第三次实验(EVIEWS实现多元线性回归
基于EVIEWS软件下的多元线性回归分析

基于EVIEWS软件下的多元线性回归分析基于EVIEWS软件下的多元线性回归分析1. 引言多元线性回归分析是统计学中常用的一种方法,用于探究多个自变量对于因变量的影响程度和相关关系。
EVIEWS是一款常用的计量经济学软件,提供了多元线性回归模型的分析工具,具有高度的可视化和分析能力。
本文将利用EVIEWS软件,进行多元线性回归分析,探究自变量与因变量之间的关系。
2. 方法2.1 数据收集本研究收集了一份包含多个自变量和一个因变量的数据集。
自变量可以是各种影响因素,如年龄、性别、教育程度等,而因变量可以是根据自变量变化而得出的某种结果,如收入、消费水平等。
通过EVIEWS软件导入并编辑数据,确保数据的准确性和完整性。
2.2 模型构建在EVIEWS软件中,选择合适的多元线性回归模型。
首先,根据研究目的和现实情况,选择一个因变量和多个自变量,并进行变量选择和变量处理。
然后,在EVIEWS软件中建立多元线性回归模型,将因变量作为依变量,自变量作为自变量。
2.3 模型分析进行多元线性回归分析后,EVIEWS软件将给出模型的各项统计指标,包括回归系数、截距项、方差分析表等,并进行显著性检验,以判断自变量的影响是否显著。
此外,EVIEWS软件还能够提供模型残差的分析结果,用于检验模型的合理性和适用性。
3. 结果与讨论将多元线性回归模型的结果进行解读。
回归系数表示了自变量单位变化对因变量的变化程度。
通过检验回归系数的显著性水平,可以判断自变量的影响是否具有统计学意义。
方差分析表则能够提供模型的拟合程度,判断模型是否能够解释因变量的变异情况。
在讨论中,可以分析模型结果是否符合研究假设,自变量与因变量之间的关系是否与预期一致。
如果模型结果不如预期,可以进一步分析可能的原因,并考虑是否需要增加或调整自变量,以提高模型的解释力。
4. 结论本文利用EVIEWS软件进行了多元线性回归分析,通过分析回归系数、方差分析表等结果,探究了自变量与因变量之间的关系。
Eviews实验报告

Eviews实验报告
本次实验使用Eviews对数据进行了分析和建模,主要分为以下几个部分:
一、数据预处理
1. 数据清洗:对数据进行了初步的检查和清洗,处理了数据中的缺失值和异常值;
2. 数据变换:对原始数据进行了对数化处理,使其符合正态分布。
二、数据分析
1. 描述性统计:通过统计均值、标准差、相关系数等指标,对数据进行了分析和描述;
2. 单因素分析:使用单因素方差分析对不同自变量与因变量之间的关系进行了检验。
三、建模分析
1. 模型选择:根据变量相关性和变量显著性等因素,最终选择了一组自变量,建立了多元线性回归模型;
2. 模型检验:对建立的模型进行了残差分析,验证了模型的可靠性和稳定性;
3. 预测分析:利用建立的模型对新数据进行了预测,并进行了模型预测精度的评估。
四、实验结论
通过Eviews的分析和建模,得出了以下结论:
1. 数据清洗和变换可以提高数据分析的准确性和可靠性;
2. 描述性统计和单因素分析可以为建模提供有用的参考和决策依据;
3. 多元线性回归模型可以较好地解释自变量与因变量之间的关系,并可进行预测和决策分析。
综上所述,本次实验通过Eviews软件对数据进行了分析和建模,得出了有关数据的一些重要结论,为后续数据分析和决策提供了基础和支持。
计量经济学实验三

多元回归模型与非线性回归模型【实验目的】掌握多元回归模型参数估计,特别是非线性回归模型的转化、参数估计及检验方法。
【实验内容】一、多元回归模型参数估计;二、生成序列以及可线性化模型的参数估计;三、不可线性化模型的迭代估计法的Eviews 软件的实现方式。
【实验数据】建立我国国有独立核算工业企业生产函数。
根据生产函数理论,生产函数的基本形式为:()ε,,,K L t f Y =。
其中,L 、K 分别为生产过程中投入的劳动与资金,时间变量t 反映技术进步的影响。
表3-1列出了我国1978-1994年期间国有独立核算工业企业的有关统计资料;其中产出Y 为工业总产值(可比价),L 、K 分别为年末职工人数和固定资产净值(可比价)。
资料来源:根据《中国统计年鉴-1995》和《中国工业经济年鉴-1995》计算整理【实验步骤】Y=AK一、建立多元线性回归模型㈠建立包括时间变量的三元线性回归模型; μββββ++++=L K T Y 3210在命令窗口依次键入以下命令即可: ⒈建立工作文件: CREATE A 78 94 ⒉输入统计资料: DATA Y L K ⒊生成时间变量t : GENR T=@TREND(77) ⒋建立回归模型: LS Y C T L K 则生产函数的估计结果及有关信息如图3-1所示。
图3-1 我国国有独立核算工业企业生产函数的估计结果 因此,我国国有独立工业企业的生产函数为:K L t y 7764.06667.06789.7732.675ˆ+++-= (模型1) t =9958.02=R 9948.02=R 551.1018=F模型的计算结果表明,我国国有独立核算工业企业的劳动力边际产出为,资金的边际产出为,技术进步的影响使工业总产值平均每年递增亿元。
回归系数的符号和数值是较为合理的。
9958.02=R ,说明模型有很高的拟合优度,F 检验也是高度显著的,说明职工人数L 、资金K 和时间变量t 对工业总产值的总影响是显著的。
经验分享使用eviews做回归分析

