经典图论算法
迪杰斯特拉算法用于求解拓扑排序问题

一、引言在计算机科学中,算法是解决问题的步骤和方法的描述。
而拓扑排序问题是图论中的一个经典问题,它主要用于对有向无环图(DAG)进行排序。
迪杰斯特拉算法是一种经典的图论算法,被广泛应用于求解最短路径问题。
然而,很少有人知道,迪杰斯特拉算法也可以用于求解拓扑排序问题。
本文将详细介绍迪杰斯特拉算法在求解拓扑排序问题中的应用,并对其算法原理和具体步骤进行详细解析。
二、迪杰斯特拉算法简介1.迪杰斯特拉算法的背景迪杰斯特拉算法由荷兰数学家艾兹赫尔·迪杰斯特拉在1959年提出,用于求解单源最短路径问题。
该问题是在具有权值的有向图中,从一个顶点到其他所有顶点的最短路径。
迪杰斯特拉算法采用贪心的策略,通过逐步确定源节点到其他节点的最短路径。
该算法具有良好的时间复杂度,并且被广泛应用于路由算法、网络拓扑等领域。
2.迪杰斯特拉算法的原理迪杰斯特拉算法的核心思想是将图中的节点分为两个集合:已访问集合(S)和未访问集合(U)。
算法从起始节点开始,计算到达其他节点的最短路径,并将这些节点逐步加入已访问集合中。
具体步骤如下:步骤1:初始化起始节点和集合S。
将起始节点的最短路径设置为0,其余节点的最短路径设置为正无穷大。
步骤2:选择未访问集合中最短路径的节点,将其加入已访问集合S。
步骤3:更新与新加入节点相邻节点的最短路径。
如果通过新加入节点可以获得更短的路径,更新相邻节点的最短路径。
步骤4:重复步骤2和步骤3,直到所有节点都已加入已访问集合S。
步骤5:算法结束,所有节点的最短路径已经计算完成。
三、拓扑排序问题及其求解1.拓扑排序问题的定义拓扑排序是指将有向无环图中的节点线性排序,使得任意一条有向边的起点在排序中都排在终点的前面。
拓扑排序满足任意一条有向边(u, v)的起点u在排序中都排在终点v的前面。
拓扑排序问题常用于任务调度、依赖关系分析等场景中。
2.拓扑排序问题的解决方法迪杰斯特拉算法可以用于求解拓扑排序问题的原因在于,当图中不存在环时,每个节点的最短路径都可以唯一确定。
图论中的生成树计数算法

图论中的生成树计数算法生成树是图论中重要的概念之一,它是指由给定图的节点组成的树形结构,其中包含了原图中的所有节点,但是边的数量最少。
生成树的计数问题是指在一个给定的图中,有多少种不同的生成树。
生成树计数算法是解决这个问题的关键步骤,本文将介绍一些常见的生成树计数算法及其应用。
1. Kirchhoff矩阵树定理Kirchhoff矩阵树定理是图论中经典的生成树计数方法之一。
该定理是由Kirchhoff在19世纪提出的,它建立了图的Laplacian矩阵与其生成树个数的关系。
Laplacian矩阵是一个$n\times n$的矩阵,其中$n$是图中的节点数。
对于一个连通图而言,Laplacian矩阵的任意一个$n-1$阶主子式,其绝对值等于该图中生成树的个数。
应用示例:假设我们有一个无向连通图,其中每个节点之间的边权均为1。
我们可以通过计算图的Laplacian矩阵的任意一个$n-1$阶主子式的绝对值来得到该图中的生成树个数。
2. Prufer编码Prufer编码是一种编码方法,可用于求解生成树计数问题。
它是基于树的叶子节点的度数的编码方式。
Prufer编码将一个树转换为一个长度为$n-2$的序列,其中$n$是树中的节点数。
通过给定的Prufer序列,可以构造出对应的生成树。
应用示例:假设我们有一个具有$n$个节点的有标号的无根树。
我们可以通过构造一个长度为$n-2$的Prufer序列,然后根据Prufer编码的规则构造出对应的生成树。
3. 生成函数方法生成函数方法是一种利用形式幂级数求解生成树计数问题的方法。
通过将图的生成树计数问题转化为生成函数的乘法运算,可以得到生成函数的一个闭形式表达式,从而求解生成树的个数。
应用示例:假设我们有一个具有$n$个节点的有根树,其中根节点的度数为$d$。
我们可以通过生成函数方法求解出该有根树中的生成树个数。
4. Matrix-Tree定理Matrix-Tree定理是对Kirchhoff矩阵树定理的一种扩展,适用于带权图中生成树计数的问题。
经典图论问题

5经典图论问题5.1 一笔画问题一笔画算法即是从起点a开始选择关联边(第一这条边不是往回倒,第二这条边在前面延伸路上没有出现过)向前延伸,如果到达终点b,得到a—b迹,判断路上的的边数是否为图的总边数,是就终止,否则选择迹上某个关联边没有用完的顶点v,用同样方式再搜索v—v的闭迹,添加到a—b迹上,即得到a—v---v—b迹,如果这个迹的边数还没有达到总边数,则再选择迹上某个关联边没有用完的顶点。
逐步扩展即可。
二、弗罗莱(Fleury )算法任取v 0∈V(G),令P 0=v 0;设P i =v 0e 1v 1e 2…e i v i 已经行遍,按下面方法从中选取e i+1: (a )e i+1与v i 相关联;(b )除非无别的边可供行遍,否则e i+1不应该为G i =G-{e 1,e 2, …, e i }中的桥(所谓桥是一条删除后使连通图不再连通的边);(c )当(b )不能再进行时,算法停止。
5.2 中国邮递员问题(CPP )规划模型:设ij x 为经过边j i v v 的次数,则得如下模型。
∑∈=Ev v ij ijji x z ϖmin∑∑E∈E∈∈=j i i k v v i v v ki ij V v x x ,E ∈∈≤j i ij v v N x ,1..t s5.3旅行推销员问题(TSP,货郎担问题)(NPC问题)定义:包含图G的所有定点的路(圈)称为哈密顿路(圈),含有哈密顿圈得图称为哈密顿图。
分析:从一个哈密顿圈出发,算法一:(哈密顿圈的充要条件:一包含所有顶点的连通子图,二每个顶点度数为2)象求最小生成树一样,从最小权边加边,顶点度数大于3以及形成小回路的边去掉。
算法二:算法三:示例:设旅行推销员的矩阵为⎪⎪⎪⎪⎪⎭⎫ ⎝⎛01086100111281101565150规划模型:先将一般加权连通图转化成一个等价的加权完全图,设当从i v 到j v 时,1=ij x ,否则,0=ij x ,则得如下模型。
数学建模十大经典算法

