数据结构第7章 图2
第7章 图-有向无环图

算法的执行步骤: 算法的执行步骤: 1、用一个数组记录每个结点的入度。将入度为零的 、用一个数组记录每个结点的入度。 结点进栈。 结点进栈。 2、将栈中入度为零的结点V输出。 、将栈中入度为零的结点 输出 输出。 3、根据邻接表找到结点 的所有的邻接结点, 并将 、根据邻接表找到结点V的所有的邻接结点 的所有的邻接结点, 这些邻接结点的入度减一。 这些邻接结点的入度减一 。 如果某一结点的入度变 为零,则进栈。 为零,则进栈。
3
2
3、找到全为零的第 k 列,输出 k 、 4、将第 k 行的全部元素置为零 、 行的全部元素置为零
…………………
7
53、4;直至所有元素输出完毕。 、 ;直至所有元素输出完毕。
1 2 3 4 5 6 7
0 1 1 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0
template<class T> int BinaryTree <T>:: NumOfOne ( node <T> *t )
{ int k=0; if (t==NULL ) //空二叉树 //空二叉树 return 0; if (t所指结点 的度为 k=1 所指结点 的度为1) k=1; d1= NumOfOne ( t->lchild); //递归求左子树叶结点数 //递归求左子树叶结点数 d2= NumOfOne ( t->rchild); } //递归求右子树叶结点数 //递归求右子树叶结点数 return (d1+d2+k);
A B
AOE网络:结点为事件,有向边指向表示事件的执行次序。 网络:结点为事件,有向边指向表示事件的执行次序。 网络 有向边定义为活动,边的权值为活动进行所需要的时间。 有向边定义为活动,边的权值为活动进行所需要的时间。
第7章图_数据结构

v4
11
2013-8-7
图的概念(3)
子图——如果图G(V,E)和图G’(V’,E’),满足:V’V,E’E 则称G’为G的子图
2 1 4 3 5 6 3 5 6 1 2
v1 v2 v4 v3 v2
v1 v3 v4
v3
2013-8-7
12
图的概念(4)
路径——是顶点的序列V={Vp,Vi1,……Vin,Vq},满足(Vp,Vi1),
2013-8-7 5
本章目录
7.1 图的定义和术语 7.2 图的存储结构
7.2.1 数组表示法 7.2.2 邻接表 ( *7.2.3 十字链表 7.3.1 深度优先搜索 7.3.2 广度优先搜索 7.4.1 图的连通分量和生成树 7.4.2 最小生成树
*7.2.4 邻接多重表 )
7.3 图的遍历
连通树或无根树
无回路的图称为树或自由树 或无根树
2013-8-7
18
图的概念(8)
有向树:只有一个顶点的入度为0,其余 顶点的入度为1的有向图。
V1 V2
有向树是弱 连通的
V3
V4
2013-8-7
19
自测题
7. 下列关于无向连通图特性的叙述中,正确的是
2013-8-7
29
图的存贮结构:邻接矩阵
若顶点只是编号信息,边上信息只是有无(边),则 数组表示法可以简化为如下的邻接矩阵表示法: typedef int AdjMatrix[MAXNODE][MAXNODE];
*有n个顶点的图G=(V,{R})的邻接矩阵为n阶方阵A,其定 义如下:
1 A[i ][ j ] 0
【北方交通大学 2001 一.24 (2分)】
数据结构 第7章习题答案

第7章 《图》习题参考答案一、单选题(每题1分,共16分)( C )1. 在一个图中,所有顶点的度数之和等于图的边数的 倍。
A .1/2 B. 1 C. 2 D. 4 (B )2. 在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的 倍。
A .1/2 B. 1 C. 2 D. 4 ( B )3. 有8个结点的无向图最多有 条边。
A .14 B. 28 C. 56 D. 112 ( C )4. 有8个结点的无向连通图最少有 条边。
A .5 B. 6 C. 7 D. 8 ( C )5. 有8个结点的有向完全图有 条边。
A .14 B. 28 C. 56 D. 112 (B )6. 用邻接表表示图进行广度优先遍历时,通常是采用 来实现算法的。
A .栈 B. 队列 C. 树 D. 图 ( A )7. 用邻接表表示图进行深度优先遍历时,通常是采用 来实现算法的。
A .栈 B. 队列 C. 树 D. 图 ()8. 已知图的邻接矩阵,根据算法思想,则从顶点0出发按深度优先遍历的结点序列是( D )9. 已知图的邻接矩阵同上题8,根据算法,则从顶点0出发,按深度优先遍历的结点序列是A . 0 2 4 3 1 5 6 B. 0 1 3 5 6 4 2C. 0 4 2 3 1 6 5D. 0 1 2 34 6 5 ( D )10. 已知图的邻接表如下所示,根据算法,则从顶点0出发按深度优先遍历的结点序列是( A )11. 已知图的邻接表如下所示,根据算法,则从顶点0出发按广度优先遍历的结点序列是A .0 2 4 3 1 5 6B. 0 1 3 6 5 4 2C. 0 1 3 4 2 5 6D. 0 3 6 1 5 4 2⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡0100011101100001011010110011001000110010011011110A .0 1 3 2 B. 0 2 3 1 C. 0 3 2 1 D. 0 1 2 3(A)12. 深度优先遍历类似于二叉树的A.先序遍历 B. 中序遍历 C. 后序遍历 D. 层次遍历(D)13. 广度优先遍历类似于二叉树的A.先序遍历 B. 中序遍历 C. 后序遍历 D. 层次遍历(A)14. 任何一个无向连通图的最小生成树A.只有一棵 B. 一棵或多棵 C. 一定有多棵 D. 可能不存在(注,生成树不唯一,但最小生成树唯一,即边权之和或树权最小的情况唯一)二、填空题(每空1分,共20分)1. 图有邻接矩阵、邻接表等存储结构,遍历图有深度优先遍历、广度优先遍历等方法。
数据结构章节练习题2

