arcgis半变异函数
半变异函数(第一部分)

半变异函数(第一部分)
半变异函数是概率论中一种重要的概率分布。
它属于正态分布的一种变形,属于一类非对称性的分布。
半变异函数的形式是:y = (2/σ√2π) (1+x2/σ2) -1/2 α,其中σ代表标准差,α 代表偏度参数。
4个参数的半变异函数关系性更加紧密,根据参数的不同,它的几何形状形可能会发生改变,这也是其它变异函数的不同之处。
半变异函数有若干重要的特点。
其中,分布的峰值与基线均出现在分布的中心位置,与正态分布在两端出现最大值不同。
并且,它还具有较宽的左右两侧分布,使得半变异性分布在极端情况下也更具有延展性。
此外,半变异函数可用来选择特定的观测值,可应用于差异分析,还能够表征观测值的非线性特征,从而能够更准确地反映数据中存在的模式。
半变异函数经过长期发展,已经成为统计分析中重要的工具,它不仅可以应用于波动分析、风险分析,同时还可以作为进行统计计算和模型构建的重要基础。
通过灵活运用半变异函数,研究人员以及经济相关的决策者可以从不同的层面深入研究问题的解决方案,为社会发展注入新的动力,推动社会经济的发展。
ArcGIS教程:几种克里金法的概述
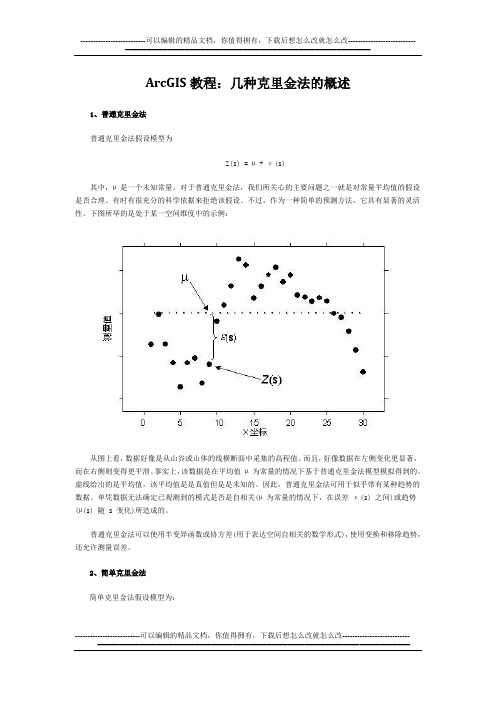
ArcGIS教程:几种克里金法的概述1、普通克里金法普通克里金法假设模型为Z(s) = µ + ε(s)其中,µ 是一个未知常量。
对于普通克里金法,我们所关心的主要问题之一就是对常量平均值的假设是否合理。
有时有很充分的科学依据来拒绝该假设。
不过,作为一种简单的预测方法,它具有显著的灵活性。
下图所举的是处于某一空间维度中的示例:从图上看,数据好像是从山谷或山体的线横断面中采集的高程值。
而且,好像数据在左侧变化更显著,而在右侧则变得更平滑。
事实上,该数据是在平均值µ 为常量的情况下基于普通克里金法模型模拟得到的。
虚线给出的是平均值,该平均值是是真值但是是未知的。
因此,普通克里金法可用于似乎带有某种趋势的数据。
单凭数据无法确定已观测到的模式是否是自相关(µ 为常量的情况下,在误差ε(s) 之间)或趋势(µ(s) 随 s 变化)所造成的。
普通克里金法可以使用半变异函数或协方差(用于表达空间自相关的数学形式),使用变换和移除趋势,还允许测量误差。
2、简单克里金法简单克里金法假设模型为:Z(s) = µ + ε(s)其中,µ 是已知常量例如,下图中使用的数据与普通克里金法和泛克里金法概念介绍中所使用的数据相同,观测数据以实心圆的形式给出:虚线表示的已知常量为µ。
这点可以与普通克里金法进行比较。
对于简单克里金法,因为假设确切已知µ,那么也确切已知数据位置上的ε(s)。
对于普通克里金法,如果估算了µ,那么也会估算ε(s)。
如果已知ε(s),可以比估算ε(s)时更好地估算自相关。
通常,已知确切平均值µ 的假设是不现实的。
但是,有时候,假定一个基于物理的模型能够给出已知趋势却是有意义的。
由此可以使用模型和观测值的差值(称为残差),并且假设残差中的趋势已知为零,可以在残差上使用简单克里金法。
简单克里金法可以使用半变异函数或协方差(用于表达自相关的数学形式)和变换,并且允许测量误差。
ArcGIS中空间数据统计、插值分析-以克里金插值法为例--胡碧峰解析

可采用一个线性组合来估计:
n
z*x0 i zxi i 1
无偏性和估计方差最小被作为 选取的标准 i
无偏 E Zx0 Z * x0 0 最优 Var Zx0 Z * x0 min
2、直方图:直方图显示数据的概率分布特征以及概括 性的统计指标。从图中可观察分析数据是否为正态分布。克
里格方法对正态数据的预测精度最高,而且有些空间分析方法特 别要求数据为正态分布。
3、正态QQ Plot图: 检查数据的正态分布情况。作图原理是用分位图
思想。直线表示正态分布,从图中可以看出数据很接 近正态分布
j
E
Z *x0 Zx0 2
2
n
j
0,
i1
j 1, , n
Z*(x0)
1、数据检查,即空间数据探索分析。此功能主要通过 Explore Data菜单中实现。扩展模块提供了多种分析工具, 这些工具主要是通过生成各种视图,进行交互性分析。 如直方图、QQ plot图、半变异函数/协方差图等。
(3)趋势分析图。 蓝线表示南北方向,呈近似水平,可见南北方向无
趋势。绿线表示东西方向,呈倒"U"形,可用二阶曲线 拟合,在后面进行表面预测时将会去除。
4、半变异函数/协方差函数。 该图可以反应数据的空间相关
程度,只有数据空间相关,才有必要进行空间插值法。图表的横 坐标表示任两点的空间距离,纵标表示该两点的半变异函数值。 根据距离越近越相似的原理,因而x值越小,y值应该越小。
克里金插值
克里金方法(Kriging), 是以南非矿 业工程师D.G.Krige (克里格)名字命名的一 项实用空间估计技术,是地质统计学 的重 要组成部分,也是地质统计学的核心。
