ;}/*------------------------------------------------------------------------------------------*//*----------------------------------------主方法-------------------------------------------*/public static void main(String[ ] args) throws IOException {System.out.print( "请输入欲识别的实数:" ) ;BufferedReader buf = new BufferedReader( new InputStreamReader( System.in ) ) ;new RealNumberIdentified( ).identifiedProcess( buf.readLine( ) ) ;}/*------------------------------------------------------------------------------------------*/}三、实验结果四、讨论、分析和心得在本次试验我并没有采用课本中提供的算法,而是将在课本中学到的状态转化图和自动机的理论加以利用以基本实现本次实验的要求。
编译原理无符号数识别程序设计

编译原理无符号数识别程序设计1.实验目的设计无符号数识别程序2.实验要求无符号数的有穷自动机的实现3.实验环境VC++6.04.实验原理1、无符号数的BNF描述如下:0.<无符号数> → d <余留无符号数> | . <十进制数> | e <指数部分>1.<余留无符号数> → d <余留无符号数> | . <十进制数> | e <指数部分> | ε2.<十进制小数> → d <余留十进制小数>3.<余留十进制小数> e <指数部分> | d <余留十进制小数> | ε4.<指数部分> → d <余留整指数> | + <整指数> | - <整指数> 5.<整指数> → d <余留整指数>6.<余留整指数> → d <余留整指数> | ε2、将G[<无符号数>]文法转换成有穷自动机。
3、构造状态矩阵;将有穷自动机的状S1 S2 ……Sn及输入的字a1 a2 ……am 构成一个n*m的矩阵。
1、状态矩阵设计出一个词法分析程序识别无符号数。
2、扫描无符号数,根据文法给出无符号数出错的位置。
3、工具:C语言或其它高级语言4、实践时间:8学时无符号数的有穷自动机实现的思想用0-----表示无符号数;用1-----表示余留无符号数;用2----表示十进制小数;用3-----表示余留十进制小数;用4-----表示指数部分;用5-----表示整指数;用6-----表示余留整指数。
输入无符号数序列,从左到右扫描,遇到“#”号结束扫描。
设一个字符数组,接收输入的无符号数,对输入的无符号数逐一进行分析,用一个中间变量接收当前字符。
当前字符值发生错误时,输出错误信息;当前字符值正确时,分析下一个字符,反复判断,直至分析完毕。
词法分析程序

词法分析程序⼀、词法分析程序功能:词法分析器的功能为输⼊源程序,按照构词规则分解成⼀系列单词符号。
单词是语⾔中具有独⽴意义的最⼩单位,包括关键字、标识符、运算符、界符和常量等(1) 关键字是由程序语⾔定义的具有固定意义的标识符。
例如,Pascal 中的begin,end,if,while都是保留字。
这些字通常不⽤作⼀般标识符。
(2) 标识符⽤来表⽰各种名字,如变量名,数组名,过程名等等。
(3) 常数常数的类型⼀般有整型、实型、布尔型、⽂字型等。
(4) 运算符如+、-、*、/等等。
(5) 界符如逗号、分号、括号、等等。
⼆、符号与种别码对照表三、代码实现:#include <stdio.h>#include <stdlib.h>#include <string.h>#define SIZE 100char prog[SIZE],ch,token[8];int p=0,syn,n,i;char *keyword[6]={"begin","then","if","while","do","end"};//定义关键字数组void scaner();void main(){int select=-1;p=0;printf("请输⼊源程序字符串(以'#'结束):\n");do{ch=getchar();prog[p++]=ch;}while(ch!='#');p=0;do{scaner();switch(syn){case -1:printf("词法分析出错\n");break;default :printf("<%d,%s>\n",syn,token);break;}}while(syn!=0);printf("词法分析成功\n");getchar();}void scaner(){for(n=0;n<8;n++){token[n]='\0';}n=0;ch=prog[p++];while(ch==''){ch=prog[p++];}if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')){do{token[n++]=ch;ch=prog[p++];}while((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')||(ch>='0'&&ch<='9'));syn=10;for(n=0;n<6;n++)//在六个关键字中对⽐{if(strcmp(token,keyword[n])==0)syn=n+1;}p--;}else if(ch>='0'&&ch<='9')//判断输⼊的是否为整数常数{p--;do{token[n++]=prog[p++];ch=prog[p];}while(ch>='0'&&ch<='9');syn=11;return;}else{switch(ch){case'+':syn=13;token[0]=ch;break;case'-':syn=14;token[0]=ch;break;case'*':syn=15;token[0]=ch;break;case'/':syn=16;token[0]=ch;break;case':':syn=17;token[0]=ch;ch=prog[p++];if(ch=='='){token[1]=ch;syn++;}else p--;break;case'<':syn=20;token[0]=ch;ch=prog[p++];if(ch=='>'){token[1]=ch;syn++;}else if(ch=='='){token[1]=ch;syn=syn+2;}else p--;break;case'>':syn=23;token[0]=ch;ch=prog[p++];if(ch=='='){token[1]=ch;syn++;}else p--;break;case'=':syn=25;token[0]=ch;break;case';':syn=26;token[0]=ch;break;case'(':syn=27;token[0]=ch;break;case')':syn=28;token[0]=ch;break;case'#':syn=0;token[0]=ch;break;default: printf("词法分析出错! 请检查是否输⼊⾮法字符\n");syn=-1;break; }}}四、程序运⾏结果截图:。
词法分析程序(C语言编写,针对PL_0语言)

#include <stdio.h>#include <stdlib.h>#include <string.h>#define NORW 13 /* of reserved words */#define TXMAX 100 /* length of identifier table */#define NMAX 14 /* max number of digits in numbers */#define AL 10 /* length of identifiers */#define AMAX 2047 /* maxinum address */#define LEVMAX 3 /* max depth of block nesting */#define CXMAX 200 /* size of code array */#define STACKSIZE 500char *symbol[32]= {"nul","ident","number","plus","minus","times","slash","oddsym","eql","neq","lss","leq","gtr","geq","lparen","rparen","comma","semicolon","period","becomes","beginsym","endsym","ifsym","thensym","whilesym","writesym","readsym","dosym","callsym","constsym","varsym","procsym"}; /* type of symbols */c har *word[NORW]={"begin","call","const","do","end","if","odd","procedure","read","then","var","while","write"}; /* table of reserved words */ char *wsym[NORW]={ "beginsym","callsym","constsym","dosym","endsym","ifsym", "oddsym","procsym","readsym","thensym","varsym","whilesym","writesym"};char *mnemonic[8]= {"lit","opr","lod","sto","cal","ini","jmp","jpc"};char ch; /* last char read */char id[AL+1]; /*last identifier read */char sym[10]; /* last symbol read */char line[81];char a[AL+1],fname[AL+1];enum object{constant,variable,procedur};enum object kind;enum fct{lit,opr,lod,sto,cal,ini,jmp,jpc};enum listswitcher{false,true}; /*true set list object code */enum listswitcher listswitch;FILE *fa;FILE *fa1, *fa2;FILE *fin, *fout;int num; /* last number read */int cc; /* character count */int ll; /* line length */int cx; /* code allocation index */int err;int lev=0,tx=0,dx=3;int linecnt=0;struct instruction{enum fct f; /* function code */int l; /* level */int a; /* displacement addr */}; /* lit 0,a: load constant aopr 0,a: execute opr alod l,a: load variable 1, asto l,a: store variable 1, acal l,a: call procedure a at level 1int 0,a: increment t-register by ajmp 0,a: jump to ajpc 0,a: jump conditional to a */ struct instruction code[CXMAX+1];struct table1{char name[AL+1];enum object kind;int val,level,adr,size;};struct table1 table[TXMAX+1];struct node{c har *pa[32];}*declbegsys,*statbegsys,*facbegsys,*tempsetsys; int in(str, set)char *str;struct node *set;{i nt i=0;w hile(set->pa[i]!=NULL){if(strcmp(str,set->pa[i])==0)return( 1 );elsei++;}r eturn( 0 );}struct node *add(set1,set2)struct node *set1,*set2;{i nt i=0,j=0,k=0,cnt;s truct node *pt;p t=(struct node *)malloc(sizeof(struct node));f or(cnt=0; cnt < 32; cnt++)pt->pa[cnt]=(char*)malloc(10*sizeof(char));w hile(set1->pa[i]!=NULL)strcpy(pt->pa[j++],set1->pa[i++]);w hile(set2->pa[k]!=NULL){if (in(set2->pa[k],set1)==0)strcpy(pt->pa[j++],set2->pa[k++]);elsek++;}p t->pa[j]=NULL;r eturn( pt );}error(int n){i nt i;p rintf ("***");f puts ("***", fa1);f or (i=0;i<cc;i++){printf (" ");}f or (i=0;i<cc;i++){fputs (" ",fa1);}p rintf ("error%d\n",n);f printf (fa1, "error%d\n",n);e rr=err+1;}void get_ch( ){i f (cc==ll+1){if (feof(fin)){printf ("program incomplete");}ll= 0;cc= 0;while ((!feof(fin)) && ((ch=fgetc(fin))!