[经验分享] 使用eview s做线性回归分析Glossa ry:ls(least square s)最小二乘法R-sequar ed样本决定系数(R2):值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,解决这个问题使用来调整Adjust R-seqaur ed()S.E of regression回归标准误差Log likelihood对数似然比:残差越小,L值越大,越大说明模型越正确Durbin-Watson stat:DW统计量,0-4之间Mean dependent var因变量的均值S.D. dependent var因变量的标准差Akaike info criter ion赤池信息量(AIC)(越小说明模型越精确)Schwar z ctiter ion:施瓦兹信息量(SC)(越小说明模型越精确)Prob(F-statis t ic)相伴概率fitted(拟合值)线性回归的基本假设:1.自变量之间不相关2.随机误差相互独立,且服从期望为0,标准差为σ的正态分布3.样本个数多于参数个数建模方法:ls y c x1 x2 x3 ...x1 x2 x3的选择先做各序列之间的简单相关系数计算,选择同因变量相关系数大而自变量相关系数小的一些变量。
模型的实际业务含义也有指导意义,比如m1同g dp肯定是相关的。
模型的建立是简单的,复杂的是模型的检验、评价和之后的调整、择优。
模型检验:1)方程显著性检验(F检验):模型拟合样本的效果,即选择的所有自变量对因变量的解释力度F大于临界值则说明拒绝0假设。
Eviews给出了拒绝0假设(所有系统为0的假设)犯错误(第一类错误或α错误)的概率(收尾概率或相伴概率)p 值,若p小于置信度(如0.05)则可以拒绝0假设,即认为方程显著性明显。
Eviews处理多元回归分析操作步骤

操作步骤1.建立工作文件(1)建立数据的exel电子表格(2)将电子表格数据导入eviewsFile-open-foreign data as workfile,得到数据的Eviews工作文件和数据序列表。
2.计算变量间的相关系数在窗口中输入命令:cor coilfuture dow shindex nagas opec ueurope urmb,点击回车键,得到各序列之间的相关系数。
结果表明Coilfuture数列与其他数列存在较好的相关关系。
3.时间序列的平稳性检验(1)观察coilfuture序列趋势图在eviews中得到时间序列趋势图,在quick菜单中单击graph,在series list对话框中输入序列名称coilfuture,其他选择默认操作。
图形表明序列随时间变化存在上升趋势。
(2)对原序列进行ADF平稳性检验quick-series statistics-unit root test,在弹出的series name对话框中输入需要检验的序列的名称,在test for unit root in 选择框中选择level,得到原数据序列的ADF检验结果,其他保持默认设置。
得到序列的ADF平稳性检验结果,检测值0.97大于所有临界值,则表明序列不平稳。
以此方法,对各时间序列依次进行ADF检验,将检验值与临界值比较,发现所有序列的检验值均大于临界值,表明各原序列都是非平稳的。
(3)时间序列数据的一阶差分的ADF检验quick-series statistics-unit root test,在series name对话框中输入需要检验的序列的名称,在test for unit root in 选择框中选择1nd difference,对其一阶差分进行平稳性检验,其他保持默认设置。
得到序列的ADF平稳性检验结果,检测值-7.8远小于所有临界值,则表明序列一阶差分平稳。
以此方法,对各时间序列的一阶差分依次进行ADF检验,将检验值与临界值比较,发现所有序列的检验值均小于临界值,表明各序列一阶差分都是平稳的。
多元线性回归实验报告
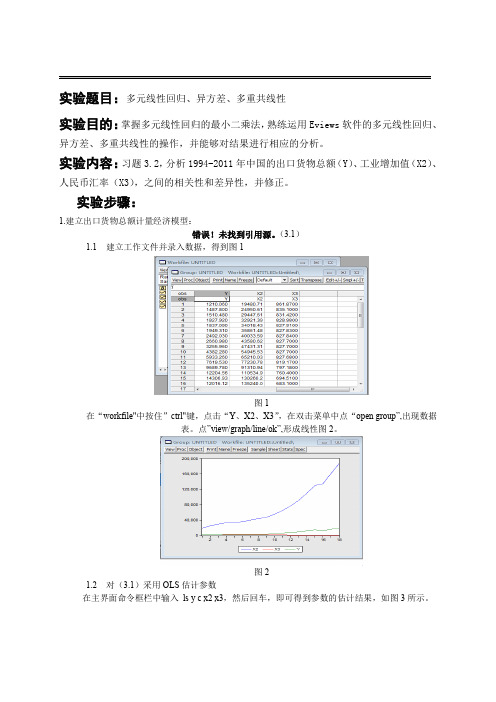
实验题目:多元线性回归、异方差、多重共线性实验目的:掌握多元线性回归的最小二乘法,熟练运用Eviews软件的多元线性回归、异方差、多重共线性的操作,并能够对结果进行相应的分析。
实验内容:习题3.2,分析1994-2011年中国的出口货物总额(Y)、工业增加值(X2)、人民币汇率(X3),之间的相关性和差异性,并修正。
实验步骤:1.建立出口货物总额计量经济模型:错误!未找到引用源。
(3.1)1.1建立工作文件并录入数据,得到图1图1在“workfile"中按住”ctrl"键,点击“Y、X2、X3”,在双击菜单中点“open group”,出现数据表。
点”view/graph/line/ok”,形成线性图2。
图21.2对(3.1)采用OLS估计参数在主界面命令框栏中输入ls y c x2 x3,然后回车,即可得到参数的估计结果,如图3所示。
图 3根据图3中的数据,得到模型(3.1)的估计结果为(8638.216)(0.012799)(9.776181)t=(-2.110573) (10.58454) (1.928512)错误!未找到引用源。
错误!未找到引用源。
F=522.0976从上回归结果可以看出,拟合优度很高,整体效果的F检验通过。
但当错误!未找到引用源。
=0.05时,错误!未找到引用源。
=错误!未找到引用源。
2.131.有重要变量X3的t检验不显著,可能存在严重的多重共线性。
2.多重共线性模型的识别2.1计算解释变量x2、x3的简单相关系数矩阵。
点击Eviews主画面的顶部的Quick/Group Statistics/Correlatios弹出对话框在对话框中输入解释变量x2、x3,点击OK,即可得出相关系数矩阵(同图4)。
相关系数矩阵图4由图4相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实解释变量之间存在多重共线性。
2.2多重共线性模型的修正将各变量进行对数变换,在对以下模型进行估计。
Eviews-多元回归模型

