流水线(Pipeline)介绍
流水线(Pipeline)介绍

ADD Ra,Rb, Rc LD Rf,F SD Ra,A
IF ID EX MEM WB
IF ID EX MEM WB
SUB Rd,Re, Rf SD Rd,D
IF ID EX MEM WB
IF ID EX MEM WB
28
动态调度
有些信息在译码时难以确定,如是否发生异 常、访存操作需要多少周期等,静态调度就 不能完成。 动态调度:硬件会重新安排指令的执行顺序 以减少停顿并同时保持数据流和异常行为。 优点:有些相关编译无法检测、编译器更加 简单、程序性能对机器依赖少
i: DSUB R1,R2,R3 j: DADD R4,R1,R3
17
写后写冲突(WAW: Write After Write) 在 i 写入之前,j 先写。最后写入的结果 i 是 错误的。 这对应“输出相关”,寄存器换名技术可以 消除 i: DSUB R1,R4,R3
j: DADD R1,R2,R3 k: DMUL R6,R1,R7
Tomasulo算法小结
通过动态调度缓解流水线阻塞:例如减少CACHE 失效对性能的影响 保留站:重命名寄存器+缓存源操作数 •避免寄存器成为瓶颈 •避免WAW和WAR阻塞 •缺点: •硬件复杂性 •结果总线成为瓶颈,多条结果总线增加硬 件复杂度
39
流水线技术一直是提高处理器速度的最有效 技术之一。但目前的在相关处插入阻塞,转发技 术,编译器调度都是尽量分离相关问题的指令, 使他们不会导致冲突,从而减少暂停的影响。虽 然都会相应的显著减少数据相关的次数提高流水 效率,但也会不可避免的增加硬件复杂度和编译 器的复杂性。 而动态调度则可以以硬件的方式调整指令执 行顺序,使不相关的后续指令得以不受暂停的影 响而继续执行,可以在降低编译器复杂度的同时 处理一些编译阶段无法知道的相关,在出现数据 冒险是尽量避免出现流水暂停。
什么是自动化流水线?

什么是自动化流水线?自动化流水线(Automation Pipeline)是一种软件开发和部署流程的自动化方法。
它可以将软件开发流程和软件部署流程自动化,使得整个软件开发和部署流程被分解成为多个小的阶段,可以由一些自动化工具去管理和执行。
自动化流水线的目标是减少人工操作,减少人为错误,提高部署的效率和可靠性。
自动化流水线由多个自动化工具组成,这些工具可以实现自动化构建、测试、打包和部署任务。
自动化流水线的优点包括:•提高软件开发和部署的效率•减少手动操作的几率,减少出错的几率•提高软件部署的效率和可靠性•大量节省公司的人工成本•可以灵活配置不同环境和构建版本自动化流水线的主要组成部分包括版本控制、构建、测试、打包、部署等环节。
在这些环节中,自动化流水线需要用到多个自动化工具,下面是一些常用的自动化工具:版本控制工具版本控制工具是自动化流水线的第一步,它用来管理代码的版本,包括代码的提交,回滚,合并等操作。
版本控制工具可以帮助开发人员协同开发代码,在代码变更时保证代码的一致性和可追溯性。
常用的版本控制工具有Git、SVN等。
构建工具构建工具用来将源代码编译成可执行文件或者部署包。
构建工具可以帮助开发人员自动编译源代码,并在编译成功后生成可执行文件。
常见的构建工具有Gradle、Maven、Ant等。
测试工具测试工具是自动化流水线的核心部分,它可以通过自动化测试来优化软件的性能、功能和质量。
测试工具可以帮助开发人员在代码构建完成后自动运行测试用例,自动化检查代码的正确性和性能影响。
常见的测试工具有JUnit、Selenium、JMeter等。
打包工具打包工具是将构建好的软件打包成安装包或者部署包的工具。
打包工具可以将构建好的软件和其依赖的库文件打包成可执行的安装包或者部署包,以加快软件部署的速度。
常见的打包工具有IzPack、NSIS、ANTInstaller等。
部署工具部署工具用来将打包好的软件部署到特定的环境中。
流水线基础-Pipeline
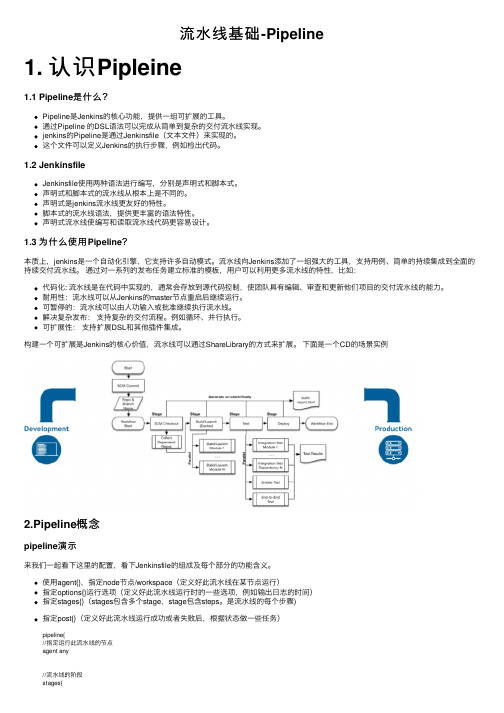
流⽔线基础-Pipeline1. 认识Pipleine1.1 Pipeline是什么?Pipeline是Jenkins的核⼼功能,提供⼀组可扩展的⼯具。
通过Pipeline 的DSL语法可以完成从简单到复杂的交付流⽔线实现。
jenkins的Pipeline是通过Jenkinsfile(⽂本⽂件)来实现的。
这个⽂件可以定义Jenkins的执⾏步骤,例如检出代码。
1.2 JenkinsfileJenkinsfile使⽤两种语法进⾏编写,分别是声明式和脚本式。
声明式和脚本式的流⽔线从根本上是不同的。
声明式是jenkins流⽔线更友好的特性。
脚本式的流⽔线语法,提供更丰富的语法特性。
声明式流⽔线使编写和读取流⽔线代码更容易设计。
1.3 为什么使⽤Pipeline?本质上,jenkins是⼀个⾃动化引擎,它⽀持许多⾃动模式。
流⽔线向Jenkins添加了⼀组强⼤的⼯具,⽀持⽤例、简单的持续集成到全⾯的持续交付流⽔线。
通过对⼀系列的发布任务建⽴标准的模板,⽤户可以利⽤更多流⽔线的特性,⽐如:代码化: 流⽔线是在代码中实现的,通常会存放到源代码控制,使团队具有编辑、审查和更新他们项⽬的交付流⽔线的能⼒。
耐⽤性:流⽔线可以从Jenkins的master节点重启后继续运⾏。
可暂停的:流⽔线可以由⼈功输⼊或批准继续执⾏流⽔线。
解决复杂发布:⽀持复杂的交付流程。
例如循环、并⾏执⾏。
可扩展性:⽀持扩展DSL和其他插件集成。
构建⼀个可扩展是Jenkins的核⼼价值,流⽔线可以通过ShareLibrary的⽅式来扩展。
下⾯是⼀个CD的场景实例2.Pipeline概念pipeline演⽰来我们⼀起看下这⾥的配置,看下Jenkinsfile的组成及每个部分的功能含义。
使⽤agent{},指定node节点/workspace(定义好此流⽔线在某节点运⾏)指定options{}运⾏选项(定义好此流⽔线运⾏时的⼀些选项,例如输出⽇志的时间)指定stages{}(stages包含多个stage,stage包含steps。
什么是流水线技术pipeline

