mysql索引初探.ppt
MySQL事务、索引、数据恢复和备份全套电子课件完整版ppt整本书电子教案最全教学教程整套课件

| Field | Type
| Null | Key | Default | Extra
|
+-------+--------------+------+-----+---------+----------------+
| id | int(11)
| NO | PRI | NULL | auto_increment |
只转储给定的WHERE条件选择的记录
该选项是速记;等同于指定 --add-drop-tables --add-locking --create-option --disable-keys--extended-insert --lock-tables --quick --set-charset
24/32
作用
避免同一个表中某数据列中的值重复
与主键索引的区别
主键索引只能有一个 唯一索引可有多个
示例
CREATE TABLE `Grade` (
`GradeID` INT(11) AUTO_INCREMENT PRIMARY
KEY,
`GradeName` VARCHAR(32) NOT NULL UNIQUE
顾客A在线购买一款商品,价格为500.00元,采用网上银行转账的 方式支付
假如顾客A银行卡的余额为2000.00元,且向卖家B支付购买商品费 用500.00元,起始卖家B的账号金额10000.00元
创建数据库shop和创建表account并插入2条数据
+-------+--------------+------+-----+---------+----------------+
《数据库索引》课件

目录 Contents
• 引言 • 数据库索引的类型 • 数据库索引的创建与维护 • 数据库索引的性能优化 • 数据库索引的案例分析 • 总结与展望
01
引言
数据库索引的定义
数据库索引是一种数据结构,用于快 速检索数据库表中的数据。它通过创 建一个指向表中数据的指针,提高了 查询速度和数据检索效率。
唯一索引
确保索引列的唯一性,但不要求非空 。
全文索引
用于文本搜索。
控制索引的列数
单列索引
只对单个列创建索引。
多列索引
对多个列创建复合索引,但查询 时需要满足复合索引的最左前缀 原则。
避免在索引列上使用函数或运算
01
避免在索引列上使用函数或运算 ,这会导致索引失效,从而影响 查询性能。
02
例如,应避免在索引列上使用 `UPPER()`、`LOWER()`、 `TRIM()` 等函数。
定期重建和重新组织索引
随着数据的插入、更新和删除,索引可能会变得碎片化,影 响性能。
定期重建和重新组织索引可以优化性能,并保持索引的健康 状态。
05
数据库索引的案例分析
案例一:使用索引优化查询性能
总结词
通过合理使用索引,可以显著提高数据库查询性能。
详细描述
在大型数据库中,如果没有索引,查询性能可能会变得很 差。通过创建合适的索引,可以快速定位到所需的数据, 大大减少查询时间。
全文索引
总结词
用于全文搜索的索引。
详细描述
全文索引是一种特殊的索引类型,主要用于全文搜索。全文索引将文本内容拆分成多个词汇,并建立词汇与记录 之间的对应关系,通过全文索引可以快速查找到包含特定词汇的记录。全文索引在文本搜索、内容筛选等方面具 有重要作用。
Mysql索引简入门

28 type: ref
29 possible_keys: index1_id
