面板数据选择
如何进行面板数据模型的假设检验和模型选择

如何进行面板数据模型的假设检验和模型选择面板数据模型是一种广泛应用于社会科学研究中的统计分析方法,它能够处理跨时间和个体的数据,克服了截面数据和时间序列数据各自的局限性。
在进行面板数据模型分析时,假设检验和模型选择是两个重要的步骤,能够帮助我们验证模型的有效性和选择最佳的模型。
一、面板数据模型的假设检验面板数据模型的假设检验主要包括固定效应模型和随机效应模型的检验。
1. 固定效应模型的假设检验固定效应模型的核心假设是个体效应不随时间变化,只存在个体间的差异。
以下是固定效应模型的假设检验步骤:首先,我们需要进行单位根检验,以判断个体变量是否是非平稳的。
常用的单位根检验方法有ADF(Augmented Dickey-Fuller)检验和KPSS(Kwiatkowski–Phillips–Schmidt–Shin)检验。
其次,我们需要进行系数的显著性检验,以判断个体效应是否存在显著差异。
在面板数据模型中,通常使用固定效应估计器,该估计器通过对个体效应进行固定效应变换,进而估计出个体与时间变量的关系。
最后,我们需要进行模型整体拟合程度的检验,以判断模型是否具有合理的拟合度。
通常可以使用R平方、调整R平方等指标来评估模型的整体拟合程度。
2. 随机效应模型的假设检验随机效应模型的核心假设是个体效应与解释变量的无关性,即个体效应是随机的。
以下是随机效应模型的假设检验步骤:首先,我们需要进行随机效应的显著性检验,以判断个体效应是否存在显著差异。
通常采用最大似然估计方法来估计个体效应的方差,然后使用Wald检验或似然比检验进行显著性检验。
其次,我们需要进行随机效应与解释变量的相关性检验,以判断个体效应是否与解释变量相关。
通常可以使用F检验或t检验来进行相关性检验。
最后,我们需要进行模型整体拟合程度的检验,以判断模型是否具有合理的拟合度。
同样可以使用R平方、调整R平方等指标来评估模型的整体拟合程度。
二、面板数据模型的模型选择在进行面板数据模型分析时,我们常常面临着多种模型选择的困扰。
面板数据分析简要步骤与注意事项(面板单位根—面板协整—回归分析)

面板数据分析简要步骤与注意事项(面板单位根检验—面板协整—回归分析)面板数据分析方法:面板单位根检验—若为同阶—面板协整—回归分析—若为不同阶—序列变化—同阶建模随机效应模型与固定效应模型的区别不体现为R2的大小,固定效应模型为误差项和解释变量是相关,而随机效应模型表现为误差项和解释变量不相关。
先用hausman检验是fixed 还是random,面板数据R-squared值对于一般标准而言,超过0.3为非常优秀的模型。
不是时间序列那种接近0.8为优秀。
另外,建议回归前先做stationary。
很想知道随机效应应该看哪个R方?很多资料说固定看within,随机看overall,我得出的overall非常小0.03,然后within是53%。
fe和re输出差不多,不过hausman检验不能拒绝,所以只能是re。
该如何选择呢?步骤一:分析数据的平稳性(单位根检验)按照正规程序,面板数据模型在回归前需检验数据的平稳性。
李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。
这种情况称为称为虚假回归或伪回归(spurious regression)。
他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。
因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。
因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。
而检验数据平稳性最常用的办法就是单位根检验。
首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。
单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993)很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。
面板数据的常见处理

面板数据的常见处理面板数据是一种特殊的数据结构,通常用于经济学和社会科学研究中。
它由多个个体或者单位在一段时间内的观测数据组成,每一个个体或者单位都有多个时间点的观测值。
面板数据的处理涉及到数据清洗、数据转换、数据分析和模型建立等多个方面。
一、数据清洗1. 缺失值处理:面板数据中往往存在缺失值,可以使用插补方法(如均值插补、回归插补等)填补缺失值,确保数据的完整性。
2. 异常值处理:对于异常值,可以采用删除、替换或者标记的方式进行处理,以避免对后续分析的影响。
3. 数据去重:检查数据中是否存在重复观测,如有重复观测,需要进行去重操作,以保证数据的准确性。
二、数据转换1. 时间转换:将面板数据中的时间变量进行转换,常见的转换包括将日期格式转换为年份或者季度,方便后续的时间序列分析。
2. 变量转换:对于需要进行计算的变量,可以进行变量转换,如对数转换、百分比转换等,以满足模型的要求。
3. 数据合并:如果面板数据分散在多个数据集中,需要进行数据合并操作,将不同数据集中的观测值按照像应的标识变量进行合并。
三、数据分析1. 描述性统计:对面板数据进行描述性统计,包括计算均值、标准差、最大值、最小值等,以了解数据的基本特征。
2. 相关性分析:通过计算面板数据中变量之间的相关系数,判断变量之间的相关性,以便进行进一步的分析。
3. 面板数据模型:根据面板数据的特点,可以建立面板数据模型,如固定效应模型、随机效应模型等,进行深入的数据分析和预测。
四、模型建立1. 变量选择:根据面板数据的特点和研究目的,选择合适的自变量和因变量进行模型建立,避免多重共线性和过度拟合问题。
2. 模型估计:使用合适的面板数据模型进行参数估计,如最小二乘法、广义最小二乘法等,得到模型的估计结果。
3. 模型评估:对建立的模型进行评估,包括模型的拟合优度、统计显著性等指标,以判断模型的有效性和可靠性。
以上是面板数据的常见处理方法,通过数据清洗、数据转换、数据分析和模型建立等步骤,可以对面板数据进行全面的处理和分析,得到准确的研究结果。
Stata面板数据回归分析中的工具变量法如何选择合适的工具变量