arcgis克里金插值无法估算半变异函数

arcgis克里金插值无法估算半变异函数以arcgis克里金插值无法估算半变异函数为标题克里金插值是一种常用的地理信息系统(GIS)插值方法,可用于估算未知位置的数值。
然而,克里金插值在一些情况下可能无法有效估算半变异函数,这是因为半变异函数的特性与克里金插值的假设之间存在不匹配。
半变异函数是地统计学中常用的工具,用于描述变量值在空间上的变化程度。
它可以通过计算不同距离下的半方差来确定。
半方差表示两个位置之间的变量值差异程度,距离越大,半方差值越大,说明变量值的差异越大。
半变异函数的形状和参数可以提供有关空间变量结构的重要信息,从而可以用于空间数据的插值和预测。
然而,克里金插值方法在估算半变异函数时存在一些限制。
首先,克里金插值假设数据是平稳的,即在空间上具有相似的统计特性。
然而,实际数据往往呈现出空间非平稳性,即在不同位置上具有不同的统计特性。
这导致克里金插值无法准确地估算半变异函数的形状和参数。
克里金插值假设数据的半变异函数是稳定的,即在不同距离下具有相似的半方差值。
然而,实际数据往往呈现出非稳定性,即半方差值在不同距离下发生明显变化。
这使得克里金插值无法准确地估算半变异函数的参数,从而影响插值结果的可靠性。
克里金插值还假设数据的半变异函数是光滑的,即在不同距离下具有连续的半方差值。
然而,实际数据往往呈现出非光滑性,即半方差值在不同距离下出现跳跃或断裂。
这使得克里金插值无法准确地估算半变异函数的形状,从而导致插值结果的不准确性。
为了解决克里金插值无法估算半变异函数的问题,可以尝试使用其他插值方法或改进的克里金插值方法。
例如,可以尝试使用反距离加权插值(IDW)方法,该方法在估算插值值时不需要假设数据的平稳性、稳定性和光滑性。
另外,也可以尝试使用基于样条函数的插值方法,该方法可以更好地拟合非光滑的半变异函数。
克里金插值在估算半变异函数时存在一些限制,特别是在数据呈现空间非平稳性、非稳定性和非光滑性的情况下。
ArcGIS地统计分析

最新课件
6
1.Histogram(直方图)
Histogram(直方图)指对采样数据按一定的分级方案 进行分级,统计采样点落入各个级别中的比例,并通 过柱状图表现出来。直方图可以直观的反映采样数据 分布特征与规律。
最新课件
7
2.QQPlot分布图
QQPlot分布图是可以将现有数据的分布与标准 正态分布对比,从而来分析和评价现有数据。 如果数据图形越接近一条直线,则它越接近于 服从正态分布。
最新课件
3
最新课件
4
一、Explore Data(探索性数据分析)
探索性数据分析是为了让用户更深入地认识研究对象 ,从而对与其数据相关的问题做出更好的分析与决策。
探索性数据分析可以确定数据属性,探测数据分布、 查找异常值、分析全局变化趋势、研究空间自相关和理 解多种数据集之间相关性。
最新课件
5
在地统计分析中,克里格插值方法建立在一定的 假设基础上。普通克里格法、简单克里格法和泛克 里格法等都假设数据服从正态分布。如果数据不服 从正态分布,需要进行一定的数据变换,使其服从 正态分布。正态分布的检验可以通过直方图和正态 QQPlot分布图完成。
多边形生成的要求就是多边形内任何位置距这一样点的距离都比到其他样点的距离要近5semivariogramcovariancecloud半变异协方差函数云半变异协方差函数云表示的是数据集中所有样点对的半变异值和协方差并把它们用两点间距离的函数来表示用此函数作图来表示描述空间自相关及方向变异大部分的地理现象都具有空间相关特性即距离越近的两事物越相似
ArcGIS地统计分析功能是借助于ArcGIS地统计分析 模块(ArcGIS Geostatistical Analyst)来实现的。
克里格方法的半变异函数

克里格方法的半变异函数The semivariogram in the Kriging method is a fundamental tool for spatial interpolation and analysis. It quantifies the spatial variability of a variable by measuring the degree of similarity or dissimilarity between values at different locations. The semivariogram represents the variance of the differences between values at various distances, providing insights into the spatial structure and autocorrelation of the data.克里格方法中的半变异函数是空间插值和分析的基本工具。
