SPSS第二章
第2章spss21教程完整版

9.
该工具是否可利用现有的数据和设备:选择一种数据挖掘工具,它
能利用现存的数据——或数据库中或文件中,也能与现有的分析和
可视化工具相兼容。你不会愿意因为不能利用现有的数据库而浪费 时间和资源再新建一个。
10. 选择一种可发送一致的、高质的结果的工具:要得到准确的结果,
需利用在各种情形下都能很好工作的、适应性强的数据挖掘环境和 各种数据的工具,而不是单一地为某一类型的数据或环境而设计的
2.
选择用于在商务理解和数据挖掘技术方面起到沟通作用的工具:确保工具
所用的步骤与数据挖掘的商务需要相匹配。
3.
确保工具可对现有的数据资源和格式进行操作:如果能选择一种能提取和
合并多来源、多格式数据,将会节省时间和金钱,并最大可能地得到可靠
结果的工具。这一点很重要,尤其是在数据挖掘过程的后期发现不得不从 新的来源加入新的数据时。
工具。工具应该能管理任何可能有助于阐释商务问题的数据。
11. 工具的开发能力:选择一种能将结果合并入现有的和将来的操作应 用中的工具,是很重要的。
12. 评估与工具相关的所有权潜在的成本。
SPSS Base
SPSS Base是一个服务于分析过程——计划、数据收集,数据获取和管理、分 析、报告和开发的,有标准组件、紧密结合、全系列的产品线,也是数据挖掘 程序的关键组件。首先,SPSS可以让你更快访问和分析大型数据,并且可以处
SPSS Clementine
Clementine是ISL(Integral Solutions Limited)公司开发的数据挖掘工具平台。 1999年,SPSS公司收购了ISL公司,对Clementine产品进行重新整合和开发, 现在Clementine已经成为SPSS公司的又一亮点。 Clementine使你的企业在多方面受益。例如: 可以改善客户获得和保持; 提高客户的生命周期价值; 识别并最小化风险和欺诈; 缩短产品开发过程中质量维护的周期; 支持科学研究。
SPSS教程第02章

第二章SPSS的数据管理第一节数据的输入2.1.1 变量的定义2.1.2 数据格式化2.1.3 数据的输入2.1.4 缺失值处理2.1.5 变量标签2.1.6 数据管理器列宽定义第二节数据的编辑2.2.1 数据的增删2.2.2 数据的整理2.2.3 数据的算术处理第三节数据文件的管理2.3.1 数据文件的调用2.3.2 数据文件的连接2.3.3 数据文件的保存统计分析离不开数据,因此数据管理是SPSS的重要组成部分。
详细了解SPSS的数据管理方法,将有助于用户提高工作效率。
SPSS的数据管理是借助于数据管理窗口和主窗口的File、Data、Transform等菜单完成的。
第一节数据的输入2.1.1 变量的定义先激活数据管理窗口,然后选Data菜单的Define Variable...命令项,弹出Define Variable对话框(见图1.1),在Variable Name:框内输入变量名,如本例为x1。
图1.1 变量定义对话框返回目录返回全书目录2.1.2 数据格式化在Define Variable对话框中点击Type...钮,弹出Define Variable Type对话框(如图1.2所示),用户可根据具体资料的属性对数据进行格式化。
Define Variable Type对话框中列出如下7种数据类型:图1.2 定义变量类型对话框1、Numeric:数值型,同时定义数值的宽度(Width),即整数部分+小数点+小数部分的位数,默认为8位;定义小数位数(Decimal Places),默认为2位。
2、Comma:加显逗号的数值型,即整数部分每3位数加一逗号,其余定义方式同数值型。
3、Dot:3位加点数值型,无论数值大小,均以整数形式显示,每3位加一小点(但不是小数点),可定义小数位置,但都显示0,且小数点用逗号表示。
如1.2345显示为 12.345,00(实际是12345E-4).4、Scientific notation:科学记数型,同时定义数值宽度(Width)和小数位数(Decimal Places),在数据管理窗口中以指数形式显示。
SPSS第2章

29
2.3 输入数据--注意事项
准确的数据是统计分析的基础。要严格控制数据录入错误。 可以用EPIData、ACCESS、VFP等软件编制数据录入管理 程序;由两个数据录入员独立录入,得两份独立的数据文件; 再对两份数据文件进行校对;确认无误后,锁定数据文件。 SPSS可以打开这些软件生成的数据文件, 然后保存为SPSS的数据文件,进行数据处理。
加入 更改 删除
20
2.2 变量设置--缺失值
缺失值
缺失值(Missing Value) 在实际的科研工作中往往会因为某种原因使记录的数据失真, 或没有测到,或没有记录。 在SPSS中,字符型变量默认的缺失值为空格;数值型变量的 失真数据与缺失数据,统称为“缺失值”。 对缺失值在定义变量属性时应该给出明确的定义。 各分析过程对缺失值的处理都有默认的方法,也可以由用户指 定如何处理这些缺失值。
11
2.2 变量设置--类型
类型 SPSS变量有三种基本类型:数值型、字符型、日期型。 数值型变量又按不同要求分为五种。共可定义八种类型的变量。 系统默认的变量类型为标准数值型变量(Numeric)。 每种类型的变量由系统给定默认长度。所谓长度指显示该变量值 所占的字节数,也就是用字符数表示的显示宽度。 小数点和其它定界符(/和E等)包括在总长度内。 (12/31/2004,1.23E-03)
变量标签 性别 组别 医院编号
疗效
变量值 1 2 1 2 1 2 3 1 2 3 4
变量值标签 男 女 试验组 对照组 中日医院 协和医院 友谊医院 痊愈 显效 好转 无效
变量值标签
变量值标签是对 变量所取的值附 加的说明
19
2.2 变量设置--变量值标签
变量值标签
SPSS第2章

Graph
• Chart Builder • Interactive
– Bar, Dot, Line, Ribbons, Drop Lines, Area Chart, Pie (Simple, Clustered, Plotted ) – Boxplot, Error Bar – Histogram – Scatterplot