什么是流水线技术pipeline/uid-9185047-id-445171.html2010流水线(Pipeline)技术是目前广泛应用于微处理芯片(CPU)中的一项关键技术,但对许多非专业性的读者来说,这个名词过于抽象,加上P6(高能奔腾)应用的超流水线(Super Pipeline)技术,更令人一头雾水,不知所云。
本文以简单、形象、非专业的语言来介绍这一技术,加深大家对其的理解。
流水线技术指的是对CPU内部的各条指令的执行方式的一种形容,要了解它,就必须先了解指令及其执行过程。
一、计算机指令及其执行过程计算机指令,就是告诉CPU要做什么事的一组特定的二进制集合。
如果我们将CPU比喻成一个加工厂,那么,一条指令就好比一张订单,它引发了CPU__加工厂的一系列动作,最后分别得到了运算结果和产品。
那么,它们到底是怎样工作的呢?首先,要有一个接收订单的部门——CPU的取指令机构;其次,还要有完成订单的车间——CPU的执行指令机构。
在工厂中,一张订单上的产品被分成了许多道工序,而指令亦在CPU中转换成了许多条对应的微操作,依次完成它们,就执行完了整条指令。
二、执行指令的方式及流水线技术在低档的CPU中,指令的执行是串行的,简单地说,就是执行完了一条指令后,再执行下一条指令,好比我们上面提到的那个加工厂在创业之初,只有一间小车间及孤军奋战的老板,那么,当他接到一张订单之后,他必然忙于完成第1张订单,而没有能力去接第2张订单。
这样接订单→完成订单→接订单→……取指令→执行指令→取指令→……是一个串行的过程。
后来,老板发现接受订单不费太多时间,而且他还有了一个帮工,他们可以相互独立地工作,这样,老板就在完成上张订单产品的同时,接受下一张订单的订货。
这表现在CPU上就是取指令机构与执行指令机构的分开,这样从CPU整体来看,CPU在执行上条指令的同时,又在并行地取下条指令。
这在CPU技术上是一个质的飞跃,它使得CPU从串行工作变为并行工作,从而具有了流水线的雏型。
流水线(Pipeline)介绍PPT课件

.
16
写后读冒险(RAW: Read After Write)
❖ 在 i 写入之前,j 先去读。j 会错误的获取旧 值。
❖ 这对应“真数据相关”,为了确保j可以得到 正确的i值,必须保持程序的顺序。
i: DSUB R1,R2,R3 j: DADD R4,R1,R3ຫໍສະໝຸດ DSUB R4,R1,R5
IM
Reg
DM
Reg
XOR R6,R1,R7
IM
Reg
DM
AND R8,R1,R9
IM
Reg
OR R10,R1,R11
IM
Reg
AND,OR操作不会暂停,但是DSUB,XOR指
令需要等待DADD在WB阶段写回数据后才
可以执行。
.
15
2.4 数据冒险的解决办法
❖ 根据指令中读写访问的顺序,可以将数据冒 险分为三类。分别是:
处理器流水线相 关技术
报告人:Hardy
.
1
流水线技术
❖1.流水线的概念 ❖2.流水线的冒险和冒险的解决办法 ❖3.多发射处理器
.
2
1.流水线的概念
❖ 流水线技术:
把一个重复的过程分解为若干个子过程,每个子过 程由专门的功能部件来实现。将多个处理过程在时 间上错开,依次通过各功能段,这样,每个子过程 就可以与其他子过程并行进行。
.
5
采用相同的功能模块,指令顺序执行和按照流水线
技术执行,在时间上可以看出流水线指令的执行速
度提高了4倍。
.
6
流水线的基本作用
流水线增大了CPU的指令吞吐量—即单位时 间执行指令的条数,但是它未减少指令各自 的执行时间。实际上流水线技术要对流水线 附加一些控制,因而了增加开销,使单条指 令执行时间略有增加。吞吐量的增大意味着 程序运行的更快,总的执行时间变短,尽管 没有一条指令的执行变快。
pipelines 用法

pipelines 用法
Pipelines是一个在软件开发和数据处理中常见的概念,它可以用于多个领域,包括软件开发、数据处理和机器学习等。
在软件开发中,pipeline通常用于描述一系列的处理步骤,这些步骤按照一定的顺序依次执行,每个步骤的输出作为下一个步骤的输入。
在数据处理中,pipeline用于描述数据流经过一系列的处理步骤,如数据清洗、转换、分析和可视化等。
在机器学习中,pipeline描述了数据在模型训练过程中经历的一系列预处理和建模步骤。
在软件开发中,pipeline可以用于自动化构建、测试和部署软件。
例如,在持续集成/持续部署(CI/CD)中,开发人员可以创建一个pipeline来自动执行代码编译、单元测试、集成测试和部署到生产环境等步骤,从而提高开发效率和代码质量。
在数据处理中,pipeline可以用于构建数据处理流程,例如数据清洗、特征提取、建模和评估等步骤。
通过使用pipeline,数据处理过程可以更加清晰和可维护,同时可以方便地对新数据进行相同的处理流程。
在机器学习中,pipeline通常用于将数据预处理步骤(如标准
化、特征选择、特征转换等)和模型训练步骤(如模型选择、参数
调优等)组合成一个整体的流程。
这样做的好处是可以将整个流程
封装成一个模型,方便进行部署和使用。
总的来说,pipelines的用法可以帮助我们更加高效地进行软
件开发、数据处理和机器学习,它可以提高工作效率、降低错误率,并且使得整个流程更加可控和可维护。
ARM流水线

