第七章 指令流水线
计算机指令流水线回顾

计算机指令流水线回顾计算机指令流水线是一种高效的指令执行技术,旨在提高计算机的运行速度。
在本文中,我们将回顾计算机指令流水线的基本原理、优点和局限性,并提供相关题库类型的答案和解析。
一、引言计算机指令流水线是一种并行处理技术,它允许多个指令同时在不同的处理阶段执行,以提高指令执行的速度和效率。
本节将介绍计算机指令流水线的定义和基本原理。
二、计算机指令流水线的原理计算机指令流水线是基于指令执行的并行处理技术。
它将一条指令的执行划分为多个阶段,并且允许多个指令同时在不同的阶段执行。
下面是计算机指令流水线的基本原理:1. 指令划分阶段:将一条指令划分为多个独立且可执行的子指令。
2. 指令执行阶段:每个子指令在不同的处理阶段执行,例如指令提取、指令解码、操作数获取等。
3. 管道寄存器:用于在不同的阶段之间传递数据和指令。
4. 阶段并行执行:多个指令在不同的阶段同时执行,实现指令级并行。
5. 超标量流水线:同时执行多条指令。
三、计算机指令流水线的优点计算机指令流水线相较于传统的顺序执行方式,具有以下优点:1. 提高吞吐量:通过并行执行多条指令,大大提高了计算机的吞吐量。
2. 提高运行速度:指令流水线的并行执行能够加快指令的执行速度,提高计算机的运行效率。
3. 提高资源利用率:指令流水线可以充分利用计算机的硬件资源,使处理器单元始终保持繁忙状态。
四、计算机指令流水线的局限性虽然计算机指令流水线有很多优点,但也存在一些局限性:1. 指令依赖:由于指令之间存在数据或控制依赖关系,可能导致流水线的暂停或冲突,进而影响指令的执行速度和效率。
2. 硬件成本:为了实现指令流水线,需要增加硬件资源和复杂的控制电路,导致成本的增加。
3. 分支预测错误:分支指令的预测错误或错误的预测会导致流水线的中断和重组。
五、题库类型答案与解析在计算机指令流水线的相关题库中,我们可以通过以下方式给出答案与解析:1. 填空题:要求填写与指令流水线相关的概念、原理或术语。
指令流水线

第七章指令流水线2. 简单回答下列问题。
(参考答案略)(1)流水线方式下,一条指令的执行时间缩短了还是加长了?程序的执行时间缩短了还是加长了?为什么?(2)具有什么特征的指令集易于实现指令流水线?(3)流水线处理器中时钟周期如何确定?单条流水线处理器的CPI为多少?每个时钟周期一定有一条指令完成吗?为什么?(4)流水线处理器的控制器实现方式更类似于单周期控制器还是多周期控制器?(5)为什么要在各流水段之间加寄存器?各流水段寄存器的宽度是否都一样?为什么?(6)你能列出哪几种流水线被阻塞的情况?你知道硬件和软件是如何处理它们的吗?(7)超流水线和多发射流水线的主要区别是什么?(8)静态多发射流水线和动态多发射流水线的主要区别是什么?(9)为什么说Pentium 4是“CISC壳、RISC核”的体系结构?3. 假定在一个五级流水线(如P.205图7.1所示)处理器中,各主要功能单元的操作时间为:存储单元:200ps;ALU和加法器:150ps;寄存器堆读口或写口:50ps。
若执行阶段EX 所用的ALU操作时间缩短20%,则能否加快流水线执行速度?如果能的话,能加快多少?如果不能的话,为什么?若ALU操作时间增加20%,对流水线的性能有何影响?若ALU 操作时间增加40%,对流水线的性能有何影响?参考答案:a. ALU操作时间缩短20%不能加快流水线指令速度。
因为存储单元的时间为200ps,所以流水线的时钟周期不会因为ALU操作时间的缩短而变短。
b. ALU操作时间延长20%时,变为180ps,比200ps小,对流水线性能没有影响;c. ALU操作时间延长40%时,变为210ps,比200ps大,所以,流水线的时钟周期将变为210,其效率降低了(210-200)/200=5%。
4. 假定某计算机工程师想设计一个新CPU,一个典型程序的核心模块有一百万条指令,每条指令执行时间为100ps。
(1)在非流水线处理器上执行该程序需要花多长时间?(2)若新CPU是一个20级流水线处理器,执行上述同样的程序,理想情况下,它比非流水线处理器快多少?(3)实际流水线并不是理想的,流水段间数据传送会有额外开销。
第七章 指令流水线

第一讲 流水线数据通路和控制逻辑 第二讲 流水线冒险与高级流水线基概念
第一讲 流水线数据通路和控制 主要内容
°日常生活中的流水线处理例子:洗衣服 °单周期处理器模型和流水线性能比较 °如何设计流水线数据通路
• 以MIPS指令子集来说明 °如何设计流水线控制逻辑
R-type
1
2
3
Ifetch Reg/Dec Exec
4 Mem
NOOP! 5
Wr
°加一个NOP阶段以延迟“写”操作: • 把“写”操作安排在第5阶段, 这样使R-Type的Mem阶段为空NOP
Clock Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9
Load Ifetch Reg/Dec Exec Mem Wr
R-type Ifetch Reg/Dec Exec Wr
R-type Ifetch Reg/Dec Exec Wr
°上述流水线有个问题: 两条指令试图同时写寄存器,因为
• Load在第5阶段用寄存器写口 • R-type在第4 阶段用寄存器写口
New Value
Register File Write Time
RegWr busA busB Address busW
Old Value
New Value
2
Old Value
Delay through Extender & Mux Old Value
Register File Access Time New Value
Load指令的流水线
CPU提速之指令流水线与超标量技术