它通过测量不同位置之间值的相似性或差异性来量化变量的空间变异性。
半变异函数表示在不同距离上值之间差异的方差,为数据的空间结构和自相关性提供了深刻见解。
The semivariogram is typically plotted as a function of distance, with the x-axis representing the separation distance between data points and the y-axis representing the semivariance. This plot helps identify the range, sill, and nugget effect, which are key parameters in Kriging interpolation. The range indicates the distance at which values become spatially independent, the sill represents the maximum semivariance or total spatial variability, and the nugget effect accounts for the variability that cannot be explained by spatial autocorrelation.半变异函数通常作为距离的函数进行绘制,其中x轴表示数据点之间的分离距离,y轴表示半变异值。
arcgis半变异函数

arcgis半变异函数ArcGIS是一款常用的地理信息系统软件,其中半变异函数是地理数据分析中的一项重要方法。
本文将从概念、应用和计算方法三个方面详细介绍ArcGIS中的半变异函数。
一、概念半变异函数是用来描述地理现象在空间上的变异程度的统计函数。
它可以帮助我们分析地理现象的空间分布规律,并从中获取有关特征的重要信息。
半变异函数可以用来研究各种地理现象,如土地利用、气候变化、经济发展等。
二、应用半变异函数在地理数据分析中有着广泛的应用。
首先,它可以用来评估地理现象的空间相关性。
通过计算半变异函数,我们可以得到不同距离下地理现象的相关性系数,从而判断其空间相关性的强弱。
这对于决策制定者来说非常重要,可以帮助他们更好地理解地理现象的空间特征。
半变异函数可以用来揭示地理现象的空间自相关性。
地理现象往往具有一定的空间自相关性,即相似地理位置上的观测值之间存在相关性。
半变异函数可以帮助我们量化这种相关性,并找出相关性的范围和强度。
这对于地理模型的构建和预测具有重要意义。
半变异函数还可以用来优化采样点的布局。
在地理数据采集过程中,选择合适的采样点位置是非常关键的。
通过分析半变异函数,我们可以确定最佳采样点的位置,从而提高采样效率和数据质量。
三、计算方法在ArcGIS中,可以使用半变异函数工具来计算半变异函数。
首先,需要将地理数据导入ArcGIS软件中。
然后,在工具箱中选择半变异函数工具,并设置好参数,如变量、距离阈值等。
接下来,点击运行按钮,ArcGIS会自动计算半变异函数,并在地图上显示结果。
用户可以根据需要对结果进行进一步的分析和处理。
需要注意的是,计算半变异函数时需要注意数据的空间分布和采样密度。
如果数据分布不均匀或采样密度不足,可能会导致计算结果不准确。
因此,在使用半变异函数进行地理数据分析时,务必要进行数据预处理和合理采样,以确保结果的可靠性和准确性。
ArcGIS中的半变异函数是一种重要的地理数据分析方法。
半变异函数——精选推荐

半变异函数半变异函数半变异函数通常会应⽤在克⾥⾦插值中,⽤于检验所采集的样本数据中是否存在空间⾃相关。
若空间⾃相关弱或没有空间⾃相关则不能⽤克⾥⾦进⾏插值。
那⽤什么呀?我现在还没学到意义:对空间⾃相关这⼀概念进⾏了量化分析,研究其邻近范围到底相似多少。
半变异函数的定义:半变异函数和普通的函数⼀样,拥有⾃变量和因变量,其中⾃变量是步长h,因变量是半变异函数值\gamma(h),其函数式为:\gamma(h)=\frac{1}{2n(h)}\sum_{s=1}^{n(h)}[x(s)-x(s+h)]^2式中,s为样本点,x(s)为样本点s的属性值,n(h)为距离为h的点对数。
故求出半变异函数值是,样本点s和距离其h的样本点属性差值的平⽅的平均值。
半变异函数值在坐标中显⽰为离散的点,将这些点拟合为曲线需要进⾏建模。
半变异函数⼀般⽤变异曲线来表⽰,横坐标为步长,纵坐标为半变异函数值。
如下图所⽰:由图中可以看出距离越远,半变异函数值越⼤,说明两点间的属性相关性就越⼩;因此当距离越近,半变异函数值越⼩,相关性越⼤。