ARM 流水线[整理]2007-3-20 16:07:00流水线(Pipeline)简介流水线设计就是将组合逻辑系统地分割,并在各个部分(分级)之间插入寄存器,并暂存中间数据的方法。
目的是提高数据吞吐率(提高处理速度)。
流水线缩短了在一个时钟周期内给的那个信号必须通过的通路长度,从而可以提高时钟频率。
例如:一个2级组合逻辑,假定每级延迟相同为Tpd,无流水线的总延迟就是2Tpd,可以在一个时钟周期完成,但是时钟周期受限制在2Tpd;如果使用流水线,每一级加入寄存器(延迟为Tco)后,单级的延迟为Tpd+ Tco,每级消耗一个时钟周期,流水线需要2个时钟周期来获得第一个计算结果,称为首次延迟,它要2*(Tpd+Tco),但是执行重复操作时,只要一个时钟周期来获得最后的计算结果,称为吞吐延迟(Tpd+Tco);可见只要Tco小于Tpd,流水线可以提高速度。
实现流水线的代价:1.消耗寄存器-就是消耗硅片面积(想想20级流水线的某著名CPU吧)2.流水线长则消耗更多时钟周期。
(如果流水线反复启动,则会损失速度,想想某CPU著名的高频率低效能吧)下面附上一段流水线在CPU设计中的应用和问题进行简要介绍对于一条具体的指令执行过程,通常可以分为五个部分:取指令,指令译码,取操作数,运算(ALU),写结果。
其中前三步一般由指令控制器完成,后两步则由运算器完成。
按照传统的方式,所有指令顺序执行,那么先是指令控制器工作,完成第一条指令的前三步,然后运算器工作,完成后两步,在指令控制器工作,完成第二条指令的前三步,在是运算器,完成第二条指令的后两部……很明显,当指令控制器工作是运算器基本上在休息,而当运算器在工作时指令控制器却在休息,造成了相当大的资源浪费。
解决方法很容易想到,当指令控制器完成了第一条指令的前三步后,直接开始第二条指令的操作,运算单元也是。
这样就形成了流水线系统,这是一条2级流水线。
如果是一个超标量系统,假设有三个指令控制单元和两个运算单元,那么就可以在完成了第一条指令的取址工作后直接开始第二条指令的取址,这时第一条指令在进行译码,然后第三条指令取址,第二条指令译码,第一条指令取操作数……这样就是一个5级流水线。
流水线技术 ppt课件

T P T 1 T 2 T K(n 1 ) M a x(T 1,T 2, T K )
▪K为流水线段数,Ti为第i段所需要的时间
❖指令流水线的吞吐率
单位时间内流水线所完成的指令数
n TP
kT (n 1)T
▪N为通过流水线的指令数 ▪T为指令流水线各个流水段的时间 ▪kT为指令流水线的填充时间
ADD R1, R2, R3 ; (R1) + (R2) → R3 OR R3, R2, R6 ; (R2) ^ (R3) → R6 SUB R3, R4, R5 ; (R4) - (R3) → R5
时钟周期 1 2 3 4
5
6
ADD IF ID EX —— WB
OR
IF ID EX —— WB
6
❖最大吞吐率
当流水线充满之后,理想情况下每个周期都有一条指令完成
1 T P max
T
❖最大吞吐率和实际吞吐率之间的关系
TPkT(n n1)Tkn n1T 11k 11TPm ax n
当n>>k时,TP≈TPmax
❖MIPS与吞吐率
TPMIPS106
MIPS:单位时间内所完成的指令数
7
❖加速比
时钟周期 1 2 3 4 5
6
7
8
指令1 IF ID EX MEM WB
指令2
IF ID EX MEM WB
指令3
IF ID EX MEM WB
指令4
IF ID EX MEM WB
13
❖争用同一个硬件资源,又称资源相关、冲突
时钟周期 1 2 3 4
5
6
7
8
指令1 Ik时,Sp≈k 增加流水线深度可以提高加速比
自动化流水线的常识介绍

自动化流水线的常识介绍随着技术的不断发展,软件开发的复杂性也不断增加,传统的手动开发方式已经无法满足现代软件开发的要求。
在这种情况下,自动化流水线成为了软件开发领域中必不可少的组成部分。
本文将着重介绍自动化流水线的常识,帮助开发人员更好地理解和应用自动化流水线。
什么是自动化流水线自动化流水线(Automated Pipeline)是一种软件开发工具链,它将软件开发中的各种任务自动化处理,形成一条自动化的流水线。
自动化流水线通常包括持续集成、自动化构建、自动化测试、自动化部署等一系列环节。
通过自动化流水线的集成运行,使得软件开发过程更加高效、可靠,可以加快软件交付速度,提高软件开发质量,减少不必要的人工操作和出错风险。
自动化流水线的常用工具自动化流水线中包括了许多不同的工具,下面是自动化流水线常用的一些工具。
JenkinsJenkins 是目前使用最为广泛的持续集成工具之一。
它支持多种语言和技术平台,支持自动化构建、测试、部署等功能。
Jenkins 还提供了丰富的插件,可以方便地扩展其功能。
GitLab CI/CDGitLab 是一个开源的代码托管平台,而 GitLab CI/CD 则是 GitLab 的持续集成和持续部署系统。
它可以与 GitLab 集成,支持自动化构建、测试、部署等功能。
同时,GitLab CI/CD 还支持 Docker,可以让使用者方便地进行微服务的部署。
Travis CITravis CI 是一款基于云计算的持续集成服务,它可以与 GitHub 和 Bitbucket 集成,支持自动化构建、测试、部署等功能。
由于其易用性和灵活性得到了越来越多的使用者。
以上只是自动化流水线中常用的几个工具,还有很多其他的工具可以用来搭建自动化流水线。
自动化流水线的优点自动化流水线有以下优点:提高软件开发速度自动化流水线可以自动化处理软件开发流程中的各个环节,大大缩短了软件开发的周期,提高了软件的开发速度。
什么是倍速链流水线?