数学建模十大经典算法数学建模是将现实问题抽象化成数学问题,并通过数学模型和算法进行解决的过程。
在数学建模中,常用的算法能够帮助我们分析和求解复杂的实际问题。
以下是数学建模中的十大经典算法:1.线性规划算法线性规划是一种用于求解线性约束下的最优解的方法。
经典的线性规划算法包括单纯形法、内点法和对偶理论等。
这些算法能够在线性约束下找到目标函数的最大(小)值。
2.整数规划算法整数规划是在线性规划的基础上引入了整数变量的问题。
经典的整数规划算法包括分枝定界法、割平面法和混合整数线性规划法。
这些算法能够在整数约束下找到目标函数的最优解。
3.动态规划算法动态规划是一种将一个问题分解为更小子问题进行求解的方法。
经典的动态规划算法包括背包问题、最短路径问题和最长公共子序列问题等。
这些算法通过定义递推关系,将问题的解构造出来。
4.图论算法图论是研究图和图相关问题的数学分支。
经典的图论算法包括最小生成树算法、最短路径算法和最大流算法等。
这些算法能够解决网络优化、路径规划和流量分配等问题。
5.聚类算法聚类是将相似的数据点划分为不相交的群体的过程。
经典的聚类算法包括K均值算法、层次聚类算法和密度聚类算法等。
这些算法能够发现数据的内在结构和模式。
6.时间序列分析算法时间序列分析是对时间序列数据进行建模和预测的方法。
经典的时间序列分析算法包括平稳性检验、自回归移动平均模型和指数平滑法等。
这些算法能够分析数据中的趋势、周期和季节性。
7.傅里叶变换算法傅里叶变换是将一个函数分解成一系列基础波形的过程。
经典的傅里叶变换算法包括快速傅里叶变换和离散傅里叶变换等。
这些算法能够在频域上对信号进行分析和处理。
8.最优化算法最优化是研究如何找到一个使目标函数取得最大(小)值的方法。
经典的最优化算法包括梯度下降法、共轭梯度法和遗传算法等。
这些算法能够找到问题的最优解。
9.插值和拟合算法插值和拟合是通过已知数据点来推断未知数据点的方法。
经典的插值算法包括拉格朗日插值和牛顿插值等。
图论在交通网络优化中的应用

图论在交通网络优化中的应用交通网络的优化一直是一个重要的研究领域,通过合理的路线规划和流量管理,可以提高交通效率,减少拥堵和能源消耗。
图论作为数学的一个分支,广泛应用于交通网络优化中,帮助我们解决这些问题。
本文将探讨图论在交通网络优化中的应用,并介绍一些经典的图论算法。
一、交通网络模型与图论在研究交通网络优化之前,我们需要将交通网络抽象成数学模型。
交通网络通常可以用图的形式来表示,其中路口是节点,道路是边。
图论提供了一些基本的概念和方法来描述和分析交通网络。
1. 图的基本概念- 节点(vertex):在交通网络中,节点表示路口或交叉口。
每个节点可以有多个与之相连的边,表示与其他路口的连接。
- 边(edge):边表示路径,连接两个节点。
在交通网络中,边可以是双向的,也可以是单向的。
- 权重(weight):边上的权重表示从一个节点到另一个节点的代价或距离。
在交通网络中,权重可以表示道路的长度、通行能力或其他影响路线选择的因素。
2. 图的类型- 无向图(undirected graph):在无向图中,边没有方向,可以从一个节点到另一个节点,也可以反过来。
- 有向图(directed graph):在有向图中,边有方向,只能从一个节点指向另一个节点。
- 带权图(weighted graph):在带权图中,边上有权重值,可以表示路径的距离、时间或其他影响因素。
二、最短路径算法最短路径算法是图论中最基本且常用的问题之一,在交通网络优化中具有重要的应用。
最短路径算法旨在找到两个节点之间的最短路径,这对于寻找出行路线、减少交通拥堵、优化路径规划等都是至关重要的。
1. 迪杰斯特拉算法(Dijkstra's algorithm)迪杰斯特拉算法是一种解决单源最短路径问题的贪心算法。
通过逐步选择离源节点最近的节点,并更新到达其他节点的最短距离,最终找到源节点到其他所有节点的最短路径。
这个算法可以用于交通网络中,帮助人们找到最佳的出行路线。
经典图论问题

5经典图论问题5.1 一笔画问题5.2 中国邮递员问题(CPP)规划模型:设ij x 为经过边j i v v 的次数,则得如下模型。
∑E∈ji v v ijijxw max∑∑E∈E∈∈=j i i k v v i v v ki ij V v x x ,E ∈∈≤j i ij v v N x ,15.3 旅行推销员问题(TSP )分析:算法一:象求最小生成树一样,从最小权边加边,顶点度数大于3以及形成小回路的边去掉。
算法二:算法三:规划模型:先将一般加权连通图转化成一个等价的加权完全图,设当从i v 到j v 时,1 ij x ,否则,0=ij x ,则得如下模型。
∑∑==n i nj ijij xw 11min∑===nj ijn i x1,,1,1∑===ni ijn j x1,,1,1 1,,2-=n kn i i k x x x k i i i i i i k 1,,,1113221=-≤+++ 0=ij x 或1,j i n j i ≠=,,,1,5.4 排课表问题 问题一定理:最小边色数()G χ'等于最大顶点度数()G ∆。
以下加边循环算法为多项式时间算法:就是加边让每个顶点的度数一样(为最大度数),然后求一组完美匹配M ,着同样颜色,然后从图中去掉M 中的边,再求第二组完美匹配。
问题二:基本思想是:由给定的教室数与总课时数确定教学时间长度(即匹配数--色数),在没有考虑教室数限制所计算的匹配数基础上,增加空匹配至时间长度个,然后调节匹配边差大于1的匹配,直到满足要求。
克鲁斯卡尔算法最短路径c