='\n')){putchar(ch);fputc(ch,fa1);line[ll++]=ch;}printf ("\n");line[ll]=ch;fprintf (fa1,"\n");}c h=line[cc++];}void getsym( ){i nt i,j,k;w hile(ch==' '||ch=='\t'||ch=='\n')get_ch( );i f (ch>='a'&&ch<='z'){ /* id or reserved word */k=0;do {if(k<AL){a[k]=ch;k=k+1;}get_ch( );}while((ch>='a'&&ch<='z')||(ch>='0'&&ch<='9'));a[k]='\0';strcpy(id,a);i=0;j=NORW-1;do { /* look up reserved words by binary search */k=(i+j)/2;if (strcmp(id,word[k])<=0) j=k-1;if (strcmp(id,word[k])>=0) i=k+1;}while (i<=j);if (i-1>j) strcpy(sym,wsym[k]);else strcpy(sym,"ident");}e lse if (ch>='0'&&ch<='9'){ /* number */k=0;num=0;strcpy(sym,"number");do {num=10*num+(int)ch-'0';k=k+1;get_ch( );}while(ch>='0'&&ch<='9');if(k>NMAX) error(30);}e lse if (ch==':'){get_ch( );if (ch=='='){strcpy(sym,"becomes");get_ch( );}else strcpy(sym,"nul");}e lse if (ch=='<'){get_ch( );if (ch=='='){strcpy(sym,"leq");get_ch( );}else strcpy(sym,"lss");}e lse if (ch=='>'){get_ch( );if (ch=='='){strcpy(sym,"geq");get_ch( );}else strcpy(sym,"gtr");}e lse {switch(ch){case '+': strcpy(sym,"plus");break;case '-': strcpy(sym,"minus");break;case '*': strcpy(sym,"times");break;case '/': strcpy(sym,"slash");break;case '(': strcpy(sym,"lparen");break;case ')': strcpy(sym,"rparen");break;case '=': strcpy(sym,"eql");break;case ',': strcpy(sym,"comma");break;case '.': strcpy(sym,"period");break;case '#': strcpy(sym,"neq");break;case ';': strcpy(sym,"semicolon");break;}get_ch( );}}void gen(x,y,z)enum fct x;int y,z;{i f (cx>CXMAX){printf("program too long");}c ode[cx].f=x;c ode[cx].l=y;c ode[cx].a=z;c x++;}void test(s1,s2,n)struct node *s1,*s2;int n;{i f (in(sym,s1)==0){error(n);s1=add(s1,s2);while(in(sym,s1)==0) getsym( );}}void enter(k) /* enter object into table */ enum object k;{t x=tx+1;s trcpy(table[tx].name,id);t able[tx].kind=k;s witch(k){case constant:if (num>NMAX){error(31);num=0;}table[tx].val=num;break;case variable:table[tx].level=lev;table[tx].adr=dx;dx++;break;case procedur:table[tx].level=lev;break;}}int position(id) /* find identifier in table */ char id[10];{i nt i;s trcpy(table[0].name,id);i=tx;w hile (strcmp(table[i].name,id)!=0)i--;r eturn i;}void constdeclaration( ){i f (strcmp(sym,"ident")==0){getsym( );if (strcmp(sym,"eql")==0||strcmp(sym,"becomes")==0){if (strcmp(sym,"becomes")==0) error(1);getsym( );if (strcmp(sym,"number")==0){enter(constant);getsym( );}else error(2);}else error(3);}e lse error(4);}void vardeclaration( ){i f (strcmp(sym,"ident")==0){enter(variable);getsym( );}e lse error(4);}void listcode(int cx0) /* list code generated for this block */ {i nt i;i f (listswitch==true){for(i=cx0;i<=cx-1;i++){printf("%2d %5s %3d %5d\n",i,mnemonic[(int)code[i].f],code[i].l,code[i].a);fprintf(fa,"%2d %5s %3d %5d\n",i,mnemonic[(int)code[i].f],code[i].l,code[i].a);}}}void factor(fsys)struct node *fsys;{v oid expression( );i nt m=0,n=0,i;c har *tempset[ ]={"rparen",NULL};s truct node *temp;t emp=(struct node *)malloc(sizeof(struct node));w hile(tempset[m]!=NULL)temp->pa[n++]=tempset[m++];t emp->pa[n]=NULL;t est(facbegsys,fsys,24);w hile(in(sym,facbegsys)==1){if (strcmp(sym,"ident")==0){i=position(id);if (i==0) error(11);else switch(table[i].kind){case constant: gen(lit,0,table[i].val);break; /*some thing error here(lev)*/ case variable: gen(lod,lev-table[i].level,table[i].adr);/*must use para pass in*/break;case procedur: error(21);break;}getsym( );}else if (strcmp(sym,"number")==0){if (num>AMAX){error(31);num=0;}gen(lit,0,num);getsym( );}else if (strcmp(sym,"lparen")==0){getsym( );expression(add(temp,fsys));if (strcmp(sym,"rparen")==0) getsym( );else error(22);}test(fsys,facbegsys,23);}}void term(fsys)struct node *fsys;{i nt i=0,j=0;c har mulop[10];c har *tempset[ ]={"times","slash",NULL};s truct node *temp;t emp=(struct node *)malloc(sizeof(struct node));w hile(tempset[i]!=NULL)temp->pa[i++]=tempset[j++];t emp->pa[i]=NULL;f actor(add(temp,fsys));w hile (in(sym,temp)==1){strcpy(mulop,sym);getsym( );factor(add(temp,fsys));if (strcmp(mulop,"times")==0) gen(opr,0,4);else gen(opr,0,5);}}void expression(fsys)struct node *fsys;{i nt m=0,n=0;c har addop[10];c har *tempset[ ]={"plus","minus",NULL};s truct node *temp;t emp=(struct node *)malloc(sizeof(struct node));w hile(tempset[m]!=NULL)temp->pa[n++]=tempset[m++];t emp->pa[n]=NULL;i f(in(sym,temp)==1){strcpy(addop,sym);getsym( );term(add(fsys,temp));if (strcmp(addop,"minus")==0) gen(opr,0,1);}e lse term(add(fsys,temp));w hile (in(sym,temp)==1){strcpy(addop,sym);getsym( );term(add(fsys,temp));if (strcmp(addop,"plus")==0) gen(opr,0,2);else gen(opr,0,3);}}void condition(fsys)struct node *fsys;{i nt i=0,j=0;c har relop[10];c har *tempset[ ]={"eql","neq","lss","leq","gtr","geq",NULL}; s truct node *temp;t emp=(struct node *)malloc(sizeof(struct node));w hile(tempset[i]!=NULL)temp->pa[j++]=tempset[i++];t emp->pa[j]=NULL;i f (strcmp(sym,"oddsym")==0){getsym( );expression(fsys);gen(opr,0,6);}e lse {expression(add(temp,fsys));if (in(sym,temp)==0) error(20);else {strcpy(relop,sym);getsym( );expression(fsys);if(strcmp(relop,"eql")==0) gen(opr,0,8);if(strcmp(relop,"neq")==0) gen(opr,0,9);if(strcmp(relop,"lss")==0) gen(opr,0,10);if(strcmp(relop,"geq")==0) gen(opr,0,11);if(strcmp(relop,"gtr")==0) gen(opr,0,12);if(strcmp(relop,"leq")==0) gen(opr,0,13);}}}void statement(fsys,plev)struct node *fsys;int plev;{i nt i,cx1,cx2,m=0,n=0;c har *tempset1[ ]={"rparen","comma",NULL};c har *tempset2[ ]={"thensym","dosym",NULL};c har *tempset3[ ]={"semicolon","endsym",NULL};c har *tempset4[ ]={"semicolon",NULL};c har *tempset5[ ]={"dosym",NULL};c har *tempset6[ ]={NULL};s truct node *temp1,*temp2,*temp3,*temp4,*temp5,*temp6; t emp1=(struct node *)malloc(sizeof(struct node));t emp2=(struct node *)malloc(sizeof(struct node));t emp3=(struct node *)malloc(sizeof(struct node));t emp4=(struct node *)malloc(sizeof(struct node));t emp5=(struct node *)malloc(sizeof(struct node));t emp6=(struct node *)malloc(sizeof(struct node));w hile(tempset1[m]!=NULL)temp1->pa[n++]=tempset1[m++];t emp1->pa[n]=NULL;m=0;n=0;w hile(tempset2[m]!=NULL)temp2->pa[n++]=tempset2[m++];t emp2->pa[n]=NULL;m=0;n=0;w hile(tempset3[m]!=NULL)temp3->pa[n++]=tempset3[m++];t emp3->pa[n]=NULL;m=0;n=0;w hile(tempset4[m]!=NULL)temp4->pa[n++]=tempset4[m++];t emp4->pa[n]=NULL;m=0;n=0;w hile(tempset5[m]!=NULL)temp5->pa[n++]=tempset5[m++];t emp5->pa[n]=NULL;m=0;n=0;w hile(tempset6[m]!=NULL)temp6->pa[n++]=tempset6[m++];t emp6->pa[n]=NULL;m=0;n=0;i f (strcmp(sym,"ident")==0){i=position(id);if (i==0)error(11);else {if (table[i].kind!=variable){error(12);i=0;}}getsym( );if (strcmp(sym,"becomes")==0) getsym( );else error(13);expression(fsys);if (i!=0)gen(sto,plev-table[i].level,table[i].adr);}e lse if (strcmp(sym,"readsym")==0){getsym( );if (strcmp(sym,"lparen")!=0) error(24);else {do{getsym( );if (strcmp(sym,"ident")==0) i=position(id);else i=0;if (i==0) error(35);else {gen(opr,0,16);gen(sto,plev-table[i].level,table[i].adr);}getsym( );}while(strcmp(sym,"comma")==0);}if (strcmp(sym,"rparen")!=0) {error(22);while(in(sym,fsys)==0) getsym( );}else getsym( );}e lse if (strcmp(sym,"writesym")==0){getsym( );if (strcmp(sym,"lparen")==0){do{getsym( );expression(add(temp1,fsys));gen(opr,0,14);}while(strcmp(sym,"comma")==0);if (strcmp(sym,"rparen")!=0) error(33);else getsym( );}gen(opr,0,15);}e lse if (strcmp(sym,"callsym")==0){getsym( );if (strcmp(sym,"ident")!