Number of Cylinders
真正的3-D图
标出误差均数可信区间的3-D图
条图图组
American
150
European
Horsepower Horsepower
100
50
0
Japanese
150
100
50
0 3 Cylinders 4 Cylinders 5 Cylinders 6 Cylinders 8 Cylinders
75
3 Cylinders 4 Cylinders 5 Cylinders 6 Cylinders 8 Cylinders
Number of Cylinders
线图
Country of Origin
150
American European Japanese
Dot/Lines show Means
用色彩标注的复式条图
150
3 4 5 6 8
Cylinder s Cylinder s Cylinder s Cylinder s Cylinder s
Hor sep owe r
100
50
0 American European Japanese
SPSS第2章

•数据选择的基本操作步骤如下:
• 1.打开要操作的数据文件 • 2. 在菜单上选择“数据(data)”菜 单——选择“选择个案项(Select cases)”——呈现数据选择对话框 • 3. 数据选择对话框左面的框中呈现的 是工作数据文件中的变量,可以从中 选择一些变量作为被选择的变量 • 4.数据选择对话框右面的选择框中有 五种不同的选择方式:
Bank3.sav。筛选出数据文件中年龄 为20-30岁的男性员工的起始工作 (salbeg)和现在工资(salnow)的 数据,并将该文件保存在E盘中的文 件夹中,起名为agg1.sav。(数据选 择功能) 2、打开Bank.sav数据文件,另存为Bank3.sav。 筛选出数据文件中年龄大于30岁的女性员工 的起始工作(salbeg)和现在工资(salnow) 的数据,并将该文件保存在E盘中的文件夹中, 起名为agg2.sav。(数据选择功能)
2.2.1 单元值的查找
• 通常,已输入的数据有时需要修改, 可直接用方向键或鼠标移动到要修改 的单元,输入新数据。 若数据文件较大,且知道要修改的数 据单元的行号时,可通过查找特定行 进行。 • 选择菜单“编辑”==> “ ==> “转到个案” , • 或者 “转向个案”打开数据框
• 输入行号即可。
2.1.1 定义变量
• 该资料是定量资料,设计为 成组设计,因此我们需要建 立两个变量,一个变量代表 血磷值,习惯上取名为X,另 一个变量代表观察对象是健 康人还是克山病人,习惯上 取名为GROUP。
2.1.1 定义变量
现在,第一、第二列的名称均为深色显示,表明 这两列已经被定义为变量,其余各列的名称仍为 灰色的“var”,表示尚未使用。同样地,各行 的标号也为灰色,表明现在还未输入过数据,即 该数据集内没有记录。
spss学习第二章课件

Step04:完成操作 最后,单击【确定】按钮,数据即可导入成功。此时,
SPSS的数据浏览窗口中会出现相关的数据内容。
spss学习第二章
2.2 SPSS数据文件的 属性
2.2.1变量名称
spss学习第二章
2.2.2变量类型
变量类型是指每个变量取值的类型。SPSS提供了三种基本 数据类型:数值型、字符型和日期型。
spss学习第二章
2.2.3变量宽度
变量宽度是指在数据窗口中变量列所占的单元格的列宽 度,一般用户采用系统默认选项即可。值得注意的是,如果 变量宽度大于变量格式宽度,此时数据窗口中显示变量名的 字符数不够,变量名将被截去尾部作不完全显示。被截去的 部分用“*”号代替。
spss学习第二章
2.1.3利用数据库导入数据
打开软件后,现在菜单栏中的【文件】→【打开数据库】→【新 建查询】命令,弹出【数据库向导】对话框。通过这个数据库向 导窗口,用户可以选择需要打开的文件类型,并按照窗口上的 提示进行相关操作。
spss学习第二章
SPSS提供了专门2.1.4从文本向导导入数据文件 读取文本文件的功能。打开软件后,现在菜单栏中的【文件】
2.2.4变量小数
变量小数位数可以设置变量的小数位数,系统默认为两 位。
2.2.5变量名标签
变量名标签增强变量名的可视性和统计分析结果的可读 性。它可用中文,总长度可达120个字符。同时该属性可以省 略,但建议最好给出变量名的标签。
spss学习第二章
2.2.6变量值标签
变量值标签是对变量的可能的取值的含义进行进一步说明。变量 值标签特别对于数值型变量表示非数值型变量时尤其有用。 定义和修改变量值标签,可以双击要修改值的单元格,在弹出的 对话框的【值】文本框中输入变量值,在 【标签】文本框中输入变 量值标签,然后单击【添加】按钮将对应关系选入下边的白框中。 同时,可以单击【改变】和【移动】按钮对已有的标签值进行修改和 剔除。最后单击【确定】按钮返回主界面。
SPSS第二章

可以是任何字母、数字或_、@、#、$等符号。
变量最后一个字符不能是句号。 变量名总长度不能超过64个字符(即32个汉字)。 不能使用空白字符或其他特殊字符(如“!”、 “?”等)。
3
变量命名必须惟一,不能有两个相同的变
量名。 在SPSS中不区分大小写。例如,HXH、hxh 或Hxh对SPSS而言,均为同一变量名称。图2定义变量类型对话框
也可以单击数据编辑窗口左下方的
“Variable View”标签或双击列的题头,显 示变量定义视图窗口,然后单击要输出变量 的行头,这时整个行被选中,然后单击鼠标 右键,在其快捷菜单中选择“Clear”项。
2.5 数据文件的合并和分组
统计分析的首要任务是将数据输入到计
算机中。在数据量较大时,经常需要将一份 大的数据文件分成几个小部分,分别由几个 人输入,然后将若干个小的数据文件合并成 一个大的数据文件。
第二章 数据与数据文件
SPSS
统计分析
2.1
2.2 2.3 2.4 2.5
定义变量 数据的输入与保存 数据的编辑 变量的操作 数据文件的合并和分组
SPSS对数据的处理是以变量为前提
的,因此本章首先介绍定义变量、输入 数据,再介绍保存数据、操作数据文件.
