多变量模型
第四讲---多变量优化模型

2
函数存在唯一的驻点
(1) A是正定矩阵
对称矩阵
xmin A 1b, f min c bT A 1b
(2) A是负定矩阵
(2) a>0, 抛物线开口向下,
xmax b 4ac b 2 arg max{ f ( x)} , f max x 2a 4a
xmax A 1b, f max c bT A 1b
问题描述的一般形式
可行解集合
S {x n : gi (x) ci , i 1, 2,, m}
min{ f ( x)} n
x
多变量线性回归模型

多变量线性回归模型
多变量线性回归是一种常见的统计分析方法,旨在找出至少两个变量之间的线性关系。
多变量线性回归分析是指,它试图拟合可以描述两个变量之间相互关系的线性模型。
与单
变量回归模型不同,多变量回归模型研究多个变量间的联系,它可以解释某一变量的改变
的影响因素有多少,且各自的影响大小,同时也能衡量变量之间的紧密程度与相互影响的
关系。
多变量线性回归模型由几部分组成:回归系数、偏差项、方差和残差。
回归系数是定
义线性关系的参数,它可以帮助用户预测输出数据的变化。
偏差项是模型的预料之外的偏
离量,这些偏离可以解释数据之间的不匹配率。
方差反映你的数据分布范围。
最后,残差
是预测值和实际值之间的差异。
与单变量回归模型相比,多变量回归模型有许多优点:
(1)可以更好地满足数据需求:多变量回归模型可以根据多个变量中的信息来预测
结果;
(2)可以更有效地更新数据:多变量回归可以动态更新数据,通过实时学习和训练
参数,只要输入变量发生变化,就可以更新数据;
(3)可以更准确地识别结果:由于涉及多个变量,多变量回归模型可以从多个角度
输入所有变量,因此,可以更准确地识别确定的结果。
总之,多变量线性回归模型是一种有效的统计分析技术,可以帮助用户解释多个变量
之间的线性关系,并分析每个变量的影响程度,同时也可以更有效地更新数据,以及准确
地分析结果。
多变量回归模型的建立步骤

多变量回归模型的建立步骤
多变量回归模型是一种用于分析多个自变量和一个因变量之间
关系的统计方法,适用于许多领域,如经济、金融、医学等。
建立一个可靠的多变量回归模型需要以下步骤:
1. 确定因变量和自变量:明确要研究的因变量和自变量,并对其进行量化。
2. 数据收集和整理:收集与自变量和因变量相关的数据,并对数据进行整理和清洗。
3. 变量筛选:通过统计学方法或专家经验对自变量进行筛选,选择与因变量相关性高的自变量。
4. 模型建立:将数据带入多元线性回归方程中,得到多变量回归模型。
5. 模型检验:进行模型的显著性检验、残差分析、多重共线性检验等,验证模型的可靠性和有效性。
6. 模型应用和解释:利用模型预测或解释因变量的变化,同时可以进行模型的调整和改进。
总之,建立多变量回归模型需要进行多个环节的研究和分析,需要综合运用统计学、经济学等知识,以确保模型的可靠性和实用性。
- 1 -。
多变量分析模型

多变量财务风险分析模型美国纽约大学爱德华奥特曼(Edward Alunan)教授在1968年提出的z分数模型(z—score model)。
爱德华奥特曼利用多变量的线性模型来预测公司的经营状况,并提出用Z值作为判别标准。
Z分数模型的表达式为:Z=0.012 X1+0.014 X2+O.033 X3+O.006 X4+O.999 X5其中:X l=(期末流动资产一期末流动负债)期/末总资产,即营运资本/资产总额,反映了企业资产的折现能力和规模特征;X2=期末留存收益/期末总资产,反映了企业的累积获利能力;X3=息税前利润/期末总资产,即总资产息税前利润率,该指标主要是从企业各种资金来源(包括所有者权益和负债)的角度对企业资产的使用效益进行评价,是反映企业财务失败的最有力依据之一;X4=期末股东权益的市场价值/期末总负债,衡量企业财务结构,表明所有者权益和债权人权益相对关系的比率,反映一个企业在破产前的衰弱程度;X5=本期销售收/总资产,即总资产周转率,企业总资产的营运能力集中反映在总资产的经营水平上,因此,总资产周转率可以用来分析企业全部资产的使用效率。
Z分数模型从企业的资产规模、折现能力、获利能力、财务结构、偿债能力、资产利用效率等方面综合反映了企业财务状况,进一步推动了财务预警的发展。
奥特曼教授通过对Z分数模型的研究分析得出:Z值越小,该企业遭受财务失败的可能性就越大。
美国企业Z值的临界值为1.8,具体判断标准如下所示:Z>3.0,表明财务失败的可能性很小;2.8<Z≤3.0,表明有财务失败可能;1.8<Z ≤2.8,财务失败可能性很大;Z≤l.8,财务失败可能性非常大。
奥特曼教授选择了1968年尚在持续经营的33家美国企业过行预测,其准确率令人满意,而且分析根据的资料越新,准确率越高。
如依据l临近财务失败的报表资料预测其准确率为96%,依据财务失败前一年的报表预测准确率为72%。
多变量关系统计模型