=0) error(14);else {i=position(id);if (i==0) error(11);else {if (table[i].kind==procedur)gen(cal,plev-table[i].level,table[i].adr);else error(15);}getsym( );}}e lse if (strcmp(sym,"ifsym")==0){getsym( );condition(add(temp2,fsys));if (strcmp(sym,"thensym")==0) getsym( );else error(16);cx1=cx;gen(jpc,0,0);statement(fsys,plev);code[cx1].a=cx;}e lse if (strcmp(sym,"beginsym")==0){getsym( );statement(add(temp3,fsys),plev);while(in(sym,add(temp4,statbegsys))==1){if (strcmp(sym,"semicolon")==0) getsym( );else error(10);statement(add(temp3,fsys),plev);}if (strcmp(sym,"endsym")==0) getsym( );else error(17);}e lse {if (strcmp(sym,"whilesym")==0){cx1=cx;getsym( );condition(add(temp5,fsys));cx2=cx;gen(jpc,0,0);if (strcmp(sym,"dosym")==0) getsym( );else error(18);statement(fsys,plev);gen(jmp,0,cx1);code[cx2].a=cx;}}t est(fsys,temp6,19);}void block(plev,fsys)int plev;struct node *fsys;{i nt m=0,n=0;i nt dx0=3; /* data allocation index */ i nt tx0; /* initial table index */i nt cx0; /* initial code index */c har *tempset1[ ]={"semicolon","endsym",NULL};c har *tempset2[ ]={"ident","procsym",NULL};c har *tempset3[ ]={"semicolon",NULL};c har *tempset4[ ]={"ident",NULL};c har *tempset5[ ]={NULL};s truct node *temp1,*temp2,*temp3,*temp4,*temp5;t emp1=(struct node *)malloc(sizeof(struct node));t emp2=(struct node *)malloc(sizeof(struct node));t emp3=(struct node *)malloc(sizeof(struct node));t emp4=(struct node *)malloc(sizeof(struct node));t emp5=(struct node *)malloc(sizeof(struct node));w hile(tempset1[m]!=NULL)temp1->pa[n++]=tempset1[m++];t emp1->pa[n]=NULL;m=0;n=0;w hile(tempset2[m]!=NULL)temp2->pa[n++]=tempset2[m++];t emp2->pa[n]=NULL;m=0;n=0;w hile(tempset3[m]!=NULL)temp3->pa[n++]=tempset3[m++];t emp3->pa[n]=NULL;m=0;n=0;w hile(tempset4[m]!=NULL)temp4->pa[n++]=tempset4[m++];t emp4->pa[n]=NULL;m=0;n=0;w hile(tempset5[m]!=NULL)temp5->pa[n++]=tempset5[m++];t emp5->pa[n]=NULL;m=0;n=0;l ev=plev;t x0=tx;t able[tx].adr=cx;g en(jmp,0,1);i f (plev>LEVMAX) error(32);d o{if (strcmp(sym,"constsym")==0){getsym( );do{constdeclaration( );while(strcmp(sym,"comma")==0){getsym( );constdeclaration( );}if (strcmp(sym,"semicolon")==0) getsym( );else error(5);}while(strcmp(sym,"ident")==0);}if (strcmp(sym,"varsym")==0){getsym( );do{dx0++;vardeclaration( );while (strcmp(sym,"comma")==0){getsym( );dx0++;vardeclaration( );}if (strcmp(sym,"semicolon")==0) getsym( );else error(5);}while(strcmp(sym,"ident")==0);}while (strcmp(sym,"procsym")==0){getsym( );if (strcmp(sym,"ident")==0){enter(procedur);getsym( );}else error(4);if (strcmp(sym,"semicolon")==0) getsym( );else error(5);block(plev+1,add(temp3,fsys));lev=lev-1;if (strcmp(sym,"semicolon")==0){getsym( );test(add(statbegsys,temp2),fsys,6);}else error(5);}test(add(statbegsys,temp4),declbegsys,7);}while(in(sym,declbegsys)==1);c ode[table[tx0].adr].a=cx;t able[tx0].adr=cx;t able[tx0].size=dx0;c x0=cx;g en(ini,0,dx0);s tatement(add(temp1,fsys),plev);g en(opr,0,0);t est(fsys,temp5,8);l istcode(cx0);}int base(l,b,s)int l;int *b;int s[STACKSIZE];{int b1;b1=*b; /*find base l level down */ while(l>0){b1=s[b1];l=l-1;}return b1;}void interpret( ){i nt p=0; /* p:program register*/ i nt b=1; /* b:base register*/i nt t=0; /* t:topstack registers */ s truct instruction i;i nt s[STACKSIZE]; /* datastore */p rintf("start pl0\n");s[0]=0;s[1]=0;s[2]=0;s[3]=0;d o{i=code[p];p=p+1;switch(i.f){case lit: t=t+1;s[t]=i.a;break;case opr:switch(i.a){ /*operator*/case 0: t=b-1; /*return*/p=s[t+3];b=s[t+2];break;case 1: s[t]=-s[t];break;case 2: t=t-1; /*plus*/s[t]=s[t]+s[t+1];break;case 3: t=t-1; /*minus*/s[t]=s[t]-s[t+1];break;case 4: t=t-1; /*times*/s[t]=s[t]*s[t+1];break;case 5: t=t-1;s[t]=s[t]/s[t+1];break;case 6: if (s[t]%2==0) s[t]=0;else s[t]=1;break;case 8: t=t-1;if (s[t]==s[t+1]) s[t]=1;else s[t]=0;break;case 9: t=t-1;if (s[t]==s[t+1]) s[t]=0;else s[t]=1;break;case 10:t=t-1;if (s[t]<s[t+1]) s[t]=1;else s[t]=0;break;case 11:t=t-1;if (s[t]>=s[t+1]) s[t]=1;else s[t]=0;break;case 12:t=t-1;if (s[t]>s[t+1]) s[t]=1;else s[t]=0;break;case 13:t=t-1;if (s[t]<=s[t+1]) s[t]=1;else s[t]=0;break;case 14:printf("%d",s[t]);fprintf(fa2,"%d",s[t]);t=t-1;break;case 15:printf("\n");fprintf(fa2,"\n");break;case 16:t=t+1;printf("?");fprintf(fa2,"?");scanf("%d",&s[t]);fprintf(fa2,"%d",s[t]);break;}break;case lod: t=t+1;s[t]=s[base(i.l,&b,s)+i.a];break;case sto: s[base(i.l,&b,s)+i.a]=s[t]; /*ptrintf("%d",s[t])*/t=t-1;break;case cal: s[t+1]=base(i.l,&b,s); /*generate new block mark */ s[t+2]=b;s[t+3]=p;b=t+1;p=i.a;break;case ini:t=t+i.a;break;case jmp:p=i.a;break;case jpc:if (s[t]==0) p=i.a;t=t-1;break;}}while(p!=0);f close(fa2);}main( ){i nt m=0,n=0;c har *declbeg[ ]={"constsym","varsym","procsym",NULL};c har *statbeg[ ]={"beginsym","callsym","ifsym","whilesym",NULL};c har *facbeg[ ]={"ident","number","lparen",NULL};c har *tempset[ ]={"period","constsym","varsym","procsym",NULL};d eclbegsys=(struct node *)malloc(sizeof(struct node));s tatbegsys=(struct node *)malloc(sizeof(struct node));f acbegsys=(struct node *)malloc(sizeof(struct node));t empsetsys=(struct node *)malloc(sizeof(struct node));w hile(declbeg[m]!=NULL)declbegsys->pa[n++]=declbeg[m++];d eclbegsys->pa[n]=NULL;m=0;n=0;w hile(statbeg[m]!=NULL)statbegsys->pa[n++]=statbeg[m++];s tatbegsys->pa[n]=NULL;m=0;n=0;w hile(facbeg[m]!=NULL)facbegsys->pa[n++]=facbeg[m++];f acbegsys->pa[n]=NULL;m=0,n=0;w hile(tempset[m]!=NULL)tempsetsys->pa[n++]=tempset[m++];t empsetsys->pa[n]=NULL;i f((fa1=fopen("fa1.txt","w"))==NULL){printf("Cannot open file\n");exit( 0 );}p rintf("Input file?\n");f printf(fa1,"Input file?\n");s canf("%s",fname);f printf(fa1,"%s",fname);i f((fin=fopen(fname,"r"))==NULL){printf("Cannot open file according to given filename\n");exit( 0 );}p rintf("list object code?\n");s canf("%s",fname);f printf(fa1,"list object code?\n");i f (fname[0]=='y')listswitch=true;e lselistswitch=false;e rr=0;c c=1; cx=0; ll=0;c h=' ';g etsym( );i f((fa=fopen("fa.txt","w"))==NULL){printf("Cannot open fa.txt file\n");exit( 0 );}i f((fa2=fopen("fa2.txt","w"))==NULL){printf("Cannot open fa2.txt file\n");exit( 0 );}b lock(0,add(statbegsys,tempsetsys));f close(fa);f close(fa1);i f (strcmp(sym,"period")!=0)error(9);i f (err==0)interpret( );elseprintf("%d errors in PASCAL program\n",err);f close (fin);}。
完整word版,实验一 识别无符号数的词法分析器设计实现
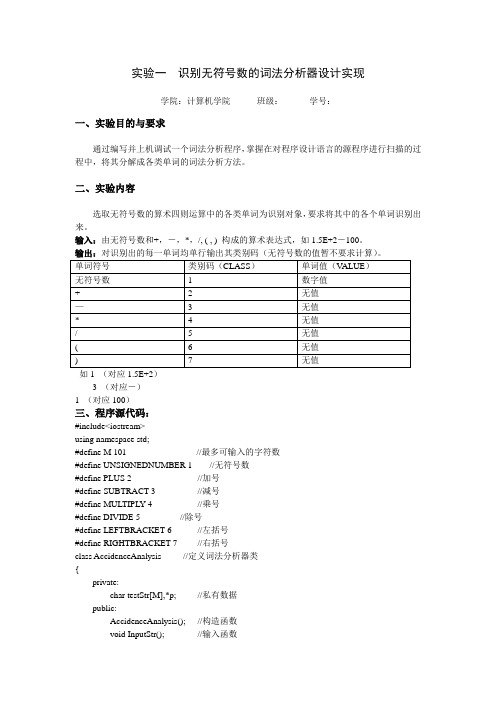
实验一识别无符号数的词法分析器设计实现学院:计算机学院班级:学号:一、实验目的与要求通过编写并上机调试一个词法分析程序,掌握在对程序设计语言的源程序进行扫描的过程中,将其分解成各类单词的词法分析方法。
二、实验内容选取无符号数的算术四则运算中的各类单词为识别对象,要求将其中的各个单词识别出来。
输入:由无符号数和+,-,*,/, ( , ) 构成的算术表达式,如1.5E+2-100。
输出:对识别出的每一单词均单行输出其类别码(无符号数的值暂不要求计算)。