Stata面板数据回归分析中的工具变量法如何选择合适的工具变量工具变量法(Instrumental Variable,简称IV)在面板数据回归分析中被广泛应用。
它通过引入外生变量作为工具变量来解决内生性问题,从而使得回归结果更具可靠性和稳健性。
在Stata软件中,选择合适的工具变量对于IV估计的准确性起着至关重要的作用。
本文将介绍在Stata面板数据回归分析中如何选择合适的工具变量。
一、IV方法简介在介绍IV方法如何选择合适的工具变量之前,先简要介绍一下IV方法的原理和步骤。
IV方法是通过引入工具变量来解决内生性问题,从而得到一致性的估计。
其基本思想是找到一个与内生变量相关但与误差项不相关的变量作为工具变量,从而通过工具变量的外生性来消除内生性引起的估计偏误。
IV方法的具体步骤如下:1. 识别工具变量:首先需要找到一个与内生变量相关但与误差项不相关的变量作为工具变量。
工具变量的选择要满足两个条件:与内生变量有相关性,与误差项无相关性。
2. 检验工具变量:选择好的工具变量需要经过检验,以确保其满足与内生变量相关但与误差项不相关的要求。
常用的检验方法有Hausman检验和Sargan检验。
3. 使用工具变量进行回归:将选定的工具变量引入回归方程中,通过工具变量的外生性来消除内生性引起的估计偏误。
二、选择合适的工具变量在选择合适的工具变量时,需要考虑以下几个因素:1. 相关性:工具变量应该与内生变量有一定的相关性,才能正确地估计内生变量对因变量的影响。
相关性可以通过计算相关系数来衡量,一般要求相关系数大于0.1。
2. 排除性:工具变量与误差项无相关性,即工具变量不能受到其他未观测到的因素的影响。
排除性通常通过进行统计检验来验证,常用的检验方法有Hausman检验和Sargan检验。
3. 弱工具变量:如果工具变量过弱,即相关系数过小,会导致估计结果的方差增大,同时降低估计的准确性和稳健性。
一般来说,工具变量的F统计量应大于10,同时第一阶段回归的R-squared要大于0.1。
面板数据分析

总结词
功能强大,易于上手,适合初学者和小型数据 分析任务
01
总结词
操作简便,可视化效果好
03
总结词
适合小型数据量处理
05
02
详细描述
Excel提供了丰富的数据分析工具,如数据透 视表、条件格式、数据筛选等,可以方便地 进行数据清洗、整理和可视化。
04
详细描述
Excel提供了多种图表类型,如柱状图、 折线图、饼图等,可以直观地展示数 据之间的关系和趋势。
详细描述
SQL需要依赖数据库管理系统(DBMS)的支 持,对于没有安装DBMS的计算机无法独立运 行。
06 面板数据分析案例研究
案例一:股票市场面板数据分析
总结词
股票市场数据具有时间序列和横截面两个维 度,通过面板数据分析可以揭示股票价格和 交易量的动态变化,以及不同股票之间的相 互关系。
详细描述
特点
面板数据能够提供更丰富、更全面的 信息,因为它不仅包括每个个体的特 征,还包括这些特征随时间的变化情 况。
面板数据的重要性
提供更准确的估计
提高预测准确性
面板数据可以提供更准确的估计和预 测,因为它考虑了时间和个体效应, 这有助于减少误差和偏差。
面板数据可以用于预测未来的趋势和 结果。通过分析过去的数据,我们可 以建立模型并预测未来的变化。
描述性统计
计算关键变量的均值、中位数、众数、 标准差等统计量,初步了解数据的分 布和特征。
相关性分析
通过计算相关系数或可视化散点图, 探索变量之间的关联性。
数据分布可视化
绘制直方图、箱线图等,直观展示数 据的分布情况。
时间序列趋势分析
通过折线图或柱状图,分析时间序列 数据的趋势和周期性变化。
面板数据模型选择-张晓桐

关系的面板数据研究 案例 1:工业 SO2 排放及人均 GDP 关系的面板数据研究 :
个省级地区(不包括重庆、西藏和港澳台地区) 以中国 29 个省级地区(不包括重庆、西藏和港澳台地区)1995-2006 年间 12 年的面板数据来对我国的经济增长与环境问题做出分析, 年的面板数据来对我国的经济增长与环境问题做出分析,所选数据均为平衡 面板数据, 组数据。 其中, RGDP 表示人均国内生产总值 单位: ) 面板数据, 348 组数据。 共 其中, (单位: 元 , SO2 表示工业二氧化硫排放量(单位:吨)。用 BJ、TJ、HEB、SX、NMG、 表示工业二氧化硫排放量(单位: )。用 、 、 、 、 、 LN、JL、HLJ、SH、JS、ZJ、AH、FJ、JX、SD、HEN、HUB、HUN、 、 、 、 、 、 、 、 、 、 、 、 、 、 GD、GX、HAN、SC、GZ、YN、SHX、GS、QH、NX、XJ 分别表示北京、 、 、 、 、 、 、 、 、 、 、 分别表示北京、 天津、河北、山西、内蒙古、辽宁、吉林、黑龙江、上海、江苏、浙江、 天津、河北、山西、内蒙古、辽宁、吉林、黑龙江、上海、江苏、浙江、安 徽、福建、江西、山东、河南、湖北、湖南、广东、广西、海南、四川、贵 福建、江西、山东、河南、湖北、湖南、广东、广西、海南、四川、 云南、陕西、甘肃、青海、宁夏、新疆。 州、云南、陕西、甘肃、青海、宁夏、新疆。 各地区 1995-2006 的人均国内生产总值和工业二氧化硫排放量数据均来 中国统计年鉴》。 自于 1996-2007 年《中国统计年鉴》。
关系的面板数据研究 案例 1:工业 SO2 排放及人均 GDP 关系的面板数据研究 :
线性混合模型估计结果是 线性混合模型估计结果是 SO2it = 557081.4 + 1.1111 RGDPit (16.0) (0.4) ) ) R2 = 0.0005,DW=0.11, N×T= 29×12= 348 , × × 说明二氧化硫排放量 二氧化硫排放量( 人均国内生产总值( 之间不 说明二氧化硫排放量(SO2it, 吨)与人均国内生产总值(RGDPit, 元)之间不 知数据一定非常散。 存在线性关系。 存在线性关系。由可决系数 R2 = 0.0005 知数据一定非常散。 二次多项式混合模型估计结果是 SO2it = 423499.3 + 23.4691 RGDP it - 0.00055 RGDP it 2 (8.0) (3.2) ) ) (-3.3) ) R2 = 0.0315,DW=0.12, N×T= 29×12= 348 , × × 说明二氧化硫排放量 二氧化硫排放量( 人均国内生产总值( 说明二氧化硫排放量(SO2it)与人均国内生产总值(RGDPit)有可能存在二 知数据一定非常散。 次非线性关系。 次非线性关系。由可决系数 R2 = 0.0315 知数据一定非常散。 据此就可以建立二次多项式形式的面板数据模型吗 首先分析数据散点图 分析数据散点图。 据此就可以建立二次多项式形式的面板数据模型吗?首先分析数据散点图。
论文写作中的面板数据分析