多变量关系统计模型
多变量关系统计模型是一种用于描述和分析多个变量之间关系
的数学模型。
在现实世界中,许多现象都是由多个变量相互影响而
产生的,因此需要建立多变量关系统计模型来揭示它们之间的复杂
关系。
在多变量关系统计模型中,通常会涉及到多个因变量和自变量,它们之间可能存在线性或非线性关系。
通过建立数学方程或者统计
模型,可以揭示这些变量之间的关系,从而帮助人们更好地理解现
象的本质和规律。
多变量关系统计模型在许多领域都有着广泛的应用,比如经济学、社会学、生态学、医学等。
在经济学中,可以利用多变量关系
统计模型来分析不同经济指标之间的关系,从而预测未来的经济发
展趋势;在医学领域,可以利用多变量关系统计模型来分析疾病的
发展规律和治疗效果。
然而,建立多变量关系统计模型并不是一件容易的事情,因为
它涉及到多个变量之间复杂的相互作用。
需要充分的数据支持和统
计分析方法来验证模型的有效性和准确性。
总之,多变量关系统计模型是一种强大的工具,可以帮助人们更好地理解和分析复杂的现实世界中的现象,为决策和预测提供有力的支持。
随着数据分析和数学建模技术的不断发展,相信多变量关系统计模型将会在更多的领域得到广泛的应用。
多变量调整模型 -回复

多变量调整模型-回复多变量调整模型在统计学和经济学中被广泛应用,用于探究多个变量之间的关系。
在此文章中,我们将一步一步回答有关多变量调整模型的问题,并探讨其在研究中的应用。
第一步:了解多变量调整模型的基本概念多变量调整模型是一种用于分析多个自变量与一个因变量之间关系的统计模型。
其基本原理是通过控制其他可能干扰因素的影响,来准确评估自变量对因变量的影响。
这种模型可以帮助研究者分离出自变量的独立贡献,并排除其他可能的混淆因素。
第二步:选择合适的模型在多变量调整模型中,我们通常使用线性回归模型,也可以根据问题的需要选择其他的模型。
线性回归模型的基本形式为Y = β0 + β1X1 + β2X2 + …+ βnPn + ε,其中Y是因变量,X1,X2,…,Xn是自变量,β0,β1,β2,…,βn是回归系数,ε是随机误差项。
通过最小二乘法等方法,可以估计出回归系数的值。
第三步:数据收集与准备在执行多变量调整模型之前,我们需要收集相应的数据。
这些数据应当包含因变量和各个自变量的取值,并且经过适当的数据清洗和预处理。
这可能包括处理缺失值、异常值,以及进行数据标准化等操作,以确保数据的质量和可靠性。
第四步:模型拟合与解释一旦数据准备就绪,我们可以将数据导入模型进行拟合和解释。
通过计算回归系数的值,我们可以得出自变量对于因变量的影响程度。
这些系数可以解释自变量对因变量变化的方向和幅度。
例如,如果回归系数为正数,则表示自变量上升将导致因变量的增加,而如果回归系数为负数,则表示自变量上升将导致因变量的减少。
第五步:模型评估与诊断在拟合模型后,我们需要对模型进行评估和诊断,以确保其的准确性和有效性。
常见的评估方法包括计算拟合优度、残差分析、多重共线性检验等。
这些方法可以帮助确定模型是否合适,是否需要调整或改进。
第六步:模型调整与改进如果模型的评估结果不理想,则需要对模型进行调整和改进。
可能需要添加或删除自变量,或者使用其他模型来解决问题。
多变量分析详析模型与多元线性回归