2.1 定 义 变 量
启动SPSS后,出现如图2-1所示数据编 辑窗口。由于目前还没有输入数据,因此
SPSS的保留字(Reserved Keywords)不能
作为变量的名称,如ALL、AND、WITH、OR等。
2.定义变量类型(TYPE)
单击Type相应单元中的按钮,弹出如图2-3所示的
对话框,在对话框中选择合适的变量类型并单击
“OK”按钮,即可定义变量类型。
SPSS课件02

SPSS数据文件的合并
当数据量较多时经常会把一份大的数据分成 几个小的部分,有几个录入员分别录入,以期加快 数据录入速度,但一份完整的数据被分别存储在几 个数据文件中,如果要分析这份数据就必须首先将 若干个小的数据文件合并起来。要实现两个或多个 SPSS数据文件的合并,应首先将其中的某个数据 文件读入数据编辑窗口中,然后依次与其他数据文 件合并。合并的方式有两种:纵向合并和横向合并。
输入要寻找观 测量序号
2、按变量值定位: Edit+Find
• 将当前单元定位在某变量列的任何一个个案上 • 选择菜单 Edit---Find ,出现如下对话框 • 输入定位变量值并确认
于是, SPSS自动对指定的变量进行搜索,并将 当前单元定位于定位变量值相等的第一个个案上。
插入和删除一个个案
String(字符型)
字符型也是SPSS较常用的数据类型, 由一个字符串组成。如职工号码、姓名、地 址等变量都可以定义为字符型数据。字符型 数据的默认显示宽度为8个字符,不能够进 行算术运算,并区分大小写字母。
Date(日期型)
日期型数据用来表示日期或者时间,如生 日、成立日期等变量可以定义为日期型数据。 显示格式:dd-mmm-yyyy;mm/dd/yyyy。
定义显 示宽度
定义 对齐 方式
定义变 量类型
变量值 定义变量名标签 定义度量尺度 标签
定义变量类 型对话框
定义变量值标 签对话框
定义变量缺省值 对话框
SPSS数据文件的建立练习
• 根据居民储蓄调查问卷,建立SPSS格式的 数据文件。
SPSS数据的录入与编辑
1 录入 定义好SPSS数据结构后,可将具体的 数据输入到SPSS中,最终形成SPSS数据 文件。 SPSS数据的录入操作在数据编辑窗 口中的Data View卡片中实现。其操作方法 与EXCEL基本类似,也是以电子表格的方 式进行录入。录入带有变量值标签的数据时, 可以在下拉按钮中的值标签列表中选择一个 作为输入。
spss第二章变量计算及转换
2.4 特定变量值计数
(1)执行Transform---Count命令 打开Count Occurrences of Values within Cases
在对话框的Target Variable中输入目标变量名,用于保存 计数结果。Target label框中输入变量名标签。
(1) Value: 输入要计数的特定的变量值 (2)System-missing:系统缺损值出现的次数 (3)System-or use-missing:系统缺损值或用户自定义缺损值出现的次数 (4)Range:[ ]through[ ] : 针对数值连续可变的数值型变量的计数 (5)Range: Lowest through :
用这货Recode-Into Different Variable
2.5 变量重新赋值
2.5.1 重新赋值给同一个变量
1.主菜单Transform 选择Recode Into Same Variable - old and new value
2.5 变量重新赋值
2.选择要进行编码的变量名,送入Numeric Variable矩形 3.通过条件表达式建立参与编码的观测量子集
2.5 变量重新赋值
Range:[ ]through [ ]:
连续取值的变量与编码的对应关系
Range:Lowest through[ ]: 变量值 的上限
Range:[ ]through highest: 变量值的下限
ห้องสมุดไป่ตู้
All other value:
剩下的尚未指定的变量可以指定为同
3. SPSS内部函数(180个) (1) 算术函数 (2) 统计函数 (3) 概率函数
spss第二章,数据的编码、录入与整理
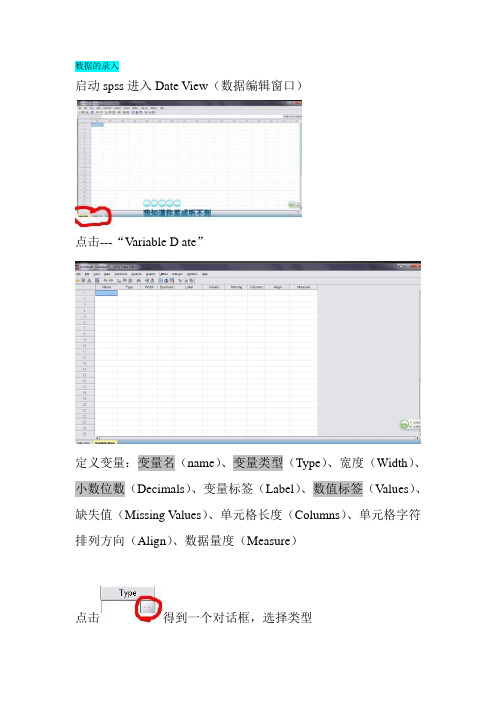
数据的录入启动spss进入Date View(数据编辑窗口)点击---“Variable D ate”定义变量:变量名(name)、变量类型(Type)、宽度(Width)、小数位数(Decimals)、变量标签(Label)、数值标签(Values)、缺失值(Missing V alues)、单元格长度(Columns)、单元格字符排列方向(Align)、数据量度(Measure)点击得到一个对话框,选择类型系统默认宽度为8,小数位2位;一般数字和字符比较常用-------Lable中可以取汉字名字方便查看------Values中可以设定数值标签,既将非数值的记录转换成数值;比如:性别1-女,2-男(一般默认为none)如图填写,点击----“And”----“OK”。