当距离为0时,理论上半变异函数值为0,但由于测量误差的影响,其通常不为0,就称为块⾦效应C_0。
变程:当对象属性之间存在空间⾃相关时,变异曲线就会随着距离的增加逐渐趋于平稳。
当变异曲线⾸次呈现⽔平状态的距离称为变程。
⽐该变程距离近的样本点具有空间⾃相关,⽐该变程距离远的样本点不具有空间⾃相关。
基台:半变异函数在变程处取得的函数值称为基台。
偏基台为基台值减去块⾦效应。
步长⼤⼩的选择:步长⼤⼩的选择对于经验半变异函数有着重要的影响。
例如,如果步长过⼤,短程⾃相关可能会被掩盖。
确定步长⼤⼩的另⼀种⽅法是使⽤平均最近邻⼯具确定点与最近的相邻要素之间的平均距离。
这可提供⼀个⾮常好的步长⼤⼩,因为所有步长都会在其中⾄少包含数个点对。
变异函数模型Processing math: 0%。
ArcGIS中几种插值方法简述

ArcGIS中几种插值方法简述
ArcGIS中几种插值方法简述
ArcGIS中几种插值方法简述
插值是通过cell样本数据计算得到的一幅栅格影像,作用是预测某一区域内样本数据以外的该属性值。
在高程,降雨量,矿产,噪音分析等具有广泛应用。
以下是几种在ArcGIS中常见的插值方法:
IDW:确定性插值方法。
每个栅格单元内的样本点数据距离单元内加权平均距离点的距离为自变量,点对平均距离点的影响与其距离幂值成反比,适合样本密集情况下进行分析。
Kriging:与IDW类似,通过半变异函数,可以对预测的确定性或准确性提供某种度量。
Natural neighbour:可找到距查询点最近的输入样本子集,并基于区域大小按比例对这些样本应用权重来进行插值。
Spline:确定性插值方法。
使用可最小化整体表面曲率的数学函数来估计值,以生成恰好经过输入点的平滑表面。
Spline with Barriers:障碍以面要素或折线(polyline) 要素的形式输入。
过单向多格网技术,以初始的粗糙格网(在本例中是已按输入数据的平均间距进行初始化的格网)为起点在一系列精细格网间移动,直至目标行和目标列的间距足以使表面曲率接近最小值为止。
Topo to Raster:旨在用于创建可更准确地表示自然水系表面的表面,而且通过这种技术创建的表面可更好的保留输入等值线数据中的山脊线和河流网络。
Trend:由数学函数(多项式)定义的平滑表面与输入样本点进行拟合的全局多项式插值法。
趋势表面会逐渐变化,并捕捉数据中的粗尺度模式。
ARCGIS地统计分析-毕业设计全文

在嵌入GIS支持方面,ArcGIS 9 提供了ArcGIS Engine,是应用于ArcGIS Desktop应用框架之外的嵌入式ArcGIS组件。使用ArcGIS Engine,开发者在C++、COM、.NET和Jave环境中使用简单的接口获取任意GIS功能的组合来构建专门的GIS应用解决方案。
2.Server GIS
ArcGIS 9 所包含的三种服务端产品:ArcSDE、ArcIMS和ArcGIS Server。
ArcSDE是管理地理信息的高级空间数据服务器。ArcIMS则是一个可伸缩的,通过开放的Internet协议进行GIS地图、数据和元数据发布的地图服务器。ArcGIS Server是应用服务器,用于构建中式的企业GIS应用,基于SOAP的Web serveices 和Web应用,包含在企业和Web框架上建设服务端GIS应用的共享GIS软件对象库。
3.灵活的定制与开发
ArcGIS的Desktop部分通过一系列可视化应用操作界面,满足了大多数终端用户的需求,同时,也为更高级的用户和开发人员提供了全面的客户化定制功能。
Key words:ARCGIS,Geostatistics,Kriging,interpolation algorithm
第一章 绪
1.1 课题的目的意义
地统计学是在大量样本的基础上,通过分析样本间的规律,探索其分布规律,并进行预测。地统计学认为研究区域中的所有样本值都是随机过程的结果,即所有样本值都不是相互独立的,是遵循一定的内在规律的。因此地统计学就是要揭示这种内在规律,并进行预测。而地统计分析的核心就是通过对采样数据的分析、对采样区地理特征的认识选择合适的空间内插方法创建表面。因此本次设计就是为了掌握ArcGIS地统计分析的三个主要模块,选用克里格方法生成高程表面完成多种地统计分析,比较不同方法进行表面预测的优劣。
ArcGIS教程:地统计模型的组成
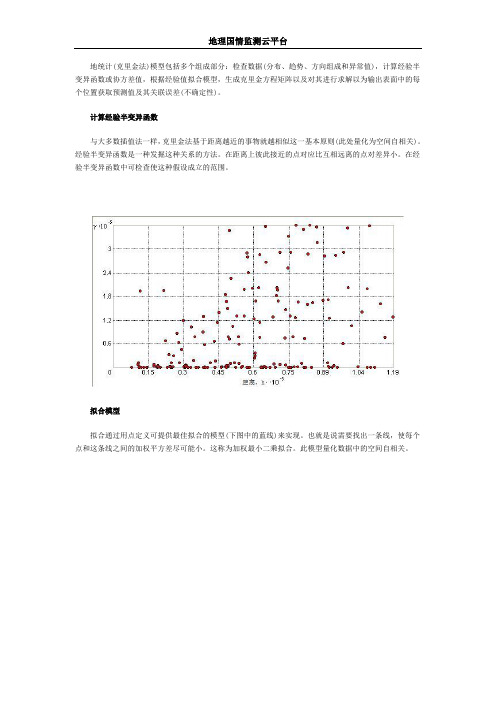
地统计(克里金法)模型包括多个组成部分:检查数据(分布、趋势、方向组成和异常值),计算经验半变异函数或协方差值,根据经验值拟合模型,生成克里金方程矩阵以及对其进行求解以为输出表面中的每个位置获取预测值及其关联误差(不确定性)。
计算经验半变异函数