论文写作中的面板数据分析面板数据分析在论文写作中扮演着重要的角色。
面板数据是指跨时间和个体的数据集,它允许研究者在多个时间点和多个个体之间进行比较和分析。
本文将探讨面板数据分析在论文写作中的应用,并介绍一些常用的面板数据分析方法。
一、面板数据的特点面板数据具有以下几个特点:1. 时间维度:面板数据包含多个时间点的观测值,可以追踪和比较个体在不同时间点的变化。
2. 个体维度:面板数据包含多个个体的观测值,可以进行跨个体的比较和分析。
3. 个体固定效应:面板数据的个体固定效应是指个体的不可观测的特征或个体特定的影响因素对观测值的影响,可以通过面板数据分析方法进行控制。
二、面板数据的优势面板数据分析相较于截面数据和时间序列数据有以下优势:1. 更有效的利用数据:面板数据可以更充分地利用横向和纵向的信息,提高估计的效率和准确性。
2. 控制个体异质性:面板数据可以通过固定效应模型或随机效应模型控制个体的异质性,避免估计结果的偏误。
3. 分析动态变化:面板数据可以分析个体在时间上的动态变化,研究个体在不同时间点的变化趋势和影响因素。
三、面板数据分析方法在论文写作中,常用的面板数据分析方法包括:1. 固定效应模型:固定效应模型通过引入个体的固定效应控制个体的异质性,适用于个体固定特征对观测值的影响较大的情况。
2. 随机效应模型:随机效应模型通过引入个体的随机效应控制个体的异质性,适用于个体固定特征对观测值的影响较小的情况。
3. 差分法:差分法通过对面板数据进行一阶或高阶的差分,消除个体固定效应,从而探索个体间的变化差异。
4. 合成控制法:合成控制法通过建立一个人工合成的控制组,来研究政策或处理效应。
四、面板数据分析的应用面板数据分析在各个学科和领域中都有广泛的应用,如经济学、管理学、社会学等。
具体应用包括:1. 经济学研究中,可以利用面板数据分析探索不同政策对经济增长的影响,研究企业的投资决策和市场行为等。
2. 管理学研究中,可以利用面板数据分析来研究企业的绩效评估、人力资源管理、创新能力等问题。
面板数据、工具变量选择和HAUSMAN检验的若干问题及在STATA中的实现

面板数据、工具变量选择和HAUSMAN检验的若干问题*第一节关于面板数据PANEL DATA1、面板数据回归为什么好一般而言,面板数据模型的误差项由两部分组成,一部分是与个体观察单位有关的,它概括了所有影响被解释变量,但不随时间变化的因素,因此,面板数据模型也常常被成为非观测效应模型;另外一部分概括了因截面因时间而变化的不可观测因素,通常被成为特异性误差或特异扰动项(事实上这第二部分误差还可分成两部分,一部分是不因截面变化但随时间变化的非观测因素对应的误差项Vt,这一部分一般大家的处理办法是通过在模型中引入时间虚拟变量来加以剥离和控制,另一部分才是因截面因时间而变化的不可观测因素。
不过一般计量经济学的面板数据分析中都主要讨论两部分,在更高级一点的统计学或计量经济学中会讨论误差分量模型,它一般讨论三部分误差)。
非观测效应模型一般根据对时不变非观测效应的不同假设可分为固定效应模型和随机效应模型。
传统上,大家都习惯这样分类:如果把非观测效应看做是各个截面或个体特有的可估计参数,并且不随时间而变化,则模型为固定效应模型;如果把非观测效应看作随机变量,并且符合一个特定的分布,则模型为随机效应模型。
不过,上述定义不是十分严谨,而且一个非常容易让人产生误解的地方是似乎固定效应模型中的非观测效应是随时间不变的,是固定的,而随机效应模型中的非观测效应则不是固定的,而是随时间变化的。
一个逻辑上比较一致和严谨,并且越来越为大家所接受的假设是(参见Wooldridge的教材和Mundlak1978年的论文),不论固定效应还是随机效应都是随机的,都是概括了那些没有观测到的,不随时间而变化的,但影响被解释变量的因素(尤其当截面个体比较大的时候,这种假设是比较合理的)。
非观测效应究竟应假设为固定效应还是随机效应,关键看这部分不随时间变化的非观测效应对应的因素是否与模型中控制的观测到的解释变量相关,如果这个效应与可观测的解释变量不相关,则这个效应成为随机效应。
面板数据分析方法

面板数据分析方法
面板数据是指多个观察对象在同一时间序列下的数据。
面板数据分析方法可以帮助我们更好地理解时间序列数据,并进一步得出结论,这些数据通常用于经济学研究和社会科学研究。
以下是一些常用的面板数据分析方法:
1. 固定效应模型(Fixed Effects Model):固定效应模型是一种广泛应用于分析面板数据的方法。
它可以帮助我们控制可能影响结果的变量,并提高模型的可靠性和准确性。
2. 随机效应模型(Random Effects Model):随机效应模型与固定效应模型类似,但是它假设未观测到的变量对结果有影响,并对这种影响进行建模。
3. 差分法(Differences-in-Differences):差分法是一种比较两个实验组之间差异的方法。
在差分法中,我们比较一个实验组的结果与一个对照组的结果,以确定实验组的结果是否受到实验的影响。
4. 面板单位根检验(Panel Unit Root Test):面板单位根检验可以帮助我们确定一个时间序列是否具有单位根,这在面板数据分析中十分有用。
如果一个序列具有单位根,这意味着它是非平稳的,需要进行差分或其他方法来消除这种影响。
5. 面板数据模型选择(Model Selection):在进行面板数据分析时,我们需要选择一个合适的模型来准确地描述数据。
面板数据模型选择方法包括信息准则法、比较误差方差分解和Hausman检验等。
这些方法可以帮助我们更好地理解面板数据,并从中得出有意义的结论。
面板数据的常见处理