吞吐率
存在问题
1.超标量处理机都重复设置有多个相同的指令执行部件,而超流水线处理 机 只是把同一个指令执行部件分解为多个流水极。
2.超流水线处理机要比超标量处理机条件转移等操作造成的损失大。 3.超流水线处理机的启动延迟比超标量处理机大 4.因为超线程技术是对多任务处理有优势,因此当运行单线程运用软件时,超线 程技术将会降低系统性能,尤其在多线程操作系统运行单线程软件时将容易出现 此问题。
介绍并分析“CPU提速之指令流水线与超标量技术”
生如夏花
目录
原理
存在问题
解决办法
注意事项
原理介绍
超流水线是通过细化流水、提高主频,使得 在一个机器周期内完成一个甚至多个操作, 其实质是以空间换取时间。 超标量,CPU架构是指在一颗处理器内核中 实行了指令级并行的一类并行运算。这种技 术能够在相同的CPU主频下实现更高的CPU
注意事项
对于一些需要处理器进行运算的工作来说(专门为超线程或多核、多处理器设计 的程序),开启超线程功能绝对能够让平台的运算能力得到有效的提升,如果您 经常使用7-Zip和WinRAR等软件对文件进行压缩和解压缩,那么一定要开启超线 程,可以起到事半功倍的效果。 而对于偏向游戏的玩家来说,是否开启超线程,就要根据具体情况来抉择了。 首先,要看玩家在运行游戏的过程中,处理器的负载状态。比如有的玩家喜欢 双开、多开游戏客户端,那么平台会长时间运行在高负载的状态下,根据我们 之前的测试结果可以发现,在这种情况下,将超线程功能关闭,往往能够获得 更好的游戏体验。
Thanks
公司名公司名公司名公司名
Hale Waihona Puke 5.在打开超线程支持后,如果处理器以双处理器模式工作,那么处理器内部缓存 就会被划分成几区域,互相共享内部资源。对于不支持多处理器工作的软件在双 处理器上运行时出错的概率要比单处理器上高很多。
指令集的实现与流水线结构

18
Computer Architecture Spring 2016
算术流水线
19
Computer Architecture Spring 2016
算术流水线
20
Computer Architecture Spring 2016
算术流水线
21
Computer Architecture Spring 2016
4、流水线需要有“填充时间”(第一个任务流出结果所需的时间), 在此之后流水过程才进入稳定工作状态,每一个时钟周期(拍)流出 一个结果;
5、流水技术适合于大量重复的时序过程,只有输入端能连续地提供 任务,流水线的效率才能充分发挥。
8
Computer Architecture Spring 2016
部件级、处理机级及处理机间流水线
所谓部件级流水线又叫运算操作流水线(Arithmetic pipelines),它是把处理机的算术逻辑部件分段,以便为各 种数据类型进行流水操作。
所谓处理机级流水线,又叫指令流水线(Instruction pipelines),它是把解释指令的过程按照流水方式处理。
所谓处理机间流水线,又叫宏流水线(Macro pipelines)。
段空 号间
8 7 6
浮点加 1 2 3 … … n-1 n
定点乘 一
一二 一二三
5
1 2 3 … … n-1 n
4
1 2 3 … … n-1 n
3
1 2 3 … … n-1 n
2
1 2 3 … … n-1 n
1 1 2 3 … … n-1 n
一二三四
时间
静态流水线 11
Computer Architecture Spring 2016
流水线相关性分析

1、指令流水线中主要有结构相关、数据相关、控制相关。
相关影响流水线性能。
程序中出现的数据相关lbu r3,0x0(r2)需要在WB周期才能将值写入r3里,而后续的指令seqi r5,r3,0x0a在intEx周期里读取r3寄存器的值,发生了读写相关。
正常它的执行阶段需要等待上一条指令将值写入r3后才能读r3寄存器的值,所以为了避免冲突,这里我们采用定向技术,在发生数据相关时,等待前面计算结果的指令并不一定真的马上就用到该计算结果,如果能够将该计算结果从其产生的地方直接送到其他指令需要它的地方,就可以避免暂停。
程序中出现的控制相关Movi2fp f10,r1在IF指令周期后为aborted。
原因在于:第二条指令jal InputUnsigned为无条件转移指令,但是只有在该指令译码的时候才可以知道转移的位置。
但是此时Movi2fp f10,r1指令已经取出,所以需要将该指令流水清空,由于是刚执行了IF指令,所以只需要重新取新的指令就可以了。
程序中出现的结构相关由于以上指令add r1,r1,r3的intEx的执行延迟了4个指令周期,所以addi r2,r2,0x1指令就不能在add r1,r1,r3的intEx的执行前进入ID指令译码的执行。
所以这里出现了指令译码器的争用。
因而发生了结构相关。
2、考察增加浮点运算部件对性能的影响下面两组数据来自Statistics窗口,都是5的阶乘,分别是运算部件设置为一个,运算部件设置为两个的数据统计。
通过比较可以发现,这两组数据在性能统计上是一样的。
所以增加浮点运算部件对性能的影响没有什么影响(对于该程序而言)。
3、考察增加forward部件对性能的影响左右分别是采用forwarding和没有采用forwarding部件的统计效果。
性能比较必须是计算同一个值的时候。
通过比较发现,采用forwarding 技术,总的周期数为95次,暂停了31次。
而没有采用forwarding 技术则总的周期数为112次,暂停了49次。
流水线原理——ILP