30 key: index1_id
31 key_len: 5
32 ref: const
注意:选择索引的最终目的是为了使查询的速度变快。上面给出的原则是最基本的准则,但不能拘泥于上面的准则。读者要在以后的学习和工作中进行不断的实践。根据应用的实际情况进行分析和判断,选择最合适的索引方式。
7.2 创建索引
创建索引是指在某个表的一列或多列上建立一个索引,以便提高对表的访问速度。创建索引有3种方式,这3种方式分别是创建表的时候创建索引、在已经存在的表上创建索引和使用ALTER TABLE语句来创建索引。本节将详细讲解这3种创建索引的方法。
2.为经常需要排序、分组和联合操作的字段建立索引
经常需要ORDER BY、GROUP BY、DISTINCT和UNION等操作的字段,排序操作会浪费很多时间。如果为其建立索引,可以有效地避免排序操作。
3.为常作为查询条件的字段建立索引
如果某个字段经常用来做查询条件,那么该字段的查询速度会影响整个表的查询速度。因此,为这样的字段建立索引,可以提高整个表的查询速度。
索引有其明显的优势,也有其不可避免的缺点。
索引的优点是可以提高检索数据的速度,这是创建索引的最主要的原因;对于有依赖关系的子表和父表之间的联合查询时,可以提高查询速度;使用分组和排序子句进行数据查询时,同样可以显著节省查询中分组和排序的时间。
索引的缺点是创建和维护索引需要耗费时间,耗费时间的数量随着数据量的增加而增加;索引需要占用物理空间,每一个索引要占一定的物理空间;增加、删除和修改数据时,要动态的维护索引,造成数据的维护速度降低了 。
第三章 MySQL索引

5 全文索引
全文索引在 MySQL 中是一个 FULLTEXT 类型索引。FULLTEXT 索 引用于 MyISAM 表,可以在 CREATE TABLE 时或之后使用 ALTER TABLE 或 CREATE INDEX 在 CHAR、VARCHAR 或TEXT 列上创 建。对于大的数据库,将数据装载到一个没有 FULLTEXT 索引的表 中,然后再使用ALTER TABLE (或 CREATE INDEX) 创建索引,这 将是非常快的。将数据装载到一个已经有FULLTEXT 索引的表中,将 是非常慢的。 全文搜索通过 MATCH() 函数完成。
5 全文索引
删除索引的语法: DROP INDEX index_name ON tableName
6 单列索引和组合索引
索引分单列索引和组合索引 单列索引:即一个索引只包含单个列,一个表可以有多个单列索引, 但这不是组合索引。 组合索引:即一个索包含多个列。 为了对比两者,再建一个表: CREATE TABLE myIndex ( i_testID INT NOT NULL AUTO_INCREMENT, vc_Name VARCHAR(50) NOT NULL, vc_City VARCHAR(50) NOT NULL, i_Age INT NOT NULL, i_SchoolID INT NOT NULL, PRIMARY KEY (i_testID) ); 在这 10000 条记录里面 7 上 8 下地分布了 5 条 vc_Name="erquan" 的记录,只不过 city,age,school 的组合各不相同。
பைடு நூலகம்
2 普通索引
• 修改表结构: ALTER table tableName ADD INDEX [index_name] [index_type] (index_col_name,...) 在列 id 上添加索引
MySQL基础通关脑图-索引
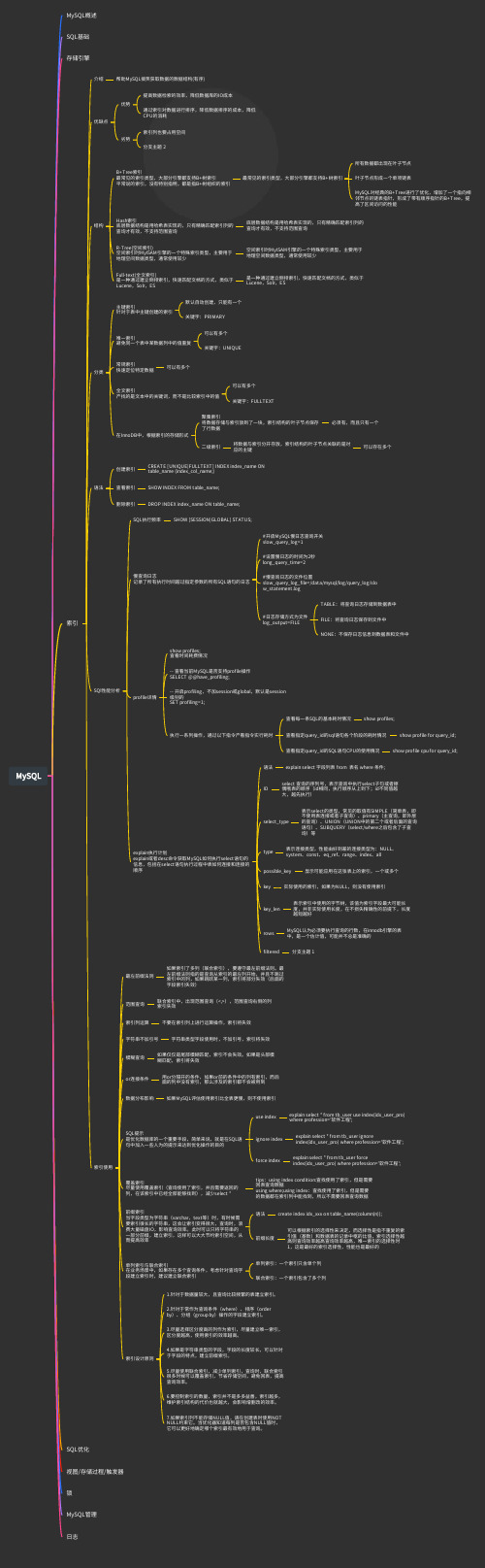
My S QL My S QL概述S QL基础存储引擎索引S QL优化视图/存储过程/触发器锁My S QL管理⽇志介绍优缺点结构分类语法S Q l性能分析索引使⽤最左前缀法则范围查询索引列运算字符串不加引号模糊查询or连接条件数据分布影响S QL提⽰是优化数据库的一个重要⼿段,简单来说,就是在S QL语句中加⼊一些⼈为的提⽰来达到优化操作的⽬的覆盖索引尽量使⽤覆盖索引(查询使⽤了索引,并且需要返回的列,在该索引中已经全部能够找到),减少selec t *前缀索引当字段类型为字符串(v arc h ar,t e xt等)时,有时候需要索引很⻓的字符串,这会让索引变得很⼤,查询时,浪费⼤量磁盘IO,影响查询效率。
此时可以只将字符串的一部分前缀,建⽴索引,这样可以⼤⼤节约索引空间,从⽽提⾼效率单列索引与联合索引在业务场景中,如果存在多个查询条件,考虑针对查询字段建⽴索引时,建议建⽴联合索引索引设计原则S QL执⾏频率慢查询⽇志记录了所有执⾏时间超过指定参数的所有S QL语句的⽇志p ro fi le详情e xp la i n执⾏计划e xp la i n或者d esc命令获取My S QL如何执⾏selec t语句的信息,包括在selec t语句执⾏过程中表如何连接和连接的顺序1.针对于数据量较⼤,且查询⽐较频繁的表建⽴索引。
2.针对于常作为查询条件(wh ere)、排序(or d erby)、分组(grou p by)操作的字段建⽴索引。
3.尽量选择区分度⾼的列作为索引,尽量建⽴唯一索引,区分度越⾼,使⽤索引的效率越⾼。
4.如果是字符串类型的字段,字段的⻓度较⻓,可以针对于字段的特点,建⽴前缀索引。
5.尽量使⽤联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提⾼查询效率。
6.要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越⼤,会影响增删改的效率。
《数据库索引》幻灯片

以下图展示了聚集索引〔Innodb〕与非聚集索引〔MyISAM)的索 引布局:
索引高效使用
2.在聚集索引的表中插入新行,当行必须被移动的时候,会进展分页。分页会占 用更多的存储空间。
3.第二索引会变大,因为它们叶子节点要包含被引用行的主键列。这样第二索引 的查找需要两次,首先找到引用行的主键列,然后查找行数据。
B-Tree索引的局限: 1.没有从索引列的最左边开场将不起作用。 2.不能跳过索引中的列,不然只有索引前一局部的索引生效。 3.不能优化第一个范围条件右边的列。
索引类型
哈希索引 对于每一行,存储引擎根据被索引的列计算出哈希码,它是一个很小的 值,并且有可能和其它行的哈希码不同,它把哈希码保存到索引中, 并且保存了一个哈希表中每一行的一个指针。 在哈希索引的数据构造中,索引的哈希值是有序的,但是指针指向的数 据行不是有序的。 哈希索引哈希值的长度不会依赖于索引列,TINNYINT的索引和大型 字符串的索引大小是一样的。所以查找速度还是很快的。但是也有一 些缺点:
《数据库索引》幻灯片
本课件PPT仅供大家学习使用 学习完请自行删除,谢谢! 本课件PPT仅供大家学习使用 学习完请自行删除,谢谢! 本课件PPT仅供大家学习使用 学习完请自行删除,谢谢! 本课件PPT仅供大家学习使用 学习完请自行删除,谢谢!
索引根底
索引是提高查询速度的最重要的工具。当然还有其它的一些技术 可供使用,但是一般来说引起最大性能差异的都是索引的正确使用与 否。
主键索引与第二索引
索引分类
索引类型
使用B-Tree索引的查询类型 B-Tree索引能够很好的用于全键值,键值范围以及键前缀的索引查找,
mysql教程PPT(无水印)

MySQL的应用场景
网站和Web应用
MySQL是许多流行的网站和Web应用 的数据库首选。
数据仓库和分析
MySQL可以用于构建数据仓库和进 行数据分析,支持大数据处理和数据
挖掘。
企业应用
MySQL适用于各种企业级应用,如 客户关系管理(CRM)、人力资源管 理和财务管理等。
游戏开发
MySQL可以用于游戏开发中的后端 数据库管理,支持游戏数据存储和查 询。
04 安全性
随着网络安全问题的日益突出, MySQL将加强数据加密、身份验 证等方面的安全措施,确保用户 数据的安全与隐私。
THANKS
日志记录
01
启用并配置MySQL的日志记录功能,记录用户的活动和数据库
的更改。
安全审计
02
定期审查和分析日志记录,发现潜在的安全威胁和异常行为。
日志轮换和管理
03
设置日志轮换计划,定期清理旧的日志文件,确保日志文件不
会无限制增长。
06
MySQL与其他数据库的比较 和未来发展
与其他数据库的比较
Oracle
表的创建和管理
创建表
使用`CREATE TABLE`语 句创建一个新的表。
删除表
使用`DROP TABLE`语 句删除一个存在的表。
修改表
使用`ALTER TABLE`语 句修改一个存在的表。
数据插入、查询、更新和删除
数据插入
使用`INSERT INTO`语句将数据 插入到表中。
数据查询
使用`SELECT`语句查询表中的 数据。
数据库的备份和恢复
备份
备份是创建数据库副本的过程,用于防止数据丢失和灾难恢复。MySQL支持多 种备份方法,如全备份、增量备份和差异备份。
mysql索引初探

组合索引
• 创建组合索引 create table ‘key_t’ ( ‘id’ int(11) not null auto_increment, ‘key1’ int(11) not null, ‘key2’ int(11) not null, ‘key3‘ int(11) not null, primary key (‘id’), key ‘normak_key’ (‘key1’, ‘key2’, ‘key3’) )
使用explain解析查询
• 很多时候我们需要知道为哪些字段建立索 引。 • 使用explain可以用来帮助我们分析任何的查 询语句,但是不包括哪些导致数据更新的 语句(例如update语句)。
使用慢查询分析工具
• 在mysql中开启慢查询日至,在f增加 以下配置。 • long_query_time = 1 • log-slow-queries = /data/var/mysql_slow.log
– 创建表时指定
create table test ( id int not null, username varchar(16) not null, unique [indexname] (username(length)) )
主键索引
• 主键索引:是一种特殊的唯一索引,不允 许有空值。 一般是在创建表的时候同时创建。
组合索引
有的时候我们有多个查询条件时,例如: … where a = 1 and b = 2 … where a = 1 order by b … where a = 1 group by b 这中情况下即使我们分别给a和b都建立了索 引,它们仍然也不能同时发挥作用。为了应 付这样的查询,我们需要使用组合索引。
Mysql 索引初探
对mysql索引的研究和学习

一、索引是什么MySQL官方对索引的定义为:索引(Index)是帮助MySQL 高效获取数据的数据结构,而MYSQL使用的数据结构是:B+树1.1 局部性原理程序和数据的访问都有聚集成群的倾向,在一个时间段内,仅使用其中一小部分,在最近的将来将用到的信息很可能与现在正在使用的信息在空间地址上是临近的(称空间局部性),或者最近访问过的程序代码和数据,很快又被访问的可能性很大(称时间局部性)。
1.2 磁盘预读预读的长度一般为页(page)的整数倍页是存储器的逻辑块,操作系统往往将主存和磁盘存储区分割成连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页大小通常为4K),主存和磁盘以页为单位交换数据1.3 简介在使用数据库中,通常数据库查询是数据库的最主要功能之一。
但每种查找算法都只能应用于特定的数据结构之上。
•例如二分查找要求被检索数据有序•而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。
这种数据结构,就是索引。
索引一般以文件形式存储在磁盘上,索引检索需要磁盘I/O操作。
所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。
1.索引是帮助MYSQL 高效获取数据的数据结构2.索引存储在文件系统中3.索引的文件存储形式与存储引擎有关4.索引文件的结构:hash、二叉树、B树、B+树二、索引的分类2.1 hash这里有一个mysql数据文件,有Id和name两个列,如果我们用hash格式存储的话(hash表),我们只要计算出某一个列的hash值,把它按照按照数组的长度取一个模,就可以取到从0-7n个下标的位置,这样的话效率其实是比较高的,但是用hash表存储,它具备一定的缺点:1.利用hash存储的话需要将所有的数据文件添加到内存中,比较耗费内存空间2.如果所有的查询都是等值查询,那么hash确实很快,但是在企业或者实际工作环境中范围查找的数据更多,而不是等值查询,因为hash就不太适合了,因此在mysql里面并没有选择hash存储的格式2.2 二叉树索引格式:对于树有他是有一个更新跌过的顺序在里面,不要一上来就看结构,先是了解什么树,树都是由一个树根,然后有n多个分支组成,这些分支就是一些树形结构,多你有多个树分支(多元素)的时候,这个时候查找效率就会比较低,因此就有了二叉树的东西,二叉树为什么会好用一点,因为二叉树它是都有两个分支,但是两个分支的话,会导致一个效果,就是每次我们在查找数据的时候,类似于二分查找的,但是二叉树也有自己不太好的地方,大家可以看我们上图中的二叉树的索引格式,在左边的节点会比较短一点(只需要读三次),而右边的节点会长很多(需要读五次),会导致树的深度比较深,每一次树的节点读取,都会有一次IO,深度越高,IO越高,会影响我们数据读取的效率,因此也有了(平衡二叉树)和(红黑树)平衡二叉树:维护一个平衡,就是左子树和右子树高度之差,不能大于1,但是对于我们上面的格式就不太适合,因为他已经超过1了,但是AVL树也会有一个问题就是调整的次数太频繁了,它里面涉及到了一个操作就是旋转,一种左旋,一个右旋,为了保持平衡需要N多次的旋转,这样的旋转其实是很浪费时间的,每次新增或者删除的时候,都要经历N多次旋转,效率太低了推荐大家一个网站,可以直接看到AVL树操作过程,有不了解的同学可以去看一看,很形象:AVL Trees (Balanced binary search trees)红黑树:本身也是一个平衡树,但是它从中间做了一个权衡,就是损失一部分平衡的性能,但是又保持了相对的平衡,它做了这样一个操作,就是最长子树的高度,只要不超过最短子树的两倍,就可以了,同时在红黑树中它引入了红和黑两个节点信息,有了这些信息它可以帮助我们做一个平衡,在AVL树有旋转保持平衡,而红黑树有了旋转和变色两种来保持平衡,红黑树是AVL树的进阶,它损失了一部分平衡的性能,但是维护了我们插入和删除数据的高效,虽然它损失了一部分性能,但是它依然是一个平衡树,既然是平衡树,他最长子树,不超过最短子树的两倍,那意味着如果最短子树是4 ,那么最长子树就是8,这样在们查找数据的时候,又不是一个二分查找了,效率又会变低无论是二叉树还是红黑树,都会因为树的深度过深而造成IO次数变多,影响数据的读取的效率,最重要的就是减少IOIO是我们IT行业中的一个瓶颈,一个是磁盘IO一个是网络IO,我们作为软件开发,是没有办法去调整硬件方面的瓶颈,只能从从程序里面减少我们的IO量,我们有两个方向,一个是减少IO的次数,一个是减少IO的量,从这两个方面去解决,比如说原来我们读取数据要读10次,现在只要读取一次,这样的IO量就少了10倍,原来我们需要读1MB的数据,现在只要读1KB的数据,这也就是为什么我们在写mysql查询语句的时候不推荐使用select * from ,因为这样的查询会查询到N多个字段,本来我只要两个字段,但是给了我30个字段,这样会导致IO量增加了,因此我们就会去考虑,关于索引的次数能不能减少,因此下面就引出了我们的——B树2.3 B树B树的特点:•所有的键值分布在整颗树中•搜索有可能在非叶子结点结束,在关键字全集内做一次查找,性能逼近二分查找•每个节点最多拥有m个子树•根节点至少有2个子树•分支节点至少拥有m/2颗子树(除根节点和叶子节点外都是分支节点)•所有叶子节点都在同一层,每个节点最多可以有m-1个key,并且以升序排列B树结构说明:示例图说明:每个节点占用一个磁盘块,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址,两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。
MySQL(五)MySQL中的索引详讲

MySQL(五)MySQL中的索引详讲 序⾔ 之前写到MySQL对表的增删改查(查询最为重要)后,就感觉MySQL就差不多学完了,没有想继续学下去的⼼态了,原因可能是由于别⼈的影响,觉得对于MySQL来说,知道了⼀些复杂的查询,就够了,但是我认为,不管有没有⽤,现在学着不懂的东西,说明就是⾃⼰薄弱的地⽅,多学才能⽐别⼈更强 --WZY⼀、什么是索引?为什么要建⽴索引? 索引⽤于快速找出在某个列中有⼀特定值的⾏,不使⽤索引,MySQL必须从第⼀条记录开始读完整个表,直到找出相关的⾏,表越⼤,查询数据所花费的时间就越多,如果表中查询的列有⼀个索引,MySQL能够快速到达⼀个位置去搜索数据⽂件,⽽不必查看所有数据,那么将会节省很⼤⼀部分时间。
例如:有⼀张person表,其中有2W条记录,记录着2W个⼈的信息。
有⼀个Phone的字段记录每个⼈的电话号码,现在想要查询出电话号码为xxxx的⼈的信息。
如果没有索引,那么将从表中第⼀条记录⼀条条往下遍历,直到找到该条信息为⽌。
如果有了索引,那么会将该Phone字段,通过⼀定的⽅法进⾏存储,好让查询该字段上的信息时,能够快速找到对应的数据,⽽不必在遍历2W条数据了。
其中MySQL中的索引的存储类型有两种:BTREE、HASH。
也就是⽤树或者Hash值来存储该字段,要知道其中详细是如何查找的,就需要会算法的知识了。
我们现在只需要知道索引的作⽤,功能是什么就⾏。