面板数据的常见处理引言概述:面板数据是指在一定时间跨度内,对多个个体单位进行观察和测量得到的数据集合。
面板数据具有时间序列和横截面数据的特点,因此在处理面板数据时需要采取一些特定的方法和技巧。
本文将介绍面板数据的常见处理方法,包括数据清洗、平衡面板处理、面板数据变换、面板数据建模以及固定效应和随机效应模型。
一、数据清洗:1.1 缺失值处理:面板数据中常常存在缺失值,需要进行处理。
可以采用删除法、替代法和插补法等方法。
删除法是直接删除含有缺失值的观测值,但会导致样本减少;替代法是用平均值、中位数等代替缺失值,但可能引入估计偏误;插补法是利用其他变量的信息进行插补,如回归插补、多重插补等。
1.2 异常值处理:面板数据中可能存在异常值,需要进行识别和处理。
可以通过箱线图、散点图等方法进行异常值检测,然后采取删除、替代或修正等方式进行处理。
1.3 数据转换:面板数据中的变量可能需要进行转换,以满足建模的要求。
常见的数据转换包括对数变换、差分变换、标准化等。
对数变换可以使数据更加符合正态分布,差分变换可以消除时间序列相关性,标准化可以消除不同变量单位的影响。
二、平衡面板处理:2.1 平衡面板的定义:平衡面板是指在面板数据中,每个个体单位在每个时间点都有观测值的情况。
然而,实际面板数据中往往存在非平衡面板的情况,即某些个体单位在某些时间点没有观测值。
2.2 面板数据的平衡化方法:对于非平衡面板数据,可以采用删除法、插补法或加权法等方法进行平衡化处理。
删除法是直接删除非平衡的观测值,但会导致样本减少;插补法是利用已有观测值进行插补,如线性插值、多重插补等;加权法是给予有观测值的个体单位更大的权重,以弥补非平衡带来的偏误。
2.3 面板数据平衡性的检验:平衡面板处理后,需要对平衡性进行检验。
可以通过计算面板数据的平衡率、面板数据的观测数等指标进行检验,以确保平衡面板的有效性。
三、面板数据变换:3.1 横向平均化:对于面板数据中的个体单位,可以计算它们在不同时间点上的平均值,以得到横向平均化的结果。
面板数据模型入门讲解

面板数据模型入门讲解面板数据模型是经济学和社会科学研究中常用的一种数据分析方法。
它是对跨时间和跨个体的数据进行统计分析的一种有效方式。
本文将介绍面板数据模型的基本概念、应用场景以及如何进行面板数据的建模和分析。
一、面板数据模型的基本概念面板数据模型是指在一段时间内,对多个个体(如个人、家庭、企业等)进行观测得到的数据。
它包含了时间维度和个体维度,可以用来分析个体和时间对变量之间的关系。
面板数据模型的优势在于可以控制个体固定效应和时间固定效应,从而减少了误差项的异质性。
面板数据模型可以分为两种类型:平衡面板数据和非平衡面板数据。
平衡面板数据是指在每一个时间点上,每一个个体都有观测值;非平衡面板数据则是指在某些时间点上,某些个体可能没有观测值。
根据面板数据的类型,我们可以选择不同的面板数据模型进行分析。
二、面板数据模型的应用场景面板数据模型在经济学和社会科学的研究中有广泛的应用。
例如,经济学家可以利用面板数据模型来研究个体的收入与教育水平之间的关系,企业可以利用面板数据模型来研究市场份额与广告投入之间的关系。
面板数据模型还可以用于政策评估。
例如,政府实施了一项教育政策,为了评估该政策的效果,可以利用面板数据模型来比较政策实施先后个体的教育水平变化。
这样可以更准确地评估政策的影响。
三、面板数据模型的建模和分析在进行面板数据模型的建模和分析时,需要考虑以下几个步骤:1. 确定面板数据的类型:首先需要确定面板数据是平衡面板数据还是非平衡面板数据。
如果是非平衡面板数据,需要考虑如何处理缺失观测值的问题。
2. 检验面板数据的平稳性:面板数据模型的前提是变量是平稳的。
可以通过单位根检验等方法来检验变量的平稳性。
3. 选择面板数据模型:根据面板数据的特点和研究问题的需要,选择适合的面板数据模型。
常用的面板数据模型包括固定效应模型、随机效应模型和混合效应模型等。
4. 进行面板数据模型的估计和判断:利用面板数据模型进行参数估计和假设检验。
面板数据

3
解释设定个体固定效应模型的原因。假定有面板数据模型
yit = 0+ Xit 1+ 2zi+it i = 1, 2, …, N; t = 1, 2, …, T
;
记第 i 个横截面的数据为
y i1 yi2 yi y iT
xi11 1 xi 2 Xi x1 iT
xi2 1 xi22
2 xiT
i1 xiK 1 K xi 2 i2 ; i K xiT iT
面板数据用双下标变量表示。
yi t, i = 1, 2, …, N; t = 1, 2, …, T
i对应面板数据中不同个体。N表示面板数 据中含有N个个体。t对应面板数据中不同 时点。T表示时间序列的最大长度。 若固定t不变,yi ., ( i = 1, 2, …, N)是横截 面上的N个随机变量; 若固定i不变,y. t, (t = 1, 2, …, T)是纵剖 面上的一个时间序列(个体)。
混合估计模型
是指从时间上看,不同个体之间不存在显 著性差异;从截面上看,不同截面之间也 不存在显著性差异。在横截面上无个体差 异,则可以直接把面板数据混合在一起用 普通最小二乘法(OLS)估计参数。即混 合估计模型满足1= 2= 3=…= N, 1= 2 = 3 =…= N ,模型可表示为: yit = + Xit ' +it, i = 1, 2, …, N; t = 1, 2, …, T
与横截面数据和时间序列数据的区别
从横截面(cross section)上看,面板数 据是由若干个体(entity, unit, individual) 在某一时刻构成的截面观测值;
面板数据分析