克鲁斯卡尔算法最短路径c克鲁斯卡尔算法是一种经典的图论算法,用于寻找无向图的最小生成树。
它的目标是找到一棵包含所有顶点的树,使得树上所有边的权重之和最小。
这个算法由克鲁斯卡尔于1956年提出,被广泛应用于各个领域,特别是网络设计和优化问题。
首先,让我们以一个生动的例子来解释克鲁斯卡尔算法的基本思想。
假设我们有一个旅行家打算游历一个国家的各个城市,这些城市之间的距离各不相同。
旅行家希望在耗费最小的情况下,能够依次访问所有城市并返回原点。
这个问题可以转化为一个图论问题,我们可以将城市看作图中的顶点,距离则表示边的权重。
在这个例子中,克鲁斯卡尔算法的运作如下:1. 首先,我们将所有的边按照权重从小到大进行排序。
2. 然后,我们按照排序后的顺序逐个考虑每一条边。
对于每一条边,如果它连接的两个顶点之间还没有路径,则选择这条边,并把这两个顶点加入生成树的集合中。
3. 重复步骤2,直到生成树的集合中包含了所有的顶点。
通过这个算法,我们能够找到连接所有城市并具有最小总距离的路径。
这样,旅行家就可以以最短的路线游历完所有的城市。
不仅在旅行问题中,克鲁斯卡尔算法在现实生活中也有很大的指导意义。
例如,在网络设计中,我们需要将服务器连接起来以提供高效的数据传输。
通过应用克鲁斯卡尔算法,我们可以找到连接服务器的最短路径,以提高网络的传输效率。
同样地,在电力系统的规划中,克鲁斯卡尔算法可以帮助我们找到连接各个发电站和负载站点的最短电力传输线路,以减少能源损耗。
克鲁斯卡尔算法的优势在于它简单易懂、易于实现,并且能够找到最短路径。
然而,这个算法也有一些限制。
首先,它只适用于无向图,对于有向图需要进行一些额外的处理。
其次,如果图中存在环路,克鲁斯卡尔算法可能无法给出正确的结果。
此外,当图的规模非常大时,算法的时间复杂度较高,效率较低。
总之,克鲁斯卡尔算法是一种寻找最小生成树的经典算法,在不同领域具有广泛的应用。
通过它,我们可以找到连接顶点的最短路径,并在旅行、网络设计和电力系统规划等领域中得到有意义的指导。
迪杰斯特拉算法和弗洛伊德算法的区别

迪杰斯特拉算法和弗洛伊德算法的区别迪杰斯特拉算法(Dijkstra Algorithm)和弗洛伊德算法(Floyd Algorithm)是两种经典的图论算法,用于解决带权有向图中的最短路径问题。
它们在算法思想、应用场景和时间复杂度等方面存在一些区别。
以下是对两者的详细解释。
一、算法思想:1.迪杰斯特拉算法:迪杰斯特拉算法采用贪心的策略,通过一步一步地逐渐扩展路径,找到所有结点的最短路径。
它将所有结点分为两个集合,一个是已找到最短路径的结点集合S,一个是还未找到最短路径的结点集合V-S。
算法每一次从V-S中选择与起点到达路径最短的结点加入到S中,并更新起点到V-S中剩余结点的最短路径。
2.弗洛伊德算法:弗洛伊德算法采用动态规划的思想,通过逐步优化计算出任两个结点之间的最短路径。
算法维护一个二维数组,其中每个元素表示两个结点之间的最短路径长度。
算法通过不断更新这个数组,使得其中的每个元素都表示它们之间的最短路径长度。
二、应用场景:1.迪杰斯特拉算法:2.弗洛伊德算法:弗洛伊德算法适用于解决多源最短路径问题,即找到任意两个结点之间的最短路径。
它可以处理带负权边的图,但是不能处理带有负权环的图。
它常被应用于计算多结点之间的最短距离、网络环路检测和最佳连通性等问题。
三、时间复杂度:1.迪杰斯特拉算法:迪杰斯特拉算法的时间复杂度为O(V^2),其中V是图中的结点数。
在每次循环中,需要选取一个结点加入S集合,并对其相邻结点进行松弛操作,因此需要进行V次循环。
在每次循环中,需要找到V-S集合中距离最短的结点,这需要遍历V个结点。
总的时间复杂度为O(V^2)。
2.弗洛伊德算法:弗洛伊德算法的时间复杂度为O(V^3),其中V是图中的结点数。
算法通过三重循环遍历所有结点对,对每个结点对进行松弛操作。
总的时间复杂度为O(V^3)。
综上所述,迪杰斯特拉算法和弗洛伊德算法在算法思想、应用场景和时间复杂度等方面存在一些区别。
dijkstra最短路径算法步骤离散数学

dijkstra最短路径算法步骤离散数学Dijkstra最短路径算法是一种经典的图论算法,用于解决单源最短路径问题。
它由荷兰计算机科学家艾兹赫尔·迪科斯彻在1956年提出,被广泛应用于网络路由算法等领域。
Dijkstra算法的核心思想是通过不断更新节点之间的最短路径来找到从源节点到目标节点的最短路径。
在离散数学中,Dijkstra算法是一种十分重要的算法,在实际应用中也具有很高的效率和可靠性。
Dijkstra算法的步骤相对简单,但是需要一定的数学基础和思维逻辑。
首先,需要定义一个起始节点,将其到其他所有节点的距离初始化为无穷大,然后将其加入到一个集合中。
接着,选择集合中距离起始节点最近的节点作为当前节点,更新当前节点到其他节点的距离,如果通过当前节点到其他节点的距离比起始节点到其他节点的距离更短,则更新最短距离。
重复这个过程,直到所有节点都被遍历过一次,最终得到从起始节点到其他所有节点的最短路径。
在离散数学中,Dijkstra算法常常被用来解决网络连接、通信传输等问题。
例如,在计算机网络中,路由器通过Dijkstra算法计算最短路径,将数据包发送到目标地址,保证通信的快速和稳定。
又如在电力系统中,Dijkstra算法可以用来优化电网的输电路径,减少能量损耗,提高供电质量。
因此,学习和掌握Dijkstra算法对于离散数学的学习和实践具有重要意义。
除了Dijkstra算法,离散数学还包括许多其他重要的内容,如图论、集合论、逻辑推理等。
图论是离散数学的一个重要分支,研究图的性质和图之间的关系。
集合论是研究集合及其元素之间的关系和性质的数学分支,是数学中的基础理论之一。
逻辑推理是研究命题之间推理关系的数学分支,是数学和哲学的交叉领域。
这些内容共同构成了离散数学这门学科的基础,对于理解和应用数学知识具有重要意义。
总的来说,Dijkstra最短路径算法是离散数学中的一个重要内容,通过学习和掌握该算法,可以更好地理解和运用离散数学知识。
dijkstra 标号法 floyd