⼆、MySQL中索引的优点和缺点和使⽤原则 优点: 2、所有的MySql列类型(字段类型)都可以被索引,也就是可以给任意字段设置索引 3、⼤⼤加快数据的查询速度 缺点: 1、创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加 2、索引也需要占空间,我们知道数据表中的数据也会有最⼤上线设置的,如果我们有⼤量的索引,索引⽂件可能会⽐数据⽂件更快达到上线值 3、当对表中的数据进⾏增加、删除、修改时,索引也需要动态的维护,降低了数据的维护速度。
Mysql索引

索引MySQL官方对索引的定义为:索引(index)是帮助MySQL高效获取数据的数据结构。
可以得到索引的本质:索引是数据结构。
你可以简单理解为”排好序的快速查找数据结构“。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。
我们平常所说的索引,如果没有特别指明,都是指B树(多路搜索树,并不一定是二叉的)结构组织的索引。
其中聚集索引,次要索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引,当然除了B+树这种类型的索引之外,还有哈希索引(hash index等)优势:(1)类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本。
(2)通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
劣势:(1)实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引也是要占用空间的。
(2)虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。
(3)因为更新表,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新带来的键值变化后的索引信息。
索引的目的在于提高查询效率,可以类比字典。
如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql。
如果没有索引,那么你可能需要a-----z,如果我想找到java开头的单词呢?或者oracle开头的单词呢?是不是觉得如果没有索引,这个事情根本无法完成?索引分类:单值索引:即一个索引只包含单个列,一个表可以有多个单列索引。
唯一索引:索引列的值必须唯一,但允许有空值。
复合索引:即一个索引包含多个列。
创建索引:CREATE [UNIQUE] INDEX indexName ON mytable(columnname(length));ALTER mytable ADD [UNIQUE] INDEX[indexName] ON (columnname(length));删除索引:DROP INDEX [indexName] ON mytable;查看索引:SHOW INDEX FORM table_name;mysql索引结构:(1)BTree索引初始化介绍一颗b+树,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。
第9章 MySQL索引 第1节 索引

3. 不合理使用索引的注意事项
不应该创建索引:对于那些在查询中很少使用或者参考的列不应该创建索引
应该增加索引用:对于那些只有很少数据值的列也不应该增加索引用
不应该增加索引:对于那些定义为text、image和bit数据类型的列不应该增加 索引。
当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就 降低了数据的特征,即唯一性索引和复合索引。 唯一性索引保证在索引列中的全部数据是唯一的,不会包含冗余数据。 复合索引就是一个索引创建在两个列或者多个列上。
3. 索引的分类
普通索引:在创建普通索引时,不附加任何限制条件。 唯一性索引:使用UNIQUE参数可以设置索引为唯一性索引。 全文索引:使用FULLTEXT参数可以设置索引为全文索引。 单列索引:在表中的单个字段上创建索引。 多列索引:多列索引是在表的多个字段上创建一个索引。
注意:如果从表中删除某列,则索引会受影响。对于多列组合的索引,如果删 除其中的某列,则该列也会从索引中删除。如果删除组成索引的所有列,则整个索 引将被删除。
9.3 设计原则和注意事项
1.索引的设计原则 2.合理使用索引注意事项 3.不合理使用索引的注意事项
1. 索引的设计原则
选择唯一性索引 为经常需要排序、分组和联合操作的字段建立索引 为常作为查询条件的字段建立索引 限制索引的数目 尽量使用数据量少的索引 尽量使用前缀来索引 删除不再使用或者很少使用的索引
在已存在的表上创建索引 语法格式: create index 索引名 ON 表名 (属性名 [ ( 长度) ] [ asc | desc ]);
使用alter table语句来创建索引。 语法格式: alter table table_name add index | key [索引名] ( 属性名 [ ( 长度 ) ] [ asc | desc ])
MySQL索引

MySQL索引前⾔因为现在使⽤的mysql默认存储引擎是Innodb,所以本篇⽂章重点讲述Innodb下的索引,顺带简单讲述其他引擎。
希望⼩伙伴们能通过这⽚⽂章对mysql的索引有更加清晰的认识,废话不多说,我们开始吧。
索引介绍⾸先,我们先带着⼀些问题来看接下来的内容。
索引是个什么东西?我们可以创建哪些索引?哪些字段适合建⽴索引呢?索引是不是越多越好呢?为什么我们不建议使⽤uuid、⾝份证号等数据做为主键?为什么不建议使⽤select * from table?我们使⽤模糊匹配 ’%三‘ ’张%‘ 在前在后会影响索引的使⽤吗?上⾯的问题我们⼤家可能都存在或者部分存在疑惑,接下来就是解惑的时间。