与大多数插值法一样,克里金法基于距离越近的事物就越相似这一基本原则(此处量化为空间自相关)。
经验半变异函数是一种发掘这种关系的方法。
在距离上彼此接近的点对应比互相远离的点对差异小。
在经验半变异函数中可检查使这种假设成立的范围。
拟合模型
拟合通过用点定义可提供最佳拟合的模型(下图中的蓝线)来实现。
也就是说需要找出一条线,使每个点和这条线之间的加权平方差尽可能小。
这称为加权最小二乘拟合。
此模型量化数据中的空间自相关。
创建矩阵
克里金方程包含在依赖于测量采样位置和预测位置的空间自相关的矩阵和矢量中。
空间自相关值来自于半变异函数模型。
矩阵和矢量确定分配给搜索邻域中的每个测量值的克里金权重。
进行预测
根据测量值的克里金权重,软件对包含未知值的位置计算预测值。
arcgis中七种插值方法的对比分析

反距离权重法的工作原理反距离权重(IDW) 插值使用一组采样点的线性权重组合来确定像元值。
权重是一种反距离函数。
进行插值处理的表面应当是具有局部因变量的表面。
此方法假定所映射的变量因受到与其采样位置间的距离的影响而减小。
例如,为分析零售网点而对购电消费者的表面进行插值处理时,在较远位置购电影响较小,这是因为人们更倾向于在家附近购物。
使用幂参数控制影响反距离权重法主要依赖于反距离的幂值。
幂参数可基于距输出点的距离来控制已知点对内插值的影响。
幂参数是一个正实数,默认值为2。
通过定义更高的幂值,可进一步强调最近点。
因此,邻近数据将受到最大影响,表面会变得更加详细(更不平滑)。
随着幂数的增大,内插值将逐渐接近最近采样点的值。
指定较小的幂值将对距离较远的周围点产生更大影响,从而导致更加平滑的表面。
由于反距离权重公式与任何实际物理过程都不关联,因此无法确定特定幂值是否过大。
作为常规准则,认为值为30 的幂是超大幂,因此不建议使用。
此外还需牢记一点,如果距离或幂值较大,则可能生成错误结果。
可将所产生的最小平均绝对误差最低的幂值视为最佳幂值。
ArcGIS Geostatistical Analyst 扩展模块提供了一种研究此问题的方法。
1. 3限制用于插值的点也可通过限制计算每个输出像元值时所使用的输入点,控制内插表面的特性。
限制经考虑的输入点数可加快处理速度。
此外,由于距正在进行预测的像元位置较远的输入点的空间相关性可能较差或不存在,因此有理由将其从计算中去除。
可直接指定要使用的点数,也可指定会将点包括到插值内的固定半径。
2. 4可变搜索半径可以使用可变搜索半径来指定在计算内插像元值时所使用的点数,这样一来,用于各内插像元的半径距离将有所不同,而具体情况将取决于必须在各内插像元周围搜索多长距离才能达到指定的输入点数。
由此将导致一些邻域较小而另一些邻域较大,这是由位于内插像元附近的测量点的密度所决定的。
另外,也可指定搜索半径不得超出的最大距离(以地图单位为单位)。
arcgis克里金插值法原理

克里金插值法(Kriging Interpolation)是一种用于空间数据插值的地统计学方法,常用于地理信息系统(GIS)软件如ArcGIS中。
它基于统计学原理,根据已知点的空间分布和变量值,预测未知位置的变量值。
以下是克里金插值法的基本原理:
1. 空间自相关性:克里金插值法的核心思想是假设同一地理区域内的点之间存在空间自相关性,即相邻点之间的变量值具有一定的关联性。
这意味着离得越近的点之间的变化趋势可能更相似。
2. 半变异函数:插值过程中使用了半变异函数(Semi-Variogram Function)来描述点之间的变异性。
半变异函数展示了不同距离下变量值之间的相关性或协方差。
这个函数可以帮助确定变量值在不同方向上的变异性和相关性。
3. 权重计算:在插值过程中,为了预测未知点的变量值,需要根据已知点的位置、变量值以及它们之间的空间关系来计算权重。
与离目标点距离近且变异性较小的点会得到较大的权重,而距离远或变异性大的点则得到较小的权重。
4. 插值预测:通过计算权重,将已知点的变量值加权平均,从而预测未知点的变量值。
权重的计算基于半变异函数和点之间的距离。
5. 交叉验证:为了评估插值的精度,通常会采用交叉验证方法。
该方法将已知数据分成训练集和测试集,通过对测试集进行插值并与真实值比较,评估克里金插值法的预测能力。
总之,克里金插值法通过考虑空间自相关性和半变异函数,利用已知点之间的关系来预测未知点的变量值。
这使得它在GIS等领域中广泛用于空间数据插值和预测。
1/ 1。
半变异函数的求解

半变异函数的求解克里金差值首先需要求取半变异函数,它是矢量距离h的函数,但这个问题似乎一直是大家纠结的问题,我也很纠结。
实际工作中,采样点位并未位于正规网格节点上,甚至较为离散,所以在计算半变异函数值时,要考虑角度容差和距离容差;也就是说,在理论上,x+h数据是足够的,但实际上,x+h 数据极少,因此必须考虑容差。
在矢量h的角度容差和距离容差范围内,都可以看做是x+h,这样才能计算半变异函数值。
在半变异函数的求解中,最方便又常用的软件就是GS+和Surfer(不要提ArgGIS),两者区别在哪?个人认为主要在以下三个方面:(1)容差。
我们知道,在看各向异性时,一般都是以0度(即x轴正向)为始,45度为间隔,看8个方向上的各向异性。
在GS+中,默认角度容差为22.5度,这个数字化刚刚好(这个容易理解),而Surfer中默认为90度,那也就是说surfer中考虑各向异性仅仅考虑x轴正向和x轴负向两个方向,当然这个似乎可以改变。
(2)距离选择。
GS+中有两个距离,一个是最大滞后距离,一个是计算间隔,其中计算间隔才是决定半变异函数模型的主要参数;surfer中只有一个,是最大滞后距离。
最大滞后距离(是否也就是搜索半径呢?我个人认为是),GS+选择的是x、y轴两者最大距离的1/2,surfer选择的是对角线距离最大值的1/3。
但这个数值我个人认为影响不大(只要不是太离谱),它影响的仅仅是点对数的多少(因为在实际工作中,各自距离的1/2和1/3都应该超出了样品的相关性范围)。
不过对于搜索半径,我也看到一些资料说选择采样间隔的2.5倍到3倍。
(3)各向异性的整体考虑。
GS+中,在半变异函数计算中并未整体考虑各向异性(我个人认为,不知道是否对),而surfer考虑了,但是surfer中的自动拟合参数似乎有些问题;而且,模型得自己选择并进行比较得出最优结果,而GS+默认选择的已经是最优的。
不知道上述观点大家是否同意?大家一起讨论讨论。
ArcGIS教程:半变异函数与协方差函数
半变异函数和协方差函数将邻近事物比远处事物更相似这一假设加以量化。
半变异函数和协方差都将统计相关性的强度作为距离函数来测量。
对半变异函数和协方差函数建模的过程将半变异函数或协方差曲线与经验数据拟合。
目标是达到最佳拟合,并将对现象的认知纳入模型。
之后模型便可用于预测。
在拟合模型时,浏览数据中的方向自相关。
基台、变程和块金是模型的重要特征。
如果数据中有测量误差,请使用测量值误差模型。
跟踪这一链接来了解如何将模型与经验半变异函数拟合。
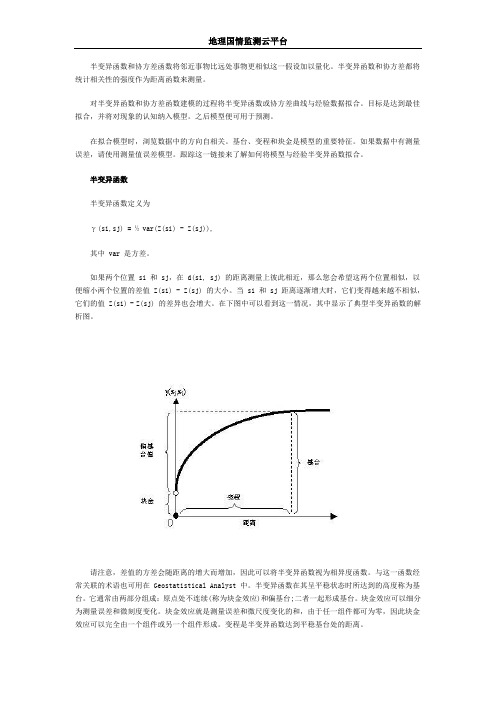
半变异函数半变异函数定义为γ(si,sj) = ½ var(Z(si) - Z(sj)),其中 var 是方差。
如果两个位置 si 和 sj,在 d(si, sj) 的距离测量上彼此相近,那么您会希望这两个位置相似,以便缩小两个位置的差值 Z(si) - Z(sj) 的大小。
当 si 和 sj 距离逐渐增大时,它们变得越来越不相似,它们的值 Z(si) - Z(sj) 的差异也会增大。
在下图中可以看到这一情况,其中显示了典型半变异函数的解析图。
请注意,差值的方差会随距离的增大而增加,因此可以将半变异函数视为相异度函数。
与这一函数经常关联的术语也可用在 Geostatistical Analyst 中。
半变异函数在其呈平稳状态时所达到的高度称为基台。
它通常由两部分组成:原点处不连续(称为块金效应)和偏基台;二者一起形成基台。
块金效应可以细分为测量误差和微刻度变化。
块金效应就是测量误差和微尺度变化的和,由于任一组件都可为零,因此块金效应可以完全由一个组件或另一个组件形成。
变程是半变异函数达到平稳基台处的距离。
协方差函数协方差函数定义为C(si, sj) = cov(Z(si), Z(sj)),其中 cov 是协方差。
协方差是相关性的缩放版。
因此当两个位置,si 和 sj 彼此相近时,您会希望这两个位置相似,而他们的协方差(相关性)会变大。
当 si 和 sj 距离逐渐增大时,它们变得越来越不相似,并且它们的协方差会变为零。
半变异函数的求解
半变异函数的求解克里金差值首先需要求取半变异函数,它是矢量距离h的函数,但这个问题似乎一直是大家纠结的问题,我也很纠结。
实际工作中,采样点位并未位于正规网格节点上,甚至较为离散,所以在计算半变异函数值时,要考虑角度容差和距离容差;也就是说,在理论上,x+h数据是足够的,但实际上,x+h 数据极少,因此必须考虑容差。
在矢量h的角度容差和距离容差范围内,都可以看做是x+h,这样才能计算半变异函数值。
在半变异函数的求解中,最方便又常用的软件就是GS+和Surfer(不要提ArgGIS),两者区别在哪?个人认为主要在以下三个方面:(1)容差。
我们知道,在看各向异性时,一般都是以0度(即x轴正向)为始,45度为间隔,看8个方向上的各向异性。
在GS+中,默认角度容差为22.5度,这个数字化刚刚好(这个容易理解),而Surfer中默认为90度,那也就是说surfer中考虑各向异性仅仅考虑x轴正向和x轴负向两个方向,当然这个似乎可以改变。
(2)距离选择。
GS+中有两个距离,一个是最大滞后距离,一个是计算间隔,其中计算间隔才是决定半变异函数模型的主要参数;surfer中只有一个,是最大滞后距离。