什么是倍速链流水线?前言随着互联网时代的到来,数据处理和数据传输需求不断增长。
为满足不断增长的需求,高性能计算机应运而生,成为数据处理、计算和分析等领域中的重要工具。
然而,对于一些需要进行大量复杂计算的应用场景,单台高性能计算机的计算能力是无法满足要求的。
在这种情况下,可以采用倍速链流水线技术来提高计算效率。
什么是倍速链流水线?倍速链流水线(pipeline)是一种利用多台高性能计算机协同工作的计算模式。
它将一组独立的计算任务分成多个任务阶段,并将每个任务阶段分配给不同的计算机节点进行处理,从而达到计算能力的倍增。
倍速链流水线的原理在倍速链流水线的计算模式中,原始任务被分解为多个互相独立的子任务。
每个子任务都需要处理相同的素材和数据,但是需要依次进行不同的处理步骤。
这些处理步骤被按照一定的顺序划分为多个阶段。
在每个阶段结束后,子任务会被传递到下一阶段进行进一步的处理。
在倍速链流水线的计算模式中,每个计算节点都只处理一个任务阶段。
当一个任务阶段处理完成后,任务会被传递到下一个节点进行处理,而当前节点则开始处理下一个节点的任务。
这个过程就像一条流水线一样,从而使得任务的处理能力被倍增。
倍速链流水线的优点提高计算效率倍速链流水线技术通过将计算任务分解并分配给多个计算节点并行处理,来提高计算效率。
这种技术使得计算能力被倍增,从而使得大量数据的处理变得更加高效。
提高稳定性倍速链流水线技术可以通过将计算任务分解并分配给多个计算节点并行处理,提高计算机集群的稳定性。
在个别节点失效的情况下,其他未失效的节点可以继续进行计算任务,从而保证计算的完整性和稳定性。
提高可扩展性倍速链流水线技术可以通过增加计算节点的数量来扩展计算能力。
这种方式很灵活,可以根据需要随时进行扩展,从而满足不同的计算需求。
倍速链流水线的应用领域倍速链流水线技术可以在很多领域中应用,包括:•视频编码和解码•图像处理和计算机视觉•语音识别和转录•数据处理和分析结论倍速链流水线技术是一种并行计算模式,可以通过多个计算节点共同协作来提高计算效率,提高稳定性和提高可扩展性。
TBB_pipeline(精)

Intel TBB:Pipeline,软件流水线的威力参观过工厂装配线的人一定对流水线这个名字不陌生,半成品在皮带机上流过一系列的流水线节点,每个节点以自己的方式进一步装配,然后传给下一节点。
现代的高性能CPU均采用了这种流水线设计,将计算任务分为取指,译码,执行,访存,反馈等几个阶段。
采用流水线设计的最大优点就是增加了系统吞吐量,例如,当第一条指令处于执行阶段的时候,译码单元可以在翻译第二条指令,而取指单元则可以去加载第三条指令。
甚至,在某些节点还可以并行执行,例如,现代的MIMD多指令多数据的计算机,可以在同一时间执行多条指令,或者同时更新多个数据。
在Intel认识到频率已成为CPU性能瓶颈之后,多核处理器应运而生。
如今高性能程序设计的根本已经转变为如何更充分的利用CPU资源,更快更多地处理数据,而Intel所开发的开源TBB库巧妙的利用了流水线这种思想,实现了一个自适应的高性能软件流水线TBB::pipeline。
本文将会以text_filt er为例,简单介绍pipeline的实现原理和一些关键技术点,以求达到抛砖引玉的效果。
介绍TBB::pipeline之前不得不先说一下TBB库的引擎-task scheduler,它又被称为TBB库的心脏[Intel TBB nutshell book],是所有算法的基础组件,用于驱动整个TBB库的运作。
例如,TBB库所提供的parallel_for算法,里面就有task scheduler的踪影,pipeline也不例外。
先看看parallel_for的实现:template<typenameRange, typename Body>void parallel_for( const Range& range, const Body& body, const simple_partitioner& partitioner=simple_partitioner() ) {internal::start_for<Range,Body,simple_partitioner>::run(range,b ody,partitioner);}再往下看:template<typenameRange, typename Body, typename Partitioner>class start_for: public task {Range my_range;const Body my_body;typename Partitioner::partition_type my_partition;/*override*/ task* execute();//! Constructor for root task.start_for( const Range& range, const Body& body, Partitioner& p artitioner ) :...}可以看到,class start_for是从task继承的,而这个class task,就是task scheduler中进行任务调度的基本元素---task,这也是TBB库的灵魂所在。
pipeline_的groovy的call_的的用法

