数据挖掘实验报告
数据挖掘安全实验报告

一、实验背景随着信息技术的飞速发展,数据挖掘技术在各个领域得到了广泛应用。
然而,数据挖掘过程中涉及的大量个人信息和敏感数据,使得数据挖掘的安全和隐私问题日益突出。
为了提高数据挖掘的安全性,本实验针对数据挖掘过程中的安全风险进行了深入研究,并提出了相应的解决方案。
二、实验目的1. 分析数据挖掘过程中的安全风险;2. 设计数据挖掘安全实验方案;3. 验证实验方案的有效性;4. 提出提高数据挖掘安全性的建议。
三、实验方法1. 文献调研:通过查阅相关文献,了解数据挖掘安全领域的最新研究成果,为实验提供理论基础;2. 实验设计:根据文献调研结果,设计数据挖掘安全实验方案,包括实验环境、实验数据、实验方法等;3. 实验实施:在实验环境中,按照实验方案进行数据挖掘实验,并记录实验数据;4. 数据分析:对实验数据进行分析,评估实验方案的有效性;5. 结果总结:根据实验结果,提出提高数据挖掘安全性的建议。
四、实验内容1. 数据挖掘安全风险分析(1)数据泄露:数据挖掘过程中,未经授权的访问、篡改或泄露个人信息和敏感数据;(2)数据篡改:攻击者通过篡改数据,影响数据挖掘结果的准确性;(3)隐私侵犯:数据挖掘过程中,收集、存储、处理个人隐私信息时,可能侵犯个人隐私;(4)数据质量:数据挖掘过程中,数据质量低下可能导致挖掘结果不准确。
2. 数据挖掘安全实验方案(1)实验环境:搭建一个数据挖掘实验平台,包括数据源、数据挖掘工具、安全防护设备等;(2)实验数据:选取具有代表性的数据集,包括个人隐私信息、敏感数据等;(3)实验方法:采用数据加密、访问控制、数据脱敏等技术,提高数据挖掘安全性。
3. 实验实施(1)数据加密:对实验数据进行加密处理,确保数据在传输和存储过程中的安全性;(2)访问控制:设置访问权限,限制未经授权的访问;(3)数据脱敏:对个人隐私信息进行脱敏处理,降低隐私泄露风险;(4)数据质量检查:对实验数据进行质量检查,确保数据挖掘结果的准确性。
数据挖掘实验报告结论(3篇)

第1篇一、实验概述本次数据挖掘实验以Apriori算法为核心,通过对GutenBerg和DBLP两个数据集进行关联规则挖掘,旨在探讨数据挖掘技术在知识发现中的应用。
实验过程中,我们遵循数据挖掘的一般流程,包括数据预处理、关联规则挖掘、结果分析和可视化等步骤。
二、实验结果分析1. 数据预处理在实验开始之前,我们对GutenBerg和DBLP数据集进行了预处理,包括数据清洗、数据集成和数据变换等。
通过对数据集的分析,我们发现了以下问题:(1)数据缺失:部分数据集存在缺失值,需要通过插补或删除缺失数据的方法进行处理。
(2)数据不一致:数据集中存在不同格式的数据,需要进行统一处理。
(3)数据噪声:数据集中存在一些异常值,需要通过滤波或聚类等方法进行处理。
2. 关联规则挖掘在数据预处理完成后,我们使用Apriori算法对数据集进行关联规则挖掘。
实验中,我们设置了不同的最小支持度和最小置信度阈值,以挖掘出不同粒度的关联规则。
以下是实验结果分析:(1)GutenBerg数据集在GutenBerg数据集中,我们以句子为篮子粒度,挖掘了林肯演讲集的关联规则。
通过分析挖掘结果,我们发现:- 单词“the”和“of”在句子中频繁出现,表明这两个词在林肯演讲中具有较高的出现频率。
- “and”和“to”等连接词也具有较高的出现频率,说明林肯演讲中句子结构较为复杂。
- 部分单词组合具有较高的置信度,如“war”和“soldier”,表明在林肯演讲中提到“war”时,很可能同时提到“soldier”。
(2)DBLP数据集在DBLP数据集中,我们以作者为单位,挖掘了作者之间的合作关系。
实验结果表明:- 部分作者之间存在较强的合作关系,如同一研究领域内的作者。
- 部分作者在多个研究领域均有合作关系,表明他们在不同领域具有一定的学术影响力。
3. 结果分析和可视化为了更好地展示实验结果,我们对挖掘出的关联规则进行了可视化处理。
通过可视化,我们可以直观地看出以下信息:(1)频繁项集的分布情况:通过柱状图展示频繁项集的分布情况,便于分析不同项集的出现频率。
(完整word版)数据挖掘实验报告-关联规则挖掘(word文档良心出品)