第七章图一、选择题1.图中有关路径的定义是()。
A.由顶点和相邻顶点序偶构成的边所形成的序列B.由不同顶点所形成的序列C.由不同边所形成的序列D.上述定义都不是2.设无向图的顶点个数为n,则该图最多有()条边。
A.n-1 B.n(n-1)/2 C.n(n+1)/2 D.0 E.n23.一个n个顶点的连通无向图,其边的个数至少为()。
A.n-1 B.n C.n+1 D.nlogn;4.要连通具有n个顶点的有向图,至少需要()条边。
A.n-l B.n C.n+l D.2n5.一个有n个结点的图,最少有(B )个连通分量,最多有(D )个连通分量。
A.0 B.1 C.n-1 D.n6. 下列说法不正确的是()。
A.图的遍历是从给定的源点出发每一个顶点仅被访问一次C.图的深度遍历不适用于有向图B.遍历的基本算法有两种:深度遍历和广度遍历D.图的深度遍历是一个递归过程7.无向图G=(V,E),其中:V={a,b,c,d,e,f},E={(a,b),(a,e),(a,c),(b,e),(c,f),(f,d),(e,d)},对该图进行深度优先遍历,得到的顶点序列正确的是()。
A.a,b,e,c,d,f B.a,c,f,e,b,d C.a,e,b,c,f,d D.a,e,d,f,c,b8. 在图采用邻接表存储时,求最小生成树的Prim 算法的时间复杂度为( )。
A. O(n)B. O(n+e)C. O(n2)D. O(n3)9. 求解最短路径的Floyd算法的时间复杂度为( )。
A.O(n) B. O(n+c) C. O(n*n)D. O(n*n*n)10.已知有向图G=(V,E),其中V={V1,V2,V3,V4,V5,V6,V7},E={<V1,V2>,<V1,V3>,<V1,V4>,<V2,V5>,<V3,V5>,<V3,V6>,<V4,V6>,<V5,V7>,<V6,V7>},G的拓扑序列是()。
数据结构课后习题答案第七章
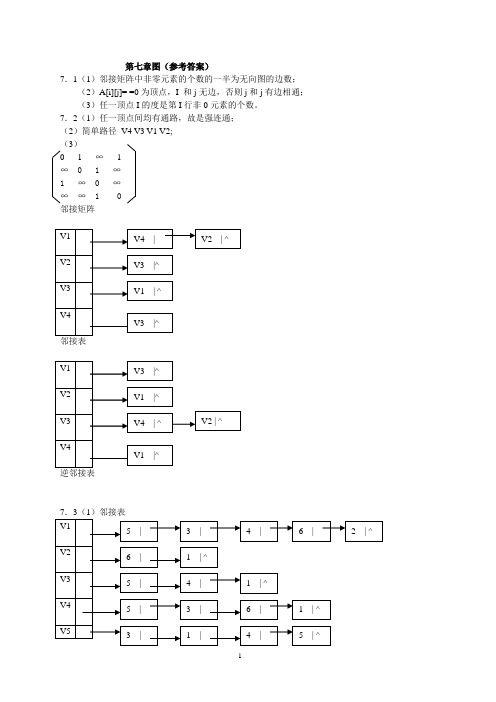
第七章图(参考答案)7.1(1)邻接矩阵中非零元素的个数的一半为无向图的边数;(2)A[i][j]= =0为顶点,I 和j无边,否则j和j有边相通;(3)任一顶点I的度是第I行非0元素的个数。
7.2(1)任一顶点间均有通路,故是强连通;(2)简单路径V4 V3 V1 V2;(3)0 1 ∞ 1∞ 0 1 ∞1 ∞ 0 ∞∞∞ 1 0邻接矩阵邻接表(2)从顶点4开始的DFS序列:V5,V3,V4,V6,V2,V1(3)从顶点4开始的BFS序列:V4,V5,V3,V6,V1,V27.4(1)①adjlisttp g; vtxptr i,j; //全程变量② void dfs(vtxptr x)//从顶点x开始深度优先遍历图g。
在遍历中若发现顶点j,则说明顶点i和j间有路径。
{ visited[x]=1; //置访问标记if (y= =j){ found=1;exit(0);}//有通路,退出else { p=g[x].firstarc;//找x的第一邻接点while (p!=null){ k=p->adjvex;if (!visited[k])dfs(k);p=p->nextarc;//下一邻接点}}③ void connect_DFS (adjlisttp g)//基于图的深度优先遍历策略,本算法判断一邻接表为存储结构的图g种,是否存在顶点i //到顶点j的路径。
设 1<=i ,j<=n,i<>j.{ visited[1..n]=0;found=0;scanf (&i,&j);dfs (i);if (found) printf (” 顶点”,i,”和顶点”,j,”有路径”);else printf (” 顶点”,i,”和顶点”,j,”无路径”);}// void connect_DFS(2)宽度优先遍历全程变量,调用函数与(1)相同,下面仅写宽度优先遍历部分。
第7章树和二叉树(2)-数据结构教程(Java语言描述)-李春葆-清华大学出版社

