6 蛋白组相关数据库及使用
生物信息研究中常用蛋白质数据库的总结

生物信息研究中常用蛋白质数据库简述内蒙古工业大学理学院呼和浩特孙利霞2010.1.5摘要:在后基因组时代生物信息学的研究当中,离不开各种生物信息学数据库。
尤其在蛋白质从序列到功能的研究当中,目前各种行之有效的方法都是基于各种层次和结构的蛋白质数据库。
随着计算机技术及网络技术的发展,目前的蛋白质数据库不论是所包含数据量还是功能都日新月异,新的数据库层出不穷。
一个新手面对如此浩瀚的数据量往往无从下手。
本文粗浅地为目前蛋白质数据库的使用勾画出一个轮廓,作为自己蛋白质研究入门的一个引导。
关键词:蛋白质;数据库0 引言随着科技的发展,个人的知识往往赶不上快速膨胀的信息量,人们为了解决这个问题,便创建了形形色色的数据库。
蛋白质数据库是指:在蛋白质研究领域根据实际需要,对蛋白质序列、蛋白质结构以及文献等数据进行分析、整理、归纳、注释,构建出具有特殊生物学意义和专门用途的数据库。
蛋白质数据库总体上可分为两大类:蛋白质序列数据库和蛋白质结构数据库,蛋白质序列数据库来自序列测定,结构数据库来自X-衍射和核磁共振结构测定(详见图1)。
这些数据库是分子生物信息学的基本数据资源。
上世纪90年代,我国从事蛋白质研究的学者使用的蛋白质数据库储存介质还是国外实验室发布的激光光盘[1]。
信息的传播储存甚为不便。
随着蛋白质研究的发展飞快,同时伴随着计算机和因特网发展,蛋白质数据库的储存传播方式也发生的巨大的变化。
进入21世纪后,我们所用的各种蛋白质数据库都发展成为存储在网络服务器上,基于“服务器—客户机”的访问查询方式。
伴随着计算机及物理测试技术的发展数据库的容量和功能成数量级膨胀。
但是面对如此浩瀚的数据,新手往往感到无从下手,在需要时找不到自己需要的合适数据库。
本文从目前蛋白质数据库建立的的逻辑层次出发,系统地简绍了常用蛋白质数据的概况,它们的查询方法以及它们相互之间的联系。
同时尽量不涉及数据库建设和维护方面的计算机和网络这些数据库底层的技术,为蛋白质研究的入门者及对蛋白质感兴趣的人员的一个引导。
rcsb pdb数据库使用方法与步骤

rcsb pdb数据库使用方法与步骤如何使用RCSB PDB数据库# 第一步:访问RCSB PDB网站首先,打开您的网络浏览器,并在地址栏中输入“PDB(Protein Data Bank)的官方网站。
# 第二步:浏览数据库一旦进入RCSB PDB官方网站,您将看到一个简洁且易于使用的界面。
该界面列出了各种与蛋白质结构相关的信息,其中包括蛋白质的序列、结构、功能以及相应的文献引用。
# 第三步:搜索蛋白质结构在RCSB PDB的主页上,您可以在顶部的搜索框中输入蛋白质的名称、PDB ID(四个字母的标识符)或其他相关信息。
按下回车键后,系统将为您提供满足您搜索条件的结果列表。
# 第四步:筛选搜索结果当您获得一系列搜索结果时,您可以使用不同的筛选器来缩小结果范围。
例如,您可以根据蛋白质的来源(如人类、大肠杆菌等)或发布日期进行筛选。
# 第五步:了解蛋白质结构选择一个感兴趣的蛋白质结构后,您将进入该蛋白质结构的详细页面。
这个页面将提供关于蛋白质的详细信息,包括它的PDB ID、生物学功能、相关文献以及其结构的三维可视化图像。
# 第六步:浏览蛋白质结构的细节在蛋白质的详细页面中,您可以浏览蛋白质结构的更多细节。
您可以选择查看蛋白质的原子坐标、氨基酸序列、二级结构信息以及其他与结构相关的数据。
# 第七步:下载蛋白质结构如果您对蛋白质结构感兴趣并希望将其保存到您的本地计算机上进行后续研究,您可以在详细页面上找到一个“Download Files”或类似的选项。
点击该选项后,您将有机会选择以PDB格式、FASTA格式或其他常见格式下载蛋白质结构数据。
# 第八步:使用高级搜索功能RCSB PDB还提供了强大的高级搜索功能,以帮助您更精确地查找特定的蛋白质结构。
您可以使用高级搜索功能来制定更复杂的搜索查询,例如根据蛋白质的拓扑结构、配体或与其相互作用的其他分子进行搜索。
# 第九步:利用工具和资源在RCSB PDB网站上,您还可以利用各种工具和资源来进一步研究蛋白质结构。
Uniprot数据库介绍及信息检索下载指南

UniProt数据库一、UniProt数据库简介蛋白质组常用数据库——UniProt数据库,是信息最丰富、资源最广的蛋白质数据库。
它由Swiss-Prot、TrEMBL 和PIR-PSD三大数据库的数据整合而成,数据主要来自于基因组测序项目完成后,后续获得的蛋白质序列,并包含了大量来自文献的蛋白质生物功能的信息。
一般蛋白质组搜库首选数据库也是UniProt,所以对于通过UniProt库搜库的组学数据,可以在此网站中进行蛋白功能查询。
UniProt数据库可以提供的信息包括蛋白功能描述、GO条目、细胞定位、组织特异性表达情况、生理病理情况描述、互作蛋白、Domain、翻译后修饰位点等信息。
蛋白的信息描述段落均会标出引用文章,并且可以跳转到PubMed界面进行浏览。
UniProt 数据库由UniProt 知识库(UniProtKB )、UniProt 档案(UniParc )、UniProt 参考资料库(UniRef)以及UniProt元基因组学与环境微生物序列数据库(UniMES)构成。
UniProtKB全称 UniProt Knowledgebase(UniProt知识库)它是经过专家校验的数据集,主要由两部分组成:UniProtKB/Swiss-Prot (包含检查过的、手工注释的条目) 和 UniProtKB/TrEMBL (包含未校验的、自动注释的条目)。
Swiss-Prot 数据库特点高质量的、手工注释的、非冗余的数据集;主要来自文献中的研究成果和E-value校验过计算分析结果。
有质量保证的数据才被加入该数据库!TrEMBL数据集包含高质量的计算分析结果,一般都在自动注释中富集,主要应对基因组项目获得的大量数据流以人工校验在时间上和人力上的不足。
它能注释所有可用的蛋白序列。
在三大核酸数据库(EMBL-Bank/GenBank/DDBJ)中注释的编码序列都被自动翻译并加入该数据库中。
它也有来自PDB数据库的序列,以及Ensembl、Refeq和CCDS基因预测的序列。
蛋白质数据库使用说明

引言:蛋白质数据是生物信息学领域中非常重要的资源之一,它提供了大量关于蛋白质序列、结构、功能以及相互作用等方面的信息。
本文旨在介绍如何使用蛋白质数据库,帮助用户更好地利用这一资源进行研究。
概述:蛋白质数据库是一个集成了许多蛋白质信息的在线资源,用户可以通过搜索、浏览、等方式获取所需的信息。
其中,常用的蛋白质数据库包括NCBI、UniProt、PDB等。
这些数据库提供了丰富的蛋白质数据,并且不断更新以满足用户需求。
正文内容:1.数据库搜索功能1.1.关键词搜索1.1.1.输入蛋白质名称1.1.2.输入序列片段1.1.3.输入关键词1.2.高级搜索选项1.2.1.提供更精确的搜索结果1.2.2.支持过滤和排序功能1.2.3.可以根据相关字段进行搜索2.数据库浏览功能2.1.蛋白质分类2.1.1.按物种分类2.1.2.按功能分类2.1.3.按家族分类2.2.数据表格浏览2.2.1.查看蛋白质基本信息2.2.2.查看蛋白质序列2.2.3.查看蛋白质结构2.3.数据图谱浏览2.3.1.查看蛋白质相互作用网络2.3.2.查看蛋白质结构域分布2.3.3.查看蛋白质功能注释3.数据库功能3.1.蛋白质序列数据3.1.1.全部序列3.1.2.特定物种的序列3.2.蛋白质结构数据3.2.1.已解析的蛋白质结构3.2.2.蛋白质结构预测结果3.3.蛋白质相互作用数据3.3.1.已验证的相互作用数据3.3.2.预测的相互作用数据4.数据库工具与资源4.1.序列比对工具4.1.1.BLAST4.1.2.PSIBLAST4.2.结构预测工具4.2.1.SWISSMODEL4.2.2.Phyre24.3.功能注释资源4.3.1.GeneOntology4.3.2.InterPro4.4.数据库交互接口4.4.1.提供API接口4.4.2.支持数据提交与5.数据库更新与维护5.1.数据更新频率5.2.数据质量保证5.3.用户反馈与支持5.4.数据库版本与历史记录总结:蛋白质数据库为研究人员提供了丰富的蛋白质信息资源,通过搜索、浏览、等功能,用户可以轻松地获取需要的数据。
基因及蛋白质数据库的构建与应用

基因及蛋白质数据库的构建与应用随着生命科学技术的不断发展和进步,基因及蛋白质数据库在科学研究和医学领域的作用愈发重要。
本文将从数据库的构建、分类和应用三个方面进行讲解。
一、基因及蛋白质数据库的构建构建基因及蛋白质数据库的过程主要包括以下几个步骤:1. 采集、整理数据。
对于已经发表的基因及蛋白质相关的论文、文献资料和相关数据库信息等进行采集和整理,从而建立一个完整的信息资源库。
2. 数据库建立和优化。
根据采集的数据和相关技术要求,选择合适的数据库软件,进行数据库建立和优化,使它能够方便有效地存储和检索数据。
3. 数据录入、整合。
将采集的数据进行规范化处理,并将其录入到数据库中,实现数据的整合和统一管理。
4. 数据质量检查和维护。
对于数据进行质量检查、修正和维护,确保数据的可靠性和准确性。
二、基因及蛋白质数据库的分类按照功能和数据类型的分类,基因及蛋白质数据库一般分为以下几种:1. 基因结构和序列数据库。
包括生物物种基因组的测序结果、基因和基因间的区域序列、基因的功能等。
2. 蛋白质序列和结构数据库。
包括蛋白质序列、二级结构、比较模型、同源模型等信息。
3. 基因表达数据库。
主要包括基因表达调控、启动子、编码和序列间调控因素等信息。
4. 基因特定数据库。
如免疫学数据库、药物基因相互作用数据库等,为特定研究领域的数据提供了支持。
三、基因及蛋白质数据库的应用基因及蛋白质数据库在许多领域中都有着重要的应用价值。
1. 科研领域。
利用基因及蛋白质数据库,研究人员可以快速获取和跟踪特定基因或蛋白质的信息,挖掘并分析相关信息,进一步研究其功能和调节机制,从而探索新的基因和蛋白质功能以及治疗某些疾病的方法。
2. 医学领域。
基因及蛋白质数据库是研究疾病发生发展机制的重要工具。
医学研究人员可以通过基因及蛋白质数据库对特定基因或蛋白质进行深入研究,了解其功能及其与疾病的关系,从而探索新的诊断、预防和治疗方法。
3. 生物制药领域。
蛋白质数据库

蛋⽩质数据库
⼀、蛋⽩质数据库
》序列数据库:Uniprot (蛋⽩质序列和具有综合功能注释⽬录的中⼼资源库)
PIR (提供蛋⽩质序列数据和分析⼯具)
》结构数据库:PDB (实验测定的⽣物⼤分⼦三维结构)
MMDB
》模体及结构域数据库:PROSITE (蛋⽩质序列功能位点数据库)
Pfom (使⽤基于隐马模型的多序列⽐对对蛋⽩质进⾏家族分类) 》蛋⽩质分类数据库:SCOP (提供已知结构蛋⽩质间的结构和进化关系信息)
CAHT
HSSP
DSSP
⼆、蛋⽩质组数据库
》SWEISS PROT 2DE PAGE / neXtProt / PaxDb / PeptideAtlas / PRIDE
涉及不同⽣物、不同器官、组织、细胞的蛋⽩质图谱数据
三、蛋⽩质互作组数据库
》HPRD / DIP / INTERACT
四、综合型数据库
》ExPASy。
蛋白质组科学数据库建设及应用

蛋白质组科学数据库建设及应用在科技的海洋中,蛋白质组科学数据库如同一艘巨轮,承载着人类对生命奥秘的探索。
它的建设与应用,不仅是科学研究的重要工具,更是推动生物医学发展的强大引擎。
首先,我们要明确蛋白质组科学数据库的重要性。
它就像是一座巨大的图书馆,里面收藏着关于蛋白质的各种信息。
这些信息包括蛋白质的结构、功能、相互作用等等,对于科学家来说,它们是研究生命现象的关键线索。
没有这些信息,科学家们就像是在黑暗中摸索,难以取得突破性的进展。
因此,建设一个全面、准确、易用的蛋白质组科学数据库,对于推动科学研究具有重要意义。
然而,建设这样一个数据库并非易事。
它需要大量的数据收集、整理和分析工作。
这就像是在一片茫茫大海中寻找宝藏,需要耐心和毅力。
同时,随着科学技术的发展,新的研究成果不断涌现,数据库也需要不断更新和维护。
这就像是一场永无止境的战斗,需要我们持续投入精力和资源。
那么,如何建设一个优秀的蛋白质组科学数据库呢?我认为可以从以下几个方面着手:首先,加强数据的收集和整理。
我们需要建立一个完善的数据收集体系,确保数据的全面性和准确性。
同时,我们还需要进行数据清洗和整理,去除重复和错误的信息,提高数据的质量。
其次,优化数据库的设计和结构。
一个好的数据库应该具有良好的用户体验,方便用户查询和使用。
我们可以借鉴其他优秀数据库的经验,结合蛋白质组科学的特点,设计出更加人性化的界面和功能。
再次,加强数据库的维护和更新。
随着研究的深入和技术的发展,新的数据会不断产生。
我们需要及时将这些新数据纳入数据库,保持数据的时效性。
同时,我们还需要注意数据库的安全性和稳定性,防止数据丢失或泄露。
最后,加强与其他数据库的合作与交流。
蛋白质组科学并不是孤立的研究领域,它与其他学科有着密切的联系。
通过与其他数据库的合作与交流,我们可以共享资源、互补优势,共同推动科学的进步。
当然,建设一个优秀的蛋白质组科学数据库只是第一步。
如何将其应用于实际研究中,发挥其最大的价值,才是我们更应该关注的问题。
蛋白质数据库使用说明

蛋白质数据库使用说明蛋白质数据库使用说明概述本文档提供了蛋白质数据库使用说明,包括数据库访问方式、数据搜索和分析方法等。
通过阅读本文档,用户将了解如何有效地利用蛋白质数据库进行蛋白质相关研究。
1. 数据库访问方式1.1 网站访问蛋白质数据库可以通过网站进行访问。
用户需要在浏览器中输入数据库的网址,并使用提供的用户名和密码进行登录。
一旦登录成功,用户将可以浏览数据库中的蛋白质信息。
1.2 API接口蛋白质数据库通常也提供了API接口,用户可以通过编程方式获取和操作数据库中的数据。
通过API接口,用户可以实现自动化的数据获取和分析。
2. 数据搜索2.1 关键词搜索用户可以通过关键词搜索来查找与特定蛋白质相关的信息。
在数据库的搜索框中输入关键词,数据库将返回与关键词相关的蛋白质条目。
2.2 高级搜索蛋白质数据库通常也提供了高级搜索功能,用户可以使用更复杂的搜索方式来满足特定需求。
高级搜索功能包括使用逻辑运算符、指定搜索范围等。
3. 数据分析3.1 蛋白质比对用户可以使用蛋白质数据库中的比对工具来进行蛋白质比对分析。
比对工具可以帮助用户找到在不同蛋白质序列之间的相似性和差异性。
3.2 功能注释蛋白质数据库还提供了功能注释工具,可以帮助用户预测蛋白质的功能。
用户可以根据数据库中的注释信息来了解蛋白质的功能和作用。
4. 数据蛋白质数据库通常也提供数据功能,用户可以将数据库中的数据到本地进行进一步的分析和处理。
功能可以提供多种格式的数据文件,如文本文件、Excel文件等。
附件本文档没有涉及附件。
法律名词及注释本文档没有涉及法律名词及注释。
蛋白质分析相关数据库及网站
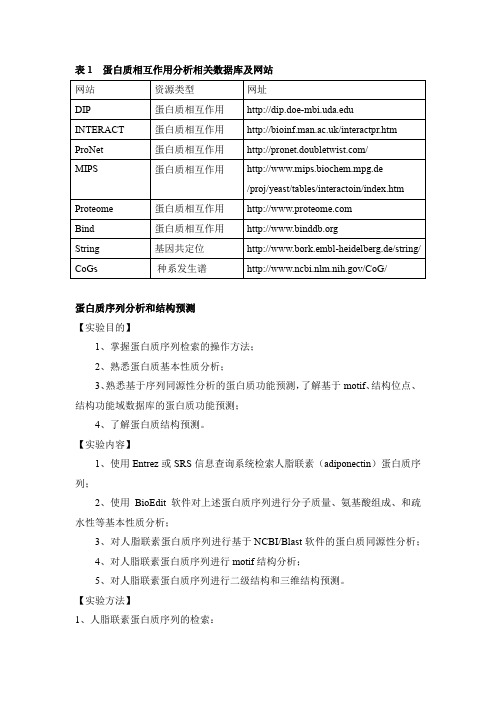
表1蛋白质相互作用分析相关数据库及网站蛋白质序列分析和结构预测【实验目的】1、掌握蛋白质序列检索的操作方法;2、熟悉蛋白质基本性质分析;3、熟悉基于序列同源性分析的蛋白质功能预测,了解基于motif、结构位点、结构功能域数据库的蛋白质功能预测;4、了解蛋白质结构预测。
【实验内容】1、使用Entrez或SRS信息查询系统检索人脂联素(adiponectin)蛋白质序列;2、使用BioEdit软件对上述蛋白质序列进行分子质量、氨基酸组成、和疏水性等基本性质分析;3、对人脂联素蛋白质序列进行基于NCBI/Blast软件的蛋白质同源性分析;4、对人脂联素蛋白质序列进行motif结构分析;5、对人脂联素蛋白质序列进行二级结构和三维结构预测。
【实验方法】1、人脂联素蛋白质序列的检索:(1)调用Internet浏览器并在其地址栏输入Entrez网址(/Entrez);(2)在Search后的选择栏中选择protein;(3)在输入栏输入homo sapiens adiponectin;(4)点击go后显示序列接受号及序列名称;(5)点击序列接受号NP_004788 (adiponectin precursor;adipose most abundant gene transcript 1 [Homo sapiens])后显示序列详细信息;(6)将序列转为FASTA格式保存(参考上述步骤使用SRS信息查询系统检索人脂联素蛋白质序列);2、使用BioEdit软件对人脂联素蛋白质序列进行分子质量、氨基酸组成和疏水性等基本性质分析:打开BioEdit软件→将人脂联素蛋白质序列的FASTA格式序列输入分析框→点击左侧序列说明框中的序列说明→点击sequence栏→选择protein→点击Amino Acid Composition→查看该蛋白质分子质量和氨基酸组成;或者选择protein后,点击Kyte & Doolittle Mean Hydrophobicity Profile→查看该蛋白质分子疏水性水平;3、人脂联素蛋白质序列的蛋白质同源性分析:(1)进入NCBI/Blast网页;(2)选择Protein-protein BLAST (blastp);(3)将FASTA格式序列贴入输入栏;(4)点击BLAST;(5)查看与之同源的蛋白质;4、人脂联素蛋白质序列的motif结构分析:(1)进入http://hits.isb-sib.ch/cgi-bin/PFSCAN网页;(2)将人脂联素蛋白质序列的FASTA格式序列贴入输入栏;(3)点击Scan;(4)查看分析结果(注意Prosite Profile中的motif information);5、人脂联素蛋白质序列的二级结构预测:(1)进入下列蛋白结构预测服务器网址http://www.embl-heidelberg.de/predictprotein//predictprotein.html(The PredictProtein Server);(2)在You can栏点击default;(3)填写email地址和序列名称;(4)将人脂联素蛋白质序列的FASTA格式序列贴入输入栏点击Submit;(5)从email信箱查看分析结果;6、人脂联素蛋白质序列的三维结构预测:(1)进入/swissmod/SWISS-MODEL.html (SwissModel First Approach Mode)网页;(2)填写email地址、姓名和序列名称;(3)将人脂联素蛋白质序列的FASTA格式序列贴入输入栏;(4)点击Send Request;(5)从email信箱查看分析结果(注:需下载软件入rasmol查看三维图象)。
常用的生物数据库(二)

