HACMP维护手册
双机的维护操作

双机的维护操作HACMP 双机系统的启动要启动HACMP 双机系统必须要有root 用户的特权分别进入到系统各节点主机在命令行上执行下述命令即可。
# smitty clstart 或# /usr/sbin/cluster/etc/rc.cluster -boot -N -i需要注意的是在双机系统中HACMP 双机软件先启动的节点将成为主节点拥有资源,后启动的节点将成为备节点。
HACMP 双机系统的关闭要关闭某节点上的HACMP 双机软件必须要有该节点root 用户的特权,以root 用户进入到该节点主机在命令行上执行下述命令即可。
# smitty clstop或# clstop -gr说明:若该节点是主节点并且备节点上的HACMP 软件亦正常运行,则clstop 关闭模式的三种选项行为不同。
◆forced:是指立即关闭双机软件不调用任何客户应用的善后处理例程。
◆Graceful:是指在关闭双机软件时将调用客户应用预定义的善后处理例程。
◆takeover:是指该节点将关闭双机软件并释放资源请求备节点进行接管。
检查HACMP 双机软件在该节点是否已启,动命令如下:# lssrc -g cluster若是系统显示出下面类似的信息则说明HACMP 双机软件已正常启动.Subsystem Group PID StatusClstrmgr cluster 22500 activeClsmuxpd cluster 23674 activeClinfo cluster 28674 active察看双机系统的当前状态:# /usr/sbin/cluster/clstat -a如果双机系统一切工作正常则系统将显示下述类似信息:clstat - HACMP for AIX Cluster Status Monitor------------------------------------------------------------------------------------- Cluster: cluster(80) Thu Jan 20 08:45:17 TAIST 2000State: UP Nodes: 2SubState: STABLENode: oracle1 State: UPInterface: oracle1_svc (0) Address: 10.75.9.41State: UPInterface: oracle1_tty (1) Address: 0.0.0.0State: UPNode: oracle2 State: UPInterface: oracle2_svc (0) Address: 10.75.9.41State: UPInterface: oracle2_tty (1) Address: 0.0.0.0State: UPAIX常用命令集命令功能简介cat fn | more -查看文件的内容cat fn fn > newfile -把两个文件结合成一个文件cd -回到用户的默认路径cd / -到根目录cd /xxxx -change you to a DIR anywhere in system cd .. -到上一级目录cd xxxxx -will change you to a DIR in current dircfgmgr -v -搜索并配置新设备cp oldfn newfn -拷贝文件cp oldfn Dirn -把文件拷贝到其他目录crontab -l -list crontab entries for the current userctrl + v -SMIT 或diag 菜单中向下翻一页ctrl + 6 -SMIT 或diag 菜单中向上翻一页del fn -same as rm -i,promts to remove fndf -I -查看文件系统状态(no inodes)df -k -(k) show status in 1024 bites(1mb)diag –a -updates changes in hardware configurationdiag -ed xxxx -分析某设备的故障记录diag -Ad xxxx -对某设备进行高级诊断diag -cd rmtX -resets tape drivedosformat -formats a diskette to DOSdosdir -列出DOS 格式软盘中的内容dosread XX YY -从DOS 格式软盘拷贝文件到主机doswrite YY XX -从主机拷贝文件到DOS 格式软盘errpt | more -查看简短的故障信息errpt -a -查看详细故障信息errpt -s Mmddhhmmyy -查看某日期以后的故障记录errpt -aj XXXXXXX -看某个故障ID 的详细记录(XXX=1st column)errpt -d S -查看软件故障记录errpt -j XXXXXXX -list summary report by ID number.errpt -aN XXXXXX -查看某设备的详细故障信息errpt -N XXXXXXX -查看某设备的简短故障信息errclear 0 -清除系统所有故障记录errclear -N XXXXX 0 -清除某设备的故障记录, 0=all entererrclear -j XXXXX 0 -clears errorlog by ID number.finger -same as who but with more detailsformat -格式化一张UNIX 格式的软盘hostname -查看当前主机名host (hostname) -responds with internet addressinstfix -ik IPAR# -查看某个补丁是否完全安装lppchk -v -checks install status of LPPslpstat -查看打印队列情况lsattr -El xxxxxx -查看设备的设置信息lsattr -El sys0 -查看系统序列号微码及其他主要配置信息lsdev -C | more -查看系统设备配置(devices)lsdev -Cc xxxxx -listdevices(xxx=tty,printer,disk,memory,adpter)lsdev -Cs scsi -查看所有SCSI 设备lsdev -Cc tape -查看所有磁带设备lsdev -Cs pci -查看pci 设备lscons -查看当前主控台设备lscfg -列出所有硬件设备lscfg -vpl XXXXX -list config info(VPD) of a device(rmt0,hdisk,etc)lsfs -列出所有文件系统+ data from "df" cmdlslpp -L | more -列出系统已安装的软件lslpp -w fn -列出文件所属的文件组(文件名要用绝对路径)lslv -m hd5 -finds boot drive under pv1 columnlsps -a -查看内存交换区的使用情况lspv -lists information about the physical volumeslspv hdisk# -list drive infolspv -l hdisk# -列出hdisk#上的逻辑卷lsuser -f ALL -lists all attributes for all userslsvg -列出所有已定义的卷组lsvg -p XXXXXX -列出卷组中的盘(xxxxx= volume name)oslevel -q -查看AIX 版本pg -reads and displays text one screen at a timepdisable -makes unavailable or shows all disabled tty's pdisable tty# -停止一个tty 端口penable -makes available or shows all enabled tty'spenable tty# -enables a ttyps -el |more -列出运行中的进程(程序)r -重复上一条命令r mount -重复上一条mount 命令rmdev -l XXXXX -停止设备的使用但保留其定义在ODM中rmdev -l XXXXX -d -停止设备的使用并删除其在ODM中的定义set -o vi -sets up to veiw cammands that have been run smit ***** -(*****= tape,disk,tty,etc.快速路径)vmstat 1 10 -reports virtual memory statistics for 10 seconds iostat # # -reports CPU,disk & cdrom statisticslsattr -El ssaX -list attributes of SSA adapterslscfg -vl ssaX -list VPD of SSA adapterslsdev -C | grep SSA -list all SSA deviceslslpp -L | grep SSA -list SSA device driverslscfg -vl pdisk# -list VPD of pdisksssaxlate -l hdiskX -list hdisk to pdisk assignmentssaxlate -l pdiskX -list pdisk to hdisk assignmentssa_ela -analyze SSA errorlogs and give SRN。
HACMP配置与维护手册

POWER HA5.5配置与维护手册2010年9月2日目录第一章一体化系统HACMP配置 (3)§1.1系统结构图 (3)§1.2拓扑规划 (3)§1.3磁盘资源规划 (4)§1.4应用规划 (5)§1.5操作系统要求 (6)第二章HACMP日常维护 (8)§2.1HACMP服务正常启停 (8)§2.1.1HACMP启动 (8)§2.1.2停止HA (9)§2.2查看HACMP集群服务状态 (10)§2.2.1查看HACMP服务状态 (10)§2.2.2查看资源组的状态 (10)§2.2.3查看HACMP集群状态 (11)第三章系统切换方案 (12)§3.1rlw1机器应用出现故障,HACMP资源切换 (12)§3.1.1切换rlw1_apprg资源组 (12)§3.1.2恢复rlw1_apprg资源组 (13)§3.2hg2机器应用出现故障,HACMP资源切换 (15)§3.2.1切换rlw2_orarg资源组 (15)§3.2.2恢复rlw2_orarg资源组 (17)第四章HACMP切换测试 (19)§4.1网卡故障模拟测试 (19)§4.2rlw1 系统单机故障模拟测试 (20)§4.3rlw2 系统单机故障模拟测试 (22)§4.4rlw1系统HA 手工切换测试 (24)§4.5rlw2系统HA 手工切换测试 (26)第一章一体化系统HACMP 配置§1.1 系统结构图§1.2 拓扑规划P780(1)主机(LPAR rlw1)共享磁盘阵列(HDS USPV 存储系统)心跳线(tty0)ent2ent0 P780(2) 主机(LPAR rlw2)ent2ent0Service NetworkPersistent Networkrlw1机器boot1地址配置在第一块外置网卡上(en0),将boot2地址配置在第二块外置网卡(en2),persistent ip地址绑在第二块外置网卡上(en2);rlw2机器boot1地址配置在第一块外置网卡上(en0),将boo2地址配置在第二块外置网卡(en2),persistent ip地址绑在第二块外置网卡上(en2)。
HACMP简单配置手册

H A C M P High Availability Cluster Multi – Processing一、Cluster 系统规划1:资源规划HACMP 给客户端提供高可用性的资源环境,当HACMP集群中的节点失效或按正常程序退出群集时,群集管理器将重新在剩余的节点中分配资源。
在HACMP中定义了以下资源类型:z卷组z磁盘z文件系统z要”Mount”到“网络文件系统”上的文件系统z要”Export”到“网络文件系统”上的文件系统z Service IP地址z应用程序(1)资源组群集中的每个资源被定义为资源组的一部分,这样做可以将有关联的资源聚集在一起,以提供特殊服务;同时,资源组还包括能够获得资源及提供这些资源到客户端的节点列表。
有三种类型的资源组:z Cascadingz Rotatingz Concurrent每种类型的资源组描述了节点在群集中的不同关系类型,及节点进入或离开群集的不同表现。
Cascading资源组中的节点设置优先等级,优先级最高的节点是活动节点,控制着整个资源组。
当优先级最高的节点失效时,次高优先级的节点控制资源组;当优先级最高的节点重新加入群集时,它将重新获得对资源组的控制权。
Rotating资源组涉及的不是某一个特定的节点,而是多个节点都有能力采用的共享的IP地址相联系,当定义了共享适配卡的第一个节点加入群集时,它将获得和共享IP地址相关联的Rotating资源组。
当控制Rotating资源组的节点离开群集时,下一个存在的节点获得该Rotating资源组;当该节点重新加入群集时,它将处于待机状态,而不重新获得该Rotating资源组的控制权。
Concurrent资源组能被多个节点同时共享,当一个节点失效时,没有任何接管工作发生;当失效节点重新加入群集时,它将和其它节点同时访问Concurrent资源组。
对于上述三种资源组分别可用一句话来进行概述:Cascading --- 活动节点使用最高优先l,…lk:,级控制资源组。
HACMP日常维护和配置

HACMP日常系统管理1:日常日志:日常日志主要是记录平时事件的启动,从中可以了解HACMP的动作,例如主机standby网卡故障,有fail_standby事件发生,系统管理员可从日志中得知何时出的故障,及有没有解决。
主要日志文件有:/tmp/hacmp.out:记录HACMP启动或有动作时执行的各事件。
此文件一天刷新一次,保留七天,文件保存为/tmp/hacmp.out.1-7;/usr/adm/cluster.log:记录HACMP的错误信息及各事件,另记录事件发生的时间;/tmp/cm.log:保存HACMP中clstrmgr进程产生信息的时间;/usr/sbin/cluster/history/cluster.mmdd:HACMP的历史记录文件。
2:启动和关闭HACMP:每次机器启动后,由系统管理员手工启动HACMP,机器shutdown前,手工关闭HACMP。
启动命令:# smit clstart 选项按缺省,启动顺序为先启主机,待主机的/tmp/hacmp.out文件中node_up_local_complete执行完后,再启动备机的HACMP;关闭命令:# smit clstop shutdown mode选项要确认为graceful。
当出现以下情况时须按指定步骤操作:主、备机在关电后,再次启动时,备机正常,主机不能启动。
指定步骤:在备机上执行# smit hacmp 选择cluster configuration进入,选择Cluster Resources进入,选择Chage/show Resources for a Resource Group进入,将Inactive Takeover Activated 改为true执行。
退出到命令行,启动HACMP,这时备机接管主机的资源。
3:查看HACMP状态:在HACMP中,它启动一个进程来监控各节点。
用# ps –ef|grep clinfo 命令查看clinfo 进程是否启动。
HACMP操作及注意事项

HACMP操作及注意事项
一.启动HACMP:
主机启动后先在一台主机,如S85上执行smitty clstart ,启动完后再在另一台机,如M80上执行smitty clstart ,HACMP启动db2也自动启动。
二.关闭及切换HACMP:
由于安装的HACMP为cascading方式,S85为主节点,M80为次节点。
在S85主机上上执行smitty clstop,有三个选项graceful、takeover、forced,如选graceful,S85上的HACMP正常停止,S85上的资源如datavg、s85_svc、datavg上的文件系统、应用系统不切换给M80;如选takeover,S85上S85上的HACMP 正常停止,S85上的资源如datavg、s85_svc、datavg上的文件系统、应用系统切换给M80;如选forced S85上的HACMP强行停止,S85上的资源如datavg、s85_svc、datavg上的文件系统、应用系统不切换给M80;
若S85出现故障而宕机或用takove切换,S85重新正常启动HACMP后,S85上的资源如datavg、s85_svc、datavg上的文件系统、应用系统又切换回S85。
三.HACMP注意事项:
在一台主机如S85上增加文件系统、改变文件系统大小、增
加逻辑卷时,需在另一台主机如M80上进行exportvg 和importvg操作。
HACMP工作原理及运维管理

HACMP 工作原理及运维管理目录1. HACMP双机系统的功能介绍 (3)2. HACMP双机系统的工作原理 (3)3. HACMP双机系统结构图 (3)4. HACMP安装配置前需作的准备工作 (4)5。
HACMP的常用命令 (4)6。
HACMP常见故障解决 (6)1.HACMP双机系统的功能介绍Hacmp(High Availability Cluster Multi—Processing)双机热备份软件的主要功能是提高客户计算机系统及其应用的可靠性,而不是单台主机的可靠性。
2.HACMP双机系统的工作原理1.作为双机系统的两台服务器(主机A和B)同时运行Hacmp软件2。
服务器除正常运行自机的应用外,同时又作为对方的备份主机3.两台主机系统(A和B)在整个运行过程中,通过“心跳线”相互监测对方的运行情况(包括系统的软硬件运行、网络通讯和应用运行情况等)4.一旦发现对方主机的运行不正常(出故障)时,故障机上的应用就会立即停止运行,本机(故障机的备份机)就会立即在自己的机器上启动故障机上的应用,把故障机的应用及其资源(包括用到的IP地址和磁盘空间等)接管过来,使故障机上的应用在本机继续运行5.应用和资源的接管过程由Ha软件自动完成,无需人工干预6。
当两台主机正常工作时,也可以根据需要将其中一台机上的应用人为切换到另一台机(备份机)上运行3.HACMP双机系统结构图4.HACMP安装配置前需作的准备工作1。
划分清楚两台服务器主机各自要运行的应用(如A机运行应用,B机作为standby) 2. 给每个应用(组)分配Service_ip、Standby_ip、boot_ip和心跳线tty,3。
按照各主机的应用的要求,建立好各自的磁盘组,并分配好磁盘空间4. 根据Ha软件的要求,对服务器操作系统的参数作必要的修改5.HACMP的常用命令1、查看Cluster的运行情况:#/usr/sbin/cluster/clinfo –a#/usr/sbin/cluster/clstat/usr/sbin/cluster/clstat可以帮助你查看当前HACMP的节点状态。
AIXHACMP日常维护

AIX HACMP平时保护-------启动、封闭AIX HACMP和查HACMP运转状态的方法察( 提示:一般先要先封闭双机软件,再履行shutdown– h 命令封闭AIX操作系统) 1,启动的方法,以root在控制台上履行smitty clstart (参数都用以下的缺省值,不要变动)启动时先启动主机上的双机软件,再启动备机上的双机软件。
(主机上双机启动时自动把数据库启动成on-line状态,此外主机上的service_ip (就是对外服务的IP)就替代了本来的boot_ip(固定配置在主网卡en0 上的 IP),因此成立在控制台上启动)#smitty clstartStart Cluster ServicesType or select values in entry fields.Press Enter AFTER making all desired changes.[Entry Fields]* Start now, on system restart or both nowBROADCAST message at startup?trueStartup Cluster Lock Services?falseStartup Cluster Information Daemon?falseCluster to re-acquire resources falseafter forced down?2,关双机软件的方法,先封闭备机上的双机软件,再封闭主机上的双机软件(不需要严格次序,可是建议这样做)(主机上双机封闭时自动把数据库也封闭成off-line状态,此外主机上的service_ip (就是对外服务的IP) 就被开释掉,本来的boot_ip(固定配置在主网卡en0 上的 IP) 又恢复起来了 ,因此成立在控制台上启动)以root用户在控制台上履行smitty clstopStop Cluster ServicesType or select values in entry fields.Press Enter AFTER making all desired changes.[Entry Fields]* Stop now, on system restart or both nowBROADCAST cluster shutdown?true* Shutdown mode graceful(graceful or graceful with takeover, forced)3,查察双机软件能否运转的方法以一般用户履行下边的命令( 两个subsystem的状态都是active就表示正常) $ lssrc -g clusterSubsystem clstrmgrES clsmuxpdESGroupclusterclusterPID Status868436active720992active。
HACMP简要使用手册

HACMP 简要¾# smit hacmpCluster Configuration配置高可靠热备集群HACMPCluster Topology -> Synchronize Cluster Topology同步拓扑:Node, Adapter(Boot, Service, Standby, tty).Cluster Resources -> Synchronize Cluster Resources同步资源:IP, VG, FS, App.Cluster Resources -> Define Application Servers-> Change/Show an Application Server起停脚本路径:Start, Stop scriptsCluster Verification -> Verify Cluster验证集群的逻辑同步。
¾# smit clstart起动高可靠热备集群HACMP。
Start now, on system restart or both:[Now] [Restart] [Both] 建议选[Now],集群进程clstrmgr & clsmuxpd将会起来 BROADCAST message at startup?:[No] [Yes]是否在登录窗口弹出HACMP起动提醒信息。
Startup Cluster Lock Services?:[No] [Yes]并发(concurrent)配置选[Yes],集群进程cllockd将会起来。
Startup Cluster Information Daemon?:[Yes] [No]集群进程clinfo将会起来。
可用来监视集群状态信息。
¾# smit clstop停止高可靠热备集群HACMP。
Stop now, on system restart or both:[Now] [Restart] [Both] 集群进程clstrmgr , clsmuxpd & clinfo ... 将会停止 BROADCAST cluster shutdown?:[No] [Yes]是否在登录窗口弹出HACMP停止提醒信息。
HAAS VMC维护指南:15个简单的预防性维护步骤说明书