面板数据分析引言面板数据,也称为纵向数据或长期追踪数据,是统计学中一种常见的数据类型。
它包含了多个观测单位(个体)在多个时间点上的观测数值,通常用于研究个体随时间变化的动态特征以及个体之间的差异。
本文将介绍面板数据分析的基本概念、应用场景以及常用的方法。
面板数据的特点面板数据与传统的横断面数据和时间序列数据相比,具有以下几个特点:1.面板数据可以捕捉到不同个体之间的差异,因为它包含了多个个体的观测值。
这使得面板数据分析更能够揭示个体之间的异质性。
2.面板数据可以捕捉到个体随时间的变化。
通过观察同一组个体在不同时间点上的观测值,我们可以分析其变化趋势以及时间的影响。
3.面板数据可以提供更准确的估计结果。
面板数据的观测值来自同一组个体,这意味着我们可以利用个体之间的差异来增加估计的准确性,减少估计的标准误差。
面板数据分析的应用场景面板数据分析在经济学、社会学、医学等领域都有广泛的应用。
以下是一些常见的应用场景:1.经济学中的面板数据分析可以用于研究个体或企业的投资行为、消费行为等经济决策的动态特征,从而为经济政策制定提供依据。
2.社会学中的面板数据分析可以用于研究个体或家庭的社会行为,如教育投资、就业状况等。
这些研究可以帮助我们了解社会问题的根源以及改善社会政策的方向。
3.医学中的面板数据分析可以用于研究疾病的发展过程以及治疗效果的评估。
通过观察患者在不同时间点上的生理指标变化,我们可以了解疾病的演变规律以及治疗手段的效果。
面板数据分析的方法面板数据分析有多种方法,下面介绍几种常用的方法:1.固定效应模型:固定效应模型是一种常用的面板数据分析方法,它将个体特定的固定效应引入模型中。
通过固定效应模型,我们可以分析个体固有的特征对观测值的影响。
2.随机效应模型:随机效应模型是另一种常用的面板数据分析方法,它将个体特定的随机效应引入模型中。
与固定效应模型不同,随机效应模型允许个体之间的差异是随机的,而不是固定的。
经济学实证研究中的面板数据分析方法比较

经济学实证研究中的面板数据分析方法比较面板数据(Panel Data),也称为长期数据或混合数据,是指在一定时间内对多个个体或企业进行观测的数据。
面板数据分析方法是经济学实证研究中常用的一种分析工具。
本文旨在比较不同的面板数据分析方法,探讨它们的优劣与适用情况。
一、面板数据的特点面板数据有以下几个显著特点:1. 包含个体特征和时间维度。
即数据中观测个体之间存在差异,而且可以根据时间轴进行观测。
2. 具备更多的信息。
相对于横截面数据或时间序列数据,面板数据可以提供更为全面和详尽的信息,有助于更准确地进行经济学实证研究。
3. 更好地解决内生性问题。
面板数据可以通过个体固定效应或时段固定效应来控制个体异质性和时间变化的影响,从而更好地解决内生性问题。
基于以上特点,面板数据分析方法成为经济学实证研究中重要且有效的分析工具。
二、面板数据分析方法在面板数据分析中,常用的方法主要包括以下几种:1. 固定效应模型固定效应模型假设不同个体之间存在固定的差异,而这些个体差异会对变量的影响造成一定程度的固定效应。
该模型将这些固定效应当作个体的特征进行分析,用于探究个体特征对经济现象的影响。
2. 随机效应模型随机效应模型认为不同个体之间的差异是随机的,并不具备固定效应。
该模型通过引入个体随机效应、错误项相关性等,对面板数据进行分析,得出影响因素对个体和时间的影响。
3. 差异化面板数据模型差异化面板数据模型将固定效应模型和随机效应模型综合起来,将随机效应和固定效应作为影响因素的一部分进行分析。
该模型能够更好地反映个体之间的差异以及个体随时间变化的影响。
4. 两阶段最小二乘法(2SLS)2SLS方法采用两个步骤来估计模型参数。
首先,通过工具变量法或广义矩估计法获取外生变量的估计值;然后,将估计值代入原回归方程中进行估计。
该方法主要用于解决内生性问题。
不同的面板数据分析方法适用于不同的研究问题和数据特点。
研究者需要根据具体情况选择适合的方法,以确保研究结果的准确性和可信度。
面板数据分析方法步骤全解

面板数据分析方法步骤全解面板数据分析是一种重要的统计分析方法,广泛应用于经济、金融、社会科学等领域。
它可以有效地处理多个观测单位在不同时间点上的数据,提供了更为精确和全面的分析结果。
本文将介绍面板数据分析的基本概念、步骤和常见方法。
一、面板数据的基本概念面板数据也被称为追踪数据、长期数据或纵向数据,它是一种将多个观测单位在不同时间点上的数据进行整合的方式。
面板数据分为两种类型:平衡面板和非平衡面板。
平衡面板是指每个观测单位在每个时间点上都有完整的数据,而非平衡面板则允许观测单位在某些时间点上缺失数据。
面板数据的优势在于可以充分利用时间序列和截面数据的信息,提供更为准确和有力的分析结果。
然而,面板数据的分析往往需要解决一些特殊的问题,比如异质性、序列相关性和观测单位间的相关性等。
二、面板数据分析的步骤1. 数据准备:面板数据分析的第一步是准备好所需的数据。
这包括收集和整理各个观测单位在不同时间点上的数据,并进行数据清洗和处理。
在数据准备阶段,需要注意保持数据的一致性和完整性,排除异常值和缺失数据等。
2. 描述性统计:在面板数据分析中,描述性统计是了解数据特征和趋势的基础。
通过计算各个变量的均值、标准差、最大值、最小值等统计量,可以对数据的分布和变化进行初步分析。
此外,还可以绘制折线图、柱状图等图表,直观地展示数据的变化趋势。
3. 模型选择:选择适当的模型是面板数据分析的核心步骤。
常见的面板数据分析模型包括固定效应模型、随机效应模型和混合效应模型。
固定效应模型假设每个观测单位的效应是固定的,而随机效应模型假设每个观测单位的效应是随机的。
混合效应模型则将两者结合起来,既考虑了固定效应,又考虑了随机效应。
4. 假设检验:在面板数据分析中,假设检验是判断模型的显著性和一致性的重要方法。
通过假设检验可以判断各个变量之间的关系是否显著,以及模型的拟合程度如何。
常用的假设检验方法包括t检验、F检验等,可以用于检验模型参数的显著性和方差的平稳性。
经济学毕业论文中的面板数据模型分析方法选择