dijkstra 标号法floyd全文共四篇示例,供读者参考第一篇示例:Dijkstra算法和Floyd算法是两种最经典的图论算法,用来解决最短路径问题。
它们分别有着独特的算法思想和实现方式,在不同的场景中表现出各自的优势。
本文将介绍Dijkstra算法和Floyd算法的基本原理和应用,以及它们之间的区别和优缺点。
让我们来了解一下Dijkstra算法。
Dijkstra算法是由荷兰计算机科学家艾兹赫·迪克斯特拉于1956年提出的,用来解决单源最短路径问题。
所谓单源最短路径问题,就是给定一个带权有向图G=(V, E),其中V为顶点集合,E为边集合,每条边的权值为正数,以及一个源点s,求出从源点s到图中其他所有顶点的最短路径。
Dijkstra算法的基本思想是以源点为中心,逐步找出源点到其他各顶点的最短路径。
具体步骤如下:1. 创建一个集合S,用来存放已确定最短路径的顶点,初始时将源点加入其中;2. 初始化一个数组dist,用来记录从源点到各顶点的最短距离,初始时将源点到自身的距离设为0,其余顶点的距离设为无穷大;3. 重复以下步骤直到集合S包含所有顶点:a. 从dist中找出当前距禓源点最近的顶点u,将其加入集合S;b. 更新以u为起点的边的权值,更新dist数组中相应的距禓;4. 得到源点到其他各顶点的最短路径。
Dijkstra算法的时间复杂度为O(V^2),其中V为顶点数,这主要取决于选取最短路径顶点的方式。
当使用最小堆或斐波那契堆优化时,时间复杂度可以降至O(E+VlogV)。
1. 初始化一个二维数组dist,用来记录任意两顶点之间的最短路径距禓,初始时将dist[i][j]设为顶点i到顶点j的直接距禓,如果i和j 之间没有直接边,则设为无穷大;2. 重复以下步骤直到二维数组dist不再更新:a. 遍历所有顶点对(i, j),尝试以顶点k为中转点,更新dist[i][j]的值;3. 得到任意两顶点之间的最短路径。
hierholzer算法算法原理

1. Hierholzer算法的基本概念Hierholzer算法是一种用来寻找欧拉回路的经典算法。
它的基本原理是通过遍历图中的所有边,找到一条路径,使得每个节点都被经过且每条边都被遍历到。
欧拉回路是一种经过图中每条边一次且回到起点的路径,这种路径的存在性以及如何找到它一直是图论中的一个经典问题。
2. 经典图的定义在讲解Hierholzer算法的原理之前,我们需要先了解一些经典图的定义。
图是一种由节点和边构成的数据结构,一般用G(V, E)来表示,其中V是节点的集合,E是边的集合。
当图中的每条边都不重复出现且每个节点之间都存在相互连接的边时,称这种图为欧拉图。
而欧拉回路则是在欧拉图的基础上,经过图中每条边一次且回到起点的路径。
3. Hierholzer算法的基本思路在讲解Hierholzer算法的具体原理之前,我们先来了解一下它的基本思路。
Hierholzer算法的基本思路是利用递归的方式来在欧拉图中寻找欧拉回路。
它的核心是通过拆边和回溯的方式,找到一条满足条件的路径,并将其合并成一条欧拉回路。
4. Hierholzer算法的具体步骤Hierholzer算法的具体步骤可以大致分为以下几个步骤:- 从图中任意选取一个节点作为起点,将其入栈。
- 对起点进行深度优先遍历,直到遇到没有未访问的边的节点,将节点加入到路径中。
- 如果当前节点的邻接节点还有未访问的边,则将当前节点入栈,并选择一个邻接节点作为下一个起点进行深度优先遍历。
- 如果当前节点的邻接节点都已经访问完,则将该节点加入到路径末尾,并将栈中的节点依次加入到路径中,直到找到一个出边没有访问的节点。
- 重复以上步骤直到所有的边都被经过。
5. Hierholzer算法的应用Hierholzer算法在实际生活中有很多应用,比如在网络路由系统中寻找最优路径、在交通规划中寻找最优车辆行驶路线等。
另外,在图论研究中,Hierholzer算法也被广泛应用于求解欧拉回路的问题,并且它的时间复杂度相对较低,适用于大规模的图。
迪杰斯特拉和弗洛伊德算法

迪杰斯特拉和弗洛伊德算法1. 简介迪杰斯特拉(Dijkstra)算法和弗洛伊德(Floyd)算法是图论中两个重要的最短路径算法。
最短路径问题是图论中的经典问题之一,它的目标是找到两个节点之间的最短路径。
迪杰斯特拉算法是由荷兰计算机科学家Edsger W. Dijkstra于1956年提出的,用于解决带权有向图中的单源最短路径问题。
它采用了贪心策略,通过逐步扩展已找到的最短路径来逐步确定最短路径。
弗洛伊德算法是由美国计算机科学家Robert W. Floyd于1962年提出的,用于解决带权有向图中的多源最短路径问题。
它采用了动态规划的思想,通过逐步更新所有节点之间的最短路径来求解最短路径问题。
2. 迪杰斯特拉算法2.1 算法思想迪杰斯特拉算法通过维护一个距离数组和一个已访问数组来求解最短路径。
距离数组用于记录源节点到其他节点的最短距离,已访问数组用于标记已经确定最短路径的节点。
算法的基本思想是从源节点开始,每次选择一个距离最小且未访问过的节点,将其标记为已访问,并更新与其相邻节点的最短距离。
重复这个过程,直到所有节点都被标记为已访问。
2.2 算法步骤迪杰斯特拉算法的具体步骤如下:1.创建一个距离数组dist[],用于记录源节点到其他节点的最短距离。
初始时,将源节点到其他节点的距离都设置为无穷大,将源节点的距离设置为0。
2.创建一个已访问数组visited[],用于标记已经确定最短路径的节点。
初始时,将所有节点的已访问状态都设置为false。
3.重复以下步骤,直到所有节点都被标记为已访问:–选择一个距离最小且未访问过的节点u。
–将节点u标记为已访问。
–更新与节点u相邻节点v的最短距离:•如果通过节点u可以获得比dist[v]更短的距离,则更新dist[v]为新的最短距离。
4.最终,距离数组dist[]中记录的就是源节点到其他节点的最短距离。
2.3 算法示例假设有一个带权有向图如下所示:2(1)-->--(3)| / |4 | / | 1| / |(0)-->--(2)3源节点为节点0,我们希望求解源节点到其他节点的最短路径。
弗洛伊德算法和迪杰斯特拉算法