pipeline 的groovy的call 的的用法1. 引言1.1 概述在软件开发和持续集成过程中,Pipeline(流水线)是一种广泛应用的概念。
通过Pipeline,我们可以将软件开发的各个步骤自动化地连接起来,从而实现高效、可靠的持续集成和交付。
Groovy作为一种强大而灵活的脚本语言,在构建和管理Pipeline时发挥了重要作用。
本文将重点探讨Groovy中使用pipeline进行调用的方法和技巧。
1.2 文章结构本文主要分为五个部分:引言、正文、Groovy中pipeline的概念和用法、pipeline 的call方法的使用方式和应用场景以及结论。
在正文部分我们将对pipeline进行简单介绍,并详细讨论Groovy语言在这一领域中的特点和优势。
然后我们会深入研究使用Groovy调用pipeline的基本语法和示例。
接下来,我们将重点关注pipeline中call方法的使用方式,并与其他方法进行对比分析,同时介绍在实际项目中call方法典型应用场景。
最后,我们将总结pipeline的groovy call 方法的用法及其重要性,并展望未来可能遇到的挑战和趋势。
1.3 目的通过本文,读者将能够了解到Groovy在pipeline中的重要性和灵活性。
我们将介绍使用Groovy语言调用pipeline的基本语法和示例,帮助读者在实际项目中快速应用这一技术。
此外,我们还会深入探讨pipeline的call方法,并分析其与其他方法的对比,为读者提供更全面的选择。
最后,我们通过总结和展望,帮助读者更好地理解pipeline在软件开发和持续集成中的价值,并预测未来可能出现的发展趋势。
以上为“1. 引言”部分内容,请根据需要进行修改或完善。
2. 正文Pipeline是一种常用的软件开发模式,它在软件开发过程中起到了关键的作用。
Groovy是一种基于Java语法的动态编程语言,其具有简洁、灵活和可读性强等特点。
pipeline 参数定义

pipeline 参数定义
在软件开发中,pipeline(管道)是一种常用的工具,它通常用来定义一系列的操作步骤,以便将数据和任务从一个步骤传递到下一个步骤。
在 pipeline 中,参数定义是非常重要的一环,它可以帮助我们准确地定义每个操作步骤所需的参数,从而确保 pipeline 的正确性和可靠性。
在 pipeline 中,参数定义通常包括以下几个方面:
1. 参数类型:定义每个参数的数据类型,如字符串、数值、布尔值等。
2. 参数名称:为每个参数指定一个名称,以便在后续操作中使用。
3. 参数默认值:为每个参数设置一个默认值,以便在使用时可以调用默认值。
4. 参数描述:为每个参数提供详细的描述,包括参数的作用、使用方法、取值范围等信息。
5. 参数限制:为每个参数设置一些限制条件,如参数取值范围、参数值的格式等。
在实际使用中,如果我们能够准确地定义 pipeline 参数,就可以有效地提高 pipeline 的可靠性和效率,减少程序出错的概率,也可以更加方便地对 pipeline 进行维护和修改。
因此,合理地定义pipeline 参数非常重要,它可以让我们更好地完成软件开发工作。
- 1 -。
11.jenkins流水线pipeline

11.jenkins流⽔线pipelineJenkins流⽔线pipeline流⽔线的概念⼯⼚:实体产品的⽣产环节,如:华为⼿机⽣产流⽔线IT企业:软件⽣产环节,如:需求调研,需求设计,概要设计,详细设计,编码,单元测试,集成测试,系统测试,⽤户验收测试,交付市场需求调研--可⾏性研究--产品项⽬⽴项--需求调研开发--设计开发测试--发布运⾏维护脚本式流⽔线pipeline的出现代表企业⼈员可以更⾃由的通过代码来实现不同的⼯作流程两种语法结构声明式:语法繁琐脚本式:语法简洁Jenkins pipelineJenkins2.0开始加⼊的功能pipeline:⽤代码定义⼀起软件的⽣产过程:构建-单元测试-⾃动化测试-性能-安全-交付流⽔线结构简介脚本式语法node定义脚本任务执⾏在哪台机器node('机器的标签'){待执⾏的任务}node:节点(某台机器),执⾏任务的具体环境stage:环节,表⽰⼀组操作,通常⽤来逻辑划分,stage表⽰某个环节,对应的是视图中的⼩⽅块,可以⾃由定义环节名称和其中要执⾏的代码(可以没有,但是建议有)创建⼀个流⽔线型的任务输⼊名字,选择流⽔线类型,点击确定切换到流⽔线,输⼊测试脚本node('gavin_win10'){echo '执⾏pipeline测试'}点击保存,然后点击⽴即构建进⾏测试Console OutputStarted by user unknown or anonymousRunning in Durability level: MAX_SURVIVABILITY[Pipeline] Start of Pipeline[Pipeline] nodeRunning on gavin_win10 in D:\jenkins-workspace\workspace\test_pipeline_style_demo1 [Pipeline] {[Pipeline] echo执⾏pipeline测试[Pipeline] }[Pipeline] // node[Pipeline] End of PipelineFinished: SUCCESSnode('gavin_win10'){stage('阶段1'){echo '执⾏pipeline测试'}stage('阶段2'){echo '执⾏pipeline测试'}stage('阶段3'){echo '执⾏pipeline测试'}stage('阶段4'){echo '执⾏pipeline测试'}}发现没有视图,⼩⽅块需要安装pipeline插件在插件管理菜单中搜索pipeline,然后点击安装,重启Jenkins即可node和stage可以相互嵌套stage('阶段1'){node(){sh "echo '执⾏pipeline测试'"}node('gavin_win10'){stage('阶段2'){echo '执⾏pipeline测试'}stage('阶段3'){echo '执⾏pipeline测试'}stage('阶段4'){bat "echo '执⾏pipeline测试'"}}}构建,控制台报错;Console OutputStarted by user gavinRunning in Durability level: MAX_SURVIVABILITY[Pipeline] Start of Pipeline[Pipeline] stage[Pipeline] { (阶段1)[Pipeline] nodeStill waiting to schedule task‘Jenkins’ is reserved for jobs with matching label expression解决;设置为尽可能的使⽤该节点Jenkinsfile管理流⽔线在项⽬跟⽬录下创建⼀个Jenkinsfile⽂件,输⼊以下测试内容node('gavin_win10'){stage('webapi测试'){echo '执⾏webapi测试'}stage('webui测试'){echo '执⾏webui测试'}stage('⽣成测试报告'){echo '执⾏⽣成测试报告'}stage('邮件通知'){echo '执⾏邮件通知'}}配置触发器Generic Webhook Trigger只需要配置token即可推送Jenkinsfile到gitee仓库等待Jenkins⾃动构建成功在Jenkinsfile⾥⾯执⾏脚本相当于在Jenkins的workspace下⾯执⾏命令但是发现workspace下⾯没有当前项⽬原因是还没有拉取项⽬,只是执⾏了Jenkinsfile⽂件解决:node('gavin_win10'){checkout scm //检出代码--作⽤相当于git clone/pull代码编码代码执⾏命令直接⽤pytest的命令⾏⽅式来执⾏stage('webapi测试'){pytest tc/D-管理员登录 -s --alluredir=tmp/report --clean-alluredirecho '执⾏webapi测试'}1 error原因:在Windows下执⾏,需要把命令包在双引号中bat "pytest tc/D-管理员登录 -s --alluredir=tmp/report --clean-alluredir"继续推送构建⼜报新的错误INTERNALERROR> OSError: [WinError 123] ⽂件名、⽬录名或卷标语法不正确。
JenkinsPipeline流水线项目构建