详析模型的步骤
变量选择
选择与预测目标相关的变量,排除无关 或冗余的变量,以提高模型的预测精度
和解释性。
模型评估
利用已知数据对模型进行训练和验证, 评估模型的预测精度和稳定性,对模
型进行优化和调整。
模型构建
根据选择的变量,选择合适的数学模 型进行建模,如线性回归、逻辑回归、 决策树等。
模型应用
将训练好的模型应用于实际数据,进 行预测或推断,并给出相应的解释和 建议。
残差图:通过观察残差与预测值 之间的关系,判断模型是否满足 线性、同方差性和无异常值的假 设。
模型的优化方法
增加变量
通过增加解释变量的数量,提高模型对被解 释变量的解释力度。
变换变量
对某些非线性关系的解释变量进行变换,使 其满足线性关系假设。
删除变量
删除对被解释变量贡献不大的解释变量,简 化模型并提高解释力度。
多元线性回归模型的参数解释
β0(截距)
表示当所有自变量为0时,因变量的估计值。
β1, β2, ..., βp(回归系数)
表示自变量对因变量的影响程度。回归系数的符号表示影响方向(正相关或负相关),绝对值表示影 响程度。
ε(误差项)
表示无法由模型解释的因变量变异,通常假定其服从正态分布。
04
多变量分析详析模型
01
03
然而,多元线性回归模型也存在一些限制和假设,如 线性关系、误差项的独立同分布等,需要在使用时进
行合理考虑和检验。
04
在实际应用中,多元线性回归模型具有广泛的应用领 域,如经济、金融、医学、社会科学等,能够帮助决 策者进行预测和制定策略。
研究展望
随着大数据和机器学习技术 的发展,多变量分析的方法 和技术也在不断进步和创新 。未来可以探索更加复杂和 灵活的模型和方法,以更好 地处理多变量之间的关系和 数据复杂性。
多变量隐马尔可夫模型

多变量隐马尔可夫模型多变量隐马尔可夫模型(Multivariate Hidden Markov Model,简称MHMM)是一种常用的统计模型,用于描述多个随机变量之间的概率关系。
它是隐马尔可夫模型(Hidden Markov Model,简称HMM)在多维空间中的扩展,广泛应用于语音识别、自然语言处理、生物信息学等领域。
隐马尔可夫模型是一种用来描述状态序列和观测序列之间关系的概率模型。
在传统的HMM中,观测序列是一维的,即每个时刻只观测到一个状态。
而在多变量隐马尔可夫模型中,观测序列是多维的,即每个时刻观测到多个状态。
这种模型能够更准确地捕捉到多个变量之间的相关性,提高模型的表达能力和预测准确度。
在多变量隐马尔可夫模型中,有两个基本假设:观测序列和状态序列之间的条件独立性假设,以及状态转移概率和观测概率的马尔可夫性假设。
根据这两个假设,可以通过对观测序列的统计推断来估计模型的参数,进而进行状态预测和序列生成。
多变量隐马尔可夫模型由三个要素组成:初始状态概率向量、状态转移矩阵和观测概率矩阵。
初始状态概率向量表示模型在初始时刻各个状态的概率分布;状态转移矩阵表示模型在各个时刻状态之间转移的概率;观测概率矩阵表示模型在各个状态下观测到各个观测值的概率分布。
通过这些要素,可以计算出给定观测序列的概率,进而进行状态预测和序列生成。
在实际应用中,多变量隐马尔可夫模型常用于语音识别和自然语言处理。
在语音识别中,观测序列可以表示为一段语音信号的频谱特征序列,状态序列可以表示为对应的语音单元序列(如音素或音节);在自然语言处理中,观测序列可以表示为一段文本的词向量序列,状态序列可以表示为对应的词性序列。
通过训练多变量隐马尔可夫模型,可以提高语音识别和自然语言处理的准确性和效率。
多变量隐马尔可夫模型是一种强大的统计模型,能够描述多个随机变量之间的概率关系。
它在语音识别、自然语言处理、生物信息学等领域有着广泛的应用。
第十六讲多变量分析--详析模型

10
在因果分析中,第三类变项(变量)称为前置 变项—因它在因果模型中是先于x和y的
引进若干w,辨别x和y的因果关系是不是虚假 的:如果我们能控制w,使之不变,而x变化时 y也起变化,那么,x和y的关系可能就是真实 的。
除了W的影响外,还
会有其他因素的影响
11
教育水平
生育子女数
重男轻女
25
2、结果 完全阐明:X完全是通过T影响Y的 不能阐明:X完全不是通过T而影响Y 部分阐明:X是部分通过T影响Y的
26
(三)条件分析与互动效果
关注的是在不同情况下,X和Y的关系会不同吗? 条件分析就是以第三类变项(如C)为基础来了解X与
Y在不同情况下的关系。 结果:如果在各组中X与Y的关系大致上相同,则表示
家庭经济水平
住房拥挤
夫妻冲突 ?
14
因此引进经济水平变量,再进行分析
15
2、研究的结果
(1)x与y的关系消失:表示X和Y的关系是 虚假的,他们的原关系是因为W所致。
W
X
Y
16
(2)X与Y的关系维持原状:X与Y的 关系可能是真实的,并非由W所致
W
X
Y
17
(3)X与Y虽仍有关系,但其相关度减弱 了,也就是各分表中x与y的关系不等于0, 但相关程度却低于原表中的相关。
如果,在控制T以后X变而Y亦变,则证明T是 无关紧要的,即X不是通过T而影响Y的。
研究的方法:与因果分析相同,通过分解T比 较X与Y的关系。
23
例:调查了近300名年纪相近的妇女,发展教育水 平(x)越高,子女数目(y)越少(G=-0.70)。为什 么?
(1)如果以晚婚来解释,教育水平越高的妇女结婚 越晚,因而生的孩子就较少。
多变量预警模型名词解释