弗洛伊德算法和迪杰斯特拉算法弗洛伊德算法和迪杰斯特拉算法是图论中两种重要的、经典的最短路径算法。
它们各自具有不同的应用场景、原理和实现方式。
本文将对这两种算法进行详细的介绍和比较。
一、弗洛伊德算法弗洛伊德算法(Floyd-Warshall algorithm),又称为吉尔伯特–约翰逊–斯特拉松算法,是一种用于寻找加权图中多源最短路径的算法,即求出图中任意两点之间的最短距离。
弗洛伊德算法通过动态规划的思想来实现,时间复杂度为O(n^3)。
对于给定的加权图G(V,E),其中V表示节点集合,E 表示边集合,弗洛伊德算法的具体步骤如下:1.初始化:对于节点i、j之间的边,设置dis[i][j]为其边权,如果i和j之间没有边,则将dis[i][j]设为一个较大的值,例如INF(正无穷)。
2.中转顶点遍历:给定一个中转顶点k,遍历所有节点对(i,j),如果dis[i][j]>dis[i][k]+dis[k][j],则更新dis[i][j]的值,即dis[i][j]=dis[i][k]+dis[k][j]。
3.遍历所有中转顶点:重复步骤2,直到遍历完所有的中转顶点。
4.输出结果:最终的dis矩阵即为任意两点之间的最短距离。
弗洛伊德算法的优点在于:适用于稠密图和有向图;可以处理负权边的情况,但是不允许存在负权环,否则会得到不正确的结果。
二、迪杰斯特拉算法迪杰斯特拉算法(Dijkstra algorithm),是一种用于寻找加权图中单源最短路径的算法,即求出从给定顶点s 出发到其他顶点的最短路径。
迪杰斯特拉算法通过贪心策略来实现,即每次选择权值最小的点,时间复杂度为O(n^2)。
对于给定的加权图G(V,E)和起始点s,迪杰斯特拉算法的具体步骤如下:1.初始化:将起点s的dis[s]设为0,将其余顶点的dis[i]设为无穷大。
2.遍历所有顶点:遍历所有顶点,每次找到未标记原点中权值最小的顶点u,将它标记,并对相邻的未标记顶点进行松弛操作,即dis[v]=min(dis[v],dis[u]+w(u,v))。
图论经典问题
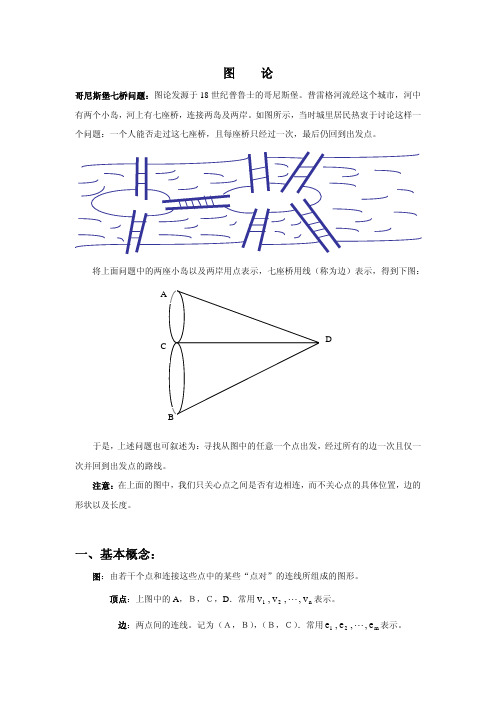
图 论哥尼斯堡七桥问题:图论发源于18世纪普鲁士的哥尼斯堡。
普雷格河流经这个城市,河中有两个小岛,河上有七座桥,连接两岛及两岸。
如图所示,当时城里居民热衷于讨论这样一个问题:一个人能否走过这七座桥,且每座桥只经过一次,最后仍回到出发点。
将上面问题中的两座小岛以及两岸用点表示,七座桥用线(称为边)表示,得到下图:于是,上述问题也可叙述为:寻找从图中的任意一个点出发,经过所有的边一次且仅一次并回到出发点的路线。
注意:在上面的图中,我们只关心点之间是否有边相连,而不关心点的具体位置,边的形状以及长度。
一、基本概念:图:由若干个点和连接这些点中的某些“点对”的连线所组成的图形。
顶点:上图中的A ,B,C,D .常用表示。
n 21 v , , v , v 边:两点间的连线。
记为(A,B),(B,C).常用表示。
m 21e , , e , e次:一个点所连的边数。
定点v的次记为d(v).图的常用记号:G=(V,E),其中,}{v V i =,}{e E i =子图:图G的部分点和部分边构成的图,成为其子图。
路:图G中的点边交错序列,若每条边都是其前后两点的关联边,则称该点边序列为图G的一条链。
圈(回路):一条路中所含边点均不相同,且起点和终点是同一点,则称该路为圈(回路)。
有向图:,其中(,)G N A =12{,,,}k N n n n = 称为的顶点集合,A a 称为G 的弧集合。
G {(,)ij i j }n n ==若,则称为的前驱, 为n 的后继。
(,)ij i j a n n =i n j n j n i 赋权图(网络):设是一个图,若对G 的每一条边(弧)都赋予一个实数,称为边的权,。
记为。
G (,,)G N E W =两个结论:1、图中所有顶点度数之和等于边数的二倍; 2、图中奇点个数必为偶数。
二、图的计算机存储:1. 关联矩阵简单图:,对应(,)G N E =N E ×阶矩阵()ik B b =10ik i k b ⎧=⎨⎩点与边关联否则简单有向图:,对应(,)G N A =N A ×阶矩阵()ik B b =110ik ik ik a i b a i ⎧⎪=−⎨⎪⎩弧以点为尾弧以点为头否则2. 邻接矩阵简单图:,对应(,)G N E =N N ×阶矩阵()ij A a =10ij i j a ⎧=⎨⎩点与点邻接否则简单有向图:,对应(,)G N A =N N ×阶矩阵()ij A a =10ij i ja ⎧=⎨⎩有弧从连向否则5v 34v01010110100101011110101000110111101065432166654321⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=×v v v v v v A v v v v v v3. 权矩阵:简单图:,对应(,)G N E =N N ×阶矩阵()ij A a =ij ij i j a ω⎧=⎨∞⎩点与点邻接否则123456781234567802130654.5061002907250473080 v v v v v v v v v v v v v v v v 48∞∞∞∞⎡⎤⎢⎥∞∞∞∞∞⎢⎥⎢⎥∞∞∞∞∞⎢⎥∞∞∞∞∞⎢⎥⎢⎥∞∞∞∞⎢⎥∞∞∞∞⎢⎥⎢⎥∞∞∞∞⎢⎥∞∞∞∞∞∞⎢⎥⎣⎦三、图的应用:例:如图,用点代表7个村庄,边上的权代表村庄之间的路长,现在要在这7个村庄中布电话线,如何布线,使材料最省?分析:需要将图中的边进行删减,使得最终留下的图仍然连通,并且使总的权值最小。
佛洛伊德算法

佛洛伊德算法摘要:1.引言2.佛洛伊德算法的概念和原理3.佛洛伊德算法的应用领域4.佛洛伊德算法的优缺点5.结论正文:1.引言佛洛伊德算法,是一种经典的图论算法,由奥地利心理学家、精神分析学创始人西格蒙德·佛洛伊德于20 世纪初提出。
该算法主要应用于寻找无向图的最大环、最小生成树、最短路径等问题。
本文将从佛洛伊德算法的概念和原理、应用领域、优缺点等方面进行介绍。
2.佛洛伊德算法的概念和原理佛洛伊德算法是一种基于图的搜索算法,其基本思想是以图的顶点为起点,沿着边的方向进行搜索,不断更新路径,直到找到目标顶点或者无法继续搜索为止。
在搜索过程中,佛洛伊德算法记录下所有可能的路径,以及这些路径的长度。
通过比较这些路径的长度,可以找到最短路径。
3.佛洛伊德算法的应用领域佛洛伊德算法广泛应用于图论的各种问题中,如寻找无向图的最大环、最小生成树、最短路径等。
其中,最短路径问题是佛洛伊德算法应用最为广泛的领域之一。
在实际应用中,佛洛伊德算法可以帮助我们快速找到网络中最短路径,从而提高网络传输效率、降低运输成本等。
4.佛洛伊德算法的优缺点佛洛伊德算法的优点在于其简单易懂、实现简单,且具有一定的效率。
特别是在规模较小的问题中,佛洛伊德算法的性能表现较好。
然而,佛洛伊德算法也存在一些缺点,如算法的复杂度较高,随着图规模的增大,计算时间将显著增加,可能导致算法无法在合理的时间内完成计算。
5.结论总的来说,佛洛伊德算法是一种具有广泛应用价值的图论算法。
尽管存在一些缺点,但在解决一些规模较小的图问题时,佛洛伊德算法仍然具有较高的效率和实用性。
最优路径经典算法

最优路径经典算法最优路径问题是在图论中一个经典的问题,其目标是找到两个节点之间的最短路径或最小权值路径。
在解决最优路径问题的过程中,有多种算法可以使用。
下面将列举十个经典的最优路径算法。
1. Dijkstra算法:Dijkstra算法是一种贪心算法,用于解决单源最短路径问题。
它通过不断更新起点到各个节点的最短路径,最终得到起点到终点的最短路径。
2. Bellman-Ford算法:Bellman-Ford算法可以解决带有负权边的最短路径问题。
它通过迭代的方式不断更新起点到各个节点的最短路径,直到收敛为止。
3. Floyd-Warshall算法:Floyd-Warshall算法可以解决所有节点对之间的最短路径问题。
它通过动态规划的方式计算任意两个节点之间的最短路径。
4. A*算法:A*算法是一种启发式搜索算法,常用于解决图上的最短路径问题。
它通过综合考虑节点的实际距离和估计距离,选择下一个最有可能到达终点的节点进行搜索。
5. 最小生成树算法:最小生成树算法用于解决无向图的最小生成树问题。
其中Prim算法和Kruskal算法是两种常用的最小生成树算法,它们都可以用于寻找最优路径。
6. Johnson算法:Johnson算法是一种解决带有负权边的最短路径问题的算法。
它通过引入一个新的节点,并利用Bellman-Ford算法来计算每个节点到新节点的最短路径,然后再利用Dijkstra算法求解最短路径。
7. SPFA算法:SPFA算法是一种解决单源最短路径问题的算法,它是对Bellman-Ford算法的一种优化。
SPFA算法使用了队列来存储需要更新的节点,减少了不必要的更新操作。
8. Yen算法:Yen算法是一种解决最短路径问题的算法,它可以找到第k短的路径。
Yen算法通过删除已经找到的路径上的一条边,并重新计算最短路径来寻找第k短的路径。
9. Bidirectional Search算法:Bidirectional Search算法是一种解决最短路径问题的算法,它同时从起点和终点开始搜索,直到两个搜索路径相交。
佛洛依德算法

佛洛依德算法佛洛依德算法(Floyd-Warshallalgorithm)是一种经典的图论算法,用于求解任意两点之间的最短路径。
它由美国计算机科学家罗伯特·弗洛伊德(Robert Floyd)和另一位科学家斯蒂芬·沃沃舍尔(Stephen Warshall)在1959年独立提出,因此得名。
该算法的基本思想是动态规划。
具体来说,它通过不断更新每个顶点到其他顶点的最短路径长度,逐步得到所有顶点之间的最短路径。
该算法的时间复杂度为 O(n^3),其中 n 表示图的顶点数,因此它适用于较小规模的图。
下面我们来详细介绍一下佛洛依德算法的实现过程。
1. 初始化首先,我们需要将每个顶点之间的距离初始化为它们之间的实际距离(如果存在直接连接的边),或者无穷大(如果它们之间没有直接连接的边)。
同时,对于每个顶点 i,我们将其到自身的距离设为0。
2. 逐步更新接下来,我们通过逐步更新每个顶点之间的距离,逐步得到它们之间的最短路径。
具体来说,我们假设 k 是当前已经处理完的顶点中的最大编号,然后对于每一对顶点 i 和 j,我们检查是否存在一条从 i 到 j 经过顶点 k 的路径,如果存在,就更新 i 到 j 的最短距离为 i 到 k 的距离加上 k 到 j 的距离,即:dist[i][j] = min(dist[i][j], dist[i][k] + dist[k][j])其中 dist[i][j] 表示顶点 i 到顶点 j 的最短距离。
这个公式的含义是,我们考虑从 i 到 j 经过顶点 k 的路径是否更短,如果更短,就更新最短距离。
3. 完成最后,当 k 逐渐增大直到达到 n-1(即所有顶点都被处理完毕),我们就得到了所有顶点之间的最短路径。
下面是佛洛依德算法的具体实现代码(使用 Python 语言):```pythondef floyd_warshall(graph):n = len(graph)dist = [[float('inf') for _ in range(n)] for _ in range(n)] for i in range(n):for j in range(n):if i == j:dist[i][j] = 0elif graph[i][j] != 0:dist[i][j] = graph[i][j]for k in range(n):for i in range(n):for j in range(n):dist[i][j] = min(dist[i][j], dist[i][k] + dist[k][j])return dist```该函数的参数 graph 表示输入的邻接矩阵,返回值 dist 表示每个顶点之间的最短距离。
最小权匹配算法

最小权匹配算法
最小权匹配算法是一种经典的图论算法,用于在加权二分图中求解最小权匹配。
该算法主要基于匈牙利算法,在其基础上引入了增广路的概念和优化措施,能够更加高效地解决问题。
算法的基本思想是,从左侧顶点开始,依次尝试与其匹配的右侧顶点。
如果右侧顶点已经被匹配,则需要尝试寻找其他未匹配的右侧顶点。
为了避免重复寻找,可以使用一个标记数组记录每个右侧顶点是否已经被访问,从而只需要寻找未被访问的右侧顶点。
在寻找增广路时,算法采用了一种类似于深度优先搜索的方式,通过递归的方式不断寻找未匹配的右侧顶点,直到找到一条已匹配的边为止。
这条已匹配的边将会成为增广路的一部分,然后将会反向匹配所有在增广路上的边,从而完成一次匹配。
为了优化算法效率,可以使用一些技巧,如路径压缩和重贴标记等。
这些技巧可以减少算法的递归次数和标记数组的遍历次数,从而提高算法的运行速度。
最小权匹配算法在实际应用中有着广泛的应用,比如在推荐系统、聚类分析和社交网络等领域。
通过使用该算法,可以快速地找到最佳匹配方案,从而提高系统的推荐准确性和用户体验。
- 1 -。
七桥问题 算法

七桥问题是一个经典的图论问题,它涉及到如何从哥尼斯堡的一个地方开始,遍历城市的七座桥,每座桥只过一次,最后回到开始的地方。
解决七桥问题的算法可以采用图遍历的方式。
具体来说,我们可以用深度优先搜索(DFS)或者广度优先搜索(BFS)算法来遍历图,寻找遍历每座桥恰好一次的路径。
在DFS中,我们可以从起点开始,递归地探索所有可能的路径,直到找到符合条件的路径或者搜索完所有可能的路径。
在搜索过程中,我们需要记录已经访问过的节点,以避免重复访问。
在BFS中,我们可以使用队列来存储待探索的节点,每次从队列中取出一个节点,探索其所有未访问的相邻节点,并将其加入队列中。
这样不断重复,直到找到符合条件的路径或者队列为空。
无论是DFS还是BFS,都需要用到图的表示方法。
常用的图的表示方法有邻接矩阵和邻接表。
邻接矩阵表示法比较直观,但是存储空间比较大;邻接表表示法存储空间较小,但是在表示节点之间的关系时需要一些额外的数据结构。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
图论中的常用经典算法第一节最小生成树算法一、生成树的概念若图是连通的无向图或强连通的有向图,则从其中任一个顶点出发调用一次bfs或dfs后便可以系统地访问图中所有顶点;若图是有根的有向图,则从根出发通过调用一次dfs或bfs亦可系统地访问所有顶点。
在这种情况下,图中所有顶点加上遍历过程中经过的边所构成的子图称为原图的生成树。
对于不连通的无向图和不是强连通的有向图,若有根或者从根外的任意顶点出发,调用一次bfs或dfs后不能系统地访问所有顶点,而只能得到以出发点为根的连通分支(或强连通分支)的生成树。
要访问其它顶点则还需要从没有访问过的顶点中找一个顶点作为起始点,再次调用bfs 或dfs,这样得到的是生成森林。
由此可以看出,一个图的生成树是不唯一的,不同的搜索方法可以得到不同的生成树,即使是同一种搜索方法,出发点不同亦可导致不同的生成树。
如下图:但不管如何,我们都可以证明:具有n个顶点的带权连通图,其对应的生成树有n-1条边。
二、求图的最小生成树算法严格来说,如果图G=(V,E)是一个连通的无向图,则把它的全部顶点V和一部分边E’构成一个子图G’,即G’=(V, E’),且边集E’能将图中所有顶点连通又不形成回路,则称子图G’是图G的一棵生成树。
对于加权连通图,生成树的权即为生成树中所有边上的权值总和,权值最小的生成树称为图的最小生成树。
求图的最小生成树具有很高的实际应用价值,比如下面的这个例题。
例1、城市公交网[问题描述]有一张城市地图,图中的顶点为城市,无向边代表两个城市间的连通关系,边上的权为在这两个城市之间修建高速公路的造价,研究后发现,这个地图有一个特点,即任一对城市都是连通的。
现在的问题是,要修建若干高速公路把所有城市联系起来,问如何设计可使得工程的总造价最少。
[输入]n(城市数,1<=n<=100)e(边数)以下e行,每行3个数i,j,w ij,表示在城市i,j之间修建高速公路的造价。
[输出]n-1行,每行为两个城市的序号,表明这两个城市间建一条高速公路。
[举例]下面的图(A)表示一个5个城市的地图,图(B)、(C)是对图(A)分别进行深度优先遍历和广度优先遍历得到的一棵生成树,其权和分别为20和33,前者比后者好一些,但并不是最小生成树,最小生成树的权和为19。
[问题分析]出发点:具有n个顶点的带权连通图,其对应的生成树有n-1条边。
那么选哪n-1条边呢?设图G的度为n,G=(V,E),我们介绍两种基于贪心的算法,Prim 算法和Kruskal算法。
1、用Prim算法求最小生成树的思想如下:①设置一个顶点的集合S和一个边的集合TE,S和TE的初始状态均为空集;②选定图中的一个顶点K,从K开始生成最小生成树,将K加入到集合S;③重复下列操作,直到选取了n-1条边:选取一条权值最小的边(X,Y),其中X∈S,not (Y∈S);将顶点Y加入集合S,边(X,Y)加入集合TE;④得到最小生成树T =(S,TE)上图是按照Prim算法,给出了例题中的图(A)最小生成树的生成过程(从顶点1开始)。
其中图(E)中的4条粗线将5个顶点连通成了一棵最小生成树。
Prim算法的正确性可以通过反证法证明。
因为操作是沿着边进行的,所以数据结构采用边集数组表示法,下面给出Prim算法构造图的最小生成树的具体算法框架。
①从文件中读入图的邻接矩阵g;②边集数组elist初始化;For i:=1 To n-1 DoBeginelist[i].fromv:=1;elist[i].endv:=i+1;elist[i].weight:=g[1,i+1];End;③求出最小生成树的n-1条边;For k:=1 To n-1 DoBeginmin:=maxint;m:=k;For j:=k To n-1 Do {查找权值最小的一条边}If elist[j].weight<min Then Begin min:=elist[j].weight;m:=j;End;If m<>k Then Begin t:=elist[k];elist[k]:=elist[m];elist[m]:=t;End;{把权值最小的边调到第k个单元}j:=elist[k].endv; {j为新加入的顶点}For i:=k+1 To n-1 Do {修改未加入的边集}Begin s:=elist[i].endv; w:=g[j,s];If w<elist[i].weightThen Begin elist[i].weight:=w;elist[i].fromv:=j;End;End;End;④输出;2、用Kruskal算法求最小生成树的思想如下:设最小生成树为T=(V,TE),设置边的集合TE的初始状态为空集。
将图G中的边按权值从小到大排好序,然后从小的开始依次选取,若选取的边使生成树T不形成回路,则把它并入TE 中,保留作为T的一条边;若选取的边使生成树形成回路,则将其舍弃;如此进行下去,直到TE 中包含n-1条边为止。
最后的T即为最小生成树。
如何证明呢?下图是按照Kruskal算法给出了例题中图(A)最小生成树的生成过程:Kruskal算法在实现过程中的关键和难点在于:如何判断欲加入的一条边是否与生成树中已保留的边形成回路?我们可以将顶点划分到不同的集合中,每个集合中的顶点表示一个无回路的连通分量,很明显算法开始时,把所有n个顶点划分到n个集合中,每个集合只有一个顶点,表明顶点之间互不相通。
当选取一条边时,若它的两个顶点分属于不同的集合,则表明此边连通了两个不同的连通分量,因每个连通分量无回路,所以连通后得到的连通分量仍不会产生回路,因此这条边应该保留,且把它们作为一个连通分量,即把它的两个顶点所在集合合并成一个集合。
如果选取的一条边的两个顶点属于同一个集合,则此边应该舍弃,因为同一个集合中的顶点是连通无回路的,若再加入一条边则必然产生回路。
下面给出利用Kruskal算法构造图的最小生成树的具体算法框架。
①将图的存储结构转换成边集数组表示的形式elist,并按照权值从小到大排好序;②设数组C[1..n-1]用来存储最小生成树的所有边,C[i]是第i次选取的可行边在排好序的elist中的下标;③设一个数组S[1..n],S[i]都是集合,初始时S[i]= [ i ]。
i:=1;{获取的第i条最小生成树的边}j:=1;{边集数组的下标}While i<=n-1 DoBeginFor k:=1 To n Do Begin {取出第j条边,记下两个顶点分属的集合序号}If elist[j].fromv in s[k] Then m1:=k;If elist[j].endv in s[k] Then m2:=k;End;If m1<>m2 Then Begin {找到的elist第j条边满足条件,作为第i条边保留}C[i]:=j;i:=i+1;s[m1]:=s[m1]+s[m2];{合并两个集合}s[m2]:=[ ]; {另一集合置空}End;j:=j+1; {取下条边,继续判断}End;④输出最小生成树的各边:elist[C[i]]3、总结以上两个算法的时间复杂度均为O(n*n)。
参考程序见Prim.pas和Kruskal.pas。
请大家用以上两种算法完成例1。
三、应用举例例2、最优布线问题(wire.pas,wire.exe)[问题描述]学校有n台计算机,为了方便数据传输,现要将它们用数据线连接起来。
两台计算机被连接是指它们时间有数据线连接。
由于计算机所处的位置不同,因此不同的两台计算机的连接费用往往是不同的。
当然,如果将任意两台计算机都用数据线连接,费用将是相当庞大的。
为了节省费用,我们采用数据的间接传输手段,即一台计算机可以间接的通过若干台计算机(作为中转)来实现与另一台计算机的连接。
现在由你负责连接这些计算机,你的任务是使任意两台计算机都连通(不管是直接的或间接的)。
[输入格式]输入文件wire.in,第一行为整数n(2<=n<=100),表示计算机的数目。
此后的n行,每行n个整数。
第x+1行y列的整数表示直接连接第x台计算机和第y台计算机的费用。
[输出格式]输出文件wire.out,一个整数,表示最小的连接费用。
[样例输入]30 1 21 0 12 1 0[样例输出]2(注:表示连接1和2,2和3,费用为2)[问题分析]本题是典型的求图的最小生成树问题,我们可以利用Prim算法或者Kruskal算法求出,下面的程序在数据结构上对Kruskal算法做了一点修改,具体细节请看程序及注解。
[参考程序]Program wire(Input, Output);var g : Array [1..100, 1..100] Of Integer;{邻接矩阵}l : Array [0..100] Of Integer; {l[i]存放顶点i到当前已建成的生成树中任意一顶点j的权值g[i,j]的最小值} u : Array [0..100] Of Boolean; { u[i]=True,表示顶点i还未加入到生成树中;u[i]=False,表示顶点I已加入到生成树中 } n, i, j, k, total : Integer;BeginAssign(Input, 'wire.in');Reset(Input);Assign(Output, 'wire.out');Rewrite(Output);Readln(n);For i := 1 To n Do BeginFor j := 1 To n Do Read(g[i,j]);Readln;End;Fillchar(l, sizeof(l), $7F); {初始化为maxint}l[1] := 0; {开始时生成树中只有第1个顶点}Fillchar(u, sizeof(u), 1); {初始化为True,表示所有顶点均未加入}For i := 1 To n DoBegink := 0;For j := 1 To n Do {找一个未加入到生成树中的顶点,记为k,要求k到当前生成树中所有顶点的代价最小}If u[j] And (l[j] < l[k]) Then k := j;u[k] := False; {顶点k加入生成树}For j := 1 To n Do {找到生成树中的顶点j,要求g[k,j]最小}If u[j] And (g[k,j] < l[j]) Then l[j] := g[k,j];End;total := 0;For i := 1 To n Do Inc(total, l[i]); {累加}Writeln(total);Close(Input);Close(Output);End.第二节最短路径算法最短路径是图论中的一个重要问题,具有很高的实用价值,也是信息学竞赛中常见的一类中等难度的题目,这类问题很能联系实际,考察学生的建模能力,反映出学生的创造性思维,因为有些看似跟最短路径毫无关系的问题也可以归结为最短路径问题来求解。