llxx@ 18
直到C6,数据才可用
指令调度
• 指令调度,是RISC微处理器编译技术之一。 • 指令调度是解决数据相关的最经济的方法,它可以解决RAW、WAR 和WAW数据相关。 • 假设有这样一个指令序列: I0: R1+R2R3 I1: R3+R4R5 I2: R7 OR R8R9 • 假定我们按下列方法重新安排指令次序: R1+R2 R3 R7 OR R8 R9 R3+R4 R5
从此开始,每个 周期流出一条指 令,IPC≈1
Execute Store res.
pipelined instruction execution
Time
llxx@
9
流水线分类
• 单功能流水线:只能完成一种功能的流水线,如浮点加法 流水线。 • 多功能流水线:流水线的各段可以进行不同的连接,从而 使流水线在不同的时间完成不同的功能。 • 静态流水线:在某一时间段内,流水线的各段只能按同一 种功能的连接方式工作,即只有当输入是一串相同性质的 操作时其性能才能得到发挥。 • 动态流水线:在某一段时间内,某些段正在实现某类操作 (定点乘),其他段却在实现另一类操作(浮点加)。 • 线性流水线:流水线的各段串行连接,没有反馈回路。 • 非线性流水线:流水线中除了串行的通路,还有反馈回来。 • 顺序流水线:流水线的流出顺序与其流入顺序相同。 • 乱序流水线:流水线的流出顺序与其流入顺序不同。
Pipelined
non-pipelined dish cleaning
Time
pipelined dish cleaning
Time
• 流水过程由多个相互联系的子过程组成,每个子过程称为 流水线的“级”或“段”。
计算机体系结构之流水线技术(ppt 125页)

张伟 计算机学院
大纲
1 概念定义 2 流水线分类 3 MIPS五级流水线 4 性能分析 5 流水线相关 6 高级流水线技术
1 概念定义
洗衣店的例子
A, B, C, D 均有一些衣物要 清洗,甩干,折叠
清洗要花30 分钟 甩干要用40 分钟 叠衣物也需要20 分钟
流水线输出端任务流出的顺序与输入端任务流 入的顺序相同。
异步流动流水线(乱序流水线):
流水线输出端任务流出的顺序与输入端任务流 入的顺序不同。
3 MIPS五级流水线
DLX(Dancing Links)
DLX 是一种简单的指令集(教学、简单芯片) 在不流水的情况下,如何实现DLX。
实现DLX指令的一种简单数据通路
4. 存储器访问周期MEM(Memory Access) 5. 写回周期WB(Write Back)
MIPS的简单实现
Instruction Fetch
Instr. Decode Reg. Fetch
Next PC
Next SEQ PC
4
RS1
RS2
Execute Addr. Calc
Zero?
RD
增加了向后传递IR和从MEM/WB.IR回送到通用寄存 器组的连接。
将对PC的修改移到了IF段,以便PC能及时地加 4,为取下一条指令做好准备。
2. 每一个流水段进行的操 作
IR[rs]=IR6..10 IR[rt]=IR11..15 IR[rd]=IR16..20
流水线的每个流水段的操作
将有效地址计算周期和执行周期合并为一个时钟周期,这
是因为MIPS指令集采用load/store结构,没有任何指令
需要同时进行数据有效地址的计算、转移目标地址的计算
指令流水线的分类

指令流水线的分类文章目录••oooo指令流水线的分类1.部件功能级、处理机级和处理机间级流水线根据流水线使用的级别的不同,流水线可分为部件功能级流水线、处理机级流水线和处理机间流水线。
部件功能级流水就是将复杂的算术逻辑运算组成流水线工作方式。
例如,可将浮点加法操作分成求阶差、对阶、尾数相加以及结果规格化等4个子过程。
处理机级流水是把一条指令解释过程分成多个子过程,如前面提到的取指、译码、执行、访存及写回5 个子过程。
处理机间流水是一种宏流水,其中每一个处理机完成某一专门任务,各个处理机所得到的结果需存放在与下一个处理机所共享的存储器中。
2.单功能流水线和多功能流水线按流水线可以完成的功能,流水线可分为单功能流水线和多功能流水线。
单功能流水线指只能实现一种固定的专门功能的流水线;多功能流水线指通过各段间的不同连接方式可以同时或不同时地实现多种功能的流水线。
3.动态流水线和静态流水线按同一时间内各段之间的连接方式,流水线可分为静态流水线和动态流水线。
静态流水线指在同一时间内,流水线的各段只能按同一种功能的连接方式工作。
动态流水线指在同一时间内,当某些段正在实现某种运算时,另一些段却正在进行另一种运算。
这样对提高流水线的效率很有好处,但会使流水线控制变得很复杂。
4.线性流水线和非线性流水线按流水线的各个功能段之间是否有反馈信号,流水线可分为线性流水线与非线性流水线。
线性流水线中,从输入到输出,每个功能段只允许经过一次,不存在反馈回路。
非线性流水线存在反馈回路,从输入到输出过程中,某些功能段将数次通过流水线,这种流水线适合进行线性递归的运算。
第七章 指令系统