二叉树也称为二分树,它是有限的结点集合,这个集合或者是空,或者由 一个根结点和两棵互不相交的称为左子树和右子树的二叉树组成。 二叉树中许多概念与树中的概念相同。 在含n个结点的二叉树中,所有结点的度小于等于2,通常用n0表示叶子结 点个数,n1表示单分支结点个数,n2表示双分支结与度为2的树是不同的。
度为2的树至少有3个结点,而二叉树的结点数可以为0。 度为2的树不区分子树的次序,而二叉树中的每个结点最多有 两个孩子结点,且必须要区分左右子树,即使在结点只有一棵 子树的情况下也要明确指出该子树是左子树还是右子树。
2/35
归纳起来,二叉树的5种形态:
Ø
4/35
3. 满二叉树和完全二叉树
在一棵二叉树中,如果所有分支结点都有左孩子结点和右孩子结点,并且 叶子结点都集中在二叉树的最下一层,这样的二叉树称为满二叉树。
可以对满二叉树的结点进行层序编号,约定编号从树根为1开始,按照层 数从小到大、同一层从左到右的次序进行。
满二叉树也可以从结点个数和树高度之间的关系来定义,即一棵高度为h 且有2h-1个结点的二叉树称为满二叉树。
R={r} r={<ai,aj> | ai,aj∈D, 1≤i,j≤n,当n=0时,称为空二叉树;否则其中
有一个根结点,其他结点构成根结点的互不相交的左、右子树,该 左、右两棵子树也是二叉树 } 基本运算: void CreateBTree(string str):根据二叉树的括号表示串建立其存储结构。 String toString():返回由二叉树树转换的括号表示串。 BTNode FindNode(x):在二叉树中查找值为x的结点。 int Height():求二叉树的高度。 … }
5
E
北京理工大学数据结构图课件

B C D
第 5 页
E
7.1 图的定义与术语
3、无向图——无向图G是由两个集合V(G)和 E(G)组成的。 其中:V(G)是顶点的非空有限集。 E(G)是边的有限集合,边是顶点的 无序对,记为 (v,w) 或 (w,v),并且 (v,w)=(w,v)。
第 6 页
7.1 图的定义与术语
例如:
G2 = <V2,E2> V2 = { v0 ,v1,v2,v3,v4 } E2 = { (v0,v1), (v0,v3), (v1,v2), (v1,v4), (v2,v3), (v2,v4) }
V5
第 15 页
7.1 图的定义与术语
非 连 通 图
V0
V1
V2
V3
V0
V1 V3
V2
强连通分量
第 16 页
7.1 图的定义与术语
7、生成树
包含无向图 G 所有顶点的极小连通子图称为G生 成树。 极小连通子图意思是:该子图是G的连通子图, 在该子图中删除任何一条边,子图不再连通。
V0 V2 V3 V4 V3 连通图G1 V1 V0 V1 连通 所有顶点 V4 无回路
第 22 页
7.2 图的存储结构 3、有向图的逆邻接表 顶点:用一维数组存储(按编号顺序) 以同一顶点为终点的弧:用线性链表存储。
vexdata V0 V1 0 1 v0 v1 v2
v3
firstarc 3 0 0 ^ ^
V2
V3
2 3
^
^
2
章 类似于有向图的邻接表,所不同的是: 以同一顶点为终点弧:用线性链表存储
Boolean visited[MAX]; // 访问标志数组
数据结构习题及答案与实验指导(树和森林)7

第7章树和森林树形结构是一类重要的非线性结构。
树形结构的特点是结点之间具有层次关系。
本章介绍树的定义、存储结构、树的遍历方法、树和森林与二叉树之间的转换以及树的应用等内容。
重点提示:●树的存储结构●树的遍历●树和森林与二叉树之间的转换7-1 重点难点指导7-1-1 相关术语1.树的定义:树是n(n>=0)个结点的有限集T,T为空时称为空树,否则它满足如下两个条件:①有且仅有一个特定的称为根的结点;②其余的结点可分为m(m>=0)个互不相交的子集T1,T2,…,T m,其中每个子集本身又是一棵树,并称为根的子树。
要点:树是一种递归的数据结构。
2.结点的度:一个结点拥有的子树数称为该结点的度。
3.树的度:一棵树的度指该树中结点的最大度数。
如图7-1所示的树为3度树。
4.分支结点:度大于0的结点为分支结点或非终端结点。
如结点a、b、c、d。
5.叶子结点:度为0的结点为叶子结点或终端结点。
如e、f、g、h、i。
6.结点的层数:树是一种层次结构,根结点为第一层,根结点的孩子结点为第二层,…依次类推,可得到每一结点的层次。
7.兄弟结点:具有同一父亲的结点为兄弟结点。
如b、c、d;e、f;h、i。
8.树的深度:树中结点的最大层数称为树的深度或高度。
9.有序树:若将树中每个结点的子树看成从左到右有次序的(即不能互换),则称该树为有序树,否则称为无序树。
10.森林:是m棵互不相交的树的集合。
7-1-2 树的存储结构1.双亲链表表示法以图7-1所示的树为例。
(1)存储思想:因为树中每个元素的双亲是惟一的,因此对每个元素,将其值和一个指向双亲的指针parent构成一个元素的结点,再将这些结点存储在向量中。
(2)存储示意图:-1 data:parent:(3)注意: Parrent域存储其双亲结点的存储下标,而不是存放结点值。
下面的存储是不正确的:-1 data:parent:2.孩子链表表示法(1)存储思想:将每个数据元素的孩子拉成一个链表,链表的头指针与该元素的值存储为一个结点,树中各结点顺序存储起来,一般根结点的存储号为0。
数据结构教程李春葆课后答案第7章树和二叉树