经济学毕业论文中的面板数据模型分析方法选择在经济学毕业论文中,面板数据模型的选择是非常重要的一环。
面板数据模型以其能够充分利用交叉面(cross-section)和时间面(time-series)数据,帮助分析经济现象和政策效果而被广泛运用。
本文将探讨面板数据模型的分析方法选择,并介绍几种常见的面板数据模型。
1. 引言面板数据模型是一种同时利用纵向和横向数据的统计方法。
相对于纯粹的横截面数据或时间序列数据,面板数据模型能提供更多的信息和更准确的结果。
因此,在经济学毕业论文中,选择合适的面板数据模型非常重要。
2. 面板数据模型简介面板数据模型分为固定效应模型(Fixed Effects Model)和随机效应模型(Random Effects Model)。
固定效应模型假设个体间存在固定的差异,而随机效应模型则假设这些差异由于随机因素而产生。
具体选择何种模型需要根据实际情况进行判断。
3. 面板数据模型的选择方法1) Hausman检验(Hausman test)Hausman检验是一种判断固定效应模型和随机效应模型哪种更合适的常用方法。
它基于两种模型的估计量的差异,判断是否存在可观测的外生性。
2) 收敛性检验(Convergence test)在进行面板数据模型分析之前,需要进行收敛性检验。
收敛性检验用于判断面板数据模型是否可以得到一致的估计结果。
3) 多重共线性检验(Multicollinearity test)多重共线性可能导致面板数据模型产生无效的估计结果,因此需要进行多重共线性检验。
常用的检验方法包括方差膨胀因子(Variance Inflation Factor,VIF)和条件指数(Condition Index)。
4) 随机效应模型与固定效应模型对比如果Hausman检验的p值小于0.05,拒绝随机效应模型,可以选择固定效应模型。
否则,可以采用随机效应模型。
4. 面板数据模型实证分析以“中国就业效应的跨国比较”为例,我们来进行面板数据模型的实证分析。
如何选择适当的面板数据回归模型固定效应还是随机效应

如何选择适当的面板数据回归模型固定效应还是随机效应如何选择适当的面板数据回归模型:固定效应还是随机效应在进行面板数据回归分析时,一个重要的问题是选择适当的模型来控制面板特征和个体间的异质性。
其中,固定效应模型(Fixed Effects Model)和随机效应模型(Random Effects Model)是常用的两种方法。
本文将重点讨论如何选择适当的面板数据回归模型,包括固定效应模型和随机效应模型的基本原理、适用条件以及实施步骤。
1. 固定效应模型固定效应模型是一种通过控制个体固定效应来解决面板数据回归中个体间异质性的方法。
也就是说,固定效应模型假设个体固定效应对因变量的解释存在差异,但是在解释变量上是常数。
固定效应模型的基本原理是加入个体固定效应项,在个体内部的观测值上利用时间序列变化进行估计。
固定效应模型的主要优点是对个体固定效应的控制,能够更准确地估计个体自身的影响因素。
固定效应模型的适用条件包括:个体固定效应存在,并且与解释变量无关;个体固定效应对因变量的解释具有显著差异;解释变量中不含个体间的变化。
如果以上条件满足,可以采用固定效应模型进行面板数据回归分析。
实施固定效应模型的步骤如下:(1)数据处理:根据面板数据的特点进行数据整理和转换,确保数据的准确性和一致性。
(2)检验个体固定效应:通过统计方法或绘制图表来判断个体固定效应是否存在,并且与解释变量无关。
(3)估计固定效应:引入虚拟变量或时间固定效应来表示不同个体或时间的差异,并将其纳入回归模型进行估计。
(4)模型评估:对固定效应模型进行统计推断和模型拟合度评估,确保模型的有效性和可靠性。
2. 随机效应模型随机效应模型是一种通过考虑个体随机效应来克服面板数据回归中个体异质性的方法。
该模型假设个体随机效应与解释变量相关,并且具有随机性。
随机效应模型的基本原理是引入个体随机效应项,并将其纳入回归模型进行估计。
随机效应模型的优点是能够控制个体间的时间不变影响,更关注个体与解释变量的相关性。
Stata面板数据回归分析中的样本选择偏误问题及解决方法