第7章指令系统(一)选择题1.二地址指令中,操作数的物理位置可安排在(可多选)A.两个主存单元 B 两个寄存器C一个主存单元和一个寄存器 D 栈顶和次栈顶2.寄存器间接寻址方式中,操作数在A.通用寄存器B.堆钱 C 主存单元3.基址寻址方式中,操作数的有效地址是A.基址寄存器内容加上形式地址(位移量)B.程序计数器内容加上形式地址c.变址寄存器内容加上形式地址4.采用基址寻址可扩大寻址范围,且A.基址寄存器内容由用户确定,在程序执行过程中不可变B.基址寄存器内容由操作系统确定,在程序执行过程中不可变c.基址寄存器内容由操作系统确定,在程序执行过程中可变5.变址寻址和基址寻址的有效地址形成方式类似,但是A.变址寄存器的内容在程序执行过程中是不可变的B.在程序执行过程中,变址寄存器、基址寄存器和内容都是可变的C.在程序执行过程中,基址寄存器的内容不可变,变址寄存器中的内容可变6.堆找寻址方式中,设A为累加器,SP为堆楼指示器,Msp为SP指示的钱顶单元,如果进栈操作的动作顺序是(A)→Msp,(SP)-1→SP,那么出栈操作的动作顺序应为A. (Msp)→A,(SP) +1→SPB. (SP) +1→SP,(Msp)→AC. (SP)-1→SP,( Msp)→A7.设变址寄存器为X,形式地址为D,某机具有先变址再间址的寻址方式,则这种寻址方式的有效地址为A. EA=(X)+DB. EA=(X)+(D)C. EA=((X)+D)8. IBM PC中采用了段寻址方式,在寻访一个主存具体单元时,由一个基地址加上某寄存器提供的16位偏移量来形成20位物理地址。
这个基地址由来提供。
A.指令中的直接地址(16位)自动左移4位B. CPU中的四个16位段寄存器之一自动左移4位C. CPU中的累加器(16位)自动左移4位9.指令的寻址方式有顺序和跳跃两种,采用跳跃寻址方式可以实现A.程序浮动B.程序的无条件转移和浮动C.程序的条件转移和无条件转移10.扩展操作码是A.操作码字段以外的辅助操作字段的代码B.指令格式中不同字段设置的操作码C.一种指令优化技术,即让操作码的长度随地址数的减少而增加,不同地址数的指令可以具有不同的操作码长度11.设相对寻址的转移指令占两个字节,第一字节是操作码,第二字节是相对位移量(用补码表示),若CPU每当从存储器取出一个字节时,即自动完成(PC)+1→PC,设当前PC的内容为2000H,要求转移到2008H地址,则该转移指令第二字节的内容应为A. 08HB. 06 HC.0AH12.设相对寻址的转移指令占两个字节,第一字节是操作码,第二字节是相对位移量(用补码表示),若CPU每当从存储器取出一个字节时,即自动完成(PC)+ 1→PC 设当前PC的内容为2009H,要求转移到2000H地址,则该转移指令第二字节的内容应为A. F5HB. F7HC. 09H13.设相对寻址的转移指令占两个字节,第一字节是操作码,第二字节是相对位移量(可正可负),则转移的地址范围是A. 255B. 256C. 25414.直接、间接、立即三种寻址方式指令的执行速度,由快至慢的排序是A.直接、立即、间接B.直接、间接、立即C.立即、直接、间接15.为了缩短指令中地址码的位数,应采用寻址。
如何利用流水线技术提高程序执行效率(十)

如何利用流水线技术提高程序执行效率随着科技的不断发展,程序执行效率成为了计算机工程师关注的重点。
而流水线技术作为一种能够提高程序执行效率的重要方法,被广泛应用于硬件设计和优化。
本文将介绍流水线技术以及如何利用流水线技术提高程序执行效率。
一、流水线技术的基本原理流水线技术是将任务分解成多个阶段,每个阶段只负责完成特定的子任务,然后将多个子任务串行执行,从而将整个任务加速完成的一种方法。
流水线技术的基本原理是将任务划分为多个子任务,并通过数据流向和控制信号来实现子任务之间的交互与协调。
通过流水线技术,计算机能够同时执行多个任务,从而提高了任务的并行度,加快了程序的执行速度。
二、流水线技术在程序执行效率中的应用1. 数据流水线在计算机中,许多任务都可以用数据流的形式来表示。
数据流水线是指将数据操作分成多个阶段,每个阶段负责特定的数据操作,并通过流水线寄存器将数据传递给下一个阶段进行处理。
通过数据流水线,可以同时进行多个数据操作,从而提高程序的执行效率。
例如,在图像处理任务中,可以将图像数据流水化处理,分成图像输入、图像滤波、图像变换等多个阶段,并通过数据流水线将图像数据传递给不同的阶段进行并行处理,从而加快图像处理的速度。
2. 指令流水线指令流水线是指将程序的执行划分为多个指令阶段,并通过流水线寄存器将指令传递给下一个阶段进行执行。
通过指令流水线,计算机能够同时执行多个指令,从而提高了指令的并行度,加快了程序的执行速度。
例如,在处理器中,可以将指令流水线划分为取指阶段、译码阶段、执行阶段、访存阶段和写回阶段等多个阶段,并通过流水线寄存器将指令传递给不同的阶段进行并行处理,从而加快程序的执行速度。
三、流水线技术在优化程序执行中的挑战然而,尽管流水线技术可以提高程序执行效率,但也面临着一些挑战。
首先,流水线技术对任务的划分和阶段之间的依赖关系有一定的要求,如果任务划分不合理或者阶段之间的依赖关系复杂,会导致流水线的效率降低。
流水线操作技术
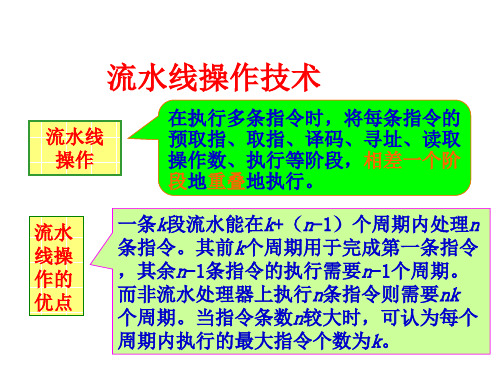
发生流水线冲突的例子
数据 未准 备好 冲突
在流水线的寻址 阶段生成地址
冲突
数据未准备好
在流水线的执行 阶段进行写操作
解决 无等待周期问题
19
总线 冲突
在流水线的 发生流水线冲突的例子 执 行 阶 段 进
行写操作
冲突
同时利用E总线
读数阶段 将 常 数 10 写到AR1
解决
新冲突
数据未准备好
CPU自动地 将STM的写 操作延迟 一个周期
1
预取指P 取指F 译码D 寻址A 读取操作数R 执行X
流水线操作
在第一个机器 周 期 用 PC 中 的 内容加载PAB
在第二个机器周 期用读取到的指 令字加载PB。
第三个周期用PB的内容加载 指令寄存器IR,对IR内的指 令进行译码,产生执行指令 所需要的一系列控制信号。 2
流水线操作
预取指P 取指F 译码D 寻址A 读取操作数R 执行X
插入1个 所有其它存储指令 包括EXP
所有其它存储指令 令
SXM C16 FRCT OVM A 或B
在RPTB[D]前读 BRC
所有存储指令 包括SSXM和RSXM
修改累加器然后读 MMR
STM # lk,BRC
所有其它存储指令
ST # lk,BRC
MVDK Smem,BRC
MVMD MMR,BRC
利用前半周期 利用前半周期 利用后半周期 利用后半周期
14
CPU同时访问DARAM的同一存储器块就会发生时 序上的冲突的情况:
同时从同一存储器块中取指和取操作数(都在 前半个周期);
同时对同一存储器块进行写操作和读(第二个 数)操作(都在后半周期)。
关于ARM指令流水线知识