多元回归分析案例——中国税收增长的分析一、研究的目的要求改革开放以来,随着经济体制改革的深化和经济的快速增长,中国的财政收支状况发生很大变化,中央和地方的税收收入1978年为519.28亿元,到2002年已增长到17636.45亿元,25年间增长了33倍,平均每年增长%。
为了研究影响中国税收收入增长的主要原因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经济模型。
影响中国税收收入增长的因素很多,但据分析主要的因素可能有:(1)从宏观经济看,经济整体增长是税收增长的基本源泉。
(2)公共财政的需求,税收收入是财政收入的主体,社会经济的发展和社会保障的完善等都对公共财政提出要求,因此对预算支出所表现的公共财政的需求对当年的税收收入可能会有一定的影响。
(3)物价水平。
我国的税制结构以流转税为主,以现行价格计算的GDP等指标和经营者的收入水平都与物价水平有关。
(4)税收政策因素。
我国自1978年以来经历了两次大的税制改革,一次是1984-1985年的国有企业利改税,另一次是1994年的全国范围内的新税制改革。
税制改革对税收会产生影响,特别是1985年税收陡增215.42%。
但是第二次税制改革对税收增长速度的影响不是非常大。
因此,可以从以上几个方面,分析各种因素对中国税收增长的具体影响。
二、模型设定为了全面反映中国税收增长的全貌,选择包括中央和地方税收的“国家财政收入”中的“各项税收”(简称“税收收入”)作为被解释变量,以反映国家税收的增长;选择“国内生产总值(GDP)”作为经济整体增长水平的代表;选择中央和地方“财政支出”作为公共财政需求的代表;选择“商品零售物价指数”作为物价水平的代表。
由于财税体制的改革难以量化,而且1985年以后财税体制改革对税收增长影响不是很大,可暂不考虑税制改革对税收增长的影响。
所以解释变量设定为可观测的“国内生产总值”、“财政支出”、“商品零售物价指数”等变量。
eviews多元的回归