Stata面板数据回归分析中的样本选择偏误问题及解决方法在进行Stata面板数据回归分析时,样本选择偏误是一种常见的问题。
样本选择偏误是指在样本选取过程中,观察特征与样本选择有关,从而导致样本集不是总体集的随机子集,进而影响回归结果的一种偏误。
本文将介绍样本选择偏误的原因,以及解决这一问题的方法。
一、样本选择偏误的原因1. 非随机样本选择样本选择偏误往往源于样本在选取过程中的非随机性。
研究者往往会根据某些特定的标准或者限制来选择样本,例如只选择某个时间段的数据、只选择满足特定条件的个体等。
这样的非随机性选择可能会导致样本集与总体集存在差异,从而引发样本选择偏误。
2. 缺失数据当样本中存在缺失数据时,如果这些缺失数据与回归变量或者结果变量相关,那么在对样本进行选择的过程中,就会引入样本选择偏误。
因此,处理缺失数据也是避免样本选择偏误的重要一环。
二、解决样本选择偏误的方法1. 使用倾向得分匹配倾向得分匹配是一种常用的方法,可以通过建立样本选择的概率模型来估计每个样本被选择的概率,然后根据估计得到的概率进行样本匹配。
通过匹配,使得样本选择的概率更加接近于随机选择的概率,从而减少样本选择偏误。
2. 反向确认性选择反向确认性选择是一种可以有效解决样本选择偏误的方法。
该方法通过将样本分为两个部分,一部分用于样本选择,另一部分用于估计回归模型。
然后通过比较两部分样本的结果,确定样本选择对回归结果的影响。
通过反向确认性选择,可以消除样本选择偏误对回归结果的影响。
3. 使用面板数据分析方法面板数据分析方法可以通过引入个体固定效应或者时间固定效应来控制样本选择偏误。
个体固定效应允许通过控制个体固定效应来消除样本选择偏误,时间固定效应则通过控制时间固定效应来消除样本选择偏误。
面板数据分析方法可以更好地解决样本选择问题,并提高回归结果的准确性。
总结:Stata面板数据回归分析中的样本选择偏误是一种常见的问题。
为了解决这一问题,可以使用倾向得分匹配、反向确认性选择或者面板数据分析方法等不同的方法。
Eviews面板数据操作
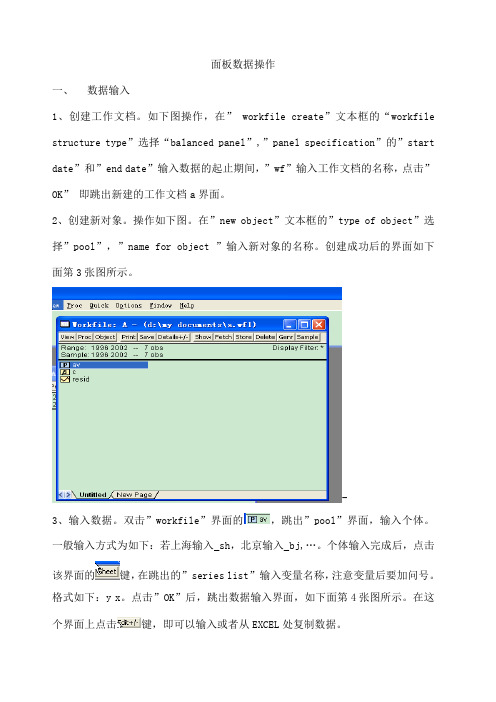
面板数据操作一、数据输入1、创建工作文档。
如下图操作,在” workfile create”文本框的“workfile structure type”选择“balanced panel”,”panel specification”的”start date”和”end date”输入数据的起止期间,”wf”输入工作文档的名称,点击”OK”即跳出新建的工作文档a界面。
2、创建新对象。
操作如下图。
在”new object”文本框的”type of object”选择”pool”,”name for object ”输入新对象的名称。
创建成功后的界面如下面第3张图所示。
-3、输入数据。
双击”workfile”界面的,跳出”pool”界面,输入个体。
一般输入方式为如下:若上海输入_sh,北京输入_bj,…。
个体输入完成后,点击该界面的键,在跳出的”series list”输入变量名称,注意变量后要加问号。
格式如下:y x。
点击”OK”后,跳出数据输入界面,如下面第4张图所示。
在这个界面上点击键,即可以输入或者从EXCEL处复制数据。
在输入数据后,记得保存数据。
保存操作如下:在跳出的“workfile save”文本框选择“ok”即可,则自动保存到我的文档。
然后在“workfile”界面如下会显示保存路径:d:\my documents\。
若要保存到自己选择的路径下面,则在保存时选择“save as”,在跳出的文本框里选择自己要保存的路径以及命名文件名称。
4、单位根检验。
一般回归前要检验面板数据是否存在单位根,以检验数据的平稳性,避免伪回归,或虚假回归,确保估计的有效性。
单位根检验时要分变量检验。
(补充:网上对面板数据的单位根检验和协整检验存在不同意见,一般认为时间区间较小的面板数据无需进行这两个检验。
)(1)生成数据组。
如下图操作。
点击”make group”后在跳出的”series list”里输入要单位根检验的变量,完成后就会跳出如下图3所示的组数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
以每个截面观测值为一种符号的面板数据散点图如下(图中把 1995、2001 和 2006 年 数据分别连在一起。):发现二氧化硫排放量(SO2)有逐年增加的趋势。
SO2_BJ SO2_TJ SO2_HEB SO2_SX SO2_NMG SO2_LN SO2_JL SO2_HLJ SO2_SH SO2_JS 2400000 2000000 1600000 1200000 800000 400000 0 0 10000 20000
800000 so2 700000 600000 500000 400000 300000 200000 rgdp 100000 0 10000 20000 30000 40000 50000 60000
案例 1: 工业 SO2 排放及人均 GDP 关系的面板数据研究
Grossman and Krueger (1991) 用人均收入变化的三类效应来解释该 现象的出现: 经济发展意味着更大规模的经济活动与资源需求量, 因而对环境产生负面的规模效应;但同时经济发展又通过正的技术进 步效应(例如更为环保的新技术的使用)以及结构效应(例如产业结构 的升级与优化) 减少了污染排放、改善了环境质量。因此, 这三类效 应共同决定了环境质量与经济发展之间的这一倒 U 型曲线关系。
案例 1:工业 SO2 排放及人均 GDP 关系的面板数据研究
以中国 29 个省级地区(不包括重庆、西藏和港澳台地区)1995-2006 年间 12 年的面板数据来对我国的经济增长与环境问题做出分析,所选数据均为平衡 面板数据, 348 组数据。 共 其中, RGDP 表示人均国内生产总值 (单位: 元) , SO2 表示工业二氧化硫排放量(单位:吨)。用 BJ、TJ、HEB、SX、NMG、 LN、JL、HLJ、SH、JS、ZJ、AH、FJ、JX、SD、HEN、HUB、HUN、 GD、GX、HAN、SC、GZ、YN、SHX、GS、QH、NX、XJ 分别表示北京、 天津、河北、山西、内蒙古、辽宁、吉林、黑龙江、上海、江苏、浙江、安 徽、福建、江西、山东、河南、湖北、湖南、广东、广西、海南、四川、贵 州、云南、陕西、甘肃、青海、宁夏、新疆。 各地区 1995-2006 的人均国内生产总值和工业二氧化硫排放量数据均来 自于 1996-2007 年《中国统计年鉴》。
SO2_95_06
SO2_95_06F1
2500000 2000000 1500000 1000000 500000 0 -500000 0
SO2_95_06 vs. Polynomial (degree=2) of RGDP
10000
20000
30000 RGDP
40000
50000
60000
线性混合模型的回归直线
SO2_HAN SO2_SC SO2_GZ SO2_YN SO2_SHX SO2_GS SO2_QH SO2_NX SO2_XJ