什么是索引在关系数据库中,索引是⼀种单独的、物理的对数据库表中⼀列或多列的值进⾏排序的⼀种存储结构,它是某个表中⼀列或若⼲列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。
索引的作⽤相当于图书的⽬录,可以根据⽬录中的页码快速找到所需的内容。
mysql中索引有哪些类型普通索引通索引是mysql⾥最基本的索引,没有什么特殊性,在任何⼀列上都能进⾏创建。
-- 创建索引的基本语法CREATE INDEX indexName ON table(column(length));-- 例⼦ length默认我们可以忽略CREATE INDEX idx_name ON user(name);主键索引我们知道每张表⼀般都会有⾃⼰的主键,mysql会在主键上建⽴⼀个索引,这就是主键索引。
主键是具有唯⼀性并且不允许为NULL,所以他是⼀种特殊的唯⼀索引。
⼀般在建⽴表的时候选定。
复合索引复合索引也叫组合索引,指的是我们在建⽴索引的时候使⽤多个字段,例如同时使⽤⾝份证和⼿机号建⽴索引,同样的可以建⽴为普通索引或者是唯⼀索引。
复合索引的使⽤复合最左原则。
举个例⼦我们使⽤ phone和name创建索引。
-- 创建索引的基本语法CREATE INDEX indexName ON table(column1(length),column2(length));-- 例⼦CREATE INDEX idx_phone_name ON user(phone,name);我们看下⾯的查询语句,SELECT * FROM user_innodb where name = '程冯冯';SELECT * FROM user_innodb where phone = '151********';SELECT * FROM user_innodb where phone = '151********' and name = '程冯冯';顺序不⼀样,为什么4可以⽤到索引呢?是因为mysql本⾝就有⼀层sql优化,他会根据sql来识别出来该⽤哪个索引,我们可以理解为3和4在mysql眼中是等价的。
mysql分享之索引1

520093696
20.5
索引设计与创建
索引创建 创建索引需考虑执行频率及其带来的负面影响,原则是确保收 益为正 在建表时,应充分考虑需要添加什么索引,尽量避免上线后添 加索引 4.1 创建索引过程 5.5 创建索引过程 创建索引过程需要锁表!!!!
要决定是否创建一个索引需要知道什么信息?
mysql分享之索引
Agenda
索引简介 索引结构 索引设计与创建 索引与查询 索引与DML 索引与锁 索引使用误区
索引维护技巧
Agenda
索引简介 索引结构 索引设计与创建 索引与查询 索引与DML 索引与锁 索引使用误区
索引维护技巧
索引简介
索引定义
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库 表中的特定信息
Agenda
索引简介 索引结构 索引设计与创建 索引与查询 索引与DML 索引与锁 索引使用误区
索引维护技巧
索引维护技巧/注意点
长字段索引(如URL) innodb索引只能索引767字节;myisam只能索引1000字节 大索引占用空间多;索引高度高;降低buffer命中率 模拟hash索引,添加一字段,存储其hash值 需要维护多个索引 version>=5.5,逐个添加或者删除 version<5.5,多个操作合并为一个,如alter table t drop key a,add key b(col); 提高索引空间利用率 一般索引的空间利用率在60%-70% 按照索引的顺序写入数据可提升索引空间利用率 版本<5.5,无解,除非索引顺序和主键顺序一致 版本>=5.5,条件允许的话,写入数据前删除主键以外所有索引,按主键顺序写入索引, 然后再创建复制索引 扩展索引 如索引从一个字段扩展为两个字段 版本<5.5,在一个SQL中处理 版本>=5.5,先添加新索引,再删除老索引
MySQL 索引深度解析

MySQL 索引深度解析简单理解就是去看一本书的‘索引’部分,如果想找到一本书的特定部分,一般会先看书的‘索引’,然后找到对应的页码。
‘索引’可以理解为‘目录’。
在MYSQL中存储引擎用类似的方法使用索引,先在索引中找到对应值,然后根据匹配的索引记录找到对应的数据行。
1.索引有什么用?加快检索表中数据,亦即能协助信息搜索者尽快的找到符合限制条件的记录ID。
2.索引怎么用?在查询时where条件为有索引的字段的情况下以及符合使用规则的时候就会使用索引。
3.索引的分类(按照类型)3.1.B-Tree索引3.1.1.特点B-Tree上的值都是有序存储的,并且每个叶子页到根节点的距离都相同。
叶子节点的指针指向的是被索引的数据而不是其他的节点页。
3.1.2.检索原理首先从根节点进行二分查找,如果找到则返回对应节点的data,否则对相应区间的指针指向的节点递归进行查找,直到找到节点或未找到节点返回null指针。
3.1.3.缺点1.插入删除新的数据记录会破坏B-Tree的性质,因此在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质。
会造成IO操作频繁。
2.区间查找可能需要返回上层节点重复遍历,IO操作繁琐。
3.2.B+Tree索引3.2.1特点相比B-Tree,B+Tree在原有基础上,还有以下不同点:非叶子节点不存储data,只存储索引key;只有叶子节点才存储data。
3.2.2.MySQL的B+Tree在经典B+Tree的基础上增加了顺序访问指针优化。
在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。
提高了范围查询性能:如果要查询key为从10到50的所有数据记录,当找到10后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提高了区间查询效率。
因为无需像B-Tree那样返回上层父节点重复遍历查找减少IO操作。
结构如下:3.2.3.为什么Mysql选择B+TREE索引? B+TREE索引有什么好处?索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
– 创建表时指定
create table test ( id int not null, username varchar(16) not null, unique [indexname] (username(length))
)
主键索引
• 主键索引:是一种特殊的唯一索引,不允 许有空值。
一般是在创建表的时候同时创建。
key2, key3 • select * from key_t where key1= 1 order by
key2
组合索引
select * from key_t where key2 = 777 limit 10 上面的查询其实是使用了normal_key的索引, 它的结果是基于normal_key索引de扫瞄,而 不是基于数据本身的扫描。
– 删除索引 – drop index [indexname]on table
唯一索引
• 唯一索引 索引列的值必须唯一,但允许有空 值。
– 创建索引
• create unique index indexname on table (colunm(length))
– 修改表结构
• alter table add unique [indexname] on (colunm(length))
当组合索引不能发挥作用时将会带来严重的 查询负担,一个包含多个字段的组合索引的 尺寸可能已经超过了数据本身。 根据查询的需求来设计有针对性的组合索引。
使用explain解析查询
• 很多时候我们需要知道为哪些字段建立索 引。
• 使用explain可以用来帮助我们分析任何的查 询语句,但是不包括哪些导致数据更新的 语句(例如update语句)。
引本身的更新。 • 需要开发人员来维护索引。
索引失效的情况
• 有些where条件会导致索引无效 • where子句的查询条件里有!=,mysql将无法使用索引。 • where子句使用了mysql的函数时,索引将无效。例
如:select * from web_news where left(title, 4) = ‘1111’; • 在使用like进行搜索匹配时,这样索引时有效的。例 如:select * from web_news where title like ‘111%’, 而’%...%’时无效的。 • 使用or语句来连接条件。例如:select * from t where num = 10 or num = 20 • 当索引列有大量重复数据时,sql查询可能不会去利 用索引。Mysql ຫໍສະໝຸດ 引初探朱振超索引是什么
Mysql官方对索引的定义为:索引是帮助 Mysql高效获取数据的数据结构。
普通索引
• 普通索引 最基本的类型,没有任何限制 – 创建索引 • create index indexname on table(columun(length)) – 修改表结构 • alter table add index indexname on column(length) – 创建表的时候创建索引 create table ‘test’ ( ‘id’ int not null auto_increment, ‘title’ char(255), primary key(‘id’), index [indexname] (title(length)) )
使用慢查询分析工具
• 在mysql中开启慢查询日至,在f增加 以下配置。
• long_query_time = 1 • log-slow-queries = /data/var/mysql_slow.log
索引的代价
• 索引文件本身耗费存储空间 • 当建立索引的字段发生更新时,会引发索
组合索引
• 创建组合索引 create table ‘key_t’ ( ‘id’ int(11) not null auto_increment, ‘key1’ int(11) not null, ‘key2’ int(11) not null, ‘key3‘ int(11) not null, primary key (‘id’), key ‘normak_key’ (‘key1’, ‘key2’, ‘key3’) )
组合索引
• 在组合索引有一个原则叫最左前缀。 • select * from key_t where key1 = 1 • select * from key_t where key1 = 1 and key2=
2 • select * from key_t where key1 =1 order by
组合索引
有的时候我们有多个查询条件时,例如: … where a = 1 and b = 2 … where a = 1 order by b … where a = 1 group by b 这中情况下即使我们分别给a和b都建立了索 引,它们仍然也不能同时发挥作用。为了应 付这样的查询,我们需要使用组合索引。