教材中练习题及参考答案
1. 有一棵树的括号表示为 A(B,C(E,F(G)),D),回答下面的问题: (1)指出树的根结点。 (2)指出棵树的所有叶子结点。 (3)结点 C 的度是多少? (4)这棵树的度为多少? (5)这棵树的高度是多少? (6)结点 C 的孩子结点是哪些? (7)结点 C 的双亲结点是谁? 答:该树对应的树形表示如图 7.2 所示。 (1)这棵树的根结点是 A。 (2)这棵树的叶子结点是 B、E、G、D。 (3)结点 C 的度是 2。 (4)这棵树的度为 3。 (5)这棵树的高度是 4。 (6)结点 C 的孩子结点是 E、F。 (7)结点 C 的双亲结点是 A。
12. 假设二叉树中每个结点值为单个字符,采用二叉链存储结构存储。设计一个算法 计算一棵给定二叉树 b 中的所有单分支结点个数。 解:计算一棵二叉树的所有单分支结点个数的递归模型 f(b)如下:
f(b)=0 若 b=NULL
6 f(b)=f(b->lchild)+f(b->rchild)+1 f(b)=f(b->lchild)+f(b->rchild)
表7.1 二叉树bt的一种存储结构 1 lchild data rchild 0 j 0 2 0 h 0 3 2 f 0 4 3 d 9 5 7 b 4 6 5 a 0 7 8 c 0 8 0 e 0 9 10 g 0 10 1 i 0
答:(1)二叉树bt的树形表示如图7.3所示。
a b c e h j f i d g e h j c f i b d g a
对应的算法如下:
void FindMinNode(BTNode *b,char &min) { if (b->data<min) min=b->data; FindMinNode(b->lchild,min); //在左子树中找最小结点值 FindMinNode(b->rchild,min); //在右子树中找最小结点值 } void MinNode(BTNode *b) //输出最小结点值 { if (b!=NULL) { char min=b->data; FindMinNode(b,min); printf("Min=%c\n",min); } }
数据结构(C语言版)_第7章 图及其应用

实现代码详见教材P208
7.4 图的遍历
图的遍历是对具有图状结构的数据线性化的过程。从图中任 一顶点出发,访问输出图中各个顶点,并且使每个顶点仅被访 问一次,这样得到顶点的一个线性序列,这一过程叫做图的遍 历。
图的遍历是个很重要的算法,图的连通性和拓扑排序等算法 都是以图的遍历算法为基础的。
V1
V1
V2
V3
V2
V3
V4
V4
V5
图9.1(a)
图7-2 图的逻辑结构示意图
7.2.2 图的相关术语
1.有向图与无向图 2.完全图 (1)有向完全图 (2)无向完全图 3.顶点的度 4.路径、路径长度、回路、简单路径 5.子图 6.连通、连通图、连通分量 7.边的权和网 8.生成树
2. while(U≠V) { (u,v)=min(wuv;u∈U,v∈V-U); U=U+{v}; T=T+{(u,v)}; }
3.结束
7.5.1 普里姆(prim)算法
【例7-10】采用Prim方法从顶点v1出发构造图7-11中网所对 应的最小生成树。
构造过程如图7-12所示。
16
V1
V1
V2
7.4.2 广度优先遍历
【例7-9】对于图7-10所示的有向图G4,写出从顶点A出发 进行广度优先遍历的过程。
访问过程如下:首先访问起始顶点A,再访问与A相邻的未被 访问过的顶点E、F,再依次访问与E、F相邻未被访问过的顶 点D、C,最后访问与D相邻的未被访问过的顶点B。由此得到 的搜索序列AEFDCB。此时所有顶点均已访问过, 遍历过程结束。
【例7-1】有向图G1的逻辑结构为:G1=(V1,E1) V1={v1,v2,v3,v4},E1={<v1,v2>,<v2,v3>,<v2,v4>,<v3,v4>,<v4,v1>,<v4,v3>}
第7章图(下)-数据结构简明教程(第2版)-微课版-李春葆-清华大学出版社

成
树
(1)置U的初值等于V(即包含有G中的全部顶点),TE的初
和 最
值为空集(即图T中每一个顶点都构成一个连通分量)。
小
(2)将图G中的边按权值从小到大的顺序依次选取:若选取
生
成
的边未使生成树T形成回路,则加入TE;否则舍弃,直到TE中包
树
含n-1条边为止。
实现克鲁斯卡尔算法的关键是如何判断选取的边是否与生成树 中已保留的边形成回路?
7.4
建立了两个辅助数组closest和lowcost。
所有顶点分为U和V-U两个顶点集。
U中的顶点i:lowcost[i]=0;
生
V-U中的顶点j:lowcost[j]>0。
成
树
和
最
小 生
i
j
成
树
U中i:lowcost[i]=0
V-U中j:lowcost[j]>0
7.4
实现普里姆算法(2/3):
生
通过深度优先遍历产生的生成树称为深度优先生成树。
成
树
通过广度优先遍历产生的生成树称为广度优先生成树。
和
最
小
生
成
树
无向图进行遍历时:
7.4
连通图:仅需要从图中任一顶点出发,进行深度优先遍历或广
度优先遍历便可以访问到图中所有顶点,因此连通图的一次遍
历所经过的边的集合及图中所有顶点的集合就构成了该图的一
7.4
为此设置一个辅助数组vset[0..n-1],它用于判定两个顶点之
生
间是否连通。
成
数组元素vset[i](初值为i)代表编号为i的顶点所属的连通
树
子图的编号。
和
数据结构-第7章图答案

7.3 图的遍历 从图中某个顶点出发游历图,访遍图中其余顶点, 并且使图中的每个顶点仅被访问一次的过程。 一、深度优先搜索 从图中某个顶点V0 出发,访问此顶点,然后依次 从V0的各个未被访问的邻接点出发深度优先搜索遍 历图,直至图中所有和V0有路径相通的顶点都被访 问到,若此时图中尚有顶点未被访问,则另选图中 一个未曾被访问的顶点作起始点,重复上述过程, 直至图中所有顶点都被访问到为止。
void BFSTraverse(Graph G, Status (*Visit)(int v)) { // 按广度优先非递归遍历图G。使用辅助队列Q和访问标志数组 visited。 for (v=0; v<G.vexnum; ++v) visited[v] = FALSE; InitQueue(Q); // 置空的辅助队列Q for ( v=0; v<G.vexnum; ++v ) if ( !visited[v]) { // v尚未访问 EnQueue(Q, v); // v入队列 while (!QueueEmpty(Q)) { DeQueue(Q, u); // 队头元素出队并置为u visited[u] = TRUE; Visit(u); // 访问u for ( w=FirstAdjVex(G, u); w!=0; w=NextAdjVex(G, u, w) ) if ( ! visited[w]) EnQueue(Q, w); // u的尚未访问的邻接顶点w入队列Q
4。邻接多重表
边结点
mark ivex
顶点结点
ilink
jvex
jlink
info
data
firstedge
#define MAX_VERTEX_NUM 20 typedef emnu {unvisited, visited} VisitIf; typedef struct Ebox { VisitIf mark; // 访问标记 int ivex, jvex; // 该边依附的两个顶点的位置 struct EBox *ilink, *jlink; // 分别指向依附这两个顶点的下一条 边 InfoType *info; // 该边信息指针 } EBox; typedef struct VexBox { VertexType data; EBox *firstedge; // 指向第一条依附该顶点的边 } VexBox; typedef struct { VexBox adjmulist[MAX_VERTEX_NUM]; int vexnum, edgenum; // 无向图的当前顶点数和边数 } AMLGraph;
《数据结构》第 7 章 图

v3
v4 v5 v4
v3
v5 v4
v3
v5 v4
v3
v5 v4
v3
v5
注
一个图可以有许多棵不同的生成树。 所有生成树具有以下共同特点: 生成树的顶点个数与图的顶点个数相同; 生成树是图的极小连通子图; 一个有 n 个顶点的连通图的生成树有 n-1 条边; 生成树中任意两个顶点间的路径是唯一的; 在生成树中再加一条边必然形成回路。 含 n 个顶点 n-1 条边的图不一定是生成树。
A1 = {< v1, v2>, < v1, v3>, < v3, v4>, < v4, v1>} v1 v2
有向图
v3
v4
制作:计算机科学与技术学院 徐振中
数据结构 边:若 <v, w>∈VR 必有<w, v>∈VR,则以 无序对 (v, w) 代表这两个有序对,表示 v 和 w 之 间的一条边,此时的图称为无向图。 G2 = (V2, E2) V2 = {v1, v2, v3, v4, v5}
第七章 图
E2 = {(v1, v2), (v1, v4), (v2, v3), (v2, v5) , (v3, v4), (v3, v5)} v1
G2
v3
v2
无向图
v4
v5
制作:计算机科学与技术学院 徐振中
数据结构
第七章 图
例:两个城市 A 和 B ,如果 A 和 B 之间的连线的涵义是 表示两个城市的距离,则<A, B> 和 <B, A> 是相同的, 用 (A, B) 表示。 如果 A 和 B 之间的连线的涵义是表示两城市之 间人口流动的情况,则 <A, B> 和 <B, A> 是不同的。 北京 <北京,上海> (北京,上海) <上海,北京> <北京,上海> 北京 上海 上海
数据结构第七章--图(严蔚敏版)
8个顶点的无向图最多有 条边且该图为连通图 个顶点的无向图最多有28条边且该图为连通图 个顶点的无向图最多有 连通无向图构成条件:边 顶点数 顶点数-1)/2 顶点数*(顶点数 连通无向图构成条件 边=顶点数 顶点数 顶点数>=1,所以该函数存在单调递增的单值反 顶点数 所以该函数存在单调递增的单值反 函数,所以边与顶点为增函数关系 所以28个条边 函数 所以边与顶点为增函数关系 所以 个条边 的连通无向图顶点数最少为8个 所以28条边的 的连通无向图顶点数最少为 个 所以 条边的 非连通无向图为9个 加入一个孤立点 加入一个孤立点) 非连通无向图为 个(加入一个孤立点
28
无向图的邻接矩阵为对称矩阵
2011-10-13
7.2
图的存储结构
Wij 若< vi,vj > 或<vj,v i > ∈E(G)
若G是网(有权图),邻接矩阵定义为 是网(有权图), ),邻接矩阵定义为
A [ i,j ] = , 0或 ∞
如图: 如图:
V1
若其它
V2
3 4
2
V3
2011-10-13
C
A
B
D 2011-10-13 (a )
3
Königsberg七桥问题
• Königsberg七桥问题就是说,能否从某点出发 通过每桥恰好一次回到原地?
C
C
A B
.
A D
B
D (a)
2011-10-13
(b)
4
第七章 图
7.1 图的定义 7.2 图的存储结构 7.3 图的遍历 7.4 图的连通性问题 7.5 有向无环图及其应用 7.6 最短路径
2011-10-13
第7章 图

假设一个连通图有 n 个顶点和 e 条边, 其中 n-1 条边和 n 个顶点构成一个极小 连通子图,称该极小连通子图为此连通图 的生成树 生成树。 生成树 B A F E C D 对非连通图,则 称由各个连通分 量的生成树的集 合为此非连通图 的生成森林 生成森林。 生成森林
基本操作
结构的建立和销毁 对顶点的访问操作 插入和删除顶点 插入和删除弧 对邻接点的操作 遍历
假若顶点v 和顶点w 之间存在一条边, 则称顶点v 和w 互为邻接点 邻接点, 邻接点
边(v,w) 和顶点v 和w 相关联 相关联。 和顶点v相关联的边的数目 边的数目定义为顶点v的度, 边的数目 度 记为TD(v)。 记为TD( TD
B A F
C D E
例如: 例如: 右侧图中 TD(B) = 3 TD(A) = 2
个顶点相同的路径。
若图G中任意两个顶 点之间都有路径相通, 则称此图为连通图 连通图; A 连通图 B A F E C D
B
C D
F
E
若无向图为非连通图, 则图中各个极大连通 子图称作此图的连通 连通 分量。 分量
若任意两个顶点之间都存在 对有向图, 对有向图, 一条有向路径,则称此有向图为强连通图 强连通图。 强连通图 否则,其各个强连通子图称作它的 强连通分量。 强连通分量 A B C F E B C F A E
// 点”。若 w 是 v 的最后一个邻接点,则 // 返回“空”。
插入和删除顶点
InsertVex(&G, v); //在图G中增添新顶点v。 DeleteVex(&G, v); // 删除G中顶点v及其相关的弧。
插入和删除弧
InsertArc(&G, v, w); // 在G中增添弧<v,w>,若G是无向的, //则还增添对称弧<w,v>。 DeleteArc(&G, v, w); //在G中删除弧<v,w>,若G是无向的, //则还删除对称弧<w,v>。
数据结构 习题 第七章 图 答案