回归模型的估计和统计检验一、实验目的:使用EViews软件进行多元回归估计和统计检验二、实验内容:考察中国1980-2001年被解释变量国债发行总量(DEBT,亿元)与选择3个解释变量,财政赤字额(DEF,亿元),国内生产总值(GDP,百亿元),年还本付息额(REPAY,亿元)是否存在线性关系。
数据如下:Obs DEBT DEF GDP REPAY 1980 43.01 68.9 45.178 28.58 1981 121.74 -37.38 48.624 62.89 1982 83.86 17.65 52.947 55.52 1983 79.41 42.57 59.345 42.47 1984 77.34 58.16 71.71 28.9 1985 89.85 -0.57 89.644 39.56 1986 138.25 82.9 102.022 50.17 1987 223.55 62.83 119.625 79.83 1988 270.78 133.97 149.283 76.76 1989 407.97 158.88 169.092 72.37 1990 375.45 146.49 185.479 190.07 1991 461.4 237.14 216.178 246.8 1992 669.68 258.83 266.381 438.57 1993 739.22 293.35 346.344 336.22 1994 1175.25 574.52 467.594 499.36 1995 1549.76 581.52 584.781 882.96 1996 1967.28 529.56 678.846 1355.03 1997 2476.82 582.42 744.626 1918.37 1998 3310.93 922.23 783.452 2352.92 1999 3715.03 1743.59 820.6746 1910.53 2000 4180.1 2491.27 894.422 1579.82 2001 4604 2516.54 959.333 2007.73数据来源:中国统计年鉴,中国统计出版社三、实验过程1.工作文件,或录入数据,建立组group01(1)作散点图从散点图可以看出国债发行总量(Y)与财政赤字额(X2),国内生产总值(X3),年还本付息额(X4)大体呈现为线性关系,为分析中国国债的发行额与经济总规模,财政赤字的多少,每年的还本付息能力变动的数量规律性,可以建立如下简单线性回归模型:Y t = β1 +β2 X 2t +β3X 3t +β4 X 4t + u t(3)估计参数利用Eviews 估计模型参数,点击‘quick ’下拉菜单中的‘Estimate Equation ’,在出现的对话框的‘Equation Specification ’栏中键入‘Y C X2 X3 X4’,回车即出现回归结果:Dependent Variable: Y Method: Least Squares Date: 12/01/10 Time: 17:13 Sample: 1980 2001Included observations: 22VariableCoefficientStd. Error t-Statistic Prob.C 4.314008 21.66725 0.199103 0.8444 X2 0.995403 0.031613 31.48699 0.0000 X3 0.345202 0.154470 2.234756 0.0384 X40.8797600.04950817.770220.0000R-squared0.998955 Mean dependent var 1216.395 Adjusted R-squared 0.998781 S.D. dependent var1485.993 S.E. of regression 51.88705 Akaike infocriterion10.89898 Sum squared resid 48460.78 Schwarz criterion11.09735 Log likelihood -115.8888 Hannan-Quinncriter.10.94571 F-statistic 5735.346 Durbin-Watson stat 2.116834 Prob(F-statistic)0.000000根据表中数据,模型估计结果为432879760.0345202.0995403.0314008.4ˆX X X Y +++= (21.66725)(0.031613) (0.154470) (0.049508) t= (0.199103)(31.48699) (2.234756) (17.77022)998955.0R 2= 998781.02=R F=5735.346(4)模型检验 1、经济意义检验模型估计说明,在假定其他变量不变的情况下,当年财政赤字额每增长1%,平均来说当年国债发行总量会增长0.995403%;在假定其他变量不变的情况下,当年GDP 每增长1%,平均来说当年国债发行总量会增长0.345202%;在假定其他变量不变的情况下,当年年还本付息率每增长1%,平均来说当年国债发行总量会增长0.879760%。
多元线性回归分析(Eviews论文)

楚雄师范学院数学系09级01班韩金伟学号:*********** 2011—2012学年第二学期《数据分析》期末论文题目影响成品钢材需求量的回归分析姓名韩金伟学号***********系(院)数学系专业数学与应用数学2012年 6 月 19 日题目:影响成品钢材需求量的回归分析摘要:随着社会经济的不断发展,科学技术的不断进步,统计方法越来越成为人们必不可收的工具盒手段。
应用回归分析是其中的一个重要分支,本着国家经济水平的不断提高,我们采用回归分析的方法对我国成品钢材的需求量进行分析应用。
为了使分析的模型具有社会实际意义,我们引用了1980——1998年的成品钢材、原油、生铁、原煤、发电量、铁路货运量、固定资产投资额、居民消费、政府消费9个不同的量来进行回归分析。
通过建立回归模型充分说明成品钢材需求量与其他8个变量的关系,以及我国社会经济的实际发展情况和意义。
关键字:线性回归回归分析社会经济回归模型成品钢材多元回归国家经济社会发展目录第1章题目叙述 (1)第2章问题假设 (1)第3章问题分析 (2)第4章数据的预处理 (3)4.1 曲线统计图 (3)4.2 散点统计图 (4)4.3 样本的相关系数 (4)第5章回归模型的建立 (5)第6章回归模型的检验 (6)6.1 F检验 (6)6.2 T检验 (6)6.3 T检验分析 (6)6.4 Chow断点检验 (8)6.5 Chow预测检验 (8)第7章违背模型基本假设的情况 (9)7.1 异方差性的检验 (9)7.1.1残差图示检验 (9)7.1.2 怀特(White)检验 (9)7.2 自相关性的检验 (10)7.2.1 LM检验 (10)7.2.2 DW检验 (10)第8章自变量选择与逐步回归 (10)8.1 前进逐步回归法 (10)8.1.1 前进逐步回归 (10)8.1.2 前进逐步回归模型预测 (11)8.2 后退逐步回归法 (12)8.2.1 后退逐步回归 (12)8.2.2 后退逐步回归模型预测 (13)第9章多重共线性的诊断及消除 (14)9.1 多重共线性的诊断 (14)9.2 消除多重共线性 (15)第10章回归模型总结 (17)参考文献 (18)附录: (19)楚雄师范学院 数学系 09级01班 韩金伟 学号:20091021135影响成品钢材需求量的回归分析第1章 题目叙述理论上认为影响成品钢材的需求量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。
第三次实验(EVIEWS实现多元线性回归)