最大滞后距离(是否也就是搜索半径呢?我个人认为是),GS+选择的是x、y轴两者最大距离的1/2,surfer选择的是对角线距离最大值的1/3。
但这个数值我个人认为影响不大(只要不是太离谱),它影响的仅仅是点对数的多少(因为在实际工作中,各自距离的1/2和1/3都应该超出了样品的相关性范围)。
不过对于搜索半径,我也看到一些资料说选择采样间隔的2.5倍到3倍。
(3)各向异性的整体考虑。
GS+中,在半变异函数计算中并未整体考虑各向异性(我个人认为,不知道是否对),而surfer考虑了,但是surfer中的自动拟合参数似乎有些问题;而且,模型得自己选择并进行比较得出最优结果,而GS+默认选择的已经是最优的。
不知道上述观点大家是否同意?大家一起讨论讨论。
ArcGIS教程:经验半变异函数

ArcGIS教程:经验半变异函数一、创建经验半变异函数要创建经验半变异函数,确定所有位置对值平方差。
将这些位置对绘制成图后(y 轴坐标为平方差的一半,x 轴坐标为位置间距),该图称为半变异函数云。
以下场景显示了一个位置(红点)与其他 11 个位置的配对情况。
变异分析的主要目标之一就是探索和量化空间依赖性(又称空间自相关)。
空间自相关对距离越近的事物就越相似这一假设进行量化。
因此,位置对的距离越近(在半变异函数云的 x 轴上最左侧),具有的值就越相似(在半变异函数云的 y轴上较低处)。
位置对的距离变得越远(在半变异函数云的 x 轴上向右移动),就应该变得越不同,平方差就会更高(在半变异函数云的 y 轴上向上移动)。
由于存在计算局限性(计算时间和内存限制),如果输入数据集的观测值数大于 5000,Geostatistical Analyst 将为结构分析和半变异函数模型拟合随机选择 5000 个观测值(大约提供 1200 万个点对)。
生成的模型(表面)通常不受随机采样影响,因为所有数据都用于生成预测值。
但如果数据集有一些非常大的值,它们不一定在用于生成经验半变异函数/协方差值的子集中,因此估计的半变异函数模型可能不同于使用整个数据集估计的半变异函数模型。
二、经验半变异函数分组正如创建经验半变异函数中位置的地表和半变异函数云所示,快速绘制每个位置对变得难以处理。
存在太多点以至于图变得非常拥挤,而根据图只可解释很少内容。
要减少经验半变异函数中点的数量,将根据彼此间的距离分组位置对。
此分组过程称为分组(binning)。
分组是一个两阶段的过程。
第一阶段首先,组成点对,然后,将这些对分组以使它们具有一致的距离和方向。
在 12 个位置的地表场景中,可以看到所有位置与一个位置(红色点)的配对。
位置对之间相似颜色的连接线表示分组距离相似。
会对所有可能的对执行该过程。
可以看到,在配对过程中,每增加一个位置,对的数目将迅速增大。
ArcGIS教程:几种克里金法的概述
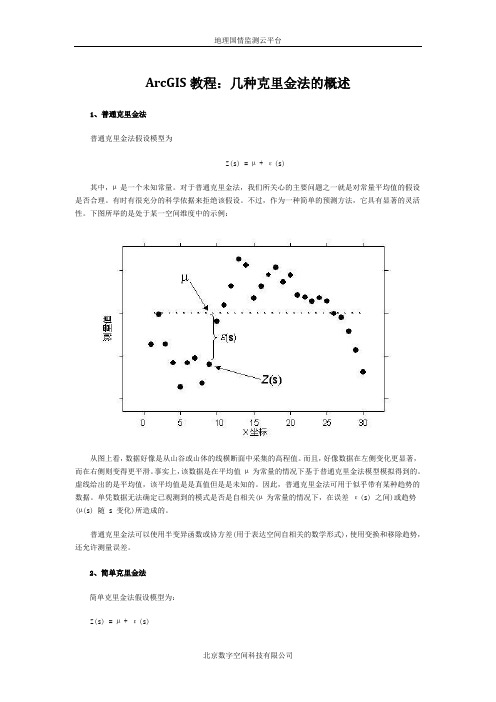
ArcGIS教程:几种克里金法的概述1、普通克里金法普通克里金法假设模型为Z(s) = µ + ε(s)其中,µ 是一个未知常量。
对于普通克里金法,我们所关心的主要问题之一就是对常量平均值的假设是否合理。
有时有很充分的科学依据来拒绝该假设。
不过,作为一种简单的预测方法,它具有显著的灵活性。
下图所举的是处于某一空间维度中的示例:从图上看,数据好像是从山谷或山体的线横断面中采集的高程值。
而且,好像数据在左侧变化更显著,而在右侧则变得更平滑。
事实上,该数据是在平均值µ 为常量的情况下基于普通克里金法模型模拟得到的。
虚线给出的是平均值,该平均值是是真值但是是未知的。
因此,普通克里金法可用于似乎带有某种趋势的数据。
单凭数据无法确定已观测到的模式是否是自相关(µ 为常量的情况下,在误差ε(s) 之间)或趋势(µ(s) 随 s 变化)所造成的。
普通克里金法可以使用半变异函数或协方差(用于表达空间自相关的数学形式),使用变换和移除趋势,还允许测量误差。
2、简单克里金法简单克里金法假设模型为:Z(s) = µ + ε(s)其中,µ 是已知常量例如,下图中使用的数据与普通克里金法和泛克里金法概念介绍中所使用的数据相同,观测数据以实心圆的形式给出:虚线表示的已知常量为µ。
这点可以与普通克里金法进行比较。
对于简单克里金法,因为假设确切已知µ,那么也确切已知数据位置上的ε(s)。
对于普通克里金法,如果估算了µ,那么也会估算ε(s)。
如果已知ε(s),可以比估算ε(s)时更好地估算自相关。
通常,已知确切平均值µ 的假设是不现实的。
但是,有时候,假定一个基于物理的模型能够给出已知趋势却是有意义的。
由此可以使用模型和观测值的差值(称为残差),并且假设残差中的趋势已知为零,可以在残差上使用简单克里金法。
