eviews一元线性回归案例
最新计量经济学案例分析一元回归模型实例分析

案例分析1— 一元回归模型实例分析依据1996-2005年《中国统计年鉴》提供的资料,经过整理,获得以下农村居民人均消费支出和人均纯收入的数据如表2-5:表2-5 农村居民1995-2004人均消费支出和人均纯收入数据资料 单位:元 年度 1995199619971998199920002001200220032004人均纯收入1577.7 1926.1 2090.1 2161.1 2210.3 2253.4 2366.4 2475.6 2622.2 2936.4人均消费支出1310.4 1572.1 1617.2 1590.3 1577.4 1670.1 1741.1 1834.3 1943.3 2184.7一、建立模型以农村居民人均纯收入为解释变量X ,农村居民人均消费支出为被解释变量Y ,分析Y 随X 的变化而变化的因果关系。
考察样本数据的分布并结合有关经济理论,建立一元线性回归模型如下:Y i =β0+β1X i +μi根据表2-5编制计算各参数的基础数据计算表。
求得:082.1704035.2262==Y X∑∑∑∑====3752432495.1986.788859011.516634423.1264471222ii i i iX y x y x 根据以上基础数据求得:623865.0423.126447986.788859ˆ21===∑∑iii xyx β8775.292035.2262623865.0082.1704ˆˆ10=⨯-=-=X Y ββ 样本回归函数为:ii X Y 623865.08775.292ˆ+= 上式表明,中国农村居民家庭人均可支配收入若是增加100元,居民们将会拿出其中的62.39元用于消费。
二、模型检验1.拟合优度检验952594.0011.516634423.1264471986.788859))(()(22222=⨯==∑∑∑iii i yx y x r2.t 检验525164.3061 210423.12644710.623865011.166345 2ˆˆ222122=-⨯-=--=∑∑n x y iiβσ049206.0423.1264471525164.3061ˆ)ˆ()ˆ(2211====∑ie xVar S σββ6717.112525164.3061423.126447110137.52432495ˆ)ˆ()ˆ(22200=⨯===∑∑σββii e xn X Var S 在显著性水平α=0.05,n-2=8时,查t 分布表,得到:306.2)2(2=-n t α提出假设,原假设H 0:β1=0,备择假设H 1:β1≠067864.12049206.0623865.0)ˆ(ˆ)ˆ(111==-=ββββe S t)2(67864.12)ˆ(21->=n t t αβ,差异显著,拒绝β1=0的假设。
计量经济学eviews一元线性回归模型实验指导

计量经济学eviews一元线性回归模型实验指导民家庭人均生活消费支出与家庭人均纯收入大致呈现出线性相关关系。
(CD 表示农村居民家庭人均生活消费支出,RD 农村居民家庭人均纯收入)图2.4.1 RD —CD 散点图故假设二者之间关系设定为一元线性回归模型:i i i rd cd μββ++=10,其中cd i 各地区农村居民家庭人均生活消费支出,rd i 为各地区农村居民家庭人均纯收入,μi 为随机误差项,即除人均收入外,影响农村居民家庭人均生活消费支出的其他因素。
假设该模型满足古典假设,可运用OLS 方法估计模型的参数。
利用计量经济学软件EViews5.0。
建立工作文件STEP1:进入EViews 目录,然后双击EViews 程序图标,进入EViews 主页见图2.4.2。
图2.4.2 EViews工作界面STEP2:点击Eviews主页面菜单File\New\Workfile见图2.4.3,弹出workfile Create对话框(图2.4.4)。
在workfile structure type中选择Unsteuctured/Undated【由于本例是截面数据】,并在observation中输入观察值得个数,本例为31(图2.4.4),点击OK出现数据编辑窗口(图2.4.5)。
C——截距项;resid——残差项。
图2.4.3图2.4.4图2.4.5图2.4.6STEP3:点击Eviews 主菜单顶部按钮“objects/new objects ”,弹出new objects 对话框(图2.4.6),在Type of Object 中选择group ,并给new objects 一个名字G01,然后点击OK ,弹出对话框中即可输入变量及变量值(图2.4.7)。
图2.4.7图2.4.8 STEP4:点击图2.4.7表格中第一列顶部的灰色条,该列全部变蓝,输入变量名RD—农村居民家庭人均纯收入,然后从数据文件中导出变量RD各地区观测值;同理可定义第二列为CD —农村居民家庭人均生活消费支出,从数据文件中导出变量CD各地区观测值,见图2.4.8。
eviews一元线性回归案例.

