模式识别-模板匹配法页PPT文档
合集下载
模式识别模板匹配法

• 参数估计法
• 仅知道各类样本的类概率密度P( X / ωi )的函数形式,函数
中的参数末知
• 由学习样本估计类概率密度函数中的参数
模式识别,第二章
24
统计模式识别基础
• 非参数估计法
• 几乎无先验知识,类概率密度函数形式均末知 • 直接由学习样本进行分类器设计
• 线性判别函数
• 基于对学习样本的分析,得到线性判别函数 • 由线性判别函数决定的分界面,将特征空间划分为若干区域 • 根据待识样本落入哪个区域来进行分类
模式识别,第二章
13
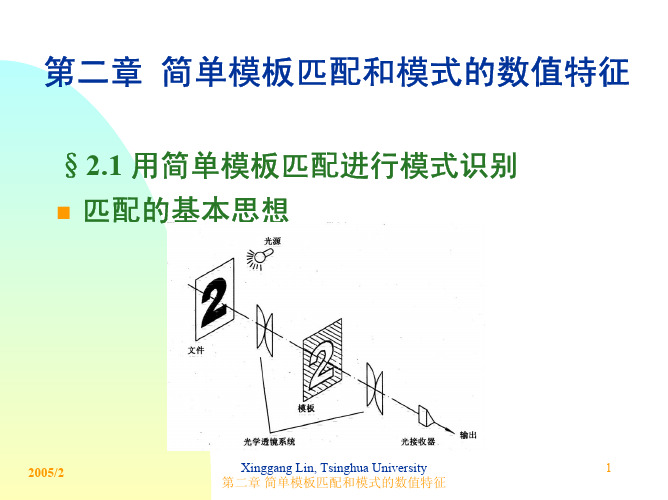
模板匹配法原理及过程
• 识别过程
• 对待识样本进行特征提取,得到特征向量X • 计算待识样本特征向量X与模板向量X1, X2, ﹒﹒﹒ XC之间的
距离 D1, ,﹒﹒﹒,DC
• 若Di = min { Dj },j=1, 2 , ﹒﹒﹒,C,且 Di <ε,则判样本X
属于第i类,,记为X∈Wi
欧氏距离
样本相似度
平方和距离 绝对值距离
加权距离
模式识别,第二章
基本概念
• 欧氏距离
设有两个n维特征向量X1和 X2
X1
X [x , x , x ]T
1
12 12
1n
X [x , x , x ]T
2
21
22
2n
则此二样本的欧氏距离定义为:
X X X
1
2
x x 2 x x 2 x x 2
i
例如:乙肝病诊断
P( ) 0.99, P( ) 0.01
1
2
手写体数字识别
P( ) P( ) 0.1
1
10
模式识别,第二章
19
• 仅知道各类样本的类概率密度P( X / ωi )的函数形式,函数
中的参数末知
• 由学习样本估计类概率密度函数中的参数
模式识别,第二章
24
统计模式识别基础
• 非参数估计法
• 几乎无先验知识,类概率密度函数形式均末知 • 直接由学习样本进行分类器设计
• 线性判别函数
• 基于对学习样本的分析,得到线性判别函数 • 由线性判别函数决定的分界面,将特征空间划分为若干区域 • 根据待识样本落入哪个区域来进行分类
模式识别,第二章
13
模板匹配法原理及过程
• 识别过程
• 对待识样本进行特征提取,得到特征向量X • 计算待识样本特征向量X与模板向量X1, X2, ﹒﹒﹒ XC之间的
距离 D1, ,﹒﹒﹒,DC
• 若Di = min { Dj },j=1, 2 , ﹒﹒﹒,C,且 Di <ε,则判样本X
属于第i类,,记为X∈Wi
欧氏距离
样本相似度
平方和距离 绝对值距离
加权距离
模式识别,第二章
基本概念
• 欧氏距离
设有两个n维特征向量X1和 X2
X1
X [x , x , x ]T
1
12 12
1n
X [x , x , x ]T
2
21
22
2n
则此二样本的欧氏距离定义为:
X X X
1
2
x x 2 x x 2 x x 2
i
例如:乙肝病诊断
P( ) 0.99, P( ) 0.01
1
2
手写体数字识别
P( ) P( ) 0.1
1
10
模式识别,第二章
19
模式识别详细PPT

迁移学习在模式识别中广泛应用于目标检测、图像分类等任务,通过将预训练模 型(如ResNet、VGG等)应用于新数据集,可以快速获得较好的分类效果。
无监督学习在模式识别中的应用
无监督学习是一种从无标签数据中提取有用信息的机器学习方法,在模式识别中主要用于聚类和降维 等任务。
无监督学习在模式识别中可以帮助发现数据中的内在结构和规律,例如在图像识别中可以通过聚类算 法将相似的图像分组,或者通过降维算法将高维图像数据降维到低维空间,便于后续的分类和识别。
通过专家知识和经验,手 动选择与目标任务相关的 特征。
自动特征选择
利用算法自动筛选出对目 标任务最相关的特征,提 高模型的泛化能力。