JenkinsPipeline流⽔线项⽬构建1. Pipeline简介1. 概念Pipeline,简单来说,就是⼀套运⾏在Jenkins上的⼯作流框架,将原来独⽴运⾏于单个或者多个节点的任务连接起来,实现单个任务难以完成的复杂流程编排和可视化的⼯作。
2. 使⽤Pipeline有以下好处(来⾃翻译⾃官⽅⽂档):代码:Pipeline以代码的形式实现,通常被检⼊源代码控制,使团队能够编辑,审查和迭代其传送流程。
持久:⽆论是计划内的还是计划外的服务器重启,Pipeline都是可恢复的。
可停⽌:Pipeline可接收交互式输⼊,以确定是否继续执⾏Pipeline。
多功能:Pipeline⽀持现实世界中复杂的持续交付要求。
它⽀持fork/join、循环执⾏,并⾏执⾏任务的功能。
可扩展:Pipeline插件⽀持其DSL的⾃定义扩展,以及与其他插件集成的多个选项。
3. 如何创建Jenkins Pipeline呢?Pipeline脚本是由Groovy语⾔实现的,但是我们没必要单独去学习GroovyPipeline⽀持两种语法:Declarative(声明式)和Scripted Pipeline(脚本式)语法Pipeline也有两种创建⽅法:可以直接在 Jenkins的 Web UI界⾯中输⼊脚本;也可以通过创建⼀个 Jenkinsfile脚本⽂件放⼊项⽬源码库中(⼀般我们都推荐在 Jenkins中直接从源代码控制(SCM)中直接载⼊ Jenkinsfile Pipeline这种⽅法)。
2. 安装Pipeline插件Manage Jenkins->Manage Plugins->可选插件安装插件后,创建项⽬的时候多了 “流⽔线”类型3. Pipeline语法快速⼊门1. Declarative声明式-Pipeline创建项⽬点击确定流⽔线 ->选择HelloWorld模板⽣成内容如下:stage:代表流⽔线中的某个阶段,可能出现n个。
Jenkins-Pipeline详解

Jenkins-Pipeline详解1 - Jenkins Pipeline在Jenkins 2.0中,基于 Jenkins Pipeline,⽤户可以在⼀个 JenkinsFile 中快速实现⼀个项⽬的从构建、测试以到发布的完整流程,灵活⽅便地实现持续交付,并且可以保存和管理这个流⽔线的定义。
也就是说,Jenkins 2.0把Jenkins1.0中相关配置信息都转换成Code形式,即Pipeline as Code。
Jenkinsfile是⼀个⽂本⽂件,包含了流⽔线的逻辑,定义了流⽔线的各个阶段,在每个阶段可以执⾏相应的任务;是流⽔线概念在Jenkins中的表现形式,实现了构建步骤代码化、构建过程视图化;不同的Jenkins Plugin 扩展了Pipeline DSL可⽤的步骤和操作。
1.1 使⽤条件Jenkins 2.x或更⾼版本安装了Pipeline插件1.2 创建⽅式以流⽔线任务为例:在Jenkins job配置页⾯的pipeline部分,可以选择pipeline script 或者 pipeline script from SCM点击“Pipeline Syntax”可以查看Pipeline内置⽂档。
pipeline script :直接script输⼊框⾥⾯输⼊pipeline script语句即可pipeline script from SCM :配置代码存储地址,并指定Jenkinsfile路径1.3 pipeline 语法通过Groovy语⾔来实现pipeline。
2 - 脚本式(Scripted Pipeline)在Scripted Pipeline的JenkinsFile 中可以定义多个 Groovy 函数来扩展 Jenkins Pipeline 的能⼒,实现脚本式pipeline,其实就是在写Groovy代码。
因此这种⽅式受 Jenkins 的限制较少,可以灵活控制和定义⼀个流⽔线,实现复杂的功能。
外企中说的pipeline

外企中说的pipeline
公司说pipeline是当前有潜在销售机会存在的意思。
企业级销售,要求每周都要有数字,可大可小,但这个流不能断。
这就要求每个销售都要有足够的Pipeline,分别是:
1、Commit or Upside要求每个销售有快速的执行能力,拜访客户后要迅速转化成销售机会,评估项目金额,项目周期,在CRM中创建项目机会。
可以选择是commit的订单,commit在哪一周(即从销售端评估肯定会进的数字);也可以选择是upside(即从目前进度来看,不确定会不会进数)。
每一周销售要保证有几张commit的单子来保证当周的数字,更要有若干upside的单子作为后续数字保证,循环往复。
2、红绿灯:
给每个销售设计红黄绿灯机制,每周有数字,有产出的是绿灯;中断一到二周的设黄灯;连续三周没有产出的红灯,连续的红黄灯,很有可能面临被炒鱿鱼的风险。
利用这种机制做销售commit的管理,从老板的角度可以很好的管理把控每一个销售员的业绩情况。
外企pipeline指的是正在操作的进展情况,也指某一个职位正在进行的候选人情况等。
pipeline能够让销售保持工作的连续性,并且及时跟进。
要求每周都要有数字,可大可小,但这个流不能断。
流水线(Pipeline)介绍共53页文档

25、学习是劳动,是充(Pipeline)介绍
36、“不可能”这个字(法语是一个字 ),只 在愚人 的字典 中找得 到。--拿 破仑。 37、不要生气要争气,不要看破要突 破,不 要嫉妒 要欣赏 ,不要 托延要 积极, 不要心 动要行 动。 38、勤奋,机会,乐观是成功的三要 素。(注 意:传 统观念 认为勤 奋和机 会是成 功的要 素,但 是经过 统计学 和成功 人士的 分析得 出,乐 观是成 功的第 三要素 。
39、没有不老的誓言,没有不变的承 诺,踏 上旅途 ,义无 反顾。 40、对时间的价值没有没有深切认识 的人, 决不会 坚韧勤 勉。
21、要知道对好事的称颂过于夸大,也会招来人们的反感轻蔑和嫉妒。——培根 22、业精于勤,荒于嬉;行成于思,毁于随。——韩愈
1.5bit pipeline 理解 -回复

1.5bit pipeline 理解-回复什么是1.5位流水线?为什么流水线设计中会出现这样一个概念?1.5位流水线的工作原理是什么?它与传统的1位和2位流水线有何不同?如何选择合适的流水线长度?这些问题将在以下文章中一一解答。
1.5位流水线是一种在计算机架构中常用的技术手段,旨在提高指令执行的效率和并行性。
正如其名,1.5位流水线介于传统的1位和2位流水线之间。
为了更好地理解该概念,我们首先需要了解什么是流水线以及为什么需要引入这种技术。
在计算机执行指令的过程中,每个指令需要经过取指、译码、执行、访存和写回等多个步骤。
传统的单周期处理器按照这些步骤依次执行指令,即每条指令需要等待上一条指令完成后才能开始。
这样会导致指令之间存在空闲时间,造成计算机资源的浪费。
为了提高计算机指令的执行效率,流水线技术应运而生。
流水线将每个步骤进行切分,使得多条指令可以同时在不同的步骤上运行,从而实现指令的重叠执行。
这样可以大大提高指令的执行效率和整体的吞吐量。
传统的1位流水线是将每个步骤划分为一个时钟周期进行执行。
例如,第一个周期用于取指,第二个周期用于译码,第三个周期用于执行,以此类推。
这种流水线的设计简单,容易实现,但效率有限,因为无法将每个步骤进一步划分。
而2位流水线则将每个步骤划分为两个时钟周期进行执行,即每个步骤可以分为两个子步骤。
这样可以更细粒度地管理指令的执行,提高流水线的效率。
然而,2位流水线的设计复杂度较高,可能需要更多的硬件资源。
在这样的背景下,1.5位流水线应运而生。
1.5位流水线将每个步骤划分为一个时钟周期和半个时钟周期,即每个步骤可以分为一个完整的子步骤和一个部分子步骤。
这样相对于1位流水线,1.5位流水线可以更细致地划分指令的执行,提高流水线的效率。
而相较于2位流水线,1.5位流水线的设计简单度更高,需要的硬件资源较少。
1.5位流水线的工作原理如下所示。
在一个完整的时钟周期内,每个步骤需要分为一个完整的子步骤和一个部分子步骤。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ADD Ra,Rb, Rc LD Rf,F SD Ra,A
IF ID EX MEM WB
IF ID EX MEM WB
SUB Rd,Re, Rf SD Rd,D
IF ID EX MEM WB
IF ID EX MEM WB
28
动态调度
有些信息在译码时难以确定,如是否发生异 常、访存操作需要多少周期等,静态调度就 不能完成。 动态调度:硬件会重新安排指令的执行顺序 以减少停顿并同时保持数据流和异常行为。 优点:有些相关编译无法检测、编译器更加 简单、程序性能对机器依赖少
处理器流水线相 关技术
报告人:Hardy
1
流水线技术
1.流水线的概念 2.流水线的冒险和冒险的解决办法 3.多发射处理器
2
1.流水线的概念
流水线技术:
把一个重复的过程分解为若干个子过程,每个子过 程由专门的功能部件来实现。将多个处理过程在时 间上错开,依次通过各功能段,这样,每个子过程 就可以与其他子过程并行进行。
15
2.4 数据冒险的解决办法
根据指令中读写访问的顺序,可以将数据冒 险分为三类。分别是: 写后读(RAW) 写后写 (WAW) 读后写 (WAR)
16
写后读冒险(RAW: Read After Write) 在 i 写入之前,j 先去读。j 会错误的获取旧 值。 这对应“真数据相关”,为了确保j可以得到 正确的i值,必须保持程序的顺序。
SUB Rd,Re, Rf SD Rd,D
IF ID 停 EX MEM WB
IF 停 ID EX MEM WB
27
调度后执行情况(采用了转发技术)
LD LD Rb,B Rc,C IF ID EX MEM WB IF ID EX MEM WB
LD
Re,E
IF ID EX MEM WB
IF ID EX MEM WB
25
例1 请为下列表达式生成没有暂停的流水线 指令序列: a=b+c ; d=e-f ; 假设载入延迟为1个时钟周期。
两条ALU指令(ADD Ra, Rb,Rc 和 SUB Rd,Re, Rf)分别和两条Load指令 (LW Rc,c和LW Rf,f) 之间存在数据相关。为了保 证流水线正确执行调度前的 指令序列,必须在指令执行 过程中插入两个时钟周期的 暂停。但是考察调度后的指 令序列不难发现,由于流水 线允许转发,就不必在指令 执行过程中插入任何暂停周 期。
Tomasulo算法小结
通过动态调度缓解流水线阻塞:例如减少CACHE 失效对性能的影响 保留站:重命名寄存器+缓存源操作数 •避免寄存器成为瓶颈 •避免WAW和WAR阻塞 •缺点: •硬件复杂性 •结果总线成为瓶颈,多条结果总线增加硬 件复杂度
39
流水线技术一直是提高处理器速度的最有效 技术之一。但目前的在相关处插入阻塞,转发技 术,编译器调度都是尽量分离相关问题的指令, 使他们不会导致冲突,从而减少暂停的影响。虽 然都会相应的显著减少数据相关的次数提高流水 效率,但也会不可避免的增加硬件复杂度和编译 器的复杂性。 而动态调度则可以以硬件的方式调整指令执 行顺序,使不相关的后续指令得以不受暂停的影 响而继续执行,可以在降低编译器复杂度的同时 处理一些编译阶段无法知道的相关,在出现数据 冒险是尽量避免出现流水暂停。