------在Missing中系统默认缺失值“none”用户可自己定义-------其他几项一般都用默认数据的录入-------回到“Date View”中逐个录入数据------“File”--“Save”(或者Ctrl+s)保存到适当的位置内即可数据的导入-----“File”---“Open”---“Date”数据的整理:数据分值转换数据分值的转换时通过对数据的重编码来实现的。
(比如将选项ABCD变成数值进行积分)----数据输入后----“Transform”--“Recode into different Variables”选中其中一个变量将其移到Numeric Variable->Output V ariable在那么中重编码----点击“Change”----“Old And New Values”例如:“Old”中写A----“New”中写1,此时A对应的数值就是1;同理写BCD-------点击“And”----“continue”----回到前一个界面-------将其它需要重编码的都编写一次(不要为了偷懒而一次性写,不会达到相同效果)------编完后-----点击“OK”表2.13前身量表的统分假定一个量表由两个分量表组成,其一为1、2、5、8、9题组成,另一个由3、4、6、7、10题,要求计算出分量表和总量表的分。
spss第二章分析前的准备

Valid
1.00 2.00 3.00 Total Missing .00 Total
Part two 分析前的准备
四 利用已有的变量计算产生新变量 Transform Compute eg: 请问你父母的年龄: 父亲 ___ 岁 母亲 ___ 岁 计算父母年龄之差
计算公式
新变量变 量名
P31
只合并两个文件中相同的变量的观
测量时,单击OK
追加外部数据文件中不同的变量的
观测量时:
配对时要求变 量类型,宽度相 同
0:当前文件的数据 1:外部文件的数据
Part two 分析前的准备
六 拆分数据文件
data
split files
对变量分层进行固定水平分析
A1
B13性别:未缓解10 Nhomakorabea13 23
合计
12 27 39
判断化疗对于缓解症状是否有效。
Part two 分析前的准备
八 数据分类汇总(p77): Data Aggregate
对数据分类汇总
按照指定的分类变量对所有观测量 分组,对每组变量中所包含的各观 测量求描述性统计量,并可生成新 的数据文件保存统计量。
Data
Weight cases
什么时候进行加权
1
变量中某个选项的比例过高
进行加权
数据不加权 选择的加权 变量
加权前
加权后
Part two 分析前的准备
2 数据中存在表明相同的变量值出现的频 数的变量时,需对频数加权
两化疗组的缓解率比较
治疗组
单纯化疗 复合化疗 合计
spss第二章

开放性问卷的处理方法
• 1、对回答进行分类。 • 2、建立回答类别与对应的数量关系, 进行编码。
• • • • 我最适应的是:_________________________ 我最满意的是:_________________________ 最不适应的是:_______________________ 压力最大的是:_______________________
资料的审查 编码
数据资料的形式: • 封闭性问卷资料与开放性问卷资料。 • 不同的资料形式均要求对资料进行审查,但在编 码时有不同的要求。
资料的审查
• 主要考察二个方面: 1.资料的完整性(关键) 2.资料的合理性
资料的完整性审查
包括资料总体上的完整性和每份资料的完 整性。 整性。 资料总体的完整性主要考虑问卷发放的数 回收率等。 量、回收率等。 每份资料的完整性主要看问卷的填答情况, 每份资料的完整性主要看问卷的填答情况, 是否是有效问卷。 是否是有效问卷。
• 问题5 开学以来我经常从事的休闲活动是 (可以重复选择) 1. □运动 2.□KTV 3.□郊游 4.□跳舞 5. □爬山 6.□玩牌 7.□下棋 8.□逛街 9.□聊天 10.□看书 11.□上网打游戏机 12.□看电视 13.□看电影
多项排序选择题
• 问题 您选择职业考虑的主要因素有(依 问题6 您选择职业考虑的主要因素有( 据重要性大小排列,限选三项) 据重要性大小排列,据
上机练习