如1 (对应1.5E+2)3 (对应-)1 (对应100)三、程序源代码:#include<iostream>using namespace std;#define M 101 //最多可输入的字符数#define UNSIGNEDNUMBER 1 //无符号数#define PLUS 2 //加号#define SUBTRACT 3 //减号#define MULTIPL Y 4 //乘号#define DIVIDE 5 //除号#define LEFTBRACKET 6 //左括号#define RIGHTBRACKET 7 //右括号class AccidenceAnalysis //定义词法分析器类{private:char testStr[M],*p; //私有数据public:AccidenceAnalysis(); //构造函数void InputStr(); //输入函数void Output(int a,char *p1,char *p2); //输出函数int IsAcceptantCharacter(char *p); //判断输入字符是否属于字符集int IsOperator(char *p); //判断字符是否是字符集[+,-,*,/,(,)]中的字符int IsUnsignedNum(char *p); //判断字符是否是0--9的整数void AbnormityExamine(char a[]);void IdentifyOperator(char *p); //识别字符集[+,-,*,/,(,)]中的字符void AssortIdentify(); //对输入字符分类识别};AccidenceAnalysis::AccidenceAnalysis(){int i;for(i=0;i<M;i++)testStr[i]='\0';p=&testStr[0]; //指针P指向字符数组首元素}void AccidenceAnalysis::InputStr(){cout<<"\t请按要求输入您要分析的语句,所输字符应在要求范围(不超过"<<M<<")之内,并按回车键运行:";char ch;int i=0;while((ch=cin.get())!='\n'){testStr[i]=ch;i++;}AbnormityExamine(testStr);}void AccidenceAnalysis::AbnormityExamine(char a[]){int j=0;char *ptr1,*ptr2;ptr1=a;ptr2=a;while(*ptr2!='\0'){j++;if(!IsAcceptantCharacter(ptr2)){cout<<"\t您输入的第"<<j<<"个字符"<<*ptr2<<" 不可以被此程序识别!"\ <<" 将被跳过."<<endl;ptr2++;continue;}else{*ptr1=*ptr2;ptr1++;ptr2++;}}while(ptr1<=ptr2){*ptr1='\0';ptr1++;}}void AccidenceAnalysis::Output(int a,char *p1,char *p2) {cout<<"\t类别码:"<<a<<" 单词值:";while(p1<=p2){cout<<*p1;p1++;}cout<<endl;}int AccidenceAnalysis::IsOperator(char *p){char ch=*p;if(ch=='+'||ch=='-'||ch=='*'||ch=='/'||ch=='('||ch==')') return 1;elsereturn 0;}int AccidenceAnalysis::IsUnsignedNum(char *p){char ch=*p;if('0'<=ch&&ch<='9')return 1;elsereturn 0;}int AccidenceAnalysis::IsAcceptantCharacter(char *p) {。
实验二 无符号数的算术四则运算LR语法分析器设计实现

实验二无符号数的算术四则运算LR语法分析器设计实现学院:计算机学院班级:学号:一、实验目的与要求通过设计、编制、调试一个典型的语法分析程序,实现对实验一所得词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。
二、实验内容对无符号数的算术四则运算,编制一个语法分析程序。
输入:由实验一输出的单词串,入1,3,1。
输出:如果输入单词串是合法的无符号数的算术四则运算,输出“yes”,并且给出每一步的分析过程;如果不是无符号数的算术四则运算,输出“No”;并且输出分析所得的中间结果,包括分析栈、符号栈、当前应被归约的最左子串、归约后所得的符号等。
三、实验源代码:#include<iostream>#include<iomanip>using namespace std;int chart[16][11]={{101,101,101,101,104,101,105,101,1,2,3},//定义SLR(1)分析表{106,107,101,101,101,101,101,acc,101,101,101},{203,203,108,109,101,203,101,203,101,101,101},{206,206,206,206,101,206,101,206,101,101,101},{101,101,101,101,104,101,105,101,10,3,2},{208,208,208,208,101,208,101,208,101,101,101},{101,101,101,101,104,101,105,101,101,12,3},{101,101,101,101,104,101,105,101,101,13,3},{101,101,101,101,104,101,105,101,101,101,14},{101,101,101,101,104,101,105,101,101,101,15},{106,107,101,101,101,111,101,101,101,101,101},{207,207,207,207,101,207,101,207,101,101,101},{201,201,108,109,101,201,101,201,101,101,101},{202,202,108,109,101,202,101,202,101,101,101},{204,204,204,204,101,204,101,204,101,101,101},{205,205,205,205,101,205,101,205,101,101,101}};int i,j;class GrammerAnalysis{private:int LeftSymStr[M],*p1;//定义余留符号串和指向它的指针int Status[M],*p2;//定义状态和指向它的指针int Stack[M],*p3;//定义分析栈和指向它的指针int TopSat,InpSym;//栈顶状态,当前输入单词public:GrammerAnalysis();~GrammerAnalysis();int ConcludeSwitch(int a);////用来归约的产生式号,返回ETF,9,10,11int ETFtoNum(int a);//查GOTO表用来转换int SearchAction(int a,int b);//查询动作表int SearchGoto(int a,int b);//查询状态转移表int BackChNum(int a);//归约产生式回退字符个数void InputWords();//输入单词void PushStatus(int a);//状态号压栈void Advance(int a);//将余留符号串的当前字符移入分析栈void PopStack(int a);//归约时分析栈回退字符void PopStatus(int a);//归约时状态栈栈回退字符void NumToChar(int a);//数字转换为字符void StaNumToStaCh(int a);//状态号大于10时转换为字符void Output(int *p1,int *p2,int *p3);void Analysis();void Error();};int GrammerAnalysis::SearchAction(int a,int b){return ACTION[a][b-1];}int GrammerAnalysis::SearchGoto(int a,int b){return GOTO[a][b];}void GrammerAnalysis::StaNumToStaCh(int a){switch(a){case 10:cout<<"A";break;case 11:cout<<"B";break;case 12:cout<<"C";break;case 13:break;case 14:cout<<"E";break;case 15:cout<<"F";break;default:break;}}void GrammerAnalysis::NumToChar(int a) {switch(a){case 1:cout<<"i";break;case 2:cout<<"+";break;case 3:cout<<"-";break;case 4:cout<<"*";break;case 5:cout<<"/";break;case 6:cout<<"(";break;case 7:cout<<")";break;case 8:cout<<"#";break;case 9:cout<<"E";break;case 10:break;case 11:cout<<"F";break;default:break;}}void GrammerAnalysis::Output(int *p1,int *p2,int *p3) {int static k=11;cout<<k<<" ";int *p4;p4=&Status[0];while(p4<=p2){if(*p4>=10)StaNumToStaCh(*p4);elsecout<<*p4;p4++;}cout<<"\t"<<" ";int *p5;p5=&Stack[0];while(p5<=p3){NumToChar(*p5);p5++;}cout<<" \t";int *p6;p6=p1;p6--;do{p6++;cout.setf(ios::right);NumToChar(*p6);}while(*p6!=8);cout<<" ";cout<<"\t";cout.setf(ios::left);if(SearchAction(*p2,*p1)/10==1){cout<<"S"<<SearchAction(*p2,*p1)%10;cout<<"\t";int nextStatus=SearchAction(*p2,*p1)%10;//下一状态if(nextStatus>=10)StaNumToStaCh(nextStatus);elsecout<<nextStatus;}else if(SearchAction(*p2,*p1)/10==2){cout<<"R"<<SearchAction(*p2,*p1)%10;cout<<"\t";int a=BackChNum(SearchAction(*p2,*p1)%10);int *Ptr=p2;while(a!=0){Ptr--;a--;}intnextStatus=SearchGoto(*Ptr,ETFtoNum(ConcludeSwitch(SearchAction(*p2,*p1)%10)));if(nextStatus>=10)StaNumToStaCh(nextStatus);elsecout<<nextStatus;}else if(SearchAction(*p2,*p1)/10==11){cout<<"S"<<"15";cout<<"\t"<<"F";}else if((SearchAction(*p2,*p1)/10)==3)cout<<"acc";k++;cout<<endl<<endl;if(k%99==0)k=11;}GrammerAnalysis::GrammerAnalysis(){for(int i=0;i<M;i++){LeftSymStr[i]=-1;Status[i]=-1;Stack[i]=-1;}Status[0]=0;Stack[0]=8;p1=&LeftSymStr[0];p2=&Status[0];p3=&Stack[0];}int main() {GrammerAnalysis Gra;Gra.InputWords();Gra.Analysis();return 0;}四、实验结果及分析:1 正确的输入2错误的输入:。
词法分析程序的设计与实现

词法分析程序的设计与实现方法1:采用C作为实现语言,手工编制一.文法及状态转换图1.语言说明:C语言有以下记号及单词:(1)标识符:以字母开头的、后跟字母或数字组成的符号串。
(2)关键字:标识符集合的子集,该语言定义的关键字有32个,即auto,break,case,char,const,continue,default,do,double,else,enum, extern,float,for,goto,if,int,long,register,return,short,signed,static, sizeof,struct,switch,typedef ,union,unsigned ,void, volatile和while。
(3)无符号数:即常数。
(4)关系运算符:<,<=,==,>,>=,!=。
(5)逻辑运算符:&&、||、!。
(6)赋值号:=。
(7)标点符号:+、++、-、--、*、:、;、(、)、?、/、%、#、&、|、“”、,、.、{}、[]、_、^等(8)注释标记:以“/*”开始,以“*/”结束。
(9)单词符号间的分隔符:空格。
2.记号的正规文法:仅给出各种单词符号的文法产生式(1)标识符的文法id->letter ridrid->ε|letter rid|digit rid(2)无符号整数的文法digits->digit remainderremainder->ε|digit remainder(3)无符号数的文法num->digit num1num1->digit num1|. num2|E num4|εnum2->digit num3num3->digit num3|E num4|εnum4->+digits|-digits|digit num5digits->digit num5num5->digit num5|ε(4)关系运算符的文法relop-> <|<=|==|>|>=|!=(5)赋值号的文法assign_op->=(6)标点符号的文法special_symbol->+|-|*|%|#|^|(|)|{|}|[|]|:|;|”|?|/|,|.& (7)逻辑运算符的文法logic->&&| || | !(8)注释头符号的文法note->/starstar->*3.状态转换图其中,状态0是初始状态,若此时读入的符号是字母,则转换到状态1,进入标识符识别过程;如果读入的是数字,则转换到状态2,进入无符号数识别过程;……;若读入的符号是/,转换到状态11,再读入下一个符号,如果读入的符号是*,则转换到状态12,进入注释处理状态;如果在状态0读入的符号不是语言所定义的单词符号的开始字符,则转换到状态13,进入错误处理状态。
无符号数的词法分析程序