7/2/2013
榆林学院数学系统计教研室
9
三、检验方程
1、经济意义检验
模型结果表明在假定户主受教育年限不 变的情况下,家庭月平均收入增加1元,家 庭书刊年消费支出将增加0.086元;在假定 家庭平均月收入不变的情况下,户主受教育 年数增加1年,家庭书刊年消费支出将增加 52.37元。这与我们的认识大致相符。
7/2/2013
榆林学院数学系统计教研室
11
四、进行点预测和区间预测
现有一户家庭的月均收入为4000元,户主受教育年数为 18年,预测该户家庭的书刊消费是多少,构造该估计值 95%的置信区间。
7/2/2013
榆林学院数学系统计教研室
12
四、进行点预测和区间预测
可得当X1=4000,X2=18时,Y等于1238.45。 由单值预测和条件均值预测的公式:
10222021一绘制散点图和样本相关阵从样本相关阵可以看出家庭书刊消费与家庭收入户主受教育年数之间的相关系数高达0788517和0960757说明家庭书刊消费与家庭收入户主受教育年数有显著的线性关系可以考虑建立二元线性回归模型
《计量经济学》实验指导 ——基于Eviews软件 实验三:运用EVIEWS建立多元线 性回归并进行相关检验
7/2/2013
榆林学院数学系统计教研室
5
一、绘制散点图和样本相关阵
从样本相关阵可以看出,家庭书刊消费与 家庭收入、户主受教育年数之间的相关系数高 达0.788517和0.960757 ,说明家庭书刊消 费与家庭收入、户主受教育年数有显著的线性 关系,可以考虑建立二元线性回归模型。
7/2/2013
7/2/2013
榆林学院数学系统计教研室
2
多元线性回归模型建模步骤
基于EVIEWS软件下的多元线性回归分析

月份
1月
2月
3月
4月
5月
6月
7月Βιβλιοθήκη 8月 9月 1 O月
1 1月
1 2月
气温 ( ) ℃
87 _
1. 22
1. 48
1. 51
1. 58
1. 7 9
2. 07 0
2. 23 0
1.0 75
1. 20 9
1. 03 0
由图 l 出,大多数散点都分布在一条直线附近 ,可认为生物量和气温呈高度线性 。 看 3 建立 模型 如果 散点 图表 明变 量 间有较 强 的线 性 关系 ,可 以通 过 估计 参数 建立 模 型 。建立 方 程通 常有 两种 菜 单操作方法 :一是在主菜单 中选 O j c sN w b e t ,在新建对象对话框 中选对象为 Eu t o ,并 b et/ e jc s O q a in 命 名 ,点击 o ;另 一种 是选 Q ikE tm t q a in K uc / s ia eEu to 。两种 操 作都 会 出现如 图 2的方程定 义对 话框 。 这一步骤对 以后各种模型建立都实用。 建模时, 在方程定义一栏 中的输入 内容也有两种完全等价的选 择:
收 稿 日期 :0 1 0 - 6 2 1- 3 2
基 金 项 目: 州 省教 育厅 自然 科 学基 金 ( 科 教 2 1 1 1 “ 贵 黔 0 0 0 ) 六盘 水地 区 高速 公 路 护 坡 植 物 种 类 合 理 配置 及 演 替 数 学模 型 研 究” 段 性 成 果 : 盘 水 师 范 学 院 科 研 目(P S 0 0 1 “ 盘 水 地 区 高速 公 路 边 坡 植 物 群 演 替 数 学模 型 研 究 ” 段 性 成 阶 六 L S YZ 11 ) 六 阶 果: 六盘 水 师 范 学 院 “ 学 教 育 教 学 团 队 ”L S Y x 2 1 O ) 段 性 成果 . 数 (P S jt 0 12 阶 d
第三讲eviews多元线性回归模型ppt课件

“雪亮工程"是以区(县)、乡(镇) 、村( 社区) 三级综 治中心 为指挥 平台、 以综治 信息化 为支撑 、以网 格化管 理为基 础、以 公共安 全视频 监控联 网应用 为重点 的“群 众性治 安防控 工程” 。
3.2 多元线性回归模型的检验
3.2.1 拟合优度检验
拟合优度是指样本回归直线与观测值之间的拟合程度。 1.多重决定系数
总离差平方和=残差平方和+ 回归平方和 自由度: (n-1)= (n-k-1)+ k ESS:由回归直线(即解释变量)所解释的部分,表示x对y的线性影响。 RSS:是未被回归直线解释的部分,由解释变量x对y影响以外的因素而造成的。
507.7
613.9
563.4
501.5
781.5
541.8
611.1
1222.1
793.2
660.8
792.7580.8Fra bibliotek612.7
890.8
1121.0
1094.2
1253.0
家庭收入 x 1027.2 1045.2 1225.8 1312.2 1316.4 1442.4 1641.0 1768.8 1981.2 1998.6 2196.0 2105.4 2147.4 2154.0 2231.4 2611.8 3143.4 3624.6
“雪亮工程"是以区(县)、乡(镇) 、村( 社区) 三级综 治中心 为指挥 平台、 以综治 信息化 为支撑 、以网 格化管 理为基 础、以 公共安 全视频 监控联 网应用 为重点 的“群 众性治 安防控 工程” 。
多重决定系数或决定系数是指解释变差占总变差的比重,用来表述解 释变量对被解释变量的解释程度:
经验分享,使用eviews做回归分析

[经验分享] 使用eviews做线性回归分析Glossary:ls(least squares)最小二乘法R-sequared样本决定系数(R2):值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,解决这个问题使用来调整Adjust R-seqaured()S.E of regression回归标准误差Log likelihood对数似然比:残差越小,L值越大,越大说明模型越正确Durbin-Watson stat:DW统计量,0-4之间Mean dependent var因变量的均值S.D. dependent var因变量的标准差Akaike info criterion赤池信息量(AIC)(越小说明模型越精确)Schwarz ctiterion:施瓦兹信息量(SC)(越小说明模型越精确)Prob(F-statistic)相伴概率fitted(拟合值)线性回归的基本假设:1.自变量之间不相关2.随机误差相互独立,且服从期望为0,标准差为σ的正态分布3.样本个数多于参数个数建模方法:ls y c x1 x2 x3 ...x1 x2 x3的选择先做各序列之间的简单相关系数计算,选择同因变量相关系数大而自变量相关系数小的一些变量。
模型的实际业务含义也有指导意义,比如m1同gdp肯定是相关的。
模型的建立是简单的,复杂的是模型的检验、评价和之后的调整、择优。
模型检验:1)方程显著性检验(F检验):模型拟合样本的效果,即选择的所有自变量对因变量的解释力度F大于临界值则说明拒绝0假设。
Eviews给出了拒绝0假设(所有系统为0的假设)犯错误(第一类错误或α错误)的概率(收尾概率或相伴概率)p 值,若p小于置信度(如0.05)则可以拒绝0假设,即认为方程显著性明显。
2)回归系数显著性检验(t检验):检验每一个自变量的合理性|t|大于临界值表示可拒绝系数为0的假设,即系数合理。
Eviews线性回归教程

一、数据的导入与基本统计量
EViews提供序列的各种统计图、统计方法及过程。
当用前述的方法向工作文件中读入数据后,就可以对
这些数据进行统计分析和图表分析。
计算公式如下:
AIC 2l T 2k T
其中l 是对数似然值 l T (1 log( 2 π) log( uˆuˆ / T ))
2
我们进行模型选择时,AIC值越小越好。例如,可以通过选 择最小AIC值来确定一个滞后分布的长度。
第24页/共41页
(9). Schwarz准则 Schwarz准则是AIC准则的替代方法:
峰度(Kurtosis) 度量序列分布的凸起或平坦程度,
计算公式如下
K 1 N
yi
y
4
N i1 ˆ
意义同S中
,正态分布的
K
值为3。如果
K
值大于3,
分布的凸起程度大于 正态分布;如果K值小于3,序列分布相
对于正态分布是平坦的。
第7页/共41页
Jarque-Bera 检验 检验序列是否服从正态分布。统计
工资差别
为了解工作妇女是否受到了歧视,可以用美国统计局的“当前人口调查” 中的截面数据研究男女工资有没有差别。这项多元回归分析研究所用到的变 量有:
W — 雇员的工资(美元/小时)
1;若雇员为妇女 SEX =
0;其他
ED — 受教育的年数 AGE — 雇员的年龄
1;若雇员不是西班牙裔也不是白人
NONWH = 0;其他
ARCH方法。 EViews计算R2 的公式为:
计量经济学多元线性回归分析eviews操作PPT课件

人均GDP GDPP 1602.3 1727.2 1949.8 2187.9 2436.1 2663.7 2889.1 3111.9 3323.1 3529.3 3789.7
该两组数据是1978~2000年的时间序列数据 (time series data)
1、建立模型 拟建立如下一元回归模型
CONSP C GDPP 采用Eviews软件进行回归分析的结果见下表
μ~ N(0, 2I) 同一元回归一样,多元回归还具有如下两个重要假设:
假设7,样本容量趋于无穷时,各解释变量的方差趋于有 界常数,即n∞时,
1
n
x
2 ji
1 n
( X ji X j )2 Q j
或
1 xx Q n
其中:Q为一非奇异固定矩阵,矩阵x是由各解释变量 的离差为元素组成的nk阶矩阵
nk nk
第15页/共63页
四、参数估计量的性质
在满足基本假设的情况下,其结构参数的普
通最小二乘估计、最大或然估计及矩估计仍具 有:
同时,随线着性样性本、容无量偏增性加、,有参效数性估。计量具有: 渐近无偏性、渐近有效性、一致性。
1、线性性
βˆ (XX)1 XY CY
其中,C=(X’X)-1 X’ 为一仅与固定的X有关的行向量
2 ki
ki
ˆ 0 ˆ1
ˆ k
1 X 11
X k1
1 X 12
X k2
1 Y1 X 1n Y2 X kn Yn
即
(XX)βˆ XY
由于X’X满秩,故有 βˆ (XX)1 XY
第11页/共63页
将上述过程用矩阵表示如下:
即求解方程组:
βˆ (Y
Xβˆ )(Y
【免费下载】运用EVIEWS建立多元线性回归并进行相关检验

五、写出估计方程
Yi 626.5093 9.790570X1 0.28618X 2
(40.13010) (3.197843) (0.05838)
t=(15.611195) (-3.061617) (4.902030)
R2 0.902218 R2 =0.874281
六、随机干扰项
2
e'e
n k 1
e'e (Y Yˆ)' (Y Yˆ) (Y X ˆ)' (Y X ˆ) Y 'Y Y ' X ˆ =2116.85
所以ˆ 2 2116.85 302.41
10 2 1
由 OLS 表得 R2 0.902218
七、由 OLS 可得 F=32.29 F0.05(2,7) 4.74
因为 32.29>4.74,所以方程的总体线性性显著成立
由 OLS 表可得 C 的 t 值为 15.61 X1 的 t 值为-3.06
X2 的值为 4.90
t0.025(7 )2.365
所以常输项,X1 和 X2 的总体参数都显著的异于零
将数据分别代入以下三个式子:
ˆ0 t0.025 Sˆ0
ˆ1 t0.025 Sˆ1
t0.025
Sˆ2
Y 的均值
SYˆ0 =37.05
间为(768.58,943.82)
Y 的个值 SYˆ0
t0.025(7 )2.365
=40.93 t0.025(7)2.365
所以 Y 的个值在 95%的置信区间为(759.41,952.99)
第二个实验 输入数据,对其进行回归分析输出 OLS 表
姓名:jelly
对某商品的消 费支出 Y
591.9 654.5 623.6
使用eviews做线性回归分析

模型检验:1)方程显著性检验(F检验):模型拟合样本的效果,即选择的所有自变量对因变量的解释力度F大于临界值则说明拒绝0假设。
Eviews给出了拒绝0假设(所有系统为0的假设)犯错误(第一类错误或α错误)的概率(收尾概率或相伴概率)p值,若p小于置信度(如0.05)则可以拒绝0假设,即认为方程显著性明显。
2)回归系数显著性检验(t检验):检验每一个自变量的合理性|t|大于临界值表示可拒绝系数为0的假设,即系数合理。
t分布的自由度为n-p-1,n为样本数,p为系数位置3)DW检验:检验残差序列的自相关性,检验基本假设2(随机误差相互独立)残差:模型计算值与资料实测值之差为残差0<=dw<=dl 残差序列正相关,du<dw<4-du 无自相关,4-dl<dw<=4负相关,若不在以上3个区间则检验失败,无法判断demo中的dw=0.141430 ,dl=1.73369,du=1.7786,所以存在正相关模型评价目的:不同模型中择优1)样本决定系数R-squared及修正的R-squaredR-squared=SSR/SST 表示总离差平方和中由回归方程可以解释部分的比例,比例越大说明回归方程可以解释的部分越多。
Adjust R-seqaured=1-(n-1)/(n-k)(1-R2)2)对数似然值(Log Likelihood,简记为L)残差越小,L越大3)AIC准则AIC= -2L/n+2k/n, 其中L为log likelihood,n为样本总量,k为参数个数。
AIC可认为是反向修正的L,AIC越小说明模型越精确。
4)SC准则SC= -2L/n + k*ln(n)/n用法同AIC非常接近预测forecastroot mean sequared error(RMSE)均方根误差Mean Absolute Error(MAE)平均绝对误差这两个变量取决于因变量的绝对值,MAPE(Mean Abs. Percent Error)平均绝对百分误差,一般的认为MAPE<10则认为预测精度较高Theil Inequality Coefficient(希尔不等系数)值为0-1,越小表示拟合值和真实值差异越小。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、绘制散点图和样本相关阵
从样本相关阵可以看出,家庭书刊消费与 家庭收入、户主受教育年数之间的相关系数高 达0.788517和0.960757 ,说明家庭书刊消 费与家庭收入、户主受教育年数有显著的线性 关系,可以考虑建立二元线性回归模型。
二、估计方程
二、估计方程
三、撰写方程
Y ˆ i (5 0 4.90 .1 466 02 2 6)0 . (0 8 06 .04 25 93X 61 ) (5 2 5..3 207 20 13 7X )2
三、检验方程
2、统计检验
从回归估计结果看出,模型拟合较好。可决系数为 0.951235,表明家庭书刊消费支出变化的95.12%可由家 庭月均收入和户主受教育年数来解释。
从回归模型的F检验值来看,F统计量的值为146.297, 对应的p值为0.000000,说明模型整体上高度显著。
从变量的t检验值来看,家庭月均收入参数对应的t 统计 量为2.944186, 所对应的P值为0.0101;户主受教育年数 参数对应的t 统计量为10.06702, 所对应的P值为0.0000; 两者对应的p值均明显小于0.05,均可判断家庭月均收入和 户主受教育年数对家庭书刊消费支出均有显著影响。
《计量经济学》实验指导 ——基于Eviews软件
实验三:运用EVIEWS建立多元线 性回归并进行相关检验
Email:
实验目的
学习和掌握用Eviews做变量间的相关矩阵; 掌握运用eviews做多元线性回归的估计; 看懂eviews估计的多元线性回归方程结果; 根据输出结果书写方程、进行模型检验、解
释系数意义和预测; 借助EVIEWS软件进行受约束检验。
多元线性回归模型建模步骤
一、根据所研究的问题提出因变量和自变量, 搜集数据。
二、绘制散点图和样本相关阵,观察自变量和因 变量间的大致关系。
三、如果为线性关系,则建立多元线性回归方程 并估计方程。
四、根据eviews输出结果写出方程,对方程进行 检验(拟合优度检验、F检验和t检验)。
t= (-1.011244) (2.944186) (10.06702) R2=0.951235 R2 0.944732
F=146.2974
三、检验方程1ຫໍສະໝຸດ 经济意义检验模型结果表明在假定户主受教育年限不 变的情况下,家庭月平均收入增加1元,家 庭书刊年消费支出将增加0.086元;在假定 家庭平均月收入不变的情况下,户主受教育 年数增加1年,家庭书刊年消费支出将增加 52.37元。这与我们的认识大致相符。
2
2
Y ˆ 0 t ˆ1 X 0 ( X X ) 1 X 0 Y 0 Y ˆ 0 t ˆ1 X 0 ( X X ) 1 X 0
2
2
由估计结果知:ˆ60.82273将ˆ和X 代入可得:
[1137.87,1339.02] [1074.37,1402.53]
受约束回归
一、受约束回归步骤
五、如果通过检验,解释方程并应用(预测)。
例:
例:经研究发现,家庭书刊消费受家庭收入及户主受教 育年数的影响。现收集了某地区部分家庭抽样调查得到 的样本数据。试建立模型对上述理论进行验证和分析。 数据如下:
一、绘制散点图和样本相关阵
从上面两散点图可以看出家庭书刊消费与 家庭收入、户主受教育年数大致呈线性关系且 随着家庭收入和户主受教育年数的逐渐增大家 庭书刊消费也呈逐渐增大的趋势。
四、进行点预测和区间预测
现有一户家庭的月均收入为4000元,户主受教育年数为 18年,预测该户家庭的书刊消费是多少,构造该估计值 95%的置信区间。
四、进行点预测和区间预测
可得当X1=4000,X2=18时,Y等于1238.45。
由单值预测和条件均值预测的公式:
Y ˆ 0 t ˆX 0 ( X X ) 1 X 0 E ( Y 0 ) Y ˆ 0 t ˆX 0 ( X X ) 1 X 0
论。
实验作业
1、作业11、作业13 2、实验报告要求同一元线性回归模型,文件名为
“姓名+学号+运用EVIEWS建立多元线性回 归模型实验报告”。 例如:雷鸣强+44021103+运用EVIEWS建立多 元线性回归模型实验报告
The end. Thank you!
1、设定无约束回归模型形式 2、根据约束条件化简受约束回归模型 3、分别估计无约束回归和受约束回归模型,
分别得到 RSSU和RSSR 。 4、根据得到的RSSU和RSSR ,运用F统计量进行
检验。 F (R R R S U R /S n S U ( ) k S / S U k U (1 S )k R )~ F (k U k R ,n k U 1 ) 5、根据计算出的统计量做出约束是否成立的结