1、尝试建立一个有五个变量:学号、性别、英语成绩、数学 、尝试建立一个有五个变量 学号 性别、英语成绩、 学号、 成绩、智商的数据文件,要求输入至少6个个案的数据 个个案的数据。 成绩、智商的数据文件,要求输入至少 个个案的数据。 文件名为:姓名SPSS2a 文件名为:姓名
SPSS统计分析第二章

4. 如何定义一个变量
我们首先单击左下角的“Variable
View”
进入定义变量属性的界面,在此界面上可 以定义变量名、变量的类型、变量的长度 及小数位数、变量标签及其值标签、变量 的格式(包含显示栏宽度、对齐方式、缺 省值标签等等)。
定义一个变量的步骤如下:
运行spss 进入定义变量界面 定义变量名 变量类型的定义 定义变量标签 定义变量标签值 定义用户缺省值 定义变量的显示格式 定义变量的测度类型
第一种为诸如第一种为诸如25251643516435的普通书写方式的普通书写方式第二种书写方式为科学计数法即采用指数第二种书写方式为科学计数法即采用指数来表示数值它的主要用途为表示特别大来表示数值它的主要用途为表示特别大或特别小的数值例如或特别小的数值例如134e11134e11表示表示13410134101111254e22表示表示254102541022字符串常量是由单引号或双引号括起来字符串常量是由单引号或双引号括起来的一串字符如果字符串中带有的一串字符如果字符串中带有??字符字符则此字符变量应由双引号包含起来则此字符变量应由双引号包含起来例如例如life日期型常量在日期型常量在spssspss中表现为特殊的格中表现为特殊的格式
“It’s life”
③ 日期型常量
日期型常量在SPSS中表现为特殊的格
式.在下文中会详细讲述其格式及用法。
(2)SPSS变量
SPSS变量与数学中的定义类似,均指值可 变的量。但与一般数学中不同的是:除了 定义变量名之外,在SPSS中还要定义它的 其他四个属性即变量类型(type)、变量标 签和值标签(label 和Values)、缺省值 定义(missing values)、变量的列格式 (column format)。在定义SPSS变量时至 少应定义变量名和变量类型,而其他属性 则可以采用默认值。
spss教程第二章

第二章数据文件的管理(上)(医学统计之星:张文彤)最后一次更新时间:2.1建立与保存数据文件-File菜单2.1.1 新建数据文件2.121 直接打开2.122 使用数据库查询打开2.1.2.3 使用文本导入向导读入文本文件2.1.2 打开其他格式的数据文件2.1.3保存数据文件2.1.4 File菜单中的其他条目2.2 编辑数据文件2.2.1 定义新变量2.2.1.1 直接定义新变量2.2.1.2 从原有变量计算新变量-Transform菜单2.2.2 数据的录入2.2.2.1 直接录入2.2.2.2 数据录入技巧2.3 进一步整理数据文件-Data菜单不言而喻,一切统计分析都是以数据为基础的,因此统计软件的数据管理能力非常重要。
SPSS以其豪华的界面为依托,为用户提供的便捷的数据管理功能,下面我们就来具体看一下。
§2.1建立与保存数据文件和大多数应用软件相同,SPSS中数据文件的管理功能基本上都集中在了File菜单上,该菜单的组织结构和WORD等也极为相似,因此这里我们只介绍比较有特色的几个菜单项。
I SPSS 10.0有三个主要窗口界面:数据管理窗口、程序编辑窗口和结果浏览窗口;另有两个不常用的窗口:结果草稿浏览窗口和VBs脚本语言编辑窗口。
他们共享许多菜单项,如File菜单就大部分相同,这里介绍的许多内容在五个窗口中都是通用的。
2.1.1 新建数据文件如果你正从头开始进行一个新的课题,刚刚把数据收集上来,要做统计分析,自然需要新建一个数据库,然后将所有的数据从纸上请到计算机里。
在SPSS中,新建一个数据库容易的不得了一一已经到了什么都不用做的地步!是这样,当你进入SPSS系统时,系统就已经生成了一个空数据文件,即你看到的空白的数据管理界面。
你只要按自己的需要定义变量,输入数据然后存盘就是了(这些操作马上会讲到)。
2.1.2 打开其他格式的数据文件凡是做过数据输入工作的人都知道:这活又费眼睛又累人,出错太多了还要挨批评,非常影响个人的光辉形象算了,还是在有限的经费里划几百美元出来雇个打字小姐吧(怎么用美元?因为我请了个老外!)。
spss教程第二章--均值比较检验与方差分析

第二章均值比较检验与方差分析在经济社会问题的研究过程中,常常需要比较现象之间的某些指标有无显著差异,特别当考察的样本容量n比较大时,由随机变量的中心极限定理知,样本均值近似地服从正态分布。
所以,均值的比较检验主要研究关于正态总体的均值有关的假设是否成立的问题。
◆本章主要内容:1、单个总体均值的 t 检验(One-Sample T Test);2、两个独立总体样本均值的 t 检验(Independent-Sample T Test);3、两个有联系总体均值均值的 t 检验(Paired-Sample T Test);4、单因素方差分析(One-Way ANOVA);5、双因素方差分析(General Linear Model Univariate)。
◆假设条件:研究的数据服从正态分布或近似地服从正态分布。
在Analyze菜单中,均值比较检验可以从菜单Compare Means,和General Linear Model得出。
如图2.1所示。
图2.1 均值的比较菜单选择项§2.1 单个总体的t 检验(One-Sample T Test)分析单个总体的 t 检验分析也称为单一样本的 t 检验分析,也就是检验单个变量的均值是否与假定的均数之间存在差异。
如将单个变量的样本均值与假定的常数相比较,通过检验得出预先的假设是否正确的结论。
例1:根据2002年我国不同行业的工资水平(数据库SY-2),检验国有企业的职工平均年工资收入是否等于10000元,假设数据近似地服从正态分布。
首先建立假设:H0:国有企业工资为10000元;H1:国有企业职工工资不等于10000元打开数据库SY-2,检验过程的操作按照下列步骤:1、单击Analyze →Compare Means →One-Sample T Test,打开One-Sample T Test 主对话框,如图2.2所示。
图2.2 一个样本的t检验的主对话框2、从左边框中选中需要检验的变量(国有单位)进入检验框中。
spss第二章变量计算及转换
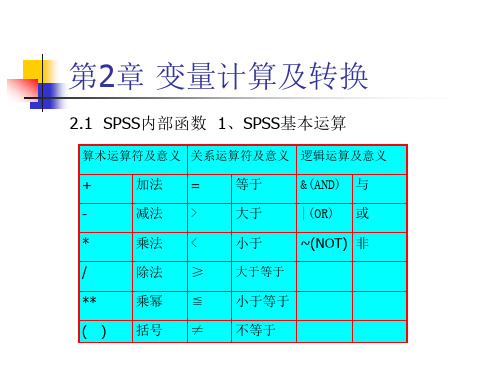
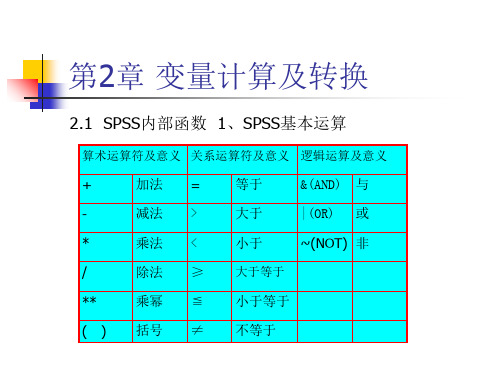
2.1 SPSS内部函数 1、SPSS基本运算
算术运算符及意义 关系运算符及意义 逻辑运算及意义
+
加法 =
等于
&(AND) 与
-
减法 >
大于
|(OR) 或
*
乘法 <
小于
~(NOT) 非
/
除法 ≥ 大于等于
**
乘幂 ≦ 小于等于
( ) 括号 ≠ 不等于
第2章 变量计算及转换
2. SPSS表达式 (1) 算术表达式 A+B (2) 关系表达式 A>B (3) 逻辑表达式 A>b&C=6 逻辑运算中优先级的顺序为:最高级为not, 其次为and,最后为or。
6.排秩的类型,单击Rank Type
2.7 观测量求秩
(1)Rank:
普通秩
(2)Savage score: 基于指数分布规律计算出的一种秩
(3)Fractional rank: 分数形式的秩
(4)Fractional rank as %: 百分比形式的秩
(5)Sum of weights: 加权观测量的总和
3. SPSS内部函数(180个) (1) 算术函数 (2) 统计函数 (3) 概率函数
2.2 变量计算及其运用
Compute 命令 (1)打开数据文件,执行Transform—Compute命令
2.2 变量计算及其运用
(2)输入计算表达式。 (3)定义新变量以及类型。在Target(目标)框中定义目
(6)若选Convert numeric string to numbers 中选项, 则可将字符型转换为数值型
(7)可以同时对多个变量值进行编码
SPSS第二章

数据结构
首先必须定义数据结构, 包括名称、类型、缺 省值等;
数据内容
然后按照定义好的数据 结构,输入和编辑 数据。
2.1.2 SPSS的基本组织方式 SPSS的基本组织方式
SPSS的数据形成一张二维表格,主要有两种方式: 1. 原始数据的组织方式:
• 每一行称为一个个案(case); • SS文件的保存: SPSS文件的保存:
– 基本操作:File->save data 或者 save as 基本操作:File– 默认的文件格式是以.sav为扩展名; 默认的文件格式是以.sav为扩展名; – 支持Excel格式文件,支持.xls为扩展名; 支持Excel格式文件,支持.xls为扩展名; – 数据库文件(.dbf)和文本文件(.dat); 数据库文件(.dbf)和文本文件(.dat);
2.6 SPSS和其他格式文件的读取 SPSS和其他格式文件的读取
• 直接读取的操作:
– 基本操作:File->Open->Data; – 直接打开后缀名为 .sav .xls .dbf .sas7bdat 的文件;
• 使用文本向导从文本文件读入数据:
– 基本操作:File->Read Text Data; – 正确识别分隔数据项,用分隔符分隔,分隔符有 Tab,逗号,分号,空格和其他符号; – 第一行是否有变量名; – 数据时如何安排的,范围,每行几个数据等等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• 增加变量有两种方式:
一是两个数据文件按观测量顺序一对一地横向合并; 二是按关键变量合并,即要求两个数据文件必须有一个共同的关键变
量,两个数据文件中关键变量值相同的观测量合并为一个观测量。
1、打开数据a2-1.sav与数据a2-2.sav,我们来演示打开多 个数据文件合并数据的方式。
“变量名称是否包含在文件的顶 部?”选项:如果变量名称包含 在文件的顶部选择“是”;没有 选择“否”。本例中变量名称包 含在文件顶部,选择“是”。
点击“下一步”
5、进入第3步。这里有三个选项需要设置
“第一个数据个案从哪个行号开 始?”选项:该输入框用于选择 数据读取的起始行,如果数据文 件中包含标签,那么该数据文件 的起始行就不是第一行。本例中 由于第一行包含标签故输入 “2”。
– 变量名最多可包含 64 个字节,并且第一个字符必须是字母或字符 @、# 或 $ 之一。后续字符可以是字母、数字、非标点字符和句 点 (.) 的任意组合。在双字节语言(例如中文)中,64 个字节通 常意味着 32 个字符。
• 定义变量包括:变量名、变量类型、变量宽度、小数位数 、变量标签、数值标签、缺失值、变量栏宽度、数据对齐 方式、变量的度量标准。
– 度量标准, 分为度量、有序和名义。这对应于统计上所讲的等距与 等比、顺序、称名变量。
• 在SPSS的数据视图中,数据文件是按个案(行)和变量(列) 组织的。
• 个案表示各个调查对象。
• 变量表示对调查中提出的每个问题的回答。
例子
• 问卷的组成: –指导语 –人口统计学资料 –各个分问卷
例子
在本例中,数据a2-1.sav与数据a2-2.sav的顺序是一一 对应的,我们可以直接按照增加变量的第一种方式,直接 点击确定合并;也可以按照关键变量来进行合并,在正式 合并之前我们已经把数据按照关键变量进行升序排列。我 们下面演示的是第二种按关键变量合并的方法。
• 用户可以在数据编辑器窗口进 行数据输入、观察,编辑和统 计分析等操作。
1、标题栏。显示窗口名称和编辑的数据文件名。如果当前 数据编辑器中是一个新建的文件,其显示为“未标题1[数 据集0]-SPSS Statistics数据编辑器”。
2、菜单栏包括“文件”、“编辑”、“视图”、“数据” 、“转换”、“分析”、“图形”、 “实用程序”,“附 加内容”、“窗口”和“帮助”菜单,这此菜单可以实现 编辑数据与变量、定义系统参数、设置显示方式、绘制图 形、进行各项数据分析和查阅帮助等功能。
2、打开数据文件,开始数 据的导入。
“从第一行数据读取变量名”复选框,如勾选该该复选框系统会将Excel 数据文件第一行作为变量名读入。 “工作表”下拉框:如果读取的Excel数据文件中有多个数据表用户可以 在该下拉框中选择要读取的工作表。 “范围”输入框:和果用户 希望读取Excel工作表中的部分数据可以在输 入框中输入相应的数据范围。 “字符串列的最大宽度”输入框:该输入框用于设置字符串变量的最大宽 度,直接输入自定义宽度即可。
导入完成后的效果图
第四节 SPSS中合并数据文件
可以使用两种不同的方式合并两个文件中的数据:
1、包含相同变量但不同个案的SPSS数据文件。 2、包含相同个案但不同变量的 SPSS 数据文件。
从菜单中选择:<数据>-<合并文件> 选择<添加个案>或<添加变量> ,如右图所示。
一、添加个案
• “添加个案”将数据与另外一个包含相同变量(列)但不 同个案(行)的外部SPSS数据文件合并在一起。
• 在这一讲中,我们用到数据a1-1.sav与数据a1-2.sav。 • 数据a1-1.sav与数据a1-2.sav有相同的变量。我们的目的是
将这两个数据合并到一起。
1、首先打开数据a1-1.sav。从菜单中选择:<文件 >-<打开>-<数据>,打开数据a1-1.sav。
通过数据视图窗口我们发现数据 a1-1.sav中共有4个个案。我们要 将数据a1-1.sav与未打开的数据 a1-2.sav进行合并。
“文本限定符是什么”选项:如果 数据中有文本,需要在这里指定相 应的标记符号。本例中没有,选择 “无”。
7、进入第五步
该对话框用于设置变量的名称和数据格式,用户“数据预览”表 格中选择相应的变量,即可在“变量名称”输入框中输入变ห้องสมุดไป่ตู้名 称在“数据格式”下拉列表中选择相应的数据格式。
8、进入第六步”。
3、常用工具按钮,显示自定义的SPSS常用工具。
4、单元格信息显示栏。该显示栏用于显示单元格位置和单 元格的内容等相关信息。灰色显示的区域为提示区,显示 单元格的位置,空白区域为数据编辑区,该区域内显示当 前选中的单元格的内容,用户可以在该区域输入或修改相 应的内容。
5、 数据编辑显示区。在窗口的中部是编辑显示区,该区最 左边列显示单元序列号,最上边一行显示变量名称选定的 单儿格呈反色显示,其内容将出现在数据和单元格信息显 示栏中,在此输入或修改单元格内容。
• 建立数据文件的步骤: –根据需要设置变量 –定义变量属性 –输入数据
第三节 SPSS其他数据格式的导入
• 在观实的分析应用中,许多数据并不是以SPSS数据格式保 存的。因此我们需要能够读取这些不同格式的数据。SPSS 提供了与多种应用软们的接口,支持多种格式的数据文件 格式。用户可以方便地将其他数据格式文件导入其中。
3、设置完成后,单击“确定”按钮读入Excel数 据。结果如下图所示。
二、从文本文件中导入数据
1、从菜单中选择:<文件>-<打开>-<数据>,选择 Text (*.txt) 作为您要查看的文件类型。 以SPSS自带的 demo.txt为例。demo.txt一般位于SPSS安装目录下的 Samples\Simplified Chinese文件夹中,笔者计算机中 SPSS是默认安装的,那么demo.txt的绝对位置就是
“如何表示个案”选项:是一行 表示一个个案还是变量的特定编 号表示个案。本例中是一行表示 一个个案。
“您要导入多少个个案?”:是全部个案,还是前 多少个个案,或者是随机导入指定数目的个案。本 例中选择导入全部个案。
6、进入第四步。有两个选项需要设置。
“变量之间有哪些分隔符”选项: 本例中变量之间是以“TAB”为分隔 符的,因此选择“制表符”,如果 变量之间是用空格、逗号或其他符 号来分割的,可以做相应的选择。
– 变量类型,指定每个变量的数据类型。缺省情况下,假定所有新变 量都为数值变量。可以使用“变量类型”来更改数据类型。
– 宽度(最大位数)。
– 小数位数,显示的小数位数。受宽度的限制。
– 变量标签,可以为描述性变量标签分配最多可达 256 个的字符( 在双字节语言中则为 128 个字符)。变量标签可以包含空格和变量 名称中所不允许的保留字符。
一、从Microsoft Excel 中读取数据
1、从菜单中选择:<文件>-<打开>-<数据>,选择 Excel (*.xls) 作为您要查看的文件类型。 以SPSS自带的 demo.xls为例。demo.xls一般位于SPSS安装目录下的 Samples\Simplified Chinese文件夹中,笔者计算机中 SPSS是默认安装的,那么demo.xls的绝对位置就是 C:\Program Files\SPSSInc\Statistics17\Samples\Simplified Chinese。
从菜单中选择:<数据>-<合并文件>-<添加变量>,打开如 下图所示的对话框。
• 在“打开的数据集”中选择“a2-2.sav[数据集2]”,然 后点击“继续”。
2、 在打开的如上图所示的对话框中,左栏“已排除的变量 ”列出的是两个文件中的同名变量。只有这样的变量一可 以作为关键变量。对话框右侧“新的活动数据集”矩形框 中,列出了可以在新工作数据文件中存在的变量。
如果用户希望将本次设置的文件 格式作为规则保存,以便在导入 类似的文本数据文件时无须重新 没置,可以在“您要保存此文件 格式以备以后使用吗"选项组中 选择”是",并输入文件的保存 路径。
“您要粘贴语法吗?”如果用户选择“是”,那么单击完成后,会把相应 的相应的语法命令粘贴到语法编辑器中。本例中选择“否”。单击“完成” 完成数据的导入。
– 值标签,您可以为每个变量值分配描述值标签。当您的数据文件 使用数值代码表示非数值类别时(例如:代码 1 和 2 代表 male 和 female),此过程特别有用。
• 定义变量包括:变量名、变量类型、变量宽度、小数位数、 变量标签、数值标签、缺失值、列宽、数据对齐方式、变量 的度量标准。
– 缺失值将指定数据值定义为用户缺失值,并将其从大多数计算中排 除。
C:\Program Files\SPSSInc\Statistics17\Samples\Simplified Chinese
2、打开数据文件,开始数据的导入
3、单击“打开”按钮,打开如下图所示的对话框
4、点击“下一步”。进入第二步,这里有两个选项要设置
“变量是如何排列的?”选项: 如果用户文本文件数据中的变量 是用特定符号分割开的,那么选 择“分割”;如果每个变量的宽 度是固定的,那么选择“固定宽 度”。本例中的数据是用“TAB” 符号分割的,因此选择“分割”。
– 列宽,可以直接输入数字指定列宽。也可以通过单击并拖拽列边框 来更改数据视图中的列宽。对于数值型变量,超过列宽的部分将以 “…”表示。
– 对齐方式,对齐控制着数据视图中数据值和/或值标签的显示。缺省 对齐方式为数值变量在右边,字符串变量在左边。此设置只影响数 据编辑器中的显示 。有左对齐、右对齐、居中对齐三种方式。