i: DSUB R1,R2,R3 j: DADD R4,R1,R3
17
写后写冲突(WAW: Write After Write) 在 i 写入之前,j 先写。最后写入的结果 i 是 错误的。 这对应“输出相关”,寄存器换名技术可以 消除 i: DSUB R1,R4,R3
j: DADD R1,R2,R3 k: DMUL R6,R1,R7
26
调度前执行情况(采用了转发技术)
LD Rb,B IF ID
LD
Rc,C
IF
EX ME WB M ID EX MEM WB IF ID 停 EX MEM WB IF 停 ID EX MEM WB
ADD Ra,Rb, Rc SD Ra,A
LD
LD
Re,E
Rf,F
IF ID EX MEM WB
IF ID EX MEM WB
7
2.流水线的冒险
尽管流水线可以带来处理器性能上的提高,但是不 是所有的指令就直接可以进行流水线操作,在指令 执行中的下一个周期中的下一条指令不能执行,这 种情况叫做冒险。有三类冒险:
1.结构冒险 2.数据冒险 3.控制冒险 流水线中的冒险会引起流水线停顿,部分指令就要延期执行。
8
2.1 结构冒险
当一条指令试图读取一个由前一条装载指令读入的寄存器时, 就无法使用转发解决数据冒险问题了。
23
对于装载指令的存在,我们采用了插入阻塞 (气泡,)方法解决问题。增加一个冒险检 测单元,一旦发现装载指令后就在其他需要 这个结果的指令前插入阻塞。直到可以使用 转发技术或指令可以得到结果为止。
24
编译器调度(静态调度)
Can’t happen in MIPS 5 stage pipeline because: - All instructions take 5 stages, and - Writes are always in stage 5
18
读后写冲突(WAR: Write After Read)
在 i 读之前,j 先写。i 读出的内容是错误的! 这对应“反相关” ,寄存器换名技术可以消 除
11
为消除资源冲突而插入的流水线气泡 (Bubble)
时间(时钟周期) 1 load M 2 Reg 3
ALU
4 M
5 Reg
6
7
8
ALU
指令 i+1
M
Reg
M
Reg
ALU
指令 i+2
M
ห้องสมุดไป่ตู้
Reg
M
Reg
暂
停
气泡
气泡
气泡
气泡
气泡
ALU
指令 i+3
M
Reg
M
12
解决办法二
设置相互独立的指令存储器和数据存储器或 设置相互独立的指令Cache和数据Cache。
20
在原始的数据通路中用流水线寄存器将流水线各部分分 开,这些寄存器可以存储所有穿过它的数据,寄存器的宽度 都足够大。目前流行的有128位,97位,64位。 有了流水线寄存器后,转发就变的简单了。在指令执行 的五个阶段中间各加了个寄存器记录流过的数据。
21
时间(时钟周期) 1 ADD R1,R2,R3 IM 2 Reg 3 4 DM 5 Reg 6
29
动态调度的思想
基本思想 :•把相关的解决尽量延迟到马上就会出错的时候 •前面指令的stall不影响后面指令继续前进 把译码分成两个阶段:发射和读操作数 •发射:指令译码,检查结构相关 •读操作数:检查操作数是否准备好,准备好就 读数,否则等待,当一条指令在读操作数阶段 等待时,后面指令的发射可以继续进行 •乱序执行: •指令进入是有序的 •执行可以乱序,只要没有相关就可执行,多条 指令同时执行 •结束可以乱序,也可以有序(主要是精确例外 的需要),乱序结束会导致WAR相关(静态 流水线中只有RAW和WAW相关) 30
Tomasulo算法
IBM 360/91中首次使用,由Robert Tomasulo提出 的一种支持乱序执行的高级方案。它会跟踪指令的 操作数何时可用,将RAW冒险降至最低,并在硬件 中引入寄存器重命名功能,将WAW和WAR冒险降 至最低。 现代处理器使用了该算法的各种变体,但是核心都 是: 1.跟踪指令相关以允许在操作数可用时立即执行 指令。 2.重命名寄存器以避免WAR和WAW冒险。 31
32
Tomasulo算法的流水阶段
1.发射:把操作队列的指令根据操作类型送到 保留站(如果保留站有空),发射过程中读 寄存器的值和结果状态域 2.执行:如果所需的操作数都准备好,则执行, 否则侦听结果总线并接收结果总线的值。
3.写回:把结果送到结果总线,释放保留站
33
34
35
36
37
38
流水线的描述:最常用的方法是时间-空间图
横坐标:表示时间,即各个任务在流水线中所
经过的时间 纵坐标:表示空间,即流水线的各个子过程, 也称为级、流水线深度(Stage)
3
流水线时间空间图
4
流水线技术应用到处理器中就是采用流水线 方式执行指令。一个MIPS指令包包含五个处 理步骤: 1.取指令周期(IF) 2.指令译码/读寄存器周期(ID) 3.执行操作/计算地址(EX) 4.从数据存储器中读取操作数(MEM) 5.将结果写回寄存器堆(WB)
14
时间(时钟周期) 1 DADD R1, R2, R3 IM 2 Reg 3 4 DM 5 Reg 6
ALU
ALU
DSUB R4,R1,R5
IM
Reg
DM
Reg
ALU
XOR R6,R1,R7
IM
Reg
DM
ALU
AND R8,R1,R9
IM
Reg
OR R10,R1,R11
IM
Reg
AND,OR操作不会暂停,但是DSUB,XOR指 令需要等待DADD在WB阶段写回数据后才 可以执行。
5
采用相同的功能模块,指令顺序执行和按照流水线 技术执行,在时间上可以看出流水线指令的执行速 度提高了4倍。
6
流水线的基本作用
流水线增大了CPU的指令吞吐量—即单位时 间执行指令的条数,但是它未减少指令各自 的执行时间。实际上流水线技术要对流水线 附加一些控制,因而了增加开销,使单条指 令执行时间略有增加。吞吐量的增大意味着 程序运行的更快,总的执行时间变短,尽管 没有一条指令的执行变快。