多变量预警模型名词解释
1. 多变量预警模型:一个由多个不同变量组合而成的模型,用于对特定情况进行预测和预警,一般采用统计方法和机器学习算法进行建模和优化。
2. 变量:在多变量预警模型中,指用来描述和衡量某种现象或情况的属性,如时间、地点、温度、湿度、风速等。
3. 统计学方法:包括回归分析、时间序列分析、因子分析、聚类分析等,用于探索变量之间的相关性和影响。
4. 机器学习算法:包括决策树、神经网络、支持向量机、随机森林等,能够从数据中学习和发现规律,对模型进行训练和优化。
5. 预测:将模型用于未来情况的预测,基于历史数据和现有信息,对潜在风险进行评估和预警。
6. 预警:基于预测结果和特定阈值,发出警报或提醒,以采取相应的措施进行干预或预防。
四计量经济学多变量回归分析模型

n
2
Min[Yi ( 0 1 X 1i ... p X pi )]
i 1
n
^
^
^
2
• 根据最 小二乘原 理,参数 估计值应 该是右列 方程组的 解
ˆ 0 ˆ 1 ˆ 2 ˆ k
ˆ ˆ X ˆ X ˆ X ˆ Y i 0 1 1i 2 2i ki Ki
2 ˆ Q e (Yi Yi ) i 1 2 i i 1 n n
i=1,2…n
其 中
ˆ ˆ X ˆ X ˆ X )) (Yi ( 0 1 1i 2 2i k ki
1 Y1 X 1n Y2 Y X kn n
0 1 β 2 k
X 11 X 12 X 1n
X 21 X X kn n ( k 1 )
( k 1 )1
1 μ 2 n n 1
用来估计总体回归函数的样本回归函数为:
ˆ ˆ X ˆ X ˆ X ˆ Y i 0 1 1i 2 2i ki ki
ˆ ˆ X ˆ X ˆ X e 其随机表示式: Yi 0 1 1i 2 2i ki ki i
ei称为残差或剩余项(residuals),可看成 是总体回归函数中随机扰动项i的近似替代。
表示:各变量X值固定时Y的平均响应。
j也被称为偏回归系数,表示在其他解释变
量保持不变的情况下,X j每变化1个单位时,Y的 均值E(Y)的变化; 或者说j给出了X j的单位变化对Y均值的 “直接”或“净”(不含其他变量)影响。
多变量回归分析模型
我们,可以选择一些最重要的因素,而且比 较容易收集特别是在社会上人们更加关注这 些变量。 我们的模型可以是这样的:
log( ) = β0 +β1Sex β2Edu β3Epr β4Maj β5Pos ε Wage + + + + +
2011-1-19
中山大学南方学院经济系
16
这里,wage=工资水平 Sex =性别 Edu =学历 Epr =工作经验 Maj =专业种类 pos =职务高低 这里我们通过最小二乘法要估计的参数值。 我们对“工资水平”这个变量取对数,为的 是在预测时确保得到正值。
2011-1-19 中山大学南方学院经济系 28
小结
总的来说,当我们在设计回归分析模型的时 候,既要考虑必要性,又要考虑可能性。 必要性,就是该自变量在影响因变量上面的 重要程度。 可能性,就是指是否可以取到样本。 当然,某一自变量从理论上看来非常必要的 因素,但在实际研究的过程中很难取到样本 ,那么我们就要想办法找到一个能够替代该 变量的可取变量。
2011-1-19
中山大学南方学院经济系
4
TSS表示________; RSS表示________; ESS表示________。
2011-1-19
中山大学南方学院经济系
5
Y 在计量经济学的回归模型中, i 表示 ________; Yˆi 表示________;
表示________。 表示________,可以通过________计算 公式得到。
2011-1-19
中山大学南方学院经济系
26
我们可以通过以下模型来估计:
GDPt = β 0 + β1GDPt −1 + β 2 G g + β 3 I f + + β 4WTOt + β 5 Pt + ε t
贝叶斯共享参数多变量联合模型

贝叶斯方法是一种统计推断方法,可以用来估计参数的后验分布,根据数据更新对参数的先验信念。
在贝叶斯统计中,共享参数多变量联合模型通常指的是多个随机变量之间共享相同的参数,通过贝叶斯方法来进行联合建模和推断。
一个典型的共享参数多变量联合模型可以用贝叶斯网络(Bayesian Network)或潜变量模型(Latent Variable Model)来表示。
在这样的模型中,不同的随机变量之间可能存在依赖关系,共享相同的参数或潜在变量来描述它们之间的关系。
通过贝叶斯方法,我们可以利用观测数据来估计模型中的参数和潜在变量,并对未观测的变量进行推断。
在实际应用中,共享参数多变量联合模型可以被广泛用于各种领域,比如机器学习、计算机视觉、自然语言处理等。
常见的模型包括多任务学习(Multi-Task Learning)、深度生成模型(Deep Generative Models)等,这些模型可以通过共享参数或潜在变量来提高模型的泛化能力和效率。
多变量调整模型

多变量调整模型多变量调整模型,也称为多元回归模型,是一种应用于数据分析和预测的方法。
它可以帮助我们理解多个自变量与因变量之间的关系,并进行预测和解释。
在多变量调整模型中,我们考虑多个自变量对因变量的影响,并通过适当的统计方法来估计它们之间的关系。
这个模型可以用数学公式表示为:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε其中,Y是因变量,X1, X2, ..., Xn是自变量,β0, β1, β2, ..., βn是回归系数,ε是误差项。
回归系数表示了自变量对因变量的影响程度,误差项则表示了模型无法解释的部分。
多变量调整模型的建立过程通常包括以下几个步骤:1. 收集数据:首先需要收集相关的数据,包括自变量和因变量的观测值。
这些数据应该是对问题领域的真实反映,样本的大小也需要足够大,以保证模型的准确性和可靠性。
2. 变量选择:根据问题的需求和数据的特点,选择合适的自变量。
可以使用相关性分析、主成分分析等方法来帮助选择合适的自变量。
3. 模型拟合:使用最小二乘法等方法,对模型进行拟合,估计回归系数。
拟合过程中会计算残差(观测值与模型估计值之间的差异),并进行统计检验来评估模型的拟合程度。
4. 模型评估:对模型进行评估,包括检验假设、分析回归系数的显著性、解释模型的可靠性等。
可以使用t检验、F检验等方法进行评估。
5. 模型解释:解释回归系数的含义和影响。
回归系数可以告诉我们自变量对因变量的贡献大小和方向。
例如,正的回归系数表示自变量对因变量的影响是正向的,负的回归系数表示自变量对因变量的影响是负向的。
多变量调整模型的优点在于可以同时考虑多个自变量对因变量的影响,减少了单变量分析可能引入的偏误和混淆。
通过控制其他自变量的影响,我们可以更准确地评估每个自变量对因变量的影响,提高模型的预测能力。
不过,多变量调整模型的建立也存在一些限制。
首先,模型的拟合结果和解释可能受到数据质量和样本大小的限制。
第四讲---多变量优化模型
4.3 无约束优化问题的求解方法 Matlab库函数及其使用说明
优化向 量的范 围限制
[x, FVAL, EXITFLAG, OUTPUT, GRAD, HESSIAN] =fminunc(FUN,x,options,varargin)
极小 值点
极小 值
迭代次 数等信 息
最优 点梯 度
最优点 Hessian 矩阵
雷达信号处理国防科技重点实验室
4.1 多变量优化建模举例
优化模型
max P( s, t ) (339 0.01s 0.003t s (399 0.004s 0.01t )t (400000 195s 225t )} subject to s 0, t 0
最优的生产方案是:19寸生产4735台,21寸 生产7043台, 最大利润为 553641(美元)
雷达信号处理国防科技重点实验室
4.3 无约束优化问题的求解方法
min{ f ( x)} n
x
n>1情况
f (x) xT Ax 2bT x c, f ( x) 2 Ax 2b 0 x A 1b (A 是可逆的对称矩阵) T T T AA x Ax x x 2
•黑色变量-决策/优化变量 •蓝色变量-中间变量 •红色变量-优化变量
基本假设(变量间相互关系)
p 339 0.01s 0.003t q 399 0.004 s 0.01t R ps qt C 400000 195s 225t P R C s0 t0
数学建模基础
第四讲: 多变量优化模型
---水鹏朗 雷达信号处理国防科技重点实验室
4.1 多变量优化建模举例
多变量probit模型stata代码

多变量probit模型stata代码
多变量probit模型是处理多个相关变量的二元选择问题的有效工具。
在Stata中,可以使用“cmp”命令来估计多变量probit模型。
该模型可以根据特定的预测变量来预测个体的选择情况,例如在某个产品市场上的购买行为。
以下是多变量probit模型在Stata中的代码实现步骤:
步骤1:建立数据框
首先需要在Stata中建立一个包含所有需要估计的变量的数据框。
假设我们的数据框名称为“mydata”,包含三个二元选择变量“y1”、“y2”和“y3”,以及三个预测变量“x1”、“x2”和“x3”。
步骤2:运行cmp命令
使用cmp命令来估计多变量probit模型,以预测所有三个选择变量。
命令语法如下:
cmp (y1 y2 y3) (x1 x2 x3)
其中,括号中的“y1 y2 y3”表示我们要预测的三个二元选择变量,“x1 x2 x3”中包含了我们用来预测选择变量的三个预测变量。
步骤3:解释结果
输出的结果中,最重要的是协方差矩阵和误差方差矩阵。
这些矩阵可以用来计算相关变量之间的关系以及预测模型的准确性。
此外,还可以利用输出的结果来计算每个预测变量对于每个选择变量的影响。
这可以通过计算每个预测变量的系数来实现。
综上所述,多变量probit模型是一个有效的工具,可以用来处理多个相关变量的二元选择问题。
在Stata中,可以使用“cmp”命令来估计此类模型,并通过相关结果来解释变量之间的关系以及预测模型的准确性。
多变量模型

40000a 49
40000a 49
40000a 49
(400000 195 1662000 225(8700 581700 ))
40000a 49
40000a 49
图1.5画出了P关于a的曲线图。由图上显示,19英寸彩
电的价格弹性系数a的提高,会导致利润的下降。
而当a=0.01时有:
常量
1.两种彩电的初始定价:339美元和399美元; 2.其对应的成本分别为:195美元和225美元; 3.每种彩电多销售一台,平均售价下降系数a=0.01 美元(称为价格弹性系数),两种彩电之间的销售 相互影响系数分别为0.004美元和0.003美元; 4.固定成本为400000美元。
变量之间的相互关系确定:
可以用相对改变量衡量结果对参数的敏感程度。s对a 的灵敏性记作 S(s,,a定) 义为
S(s,a) ds a
da s
当a=0.01时有:
S (s, a)
ds
a
1.14
da s
同理可得:
S(t,a) dt a 0.268 da t
如果19英寸彩电的价格弹性系数在0.01美元/台的基
础上提高10%,则我们应该将19英寸彩电的生产量在4735 台
1)产量对a的灵敏性分析
在模型中我们假设a=0.01美元/台,将其带入前面的公 式中,我们得到:
P(s,t) (339-as 0.003t)s (399 0.004s 0.01t)t (400000 195s 225t)
令P关于s,t的偏导数为零,则:
s(a) 1662000 40000a 49
(3)
da s da t da a
由于在极值点P s与P t 都为零,则有
多变量probit模型stata代码