Maintenance Training Guide15 Easy Steps for Preventive Maintenance on Your HAAS VMC1.Clean chips from tool changer (50 hours of running)2.Clean chips from way covers and bottom pan (50 hours of running)3.Grease pull studs (50 hours of running)4.Clean and lubricate the spindle taper (50 hours of running)5.Inspect the tool changer cambox oil level (200 hours of running)6.Inspect the axes grease reservoir lubrication tank level (200 hours of running)7.Inspect way covers and lubricate (200 hours of running)8.Clean vector drive air vents and filters (200 hours powered on)9.Inspect the oil levels of the gearbox (200 hours powered on)10.C lean coolant filter, replace coolant and clean coolant tank (1200 hours powered on)11.I nspect hoses for cracking (1200 hours powered on)12.C heck probe batteries and calibration (1200 hours powered on)13.G rease tool changer cams (2400 hours of running)14.R eplace and clean oil, oil filter and oil tanks (2400 hours of running)15.R eplace gearbox oil (2400 hours powered on)Common Maintenance PartsGrease & Oil:Axis Grease Refill 93-1933Spindle Oil 93-2220AFilters:Coolant Chip Tray Filter (10pcs) 30--10904High Pressure Coolant Bag 93-9130Probe Parts:Ceramic Stylus (Spindle Probe) 60-0026Disk Stylus (Table Probe) 60-0028Stylus Holder (Table Probe) 60-0029Link Break Protect (Table Probe) 60-0030Extension (Table Probe) 60-0034Probe Batteries (2 needed per probe) 99-43553。
HACMP 5.X安装设置手册

HACMP v5.x安装设置手册版本 v1.0二零零八年五月神州数码(中国)技有限公司文档控制更改记录版本创建/修改时间编制/修改者文件/修改内容审批人v1.0 2008-5-29 贾志锋创建文档审阅姓名职位发布姓名职位目录目录 (3)HACMP v5.x安装配置 (4)1.1、了解HACMP的基本概念 (4)1.2、 HACMP规划 (4)1.3、安装HACMP软件 (6)1.3.1、操作系统版本 (6)1.3.2、安装依赖的软件包 (6)1.3.3、安装HACMP v5.4 (8)1.4、 HACMP配置规划 (10)1.4.1、 HACMP规划表格 (10)1.4.2、配置IP和网络 (11)1.4.3、编辑/etc/hosts文件 (12)1.4.4、编写应用服务器启动停止脚本 (12)1.4.5、创建共享卷组和文件系统 (13)1.4.6、配置非TCP/IP网络 (16)1.5、 HACMP Standard配置 (17)1.5.1、添加 cluster和节点 (18)1.5.2、配置cluster资源 (18)1.5.3、创建并配置资源组 (20)1.5.4、同步HACMP的配置 (21)1.6、 HACMP Extended配置 (21)1.6.1、配置串口心跳 (22)1.6.2、配置永久IP (24)1.6.3、同步HACMP的配置 (25)1.7、 HACMP启动和测试 (25)1.7.1、启动HACMP (25)1.7.2、 HACMP切换测试 (26)HACMP v5.x安装配置1.1、了解HACMP的基本概念对于从事IBM售后技术支持工作的人员,深刻理解IBM各项技术的基本概念是做技术支持工作的基本要求,只有掌握了基础的东西,才能使自己的知识更加的巩固,才能灵活的运用技术,解决工作中遇到的各种故障;同时,是知识扩展能力更强,能举一反三,更好的理解客户的真正的需求,能够给客户提供更成熟、更适合客户的解决方案。
中间业务平台HACMP安装配置指南