常用的生物数据库(二)引言概述:生物数据库是生物信息学领域的重要工具,可以帮助研究人员存储、管理和共享生物数据。
本文将介绍常用的生物数据库(二),以便研究人员更好地利用这些资源进行生物学研究。
正文内容:一、蛋白质相互作用数据库1. STRING数据库:提供蛋白质相互作用预测和注释功能。
2. IntAct数据库:收集整理蛋白质相互作用数据,提供数据检索和分析工具。
3. BioGRID数据库:整合多种物种的蛋白质相互作用数据,并提供丰富的功能注释。
二、基因组数据库1. GenBank数据库:包含大量的序列数据,包括基因组、转录本和蛋白质序列等。
2. ENSEMBL数据库:集成了各种生物信息学工具,提供全面的基因组注释信息。
3. UCSC数据库:基于人类基因组构建的浏览器,提供详细的基因组注释和可视化功能。
三、表达谱数据库1. GEO数据库:收集了大量的基因表达谱数据,可进行数据检索和分析。
2. ArrayExpress数据库:包含了来自各种高通量技术的表达谱数据,提供数据下载和分析工具。
3. TCGA数据库:整合了多种癌症的基因表达数据,可进行差异表达和生存分析等研究。
四、突变数据库1. dbSNP数据库:记录了常见的单核苷酸多态性(SNP)数据,是研究遗传变异的重要资源。
2. COSMIC数据库:专注于癌症相关的突变数据,包含了大量的突变谱系和功能注释信息。
3. ClinVar数据库:整合了与人类疾病相关的遗传变异数据,提供临床相关的注释信息。
五、药物数据库1. DrugBank数据库:收录了大量的药物信息,包括结构、作用机制和药理学数据等。
2. PubChem数据库:提供了大量的小分子化合物数据,可进行化学结构搜索和药物筛选等研究。
3. ChEMBL数据库:整合了化合物活性数据和药物靶点信息,可用于药物发现和优化。
总结:生物数据库为生物学研究提供了丰富的数据资源和分析工具。
蛋白质相互作用数据库、基因组数据库、表达谱数据库、突变数据库和药物数据库是常用的生物数据库之一。
使用生物大数据技术进行蛋白质组学分析的步骤指南

使用生物大数据技术进行蛋白质组学分析的步骤指南生物大数据技术在生物科学研究中扮演着至关重要的角色,它为我们揭示了生命中的许多奥秘。
蛋白质组学分析是生物大数据技术的一个重要应用领域,它可以帮助我们深入了解蛋白质在生物体内的功能和相互作用。
本文将为您提供一个使用生物大数据技术进行蛋白质组学分析的步骤指南。
第一步:收集蛋白质组学数据蛋白质组学分析的第一步是收集蛋白质组学数据。
这些数据可以来自已有的公共数据库或实验室内的实验测量。
公共数据库如UniProt、NCBI和Ensembl等收集了大量蛋白质相关的信息,包括序列、结构、功能等。
在实验室内,可以通过质谱和二维凝胶电泳等技术获取蛋白质样本的信息。
第二步:预处理数据蛋白质组学数据通常很大且复杂,需要进行预处理以减少噪声和误差。
常见的预处理步骤包括数据过滤、去噪声、归一化和标准化等。
数据过滤可以去除低质量的数据点,降低假阳性率。
去噪声可以通过平滑或滤波等方法来减少数据中的噪声。
归一化可以消除不同样本之间的技术差异,以确保数据的可比性。
标准化可以使数据的分布符合统计假设,方便后续的分析和比较。
第三步:蛋白质鉴定和注释蛋白质组学分析的核心任务之一是鉴定和注释蛋白质。
在这一步骤中,可以利用数据库搜索算法如BLAST、Mascot和Sequest等来将实验测量得到的蛋白质质谱数据与已知的蛋白质序列进行匹配。
匹配的结果可以通过计算得分、质量匹配率和特异性评估来判定其可靠性。
同时还需要对鉴定出的蛋白质进行注释,包括结构域、功能、亚细胞定位等方面的信息。
第四步:差异表达分析差异表达分析是蛋白质组学研究中的一项重要任务,可以帮助我们了解不同条件下蛋白质表达的变化。
通过比较不同样本之间的蛋白质表达水平,可以发现差异表达的蛋白质,并进一步分析其功能和相互作用。
差异表达分析常用的方法包括t检验、方差分析、贝叶斯统计和机器学习等。
第五步:功能富集分析功能富集分析可以帮助我们理解差异表达的蛋白质的功能和参与的通路。
生物信息学6二级数据库及数据库的格式

GDB、AceDB、SCOP、CATH等都已经具有二级数据库的特色)
1、基因组信息二级数据库
TransFac(真核生物基因转录调控因子数据库) 德国生物工程研究所开发维护,始建于1988年。 包括顺式调控位点、基因、转录因子、细胞来源、分类和 调控位点核苷酸分布6个子库。
1 GenBank中DNA序列格式 2 EMBL序列格式 3 SwissProt序列格式 4 FASTA序列格式 5 NBRF序列格式 6 Intelligenetics序列格式
7 GCG序列格式 8 PIR/CODATA序列格式 9 Plain/ASCII.Staden序列格式 10 ASN.1序列格式 11 GDE格式
mutation sequence position, change in sequence for mutation
SQ
count of A, C, G, T and other symbols
gaattcgata aatctctggt ttattgtgca gtttatggtt ccaaaatcgc cttttgctgt 60
>YCZ2_YEAST protein in EMR 3’ region MKAVVIEDGKAVVKEGVPIPELEEGFV GNPTDWAHIDYKVGPQGSILGCDAAGQ IVKLGPAVDPKDFSIGDYIYGFIHGSS VRFPSNGAFAEYSAISTVVAYKSPNEL KFLGEDVLPAGPVRSLEGAATIPVSLT*
• NBRF序列格式(或称PIR格式)已经被用于the National
Biomedical Research Foundation/Protein Information Resource(NBRF)。网站()中 的PIR数据库中得到并不是这种紧缩格式,而是一种包括 很多信息的扩展格式。Fig 2.10显示了PIR序列格式的一 个例子。第一行包括一个起始的“>”字符,接着是一个双 字符编码,例如P表示完整序列,F表示片断,后面的1或 2显示了序列的类型,接着是一个分号,接着是一个4到6
科研干货——蛋白组学研究常用数据库分享

科研干货——蛋白组学研究常用数据库分享2.PIR(Protein Information Resource)4.CORUM(Collection of experimentally verified mammalian protein complexes)https://mips.helmholtz-muenchen.de/corum/简介:哺乳动物蛋白复合物数据库,提供的数据包括蛋白复合物名称、亚基、功能、相简介:人体细胞粘附分子数据库7.GELBANK网址:简介:提供全基因组的二维凝胶电泳图谱,搜集了已知基因组信息生物的蛋白质组二维凝胶电泳图。
可通过描述相对分子质量、等电点和蛋白质序列信息进行快速检索8.SWISS-2DPAGE网址:/ch2d/简介:提供人类、小鼠、大肠杆菌、酿酒酵母、盘基网柄菌的2D-PAGE参考图9.SysPIMP(Systematical Platform for Identifying Mutated Proteins)网址:/简介:通过质谱技术建立的蛋白质突变数据库10.Sys-BodyFluid网址:/bodyfluid/简介:人体体液蛋白组研究数据库11.DB-PABP网址:/DB_PABP/简介:聚阴离子结合蛋白数据库12.IUPHAR-DB网址:简介:G蛋白偶联受体、离子通道数据库13.GLIDA网址:http://pharminfo.pharm.kyoto-u.ac.jp/services/glida/简介:G蛋白偶联受体-配体数据库14.LOCATE16.ConsensusPathDBhttp://cpdb.molgen.mpg.de简介:人类功能作用网络数据库,提供蛋白质互作、生化反应、基因调控等作用网数据http://stitch.embl.de/ 简介:蛋白质-化合物作用网数据库20.Reactome简介:人体生命活动路径与过程数据库,提供生化过程网络图,并对参与其中的蛋白质分子有详细注解/NOPdb3.0/简介:核仁蛋白组数据库22.3DID(3D interacting domains)简介:结构域互作数据库24.PiSite(Database of Protein interaction sites)http://pisite.hgc.jp为基础,在蛋白质序列中搜寻互作位点/Software/Pfam简介:提供多序列比对服务和并提供共同的蛋白质结构域的隐马尔可夫模型26.InterPreTS(Interaction Prediction through Tertiary Structure)http://www.russell.embl.de/cgi-bin/interprets2简介:提供通过三级结构预测蛋白质相互作用的服务,可输入两个蛋白质的序列信息进27.Predictome简介:预测蛋白质间功能关系的数据库28.PDB(Protein Data Bank)。
蛋白质常用数据库一文看懂!

蛋白质常用数据库|一文看懂!蛋白质数据库是指专门存储蛋白质相关信息的数据库。
它们收集、整理和存储大量的蛋白质数据,包括蛋白质序列、结构、功能、互作关系、表达模式、疾病关联等信息。
蛋白质数据库提供了对这些数据的检索、查询和分析功能,为科学研究人员、生物信息学家和药物研发人员等提供了重要的资源。
蛋白质数据库的内容通常来自于实验室实际测定的蛋白质数据,如蛋白质序列测定、结晶学、核磁共振、质谱等技术获得的数据。
这些数据经过验证和标准化后,被整合到数据库中,使研究者能够方便地访问和利用这些数据进行各种研究工作。
下面是笔者总结的常用蛋白质数据库及网址,供大家参考。
⓪BioXFinder:BioXFinder是国内第一个也是唯一一个生物数据库:收录50多万条高质量的、整合多个来源数据,手工注释的非冗余的蛋白质信息,包含蛋白质的基本信息、序列、序列特征、功能、名称和谱系、亚细胞定位、疾病与变异、翻译后修饰、表达、相互作用等信息。
蛋白结构库:收录19多万条经过X射线单晶衍射、核磁共振、电子衍射等实验手段确定的蛋白质结构数据。
包括蛋白3D结构、基本信息、实验数据、参考文献等。
①UniProt:UniProt是一个综合性的蛋白质数据库,提供了大量蛋白质的序列、结构、功能、互作关系和注释信息。
它整合了多个来源的数据,包括Swiss-Prot、TrEMBL和PIR数据库。
②Protein Data Bank (PDB):PDB是存储蛋白质和其他生物大分子结构的数据库。
它提供了实验确定的蛋白质结构的三维坐标数据,可用于结构生物学研究、药物设计和分子模拟等领域。
③NCBI Protein:NCBI Protein是美国国家生物技术信息中心(NCBI)提供的蛋白质数据库,包含了大量的蛋白质序列数据,可以进行蛋白质的基本信息查询和比对分析。
④Ensembl:Ensembl是一个综合性的基因组注释数据库,包含了多个物种的基因组序列、基因结构、转录本和蛋白质信息。
6-蛋白质序列分析

FASTA格式 SWISS-PROT格式 PDB格式
2. 理化特性分析--基于一级结构的预测
理化特性分析
相对分子量、氨基酸组成、等电点、酶切特性、疏水 性等、亲水性,及消光系数等
常用工具
蛋白的功能位点是与其三维结构紧密相关 的,局部区域符合某种pattern不能保证一 定会具有对应的性质,要根据实际情况, 谨慎对待pattern 预测结果。
PROSITE 工具
ScanProsite
搜索蛋白序列是否含PROSITE数据库中存有的模式或是功能位点;搜 索Swiss-Prot中符合某种模式的蛋白以及蛋白三维结构数据库PDB中 含有该模式的蛋白,可察看其三维结构。
2. 蛋白质序列数据库
/
/swissprot/
3. 蛋白质模体及结构域数据库
PROSITE蛋白质家族和结构域数据库 (/prosite/ )
PROSITE数据库收集了有显著生物学意义的蛋白质位点序 列、蛋白质特征序列谱库以及序列模型,
注意问题
不要把所有搜索结果用在比对中 对搜索结果进行手工校正,将显著性不高的序列,非
蛋白质家族的序列剔除掉。
6. 同源建模
如果蛋白质序列有显著的同源序列(相似 性>50%,尤其是与已知结构的蛋白质之间 有显著同源性时,即可进行同源建模
以已知结构的蛋白质为模板进行精确的结构模 型构建
数字表示氨基酸个数。 [AC]-x-V-x(4)-{ED}This pattern is translated as: [Ala or Cys]-any-Val-any-any-any-any-{any but Glu or Asp}
蛋白质序列PIR和PDB使用方法

随着核酸数据库不断发展以及数据库的建立,蛋白质序列、结构、功能不断引起人们的重视,生命科学的研究中蛋白质的研究显得尤为重要,一系列的蛋白质序列数据随之产生,数据库也在研究蛋白质的过程中有着不可或缺的地位。
本文主要通过实验说明蛋白质序列数据库PIR及蛋白质结构数据库PDB的使用方法,返回结果的含义,以及如何下载数据和批量下载数据。
由于蛋白质序列测定技术先于DNA序列测定技术问世,蛋白质序列的搜集也早于DNA序列。
蛋白质序列数据库的雏形可以追溯到60年代。
60年代中期到80年代初,美国国家生物医学研究基金会(National Biomedical Research Foundation,简称NBRF)Dayhoff领导的研究组将搜集到的蛋白质序列和结构信息以“蛋白质序列和结构地图集”(Atlas of Protein Sequence and Structure)的形式发表,主要用来研究蛋白质的进化关系。
时至今日,国际上已建立了许多关于生物分子的数据库,主要包括基因组图谱数据库、核酸序列数据库、蛋白质序列数据库、蛋白质结构数据库、生物大分子结构数据库等。
这些数据库均为公共数据库,由特定的组织维护、以及发布相关序列信息,供生物研究学者使用,称为生物研究中的必要工具之一,随着科学技术的发展,这些数据库不断壮大,也为研究人员提供了大量有用的数据。
本文主要通过课程实验,展示蛋白质序列数据库PIR及蛋白质结构数据库PDB的相关使用方法。
本论蛋白质序列数据库PIR介绍1984年,“蛋白质信息资源”(Protein Information Resource,简称PIR)计划正式启动,蛋白质序列数据库PIR也因此而诞生。
与核酸序列数据库的国际合作相呼应,1988年,美国的NBRF、日本的国际蛋白质信息数据库(Japanese International Protein Information Database,简称JIPID)和德国的慕尼黑蛋白质序列信息中心(Munich Information Center for Protein Sequences,简称MIPS)合作成立了国际蛋白质信息中心(PIR-International),共同收集和维护蛋白质序列数据库PIR。
蛋白质生物信息学-数据库

Pfam数据库由英国生物化学物理研究所(European Bioinformatics Institute,EBI) 维护,利用隐马尔可夫模型(Hidden Markov Model,HMM)进行蛋白质序列分析 ,将序列划分为不同的家族。Pfam数据库提供了丰富的注释信息和可视化的家族结构
图。
外,Pfam数据库还提供了丰富的注释信息 ,有助于深入了解蛋白质家族的特性和进化
关系。
InterPro数据库在蛋白质功能预测中的应用
总结词
InterPro数据库整合了多种蛋白质序列和结构信息,为 预测蛋白质功能提供了全面的资源。
详细描述
InterPro数据库将多个蛋白质数据库(如SWISS-PROT 、Pfam等)进行整合,提供了一个统一的查询平台。通 过比对InterPro数据库,可以同时获取多个数据库中的 注释信息,从而更全面地了解蛋白质的结构和功能。此 外,InterPro数据库还提供了功能域、跨膜结构等更深 入的信息,有助于更准确地预测蛋白质的功能。
云计算平台将提供更灵活、可扩展的计算资源, 支持蛋白质生物信息学数据库的高效运行和数据 共享。
人工智能和机器学习
人工智能和机器学习技术将被应用于蛋白质生物 信息学数据库,以自动提取有价值的信息,提高 数据分析的准确性和效率。
数据库在蛋白质生物信息学中的重要性和应用前景
蛋白质结构预测
数据库中存储的蛋白质序列和结构信息,可用于预测蛋白质的三维 结构,有助于理解蛋白质的功能和相互作用。
选择合适的查询方式
根据需要选择合适的查询方式,如 简单查询或复合查询。
使用适当的关键词
选择与主题相关的关键词进行查询 ,避免使用过于宽泛或模糊的关键 词。
筛选结果
蛋白质数据库介绍

SWISS-PROT或TrEMBL /sprotPIRMIPSJIPID已经和ExPASy 三、蛋白质二级结构预测网站(数据库)4始建于基于对蛋白质家族中同源序列多重序列比对得到的保守区域,这些区域通常与生物学功能相关。
数据库包括两个数据库文件:数据文件Prosite5蛋白质二级结构构象参数数据库DSSP6蛋白质家族数据库FSSP7同源蛋白质数据库HSSP在前面已经述说过了。
第二节、蛋白质序列分析方法一、多序列比对双序列比对是序列分析的基础。
序列之间的关系,生物学模式方面起着相当重要的作用。
多序列比对有时用来区分一组序列之间的差异,但其主要用于描述一组序列之间的相似性关系,法建立在某个数学或生物学模型之上。
因此,正如我们不能对双序列比对的结果得出果也没有绝对正确和绝对错误之分,相似性关系以及它们的生物学特征。
我们称比对前序列中残基的位置为绝对位置。
置Ⅰ相对位置。
显然,同一列中所有残基的相对位置相同,而每个残基的绝对位置不同,因为它们来自不同的序列。
绝对位置是序列本身固有的属性,也就比对过程赋予它的属性。
算法复杂性多序列比对的计算量相当可观,时间和内存空间与这两个序列的长度有关,或者说正比于这两个序列长度的乘积,用(的两维空间扩展到三维,即在原有二维平面上增加一条坐标轴。
这样算法复杂性就变成了(例如,如果用某种颜色表示一组高度保守的残基,则某个序列的某一位点发生突变时,则由于颜色不同,就可以很快找出。
颜色的选择可以根据主观愿望和喜好,但最好和常规方法一致。
用来构筑三维模型的按时氨基酸残基组件和三维分子图形软件所用的颜色分类方法,比较容易为大家接受(表2)。
多序列比对程序的另一个重要用途是定量估计序列间的关系,关系。
关系。
相似性值低于预料值,那么有可能是序列间亲缘关系较远,也可能是比对中有错误之处2同步法实质是把给定的所有序列同时进行比对,而不是两两比对或分组进行比对。
其基本思想是将一个二维的动态规划矩阵扩展到三维或多维。
pfam数据库

PFAM数据库PFAM数据库是一个用于蛋白质序列家族分类的工具。
它基于蛋白质序列的共同结构和功能特征,将蛋白质序列分组成家族,从而帮助研究人员理解蛋白质的功能和进化过程。
本文将介绍PFAM数据库的基本概念、分类方法和应用情况。
1. PFAM数据库简介PFAM数据库是一个用于预测蛋白质结构和功能的数据库。
它采用蛋白质序列的保守特征,将相似的序列归类为同一个家族。
PFAM数据库包含了大量的蛋白质家族信息,可以帮助研究人员在蛋白质序列中发现潜在的功能和结构信息。
2. PFAM数据库的分类方法PFAM数据库主要基于蛋白质序列的保守结构域来进行分类。
它将蛋白质序列中相同或相似的结构域组合成家族,每个家族都包含了具有相似结构和功能的蛋白质。
PFAM数据库还提供了丰富的注释信息,帮助用户更好地理解每个家族的功能和特点。
3. PFAM数据库的应用情况PFAM数据库在生物信息学和分子生物学领域被广泛应用。
研究人员可以利用PFAM数据库来预测新发现的蛋白质的结构和功能,通过比对已知家族信息来推测未知蛋白质的特性。
此外,PFAM数据库还可以用于蛋白质序列的分类和进化分析,帮助研究人员揭示不同蛋白质家族之间的关系和进化过程。
4. 结语PFAM数据库作为一个用于蛋白质家族分类的重要工具,在生物信息学研究中扮演着重要的角色。
通过分析蛋白质序列的保守结构域,PFAM数据库可以帮助研究人员更好地理解蛋白质的功能和进化过程,为生物学研究提供了有力的支持。
希望本文介绍的内容能够帮助读者更深入地了解PFAM数据库及其在蛋白质研究中的应用。
pfam数据库使用方法

pfam数据库使用方法Pfam数据库使用方法Pfam数据库是一个广泛使用的蛋白质家族数据库,它包含了大量的蛋白质序列和结构信息。
在生物信息学领域,Pfam数据库是一个非常重要的工具,可以帮助研究人员快速地找到与自己研究相关的蛋白质家族信息。
本文将按照不同的类别介绍Pfam数据库的使用方法。
1. 搜索功能Pfam数据库的搜索功能非常强大,可以根据关键词、蛋白质名称、序列等多种方式进行搜索。
在搜索框中输入关键词,系统会自动匹配相关的蛋白质家族信息,并列出相应的结果。
用户可以根据需要选择相应的蛋白质家族进行进一步的研究。
2. 蛋白质家族分类Pfam数据库将蛋白质家族按照不同的分类进行了划分,包括结构域、功能域、重复序列等。
用户可以根据自己的需要选择相应的分类进行研究。
例如,如果用户需要研究与酶活性相关的蛋白质家族,可以选择“酶活性”分类进行搜索。
3. 蛋白质家族信息Pfam数据库提供了详细的蛋白质家族信息,包括家族名称、序列、结构、功能等。
用户可以根据自己的需要选择相应的信息进行查看。
例如,如果用户需要研究与蛋白质结构相关的信息,可以选择“结构”信息进行查看。
4. 序列比对Pfam数据库提供了序列比对功能,可以将用户输入的序列与数据库中的蛋白质序列进行比对。
用户可以根据比对结果进行进一步的研究。
例如,如果用户需要研究与某个蛋白质家族相关的序列,可以将该序列与数据库中的蛋白质序列进行比对。
5. 数据下载Pfam数据库提供了数据下载功能,用户可以将数据库中的数据下载到本地进行研究。
下载的数据包括蛋白质序列、结构、功能等信息。
用户可以根据自己的需要选择相应的数据进行下载。
总之,Pfam数据库是一个非常重要的蛋白质家族数据库,可以帮助研究人员快速地找到与自己研究相关的蛋白质家族信息。
本文按照不同的类别介绍了Pfam数据库的使用方法,希望能够对读者有所帮助。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Protein – 某一蛋白信息
Protein – 某一蛋白信息
Protein – 某一蛋白信息
Protein – 某一蛋白信息
Protein – 某一蛋白信息 – FASTA格式
CDD – Conserved Domain Database
transferrin
CDD – transferrin
PIR提供三种类型的检索服务: 一是基于文本的交互式查询, 用户通过关键字进行数据查询。 二是标准的序列相似性搜索, 包括BLAST、FastA等。
三是结合序列相似性、注释信息 和蛋白质家族信息的高级搜索, 包括按注释分类的相似性搜索、 结构域搜索等。
2、SWISS-PROT
SWISS-PROT (http://www.expasy.ch/sprot/sprot-top.html) 是目前国际上比较权威的蛋白质序列数据库,其中的蛋白 质序列是经过注释的
• 一种是隐式序列信息(implicit sequence)
PDB的隐式序列即为立体化学数据,包括每 个原子的名称和原子的三维坐标。
GenBank - Structure
transferrin
GenBank – Structure - Transferrin
PDB文件 示意
HEADER HYDROLASE 19-FEB-97 1ADZ TITLE THE SOLUTION STRUCTURE OF THE SECOND KUNITZ DOMAIN OF TITLE 2 TISSUE FACTOR PATHWAY INHIBITOR, NMR, 30 STRUCTURES COMPND MOL_ID: 1; COMPND 2 MOLECULE: TISSUE FACTOR PATHWAY INHIBITOR; 。。。。。。 COMPND 8 BIOLOGICAL_UNIT: MONOMER SOURCE MOL_ID: 1; 。。。。。。 SOURCE 7 EXPRESSION_SYSTEM_PLASMID: PFLAG KEYWDS HYDROLASE, INHIBITOR, COAGULATION EXPDTA NMR, 30 STRUCTURES AUTHOR M.J.M.BURGERING,L.P.M.ORBONS REVDAT 1 25-FEB-98 1ADZ 0 JRNL AUTH M.J.BURGERING,L.P.ORBONS,A.VAN DER DOELEN, 。。。。。。 REMARK 1 REFERENCE 1 REMARK 1 AUTH M.T.STUBBS II REMARK 1 TITL STRUCTURAL ASPECTS OF FACTOR XA INHIBITION 。。。。。。 REMARK 999 SEQUENCE REMARK 999 1ADZ SWS P10646 1 111 NOT IN ATOMS LIST REMARK 999 1ADZ SWS P10646 183 304 NOT IN ATOMS LIST REMARK 999 THE FIRST NINE RESIDUES ARE NOT PART OF THE TFPI DOMAIN II REMARK 999 SEQUENCE BUT ARE FROM THE PFLAG PEPTIDE CLONING VECTOR. DBREF 1ADZ 1 71 SWS P10646 TFPI_HUMAN 112 182 SEQADV 1ADZ ASP 1 SWS P10646 ILE 112 ENGINEERED SEQADV 1ADZ TYR 2 SWS P10646 ILE 113 ENGINEERED SEQRES 1 71 ASP TYR LYS ASP ASP ASP ASP LYS LEU LYS PRO ASP PHE SEQRES 2 71 CYS PHE LEU GLU GLU ASP PRO GLY ILE CYS ARG GLY TYR SEQRES 3 71 ILE THR ARG TYR PHE TYR ASN ASN GLN THR LYS GLN CYS SEQRES 4 71 GLU ARG PHE LYS TYR GLY GLY CYS LEU GLY ASN MET ASN SEQRES 5 71 ASN PHE GLU THR LEU GLU GLU CYS LYS ASN ILE CYS GLU SEQRES 6 71 ASP GLY PRO ASN GLY PHE HELIX 1 1 ASP 12 PHE 15 5 HELIX 2 2 ASN 34 THR 36 5 HELIX 3 3 LEU 57 ILE 63 1 SHEET 1 A 2 ARG 29 ASN 33 0 SHEET 2 A 2 GLN 38 PHE 42 -1 N PHE 42 O ARG 29 CRYST1 1.000 1.000 1.000 90.00 90.00 90.00 P 1 1
蛋白质组相关数据库
第一节 蛋白质序列数据库
1、PIR(Protein Information Resource)
/pirwww/
• 目的: 帮助研究者鉴别和解释蛋白质序列信息, 研究分子进化、功能基因组。 • 它是一个全面的、经过注释的、非冗余的蛋白 质序列数据库。 • 所有序列数据都经过整理,超过99%的序列已 按蛋白质家族分类,一半以上还按蛋白质超家 族进行了分类。
How to search?
NCBI Homepage
选择某个子数据库 ↓ 空搜索 ↓ 直接进入该子库的主页
Genbank - Protein Homepage
AGGF1
某个蛋白
某个疾病
某个生物学过程
其他特别主题
Protein – AGGF1
Protein – development
development
除了蛋白质序列数据之外,PIR还包含以下信息:
(1)蛋白质名称、蛋白质的分类、蛋白质的来源; (2)关于原始数据的参考文献; (3)蛋白质功能和蛋白质的一般特征,包括基因表达、翻 译后处理、活化等; (4)序列中相关的位点、功能区域。
蛋白质知识整合数据库 蛋白质家族分类系统 蛋白质序列数据库 非冗余的参考性蛋白数据库 通用蛋白质数据库
SWISS-PROT中的数据来源于不同源地: (1)从核酸数据库经过翻译推导而来; (2)从蛋白质数据库PIR挑选出合适的数据; (3)从科学文献中摘录; (4)研究人员直接提交的蛋白质序列数据
SWISS-PROT有三个明显的特点 :
(1)注释
在SWISS-PROT中,数据分为核心数据和注释两大类。 核心数据包括: 序列数据、参考文献、分类信息(蛋白质生物来源的描述) 注释包括: (A)蛋白质的功能描述; (B)翻译后修饰; (C)域和功能位点,如钙结合区域、ATP结合位点等; (D)蛋白质的二级结构; (E)蛋白质的四级结构,如同构二聚体、异构三聚体等; (F)与其它蛋白质的相似性; (G)由于缺乏该蛋白质而引起的疾病; (H)序列的矛盾、变化等。
• 提交序列数据
(a)编辑电子表格 (b) 利用Authorin程序 (c)WWW服务器
• 使用SWISS-PROT
(a)CD-ROM形式 (b)ftp服务器 (c)Gopher服务器 (d)WWW服务器(SRS)
• 与序列相关的操作
(a)序列查询 (b)搜索同源蛋白质序列
3. TrEMBL
TrEMBL (/trembl/index.html) 是与 SWISS-PROT相关的一个数据库。 包含从EMBL核酸数据库中根据编码序列(CDS)翻译而 得到的蛋白质序列,并且这些序列尚未集成到SWISSPROT数据库中。 TrEMBL有两个部分: (1)SP-TrEMBL(SWISS-PROT TrEMBL) 包含最终将要集成到SWISS-PROT的数据,所有的SPTrEMBL 序列都已被赋予SWISS-PROT的 登录号。 (2)REM-TrEMBL(REMaining TrEMBL) 包括所有不准备放入SWISS-PROT的数据,因此这部分 数据都没有登录号。
(2)最小冗余
• 尽量将相关的数据归并,降低数据库的冗余程度。 • 如果不同来源的原始数据有矛盾,则在相应序列特征表 中加以注释。
(3)与其它数据库的连接
对于每一个登录项,有许多指向其它数据库相关数据的 指针,这便于用户迅速得到相关的信息。 现有的交叉索引有: 到EMBL核酸序列数据库的索引, 到PROSITE模式数据库的索引, 到生物大分子结构数据库PDB的索引等 。
2、蛋白质结构分类数据库SCOP
• SCOP数据库 ( /scop/) 的目标是提供关于已知结构的蛋白质之间结构和进化 关系的详细描述,包括蛋白质结构数据库PDB中的 所有条目。 SCOP数据库除了提供蛋白质结构和进化关系信息外, 对于每一个蛋白质还包括下述信息:到PDB的连接, 序列,参考文献,结构的图像等。 可以按结构和进化关系对蛋白质分类,分类结果是一 个具有层次结构的树,其主要的层次是家族、超家族 和折叠:
• SRS有三种检索方式:快速检索、标准检索和批量检索。
SRS开始页面
SRS快速文本检索窗口
SRS检索结果页面显示的检 索结果
SRS蛋白质记录详细内容页 面
SRS蛋白质序列显示窗口
SRS标准检索页面
SRS标准检索页面检索基因名为“KRAS”蛋白序列输入示意图
SRS标准检索结果输出页面
蛋白质数据仓库UniProt 包括:
Swiss-Prot TrEMBL PIR
用户可以通过文本查询数据库,可以利用 Bபைடு நூலகம்AST程序搜索数据库,也可以直接通过FTP 下载数据。
UniProt包含3个部分: (1)UniProt Knowledgebase(UniProt) 蛋白质序列、功能、分类、交叉引用等信息存取中心 (2)UniProt Non-redundant Reference(UniRef)数据库 将密切相关的蛋白质序列组合到一条记录中 以便提高搜索速度; (3)UniProt Archive(UniParc) 资源库,记录所有蛋白质序列的历史。