多变量probit模型stata代码
在这篇文章中,我们将介绍如何使用Stata进行多变量probit 模型的分析。
Probit模型是一种常见的用于处理二元分类问题的统计模型。
在多变量probit模型中,我们将考虑多个自变量对因变量的影响,同时考虑它们之间的联合影响。
首先,我们需要输入数据集到Stata中。
假设我们的数据集包含了三个自变量X1、X2、X3,以及一个二元因变量Y。
接下来,我们需要运行命令“mvprobit Y X1 X2 X3”来进行模型拟合。
此命令将同时估计每个自变量的系数,以及它们之间的相关系数。
我们可以使用“estat correlations”命令来查看这些相关系数的估计值。
在得到模型估计值后,我们可以使用“predict”命令来进行预测。
例如,我们可以使用“predict prob”来生成每个观测值的概率预测值。
最后,我们可以使用各种命令来评估模型的质量。
例如,我们可以使用“xtabond”命令来构建混淆矩阵,或使用“roc”命令来绘制接收者操作特征(ROC)曲线。
综上所述,使用Stata进行多变量probit模型分析需要几个简单的步骤。
首先,输入数据集,然后使用“mvprobit”命令进行模型拟合。
接下来,使用“predict”命令生成预测值,并使用各种命令对模型进行评估。
- 1 -。
多变量回归模型的有偏估计
27第2卷 第24期产业科技创新 2020,2(24):27~28Industrial Technology Innovation多变量回归模型的有偏估计毛雪莲(西安财经大学行知学院,陕西 西安 710038)摘要:多变量模型的估计中经常出现模型结果异常的现象。
文章在无偏估计量不合理基础上,尝试使用有偏估计方法进行分析,结果表明有偏估计更为理想。
关键词:多变量;回归;有偏估计中图分类号:O212 文献标识码:A 文章编号:2096-6164(2020)24-0027-02多变量回归模型中,自变量之间通常存在严重的复多重共线性,对此问题的处理方法可分为两类:一类是无偏的估计,如逐步回归法,对数变换法等;一类是有偏的估计方法,如岭回归等。
哪些方法可以得到更为有效的估计结果,如何判断有效性等,本文将对此进行探讨。
这里以我国国内旅游收入为研究对象,在已有研究的基础上,鉴于近几年自驾游不断增加,模型中增加公路里程这一变量,并扩展数据到2018年。
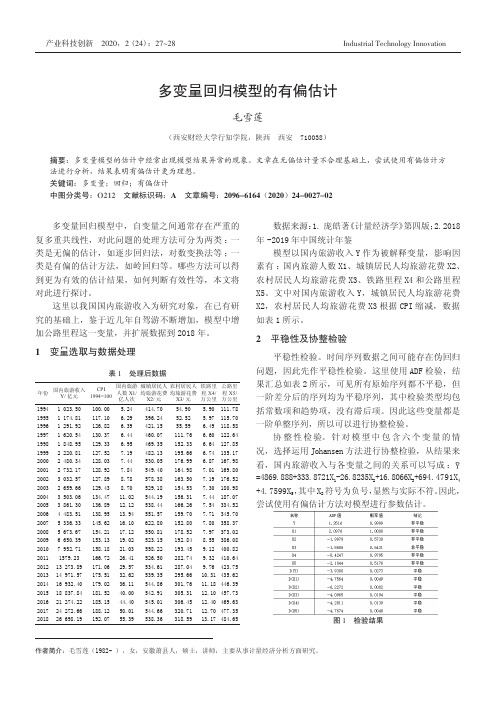
1 变量选取与数据处理表1 处理后数据年份国内旅游收入Y/亿元CPI1994=100国内旅游人数X1/亿人次城镇居民人均旅游花费X2/元农村居民人均旅游花费X3/元铁路里程X4/万公里公路里程X5/万公里1994 1 023.50100.00 5.24414.7054.90 5.90111.78 1995 1 174.81117.10 6.29396.2452.52 5.97115.70 1996 1 291.92126.82 6.39421.1555.59 6.49118.58 1997 1 620.54130.37 6.44460.07111.76 6.60122.64 1998 1 848.95129.33 6.95469.35152.33 6.64127.85 1999 2 220.81127.527.19482.13195.66 6.74135.17 2000 2 480.34128.037.44530.05176.99 6.87167.98 2001 2 732.17128.927.84549.40164.987.01169.80 2002 3 032.57127.898.78578.38163.507.19176.52 2003 2 659.66129.438.70529.18154.537.30180.98 2004 3 503.06134.4711.02544.19156.317.44187.07 2005 3 861.30136.8912.12538.44166.267.54334.52 2006 4 483.51138.9513.94551.57159.707.71345.70 2007 5 336.33145.6216.10622.80152.807.80358.37 2008 5 673.67154.2117.12550.81178.527.97373.02 2009 6 650.39153.1319.02523.15192.848.55386.08 20107 952.71158.1821.03558.22193.459.12400.82 20111579.23166.7226.41526.50282.749.32410.64 201213 273.89171.0629.57534.61287.049.76423.75 201314 971.57175.5132.62539.35295.6610.31435.62 201416 932.40179.0236.11544.86301.7611.18446.39 201518 837.84181.5240.00542.91305.3112.10457.73 201621 274.22185.1544.40545.01306.4512.40469.63 201724 272.66188.1250.01544.66320.7112.70477.35 201826 698.19192.0755.39538.36318.5913.17484.65数据来源:1.庞皓著《计量经济学》第四版;2.2018年-2019年中国统计年鉴模型以国内旅游收入Y作为被解释变量,影响因素有:国内旅游人数X1、城镇居民人均旅游花费X2、农村居民人均旅游花费X3、铁路里程X4和公路里程X5。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
图形说明
图1.1给出了函数P的3维图象,图象显示,P在内部达到 最大值; 图1.2给出了P的水平集图,从中我们可以估计出P的最 大值出现在s=5000,t=7000附近。函数P是一个抛物面,其 最高点为方程组的唯一解。
图1.1 彩电问题的利润y关于19英寸彩电的生产量x1和 21英寸彩电的生产量x2的3维图象
问题1:
一家彩电制造商计划推出两种新产品:一种19英寸立体声彩色电视
机,制造商建议零售价为339美元。另一种21英寸立体声彩色电视机,零售价 为399美元。公司付出的成本为19英寸彩店每台195美元,21英寸彩电每台
225
美元,还要加上400000美元的固定成本。在竞争的销售市场中,每年售出的 彩
电数量会影响彩电的平均售价。据估计,对每种类型的彩电,每多售出一台,
3 结果说明
简单来说,这家公司今年可以通过生产4735台19 英寸彩电和7043台21英寸彩电来获得最大利润,每 年 获得的净利润为553641美元。 19英寸彩电的每台平均售价为270.52美元;21英 寸彩电的每台平均售价为309.63美元;生产总支出为 2907950美元,相应的利润率为19%。这些数据显示 有利可图,因此建议公司推出新产品。
其中a=0.0ቤተ መጻሕፍቲ ባይዱ.
模型求解
1 求解方法: (1)求出稳定点(s0 , t0),即解方程组
P( s, t ) 0 s P( s, t ) 0 t
(2)判断是否在稳定点处取极值,方法如下:
1)先计算
2 P ( s, t ) D1 s 2 ( s
0 , t0 )
相互影响系数分别为0.004美元和0.003美元;
4.固定成本为400000美元。
变量之间的相互关系确定:
假设1:对每种类型的彩电,每多售出一台,平均销售 价格会下降1美分。
假设2:据估计,每售出一台21英寸彩电,19英寸的彩 电平均售价会下降0.3美分,而每售出一台19英寸的彩 电,21英寸彩电的平均售价会下降0.4美分。
平均销售价格会下降1美分。而且19英寸彩电的销售会影响21英寸彩电的销 售,反之也是如此。据估计,每售出一台21英寸彩电,19英寸彩电的平均售
价
会下降0.3美分,而每售出一台19英寸彩电,21英寸彩电的平均售价会下降 0.4
美分。问题是:每种彩电应该各生产多少台?
步骤:
1.问题分析、假设与符号说明 2.建立数学模型 3.模型求解 4.灵敏性分析
因此,原问题转化为求s≥0和t≥0,使得P取得最大值。
建立数学模型
由上述分析与基本假设,原问题的数学模型如下:
max P ( s, t ) (339-as 0.003t )s (399 0.01t 0.004s )t (400000 195s 225t ) s.t s 0, t 0
变量之间的相互关系确定:
因此,19英寸彩电的销售价格为: p=339 - a×s - 0.003×t,此处a=0.01 21英寸彩电的销售价格为: q=399 - 0.01×t - 0.004×s 因此,总的销售收入为: R=p×s + q×t 生产成本为: C=400000 + 195×s + 225×t 净利润为: P=R-C
1662000 40000a 49 581700 t (a) 8700 40000a 49 s(a)
(1)
图1.3,1.4画出了s(a),t(a)关于a的曲线图。 由图上显示,19英寸彩电的价格弹性系数a的提高,会导致 19英寸彩电的最优生产量s的下降,及21英寸彩电的最优生产 量t的提高。
0 0
0 , t0 )
P ( s, t ) t 2 ( s
0 , t0 )
2 计算结果 运用Mathematica计算得出:
稳定点为:(4735,7043), D1= -0.02< 0, D2=0.000351 >0, 所以P(s,t)在稳定点处取得 最大值553641.
其它数据为:p=270.52,q=309.63,C=2907950,利润率=0.190385
1)产量对a的灵敏性分析 在模型中我们假设a=0.01美元/台,将其带入前面的公 式中,我们得到:
P ( s, t ) (339-as 0.003t ) s (399 0.004s 0.01t )t (400000 195s 225t )
令P关于s,t的偏导数为零,则:
符号说明(变量)
s=19英寸彩电的售出数量(台); t=21英寸彩电的售出数量(台); p=19英寸彩电的平均销售价格(美元/台); q=21英寸彩电的平均销售价格(美元/台); C=生产彩电的成本(美元); R=彩电销售的收入(美元); P=彩电销售的利润(美元)。
常量
1.两种彩电的初始定价:339美元和399美元; 2.其对应的成本分别为:195美元和225美元; 3.每种彩电多销售一台,平均售价下降系数a=0.01 美元(称为价格弹性系数),两种彩电之间的销售
图1.2 彩电问题中关于19英寸彩电的生产量x1和 21英寸彩电的生产量x2的利润函数有的水平集图
灵敏性分析:
由于在模型中我们假设19英寸彩电的价格弹性系数 a=0.01美元/台,所以应该研究它的微小变化对模型结果的
影响。而模型主要求的是生产量以及最大利润,所以我们
只考虑a的微小变化对这两个的影响。
图1.3 s关于a的灵敏性曲线
图1.4 t关于a的灵敏性曲线
可以用相对改变量衡量结果对参数的敏感程度。s对a 的灵敏性记作 S (s,,a 定义为 )
D2
2 P ( s, t ) s 2 ( s 2 P ( s, t ) st ( s
0 , t0 )
2)判断 若D1 > 0,D2 >0,则(s0 , t0)是极小值点; 若D1 < 0,D2 >0,则(s0 , t0)是极大值点; 2 D2 <0,则(s0 , t0)不是极值点; 若 P ( s, t ) 若 则不能肯定(s0 , t0)是不是极 D s t =0, 2 ( s ,t ) 2 值点,还需进一步判定。