关于ARM指令流水线知识(周方辉)2012/10/22目录1 参考文献 (2)1.1 内部参考文献 (2)1.2 外部参考文献 (2)2 名词解释 (2)3 指令执行三步骤 (2)4 指令流水线(ARM指令) (3)4.1 三级指令流水线 (3)4.2 五级指令流水线 (5)4.3 六级指令流水线 (6)4.4 其它级指令流水线 (6)1参考文献1.1内部参考文献内部参考文献指的是周方辉自生的百度博文中的文件。
无内部参考文献。
1.2外部参考文献外部参考文献指的是相对于上述内部参考文献以外的文件。
无外部参考文献2名词解释CPI:指令周期数,一段时间内走过的指令时钟数除以被执行的指令条数,CPI>=1。
F:Fetch的缩写,取指令的意思,用在分析指令流水线中。
D:Decode,解指令码,用在分析指令流水线中。
E:Execute,执行指令,用在分析指令流水线中。
M:Memory,内存操作。
W:W riteback回写。
S:Stall,拖延clock。
L:Linkret,连接返回。
A:Adjust,调整流水线。
DI:Decode IRQ解析中断指令。
EI:Execute IRQ执行中断指令。
I:Interlock,内部锁状态。
3指令执行三步骤一般计算机指令码与数据码没有区别,存在内存中,都属于二进制数字信息。
指令码和数据码的区别是一般用PC指针从内存中读取的数据为指令码,否则就当数据码处理。
到目前为止,一般计算机执行指令是用CPU部件来执行的,通常分成:1、获取指令,通过PC指针,从内存中获取指令码;2、解析指令,使用CPU内部的指令解码器对指令码进行解析,从而得知指令功能。
3、执行指令,按照解码器得知的功能,CPU调用相应部件来执行该条指令。
三个步骤完成,我们可以抽象理解成,每条指令都通过:取指令模块——>解析指令模块——>执行指令模块,这三个模块。
如下图所示:这三个步骤的协调工作是依靠指令时钟来推动完成的,,指令时钟并不等于CPU的时钟,一个指令时钟可能有几个CPU时钟组成,这看具体的CPU而定。
计算机组成与体系结构——流水线相关知识点(常考计算)

计算机组成与体系结构——流⽔线相关知识点(常考计算) 流⽔线是软考中经常考的⼀部分内容,并且常以要求计算的形式出现,所以,这⾥详细总结⼀下流⽔线的相关知识点。
流⽔线的概念 流⽔线是指在程序执⾏时多条指令重叠进⾏操作的⼀种准并⾏处理实现技术。
即可以同时为多条指令的不同部分进⾏⼯作,以提⾼各部件的利⽤率和指令的平均执⾏速度。
我们都知道,在执⾏⼀条指令的过程中,最少要经历取指分析执⾏三个步骤,也就是说,假设有三个指令1 、2、 3,当我们在正常情况下,在执⾏指令1的时候,会⾸先对指令1按照以上三个步骤进⾏处理,处理完毕后在对指令2进⾏处理,以此类推。
⽽流⽔线的应⽤,就是像我们在⼯⼚中⼀样,当对指令1进⾏分析⼯作时,同时对指令2进⾏取指,继续执⾏,当指令1到达执⾏阶段时,指令2进⼊分析阶段1同时对于指令3进⾏取指处理,这样就⼤⼤增加了对于时间的利⽤率。
流⽔线的计算 1、流⽔线的执⾏时长 ①关于流⽔线的周期,我们需要知道的是,流⽔线周期(△t)为指令执⾏阶段中执⾏时间最长的⼀段。
②流⽔线的计算公式为: 完成⼀条指令所需的时间+(指令条数-1)*流⽔线周期,在这个公式中,⼜存在理论公式和实践公式。
理论公式: 实践公式:(k+n-1)*△t k为⼀条指令所包含的部分的多少 例题:若指令流⽔线⼀条指令分为取指、分析、执⾏三个阶段,并且这三个阶段的时间分别为取指1ns,分析2ns,执⾏1ns,则流⽔线的周期为多少?100条指令全部执⾏完毕需要执⾏的时间是多少? 分析:上⾯已经说过,流⽔线的周期为花费时间最长的阶段所花费的时间,所以流⽔线的周期就是2ns。
根据理论公式,T=(1+2+1)+(100-1)*2=4+99*2=202ns 根据实践公式,T=(3+100-1)*2=204ns 在这⾥,需要注意的是,因为流⽔线的理论公式和实践公式的结果不⼀样,但是在考试过程中可能都会考到,所以,在应⽤时,先考虑理论公式,后考虑实践公式。
计算机组成原理中的指令流水线与超标量