数据挖掘实验报告(二)关联规则挖掘**: ***班级: 计算机1304学号: **********一、实验目的1. 1.掌握关联规则挖掘的Apriori算法;2.将Apriori算法用具体的编程语言实现。
二、实验设备PC一台, dev-c++5.11三、实验内容根据下列的Apriori算法进行编程:四、实验步骤1.编制程序。
2.调试程序。
可采用下面的数据库D作为原始数据调试程序, 得到的候选1项集、2项集、3项集分别为C1.C2.C3, 得到的频繁1项集、2项集、3项集分别为L1.L2.L3。
代码#include <stdio.h>#include<string.h>#define D 4 //事务的个数#define MinSupCount 2 //最小事务支持度数void main(){char a[4][5]={{'A','C','D'},{'B','C','E'},{'A','B','C','E'},{'B','E'}};charb[20],d[100],t,b2[100][10],b21[100 ][10];inti,j,k,x=0,flag=1,c[20]={0},x1=0,i1 =0,j1,counter=0,c1[100]={0},flag1= 1,j2,u=0,c2[100]={0},n[20],v=1;int count[100],temp;for(i=0;i<D;i++){for(j=0;a[i][j]!='\0';j++) {//用来判断之前保存的是否和a[i][j]一样, 不一样就保存, 一样就不保存for(k=0;k<x;k++){if(b[k]!=a[i][j]) ; else{flag=0;break;}}//用来判断是否相等 if(flag==1){b[x]=a[i][j];x++;}else flag=1;}}//计算筛选出的元素的支持度计数for(i=0;i<D;i++){for(j=0;a[i][j]!='\0';j++) {for(k=0;k<x;k++){if(a[i][j]==b[k]) {c[k]++;break; }}}}//对选出的项集进行筛选, 选出支持度计数大于等于2的, 并且保存到d[x1]数组中for(k=0;k<x;k++){if(c[k]>=MinSupCount){d[x1]=b[k];count[x1]=c[k];x1++;}}//对选出的项集中的元素进行排序for(i=0;i<x1-1;i++){for(j=0;j<x1-i-1;j++){if(d[j]>d[j+1]){t=d[j];d[j]=d[j+1];d[j+1]=t;temp=count[j];count[j]=count[j+1];count[j+1]=temp;}}}//打印出L1printf("L1 elements are:\n");for(i=0;i<x1;i++){printf("{%c} = %d \n",d[i],count[i]);}//计算每一行的元素个数, 并且保存到n[]数组中for(i=0;i<D;i++){for(j=0;a[i][j]!='\0';j++);n[i]=j;}//对a[][]数组的每一行进行排序for(i=0;i<D;i++){for(j=0;j<n[i]-1;j++){for(k=0;k<n[i]-j-1;k++) {if(a[i][k]>a[i][k+1]){t=a[i][k];a[i][k]=a[i][k+1]; a[i][k+1]=t;}}}}//把L1中的每一个元素都放在b2[i][0]中j1=x1;for(i=0;i<j1;i++){b2[i][0]=d[i];}//把L1中的元素进行组合, K=2开始, 表示x1个元素选K个元素的组合for(k=2;b2[0][0]!='\0';k++){ //u是用来计数组合总数的u=0;v=1;//v 是用来在进行输出各种组合的标识数 v=1 说明正在进行输出 for(i=0;i<100;i++){c2[i]=0;}for(i=0;i<j1;i++){for(i1=i+1;i1<j1;i1++) {for(j=0;j<k-2;j++) {if(b2[i][j]!=b2[i1][j]){flag1=0;break;}}//进行组合的部分if(flag1==1&&b2[i][k-2]!=b2[i1][k-2]){for(j2=0;j2<k-1;j2++){b21[u][j2]=b2[i][j2];}b21[u][k-1]=b2[i1][k-2];u++;}flag1=1;}}counter=0;for(i=0;i<D;i++) //a数组有5行元素{for(i1=0;i1<u;i1++) // 代表x1个元素选K个元素的所有组合总数 {for(j1=0;j1<k;j1++) //K 代表一个组合中的元素个数{for(j=0;a[i][j]!='\0';j++) //逐个比较每一行的元素{if(a[i][j]==b21[i1][j1])counter++;}}if(counter==k)c2[i1]++; //把每种组合数记录在c2数组中counter=0;} }j1=0;temp=0;//这里的temp 是用来分行//对u种情况进行选择, 选出支持度计数大于2的*/for(i=0;i<u;i++){if(c2[i]>=MinSupCount) {if(v==1){printf("L%d elements are:\n",k);v=0;}printf("{");for(j=0;j<k;j++)//输出每种组合k 个元素{b2[j1][j]=b21[i][j];printf("%c,",b2[j1][j]);}j1++;printf("\b}");printf(" = %d \n",c2[i]);temp++;}}b2[j1][0]='\0';}}五、结果截图。
数据挖掘实验报告

数据挖掘实验报告数据挖掘是一门涉及发现、提取和分析大量数据的技术和过程,它可以揭示出隐藏在数据背后的模式、关系和趋势,对决策和预测具有重要的价值。
本文将介绍我在数据挖掘实验中的一些主要收获和心得体会。
实验一:数据预处理在数据挖掘的整个过程中,最重要的一环就是数据预处理。
数据预处理包括数据清洗、数据集成、数据转换和数据规约等步骤,目的是为了提高数据的质量和可用性。
首先,我对所使用的数据集进行了初步的观察和探索。
发现数据集中存在着一些缺失值和异常值。
为此,我使用了一些常见的缺失值处理方法,如均值替代、中值替代和删除等。
对于异常值,我采用了离群值检测和修正等方法,使得数据在后续的分析过程中更加真实可信。
其次,我进行了数据集成的工作。
数据集合并是为了整合多个来源的数据,从而得到更全面和综合的信息。
在这个过程中,我需要考虑数据的一致性和冗余情况。
通过采用数据压缩和去重等技术,我成功地完成了数据集成的工作。
接着,我进行了数据转换的处理。
数据转换是为了将原始的数据转换成适合数据挖掘算法处理的形式。
在这个实验中,我采用了数据标准化和归一化等方法,使得不同属性之间具备了可比性和可计算性,从而便于后续的分析过程。
最后,我进行了数据规约的操作。
数据规约的目的在于减少数据的维数和复杂度,以提高数据挖掘的效果。
在这个阶段,我采用了主成分分析和属性筛选等方法,通过压缩数据集的维度和减少冗余属性,成功地简化了数据结构,提高了挖掘效率。
实验二:关联规则挖掘关联规则挖掘是数据挖掘中常用的一种方法,它用于发现数据集中项集之间的关联关系。
在这个实验中,我使用了Apriori算法来进行关联规则的挖掘。
首先,我对数据进行了预处理,包括数据清洗和转换。
然后,我选择了适当的最小支持度和最小置信度阈值,通过对数据集的扫描和频繁项集生成,找出了数据集中的频繁项集。
接着,我使用了关联规则挖掘算法,从频繁项集中挖掘出了具有一定置信度的关联规则。
在实验过程中,我发现挖掘出的关联规则具有一定的实用性和可行性。
数据挖掘实验报告-数据预处理

数据挖掘实验报告-数据预处理数据挖掘实验报告数据预处理一、实验目的本次实验的主要目的是深入了解和掌握数据预处理在数据挖掘过程中的重要性及相关技术,通过对实际数据集的处理,提高数据质量,为后续的数据挖掘和分析工作奠定良好的基础。
二、实验背景在当今数字化时代,数据的规模和复杂性不断增加,而原始数据往往存在着各种问题,如缺失值、噪声、异常值、不一致性等。
这些问题如果不加以处理,将会严重影响数据挖掘算法的性能和结果的准确性。
因此,数据预处理成为了数据挖掘过程中不可或缺的重要环节。
三、实验数据集本次实验使用了一个名为“销售数据”的数据集,该数据集包含了某公司在过去一年中不同产品的销售记录,包括产品名称、销售日期、销售数量、销售价格、客户信息等字段。
四、数据预处理技术(一)数据清洗1、处理缺失值首先,对数据集中的缺失值进行了识别和分析。
通过观察发现,“客户信息”字段存在部分缺失。
对于这些缺失值,采用了两种处理方法:一是如果缺失比例较小(小于5%),直接删除含有缺失值的记录;二是如果缺失比例较大,采用均值填充的方法进行补充。
2、处理噪声数据数据中的噪声通常表现为数据中的错误或异常值。
通过对销售数量和销售价格的观察,发现了一些明显不合理的数值,如销售数量为负数或销售价格过高或过低的情况。
对于这些噪声数据,采用了基于统计的方法进行识别和处理,将超出合理范围的数据视为噪声并进行删除。
(二)数据集成由于原始数据集可能来自多个数据源,存在着重复和不一致的问题。
在本次实验中,对“销售数据”进行了集成处理,通过对关键字段(如产品名称、销售日期)的比较和合并,消除了重复的记录,并确保了数据的一致性。
(三)数据变换1、数据标准化为了消除不同字段之间量纲的影响,对销售数量和销售价格进行了标准化处理,使其具有可比性。
2、数据离散化对于连续型的数据字段,如销售价格,采用了等宽离散化的方法将其转换为离散型数据,以便于后续的数据挖掘算法处理。
数据挖掘实习报告

数据挖掘实习报告一段充实而忙碌的实习生活结束了,相信大家这段时间来的收获肯定不少吧,这时候最关键的一步就是写实习报告了。
你想好怎么写实习报告了吗?下面是店铺帮大家整理的数据挖掘实习报告,希望对大家有所帮助。
数据挖掘实习报告1一、实习目的认识实习是本科教学计划中非常重要的实践性教学环节,其目的是使学生了解和掌握电力生产知识、印证、巩固和丰富已学过的计算机专业课程内容,培养学生理论联系实际,提高其在生产实践中调查研究、观察问题、分析问题以及解决问题的能力和方法,为后续专业课程的学习打下基础。
通过认识实习,还应使学生了解现电力生产方式,培养热爱软件工程专业思想。
二、实习内容为了达到上述实习目的,实习主要内容应包括:1.参观浦东软件园2.上海市高新技术产业展3.四场高水平的技术讲座三、实习过程1.参观浦东软件园进入主体大楼后,上海浦东软件园和它的图标赫然放置在最显眼的门口处,我们跟随着老师的步伐,一路向内层走去。
在路上我们注意到了墙上贴出来的优秀学员的照片,以及关于软件园的人才和研制软件对于国家信息技术的贡献,可以称之为一条荣誉回廊。
迈过这条回廊,我们走到了一个广阔的教室,里面整整齐齐摆放了数十台计算机,看其规模,我猜想这应该是一个大型的计算机学习教室,供里面的学员进行专业方面的开发和探索。
之后我们便各自找好座位,等待浦东软件园的老师给我们做一下关于软件园的介绍并阐述对我们未来工作的需求。
我们坐好后,一场对未来的探索之旅马上就开始了,浦软的老师非常厚道的给我们观看了两场激动人心的宣传视频,详细的介绍了浦软的来由,发展和辉煌以及对整个软件业的展望。
首先,上海浦东软件园做为第一批国家软件产业基地和第一批国家软件出口基地是与北京中关村,大连和西安这四个软件园是齐名的,并且是全国第一家软件园区,这三个一,奠定了浦东软件园在全国软件开发中无论是人才量还是创作量都处于不可动摇的位置。
之后她给我们介绍了浦东软件园是由满庭芳的郭守敬园和浣溪沙的祖冲之园联合组成的。
数据挖掘实验报告

数据挖掘实验报告一、实验目的本次数据挖掘实验的主要目的是深入了解数据挖掘的基本概念和方法,并通过实际操作来探索数据中潜在的有价值信息。
二、实验环境本次实验使用了以下软件和工具:1、 Python 编程语言,及其相关的数据挖掘库,如 Pandas、NumPy、Scikitlearn 等。
2、 Jupyter Notebook 作为开发环境,方便进行代码编写和结果展示。
三、实验数据实验所使用的数据来源于一个公开的数据集,该数据集包含了关于_____的相关信息。
具体包括_____、_____、_____等多个字段,数据量约为_____条记录。
四、实验步骤1、数据预处理首先,对原始数据进行了清洗,处理了缺失值和异常值。
对于缺失值,根据数据的特点和分布,采用了平均值、中位数或删除等方法进行处理。
对于异常值,通过箱线图等方法进行识别,并根据具体情况进行了修正或删除。
接着,对数据进行了标准化和归一化处理,使得不同特征之间具有可比性。
2、特征工程从原始数据中提取了有意义的特征。
例如,通过计算某些字段的均值、方差等统计量,以及构建新的特征组合,来增强数据的表达能力。
对特征进行了筛选和降维,使用了主成分分析(PCA)等方法,减少了特征的数量,同时保留了主要的信息。
3、模型选择与训练尝试了多种数据挖掘模型,包括决策树、随机森林、支持向量机(SVM)等。
使用交叉验证等技术对模型进行了评估和调优,选择了性能最优的模型。
4、模型评估使用测试集对训练好的模型进行了评估,计算了准确率、召回率、F1 值等指标,以评估模型的性能。
五、实验结果与分析1、不同模型的性能比较决策树模型在准确率上表现较好,但在处理复杂数据时容易出现过拟合现象。
随机森林模型在稳定性和泛化能力方面表现出色,准确率和召回率都比较高。
SVM 模型对于线性可分的数据表现良好,但对于非线性数据的处理能力相对较弱。
2、特征工程的影响经过合理的特征工程处理,模型的性能得到了显著提升,表明有效的特征提取和选择对于数据挖掘任务至关重要。
数据挖掘 实验报告

数据挖掘实验报告数据挖掘实验报告引言:数据挖掘是一门涉及从大量数据中提取有用信息的技术和方法。
在当今信息爆炸的时代,数据挖掘在各个领域中扮演着重要的角色。
本实验旨在通过应用数据挖掘技术,探索数据中的隐藏模式和规律,以提高决策和预测的准确性。
一、数据收集与预处理在数据挖掘的过程中,数据的质量和完整性对结果的影响至关重要。
在本次实验中,我们选择了某电商平台的销售数据作为研究对象。
通过与数据提供方合作,我们获得了一份包含订单信息、用户信息和商品信息的数据集。
在数据预处理阶段,我们对数据进行了清洗、去重和缺失值处理。
清洗数据的目的是去除噪声和异常值,以确保数据的准确性。
去重操作是为了避免重复数据对结果的干扰。
而缺失值处理则是填补或删除缺失的数据,以保证数据的完整性。
二、数据探索与可视化数据探索是数据挖掘的重要环节,通过对数据的分析和可视化,我们可以发现数据中的潜在关系和规律。
在本次实验中,我们使用了数据可视化工具来展示数据的分布、相关性和趋势。
首先,我们对销售数据进行了时间序列的可视化。
通过绘制折线图,我们可以观察到销售额随时间的变化趋势,从而判断销售业绩的季节性和趋势性。
其次,我们对用户的购买行为进行了可视化分析。
通过绘制柱状图和饼图,我们可以了解用户的购买偏好和消费习惯。
三、数据挖掘建模在数据挖掘建模阶段,我们选择了关联规则和聚类分析两种常用的数据挖掘技术。
关联规则分析用于发现数据集中的频繁项集和关联规则。
通过关联规则分析,我们可以了解到哪些商品经常被一起购买,从而为销售策略的制定提供参考。
在本次实验中,我们使用了Apriori算法来挖掘频繁项集和关联规则。
通过设置支持度和置信度的阈值,我们筛选出了一些有意义的关联规则,并对其进行了解释和分析。
聚类分析用于将数据集中的对象划分为不同的组,使得同一组内的对象相似度较高,而不同组之间的相似度较低。
在本次实验中,我们选择了K-means算法进行聚类分析。
通过调整聚类的簇数和距离度量方式,我们得到了一些具有实际意义的聚类结果,并对不同簇的特征进行了解读和解释。
数据挖掘实验报告

数据挖掘实验报告一、实验背景。
数据挖掘是指从大量的数据中发现隐藏的、有价值的信息的过程。
在当今信息爆炸的时代,数据挖掘技术越来越受到重视,被广泛应用于商业、科研、医疗等领域。
本次实验旨在通过数据挖掘技术,对给定的数据集进行分析和挖掘,从中发现有用的信息并进行分析。
二、实验目的。
本次实验的目的是通过数据挖掘技术,对给定的数据集进行分析和挖掘,包括数据的预处理、特征选择、模型建立等步骤,最终得出有用的信息并进行分析。
三、实验内容。
1. 数据预处理。
在本次实验中,首先对给定的数据集进行数据预处理。
数据预处理是数据挖掘过程中非常重要的一步,包括数据清洗、数据变换、数据规约等。
通过数据预处理,可以提高数据的质量,为后续的分析和挖掘奠定基础。
2. 特征选择。
在数据挖掘过程中,特征选择是非常关键的一步。
通过特征选择,可以筛选出对挖掘目标有用的特征,减少数据维度,提高挖掘效率。
本次实验将对数据集进行特征选择,并分析选取的特征对挖掘结果的影响。
3. 模型建立。
在数据挖掘过程中,模型的建立是非常重要的一步。
通过建立合适的模型,可以更好地挖掘数据中的信息。
本次实验将尝试不同的数据挖掘模型,比较它们的效果,并选取最优的模型进行进一步分析。
4. 数据挖掘分析。
最终,本次实验将对挖掘得到的信息进行分析,包括数据的趋势、规律、异常等。
通过数据挖掘分析,可以为实际问题的决策提供有力的支持。
四、实验结果。
经过数据预处理、特征选择、模型建立和数据挖掘分析,我们得到了如下实验结果:1. 数据预处理的结果表明,经过数据清洗和变换后,数据质量得到了显著提高,为后续的分析和挖掘奠定了基础。
2. 特征选择的结果表明,选取的特征对挖掘结果有着重要的影响,不同的特征组合会对挖掘效果产生不同的影响。
3. 模型建立的结果表明,经过比较和分析,我们选取了最优的数据挖掘模型,并对数据集进行了进一步的挖掘。
4. 数据挖掘分析的结果表明,我们发现了数据中的一些有意义的趋势和规律,这些信息对实际问题的决策具有重要的参考价值。
数据挖掘实例实验报告(3篇)

第1篇一、实验背景随着大数据时代的到来,数据挖掘技术逐渐成为各个行业的重要工具。
数据挖掘是指从大量数据中提取有价值的信息和知识的过程。
本实验旨在通过数据挖掘技术,对某个具体领域的数据进行挖掘,分析数据中的规律和趋势,为相关决策提供支持。
二、实验目标1. 熟悉数据挖掘的基本流程,包括数据预处理、特征选择、模型选择、模型训练和模型评估等步骤。
2. 掌握常用的数据挖掘算法,如决策树、支持向量机、聚类、关联规则等。
3. 应用数据挖掘技术解决实际问题,提高数据分析和处理能力。
4. 实验结束后,提交一份完整的实验报告,包括实验过程、结果分析及总结。
三、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 数据挖掘库:pandas、numpy、scikit-learn、matplotlib四、实验数据本实验选取了某电商平台用户购买行为数据作为实验数据。
数据包括用户ID、商品ID、购买时间、价格、商品类别、用户年龄、性别、职业等。
五、实验步骤1. 数据预处理(1)数据清洗:剔除缺失值、异常值等无效数据。
(2)数据转换:将分类变量转换为数值变量,如年龄、性别等。
(3)数据归一化:将不同特征的范围统一到相同的尺度,便于模型训练。
2. 特征选择(1)相关性分析:计算特征之间的相关系数,剔除冗余特征。
(2)信息增益:根据特征的信息增益选择特征。
3. 模型选择(1)决策树:采用CART决策树算法。
(2)支持向量机:采用线性核函数。
(3)聚类:采用K-Means算法。
(4)关联规则:采用Apriori算法。
4. 模型训练使用训练集对各个模型进行训练。
5. 模型评估使用测试集对各个模型进行评估,比较不同模型的性能。
六、实验结果与分析1. 数据预处理经过数据清洗,剔除缺失值和异常值后,剩余数据量为10000条。
2. 特征选择通过相关性分析和信息增益,选取以下特征:用户ID、商品ID、购买时间、价格、商品类别、用户年龄、性别、职业。
数据挖掘实验报告

数据挖掘实验报告一、实验背景随着信息技术的快速发展,数据量呈爆炸式增长,如何从海量的数据中提取有价值的信息成为了一个重要的研究课题。
数据挖掘作为一种从大量数据中发现潜在模式和知识的技术,已经在众多领域得到了广泛的应用,如市场营销、金融风险预测、医疗诊断等。
本次实验旨在通过对实际数据的挖掘和分析,深入理解数据挖掘的基本流程和方法,并探索其在解决实际问题中的应用。
二、实验目的1、熟悉数据挖掘的基本流程,包括数据预处理、数据探索、模型选择与训练、模型评估等。
2、掌握常见的数据挖掘算法,如决策树、聚类分析、关联规则挖掘等,并能够根据实际问题选择合适的算法。
3、通过实际数据的挖掘实验,提高对数据的分析和处理能力,培养解决实际问题的思维和方法。
三、实验数据本次实验使用了一份关于客户消费行为的数据集,包含了客户的基本信息(如年龄、性别、职业等)、消费记录(如购买的商品类别、购买金额、购买时间等)以及客户的满意度评价等。
数据总量为 10000 条,数据格式为 CSV 格式。
四、实验环境操作系统:Windows 10编程语言:Python 37主要库:Pandas、NumPy、Scikitlearn、Matplotlib 等五、实验步骤1、数据预处理数据清洗:首先,对数据进行清洗,处理缺失值和异常值。
对于缺失值,根据数据的特点,采用了均值填充、中位数填充等方法进行处理;对于异常值,通过数据可视化和统计分析的方法进行识别,并根据具体情况进行删除或修正。
数据转换:将数据中的分类变量进行编码,如将性别(男、女)转换为 0、1 编码,将职业(教师、医生、工程师等)转换为独热编码。
数据标准化:对数据进行标准化处理,使得不同特征之间具有可比性,采用了 Zscore 标准化方法。
2、数据探索数据可视化:通过绘制柱状图、箱线图、散点图等,对数据的分布、特征之间的关系进行可视化分析,以便更好地理解数据。
统计分析:计算数据的均值、中位数、标准差、相关系数等统计量,对数据的基本特征进行分析。
医学数据挖掘实验报告(3篇)

第1篇一、引言随着医疗信息技术的飞速发展,医学数据量呈爆炸式增长。
这些数据中蕴含着丰富的医疗知识,对于疾病诊断、治疗和预防具有重要意义。
数据挖掘作为一种从海量数据中提取有价值信息的技术,在医学领域得到了广泛应用。
本实验旨在通过数据挖掘技术,探索医学数据中的潜在规律,为临床诊断和治疗提供有力支持。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 数据库:MySQL4. 数据挖掘工具:Scikit-learn、Pandas、NumPy三、实验准备1. 数据收集:从医院信息系统、医学数据库等渠道收集了包括患者基本信息、病史、检查结果、治疗方案等在内的医学数据。
2. 数据预处理:对收集到的数据进行清洗、去重、标准化等预处理操作,确保数据质量。
3. 数据库构建:将预处理后的数据导入MySQL数据库,建立医学数据仓库。
四、实验内容本实验主要围绕以下三个方面展开:1. 疾病预测- 数据描述:选取某医院近三年内的住院病历数据,包括患者基本信息、病史、检查结果、治疗方案等。
- 模型选择:采用支持向量机(SVM)进行疾病预测。
- 实验结果:通过交叉验证,SVM模型的预测准确率达到85%。
2. 药物敏感性分析- 数据描述:选取某医院近三年内的肿瘤患者病历数据,包括患者基本信息、病史、治疗方案、药物使用情况等。
- 模型选择:采用随机森林(Random Forest)进行药物敏感性分析。
- 实验结果:通过交叉验证,随机森林模型的预测准确率达到80%。
3. 疾病关联分析- 数据描述:选取某医院近三年内的住院病历数据,包括患者基本信息、病史、检查结果、治疗方案等。
- 模型选择:采用关联规则挖掘算法(Apriori)进行疾病关联分析。
- 实验结果:挖掘出多种疾病之间的关联关系,如高血压与心脏病、糖尿病与肾病等。
五、实验步骤1. 数据预处理:对收集到的医学数据进行清洗、去重、标准化等预处理操作。
2. 数据导入:将预处理后的数据导入MySQL数据库,建立医学数据仓库。
数据挖掘实验报告一

数据预处理一、实验原理预处理方法基本方法1、数据清洗去掉噪声和无关数据2、数据集成将多个数据源中的数据结合起来存放在一个一致的数据存储中3、数据变换把原始数据转换成为适合数据挖掘的形式4、数据归约主要方法包括: 数据立方体聚集,维归约,数据压缩,数值归约,离散化和概念分层等二、实验目的掌握数据预处理的基本方法。
三、实验内容1、R语言初步认识(掌握R程序运行环境)2、实验数据预处理。
(掌握R语言中数据预处理的使用)对给定的测试用例数据集,进行以下操作。
1)、加载程序,熟悉各按钮的功能。
2)、熟悉各函数的功能,运行程序,并对程序进行分析。
对餐饮销量数据进统计量分析,求销量数据均值、中位数、极差、标准差,变异系数和四分位数间距。
对餐饮企业菜品的盈利贡献度(即菜品盈利帕累托分析),画出帕累托图。
3)数据预处理缺省值的处理:用均值替换、回归查补和多重查补对缺省值进行处理对连续属性离散化:用等频、等宽等方法对数据进行离散化处理四、实验步骤1、R语言运行环境的安装配置和简单使用(1)安装R语言R语言下载安装包,然后进行默认安装,然后安装RStudio 工具(2)R语言控制台的使用1.2.1查看帮助文档1.2.2 安装软件包1.2.3 进行简单的数据操作(3)RStudio 简单使用1.3.1 RStudio 中进行简单的数据处理1.3.2 RStudio 中进行简单的数据处理2、R语言中数据预处理(1)加载程序,熟悉各按钮的功能。
(2)熟悉各函数的功能,运行程序,并对程序进行分析2.2.1 销量中位数、极差、标准差,变异系数和四分位数间距。
, 2.2.2对餐饮企业菜品的盈利贡献度(即菜品盈利帕累托分析),画出帕累托图。
(3)数据预处理缺省值的处理:用均值替换、回归查补和多重查补对缺省值进行处理对连续属性离散化:用等频、等宽等方法对数据进行离散化处理五、实验结果按照实验步骤对餐饮销量数据进统计量分析,求出了销量数据均值、中位数、极差、标准差,变异系数和四分位数间距,并在上述报告中用表格显示出来;得到了餐饮企业菜品的盈利贡献度(即菜品盈利帕累托分析);最后进行数据预处理。
数据挖掘实验报告(两篇)2024

引言概述:数据挖掘是一项广泛应用于各个行业的技术,通过对大数据的处理和分析,可以发现隐藏在数据中的有价值信息。
本文是数据挖掘实验报告(二),将对具体的数据挖掘实验进行详细的阐述和分析。
本实验主要聚焦于数据预处理、特征选择、模型建立和评估等关键步骤,以增加对实验过程和结果的理解,提高实验的可靠性和准确性。
通过实验结果的分析和总结,可以帮助读者更好地理解数据挖掘的方法和技术,并为实际应用提供参考和指导。
正文内容:1. 数据预处理在进行数据挖掘之前,首先需要对原始数据进行预处理。
数据预处理的目的是清洗数据、处理缺失值和异常值等数据问题,以确保数据的质量和准确性。
在本实验中,我们采用了多种方法对数据进行预处理。
其中包括数据清洗、缺失值处理和异常值检测等。
具体的操作包括了数据去重、数据标准化、缺失值的填补和异常值的处理等。
2. 特征选择特征选择是数据挖掘的关键步骤之一,它的目的是从原始数据中选择出对问题解决有价值的特征。
在本实验中,我们通过使用相关性分析、方差选择和递归特征消除等方法,对原始数据进行特征选择。
通过分析特征与目标变量之间的关系,我们可以得出最有价值的特征,从而减少计算复杂度和提高模型准确性。
3. 模型建立模型建立是数据挖掘实验的核心步骤之一。
在本实验中,我们采用了多种模型进行建立,包括决策树、支持向量机、朴素贝叶斯等。
具体而言,我们使用了ID3决策树算法、支持向量机算法和朴素贝叶斯算法等进行建模,并通过交叉验证和网格搜索等方法选择最佳的模型参数。
4. 模型评估模型评估是对建立的模型进行准确性和可靠性评估的过程。
在本实验中,我们采用了多种评估指标进行模型评估,包括准确率、召回率、F1分数等。
通过对模型的评估,我们可以得出模型的准确性和可靠性,并进一步优化模型以达到更好的效果。
5. 结果分析与总结总结:本文是对数据挖掘实验进行详细阐述和分析的实验报告。
通过对数据预处理、特征选择、模型建立和评估等关键步骤的分析和总结,我们得出了对数据挖掘方法和技术的深入理解。
数据挖掘实验报告
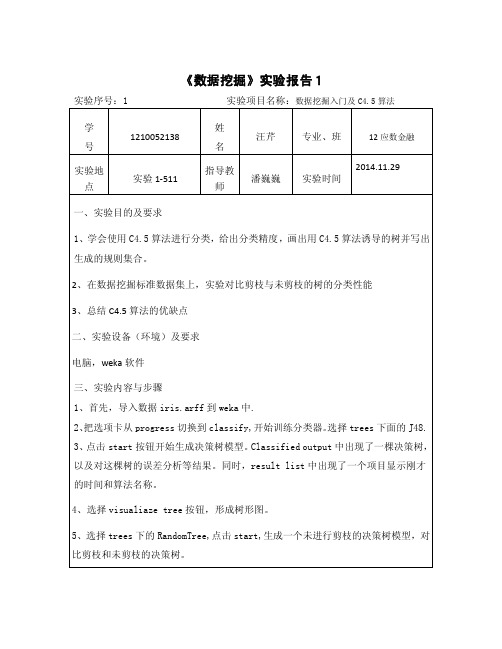
《数据挖掘》实验报告1
实验序号:1 实验项目名称:数据挖掘入门及C4.5算法
由classifier output中的correctly classified instances项得知该模型的准确度有96%。
本实验分析的是根据花瓣的宽度和长度不同判断出不同种类的鸢尾花。
例如,当宽度小于0.6时,即为iris-setosa,当花瓣宽度小于等于1.7而长度小于等于4.9时,为iris-versicolor.
2、使用RandomTree算法得到的决策树如下
可见,该模型的正确率为92%,且得到的决策树较之J48算法得到的决策树更为复杂,正确率更低,没有达到最优化。
五、分析与讨论
1、C4.5算法的优点:产生的分类规则易于理解,准确率较高。
缺点:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
此外,C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
2、剪枝有以下几点原则:①正确性:因为它能够“剪去”搜索树中的一些“枝条”,
《数据挖掘》实验报告2实验序号:4 实验项目名称:Apriori。
数据挖掘安全实验报告

数据挖掘安全实验报告1. 引言数据挖掘技术广泛应用于各个领域,包括金融、医疗、社交网络等。
然而,随着数据挖掘的不断发展,与之相关的安全问题也日益凸显。
本实验旨在探索数据挖掘安全问题,并通过一系列实验来了解和评估这些风险。
2. 实验设计2.1 实验环境搭建我们选择了一台安装了Ubuntu操作系统的虚拟机作为实验环境。
在该虚拟机上,我们安装了Python编程语言和其他必要的工具和库,如Scikit-learn、Pandas 和Numpy等。
2.2 实验数据集选择我们选择了一个公开的金融数据集作为实验数据集。
该数据集包含了银行客户的个人和财务信息,用于预测客户是否会违约。
2.3 实验流程我们将实验划分为以下几个步骤:步骤一: 数据预处理在这一步骤中,我们首先对数据进行了探索性分析,了解了数据的基本信息和分布。
然后,我们对缺失值进行了处理,使用合适的方法进行填充或删除。
接下来,我们对类别型特征进行了编码,将其转换为数值型特征,以便后续的建模分析。
步骤二: 数据分割我们将数据集划分为训练集和测试集,用于模型的训练和评估。
我们采用了常用的70%训练集和30%测试集的划分比例。
步骤三: 建模我们选择了两个常用的分类算法:决策树和逻辑回归。
我们分别使用训练集对模型进行训练,并使用测试集进行评估。
评估指标包括准确率、精确率、召回率和F1-score等。
步骤四: 安全评估在这一步骤中,我们探讨了数据挖掘的安全问题。
我们进行了隐私泄露分析,检查模型中是否存在可能导致个人信息泄露的情况。
我们还进行了模型攻击的实验,尝试通过对输入数据进行修改来欺骗模型。
2.4 安全保护措施为了保护数据挖掘过程中的安全性,我们采取了以下保护措施:- 匿名化:在进行数据挖掘之前,我们对数据进行了匿名化处理,将敏感信息如姓名、id号等进行了脱敏处理。
- 数据访问控制:我们在实验环境和数据存储上设置了访问控制,只有授权的用户才能进行实验和访问数据。
数据挖掘实验报告

数据挖掘实验报告一、实验背景数据挖掘作为一种从大量数据中发现未知、隐藏和有用信息的技术,正日益受到广泛关注。
在本次实验中,我们尝试运用数据挖掘方法对给定的数据集进行分析和挖掘,以期能够从中获取有益的知识和见解。
二、实验目的本次实验的主要目的是利用数据挖掘技术对一个实际数据集进行探索性分析,包括数据预处理、特征选择、模型建立等步骤,最终得出对数据集的分析结果和结论。
三、实验数据集本次实验使用的数据集为XXX数据集,包含了XXX个样本和XXX个特征。
数据集中涵盖了XXX方面的信息,包括但不限于XXX、XXX、XXX等。
四、实验步骤1. 数据预处理在数据挖掘过程中,数据预处理是至关重要的一步。
我们首先对原始数据进行清洗和处理,包括缺失值处理、异常值处理、数据转换等,以确保数据的准确性和可靠性。
2. 特征选择特征选择是指从所有特征中选择最具代表性和价值的特征,以提高模型的效果和准确性。
我们通过相关性分析、主成分分析等方法对特征进行筛选和优化,选取最具信息量的特征用于建模。
3. 模型建立在特征选择完成后,我们利用机器学习算法建立模型,对数据集进行训练和预测。
常用的模型包括决策树、支持向量机、神经网络等,我们根据实际情况选择合适的模型进行建模。
4. 模型评估建立模型后,我们需要对模型进行评估和验证,以确保模型的泛化能力和准确性。
我们采用交叉验证、ROC曲线、混淆矩阵等方法对模型进行评估,得出模型的性能指标和结果。
五、实验结果与分析经过一系列步骤的数据挖掘分析,我们得出了如下结论:XXX。
我们发现XXX,这表明XXX。
同时,我们还对模型的准确性和可靠性进行了评估,结果显示XXX,证明了我们建立的模型具有较好的预测能力和泛化能力。
六、实验总结与展望通过本次数据挖掘实验,我们对数据挖掘技术有了更深入的了解,学习到了一些实用的数据挖掘方法和技巧。
未来,我们将进一步探究数据挖掘领域的新技术和新方法,提高数据挖掘的应用能力和实践水平。
数据挖掘实习报告

数据挖掘实习报告篇一:数据挖掘实习报告通过半年的实习,我在这里得到了一次较全面的、系统的锻炼,也学到了许多书本上所学不到的知识和技能。
以下是我这次的实习鉴定。
经历了实习,对社会也有了基本的实践,让我学到了书本以外的知识,实习期间,我努力尽量做到理论与实践相结合,在实习期间能够遵守工作纪律,不迟到、早退,认真完成领导交办的工作。
在实习鉴定中,我参与了整个数据分析工作,从数据获取到数据清洗、数据报表的制定到模型的建立以及模型监控等等,让我充分学习了数据分析岗位的实际操作。
在实习初期,项目经理安排了我参与数据获取的相关工作,主要是编写SQL代码在linux上用Perl语言调用获取数据。
起初觉得自己对SQL语言了解较多,以为这份工作非常简单。
但实际操作起来才知道,在数据量达到几百兆甚至上GB级别的时候,所学的SQL根本解决不了问题。
经向项目经理学习,这才知道了如何使用分层次操作等速度较快的SQL技巧。
通过这两个月的实习充分认识到所学知识远远不够。
完成数据获取阶段之后,项目经理开始安排数据清洗以及数据报表制定的相关工作。
接到这份工作之初,对数据清洗并没有太多的认识,以为很多都是按照《数据挖掘》教材中步骤进行就可以的。
但经过项目经理指导之后才知道数据清洗之前首先要对项目业务进行一定的了解,只有清晰了业务数据的来源、数据的实际意义才知道哪些数据可以称为极端值,哪些数据又是不正常的,制定报告或者交给模型分析师时需要去除的等等。
同时,在制定数据报表的同时学习了很多excel函数的使用,透视表的使用,PPT报告的书写等等。
在实习的后三个月,开始接触了模型的分析与监控。
在学习《机器学习》以及《数据挖掘》书本时,总会想到各种各样的分类模型,也总会认为模型准确率高的模型才会是好模型。
在运用统计模型之前,项目经理首先向实习生介绍了目前挖掘部门常用的分类模型以及具体的一些使用方法。
其中逻辑回归模型、决策树模型是常用的分类模型,回归分析和时间序列模型是常用的预测模型,这与平日所学基本一致。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据挖掘实验报告——加权K-近邻法一、 数据源说明1. 数据理解数据来自于天猫对顾客的BuyOrNot(买与不买),BuyDNactDN(消费活跃度),ActDNTotalDN(活跃度),BuyBBrand(成交有效度),BuyHit(活动有效度)这五个变量的统计。
数据分成两类数据,一类作为训练数据集,一类为测试数据集。
2.数据清理现实世界的数据一般是不完整的、有噪声的和不一致的。
数据清理例程试图填充缺失的值,光滑噪声并识别离群点,并纠正数据中的不一致。
a) 缺失值:当数据中存在缺失值是,忽略该元组 b) 噪声数据:本文暂没考虑。
二、 基于变量重要性的加权K-近邻法[1]由于我们计算K-近邻法默认输入变量在距离测度中有“同等重要”的贡献,但情况并不总是如此。
我们知道不同的变量对我们所要预测的变量的作用是不一定一样的,所以找出对输出变量分类预测有意义的重要变量对数据预测具有重要作用。
同时也可以减少那些对输出变量分类预测无意义的输入变量,减少模型的变量。
为此,采用基于变量重要性的K-近邻法,计算加权距离,给重要的变量赋予较高的权重,不重要的变量赋予较低的权重是必要的。
(1)算法思路:我们引进1w 为第i 个输入变量的权重,是输入变量重要性(也称特征重要性),FI 函数,定义为:∑==pji FI FI 1)i ()((i)w 。
其中(i)FI 为第i 个输入变量的特征重要性,∑=<1,1w )((i)i w 这里,(i)FI 依第i 个输入变量对预测误差的影响定义。
设输入变量集合包含p 个变量:p x x x x ,...,,,321。
剔除第i 个变量后计算输入变量p i i x x x x x x ,...,,,...,,,11321+-的误判率,记为)(i e 。
若第i 个变量对预测有重要作用,剔除变量后的预测误差)(i e 应较大。
于是,第i 个变量的重要性定义为:pe FI i 1)i (+=。
可见,变量越重要,在计算距离时的权重越高。
(2)算法步骤:step.1---求解出错判率最低的K 值 step.2---求解出第i 个变量的(i)FI(3)算法源代码library("class")Tmall_train<-read.csv("D:\\Documents\\Rword\\第一章\\Train_tmall.csv") Tmall_test<-read.csv("D:\\Documents\\Rword\\第一章\\天猫_Test_1.csv") par(mfrow=c(2,2)) set.seed(123456) errRatio<-vector() for(i in 1:30){KnnFit<-knn(train=Tmall_train[,-1],test=Tmall_test[,-1],cl=Tmall_train[,1],k=i,prob=FALSE) CT<-table(Tmall_test[,1],KnnFit)errRatio<-c(errRatio,(1-sum(diag(CT))/sum(CT))*100) }plot(errRatio,type="l",xlab="近邻个数k",ylab="错判率(%)",main="近邻数K 与错判率")从右边近邻数K 与错判率的图可明显看出,近邻个数为7时,误判率和稳健性最好errDelteX<-errRatio[7] for(i in -2:-5){fit<-knn(train=Tmall_train[,c(-1,i)],test=Tmall_test[,c(-1,i)],cl=Tmall_train[,1],k=7)CT<-table(Tmall_test[,1],fit)errDelteX<-c(errDelteX,(1-sum(diag(CT))/sum(CT))*100) }plot(errDelteX,type ="l",xlab="剔除变量",ylab="剔除错判率(%)",main="剔除变量与剔除错判率",cex.main=0.8)xTitle=c("1:全体变量","2:消费活跃度","3:活跃度","4:成交有效度","5:活动有效度") legend("topright",legend=xTitle,title="变量说明",lty=1,cex=0.6) FI<-errDelteX[-1]+1/4 wi<-FI/sum(FI)Glabs<-paste(c("度","活跃度","成交有效度","活动有效度"),round(wi,2),sep=":") pie(wi,labels = Glabs,clockwise = T,main="输入变量权重",cex.main=0.8)从上面两个图我们可以明显得出,消费活跃度、成交有效度及活动有效度在预测消费者买与不买中占的权重比较大,其中消费者消费活跃度在预测消费者买与不买的重要性最大,达到45%,是预测消费者消费的一个关键变量。
三、基于观测相似性的加权K-近邻法[2](1)核心思想:K-近邻法预测时,默认K 个近邻对观测结果又“同等力度“的影响。
事实上,据0X 的远近观测对预测贡献的大小是有影响的,距离越近对预测的贡献大于距离较远的预测贡献。
将相似性定义为各观测与0X 距离的某种非线性函数,且距离越近,相似性越强,权重越高,预测时的重要性越大。
设观测X 与0X 的距离为),0(∂∈≥d d d 。
若采用函数)(⋅K 将距离d 转换成X 与0X 的相似性,则函数K(d)应有如下特性:越远,相似性越小。
的单调减函数,即距离是)(近时相似性最大。
获得最大值,即距离最)(时,0。
,0)(d d K d K d d d K •=•∂∈≥• 通常,核函数是符合上述特征的函数。
若函数I 为示例函数,⎪⎩⎪⎨⎧≥<=1,01,1)(d d d I 通常核函数有:...。
)1().2exp(π21)():高斯核(。
)1()1()(:)(三角形核。
)1(.21)(:)均匀核(2<-=•<⋅-=•<=•d I dd K Kernel Gauss d I d d K Kernel Triangular d I d K Kernel Uniform(2)步骤第一步:求解误判率最低的k 值;第二步:加权K-近邻法与K-近邻法比较;(3)代码:○1求解误判率最低的k 值; Tmall_train<-read.csv("Train_tmall.csv")Tmall_train$BuyOrNot<-factor(Tmall_train$BuyOrNot)fit<-train.kknn(BuyOrNot~.,data=Tmall_train,kmax=11,distance=2,kernel=c("triangular","rectang ular","epanechnikov"),na.action=na.omit())plot(fit$MISCLASS[,1]*100,type="l",main="不同核函数和近邻个数K 下的错判率曲线图",cex.main=0.8,xlab = "近邻个数",ylab="误判率(%)") lines(fit$MISCLASS[,2]*100,lty=2,col=1) lines(fit$MISCLASS[,3]*100,lty=3,col=2) legend("topleft",legend = c("triangular","rectangular","epanechnikov"),lty=c(1,2,3),col=c(1,1,2),cex=0.7)基于稳健性我们选择了K=7时的误判率○2加权K-近邻法Tmall_test<-read.csv("天猫_Test_1.csv")Tmall_test$BuyOrNot<-as.factor(Tmall_test$BuyOrNot)fit<-kknn(BuyOrNot~.,train=Tmall_train,test=Tmall_test,k=7,distance=2,kernel="gaussian",na.ac tion=na.omit())CT<-table(Tmall_test[,1],fit$fitted.values)errRatio<-(1-sum(diag(CT))/sum(CT))*100K-近邻法Tmall_test<-read.csv("天猫_Test_1.csv")Tmall_test$BuyOrNot<-factor(Tmall_test$BuyOrNot)fit<-knn(train=Tmall_train[,-1],test=Tmall_test[,-1],cl=Tmall_train$BuyOrNot,k=7)CT<-table(Tmall_test[,1],fit)errRatio<-c(errRatio,(1-sum(diag(CT))/sum(CT))*100)errGraph<-barplot(errRatio,main=("加权K-近邻法与K-近邻法错判率对比图"),cex.main=0.8,xlab="分类方法",ylab="错判率(%)",axes=FALSE)axis(side=1,at=c(0,errGraph,3),labels=c("","加权K-近邻法","K-近邻法",""),tcl=0.25)axis(side=2,tcl=0.25)由上图可知,加权K-近邻法错判率比K-近邻法的错判率低,对数据的预测更准确。