#include<iostream>#include<cctype>#include<cstring>#include<cmath>using namespace std;int w=0; //尾数累加器int p=0; //指数累加器int j=0; //十进制小数位数计数器int e=1; //用来记录十进制数的符号,当指数为正时为1,为负时为-1int i=0; //用来标志元素位置int d=0; //用来表示每个数值型元素对应的数值const int N=40;//用来确定输入识别符的最大长度char data[N];//存放输入的识别符bool is_digit; //标志是否是数字string CJ1;//确定是整形还是实型double CJ2;//记数值//函数声明void check(char c);//检查首字母是否是数字的函数void deal_integer(char c);//处理识别符的整数部分void deal_point(char c);//用来处理小数部分void deal_index(char c);//用来处理指数部分void s_next();// 确定实型void z_next();//确定整型void last();// 计算CJ2void error();//程序中错误处理程序void deal();//处理函数主体int main(){ //主函数cout<<"please input your data,and its maximum length is "<<N<<":"<<endl;//等待用户输入识别符cin>>data;deal();//处理函数主体last();// 计算CJ2system("pause");return 0;}void check(char c) //判断输入的首字母是否是数字{is_digit=isdigit(c);while(is_digit!=true){//输入的首字母不是数字时cout<<"\nError! Try again.."<<endl;//要求重新输入cin>>data;check(data[0]);}}void deal_integer(char c){//处理识别符的整数部分d=(int)c-48;w=w*10+d;i++;if(isdigit(data[i])!=0)//下一个仍是数值时,调用程序本身deal_integer(data[i]);}void deal_point(char c){//用来处理小数部分int temp=i;if(isdigit(c)!=0)//是数值字符时deal_integer(c);else{ error(); //错误处理程序deal();//处理函数主体}j=i-temp;//记录十进制小数位数}void deal_index(char c){//用来处理指数部分if(c=='-') {e=-1;i++;}//是'-'号时else {if(c=='+') i++;//是'+' 号时else {if(isdigit(c)==false) //非数值字符时{ error();//错误处理程序deal();//处理函数主体}else{ d=(int)c-48;//把输入字符转换为整型goto pro2;}}}if(isdigit(data[i])!=0)pro1: d=(int)(data[i])-48;pro2: p=p*10+d;i++;if(isdigit(data[i])!=0)//是数值字符时goto pro1;else if(data[i]!='\0'){//非结束标志error();//错误处理程序deal();//处理函数主体}else s_next(); // 确定实型}void s_next(){// 确定实型i--;//退一个字符CJ1="实型";}void z_next(){//确定整型i--;//退一个字符CJ1="整型";}void last(){// 计算CJ2CJ2=w*pow((double)10,e*p-j);cout<<CJ1<<": "<<CJ2<<endl;//输出}void error(){//程序中错误处理程序cout<<"\nError! Try again.."<<endl;//重新输入数据cin>>data;p=0;w=0;j=0; //所有全局变量重新初始化e=1;i=0;d=0;//exit(0);}void deal(){check(data[0]);//判断输入的首字母是否是数字deal_integer(data[i]);//处理识别符的整数部分if(data[i]=='.'){ deal_point(data[++i]);//用来处理小数部分if(data[i]=='e'||data[i]=='E')//如果是e或E时deal_index(data[++i]);//用来处理指数部分else if(data[i]!='\0'){ error();//错误处理程序deal();//处理函数主体}else s_next();// 确定实型}else { if(data[i]=='e'||data[i]=='E')//如果是e或E时{ deal_index(data[++i]);//用来处理指数部分//CJ1="整型";}else if(data[i]!='\0'){ //非结束标志error();//错误处理程序deal();//处理函数主体}elsez_next();//确定整型}}。
实验2 词法分析

实验2 词法分析(4学时)实验要求:1. TEST语言的单词符号有:标识符:字母打头,后接字母数字,识别出的标识符用ID标记。
保留字(它是标识符的子集):if,else,for,while,do,int,write,read,识别出的保留字直接用该保留字标记。
无符号整数:由数字组成,用NUM标记。
分界符:+、-、*、/、(、)、;、,>、<、{、}、!等单分界符,直接用单分界符标记。
>=、<=、!=、==等双字符分界符,直接用双分界符标记。
注释符:用/*….*/括起为了从源程序字符流中正确识别出各类单词符号,相邻的标识符、整数或保留字之间至少要用一个空格分开。
TEST语言的各类单词符号的正则文法规则如下:<ID>∷=<letter>|ID<letter>|ID<digit><NUM>∷=<digit>|NUM <digit><letter>∷= a|b|…|z|A|B|…|Z<digit>∷=1|2|…|9|0<singleword>∷=+|-|*|/|=|(|)|{|}|:|,|;|<|>|!<doubleword>∷=>=|<=|!=|==<commend_first>∷=/*<commend_last>∷=*/2、修改TESTscan()程序,添加其余符号的处理。
1、AAA.test内容:= + - * / < > ( ) [ ] { } ; : ' " , == >= <= !=if else for while do int read write 358 aaa输出BBB.test的内容为:if else for while do int read write 358 aaaif else for while do int read write NUM ID这部分实验要求同学理解单词符号。
词法分析及词法分析程序

42
识别无符号数的状态矩阵
当前状 态 0 扫描字符 d . ther d . E other d E other d other d + other d other d other 语义处理操作或接受动作 {w=0;n=0;p=0;e=1;w=w*10+d} {w=0;n=0;p=0;e=1;} error {w=w*10+d;} {return ( ICON= w ); {n++; w=w*10+d;} {return (FCON =w*pow(10,e*p-n) ) ;} {n++;w=w*10+d;} error {p=p*10+d;} e=-1; error {p=p*10+d;} error {p=p*10+d;} {return (FCON=w*pow(10,e*p-n) ); 后继状 态 1 3 1 2 4 end 2 4 end 2 6 5 5 6 6 end
实验3__识别无符号数的词法分析器设计实现c 汇总

实验三识别无符号数的词法分析器程序设计一、实验目的与要求通过编写并上机调试一个词法分析程序,掌握在对程序设计语言的源程序进行扫描的过程中,将源程序分解成各类单词的词法分析方法。
二、实验重难点DFA无符号数的词法分析器编码实现三、实验内容与要求1.阅读实验案例,明确实验要求和程序实现方案;2.参考实验案例,完善该无符号数的词法分析器设计程序。
四、实验学时2课时五、实验设备与环境C语言编译环境六、实验案例1.无符号数的词法分析器原理(1)正规式表示:Unsigned digital: d…d…d…dESd…d, it includes four regular expressions: dd* 如:5 56 567d*.dd* 如:.5 5.6 5.67d*ESdd* 如:E5 E+56 5E-67d*.dd*ESdd* 如:.5E5 5.65E+56 5.4E-67whileV T={0, ···,9, ·,+,-,E}d =0|1| ···|9S = +|-|ε(2)NFA表示:(3)经过NFA转DFA和DFA的化简后得到无符号数的DFA表示:2.设计要求选取无符号数的算术四则运算中的各类单词为识别对象,要求将其中的各个单词识别出来。
输入:由无符号数和+,-,*,/, ( , ) 构成的算术表达式,如1.5E+2-100。
如1 (对应1.5E+2)3 (对应-)1 (对应100)3、程序源代码:1.cp p4、运行结果:测试用例1:0.23E-12-E12结论:(1)案例中的程序只给出了A到B\C及其后续通路的程序,没有给出A到D及其后续通路的程序。
因此不能识别E12是一个无符号数。
测试用例2:0.23E*12/a(0.23E-12)结论:(2)案例中的程序只给出了若输入的字符串符合无符号数的DFA语法规则,将该无符号数识别出来,并没有给出当输入的字符串不符合无符号数的DFA语法规则时,如何处理。
词法分析程序设计

词法分析程序设计词法分析是编译器设计中的一个关键步骤,它负责将源代码文本转换成一系列的词法单元(tokens),这些词法单元是语法分析阶段的输入。
词法分析程序的设计通常包括以下几个主要部分:定义词法规则、构建词法分析器、生成词法单元以及错误处理。
1. 定义词法规则词法规则是词法分析器识别源代码中各种词法单元的基础。
这些规则通常包括关键字、标识符、常量(如数字和字符串)、运算符和分隔符等。
例如,对于C语言,词法规则可能包括识别`int`、`float`等关键字,以及识别变量名、数字和字符串字面量等。
2. 构建词法分析器构建词法分析器的过程通常涉及到选择一个合适的算法或工具。
常见的方法有手工编写词法分析器、使用词法分析生成器(如Lex或Flex)来自动生成词法分析器。
手工编写词法分析器手工编写词法分析器需要程序员根据词法规则,使用编程语言(如C、Java等)实现一个扫描器(scanner)。
扫描器的主要任务是逐字符地读取源代码,并根据词法规则识别出词法单元。
使用词法分析生成器使用词法分析生成器可以大大简化词法分析器的开发过程。
开发者只需定义词法规则,并使用生成器工具来生成扫描器代码。
例如,Flex是一个基于正则表达式的词法分析生成器,它可以从定义的规则中自动生成C或C++代码。
3. 生成词法单元词法单元是词法分析器输出的基本单位。
每个词法单元通常包含两个部分:类型和值。
类型指明词法单元的种类(如关键字、标识符等),而值则是词法单元的具体内容(如标识符的名称、数字的值等)。
在生成词法单元时,词法分析器需要根据识别出的词法规则,将源代码中的字符序列转换成相应的词法单元。
例如,当词法分析器读取到`123`时,它应该识别这是一个整数常量,并生成一个类型为`INTEGER`,值为`123`的词法单元。
4. 错误处理在词法分析过程中,可能会遇到不符合词法规则的字符序列,这时就需要进行错误处理。
错误处理通常包括以下几个方面:- 识别错误:当遇到无法识别的字符或字符序列时,词法分析器应该能够识别出这是一个错误。
【编译原理实验】词法分析器程序设计

【编译原理实验】词法分析器程序设计1. 实验内容设计、编制并调试⼀个简单语⾔CP(Compiler Principle)的词法分析程序,加深对词法分析原理的理解。
CP语⾔的词法:(1) 关键词: begin end if then else for while do and or not注意:所有关键词都是⼩写的。
(2) 标识符ID,与标准C语⾔⼀致,即:以下划线或字母开头的字母数字下划线组成的符号串。
(3)⽆符号整数NUM:数字串(4)运算符和分界符: +、-、*、/、>、<、=、:=、>=、<=、<>、++、--、(、)、; 、 #注意::=表⽰赋值运算符、#表⽰注释开始的部分,;表⽰语句结束,<>表⽰不等关系(5)空⽩符包括空格、制表符和换⾏符,⽤于分割ID、NUM、运算符、分界符和关键词,词法分析阶段要忽略空⽩符。
2. 实验要求(1) 给出各类单词符号的分类编码。
(2) 词法分析程序应该能发现输⼊串中的错误。
(3) 词法分析作为单独⼀遍,将词法分析程序输出的⼆元式序列保存为中间⽂件形式。
3. 设计思路先给各类单词符号编码(见下图),以⽂档的形式输⼊将要识别的符号串,并将其存放在⼀个数组中,从前往后,每次根据识别到的第⼀个字符X做出如下操作:(1)X为空⽩符:跳过X继续往下判断。
(2)X为注释符:识别注释符#,跳过其后的字符直到跳过换⾏符结束。
(3)X为数字符:记录此字符及其后⾯的字符直到遇到⼀个⾮数字符,若该⾮数字符为空⽩符、运算符或分界符,则将记录的这⼀段识别为数字串;否则,继续往后记录直到遇到空⽩符、运算符或分界符,并将记录的这⼀段识别为错误单词。
(4)X为运算符:判断X和其后的⼀个字符是否能组成运算符,若能则将X和其后的字符组合识别成运算符,否则直接识别X为运算符。
(5)X为字母符或下划线:记录此字符及其后⾯的字符直到遇到空⽩符、运算符或分界符,若记录的符号串能匹配到关键词,则将其识别为关键词,否则将其识别为标识符。
编译原理实验程序无符号数四则运算.doc

// The Compiler Of Computing Unsigned Digitals In Four Forms ,Made By //ChenShuan ,QQ:790978890,described in C++ Language#include<iostream>#include<iomanip>using namespace std; //使用标准命名空间#define M 101 //定义可输入的字符个数#define UNSIGNEDNUMBER 1 //无符号数#define PLUS 2 //加号#define SUBTRACT 3 //减号#define MULTIPLY 4 //乘号#define DIVIDE 5 //除号#define LEFTBRACKET 6 //左括号#define RIGHTBRACKET 7 //右括号#define INEFFICACIOUSSTR 8 //无效字符串/*----------------------------------------------i 1+ 2- 3* 4/ 5( 6) 7# 8E 9T 10F 11S代表移近操作1xxR代表归约操作2xxacc 300 识别成功0 识别失败-----------------------------------------------*///ACTON表,百位代表是移进还是归约操作,分别为1,2//十位和个位代表下一状态号或所用来归约的产生式号int ACTION[16][8]={{105,0,0,0,0,104,0,0},{0,106,107,0,0,0,0,300},{0,203,203,108,109,0,203,203},{0,206,206,206,20 6,0,206,206},{105,0,0,0,0,104,0,0},{0,208,208,208,208,0,208,208},{105,0,0,0,0,104,0,0},{105,0,0,0,0,104,0,0 },{105,0,0,0,0,104,0,0},{105,0,0,0,0,104,0,0},{0,106,107,0,0,0,115,0},{0,201,201,108,109,0,201,2 01},{0,202,202,108,109,0,202,202},{0,204,204,204,204,0,204,204},{0,205,205,205,205,0,205,205},{ 0,207,207,207,207,0,207,207}};//GOTO表intGOTO[10][3]={{1,2,3},{0,0,0},{0,0,0},{0,0,0},{10,2,3},{0,0,0},{0,11,3},{0,12,3},{0,0,13},{0,0, 14}};/*---------------------------------------------------------------------------------------无符号数形式分类情况1:.123E+4 || 123.4E+5 包含. + E情况2:.123E4 || 123.E4 包含. E情况3:123E+4 包含+ E情况4:.123 || 123.4 包含.