计算机组成原理中的指令流水线与超标量计算机组成原理是计算机科学中的重要概念之一,它研究了计算机的硬件组成和工作原理。
其中,指令流水线和超标量技术是提高计算机性能的重要手段。
本文将介绍指令流水线和超标量技术的基本原理,并讨论它们在计算机系统中的应用。
一、指令流水线指令流水线是一种将指令执行过程分为多个阶段,并且在每个阶段中同时执行多条指令的技术。
通过将指令执行过程划分为多个独立的阶段,可以使得指令在执行过程中能够重叠进行,从而提高了计算机的运行速度。
指令流水线通常包括取指、译码、执行、访存和写回这五个阶段。
在每个时钟周期中,各个阶段同时执行不同的指令,以提高整个系统的效率。
每个指令在通过流水线的各个阶段时,都经历了不同的处理过程,最终完成指令的执行。
指令流水线的优点在于它可以充分利用计算机资源,提高处理器的性能。
然而,指令流水线技术也存在一些问题,例如流水线冲突和分支预测错误。
流水线冲突指的是由于数据相关性等原因导致指令无法按照顺序执行,而需要等待前一条指令完成。
分支预测错误则是指在程序执行过程中,由于分支指令的条件未知,导致指令流水线中的指令被误判,从而浪费了计算资源。
二、超标量技术超标量技术是指在一个时钟周期内同时发射多条指令,并且在多个功能部件上同时执行这些指令的技术。
相比于指令流水线,超标量技术更进一步地提高了计算机的性能。
超标量技术的核心是多发射和多功能部件。
多发射指的是在一个时钟周期内同时发射多条指令到流水线中。
多功能部件则是指在处理器中使用多个功能部件,以同时执行多条指令,从而提高计算机的性能。
超标量技术的优点在于它可以同时执行多条指令,提高计算机处理的并行性。
通过在一个时钟周期中同时发射多条指令,并在多个功能部件上执行这些指令,可以充分利用计算机资源,提高处理器的性能。
然而,超标量技术也存在一些问题,例如硬件复杂度和资源分配等。
由于需要同时执行多条指令,并且在多个功能部件上执行,因此需要更多的硬件资源来支持。
指令流水线的计算

若指令流水线把一条指令分为取指、分析和执行三部分,且三部分的时间分别是t取指=2ns ,t 分析=2ns,t 执行=1ns。
则100 条指令全部执行完毕需 (4) ns。
(4)A.163 B.183 C.193 D.203 答案:D本类题有两类:第一类是各指令段,有同步时间,即有指令流操作周期.当某指令段执行完毕后,必须等到下一个操作周期来临时,才能执行下一条指令的相同段.第一题与2005年的题就是这样.其计算公式是:(指令所分段数-1)*指令流操作周期 +指令数*指令流操作周期.第二类是各指令段,没有同步时间,每段执行完毕,不需要等待,直接执行下一条执令相同的段.2006的题就是这个.其计算方法是第一条指令执行时间+(指令数-1)*各指令段执行时间中最大的执行时间==========================================================本题为第二类:(2+2+1)+(100-1)*2=203指令流水线的计算1.现有四级指令流水线,分别完成取指、取作的时间依次为数、运算、传送结果四步操作。
若完成上述操9ns、10ns、6ns、8ns。
则流水线的操作周期应设计为(1)n s。
(1)A.6B.8C.9D.10试题解析:取最大的那个微指令时间作为流水线操作周期。
答案:D2.若每一条指令都可以分解为取指、分析和执行三步。
已知取指时间t取指=4△t,分析时间t分析=3△t,执行时间t执行=5△t。
如果按串行方式执行完100条指令需要(2)△t。
如果按照流水方式执行,执行完100条指令需要(3)△t。
(2)A.1190B.1195C.1200D.1205(3)A.504B.507C.508D.510试题解析:串行执行时,总执行时间=100×(t取指+ t分析+ t执行)=100×12△t=1200△t。
连续两条指令的执行时间差为t执行= 5△t,因此100条指令的总执行时间=(t取指+ t分析+ t执行)+99×t执行= 507△t。
计算机组成原理——指令流水线