交互式特征选择
结合手动和自动特征选择 的优势,先通过自动方法 筛选出一组候选特征,再 由专家进行筛选和优化。
特征提取算法
主成分分析(PCA)
通过线性变换将原始特征转换为新的特征, 保留主要方差,降低数据维度。
将分类或离散型特征进行编码 ,如独热编码、标签编码等。
特征选择与降维
通过特征选择算法或矩阵分解 等技术,降低特征维度,提高 模型效率和泛化能力。
特征生成与转换
通过生成新的特征或对现有特 征进行组合、转换,丰富特征
表达,提高模型性能。
04
分类器设计
分类器选择
线性分类器
基于线性判别分析,适用于特征线性可 分的情况,如感知器、逻辑回归等。
结构模式识别
总结词
基于结构分析和语法理论的模式识别方法,通过分析输入数据的结构和语法进行分类和 识别。
详细描述
结构模式识别主要关注输入数据的结构和语法,通过分析数据中的结构和语法规则,将 输入数据归类到相应的类别中。这种方法在自然语言处理、化学分子结构解析等领域有
无监督学习在模式识别中的应用
无监督学习是一种从无标签数据中提取有用信息的机器学习方法,在模式识别中主要用于聚类和降维 等任务。
无监督学习在模式识别中可以帮助发现数据中的内在结构和规律,例如在图像识别中可以通过聚类算 法将相似的图像分组,或者通过降维算法将高维图像数据降维到低维空间,便于后续的分类和识别。
通过专家知识和经验,手 动选择与目标任务相关的 特征。
自动特征选择
利用算法自动筛选出对目 标任务最相关的特征,提 高模型的泛化能力。
交互式特征选择
结合手动和自动特征选择 的优势,先通过自动方法 筛选出一组候选特征,再 由专家进行筛选和优化。
特征提取算法
主成分分析(PCA)
通过线性变换将原始特征转换为新的特征, 保留主要方差,降低数据维度。
将分类或离散型特征进行编码 ,如独热编码、标签编码等。
特征选择与降维
通过特征选择算法或矩阵分解 等技术,降低特征维度,提高 模型效率和泛化能力。
特征生成与转换
通过生成新的特征或对现有特 征进行组合、转换,丰富特征
表达,提高模型性能。
04
分类器设计
分类器选择
线性分类器
基于线性判别分析,适用于特征线性可 分的情况,如感知器、逻辑回归等。
结构模式识别
总结词
基于结构分析和语法理论的模式识别方法,通过分析输入数据的结构和语法进行分类和 识别。
详细描述
结构模式识别主要关注输入数据的结构和语法,通过分析数据中的结构和语法规则,将 输入数据归类到相应的类别中。这种方法在自然语言处理、化学分子结构解析等领域有
模式识别ppt课件

pˆ N则是这些曲线
( x)
2.5,1.1为中心的正态曲线,而
之和。
由图看出:每个样本对估计的贡献与样本间
的距离有关,样本越多, PN(x)越准确。
例2:设待估计的p(x)是均值为0,方差为1的正
态密度函数。
若随机抽取X样本中的1个、 16个、 256个作
为学习样本xi,试用窗口法估计pN(x)。
| x xi |
(
)0
(保证 pˆ N ( x) 非负)
hN
( | x x i | )d ( | x x i | ) 0
(使 pˆ N ( x)dx 1)
hN
hN
④ 窗函数的选择
例:矩形窗、正态窗、指数窗、三角窗等等(只要
满足上述两条件,都可作为窗函数使用)
超立方体体积:VN h
d
N
其中
h1
hN
N
d=1,窗口为一线段 ; d=2,窗口为一平面
d=3,窗口为一立方体 ;d>3,窗口为一超立方体
窗口的选择:有多种选择
Φ(u)
方窗函数
Φ(u)
正态窗函数
Φ(u)
指数窗函数
hN
正态窗函数
1
1
,
|
u
|
(u )
2
0.其他
(u )
满足上述条件的区域序列(VN)有两种选择方法,
形成两种非参数估计方法:
1)Parzen窗法;
2)KN近邻估计
两者如何选择VN ?
1)Parzen窗法:
1
使体积VN以N的某个函数减小,例 VN
( x)
2.5,1.1为中心的正态曲线,而
之和。
由图看出:每个样本对估计的贡献与样本间
的距离有关,样本越多, PN(x)越准确。
例2:设待估计的p(x)是均值为0,方差为1的正
态密度函数。
若随机抽取X样本中的1个、 16个、 256个作
为学习样本xi,试用窗口法估计pN(x)。
| x xi |
(
)0
(保证 pˆ N ( x) 非负)
hN
( | x x i | )d ( | x x i | ) 0
(使 pˆ N ( x)dx 1)
hN
hN
④ 窗函数的选择
例:矩形窗、正态窗、指数窗、三角窗等等(只要
满足上述两条件,都可作为窗函数使用)
超立方体体积:VN h
d
N
其中
h1
hN
N
d=1,窗口为一线段 ; d=2,窗口为一平面
d=3,窗口为一立方体 ;d>3,窗口为一超立方体
窗口的选择:有多种选择
Φ(u)
方窗函数
Φ(u)
正态窗函数
Φ(u)
指数窗函数
hN
正态窗函数
1
1
,
|
u
|
(u )
2
0.其他
(u )
满足上述条件的区域序列(VN)有两种选择方法,
形成两种非参数估计方法:
1)Parzen窗法;
2)KN近邻估计
两者如何选择VN ?
1)Parzen窗法:
1
使体积VN以N的某个函数减小,例 VN
模式识别培训教程PPT(94张)

线条透视
结构密度
遮盖关系
(二)建构性知觉理论 (Constructive perception)
知觉是一个积极的和建构的过程
知觉并不是由刺激输入直接引起的,而 是所呈现刺激与内部假设、期望、知识以 及动机和情绪因素交互作用的产物
知觉有时可受到不正确的假设和期望影 响,因而也会发生错误
邻近物 体大小 对大小 知觉的 影响
现代观点则认为,知觉是主动 和富有选择性的构造过程。
黄希庭:“知觉是直接作用于感觉器 官的事物的整体在脑中的反映,是人对感 觉信息的组织和解释的过程。”
梁宁建:“知觉是人脑对客观事物的 各种属性、各个部分及其相互关系的综合 的整体的反映,它通过感觉器官,把从环 境中得到的各种信息,如光、声音、味道 等转化为对物体、事件等的经验的过程。”
2. “泛魔堂”模型(“魔城”模型)
通过特征分析识别一个字母R
3.特征分析的生理学依据
1981年诺贝尔医学奖获得者:Hubel & Wiesel
4.特征分析的行为学证据
Neisser(1964)英文字母扫描实验 固定影像与静止影像的实验
5.特征分析说的评论 优点:避开预加工、减轻记忆负担、带有学习
由有关知觉对象的一般知识开始的加工, 由此可以形成期望或对知觉对象形成假 设,这种期望或假设制约着加工的所有 阶段或水平。又称之为概念驱动加工 (Concept-Driven Processing)
•Tulving, Mandler & Baumal的实验
自变量
上下文情况:无上下文、4字上下文、8字上下文 (考察自上而下加工)
1982年他在《科学》杂志上原创性地提出 了“拓扑性质初期知觉”的理论,向半个世纪 以来占统治地位的理论提出了挑战。随后20多 年的时间里,在与国际上持不同学术观点的学 者的争论与交流中,他以令人信服的系列科学 实验不断地完善和论证着这一假说,使之成为 被越来越多的国际同行所接受的学说,进而成 为有国际影响力的理论,他的成果也被《科 学》、《美国科学院院报》等著名学术刊物多 次刊登。2004年,著名知觉杂志《Visual Cognition》以专辑的形式刊载了陈霖教授的 成果并配发了大量国际著名学者的评论性文章。
模式识别-第二章(简单模板匹配和模式
( x, y ) g ( x, y ) + ∫∫ g ( x, y )
2D
给定 f,g, 可省略 ∫∫ f
D
( x, y ) 和
取匹配程度测度
2005/2
D Xinggang Lin, Tsinghua University 第二章 简单模板匹配和模式的数值特征
= ∫∫ f ( x , y ) g ( x , y )
jnt
)
1 pn = 2π
∫0
2π
U (t ) e
jnt
dt
P0表示曲线形心位置(直流分量) 各阶系数{Pn}与曲线形状一一对应 5个平移,旋转,尺度,起始点不变量: 圆形度,细长度,密集度,凹度,形心偏差度