第7章图二.判断题部分答案解释如下。
2. 不一定是连通图,可能有若干连通分量 11. 对称矩阵可存储上(下)三角矩阵14.只有有向完全图的邻接矩阵是对称的 16. 邻接矩阵中元素值可以存储权值21. 只有无向连通图才有生成树 22. 最小生成树不唯一,但最小生成树上权值之和相等26. 是自由树,即根结点不确定35. 对有向无环图,拓扑排序成功;否则,图中有环,不能说算法不适合。
42. AOV网是用顶点代表活动,弧表示活动间的优先关系的有向图,叫顶点表示活动的网。
45. 能求出关键路径的AOE网一定是有向无环图46. 只有该关键活动为各关键路径所共有,且减少它尚不能改变关键路径的前提下,才可缩短工期。
48.按着定义,AOE网中关键路径是从“源点”到“汇点”路径长度最长的路径。
自然,关键路径上活动的时间延长多少,整个工程的时间也就随之延长多少。
三.填空题1.有n个顶点,n-1条边的无向连通图2.有向图的极大强连通子图3. 生成树9. 2(n-1) 10. N-1 11. n-1 12. n 13. N-1 14. n15. N16. 3 17. 2(N-1) 18. 度出度 19. 第I列非零元素个数 20.n 2e21.(1)查找顶点的邻接点的过程 (2)O(n+e) (3)O(n+e) (4)访问顶点的顺序不同 (5)队列和栈22. 深度优先 23.宽度优先遍历 24.队列25.因未给出存储结构,答案不唯一。
本题按邻接表存储结构,邻接点按字典序排列。
25题(1) 25题(2) 26.普里姆(prim )算法和克鲁斯卡尔(Kruskal )算法 27.克鲁斯卡尔28.边稠密 边稀疏 29. O(eloge ) 边稀疏 30.O(n 2) O(eloge) 31.(1)(V i ,V j )边上的权值 都大的数 (2)1 负值 (3)为负 边32.(1)n-1 (2)普里姆 (3)最小生成树 33.不存在环 34.递增 负值 35.16036.O(n 2) 37. 50,经过中间顶点④ 38. 75 39.O(n+e )40.(1)活动 (2)活动间的优先关系 (3)事件 (4)活动 边上的权代表活动持续时间41.关键路径 42.(1)某项活动以自己为先决条件 (2)荒谬 (3)死循环 43.(1)零 (2)V k 度减1,若V k 入度己减到零,则V k 顶点入栈 (3)环44.(1)p<>nil (2)visited[v]=true (3)p=g[v].firstarc (4)p=p^.nextarc45.(1)g[0].vexdata=v (2)g[j].firstin (3)g[j].firstin (4)g[i].firstout (5)g[i].firstout (6)p^.vexj (7)g[i].firstout (8)p:=p^.nexti (9)p<>nil (10)p^.vexj=j(11)firstadj(g,v 0) (12)not visited[w] (13)nextadj(g,v 0,w)46.(1)0 (2)j (3)i (4)0 (5)indegree[i]==0 (6)[vex][i] (7)k==1 (8)indegree[i]==047.(1)p^.link:=ch[u ].head (2)ch[u ].head:=p (3)top<>0 (4)j:=top (5)top:=ch[j].count(6)t:=t^.link48.(1)V1 V4 V3 V6 V2 V5(尽管图以邻接表为存储结构,但因没规定邻接点的排列,所以结果是不唯一的。
数据结构第三版第七章作业参考答案
//栈指针置初值
do { while (t)
//将 t 的所有左结点进栈
{ top++;
St[top]=t;
t=t->lchild;
} p=NULL; flag=1; while (top!=-1 && flag)
//p 指e当前结点的前一个已fg
的
结
点
//h置 t 的fgij为已fg过
{ t=St[top]; if (t->rchild==p) { if (t==s)
7.1 设二叉树 bt 的一种存储结构如下:
1 2 3 4 5 6 7 8 9 10 lchild 0 0 2 3 7 5 8 0 10 1 data j h f d b a c e g i rchild 0 0 0 9 4 0 0 0 0 0
其中,bt 为树根结点指针,lchild、rchild 分别为结点的左、右孩子指针域,
Ctree(t->lchild,A,2*i);
//递归构造*t 的左子树
Ctree(t->rchild,A,2*i+1); //递归构造*t 的右子树
}
}
7.5 设计一个算法,将一棵以二叉链方式存储的二叉树 t 按顺序方式存储到数组 A 中。
解:由二叉树的顺序存储方式可知本题的递归模型f()如下:
f(t,A,i):A[i]=' ';
//顺序队首尾指针 //cm=1 表示二叉树为完全二叉树 //bj=1 表示到目前为止所有结点均有左右孩子
if (b!=NULL)
{ rear++;
Qu[rear]=b;
while (first!=rear) { first++;
数据结构 C语言版(严蔚敏版)第7章 图

1
2
4
1
e6 2 4
2016/11/7
29
7.3 图的遍历
从已给的连通图中某一顶点出发,沿着一 些边访遍图中所有的顶点,且使每个顶点 仅被访问一次,就叫做图的遍历 ( Graph Traversal )。 图中可能存在回路,且图的任一顶点都可 能与其它顶点相通,在访问完某个顶点之 后可能会沿着某些边又回到了曾经访问过 的顶点。 为了避免重复访问,可设置一个标志顶点 是否被访问过的辅助数组 visited [ ]。
2
1 2
V2
V4
17
结论:
无向图的邻接矩阵是对称的; 有向图的邻接矩阵可能是不对称的。 在有向图中, 统计第 i 行 1 的个数可得顶点 i 的出度,统计第 j 行 1 的个数可得顶点 j 的入度。 在无向图中, 统计第 i 行 (列) 1 的个数可得 顶点i 的度。
2016/11/7
18
2
邻接表 (出度表)
adjvex nextarc
data firstarc
0 A 1 B 2 C
2016/11/7
1 0 1
逆邻接表 (入度表)
21
网络 (带权图) 的邻接表
6 9 0 2 1 C 2 8 3 D
data firstarc Adjvex info nextarc
2016/11/7
9
路径长度 非带权图的路径长度是指此路径 上边的条数。带权图的路径长度是指路径 上各边的权之和。 简单路径 若路径上各顶点 v1,v2,...,vm 均不 互相重复, 则称这样的路径为简单路径。 回路 若路径上第一个顶点 v1 与最后一个 顶点vm 重合, 则称这样的路径为回路或环。
自考数据结构02142-第七章

二、归并排序 1.思想:(2-路归并排序)
① n个记录的表看成n个,长度为1的有序表 ② 两两归并成 n/2 个,长度为2的有序表(n为奇数,则 还有1个长为1的表) ③再两两归并为 n/2 /2 个,长度为4的有序表 . . . 再两两归并直至只剩1个,长度为n的有序表;
共log2n 趟
2. 例:
二、快速排序★
1.基本思想:通过分部排序完成整个表的排 序;
首先取第一个记录,将之与表中其余记录比较并交换,从而将 它放到记录的正确的最终位置,使记录表分成两部分{其一(左边的) 诸记录的关键字均小于它;其二(右边的)诸记录的关键字均大于 它};然后对这两部分重新执行上述过程,依此类推,直至排序完毕。
7.5 归并排序
一、有序序列的合并(两个有序表归并成一个有 序表) 1. 思想:比较各个子序列的第一个记录的 键值,最小的一个就是排序后序列的第一个 记录。取出这个记录,继续比较各子序列现 有的第一个记录的键值,便可找出排序后的 第二个记录。如此继续下去,最终可以得到 排序结果。 2. 两个有序表归并算法 (见P199)
▲排序类型——
内部排序:全部数据存于内存;
排序过程
外部排序:需要对外村进行访问的
内部排序
按方法分
插入排序 交换排序 选择排序 归并排序
▲排序文件的物理表示:数组表示 #define n 100 /*序列中待排序记录的总数*/ typedef struct { int key; /*关键字项*/ anytype otheritem ; /*其他数据项*/ }records; typedef records list[n+1]; list r; r[0] r[1] r[2]….r[n] r[i].key——第i个记录的关键字 ▲排序指标(排序算法分析): 存储空间-空间复杂度 比较次数-时间复杂度
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第七章 图
7.1 图的类型定义 7.2 图的存储结构 7.3 图的遍历 7.4 最小生成树 7.5 有向无环图及其应用 7.6 最短路径
1
7.1 图的类型定义
图 是由一个顶点集 V 和一个关系集 R构成的数据结构。 Graph = ( V , R ) 其中: V = { ei | ei∈ElemSet, i = 1, 2, … , n }
14
数组元素结点
图的邻接表存储表示
#define MAX_VERTEX_NUM 20 typedef struct ArcNode { //边链表结点 int adjvex; // 该弧所指向的顶点的位置 struct ArcNode *nextarc; // 指向下一条弧的指针 InfoType *info; // 该弧相关信息的指针 } ArcNode;
typedef struct ArcCell { //存储弧/边的信息,即邻接矩阵 VRType adj; // VRType是顶点关系类型。 //对无权图,用1或0表示相邻否; // 对带权图,则为权值类型。 InfoType *info; // 该弧相关信息的指针 } ArcCell, 9 AdjMatrix[MAX_VERTEX_NUM][MAX_VERTEX_NUM];
4
V1
V2
V1 V3
V2
V3
v1 v2 v3 v4
0 1 1 0 0 0 0 0 0 0 0 1 1 0 0 0
V4
V4
0 1 0 1 0 1 0 1 0 1 0 1 0 1 1 1 0 1 0 0
V5
0 1 1 0 0
v1 v2 v3 v4
有向图G1 的邻接矩阵
无向图G2 的邻接矩阵
5
无向图邻接矩阵表示法特点:
R = { VR }
VR = { <v, w> | v, w∈V 且 P(v, w) } 谓词 P(v, w) 定义了 <v, w>之间关系的意义或信息。
2
7.2 图的存储表示
一、图的数组(邻接矩阵)存储表示 二、图的邻接表存储表示
三、有向图的十字链表存储表示 四、无向图的邻接多重表存储表示
3
一、邻接矩阵
13
顶点数据结点(数组元素)由两个域组成:
数据域(data): 存储顶点名称或其他信息。 链域(firstarc): 指向链表中第一个结点 (边)。
边链表的每个结点由3个域组成:
邻接点域(adjvex):指示与顶点 vi 邻接的顶点 在图中的位置。 链域(nextarc): 指示下一条边或弧的结点。 数据域(info): 存储和边或弧相关的信息。 data firstarc adjvex nextarc info 链表结点
1
4 5
2
6 8
A=
3
2
4
∞5 4 6 5 ∞∞ 8 4 ∞∞ 2 6 8 2 ∞
8
图的数组存储表示
#define INFINITY INT_MAX // 最大值∞ #define MAX_VERTEX_NUM 20 // 最大顶点个数 typedef enum {DG, DN, AG, AN} GraphKind; //{有向图,有向网,无向图,无向网}
A ∧ B C D E F 0 3 ∧ 5 ∧ 0 2 ∧
21
5 ∧
4
单链表中的结点表示 以该顶点为头的弧 5
1 ∧
vexnum = 6, arcnum = 7
网的邻接表的数据类型定义:
#define MaxV 100 typedef struct node{ //边链表的结点类型 int adjvex; // 该弧所指向的顶点的位置 float weight; //边的权值 struct node *next; // 指向下一条弧的指针 }Enode; typedef struct{ //表头结点类型 VertexType data; // 顶点信息 Enode *firste; // 指向第一条依附该顶点的弧 } Vnode;
10
邻接矩阵的数据类型定义 #define MaxV 100 //定义最大顶点数 typedef struct{ int vexes[MaxV]; //顶点表 int edges[MaxV][MaxV]; //邻接矩阵 int n,e; //顶点数n和边数e }MGraph;
11
二、邻接表
邻接表是图(包括有向图和无向图)的链式存储结 构。 对于图中的每个顶点vi,把所有邻接于vi的各个顶点 链成一个单链表,称为边链表。
无向图的邻接矩阵为对称矩阵。
B A F
C D E
0 1 0 0 1 0
1 0 0 0 1 1
0 0 0 1 0 1
0 0 1 0 0 1
1 1 0 0 0 0
0 1 1 1 0 0
7
有向图邻接矩阵表示法特点: 有向图邻接矩阵不一定是对称矩阵; 有向图的弧数是矩阵中1的个数。 顶点v的出度:等于二维数组对应行中1的个数; 顶点v的入度:等于二维数组对应列中1的个数; 有向图的总弧数为非0元素个数。 网的邻接矩阵: wij Vi邻接Vj,权值是Wij (0≤i,j≤n-1) A[i][j]= ∞ Vi与Vj不邻接
无向图中顶点vi的边链表中每个结点都对应一个与 vi关联的边; 有向图中顶点vi的边链表中每个结点都对应一个以 vi为始顶点的弧,因此称为出边表。
12
为每个顶点vi的边链表建立一个头结点,存储在一维 数组中(即顶点表),以便随机访问任一顶点的边链表。 因此,在邻接表中有两种结点: 链表结点 和 顶点结点 邻接表是一种顺序+ 链式存储结构。用顺序表存放顶 点,为每个顶点建立一个单链表,单链表中的结点表 示依附于该顶点的边或以该顶点为尾的弧。
typedef struct VexNode { // 顶点的结构表示 VertexType data; ArcBox *firstin, *firstout; // 指向以该顶点为头和尾 // 的两个链表 25 } VexNode;
typedef struct { //图结构 VexNode xlist[20]; // 顶点结点向量 int vexnum, arcnum; //顶点数和弧数 } OLGraph; 顶点结点 0 V1 1 V2 2 V3 3 V4 ^
逆邻接表
V0 V1 V2 V3
邻接表
3 0
19
有向图的邻接表
data firstarc
B A F
C D E
0 1
A
1
4 ∧
B
C D E ∧
4 ∧
5 ∧ 2 ∧
2
3
4
5
F
1
3 ∧
20
vexnum = 6, arcnum = 7
有向图的逆邻接表
data firstarc
B A F
C D E
0 1 2 3
typedef struct VNode { //头结点 VertexType data; // 顶点信息 ArcNode *firstarc; // 指向第一条依附该顶点的弧 15 } VNode, AdjList[MAX_VERTEX_NUM];
图的邻接表存储表示
typedef struct { AdjList vertices; int vexnum, arcnum; // 图的当前顶点数和弧数 int kind; // 图的种类标志 } ALGraph;
22
网的邻接表的数据类型定义:
typedef struct{ Vnode adjlist[MaxV]; int n,e; }ALGraph; //邻接表 //顶点数和边数
23
三、十字链表(有向图)
十字链表是有向图的另一种链式存储结构。 将有向图的邻接表和逆邻接表结合起来的结构。 在十字链表中有两种结点: 弧结点:存储每一条弧的信息,用链表链接在一 起。
16
无向图的邻接表示例
V0 V2 V3 V4 V1
0 V0 1 V1 2 V2 3 V3
4 V4
1 0
3 2
4 4
1
0
3
2 2
1
注意:没有画出链表结点的info域 。
17
无向图的邻接表的特点
⑴边链表中结点总数是图中边数的2倍; ⑵顶点v的度:等于v对应链表的长度 ⑶判定两顶点v ,u是否邻接:要看v对应链表中 有无对应的结点; ⑷在图中增减边:要在两个单链表插入、删除结 点; ⑸设存储顶点的一维数组大小为m(m≥图的顶点数 n), 图的边数为e,图占用存储空间为:m+2*e。 ⑹图占用存储空间与图的顶点数、边数均有关; ⑺适用于边稀疏的图。
无向图邻接矩阵是对称矩阵,同一条边表示了两次,无 向图的总边数为非0元素个数的一半; 顶点v的度:等于二维数组对应行(或列)中1的个数; 判断两顶点v、u是否为邻接点:只需判断二维数组对应 分量是否为1; 顶点不变,在图中增加、删除边:只需对二维数组对应 分量赋值1或清0;
设图的顶点数为 n ,存储图用一维数组, 数组元素有m (m>=n)个,则G占用存储空间:m+n2;G占用存储空 间只与它的顶点数有关,与边数无关;适用于边稠密 6 的图;
5 1、邻接多重表(无向图)
邻接多重表是无向图的另一种链式表示结构。 和十字链表类似。邻接多重表中,每一条边用一 个结点表示。 在邻接多重表中有两种结点: 边结点:存储每一条边的信息,用链表链接在 一起。