计算机组成原理——指令流⽔线
计算机组成原理——指令流⽔线
1. 综述
为提⾼CPU利⽤率,加快执⾏速度,将指令分为若⼲个阶段,可并⾏执⾏不同指令的不同阶段,从⽽多个指令可以同时执⾏。
在有效地控制了流⽔线阻塞的情况下,流⽔线可⼤⼤提⾼指令执⾏速度。
经典的五级流⽔线:取址、译码/读寄存器、执⾏/计算有效地址、访问内存(读或写)、结果写回寄存器。
流⽔线阻塞的情况有三种():
1. 结构相关:指令重叠执⾏的过程中,硬件资源满⾜不了指令重叠执⾏的要求,发⽣资源冲突,这时将产⽣结构相关。
解决的办法是增加硬件资源,如解决访存冲突就采⽤指令Cache和数据Cache分离的哈弗结构。
2. 数据相关:当⼀条指令需要前⾯某条指令的执⾏结果,⽽两者正在并⾏执⾏的情况下,将产⽣数据相关。
解决⽅式:数据重定向,或称为旁路技术。
3. 控制相关:有跳转语句、分⽀指令,或其他改变IP值的指令,将产⽣控制相关。
解决⽅法:分⽀预测技术,投机执⾏,延迟分⽀。
若I1和I2数据相关,如I2需要I1的结果,则I2在其译码阶段被阻塞,直到I1全部完成才恢复流动。
流水线技术 ppt课件

T P T 1 T 2 T K(n 1 ) M a x(T 1,T 2, T K )
▪K为流水线段数,Ti为第i段所需要的时间
❖指令流水线的吞吐率
单位时间内流水线所完成的指令数
n TP
kT (n 1)T
▪N为通过流水线的指令数 ▪T为指令流水线各个流水段的时间 ▪kT为指令流水线的填充时间
ADD R1, R2, R3 ; (R1) + (R2) → R3 OR R3, R2, R6 ; (R2) ^ (R3) → R6 SUB R3, R4, R5 ; (R4) - (R3) → R5
时钟周期 1 2 3 4
5
6
ADD IF ID EX —— WB
OR
IF ID EX —— WB
6
❖最大吞吐率
当流水线充满之后,理想情况下每个周期都有一条指令完成
1 T P max
T
❖最大吞吐率和实际吞吐率之间的关系
TPkT(n n1)Tkn n1T 11k 11TPm ax n
当n>>k时,TP≈TPmax
❖MIPS与吞吐率
TPMIPS106
MIPS:单位时间内所完成的指令数
7
❖加速比
时钟周期 1 2 3 4 5
6
7
8
指令1 IF ID EX MEM WB
指令2
IF ID EX MEM WB
指令3
IF ID EX MEM WB
指令4
IF ID EX MEM WB
13
❖争用同一个硬件资源,又称资源相关、冲突
时钟周期 1 2 3 4
5
6
7
8
指令1 Ik时,Sp≈k 增加流水线深度可以提高加速比
1、指令流水线基本概念