一、HACMP 双机系统配置打算在配置中间业务平台HACMP环境之前首先要制定配置打算。
在IBM HACMP 的配置指南中推举了一种配置打算表的方式〔Planning Worksheet 〕,在进展配置考虑的时候将这些表格填完即可。
通常分行中间业务平台的HACMP环境大体都有相像的拓扑环境,两个Public 类型的网络,一个用于供给中间业务效劳〔使用IP alias方式〕,另一用于连接AS/400的SNA 〔必需使用IP replacement方式〕Cluster WorksheetCluster Name:xxibp_clusterNode Name:xxMID_PRD,xxMID_BAK在主节点上配置拓扑构造然后同步到其他节点,网络拓扑如下:(1)Network概览Network Name Network Type Network Attribute Network Mask Node Namesnet_ibp Ether public 255.255.255.0 xxMID_PRD,xxMID_BAK net_sna Ether public 255.255.255.0 xxMID_PRD,xxMID_BAK net_rs232_01 RS-232 serial N/AxxMID_PRD,xxMID_BAK (2)Network内部构造Network net_ibpService地址:ibp_svc 10.1.7.33Boot地址:ibp_boot2 172.16.101.1ibp_boot1 172.16.100.1Network sna_netService地址:sna_svc 172.16.120.3Boot地址:sna_boot 172.16.120.1Standby地址:sna_stb 172.16.121.1SNA的网络配置IP〔可以使用私有地址,如172网段的任何地址,但两块网卡要在同一网段〕,只是为了能够相互切换,寻常的IP地址不用。
使用 C-SPOC HACMP 维护1
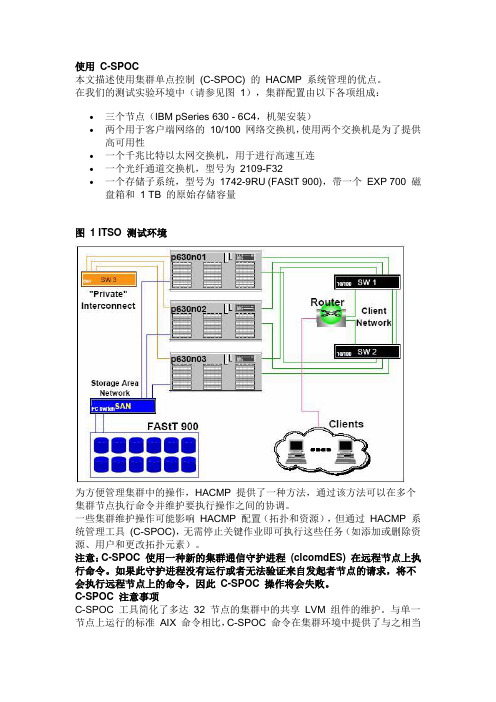
使用C-SPOC本文描述使用集群单点控制(C-SPOC) 的HACMP 系统管理的优点。
在我们的测试实验环境中(请参见图1),集群配置由以下各项组成:∙三个节点(IBM pSeries 630 - 6C4,机架安装)∙两个用于客户端网络的10/100 网络交换机,使用两个交换机是为了提供高可用性∙一个千兆比特以太网交换机,用于进行高速互连∙一个光纤通道交换机,型号为2109-F32∙一个存储子系统,型号为1742-9RU (FAStT 900),带一个EXP 700 磁盘箱和 1 TB 的原始存储容量图 1 ITSO 测试环境为方便管理集群中的操作,HACMP 提供了一种方法,通过该方法可以在多个集群节点执行命令并维护要执行操作之间的协调。
一些集群维护操作可能影响HACMP 配置(拓扑和资源),但通过HACMP 系统管理工具(C-SPOC),无需停止关键作业即可执行这些任务(如添加或删除资源、用户和更改拓扑元素)。
注意:C-SPOC 使用一种新的集群通信守护进程(clcomdES) 在远程节点上执行命令。
如果此守护进程没有运行或者无法验证来自发起者节点的请求,将不会执行远程节点上的命令,因此C-SPOC 操作将会失败。
C-SPOC 注意事项C-SPOC 工具简化了多达32 节点的集群中的共享LVM 组件的维护。
与单一节点上运行的标准AIX 命令相比,C-SPOC 命令在集群环境中提供了与之相当的功能。
通过自动执行重复任务,C-SPOC 消除了潜在的错误根源,加快了处理过程。
如果没有C-SPOC ,系统管理员将需要花费较长时间在每个集群节点上分别执行管理任务。
例如,要将一个用户添加到集群中的某些(或者所有)节点,则必须在每个集群节点上执行此任务。
使用C-SPOC 实用工具,在一个节点(发起更改的节点)上执行的命令也会在其他集群节点上执行。
C-SPOC 最大限度地减少了管理开销,并降低了节点状态不一致的可能性。
AIX HACMP 日常维护

AIX HACMP 日常维护------- 启动、关闭AIX HACMP和查看HACMP运行状态的方法(提示:一般先要先关闭双机软件,再执行shutdown –h命令关闭AIX操作系统)1, 启动的方法,以root在控制台上执行smitty clstart (参数都用如下的缺省值,不要改动)启动时先启动主机上的双机软件,再启动备机上的双机软件。
(主机上双机启动时自动把数据库启动成on-line状态,另外主机上的service_ip (就是对外服务的IP)就替换了原来的boot_ip(固定配置在主网卡en0上的IP), 所以建立在控制台上启动)#smitty clstartStart Cluster ServicesType or select values in entry fields.Press Enter AFTER making all desired changes.[Entry Fields]* Start now, on system restart or both nowBROADCAST message at startup? trueStartup Cluster Lock Services? falseStartup Cluster Information Daemon? falseCluster to re-acquire resources falseafter forced down?2, 关双机软件的方法, 先关闭备机上的双机软件,再关闭主机上的双机软件(不需要严格顺序,但是建议这样做)(主机上双机关闭时自动把数据库也关闭成off-line状态,另外主机上的service_ip (就是对外服务的IP)就被释放掉,原来的boot_ip(固定配置在主网卡en0上的IP)又恢复起来了, 所以建立在控制台上启动)以root用户在控制台上执行smitty clstopStop Cluster ServicesType or select values in entry fields.Press Enter AFTER making all desired changes.[Entry Fields]* Stop now, on system restart or both nowBROADCAST cluster shutdown? true* Shutdown mode graceful(graceful or graceful with takeover, forced)3, 查看双机软件是否运行的方法以普通用户执行下面的命令 (两个subsystem的状态都是active就表示正常) $ lssrc -g clusterSubsystem Group PID StatusclstrmgrES cluster 868436 activeclsmuxpdES cluster 720992 active。
运维安全审计系统HAC运维用户使用手册

运维安全审计系统(HAC)运维用户使用手册广州江南科友科技股份有限公司2012年3月版权声明本手册中涉及的任何文字叙述、文档格式、插图、照片、方法、过程等所有内容的版权属于广州江南科友科技股份有限公司所有。
未经广州江南科友科技股份有限公司许可,不得擅自拷贝、传播、复制、泄露或复写本文档的全部或部分内容。
本手册中的信息受中国知识产权法和国际公约保护。
版权所有,翻版必究©目录1.前言 (3)1.1 概述 (3)1.2 阅读说明 (3)1.3 适用版本 (3)1.4 使用环境 (3)2.首次登录 (4)2.1 首页 (4)2.2 浏览器设置 (5)2.3 运维客户端安装 (7)2.4 常用运维设置 (7)3.运维访问过程 (8)4.最近访问 (10)5.基本操作 (11)5.1双人复核 (11)5.2复核事例 (12)6.运维协议分类 (18)6.1全部协议 (18)6.2文本协议 (19)6.3图形协议 (20)6.4文件传输 (20)6.5应用发布 (20)7.运维事例 (22)7.1文本类运维事例 (22)7.2文件传输类运维事例 (24)7.3图形类运维事例 (24)7.4VNC运维事例 (26)7.5应用发布运维事例 (27)7.6变更工单运维事件 (29)7.7其他帐户运维 (30)7.8AS400运维事例 (31)8. 运维管理 (35)8.1 参数设置 (35)8.2 工具下载 (36)8.3 P ORTAL客户端安装 (36)9.技术支持 (40)1.前言1.1 概述本文档为运维安全审计系统的运维用户的使用手册,作为运维用户的操作指南。
1.2 阅读说明本手册包含运维用户的全部日常操作。
首次阅读此文档时,建议您重点阅读第2章节。
1.3 适用版本本手册,适用于3.6P的发布版。
1.4 使用环境HAC的运维用户主要使用WEB登录方式作为用户界面(AS400除外,需要使用专用客户端工具)。
AIX系统维护手册_HACMP系统维护_AIX基础入门_共40页