简单克里金法可以使用半变异函数或协方差(用于表达自相关的数学形式)和变换,并且允许测量误差。
6.交叉协方差云_ArcGIS 10.1超级学习手册_[共2页]
![6.交叉协方差云_ArcGIS 10.1超级学习手册_[共2页]](https://img.taocdn.com/s3/m/31aa2e2904a1b0717ed5dd1b.png)
17.2 ArcGIS 的地统计分析 453
5. 半变异函数与协方差云
半变异函数与协方差函数云表示的是数据集中所有样点对的理论半变异值和协方差,并把它们用两点间距离的函数来表示,用此函数作图来表示。
在ArcGIS 10.1中生成数据的半变异函数与协方差函数云图主要有以下步骤。
(1)在ArcMap 中加载地统计数据点图层。
(2)单击“Geostatistical Analyst ”→“探
索数据”→“半变异函数/协方差云”,如图
17-22所示,打开“半变异函数/协方差云”对
话框。
(3)检查中数据源“图层名”对话框的设
置是否正确,在“字段属性”对话框选择参见
趋势分析的字段名称。
(4)“步长大小”为最大步长,“步长数目”为步长分组个数,如图17-23所示。
图17-23 无方向性的半变异函数/协方差云图
(5)如果空间变异具有方向性,可以选择“显示搜索方向”,然后点击方向控制条、重设它或改变它的方向来浏览半变异函数云的某个方向子集,如图17-24所示。
6.交叉协方差云
交叉协方差云表示的是两个数据集中所有样点对的理论正交协方差,并把它们用两点间距离的函数来表示。
在ArcGIS 10.1中生成数据的正交协方差函数云图的主要步骤如下。
(1)在ArcMap 中加载地统计数据点图层。
(2)单击“Geostatistical Analyst ”→“探索数据”→“交叉协方差云”,如图17-25所示,打开“交叉协方差云”对话框。
图17-22 打开“半变异函数/协方差云”对话框。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
arcgis半变异函数
ArcGIS半变异函数
在地理信息系统(GIS)中,半变异函数是一种用于描述地理现象空间变异性的统计方法。
ArcGIS作为一款常用的GIS软件,提供了多种半变异函数的计算方法和工具,帮助用户分析地理数据的空间变异性,进而支持决策和规划过程。
本文将介绍ArcGIS中的半变异函数的基本概念、计算方法以及应用案例。
一、半变异函数的基本概念
半变异函数是描述地理现象空间变异性的数学函数,用于研究地理现象在空间上的相似性和差异性。
半变异函数包括两个主要参数:距离和方向。
距离参数表示观测点之间的空间间隔,方向参数表示观测点之间的方向关系。
通过计算不同距离和方向下的变异性,可以得到半变异函数的数学模型。
二、ArcGIS中的半变异函数计算方法
ArcGIS提供了多种半变异函数的计算方法,包括简单半变异函数、指数半变异函数、高斯半变异函数等。
用户可以根据具体需求选择适合的计算方法。
1. 简单半变异函数
简单半变异函数是最基本的半变异函数模型,它假设地理现象的空间变异性在不同距离上呈现简单的线性关系。
ArcGIS中提供了简单
半变异函数的计算工具,用户可以根据实际数据进行参数设置和计算。
2. 指数半变异函数
指数半变异函数假设地理现象的空间变异性在不同距离上呈现指数关系。
在ArcGIS中,用户可以使用指数半变异函数工具进行计算,通过调整参数来拟合实际数据。
3. 高斯半变异函数
高斯半变异函数假设地理现象的空间变异性在不同距离上呈现高斯分布。
ArcGIS中的高斯半变异函数工具可以帮助用户计算高斯半变异函数,并根据实际数据进行参数调整。
三、半变异函数的应用案例
半变异函数在GIS中有广泛的应用,具体包括以下几个方面:
1. 空间插值
半变异函数可以用于空间插值,通过已知观测点的数值和位置信息,推断未知位置上的数值。
通过计算半变异函数,可以确定最佳插值方法和参数,提高插值结果的准确性。
2. 空间分析
半变异函数可以用于空间分析,通过计算不同距离和方向下的变异性,揭示地理现象的空间分布规律。
例如,可以通过半变异函数分析土壤质量的空间变异性,为农业生产和土地规划提供科学依据。
3. 空间预测
半变异函数可以用于空间预测,通过已知观测点的数值和位置信息,预测未来或未知位置上的数值。
通过计算半变异函数,可以评估预测结果的可靠性和精度,为决策和规划提供支持。
四、总结
ArcGIS提供了多种半变异函数的计算方法和工具,帮助用户分析地理数据的空间变异性。
半变异函数的应用涉及空间插值、空间分析和空间预测等领域,为决策和规划提供科学依据。
在实际应用中,用户需要根据具体需求选择合适的半变异函数计算方法,并进行参数设置和结果解释。
通过合理利用ArcGIS中的半变异函数,可以更好地理解和利用地理数据的空间变异性。