指令流水线基本概念单周期MIPS 关键路径---LW 指令25:21011<<2SrcB ReadData CLKrdCLK指令字4PC+420:1615:1115:0SignImm+PCBranchSrcA ALUResult WriteDataWriteBackData++BranchAddressPC+4rsrt 0101指令A L U01T clk_to_q T regfile_readT memT aluT memT muxT setupR1#R2#W#WDWE 寄存器堆R1R2CLK RDA存储器Sign ExtendWERD A 数据存储器WD PC性能取决于最慢的指令,时钟周期过长MIPS CPU实现方案⏹单周期方案☐性能受限于最慢的指令☐结构简单,实现容易⏹多周期方案☐传统多周期◆提升性能,复用器件◆异步控制,变长指令周期☐指令流水线◆多指令并行,提升性能◆部件并发单周期指令运行动态IF ID EX MEM WB I 1取指译码执行访存写回⏹数据通路细分为5段,总时长为1个时钟周期=5T☐取指令IF (Instruction Fetch)☐指令译码ID (Instruction Decode)☐执行运算EX (Execution)☐访存阶段MEM☐结果写回WB (Write Back)单周期时空图I 2I 1时间tIFID EX MEM 空间s I 2I 1I 1I 1I 1I 2I 2I 2WB I 1T 2T 3T 4T 5T 6T 7T 8T 9T 10T完成n 条指令需要5nTI 2多周期指令运行动态IF ID EX MEM WB lw 取指译码执行访存写回add sw ⏹数据通路细分为5段,可复用功能部件☐LW 指令5个时钟周期☐BEQ 指令3个时钟周期☐ADD 指令4个时钟周期☐J 指令3个时钟周期多周期时空图Iw时间tIFID EX MEM 空间s IwIwIwIwbeqbeqbeqWB addaddaddaddI 3I 2T 2T 3T 4T 5T 6T 7T 8T 9T 10T 011T 12T完成n 条指令时间与指令有关I 1流水线指令运行动态IF ID EX MEM WB I 3I 2I 1取指译码执行访存写回⏹数据通路细分为5段,各段完全并发☐取指令IF (Instruction Fetch)☐指令译码ID (Instruction Decode)☐执行运算EX (Execution)☐访存阶段MEM☐结果写回WB (Write Back)指令流水线时空图I 1I 2I 3I 4I 5I 6I 7I 8I 9I 1I 2I 3I 4I 5I 6I 7I 8I 1I 2I 3I 4I 5I 7I 7I 1I 2I 3I 4I 5I 8I 1I 2I 3I 4I 5时间tIF ID EX MEM 空间s WB I 5I 1I 2I 3I 4完成n 条指令的时间=完成第一条指令时间5T+(n-1)*T=(n+4)TT 2T 3T 4T 5T 6T 7T 8T 9T 0理想流水线⏹适用范围☐工业自动化流水线☐指令流水线?⏹理想流水线特征☐阶段数相同:所有加工对象均通过同样的工序(阶段)不同指令阶段数不同☐段时延相同:各段传输延迟一致,不能有等待现象,取最慢的同步取指,访存段最慢☐无资源冲突:不同阶段之间无共享资源,各段完全并发取指令、取数存在内存争用☐无段间互锁:进入流水线的对象不受其他阶段的影响多条指令间存在相关和依赖◆M icroprocessor without i nterlocked p iped s tages(MIPS)指令流水线的相关、冲突、冒险(hazard)⏹资源相关☐争用主存:IF段取指令、ID段取操作数☐争用ALU:多周期方案中计算PC、分支地址,运算指令☐解决方案:增加部件消除⏹分支相关☐提前取出的指令作废,流水线清空☐流水线发生中断⏹数据相关☐指令操作数依赖于前一条指令的执行结果ADD $s1,$s2, $s3☐引起流水线停顿直到数据写回ADD $s4, $s1, $s310下节课再见…。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
复习:A Single Cycle Processor
Branch Jump Zero Clk RegDst Instruction Fetch Unit <31:26> Instruction<31:0> op <16:20> <21:25> <11:15> Rd Imm16 5 Rs 5 Rt <5:0> func <0:15> RegDst Main Control 3 ALUSrc
6 PM
7
8
9
Time
10
11
Midnight
30 40
T a s k O r d e r
40
40
40 20
串行方式为6小时,N批则为90N分钟
A
只需30+4x40+20=210分 (3.5小时)
B C
D
如果有N批衣服呢? 所花时间为:30+Nx40+20分钟 假定每一步时间均衡,则比串行方 式提高约3倍!
:
ALUopRtΒιβλιοθήκη Rd1 Mux 0
ALU Control
RegWr 5 busW 32 Clk
ALUctr 3 busA 32
0 Mux ALU Zero 32 WrEn Adr 32 MemWr 0 Mux
Rw Ra Rb 32 32-bit Registers busB 32 Extender
MemtoReg
Ideal Memory
32
Rt Rt 0 Rd 1
5 5
Ra Rb Rw busW busB 32 busA
Mux
Reg File
4
1 Mux 0
Mux
32
<< 2
2 3
ALU Control
Imm 16
Extend
32
ALUOp ALUSelB
2018年12月31日星期一
ExtOp
Pipeline.4
Ch7: Instruction Pipeline 指令流水线
第一讲 流水线数据通路和控制逻辑
第二讲 流水线冒险处理 第三讲 高级流水线技术
第一讲 流水线数据通路和控制 主要内容
° 日常生活中的流水线处理例子:洗衣服 ° 单周期处理器模型和流水线性能比较
° 什么样的指令集适合于流水线方式执行
° 如何设计流水线数据通路 • 以MIPS指令子集来说明 • 详细设计取指令部件
Instr Decode / Reg. Fetch
Address
Data Memory
Reg Wr
Rs, Rt, Rd, Op, Func
1
Old Value
Old Value Old Value Old Value
ALUctr
ExtOp ALUSrc RegWr busA busB Address busW
• 详细设计执行部件 • 分析每条指令在流水线中的执行过程,遇到各种问题: - 资源冲突 - 寄存器和存储器的信号竞争 - 分支指令的延迟 - 指令间数据相关
° 如何设计流水线控制逻辑 • 分析每条指令执行过程中的控制信号 • 给出控制器设计过程 ° 流水线冒险的概念
Pipeline.2
2018年12月31日星期一
流水方式下,所花时间主要与最长阶段时间有关!
Pipeline.8
2018年12月31日星期一
复习:Load指令的5个阶段
阶段1 阶段 2 阶段 3
32 32 0 1 32 32 RAdr
PCWrCond Zero MemWr
32 Rs 0 1 32
PCSrc IRWr RegDst RegWr ALUSelA
1
0 32 0 1 32
BrWr
32
Target
Mux
Zero ALU
Mux
Instruction Reg
32
WrAdr 32 Din Dout
A
B
C
D
如果让你来管理洗衣店,你会如何安排?
Pipelining: It’s Natural !
Pipeline.6
2018年12月31日星期一
Sequential Laundry(串行方式) 6 PM 7 8 9
Time
10
11
Midnight
30 40 20 30 40 20 30 40 20 30 40 20
T a s k O r d e r
A B
C D
° 串行方式下, 4 批衣服需要花费 6 小时(4x(30+40+20)=360分钟) ° N批衣服,需花费的时间为Nx(30+40+20) = 90N ° 如果用流水线方式洗衣服,则花多少时间呢?
Pipeline.7
2018年12月31日星期一
Pipelined Laundry: (Start work ASAP)
Pipeline.5
Delay through Control Logic New Value New Value New Value Register File Write Time New Value
2
Old Value Delay through Extender & Mux Old Value Old Value
Register File Access Time New Value
3
New Value ALU Delay New Value
Data Memory Access Time Old Value New
2018年12月31日星期一
一个日常生活中的例子—洗衣服
°Laundry Example • Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold • Washer takes • Dryer takes • “Folder” takes 30 minutes 40 minutes 20 minutes
MemtoReg
复习:Timing Diagram of a Load Instruction
Instruction Fetch
Clk PC Old Value Clk-to-Q New Value Old Value Instruction Memory Access Time New Value
1
1 32 ALUSrc
imm16 Instr<15:0>
Data In 32
16
Clk
Data Memory
ExtOp
Pipeline.3
2018年12月31日星期一
复习:Multiple Cycle Processor
° MCP: 一个功能部件在一个指令周期中可以被使用多次。
PCWr IorD PC