http://www.Da
IBM AIX+HACMP 系 统维护手册与基础入 门
更多 oracle 资料,请收藏
本文由网友 Aix china ID:mfkkqwyc866 原创 1 / 40
//www.Da
4.7.1、查看 rootvg中是否存在镜像............................................................................... ..............18 4.7.2、确定 rootvg中的磁盘.........................................................................................................18 4.7.3、确定需要更换哪块磁盘 .....................................................................................................18 4.7.4、取消磁盘镜像 .....................................................................................................................19 4.7.5、把坏盘从 rootvg 中去掉.....................................................................................................19 4.7.6、把坏盘从系统中去掉 .........................................................................................................20 4.7.7、更换新磁盘 ................................................................................................... ......................20 4.7.8、重新认新磁盘 .....................................................................................................................20 4.7.9、使新磁盘可用................................................................................... ..................................20 4.7.10、把新磁盘重新加入到 rootvg 卷组中 ...............................................................................20 4.7.11、为 rootvg 重做镜像 ...................................................................................... .....................20 4.7.12、重新设置磁盘引导区 .......................................................................................................20 4.7.13、设置系统引导顺序 ........................................................................................... ................21
运维安全审计系统HAC运维用户使用手册

运维安全审计系统HAC运维用户使用手册运维安全审计系统(HAC)运维用户使用手册广州江南科友科技股份有限公司3月版权声明本手册中涉及的任何文字叙述、文档格式、插图、照片、方法、过程等所有内容的版权属于广州江南科友科技股份有限公司所有。
未经广州江南科友科技股份有限公司许可,不得擅自拷贝、传播、复制、泄露或复写本文档的全部或部分内容。
本手册中的信息受中国知识产权法和国际公约保护。
版权所有,翻版必究©目录1.前言 ........................................................................................ 错误!未定义书签。
1.1 概述..................................................................................... 错误!未定义书签。
1.2 阅读说明............................................................................. 错误!未定义书签。
1.3 适用版本............................................................................. 错误!未定义书签。
1.4 使用环境............................................................................. 错误!未定义书签。
2.首次登录 ................................................................................ 错误!未定义书签。
2.1 首页..................................................................................... 错误!未定义书签。
HACMP维护手册

注意:我们不推荐在同一时间在多个节点上使用第三个选项来停止群
集服务。
第15页,共30页。
HACMP日常系统管理维护
• 无论何时,都应该避免用kill -9命令停止群集管理后台进程。在这种 情况下(使用kill -9命令),系统资源控制器(SRC)会检测到clstrmgr
群集多处理(CMP): 该进程提供在同一节点上多个应用共享或并发访问 数据 。
基于HACMP的高可用性解决方案提供自动失效检测、诊断 、应用恢复和节点重新控制。在恰当的应用中,HACMP还 可以在并行应用处理中提供对数据的并发访问,从而提供 更高的可扩展性。
第3页,共30页。
高可用性系统VS容错系统 容错系统: 它是提供冗余的设计为不间断操作。这样的系统中所有的
组件都是双份的(不管硬件还是软件),CPU、内存、磁 盘都有特殊的设计来提供不间断服务。这样的系统是非常 昂贵和非常专业的。只有在要求0宕机的环境中,容错系 统设备和方案才有需求。 高可用性系统: 配置为高可用性的系统是一组软件、硬件的组合,可以保 证系统失效后在可接受的宕机时间内恢复。在这种系统中 ,软件负责监测到环境故障后将应用交给另一个机器实现 队员机器的接管。因此,在这种环境下重要的是消除SPOF 。例如,如果只有一个网络连接,就需要提供第二块网卡 以备主网卡失效后接管。另一点就是通过将数据放在所有 节点都可以访问的共享磁盘上并实现镜像。
第12页,共30页。
HACMP日常系统管理维护
• 日常日志2: /tmp/cm.log:(未找到)保存HACMP中clstrmgr进程产生信
息的时间;HACMP技术人员在clstrmgr处于debug模式下排 错需要参考此文件内容。重启集群服务,这个文件就会被 重写,因此需要做好备份。(/var/hacmp/log中有参考日 志文件) /var/hacmp/adm/history/cluster.mmddyyyy:HACMP的历史 记录文件,不同日期发生的集群事件记录在不同的文件中 。mm-月 dd-日 yyyy-年
IBM磁盘阵列HACMP日常维护操作

IBM磁盘阵列HACMP日常维护操作
IBM磁盘阵列HACMP日常维护操作
登录主服务器(telnet ***.***.*.*)
启动、停止cluster服务:
登录服务器后:smitty hacmp
选择:System Management (C-SPOC)
选择:Manage HACMP Services
进入后即可启动、停止、查看hacmp的cluster
或者:
启动cluster服务:smitty clstart
停止cluster服务: smitty clstop
查询hacmp的cluster状态
登录服务器后:lssrc -g cluster
显示:Subsystem Group PID Status
clsmuxpdES(节点间通信协调) cluster 295090 active
clstrmgrES(hacmp管理) cluster 426212 active
clinfoES (进行编程时使用) cluster 418036 active
查询hacmp的cluster状态(由于是图形界面,只能在本机运行)登录服务器后:cd usr/sbin/cluster
然后:./clstat(查)
查询hacmp的cluster状态
登录服务器后:netstat -i
(其中“en2 1500 *.*.** **_svc”表示当前机器为正常状态,
如果显示“en2 1500 *.**.*** ***_boot”则表示当前机器为备份状态)。
HACMP日常操作手册