情况5:123E4 包含 E情况6:123-----------------------------------------------------------------------------------------*/class Compile //定义词法分析类{private:char TestStr[M],*p; //输入的待分析字符串,和指向它的首地址的指针int LeftSymbelStack[M],*p1;//定义余留符号串栈和指向它的首地址的指针int StatusStack[M],*p2;//定义状态栈和指向它的首地址的指针int AnalysisStack[M],*p3;//定义分析栈和指向它的首地址的指针int TopSat,InpSym;//状态栈顶状态,预留符号栈当前输入单词double CalculateStack[M],*ptrcal;//定义计算数值用的计算栈和指向它的首地址的指针double UnsignedFigure[M];//存放每个无符号数的值int ReducedActNumStack[M];//语义分析时的归约动作所用产生式代号栈char pause;//GetPuased()//程序运行暂停函数的输入变量int Count0;//初始化余留分析串数组,数组下标int Count1;//进行存数时初始化无符号数数组,数组下标int Count2;//进行取数时标记无符号数数组元素下标int Count3;//初始化归约动作产生式代号栈时,标记数组下标int Count4;//从归约动作产生式代号栈提取代号时,标记数组下标bool MarkInefficaciousStr;//标记余留分析串数组是否有无效串产生bool MarkFirstPushCalStack;//计算运算式数值时标记是否是第一次将无符号数压入计算栈public:Compile(); //构造函数~Compile(); //析构函数void InputTestStr(); //输入字符序列函数bool Start_EllegalCharExamine(); //非法字符检测函数//词法分析所用函数bool Start_AccidenceAnalysis(); //词法分析控制函数int IfLlegalChar(char *p); //判断输入字符是否属于字符集int IfOperator(char *p); //判断字符是否是字符集[+,-,*,/,(,)]中的字符int IfZeroToNine(char *p); //判断字符是否是0--9的整数void Identify_Operator(char *p); //识别字符集[+,-,*,/,(,)]中的字符char * Identify_UnsignedFigure(char *p);//识别无符号数char * Identify_InefficaciousStr(char *p1,char *p2);//识别无效字符串,在识别无符号数过程中未进入终态而无法继续识别时调用void AcciAnaly_Out_InitUnsignedFigure(int a,char *p1,char *p2); //输出词法分析结果的函数//语法分析所用函数bool Start_GrammarAnalysis();//语法分析控制函数int SearchACTION(int a,int b);//查询动作表int SearchGOTO(int a,int b);//查询状态转移表void PushStatusStack(int a);//下一个状态号压入状态栈void PushAnalysisStack(int a);//将余留符号串的当前字符移入分析栈int PopStatus_AnalysisStack_PtrBackNum(int a);//返回用产生式归约时分析栈和状态栈指针要回退字符的个数void PopAnalysisStack(int a);//归约时分析栈指针回退,回退字符数由PopStatus_AnalysisStack_PtrBackNum(int a)提供void PopStatusStack(int a);//归约时状态栈指针回退,回退字符数由PopStatus_AnalysisStack_PtrBackNum(int a)提供int GramAnaly_Reduced_ETFtoNum(int a);//归约时状态栈中用来确定产生式左边的符号数号,返回ETF,9,10,11int SearchGOTO_ETFto012(int a);//查GOTO表用来把ETF转换为列标012void GramAnaly_Out_AnalysisStackNumToChar(int a);//进行语法分析时,分析栈和预留符号栈中的数字转换为字符函数:i 1+ 2- 3* 4/ 5( 6) 7# 8E 9T 10 F 11void GramAnaly_Out_StatusStack10_15ToA_F(int a);//输出时状态栈中状态号大于10时转换为字符:10 ~15=A~Fvoid GramAnaly_Out_InitReducedActStack(int *p1,int *p2,int *p3);//输出语法分析过程,同时初始化语义分析时所用的归约动作产生式代号栈//语义分析所用函数void Start_SemanticsAnalysis();//语义分析控制函数//语义分析时输出四元式、计算运算式数值函数void SemAnaly_Out_CalculEntireV alue(int a);//输出四元式、计算整个运算式的数值void SemAnaly_Out(int a1,double a2,double a3,double a4);//语义分析四元式输出//计算无符号数所用函数int Calculate_IntegerPart(char *p1,char *p2);//计算整数部分double Calculate_DecimalPart(char *p1,char *p2);//计算小数部分double Calculate_ScientificFigure(double a,char b,int c);//计算科学计数,a为E前数,b决定是+还是-,c是次幂数,double Calculate_UnsignedFigure(char *p1,char *p2);//计算无符号数//异常处理void Start_ExceptionHandler(int a);//异常处理函数,参数说明:1:非法字符处理,2:词法错误处理,3:语法错误处理void GetPuased();//程序运行暂停点void Scroll();//输出条线};void Compile::SemAnaly_Out(int a1,double a2,double a3,double a4){char ch;switch(a1){case 1:ch='+';break;case 2:ch='-';break;case 4:ch='*';break;case 5:ch='/';break;default:break;}Scroll();cout<<"\n\t【"<<a2<<"\t"<<ch<<"\t"<<a3<<" \t="<<a4<<"】\n\n";}void Compile::Start_SemanticsAnalysis(){cout<<"\n\t语义分析结果显示:\n";do{SemAnaly_Out_CalculEntireV alue(ReducedActNumStack[Count4++]);//只有在进行归约动作时才调用计算运算式函数}while(ReducedActNumStack[Count4-1]!=0);//没有遇到语义分析时的归约动作所用产生式代号栈的栈底进行语义分析及计算}void Compile::GetPuased(){Scroll();cout<<"\t按Enter键重新输入.";cin.get(pause);system("cls");}void Compile::Start_ExceptionHandler(int a){switch(a){case 1://非法字符处理cout<<"\n\t警告!您所输入的字符序列包含非字符集字符,不可以进行词法分析!\n";GetPuased();break;case 2://词法错误处理cout<<"\n\t警告!您所输入的字符序列包含无效单词,类别码为8,不可以进行语法分析!\n";GetPuased();break;case 3://语法错误处理cout<<"\n\t警告!您所输入的字符序列不符合无符号数四则运算语法,不可以进行数值计算!\n";GetPuased();break;default:break;}}char * Compile::Identify_InefficaciousStr(char *p1,char *p2){AcciAnaly_Out_InitUnsignedFigure(INEFFICACIOUSSTR,p1,p2);return p2;}char * Compile::Identify_UnsignedFigure(char *p){char *p1=p;//p指针已变为本函数的局部变量,不再影响主调函数if(IfZeroToNine(p)){while(IfZeroToNine(p))p++;if(*p=='\0'){AcciAnaly_Out_InitUnsignedFigure(UNSIGNEDNUMBER,p1,--p);goto End;}else if(*p=='E'){p++;if(IfZeroToNine(p)){while(IfZeroToNine(p))p++;AcciAnaly_Out_InitUnsignedFigure(UNSIGNEDNUMBER,p1,--p);goto End;}else if(*p=='+'||*p=='-'){p++;if(IfZeroToNine(p)){while(IfZeroToNine(p))p++;AcciAnaly_Out_InitUnsignedFigure(UNSIGNEDNUMBER,p1,--p);goto End;}else{p=Identify_InefficaciousStr(p1,--p);goto End;}}else{p=Identify_InefficaciousStr(p1,--p);goto End;}}else if(*p=='.'){p++;while(IfZeroToNine(p))p++;if(*p=='\0'){AcciAnaly_Out_InitUnsignedFigure(UNSIGNEDNUMBER,p1,--p);goto End;}else if(*p=='E'){p++;if(IfZeroToNine(p)){while(IfZeroToNine(p))p++;AcciAnaly_Out_InitUnsignedFigure(UNSIGNEDNUMBER,p1,--p);goto End;}else if(*p=='+'||*p=='-'){p++;if(IfZeroToNine(p)){while(IfZeroToNine(p))p++;AcciAnaly_Out_InitUnsignedFigure(UNSIGNEDNUMBER,p1,--p);goto End;}else{p=Identify_InefficaciousStr(p1,--p);goto End;}}else{p=Identify_InefficaciousStr(p1,--p);goto End;}}else{AcciAnaly_Out_InitUnsignedFigure(UNSIGNEDNUMBER,p1,--p);goto End;}}else{AcciAnaly_Out_InitUnsignedFigure(UNSIGNEDNUMBER,p1,--p);goto End;}}else if(*p=='.'){p++;if(IfZeroToNine(p)){while(IfZeroToNine(p))p++;if(*p=='\0'){AcciAnaly_Out_InitUnsignedFigure(UNSIGNEDNUMBER,p1,--p);goto End;}else if(*p=='E'){p++;if(IfZeroToNine(p)){while(IfZeroToNine(p))p++;AcciAnaly_Out_InitUnsignedFigure(UNSIGNEDNUMBER,p1,--p);goto End;}else if(*p=='+'||*p=='-'){p++;if(IfZeroToNine(p)){while(IfZeroToNine(p))p++;AcciAnaly_Out_InitUnsignedFigure(UNSIGNEDNUMBER,p1,--p);goto End;}else{p=Identify_InefficaciousStr(p1,--p);goto End;}}else{p=Identify_InefficaciousStr(p1,--p);goto End;}}else{AcciAnaly_Out_InitUnsignedFigure(UNSIGNEDNUMBER,p1,--p);goto End;}}else{p=Identify_InefficaciousStr(p1,--p);goto End;}}End:return p;}int Compile::SearchACTION(int a,int b){return ACTION[a][b-1];}int Compile::SearchGOTO(int a,int b){return GOTO[a][b];}void Compile::GramAnaly_Out_StatusStack10_15ToA_F(int a) {switch(a){case 10:cout<<"A";break;case 11:cout<<"B";break;case 12:cout<<"C";break;case 13:cout<<"D";break;case 14:cout<<"E";break;case 15:cout<<"F";break;default:break;}}void Compile::GramAnaly_Out_AnalysisStackNumToChar(int a) {switch(a){case 1:cout<<"i";break;case 2:cout<<"+";break;case 3:cout<<"-";break;case 4:cout<<"*";break;case 5:cout<<"/";break;case 6:cout<<"(";break;case 7:cout<<")";break;case 8:cout<<"#";break;case 9:cout<<"E";break;case 10:cout<<"T";break;case 11:cout<<"F";break;default:break;}}void Compile::GramAnaly_Out_InitReducedActStack(int *p1,int *p2,int *p3) {cout<<"\t";int static k=11;cout<<k<<"";int *p4;p4=&StatusStack[0];while(p4<=p2)//输出状态栈信息{if(*p4>=10)GramAnaly_Out_StatusStack10_15ToA_F(*p4);elsecout<<*p4;p4++;}cout<<"\t"<<" ";int *p5;p5=&AnalysisStack[0];while(p5<=p3)//输出分析栈信息{GramAnaly_Out_AnalysisStackNumToChar(*p5);p5++;}cout<<" \t";int *p6;p6=p1;p6--;do{p6++;cout.setf(ios::right);GramAnaly_Out_AnalysisStackNumToChar(*p6);}while(*p6!=8);cout<<" ";cout<<"\t";cout.setf(ios::left);if(SearchACTION(*p2,*p1)<200){cout<<"S"<<SearchACTION(*p2,*p1)-100;cout<<"\t";int nextStatus=SearchACTION(*p2,*p1)-100;//下一状态if(nextStatus>=10)GramAnaly_Out_StatusStack10_15ToA_F(nextStatus);elsecout<<nextStatus;//输出下一状态}else if(SearchACTION(*p2,*p1)<300){cout<<"R"<<SearchACTION(*p2,*p1)-200;ReducedActNumStack[Count3++]=SearchACTION(*p2,*p1)-200;//将归约动作所用的产生式代号压入语义分析时的归约动作栈cout<<"\t";int a=PopStatus_AnalysisStack_PtrBackNum(SearchACTION(*p2,*p1)-200);int *Ptr=p2;while(a!=0){Ptr--;a--;}intnextStatus=SearchGOTO(*Ptr,SearchGOTO_ETFto012(GramAnaly_Reduced_ETFtoNum(Searc hACTION(*p2,*p1)-200)));if(nextStatus>=10)GramAnaly_Out_StatusStack10_15ToA_F(nextStatus);elsecout<<nextStatus;//输出下一状态}else if(SearchACTION(*p2,*p1)==300){cout<<"acc";ReducedActNumStack[Count3++]=0;//当语法分析成功时将0压入语义分析栈,作为结束符}k++;cout<<endl<<endl;if(k%99==0)k=11;Scroll();}Compile::Compile(){int i;for(i=0;i<M;i++)TestStr[i]='\0';p=&TestStr[0]; //指针P指向字符数组首元素for(i=0;i<M;i++){LeftSymbelStack[i]=-1;StatusStack[i]=-1;AnalysisStack[i]=-1;}StatusStack[0]=0;AnalysisStack[0]=8;//#号入栈p1=&LeftSymbelStack[0];p2=&StatusStack[0];p3=&AnalysisStack[0];ptrcal=&CalculateStack[0];MarkInefficaciousStr=true;pause='\0';Count0=0;Count1=0;Count2=0;Count3=0;Count4=0;MarkFirstPushCalStack=true;}Compile::~Compile(){}void Compile::PopAnalysisStack(int a){int i=a;do{*p3=-1;i--;if(i==0)break;p3--;}while(i>=0);}void Compile::PopStatusStack(int a){int i=a;do{*p2=-1;i--;if(i==0)break;p2--;}while(i>=0);}int Compile::GramAnaly_Reduced_ETFtoNum(int a)//归约时调用{int a1;switch(a){case 1:case 2:case 3:a1=9;break;case 4:case 5:case 6:a1=10;break;case 7:case 8:a1=11;break;default:break;}return a1;}int Compile::SearchGOTO_ETFto012(int a){int a1;switch(a){case 9:a1=0;break;case 10:a1=1;break;case 11:a1=2;break;default:break;}return a1;}int Compile::PopStatus_AnalysisStack_PtrBackNum(int a) {int a1;switch(a){case 3:case 6:case 8:a1=1;break;case 1:case 2:case 4:case 5:case 7:a1=3;break;default:break;}return a1;}void Compile::PushStatusStack(int a){*p2=a;}void Compile::PushAnalysisStack(int a){*p3=a;}bool Compile::Start_GrammarAnalysis(){bool Flag;cout<<"\t语法分析结果显示:"<<endl;Scroll();LeftSymbelStack[Count0]=8;//向余留符号串栈添加末位符号#cout<<"\t步骤"<<" "<<"状态"<<"\t"<<" 栈中符号"<<"\t"<<"余留符号串"\<<" 分析动作"<<" 下一状态"<<endl<<endl;//输出表头TopSat=0;InpSym=*p1;GramAnaly_Out_InitReducedActStack(p1,p2,p3);while(SearchACTION(TopSat,InpSym)!=300){if(SearchACTION(TopSat,InpSym)==0){cout<<"\n\tError!"<<endl;//语法分析出错时报错break;}else if(SearchACTION(TopSat,InpSym)<200){p2++;PushStatusStack(SearchACTION(TopSat,InpSym)-100);//状态号压栈TopSat=SearchACTION(TopSat,InpSym)-100;//当前状态p3++;PushAnalysisStack(InpSym);//当前字符入分析栈p1++;//p1指针后移InpSym=*p1;//当前分析字符GramAnaly_Out_InitReducedActStack(p1,p2,p3);continue;}else if(SearchACTION(TopSat,InpSym)<300){PopAnalysisStack(PopStatus_AnalysisStack_PtrBackNum(SearchACTION(TopSat,InpSym) -200));//分析栈指针回退字符数等于用来归约的产生式右边符号数PushAnalysisStack(GramAnaly_Reduced_ETFtoNum(SearchACTION(TopSat,InpSym)-200 ));//将归约后的产生式左边符号转换为数字压入分析栈PopStatusStack(PopStatus_AnalysisStack_PtrBackNum(SearchACTION(TopSat,InpSym)-20 0));//状态栈指针回退字符数等于用来归约的产生式右边符号数p2--;//计算下一状态时需用的状态号TopSat=SearchGOTO(*p2,SearchGOTO_ETFto012(*p3));//归约后的状态p2++;//p2回到即将被压栈的地方PushStatusStack(TopSat);//归约后的状态号压栈,p1指针保持不变GramAnaly_Out_InitReducedActStack(p1,p2,p3);continue;}}if(SearchACTION(TopSat,InpSym)==0){cout<<endl<<"\t语法分析失败."<<endl;Flag=false;}else{cout<<endl<<"\t语法分析完毕."<<endl;Scroll();Flag=true;}return Flag;}double Compile::Calculate_DecimalPart(char *p1,char *p2){char *p_1=p1,*p_2=p2;int i,j,m;double sum=0.0;m=p_2-p_1;i=0;while(p_1<=p_2&&i<=m){double k=1;double temp=double(*p_1-48);for(j=0;j<=i;j++)k*=0.1;temp*=k;sum+=temp;p_1++;i++;}return sum;}int Compile::Calculate_IntegerPart(char *p1,char *p2)//计算整数部分{char *p_1=p1,*p_2=p2;int i,j,sum=0;i=p_2-p_1;while(p_1<=p_2){int k=1;int temp=int(*p_1-48);for(j=0;j<i;j++)k*=10;temp*=k;sum+=temp;p_1++;i--;}return sum;}double Compile::Calculate_ScientificFigure(double a,char b,int c)//计算科学计数{double ScientificFigure;int i;if(b=='+')//E+{int k=1;for(i=0;i<c;i++)k*=10;a*=k;ScientificFigure=a;}else if(b=='-')//E-{double k=1.0;for(i=0;i<c;i++)k*=0.1;a*=k;ScientificFigure=a;}return ScientificFigure;}double Compile::Calculate_UnsignedFigure(char *p1,char *p2){double Result;char *p_1=p1,*p_2=p2;int Label1=0,Label2=0,Label3=0,Label4=0;//label1:标记. label2标记E label3标记+-号label4标记本函数的switch分支while(p_1<=p_2){if(*p_1=='.')Label1=1;if(*p_1=='E')Label2=1;if(*p_1=='+'||*p_1=='-')Label3=1;p_1++;}p_1=p1,p_2=p2;//再次初始化if(Label1==1&&Label2==1&&Label3==1)Label4=1;else if(Label1==1&&Label2==1&&Label3==0)Label4=2;else if(Label1==0&&Label2==1&&Label3==1)Label4=3;else if(Label1==1&&Label2==0&&Label3==0)Label4=4;else if(Label1==0&&Label2==1&&Label3==0)Label4=5;else if(Label1==0&&Label2==0&&Label3==0)Label4=6;switch(Label4){case 1:goto Circumstance1;//情况1break;case 2:goto Circumstance2;break;case 3:goto Circumstance3;break;case 4:goto Circumstance4;break;case 5:goto Circumstance5;break;case 6:goto Circumstance6;break;default:break;}Circumstance1:{if(*p_1=='.')//情况1:.123E+4{char *p_3=++p_1;//标记while(*p_1!='E')p_1++;--p_1;double k1=Calculate_DecimalPart(p_3,p_1);//E前数p_1+=3;int k2=Calculate_IntegerPart(p_1,p_2);//E后数p_1--;if(*p_1=='+'){Result=Calculate_ScientificFigure(k1,'+',k2);}else if(*p_1=='-'){Result=Calculate_ScientificFigure(k1,'-',k2);}}else//情况1:123.4E+5{char *p_3=p_1;//标记while(*p_1!='.')p_1++;--p_1;int k1=Calculate_IntegerPart(p_3,p_1);p_1+=2;p_3=p_1;while(*p_1!='E')p_1++;--p_1;double k2=Calculate_DecimalPart(p_3,p_1);double k3=double(k1)+k2;//E前数p_1+=3;int k4=Calculate_IntegerPart(p_1,p_2);//E后数p_1--;if(*p_1=='+'){Result=Calculate_ScientificFigure(k3,'+',k4);}else if(*p_1=='-'){Result=Calculate_ScientificFigure(k3,'-',k4);}}}return Result;Circumstance2:{if(*p_1=='.')//情况2:.123E4{char *p_3=++p_1;//标记while(*p_1!='E')p_1++;--p_1;double k1=Calculate_DecimalPart(p_3,p_1);//E前数p_1+=2;int k2=Calculate_IntegerPart(p_1,p_2);//E后数Result=Calculate_ScientificFigure(k1,'+',k2);}else//情况2:123.E4{char *p_3=p_1;//标记while(*p_1!='.')p_1++;--p_1;int k1=Calculate_IntegerPart(p_3,p_1);p_1+=2;p_3=p_1;while(*p_1!='E')p_1++;--p_1;double k2=Calculate_DecimalPart(p_3,p_1);double k3=double(k1)+k2;//E前数p_1+=2;int k4=Calculate_IntegerPart(p_1,p_2);//E后数Result=Calculate_ScientificFigure(k3,'+',k4);}}return Result;Circumstance3://情况3:123E+4{char *p_3=p_1;//标记while(*p_1!='E')p_1++;--p_1;int k1=Calculate_IntegerPart(p_3,p_1);//E前数p_1+=3;int k2=Calculate_IntegerPart(p_1,p_2);//E后数p_1--;double k3=double(k1);if(*p_1=='+'){Result=Calculate_ScientificFigure(k3,'+',k2);}else if(*p_1=='-'){Result=Calculate_ScientificFigure(k3,'-',k2);}}return Result;Circumstance4:{if(*p_1=='.')//情况4:.123{++p_1;Result=Calculate_DecimalPart(p_1,p_2);}else//情况4:123.4{char *p_3=p_1;//标记while(*p_1!='.')p_1++;--p_1;int k1=Calculate_IntegerPart(p_3,p_1);p_1+=2;double k2=Calculate_DecimalPart(p_1,p_2);Result=double(k1)+k2;}}return Result;Circumstance5://情况5:123E4{char *p_3=p_1;//标记while(*p_1!='E')p_1++;--p_1;int k1=Calculate_IntegerPart(p_3,p_1);p_1+=2;int k2=Calculate_IntegerPart(p_1,p_2);double k3=double(k1);Result=Calculate_ScientificFigure(k1,'+',k2);}return Result;Circumstance6://情况6:123{Result=Calculate_IntegerPart(p_1,p_2);}return Result;}void Compile::SemAnaly_Out_CalculEntireV alue(int a){double a1,a2,a3;if(a==1||a==2||a==4||a==5)//当为运算操作时使指针移动并将参加运算的两个数取出{a2=*ptrcal;//运算时后一个操作数a1=*(--ptrcal);//运算时前一个操作数,a3为运算结果}switch(a){case 8://对应移进操作if(MarkFirstPushCalStack==true)//第一个无符号数压入计算栈时计算栈指针不向后移动,此后每次再移入时,指针向后移动一次{*ptrcal=UnsignedFigure[Count2++];MarkFirstPushCalStack=false;}else{ptrcal++;*ptrcal=UnsignedFigure[Count2++];}break;case 1:a3=a1+a2;//对应加法操作*ptrcal=a3;//运算完毕结果压入计算栈栈顶SemAnaly_Out(1,a1,a2,a3);break;case 2:a3=a1-a2;//对应减法操作*ptrcal=a3;SemAnaly_Out(2,a1,a2,a3);break;case 4:a3=a1*a2;//对应乘法操作*ptrcal=a3;SemAnaly_Out(4,a1,a2,a3);break;case 5:a3=a1/a2;//对应除法操作*ptrcal=a3;SemAnaly_Out(5,a1,a2,a3);break;case 0:Scroll();cout<<"\n\t语义分析完毕.\n";Scroll();cout<<"\n\t运算式的数值:"<<*ptrcal<<endl;//语义分析完毕输出运算值break;default:break;}}void Compile::InputTestStr(){Scroll();cout<<"\n\t编译原理实验:无符号数四则运算编译器\n"\<<"\n\t请注意,您所输入的字符序列应在"<<M-1<<" 个字符以内!"<<endl;Scroll();cout<<"\t运算式:";char ch;int i=0;while((ch=cin.get())!='\n'){TestStr[i++]=ch;}}bool Compile::Start_EllegalCharExamine(){Scroll();int i=0,j=0;bool label=true;char *ptr,Str[3*M];ptr=TestStr;while(*ptr!='\0'){j++;if(!IfLlegalChar(ptr)){cout<<"\t您输入的第"<<j<<"个字符\t"<<*ptr<<"\t非字符集字符!"<<endl;Str[i++]='[';Str[i++]=*ptr;Str[i++]=']';ptr++;label=false;continue;}else{Str[i++]=*ptr;ptr++;}}Str[i]='\0';if(!label){cout<<endl;cout<<"\n\t您输入的序列,非字符集字符已被[]标记:"<<endl;cout<<"\n\t";for(i=0;Str[i]!='\0';){cout<<Str[i];i++;if(i%70==0)//每行最多显示70个字符cout<<endl<<"\t";}cout<<endl;}else if(label){cout<<"\t未检测到非法字符."<<endl;}return label;}void Compile::AcciAnaly_Out_InitUnsignedFigure(int a,char *p1,char *p2){LeftSymbelStack[Count0++]=a;//初始化余留分析串数组if(Count0>=100)cout<<endl<<"余留分析串数组已满!"<<endl;char *p_1=p1,*p_2=p2;if(a==1)//如果是无符号数,输出数值{cout<<"\t类别码:"<<a<<"\t 单词值:";double a1=Calculate_UnsignedFigure(p_1,p_2);UnsignedFigure[Count1++]=a1;//计算出的无符号数数值压入无符号数栈cout<<setiosflags(ios::fixed)<<setprecision(5)<<a1<<endl;}else{cout<<"\t类别码:"<<a<<"\t 单词值:";while(p_1<=p_2){cout<<*p_1;p_1++;}cout<<endl;}if(a==8)//发现一个无效串,就使Mark1为false,MarkInefficaciousStr=false;}int Compile::IfOperator(char *p){char ch=*p;if(ch=='+'||ch=='-'||ch=='*'||ch=='/'||ch=='('||ch==')')return 1;elsereturn 0;}int Compile::IfZeroToNine(char *p){char ch=*p;if('0'<=ch&&ch<='9')return 1;elsereturn 0;}int Compile::IfLlegalChar(char *p){char ch=*p;if(IfOperator(p)||IfZeroToNine(p)||ch=='E'||ch=='.')return 1;else return 0;}void Compile::Identify_Operator(char *p){char ch=*p;switch(ch){case '+':AcciAnaly_Out_InitUnsignedFigure(PLUS,p,p);break;case '-':AcciAnaly_Out_InitUnsignedFigure(SUBTRACT,p,p);break;case '*':AcciAnaly_Out_InitUnsignedFigure(MULTIPLY,p,p);break;case '/':AcciAnaly_Out_InitUnsignedFigure(DIVIDE,p,p);break;case '(':AcciAnaly_Out_InitUnsignedFigure(LEFTBRACKET,p,p);break;case ')':AcciAnaly_Out_InitUnsignedFigure(RIGHTBRACKET,p,p);break;default:break;}}void Compile::Scroll(){cout<<"\t_____________________________________________________";cout<<"___________________";}bool Compile::Start_AccidenceAnalysis(){Scroll();cout<<"\t单词分析结果显示:\n"<<endl;while(*p!='\0'){if(IfOperator(p))//识别字符集[+,-,*,/,(,)]中的字符{Identify_Operator(p);p++;//指向下一字符continue;}else if(IfZeroToNine(p)||*p=='.')//进入无符号数识别状态图{p=Identify_UnsignedFigure(p);//p作参数后为局部变量,不再影响本函数中的指针p,运算完后返回p指向的的最终位置,p++;//指向下一字符continue;}else if(*p=='E')//在识别无符号数时纠错处理的特殊情况{p=Identify_InefficaciousStr(p,p);//一开始就出现无效串p++;//指向下一字符continue;}}cout<<endl;cout<<"\t单词分析完毕."<<endl;Scroll();if(!MarkInefficaciousStr)return false;elsereturn true;}int main(){while(1)//一直循环{Compile compile;//建立compile对象compile.InputTestStr();//调用输入函数if(!compile.Start_EllegalCharExamine())//调用非法字符检测函数,{compile.Start_ExceptionHandler(1);//如果检测到非法字符,进行异常处理continue;}if(!compile.Start_AccidenceAnalysis())//如果无非法字符,开始词法分析{compile.Start_ExceptionHandler(2);//词法分析发现无效字符串,则进行异常处理continue;}if(!compile.Start_GrammarAnalysis())//词法分析成功则进行语法分析{compile.Start_ExceptionHandler(3);//语法分析失败,不符合无符号数四则运算语法规范,则进行异常处理continue;}compile.Start_SemanticsAnalysis();//语法分析成功,则进行语义分析并计算运算式数值compile.GetPuased();//进行完一次循环,暂停一下}return 0;}。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
#include <stdio.h>
#include <ctype.h>
#include <math.h>
#define DIGIT 1
#define POINT 2
#define OTHER 3
#define POWER 4
#define PLUS 5
#define MINUS 6
#define UCON 7 //Suppose the class number of unsigned constant is 7
#define ClassOther 200
#define EndState -1
int w,n,p,e,d;
int Class; //Used to indicate class of the word
int ICON;
float FCON;
static int CurrentState; //Used to present current state, the initial value:0
int GetChar (void);
int EXCUTE (int,int);
int LEX (void);
//_____________________________________________________________________________ _________________________
int HandleOtherWord (void)
{
return ClassOther;
}
//_____________________________________________________________________________ __________________________
int HandleError (void)
{printf ("Error!\n"); return 0;}
//_____________________________________________________________________________ __________________________
int GetChar (void)
{
int c;
c=getchar( );
if(isdigit(c)) {d=c-'0';return DIGIT;}
if (c=='.') return POINT;
if (c=='E'||c=='e') return POWER;
if (c=='+') return PLUS;
if (c=='-') return MINUS;
return OTHER;
}
//_____________________________________________________________________________ ___________________________
int EXCUTE (int state, int symbol)
{
switch(state)
{
case 0:switch (symbol)
{
case DIGIT: n=0;p=0;e=1;w=d;CurrentState=1;Class=UCON;break;
case POINT: w=0;n=0;p=0;e=1;CurrentState=3;Class=UCON;break;
default: HandleOtherWord( );Class=ClassOther;
CurrentState=EndState;
}
break;
case 1:switch (symbol)
{
case DIGIT: w=w*10+d;break; //CurrentState=1
case POINT: CurrentState=2;break;
case POWER: CurrentState=4;break;
default: ICON=w;CurrentState=EndState;
}
break;
case 2:switch (symbol)
{
case DIGIT: n++;w=w*10+d;break;
case POWER: CurrentState=4;break;
default: FCON=w*pow(10,e*p-n) ;CurrentState=EndState;
}
break;
case 3:switch (symbol)
{
case DIGIT: n++;w=w*10+d;CurrentState=2;break;
default: HandleError( );CurrentState=EndState;
}
break;
case 4:switch (symbol)
{
case DIGIT: p=p*10+d;CurrentState=6;break;
case PLUS: CurrentState=5;break;
default: HandleError( );CurrentState=EndState;
}
break;
case 5:switch (symbol)
{
case DIGIT: p=p*10+d;CurrentState=6;break;
default: HandleError( );CurrentState=EndState;
}
break;
case 6:switch (symbol)
{
case DIGIT: p=p*10+d;break;
default:
FCON=w*pow(10,e*p-n);
CurrentState=EndState;
}
break;
}
return CurrentState;
}
//_____________________________________________________________________________ ______________________________
int LEX (void)
{
int ch;
CurrentState=0;
while (CurrentState!=EndState)
{
ch= GetChar();
EXCUTE (CurrentState,ch);
}
return Class;
}
int main()
{
int c =LEX();
printf("%d\n",c);
printf("%lf\n",FCON);
}。