2005/2 Xinggang Lin, Tsinghua University 第二章 简单模板匹配和模式的数值特征 23
2005/2
Xinggang Lin, Tsinghua University 第二章 简单模板匹配和模式的数值特征
17
直接模板匹配法的发展
举例:弹性匹配人脸识别(丁嵘博士论文,2002年,p16)
图2.1 二维拓扑图
图2.2 表达人脸特征的二维矢量场
S
S1
2005/2
Xinggang Lin, Tsinghua University 第二章 简单模板匹配和模式的数值特征
印刷体汉字识别的一些特征(边书, P323)
复杂指数 四边码 粗外围特征 粗网格特征 笔画密度特征,等
2005/2 Xinggang Lin, Tsinghua University 第二章 简单模板匹配和模式的数值特征 24
特征轴归一化
模式的数值(字)特征
2D
给定 f,g, 可省略 ∫∫ f
D
( x, y ) 和
取匹配程度测度
2005/2
D Xinggang Lin, Tsinghua University 第二章 简单模板匹配和模式的数值特征
= ∫∫ f ( x , y ) g ( x , y )
jnt
)
1 pn = 2π
∫0
2π
U (t ) e
jnt
dt
P0表示曲线形心位置(直流分量) 各阶系数{Pn}与曲线形状一一对应 5个平移,旋转,尺度,起始点不变量: 圆形度,细长度,密集度,凹度,形心偏差度
2005/2 Xinggang Lin, Tsinghua University 第二章 简单模板匹配和模式的数值特征 23
2005/2
Xinggang Lin, Tsinghua University 第二章 简单模板匹配和模式的数值特征
17
直接模板匹配法的发展
举例:弹性匹配人脸识别(丁嵘博士论文,2002年,p16)
图2.1 二维拓扑图
图2.2 表达人脸特征的二维矢量场
S
S1
2005/2
Xinggang Lin, Tsinghua University 第二章 简单模板匹配和模式的数值特征
印刷体汉字识别的一些特征(边书, P323)
复杂指数 四边码 粗外围特征 粗网格特征 笔画密度特征,等
2005/2 Xinggang Lin, Tsinghua University 第二章 简单模板匹配和模式的数值特征 24
特征轴归一化
模式的数值(字)特征
模板匹配与模式识别PPT学习教案

第11页/共62页
部分的中心坐标,而是重合部分的左上角坐标,模板
大小为m*n
如果图像和模板在(u,v)处有和模板一致的
图案时,则m(u,v)的值很小,相反则较大。特别
是模板和图像重叠部分完全不一致的情况下,和
就不断的增大。
当差的绝对值部分和超过某一个阈值的时就
认为在该位置不存在于模板一致的图案,从而转
误差
特征处理:特征提取和特征选择
首先对识别对象的性质进行测量;利用测量值作
为分类的特征。
特征选择:
识别
对象
性质1
性质2
性质1
性质3
性质2
性质4
性质n-1
性质n
第15页/共62页
选择有区分性,可靠性,独立性好的特征
特征选择的方法:
穷举法:从m个测量值里面选取n个特征,然后对每
一种选法利用已经知道类别属性的样本进行试分类
假设特征矢量为正态分布的前提下,为简化
最大似然法,常把似然函数
第24页/共62页 P ( wi ) p ( X | wi )用其
对数 ln P ( wi ) ln p ( X | wi )代替
非监督分类
无法获得先验知识的情况下根据模式之
间的相似度进行分类。将相似性强的模式归
为同一类别,该方法又称为聚类分析其中k
识别的结果尽量与客观物体相符合。
如下所表示:
➢Y = F(X)
➢X的定义域取自特征集
➢Y的值域为类别的标号集
➢F是模式识别的判别方法
第2页/共62页
模式识别简史
1929年G.Tauschek发明阅读机,能够阅读0-9的数字。
部分的中心坐标,而是重合部分的左上角坐标,模板
大小为m*n
如果图像和模板在(u,v)处有和模板一致的
图案时,则m(u,v)的值很小,相反则较大。特别
是模板和图像重叠部分完全不一致的情况下,和
就不断的增大。
当差的绝对值部分和超过某一个阈值的时就
认为在该位置不存在于模板一致的图案,从而转
误差
特征处理:特征提取和特征选择
首先对识别对象的性质进行测量;利用测量值作
为分类的特征。
特征选择:
识别
对象
性质1
性质2
性质1
性质3
性质2
性质4
性质n-1
性质n
第15页/共62页
选择有区分性,可靠性,独立性好的特征
特征选择的方法:
穷举法:从m个测量值里面选取n个特征,然后对每
一种选法利用已经知道类别属性的样本进行试分类
假设特征矢量为正态分布的前提下,为简化
最大似然法,常把似然函数
第24页/共62页 P ( wi ) p ( X | wi )用其
对数 ln P ( wi ) ln p ( X | wi )代替
非监督分类
无法获得先验知识的情况下根据模式之
间的相似度进行分类。将相似性强的模式归
为同一类别,该方法又称为聚类分析其中k
识别的结果尽量与客观物体相符合。
如下所表示:
➢Y = F(X)
➢X的定义域取自特征集
➢Y的值域为类别的标号集
➢F是模式识别的判别方法
第2页/共62页
模式识别简史
1929年G.Tauschek发明阅读机,能够阅读0-9的数字。
第10章-模板匹配与模式识别

当差的绝对值部分和超过某一个阈值的时就 认为在该位置不存在于模板一致的图案,从而转 移到下一个位置。
还有一种方法:粗检索和细检索两个阶段。
模板一次移动若干个像素,计算匹配尺度, 先求出大致的范围。然后在大致范围内,在每次 移动一个像素,求出匹配尺度,确定对象所在位 置。
模板的要求:
检测对象大小和方向未知的情况下进行模板匹 配,需要具备各式各样大小和方向的模板,从而确 定对象及其未知。
模式,子模式,基元类似于短语,单词,字 母。因此该方法类似于语言句法结构分析,因此 称句法模式识别。
模式表示
图象输 入
预处 理
分割 描述
基元 提取
句法 分析
分类决策
识别
分析
句法
训练
基元 句法 分析
样本
选择 推断
改进
规则
结构模式识别系统框图
树分类法
树分类法:根据树型分层理论,将未知数据归属于某 一类的分类方法,是一种基于二叉树的分类方法。
特征处理:特征提取和特征选择
首先对识别对象的性质进行测量;利用测量值作 为分类的特征。
特征选择:
识别 对象
性质1 性质2 性质3 性质4 性质n
性质1 性质2 性质n-1
选择有区分性,可靠性,独立性好的特征
特征选择的方法:
穷举法:从m个测量值里面选取n个特征,然后对每
一种选法利用已经知道类别属性的样本进行试分类, 获得其正确率,分类误差最小的一组特征便是最好 的选择。
实例:句法模式识别(续)
多级树描述结构
墙壁N
L T
D 地板M
B XYZE景物A源自物体B 三角形D 长方体E
背景C
地板 M
墙N
还有一种方法:粗检索和细检索两个阶段。
模板一次移动若干个像素,计算匹配尺度, 先求出大致的范围。然后在大致范围内,在每次 移动一个像素,求出匹配尺度,确定对象所在位 置。
模板的要求:
检测对象大小和方向未知的情况下进行模板匹 配,需要具备各式各样大小和方向的模板,从而确 定对象及其未知。
模式,子模式,基元类似于短语,单词,字 母。因此该方法类似于语言句法结构分析,因此 称句法模式识别。
模式表示
图象输 入
预处 理
分割 描述
基元 提取
句法 分析
分类决策
识别
分析
句法
训练
基元 句法 分析
样本
选择 推断
改进
规则
结构模式识别系统框图
树分类法
树分类法:根据树型分层理论,将未知数据归属于某 一类的分类方法,是一种基于二叉树的分类方法。
特征处理:特征提取和特征选择
首先对识别对象的性质进行测量;利用测量值作 为分类的特征。
特征选择:
识别 对象
性质1 性质2 性质3 性质4 性质n
性质1 性质2 性质n-1
选择有区分性,可靠性,独立性好的特征
特征选择的方法:
穷举法:从m个测量值里面选取n个特征,然后对每
一种选法利用已经知道类别属性的样本进行试分类, 获得其正确率,分类误差最小的一组特征便是最好 的选择。
实例:句法模式识别(续)
多级树描述结构
墙壁N
L T
D 地板M
B XYZE景物A源自物体B 三角形D 长方体E
背景C
地板 M
墙N
模式识别基础教程PPT课件

8
典型应用
语音识别(例如:IBM ViaVoice系统) 表情分析、年龄、种族、性别分类 OCR: 车牌照、集装箱号码… 手写体识别:汉王 手势识别:基于视觉的,基于数据手套 人脸识别、指纹识别、虹膜识别… 军事目标识别 生物信息、医学图像 遥感、气象
9
模式识别方法
模板匹配 结构模式识别 句法模式识别 统计模式识别 模糊模式识别
机特征向量,用概率统计理论对其进行建模, 用统计决策理论划分特征空间来进行分类。
12
统计模式识别的一般过程
测试模式 预处理
分类
训练 预处理
训练模式
特征提 取/选择
分类
特征提 取/选择
学习分类规则 错误率检测
13
模糊模式识别
1965年Zadeh提出模糊集理论
是对传统集合理论的一种推广
传统:属于或者不属于 模糊:以一定的程度属于
这种技术具有实时性的特点,而且有可能扩展到多个姿 态的人脸检测。
18
人脸的特征表示方法
矩形特征(Harr-like特征)
矩形特征的值是所有白色矩形中点的亮度值的和减 去所有灰色矩形中点的亮度值的和,所得到的差
有4种类型的矩形特征
19
输入图像
积分图像
基于积分图像的 Haar-like特征计
7
模式分类 vs. 模式聚类
Classification Clustering
Category “A”
Categ
(Supervised Classification)
Clustering
(Unsupervised Classification)
“Good” features
“Bad” features
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
对样本进行观测、采样、量化得到的原理数据构成的向量
R [r,r,r]T
12
m
观测向量 观测值
• 观测空间
由观测向量的维数决定的m维几何空间
Applied Pattern Recognition CSE616
5
基本概念
• 特征向量
对观测向量进行特征选择和提取,得到反映事物本质特性 的特征构成的向量
11 12 121 22 2
n1 n 2 n
• 可根据各个特征在识别中的重要程度设置各加权系数
Applied Pattern Recognition CSE616
12
模板匹配法原理及过程
• 学习过程
• 对每一类已知类的学习样本进行特征提取,得到模板向量X1,
X2, ﹒﹒﹒ XC(C为类别数)
• 设置识别门限值ε • 以待识样本与模板向量之间的相似度(距离)为识别准则
• 造成样本分布不确定的原因:
• 样本本身的空间分布 • 传输处理过程中的噪声和干扰
Applied Pattern Recognition CSE616
17
统计模式识别基础
• 解决办法
• 将特征向量视为具有一定空间概率分布的随机向量 • 利用概率统计的方法进行分类器设计
Applied Pattern Recognition CSE616
1 n 2 n
• 绝对值距离(曼哈顿距离)
X x x x x x x
1121 12 22
1 n 2 n
Applied Pattern Recognition CSE616
11
基本概念
• 加权距离
D x x x x x x
模式识别
Pattern Classification
第二章: 模板匹配法
3
基本概念
• 模板匹配法
• 统计决策方法的特殊情况,也是最简单的情况 • 待分类的每一类模式只有一个唯一的标准(印刷体字符、标
准普通话)
Applied Pattern Recognition CSE616
4
基本概念
• 观测向量
15
模板匹配法的应用
• 人脸识别、模板脸 • 印刷体字符识别 • 标准普通话识别
Applied Pattern Recognition CSE616
16
统计模式识别基础
• 问题
• 模板匹配法将每一类模式的特征向量视为只有唯一标准的模
板向量
• 实际应用中,由于样本的不确定性,每一类模式在特征空间
中分布为一区域
X [x,x,x]T
12
n
特征向量 特征值
• 特征空间
由特征向量的维数决定的n维几何空间(n<m),每个特征 向量即是特征空间中的一个点
Applied Pattern Recognition CSE616
鲑鱼
6 鲈鱼
特征空间
Applied Pattern Recognition CSE616
欧氏距离
样本相似度
平方和距离 绝对值距离
加权距离
Applied Pattern Recognition CSE616
9
基本概念
ቤተ መጻሕፍቲ ባይዱ• 欧氏距离
设有两个n维特征向量X1和 X2
X [x,x,x]T
1
1212
1 n
X1 X2
X [x,x,x]T
2
2122
2 n
则此二样本的欧氏距离定义为:
18
统计模式识别基础
• 先验概率
设有C个类别的识别问题(ω1, ω2 , ﹒﹒﹒ , ωc ),则
ωi 类发生(出现)的概率P (ωi ) 称为第 i 类的先验概率。
显然:
c P() 1
i1
i
例如:乙肝病诊断
P () 0 .9,P 9 () 0 .01
1
2
手写体数字识别 P () P ( ) 0 .1
1
10
Applied Pattern Recognition CSE616
19
统计模式识别基础
• 类概率密度
指在已知样本类别为ωi 的条件下,特征向量在特征空间X
处发生的概率,记为P( X / ωi )。
显然:
P (X/
)d x1
i
P( X / ωi ) 随X的变化函数称为第 i 类的类概率密度函数。
Applied Pattern Recognition CSE616
22
统计模式识别基础
• 根据先验知识的多少,将统计方法分为:
属于第i类,,记为X∈Wi
• 若所有Di( i=1, 2 , ﹒﹒﹒,C )均大于ε,则拒识。
Applied Pattern Recognition CSE616
14
模板匹配法原理及过程
• 为提高模板匹配法的鲁棒性,可采用弹性模板匹配 • 将模板样本进行平移、旋转、缩放得到多个模板向量
Applied Pattern Recognition CSE616
XXX
1
2
xx2xx2xx2
11 21
12 22
1n
2n
Applied Pattern Recognition CSE616
10
基本概念
• 平方和距离
X 2 x x 2 x x 2 x x 2
11 21 12 22
7
基本概念
• 特征选择
• 去除次要的特征,筛选出重要的特征
• 特征提取
• 通过压缩变换或映射,降低特征维数
Applied Pattern Recognition CSE616
8
基本概念
• 样本的相似度
• 即样本的相似程度,是模式识别的重要依据 • 通常以样本特征向量在特征空间中的距离作为样本的相似度
Applied Pattern Recognition CSE616
13
模板匹配法原理及过程
• 识别过程
• 对待识样本进行特征提取,得到特征向量X • 计算待识样本特征向量X与模板向量X1, X2, ﹒﹒﹒ XC之间的
距离 D1, ,﹒﹒﹒,DC
• 若Di = min { Dj },j=1, 2 , ﹒﹒﹒,C,且 Di <ε,则判样本X
Applied Pattern Recognition CSE616
20
统计模式识别基础
一维二类情况下的类概率密度函数
Applied Pattern Recognition CSE616
21
统计模式识别基础
• 模板匹配法情况下的类概率密度函数? • 先验知识
• 先验概率和类概率密度的总称 • 统计方法即是基于样本先验知识的模式识别方法
R [r,r,r]T
12
m
观测向量 观测值
• 观测空间
由观测向量的维数决定的m维几何空间
Applied Pattern Recognition CSE616
5
基本概念
• 特征向量
对观测向量进行特征选择和提取,得到反映事物本质特性 的特征构成的向量
11 12 121 22 2
n1 n 2 n
• 可根据各个特征在识别中的重要程度设置各加权系数
Applied Pattern Recognition CSE616
12
模板匹配法原理及过程
• 学习过程
• 对每一类已知类的学习样本进行特征提取,得到模板向量X1,
X2, ﹒﹒﹒ XC(C为类别数)
• 设置识别门限值ε • 以待识样本与模板向量之间的相似度(距离)为识别准则
• 造成样本分布不确定的原因:
• 样本本身的空间分布 • 传输处理过程中的噪声和干扰
Applied Pattern Recognition CSE616
17
统计模式识别基础
• 解决办法
• 将特征向量视为具有一定空间概率分布的随机向量 • 利用概率统计的方法进行分类器设计
Applied Pattern Recognition CSE616
1 n 2 n
• 绝对值距离(曼哈顿距离)
X x x x x x x
1121 12 22
1 n 2 n
Applied Pattern Recognition CSE616
11
基本概念
• 加权距离
D x x x x x x
模式识别
Pattern Classification
第二章: 模板匹配法
3
基本概念
• 模板匹配法
• 统计决策方法的特殊情况,也是最简单的情况 • 待分类的每一类模式只有一个唯一的标准(印刷体字符、标
准普通话)
Applied Pattern Recognition CSE616
4
基本概念
• 观测向量
15
模板匹配法的应用
• 人脸识别、模板脸 • 印刷体字符识别 • 标准普通话识别
Applied Pattern Recognition CSE616
16
统计模式识别基础
• 问题
• 模板匹配法将每一类模式的特征向量视为只有唯一标准的模
板向量
• 实际应用中,由于样本的不确定性,每一类模式在特征空间
中分布为一区域
X [x,x,x]T
12
n
特征向量 特征值
• 特征空间
由特征向量的维数决定的n维几何空间(n<m),每个特征 向量即是特征空间中的一个点
Applied Pattern Recognition CSE616
鲑鱼
6 鲈鱼
特征空间
Applied Pattern Recognition CSE616
欧氏距离
样本相似度
平方和距离 绝对值距离
加权距离
Applied Pattern Recognition CSE616
9
基本概念
ቤተ መጻሕፍቲ ባይዱ• 欧氏距离
设有两个n维特征向量X1和 X2
X [x,x,x]T
1
1212
1 n
X1 X2
X [x,x,x]T
2
2122
2 n
则此二样本的欧氏距离定义为:
18
统计模式识别基础
• 先验概率
设有C个类别的识别问题(ω1, ω2 , ﹒﹒﹒ , ωc ),则
ωi 类发生(出现)的概率P (ωi ) 称为第 i 类的先验概率。
显然:
c P() 1
i1
i
例如:乙肝病诊断
P () 0 .9,P 9 () 0 .01
1
2
手写体数字识别 P () P ( ) 0 .1
1
10
Applied Pattern Recognition CSE616
19
统计模式识别基础
• 类概率密度
指在已知样本类别为ωi 的条件下,特征向量在特征空间X
处发生的概率,记为P( X / ωi )。
显然:
P (X/
)d x1
i
P( X / ωi ) 随X的变化函数称为第 i 类的类概率密度函数。
Applied Pattern Recognition CSE616
22
统计模式识别基础
• 根据先验知识的多少,将统计方法分为:
属于第i类,,记为X∈Wi
• 若所有Di( i=1, 2 , ﹒﹒﹒,C )均大于ε,则拒识。
Applied Pattern Recognition CSE616
14
模板匹配法原理及过程
• 为提高模板匹配法的鲁棒性,可采用弹性模板匹配 • 将模板样本进行平移、旋转、缩放得到多个模板向量
Applied Pattern Recognition CSE616
XXX
1
2
xx2xx2xx2
11 21
12 22
1n
2n
Applied Pattern Recognition CSE616
10
基本概念
• 平方和距离
X 2 x x 2 x x 2 x x 2
11 21 12 22
7
基本概念
• 特征选择
• 去除次要的特征,筛选出重要的特征
• 特征提取
• 通过压缩变换或映射,降低特征维数
Applied Pattern Recognition CSE616
8
基本概念
• 样本的相似度
• 即样本的相似程度,是模式识别的重要依据 • 通常以样本特征向量在特征空间中的距离作为样本的相似度
Applied Pattern Recognition CSE616
13
模板匹配法原理及过程
• 识别过程
• 对待识样本进行特征提取,得到特征向量X • 计算待识样本特征向量X与模板向量X1, X2, ﹒﹒﹒ XC之间的
距离 D1, ,﹒﹒﹒,DC
• 若Di = min { Dj },j=1, 2 , ﹒﹒﹒,C,且 Di <ε,则判样本X
Applied Pattern Recognition CSE616
20
统计模式识别基础
一维二类情况下的类概率密度函数
Applied Pattern Recognition CSE616
21
统计模式识别基础
• 模板匹配法情况下的类概率密度函数? • 先验知识
• 先验概率和类概率密度的总称 • 统计方法即是基于样本先验知识的模式识别方法