HACMP操作手册强制方式停掉HACMP:HACMP 的停止分为3 种,graceful(正常),takeover(手工切换),force(强制).下面的维护工作,很多时候需要强制停掉HACMP 来进行,此时资源组不会释放,这样做的好处是,由于IP 地址、文件系统等等没有任何影响,只是停掉HACMP 本身,所以应用服务可以继续提供,实现了在线检查和变更HACMP 的目的。
一般所有节点都要进行这样操作.强制停掉后的HACMP 启动:在修改HACMP 的配置后,大多数情况下需要重新申请资源启动,这样才能使HACMP 的配置重新生效。
日常检查及处理为了更好地维护HACMP,平时的检查和处理是必不可少的。
下面提供的检查和处理方法除非特别说明,均是不用停机,而只需停止应用即可进行,不影响用户使用。
不过具体实施前需要仔细检查状态,再予以实施。
clverify 检查这个检查可以对包括LVM 的绝大多数HACMP 的配置同步状态,是HACMP 检查是否同步的主要方式. smitty clverify->Verify HACMP Configuration回车即可经过检查,结果应是OK。
如果发现不一致,需要区别对待。
对于非LVM 的报错,大多数情况下不用停止应用,可以用以下步骤解决:1.先利用强制方式停止HACMP 服务。
同样停止host2 的HACMP 服务.1.只检查出的问题进行修正和同步:smitty hacmp ->Extended Configuration-〉Extended Verification and Synchronization这时由于已停止HACMP 服务,可以包括”自动修正和强制同步“。
对于LVM 的报错,一般是由于未使用HACMP 的C—SPOC 功能,单边修改文件系统、lv、VG 造成的,会造成VG 的timestamp 不一致。
这种情况即使手工在另一边修正(通常由于应用在使用,也不能这样做),如何选取自动修正的同步,也仍然会报failed.此时只能停掉应用,通过整理VG 来解决.cldump 检查:cldump 的监测为将当前HACMP 的状态快照,确认显示为UP,STABLE。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3、配置HACMP群集
AIX中需要配置网络、共享磁盘、LVM组件等
• • • • • 配置IP 配置串行网络 配置共享磁盘 定义LVM组件 编辑文件/.rhosts
串行网络
• 每个运行Cluster Manager进程软件的节点会通过HACMP中 配置的所有网卡持续送出Keep-alive包(心跳信号)到 Cluster的其它各个节点。HACMP就是通过检测节点间keepalive包的中断来检测网络事件。 • Keep-alive包通常在同一网络上的服务网卡间和备份网卡间 双向传输。传输中的任何中断都会激活故障检测过程,此 时,Keep–alive向所有网卡上传送。通过简单的“淘汰过 程”,故障原因被很快发现,然后群集可采取正确的事件 处理脚本处理故障。
HACMP日常系统管理维护
• 启动和关闭HACMP 启动群集是指在一个或几个节点上启动Cluster Manager, 并使客户机能够访问群集的资源。 HACMP可以配置为自动启动或手动启动,自动启动是通过 在文件/etc/inittab中的一条命令来实现的,但是配置为自 动启动后,故障节点返回群集时可能发生资源的接管,造成 不必要的停机。因此,建议配置为手动启动。启动关闭HA必 须有root权限! 启动命令:# smit clstart 选项按缺省,建议在一个节点 完全启动后再启动另一个节点,并在启动过程中监视事件脚 本的输出(tail –f /var/hacmp/log/hacmp.out.7 )。
HACMP日常系统管理维护
关闭命令:# smit clstop 该命令中尤其要注意第四个选项Select an Action on Resource Groups:指停止HACMP后,其上的资源如何处理: 三种选择 1、Bring Resource Groups Offline:释放资源,但其它节点不接管 2、Move Resource Groups:释放资源,其它节点接管资源 3、Unmanage Resource Groups:停止进程,但不释放资源(不处理)
HACMP相关术语 要理解HACMP的正确功能并利用它,就必须知道一些术语 : 1、群集(Cluster):为共享资源和相互通讯而通过网络连接 在一起的独立主机(节点)。HACMP负责定义在协同的系 统中哪个节点提供服务哪个节点不提供服务。所有节点共 同负责维护应用的功能可用。 2、节点(Node):在群集中所有运行AIX系统和HACMP软件 的IBMp系列服务器都是节点。每个节点都有一个资源集( 磁盘、文件系统、IP地址、应用)在该节点失效时可以被 群集中其他节点接管。 3、资源(Resource):是在群集配置中可以从一个节点转移 到其他节点的逻辑组件。所有必须提供高可用性应用的资 源被构成资源组(RG)。当节点失效时,资源组中的组件 被一同从一个节点移动到另一个节点。一个群集可以有多 个RG,从而提高节点的效率(也就是HACMP中的MultiProcessing)。
IBM针对AIX的高可用性解决方案--HACMP群集技术,它包括 以下两个组件:
高可用性(HA): 该进程保证应用在用户复制共享资源时是可用的。 群集多处理(CMP): 该进程提供在同一节点上多个应用共享或并发访问 数据 。
基于HACMP的高可用性解决方案提供自动失效检测、诊断 、应用恢复和节点重新控制。在恰当的应用中,HACMP还 可以在并行应用处理中提供对数据的并发访问,从而提供 更高的可扩展性。
HACMP日常系统管理维护
• 校验HACMP
执行 # /usr/es/sbin/cluster/diag/clverify,将会出现一个交 互式界面,可以检验HACMP软件(bos)和拓扑结构( topology),管理员可按提示操作。
HACMP日常系统管理维护
• 在磁盘阵列上添加逻辑卷、扩大卷组: 首先把主、备机的HACMP停下。 在主机上: # varyonvg sharevg; 扩大卷组或增加逻辑卷 (在AIX中已讲) # varyoffvg sharevg; 在备机上:# exportvg sharevg; # smit importvg 将sharevg重新import进来; # smit chvg 将sharevg在下次启动时不自动激活; # varyoffvg sharevg。
HACMP相关概念 1、群集拓扑: 包含基本的群集组件——节点、网络、通讯接口、通讯设备 、通讯适配器。 2、群集资源: 被设为高可用性的实体(例如文件系统、裸设备、服务IP标 签、应用等)。所有资源被组织成资源组(RG), HACMP保持唯一实体——资源组——的高可用性。资源组 可以被一个节点访问或者在并发应用中同时被多个节点访 问。 3、Fallover: 在活动节点出现故障时,将资源组从活动节点转移到备份 节点的动作。 4、Fallback: 原来的活动节点恢复时,将资源组切换回原节点的动作。 这是将失效节点重新集成到集群的标准动作。
HACMP日常系统管理维护
• 查看HACMP状态 在HACMP中,它启动一个进程来监控各节点。用# ps – ef|grep clinfo 命令查看clinfo进程是否启动。若未启动,有两 种方法启动此进程: 1、执行 # /usr/sbin/cluster/clinfo 2、启动HACMP时, # smit clstart 中 Startup Cluster Information Daemon (后台守护程序)改为 true 用/usr/sbin/cluster/clstat 命令查看各节点状态,因现使用的 是字符终端,出现的将是字符界面。须注意的是群集的 substate属性,正常为Stable( 稳定的;坚定的;牢固的 ),不是Stable时,HACMP可能有动作或者是不正常。
HACMP维护文档
• 什么是HACMP 在我们解释什么是HACMP以前,我们先来定义一下高可用 性的概念。 High availability:在当今复杂的环境下,成功实现IT应用的 一个关键要素就是提供不间断的应用服务和数据保护。HA 就是这样一个可以通过消除计划内/计划外宕机事件从而 向客户应用提供不间断服务的部件,它能达到消除从硬件 到软件的单点故障(SPOFs)。 实现一个高可用性解决方案,需要: 冗余服务器、冗余网络、冗余网络接口卡、监视、故障检 测、故障诊断、自动接管、自动重新控制 HACMP的主要目标就是消除单点故障。
当出现主、备机在关电后,再次启动时,备机正常,主机不能启动, 要按指定步骤操作:在备机上执行 # smit hacmp选择System Management(C-SPOC)->Resource Group and Applications->Move a Resource Group to Another Node/Site-> Move Resource Groups to Another Node->选择需要移动的资源组,选择备机节点进行接管。退出 命令行,启动HACMP,这时备机接管主机资源。
HACMP日常系统管理维护
● 获取集群状态(一) • 检查集群服务daemon状态: lssrc -g cluster; lssrc -g lock • 检查集群和网络接口状态: /usr/sbin/cluster/clstat (在smit hacmp 中用问题诊断工 具查看更好) • 查看集群记录文件: tail -f /var/hacmp/log/hacmp.out.1-7 more /var/hacmp/adm/history/cluster.mmddyyyy tail -f /var/hacmp/adm/cluster.log • 检查节点名的正确性: odmget HACMPcluster
高可用性系统VS容错系统 容错系统: 它是提供冗余的设计为不间断操作。这样的系统中所有的 组件都是双份的(不管硬件还是软件),CPU、内存、磁 盘都有特殊的设计来提供不间断服务。这样的系统是非常 昂贵和非常专业的。只有在要求0宕机的环境中,容错系 统设备和方案才有需求。 高可用性系统: 配置为高可用性的系统是一组软件、硬件的组合,可以保 证系统失效后在可接受的宕机时间内恢复。在这种系统中 ,软件负责监测到环境故障后将应用交给另一个机器实现 队员机器的接管。因此,在这种环境下重要的是消除SPOF 。例如,如果只有一个网络连接,就需要提供第二块网卡 以备主网卡失效后接管。另一点就是通过将数据放在所有 节点都可以访问的共享磁盘上并实现镜像。
HACMP日常系统管理维护
● 获取集群状态(二) • 检验集群配置: /usr/sbin/cluster/diag/clconfig -v ‘-tr’ //一般慎用 • 显示集群配置: /usr/sbin/cluster/utilities/cllscf • 显示clstrmgr版本: snmpinfo -m dump -o /usr/sbin/cluster/hacmp.defs clstrmgr
HACMP相关术语 4、接管:在群集内部节点之间传送资源的操作称为接管。 如果一个节点发生硬件故障或AIX故障,它的资源应用会 被移到另一个节点。 5、客户:客户就是可以通过局域网访问群集节点应用的一 个系统。客户通过运行客户端程序连接到应用所在的服务 器上。
HACMP的实现(此处略去)
安装配置HACMP共分三步:
我们的配置中默认是其他节点接管资源。
注意:我们不推荐在同一时间在多个节点上使用第三个选项来停止群 集服务。
HACMP日常系统管理维护
• 无论何时,都应该避免用kill -9命令停止群集管理后台进程。在这种 情况下(使用kill -9命令),系统资源控制器(SRC)会检测到clstrmgr 后台进程异常退出。这会造成系统停止并有可能造成共享存储数据的破 坏。依照资源组策略,其他节点会初始化接管。
串行网络
• 由于服务网卡和备份网卡都是采用TCP/IP进行通讯的,如 果某节点的TCP/IP子系统发生故障或者网络拥塞,就会造 成Keep-alive包无法正常传输。此时因为所有的心跳停止了 ,其它节点将错误地认为该节点故障,导致其它节点试图 接管资源,群集及其资源将处于不稳定状态。 • 因此HACMP中必须配置一条串行网络,当LAN故障时,可 以提供另外的Keep –alive路由。由于串行网络不用TCP/IP 协议,所以TCP/IP子系统的故障并不意味着HACMP故障, 使得群集可以分清网络故障和节点故障,避免出现孤立节 点