引入自相关误差矫正项AR(1)和AR(2)
dU=1.40<DW=2.14<(4-dU)=2.82,依据判别准则,随机误差项已消除自相关
13
Yˆt 115.3205 0.5876 X t 0.7819 AR(1) - 0.4194 AR(2)
整理、变换:
ˆ0
115.3205 1 0.7819 0.4194
中国农村居民消费模型
小组成员:
Page 1
经典计量经济学模型建立过程
1. 理论模型的设置 2. 模型参数的最小二乘估计 3. 计量经济学模型的四级检验
3.1 经济意义检验 3.2 统计检验
3.2.1 拟合优度检验:R2 检验 3.2.2 模型总体的显著性检验:F检验 3.2.3 变量的显著性检验:t 检验
prob=0.040946<α=0.05,则拒绝“模型不存在二阶自相关”的原假设, 认为回归模型具有明显的二阶自相关性
10
LM=nR2=7.133845 prob=0.067752>α=0.05,则不拒绝“模型不存在三阶阶自相关”的原假设。
11
二阶自相关的消除
引入自相关误差矫正项AR(1)
dL=1.18<DW=1.39<dU=1.40,依据判别准则,随机误差项尚未消除自相关
15
预测检验 1.区间预测
16
模型预测值YF与样本观测值Y的接近程度
17
t=(28.036)(8.734) 拟合优度检验:R2 检验 ,拟合优度很高。
R2=0.978831
变量的显著性检验:t 检验,拒绝原假设,则回归
6
系数均显著不为零。
异方差性——怀特检验法
eviews实验报告一元线形回归模型
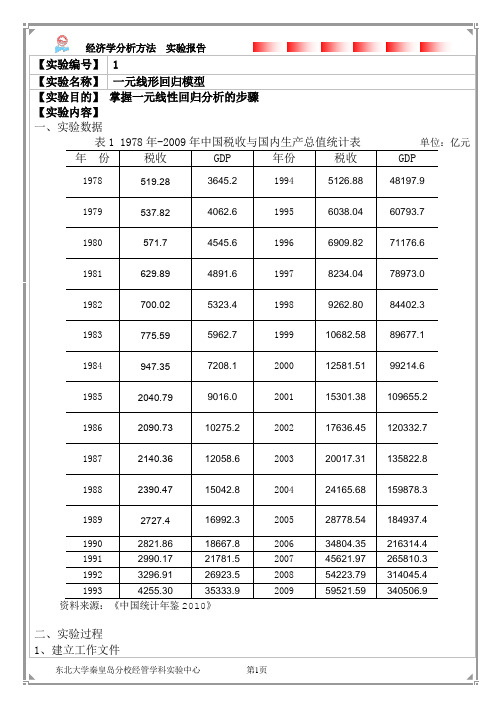
【实验编号】 1【实验名称】一元线形回归模型【实验目的】掌握一元线性回归分析的步骤【实验内容】一、实验数据表1 1978年-2009年中国税收与国内生产总值统计表单位:亿元年份税收GDP 年份税收GDP1978 519.28 3645.2 1994 5126.88 48197.91979 537.82 4062.6 1995 6038.04 60793.71980 571.7 4545.6 1996 6909.82 71176.61981 629.89 4891.6 1997 8234.04 78973.01982 700.02 5323.4 1998 9262.80 84402.31983 775.59 5962.7 1999 10682.58 89677.11984 947.35 7208.1 2000 12581.51 99214.61985 2040.79 9016.0 2001 15301.38 109655.21986 2090.73 10275.2 2002 17636.45 120332.71987 2140.36 12058.6 2003 20017.31 135822.81988 2390.47 15042.8 2004 24165.68 159878.31989 2727.4 16992.3 2005 28778.54 184937.41990 2821.86 18667.8 2006 34804.35 216314.41991 2990.17 21781.5 2007 45621.97 265810.31992 3296.91 26923.5 2008 54223.79 314045.41993 4255.30 35333.9 2009 59521.59 340506.9 资料来源:《中国统计年鉴2010》二、实验过程1、建立工作文件(1)点击桌面Eviews5.0图标,运行Eviews软件。
回归分析实验1 Eviews基本操作及一元线性回归

第一部分EViews基本操作第一章预备知识一、什么是EViewsEViews (Econometric Views)软件是QMS(Quantitative Micro Software)公司开发的、基于Windows平台下的应用软件,其前身是DOS操作系统下的TSP软件。
EViews具有现代Windows软件可视化操作的优良性。
可以使用鼠标对标准的Windows菜单和对话框进行操作。
操作结果出现在窗口中并能采用标准的Windows技术对操作结果进行处理。
EViews还拥有强大的命令功能和批处理语言功能。
在EViews的命令行中输入、编辑和执行命令。
在程序文件中建立和存储命令,以便在后续的研究项目中使用这些程序。
EViews是Econometrics Views的缩写,直译为计量经济学观察,通常称为计量经济学软件包,是专门从事数据分析、回归分析和预测的工具,在科学数据分析与评价、金融分析、经济预测、销售预测和成本分析等领域应用非常广泛。
应用领域■ 应用经济计量学■ 总体经济的研究和预测■ 销售预测■ 财务分析■ 成本分析和预测■ 蒙特卡罗模拟■ 经济模型的估计和仿真■ 利率与外汇预测EViews引入了流行的对象概念,操作灵活简便,可采用多种操作方式进行各种计量分析和统计分析,数据管理简单方便。
其主要功能有:(1)采用统一的方式管理数据,通过对象、视图和过程实现对数据的各种操作;(2)输入、扩展和修改时间序列数据或截面数据,依据已有序列按任意复杂的公式生成新的序列;(3)计算描述统计量:相关系数、协方差、自相关系数、互相关系数和直方图;(4)进行T 检验、方差分析、协整检验、Granger 因果检验;(5)执行普通最小二乘法、带有自回归校正的最小二乘法、两阶段最小二乘法和三阶段最小二乘法、非线性最小二乘法、广义矩估计法、ARCH 模型估计法等;(6)对选择模型进行Probit、Logit 和Gompit 估计;(7)对联立方程进行线性和非线性的估计;(8)估计和分析向量自回归系统;(9)多项式分布滞后模型的估计;(10)回归方程的预测;(11)模型的求解和模拟;(12)数据库管理;(13)与外部软件进行数据交换EViews可用于回归分析与预测(regression and forecasting)、时间序列(Time Series)以及横截面数据(cross-sectional data )分析。
计量经济学用eviews分析数据
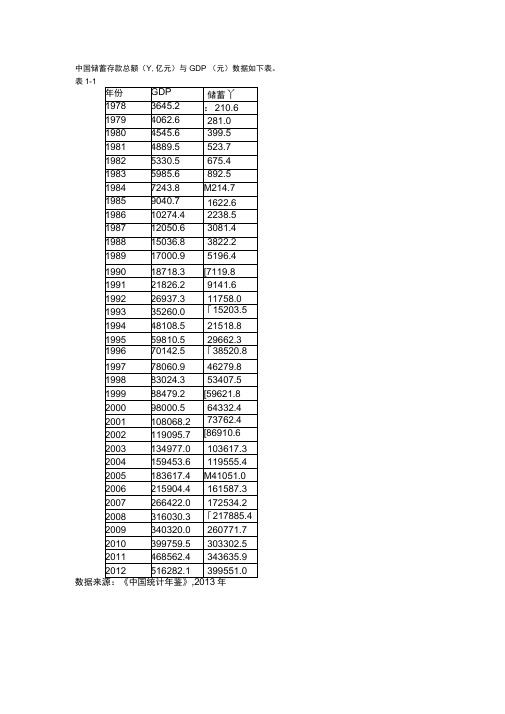
中国储蓄存款总额(Y,亿元)与GDP (元)数据如下表。
表1-1数据来源:《中国统计年鉴》年图1-1解:、估计一元线性回归模型由经济理论知,储蓄存款总额受GDP影响,当GDFP增加时,储蓄存款总额也随着增加,他们之间具有正向的同步变动趋势。
储蓄存款总额除受GDP影响之外, 还受到其他一些变量的影响及随机因素的影响,将其他变量及随机因素的影响均并到随机变量U中,根据X与丫的样本数据,作X与丫之间的散点图可以看出,他们的变化趋势是线性的,由此建立中国储蓄存款总额丫与GDF之间的一员线性回归模型。
由表1-1中样本观测数据,样本回归模型为用Eviews软件估计结果:Dependent Variable: 丫Method: Least SquaresDate: 12/14/14 Time: 10:41Sample: 1978 2012Included observations: 35R-squared 0.995724 Mean dependent var 78882.56Adjusted R-squared 0.995595 S.D. dependent var 108096.8S.E. of regression 7174.769 Akaike info criterion 20.64997Sum squared resid 1.70E+09 Schwarz criterion 20.73885Log likelihood -359.3745 Hannan-Quinn criter. 20.68065F-statistic 7684.717 Durbin-Watson stat 1.224720Prob(F-statistic) 0.000000即样本回归方程为:-4.678592 87.66252二、对估计结果做结构分析(1)对回归方程的结构分析0.762529是样本回归方程的斜率,他表示GDP勺边际增长率,说明GDP每增加1元,将有0.762529用于储蓄;-7304.294是样本回归方程的截距,他表示不受GDP影响的自发性储蓄增长。
计量经济学-一元线性回归预测模型-Eviews6完整

数学与统计学院实验报告院(系):数学与统计学学院学号:姓名:实验课程:计量经济学指导教师:实验类型(验证性、演示性、综合性、设计性):综合性实验时间:2017年 3 月 1 日一、实验课题一元线性回归预测模型二、实验目的和意义用回归模型预测木材剩余物(1)用Eviews软件建立y关于x的回归方程,并对模型和参数做假设检验;(2)求y t的点预测和平均木材剩余物产出量E(y t)的置信区间预测。
(3)假设乌伊岭林业局2000年计划采伐木材20万m3,求木材剩余物的点预测值。
三、解题思路1、录非结构型的数据;2、进行描述性统计,列出回归模型;通过看t、f等统计量,检验回归模型是否正确3、运用forecast进行内预测(1-16样本),可以得到yf的点预测;再运用[yf+se]、[yf-se]进行区间估计(运用excel操作)4、将样本范围改到17个,令x=20,运用forecast进行外预测(17-17)四、实验过程记录与结果1、原始数据:乌伊岭26.1361.4东风23.4948.3新青21.9751.8红星11.5335.9五营7.1817.8上甘岭 6.817友好18.4355翠峦11.6932.7乌马河 6.817美溪9.6927.3大丰7.9921.5南岔12.1535.5带岭 6.817朗乡17.250桃山9.530双丰 5.5213.82、用Eviews软件建立y关于x的回归方程,并对模型和参数做假设检验;模型为:y=0.404280x-0.762928通过上表t、f统计量的p值<0.05,以及残差图基本在两倍标准差的范围内波动,可以得出该模型通过原假设。
3、求yt的点预测和平均木材剩余物产出量E(yt)的置信区间预测。
Yt的点估计:E(yt)的置信区间:4、假设乌伊岭林业局2000年计划采伐木材20万m3,求木材剩余物的点预测值。
空心点为预测值,上下两个红点是预测值的范围。
所以当x=20时,y的点预测值为7.322668五、结果的讨论和分析通过以上的实验,可知:模型为:y=0.404280x-0.762928,根据相关的统计量,可以得出该模型通过参数假设检验;yt的点预测运用内预测完成,而当2000年计划采伐木材20万立方米,运用外预测,可得木材剩余物的量为7.322668万立方米的六、实验小结通过这次实验,对eviews操作界面更加熟悉;掌握了如何建立数据的回归方程,以及参数的假设检验是否正确;运用eviews进行yt的点预测以及E(yt)的区间预测;当解释变量确定时,被解释变量应该为多少。
实验课课件eviews基本操作与一元线性回归

目录
• EViews软件介绍 • EViews基本操作 • 一元线性回归模型 • EViews中进行一元线性回归分析 • 实验结果分析 • 实验总结与展望
EViews软件介绍
01
软件特点
强大的数据处理能力
EViews提供了丰富的数据处理 功能,包括数据导入、清洗、
数据转换
根据需要,可以对数据进 行转换,如对数转换、标 准化等,以适应回归分析 的要求。
建立一元线性回归模型
设定模型
选择一元线性回归模型,并确定 自变量和因变量。
模型诊断
在建立模型之前,需要进行必要的 诊断,如残差图、散点图等,以确 定是否满足线性回归的前提假设。
模型参数估计
使用最小二乘法或其他估计方法, 对模型参数进行估计。
02
输入数据时,需要确保数据的格 式和单位与实际相符,并注意数 据的完整性和准确性。
生成序列
在EViews中,可以通过多种方式生 成序列,如通过数学公式、通过已有 的序列运算、通过其他软件的数据转 换等。
生成序列时,需要确保生成的序列与 实际需求相符,并注意序列的命名和 格式。
数据的图形化表示
在EViews中,可以通过多种方式将数据图形化表示,如绘制散点图、折线图、柱 状图等。
转换和统计分析等。
多种回归分析方法
EViews支持多种回归分析方法 ,如最小二乘法、广义最小二 乘法、最大似然估计法等。
图形化界面
EViews采用图形化界面,操作 简单直观,方便用户进行数据 分析。
灵活的自定义功能
EViews支持用户自定义函数和 程序,扩展性良好。
软件界面
01
02
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3.3 计量经济学检验 3.3.1 异方差性检验 3.3.2 自相关性(序列相关性)检验 3.3.3 多重共线性检验 3.4 预测检验(可选项目) 4. 模型的修正与再检验 4.1 模型的修正 4.2 修正模型的再检验 5. 模型的应用 5.1 结构分析 5.2 经济预测
3
4
19个样本, 1个解释变 量
9
LM=nR2=6.390984 prob=0.040946<α=0.05,则拒绝“模型不存在二阶自相关”的原假设, 认为回归模型具有明显的二阶自相关性
10
LM=nR2=7.133845 prob=0.067752>α=0.05,则不拒绝“模型不存在三阶阶自相关”的原假设。
11
二阶自相关的消除
15
预测检验 1.区间预测
16
模型预测值YF与样本观测值Y的接近程度
17
整理、变换:
ˆ 0
115.3205 180.8949 1 0.7819 0.4194
最终结果:
ˆ Yt 180.8949 0.5876 X t
14
模型的应用
我们得到最终的中国农村居民消费模型
ˆ Yt 180.8949 0.5876 X t
由此可知,中国农村居民的边际消费倾向为 0.5876,即中国农民收入每增加1元,消费支 出将平均增加0.5876元。中国居民的自发性消 费为180.8949元。
引入自相关误差矫正项AR(1)
dL=1.18<DW=1.39<dU=1.40,依据判别准则,随机误差项尚未消除自相关
12
引入自相关误差矫正项AR(1)和AR(2)
dU=1.40<DW=2.14<(4-dU)=2.82,依据判别准则,随机误差项已消除自相关
13
ˆ Yt 115.3205 0.5876 X t 0.7819 AR (1) - 0.4194 AR (2)
边际消费倾向,自发消费。参数的大小和符号均符 合经济理论。 t=(28.036)(8.734) 拟合优度检验:R2 检验 ,拟合优度很高。 R2=0.978831 变量的显著性检验:t 检验,拒绝原假设,则回归 系数均显著不为零。
6
异方差性——怀特检验法
nR2=1.648682 prob=0.438524>α=0.05,则不拒绝原假设“模型不存在异方差性”。
中国农村居民消费模型
小组成员:
Page 1
经典计量经济学模型建立过程
1. 理论模型的设置
2. 模型参数的最小二乘估计 3. 计量经济学模型的四级检验 3.1 经济意义检验 3.2 统计检验
3.2.1 拟合优度检验:R2 检验
3.2.2 模型总体的显著性检验:F检验
3.2.3 变量的显著性检验:t 检验
Y与X的变化趋势是线性的。 Y 因此建立Y与X之间的一元线性回归模型: i
5
0 1 X i ui
最小二乘回归法
最小二 乘回归 法
α=0.05, 查自由度 v=19-2=17的t 分布表,得临 界值 t0.025(17)=2.11
Y t 0.599781X t 106.7574
7自相关检验DFra bibliotek检验DW=0.77 查表n=19,k=1,α=5%,得dL=1.18, dU=1.40 由于DW<dL,所以模型存在正自相关。
8
LM检验
LM=nR2=4.569035 prob=0.032555<α=0.05,则拒绝“模型不存在一阶自相关”的原假设,认 为回归模型具有明显的一阶自相关性