30000
40000
50000
60000
RGDP_BJ_XJ
从面板数据个体连线散点图看,人均国内生产总值超过 4 万元的只有北京、 天津、上海三个地区。其余 26 个省级地区仍都处于二氧化硫排放量(SO2) 逐年增加的阶段。用倒 U 字曲线拟合是不恰当的。
案例 1:工业 SO2 排放及人均 GDP 关系的面板数据研究
SO2_95_06 vs. Polynomial (degree=3) of RGDP 2400000 2000000 1600000 1200000 800000 400000 0 0 10000 20000 30000 RGDP 40000 50000 60000
面板数据模型形式的选择
张晓峒
南开大学数量经济研究所
nkeviews@
面板数据模型形式的选择
张晓峒
【摘要】 面板数据模型除了应用 F 检验和 Hausman 检验确定 应该建立混合模型、固定效应模型还是随机效应模型之外, 如何恰当地选择模型的形式也是一个重要问题。本文运用多 组经济数据展示模型形式的选择过程以及模型形式不合理时 对模型参数估计带来的影响。
案例 2:全国省级地区城镇居民人均食品支出与收入关系研究
5000 food 4000
3000
2000
1000 income 0 0 4000 8000 12000 16000 20000
案例 1:工业 SO2 排放及人均 GDP 关系的面板数据研究
回到线性拟合形式上来。与混合模型 SO2it = 557081.4 + 1.1111 RGDPit (16.0) (0.4) R2 = 0.0005,DW=0.11, NT= 2912= 348 相对应,估计个体固定效应模型如下: SO2it = … + 461948.1 + 10.5148 RGDPit (24.2) (5.2) R2 = 0.86,DW=0.79, NT= 2912= 348 从全国平均水平来看,人均国内生产总值(RGDP)每增加 1 元,二氧化硫 排放量(SO2)增加 10.5 吨。从检验结果看应该建立个体固定效应模型。
案例 1:工业 SO2 排放及人均 GDP 关系的面板数据研究
线性混合模型估计结果是 SO2it = 557081.4 + 1.1111 RGDPit (16.0) (0.4) R2 = 0.0005,DW=0.11, NT= 2912= 348 说明二氧化硫排放量(SO2it, 吨)与人均国内生产总值(RGDPit, 元)之间不 存在线性关系。由可决系数 R2 = 0.0005 知数据一定非常散。 二次多项式混合模型估计结果是 SO2it = 423499.3 + 23.4691 RGDP it - 0.00055 RGDP it 2 (8.0) (3.2) (-3.3) R2 = 0.0315,DW=0.12, NT= 2912= 348 说明二氧化硫排放量(SO2it)与人均国内生产总值(RGDPit)有可能存在二 次非线性关系。由可决系数 R2 = 0.0315 知数据一定非常散。 据此就可以建立二次多项式形式的面板数据模型吗?首先分析数据散点图。
案例 1:工业 SO2 排放及人均 GDP 关系的面板数据研究
SO2_95 SO2_96 SO2_97 SO2_98 2400000 2000000 1600000 1200000 800000 400000 0 0 10000 20000 30000 RGDP 40000 50000 60000 SO2_99 SO2_00 SO2_01 SO2_02 SO2_03 SO2_04 SO2_05 SO2_06
二氧化硫排放量(SO2it)与人均国内生产总值(RGDPit)面板数据散点图。
案例 1:工业 SO2 排放及人均 GDP 关系的面板数据研究
SO2_95_06 2400000 2000000 1600000 1200000 800000 400000 0 0 10000 20000 30000 RGDP 40000 50000 60000
案例 1:工业 SO2 排放及人均 GDP 关系的面板数据研究
分析中国二氧化硫排放量(SO2)与人均国内生产总值(RGDP)面板数据的特征。
SO2_95 SO2_96 SO2_97 SO2_98 2400000 2000000 1600000 1200000 800000 400000 0 0 10000 20000 30000 RGDP 40000 50000 60000 SO2_99 SO2_00 SO2_01 SO2_02 SO2_03 SO2_04 SO2_05 SO2_06
案例 1:工业 SO2 排放及人均 GDP 关系的面板数据研究
相对应,估计随机效应模型如下: SO2it = … + 465399.6 + 10.1736 RGDPit (6.4) (6.1) R2 = 0.10,DW=0.72, NT= 2912= 348
从检验结果看应该建立个体随机效应模型。如果建立二次多项式模型,预测 将带来很大误差。 本例不应建立倒 U 字模型, 中国目前处于工业化发展阶段, 还没有逾越二氧化硫排放量的最高值。
SO2it = 349806.2+ 41.5645 RGDPit - 0.00156 RGDPit 2 + 1.38 108 RGDPit 2 (4.3) (2.4) (-1.8) (1.2) R2 = 0.035,DW=0.12, NT= 2912= 348
SO2_95_06
面板数据的三次多项式混合模型拟合图(按库兹涅茨曲线假说拟合)。 估计结果显示这种拟合没有显著性,即不存在倒 U 字特征。
SO2_BJ SO2_TJ SO2_HEB SO2_SX SO2_NMG SO2_LN SO2_JL SO2_HLJ SO2_SH SO2_JS 2400000 2000000 1600000 1200000 8ห้องสมุดไป่ตู้0000 400000 0 0 10000 20000
SO2_ZJ SO2_AH SO2_FJ SO2_JX SO2_SD SO2_HEN SO2_HUB SO2_HUN SO2_GD SO2_GX
案例 2: 全国省级地区城镇居民人均食品支出与收入关系研究
28 个省市自治区(不包括西藏、新疆和重庆市)21 年(19852005)共 588 个观 测值。 线性混合模型估计结果是 F1it = 335.84 + 0.2667 I1it (20.6)(88.8) R2 = 0.93,DW=0.15, NT= 2821= 588 线性个体固定效应模型估计结果是 F1it = …+ 374.75 + 0.2577 I1it (26.6)(96.8) R2 = 0.95,DW=0.23, NT= 2821= 588 克服误差项自相关的线性个体固定效应模型估计结果是 F1it = …+ 604.98 + 0.2225 I1it +1.1979AR(1) -0.3620AR(2) (11.8)(34.1) (28.5) (-8.8) R2 = 0.99,DW=2.24, NT= 2821= 532 R2 = 0.99,DW=2.24,一定认为找到了模型的最好估计形式。事实并不是这样。 F1it 和 I1it 的散点图如下: