二叉排序树的可视化实现
二叉排序树

9
第9章
第三节
二、二叉排序树(插入)
查找
动态查找表
二叉排序树是一种动态查找表
当树中不存在查找的结点时,作插入操作
新插入的结点一定是叶子结点(只需改动一个 结点的指针) 该叶子结点是查找不成功时路径上访问的最后 一个结点的左孩子或右孩子(新结点值小于或 大于该结点值) 10
第9章
第三节
查找
19
在二叉排序树中查找关 键字值等于37,88,94
3
第9章
第三节
查找
动态查找表
二、二叉排序树(查找函数)中结点结构定义 二叉排序树通常采用二叉链表的形式进行存 储,其结点结构定义如下:
typedef struct BiNode { int data; BiNode *lChild, *rChild; }BiNode,*BitTree;
4
第9章
第三节
查找
动态查找表
2、二叉排序树的定义 定义二叉排序树所有用到的变量 BitTree root; int
//查找是否成功(1--成功,0--不成功) //查找位置(表示在BisCount层中的第几个位置
BisSuccess;
int
int
BisPos;
BisCount;
//查找次数(相当于树的层数)
7
第9章
第三节
查找
动态查找表
二、二叉排序树(查找函数)
else { BisSuccess = 0; root=GetNode(k);//查找不成功,插入新的结点}
} BiNode * GetNode(int k) { BiNode *s; s = new BiNode; s->data = k; s->lChild = NULL; s->rChild = NULL; return(s);}
数据结构c语言课设-二叉树排序

题目:二叉排序树的实现1 内容和要求1)编程实现二叉排序树,包括生成、插入,删除;2)对二叉排序树进展先根、中根、和后根非递归遍历;3)每次对树的修改操作和遍历操作的显示结果都需要在屏幕上用树的形状表示出来。
4)分别用二叉排序树和数组去存储一个班(50 人以上)的成员信息(至少包括学号、姓名、成绩3 项),比照查找效率,并说明在什么情况下二叉排序树效率高,为什么?2 解决方案和关键代码2.1 解决方案:先实现二叉排序树的生成、插入、删除,编写DisplayBST函数把遍历结果用树的形状表示出来。
前中后根遍历需要用到栈的数据构造,分模块编写栈与遍历代码。
要求比照二叉排序树和数组的查找效率,首先建立一个数组存储一个班的成员信息,分别用二叉树和数组查找,利用clock〔〕函数记录查找时间来比照查找效率。
2.2关键代码树的根本构造定义及根本函数typedef struct{KeyType key;} ElemType;typedef struct BiTNode//定义链表{ElemType data;struct BiTNode *lchild, *rchild;}BiTNode, *BiTree, *SElemType;//销毁树int DestroyBiTree(BiTree &T){if (T != NULL)free(T);return 0;}//清空树int ClearBiTree(BiTree &T){if (T != NULL){T->lchild = NULL;T->rchild = NULL;T = NULL;}return 0;}//查找关键字,指针p返回int SearchBST(BiTree T, KeyType key, BiTree f, BiTree &p) {if (!T){p = f;return FALSE;}else if EQ(key, T->data.key){p = T;return TRUE;}else if LT(key, T->data.key)return SearchBST(T->lchild, key, T, p);elsereturn SearchBST(T->rchild, key, T, p);}二叉树的生成、插入,删除生成void CreateBST(BiTree &BT, BiTree p){int i;ElemType k;printf("请输入元素值以创立排序二叉树:\n");scanf_s("%d", &k.key);for (i = 0; k.key != NULL; i++){//判断是否重复if (!SearchBST(BT, k.key, NULL, p)){InsertBST(BT, k);scanf_s("%d", &k.key);}else{printf("输入数据重复!\n");return;}}}插入int InsertBST(BiTree &T, ElemType e){BiTree s, p;if (!SearchBST(T, e.key, NULL, p)){s = (BiTree)malloc(sizeof(BiTNode));s->data = e;s->lchild = s->rchild = NULL;if (!p)T = s;else if LT(e.key, p->data.key)p->lchild = s;elsep->rchild = s;return TRUE;}else return FALSE;}删除//某个节点元素的删除int DeleteEle(BiTree &p){BiTree q, s;if (!p->rchild) //右子树为空{q = p;p = p->lchild;free(q);}else if (!p->lchild) //左子树为空{q = p;p = p->rchild;free(q);}else{q = p;s = p->lchild;while (s->rchild){q = s;s = s->rchild;}p->data = s->data;if (q != p)q->rchild = s->lchild;elseq->lchild = s->lchild;delete s;}return TRUE;}//整棵树的删除int DeleteBST(BiTree &T, KeyType key) //实现二叉排序树的删除操作{if (!T){return FALSE;}else{if (EQ(key, T->data.key)) //是否相等return DeleteEle(T);else if (LT(key, T->data.key)) //是否小于return DeleteBST(T->lchild, key);elsereturn DeleteBST(T->rchild, key);}return 0;}二叉树的前中后根遍历栈的定义typedef struct{SElemType *base;SElemType *top;int stacksize;}SqStack;int InitStack(SqStack &S) //构造空栈{S.base = (SElemType*)malloc(STACK_INIT_SIZE *sizeof(SElemType));if (!S.base) exit(OVERFLOW);S.top = S.base;S.stacksize = STACK_INIT_SIZE;return OK;}//InitStackint Push(SqStack &S, SElemType e) //插入元素e为新栈顶{if (S.top - S.base >= S.stacksize){S.base = (SElemType*)realloc(S.base, (S.stacksize + STACKINCREMENT)*sizeof(SElemType));if (!S.base) exit(OVERFLOW);S.top = S.base + S.stacksize;S.stacksize += STACKINCREMENT;}*S.top++ = e;return OK;}//Pushint Pop(SqStack &S, SElemType &e) //删除栈顶,应用e返回其值{if (S.top == S.base) return ERROR;e = *--S.top;return OK;}//Popint StackEmpty(SqStack S) //判断是否为空栈{if (S.base == S.top) return TRUE;return FALSE;}先根遍历int PreOrderTraverse(BiTree T, int(*Visit)(ElemType e)) {SqStack S;BiTree p;InitStack(S);p = T;while (p || !StackEmpty(S)){if (p){Push(S, p);if (!Visit(p->data)) return ERROR;p = p->lchild;}else{Pop(S, p);p = p->rchild;}}return OK;}中根遍历int InOrderTraverse(BiTree T, int(*Visit)(ElemType e)) {SqStack S;BiTree p;InitStack(S);p = T;while (p || !StackEmpty(S)){if (p){Push(S, p);p = p->lchild;}else{Pop(S, p);if (!Visit(p->data)) return ERROR;p = p->rchild;}}return OK;}后根遍历int PostOrderTraverse(BiTree T, int(*Visit)(ElemType e)) {SqStack S, SS;BiTree p;InitStack(S);InitStack(SS);p = T;while (p || !StackEmpty(S)){if (p){Push(S, p);Push(SS, p);p = p->rchild;}else{if (!StackEmpty(S)){Pop(S, p);p = p->lchild;}}}while (!StackEmpty(SS)){Pop(SS, p);if (!Visit(p->data)) return ERROR;}return OK;}利用数组存储一个班学生信息ElemType a[] = { 51, "陈继真", 88,82, "黄景元", 89,53, "贾成", 88,44, "呼颜", 90,25, "鲁修德", 88,56, "须成", 88,47, "孙祥", 87, 38, "柏有患", 89, 9, " 革高", 89, 10, "考鬲", 87, 31, "李燧", 86, 12, "夏祥", 89, 53, "余惠", 84, 4, "鲁芝", 90, 75, "黄丙庆", 88, 16, "李应", 89, 87, "杨志", 86, 18, "李逵", 89, 9, "阮小五", 85, 20, "史进", 88, 21, "秦明", 88, 82, "杨雄", 89, 23, "刘唐", 85, 64, "武松", 88, 25, "李俊", 88, 86, "卢俊义", 88, 27, "华荣", 87, 28, "杨胜", 88, 29, "林冲", 89, 70, "李跃", 85, 31, "蓝虎", 90, 32, "宋禄", 84, 73, "鲁智深", 89, 34, "关斌", 90, 55, "龚成", 87, 36, "黄乌", 87, 57, "孔道灵", 87, 38, "张焕", 84, 59, "李信", 88, 30, "徐山", 83, 41, "秦祥", 85, 42, "葛公", 85, 23, "武衍公", 87, 94, "范斌", 83, 45, "黄乌", 60, 67, "叶景昌", 99, 7, "焦龙", 89, 78, "星姚烨", 85, 49, "孙吉", 90, 60, "陈梦庚", 95,};数组查询函数void ArraySearch(ElemType a[], int key, int length){int i;for (i = 0; i <= length; i++){if (key == a[i].key){cout << "学号:" << a[i].key << " 姓名:" << a[i].name << " 成绩:" << a[i].grade << endl;break;}}}二叉树查询函数上文二叉树根本函数中的SearchBST()即为二叉树查询函数。
算法可视化演示软件开发毕业设计

算法可视化演示软件开发毕业设计目录前言 (1)第一章绪论 (2)第一节课题背景 (2)第二节课题的目的与意义 (2)第三节论文结构 (3)第二章相关知识概述 (4)第一节 Java知识相关概述 (4)一、Java的发展史 (4)二、Java的主要特性 (4)三、JDK 平台相关信息 (5)第二节 Java图形界面技术概述 (5)一、 Java Swing相关概述 (5)二、容器和布局 (7)三、事件处理 (8)第三节相关算法的介绍 (9)一、冒泡排序 (9)二、插入排序 (10)三、选择排序 (12)四、二叉查找树 (12)第四节本章小结 (15)第三章需求分析 (17)第一节系统功能需求 (17)一、系统设计目标 (17)二、系统功能需求 (17)第二节系统运行环境 (18)第三节本章小结 (18)第四章系统设计 (19)第一节系统总体描述 (19)第二节模块设计 (20)一、算法模块设计 (20)二、界面模块设计 (22)第三节系统流程图 (25)第四节本章小结 (26)第五章系统实现 (27)第一节可视化主界面的实现 (27)第二节排序算法界面所实现的功能 (28)第三节二叉查找树可视化功能的实现 (31)第四节本章小结 (33)第六章系统测试 (34)第一节问题解决及测试结果 (34)一、遇到的问题 (34)二、解决的方法 (34)三、测试结果 (34)第二节本章小结 (41)结论 (42)致谢 (43)参考文献 (44)附录 (45)一、英文原文 (45)二、英文翻译 (52)前言可视化( Visualizations)计算机图形学和图像处理技术,将数据转换成图形或图像在屏幕上显示出来,并进行交互处理的理论、方法和技术。
此次设计算法可视化( Algorithm Visualizations)就是利用可视化技术将算法可视化[1]。
排序是计算机程序设计中的一种重要操作,其功能是一个数据元素(或者记录)的任意序列,从新排列成一个按关键字有序的序列。
数据结构 二叉排序树

9.6.2 哈希函数的构造方法
构造哈希函数的目标:
哈希地址尽可能均匀分布在表空间上——均 匀性好; 哈希地址计算尽量简单。
考虑因素:
函数的复杂度; 关键字长度与表长的关系; 关键字分布情况; 元素的查找频率。
一、直接地址法 取关键字或关键字的某个线性函数值为哈希地址 即: H(key) = key 或: H(key) = a* key + b 其中,a, b为常数。 例:1949年后出生的人口调查表,关键字是年份 年份 1949 1950 1951 … 人数 … … … …
9.4 二叉排序树
1.定义:
二叉排序树(二叉搜索树或二叉查找树) 或者是一棵空树;或者是具有如下特性的二叉树
(1) 若它的左子树不空,则左子树上所有结点的 值均小于根结点的值;
(2) 若它的右子树不空,则右子树上所有结点 的值均大于等于根结点的值; (3) 它的左、右子树也都分别是二叉排序树。
例如:
H(key)
通常设定一个一维数组空间存储记录集合,则 H(key)指示数组中的下标。
称这个一维数组为哈希(Hash)表或散列表。 称映射函数 H 为哈希函数。 H(key)为哈希地址
例:假定一个线性表为: A = (18,75,60,43,54,90,46) 假定选取的哈希函数为
hash3(key) = key % 13
H(key) = key + (-1948) 此法仅适合于: 地址集合的大小 = = 关键字集合的大小
二、数字分析法
假设关键字集合中的每个关键字都是由 s 位数 字组成 (u1, u2, …, us),分析关键字集中的全体, 并从中提取分布均匀的若干位或它们的组合作为 地址。 例如:有若干记录,关键字为 8 位十进制数, 假设哈希表的表长为100, 对关键字进行分析, 取随机性较好的两位十进制数作为哈希地址。
线索二叉树

6.4 线索化二叉树从前面的讨论可知,遍历二叉树就是将非线性结构的二叉树线性化,即按一定规则将二叉树中的结点排列成一个线性序列依次访问。
如图6.20(a)所示的二叉树,经中序遍历得到线性序列:BADEC,经前序遍历得到线性序列:ABCDE,经后序遍历得到线性序列:BEDCA。
在这些线性序列中,二叉树中的每个结点(除第一个和最后一个外)有且仅有唯一的一个前趋和唯一的一个后继,很容易找到各个结点的直接前驱和直接后继。
但当以二叉链表作为二叉树的存储结构时,只能找到结点的左、右孩子,而不能直接找到前驱和后继,只有在遍历的动态过程中得到这些信息。
如果将这些信息在第一次遍历时保存起来,在需要再次对二叉树进行“遍历”时就可以将二叉树视为线性结构进行访问,从而简化遍历操作。
那么,如何存储遍历中得到的结点前驱和后继的信息呢?一个简单的办法是在每个结点上增加两个指针域fwd和bkwd,分别指向存储遍历中得到的结点前驱和后继。
fwd L child data R child bkwd这是采用多重链表来表示二叉树。
这种方法虽简单易行,但这种结构的存储密度将大大降低,浪费存储空间。
另一种方法,是利用原有链域L child 和R child的空链域。
在n个结点的二叉链表中有2n个孩子链域,其中仅有n-1个链域是用来指示结点的左右孩子,而另外n+1个链域是空链域。
现在把这些空链域利用起来,使其指向结点的前驱或后继;对那些原来就不为空的链域,则仍然指向左或右孩子。
如果把指向前驱和后继的指针称为线索(Thread),那么,如何区分指向左、右孩子的指针和指向前驱、后继的线索呢?在原结点结构上增加标志域定义为:0 Lchild为左指针,指向左孩子0 Rchild为右指针,指向右孩子ltag=rtag=1 Lchild为左线索,指向前驱 1 Rchild为右线索,指向后继以这种结点构成的二叉链表作为二叉树的存储结构,叫做线索链表,其C语言类型说明如下:Typedef struct ThreadTNode{enum{0,1} ltag, rtag;Elem Type data;Struct ThreadTNode *Lchild, *Rchild;}ThreadTNode, *ThreadTree;为了节省内存空间,我们用C语言的位段方法将结点中的左标志域和右标志域与数据域合并在一个存储单元中(即各用一位表示左标志和右标志,其余各位表示结点值)。
二叉排序树的实验报告

二叉排序树的实验报告二叉排序树的实验报告引言:二叉排序树(Binary Search Tree,简称BST)是一种常用的数据结构,它将数据按照一定的规则组织起来,便于快速的查找、插入和删除操作。
本次实验旨在深入了解二叉排序树的原理和实现,并通过实验验证其性能和效果。
一、实验背景二叉排序树是一种二叉树,其中每个节点的值大于其左子树的所有节点的值,小于其右子树的所有节点的值。
这种特性使得在二叉排序树中进行查找操作时,可以通过比较节点的值来确定查找的方向,从而提高查找效率。
二、实验目的1. 理解二叉排序树的基本原理和性质;2. 掌握二叉排序树的构建、插入和删除操作;3. 验证二叉排序树在查找、插入和删除等操作中的性能和效果。
三、实验过程1. 构建二叉排序树首先,我们需要构建一个空的二叉排序树。
在构建过程中,我们可以选择一个节点作为根节点,并将其他节点插入到树中。
插入节点时,根据节点的值与当前节点的值进行比较,如果小于当前节点的值,则将其插入到当前节点的左子树中;如果大于当前节点的值,则将其插入到当前节点的右子树中。
重复这个过程,直到所有节点都被插入到树中。
2. 插入节点在已有的二叉排序树中插入新的节点时,我们需要遵循一定的规则。
首先,从根节点开始,将新节点的值与当前节点的值进行比较。
如果小于当前节点的值,则将其插入到当前节点的左子树中;如果大于当前节点的值,则将其插入到当前节点的右子树中。
如果新节点的值与当前节点的值相等,则不进行插入操作。
3. 删除节点在二叉排序树中删除节点时,我们需要考虑不同的情况。
如果要删除的节点是叶子节点,即没有左右子树,我们可以直接删除该节点。
如果要删除的节点只有一个子树,我们可以将子树连接到要删除节点的父节点上。
如果要删除的节点有两个子树,我们可以选择将其右子树中的最小节点或左子树中的最大节点替代该节点,并删除相应的替代节点。
四、实验结果通过对二叉排序树的构建、插入和删除操作的实验,我们得到了以下结果:1. 二叉排序树可以高效地进行查找操作。
基于C#的二叉排序树图形显示系统研究与实现

二叉排序树在实际应用中 , 经常用来实现提高 数据的查寻效率 , 由于概念理解上的困难 , 但 在教学 过程中 , 学生往往不能掌握二又树 的基本操作 , 不能
在脑 海 中形 成 对应 的模 型 。所 以本 文试 图从概 念人
本系统在功能上 , 除了可以进行二叉排序树基 本操作 , 初始化、 节点的增加 、 删除、 清空所 有节点 外, 还对显示功能进行了强化 , 增加了颜色设置可以 设置界面背景颜色 、 节点的颜色和节点字体的颜色 , 还能进行二叉树节点间宽度的增大和缩小。
}
es le
{ Isr nd. eN d ,aa ; ne ( oeLf 时先要找到节点要插入 的位置, 然后在窗 1上显示出这个结点 , 3 直到所有输 人序列都插入到二叉树 中为止, 这些操作都是递归
进行 的。
} }
es le
二 叉 排 序 树 ( iaySr Te ) 称 二 叉 查 找 Bnr ot re 又
的窗 口和页面 , 只设计 了一个 主界 面 , 主界 面上完 在
成二叉排序树的显示 , 实现二叉树各种数据操作 。
( 搜索) ( i r Sa hTe) 树 Bn y er r 。其定义为 : a c e 二叉排 序树或者是空树 , 或者是满足如下性质 的二叉树 :
提供 大 量 的开 发 工具 和服 务 帮助开 发人员 开发基 于
计算和通信的各种应用。基 于这个特点 , 我们采用 C 来开发二叉排序树 图形显示系统 。 #
图 2 功能设计
甘
肃
科
技
n d . e t o e = tmp; oeLf d N e
第2 7卷
4 实现
数据结构二叉排序树

05
13
19
21
37
56
64
75
80
88
92
low mid high 因为r[mid].key<k,所以向右找,令low:=mid+1=4 (3) low=4;high=5;mid=(4+5) div 2=4
05
13
19
low
21
37
56
64
75
80
88
92
mid high
因为r[mid].key=k,查找成功,所查元素在表中的序号为mid 的值
平均查找长度:为确定某元素在表中某位置所进行的比 较次数的期望值。 在长度为n的表中找某一元素,查找成功的平均查找长度:
ASL=∑PiCi
Pi :为查找表中第i个元素的概率 Ci :为查到表中第i个元素时已经进行的比较次数
在顺序查找时, Ci取决于所查元素在表中的位置, Ci =i,设每个元素的查找概率相等,即Pi=1/n,则:
RL型的第一次旋转(顺时针) 以 53 为轴心,把 37 从 53 的左上转到 53 的左下,使得 53 的左 是 37 ;右是 90 ,原 53 的左变成了 37 的右。 RL型的第二次旋转(逆时针)
一般情况下,假设由于二叉排序树上插入结点而失去 平衡的最小子树的根结点指针为a(即a是离插入结点最 近,且平衡因子绝对值超过1的祖先结点),则失去平衡 后进行调整的规律可归纳为下列四种情况: ⒈RR型平衡旋转: a -2 b -1 h-1 a1
2.查找关键字k=85 的情况 (1) low=1;high=11;mid=(1+11) / 2=6
05
13
19
21
数据结构-C语言-树和二叉树

练习
一棵完全二叉树有5000个结点,可以计算出其
叶结点的个数是( 2500)。
二叉树的性质和存储结构
性质4: 具有n个结点的完全二叉树的深度必为[log2n]+1
k-1层 k层
2k−1−1<n≤2k−1 或 2k−1≤n<2k n k−1≤log2n<k,因为k是整数
所以k = log2n + 1
遍历二叉树和线索二叉树
遍历定义
指按某条搜索路线遍访每个结点且不重复(又称周游)。
遍历用途
它是树结构插入、删除、修改、查找和排序运算的前提, 是二叉树一切运算的基础和核心。
遍历规则 D
先左后右
L
R
DLR LDR LRD DRL RDL RLD
遍历规则
A BC DE
先序遍历:A B D E C 中序遍历:D B E A C 后序遍历:D E B C A
练习 具有3个结点的二叉树可能有几种不同形态?普通树呢?
5种/2种
目 录 导 航 Contents
5.1 树和二叉树的定义 5.2 案例引入 5.3 树和二叉树的抽象数据类型定义 5.4 二叉树的性质和存储结构 5.5 遍历二叉树和线索二叉树 5.6 树和森林 5.7 哈夫曼树及其应用 5.8 案例分析与实现
(a + b *(c-d)-e/f)的二叉树
目 录 导 航 Contents
5.1 树和二叉树的定义 5.2 案例引入 5.3 树和二叉树的抽象数据类型定义 5.4 二叉树的性质和存储结构 5.5 遍历二叉树和线索二叉树 5.6 树和森林 5.7 哈夫曼树及其应用 5.8 案例分析与实现
二叉树的抽象数据类型定义
特殊形态的二叉树
只有最后一层叶子不满,且全部集中在左边
实现二叉链表存储结构下二叉树的先序遍历的非递归算法

实现二叉链表存储结构下二叉树的先序遍历的非递归算法要实现二叉链表存储结构下二叉树的先序遍历的非递归算法,可以使用栈来辅助存储节点。
首先,创建一个空栈,并将树的根节点压入栈中。
然后,循环执行以下步骤,直到栈为空:1. 弹出栈顶的节点,并访问该节点。
2. 若该节点存在右子节点,则将右子节点压入栈中。
3. 若该节点存在左子节点,则将左子节点压入栈中。
注:先将右子节点压入栈中,再将左子节点压入栈中的原因是,出栈操作时会先访问左子节点。
下面是使用Python语言实现的例子:```pythonclass TreeNode:def __init__(self, value):self.val = valueself.left = Noneself.right = Nonedef preorderTraversal(root):if root is None:return []stack = []result = []node = rootwhile stack or node:while node:result.append(node.val)stack.append(node)node = node.leftnode = stack.pop()node = node.rightreturn result```这里的树节点类为`TreeNode`,其中包含节点的值属性`val`,以及左子节点和右子节点属性`left`和`right`。
`preorderTraversal`函数为非递归的先序遍历实现,输入参数为二叉树的根节点。
函数中使用了一个栈`stack`来存储节点,以及一个列表`result`来存储遍历结果。
在函数中,先判断根节点是否为None。
如果是,则直接返回空列表。
然后,创建一个空栈和结果列表。
接下来,用一个`while`循环来执行上述的遍历过程。
循环的条件是栈`stack`不为空或者当前节点`node`不为None。
最优二叉搜索树

8
2 最优二叉搜索树
xal
wan wil wen wim wul xem yo xul yu m
zol zom
yon
zi
A
A代表其值处于 代表其值处于wim和wul之间的可能关键码集合 代表其值处于 和 之间的可能关键码集合
9
2 最优二叉搜索树
在二叉搜索树中搜索一个元素x 在二叉搜索树中搜索一个元素
1 2 3 2 (c) (d) (a) (b) (e) 1 3 1 2 1 3 2 1 2 3
• 设每个内、外结点检索的概率相同:pi=qi=1/7, 设每个内、外结点检索的概率相同: , 求每棵树的平均比较次数(成本)。 求每棵树的平均比较次数(成本)。 • 若P1=0.5, P2=0.1, P3=0.05, q0=0.15, q1=0.1, q2=0.05, q3=0.05,求每棵树的平均比较 , 次数(成本)。 次数(成本)。 13
2 最优二叉搜索树
在检索过程中,每进行一次比较,就进入下面一层, 在检索过程中,每进行一次比较,就进入下面一层, • 对于成功的检索,比较的次数就是所在的层数加 。 对于成功的检索,比较的次数就是所在的层数加1。 • 对于不成功的检索,被检索的关键码属于那个外部结 对于不成功的检索, 点代表的可能关键码集合, 点代表的可能关键码集合,比较次数就等于此外部结 点的层数。 点的层数。
6
2 最优二叉搜索树
2、最优二叉搜索树 、
存在的两个问题 1 在实际中也会遇到不成功检索的情况。 在实际中也会遇到不成功检索的情况。 不成功检索的情况 2 在实际中,不同标识符会有不同的检索概率。 在实际中,不同标识符会有不同的检索概率。 不同的检索概率 • 对给定的标识符集合,希望给出构造二分搜索 对给定的标识符集合, 树的方法,使得所构造的二分搜索树具有最优 树的方法,使得所构造的二分搜索树具有最优 的性能。 的性能。
可视化计算(raptor)

精品文档你我共享用动态规划来解决数字三角形问题软件34刘柏呈问题由来题目的出处是《可视化计算》课本讲贪心的一道例题(Page108,例3-4),选题的原因:一,老师要求用到动态规划的思想方法。
二,raptor是个可视化的编程软件,突出可视化,就必须有图形,而数字三角形本身就是个“二叉树”综上解题思路先构图的顶点,随即生成边,构成树,各个顶点中的数字随机生成,这样就完成输入问题。
再用动态规划寻找最大的路径,最后再运用可视化的特点,把选择的过程呈现给看程序的人。
1.首先是构图,出于美观性的考虑,我将数字三角形的可行层数控制为1-6层。
由于raptor没有编辑数组,所以我用两种方式为顶点编号:1,(i,j)来表示第i行第j个数。
2,用m表示,从上到下,从左到右的第m个点。
之后就是,计算点的坐标,找出坐标的规律,并适当的纪录。
2.动态规划,主要根据,状态转移方程:f[i,j]=max{f[i-1,j],f[i-1,j-1]}+c[i,j]其中,f[i,j]表示到(i,j)点的最大累加和,c[i,j]表示第(i,j)点的值。
3.显示用到递归的解法,根据之前纪录的“父节点”来搜索路径。
算法实现第一个子图composition就是构图,用来画二叉树,i控制行数,j控制列数,二重循环来画圆和线。
注意点:一,圆的大小应该适应画布和层数,所以我令k=画布高/层数,而用k/4作为半径画圆。
二,“线不能将圆戳破”即线的出发点不能是圆心,这里,我将上层圆的圆心与它的两个子圆的圆心连线的夹角令为60度,再根据圆中直角三角形的关系,算出对应圆周上的点,作为出发点。
三,弄清一个循环中该做什么,结论是:画一个圆和两条线,这里要注意判断一下是否是最后一层,最后一层不需要画线。
dp子图是用来完成动态规划算法的,这个算法只要知道状态转移方程就比较好实现,需要注意的是边界的控制,所以需要附初值。
还有就是,我每做一步用root数组纪录一下该点的“父亲”,以便之后查找。
二叉排序树怎么构造例题

二叉排序树怎么构造例题二叉排序树(Binary Search Tree,BST)是一种特殊的二叉树,它满足以下性质,对于树中的任意节点,其左子树中的所有节点的值都小于该节点的值,而右子树中的所有节点的值都大于该节点的值。
构造二叉排序树的过程可以通过例题来说明。
假设我们有以下一组数字,8, 3, 10, 1, 6, 14, 4, 7, 13。
我们将按照顺序将它们插入到二叉排序树中。
首先,我们将第一个数字 8 作为根节点插入到树中。
接下来,我们将 3 插入到根节点的左子树中,因为 3 小于 8。
然后,我们将 10 插入到根节点的右子树中,因为 10 大于 8。
接着,我们将 1 插入到根节点的左子树的左子树中,因为 1小于 3。
然后,我们将 6 插入到根节点的左子树的右子树中,因为 6大于 3 且小于 8。
继续,我们将 14 插入到根节点的右子树的右子树中,因为 14 大于 10。
然后,我们将 4 插入到根节点的左子树的右子树的左子树中,因为 4 大于 3 且小于 6。
接着,我们将 7 插入到根节点的左子树的右子树的右子树中,因为 7 大于 6 且小于 8。
最后,我们将 13 插入到根节点的右子树的右子树的左子树中,因为 13 大于 10 且小于 14。
经过以上步骤,我们成功构造了一棵二叉排序树。
这棵树的结构如下:8。
/ \。
3 10。
/ \ \。
1 6 14。
/ \ /。
4 7 13。
这棵二叉排序树满足了所有节点的左子树值小于节点值,右子树值大于节点值的性质。
以上就是构造二叉排序树的例题过程,通过不断比较插入节点和当前节点的大小关系,我们可以构建出一个符合二叉排序树性质的树结构。
实现决策树可视化的方法

实现决策树可视化的方法决策树可视化是一种将决策树模型以图形化的方式展示出来的方法。
它能够直观地呈现出决策树的结构和节点信息,帮助用户更好地理解和解释决策树模型。
下面介绍几种实现决策树可视化的方法。
1. Graphviz:Graphviz是一种流行的图形可视化软件,可用于可视化决策树。
通过使用Graphviz提供的dot语言,我们可以将决策树的结构以图的形式展示出来。
首先,将决策树转换为.dot文件格式,然后使用Graphviz的命令行工具生成决策树的图像。
输出的图像可以保存为各种格式,如PNG、PDF等。
2. Matplotlib:Matplotlib是一个强大的绘图库,可以用于可视化决策树。
我们可以使用Matplotlib创建一个新的图形,并使用树形图的方式将决策树绘制出来。
在绘制过程中,我们可以自定义节点的样式、颜色和标签,以便更好地展示决策树的信息。
3. Plotly:Plotly是一个交互式数据可视化库,可以用于创建决策树的可视化图表。
使用Plotly,我们可以生成一个交互式的可视化图表,用户可以通过缩放、旋转和悬停来浏览决策树的各个部分。
此外,Plotly还支持将决策树通过网页发布,方便与他人共享和讨论。
4. Pydot:Pydot是一个用于创建和处理DOT语言的Python库,可以方便地将决策树生成为图像。
我们可以使用Pydot将决策树输出为图像文件,如PNG或PDF。
此外,Pydot还可以与其他库结合使用,比如在Jupyter Notebook中展示决策树图像。
综上所述,以上是几种实现决策树可视化的方法。
根据具体的需求和使用环境,我们可以选择适合自己的方法来进行决策树的可视化。
这些方法都能够帮助我们更好地理解和解释决策树模型,为决策和分析提供有力的支持。
数据结构_第9章_查找2-二叉树和平衡二叉树

F
PS
C
PR
CL Q
QL SL S SL
10
3
18
2
6 12
6 删除10
3
18
2
4 12
4
15
15
三、二叉排序树的查找分析
1) 二叉排序树上查找某关键字等于给定值的结点过程,其实 就是走了一条从根到该结点的路径。 比较的关键字次数=此结点的层次数; 最多的比较次数=树的深度(或高度),即 log2 n+1
-0 1 24
0 37
0 37
-0 1
需要RL平衡旋转 (绕C先顺后逆)
24
0
-012
13
3573
0
01
37
90
0 53 0 53
0 90
作业
已知如下所示长度为12的表:
(Jan, Feb, Mar, Apr, May, June, July, Aug, Sep, Oct, Nov, Dec)
(1) 试按表中元素的顺序依次插入一棵初始为空的二叉 排序树,画出插入完成之后的二叉排序树,并求其在 等概率的情况下查找成功的平均查找长度。
2) 一棵二叉排序树的平均查找长度为:
n i1
ASL 1
ni Ci
m
其中:
ni 是每层结点个数; Ci 是结点所在层次数; m 为树深。
最坏情况:即插入的n个元素从一开始就有序, ——变成单支树的形态!
此时树的深度为n ; ASL= (n+1)/2 此时查找效率与顺序查找情况相同。
最好情况:即:与折半查找中的判ห้องสมุดไป่ตู้树相同(形态比较均衡) 树的深度为:log 2n +1 ; ASL=log 2(n+1) –1 ;与折半查找相同。
实践教学示范中心建设实验项目明细表.
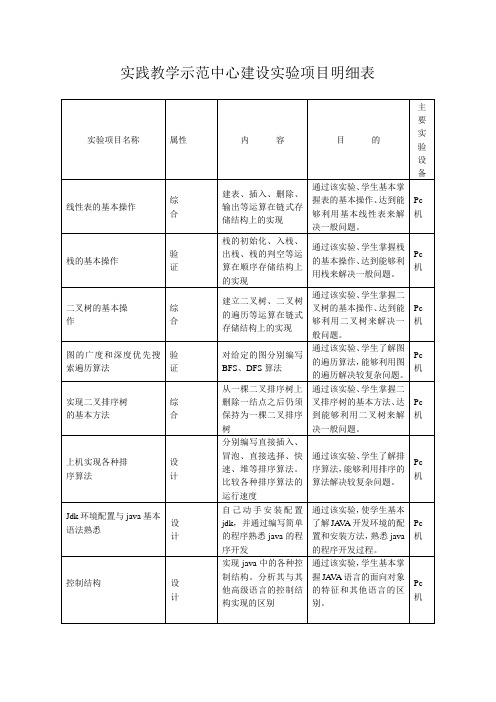
Pc机
二叉树的基本操作
综合
建立二叉树、二叉树的遍历等运算在链式存储结构上的实现
通过该实验、学生掌握二叉树的基本操作、达到能够利用二叉树来解决一般问题。
Pc机
图的广度和深度优先搜索遍历算法
验证
对给定的图分别编写BFS、DFS算法
通过该实验、学生了解图的遍历算法,能够利用图的遍历解决较复杂问题。
Pc机
Jdk环境配置与java基本语法熟悉
设计
自己动手安装配置jdk,并通过编写简单的程序熟悉java的程序开发
通过该实验,使学生基本了解JAVA开发环境的配置和安装方法,熟悉java的程序开发过程。
Pc机
控制结构
设计
实现java中的各种控制结构。分析其与其他高级语言的控制结构实现的区别
通过该实验,学生基本掌握JAVA语言的面向对象的特征和其他语言的区别。
数据库的备份、数据库的还原、SQL Server 2000的3种封锁机制、封锁命令、隔离级别、安全模式、管理数据库用户、管理数据库角色、权限管理
Pc机
数据库应用系统的初步开发
设计
系统需求分析、系统设计
、系统实施
系统需求分析、系统设计
、系统实施
Pc机
熟悉汇编语言的编程过程
验证
掌握汇编语言程序设计的上机过程,熟练使用debug程序来调试程序
掌握汇编语言程序设计的上机过程,熟练使用debug程序来调试程序
Pc机
汇编数据寻址的方法
验证
通过实际编程了解不同的寻址方式
通过实际编程了解不同的寻址方式
Pc机
数据传送指令和算术运算指令
验证
排序算法的可视化程序c语言

排序算法的可视化程序c语言标题:探索排序算法的奥秘——生动实例展示C语言可视化程序引言:排序算法是计算机科学中最基础的算法之一,它的应用范围广泛,无论是数据结构还是数据库管理系统,排序算法都扮演着至关重要的角色。
为了帮助大家更好地理解排序算法的工作原理,现在我将通过一个生动全面的C语言可视化程序,向大家展示各种常见的排序算法。
一、程序设计与实现我们将使用C语言来实现排序算法的可视化程序。
通过图形化展示,我们可以清晰地观察每个排序算法的执行过程,从而更好地理解排序算法的内部机制。
下面是一些实现细节:1. 程序采用图形化用户界面(GUI)来展示排序算法的执行过程,方便观察和比较不同算法之间的差异。
2. 程序使用随机数组作为输入数据,并对其进行排序操作。
通过不同颜色来表示不同的元素值,方便观察元素的移动和交换操作。
3. 程序支持多种常见的排序算法,包括冒泡排序、插入排序、选择排序、快速排序、归并排序等。
二、冒泡排序算法的可视化演示冒泡排序是最简单且最容易理解的排序算法之一。
它的基本思想是将待排序序列分为已排序区和未排序区,每次从未排序区中选取相邻的两个元素进行比较和交换,直到未排序区为空。
下面是冒泡排序的可视化演示:首先,程序将生成一个随机数组,我们可以在图形界面上看到一系列不同颜色的方块,每个方块代表一个数组元素。
然后,程序开始执行冒泡排序算法,将会显示出两个方块之间的比较和交换过程,交换的方块会改变颜色进行标识。
最终,当所有的比较和交换操作完成后,我们可以看到已经排好序的数组。
通过这个可视化的演示,不仅可以直观地了解冒泡排序的基本思想,还可以深入感受到排序算法的执行过程,进而理解其时间复杂度和性能优化的重要性。
三、其他排序算法的可视化演示除了冒泡排序,我们还可以使用相同的方式演示其他常见的排序算法,比如插入排序、选择排序、快速排序和归并排序等。
通过这些演示,我们可以更全面地了解不同排序算法的优劣势以及适用场景。
产生式知识的有序二叉决策图表示及其推理

Ke w r s y od
O d r iayd c indarm ( B D) Po u t n rl K o l g ao ig ree bnr e i o i a O D d s g r c o e n w e er snn d i u d e
号OD B D模 型的推理技术 。并结合实例验证 了基 于 O D B D的产
1 简
介
生 式 知识 表 示 模 型及 其 推 理 技 术 的 正 确 性 和 可行 性 。
知识表示是人工智能 和专 家系统 中一个重要 的研 究课题 。 产生式 知识表示又称产生式规则 表示法 , 目前应 用较多 的一 是
第2 7卷 第 9期
21 0 0年 9月
计算机 应 用与软 件
Co mpue p iainsa d S fwa e trAp l t c o n ot r
V0 . 7 No 9 12 . S p.2 0 e 01
产 生式 知 识 的有序 二 叉决 策 图表 示 及 其 推理
k o ld e r a o i g n O D・ a e r d c in k o e g e rs na in mo e sp e e td h n,OB n w e g e s nn ,a BD b sd p o u t n wld e rp e e tt d li r s n e .T e o o DD— a e n wld e ra o ig r l b d k o e g e s n n u e s
nr D c i i a 的产生式知识表示模型。在此基 础上 实现 了基于 O D 的知识推理规则及相关算 法, ay eio Da m) sn g r BD 并结合 实例对 O D B D模
python可视化大屏库big_screen示例详解

python可视化⼤屏库big_screen⽰例详解⽬录big_screen特点安装环境输⼊数据本地运⾏在线部署对于从事数据领域的⼩伙伴来说,当需要阐述⾃⼰观点、展⽰项⽬成果时,我们需要在最短时间内让别⼈知道你的想法。
我相信单调乏味的语⾔很难让别⼈快速理解。
最直接有效的⽅式就是将数据如上图所⽰这样,进⾏可视化展现。
具体如下:big_screen 特点便利性⼯具, 结构简单, 你只需传数据就可以实现数据⼤屏展⽰。
安装环境pip install -i https:///simple flask输⼊数据在⽂件夹 data.py 中更新你需要展⽰的数据即可,如下为部分数据展⽰:self.echart1_data = {'title': '⾏业分布','data': [{"name": "商超门店", "value": 47},{"name": "教育培训", "value": 52},{"name": "房地产", "value": 90},{"name": "⽣活服务", "value": 84},{"name": "汽车销售", "value": 99},{"name": "旅游酒店", "value": 37},{"name": "五⾦建材", "value": 2},]}self.echart2_data = {'title': '省份分布','data': [{"name": "浙江", "value": 47},{"name": "上海", "value": 52},{"name": "江苏", "value": 90},{"name": "⼴东", "value": 84},{"name": "北京", "value": 99},{"name": "深圳", "value": 37},{"name": "安徽", "value": 150},]}self.echarts3_1_data = {'title': '年龄分布','data': [{"name": "0岁以下", "value": 47},{"name": "20-29岁", "value": 52},{"name": "30-39岁", "value": 90},{"name": "40-49岁", "value": 84},{"name": "50岁以上", "value": 99},]}self.echarts3_2_data = {'title': '职业分布','data': [{"name": "电⼦商务", "value": 10},{"name": "教育", "value": 20},{"name": "IT/互联⽹", "value": 20},{"name": "⾦融", "value": 30},{"name": "学⽣", "value": 40},{"name": "其他", "value": 50},]}本地运⾏cd big_screen-master;python app.py;在线部署你可以直接像在本地⼀样运⾏脚本,这样可以运⾏成功,如果我们想让它⼀直运⾏,我们可以在线部署。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
用 LinkedBinaryTree(String s, int pred)方法建立二叉树,然后调用 show 方法可视化显示二叉
树。所建二叉树如图 3 所示。
在 文 本 框 中 输 入 二 叉 树 的 广 义 表 形 式 , 如 a(b(c,d(e,f)),i(j,k(x,y))) , 调 用 LinkedBinaryTree(String s)方法建立二叉树,然后调用 show 方法可视化显示二叉树。所建二 叉树如图 3 所示。
图 3 广义表形式建立二叉树
Binary tree object oriented description and visualization
Yangxiaobo
(The department of information engineering, Tibet Nationalities Institute, Xian Yang 712082)
化的显示,并将先序、中序和后序三种遍历算法实现动态同步可视化,这将对学生的学习提
供莫大的帮助,同时也可激发学生更浓厚的学习兴趣。
2.二叉树的面向对象描述
2.1 顶点类的设计
public class BinaryTreeNode { private BinaryTreeNode left;//The left child
Abstract:In the field of computer science, binary tree is a very important non linear structure, the realized of the visualization of binary tree has important significance. In this paper ,it is realized the visualization of binary tree by using object-oriented method and the features of complete binary tree, achieved the visualization of traversing binary tree algorithm , the dynamic visual traversing process and the algorithm of dynamic demonstration synchronously. Keywords: binary tree, visualization, object-oriented,data structure, complete binary tree
二叉排序树的可视化实现
杨晓波
摘 要:在计算机科学领域中,二叉树是一种非常重要的非线形结构,实现其可视化具有重 要意义。本文运用面向对象方法,利用完全二叉树特点实现了二叉树的可视化,实现了周游 二叉树算法的计算可视化, 实现了动态可视遍历过程和算法的动态演示同步进行。
关键词: 二叉树;可视化;面向对象;数据结构;完全二叉树 中图分类号: TP311.12 文献标识码:A 基金资助 教育部科学技术研究重点项目“西藏文物普查与旅游开发的三维影像建模技术” (编号 208137)
图 2 非完全二叉树的可视化结果
3.3 窗口刷新问题 另外在绘图的过程中,如果直接在窗口绘图,那么当发生窗口刷新(比如窗口最小化后
恢复正常)或窗口被覆盖等情况时,所绘图形将被擦除。为避免这种情图形将被擦除的情况。 3.4 二叉树可视化的应用 3.4.1 广义表形式建立二叉树
…… }
public void show() {//可视显示二叉树
…… } …… }
其中 root 成员表示二叉树的根; cursor 成员表示当前结点,称光标; 方法 LinkedBinaryTree()构造一棵空二叉树 方法 LinkedBinaryTree(String s) 构造一棵二叉树,字符串 s 是二叉树的广义表形 式,如 a(b(c,d(e,f)),i(j,k(x,y))) 方法 LinkedBinaryTree(String s) 构造一棵二叉树,字符串 s 是二叉树的先序遍历 序列,如 abc**de*g**f***,其中“*”表示子树为空 方法 drawNode() 在绘图区域绘制二叉树中的结点 方法 drawEdge() 在绘图区域绘制二叉树的边 方法 show()在指定的窗体上可视显示二叉树,
…… } public LinkedBinaryTree(String s,int pred) {//先序次序输入字符序列建立二叉树 …… } public void createPoint() {//设置完全二叉树的可视坐标
…… } public void drawNode() {//绘制结点
…… } public void drawNode() {//绘制边
1.引言
树形结构在许多方面有应用,可表示层次关系、从属关系和并列关系等。在计算机科 学领域中,树形结构是一种非常重要的非线形结构。计算机应用中常出现的嵌套数据,在各 种算法问题中,如文件管理、数据库、编译等系统中的算法,都可用树形结构得来表示。二 叉树是树形结构的另一种重要类型,许多算法问题用二叉树形式来解决简单灵活,而且树形 结构都可以转换成一棵与之对应的二叉树。因此,二叉树是树形结构的关键组成部分,有关 二叉树的各种算法也是学习数据结构课程的的重点和难点。数据结构及其算法的教学难点在 于它们的抽象性和动态性,我们在学习二叉树的算法时就遇到了难题:首先基于结构化的程 序设计思想的算法比较烦琐,同时由于传统的程序设计将数据与操作分开,是孤立地看待问 题,对于记录每个顶点的状态,维持各顶点之间的联系比较麻烦。用C或Pascal描述数据结 构,不能很好地实现抽象数据类型的思想,只有用C++或Java的类才能很自然地实现抽象数 据类型的思想,这为改良教学内容,促进软件复用和设计良好的软件架构,打下了坚实的基 础[1];其次学生上机验证二叉树的建立算法时无从知道建立的二叉树是否与所想建立的一 致;另外先序、中序和后序三种遍历的动态过程也无法形象直观的得以展现。因此我们若采 用面向对象方法描述二叉树,并为学生提供一些接口,能在屏幕上将学生建立的二叉树可视
private BinaryTreeNode right;//The right child private Object data;//The data in this node private int id; private int x,y; }
顶点类的基本成员有 left、right 和 data,left 表示结点的左子树,right 表示结点的右子 树,data 表示结点的数据域。为将复杂的数据结构以直观易懂的形式展现在屏幕上,应设计 可视数据结构。可视数据结构就是在顶点类的基本属性和操作的基础上,增加可视属性(如 顶点大小,颜色,坐标值等),并提供可视化接口供程序调用[2]。因此为了实现二叉树的可 视化增加三个成员 id、x 和 y,id 表示结点的完全化编号,x,y 表示结点的可视化坐标。 2.2 二叉树的二叉链表实现------二叉链表类的设计
图 1 完全二叉树的可视化结果
3.2 非完全二叉树的可视化实现 对于非完全二叉树,由于形态各异,为了实现起来简单而且对各种形态的二叉树均适用,
运用非完全二叉树完全化的思想来实现,在结点类中增加了一个完全化编号成员,因此各结 点的坐标采用完全二叉树中对应结点的坐标,便可很容易的实现非完全二叉树的可视化。非 完全二叉树的可视化实现如图 2 所示。
3 二叉树的可视化实现
3.1 完全二叉树的可视化实现 由于屏幕的大小是确定的,所以要将二叉树绘制在这片弹丸之地并非易事。对于教学而
言达到教学的目的就可以了,所以我们可对二叉树的高度加以限制,限制二叉树的高度最多 为 6 层,如此二叉树的大小也就限定了,最多有 63 个结点,即满二叉树。所以现在的问题 转化为将含 63 个结点的二叉树实现可视化,而可视化的关键是为 63 个结点设置坐标。我们 利用完全二叉树的的特点来实现,方法如下:可将绘图区域分成 6 层,每一层确定坐标的结 点个数和高度为 6 的完全二叉树的每层结点个数相同,即第一层 1 个,第二层 2 个,第三层 4 个,第四层 8 个,第五层 16 个,第六层 32 个。先确定第六层各个结点的坐标,将绘图区 域 x 轴平分为 33 份,得到 32 个坐标。第五层各个结点的坐标用第六层各个结点的坐标计算 得到,计算出第六层每两个结点横坐标的中点坐标,即第六层第 1 和第 2 个结点横坐标的中 点坐标便是第五层第 1 个结点的横坐标,依此类推,各层结点的横坐标便可确定。每层的结 点的纵坐标一样,需要说明的是为了保证视觉效果各层的纵坐标应拉开一定的距离,如第一 层的纵坐标为 10,第二层的纵坐标为 50,依此类推。这一过程由 createPoint()方法来实现。 接下来就是绘制结点和边的问题了,由方法 drawNode()和 drawEdge ()来实现。完全二叉树 的可视化实现如图 1 所示。
public class LinkedBinaryTree //implements BinaryTree { protected BinaryTreeNode root;
protected BinaryTreeNode cursor; protected Point p[]=new Point [64]; public LinkedBinaryTree() { root=null; cursor=null; } public LinkedBinaryTree(String s) {//广义表形式建立二叉树
图 4 先序次序输入字符序列建立二叉树
3.4.3 动态可视遍历过程和算法的动态演示同步进行的实现 我们在设计动画时采用基于形状的动画。基于形状的动画也称为“子画面”动画,是更